







1 概述
Linux内核中,内核会使用内存作为文件缓存(page cache),从而提高文件性能。文件缓存页面会添加到文件类型的LRU链表中;当内存紧张时,文件缓存页面中脏页回写到存储设备中,干净的页面丢弃;同时,Linux内核会使用存储设备作为交换分区,内核将很少使用的匿名页换出到交换分区,以便释放匿名页面,这些回收文件缓存页和匿名页面的机制称为页回收(page reclaim)。
本文主要主要从下面几个方面逐层展开论述
- 什么时候做页回收
- 页回收回收哪些页
- 页回收的过程,怎么样回收页
- 页回收中会遇到哪些问题,如何解决这些问题;
- 主线内核在页回收上的进展
1.1 历史发展
和页回收相关的一些重要特性进入内核主线
- 2.4 ~ 2.6 之间的 Reverse Map
- 3.15 Refault Distance 算法
- 5.15 DAMON(Data Access MONitor) 数据访问监控
- 5.16 page folios 基础架构(Memory folios infrastructure for a faster memory management)、改进拥塞控制(Improve write congested)
- 5.17 DAMON 更新
- 6.1 Mult-Gen LRU
1.2 社区专家
在内存管理子系统做出突出贡献的社区专家
-
Johannes Weiner
内核社区中知名的开发者,内核子系统的CGROUP、PSI、CACHESTAT主要维护者。他尤其以他在内存管理,特别是在交换(swap)、页替换算法以及内存不足(OOM)处理等领域的贡献而著名。他的工作对Linux内核的性能和稳定性有很大影响。参与了许多关于内核内存管理的讨论并提供了大量补丁。Johannes Weiner 贡献的 Refault Distance 算法合入主线3.15版本(4.4节有详细介绍);
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/6e75c16cdd264985dd35eb2b0ff22044.png)
-
Andrew Morton
在内核社区中因执行各种不同的任务而闻名:维护可能正在进入主线的补丁的 -mm 树、审查大量补丁、提供有关与社区合作的演示,以及一般来说,处理许多重要且可见的内核开发杂务。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/d496b6248cde19606701a8e12638cb34.png)
-
Rik van Riel
社区内存管理专家,Reverse Map 特性的主要贡献者(第5节详细介绍 )
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/a125854ea8f076e514fad89f67fd7305.png)
-
Mel Gorman
爱尔兰利默里克的一名内核工程师,目前在SUSE Labs 工作。拥有利默里克大学(University of Limerick)计算机科学博士学位,也是《Understanding the Linux Virtual Memory Manager》一书的作者。此前,曾在 IBM Linux 技术中心担任内存管理专家,并曾在 IBM PortalServer 的 Lotus 部门工作过。SUSE 性能团队的团队负责人、Linux内核内存管理专家、SLE 内核开发人员、上游内核开发者。内核子系统“SCHEDULER” 中“CONFIG_NUMA_BALANCING” 部分Reviewer,主线内核5.16版本重要特性“Improve write congestion”主要作者;
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/2960104c9bb70966a4823b4f12bd9e6a.png)
-
Michal Hocko
Michal Hocko 是一位活跃在Linux内核开发社区的开发者,他在Linux内核的内存管理方面贡献甚丰,包括参与处理内存回收、内存不足处理(OOM)、交换空间管理等方面的工作。他还参与维护过Linux内核的memcg(memory cgroup,内存控制组)功能,该功能是cgroups(control groups)的一部分,用于管理和限制进程组使用的内存资源。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/1ff94b1bf421af927ff63277ca8fd645.png)
-
Yu Zhao
Google 工程师,主线内核6.1版本重要特性 Mult-Gen LRU 主要作者(见第6节 “Mult-Gen LRU”)
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/cd5be367db61b985bc1ba4d3338c8b00.png)
-
SeongJae Park
2019年在首尔国立大学计算机科学系获得了博士学位,同年9月加入 Amazon 担任内核/虚拟化开发工程师,,内核子系统 DAMON(DATA ACCESS MONITOR)主要维护者(DAMON 是5.15 合入重要特性),DAMON 这是一个用于 Linux 内核的数据访问监控框架。他正在使用这个框架作为核心组件为 AWS 开发一个感知数据访问的 Linux 系统。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/19d11135a819fc2bb14101295887e397.png)
-
Matthew Wilcox
Matthew 担任 Linux 内核黑客已有 25 年。他参与了内核的许多部分,包括 Arm、PA-RISC 和 ia64 架构、TASK_KILLABLE、PCI、SCSI、NVMe、USB、文件系统、文件锁定、DAX 和 XArray。他在 Oracle 从事各种项目,包括内存管理和文件系统。他最近任命自己为 page cache 维护者。5.16内核合入重要特性“page folios” 主要作者;
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/d9ae4e6bede50f24aa3dc88010930c93.png)
1.3 社区动态
在 2023 年 Linux 存储、文件系统、内存管理和 BPF 峰会 上,Joel Fernandes 介绍了自己作为读取-复制-更新 (RCU) 子系统的联合维护者和“惰性 RCU”功能的实现者进入内存管理领域的情况。具体见 The intersection of lazy RCU and memory reclaim
在 2023 年 Linux 存储、文件系统、内存管理和 BPF 峰会上,Yu Zhu 和 Yang Shi 在内存管理领域举办了一场会议,旨在制定支持各种大小的匿名页面的路径。 具体见 Flexible-order anonymous folios
2 页回收的时机
分配内存的时候做检查让剩余内存维持在一个合理的水平上,如果迫不得已进行直接内存回收;
1)使用水位线标识剩余内存的状况
2)不同的水位线感知剩余内存对对分配的紧急程度
3)在内存分配的过程中检查水位线
2.1 水位线
内核使用high low min 三条水位线标识对系统剩余内存值的预警程度,准确的说是每个zone都有自己的水位线。分配内存过程中,剩余内存值在不同的水位线做不同的页回收策略;
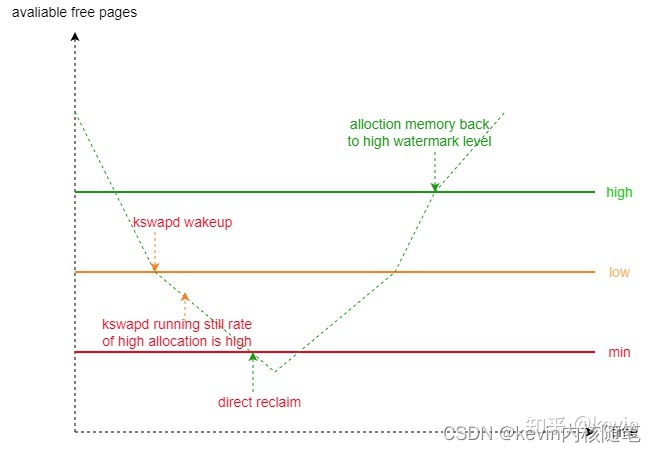
- 两种页回收方式
1)direct reclaim
在内存分配时发现空闲内存严重不足(低于min水位线),直接启动内存回收操作;在direct reclaim模式下,分配和回收是同步的关系,内存分配的过程会被内存回收的操作所阻塞,增加等待的时间。
2)background reclaim
一个更理想的情况是,我们能在内存压力不那么大的时候,就提前启动内存回收。而且,在某些场景下(比如在interrupt context或持有spinlock时),内存分配根本就是不能等待的。因此,Linux中另一种更为常见的内存回收机制是使用kswapd。kswapd进程异步被唤醒扫描zone回收内存。
总结:
1)尽量避免出现低于min水位线的情况,此时做同步的内存回收会阻塞当前分配流程
2)kswap在低于low水位线被唤醒做异步内存回收,将剩余内存保持在high水位线以上后睡眠,应设置合理的high-low水位线值保证出现burst allocation的情形,回收速度比不上分配速度的情形;
3)提高low水位线,提前做后台内存回收,不要再内存很紧张的时候再唤醒kswapd;
4)min水位线是kswapd的兜底线,kswapd可以申请min水位线以下的内存
通过"/proc/vmstat"中的"pageoutrun"和"allocstall"来查看,两者分别代表了kswapd和direct reclaim启动的次数。
- watermark初始化
每个zone都有自己独立的min, low和high三个档位的watermark值,另外还有watermark_boost水位线
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long _watermark[NR_WMARK]; //1
unsigned long watermark_boost; //2
unsigned long nr_reserved_highatomic; //3
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES]; //4
... ...
}
1) _watermark[NR_WMARK]标识zone的水位线;
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
2)watermark_boost 水位线的快速调节值,
3)nr_reserved_highatomic 为high order attomic allocation预留的内存,单位页;这个值哪里初始化的,__zone_watermark_unusable_free会用到;
4)lowmem_reserve 防止高区域类型过度借用低区域类型物理页,低区域类型保留的物理页,后面检测水位线的时候剩余内存里面是要减去lowmem_reserve;
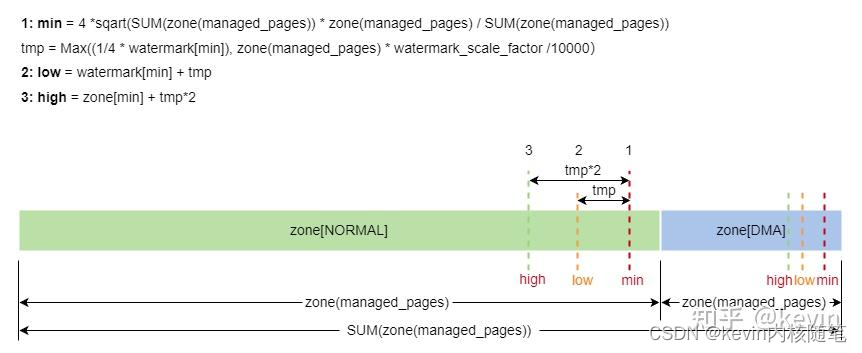
- watermark值计算
/*
* Initialise min_free_kbytes.
*
* For small machines we want it small (128k min). For large machines
* we want it large (256MB max). But it is not linear, because network
* bandwidth does not increase linearly with machine size. We use
*
*min_free_kbytes = 4 * sqrt(lowmem_kbytes), for better accuracy:
*min_free_kbytes = sqrt(lowmem_kbytes * 16)
*
* which yields
*
* 16MB:512k
* 32MB:724k
* 64MB:1024k
* 128MB:1448k
* 256MB:2048k
* 512MB:2896k
* 1024MB:4096k
* 2048MB:5792k
* 4096MB:8192k
* 8192MB:11584k
* 16384MB:16384k
*/
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10); //1
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16); //2
if (new_min_free_kbytes > user_min_free_kbytes) { //3
min_free_kbytes = new_min_free_kbytes;
if (min_free_kbytes < 128) //4
min_free_kbytes = 128;
if (min_free_kbytes > 262144) //5
min_free_kbytes = 262144;
} else {
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\n",
new_min_free_kbytes, user_min_free_kbytes);
}
setup_per_zone_wmarks(); //6
refresh_zone_stat_thresholds();
setup_per_zone_lowmem_reserve();
#ifdef CONFIG_NUMA
setup_min_unmapped_ratio();
setup_min_slab_ratio();
#endif
khugepaged_min_free_kbytes_update();
return 0;
}
postcore_initcall(init_per_zone_wmark_min)
1)lowmem_kbytes 表示DMA和NORNAL域的内存减去high watermark的内存,单位k;注意此时high watermark还没计算出来,应该是默认值0;
2)new_min_free_kbytes 等于lowmem_kbytes乘以16开方
3)user_min_free_kbytes值默认-1,如果通过/proc/sys/vm/min_free_kbytes设置了新值,则user_min_free_kbytes等于新值
4)如果new_min_free_kbytes小于128k,min_free_kbytes等于128k
5)如果new_min_free_kbytes大于262144k,min_free_kbytes等于262144kk
6)调用setup_per_zone_wmarks函数,完成zone的水位线设置
/**
* setup_per_zone_wmarks - called when min_free_kbytes changes
* or when memory is hot-{added|removed}
*
* Ensures that the watermark[min,low,high] values for each zone are set
* correctly with respect to min_free_kbytes.
