







我自己的原文哦~ https://blog.51cto.com/whaosoft/11574517
一、缺陷检测
我们知道,opencv是一个非常优秀的计算机视觉图像处理算法库,它给我们封装了好多基本的图像处理算法,免去了让我们重复造轮子的麻烦,今天我就用传统算法,根据实际工程项目,手把手教你做一个最典型的产品缺陷检测项目案例,虽然这个案例与实际生产还存在一定的差距,但是这个检测流程已经很接近实际生产了。
我们先看一下测试结果:

这个检测的主要需求就是,根据视频流中流水线上的产品,通过每一帧图像,检测出每个产品的缺陷属性,并把有缺陷的产品给标注出来,并注明缺陷类型。
项目开始之前,我先请大家安装一下opencv库
在项目开始之前,我们先思考一下整个检测流程的框架:
1,首先我们要抓取视频流中的每一帧图像
2,在抓取得每一张图像中,首先要定位出这张图片中的每一个产品,找出这件产品的边缘
3,分析所抓取每个产品的属性,分析其缺陷类型的特征,通过算法形式来对缺陷进行归类。
上面就是整个检测的基本流程,其实,在利用传统算法进行检测的时候,基本流程不会差别太大,所用算子也基本大致相同。在讲解这个检测方法之前,我先来讲解几个我们经常用到的算子:
findContours():
这个函数是查找整张图片中所有轮廓的函数,这个函数很重要,在处理图像分割尤其是查找整个图像中边缘分割时候少不了它,所以我重点说明一下,首先它的函数原型是这样的:
// 查找整张图片的所有轮廓
findContours(InputOutputArray image,
OutputArrayOfArrays contours,
OutputArray hierarchy,
int mode,
int method,
Point offset=Point());我先来讲解一下这个函数的主要参数:
1),image代表输入的图像矩阵;
2),第二个参数contours代表输出的整张图片的所有轮廓,由于轮廓坐标是一组二维坐标构成的一组数据集,因此,它的声明是一个嵌套了一层坐标数据集向量的向量:
//参数contours的声明
vector<vector<Point>> contours;3),第三个参数hierarchy顾名思义,字面的意思是层级关系,它代表各个轮廓的继承关系,也是一个向量,长度和contours相同,每个元素和contours的元素相对应,hierarchy的每一个元素是一个包含四个整形数的向量,也即:
//参数hierarchy的声明
//Vec4i 代表包含四个元素的整形向量
vector<Vec4i> hierarchy;那么这里的hierarchy究竟代表什么意思呢,其实对于一张图片,findContours()查找出所有的

个轮廓后,每个轮廓都会有自己的索引,

,而hierarchy[i]里面的四个元素

分别代表第

个轮廓:后一个轮廓的序号、前一个轮廓的序号、子轮廓的序号、父轮廓的序号,有严格的顺序。
为了更加直观说明,请看下面一张图片:

上面图片中,是一张图片中的所有轮廓,分别用序号0、1、2、3来表示,其中0有两个子轮廓,分别是1和3,而1则有一个父轮廓也有一个子轮廓,分别是0与2,它们的继承关系基本上就是这样,我们再做进一步的分析:
0号轮廓没有同级轮廓与父轮廓,但由两个子轮廓1与3,根据前面提到的四个元素的顺序分别是:下一轮廓、前一轮廓、子轮廓、父轮廓,所以其轮廓继承关系向量hierarchy为

,这里的-1表示无对应关系,而第三个元素1则代表0号轮廓的一个子轮廓为1;
同样,1号轮廓有同级轮廓3(按照索引是后一轮廓,但无前一轮廓),也有子轮廓2,父轮廓0,所以它的继承关系向量hierarchy为

;
按照同样的方法,我们还可以得到2号轮廓的继承关系向量hierarchy为:

;3号轮廓继承关系为

.
4),第四个参数mode,代表定义轮廓的检索方式:
取值一:CV_RETR_EXTERNAL,只检测最外围轮廓,包含在外围轮廓内的内围轮廓被忽略。
取值二:CV_RETR_LIST,检测所有的轮廓,包括内围、外围轮廓,但是检测到的轮廓不建立等级关系,彼此之间独立,没有等级关系,这就意味着这个检索模式下不存在父轮廓或内嵌轮廓,所以hierarchy向量内所有元素的第3、第4个分量都会被置为-1.
取值三:CV_RETR_CCOMP,检测所有的轮廓,但所有轮廓只建立两个等级关系,外围为顶层,若外围内的内围轮廓还包含了其他的轮廓信息,则内围内的所有轮廓均归属于顶层。
取值四:CV_RETR_TREE,检测所有轮廓,所有轮廓建立一个等级树结构。外层轮廓包含内层轮廓,内层轮廓还可以继续包含内嵌轮廓。
5),第五个参数method,用来定义轮廓的近似方法:
取值一:CV_CHAIN_APPROX_NONE,保存物体边界上所有连续的轮廓点到contours向量内。
取值二:CV_CHAIN_APPROX_SIMPLE,仅保存轮廓的拐点信息,把所有轮廓拐点处的点保存入contours向量内,拐点与拐点之间直线段上的信息点不予保留。
取值三:CV_CHAIN_APPROX_TC89_L1;
取值四:CV_CHAIN_APPROX_TC89_KCOS,取值三与四两者使用teh-Chinl chain 近似算法。
6),第六个参数,Point类型的offset参数,这个参数相当于在每一个检测出的轮廓点上加上该偏移量,而且Point还可以是负数。
在实际使用中,我们需要根据实际情况来选定合适的参数,比如第五个参数,如果你使用CV_CHAIN_APPROX_SIMPLE这个参数,那么返回的坐标向量集是仅包含拐点信息的,但是在上一篇文章 手把手教你编写傅里叶动画 为了得到轮廓的完整坐标数据,我必须使用CV_CHAIN_APPROX_NONE参数。请大家在实际使用过程中根据自己的实际情况来选择合适的参数
再来说下moments这个函数,其实moment在物理学中表示“力矩”的感念,“矩”在物理学中是表示距离和物理量乘积的物理量,表示物体的空间分布(至于汉语为什么把它翻译成矩这个字,我也不太明白,不知道是不是李善兰翻译的)。而在数学中,“矩”是概率论中的一个名词,它的本质是数学期望,我们从它的定义中就可以看出:
假设

是离散随机变量,

为常数,

为正整数,如果

存在,则称

为

关于

的

如果

时,称它为

阶原点矩;如果

时,称它为

阶中心距。我们知道数学期望的计算公式是

其中

是

的概率密度,从这个公式中看出,无论是在物理上,还是在数学上,矩都有种某个量与“距离”乘积的概念,因此,我们再直观一点,直接把“矩”抽象成为下面一个公式:

当

有了这方面知识,我们再回顾一下 图像处理中的矩,对于图像中的矩是图像像素强度的某个特定加权平均(矩),或者是这样的矩的函数,因为图像是二维的,对于二元有界函数

它的

阶矩为:

如果把图像看成是一块质量密度不均匀的薄板,其图像的灰度分布函数

如零阶矩表示它的总质量;一阶矩表示它的质心;二阶矩又叫惯性矩,表示图像的大小和方向,当然,对于图像来说,它的像素坐标是离散的,因此积分可用求和来计算,图像的零阶矩:

显然,对于二值化图像,由于

非

即

图像的零阶矩表示区域内的像素点数,也即区域的面积。
当

时,它的一阶矩变为:

它是横坐标

同样,当

时,它的一阶矩变为:

它是纵坐标

像素值的乘积,如果是二值化图像,每个像素点所有纵坐标的和。
根据物理意义,我们还可以得出轮廓的质心计算公式:

其中

为了获得矩的不变特征,往往采用中心矩或者归一化的中心距,在图像中中心矩的定义为:

Moments moments(
InputArray array,
bool binaryImage = false
);第一个参数是输入一个数组,也就是我们上面计算出来的contours向量,第二个参数默认为false.
我们再来看整个程序的编写方法:
首先我们使用opencv中的VideoCapture类来进行读取视频流,并抓取视频中的每一帧图像:
Mat img; //定义图像矩阵
VideoCapture cap("1.mp4");
cap.read(img);这样我们便把图像读取到img变量中了,当然,为了叙述方便,这只是其中的部分代码,实际你在运行过程中为了不断读取,外面还要嵌套个while(true)的循环。
读取到一帧图像后,我们需要对这张图像进行一些预处理,一般情况下,无论是传统算法还是深度学习算法,预处理的方法基本上都是一样的,比如灰度转换,图像滤波,二值化处理,边缘提取等等。在这里也一样,我们先对抓取到的图像进行灰度转换,灰度图像有诸多好处,比如它只包含亮度特征,而且一般情况下它是单通道的,256色调色板,一个像素占只用一个字节,储存起来非常整齐等等。
我们最终要的预处理结果是将其转化为二值化图像,二值化图像是灰度图像的一种特殊情况,它的像素亮度只有0与255两种情况,也就是非黑既白,在图像处理中,二值图像占有非常重要的地位,比如,图像的二值化有利于图像的进一步处理,使图像变得简单,使后面的计算量大大减少,而且还能能凸显出感兴趣的目标的轮廓。
灰度处理的算子接口为:
void cv::cvtColor
(InputArray src,
OutputArray dst,
int code,
int dstCn = 0)这个函数第一个参数src为输入图像,第二个参数dst为输出图像,第三个参数为需要转换的色彩空间,一般我们选取CV_BGR2GRAY即可,第四个参数默认为0.
灰度转化后,我们再进行二值化处理,这个算子比较简单,函数原型为:
void cv::threshold
(InputArray src,
OutputArray dst,
double thresh,
double maxval,
int type)同样,这个函数前两个参数分别为输入、输出参数;第三个参数thresh为设定的阈值;第四个参数maxval为设置的最大值,一般选取255;第五个参数type为阈值类型,表示当灰度值大于(或小于)阈值时将该灰度值赋成的值,其中最常用的有两个,分别是THRESH_BINARY,THRESH_BINARY_INV:
如果是THRESH_BINARY的话,表示当图像亮度值大于阈值thresh的话,将其设置为maxval,否则设置为0:

而 THRESH_BINARY_INV 则恰恰相反,当亮度大于阈值的时候,将其设置为0,否则设置为maxval:

我们再回到视频中,先截取一张图片,我们使用下面梁行代码先后对其进行灰度、二值化处理:
//灰度处理
cvtColor(img, grayImage, CV_BGR2GRAY);
//二值化处理
threshold(grayImage, binImage,
128, 255, CV_THRESH_BINARY);下面第二、第三分别是灰度、二值化处理后的结果,可见当原图经过二值化分割后,图像增强明显,明暗分离,更重要的是原本模糊的划痕变得非常清晰,特征非常明显,这对我们下一步提取划痕轮廓从而做进一步的分析带来非常大的方便:

经过预处理后,下面我们就要想办法如何判定一件产品是具有划痕或者某种缺陷的,观察上面第三章图片,最直观的区别就是不良的产品中附带黑色长条斑点,如果我们对整个圆区域进行轮廓查找的话,它的轮廓数量应该大于0才对,反之等于0. 但是首先我们要知道如何定位每一个产品的位置,并找出它的轮廓,所以,我们先对每一张预处理后的binImage图像进行轮廓查找:
//定义轮廓点集
vector<vector<Point>> contours;
//定义继承关系
vector<Vec4i> hierarchy;
//进行轮廓查找
findContours(binImage,
contours,
hierarchy,
CV_RETR_EXTERNAL,
CV_CHAIN_APPROX_NONE,
Point(0, 0));注意,在首次查找的时候,我们关心的是整个产品的轮廓,或者产品的质心坐标在哪里,所以我们只需要抓取最外轮廓即可,所以第四个参数我们设置为CV_RETR_EXTERNAL,上面已经解释过了,意为只检查最外围轮廓,目的是为了方面后面从原图中截取产品轮廓。为了方便后面计算,也为了计数方便,我先定义了一个产品类型的结构体myproduct,里面包含外接Rect,质心cx,xy,还有对应索引index. 为了去除重复,每次计算每个轮廓的位置,再根据当前帧里面的所有产品坐标与上一帧图像中产品里面的坐标进行对比,如果有两个产品在上下两帧中偏移的距离很小,那么我们可以认为它是同一件产品,否则就是新出现的产品,就需要放入我们的product容器里面,这其实在实际抓拍检测过程中,比较常用的去重方法:
for (int i = 0; i < contours.size(); i++)
{
double area = contourArea(contours[i]);
//小于18000我们认为是干扰因素
if (area > 18000)
{
Moments M = moments(contours[i]); //计算矩
double center_x = M.m10 / M.m00;
double center_y = M.m01 / M.m00;
Rect rect = boundingRect(contours.at(i));
bool isNew = true;
//必须保证产品完全出来
if (center_x > 100)
{
for (int i = 0; i < product.size(); i++)
{
double h = abs(center_x - product[i].cx);
double v = abs(center_y - product[i].cy);
if(h < 25 && v < 25)
{
isNew = false;
//说明不是新的,那就要更新一下
product[i].cx = center_x;
product[i].cy = center_y;
product[i].rect = rect;
}
}
if (isNew)
{
myproduct p;
p.cx = center_x;
p.cy = center_y;
p.rect = rect;
idx++;
p.index = idx;
product.push_back(p);
}
}
}函数计算后,product里面就包含了我们所要当前帧中的所有产品对象,包括质心、外接矩形等等,然后根据最大外接矩形的坐标,再回到原图中img中,把这个矩形包含的产品轮廓给裁剪出来,做进一步分析,裁剪的方法很简单,我们根据上面程序返回的rect,直接在原图像img中进行裁剪即可,即可得到右边小图像:
Mat roi = img(rect);
拿到上图右边截取的小图像roi, 对其再做进一步的分析,从而能够抓取到缺陷划痕的轮廓,方法还是先灰度处理再二值化操作,然后查找轮廓。但注意,这次查找轮廓的对象是我们截取的roi区域,为了分析roi区域内所有的缺陷,我们必须要找出对象中的所有轮廓,所以findcontours参数中mode参数我们就不能使用CV_RETR_EXTERNAL了,而要改用CV_RETR_TREE:
Mat grayImage;
Mat binImage;
cvtColor(roi, grayImage, CV_BGR2GRAY); //灰度处理
threshold(grayImage,
binImage,
128, 255,
CV_THRESH_BINARY); //二值化处理
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
//检测出roi内所有轮廓
findContours(binImage, contours,
hierarchy,
CV_RETR_TREE,
CV_CHAIN_APPROX_NONE,
Point(0, 0));这次返回的contours其实还包含单个产品的最外轮廓,显然不是我们想要的,对其进行适当过滤,过滤的方法很简单,还是根据面积来进行判断,进而再把缺陷部分给提取出来,我们可以用下面两行代码,将提取到的轮廓全部绘制出来:
//最后一个参数如果为负值CV_FILLED则为填充内部
//第三个参数如果为-1则绘制所有的轮廓
drawContours(roi,
contours,
-1,
Scalar(0, 0, 255), 0);
下一步我们就要想办法把产品内部的一个划痕轮廓给单独提取出来,也就是找一把“剪刀”,将它最大外接矩形给剪切出来,同时为了防止划痕周围颜色的干扰,我们还需要将剩余部分涂成黑色,方法很简单,我们需要单独定义一个mask掩模,再使用fillPoly函数将这块区域填充到我们的mask上面即可。我们看一下这个函数的原型:
//填充多边形函数
void fillPoly(InputOutputArray img,
InputArrayOfArrays pts,
const Scalar& color,
int lineType = LINE_8,
int shift = 0,
Point offset = Point());第一个参数img是输入的参数,也就是我们的mask, 第二个参数是轮廓点数据集,第三个参数为填充的颜色。但是这里边需要注意,第二个参数如果我们直接把上面那张提取轮廓得到的划痕轮廓数据集contours[index]输入进去是不行的,会报错,我尝试了多次,发现可能fillPoly函数第二个参数只接收vector<vector<Point>>类型的数据集,所以我们在使用之前需要把划痕的最大外接矩形使用findContours函数再做一次轮廓查找,得到缺陷轮廓contours_defect,方法跟上面的一样,事先先灰度处理,再阈值分割。
//定义掩膜,CV_8UC1代表单通道
Mat mask = Mat::zeros(grayImage.size(),
CV_8UC1);
//把缺陷轮廓填充掩膜
fillPoly(mask,
contours_defect,
Scalar(255, 255, 255));这里面在定义mask的时候,尽量避免使用白色背景,因为我发现在白色背景使用findContours的时候会把整个背景图片的外框也当成一个轮廓,无形之中给我们带来了不必要的麻烦。填充后的mask我们再与原图中的缺陷外接矩形轮廓做位与运算,最终将原图中的缺陷轮廓抠出来:
//图像按位与运算
bitwise_and(grayImage, mask, result);
上图中第三幅就是我们要的抠图效果,里面的灰色图案就是划痕形状图像背景是纯黑色,为我们下一步分析免去了诸多干扰。
接下来就是如何分析这张缺陷了,并把缺陷类型给标注出来。我们再看一下另外一种缺陷,比如掉漆的缺陷:

