







我们以宝可梦为例,输入宝可梦的属性数值,输出宝可梦的类别(水,火...)。
我们能不能用线性回归来解决这个问题呢?
答案是不能。因为当样本分布比较复杂时,线性回归无法做到准确的分类。逻辑回归对异常值具有很好地稳定性。
贝叶斯公式
C1=class 1 C2=class 2
公式解释:
x属于class1的概率=(x在class1中出现的概率 * class1出现的概率)/ x出现的总概率
那么我们只需要比较x属于class1和class2的概率的大小,就可以对x进行分类。这也是classification的model,当其中的P使用不同的概率分布模型,就会有不同的model。
概率分布模型
我们先假设样本数据的所有类别服从高斯分布。可以这样表示:
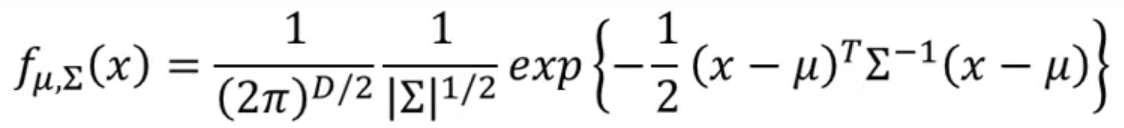
输入一个向量x,输出x在当前概率模型(即类型)下的概率。
这个model由两个因素决定:均值向量,和协方差矩阵
。
协方差则一般用来刻画两个随机变量的相似程度。
协方差的计算公式被定义为
协方差矩阵为
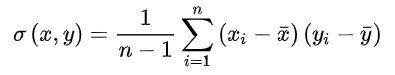

我们要怎么找到合适的 和
呢?
这里使用极大似然估计的方法。
我们要找到一组合适的 和
,使得model 生成training data的概率最高。
我们定义一个函数,表示当前的
和
生成training data的概率。
![]()
即生成每一个点的概率的乘积。
取平均值可以使
最大
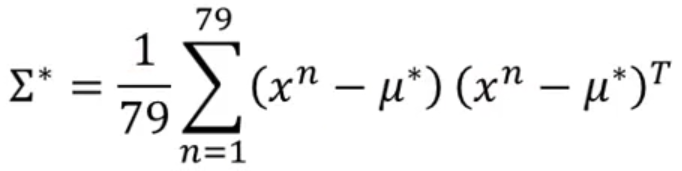
最后可以带入贝叶斯公式做一个变换(不做也ok)。问题就解决了。
tips:
有时候数据中的各个类别可能会是按照同一个协方差矩阵来分布的,这是我们可以让多个model使用同一个
。那么计算
的时候我们可以对每个model的
加权平均。
这时候类别的边界会变成一条直线。
当然,我们还可以假设data服从其它的概率分布模型。
对于只有两个选择的分类,非0即1.我们可以考虑使用伯努利概率模型。
如果所有的特征都是相互独立的,我们可以使用Naive Bayes Classifier。
总结
分类和线性回归一样可以分为三步:
(1)函数集(model)
当P(C1|x)>0.5是,x为C1类型;否则为C2类型。
(2)如何评价model的好坏
找到一组 和
,使得产生training data的概率最大。
(3)找到最好的函数
如果我们把贝叶斯公式做一个变换:
写成这种形式,那么这个function 叫做sigmoid function。
可以计算出。
如果我们使用相同的协方差矩阵,那么式子经过一系列变换,可以化成这种形式:
从这里也可以看出当使用同一个时,为什么分界线时一条直线。这里的
使用不同的
加权平均得到。
这样看来我们要计算P(C1|x)时根本不需要计算 和
,只要找到w和b就可以直接计算出概率。
如果,输出C1,否则输出C2。
![]()
![]()
我们可以定义一个loss function:
![]()
即产生training data的概率,显然,L越大,函数越好。
我们的目标是最大化L(w,b),可以做一个转化,变为最小化,可以简化计算。

交叉熵(cross entropy)
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。

在这个场景中,交叉熵用来比较p和q有多接近。
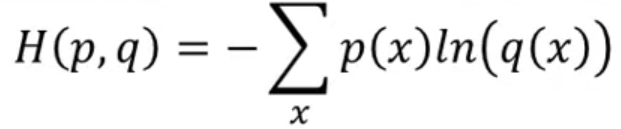
for step 3
我们可以用gradient decient来train。将loss function对wi进行偏微分。

最终化简结果为:
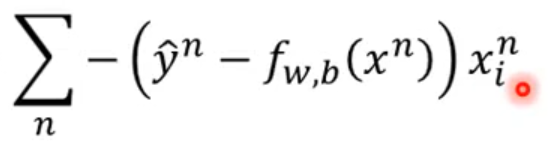
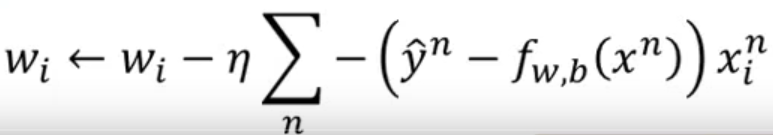
可以发现和线性回归的迭代式子完全相同。
为什么不能使用方差作为loss function?
我们用方差对wi做偏微分可以得到这个式子:
![]()
如果此时=1,
,上面式子结果是0。显然是不合理的。
画图表示就是这样

可以发现cross entropy在距离目标很远的时候斜率很大,而square error斜率很小。
生成模型和判别模型
通常来说判别模型效果要优于生成模型。
参考:https://blog.csdn.net/weixin_39910711/article/details/89483662
多分类问题
先对参数进行softmax,将范围规定在0~1内。

然后要定义相对独立的类型的编码
















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









