







我自己的原文哦~ https://blog.51cto.com/whaosoft/11979089
一、OpenCV和Streamlit搭建虚拟化妆应用
本文将介绍如何使用Streamlit和OpenCV创建一个虚拟化妆应用程序
首先需要一个预先训练好的脸部解析模型,可以从这里下载:
https://github.com/Pavankunchala/Virtual_Makeup_Streamlit/blob/main/cp/79999_iter.pth导入库
我们使用Streamlit为该应用程序创建UI,并使用 OpenCV进行图像处理,可以使用以下代码通过 pip 安装它们:
pip install streamlit
pip install opencv-python
pip install pillowimport cv2
import os
import numpy as np
from skimage.filters import gaussian
from test import evaluate
import streamlit as st
from PIL import Image, ImageColor创建函数
我们将创建一些函数来锐化图像以及解析头发:

def sharpen(img):
img = img * 1.0
gauss_out = gaussian(img, sigma=5, multichannel=True)
alpha = 1.5
img_out = (img - gauss_out) * alpha + img
img_out = img_out / 255.0
mask_1 = img_out < 0
mask_2 = img_out > 1
img_out = img_out * (1 - mask_1)
img_out = img_out * (1 - mask_2) + mask_2
img_out = np.clip(img_out, 0, 1)
img_out = img_out * 255
return np.array(img_out, dtype=np.uint8)
def hair(image, parsing, part=17, color=[230, 50, 20]):
b, g, r = color #[10, 50, 250] # [10, 250, 10]
tar_color = np.zeros_like(image)
tar_color[:, :, 0] = b
tar_color[:, :, 1] = g
tar_color[:, :, 2] = r
np.repeat(parsing[:, :, np.newaxis], 3, axis=2)
image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
tar_hsv = cv2.cvtColor(tar_color, cv2.COLOR_BGR2HSV)
if part == 12 or part == 13:
image_hsv[:, :, 0:2] = tar_hsv[:, :, 0:2]
else:
image_hsv[:, :, 0:1] = tar_hsv[:, :, 0:1]
changed = cv2.cvtColor(image_hsv, cv2.COLOR_HSV2BGR)
if part == 17:
changed = sharpen(changed)
changed[parsing != part] = image[parsing != part]
return changed标题和文件上传器
那么让我们进入应用程序部分。我们使用 streamlit 的文件上传器来动态上传不同的图像进行测试:
DEMO_IMAGE = 'imgs/116.jpg'
st.title('Virtual Makeup')
st.sidebar.title('Virtual Makeup')
st.sidebar.subheader('Parameters')
table = {
'hair': 17,
'upper_lip': 12,
'lower_lip': 13,
}
img_file_buffer = st.sidebar.file_uploader("Upload an image", type=[ "jpg", "jpeg",'png'])
if img_file_buffer is not None:
image = np.array(Image.open(img_file_buffer))
demo_image = img_file_buffer
else:
demo_image = DEMO_IMAGE
image = np.array(Image.open(demo_image))在上面的代码片段中,我首先为 Demo-Image 创建了一个变量,应用程序默认使用该变量。我使用st.title()和st.sidebar.title()将标题添加到应用程序。
同时创建了一个名为 table 的字典,它将名字与人脸解析器中的数字进行匹配。如果你想查看主仓库以获得更好的理解,你也可以添加它并解析人脸。
显示和调整大小
new_image = image.copy()
st.subheader('Original Image')
st.image(image,use_column_width = True)
cp = 'cp/79999_iter.pth'
ori = image.copy()
h,w,_ = ori.shape
#print(h)
#print(w)
image = cv2.resize(image,(1024,1024))我们使用st.image()函数显示原始图像,并将其大小调整为 1024*1024,以使其与模型兼容。我们还创建了一个包含模型路径的变量。
评估并展示
parsing = evaluate(demo_image, cp)
parsing = cv2.resize(parsing, image.shape[0:2], interpolatinotallow=cv2.INTER_NEAREST)
parts = [table['hair'], table['upper_lip'], table['lower_lip']]
hair_color = st.sidebar.color_picker('Pick the Hair Color', '#000')
hair_color = ImageColor.getcolor(hair_color, "RGB")
lip_color = st.sidebar.color_picker('Pick the Lip Color', '#edbad1')
lip_color = ImageColor.getcolor(lip_color, "RGB")
colors = [hair_color, lip_color, lip_color]
for part, color in zip(parts, colors):
image = hair(image, parsing, part, color)
image = cv2.resize(image,(w,h))
st.subheader('Output Image')
st.image(image,use_column_width = True)我们创建了一个名为valuate()的函数,可以从这里的test.py文件中找到它.
使用 streamlit 的color_picker()函数创建了一个颜色选择器,并使用 PIL 库使其兼容应用于图像。
最后,我调整输出图像的大小,然后基于图像的虚拟化妆应用程序就准备好了。
要运行应用程序,请在终端中输入以下内容:
streamlit run app.py只需将 app.py 替换为您的代码的文件名。
以下是我们得到的一些结果:



完整项目代码:
https://github.com/Pavankunchala/Virtual_Makeup_Streamlit二、OpenCV~纺织物缺陷检测->脏污、油渍、线条破损
机器视觉应用场景中缺陷检测的应用是非常广泛的,通常涉及各个行业、各种缺陷类型。今天我们要介绍的是纺织物的缺陷检测,缺陷类型包含脏污、油渍、线条破损三种,这三种缺陷与LCD屏幕检测的缺陷很相似,处理方法也可借鉴。
脏污缺陷
脏污缺陷图片如下,肉眼可见明显的几处脏污,该如何处理?

实现步骤:
【1】使用高斯滤波消除背景纹理的干扰。如下图所示,将原图放大后会发现纺织物自带的纹理比较明显,这会影响后续处理结果,所以先做滤波平滑。

gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (7,7), 0)高斯滤波结果:

【2】Canny边缘检测凸显缺陷。Canny边缘检测对低对比度缺陷检测有很好的效果,这里注意高低阈值的设置:
edged = cv2.Canny(blur, 10, 30)Canny边缘检测结果:

【3】轮廓查找、筛选与结果标记。轮廓筛选可以根据面积、长度过滤掉部分干扰轮廓,找到真正的缺陷。
contours,hierarchy = cv2.findContours(edged, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for cnt in contours:
length = cv2.arcLength(cnt,True)
if length >= 1:
cv2.drawContours(img,cnt,-1,(0,0,255),2)轮廓筛选标记结果:

油污缺陷
油污缺陷图片如下,肉眼可见明显的两处油污,该如何处理?

实现步骤:
【1】将图像从RGB颜色空间转到Lab颜色空间。对于类似油污和一些亮团的情况,将其转换到Lab或YUV等颜色空间的色彩通道常常能更好的凸显其轮廓。
LabImg = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)
L,A,B = cv2.split(LabImg)Lab颜色空间b通道效果:

【2】高斯滤波 + 二值化。
blur = cv2.GaussianBlur(B, (3,3), 0)
ret,thresh = cv2.threshold(blur,130,255,cv2.THRESH_BINARY)高斯滤波 + 二值化结果:

【3】形态学开运算滤除杂讯。
k1 = np.ones((3,3), np.uint8)
thresh = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, k1)开运算处理结果:

【4】轮廓查找、筛选与结果标记。轮廓筛选可以根据面积、宽高过滤掉部分干扰轮廓,找到真正的缺陷。
contours,hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for cnt in contours:
area = cv2.contourArea(cnt)
if area >= 50:
cv2.drawContours(img,cnt,-1,(0,0,255),2)轮廓筛选标记结果:

线条破损缺陷
线条破损缺陷图片如下,肉眼可见明显的一处脏污,该如何处理?

实现步骤:
【1】将图像从RGB颜色空间转到Lab颜色空间 + 高斯滤波。
LabImg = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)
L,A,B = cv2.split(LabImg)
blur = cv2.GaussianBlur(B, (3,3), 0)B通道高斯滤波结果:

【2】Canny边缘检测凸显缺陷。
edged = cv2.Canny(blur, 5, 10)Canny边缘检测结果:

【3】轮廓查找、筛选与结果标记。轮廓筛选可以根据面积、长度过滤掉部分干扰轮廓,找到真正的缺陷。
contours,hierarchy = cv2.findContours(edged, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for cnt in contours:
length = cv2.arcLength(cnt,True)
if length >= 10:
cv2.drawContours(img,cnt,-1,(0,0,255),2)轮廓筛选标记结果:

