







Elasticsearch的使用
1、介绍
Elasticsearch是一个(近乎)实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据, 它不但稳定、可靠、快速,而且也具有良好的水平扩展能力,是专门为分布式环境设计的,它可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。Elasticsearch是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架.
下载地址
2、特性
ElasticSearch是基于Lucene开发的分布式搜索框架,包含如下特性:
- 分布式索引、搜索。
- 索引自动分片、负载均衡。
- 自动发现机器、组建集群。
- 支持Restful 风格接口。
- 配置简单等。
- 海量数据的存储。
3、Elasticsearch对应结构
Es对数据的存储采用是:
Index(索引)------Mysql(Table)
Document(文档)-------Mysql(Table中一行数据)
选择索引(Es7.0后 ,彻底遗弃type,只有索引和文档),存储的数据就叫文档
一个索引只存储一种类型的数据
4、安装
基于Docker安装Elasticsearch
#1.创建并运行容器
docker run -d --name es9200 -e "discovery.type=single-node" -p 9200:9200 elasticsearch:7.12.1
#2.访问测试
#云服务器:开放安全组:9200
#http://ip地址:9200/
启动成功后测试访问图片如下

如果出现启动失败:
max virtual monery xxxx [65530] is to low
这个错误意思:当前默认可用内存太小了,需要设置的大一点
在服务器上执行下面的命令:
vim /etc/sysctl.conf
#输入:
vm.max_map_count=655300
#重新加载
sysctl -p
#重新启动容器:
docker start es9200
基于docker安装kibana
kibana:是一个免费且开放的用户界面,能够让对 Elasticsearch
数据进行可视化,还可以进行各种操作,跟踪查询负载,到理解请求如何流经整个应用,都能轻松完成。
ELK:标准化日志平台E:Elasticsearch 作为日志存储和分析框架,L:Logstash
作为日志采集框架,获取日志存储到Es,K:Kibana 可视化网站,可以通过网页操作ES 目前的日志服务推荐:云解决方案:
阿里云-日志服务(SLS) 行业领先的日志大数据解决方案,一站式提供数据收集、清洗、分析、可视化和告警功能。
全面提升海量日志处理能力,实时挖掘数据价值,智能助力研发/运维/运营/安全等场景
1.查询es的地址:::::或者当出现看可视化界面出现key找不到也可看看ip是否真确或者相对应的版本
docker inspect es9200
如下图

2.创建并运行容器
docker run -d --name kibana5601 -p 5601:5601 kibana:7.1.1
3.修改配置文件
docker exec -it kibana5601 bash
vi config/kibana.yml
- 更改es的地址
重启
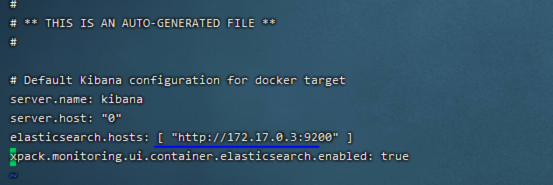
docker restart kibana5601
5、测试
访问测试
开放端口号:5601
http://ip地址:5601/
5、Kibana可视化操作ES
1.查看索引管理器