根据肉眼判断,显然左侧的掉漆缺陷背景颜色更黑一点,这是他们两种缺陷的最大区别,所以我们可以采用灰度直方图的算法对其进行分析,从而判断是何种类型。所谓灰度直方图,就是以横坐标为像素的亮度,纵坐标为对应像素的数量,将整张图片对应的像素分布给计算出来,显然,如果是掉漆缺陷的话,它的低亮度像素值(偏向黑色)占的比重更多一些,而如果是划痕的话,整体像素亮度区间会分布的高一些,我们就按照这个方法来定义缺陷的类型。在opencv中计算灰度直方图的算法已经给我们封装好了,我们来看一下函数的原型:
//计算灰度直方图
void calcHist(
const Mat* images, //输入图像指针
int nimages, //输入图像的个数
const int* channels, //需要统计的第几通道
InputArray mask, //掩膜
OutputArray hist, //输出的直方图数组
int dims, //需要统计直方图通道的个数
const int* histSize, //直方图分成区间个数指针
const float** ranges, //统计像素值的区间
bool uniform = true, //是否对得到的直方图数组进行归一化处理
bool accumulate = false); //在多个图像时,是否累计计算像素值得个数用这个函数计算后,我们需要稍微再加一点分析,将分布直方图对应像素出现的概率给计算出来即可:
MatND hist;
//256个,范围是0,255.
const int histSize = 256;
float range[] = { 0, 255 };
const float *ranges[] = { range };
const int channels = 0;
calcHist(&result, 1, &channels,
cv::Mat(), hist, 1,
&histSize, &ranges[0]);
float *h = (float*)hist.data;
double hh[256];
double sum = 0;
for (int i = 0; i < 256; ++i)
{
hh[i] = h[i];
sum += hh[i];
}最后根据出现的概率区间来对缺陷进行类型定义,值得一提的是,下面两个阈值需要根据实际情况进行调整:
double hist_sum_scratch = 0;
double hist_sum_blot = 0;
for (int i = 90; i < 135; i++)
{
hist_sum_scratch += hh[i];
}
hist_sum_scratch /= sum;
for (int i = 15; i < 90; i++)
{
hist_sum_blot += hh[i];
}
hist_sum_blot /= sum;
int type = 0;
if (hist_sum_scratch > 0.1)
{
type = 1; //划痕类型
}
if (hist_sum_blot > 0.3)
{
type = 2; //掉漆类型
}好了,上面就是整个项目的检测流程,在这里我们使用的是传统算法,其实在利用传统算法进行缺陷检测基本流程都差不多,最终无非是根据像素的分布的特征进行分类,在实际场景比较单一的情况下使用起来它的鲁棒性还算可以,比如这个视频里面,流水线颜色背景是黑色的,场景模式也比较单一,用起来不会出大问题。但是如果一旦遇到实际场景比较复杂的情况下,传统算法用起来就它的局限性就非常大,举个例子,你敢保证所有的缺陷都是这两种,你敢保证实际生产情况下所有缺陷类型直方图分布严格按照自己规定的阈值进行的?显然实际场景的复杂程度要远远超过我们的所能想到的,这个时候就要用到深度学习算法进行检测了,深度学习算法相比传统算法有诸多优点,诸如它抛开了像素层面的繁琐分析,只要前期数据量够大,它就能适应各种复杂的环境等等。
二、背景去除
什么是背景消除?
当您喜欢图像中的某个焦点部分,并希望在不影响要保留部分的情况下移除其中的干扰元素时,这称为背景移除。从技术上讲,背景移除并不像它所说的那样有效。
有时您需要从图像中删除框架前面的某些内容。因此,背景移除并不总是指擦除框架后面的材料。
为什么需要背景消除?
在数码摄影中,人们笨拙地点击数千张照片,完成后再整理出他们需要的图像。有时他们点击的照片很好,颜色、亮度和其他重要部分可能很完美,但一个错误,如背景中一些不必要的阴影或材料,就会毁掉照片!虽然所有电子商务网站都需要具有透明背景的图像,但其背后的原因是人们会将全部注意力集中在您可能想要销售的产品上。
去除图片背景是如今人们最常使用的图像处理服务。让我们看看为什么你愿意花钱去做这件事。
因此我们将重点讨论如何删除应用程序或网站背景中的背景。
现在,我们将使用OpenC 库进行像素级背景去除
一、去除黑色背景:
此方法仅侧重于去除黑色背景,因此我们将重点关注阈值技术和 alpha(不透明度参数)
具体步骤:
- 导入 opencv 库
- 加载并读取图像
- 将图像背景转换为灰色图像背景
- 此外,应用阈值技术
- 彩色图像 RGB 的分割通道
- 将 rgba 合并为彩色/多通道图像
# Import the library OpenCV
import cv2
# Import the image
file_name = r"/home/vk/Desktop/CV_BackgroundRemoval/black_backgroundremoval/6.jpg"
# Read the image
src = cv2.imread(file_name, 1)
# Convert image to image gray
tmp = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
# Applying thresholding technique
_, alpha = cv2.threshold(tmp, 0, 255, cv2.THRESH_BINARY)
# Using cv2.split() to split channels
# of coloured image
b, g, r = cv2.split(src)
# Making list of Red, Green, Blue
# Channels and alpha
rgba = [b, g, r, alpha]
# Using cv2.merge() to merge rgba
# into a coloured/multi-channeled image
dst = cv2.merge(rgba, 4)
# Writing and saving to a new image
cv2.imwrite("/home/vk/Desktop/CV_BackgroundRemoval/black_backgroundremoval/opencv_bgrm.png", dst)二. 背景去除 - 3 种方法(OpenCV)
方法 1
第一种方法,我们专注于去除前景、背景并将两者结合起来。
具体步骤:
- 执行高斯模糊以消除噪音
- 通过将像素放入 RGB 空间中的六个等距箱中来简化我们的图像。换句话说,转换成 5 x 5 x 5 = 125 种颜色
- 将图像转换为灰度并应用阈值处理以获得前景的蒙版
- 将蒙版应用到我们的合并图像上,仅保留前景(本质上是去除背景)
def bgremove1(myimage=myimage):
myimage =cv2.imread(myimage)
# Blur to image to reduce noise
myimage = cv2.GaussianBlur(myimage,(5,5), 0)
# We bin the pixels. Result will be a value 1..5
bins=np.array([0,51,102,153,204,255])
myimage[:,:,:] = np.digitize(myimage[:,:,:],bins,right=True)*51
# Create single channel greyscale for thresholding
myimage_grey = cv2.cvtColor(myimage, cv2.COLOR_BGR2GRAY)
# Perform Otsu thresholding and extract the background.
# We use Binary Threshold as we want to create an all white background
ret,background = cv2.threshold(myimage_grey,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
# Convert black and white back into 3 channel greyscale
background = cv2.cvtColor(background, cv2.COLOR_GRAY2BGR)
cv2.imwrite("method1_background_image.png",background)
# Perform Otsu thresholding and extract the foreground.
# We use TOZERO_INV as we want to keep some details of the foregorund
ret,foreground = cv2.threshold(myimage_grey,0,255,cv2.THRESH_TOZERO_INV+cv2.THRESH_OTSU) #Currently foreground is only a mask
foreground = cv2.bitwise_and(myimage,myimage, mask=foreground) # Update foreground with bitwise_and to extract real foreground
cv2.imwrite("method1_foreground_image.png",foreground)
# Combine the background and foreground to obtain our final image
finalimage = background+foreground
cv2.imwrite("method1_bm.png",finalimage)
return finalimage方法2 - 阈值技术
显然,在方法 1 中,我们执行了大量图像处理。可以看出,高斯模糊和 Otsu 阈值需要大量处理。此外,在应用高斯模糊和分箱时,我们在图像中丢失了很多细节。因此,我们希望设计一种有望更快的替代策略。考虑到效率并知道 OpenCV 是一个高度优化的库,我们选择了一种以阈值为重点的方法:
具体步骤:
- 将我们的图像转换为灰度
- 执行简单的阈值处理来为前景和背景构建蒙版
- 根据掩码确定前景和背景
- 结合前景和背景重建原始图像
def bgremove2 ( myimage=myimage ):
myimage =cv2.imread(myimage)
# 首先转换为灰度
myimage_grey = cv2.cvtColor(myimage, cv2.COLOR_BGR2GRAY)
ret,baseline = cv2.threshold(myimage_grey, 127 , 255 ,cv2.THRESH_TRUNC)
ret,background = cv2.threshold(baseline, 126 , 255 ,cv2.THRESH_BINARY)
ret,foreground = cv2.threshold(baseline, 126 , 255 ,cv2.THRESH_BINARY_INV)
foreground = cv2.bitwise_and(myimage,myimage, mask=foreground) # 用 bitwise_and 更新前景以提取真实前景
cv2.imwrite( "method2_foreground_image.png",foreground)
# 将黑白转换回 3 通道灰度
background = cv2.cvtColor(background, cv2.COLOR_GRAY2BGR)
cv2.imwrite( "method2_background_image.png",background)
# 结合背景和前景以获得最终图像
finalimage = background+foreground
cv2.imwrite( "method2_image.png",finalimage)
return finalimage方法 3 — HSV 颜色空间
到目前为止,我们一直在 BGR 颜色空间中工作。考虑到这一点,我们的图像容易出现光线不足和阴影的情况。毫无疑问,我们想知道在 HSV 颜色空间中工作是否会得到更好的结果。为了不丢失图像细节,我们还决定不执行高斯模糊或图像分级。而是专注于使用 Numpy 进行阈值处理和生成图像蒙版。一般来说,我们的策略如下:
具体步骤:
- 将我们的图像转换为 HSV 颜色空间
- 执行简单的阈值处理,使用 Numpy 根据饱和度和值创建地图
- 将 S 和 V 的映射组合成最终的蒙版
- 根据组合掩码确定前景和背景
- 结合提取的前景和背景重建原始图像
def bgremove3(myimage=myimage):
myimage =cv2.imread(myimage)
# BG Remover 3
myimage_hsv = cv2.cvtColor(myimage, cv2.COLOR_BGR2HSV)
#Take S and remove any value that is less than half
s = myimage_hsv[:,:,1]
s = np.where(s < 127, 0, 1) # Any value below 127 will be excluded
# We increase the brightness of the image and then mod by 255
v = (myimage_hsv[:,:,2] + 127) % 255
v = np.where(v > 127, 1, 0) # Any value above 127 will be part of our mask
# Combine our two masks based on S and V into a single "Foreground"
foreground = np.where(s+v > 0, 1, 0).astype(np.uint8) #Casting back into 8bit integer
background = np.where(foreground==0,255,0).astype(np.uint8) # Invert foreground to get background in uint8
background = cv2.cvtColor(background, cv2.COLOR_GRAY2BGR) # Convert background back into BGR space
cv2.imwrite("method3_background_image.png",background)
foreground=cv2.bitwise_and(myimage,myimage,mask=foreground) # Apply our foreground map to original image
cv2.imwrite("method3_foreground_image.png",foreground)
finalimage = background+foreground # Combine foreground and background
cv2.imwrite("method3_image.png",finalimage)
return finalimage以上三种方法是常用的,Thersholding,HSV,Pixel-wise Blur背景。
这样才能精准的去除背景,所以我们将重点放在深度学习上。
准确地去除背景,以便我们继续深度学习和两阶段过程。
1. 在 U2net 中生成清晰的掩码
2. 减去掩码和输入图像
现在,我讨论一下 U2net 架构,
第一阶段:U2Net
U2net:我们设计了一个简单但功能强大的深度网络架构 U2-Net,用于显著对象检测 (SOD)。我们的 U2-Net 架构是一个两级嵌套 U 结构。该设计具有以下优点:(1) 由于我们提出的 ReSidual U 块 (RSU) 中混合了不同大小的接受场,因此能够从不同尺度捕获更多上下文信息;(2) 由于这些 RSU 块中使用了池化操作,它增加了整个架构的深度,而不会显著增加计算成本。这种架构使我们能够从头开始训练深度网络,而无需使用来自图像分类任务的主干。我们实例化了所提架构的两个模型,U2-Net(176.3 MB,GTX 1080Ti GPU 上 30 FPS)和 U2-Net†(4.7 MB,40 FPS),以方便在不同环境中使用。两种模型在六个 SOD 数据集上都实现了具有竞争力的性能。
下载 — U2net 模型:
https://drive.google.com/file/d/1ao1ovG1Qtx4b7EoskHXmi2E9rp5CHLcZ/viewimport os
from skimage import io, transfor
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms#, utils
# import torch.optim as optim
import numpy as np
from PIL import Image
import glob
from data_loader import RescaleT
from data_loader import ToTensor
from data_loader import ToTensorLab
from data_loader import SalObjDataset
from model import U2NET # full size version 173.6 MB
from model import U2NETP # small version u2net 4.7 MB
# normalize the predicted SOD probability map
def normPRED(d):
ma = torch.max(d)
mi = torch.min(d)
dn = (d-mi)/(ma-mi)
return dn
def save_output(image_name,pred,d_dir):
predict = pred
predict = predict.squeeze()
predict_np = predict.cpu().data.numpy()
im = Image.fromarray(predict_np*255).convert('RGB')
img_name = image_name.split(os.sep)[-1]
image = io.imread(image_name)
imo = im.resize((image.shape[1],image.shape[0]),resample=Image.BILINEAR)
pb_np = np.array(imo)
aaa = img_name.split(".")
bbb = aaa[0:-1]
imidx = bbb[0]
for i in range(1,len(bbb)):
imidx = imidx + "." + bbb[i]
imo.save(d_dir+imidx+'.png')
def main():
# --------- 1. get image path and name ---------
model_name='u2net'#u2netp
image_dir=os.path.join(os.getcwd(),'test_data','images','input')
prediction_dir=os.path.join(os.getcwd(),'test_data','images',model_name+'_results'+os.sep)
model_dir = os.path.join(os.getcwd(),'saved_models',model_name,model_name+'.pth')
img_name_list = glob.glob(image_dir + os.sep + '*')
print(img_name_list)
# --------- 2. dataloader ---------
#1. dataloader
test_salobj_dataset = SalObjDataset(img_name_list = img_name_list,
lbl_name_list = [],
transform=transforms.Compose([RescaleT(320),
ToTensorLab(flag=0)])
)
test_salobj_dataloader = DataLoader(test_salobj_dataset,
batch_size=1,
shuffle=False,
num_workers=1)
# --------- 3. model define ---------
if(model_name=='u2net'):
print("...load U2NET---173.6 MB")
net = U2NET(3,1)
elif(model_name=='u2netp'):
print("...load U2NEP---4.7 MB")
net = U2NETP(3,1)
net.load_state_dict(torch.load(model_dir))
if torch.cuda.is_available():
net.cuda()
net.eval()
# --------- 4. inference for each image ---------
for i_test, data_test in enumerate(test_salobj_dataloader):
print("inferencing:",img_name_list[i_test].split(os.sep)[-1])
inputs_test = data_test['image']
inputs_test = inputs_test.type(torch.FloatTensor)
if torch.cuda.is_available():
inputs_test = Variable(inputs_test.cuda())
else:
inputs_test = Variable(inputs_test)