*/
void setup_per_zone_wmarks(void)
{
static DEFINE_SPINLOCK(lock);
spin_lock(&lock);
__setup_per_zone_wmarks();
spin_unlock(&lock);
}
static void __setup_per_zone_wmarks(void)
{
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
for_each_zone(zone) {
if (!is_highmem(zone))
lowmem_pages += zone_managed_pages(zone); //2
}
for_each_zone(zone) {//3 循环遍历每一个node上的zone
u64 tmp;
spin_lock_irqsave(&zone->lock, flags);
tmp = (u64)pages_min * zone_managed_pages(zone);
do_div(tmp, lowmem_pages); //4
if (is_highmem(zone)) {
/*
* __GFP_HIGH and PF_MEMALLOC allocations usually don't
* need highmem pages, so cap pages_min to a small
* value here.
*
* The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN)
* deltas control async page reclaim, and so should
* not be capped for highmem.
*/
unsigned long min_pages;
min_pages = zone_managed_pages(zone) / 1024;
min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL);
zone->_watermark[WMARK_MIN] = min_pages;
} else {
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
zone->_watermark[WMARK_MIN] = tmp; //5
}
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
tmp = max_t(u64, tmp >> 2,
mult_frac(zone_managed_pages(zone),
watermark_scale_factor, 10000)); //6
zone->watermark_boost = 0; //7
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp; //8
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2; //9
spin_unlock_irqrestore(&zone->lock, flags);
}
/* update totalreserve_pages */
calculate_totalreserve_pages();
}
2)计算除了highmem外的其他内存域的内存的managed_pages
managed_pages is present pages managed by the buddy system, which is calculated as (reserved_pages includes pages allocated by the bootmem allocator):
managed_pages = present_pages - reserved_pages;
3) 循环遍历每一个node上的zone
4)tmp 等于当前zone管理的page占所有zone管理的page加起来的和的比例乘以上一节计算出来的min_free_kbytes
5)确定zone的min水位线,当前域的min水位线等于所有域管理的内存的开方的四倍 * 当前zone管理的内存 / 所有zone管理的内存
6)tmp/4 和 zone管理的内存 * watermark_scale_factor/10000 取最大值等于tmp,watermark_scale_factor默认值是10,可以通过/proc/sys/vm/watermark_scale_factort调整
7)zone->watermark_boost = 0
8)low水位线等于min水位线加tmp(min/4 或者 zone管理的内存 * watermark_scale_factor/10000)
9)high水位线等于min水位线加tmp*2 (min/2 或者 2 * (zone管理的内存 * watermark_scale_factor/10000)))
2.2 检查水位线
什么时候检查watermak? 检查时的判断条件?
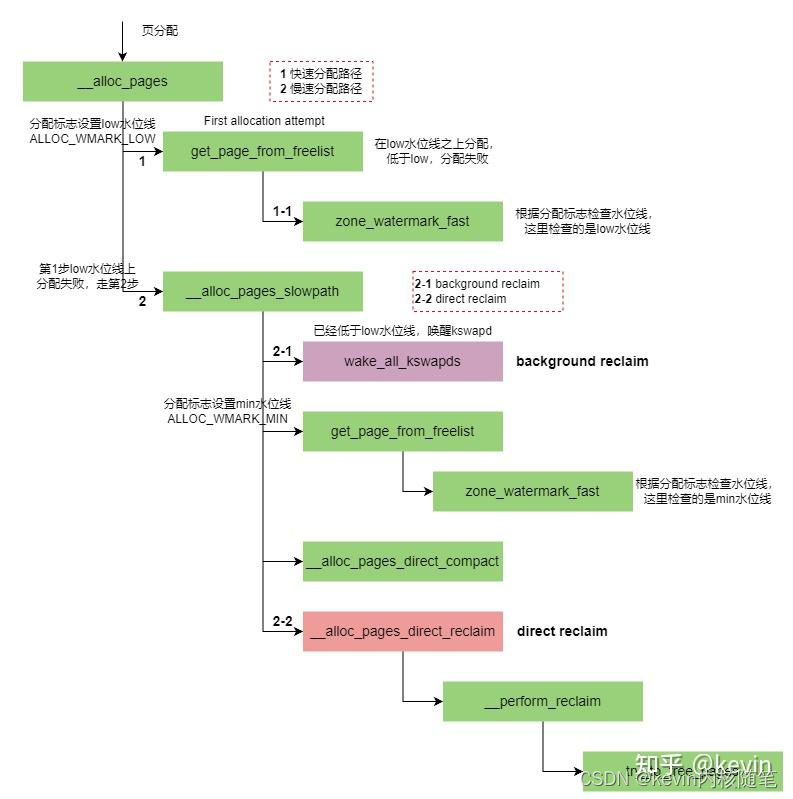
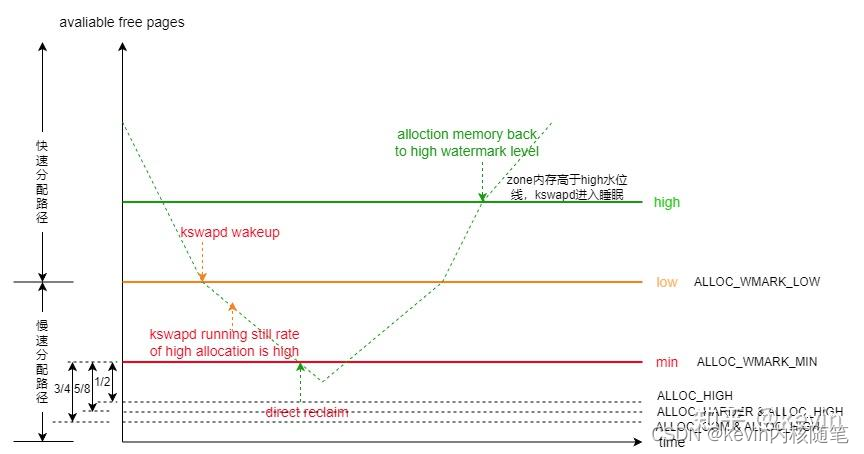
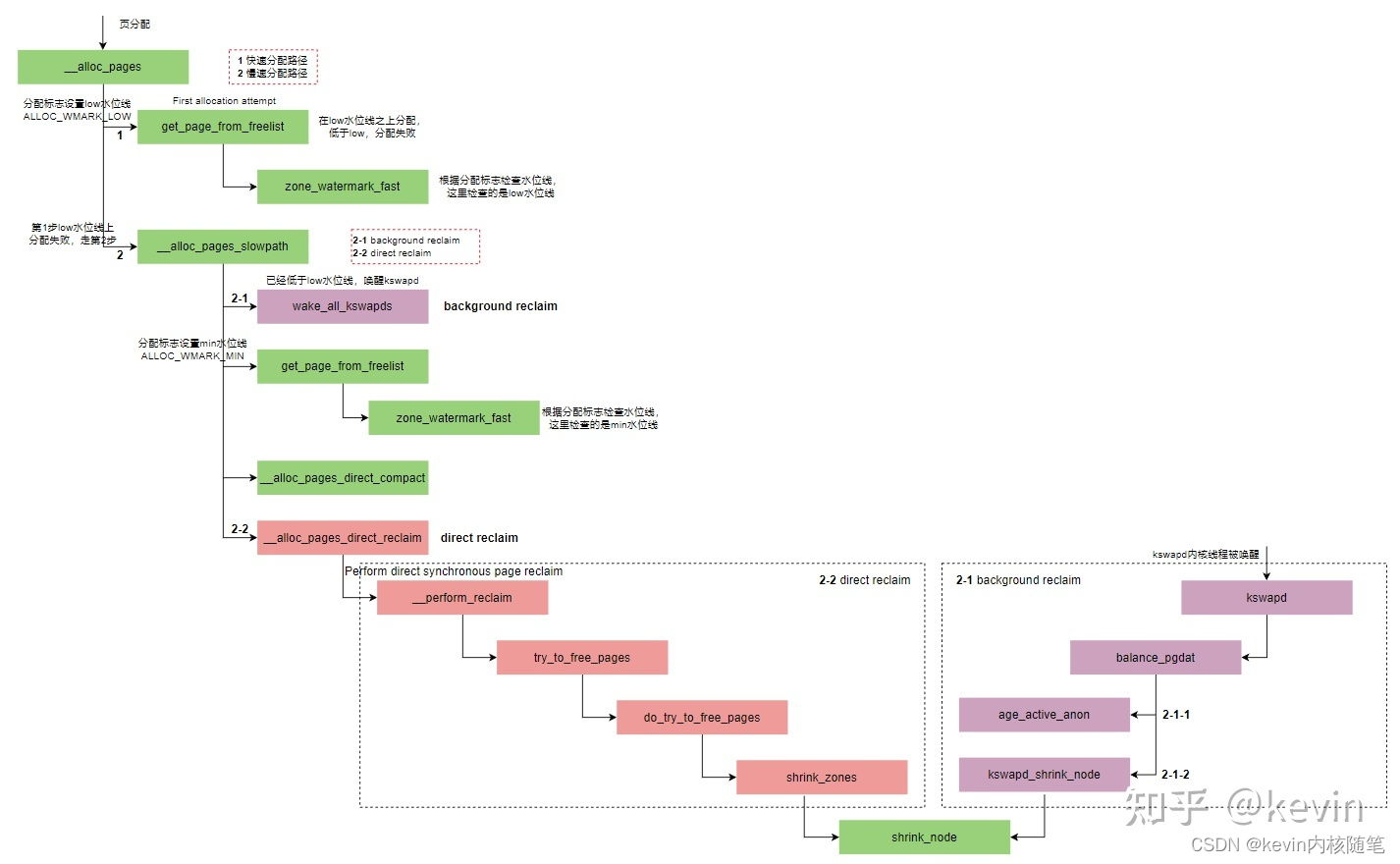
1)页分配过程中,当zone空闲页面的水位高于高水位时,zone的空闲页面比较充足,页面分配器处于快速路径上,也就是下图中的第1步就申请成功返回了;
2)页分配的过程中,当zone空闲页面的水位到达low水位时,如果分配不成功,则进入慢速路径,也就是下图中的第2步,页面分配器中的快速和慢速路径是以低水位线能否成功分配内存为分界线的。
3)慢速路径上,首先唤醒kswapd内核线程,异步扫描LRU链表和回收页面,也就是后台内存回收方式;
4)如果在慢速路径上分配不成功,则会做如下尝试。
使用水位来判断是否可以分配出内存
启动直接页面回收
尝试访问最低警戒水位下系统预留内存
启动直接内存规整机制
启动OOM Killer机制
多次尝试上次机制
5)在步骤4中会根据分配优先级来尝试访问min水位线的预留内存
对于普通优先级分配请求,不能访问min水位线的预留内存
对于高优先级分配请求,可以访问预留内存的1/2
对于优先级为艰难的分配请求,可以访问预留内存的5/8
如果线程组中有线程在分配之前被终止了,则这次分配可以适当补充,可以访问预留内存的3/4
如果分配请求中设置了__GFP_MEMALLOC 或者进程设置了PF_MEMALLOC标志位,那么可以访问系统中的全部的预留内存。
kswapd内核线程设置__GFP_MEMALLOC,背后的含义是我只要申请一点内存就能回收很多内存
6)如果上述步骤都不能分配成功,返回NULL
7)随着kswapd内核线程不断地回收内存,zone中空闲内存会越来越多,当zone中剩余内存大于high水位线,zone水位平衡了,kswapd内核线程停止工作重新进入睡眠状态;
问题:什么时候会带ALLOC_HIGH、ALLOC_HARDER、ALLOC_OOM申请标志?