Elasticsearch:
Index Managenment 实现Es的索引管理

Kibana:
Index Patterns 实现基于Kibana可视化的索引信息

2.为索引设置可视化
设置可视化之后,就可以通过Kibana进行可视化的操作



3.基于Kibana实现可视化操作
RestfulApi操作Es


6、常用的Restful API:(text和keyword区别)
text和keyword的区别就是keyword不可区分 也可以 name.keyword来使用 但是要设置索引的时候设置
#创建索引
PUT /es211
#删除索引
DELETE /es211
#创建索引
PUT /es211-lx
#设置索引的Mapping格式,定义文档格式
PUT /es211-lx/_mapping
{
"properties": {
"_class": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"id": {
"type": "long"
},
"name":{
"type":"text"
},
"sex":{
"type":"text"
},
"ctime":{
"type":"date"
}
}
}
#新增文档
POST /es211-lx/_doc/1
{
"id":1,
"name":"帅帅",
"sex":"男人",
"ctime":"2020-05-11"
}
POST /es211-lx/_doc/2
{
"id":2,
"name":"琪琪",
"sex":"女人",
"ctime":"2020-05-11"
}
#修改文档
PUT /es211-lx/_doc/2
{
"id":2,
"name":"琪琪",
"sex":"女生",
"ctime":"2020-05-11"
}
#查询单个文档
GET /es211-lx/_doc/2
#删除文档
DELETE /es211-lx/_doc/2
7、springboot操作es (Spring Data Elasticsearch)
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2.实现配置
application.yml配置 连接es服务器
spring:
elasticsearch:
rest:
uris: ip地址:9200
3.编写代码 三层
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "es2008")//标记对应的索引名称
public class Student {
private Integer id;
private String name;
private String sex;//性别
}
public interface StudentDao extends ElasticsearchRepository<Student,Integer> {
}
public interface StudentService {
String save(Student student);
Iterable<Student> all();
}
@Service
public class StudentServiceImpl implements StudentService{
@Autowired
private StudentDao dao;
@Override
public String save(Student student) {
if(dao.save(student)!=null){
return "新增成功";
}else {
return "新增失败";
}
}
@Override
public Iterable<Student> all() {
return dao.findAll();
}
}
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = EsApplication.class)
public class EsTest {
@Autowired
private StudentService studentService;
@Test
public void t1(){
Student student=new Student(1,"小王");
System.err.println(studentService.save(student));
}
@Test
public void t2(){
studentService.all().forEach((s)-> System.err.println(s));
}
}
8、es批处理
基于es实现批量的操作,比如批量新增、批量修改、批量删除
核心代码:
//1.实例化客户端对象 连接服务器
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("39.105.189.141",
9200, "http")));
//Es可以实现批量操作,方便快速进行同步数据
BulkRequest request=new BulkRequest();
//批量新增
for(int i=101;i<1000;i++){
//DeleteRequest
//UpdateRequest
//IndexRequest
request.add(new IndexRequest("es2008").id(i+"").source(
JSON.toJSONString(new Student(i,"批量-"+i,"man")),XContentType.JSON));
}
//执行批处理
BulkResponse responses=client.bulk(request,RequestOptions.DEFAULT);
System.err.println(responses.status().toString());
//3.关闭
client.close();
9、各种查询
TermQueryBuilder:词条查询
词条查询是ElasticSearch的一个简单查询。它仅匹配在给定字段中含有该词条的文档,而且是确切的、未经分析的词条。term查询会查找我们设定的准确值。term查询本身很简单,它接受一个字段名和我们希望查找的值.MatchQueryBuilder(MatchQueryBuilder输入的词条会被es解析并进行分词,在此过程中就已经转换成全小写)查询效果一样
命令模式:
POST es2008/_search
{
"from": 0,
"size": 5,
"query": {
"term": {
"name": {
"value": "批量-101"
}
}
}
}
代码:
TermQueryBuilder termQuery=QueryBuilders.termQuery("sex","man");
TermsQueryBuilder:
词条查询(Term Query)允许匹配单个未经分析的词条,多词条查询(Terms Query)可以用来匹配多个这样的词条。只要指定字段包含任一我们给定的词条,就可以查询到该文档。
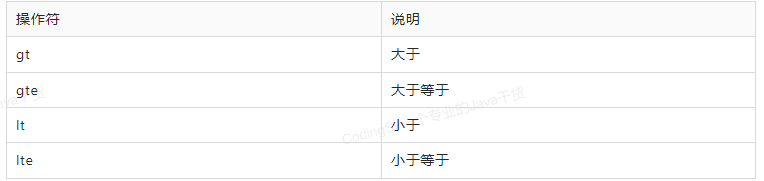
RangeQueryBuilder:
范围查询,比如数字类型、日期类型等的范围查询:gt gte lt lte
RangeQueryBuilder rangeQuery=QueryBuilders.rangeQuery("id");
rangeQuery.lt(200).gte(122);
WildcardQueryBuilder:
通配符查询,?匹配单个字符,*匹配多个字符,请注意,此查询可能会很慢,因为它需要遍历许多项。
//3.通配符查询 *任意个字符 ?单个字符
WildcardQueryBuilder wildcardQuery=QueryBuilders.wildcardQuery("name","*8");
FuzzyQueryBuilder:
模糊查询,可以使用%进行模糊,还可以指定前缀字符模糊匹配
对于中文的模糊搜索,应该先安装中文分词,比如IK分词器
我爱北京天安门
我 我爱 北京 我爱北京 天安门 北京天安门 爱北京天安门
//5.模糊查询 % super supzr
FuzzyQueryBuilder fuzzyQuery=QueryBuilders.fuzzyQuery("name","批量-232");
fuzzyQuery.prefixLength(4);//设置固定前缀匹配
BoolQueryBuilder:
布尔查询,拼接多个查询条件
常见的拼接关系:
must:必须 同时满足 类似 and
must_not:必须不 不能满足
should:应该 只有有一个满足即可 类似 or
filter:过滤 就是must替代品 只能进行数据筛选,进行额外操作
//6.布尔查询 拼接查询条件
BoolQueryBuilder boolQuery=QueryBuilders.boolQuery();
// boolQuery.should();
// boolQuery.mustNot();
// boolQuery.filter();
boolQuery.must(termQuery).must(rangeQuery);
9、1 上述的查询 (//范围查询中有获取实体类的写法)
@SpringBootTest
public class EsTest {
@Autowired
private ElasticsearchRestTemplate restTemplate;