d1,d2,d3,d4,d5,d6,d7= net(inputs_test)
# normalization
pred = d1[:,0,:,:]
pred = normPRED(pred)
# save results to test_results folder
if not os.path.exists(prediction_dir):
os.makedirs(prediction_dir, exist_ok=True)
save_output(img_name_list[i_test],pred,prediction_dir)
del d1,d2,d3,d4,d5,d6,d7
if __name__ == "__main__":
main()第 2 阶段:减去输入图像和掩码
import cv2
#subimage
subimage=Image.open('/content/drive/MyDrive/background_removal_DL/test_data/images/u2net_results/4.png')
#originalimage
original=Image.open('/content/drive/MyDrive/background_removal_DL/test_data/images/input/4.jpeg')
subimage=subimage.convert("RGBA")
original=original.convert("RGBA")
subdata=subimage.getdata()
ogdata=original.getdata()
newdata=[]
for i in range(subdata.size[0]*subdata.size[1]):
if subdata[i][0]==0 and subdata[i][1]==0 and subdata[i][2]==0:
newdata.append((255,255,255,0))
else:
newdata.append(ogdata[i])
subimage.putdata(newdata)
subimage.save('/content/drive/MyDrive/background_removal_DL/test_data/images/output/output_bgrm.png',"PNG")在这个 U2net 架构中生成 mask 输出。并减去输入和 mask 图像。但它并没有明显去除背景。所以现在新引入了 Rembg 方法。
引用:
- Rembg 是深度学习方法。
- Rembg 是骨干架构——U2Net。
- 显然,背景已被删除。
from rembg import remove
import cv2
input_path = '/home/vk/Desktop/CV_BackgroundRemoval/rembg/6.jpg'
output_path = '/home/vk/Desktop/CV_BackgroundRemoval/rembg/rembg_output2.png'
input = cv2.imread(input_path)
output = remove(input)
cv2.imwrite(output_path, output)主干比较:
完整代码:
https://github.com/VK-Ant/CV_BackgroundRemoval参考链接:
https://github.com/Nkap23/background_removal_DL
https://nisargkapkar.hashnode.dev/image-and-video-background-removal-using-deep-learning
https://www.freedomvc.com/index.php/2022/01/17/basic-background-remover-with-opencv/
https://clipingchoice.com/what-is-background-removing/
https://arxiv.org/abs/2005.09007v3三、OpenCV和K-Means聚类实现颜色分割
颜色分割是计算机视觉中使用的一种技术,可根据颜色识别和区分图像中的不同物体或区域。聚类算法可以自动将相似的颜色归为一组,而无需为每种颜色指定阈值。当处理颜色范围很广的图像或事先不知道确切阈值时,此功能非常有用。
本文中,我们将探索如何使用 K-Means聚类算法进行颜色分割,并计算每种颜色的对象数量。我们将使用“泡泡射击”游戏中的图像作为示例,根据轮廓查找和过滤气泡对象,并应用 K 均值算法将颜色相似的气泡分组在一起。这将使我们能够计算和提取颜色相似的气泡的蒙版,以供进一步的下游应用使用。我们将使用OpenCV和scikit-learn库进行图像分割和颜色聚类。
from matplotlib import pyplot as plt
import cv2
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
%matplotlib inlinimage = cv2.imread(r'bubbles.jpeg', cv2.IMREAD_UNCHANGED)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.axis('off')使用阈值提取二进制掩码
第一步是从背景中提取所有气泡。为此,我们将首先使用cv2.cvtColor()函数将图像转换为灰度,然后使用cv2.threshold()它将其转换为二进制图像,其中像素为 0 或 255。阈值设置为 60,因此所有低于 60 的像素都设置为 0,其他像素设置为 255。由于一些气泡在二进制图像上略有重叠,我们使用函数cv2.erode()将它们分开。腐蚀是一种形态学操作,可减小图像中对象的大小。它可用于去除小的白噪声,以及分离连接的对象。
image = cv2.imread(r'bubbles.jpeg', cv2.IMREAD_UNCHANGED)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_ , mask = cv2.threshold(gray, 60, 255, cv2.THRESH_BINARY)
mask = cv2.erode(mask, np.ones((7, 7), np.uint8))使用轮廓提取对象边界
下一步是在二值图像中查找对象。我们cv2.findContours()在二值图像上使用函数来检测对象的边界。轮廓定义为构成图像中对象边界的连续曲线。当使用cv2.RETR_EXTERNAL标志时,仅返回最外层的轮廓。该算法输出轮廓列表,每个轮廓代表图像中单个对象的边界。
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)过滤轮廓并提取平均颜色
为了去除不代表气泡的轮廓,我们将迭代生成的轮廓并仅选择面积较大的轮廓(大于 3000 像素)。这将使我们能够隔离气泡的轮廓并丢弃任何较小的物体,例如字母或背景的一部分。
filtered_contours = []
df_mean_color = pd.DataFrame()
for idx, contour in enumerate(contours):
area = int(cv2.contourArea(contour))
# if area is higher than 3000:
if area > 3000:
filtered_contours.append(contour)
# get mean color of contour:
masked = np.zeros_like(image[:, :, 0]) # This mask is used to get the mean color of the specific bead (contour), for kmeans
cv2.drawContours(masked, [contour], 0, 255, -1)
B_mean, G_mean, R_mean, _ = cv2.mean(image, mask=masked)
df = pd.DataFrame({'B_mean': B_mean, 'G_mean': G_mean, 'R_mean': R_mean}, index=[idx])
df_mean_color = pd.concat([df_mean_color, df])为了找到每个气泡的平均颜色,我们首先通过在黑色图像上用白色绘制气泡轮廓来为每个气泡创建一个蒙版。然后,我们将使用该cv2.mean()函数使用原始图像和气泡的蒙版计算气泡的平均蓝色、绿色和红色 (BGR) 通道值。每个气泡的平均 BGR 值存储在 pandas DataFrame 中。
使用 K-means 算法对相似颜色进行聚类
最后,我们将应用 K 均值聚类算法将颜色相似的气泡分组在一起。我们将使用轮廓的平均颜色值作为库KMeans中算法的输入数据sklearn。n_clusters超参数指定算法要创建的聚类数。在本例中,由于气泡有 6 种颜色,我们将该值设置为 6。
K 均值算法是一种流行的聚类方法,可用于将相似的数据点分组在一起。该算法的工作原理是将一组数据点作为输入,并将它们分成指定数量的聚类,每个聚类由一个质心表示。质心被初始化为数据空间内的随机位置,算法迭代地将每个数据点分配给由最接近的质心所代表的聚类。一旦所有数据点都被分配到一个聚类,质心就会更新为数据点在其聚类中的平均位置。这个过程重复进行,直到质心收敛到稳定的位置,数据点不再被重新分配到不同的聚类。通过使用 K 均值算法并以每个气泡的平均 BGR 值作为输入,我们可以将具有相似颜色的气泡分组在一起。
一旦KMeans类初始化完毕,fit_predict就会调用该方法执行聚类。该fit_predict方法返回每个对象的聚类标签,然后将其分配给数据集中的新“标签”列。这使我们能够识别哪些数据点属于哪个聚类。
km = KMeans( n_clusters=6)
df_mean_color['label'] = km.fit_predict(df_mean_color)draw_segmented_objects然后定义函数来创建一个新的蒙版图像,其中包含相同颜色的气泡。首先创建一个二进制蒙版:在黑色图像上用白色绘制所有具有相同标签的气泡的轮廓。然后,使用来自的函数将原始图像与蒙版组合,bitwise_and得到cv2一个只有具有相同标签的气泡可见的图像。为方便起见,使用函数在图像上绘制每种颜色的气泡数量cv2.putText()。
def draw_segmented_objects(image, contours, label_cnt_idx, bubbles_count):
mask = np.zeros_like(image[:, :, 0])
cv2.drawContours(mask, [contours[i] for i in label_cnt_idx], -1, (255), -1)
masked_image = cv2.bitwise_and(image, image, mask=mask)
masked_image = cv2.putText(masked_image, f'{bubbles_count} bubbles', (200, 1200), cv2.FONT_HERSHEY_SIMPLEX,
fontScale = 3, color = (255, 255, 255), thickness = 10, lineType = cv2.LINE_AA)
return masked_image对每组具有相同标签的气泡调用该draw_segmented_objects函数,以生成每种颜色的蒙版图像。可以通过计算按颜色分组后的 DataFrame 中的行数来确定每种颜色的珠子数量。
img = image.copy()
for label, df_grouped in df_mean_color.groupby('label'):
bubbles_amount = len(df_grouped)
masked_image = draw_segmented_objects(image, contours, df_grouped.index, bubbles_amount)
img = cv2.hconcat([img, masked_image])
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB) )总 结
使用 K-means 聚类进行颜色分割可以成为一种强大的工具,可根据颜色识别和量化图像中的对象。在本教程中,我们演示了如何使用 K-means 算法以及 OpenCV 和 scikit-learn 来执行颜色分割并计算图像中每种颜色的对象数量。此技术可应用于各种需要根据颜色分析和分类图像中对象的场景。
四、Python和MediaPipe~检测系统
疲劳驾驶的危害不堪设想,据了解,21%的交通事故都因此而生,尤其是高速路上,大多数车辆都是长途驾驶,加之速度快,危害更加严重。
相关部门一般都会建议司机朋友及时休息调整后再驾驶,避免酿成惨
作为视觉开发人员,我们可否帮助驾驶人员设计一套智能检测嗜睡的系统,及时提醒驾驶员注意休息?如下图所示,本文将详细介绍如何使用Python和MediaPipe来实现一个嗜睡检测系统。
实现步骤
思路:疲劳驾驶的司机大部分都有打瞌睡的情形,所以我们根据驾驶员眼睛闭合的频率和时间来判断驾驶员是否疲劳驾驶(或嗜睡)。详细实现步骤【1】眼部关键点检测。关于MediaPipe前面已经介绍过,具体可以查看下面链接的文章:------MediaPipe介绍与手势识别------
我们使用Face Mesh来检测眼部关键点,Face Mesh返回了468个人脸关键点
由于我们专注于驾驶员睡意检测,在468个点中,我们只需要属于眼睛区域的标志点。眼睛区域有 32 个标志点(每个 16 个点)。为了计算 EAR,我们只需要 12 个点(每只眼睛 6 个点)。
以上图为参考,选取的12个地标点如下:
- 对于左眼: [362, 385, 387, 263, 373, 380]
- 对于右眼:[33, 160, 158, 133, 153, 144]
选择的地标点按顺序排列:P 1、 P 2、 P 3、 P 4、 P 5、 P 6
import cv2
import numpy as np
import matplotlib.pyplot as plt
import mediapipe as mp
mp_facemesh = mp.solutions.face_mesh
mp_drawing = mp.solutions.drawing_utils
denormalize_coordinates = mp_drawing._normalized_to_pixel_coordinates
%matplotlib inline获取双眼的地标(索引)点。
# Landmark points corresponding to left eye
all_left_eye_idxs = list(mp_facemesh.FACEMESH_LEFT_EYE)
# flatten and remove duplicates
all_left_eye_idxs = set(np.ravel(all_left_eye_idxs))
# Landmark points corresponding to right eye
all_right_eye_idxs = list(mp_facemesh.FACEMESH_RIGHT_EYE)
all_right_eye_idxs = set(np.ravel(all_right_eye_idxs))
# Combined for plotting - Landmark points for both eye
all_idxs = all_left_eye_idxs.union(all_right_eye_idxs)
# The chosen 12 points: P1, P2, P3, P4, P5, P6
chosen_left_eye_idxs = [362, 385, 387, 263, 373, 380]
chosen_right_eye_idxs = [33, 160, 158, 133, 153, 144]
all_chosen_idxs = chosen_left_eye_idxs + chosen_right_eye_idx【2】检测眼睛是否闭合——计算眼睛纵横比(EAR)。要检测眼睛是否闭合,我们可以使用眼睛纵横比(EAR) 公式:EAR 公式返回反映睁眼程度的单个标量: 1. 我们将使用 Mediapipe 的 Face Mesh 解决方案来检测和检索眼睛区域中的相关地标(下图中的点P 1 - P 6)。 2. 检索相关点后,会在眼睛的高度和宽度之间计算眼睛纵横比 (EAR)。 当眼睛睁开并接近零时,EAR 几乎是恒定的,而闭上眼睛是部分人,并且头部姿势不敏感。睁眼的纵横比在个体之间具有很小的差异。它对于图像的统一缩放和面部的平面内旋转是完全不变的。由于双眼同时眨眼,所以双眼的EAR是平均的。
上图:检测到地标P i的睁眼和闭眼。
底部:为视频序列的几帧绘制的眼睛纵横比 EAR。存在一个闪烁。
首先,我们必须计算每只眼睛的 Eye Aspect Ratio:
|| 表示L2范数,用于计算两个向量之间的距离。
为了计算最终的 EAR 值,作者建议取两个 EAR 值的平均值。
一般来说,平均 EAR 值在 [0.0, 0.40] 范围内。在“闭眼”动作期间 EAR 值迅速下降。
现在我们熟悉了 EAR 公式,让我们定义三个必需的函数:distance(…)、get_ear(…)和calculate_avg_ear(…)。
def distance(point_1, point_2):
"""Calculate l2-norm between two points"""
dist = sum([(i - j) ** 2 for i, j in zip(point_1, point_2)]) ** 0.5
return distget_ear (…)函数将.landmark属性作为参数。在每个索引位置,我们都有一个NormalizedLandmark对象。该对象保存标准化的x、y和z坐标值。
def get_ear(landmarks, refer_idxs, frame_width, frame_height):
"""
Calculate Eye Aspect Ratio for one eye.
Args:
landmarks: (list) Detected landmarks list
refer_idxs: (list) Index positions of the chosen landmarks
in order P1, P2, P3, P4, P5, P6
frame_width: (int) Width of captured frame
frame_height: (int) Height of captured frame
Returns:
ear: (float) Eye aspect ratio
"""
try:
# Compute the euclidean distance between the horizontal
coords_points = []
for i in refer_idxs:
lm = landmarks[i]
coord = denormalize_coordinates(lm.x, lm.y,
frame_width, frame_height)
coords_points.append(coord)
# Eye landmark (x, y)-coordinates
P2_P6 = distance(coords_points[1], coords_points[5])
P3_P5 = distance(coords_points[2], coords_points[4])
P1_P4 = distance(coords_points[0], coords_points[3])
# Compute the eye aspect ratio
ear = (P2_P6 + P3_P5) / (2.0 * P1_P4)
except:
ear = 0.0
coords_points = None
return ear, coords_points最后定义了calculate_avg_ear(…)函数:
def calculate_avg_ear(landmarks, left_eye_idxs, right_eye_idxs, image_w, image_h):
"""Calculate Eye aspect ratio"""
left_ear, left_lm_coordinates = get_ear(
landmarks,
left_eye_idxs,
image_w,
image_h
)
right_ear, right_lm_coordinates = get_ear(
landmarks,
right_eye_idxs,
image_w,
image_h
)
Avg_EAR = (left_ear + right_ear) / 2.0
return Avg_EAR, (left_lm_coordinates, right_lm_coordinates)让我们测试一下 EAR 公式。我们将计算先前使用的图像和另一张眼睛闭合的图像的平均 EAR 值。
image_eyes_open = cv2.imread("test-open-eyes.jpg")[:, :, ::-1]
image_eyes_close = cv2.imread("test-close-eyes.jpg")[:, :, ::-1]
for idx, image in enumerate([image_eyes_open, image_eyes_close]):
image = np.ascontiguousarray(image)
imgH, imgW, _ = image.shape
# Creating a copy of the original image for plotting the EAR value
custom_chosen_lmk_image = image.copy()
# Running inference using static_image_mode
with mp_facemesh.FaceMesh(refine_landmarks=True) as face_mesh:
results = face_mesh.process(image).multi_face_landmarks
# If detections are available.
if results:
for face_id, face_landmarks in enumerate(results):
landmarks = face_landmarks.landmark
EAR, _ = calculate_avg_ear(