- 检查水位线时的判断条件
页分配过程中,根据设置的水位线标志检查水位线,在函数zone_watermark_fast中做的判断。总的逻辑是剩余内存要大于水位线加lowmem_reserve,当然计算过程中会根据分配标志对剩余内存和水位线值做一些微调;
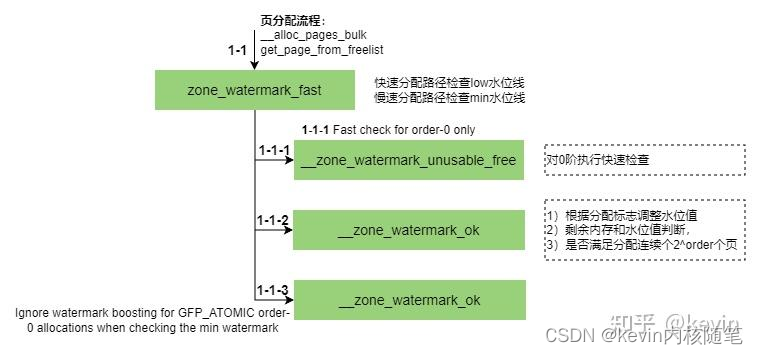
__zone_watermark_ok函数做了几件事
1)根据分配标志调整水位线值,也就是图2-2-2中的1/2,3/4,5/8出处;
2)检查是否满足剩余内存大于水位值加lowmem_reserve的和,如果大于再检查是否有连续2^order个页,不满足直接返回false;
3)检查free_area上是否有连续的order个页满足页分配请求,检查过程中考虑迁移类型(外碎片的优化);
这里要说明下zone中lowmem_reserve 作用和计算?
防止页申请过程中被过度借用,保留。防止高区域类型过度借用低区域类型物理页,低区域类型保留的物理页,计算过程有时间间有列一下
static inline bool zone_watermark_fast(struct zone *z, unsigned int order,
unsigned long mark, int highest_zoneidx,
unsigned int alloc_flags, gfp_t gfp_mask)
{
long free_pages;
free_pages = zone_page_state(z, NR_FREE_PAGES);
/*
* Fast check for order-0 only. If this fails then the reserves
* need to be calculated.
*/
if (!order) {
long fast_free;
fast_free = free_pages;
fast_free -= __zone_watermark_unusable_free(z, 0, alloc_flags);
if (fast_free > mark + z->lowmem_reserve[highest_zoneidx])
return true; //1 如果空闲页数-申请的一页 > 水位线+ lowmem_reserve,允许;
}
if (__zone_watermark_ok(z, order, mark, highest_zoneidx, alloc_flags,
free_pages))
return true;
/*
* Ignore watermark boosting for GFP_ATOMIC order-0 allocations
* when checking the min watermark. The min watermark is the
* point where boosting is ignored so that kswapd is woken up
* when below the low watermark.
*/
if (unlikely(!order && (gfp_mask & __GFP_ATOMIC) && z->watermark_boost
&& ((alloc_flags & ALLOC_WMARK_MASK) == WMARK_MIN))) {
mark = z->_watermark[WMARK_MIN];
return __zone_watermark_ok(z, order, mark, highest_zoneidx,
alloc_flags, free_pages);
}
return false;
}
/*
* Return true if free base pages are above 'mark'. For high-order checks it
* will return true of the order-0 watermark is reached and there is at least
* one free page of a suitable size. Checking now avoids taking the zone lock
* to check in the allocation paths if no pages are free.
*/
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int highest_zoneidx, unsigned int alloc_flags,
long free_pages)
{
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
/* free_pages may go negative - that's OK */
free_pages -= __zone_watermark_unusable_free(z, order, alloc_flags);
if (alloc_flags & ALLOC_HIGH) //1 分配标志设置ALLOC_HIGH,水位值调整到原来的1/2
min -= min / 2;
if (unlikely(alloc_harder)) {
/*
* OOM victims can try even harder than normal ALLOC_HARDER
* users on the grounds that it's definitely going to be in
* the exit path shortly and free memory. Any allocation it
* makes during the free path will be small and short-lived.
*/
if (alloc_flags & ALLOC_OOM) //2 分配标志设置ALLOC_HIGH & ALLOC_OOM,水位值变为原来的1/4
min -= min / 2;
else
min -= min / 4; //3 分配标志设置ALLOC_HIGH & ALLOC_HARDER,水位值变为原来的3/8
}
/*
* Check watermarks for an order-0 allocation request. If these
* are not met, then a high-order request also cannot go ahead
* even if a suitable page happened to be free.
*/
if (free_pages <= min + z->lowmem_reserve[highest_zoneidx]) //4 水位线判断条件
return false;
/* If this is an order-0 request then the watermark is fine */
if (!order) //5 如果是1页不用考虑是否连续的2^order
return true;
/* For a high-order request, check at least one suitable page is free */
for (o = order; o < MAX_ORDER; o++) { //6 从oreder阶开始检查free_area上是否有连续的order个页满足页分配请求
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) { //7 考虑迁移类型
if (!free_area_empty(area, mt))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!free_area_empty(area, MIGRATE_CMA)) { //8 分配标志设置ALLOC_CMA, free_area中大于order的MIGRATE_CMA类型类型链上有页
return true;
}
#endif
if (alloc_harder && !free_area_empty(area, MIGRATE_HIGHATOMIC)) //9 分配标志设置ALLOC_HARDER|ALLOC_OOM, free_area中大于order的MIGRATE_HIGHATOMIC类型链上有页
return true;
}
return false;
}
1) 分配标志设置ALLOC_HIGH,水位值调整到原来的1/2
2) 分配标志设置ALLOC_HIGH & ALLOC_OOM,水位值变为原来的1/4
3) 分配标志设置ALLOC_HIGH & ALLOC_HARDER,水位值变为原来的3/8
4) 水位线判断条件,剩余内存大于水位值加lowmem_reserve的和
5) 如果是1页不用考虑是否连续的2^order
6)从oreder阶开始检查free_area上是否有连续的order个页满足页分配请求 7) 考虑迁移类型
8)分配标志设置ALLOC_CMA, free_area中大于order的MIGRATE_CMA类型类型链上有页
9) 分配标志设置ALLOC_HARDER | ALLOC_OOM, free_area中大于order MIGRATE_HIGHATOMIC类型链上有页;
-
两种页回收方式
1)direct reclaim
在内存分配时发现空闲内存严重不足(低于min水位线),直接启动内存回收操作;在direct reclaim模式下,分配和回收是同步的关系,内存分配的过程会被内存回收的操作所阻塞,增加等待的时间。
2)background reclaim
一个更理想的情况是,我们能在内存压力不那么大的时候,就提前启动内存回收。而且,在某些场景下(比如在interrupt context或持有spinlock时),内存分配根本就是不能等待的。因此,Linux中另一种更为常见的内存回收机制是使用kswapd。kswapd进程异步被唤醒扫描zone回收内存。
总结:
1)尽量避免出现低于min水位线的情况,此时做同步的内存回收会阻塞当前分配流程
2)kswap在低于low水位线被唤醒做异步内存回收,将剩余内存保持在high水位线以上后睡眠,应设置合理的high-low水位线值保证出现burst allocation的情形,回收速度比不上分配速度的情形;
3)提高low水位线,提前做后台内存回收,不要再内存很紧张的时候再唤醒kswapd;
4)min水位线是kswapd的兜底线,kswapd可以申请min水位线以下的内存
通过"/proc/vmstat"中的"pageoutrun"和"allocstall"来查看,两者分别代表了kswapd和direct reclaim启动的次数。 -
代码注释
__alloc_pages函数
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW; //1 分配标志设置LOW水位线标志
gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
if (unlikely(order >= MAX_ORDER)) { //判断分配order
WARN_ON_ONCE(!(gfp & __GFP_NOWARN));
return NULL;
}
gfp &= gfp_allowed_mask;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures
* movable zones are not used during allocation.
*/
gfp = current_gfp_context(gfp); //根据当前进程的分配上下文处理分配标志
alloc_gfp = gfp;
if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac,
&alloc_gfp, &alloc_flags))
return NULL;
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered.
*/
alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp);
/* First allocation attempt */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); //2 分配2^order页
if (likely(page))
goto out;
alloc_gfp = gfp;
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_gfp, order, &ac); //3
out:
if (memcg_kmem_enabled() && (gfp & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_gfp, ac.migratetype);
return page;
}
EXPORT_SYMBOL(__alloc_pages);
1)分配标志设置LOW水位线标志(ALLOC_WMARK_LOW);
2)走快速路径,分配2^order页,后面分析get_page_from_freelist函数
3)快速路径失败,走慢速路径,后面分析__alloc_pages_slowpath函数
get_page_from_freelist函数
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
bool no_fallback;
retry:
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;
z = ac->preferred_zoneref;
//1 遍历ac->zonelist中不大于ac->high_zoneidx的所有zone
for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
//如果使能cpuset而且设置了ALLOC_CPUSET标志就检查看当前CPU是否允许在内存域zone所在结点中分配内存
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* When allocating a page cache page for writing, we
* want to get it from a node that is within its dirty
* limit, such that no single node holds more than its
* proportional share of globally allowed dirty pages.
* The dirty limits take into account the node's
* lowmem reserves and high watermark so that kswapd
* should be able to balance it without having to
* write pages from its LRU list.
*
* XXX: For now, allow allocations to potentially
* exceed the per-node dirty limit in the slowpath
* (spread_dirty_pages unset) before going into reclaim,
* which is important when on a NUMA setup the allowed
* nodes are together not big enough to reach the
* global limit. The proper fix for these situations
* will require awareness of nodes in the
* dirty-throttling and the flusher threads.
*/
//ac->spread_dirty_pages不为零标识本次内存分配用于写,可能增加赃页数
if (ac->spread_dirty_pages) {
if (last_pgdat_dirty_limit == zone->zone_pgdat) //如果当前zone所在节点被标记为赃页超标就跳过
continue;
//检查zone所在节点赃页数是否超过限制
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
if (no_fallback && nr_online_nodes > 1 &&
zone != ac->preferred_zoneref->zone) {
int local_nid;
/*
* If moving to a remote node, retry but allow
* fragmenting fallbacks. Locality is more important
* than fragmentation avoidance.
*/
local_nid = zone_to_nid(ac->preferred_zoneref->zone);
if (zone_to_nid(zone) != local_nid) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
}
//获取分配所用的水位值
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) { //检查zone中空闲内存是否在水印之上
int ret;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* Watermark failed for this zone, but see if we can
* grow this zone if it contains deferred pages.