//范围查询
@Test
public void t1(){
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.rangeQuery("money").from(300).to(3000)).build();
List<SearchHit<Worker>> workers=restTemplate.search(searchQuery, Worker.class,IndexCoordinates.of("lxes2011")).getSearchHits();
//此处是遍历出来实体类
for (SearchHit<Worker> searchHit : workers) {
//!!!!!!
Worker content = searchHit.getContent();
System.out.println(content);
}
System.err.println(workers);
}
//词条查询(精确查询)
@Test
public void t2(){
//词条查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.termQuery("company","pdd")).build();
//分页查询
searchQuery.setPageable(PageRequest.of(2,100, Sort.by(Sort.Order.desc("id"))));
List<SearchHit<Worker>> workers=restTemplate.search(searchQuery, Worker.class,IndexCoordinates.of("lxes2011")).getSearchHits();
System.err.println(workers);
}
//模糊查询
@Test
public void t3(){
//模糊查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.fuzzyQuery("name","88")).build();
//分页查询
searchQuery.setPageable(PageRequest.of(2,100, Sort.by(Sort.Order.desc("id"))));
List<SearchHit<Worker>> workers=restTemplate.search(searchQuery, Worker.class,IndexCoordinates.of("lxes2011")).getSearchHits();
System.err.println(workers);
}
//通配符查询
@Test
public void t4(){
//通配符查询 *任意字符 ?单个字符
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.wildcardQuery("name","*88*")).build();
//分页查询
searchQuery.setPageable(PageRequest.of(2,100, Sort.by(Sort.Order.desc("id"))));
List<SearchHit<Worker>> workers=restTemplate.search(searchQuery, Worker.class,IndexCoordinates.of("lxes2011")).getSearchHits();
System.err.println(workers);
}
}
补充--------
QueryBuilders.matchQuery()
会将搜索词分词,再与目标查询字段进行匹配,若分词中的任意一个词与目标字段匹配上,则可查询到。(任意一个完整的词语 后续不满足一整个单词也可以)
列如:添加语句i like eating and kuing
param = “i” 可查出i
param = “i li” 可查出
param = “i like” 可查出
param = “i like eat” 可查出
param = “and” 可查出
param = “kuing” 可查出
param = “ku” 查不出
param = “li” 查不出
param = “eat” 查不出
QueryBuilders.matchPhraseQuery()
会精确匹配查询的短语,需要全部单词和顺序要完全一样,标点符号除外。(满足顺序并且满足一整个单词 后续不满足一整个单词不可以)
列如:添加语句i like eating and kuing
param = “i” 可查出i
param = “i li” 查不出
param = “i like” 可查出
param = “i like eat” 查不出
param = “and” 可查出
param = “kuing” 可查出
param = “ku” 查不出
param = “li” 查不出
param = “eat” 查不出
** QueryBuilders.matchPhrasePrefixQuery()**
它允许对最后一个词条前缀匹配(可以半个单词就可以查到)
列如:添加语句i like eating and kuing
param = “i” 可查出i
param = “i li” 可查出
param = “i like” 可查出
param = “i like eat” 可查出
param = “and” 可查出
param = “kuing” 可查出
param = “ku” 可查出
param = “li” 可查出
param = “eat” 可查出
QueryBuilders.termQuery(“supplierName”,param)
查询内容是什么,就会按照什么去查询,并不会解析查询内容,对它分词(输入单词 不会进行分词 只查看单个单词有没有语句中包含)
列如:添加语句i like eating and kuing
param = “i” 可查出i
param = “i li” 查不出
param = “i like” 查不出
param = “i like eat” 查不出
param = “and” 可查出
param = “kuing” 可查出
param = “ku” 查不出
param = “li” 查不出
param = “eat” 查不出
10、搜索建议
创建索引
PUT /job
POST /job/_mapping
{
"properties": {
"_class": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"id":{
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"suggest": {
"type": "completion",
"analyzer": "simple",
"preserve_separators": true,
"preserve_position_increments": true,
"max_input_length": 50
}
}
},
"durl" : {
"type" : "text"
},
"salary":{
"type": "keyword"
}
}
}
搜索建议 msg = java 后面展示出很多嗯java------相关的
@Override
public List<String> get(String msg) {
List<String> list = new ArrayList<>();
CompletionSuggestionBuilder builder = new CompletionSuggestionBuilder("name.suggest");
builder.size(50).prefix(msg);
//查询本地化查询
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("name", builder);
//执行搜索建议查询
SearchResponse response = elasticsearchRestTemplate.suggest(suggestBuilder, IndexCoordinates.of("job"));
Suggest suggest = response.getSuggest();
Suggest.Suggestion name = suggest.getSuggestion("name");
for (Object o : name.getEntries()) {
Suggest.Suggestion.Entry o1 = (Suggest.Suggestion.Entry) o;
for (Object o2 : o1.getOptions()) {
Suggest.Suggestion.Entry.Option o21 = (Suggest.Suggestion.Entry.Option) o2;
list.add(o21.getText().toString());
}
}
return list;
}
11、聚合查询
聚合操作
聚合操作可以查看 比方:某个商品在条件后 聚合商品名字 查看哪个店铺以及查看这个商品在哪家店铺
如下图: 条件:(笔记本 价格区间) 聚合:(商家名字) 结果:商品可能来自同一家商家 名字聚合后就只有一个 还可以看这家商品符合条件有几个
本图转载