后记
对于上述缺陷大家可以尝试使用频域处理方法(如傅里叶变换等),本文方法仅供参考,实际应用还要根据实际图像做批量测试和优化。
三、织物缺陷图像识别方法分析
纺织业在是中国最大的日常使用及消耗相关的产业之一,且劳动工人多,生产量和对外出口量很大,纺织业的发展影响着中国经济、社会就业问题。而织物产品的质量直接影响产品的价格,进一步影响着整个行业的发展,因此纺织品质量检验是织物产业链中必不可少且至关重要的环节之一。
织物缺陷检测是纺织品检验中最重要的检验项目之一,其主要目的是为了避免织物缺陷影响布匹质量,进而极大影响纺织品的价值和销售。
长期以来,布匹的质量监测都是由人工肉眼观察完成,按照工作人员自己的经验对织物质量进行评判,这种方法明显具有许多缺点。首先,机械化程度太低,人工验布的速度非常慢;其次,人工视觉检测的评价方法因受检测人员的主观因素的影响不够客观一致,因而经常会产生误检和漏检。
目前,基于图像的织物疵点自动检测技术已成为了该领域近年来的的研究热点,其代替人工织物疵点检测的研究算法也逐渐成为可能,主流方法一般分为两大类, 一是基于传统图像处理的织物缺陷检测方法,二是基于深度学习算法的织物缺陷检测定位方法。
传统的目标检测方法主要可以表示为:特征提取-识别-定位, 将特征提取和目标检测分成两部分完成。
基于深度学习的目标检测主要可以表示为:图像的深度特征提取-基于深度神经网络的目标定位, 其中主要用到卷积神经网络。
1 织物表面缺陷检测分析
正常情况下,织物表面的每一个异常部分都被认为是织物的缺陷。
在实践中, 织物的缺陷一般是由机器故障、纱线问题和油污等造成的,如断经纬疵、粗细经纬疵、 破损疵、 起球疵、 破洞疵、 污渍疵等。然而,随着织物图案越来越复杂,相应的织物缺陷类型也越来越多,并随着纺织技术的提高, 缺陷的大小范围越来越小。在质量标准方面,一些典型的织物缺陷如图所示。

各类模式织物表面的疵点图像
由纺线到成品织物,需经过纱线纺织、裁剪、图案印染等流程,而且在每个流程中,又需要很多的程序才能完成。在各环节的施工中,如果设定条件不合适, 工作人员操作不规范,机器出现的硬件问题故障等,都有可能导致最后的纺织品发生表面存在缺陷。从理论上说,加工流程越多,则缺陷问题的机率就越高。

最常见的疵点类型及形成原因
随着科技水平的进步,纺织布匹的技术不断随之发展,疵点的面积区域必将越来越小,这无疑给织物疵点检测带来了更大的难题。疵点部分过小,之前的方法很难将其检测出来。

检测存在困难的织物疵点类型
2 图像采集与数据库构建
基于深度学习的织物疵点检测方法相比传统的方法,虽然具有检测速率快,误检率低,检测精度高等优点, 但这些方法是依赖于大量的训练数据库基础之上的。只有在训练阶段包含了尽量多的织物疵点图像,尽可能的把每种疵点的类型都输入训练网络,这样对于网络模型来说,才能反复的熟悉疵点的“模样”,即获得疵点位置的特征信息,从而记住疵点的特征信息,以在以后的检测过程中可以更好更快更准的检测到疵点的位置并标识。
首先搭建由光源、 镜头、相机、 图像处理卡及执行机构组成的织物图像采集系统,然后基于本系统,采集破洞、油污、起毛不均、漏针、撑痕、粗节等一定规模的织物疵点图像,并通过转置、 高斯滤波、图像增强等操作扩充织物图像,构建了织物图像库,为后续深度学习提供了样本支撑。

织物图像采集系统整体结构图
相机选择
工业相机是图像采集系统中的一个关键组成部分,它的好坏字节影响后续所有工作,其最终目的是得到图像数字信号。相机的选择,是必不可少的环节之一,相机的选择不仅直接影响所采集到的图像质量, 同时也与整个系统后续的运行模式直接关联。

镜头选择
镜头选择
和工业相机一样, 是图像采集系统中非常重要的的器件之一, 直接影响图片质量的好坏, 影响后续处理结果的质量和效果。同样的, 根据不同标准光学镜头可以分成不同的类, 镜头摆放实物图如图所示。

光源选择
光源的选择
也是图像采集系统中重要的组成部分,一般光的来源在日光灯和LED 灯中选择,从不同的性能对两种类型的光源进行比较。而在使用织物图像采集系统采集图像的过程中, 需要长时间进行图像采集, 同时必须保证光的稳定性等其他原因,相比于日光灯, LED 灯更适合于图像采集系统的应用。

发射光源种类确定了,接下来就是灯的位置摆放问题,光源的位置也至关重要,其可以直接影响拍出来图片的质量,更直接影响疵点部位与正常部位的差别。一般有反射和投射两种给光方式,反射既是在从布匹的斜上方投射光源,使其通过反射到相机,完成图像拍摄;另外一种透射,是在布匹的下方投射光源,使光线穿过布匹再投射到相机,完成图签拍摄,光源的安装方式对应的采集图像如下图所示。


不同光源照射的效果对比图
数据库构建
TILDA 织物图像数据库包含多种类型背景纹理的织物图像,从中选择了数据相对稍大的平纹背景的织物图像,包含 185 张疵点图像,但该图像数据存在很大的问题:虽然图片背景是均匀的,但是在没有疵点的正常背景下,织物纹理不够清晰,纹理空间不均匀,存在一些没有瑕疵,但是纹理和灰度值与整体正常背景不同的情况。

TILDA 织物图像库部分疵点图像
3 织物缺陷图像识别算法研究
由于织物纹理复杂性, 织物疵点检测是一项具有挑战性的工作。传统的检测算法不能很好的做到实时性检测的同时保持高检测率。卷积神经网络技术的出现为这一目标提供了很好的解决方案。
基于 SSD 神经网络的织物疵点检测定位方法:
步骤一:将数据集的 80% 的部分作为训练集和验证集,再将训练集占其中80% ,验证集占 20% ,剩余 20% 的部分作为测试集,得到最终的实验结果。

步骤二:将待检测的织物图像输入到步骤一训练好的织物检测模型,对织物图像进行特征提取,选取出多个可能是疵点目标的候选框。
步骤三:基于设定好的判别阈值对步骤二中的候选框进行判别得到最终的疵点目标,利用疵点目标所在候选框的交并比阈值选择疵点目标框,存储疵点的位置坐标信息并输出疵点目标框。
这个算法对平纹织物和模式织物均具有很好的自适应性及检测性能, 扩大了适用范围, 检测精度高,有效解决人工检测误差大的问题,模型易训练,操作简单。

织物疵点图像检测结果
随着深度学习技术飞速发展, 以及计算机等硬件水平的不断提升, 卷积神经网络在工业现场的应用将随之不断扩大, 织物表面疵点检测作为工业表面检测的代表性应用产业, 其应用发展将影响着整个工业领域。
四、Py~CV将照片变成卡通照片
展示如何利用OpenCV为Python中的图像提供卡通效果。
正如你可能知道的,素描或创建一个卡通并不总是需要手动完成。如今,许多应用程序可以把你的照片变成卡通照片。但是如果我告诉你,你可以用几行代码创造属于自己的效果呢?
有一个名为OpenCV的库,它为计算机视觉应用程序提供了一个公共基础设施,并优化了机器学习算法。它可以用来识别物体,检测和产生高分辨率的图像。
本文,将向你展示如何利用OpenCV为Python中的图像提供卡通效果。使用google colab来编写和运行代码。你可以在这里访问Google Colab中的完整代码
要创造卡通效果,我们需要注意两件事:边缘和调色板。这就是照片和卡通的区别所在。为了调整这两个主要部分,我们将经历四个主要步骤:
- 加载图像
- 创建边缘蒙版
- 减少调色板
- 结合边缘蒙版和彩色图像
在开始主要步骤之前,不要忘记导入notebook中所需的库,尤其是cv2和NumPy。
import cv2
import numpy as np
# required if you use Google Colab
from google.colab.patches import cv2\_imshow
from google.colab import files1. 加载图像
第一个主要步骤是加载图像。定义read_file函数,其中包括cv2_imshow以在Google Colab中加载所选图像。
def read\_file\(filename\):
img = cv2.imread\(filename\)
cv2\_imshow\(img\)
return img调用创建的函数来加载图像。
uploaded = files.upload\(\)
filename = next\(iter\(uploaded\)\)
img = read\_file\(filename\)我选择了下面的图片来转化成卡通图片。

2. 创建边缘蒙版
通常,卡通效果强调图像中边缘的厚度。我们可以使用 cv2.adaptiveThreshold() 函数检测图像中的边缘。
总之,我们可以将 egde_mask函数定义为:
def edge\_mask\(img, line\_size, blur\_value\):
gray = cv2.cvtColor\(img, cv2.COLOR\_BGR2GRAY\)
gray\_blur = cv2.medianBlur\(gray, blur\_value\)
edges = cv2.adaptiveThreshold\(gray\_blur, 255, cv2.ADAPTIVE\_THRESH\_MEAN\_C, cv2.THRESH\_BINARY, line\_size, blur\_value\)
return edges在该函数中,我们将图像转换为灰度图像。然后,利用cv2.medianBlur对模糊灰度图像进行去噪处理。
模糊值越大,图像中出现的黑色噪声就越少。然后,应用自适应阈值函数,定义边缘的线条尺寸。较大的线条尺寸意味着图像中强调的较厚边缘。
定义函数后,调用它并查看结果。
line\_size = 7
blur\_value = 7
edges = edge\_mask\(img, line\_size, blur\_value\)
cv2\_imshow\(edges\)
3. 减少调色板
照片和图画之间的主要区别——就颜色而言——是每一张照片中不同颜色的数量。
图画的颜色比照片的颜色少。因此,我们使用颜色量化来减少照片中的颜色数目。
色彩量化
为了进行颜色量化,我们采用OpenCV库提供的K-Means聚类算法。
为了在接下来的步骤中更容易实现,我们可以如下定义color_quantization 函数。
def color\_quantization\(img, k\):
# Transform the image
data = np.float32\(img\).reshape\(\(\-1, 3\)\)
# Determine criteria
criteria = \(cv2.TERM\_CRITERIA\_EPS + cv2.TERM\_CRITERIA\_MAX\_ITER, 20, 0.001\)
# Implementing K-Means
ret, label, center = cv2.kmeans\(data, k, None, criteria, 10, cv2.KMEANS\_RANDOM\_CENTERS\)
center = np.uint8\(center\)
result = center\[label.flatten\(\)\]
result = result.reshape\(img.shape\)
return result我们可以调整k值来确定要应用于图像的颜色数。
total\_color = 9
img = color\_quantization\(img, total\_color\)在本例中,我使用9作为图像的k值。结果如下所示。