*/
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS) //如果设置无水位标志就尝试从当前选定zone中分配内存
goto try_this_zone;
//程序走到这里说明空闲页在水印之下,接下来需要做内存回收,但是下面两种情况除外,1)如果系统不允许内存回收;
//2)如果目标zone和当前zone的distance不小于RECLAIM_DISTANCE
if (!node_reclaim_enabled() ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
//函数node_reclaim做内存回收
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN: //没有扫描,设置禁止扫描标志等等
/* did not scan */
continue;
case NODE_RECLAIM_FULL: //没有可以回收的页了
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac->highest_zoneidx, alloc_flags)) //回收了部分页再次检查看是否满足水印限制
goto try_this_zone;
continue;
}
}
//到这里说明选定的zone里有空闲内存
try_this_zone:
page = rmqueue(ac->preferred_zoneref->zone, zone, order, //有时间重点看下rmqueue
gfp_mask, alloc_flags, ac->migratetype); //尝试分配页
if (page) { //清除一些标志或者设置联合页等等
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page; //返回成功分配的页
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
/*
* It's possible on a UMA machine to get through all zones that are
* fragmented. If avoiding fragmentation, reset and try again.
*/
if (no_fallback) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
return NULL;
}
1)获取水位线的值,__alloc_pages里面调用get_page_from_freelist前设置的是ALLOC_WMARK_LOW标志,这里拿到的是LOW水位线标志;
2)如果使能cpuset而且设置了ALLOC_CPUSET标志就检查看当前CPU是否允许在内存域zone所在结点中分配内存
3) ac->spread_dirty_pages不为零标识本次内存分配用于写,可能增加赃页数
4)如果当前zone所在节点被标记为赃页超标就跳过
5)检查zone所在节点赃页数是否超过限制
6)获取分配所用的水位值
7) 检查zone中空闲内存是否在水印之上
8)如果设置无水位标志就尝试从当前选定zone中分配内存
9) 程序走到这里说明空闲页在水印之下,接下来需要做内存回收,但是下面两种情况除外,1)如果系统不允许内存回收;
10)如果目标zone和当前zone的distance不小于RECLAIM_DISTANCE
11) 函数node_reclaim做内存回收
12)没有扫描,设置禁止扫描标志等等
13) 没有可以回收的页了
14)回收了部分页再次检查看是否满足水印限制
15)到这里说明选定的zone里有空闲内存
16)有时间重点看下rmqueue
17) 尝试分配页
18) 清除一些标志或者设置联合页等等
19) 返回成功分配的页
3 页回收的发起
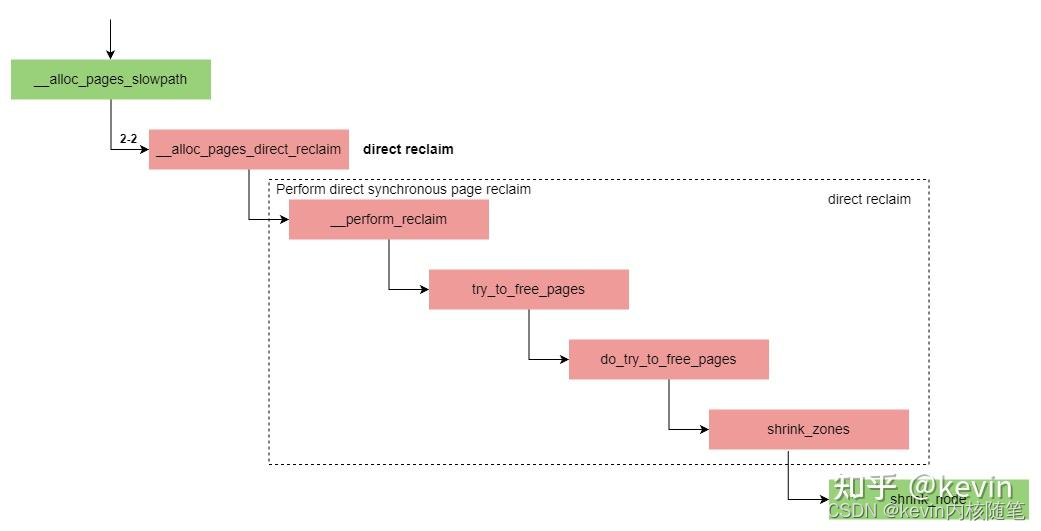
3.1 direct reclaim
1)内存分配时发现空闲内存严重不足,低于min水位线,直接启动内存回收操作,如2.2节中描述;
2)分配和回收是同步的关系,内存分配的过程会被内存回收的操作所阻塞,增加等待的时间;
2-1 direct reclaim部分
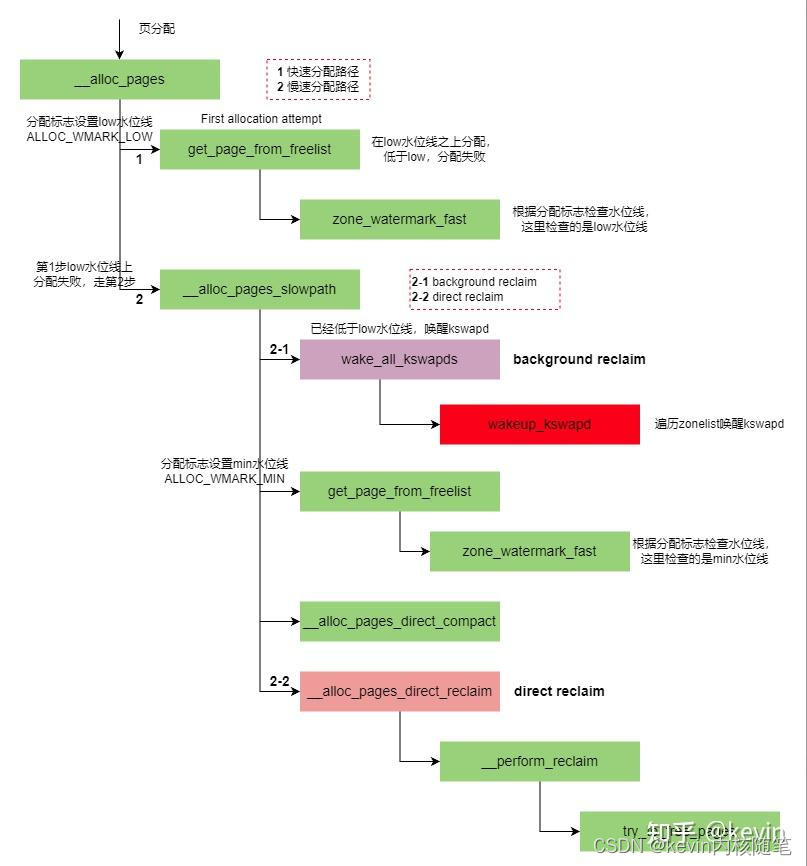
3.2 backgroud reclaim
1)内核线程kswapd负责异步回收内存,
2)每个node会创建一个kswapd%d的内核线程
3)申请内存时发现当前剩余内存低于low水位线唤醒kswapd进程,做异步的内存回收,直到剩余内存水位线高于high水位线,如前面2.2节描述
4)平衡active和inactive链表;
3.2.1 kswapd创建
/*
* This kswapd start function will be called by init and node-hot-add.
* On node-hot-add, kswapd will moved to proper cpus if cpus are hot-added.
*/
void kswapd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
if (pgdat->kswapd)
return;
pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid); //2
if (IS_ERR(pgdat->kswapd)) {
/* failure at boot is fatal */
BUG_ON(system_state < SYSTEM_RUNNING);
pr_err("Failed to start kswapd on node %d\n", nid);
pgdat->kswapd = NULL;
}
}
static int __init kswapd_init(void)
{
int nid;
swap_setup();
for_each_node_state(nid, N_MEMORY)
kswapd_run(nid); //1
return 0;
}
module_init(kswapd_init)
1)遍历每个node,调用kswapd_run;
2)创建kswapd内核线程,线程名kswapd%d,pgdat->kswapd保存了该node的kswapd内核线程的进程描述符;
node中和kswap相关的成员
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
... ...
int node_id;
wait_queue_head_t kswapd_wait; //1
wait_queue_head_t pfmemalloc_wait; //2
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */ //3
int kswapd_order; //4
enum zone_type kswapd_highest_zoneidx; //5
int kswapd_failures; //回收过程中没有达到预期的次数/* Number of 'reclaimed == 0' runs */
... ...
} pg_data_t;
1)kswapd_wait 等待队列,在需要唤醒kswapd的时候使用;
2)pfmemalloc_wait 暂时不关注;
3)kswapd 当前node上的kswapd内核线程的进程描述符;
4)kswapd_order 作为参数传递给内核线程kswapd,wakeup_kswapd函数中赋值,max(pgdat->kswapd_order, order),其中order时申请页时传入的order;
5)kswapd_highest_zoneidx 作为参数传递给内核线程kswapd,通过分配掩码计算出来zone的索引,标识页面分配器分配的最高zone;
3.2.2 kswapd唤醒
1)内存申请时,如果在low水位上无法申请内存,会通过wakeup_kswapd 唤醒kwapd
注意这里的ALLOC_KSWAPD标志,是在调用内存申请函数传入的标志参数中的,比如GFP_KERNEL
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
... ...
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
... ...
}
#define ALLOC_KSWAPD 0x800 /* allow waking of kswapd, __GFP_KSWAPD_RECLAIM set */
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define __GFP_RECLAIM ((__force gfp_t)(___GFP_DIRECT_RECLAIM|___GFP_KSWAPD_RECLAIM))
#define ___GFP_KSWAPD_RECLAIM 0x800u
*
static void wake_all_kswapds(unsigned int order, gfp_t gfp_mask,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
pg_data_t *last_pgdat = NULL;
enum zone_type highest_zoneidx = ac->highest_zoneidx; //1
for_each_zone_zonelist_nodemask(zone, z, ac->zonelist, highest_zoneidx,
ac->nodemask) {
if (last_pgdat != zone->zone_pgdat)
wakeup_kswapd(zone, gfp_mask, order, highest_zoneidx); //2
last_pgdat = zone->zone_pgdat;
}
}
1)页分配过程中通过掩码计算的分配最高zone;
2)遍历zonelist 唤醒内核线程kswapd;
3.2.3 kswapd执行
1)回收到可以分配出申请的内存且每个zone高于high水位线
2)从高向低方向扫描zone,跳过剩余内存大于high水位线的zone,回收直到至少有一个zone满足要求(剩余内存大于high水位线且能满足当前申请的order);
3)每次扫描inactive链上多少个page,从所有页面>>12(priority) 逐步加大粒度;
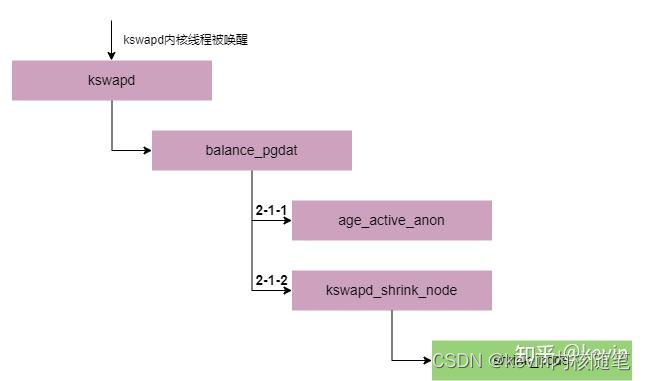
代码注释
/*
* The background pageout daemon, started as a kernel thread
* from the init process.
*
* This basically trickles out pages so that we have _some_
* free memory available even if there is no other activity
* that frees anything up. This is needed for things like routing
* etc, where we otherwise might have all activity going on in
* asynchronous contexts that cannot page things out.