-----------------上述只是案例 跟下述案例不一样
同10创建索引
实体类
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
//主要
@Document(indexName = "job")
//通过Job.of("张三")可获取job对象 结合@NotNull使用
@RequiredArgsConstructor(staticName = "of")
public class Job {
//主要
@Id
private Integer id;
@NotNull
private String name;
private String durl;
private String salary;
}
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
TermsAggregationBuilder size = AggregationBuilders.terms("group").field("name.keyword").size(9999);
NativeSearchQuery build = nativeSearchQueryBuilder.withAggregations(size).build();
SearchHits<Job> searchs = elasticsearchRestTemplate.search(build, Job.class, IndexCoordinates.of("job"));
AggregationsContainer<?> aggregations = searchs.getAggregations();
Aggregations aggregations1 = (Aggregations) aggregations.aggregations();
Aggregation group = aggregations1.get("group");
List<? extends Terms.Bucket> buckets = ((ParsedStringTerms) group).getBuckets();
for (Terms.Bucket bucket : buckets) {
//获取字段值
String key = (String) bucket.getKey();
long val = bucket.getDocCount();// 聚合字段对应的数量
System.out.println(key + ":::::" + val);
}
12、高亮显示
@RequestMapping("/test")
public List<Job> test(String msg) {
//多个字段进行匹配
MultiMatchQueryBuilder queryBuilder = new MultiMatchQueryBuilder(msg, "name", "salary");
//要高亮的字段
HighlightBuilder field = new HighlightBuilder()
.preTags("<font color='red'>")
.postTags("</font>")
.field("name")
.field("salary");
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withHighlightBuilder(field)
.build();
SearchHits<Job> searchHits = elasticsearchRestTemplate.search(build, Job.class, IndexCoordinates.of("job"));
List<Job> jobs = Lists.newArrayList();
for (SearchHit<Job> searchHit : searchHits) {
//获取高亮显示内容 当条件中的字段命中后进行高亮显示
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
//查看有没有高亮显示条件命中的 比如 name = 张三 salary没有命中 只高亮name
String salary = highlightFields.get("salary") == null ? searchHit.getContent().getSalary() : highlightFields.get("salary").get(0);
String name = highlightFields.get("name") == null ? searchHit.getContent().getName() : highlightFields.get("name").get(0);
searchHit.getContent().setSalary(salary);
searchHit.getContent().setSalary(name);
jobs.add(searchHit.getContent());
}
return jobs;
}

















 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