landmarks,
chosen_left_eye_idxs,
chosen_right_eye_idxs,
imgW,
imgH
)
# Print the EAR value on the custom_chosen_lmk_image.
cv2.putText(custom_chosen_lmk_image,
f"EAR: {round(EAR, 2)}", (1, 24),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (255, 255, 255), 2
)
plot(img_dt=image.copy(),
img_eye_lmks_chosen=custom_chosen_lmk_image,
face_landmarks=face_landmarks,
ts_thickness=1,
ts_circle_radius=3,
lmk_circle_radius=3
)结果:
如您所见,睁眼时的 EAR 值为0.28,闭眼时(接近于零)为 0.08。
【3】设计一个实时检测系统。
- 首先,我们声明两个阈值和一个计数器。
- EAR_thresh: 用于检查当前EAR值是否在范围内的阈值。
- D_TIME:一个计数器变量,用于跟踪当前经过的时间量EAR < EAR_THRESH.
- WAIT_TIME:确定经过的时间量是否EAR < EAR_THRESH超过了允许的限制。
- 当应用程序启动时,我们将当前时间(以秒为单位)记录在一个变量中t1并读取传入的帧。
- 接下来,我们预处理并frame通过Mediapipe 的 Face Mesh 解决方案管道。
- 如果有任何地标检测可用,我们将检索相关的 ( Pi )眼睛地标。否则,在此处重置t1 和重置以使算法一致)。D_TIME (D_TIME
- 如果检测可用,则使用检索到的眼睛标志计算双眼的平均EAR值。
- 如果是当前时间,则加上当前时间和to之间的差。然后将下一帧重置为。EAR < EAR_THRESHt2t1D_TIMEt1 t2
- 如果D_TIME >= WAIT_TIME,我们会发出警报或继续下一帧。
参考链接:
https://learnopencv.com/driver-drowsiness-detection-using-mediapipe-in-python/
五、使用傅里叶变换去除图像条纹杂讯
图像可以用两个域表示:空间域和频域。空间域是图像最常见的表示形式,像素值表示图像中每个点的亮度或颜色。另一方面,频域将图像表示为具有不同频率和振幅的正弦波的集合。
傅里叶变换
您是否曾经因为照片在弱光条件下出现颗粒感和噪点而感到沮丧?😩 如果是这样,您并不孤单 🫂。许多人(无论是否摄影师)都面临这个问题,尤其是在具有挑战性的照明条件下。幸运的是,傅里叶变换(一种用于图像处理的数学技术)可以通过分析图像的频率分量并揭示隐藏的模式和结构来帮助解决此问题。通过使用傅里叶变换,我们可以消除噪音并增强重要特征,使我们的照片看起来清晰明快。
傅里叶变换是图像处理中用于分析图像频率成分的强大工具。本质上,它帮助我们识别图像频域中难以在空间域中看到的复杂模式和结构。可以把它想象成戴上眼镜,让你能够更详细、更清晰地看到事物。
傅里叶变换的一个常见应用是从图像中去除噪声。噪声通常出现在图像的高频分量中,可以通过傅里叶变换轻松识别和隔离。通过分析图像的频率分量,我们可以去除噪声或不需要的特征并增强重要特征。为此,我们使用傅里叶变换将图像从空间域转换为频域,滤除噪声,然后使用逆傅里叶变换将图像转换回空间域。
如果您想在图像处理方面了解更多有关傅里叶变换的知识,请查看爱丁堡大学信息学院的这个网页:
https ://homepages.inf.ed.ac.uk/rbf/HIPR2/fourier.htm它提供了傅里叶变换的全面数学概述以及一些关于其工作原理的可视化效果。
现在我们了解了傅里叶变换在图像处理中的潜力,让我们深入了解如何使用它来改善图像质量并纠正任何失真或噪声的过程。
步骤 1:导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from skimage.color import rgb2gray
from skimage.io import imread, imshow步骤 2:加载并显示图像
image = imread('lunar_orbiter.jpg')
plt.imshow(image)
plt.title('Original Image')
plt.axis('off')
plt.show()
我们可以对该图像应用傅里叶变换来去除扫描标记并提高其质量。
步骤 3:将图像转换为灰度并计算二维傅里叶变换
将图像转换为灰度可简化分析并降低计算复杂度。计算二维傅里叶变换可获得图像的频域表示。
gray_image = rgb2gray(image)
f_image = np.fft.fft2(gray_image)步骤 4:将直流或零频分量移至中心并计算幅度谱
图像的频率分量可以帮助我们洞察图像内的空间模式和重复结构:
- 低频成分对应于平滑、渐进的变化
- 高频成分代表突然的变化和精细的细节。
- 直流分量或零频率表示图像的平均亮度。
通过了解频率成分的重要性,我们可以在图像处理中有效地使用 FT 来处理图像并发现隐藏的信息。
在计算傅里叶变换后,我们需要将零频分量(即直流分量)移至频谱的中心,以便更好地可视化低频和高频。
我们可以使用 np.fft.fftshift() 函数来实现此目的:
fshift = np.fft.fftshift(f_image)步骤 5:可视化幅度谱
为了可视化幅度谱,我们可以计算从傅里叶变换获得的复数的幅度并绘制它们:
magnitude_spectrum = 20 * np.log(np.abs(fshift))
plt.imshow(magnitude_spectrum, cmap='gray')
plt.title('Magnitude Spectrum')
plt.axis('off')
plt.show()
幅度谱是图像频率成分的直观表示。它使我们能够看到图像中的各种模式和细节,并将它们分为前面提到的三个主要频率成分:
1. 直流分量:这是零频率分量,对应于图像的平均亮度或光度。它通常位于幅度谱的中心。
2. 低频:这些成分表示图像中的平滑和渐进变化,例如大面积均匀区域、柔和渐变或亮度的缓慢过渡。它们通常位于幅度谱中心附近,围绕直流成分。低频包含的图像信息比高频更多,因为它们的幅度更高。
3. 高频:这些成分可捕捉图像中的突然变化、精细细节、边缘、纹理或噪声。它们通常位于幅度谱的外边缘,与低频相比幅度较小。
分析幅度谱有助于我们识别可能需要增强或过滤以提高图像质量的区域。在示例中,我们可以看到频谱中可见的两种主要模式,即垂直线和水平线。这些模式通常源于图像背景中存在的规则结构(例如图像中非常明显的水平扫描标记)。
这种幅度谱的可视化对于理解频率成分的分布非常重要,我们稍后可以使用它来设计针对频域特定区域的滤波器,以增强或消除原始图像(例如扫描标记)中的噪声。
步骤 6:将滤波器应用于图像的频域表示
将滤波器应用于频域表示允许我们去除不需要的频率分量(例如,图像中的扫描标记等噪声)或强调特定频率。在此示例中,我们应用垂直滤波器从图像中去除水平线。
需要注意的是,我们应该避免过滤 DC 分量,因为它代表了图像的平均亮度,修改它会影响整体亮度。这就是为什么我们在下面的代码中排除了 286(或 fshift.shape[0]//2 -1)。
由于我们将 DC 移到了中心,因此我们可以fshift.shape[1]//2沿水平轴定位频域表示(幅度谱)的中心。fshift.shape[1] 返回频域数组中的列数,将其除以 2(//2)可得到中间列。
我们应用垂直滤波器来定位频域表示中的水平线。为此,我们将中心周围垂直方向的幅度谱值(上下)设置为 1。此操作有效地滤除造成图像中水平线的频率分量。因此,当我们执行逆傅里叶变换时,水平线被抑制,图像看起来更清晰。
image_gray_fft2 = fshift.copy()
image_gray_fft2[:286, fshift.shape[1]//2] = 1
image_gray_fft2[-286:, fshift.shape[1]//2] = 1
plt.figure(figsize=(7,7))
plt.imshow(np.log(abs(image_gray_fft2)), cmap='gray');
在这个例子中,我在幅度谱中创建了一个垂直滤波器。您还可以添加水平滤波器(不包括 DC 分量),以查看它如何影响输出。(剧透警告:它并没有太大帮助。在某些情况下,您可能希望保留幅度谱中的某些模式(例如水平滤波器)以保持整体图像结构,因为删除它们可能会导致不必要的伪影或重要细节的丢失,或者可能根本没有必要。
例如,在处理带有条纹图案的图像时,删除水平线可能会损害图案的视觉完整性并添加不必要的垂直线伪影。分析图像及其频率分量至关重要,以便根据图像处理任务的具体要求和期望结果做出是否过滤这些线条的明智决定。
步骤 7:使用逆傅里叶变换获取滤波后的灰度图像并将其可视化
应用所需的滤波器后,我们可以使用逆傅里叶变换将滤波后的频域表示转换回空间域:
# 使用逆傅里叶变换
inv_fshift = np.fft.ifftshift(image_gray_fft2)
filtered_gray_image = np.fft.ifft2(inv_fshift)
filtered_gray_image = np. abs (filtered_gray_image)
# 绘制原始图像和傅里叶变换后的灰度图像
fig, ax = plt.subplots( 1 , 2 , figsize=( 14 , 7 ))
ax[ 0 ].imshow(image)
ax[ 0 ].set_title( '原始图像' )
ax[ 0 ].axis( 'off' )
ax[ 1 ].imshow(filtered_gray_image, cmap= 'gray' )
ax[ 1 ].set_title( '傅里叶变换后的灰度图像' )
ax[ 1 ].axis( 'off' )
plt.show()
步骤 8:将傅里叶变换应用于 RGB 图像的每个通道,并使用与步骤 6 相同的滤波器
现在我们已经了解了如何将傅里叶变换应用于灰度图像,让我们看看如何将其应用于彩色图像。我们可以使用之前使用的相同技术,但这次我们将其应用于 RGB 图像的每个通道。
首先,我们遍历图像的每个通道,并使用 np.fft.fft2 函数对其应用傅里叶变换。然后我们使用 np.fft.fftshift 将零频率分量移到中心,这对于过滤步骤是必要的:
transformation_channels = []
for i in range ( 3 ):
rgb_fft = np.fft.fftshift(np.fft.fft2((image[:, :, i])))
rgb_fft2 = rgb_fft.copy()
# 使用与灰度图像相同的过滤器,只需更改变量
rgb_fft2[: 286 , rgb_fft.shape[ 1 ]// 2 ] = 1
rgb_fft2[- 286 :, rgb_fft.shape[ 1 ]// 2 ] = 1
transformation_channels.append( abs (np.fft.ifft2(np.fft.ifftshift(rgb_fft2))))这里,我们使用与之前相同的垂直滤波器,但这次我们将其分别应用于每个通道。
步骤 9:合并过滤后的通道并将值剪切到有效范围内
现在我们已经过滤了 RGB 图像的每个通道,我们需要将它们组合起来以创建最终的过滤图像。我们使用函数np.dstack沿深度轴堆叠过滤后的通道,创建一个新的 3D 数组。然后我们使用将这个新图像的像素值剪裁到 0-255 的有效范围np.clip,并使用方法将像素值转换为无符号的 8 位整数astype。
filtered_rgb_image = np.dstack([transformed_channels[0], transformed_channels[1], transformed_channels[2]])
filtered_rgb_image = np.clip(filtered_rgb_image, 0, 255).astype(np.uint8)步骤 10:使用 plot_fourier_transformer 函数可视化结果
最后,我们可以使用该函数将过滤过程的结果可视化plot_fourier_transformer。此函数接受三个参数:原始图像、过滤后的灰度图像和过滤后的 RGB 图像。
def plot_fourier_transformer(image, filtered_gray_image, filtered_rgb_image):
if len(image.shape) == 2:
image = np.stack((image, image, image), axis=-1)
# Convert the image to grayscale
gray_image = rgb2gray(image[:,:,:3])
# Calculate the 2D Fourier transform and shift the zero-frequency components to the center
f_image = np.fft.fft2(gray_image)
fshift = np.fft.fftshift(f_image)
magnitude_spectrum = 20 * np.log(np.abs(fshift))
# Plot the images
fig, ax = plt.subplots(2, 3, figsize=(14, 10))
ax[0, 0].imshow(magnitude_spectrum, cmap='gray')
ax[0, 0].set_title('Magnitude Spectrum')
ax[0, 1].imshow(magnitude_spectrum, cmap='gray')
ax[0, 1].imshow(np.log(abs(image_gray_fft2)), cmap='gray')
ax[0, 1].set_title('Magnitude Spectrum with filter')
ax[0, 2].imshow(gray_image, cmap='gray')
ax[0, 2].set_title('Grayscale Image')
ax[0, 2].set_axis_off()
ax[1, 0].imshow(image)
ax[1, 0].set_title('Original Image')
ax[1, 0].set_axis_off()
ax[1, 1].imshow(filtered_gray_image, cmap='gray')
ax[1, 1].set_title('Fourier Transformed Grayscale Image')
ax[1, 1].set_axis_off()
ax[1, 2].imshow(filtered_rgb_image)
ax[1, 2].set_title('Fourier Transformed RGB Image')
ax[1, 2].set_axis_off()
# Save the Fourier-transformed RGB image
plt.savefig('filtered_rgb_image.png', dpi=300)
plt.show()
plot_fourier_transformer(image, filtered_gray_image, filtered_rgb_image)
此函数在 2x3 网格中绘制六幅图像。顶行包含灰度图像的幅度谱、应用过滤器后的灰度图像的幅度谱以及灰度图像本身。底行包含原始图像、过滤后的灰度图像和过滤后的 RGB 图像。
经过过滤的图像去除了垂直线,外观更加平滑,高频噪声更少。
完整代码:
# Load the image
image = imread('lunar_orbiter.jpg')
# Check if the input image is grayscale (2D) and convert it to a 3-channel image (3D) if necessary
if len(image.shape) == 2:
image = np.stack((image, image, image), axis=-1)
# Convert the image to grayscale
gray_image = rgb2gray(image)
# Calculate the 2D Fourier transform and shift the zero-frequency components to the center
f_image = np.fft.fft2(gray_image)
fshift = np.fft.fftshift(f_image)
magnitude_spectrum = 20 * np.log(np.abs(fshift))
image_gray_fft2 = fshift.copy()
# Apply vertical filters
image_gray_fft2[:286, fshift.shape[1]//2] = 1
image_gray_fft2[-286:, fshift.shape[1]//2] = 1
# # Apply horizontal filters - as applicable
# image_gray_fft2[fshift.shape[0]//2, :250] = 1
# image_gray_fft2[fshift.shape[0]//2, -250:] = 1
# Perform inverse Fourier transform
inv_fshift = np.fft.ifftshift(image_gray_fft2)
filtered_gray_image = np.fft.ifft2(inv_fshift)
filtered_gray_image = np.abs(filtered_gray_image)
# Fourier transform for RGB image
transformed_channels = []
for i in range(3):
rgb_fft = np.fft.fftshift(np.fft.fft2((image[:, :, i])))
rgb_fft2 = rgb_fft.copy()
# Apply vertical filters
rgb_fft2[:286, rgb_fft.shape[1]//2] = 1
rgb_fft2[-286:, rgb_fft.shape[1]//2] = 1
# # Apply horizontal filters - as applicable
# rgb_fft2[rgb_fft.shape[0]//2, :250] = 1
# rgb_fft2[rgb_fft.shape[0]//2, -250:] = 1
transformed_channels.append(
abs(np.fft.ifft2(np.fft.ifftshift(rgb_fft2))))
filtered_rgb_image = np.dstack(
[transformed_channels[0], transformed_channels[1], transformed_channels[2]])
filtered_rgb_image = np.clip(filtered_rgb_image, 0, 255).astype(np.uint8)
# Call the function
plot_fourier_transformer(image, filtered_gray_image, filtered_rgb_image)
六、预测年龄和性别
数据集
对于这个 Python 项目,我们将使用 Adience 数据集;该数据集在公共领域可用,您可以在此处找到它。该数据集作为人脸照片的基准,包括各种真实世界的成像条件,如噪声、照明、姿势和外观。这些图像是从 Flickr 相册收集的,并根据知识共享 (CC) 许可分发。它共有 26,580 张照片,2,284 名受试者来自八个年龄段(如上所述),大小约为 1GB。我们将使用的模型已经在这个数据集上进行了训练
实现步骤
步骤 1:安装 OpenCV
pip Install OpenCV步骤 2:安装 argparse 的命令
pip install argparse对于这个 Python 项目,我使用了 Adience 数据集;该数据集在公共领域可用,您可以在下面链接下载:
https://www.kaggle.com/ttungl/adience-benchmark-gender-and-age-classification该数据集作为人脸照片的基准,包括各种真实世界的成像条件,如噪声、照明、姿势和外观。这些图像是从 Flickr 相册收集的,并根据知识共享 (CC) 许可分发。它共有 8 个年龄段(如上所述)的 2,284 名受试者的 26,580 张照片,大小约为 1GB。我使用的模型已经在这个数据集上进行了训练。
其他代码待完善
七、使用Anomalib实现图像异常检测和定位
Anomalib 库的介绍是这样的:“Anomalib 是一个深度学习库,旨在收集最先进的异常检测算法,用于在公共和私有数据集上进行基准测试。Anomalib 提供了最近文献中描述的几种现成的异常检测算法实现...”。
https://github.com/openvinotoolkit/anomalib?source=post_page-----fb363639104f--------------------------------Anomalib 是一个非常强大的库,可以处理与图像异常检测和定位相关的任务。数据管理以及不同最先进模型的使用都包含在易于使用的函数和 API 中。然而,有时文档会参差不齐且不清楚。本文中,我们想深入图像异常检测世界,分析库的每个步骤和所有有趣的细节,从自定义数据集构建到训练模型服务。
构建自定义数据集
Anomalib 允许我们使用专门的 API 将基准数据集用作MVTec。另一方面,并非每个数据集都具有 MVTec 的结构,也并非每个数据集都具有异常图像,其中异常区域被适当分割。
为了增强对库的信心,我通过简化实际工业项目的规范构建了一个玩具自定义数据集。问题如下。有一台带有许多组件的工业机器。对每个组件执行一系列操作,不时更改其排列。要求验证在每个步骤结束时组件的排列是否符合要求。
为了将机器及其组件图解化,我拿了一个木箱和四个矩形乐高积木,将它们放在一个矩形的角落。初始配置包括所有水平排列的乐高积木。第一个动作是将右上方的积木逆时针旋转 90 度,这样它就从水平方向垂直排列了。因此,左上方的积木逆时针旋转 90 度,然后是左下方,最后是右下方。如图 1 所示,每个最终状态都是每个步骤结束时的正确配置。