双边滤波器
在进行颜色量化之后,我们可以使用双边滤波器来降低图像中的噪声。它会给图像带来一点模糊和锐度降低的效果。
blurred = cv2.bilateralFilter\(img, d=7,
sigmaColor=200,sigmaSpace=200\)有三个参数可根据你的首选项进行调整:
- d:每个像素邻域的直径
- sigmaColor:参数值越大,表示半等色区域越大。
- sigmaSpace:参数的值越大,意味着更远的像素将相互影响,只要它们的颜色足够接近。

4. 结合边缘蒙版和彩色图像
最后一步是将我们之前创建的边缘蒙版与彩色处理图像相结合。为此,请使用cv2.bitwise_and函数。
cartoon = cv2.bitwise\_and\(blurred, blurred, mask=edges\)我们可以在下面看到原始照片的“卡通版”。

现在你可以开始来创建你自己的卡通效果。除了在我们上面使用的参数中调整值之外,你还可以从OpenCV添加另一个函数来为你的照片提供特殊效果。代码库里还有很多东西我们可以探索。很高兴尝试!
参考文献:
- https://www.programcreek.com/python/example/89394/cv2.kmeans
- http://datahacker.rs/002-opencv-projects-how-to-cartoonize-an-image-with-opencv-in-python/
五、行为识别

本文旨在为计算机视觉最具代表性和最迷人的应用之一:人类活动识别提供简单而全面的指南。
我们的人类活动识别模型可以识别超过 400 种活动,准确率为 78.4–94.5%(取决于任务)。
活动示例如下:
- 射箭
- 腕力
- 烘烤饼干
- 数钱
- 驾驶拖拉机
- 吃热狗
- …还有更多!
人类活动识别的实际应用包括:
- 自动对磁盘上的视频数据集进行分类/归类。
- 培训和监督新员工正确执行任务(例如,制作披萨的正确步骤和程序,包括擀面团、加热烤箱、涂上酱汁、奶酪、配料等)。
- 确认食品服务人员上完厕所或处理完可能引起交叉污染的食物(即鸡肉和沙门氏菌)后已经洗过手。
- 监控酒吧/餐厅的顾客并确保他们不会喝得过多。
入门
在本教程的第一部分,我们将讨论 Kinetics 数据集,即用于训练人类活动识别模型的数据集。
从那里我们将讨论如何扩展通常使用 2D 内核的 ResNet,以利用 3D 内核,使我们能够包含用于活动识别的时空组件。
然后,我们将使用 OpenCV 库和 Python 编程语言实现两个版本的人类活动识别。
Kinetics数据集

该数据集包括:
- 400 个人类活动识别类别
- 每节课至少 400 个视频片段(通过 YouTube 下载)
- 总共30万个视频
您可以在此处查看模型可以识别的类别的完整列表。
https://github.com/opencv/opencv/blob/master/samples/data/dnn/action_recongnition_kinetics.txt要了解有关数据集的更多信息,包括如何整理它,请务必参考 Kay 等人 2017 年的论文《Kinetics 人体动作视频数据集》。
https://arxiv.org/abs/1705.06950下载人类活动识别模型
主要包含以下文件:
- action_recognition_kinetics.txt:Kinetics 数据集的类标签。
- resnet-34_kinetics.onx:Hara 等人在 Kinetics 数据集上训练的预训练和序列化的人类活动识别卷积神经网络。
- example_activities.mp4:用于测试人类活动识别的剪辑汇编。
- 我们将回顾两个 Python 脚本,每个脚本都接受上述三个文件作为输入:
- human_activity_reco.py:我们的人类活动识别脚本,每次采样N帧以进行活动分类预测。
- human_activity_reco_deque.py:一个类似的人类活动识别脚本,实现了滚动平均队列。此脚本运行速度较慢;不过,我提供了实现,以便您可以学习和试验。
代码和步骤
首先,我们需要确保您的系统中安装了所有必需的库和包。
# import the necessary packages
import numpy as np
import argparse
import imutils
import sys
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-m”, “ — model”, required=True,
help=”path to trained human activity recognition model”)
ap.add_argument(“-c”, “ — classes”, required=True,
help=”path to class labels file”)
ap.add_argument(“-i”, “ — input”, type=str, default=””,
help=”optional path to video file”)
args = vars(ap.parse_args())第 10-16 行解析我们的论点:
— 模型:训练好的人类活动识别模型的路径。
— classes:活动识别类标签文件的路径。
— input :输入视频文件的可选路径。如果命令行中未包含此参数,则将调用您的网络摄像头。
接下来,我们将加载活动识别模型:
# load the human activity recognition model
print(“[INFO] loading human activity recognition model…”)
net = cv2.dnn.readNet(args[“model”])
# grab a pointer to the input video stream
print(“[INFO] accessing video stream…”)
vs = cv2.VideoCapture(args[“input”] if args[“input”] else 0)第一行使用 OpenCV 的 DNN 模块读取 PyTorch预训练的人类活动识别模型。在下一行中,我们使用视频文件或网络摄像头实例化我们的视频流。
我们现在准备开始循环帧并执行人类活动识别。
# loop until we explicitly break from it
while True:
# initialize the batch of frames that will be passed through the
# model
frames = []
# loop over the number of required sample frames
for i in range(0, SAMPLE_DURATION):
# read a frame from the video stream
(grabbed, frame) = vs.read()
# if the frame was not grabbed then we’ve reached the end of
# the video stream so exit the script
if not grabbed:
print(“[INFO] no frame read from stream — exiting”)
sys.exit(0)
# otherwise, the frame was read so resize it and add it to
# our frames list
frame = imutils.resize(frame, width=400)
frames.append(frame)然后我们构建输入帧的 blob,很快会将其传递给人类活动识别 CNN。
# now that our frames array is filled we can construct our blob
blob = cv2.dnn.blobFromImages(frames, 1.0,
(SAMPLE_SIZE, SAMPLE_SIZE), (114.7748, 107.7354, 99.4750),
swapRB=True, crop=True)
blob = np.transpose(blob, (1, 0, 2, 3))
blob = np.expand_dims(blob, axis=0)请注意,我们使用的是blobFromImages (即复数)而不是blobFromImage (即单数)函数- 这里的原因是我们正在构建一批要通过人类活动识别网络的多幅图像,使其能够利用时空信息。
如果你在代码中插入 print(blob.shape) 语句,你会注意到 blob 具有以下维度:
(1、3、16、112、112)
让我们进一步解析一下这个维度:
- 1:批次维度。这里我们只有一个数据点正在通过网络(此处的“数据点”是指将通过网络获得单个分类的N 个帧)。
- 3:我们输入帧中的通道数。
- 16:blob 中的帧总数。
- 112(第一次出现):框架的高度。
- 112(第二次出现):框架的宽度。
此时,我们已准备好执行人类活动识别推理,然后用预测的标签注释帧并将预测显示在屏幕上:
# pass the blob through the network to obtain our human activity
# recognition predictions
net.setInput(blob)
outputs = net.forward()
label = CLASSES[np.argmax(outputs)]
# loop over our frames
for frame in frames:
# draw the predicted activity on the frame
cv2.rectangle(frame, (0, 0), (300, 40), (0, 0, 0), -1)
cv2.putText(frame, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.8, (255, 255, 255), 2)
# display the frame to our screen
cv2.imshow(“Activity Recognition”, frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord(“q”):
break使用双端队列数据结构的替代方法
正如我们之前看到的,我们正在使用
# loop until we explicitly break from it
while True:
# initialize the batch of frames that will be passed through the
# model
frames = []
# loop over the number of required sample frames
for i in range(0, SAMPLE_DURATION):
# read a frame from the video stream
(grabbed, frame) = vs.read()
# if the frame was not grabbed then we’ve reached the end of
# the video stream so exit the script
if not grabbed:
print(“[INFO] no frame read from stream — exiting”)
sys.exit(0)
# otherwise, the frame was read so resize it and add it to
# our frames list
frame = imutils.resize(frame, width=400)
frames.append(frame)这意味着:
我们从输入视频中读取了总共 SAMPLE_DURATION 帧。
我们将这些帧传递给人类活动识别模型以获得输出。
然后我们读取另一个 SAMPLE_DURATION 帧并重复该过程。
因此,我们的实施不是滚动预测。
相反,它只是抓取一些帧样本,对它们进行分类,然后转到下一批——上一批的任何帧都会被丢弃。
我们这样做的原因是为了速度。
如果我们对每个单独的帧进行分类,脚本运行将需要更长的时间。
也就是说,通过双端队列数据结构使用滚动帧预测 可以产生更好的结果,因为它不会丢弃所有先前的帧 -滚动帧预测只会丢弃列表中最旧的帧,为最新帧腾出空间。
为了了解这如何导致与推理速度相关的问题,我们假设视频文件中总共有 N 帧:
- 如果我们确实使用滚动帧预测,我们将执行 N 个分类,每个帧一个分类(当然,一旦双端队列数据结构被填满)
- 如果我们不使用滚动帧预测,我们只需要执行 N / SAMPLE_DURATION 分类,从而显著减少处理视频流所需的时间。
但是,为了使用双端队列实现滚动预测,我们必须进行以下更改:
# loop over frames from the video stream
while True:
# read a frame from the video stream
(grabbed, frame) = vs.read()
# if the frame was not grabbed then we’ve reached the end of
# the video stream so break from the loop
if not grabbed:
print(“[INFO] no frame read from stream — exiting”)
break
# resize the frame (to ensure faster processing) and add the
# frame to our queue
frame = imutils.resize(frame, width=400)
frames.append(frame)
# if our queue is not filled to the sample size, continue back to
# the top of the loop and continue polling/processing frames
if len(frames) < SAMPLE_DURATION:
continue结果
在第一个例子中,我们的人类活动识别模型正确地将该视频预测为“滑板”:

