








分类
分类(classification)即找一个函数判断输入数据所属的类别,可以是二类别问题(是/不是),也可以是多类别问题(在多个类别中判断输入数据具体属于哪一个类别)。与回归问题(regression)相比,分类问题的输出不再是连续值,而是离散值,用来指定其属于哪个类别
——
https://blog.csdn.net/hohaizx/article/details/81835381
1. 逻辑分类
api: sklearn.linear_model.LogisticRegression(solver=‘liblinear’, C=)
solver 表示逻辑函数中指数的函数关系 liblinear 表示线性函数关系 C 表示正则强度,防止过拟合, 数值越大,拟合度越小
- api的内在逻辑
首先理解逻辑函数sigmoid: y=1/(1+e^(-x))
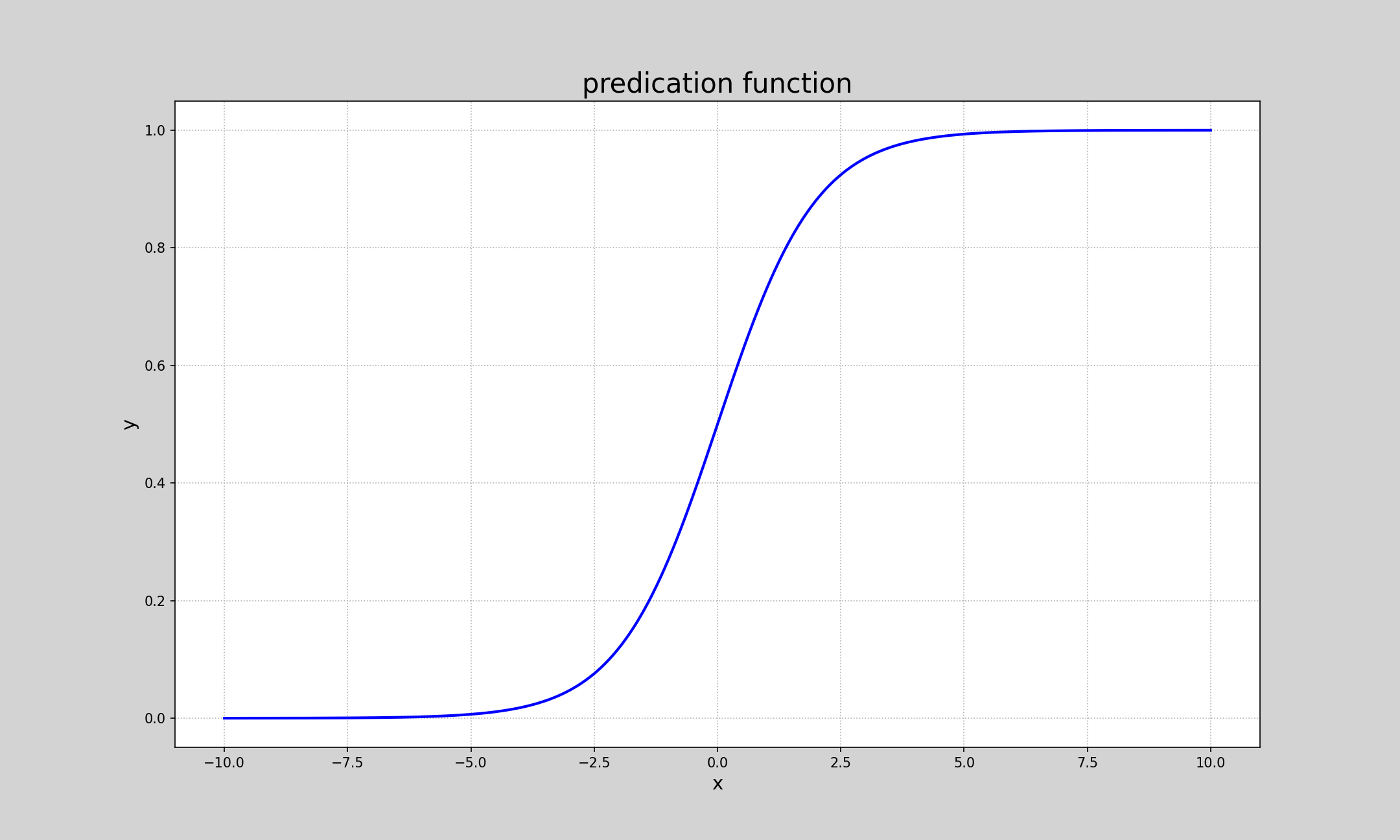
由图可知,sigmoid是一个值域为(0, 1),定义域为(-∞, +∞)的函数的函数,且当x=0时,y=0.5
根据样本的输入与输出构建线性回归模型,以回归模型的的预测输出作为sigmoid的输入,得到0-1之间的一个数值,此数值即可作为对应样本时1类的概率或者可信度;x<0 y<0.5划分为1类别的概率比较小,x>0 y>0.5划分为1类别的概率比较大,这是线性函数非线性化的一种方式。 - api的使用
代码示例:
import numpy as np
import matplotlib.pyplot as plt
x = np.array([[3, 1], [2, 5], [1, 8], [6, 4], [5, 2], [3, 5], [4, 7], [4, -1]])
y = np.array([0, 1, 1, 0, 0, 1, 1, 0])
# 绘制分类边界
l, r = x[:, 0].min() - 1, x[:, 0].max() + 1
b, t = x[:, 1].min() - 1, x[:, 1].max() + 1
n = 500
grid_x, grid_y = np.meshgrid(np.linspace(l, r, n), np.linspace(b, t, n))