任何与正确配置不同的配置都应视为异常配置。实际上,这意味着对组件的操作未正确执行。例如,如图 2 所示,如果在第一步结束时,右上方的乐高积木未完全旋转 90 度,则相应的图像为异常图像,并且异常位于未充分旋转的乐高积木的对应位置。对于此应用,我选择乐高积木旋转 30、45 和 60 度的配置作为异常图像。

为了建立数据集,我用智能手机为每种正确和异常配置录制了一段视频,帧率为 30 fps,分辨率为 1920x1080 像素。在录制过程中,我移动相机从多个角度拍摄场景,甚至不是最佳角度,以便引入真实情况下的噪音。平均而言,我拍摄正确配置约 120 秒,而异常配置约 30 秒。此外,为了引入其他噪音,我将木箱放在带有多种颜色形状的地毯上,这样通过移动相机,背景中的形状也会发生变化。
使用以下脚本,我们可以从相应的视频中提取帧,从而针对每种不同的配置,我们收集标准和异常情况的图像。我对每张图像进行中心裁剪,并将其大小调整为 256x256 像素。
import os
import cv2
def extract_frames(video_path, output_folder, final_size, offset):
# Open the video
video = cv2.VideoCapture(video_path)
success, frame = video.read()
count = 0
# Iter to extract the frames
while success:
# Crop the frames to the center to obtain a square frame
min_dim = min(frame.shape[0], frame.shape[1])
center_x, center_y = frame.shape[1] // 2, frame.shape[0] // 2
half_dim = min_dim // 2
#print("min_dim: {} - center_x: {} - center_y: {} - half_dim: {}".format(min_dim, center_x, center_y, half_dim))
cropped_frame = frame[center_y - half_dim - offset:center_y + half_dim - offset, center_x - half_dim:center_x + half_dim]
# Resize the frames to final_size
resized_frame = cv2.resize(cropped_frame, (final_size, final_size))
frame_path = f"{output_folder}/frame_{count}.jpg"
cv2.imwrite(frame_path, resized_frame) # Save the frame
success, frame = video.read() # read the next frame
count += 1
video.release()
cv2.destroyAllWindows()
return count对于每个步骤(我称之为类别),数据集具有以下数量的图像
CATEGORY: one_up
Normal 90_DEG - Number of images: 3638
Abnormal 60_DEG - Number of images: 955
Abnormal 45_DEG - Number of images: 967
Abnormal 30_DEG - Number of images: 965
------------------------------------------------------------------------
CATEGORY: two_up
Normal 90_DEG - Number of images: 3628
Abnormal 60_DEG - Number of images: 921
Abnormal 45_DEG - Number of images: 1042
Abnormal 30_DEG - Number of images: 889
------------------------------------------------------------------------
CATEGORY: three_up
Normal 90_DEG - Number of images: 3672
Abnormal 60_DEG - Number of images: 971
Abnormal 45_DEG - Number of images: 998
Abnormal 30_DEG - Number of images: 982
------------------------------------------------------------------------
CATEGORY: four_up
Normal 90_DEG - Number of images: 3779
Abnormal 60_DEG - Number of images: 996
Abnormal 45_DEG - Number of images: 1058
Abnormal 30_DEG - Number of images: 1015数据加载
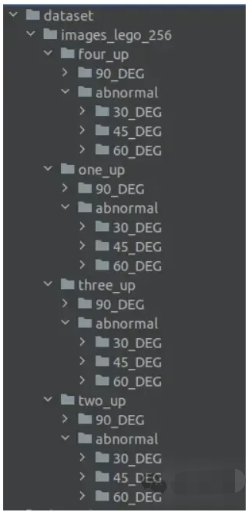
为了使用 Anomalib API 加载数据,然后在自定义数据集上训练和测试模型,文件夹树必须按照图 3 所示进行结构化。对于每个类别的每个文件夹,我必须有一个与正常图像相对应的子目录,即 90_DEG 子目录。在 90_DEG 文件夹的同一级别,必须有另一个名为“异常”的子目录。在异常子目录中,必须有与异常类型一样多的文件夹,即 30_DEG、45_DEG 和 60_DEG,每个文件夹都有相应的异常图像。
为了管理自定义数据集的数据,特别是将其拆分为训练、测试和验证子集,我们可以使用 Folder 类,如下所示。我将重点介绍 one_up 类别,但同样适用于其他类别。
from anomalib.data.image.folder import Folder
from anomalib import TaskType
from anomalib.data.utils import ValSplitMode
# set the dataset root for a particular category
dataset_root = "/home/enrico/Projects/Image_Anomaly_Detection/dataset/images_lego_256/one_up"
# Create the datamodule
datamodule = Folder(
name="one_up",
root=dataset_root,
normal_dir="90_DEG",
abnormal_dir="abnormal",
task=TaskType.CLASSIFICATION,
seed=42,
normal_split_ratio=0.2, # default value
val_split_mode=ValSplitMode.FROM_TEST, # default value
val_split_ratio=0.5, # default value
train_batch_size=32, # default value
eval_batch_size=32, # default value
#image_size=(512,512)
)
# Setup the datamodule
datamodule.setup()Folder 对象的属性必须填写如下:
- name:类别名称,即存储正常和异常图像的文件夹名称
- root:数据集的目录根,即“ one_up”目录的根
- normal_dir:存储正常图像的文件夹名称,在本例中为“ 90_DEG”
- unusual_dir:存储异常图像的文件夹名称,在本例中为“ abnormal”
- 任务:我们使用分类,因为数据集只有正常和异常图像。如果我们还有每个异常图像的分割掩码,我们可以使用分割
- 种子:每次重复相同的训练、验证和测试分割
- normal_split_ratio:在测试集不包含任何正常图像的情况下,拆分正常训练图像并添加到测试集的比例。默认情况下设置为 0.2
- val_split_mode:确定如何获取验证数据集。默认情况下设置为 FROM_TEST
- val_split_ratio:保留用于验证的训练或测试图像的比例。图像取自训练或测试集,具体取决于 val_split_mode。默认为 0.5
- train_batch_size 和 eval_batch_size:设置用于训练和验证模型的图像数量。默认情况下设置为 32
- image_size:用于设置图像宽度和高度的元组。这里进行了注释,因为我们已经将图像大小调整为 (256,256) 像素
一旦数据模块文件夹对象被实例化,我们就可以提取训练、验证和测试数据加载器来对图像批次进行迭代。图像会自动转换为在 0 和 1 之间标准化的 torch 张量。我们还可以提取与训练、验证和测试分割相对应的数据帧,检查不同数据集中正常和异常图像分布的一些统计数据,并将它们保存为 .csv 文件。
# Train images
i, data_train = next(enumerate(datamodule.train_dataloader()))
print(data_train.keys(), data_train["image"].shape) # it takes a batch of images
# for each key extract the first image
print("data_train['image_path'][0]: {} - data_train['image'][0].shape: {} - data_train['label'][0]: {} - torch.max(data_train['image][0]): {} - torch.min(data_train['image][0]): {}".format(data_train['image_path'][0], data_train['image'][0].shape, data_train['label'][0], torch.max(data_train['image'][0]), torch.min(data_train['image'][0])))
img_train = to_pil_image(data_train["image"][0].clone())
# val images
i, data_val = next(enumerate(datamodule.val_dataloader()))
# for each key extract the first image
print("data_val['image_path'][0]: {} - data_val['image'][0].shape: {} - data_val['label'][0]: {}".format(data_val['image_path'][0], data_val['image'][0].shape, data_val['label'][0]))
img_val = to_pil_image(data_val["image"][0].clone())
# test images
i, data_test = next(enumerate(datamodule.test_dataloader()))
# for each key extract the first image
print("data_test['image_path'][0]: {} - data_test['image'][0].shape: {} - data_test['label'][0]: {}".format(data_test['image_path'][0], data_test['image'][0].shape, data_test['label'][0]))
img_test = to_pil_image(data_test["image"][0].clone())
# from the datamodule extract the train, val and test Pandas dataset and collect all the info in a csv
train_dataset = datamodule.train_data.samples
test_dataset = datamodule.test_data.samples
val_dataset = datamodule.val_data.samples
# check the data distribution for each category in each data split
print("TRAIN DATASET FEATURES")
print(train_dataset.info())
print("")
print("IMAGE DISTRIBUTION BY CLASS")
print("")
desc_grouped = train_dataset[['label']].value_counts()
print(desc_grouped)
print("----------------------------------------------------------")
print("TEST DATASET FEATURES")
print(test_dataset.info())
print("")
print("IMAGE DISTRIBUTION BY CLASS")
print("")
desc_grouped = test_dataset[['label']].value_counts()
print(desc_grouped)
print("----------------------------------------------------------")
print("VAL DATASET FEATURES")
print(val_dataset.info())
print("")
print("IMAGE DISTRIBUTION BY CLASS")
print("")
desc_grouped = val_dataset[['label']].value_counts()
print(desc_grouped)
datamodule.train_data.samples.to_csv(os.path.join("/home/enrico/Projects/Image_Anomaly_Detection/data", "datamodule_train.csv"), index=False)
datamodule.test_data.samples.to_csv(os.path.join("/home/enrico/Projects/Image_Anomaly_Detection/data", "datamodule_test.csv"), index=False)
datamodule.val_data.samples.to_csv(os.path.join("/home/enrico/Projects/Image_Anomaly_Detection/data", "datamodule_val.csv"), index=False)dict_keys(['image_path', 'label', 'image']) torch.Size([32, 3, 256, 256])
data_train['image_path'][0]: /home/enrico/Projects/Image_Anomaly_Detection/dataset/images_lego_256/one_up/90_DEG/frame_3613.jpg - data_train['image'][0].shape: torch.Size([3, 256, 256]) - data_train['label'][0]: 0 - torch.max(data_train['image][0]): 0.9725490808486938 - torch.min(data_train['image][0]): 0.0
data_val['image_path'][0]: /home/enrico/Projects/Image_Anomaly_Detection/dataset/images_lego_256/one_up/90_DEG/frame_1000.jpg - data_val['image'][0].shape: torch.Size([3, 256, 256]) - data_val['label'][0]: 0
data_test['image_path'][0]: /home/enrico/Projects/Image_Anomaly_Detection/dataset/images_lego_256/one_up/90_DEG/frame_1003.jpg - data_test['image'][0].shape: torch.Size([3, 256, 256]) - data_test['label'][0]: 0
TRAIN DATASET FEATURES
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2911 entries, 0 to 2910
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 image_path 2911 non-null object
1 label 2911 non-null object
2 label_index 2911 non-null Int64
3 mask_path 2911 non-null object
4 split 2911 non-null object
dtypes: Int64(1), object(4)
memory usage: 116.7+ KB
None
IMAGE DISTRIBUTION BY CLASS
label
DirType.NORMAL 2911
Name: count, dtype: int64
----------------------------------------------------------
TEST DATASET FEATURES
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1808 entries, 0 to 1807
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 image_path 1808 non-null object
1 label 1808 non-null object
2 label_index 1808 non-null Int64
3 mask_path 1808 non-null object
4 split 1808 non-null object
dtypes: Int64(1), object(4)
memory usage: 72.5+ KB
None
IMAGE DISTRIBUTION BY CLASS
label
DirType.ABNORMAL 1444
DirType.NORMAL 364
Name: count, dtype: int64
----------------------------------------------------------
VAL DATASET FEATURES
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1806 entries, 0 to 1805
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 image_path 1806 non-null object
1 label 1806 non-null object
2 label_index 1806 non-null Int64
3 mask_path 1806 non-null object
4 split 1806 non-null object
dtypes: Int64(1), object(4)
memory usage: 72.4+ KB
None
IMAGE DISTRIBUTION BY CLASS
label
DirType.ABNORMAL 1443
DirType.NORMAL 363
Name: count, dtype: int64模型训练与测试
本文中,我不会关注模型的细节和架构。从Anomalib 文档的这个页面,我们可以找到库中实现的所有模型及其原始论文。接下来,我想重点介绍我为自定义数据集找到的最佳模型,即逆向蒸馏模型,并展示如何实现、训练和测试它。在我的 Github存储库中,您还可以找到如何训练和测试 Anomalib 中可用的其他模型。
首先,我实例化了模型。然后我在回调列表中设置了 ModelCheckpoint 和 EarlyStopping 对象。使用 ModelCheckpoint,您可以决定如何在验证阶段保存检查点。在这里,我设置了在每个时期结束时执行验证步骤的条件。因此,如果 AUROC 值大于前一步的值,那么我将覆盖检查点。使用 EarlyStopping,您可以决定如何停止训练过程。在这里,我设置了停止取决于 AUROC 指标趋势的条件。如果它不再超过等于耐心的一定时期数,那么训练就完成了。
然后我设置了记录器和引擎对象。训练开始使用引擎的 fit 函数,以数据模块和之前实例化的模型作为参数。应该记住,对于本次讨论,数据模块设置为读取与一个配置相关的数据。
from anomalib.models import ReverseDistillation
from anomalib import TaskType
from anomalib.data.image.folder import Folder
from anomalib.loggers import AnomalibWandbLogger
from anomalib.engine import Engine
from anomalib.deploy import ExportType
from lightning.pytorch.callbacks import EarlyStopping, ModelCheckpoint
# 1 - instantiate the model
model = ReverseDistillation()
# 2 - instantiate the callback for chepoint and early stopping
callbacks = [
ModelCheckpoint(
mode="max",
mnotallow="image_AUROC",
save_last=True,
verbose=True,
auto_insert_metric_name=True,
every_n_epochs=1,
),
EarlyStopping(
mnotallow="image_AUROC",
mode="max",
patience=patience,
),
]
# 3 - instantiate the logger
wandb_logger = AnomalibWandbLogger(project="image_anomaly_detection",
name=name_wandb_experiment)
# 4 - instantiate the engine
engine = Engine(
max_epochs=max_epochs,
callbacks=callbacks,
pixel_metrics="AUROC",
accelerator="auto", # \<"cpu", "gpu", "tpu", "ipu", "hpu", "auto">,
devices=1,
logger=wandb_logger,
task=TaskType.CLASSIFICATION,
)
# 5 - fit
print("Fit...")
engine.fit(datamodule=datamodule, model=model)
# 6 - test
print("Test...")
engine.test(datamodule=datamodule, model=model)
# 7 - export torch weights
print("Export weights...")
path_export_weights = engine.export(export_type=ExportType.TORCH,
model=model)
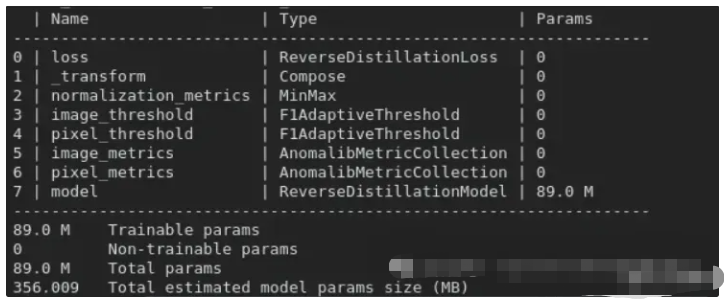
print("path_export_weights: ", path_export_weights)当训练开始时,记录器会打印一些有关模型的信息,特别是可训练参数的数量和估计的维度。
训练完成后,我使用引擎的测试功能开始测试阶段。在这种情况下,引擎会加载测试数据加载器并将最佳模型应用于测试图像。最后,记录器会在测试集上打印 AUROC 和 F1 分数。在最后一步中,我以 torch 格式导出最佳模型的权重,以便我可以在单个图像的推理阶段使用它,如下所述。