你可以明白为什么该模型也能预测“跑酷” ——滑板者正在跳过栏杆,这与跑酷者可能执行的动作类似。
如您所见,我们的人类活动识别模型虽然并不完美,但考虑到我们的技术的简单性(将 ResNet 转换为处理 3D 输入而不是 2D 输入),其表现仍然相当出色。
人类活动识别问题远未解决,但通过深度学习和卷积神经网络,我们正在取得巨大进步。
总结
为了完成这项任务,我们利用了在 Kinetics 数据集上预先训练的人类活动识别模型,该数据集包括 400-700 个人类活动(取决于您使用的数据集版本)和超过 300,000 个视频片段。
我们使用的模型是 ResNet,但有一个变化——模型架构已被修改为使用 3D 内核而不是标准的 2D 过滤器,从而使模型能够包含用于活动识别的时间组件。
六、360°视频拼接
使用树莓派相机和OpenCV实现
首先,我们需要讨论图像拼接。毫无疑问,OpenCV对此有一个很好的示例实现,并且经常能提供令人印象深刻的无缝效果。问题是我们想要制作视频,而不是静态图像,因此接下来我们需要讨论Raspberry Pi上的摄像头同步,以便同时捕获帧。最后,我们如何利用所有这些制作 360 度视频?
图像拼接
拼接是将多张重叠图像以无缝方式合并的过程,使其看起来像一张图像。
简单的拼接方法
步骤 1:拍摄一张照片,旋转相机,再拍摄一张照片。注意保留一些重叠部分。

第 2 步:运行特征算法来找到每张图片的关键点。彩色小圆圈就是关键点。这里每张图片中有 2000 多个关键点。

步骤3:匹配相似的关键点。这里有580个匹配,大部分在向日葵上。

步骤 4:计算单应性矩阵并扭曲一张图片以采用另一张图片的视角。这是从左图 (1) 的视角看到的右图 (2)。

步骤 5:并排显示图片。

旋转与平移
需要了解的一些重要信息:如果相机仅旋转而不平移,则无论距离多远,拼接效果都会很好,例如,将相机放在三脚架上拍摄静态图像,如上一节中的向日葵示例一样。
当摄像机平移时,问题就开始了。在这种情况下,只有在给定距离内拼接效果才会最佳。由于多台摄像机无法物理地位于同一点,因此摄像机平移是不可避免的。
参见下面的示例。如果我们尝试将山顶与花顶对齐,相机的任何平移都会移动背景,不同的图片将不会像纯旋转那样完美地重叠。

幸运的是,OpenCV 的样本拼接实现已经提供了缓解措施:使用GraphCut进行接缝遮罩。该算法最初设计用于创建无缝纹理。当错位穿过对比线时,错位非常明显。GraphCut 将尝试将其最小化。

例如,在这个例子中,GraphCut 避免了在蓝天上切割对比度高的屋顶(右侧)。同样,在左侧,切割更倾向于树木中较暗的区域,因为在该区域中错位不太明显。
相机硬件
一些规格:RPi 相机 v2 的水平视野为 62 度。我们使用八个摄像头实现 360° 视图。每个 Raspberry Pi 都在硬件中以 H264 编码视频流并将其存储在其 SD 卡上。在录制会话结束时,所有八个流都会在另一台计算机上收集和处理。Raspberry Pi 可以使用完整传感器以最高 42fps 的速度捕获和编码。
为了携带相机轮,它被安装在自行车推车上,并配有电池和逆变器用于供电。是的,紧凑性显然不是这里的重点……
相机同步
为了在移动时进行拼接,所有八个摄像头都需要同时捕捉一帧。它们不能在独立的时钟上运行。在 40fps 下,帧时间为 25ms(两个连续帧之间的时间)。在最坏的情况下,帧捕捉时间会相差 12.5ms,即使在低速下拼接后,视频中也会出现延迟。
我修改了相机工具raspivid,在视频帧 CPU 回调中添加了一个软件 PLL。“锁相环”(又名 PLL)将两个循环事件(即时钟)同步在一起。
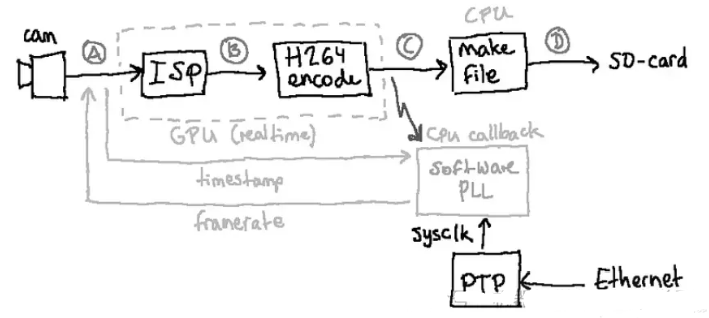
软件 PLL 在运行时改变相机的帧速率,以与Linux 系统时钟上的帧捕获时间对齐。
所有八个系统时钟均使用 PTP(精确时间协议)通过以太网同步。尽管 Raspberry Pi 以太网缺少用于高精度 PTP 时钟(硬件时间戳)的专用硬件,但它仍然经常在软件模式下使用 PTP 实现 1ms 以下的时钟同步。录制视频时,网络仅用于 PTP,不进行其他通信。
拼接管线
步骤1:录制视频
打开电源,让 PTP 稳定下来(可能需要几分钟),开始在每个 Raspberry Pi 上记录。
步骤2:对齐框架
复制视频流,将视频分割成单个 JPEG 文件,并将捕获时间信息保存在文本文件(即修改后的 raspivid PTS 文件)中找到匹配的帧。
步骤3:校准变换
在一些匹配的帧上运行 OpenCV stitching_detailed来查找变换矩阵。匹配成功与否取决于特征算法(例如 SURF、ORB 等)以及帧重叠区域中可见的细节。
如果成功,每一帧都有两个矩阵:对相机特性(例如焦距、纵横比)进行编码的相机矩阵(又名“K”)和对相机旋转进行编码的旋转矩阵(又名“R”)。
正如本文开头所解释的那样,拼接将假设纯旋转,而现实生活中并非如此。流中的每个匹配帧将具有不同的矩阵。下一步只会选择一组矩阵。
步骤4:缝合框架
使用上一步中选择的矩阵作为硬编码变换重建stitching_detailed ,并拼接所有视频帧。
步骤5:编码视频
将所有拼接的 JPEG 文件重新组装成视频并将其编码回 H264。


七、OpenCV两种不同方法实现粘连大米分割计数
本文主要介绍基于OpenCV的两种不同方法实现粘连大米分割计数
测试图如下,图中有个别米粒相互粘连,本文主要演示如何使用OpenCV用两种不同方法将其分割并计数。

方法一:基于分水岭算法
基于分水岭算法分割步骤如下:
【1】高斯滤波 + 二值化 + 开运算
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray,(5,5),0)
ret, binary= cv2.threshold(gray, 115, 255, cv2.THRESH_BINARY)
kernel = np.ones((5, 5), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel, iteratinotallow=1)
cv2.imshow('thres', binary)
【2】距离变换 + 提取前景
dist = cv2.distanceTransform(binary, cv2.DIST_L2, 3)
dist_out = cv2.normalize(dist, 0, 1.0, cv2.NORM_MINMAX)
cv2.imshow('distance-Transform', dist_out * 100)
ret, surface = cv2.threshold(dist_out, 0.35*dist_out.max(), 255, cv2.THRESH_BINARY)
cv2.imshow('surface', surface)
sure_fg = np.uint8(surface)# 转成8位整型
cv2.imshow('Sure foreground', sure_fg)