# 人为划分界限
# grid_z = np.piecewise(grid_x, [grid_x > grid_y, grid_x < grid_y], [0, 1])
# 自我识别 划分边界
mesh_x = np.column_stack((grid_x.ravel(), grid_y.ravel()))
mesh_z = model.predict(mesh_x)
grid_z = mesh_z.reshape(grid_x.shape)
plt.figure('classification', facecolor='lightgray')
plt.title('classification', fontsize=16)
plt.scatter(x[:, 0], x[:, 1], c=y, cmap='jet', label='points', s=70, zorder=3)
# 调用plt.pcolormesh绘制费雷比那界限 把可是去检查分为坐标网格,不同类填充不同颜色
plt.pcolormesh(grid_x, grid_y, grid_z, cmap='gray')
plt.legend()
plt.show()
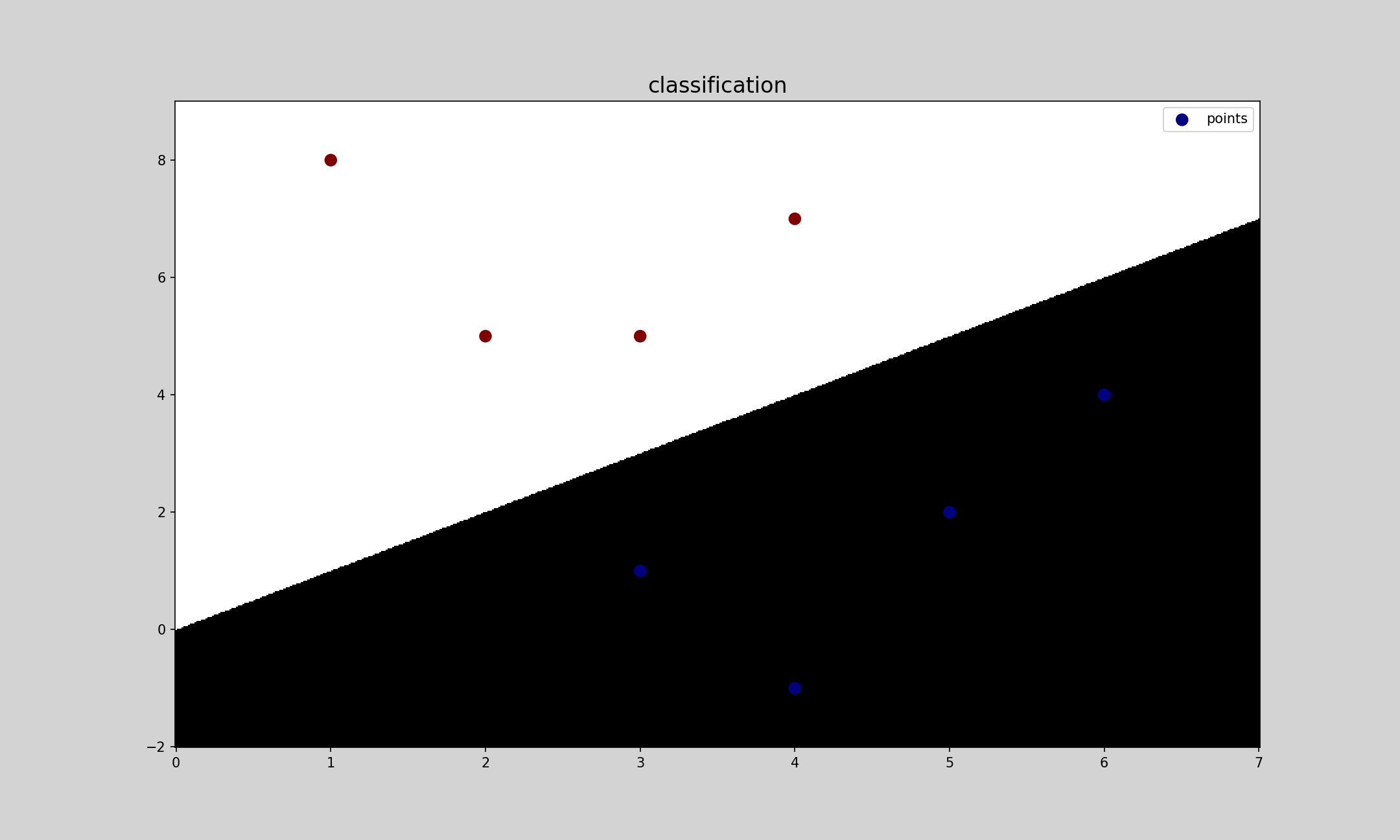
该方式是将显示的区域划分为500*500的小方格,根据划分依据填充颜色。这里有一点不明白,就是为什么不用函数线区划分,是因为在边界的点类别本来就很难界定么
3. 多元分类
上面的描述只适用于二元分类,对于多元分类则需要对属于每一种类别的概率分别进行训练,得到多个模型,最终选择概率最高的类别作为样本的分类结果,这个过程逻辑分类会自动进行分析类别个数,代码无需改动。
代码示例:
x2 = np.array([[4, 7], [3.5, 8], [3.1, 6.2], [0.5, 1], [1, 2], [1.2, 1.9], [6, 2], [5.7, 1.5], [5.4, 2.2]])
y2 = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3487
3487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