结果非常令人印象深刻,即测试集上分类问题的 AUROC 为 0.9999,F1 分数为 0.9997。图 6 中的测试集混淆矩阵也证实了这一点。

测试集验证结果:

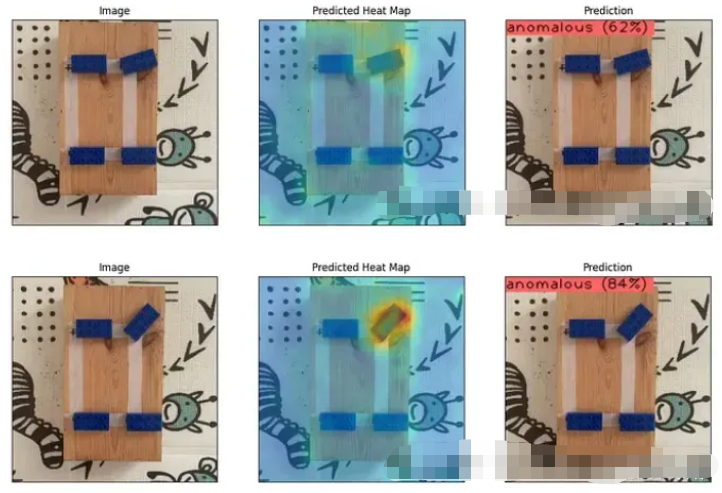
尽管二元分类问题的表现几乎完美,但热图显示,在 45_DEG 情况下,异常区域很好地集中在乐高积木周围。对于 30_DEG 和 60_DEG 的情况,预测的热图有点混乱,异常分数较低。
模型推理
有趣的是,如何仅在单个图像上测试模型,这就是在 Web 应用程序中发生的事情。使用 TorchInferencer 对象,我以 torch 格式加载最佳模型的权重。因此,一旦图像被加载和预处理,我就会应用 TorchInferencer 的预测函数来获取结果对象。此对象具有以下属性:
- pred_label:0 表示正常图像,1 表示异常图像
- pred_score:预测为异常图像的分数。因此,如果 pred_label 为 0,则为了确定 pred_score 是否正常,我使用 1-pred_score
- 图像:原始图像
- heat_map:测试图像的热图。区域越热,包含异常的概率就越高
- pred_mask:异常区域对应的黑白掩码
- 分割:根据提取的热图分割出异常区域
从掩模中我还可以提取与异常区域相对应的边界框,如下面的脚本所示。
import sys
from PIL import Image
from anomalib.deploy import TorchInferencer
import numpy as np
import cv2
from torch import as_tensor
from torchvision.transforms.v2.functional import to_dtype, to_image
import torch
from utils import show_image_list
# 1 - instantiate the TorchInferencer
inferencer = TorchInferencer(path=path_torch_model,
device="cpu")
# 2 - load and preprocess the image
image = Image.open(path_image).convert("RGB")
image = image.resize((256, 256))
image = to_dtype(to_image(image), torch.float32, scale=True) if as_tensor else np.array(image) / 255.0
# 3 - execute the prediction
result = inferencer.predict(image=image)
# result.pred_score gives the score to be anomalous
if result.pred_label == 0:
normal_score = 1 - result.pred_score
print("Normal - pred_score: {:.4f}".format(normal_score))
else:
print("Abnormal - pred_score: {:.4f}".format(result.pred_score))
# build the bounding box from the mask
image_bbox = result.image.copy()
# Find the contours of the white mask
contours, _ = cv2.findContours(result.pred_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Create the bbox around the white contours
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(image_bbox, (x, y), (x+w, y+h), (255, 0, 0), 2)
# stack three time the mask to simulate the three colour channels
mask = cv2.merge((result.pred_mask,result.pred_mask,result.pred_mask))
show_image_list(list_images=[result.image, result.heat_map, result.segmentations, mask, image_bbox],
list_titles=['image', 'heat_map', 'segmentations', 'mask', 'image_bbox'],
num_cols=3,
figsize=(20, 10),
grid=False,
title_fnotallow=20,
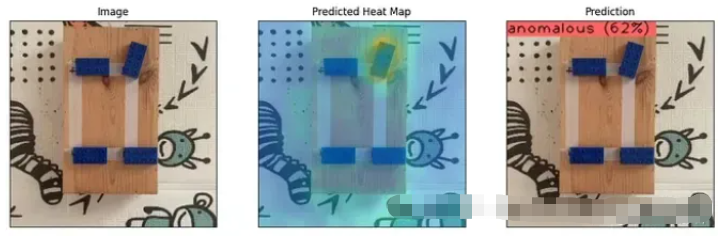
path_image=path_result)对 45_DEG 类的测试图像运行脚本,结果如下:
pred_score: 0.8513 - pred_label: 1
Abnormal - pred_score: 0.8513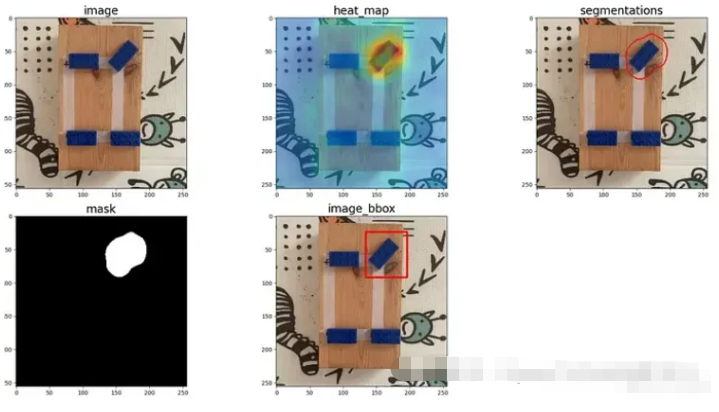
八、图像拼接--Stitching detailed使用与参数介绍
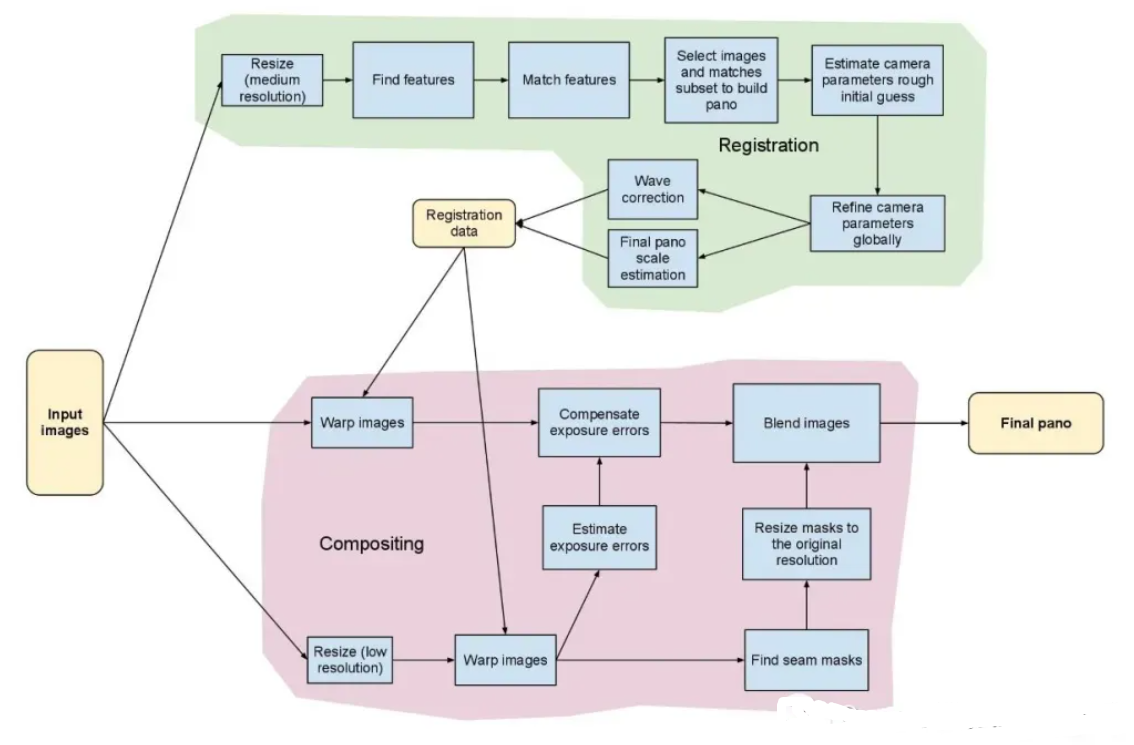
本篇文章是Stitcher类的扩展介绍,通过例程stitching_detailed.cpp的使用和参数介绍,帮助大家了解Stitcher类拼接的具体步骤和方法,先看看其内部的流程结构图(如下):
stitching_detailed.cpp目录如下,可以在自己安装的OpenCV目录下找到,笔者这里使用的OpenCV4.4版本,stitching_detailed.cpp具体源码如下目录,由于代码较多,这里不贴出来,大家找到位置自行查阅。
stitching_detail 程序运行流程
- 命令行调用程序,输入源图像以及程序的参数
- 特征点检测,判断是使用 surf 还是 orb,默认是 surf
- 对图像的特征点进行匹配,使用最近邻和次近邻方法,将两个最优的匹配的置信度 保存下来
- 对图像进行排序以及将置信度高的图像保存到同一个集合中,删除置信度比较低的图像间的匹配,得到能正确匹配的图像序列。这样将置信度高于门限的所有匹配合并到一个集合中
- 对所有图像进行相机参数粗略估计,然后求出旋转矩阵
- 使用光束平均法进一步精准的估计出旋转矩阵
- 波形校正,水平或者垂直
- 拼接
- 融合,多频段融合,光照补偿
stitching_detail 程序接口介绍
- img1 img2 img3 输入图像
- --preview 以预览模式运行程序,比正常模式要快,但输出图像分辨率低,拼接的分辨 率 compose_megapix 设置为 0.6
- --try_gpu (yes|no) 是否使用 CUDA加速,默认为 no,使用CPU模式
- /* 运动估计参数 */
- --work_megapix <--work_megapix <float>> 图像匹配时的分辨率大小,默认为 0.6
- --features (surf | orb | sift | akaze) 选择 surf 或者 orb 算法进行特征点匹配,默认为 surf
- --matcher (homography | affine) 用于成对图像匹配的匹配器
- --estimator (homography | affine) 用于转换估计的估计器类型
- --match_conf <float> 特征点匹配步骤的匹配置信度,最近邻匹配距离与次近邻匹配距离的比值,surf 默认为 0.65,orb 默认为 0.3
- --conf_thresh <float> 两幅图来自同一全景图的置信度,默认为 1.0
- --ba (no | reproj | ray | affine) 光束平均法的误差函数选择,默认是 ray 方法
- --ba_refine_mask (mask) 光束平均法设置优化掩码
- --wave_correct (no|horiz|vert) 波形校验水平,垂直或者没有 默认是 horiz(水平)
- --save_graph <file_name> 将匹配的图形以点的形式保存到文件中, Nm 代表匹配的数量,NI代表正确匹配的数量,C 表示置信度
- /*图像融合参数:*/
- --warp (plane|cylindrical|spherical|fisheye|stereographic|compressedPlaneA2B1|compressedPla neA1.5B1|compressedPlanePortraitA2B1|compressedPlanePortraitA1.5B1|paniniA2B1|paniniA1.5B1|paniniPortraitA2B1|paniniPor traitA1.5B1|mercator|transverseMercator) 选择融合的平面,默认是球形
- --seam_megapix <float> 拼接缝像素的大小 默认是 0.1
- --seam (no|voronoi|gc_color|gc_colorgrad) 拼接缝隙估计方法 默认是 gc_color
- --compose_megapix <float> 拼接分辨率,默认为-1
- --expos_comp (no|gain|gain_blocks) 光照补偿方法,默认是 gain_blocks
- --blend (no|feather|multiband) 融合方法,默认是多频段融合
- --blend_strength <float> 融合强度,0-100.默认是 5.
- --output <result_img> 输出图像的文件名,默认是 result,jpg 命令使用实例,以及程序运行时的提示:
上面使用默认参数,详细输出信息如下:
E:\Practice\OpenCV\Algorithm_Summary\Image_Stitching\x64\Debug>05_Image_Stitch_Stitching_Detailed.exe ./imgs/boat1.jpg ./imgs/boat2.jpg ./imgs/boat3.jpg ./imgs/boat4.jpg ./imgs/boat5.jpg ./imgs/boat6.jpg
Finding features...
[ INFO:0] global C:\build\master_winpack-build-win64-vc15\opencv\modules\core\src\ocl.cpp (891) cv::ocl::haveOpenCL Initialize OpenCL runtime...
Features in image #1: 500
[ INFO:0] global C:\build\master_winpack-build-win64-vc15\opencv\modules\core\src\ocl.cpp (433) cv::ocl::OpenCLBinaryCacheConfigurator::OpenCLBinaryCacheConfigurator Successfully initialized OpenCL cache directory: C:\Users\A4080599\AppData\Local\Temp\opencv\4.4\opencl_cache\
[ INFO:0] global C:\build\master_winpack-build-win64-vc15\opencv\modules\core\src\ocl.cpp (457) cv::ocl::OpenCLBinaryCacheConfigurator::prepareCacheDirectoryForContext Preparing OpenCL cache configuration for context: NVIDIA_Corporation--GeForce_GTX_1070--411_31
Features in image #2: 500
Features in image #3: 500
Features in image #4: 500
Features in image #5: 500
Features in image #6: 500
Finding features, time: 5.46377 sec
Pairwise matchingPairwise matching, time: 3.24159 sec
Initial camera intrinsics #1:
K:
[534.6674906996568, 0, 474.5;
0, 534.6674906996568, 316;
0, 0, 1]
R:
[0.91843718, -0.09762425, -1.1678253;
0.0034433089, 1.0835428, -0.025021957;
0.28152198, 0.16100603, 0.91920781]
Initial camera intrinsics #2:
K:
[534.6674906996568, 0, 474.5;
0, 534.6674906996568, 316;
0, 0, 1]
R:
[1.001171, -0.085758291, -0.64530683;
0.010103324, 1.0520245, -0.030576767;
0.15743911, 0.12035993, 1]
Initial camera intrinsics #3:
K:
[534.6674906996568, 0, 474.5;
0, 534.6674906996568, 316;
0, 0, 1]
R:
[1, 0, 0;
0, 1, 0;
0, 0, 1]
Initial camera intrinsics #4:
K:
[534.6674906996568, 0, 474.5;
0, 534.6674906996568, 316;
0, 0, 1]
R:
[0.8474561, 0.028589081, 0.75133896;
-0.0014587968, 0.92028928, 0.033205934;
-0.17483309, 0.018777205, 0.84592116]
Initial camera intrinsics #5:
K:
[534.6674906996568, 0, 474.5;
0, 534.6674906996568, 316;
0, 0, 1]
R:
[0.60283858, 0.069275051, 1.2121853;
-0.014153662, 0.85474133, 0.014057174;
-0.29529575, 0.053770453, 0.61932623]
Initial camera intrinsics #6:
K:
[534.6674906996568, 0, 474.5;
0, 534.6674906996568, 316;
0, 0, 1]
R:
[0.41477469, 0.075901195, 1.4396564;
-0.015423983, 0.82344943, 0.0061162044;
-0.35168326, 0.055747174, 0.42653102]
Camera #1:
K:
[1068.953598931666, 0, 474.5;
0, 1068.953598931666, 316;
0, 0, 1]
R:
[0.84266716, -0.010490002, -0.53833258;
0.004485324, 0.99991232, -0.01246338;
0.53841609, 0.0080878884, 0.84264034]
Camera #2:
K:
[1064.878323247434, 0, 474.5;
0, 1064.878323247434, 316;
0, 0, 1]
R:
[0.95117813, -0.015436338, -0.3082563;
0.01137107, 0.99982315, -0.014980057;
0.308433, 0.010743499, 0.95118535]
Camera #3:
K:
[1065.382193682081, 0, 474.5;
0, 1065.382193682081, 316;
0, 0, 1]
R:
[1, -1.6298145e-09, 0;
-1.5716068e-09, 1, 0;
0, 0, 1]
Camera #4:
K:
[1067.611537959627, 0, 474.5;
0, 1067.611537959627, 316;
0, 0, 1]
R:
[0.91316396, -7.9067249e-06, 0.40759254;
-0.0075879274, 0.99982637, 0.017019274;
-0.4075219, -0.018634165, 0.91300529]
Camera #5:
K:
[1080.708135180496, 0, 474.5;
0, 1080.708135180496, 316;
0, 0, 1]
R:
[0.70923853, 0.0025724203, 0.70496398;
-0.0098195076, 0.99993235, 0.0062302947;
-0.70490021, -0.01134116, 0.70921582]
Camera #6:
K:
[1080.90412660159, 0, 474.5;
0, 1080.90412660159, 316;
0, 0, 1]
R:
[0.49985889, 3.5938341e-05, 0.86610687;
-0.00682831, 0.99996907, 0.0038993564;
-0.86607999, -0.0078631733, 0.49984369]
Warping images (auxiliary)...
Warping images, time: 0.0791121 sec
Compensating exposure...
Compensating exposure, time: 0.72288 sec
Finding seams...
Finding seams, time: 3.09237 sec
Compositing...
Compositing image #1
Multi-band blender, number of bands: 8
Compositing image #2
Compositing image #3
Compositing image #4
Compositing image #5
Compositing image #6
Compositing, time: 13.7766 sec
Finished, total time: 29.4535 sec输入图像boat1.jpg、boat2.jpg、boat3.jpg、boat4.jpg、boat5.jpg、boat6.jpg如下(可以在OpenCV安装目录下找到D:\OpenCV4.4\opencv_extra-master\testdata\stitching)






