







首先,我认为,之所以需要序列化,核心目的是为了解决网络通信之间的对象传输问题。
也就是说,如何把当前JVM进程里面的一个对象,跨网络传输到另外一个JVM进程里面。
而序列化,就是把内存里面的对象转化为字节流,以便用来实现存储或者传输。
反序列化,就是根据从文件或者网络上获取到的对象的字节流,根据字节流里面保存的对象描述信息和状态。
重新构建一个新的对象。
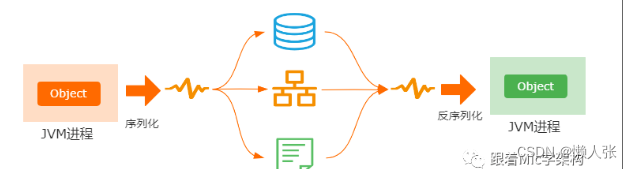
其次呢,序列化的前提是保证通信双方对于对象的可识别性,所以很多时候,我们会把对象先转化为通用的解析格式,比如json、xml等。然后再把他们转化为数据流进行网络传输,从而实现跨平台和跨语言的可识别性。
最后,我再补充一下序列化选择。
市面上开源的序列化技术非常多,比如Json、Xml、Protobuf、Kyro、hessian等等。
那在实际应用里面,哪种序列化最合适,我认为有几个关键因素。
序列化之后的数据大小,因为数据大小会影响传输性能
序列化的性能,序列化耗时较长会影响业务的性能
是否支持跨平台和跨语言
技术的成熟度,越成熟的方案使用的公司越多,也就越稳定。
















 8528
8528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