*
* If there are applications that are active memory-allocators
* (most normal use), this basically shouldn't matter.
*/
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int highest_zoneidx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t *)p;
struct task_struct *tsk = current;
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id); //1
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(tsk, cpumask);
/*
* Tell the memory management that we're a "memory allocator",
* and that if we need more memory we should get access to it
* regardless (see "__alloc_pages()"). "kswapd" should
* never get caught in the normal page freeing logic.
*
* (Kswapd normally doesn't need memory anyway, but sometimes
* you need a small amount of memory in order to be able to
* page out something else, and this flag essentially protects
* us from recursively trying to free more memory as we're
* trying to free the first piece of memory in the first place).
*/
tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD; //2
set_freezable();
WRITE_ONCE(pgdat->kswapd_order, 0);
WRITE_ONCE(pgdat->kswapd_highest_zoneidx, MAX_NR_ZONES);
for ( ; ; ) {
bool ret;
alloc_order = reclaim_order = READ_ONCE(pgdat->kswapd_order);
highest_zoneidx = kswapd_highest_zoneidx(pgdat,
highest_zoneidx);
kswapd_try_sleep:
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
highest_zoneidx);
/* Read the new order and highest_zoneidx */
alloc_order = READ_ONCE(pgdat->kswapd_order);
highest_zoneidx = kswapd_highest_zoneidx(pgdat,
highest_zoneidx);
WRITE_ONCE(pgdat->kswapd_order, 0);
WRITE_ONCE(pgdat->kswapd_highest_zoneidx, MAX_NR_ZONES);
ret = try_to_freeze();
if (kthread_should_stop())
break;
/*
* We can speed up thawing tasks if we don't call balance_pgdat
* after returning from the refrigerator
*/
if (ret)
continue;
/*
* Reclaim begins at the requested order but if a high-order
* reclaim fails then kswapd falls back to reclaiming for
* order-0. If that happens, kswapd will consider sleeping
* for the order it finished reclaiming at (reclaim_order)
* but kcompactd is woken to compact for the original
* request (alloc_order).
*/
trace_mm_vmscan_kswapd_wake(pgdat->node_id, highest_zoneidx,
alloc_order);
reclaim_order = balance_pgdat(pgdat, alloc_order,
highest_zoneidx);
if (reclaim_order < alloc_order)
goto kswapd_try_sleep;
}
tsk->flags &= ~(PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD);
return 0;
}
1)kswapd执行时传入的参数时pgdat,这里通过node id拿到当前的CPU掩码
2)设置内核线程kswapd的进程描述福的标志,设置PF_MEMALLOC、PF_SWAPWRITE、PF_SWAPD这几个标志,其中PF_MEMALLOC表示可以申请min水位线以下的内存,PF_SWAPWRITE允许写交换分区,PF_SWAPD表示是kswapd线程;
3.3 shrink_node
两种内存回收最终都调到了shrink_node函数,shrink_node函数完成页回收,
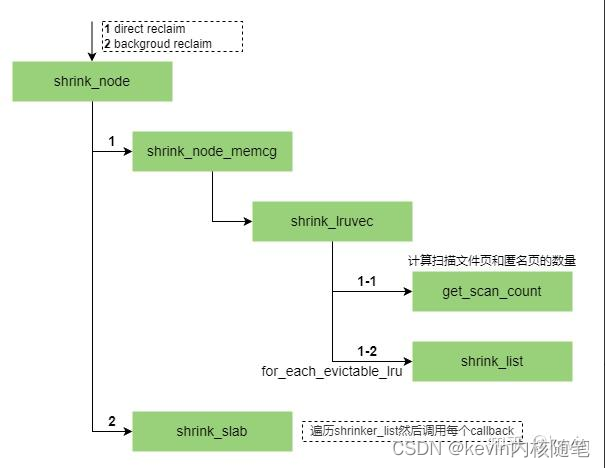
4 页回收的实现
先回答页回收,回收的是哪些页?为啥这些页能回收,哪些页不能回收;
4.1 页的组织方式
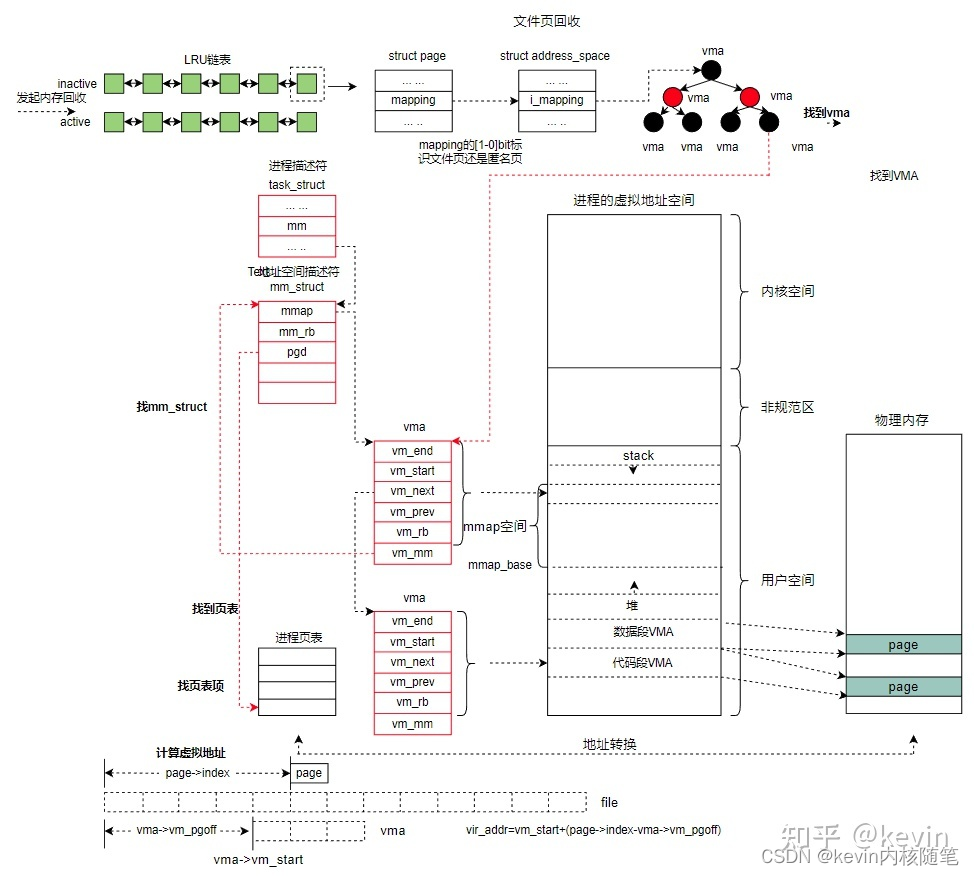
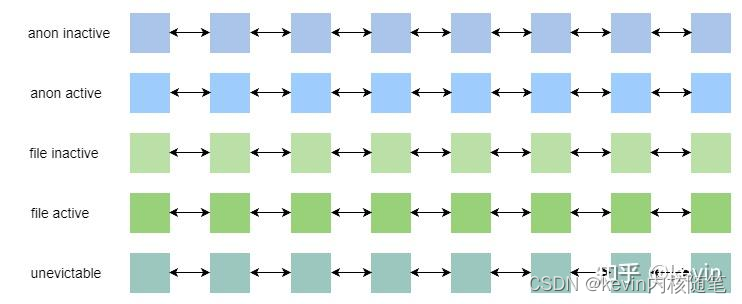
每个node上,根据页的类型(文件的和匿名的)和活跃程度(最近是否被访问)分成5条链表,再加上不可回收的页,共五条链表;
问题:页回收回收哪些页?什么是匿名页,文件页?
匿名页和文件页是从页的内容是否和文件关联的角度描述的,
/*
* We do arithmetic on the LRU lists in various places in the code,
* so it is important to keep the active lists LRU_ACTIVE higher in
* the array than the corresponding inactive lists, and to keep
* the *_FILE lists LRU_FILE higher than the corresponding _ANON lists.
*
* This has to be kept in sync with the statistics in zone_stat_item
* above and the descriptions in vmstat_text in mm/vmstat.c
*/
#define LRU_BASE 0
#define LRU_ACTIVE 1
#define LRU_FILE 2
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
struct zone node_zones[MAX_NR_ZONES];
... ...
/* Fields commonly accessed by the page reclaim scanner */
/*
* NOTE: THIS IS UNUSED IF MEMCG IS ENABLED.
*
* Use mem_cgroup_lruvec() to look up lruvecs.
*/
struct lruvec __lruvec; //1
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
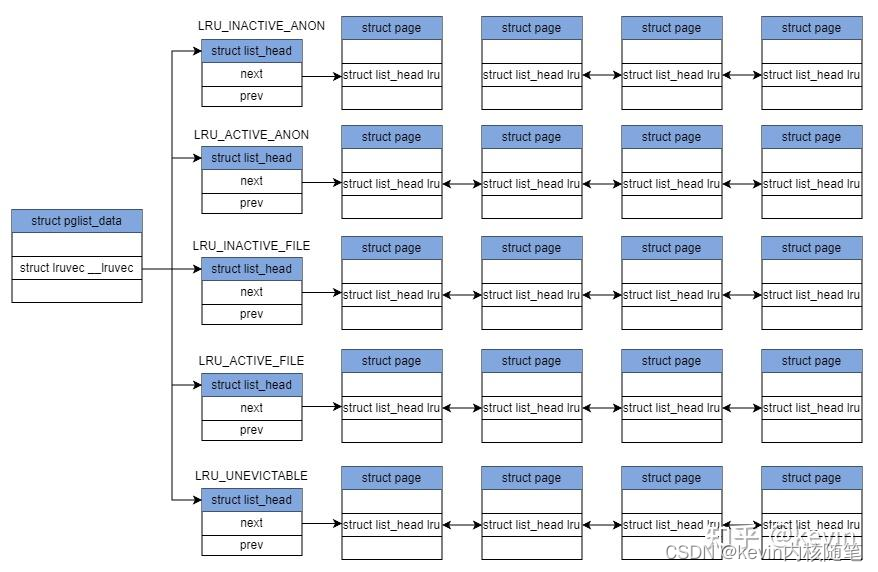
1)__lruvec 做page reclaim的lru链;
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE, //匿名页的inactive链表
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE, //匿名页的active链表
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE, //文件页的inactive链表
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE, //文件页的active链表
LRU_UNEVICTABLE, //不可回收页链表
NR_LRU_LISTS
};
struct lruvec {
struct list_headlists[NR_LRU_LISTS]; //2 链表数组
/* per lruvec lru_lock for memcg */
spinlock_tlru_lock; //3
/*
* These track the cost of reclaiming one LRU - file or anon -
* over the other. As the observed cost of reclaiming one LRU
* increases, the reclaim scan balance tips toward the other.
*/
unsigned long anon_cost; //4
unsigned long file_cost; //5
/* Non-resident age, driven by LRU movement */
atomic_long_t nonresident_age; //6
/* Refaults at the time of last reclaim cycle */
unsigned long refaults[ANON_AND_FILE]; //7
/* Various lruvec state flags (enum lruvec_flags) */
unsigned longflags;
#ifdef CONFIG_MEMCG
struct pglist_data *pgdat;
#endif
};
2) lists[NR_LRU_LISTS] 链表数组,包含五条链表,文件页、匿名页的active和inactive,不可回收的页
3)lru_lock 防止并发的自旋锁
4)anon_cost 回收的dirty匿名页的数量
5)file_cost 回收的dirty文件页的数量
6)nonresident_age 从inactive移出页的数量,包括页面从inactive链表升级到active链表和页面从inactive链表移出回收;
7)refaults[ANON_AND_FILE];
4.8内核之前,LRU链表是按照zone配置的,只有active和inactive链表,为什么从zone改成node?