结果图:

参数warp_type 设置为"plane",效果图如下:

参数warp_type 设置为"fisheye",效果图如下(旋转90°后):

其他的参数可以根据自己需要修改,如果要自己完成还需要详细了解拼接步骤再优化。
九、OpenCV 和 MediaPipe ~手语识别
手语是全世界数百万人的重要交流工具。在这个项目中,我开发了一个利用人工智能和计算机视觉来解码手语手势的系统。通过利用 OpenCV、MediaPipe 和机器学习技术,系统可以检测手势并将其归类为有意义的类别。本文将引导您了解实施过程以及在开发过程中获得的见解。
项目目标
该项目的主要目标包括:
- 捕获实时视频源。
- 使用 MediaPipe 的整体模型检测面部、手部和身体特征。
- 将检测到的地标导出为结构化格式。
- 训练机器学习模型对手语手势进行分类。
- 手语手势的实时预测和可视化。
使用的工具和库
- MediaPipe:用于面部、手部和姿势的整体标志检测。
- OpenCV:用于视频捕获和图像处理。
- NumPy:用于数值运算和数据操作。
- Pandas:处理和分析数据集。
- scikit-learn:用于训练和评估机器学习模型。
- pickle:保存和加载训练过的模型。
步骤 1:设置 MediaPipe 进行人脸关键点检测
MediaPipe 的整体模型用于检测面部、手部和姿势特征。核心设置如下:
import mediapipe as mp
import cv2
mp_drawing = mp.solutions.drawing_utils
mp_holistic = mp.solutions.holistic
cap = cv2.VideoCapture(1)
with mp_holistic.Holistic(min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic:
while cap.isOpened():
ret, frame = cap.read()
# Convert image to RGB
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = holistic.process(image)
# Convert back to BGR
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# Draw landmarks
mp_drawing.draw_landmarks(image, results.face_landmarks, mp_holistic.FACEMESH_CONTOURS)
mp_drawing.draw_landmarks(image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS)
cv2.imshow('Webcam Feed', image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()步骤 2:数据收集
为了训练机器学习模型,我们需要标记数据。检测到的地标将导出到 CSV 文件中以供进一步处理:
import csv
import numpy as np
num_coords = len(results.pose_landmarks.landmark) + len(results.face_landmarks.landmark)
landmarks = ['class'] + [f'{axis}{i}' for i in range(1, num_coords + 1) for axis in ['x', 'y', 'z', 'v']]
with open('coords.csv', mode='w', newline='') as f:
csv_writer = csv.writer(f, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
csv_writer.writerow(landmarks)
class_name = "Hello"
cap = cv2.VideoCapture(1)
with mp_holistic.Holistic(min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic:
while cap.isOpened():
ret, frame = cap.read()
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = holistic.process(image)
try:
pose = results.pose_landmarks.landmark
pose_row = [val for landmark in pose for val in [landmark.x, landmark.y, landmark.z, landmark.visibility]]
face = results.face_landmarks.landmark
face_row = [val for landmark in face for val in [landmark.x, landmark.y, landmark.z, landmark.visibility]]
row = [class_name] + pose_row + face_row
with open('coords.csv', mode='a', newline='') as f:
csv_writer = csv.writer(f, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
csv_writer.writerow(row)
except:
pass
cv2.imshow('Webcam Feed', frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()步骤 3:训练模型
利用收集到的数据,训练多个机器学习模型来对手势进行分类。
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# Load the data
df = pd.read_csv('coords.csv')
X = df.drop('class', axis=1)
y = df['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train the model
model = make_pipeline(StandardScaler(), RandomForestClassifier())
model.fit(X_train, y_train)
# Evaluate the model
predictions = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, predictions)}")步骤 4:实时手势识别
最后,训练好的模型用于实时识别手势:
import pickle
with open('gesture_model.pkl', 'wb') as f:
pickle.dump(model, f)
cap = cv2.VideoCapture(1)
with mp_holistic.Holistic(min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic:
while cap.isOpened():
ret, frame = cap.read()
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = holistic.process(image)
try:
pose = results.pose_landmarks.landmark
face = results.face_landmarks.landmark
row = [val for landmark in pose for val in [landmark.x, landmark.y, landmark.z, landmark.visibility]]
row += [val for landmark in face for val in [landmark.x, landmark.y, landmark.z, landmark.visibility]]
with open('gesture_model.pkl', 'rb') as f:
model = pickle.load(f)
gesture = model.predict([row])[0]
print(f"Predicted Gesture: {gesture}")
except:
pass
cv2.imshow('Webcam Feed', frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()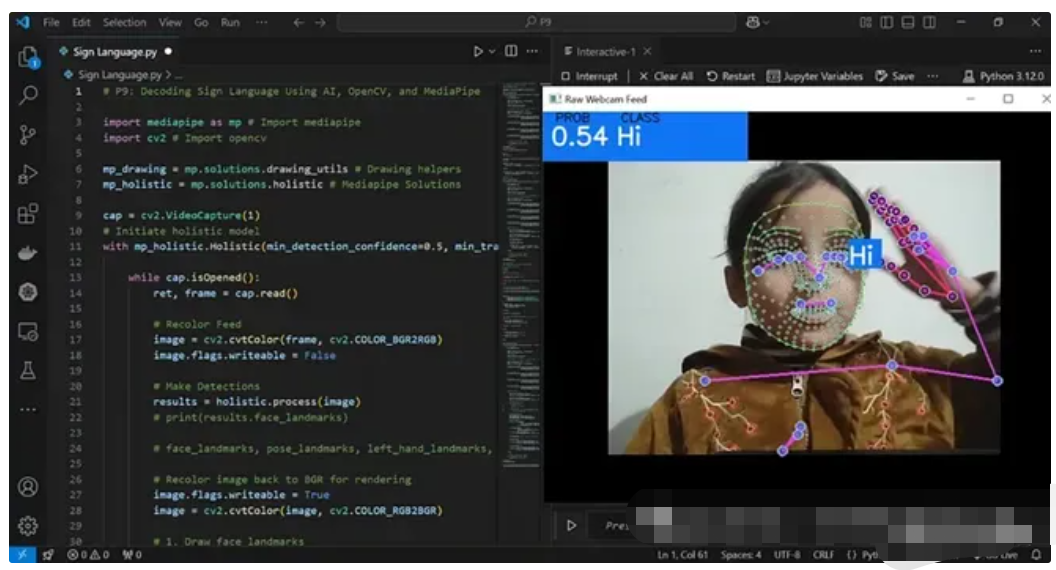
该项目展示了人工智能和计算机视觉在解码手语手势方面的强大功能。通过进一步改进,这种方法可以扩展到构建更具包容性的技术,为听力和言语障碍群体弥合沟通鸿沟。从将该系统集成到智能手机到增强各个行业的可访问性,可能性无穷无尽。
源码下载:
https://github.com/iamramzan/Decoding-Sign-Language-Using-AI-OpenCV-and-MediaPipe十、树莓派上使用OpenCV
创建产品不仅仅涉及软件,硬件也起着至关重要的作用。具体来说,在计算机视觉中,我们需要紧凑的边缘硬件来部署我们的对象检测模型或算法。边缘设备是位于网络边缘、靠近数据源和最终用户的计算硬件。这些设备通过在本地(“边缘”)处理数据来减少延迟和带宽使用,从而以紧凑的尺寸实现实时响应。Raspberry Pi 是最广泛使用的边缘设备之一,而 OpenCV 是最广泛使用的计算机视觉库。那么,让我们看看如何使用 Raspberry Pi 和 OpenCV 在边缘本地部署应用程序,让每个人都可以访问它。
树莓派(Raspberry Pi) 简介
Raspberry Pi 是一款信用卡大小的计算机,可以执行通常由台式机和服务器处理的各种计算任务。它运行在基于 ARM 的处理器上,并支持多种操作系统,主要是基于 Debian 的 Linux 发行版 Raspberry Pi OS(以前称为 Raspbian)。Raspberry Pi 具有内置 GPIO(通用输入/输出)引脚、网络功能以及对摄像头和传感器等外围设备的支持,是寻求经济高效的计算解决方案的业余爱好者、教育工作者和专业人士的理想选择。
但在深入了解 Raspberry Pi 规格之前,让我们先来看看当今的全球边缘计算市场。
随着组织采用分布式计算,边缘计算市场正在经历快速增长。全球在边缘计算方面的支出正在激增:IDC估计,到 2032 年,企业和服务提供商的支出将达到 2060 亿美元,到 2040 年将增长到 3780 亿美元左右。
采用这种技术的原因是 AR/VR、3D、物联网、5G 等技术的快速发展。因此,了解边缘计算不仅有利于掌握技术知识,还有助于让您与行业保持同步。我们的目标是学习如何设置 Raspberry Pi 并使用它来运行边缘应用程序!