【3】标记位置区域
# 未知区域标记为0
markers[unknown == 255] = 0
kernel = np.ones((5, 5), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_DILATE, kernel, iteratinotallow=1)
unknown = binary - sure_fg
cv2.imshow('unknown',unknown)
【4】分水岭算法分割
markers = cv2.watershed(img, markers=markers)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(markers)【5】轮廓查找和标记
contours,hierarchy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for cnt in contours:
M = cv2.moments(cnt)
cx = int(M['m10']/M['m00'])
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])#轮廓重心
cv2.drawContours(img,contours,-1,colors[rd.randint(0,5)],2)
cv2.drawMarker(img, (cx,cy),(0,255,0),1,8,2)
方法二:轮廓凸包缺陷方法
基于轮廓凸包缺陷分割步骤如下:
【1】高斯滤波 + 二值化 + 开运算
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray,(5,5),0)
ret, binary= cv2.threshold(gray, 115, 255, cv2.THRESH_BINARY)
kernel = np.ones((5, 5), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel, iteratinotallow=1)
cv2.imshow('thres', binary)
【2】轮廓遍历 + 筛选轮廓含有凸包缺陷的轮廓
contours,hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for cnt in contours:
hull = cv2.convexHull(cnt,returnPoints=False)#默认returnPoints=True
defects = cv2.convexityDefects(cnt,hull)
#print defects
pt_list = []
if defects is not None:
flag = False
for i in range(0,defects.shape[0]):
s,e,f,d = defects[i,0]
if d > 4500:
flag = True
【3】将距离d最大的两个凸包缺陷点连起来,将二值图中对应的粘连区域分割开,红色圆标注为分割开的部分
if len(pt_list) > 0:
cv2.line(binary,pt_list[0],pt_list[1],0,2)
cv2.imshow('binary2',binary)

【4】重新查找轮廓并标记结果
contours,hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for cnt in contours:
try:
M = cv2.moments(cnt)
cx = int(M['m10']/M['m00'])
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])#轮廓重心
cv2.drawContours(img,cnt,-1,colors[rd.randint(0,5)],2)
cv2.drawMarker(img, (cx,cy),(0,0,255),1,8,2)
except:
pass
八、图像轮廓检测与绘制详解
在计算机视觉和图像处理中,轮廓是沿着物体边界连接具有相同强度或颜色的连续点的曲线或边界。换句话说,轮廓表示图像中物体的轮廓。
图像轮廓绘制是检测和提取图像中物体的边界或轮廓的过程。本质上,图像轮廓绘制涉及识别形成连续曲线的相似强度或颜色的点,从而勾勒出物体的形状。
轮廓在许多图像处理和计算机视觉任务中至关重要,因为它们可以有效地分割、分析和提取图像中各种对象的特征。图像轮廓通常用于简化图像,只关注重要的结构元素(即对象边界),同时忽略不相关的细节,如纹理或对象内的细微变化。下图显示了轮廓的一个示例。在图像中检测到了苹果的形状。

图像轮廓的工作原理
图像轮廓绘制通常涉及以下步骤:
- 预处理
- 二进制转换
- 轮廓检测
- 轮廓绘制
让我们逐一讨论一下每个步骤。
预处理
如果是彩色图像,则将其转换为灰度图像。可选地,应用平滑滤波器(例如高斯模糊)来减少噪声,这有助于实现更好的轮廓检测结果。
# Convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply Gaussian Blur to reduce noise
blurred = cv2.GaussianBlur(gray, (5, 5), 0)二值图转换
应用阈值或边缘检测(例如,使用 Canny 边缘检测器)将灰度图像转换为二进制图像。在二进制图像中,对象由白色像素(前景)表示,背景由黑色像素表示。
阈值处理有助于根据像素强度突出显示感兴趣的区域,而边缘检测则可以强调发生急剧强度变化的边界。
# Apply binary thresholding
# The threshold value (150) may need adjustment based on your image's lighting and contrast
ret, thresh = cv2.threshold(blurred, 150, 255, cv2.THRESH_BINARY_INV)轮廓检测
使用算法检测二值图像中的轮廓。OpenCV 中用于轮廓检测的常用函数是 cv2.findContours(),它返回图像中所有检测到的轮廓的列表。
轮廓由点列表表示,每个点代表沿对象边界的像素位置。
# Find contours in the threshold image
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)轮廓绘制
一旦检测到轮廓,就可以通过使用 cv2.drawContours() 在原始图像或空白画布上绘制轮廓来实现可视化。这有助于可视化对象的边界。
# Draw the largest contour on both images
cv2.drawContours(image, contours, -1, (14, 21, 239), 5)
Here’s is an Example
# Read the image
image = cv2.imread('shapes_2.jpg')
# Convert to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply thresholding to create a binary image
_, binary = cv2.threshold(gray, 200, 255, cv2.THRESH_BINARY_INV)
# Find contours in the binary image
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Create copies of the original image to draw contours
contour_image = image.copy()
contour_on_original = image.copy()
# Draw the contours on the binary (black) image
contour_black = np.zeros_like(image)
cv2.drawContours(contour_black, contours, -1, (0, 255, 0), 2)
# Draw the contours on the original image
cv2.drawContours(contour_on_original, contours, -1, (255,0, 0), 5)输出如下:

cv2.findContours() 函数
cv2.findContours() 方法是 OpenCV 库中用于检测图像轮廓的重要函数。下面,我将详细解释此函数,介绍其所有参数及其用途。
以下是函数定义:
contours, hierarchy = cv2.findContours(image, mode, method[, contours[, hierarchy[, offset]]])该函数接受各种参数/参数,如下所述。
- image-图像 (输入图像)
这是要从中找到轮廓的源图像。输入图像必须是二进制图像,这意味着它应该只包含两个像素值,通常为 0(黑色)表示背景,255(白色)表示对象。
通常,这是通过使用阈值或边缘检测来创建合适的二进制图像来实现的。请注意,cv2.findContours() 会修改输入图像,因此如果您需要保留原始图像,通常建议传递副本。
- mode-模式 (轮廓检索模式)
此参数指定如何检索轮廓。它控制轮廓的层次结构,对于嵌套或重叠对象特别有用。它包括 cv2.RETR_EXTERNAL、cv2.RETR_LIST、cv2.RETR_CCOMP、cv2.RETR_TREE 等模式。所有这些模式都在下面的“轮廓检索模式”部分中进行了说明。
- method-方法 (轮廓近似法)
此参数控制轮廓点的近似方法,本质上影响精度和用于表示轮廓的点数。常用方法包括 cv2.CHAIN_APPROX_NONE、cv2.CHAIN_APPROX_SIMPLE、cv2.CHAIN_APPROX_TC89_L1、cv2.CHAIN_APPROX_TC89_KCOS。这些方法在下面的“轮廓近似方法”部分中解释。
- contours-轮廓 (输出参数)
这是所有检测到的轮廓的输出列表。每个单独的轮廓都表示为定义轮廓边界的点(x,y 坐标)的 NumPy 数组。轮廓通常存储为包含一个或多个轮廓的 Python 列表。
- hierarchy-层次结构 (输出参数)
这是一个可选的输出参数,存储了轮廓之间的层级关系信息,每条轮廓有四条信息[Next, Previous, First_Child, Parent]。
下一个:同一层次结构的下一个轮廓的索引。
上一个:同一层次结构中前一个轮廓的索引。
First_Child:第一个子轮廓的索引。
父级:父轮廓的索引。
如果值为 -1,则表示没有相应的轮廓(例如,没有父轮廓或没有子轮廓)。
- offset-偏移量(可选)
此参数用于将轮廓点移动一定偏移量(x 和 y 值的元组)。如果您正在处理子图像并需要将检测到的轮廓移回以匹配其在原始图像中的位置,这将非常有用。它在大多数常见场景中很少使用。
- 该函数返回以下值。
contours-轮廓:检测到的轮廓列表。
hierarchy-层次结构:轮廓的层次结构,如果您需要了解轮廓之间的父子关系,这很有用。
OpenCV 中的轮廓检索模式
OpenCV 的 cv2.findContours() 函数中的轮廓检索模式控制轮廓的检索方式,包括是否考虑轮廓的层次结构(即父子关系)。此模式对于确定检测到的轮廓的结构及其在图像中的关系至关重要,尤其是在处理嵌套或重叠对象时。对于本节中的示例,我们将创建合成二进制图像,其中包含四个嵌套的黑白交替同心圆。
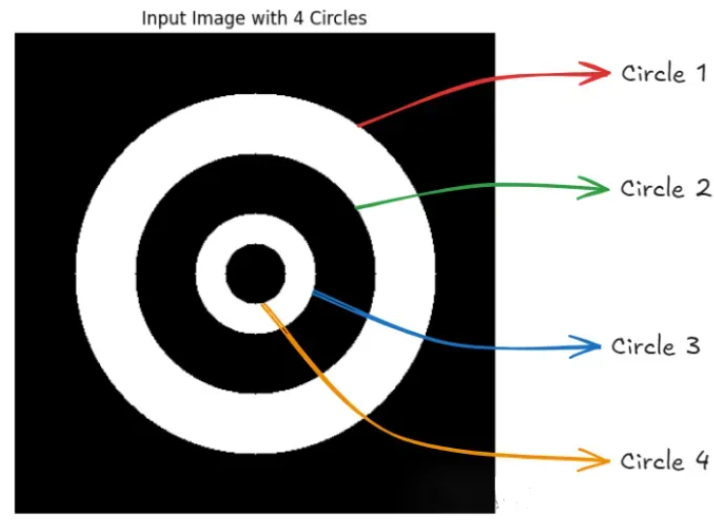
OpenCV 中有四种主要的轮廓检索模式。让我们分别了解一下。
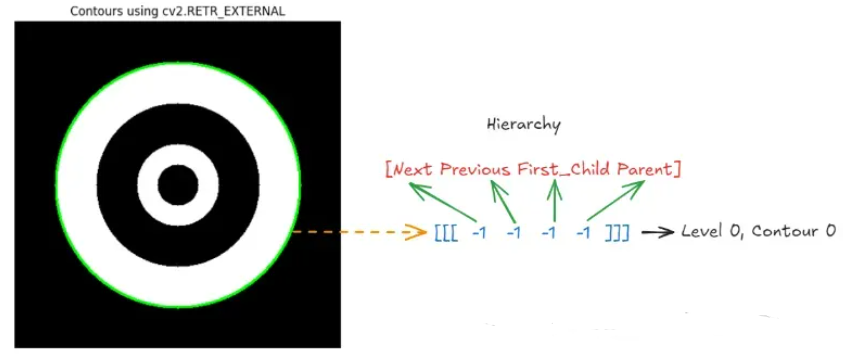
cv2.RETR_EXTERNAL
此模式用于仅检索最外层轮廓。它会忽略包含在另一个轮廓(轮廓的层次结构级别)内的任何轮廓。它实际上只考虑外部边界,而忽略内部嵌套轮廓。
如果您只对物体的外部边界感兴趣,例如检测桌子上的硬币或将物体与背景隔离,此模式非常有用。当嵌套轮廓与您的分析无关时,此模式非常有效。
例如,在我们输入的嵌套圆圈图像中,cv2.RETR_EXTERNAL 将仅检索外圆,而忽略内圆。
以下是我们可以用来处理上述图像的代码:
# Find contours using cv2.RETR_EXTERNAL
contours, _ = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Convert image to color for visualization
image_color = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
# Draw the outer contours in green
cv2.drawContours(image_color, contours, -1, (0, 255, 0), 2)在上面的代码中,cv2.RETR_EXTERNAL 模式仅查找最外层轮廓(完全忽略内层圆)。外层轮廓用绿色绘制。下图左侧显示代码返回的输出,其中仅检测到外层圆,右侧显示 cv2.findContours() 函数返回的层次结构,其中只有一个轮廓(针对外层圆)。在这种情况下,所有四个值(即下一个、上一个、第一个子项、父项)均为 -1,这意味着轮廓完全孤立,没有层次关系。
cv2.RETR_LIST
此模式用于检索图像中的所有轮廓,但不建立它们之间的任何父子关系。所有轮廓都存储在一个简单的列表中。此模式本质上使层次结构扁平化。它不区分外部和内部轮廓,并将每个轮廓视为独立的,没有层次分组。
当您不需要有关不同轮廓之间关系的信息而只需要整个轮廓集时,此模式很有用,例如分析图像中每个对象的形状或边界。
例如,在同样的嵌套圆的绘制中,cv2.RETR_LIST 会把所有的外圆和内圆都取出来,但是不会定义任何层级关系(父子关系或者多级关系),每个圆都是独立处理的。以下是示例代码。
# Find contours using cv2.RETR_LIST
contours, _ = cv2.findContours(image, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# Convert image to color for visualization
image_color = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
# Draw all contours in green
cv2.drawContours(image_color, contours, -1, (0, 255, 0), 2)cv2.RETR_LIST 模式检测所有轮廓,并单独处理每个轮廓(外圆以及所有内圆)。轮廓以绿色绘制。
下图显示了代码的输出(左侧),检测到了所有圆。图像的右侧显示了 cv2.findContours() 函数返回的层次结构,该层次结构表示图像中检测到的四个轮廓之间的关系,其中每个轮廓都处于同一级别(级别 0)并且没有父轮廓或子轮廓。此处,在层次结构中,所有轮廓的“第一个子轮廓”和“父轮廓”值均为 -1,表示未检测到父子关系。
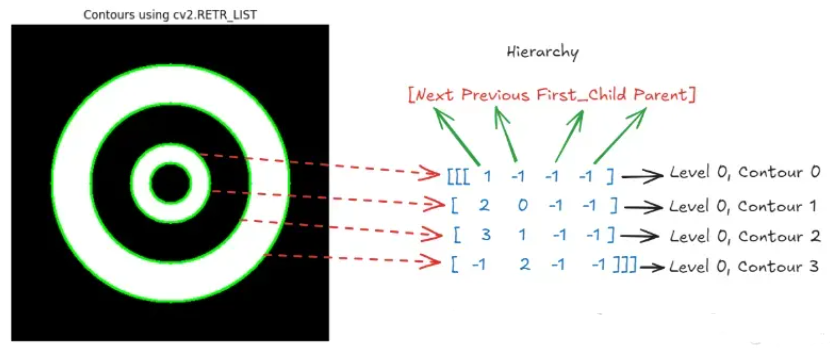
cv2.RETR_CCOMP
此模式用于检索所有轮廓,并将它们组织成两级层次结构。轮廓按层次排列。层次结构中只有两个级别。第一级表示对象的外部边界,第二级表示对象内部的轮廓。
当您需要一个简单的层次结构,并且外部边界和各自的内部对象边界之间有明显区分时,此模式很有用。
例如,在我们的输入图像中,cv2.RETR_CCOMP 将把外圆存储为第一级(级别 0)轮廓,将内圆存储为第二级(级别 1)轮廓。每对轮廓(外轮廓在级别 0,内轮廓在级别 1)都被视为一个组件。以下是示例代码。
# Find contours using cv2.RETR_CCOMP
contours, hierarchy = cv2.findContours(image, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
# Convert image to color for visualization
image_color = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
# Draw contours based on the two-level hierarchy
for i, contour in enumerate(contours):
if hierarchy[0][i][3] == -1: # If it is an outer contour
cv2.drawContours(image_color, [contour], -1, (0, 255, 0), 2) # Green for outer contours
else: # If it is an inner contour (hole)
cv2.drawContours(image_color, [contour], -1, (0, 0, 255), 2) # Blue for inner contourscv2.RETR_CCOMP 模式查找轮廓并将其组织成两级层次结构。下图显示了代码的输出(左侧),检测到两级层次结构中的所有圆。图像的右侧显示了 cv2.findContours() 函数返回的层次结构,该层次结构表示四个轮廓之间的关系,但与前面的示例不同,此层次结构包括父子关系。
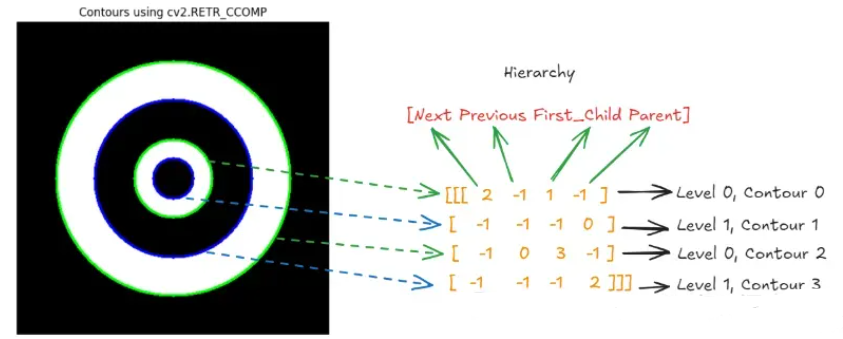
cv2.RETR_TREE
此模式用于检索所有轮廓并将它们组织成完整的层次结构(即树结构)。此模式提供轮廓之间层次关系的最全面表示,包括父轮廓、子轮廓、兄弟轮廓和嵌套轮廓。所有轮廓都以完整的父子关系组织,这意味着不仅跟踪外部和内部轮廓,还跟踪这些内部轮廓中存在的任何嵌套。这形成了一个完整的树状层次结构。
此模式适用于需要了解嵌套对象完整结构的复杂图像,例如分析文档中的轮廓或了解重叠形状。它提供有关轮廓如何相互嵌套的详细信息。
例如,对于嵌套圆,cv2.RETR_TREE 会将它们组织成一个完整的树结构,其中最大的圆是根(父圆),每个连续的小圆都是前一个圆的子圆。以下是示例代码。
# Find contours using cv2.RETR_TREE
contours, hierarchy = cv2.findContours(image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Convert image to color for visualization
image_color = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
# Draw contours based on hierarchy levels
for i, contour in enumerate(contours):
level = 0
# Traverse the hierarchy to determine the level of the contour
parent = hierarchy[0][i][3]
while parent != -1:
level += 1
parent = hierarchy[0][parent][3]
# Use different colors for the first and second levels
if level == 0:
cv2.drawContours(image_color, [contour], -1, (0, 255, 0), 2) # Green for first level (outermost)
elif level == 1:
cv2.drawContours(image_color, [contour], -1, (0, 0, 255), 2) # Red for second level (inner)
else:
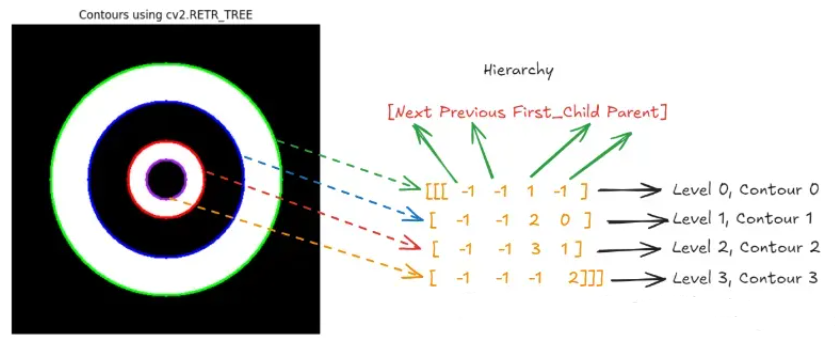
cv2.drawContours(image_color, [contour], -1, (255, 0, 0), 2) # Blue for deeper levelscv2.RETR_TREE 模式会找到所有轮廓,并将它们组织成具有完整层次结构的多个级别。最大的外圆是根(父圆),第二个圆是最大外圆的子圆,第三个内圆是第二个圆的子圆,依此类推。
下图显示了代码的输出(左侧),该代码检测到了所有圆的完整层次结构。图像的右侧显示了 cv2.findContours() 函数返回的层次结构,该层次结构表示具有父子关系的四个轮廓之间的关系。它创建了一个嵌套轮廓链,其中每个轮廓都包含下一个轮廓,形成一直到第四个轮廓的父子关系。每个轮廓都嵌套在前一个轮廓内,形成严格的父子链。同一级别没有“兄弟”轮廓,每个轮廓都是前一个轮廓的子轮廓。这种层次结构在处理同心形状或其他形式时很常见,其中一个轮廓以严格嵌套的方式包围另一个轮廓。
轮廓法比较
以下是所有模式的比较:

cv2.RETR_EXTERNAL:仅检索最外层轮廓,忽略内层轮廓。
cv2.RETR_LIST:所有轮廓都被独立处理,并且不应用任何层次结构。
cv2.RETR_CCOMP:轮廓被组织成两级层次结构。
cv2.RETR_TREE:轮廓被组织成完整的层次结构,显示嵌套轮廓的所有父子关系。
轮廓检索模式用于确定如何在图像中提取和组织轮廓。它允许控制轮廓之间的层次关系,例如区分外部边界和嵌套结构。
轮廓逼近法
OpenCV 的 cv2.findContours() 函数中的轮廓近似方法决定了如何通过近似轮廓点来表示轮廓,这直接影响轮廓表示的存储和精度。通过使用不同的近似方法,可以控制用于表示轮廓的点数,在内存效率和轮廓精度之间取得平衡。
cv2.findContours() 函数提供了不同的轮廓近似方法,这些方法决定了检测到的边界点的表示方式。让我们详细看看这些方法。
轮廓近似方法由 cv2.findContours() 中的 method 参数定义。它们控制轮廓边界点的存储精度。常用方法有:
cv2.CHAIN_APPROX_NONE
此方法存储轮廓边界上的所有点。通过保留轮廓上的每个点,它提供了轮廓的最详细表示。由于存储了每个边界点,因此此方法占用的内存最多,并且计算成本很高。
cv2.CHAIN_APPROX_NONE 适用于需要高度精确的轮廓表示(例如需要精确测量时)。它还可用于涉及轮廓边界上所有点的进一步分析,例如跟踪点或执行变换。
例如,如果您有一个不规则的波浪形轮廓,cv2.CHAIN_APPROX_NONE 将确保捕获轮廓的最小细节。以下是示例代码。
# Draw a star shape
pts = np.array([[200, 50], [220, 150], [300, 150], [240, 200], [260, 300],
[200, 250], [140, 300], [160, 200], [100, 150], [180, 150]], np.int32)
pts = pts.reshape((-1, 1, 2))
cv2.polylines(image, [pts], isClosed=True, color=255, thickness=2)
# Find contours using cv2.CHAIN_APPROX_NONE
contours, _ = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# Convert image to color for visualization
image_contour = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR) # Image for contours
image_points = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR) # Image for points
# Draw the contours in green on the contour image
for contour in contours:
cv2.drawContours(image_contour, [contour], -1, (0, 255, 0), 2) # Draw contours in green
# Draw the points in red on the points image
for contour in contours:
for point in contour:
cv2.circle(image_points, tuple(point[0]), 1, (255, 0, 0), -1) # Red dots for points
此代码可让您看到 cv2.CHAIN_APPROX_NONE 如何捕获并显示轮廓边界上的所有点,从而展示其表示形状的精确度。您可以清楚地看到代表整个轮廓的绿线。
红点表示沿轮廓存储的每个点,强调 cv2.CHAIN_APPROX_NONE 捕获每个点,即使是沿直线和曲线。这种方法允许您验证所有点确实已存储和可视化,突出了 cv2.CHAIN_APPROX_NONE 的精度和细节。
cv2.CHAIN_APPROX_SIMPLE
该方法通过删除直线上的所有冗余点来压缩轮廓的表示。它仅存储每个段的端点,从而有效地用更少的点近似轮廓。这显著减少了内存使用量,同时保留了轮廓的一般形状。
它最常用于典型的轮廓检测任务,在这些任务中,您需要物体的整体形状,但不需要边界上的每个细节。适用于检测简单形状(例如矩形、圆形),这些形状只需要关键点来表示轮廓的结构。
例如,如果您有一个矩形对象,CHAIN_APPROX_SIMPLE 将仅存储四个角,消除边缘上的冗余点。以下是示例代码。
# Create a synthetic image with a rectangle
image = np.zeros((400, 400), dtype=np.uint8)
cv2.rectangle(image, (100, 100), (300, 300), 255, -1) # Draw a filled rectangle
# Find contours using cv2.CHAIN_APPROX_SIMPLE
contours, _ = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Convert image to color for visualization
image_contours = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
image_keypoints = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
# Draw the simplified contours (keypoints only) on `image_contours`
for contour in contours:
# Draw contours in green
cv2.drawContours(image_contours, [contour], -1, (0, 255, 0), 2)
# Draw keypoints (points of the contour) on `image_keypoints`
for contour in contours:
for point in contour:
# Draw key points (red dots) for each contour
cv2.circle(image_keypoints, tuple(point[0]), 5, (0, 0, 255), -1)
对于矩形等简单形状,cv2.CHAIN_APPROX_SIMPLE 将轮廓点减少到仅角落,有效地显示了此方法的效率。通过消除冗余点,此方法减少了内存使用量,非常适合整体形状比精确边界细节更重要的场景。
cv2.CHAIN_APPROX_TC89_L1
该方法使用 Teh-Chin 链近似算法,与 CHAIN_APPROX_NONE 相比,该算法使用更少的点来近似轮廓。
这是一种中间方法,试图在轮廓精度和点数之间取得平衡。CHAIN_APPROX_TC89_L1 提供了一种优化的表示,它使用的点比 CHAIN_APPROX_NONE 少,但可能比 CHAIN_APPROX_SIMPLE 保留更多细节。
当您需要优化内存使用但与 CHAIN_APPROX_SIMPLE 相比仍需要更高的精度时很有用。
例如,如果您需要平滑的轮廓表示以进行跟踪或用于涉及简化波浪边缘的应用程序,则 CHAIN_APPROX_TC89_L1 可能是一个合适的选择。以下是示例代码。
# Create a synthetic image with a wavy contour (e.g., sinusoidal wave shape)
image = np.zeros((400, 400), dtype=np.uint8)
# Draw a wavy contour using a sinusoidal function
for x in range(50, 350):
y = int(200 + 50 * np.sin(x * np.pi / 50))
cv2.circle(image, (x, y), 2, 255, -1)
# Find contours using cv2.CHAIN_APPROX_TC89_KCOS
contours, _ = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_L1)
# Convert the image to color for different visualizations
image_contour = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR) # Image for contours
image_points = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR) # Image for points
# Draw the contours on the contour image
for contour in contours:
cv2.drawContours(image_contour, [contour], -1, (0, 255, 0), 2) # Draw contours in green
# Draw the points on the points image
for contour in contours:
for point in contour:
cv2.circle(image_points, tuple(point[0]), 1, (0, 0, 255), -1) # Red dots for key points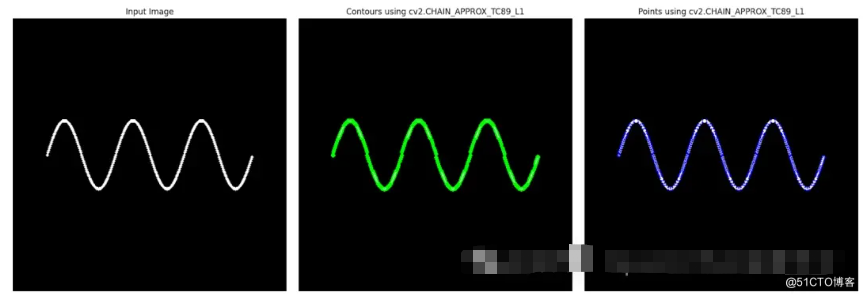
与 cv2.CHAIN_APPROX_NONE 相比,此方法使用更少的点,同时保留了大量细节。它对于不需要完整细节但又不理想的波浪形或不规则形状特别有用。结果显示了 cv2.CHAIN_APPROX_TC89_L1 如何提供平滑且优化的轮廓表示,适用于内存效率和轮廓精度都很重要的应用。
cv2.CHAIN_APPROX_TC89_KCOS
与 CHAIN_APPROX_TC89_L1 类似,此方法也使用 Teh-Chin 链近似,但与 CHAIN_APPROX_TC89_L1 相比,近似程度略有不同。此方法通常会稍微更积极地减少点数,同时仍能捕捉轮廓的关键特征。
它减少了点数,但与 CHAIN_APPROX_TC89_L1 相比,确切的行为可能略有不同。当您想要比 CHAIN_APPROX_TC89_L1 更积极的轮廓点压缩并且只需要保留最关键的点时,使用此方法。
例如,当内存和速度至关重要,并且轮廓不是很复杂时,CHAIN_APPROX_TC89_KCOS 可以在效率和轮廓细节之间提供良好的平衡。以下是示例代码。
# Create a synthetic image with a wavy contour (e.g., sinusoidal wave shape)
image = np.zeros((400, 400), dtype=np.uint8)
# Draw a wavy contour using a sinusoidal function
for x in range(50, 350):
y = int(200 + 50 * np.sin(x * np.pi / 50))
cv2.circle(image, (x, y), 2, 255, -1)
# Find contours using cv2.CHAIN_APPROX_TC89_KCOS
contours, _ = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_KCOS)
# Convert the image to color for different visualizations
image_contour = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR) # Image for contours
image_points = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR) # Image for points
# Draw the contours on the contour image
for contour in contours:
cv2.drawContours(image_contour, [contour], -1, (0, 255, 0), 2) # Draw contours in green
# Draw the points on the points image
for contour in contours:
for point in contour:
cv2.circle(image_points, tuple(point[0]), 1, (0, 0, 255), -1) # Red dots for key points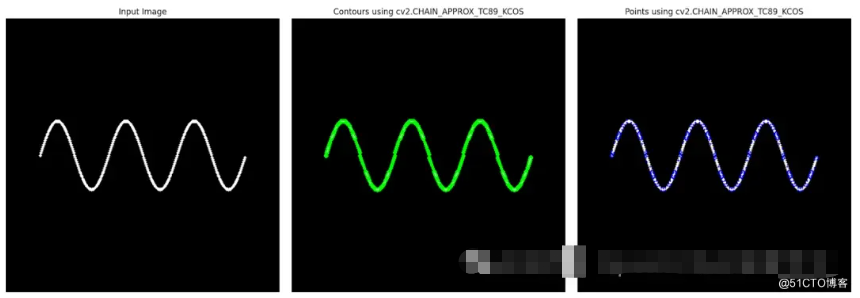
cv2.CHAIN_APPROX_TC89_KCOS 的输出
与 cv2.CHAIN_APPROX_TC89_L1 相比,此方法可更积极地减少轮廓点,适用于需要最少点数同时保留一般形状的应用。通过进一步减少点数,此方法可优化内存使用率和处理速度,非常适合轮廓不需要高度详细的场景。
轮廓近似方法很重要,因为它有助于控制用于表示轮廓形状的细节级别。通过选择适当的近似方法,您可以在计算效率和给定应用所需的精度之间取得平衡。当轮廓细节级别会影响性能和准确性时,这种灵活性尤其有用。
九、测量图像的亮度
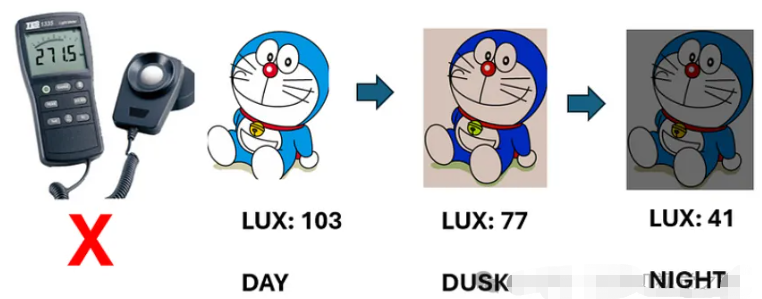
并非每个人都拥有照度计(见上图)。通常,我们只是用手机拍照,然后尝试通过调整对比度来处理图像。
然而,在工业上,我们需要将调整后的图像与精确的测量值进行比较。那么,我们如何实现这一点呢?
一种方法是使用公式将图像像素值转换为相应的亮度值。
此代码首先将图像分成三个独立的 HSV 通道:
- H(色调):控制颜色。
- S(饱和度):控制颜色强度。
- V(值):控制亮度。
然后执行以下操作:
- 稍微降低亮度来模拟清晨的昏暗或夜幕降临。
- 增加对比度以获得柔和、发光的效果。
- 添加暖色调(橙色/黄色)来模拟清晨的阳光。
- 调整饱和度来创造略带梦幻的效果。
- 使用PIL库增强对比度。
现在我们来尝试一下以下三段代码:
- 将 V(亮度)通道乘以 a brightness_factor(例如,0.4→ 40% 亮度)。
- 用于np.clip(..., 0, 255)确保像素值保持在有效范围内(0-255)。
- 应用enhance(contrast_factor)以增加对比度 1.2 倍(默认值)。
A)运行代码将图片转换为黎明图片