32位处理器时代设计的,同一个内存节点的不同zone中存在着不同的页面老化速度,举个例子,应用程序在不同的zone中非配内存,在zone[HIGH]中分配的页面已经回收了,在zone[NORMAL]中非配的页面还在LRU链表中,理想情况下他们应该在同一时间周期内被回收。
4.1.2 LRU链表建立
页面是如何加入LRU链表的?
1)page的flag成员使用了两个标志PG_referenced和PG_active两个标志标识页面的活跃程度,PG_active 标识活跃程度(0 inactive链 1 active链);
2)PG_referenced 标志位标识最近是否被访问过 ,0 最近未被访问过,1 最近被访问过
3)page通过FIFO的方式插入active和inactive链;

include/linux/page-flags-layout.h
/*
* page->flags layout:
*
* There are five possibilities for how page->flags get laid out. The first
* pair is for the normal case without sparsemem. The second pair is for
* sparsemem when there is plenty of space for node and section information.
* The last is when there is insufficient space in page->flags and a separate
* lookup is necessary.
*
* No sparsemem or sparsemem vmemmap: | NODE | ZONE | ... | FLAGS |
* " plus space for last_cpupid: | NODE | ZONE | LAST_CPUPID ... | FLAGS |
* classic sparse with space for node:| SECTION | NODE | ZONE | ... | FLAGS |
* " plus space for last_cpupid: | SECTION | NODE | ZONE | LAST_CPUPID ... | FLAGS |
* classic sparse no space for node: | SECTION | ZONE | ... | FLAGS |
*/
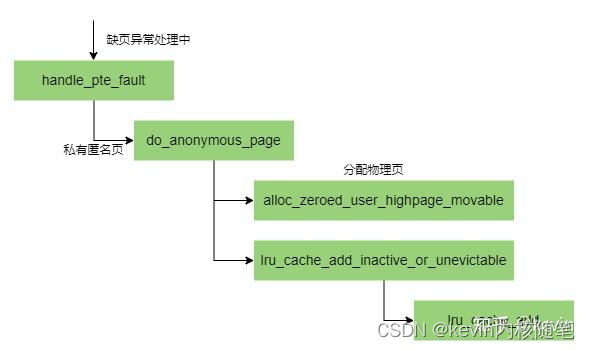
匿名页LRU链表建立
/**
* lru_cache_add - add a page to a page list
* @page: the page to be added to the LRU.
*
* Queue the page for addition to the LRU via pagevec. The decision on whether
* to add the page to the [in]active [file|anon] list is deferred until the
* pagevec is drained. This gives a chance for the caller of lru_cache_add()
* have the page added to the active list using mark_page_accessed().
*/
void lru_cache_add(struct page *page)
{
struct pagevec *pvec;
VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page); //检查标志,同时设置active和unevictable触发BUG_ON
VM_BUG_ON_PAGE(PageLRU(page), page);
get_page(page);
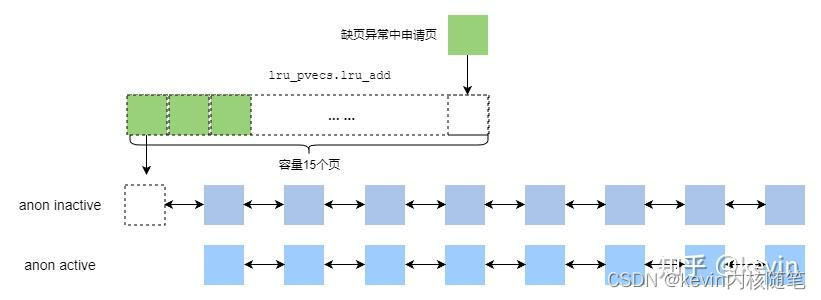
local_lock(&lru_pvecs.lock);
pvec = this_cpu_ptr(&lru_pvecs.lru_add); //拿到当前cpu的lru_pvecs.lru_add
if (pagevec_add_and_need_flush(pvec, page)) //判断15个是不是
__pagevec_lru_add(pvec); //调用 __pagevec_lru_add
local_unlock(&lru_pvecs.lock);
}
/*
* Add the passed pages to the LRU, then drop the caller's refcount
* on them. Reinitialises the caller's pagevec.
*/
void __pagevec_lru_add(struct pagevec *pvec)
{
int i;
struct lruvec *lruvec = NULL;
unsigned long flags = 0;
for (i = 0; i < pagevec_count(pvec); i++) {
struct page *page = pvec->pages[i]; //循环拿到每一个页
lruvec = relock_page_lruvec_irqsave(page, lruvec, &flags); //拿到lurvec
__pagevec_lru_add_fn(page, lruvec); //调用__pagevec_lru_add_fn处理page
}
if (lruvec)
unlock_page_lruvec_irqrestore(lruvec, flags);
release_pages(pvec->pages, pvec->nr);
pagevec_reinit(pvec);
}
static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec)
{
int was_unevictable = TestClearPageUnevictable(page);
int nr_pages = thp_nr_pages(page);
VM_BUG_ON_PAGE(PageLRU(page), page);
/*
* Page becomes evictable in two ways:
* 1) Within LRU lock [munlock_vma_page() and __munlock_pagevec()].
* 2) Before acquiring LRU lock to put the page to correct LRU and then
* a) do PageLRU check with lock [check_move_unevictable_pages]
* b) do PageLRU check before lock [clear_page_mlock]
*
* (1) & (2a) are ok as LRU lock will serialize them. For (2b), we need
* following strict ordering:
*
* #0: __pagevec_lru_add_fn #1: clear_page_mlock
*
* SetPageLRU() TestClearPageMlocked()
* smp_mb() // explicit ordering // above provides strict
* // ordering
* PageMlocked() PageLRU()
*
*
* if '#1' does not observe setting of PG_lru by '#0' and fails
* isolation, the explicit barrier will make sure that page_evictable
* check will put the page in correct LRU. Without smp_mb(), SetPageLRU
* can be reordered after PageMlocked check and can make '#1' to fail
* the isolation of the page whose Mlocked bit is cleared (#0 is also
* looking at the same page) and the evictable page will be stranded
* in an unevictable LRU.
*/
SetPageLRU(page); //设置LRU标志
smp_mb__after_atomic();
if (page_evictable(page)) {
if (was_unevictable)
__count_vm_events(UNEVICTABLE_PGRESCUED, nr_pages);
} else {
ClearPageActive(page);
SetPageUnevictable(page);
if (!was_unevictable)
__count_vm_events(UNEVICTABLE_PGCULLED, nr_pages);
}
add_page_to_lru_list(page, lruvec);
trace_mm_lru_insertion(page);
}
static __always_inline void add_page_to_lru_list(struct page *page,
struct lruvec *lruvec)
{
enum lru_list lru = page_lru(page); //获取页应该加载哪条LRU链表上
update_lru_size(lruvec, lru, page_zonenum(page), thp_nr_pages(page));
list_add(&page->lru, &lruvec->lists[lru]);
}
static __always_inline enum lru_list page_lru(struct page *page)
{
enum lru_list lru;
VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page); //9 page不可能同时置PG_active和PG_unevictable
if (PageUnevictable(page)) //10 不可回收页,返回不可回收LRU链的下标值
return LRU_UNEVICTABLE;
lru = page_is_file_lru(page) ? LRU_INACTIVE_FILE : LRU_INACTIVE_ANON; //11 判断有是文件页还是匿名页
if (PageActive(page)) //12 注意这里代码,pagecache第一次预读页到page cache的时候,同步会加入到inactive链表(第一次访问页的时候设置了PG_reference,没有设置PG_active)
lru += LRU_ACTIVE;
return lru;
}
文件页LRU链表建立
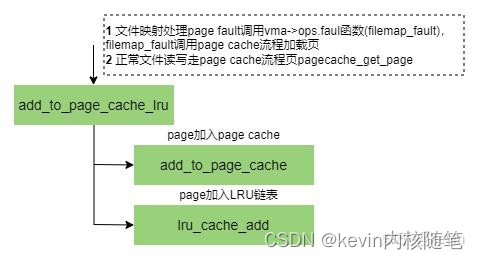

int add_to_page_cache_lru(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
void *shadow = NULL;
int ret;
__SetPageLocked(page);
ret = __add_to_page_cache_locked(page, mapping, offset,
gfp_mask, &shadow); //1 把page加到page cache的xarray中
if (unlikely(ret))
__ClearPageLocked(page);
else {
/*
* The page might have been evicted from cache only
* recently, in which case it should be activated like
* any other repeatedly accessed page.
* The exception is pages getting rewritten; evicting other
* data from the working set, only to cache data that will
* get overwritten with something else, is a waste of memory.
*/
WARN_ON_ONCE(PageActive(page));
if (!(gfp_mask & __GFP_WRITE) && shadow) //2 不是写操作& shadow不为空(回收后重新读入的page)
workingset_refault(page, shadow); //3第一次加入page cache的页shadow为NULL,如果是被回收重新读入page cache,对应的shadow不为空
lru_cache_add(page); //4 把page加到LRU链表
}
return ret;
}
EXPORT_SYMBOL_GPL(add_to_page_cache_lru);
1)把page加到page cache的xarray中;
2)不是写操作& shadow不为空(回收后重新读入的page);
3)第一次加入page cache的页shadow为NULL,如果是被回收重新读入page cache,对应的shadow不为空;
4) 调用lru_cache_add把page加到LRU链表;
页面的老化
对于有映射的页面(mapped页面),在回收扫描时,通过 reverse mapping 检查 PTE 的 Access 位来判断页面最近有没有被访问过。
对于文件缓存页面(页面在文件的 offset 来作为索引的),则可以在 page 被访问后,立即使用 mark_page_accessed() 进行 PG_referenced 的标记。
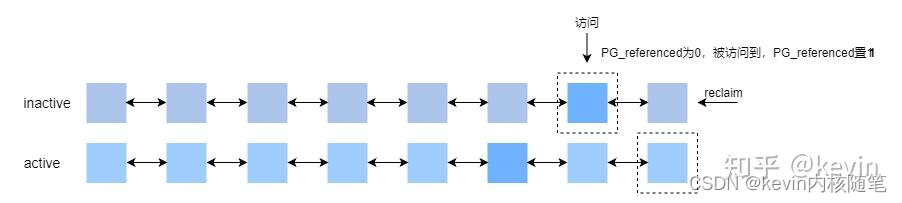
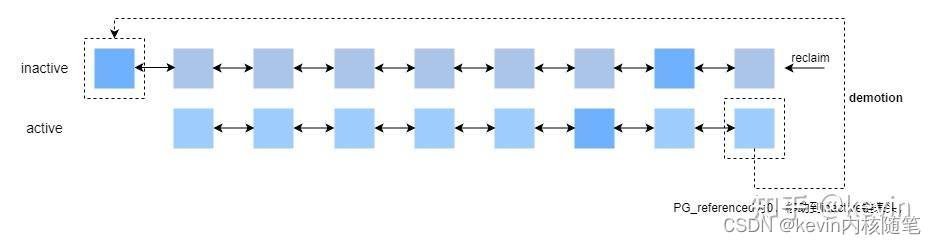
1)inactive,unreferenced->inactive,referenced
inactive链上PG_reference为0的页被访问后PG_reference变为1
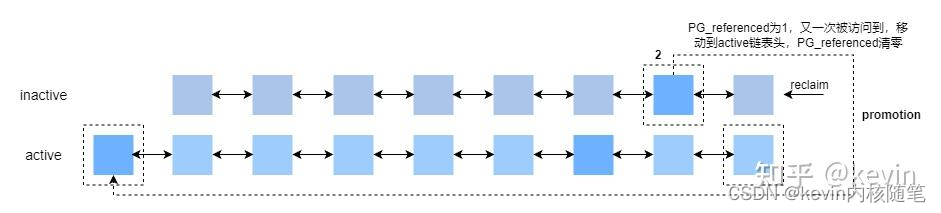
2)inactive,referenced->active,unreferenced
inactive中PG_referenced为1的page再次被访问时,将PG_active置1,PG_reference清0放入active链表头部, 也就是说该page在inactive中被访问了两次,两个PG_referenced换来了PG_active,即二次机会法,这个从inactive链表到active链表的过程叫promotion。(这个是在回收inactive链表时判断每个页的处理方式是调用rmap判断pte的young标志做的,见4.8.1);
3)active,unreferenced->active,referenced
active链的尾端page的PG_reference为1,被访问过了,放回active链头,把PG_reference清0;
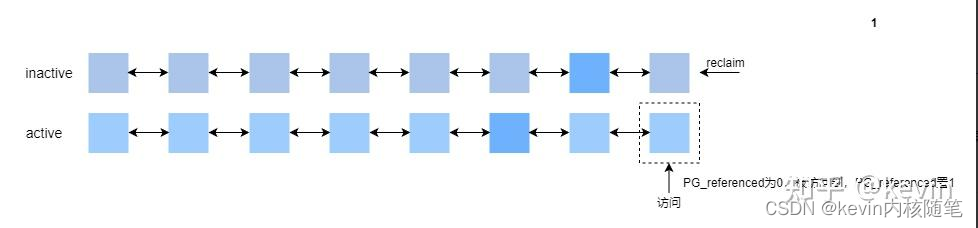
4)active->inactive
当 active list 中的一个 page 在到达链表尾端时,如果其 PG_referenced 位为 1,则被放回链表头部,但同时其PG_referenced 会被清 0。如果其 PG_referenced 位为 0,那么就会被放入 inactive list 的头部,这个过程叫做demotion;
/*
* Mark a page as having seen activity.