现在,让我们回到 Raspberry Pi。自 2012 年推出以来,Raspberry Pi 已经发生了巨大的变化。全球已售出超过 6000 万台,使其成为有史以来最受欢迎的计算机之一。我们将在文章中使用最新的 Raspberry Pi 5。它具有 2.4 GHz Cortex-A76 处理器、增强型 GPU(VideoCore VII)和改进的 PCIe 支持连接性。此外,它超级便宜,起价仅为50 美元,让每个人都能使用计算。
设置你的树莓派
主要涉及两个步骤:
1. 安装并刷新 Raspberry Pi 操作系统
首先,你需要安装 rpi-imager。有两种方法:
- 从raspberrypi.com/software下载最新版本并运行安装程序。
- 使用你的包管理器从终端安装它:sudo apt install rpi-imager。
安装 Imager 后,单击 Raspberry Pi Imager 图标或运行 rpi-imager 来启动该应用程序。
现在,我们需要一张 SD 卡来安装和执行我们的 Raspberry Pi OS。本文使用的是 Sandisk Ultra 64 GB 卡。
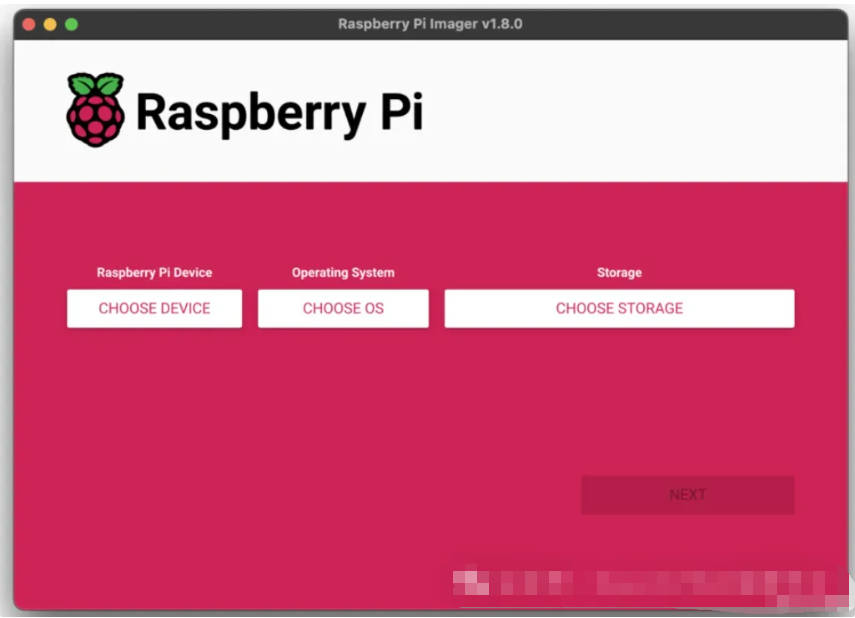
现在,我们必须选择设备(Raspberry Pi 5)、操作系统(Raspberry Pi OS 64 位)和存储设备(我们的 SD 卡)。然后,还有另一个步骤:
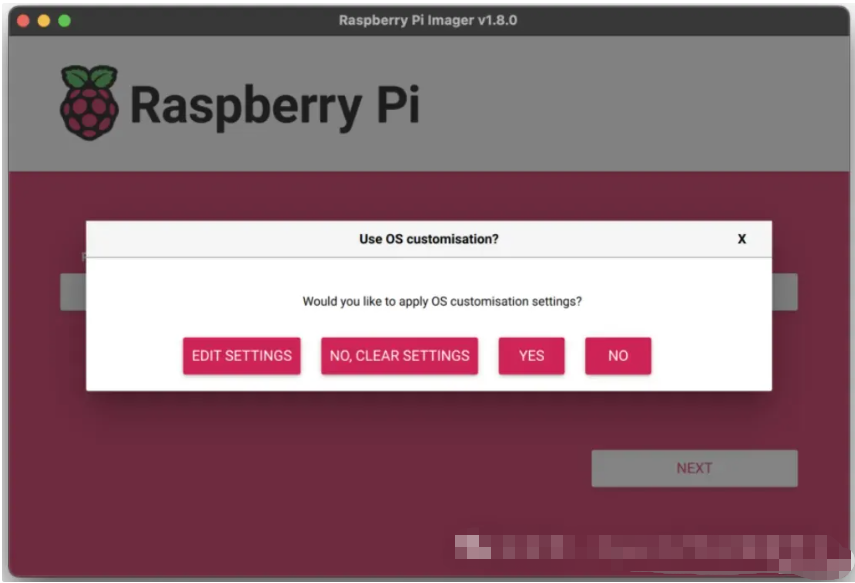
我们不想在操作系统中进行任何自定义。我们将单击“否”并继续。最后,我们对“您确定要继续吗?”弹出窗口回答“是”,开始将数据写入存储设备。
如果您看到管理员提示要求获得读取和写入存储介质的权限,请允许 Imager 继续。
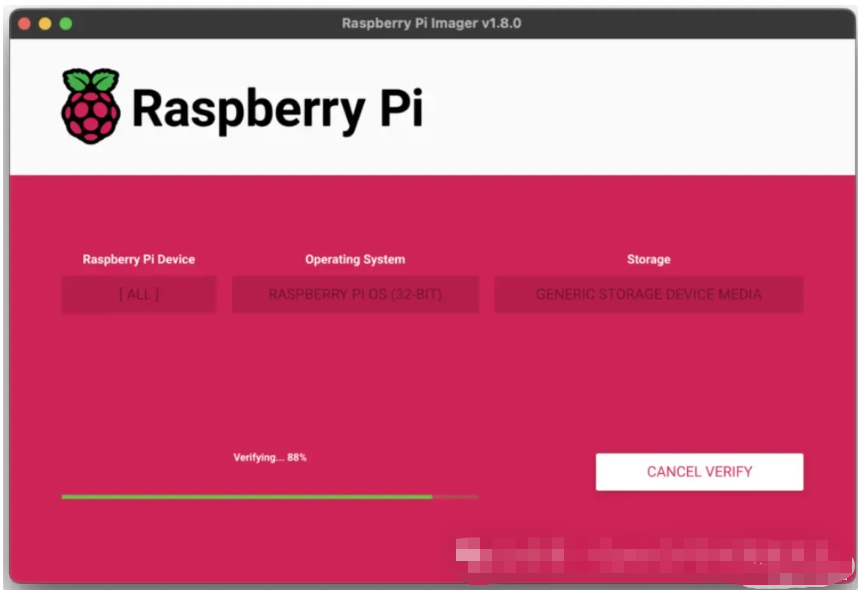
安装完成后,我们将看到这样的成功消息:
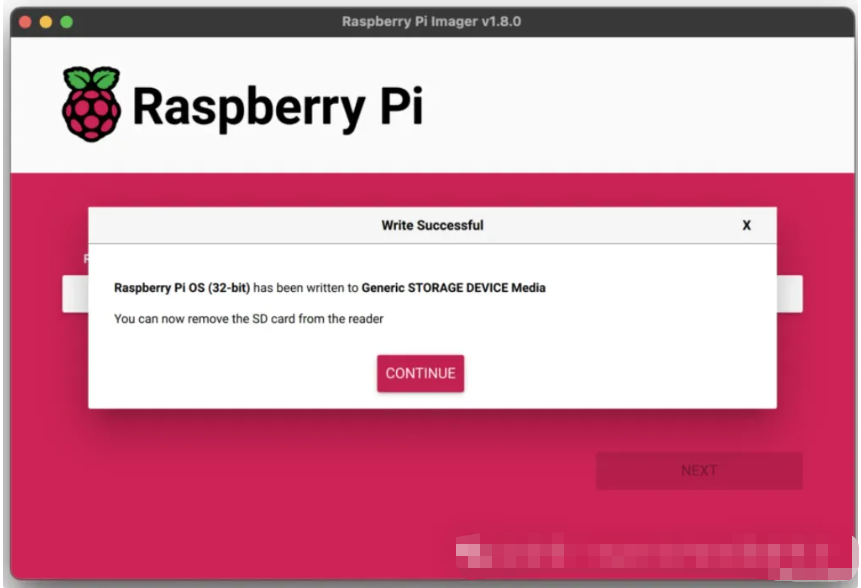
我们现在可以从存储设备启动 Raspberry Pi!
2. Raspberry Pi OS 的首次启动配置
现在,我们启动 Raspberry Pi 并按照说明进行操作:
- 设置国家和语言:选择您的国家、语言和时区。
- 更改密码:为“pi”用户设置新密码以增强安全性。
- 连接到网络:选择并连接到 Wi-Fi 网络或 LAN(如果可用)。
- 更新软件:允许系统检查并安装最新更新。
中间会有一个步骤要求您在Labwc和Wayfire之间进行选择。两者都是基于 Wayland 的轻量级窗口管理器,适用于 Raspberry Pi。请选择Labwc,因为它是最新版本。
安装 Miniconda 并设置 Python 环境
首先,我们进入miniconda 官方下载页面,选择Miniconda3-latest-Linux-aarch64.sh文件。Raspberry Pi 5 采用基于 ARM 的处理器,具体来说是 ARMv8(64 位)架构。aarch64明确指的是 64 位 ARM 架构,与 Raspberry Pi 5 的 CPU 完美匹配。
我们将通过下载来开始该过程:
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh -O ~/miniconda3/miniconda.sh然后安装它:
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3初始化conda环境:
~/miniconda3/bin/conda init bashrm -rf ~/miniconda3/miniconda.sh此后,打开一个新的终端窗口,您将看到 conda基础环境已添加到终端。
我们的 Python 环境现在已经准备好了,可以准备安装 OpenCV。
安装 VSCode 和 OpenCV
安装 VSCode
Raspberry Pi OS 支持许多必备应用程序,例如 VS Code。我们只需选择屏幕左上角的 Raspberry 图标。从下拉菜单中选择“首选项”>“推荐软件”,您就会找到包管理器。
您可以在此处看到 VS Code 图标;我们必须选择它,然后它将安装在我们的 Raspberry Pi 中。
安装 OpenCV
要在 Raspberry Pi 上安装 OpenCV,我们首先需要安装该库。有几种方法可以做到这一点,但最简单和推荐的选项是使用 pip 包系统。
在安装任何软件之前,最好先更新系统。在终端中运行以下命令:
sudo apt update
sudo apt upgradeOpenCV 需要我们首先安装几个依赖项。运行以下命令来安装必要的库:
sudo apt install build-essential cmake git libgtk-3-dev libavcodec-dev libavformat-dev libswscale-dev现在,我们将安装 OpenCV:
pip install opencv-python最后,我们就可以运行我们的程序了。
在 Raspberry Pi 上运行示例 OpenCV Python 脚本
因此,我们将运行这个简单的 Python 脚本,使用 OpenCV 读取图像:
import cv2
import time
# Initialize video capture
capture = cv2.VideoCapture(0)
capture.set(cv2.CAP_PROP_FRAME_WIDTH, 1024)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 576)
capture.set(cv2.CAP_PROP_FPS, 30) # Requesting 30 FPS from the camera
# Background subtractor
bg_subtractor = cv2.createBackgroundSubtractorMOG2()
# Current mode
mode = "normal"
# FPS calculation
prev_time = time.time()
# Video writer initialization with explicit FPS
save_fps = 15.0 # Adjust this based on your actual processing speed
fourcc = cv2.VideoWriter_fourcc(*"XVID")
out = cv2.VideoWriter("output.avi", fourcc, save_fps, (1024, 576))
while True:
ret, frame = capture.read()
if not ret:
break
frame = cv2.flip(frame, 1)
display_frame = frame.copy()
if mode == "threshold":
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
_, display_frame = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
display_frame = cv2.cvtColor(display_frame, cv2.COLOR_GRAY2BGR)
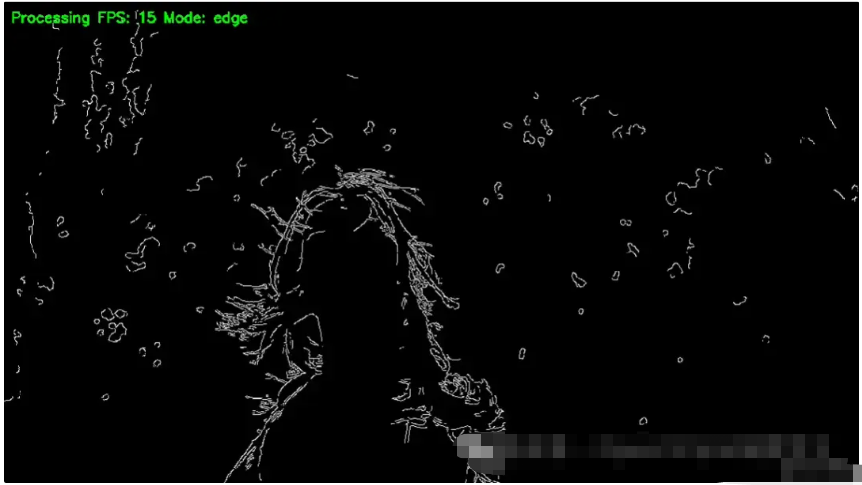
elif mode == "edge":
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 100, 200)
display_frame = cv2.cvtColor(edges, cv2.COLOR_GRAY2BGR)
elif mode == "bg_sub":
fg_mask = bg_subtractor.apply(frame)
display_frame = cv2.bitwise_and(frame, frame, mask=fg_mask)
elif mode == "contour":
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
display_frame = cv2.drawContours(frame.copy(), contours, -1, (0, 255, 0), 2)
# Calculate actual processing FPS
curr_time = time.time()
processing_fps = 1 / (curr_time - prev_time)
prev_time = curr_time
# Display actual processing FPS
cv2.putText(
display_frame, f"FPS: {int(processing_fps)} Mode: {mode}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2
)
# Write frame to video
out.write(display_frame)
# Show video
cv2.imshow("Live Video", display_frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("t"):
mode = "threshold"
elif key == ord("e"):
mode = "edge"
elif key == ord("b"):
mode = "bg_sub"
elif key == ord("c"):
mode = "contour"
elif key == ord("n"):
mode = "normal"
elif key == ord("q"):
break
# Clean up
capture.release()
out.release()
cv2.destroyAllWindows()在这个脚本中,我们实现了四种不同的 OpenCV 算法,广泛应用于图像处理和计算机视觉中。
- 阈值
- 边缘检测
- 背景减法
- 轮廓检测
运行脚本:
python video.py在运行脚本之前,请确保您已将 USB 摄像头与 Raspberry Pi 连接。
您将看到的结果:


到目前为止,您已成功设置了 Raspberry Pi,将 Raspberry Pi 操作系统刷入 SD 卡,安装了 Miniconda,并创建了 Python 环境。您还安装了 VS Code 和 OpenCV,然后使用摄像头测试了 Python 脚本以执行各种实时视频处理任务,如边缘检测、背景减法和轮廓跟踪。
随着边缘计算不断蓬勃发展并连接物理世界和数字世界,了解如何使用 Raspberry Pi 等设备将使您与行业的最新趋势和创新保持同步。
https://www.raspberrypi.com/documentation/computers/getting-started.html

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