*
* inactive,unreferenced->inactive,referenced //1
* inactive,referenced->active,unreferenced //2
* active,unreferenced->active,referenced //3
*
* When a newly allocated page is not yet visible, so safe for non-atomic ops,
* __SetPageReferenced(page) may be substituted for mark_page_accessed(page).
*/
void mark_page_accessed(struct page *page)
{
page = compound_head(page); //复合页取head page
if (!PageReferenced(page)) { //PG_reference没有置位时 ,对应情况1和3, inactive,unreferenced->inactive,referenced, active,unreferenced->active,referenced
SetPageReferenced(page); //PG_reference置位
} else if (PageUnevictable(page)) { //如果是不可回收页
/*
* Unevictable pages are on the "LRU_UNEVICTABLE" list. But,
* this list is never rotated or maintained, so marking an
* evictable page accessed has no effect.
*/
} else if (!PageActive(page)) { //PG_active没有置位时, 对应情况2, inactive,referenced->active,unreferenced
/*
* If the page is on the LRU, queue it for activation via
* lru_pvecs.activate_page. Otherwise, assume the page is on a
* pagevec, mark it active and it'll be moved to the active
* LRU on the next drain.
*/
if (PageLRU(page))
activate_page(page);
else
__lru_cache_activate_page(page);
ClearPageReferenced(page);
workingset_activation(page);
}
if (page_is_idle(page))
clear_page_idle(page);
}
EXPORT_SYMBOL(mark_page_accessed);
页面回收过程中扫描inactive LRU链表时, page_check_refereces被调用,
4.2 回收时页的选择
两个维度,回收时选择匿名页还是文件页,回收时扫描页的数量是多少?
1)做页回收时,匿名页和文件页的回收代价是不一样的,干净的文件页可以直接丢弃,脏文件页要回写,匿名页要做逆向映射断开映射并重新填写页表项把内容写入交换分区;映射的文件页也要做逆向映射断开映射内容写入文件;
2)回收过程中扫描文件页和匿名页的数量怎么确定?扫描多少个匿名页,多少个文件页?
回收时扫描的页数:
扫描优先级用来控制一次扫描的页数,如果扫描优先级是n,那么一次扫描的页数是LRU中链表总数>>n,扫描优先级越小扫描的页数越多,页回收算法扫描优先级默认从12开始,如果没能达成回收目标,就减小扫描优先级的值继续扫描,直至扫描优先级的值为0;
回收时扫描文件页还是匿名页?
1)没有交换分区,扫描文件页
2)swappiness=0 扫描文件页
3)系统接近oom(sc->priority=0)且设置了swappiness,文件页和匿名页都扫描
4)剩余内存+LRU链表上的文件页小于highs水位线,此时回收文件页已经没啥用了,回收匿名页
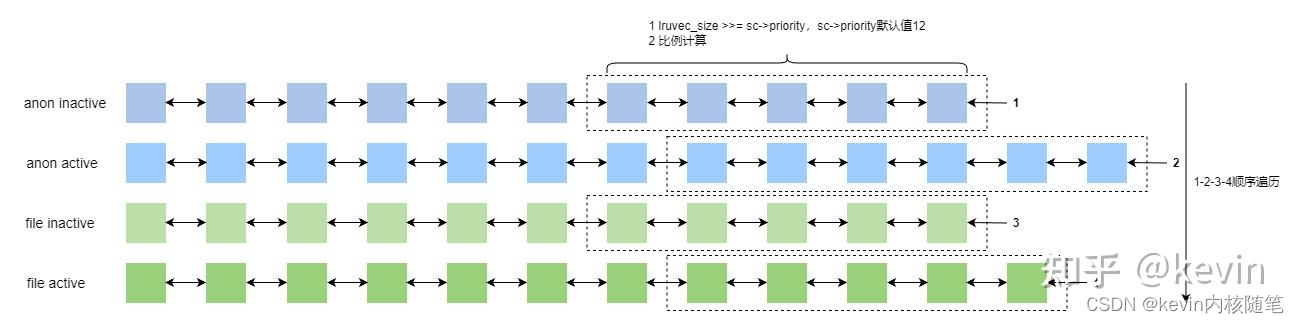
回收时扫描文件页和匿名页的数量
1)如果只扫面一种页,scan >>= sc->priority(扫描优先级,默认值12)
2)文件页匿名页都要扫描的话,文件页和匿名页的数量按比例计算,比例计算在代码里面;
代码注释
/*
* Determine how aggressively the anon and file LRU lists should be
* scanned. The relative value of each set of LRU lists is determined
* by looking at the fraction of the pages scanned we did rotate back
* onto the active list instead of evict.
*
* nr[0] = anon inactive pages to scan; nr[1] = anon active pages to scan
* nr[2] = file inactive pages to scan; nr[3] = file active pages to scan
*/
static void get_scan_count(struct lruvec *lruvec, struct scan_control *sc,
unsigned long *nr)
{
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
struct mem_cgroup *memcg = lruvec_memcg(lruvec);
unsigned long anon_cost, file_cost, total_cost;
int swappiness = mem_cgroup_swappiness(memcg);
u64 fraction[ANON_AND_FILE];
u64 denominator = 0; /* gcc */
enum scan_balance scan_balance;
unsigned long ap, fp;
enum lru_list lru;
/* If we have no swap space, do not bother scanning anon pages. */
if (!sc->may_swap || !can_reclaim_anon_pages(memcg, pgdat->node_id, sc)) {
scan_balance = SCAN_FILE; //1
goto out;
}
/*
* Global reclaim will swap to prevent OOM even with no
* swappiness, but memcg users want to use this knob to
* disable swapping for individual groups completely when
* using the memory controller's swap limit feature would be
* too expensive.
*/
if (cgroup_reclaim(sc) && !swappiness) {
scan_balance = SCAN_FILE; //2
goto out;
}
/*
* Do not apply any pressure balancing cleverness when the
* system is close to OOM, scan both anon and file equally
* (unless the swappiness setting disagrees with swapping).
*/
if (!sc->priority && swappiness) {
scan_balance = SCAN_EQUAL; //3
goto out;
}
/*
* If the system is almost out of file pages, force-scan anon.
*/
if (sc->file_is_tiny) {
scan_balance = SCAN_ANON; //4
goto out;
}
/*
* If there is enough inactive page cache, we do not reclaim
* anything from the anonymous working right now.
*/
if (sc->cache_trim_mode) {
scan_balance = SCAN_FILE; //5
goto out;
}
scan_balance = SCAN_FRACT; //6
/*
* Calculate the pressure balance between anon and file pages.
*
* The amount of pressure we put on each LRU is inversely
* proportional to the cost of reclaiming each list, as
* determined by the share of pages that are refaulting, times
* the relative IO cost of bringing back a swapped out
* anonymous page vs reloading a filesystem page (swappiness).
*
* Although we limit that influence to ensure no list gets
* left behind completely: at least a third of the pressure is
* applied, before swappiness.
*
* With swappiness at 100, anon and file have equal IO cost.
*/
total_cost = sc->anon_cost + sc->file_cost;
anon_cost = total_cost + sc->anon_cost;
file_cost = total_cost + sc->file_cost;
total_cost = anon_cost + file_cost;
ap = swappiness * (total_cost + 1);
ap /= anon_cost + 1;
fp = (200 - swappiness) * (total_cost + 1);
fp /= file_cost + 1;
fraction[0] = ap;
fraction[1] = fp;
denominator = ap + fp;
out:
for_each_evictable_lru(lru) {
int file = is_file_lru(lru);
unsigned long lruvec_size;
unsigned long low, min;
unsigned long scan;
lruvec_size = lruvec_lru_size(lruvec, lru, sc->reclaim_idx);
mem_cgroup_protection(sc->target_mem_cgroup, memcg,
&min, &low);
if (min || low) {
/*
* Scale a cgroup's reclaim pressure by proportioning
* its current usage to its memory.low or memory.min
* setting.
*
* This is important, as otherwise scanning aggression
* becomes extremely binary -- from nothing as we
* approach the memory protection threshold, to totally
* nominal as we exceed it. This results in requiring
* setting extremely liberal protection thresholds. It
* also means we simply get no protection at all if we
* set it too low, which is not ideal.
*
* If there is any protection in place, we reduce scan
* pressure by how much of the total memory used is
* within protection thresholds.
*
* There is one special case: in the first reclaim pass,
* we skip over all groups that are within their low
* protection. If that fails to reclaim enough pages to
* satisfy the reclaim goal, we come back and override
* the best-effort low protection. However, we still
* ideally want to honor how well-behaved groups are in
* that case instead of simply punishing them all
* equally. As such, we reclaim them based on how much
* memory they are using, reducing the scan pressure
* again by how much of the total memory used is under
* hard protection.
*/
unsigned long cgroup_size = mem_cgroup_size(memcg);
unsigned long protection;
/* memory.low scaling, make sure we retry before OOM */
if (!sc->memcg_low_reclaim && low > min) {
protection = low;
sc->memcg_low_skipped = 1;
} else {
protection = min;
}
/* Avoid TOCTOU with earlier protection check */
cgroup_size = max(cgroup_size, protection);
scan = lruvec_size - lruvec_size * protection /
(cgroup_size + 1);
/*
* Minimally target SWAP_CLUSTER_MAX pages to keep
* reclaim moving forwards, avoiding decrementing
* sc->priority further than desirable.
*/
scan = max(scan, SWAP_CLUSTER_MAX);
} else {
scan = lruvec_size;
}
scan >>= sc->priority;
/*
* If the cgroup's already been deleted, make sure to
* scrape out the remaining cache.
*/
if (!scan && !mem_cgroup_online(memcg))
scan = min(lruvec_size, SWAP_CLUSTER_MAX);
switch (scan_balance) {
case SCAN_EQUAL:
/* Scan lists relative to size */
break;
case SCAN_FRACT:
/*
* Scan types proportional to swappiness and
* their relative recent reclaim efficiency.
* Make sure we don't miss the last page on
* the offlined memory cgroups because of a
* round-off error.
*/
scan = mem_cgroup_online(memcg) ?
div64_u64(scan * fraction[file], denominator) :
DIV64_U64_ROUND_UP(scan * fraction[file],
denominator);
break;
case SCAN_FILE:
case SCAN_ANON:
/* Scan one type exclusively */
if ((scan_balance == SCAN_FILE) != file)
scan = 0;
break;
default:
/* Look ma, no brain */
BUG();
}
nr[lru] = scan;
}
}
1)文件没有swap空间,扫描文件页
2)swappiness等于0,扫描文件页
3)!sc->priority && swappiness 为真,同等力度扫描文件页和匿名页
4)设置了sc->file_is_tiny,扫描匿名页
5)如果设置了sc->cache_trim_mode,扫描文件页
6)前面的条件都不满足,按比例扫描文件页和匿名页;
4.3 inactive和active平衡
1)inactive和active链表的矛盾关系;
2)希望匿名页的inactive链表越短越好,这样做页回收时会相对容易一些
3)文件页的inactive链应该足够短,这样可以把大部分的页留在active链上避免被回收掉,
4)inactive链也应该足够大,这样页有机会在回收之前被再次被访问到
https://lwn.net/Articles/495543
/*
* The inactive anon list should be small enough that the VM never has
* to do too much work.
*
* The inactive file list should be small enough to leave most memory
* to the established workingset on the scan-resistant active list,
* but large enough to avoid thrashing the aggregate readahead window.
*
* Both inactive lists should also be large enough that each inactive
* page has a chance to be referenced again before it is reclaimed.
*
* If that fails and refaulting is observed, the inactive list grows.
*
* The inactive_ratio is the target ratio of ACTIVE to INACTIVE pages
* on this LRU, maintained by the pageout code. An inactive_ratio
* of 3 means 3:1 or 25% of the pages are kept on the inactive list.
*
* total target max
* memory ratio inactive
* -------------------------------------
* 10MB 1 5MB
* 100MB 1 50MB
* 1GB 3 250MB
* 10GB 10 0.9GB
* 100GB 31 3GB
* 1TB 101 10GB
* 10TB 320 32GB
*/
static bool inactive_is_low(struct lruvec *lruvec, enum lru_list inactive_lru)
{
enum lru_list active_lru = inactive_lru + LRU_ACTIVE;
unsigned long inactive, active;
unsigned long inactive_ratio;
unsigned long gb;
inactive = lruvec_page_state(lruvec, NR_LRU_BASE + inactive_lru);
active = lruvec_page_state(lruvec, NR_LRU_BASE + active_lru);
gb = (inactive + active) >> (30 - PAGE_SHIFT);
if (gb)
inactive_ratio = int_sqrt(10 * gb);
else
inactive_ratio = 1;
return inactive * inactive_ratio < active;
}
4.4 refault distance算法
https://zhuanlan.zhihu.com/p/502768917
4.5 跟踪LRU活动情况
页面回收是在页面申请的上下文或者kswapd上下文中做的,LRU链表中,页面被其他进程释放了,那么LRU链表如何知道页面已经被释放了,换句话说就是存在多个内核路径同时操作LRU链表释放页的可能,即并发问题。
4.6 判断页回收完成
每次触发页回收后,页回收要回收到什么程度回收才算结束?
剩余内存高于high水位线,并且能分配出order(申请时的order)次幂个连续的页面。
/*
* Returns true if there is an eligible zone balanced for the request order
* and highest_zoneidx
*/
static bool pgdat_balanced(pg_data_t *pgdat, int order, int highest_zoneidx)
{
int i;
unsigned long mark = -1;
struct zone *zone;
/*
* Check watermarks bottom-up as lower zones are more likely to
* meet watermarks.
*/
for (i = 0; i <= highest_zoneidx; i++) { //1
zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
mark = high_wmark_pages(zone);
if (zone_watermark_ok_safe(zone, order, mark, highest_zoneidx)) //2
return true;
}
/*
* If a node has no populated zone within highest_zoneidx, it does not
* need balancing by definition. This can happen if a zone-restricted
* allocation tries to wake a remote kswapd.
*/
if (mark == -1)
return true;
return false;
}
1)从低zone向高zone遍历每一个zone;
2)zone_watermark_ok_safe函数中判断如果剩余内存高于high水位线,并且能分配出order次幂个连续的页面。
4.7 页回收优化
页回收做过的大的优化,待完成,有空贴一下;
4.8 回收active和inactive页
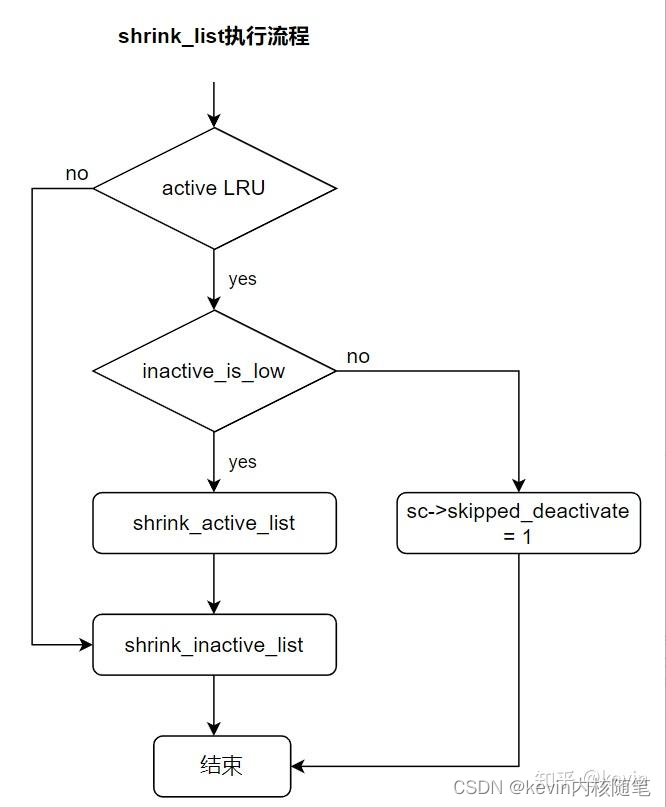
shrink_list的流程
4.8.1 回收inactive页
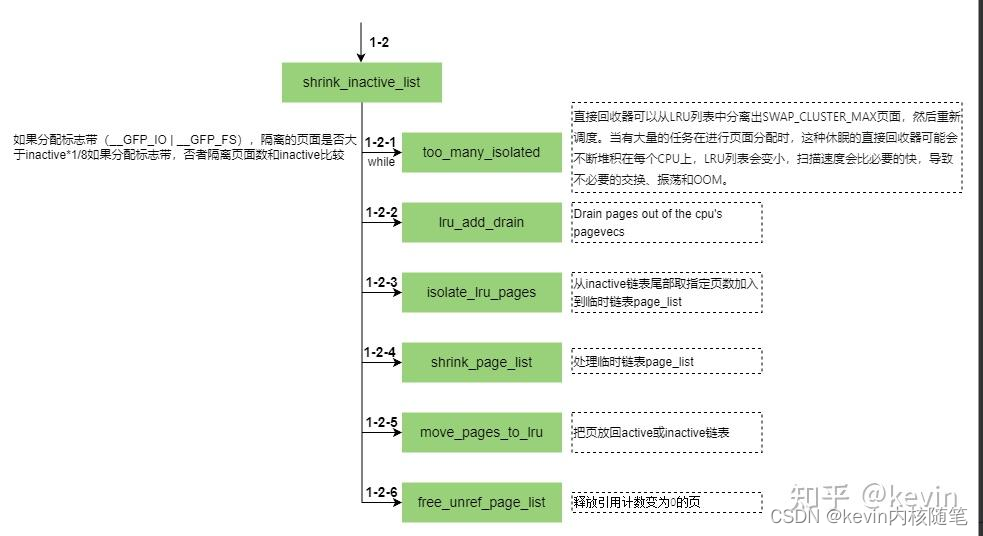
上图中1-2-4中怎么处理临时链表page_list中的每个页?
函数page_check_references检查页最近是否被访问过,返回页的处理方式(页转换成active page,页保留在inactve LRU中、页被回收);
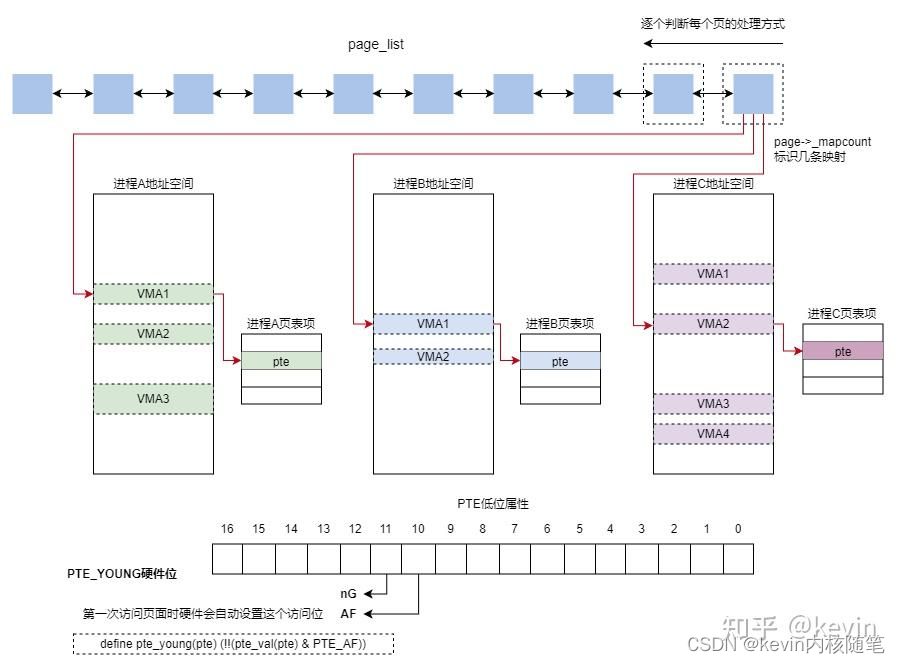
其实就是调用map_walk是rwc中.rmap_one设置为page_referenced_one,走了一把rmap流程检查pte中的young标志判断该页最近是否有被访问过,访问过要把该页从inactive链表移动到avtive链表,俗称promote;
具体描述下页的三种处理方式:
1)页被回收
2)页转换成active page
3)页保留在inactive LRU
4.8.2 回收active页
略
5 reverse map
待更新,
欢迎关注微信订阅号kevin内核随笔,获取最新更新

















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