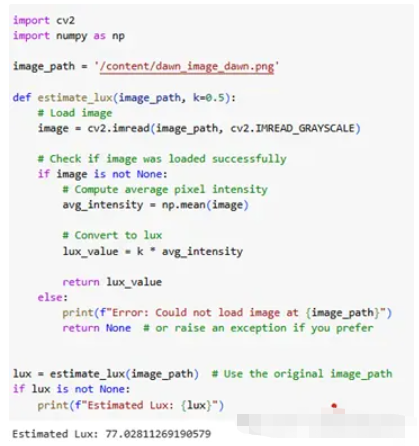
B)运行代码提取图像的亮度值
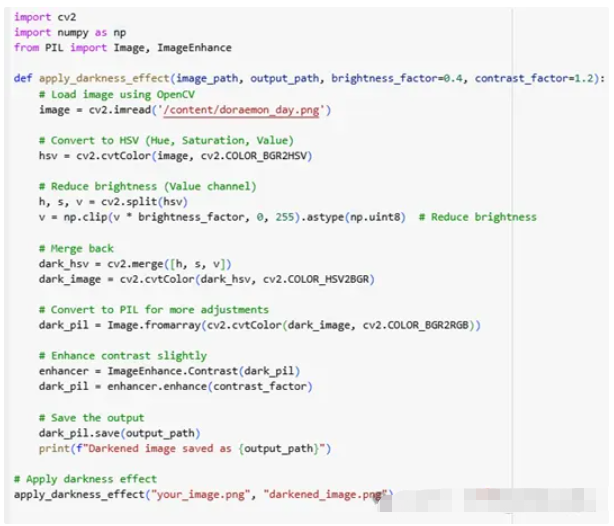
C)运行代码以转换为昏暗的灯光
源码链接:
https://github.com/elvenkim1/opencv十、老人跌倒智能监测
使用Python、OpenCV和MediaPipe搭建一个老人跌倒智能监测系统。
老人监测系统是一种智能检测系统,可以检测老人是否躺在床上或是否跌倒在地。这是一个解决实际问题的程序,可用于在您外出工作或外出时监控家中的老人,以便在出现任何问题时通知您。
实现步骤
【1】导入必要的模块: 在 python 中导入 Numpy、MediaPipe 和 opencv
【2】定义一个计算角度的函数:
由于我们将根据我们使用 OpenCV 获得的角度和坐标来假设一个人是在行走还是跌倒在地上,因此,我们必须计算角度,最简单的方法是定义一个函数,然后调用它在程序中。
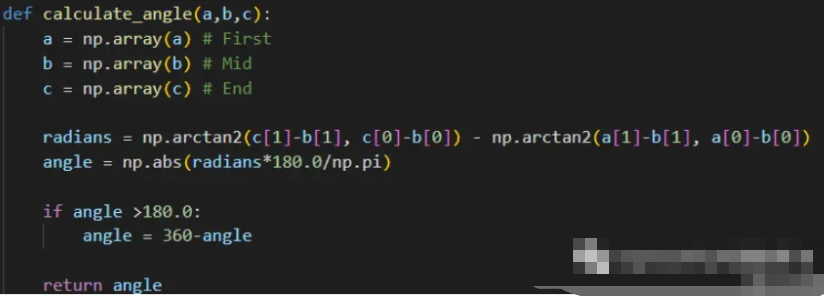
【3】查找坐标:
我们还必须找到坐标,以便我们可以在条件下使用它们,也可以将它们与calculate_angle函数一起使用。
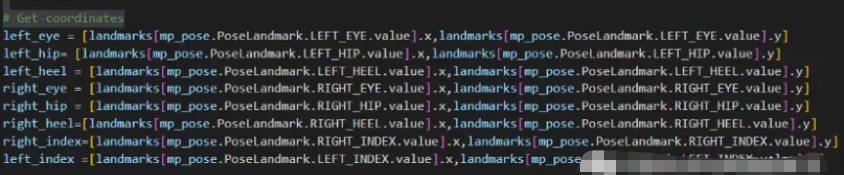
【4】如何知道主体(老人)是安全的还是跌倒的?
我们将借助从 cv2 和 mediapipe 获得的坐标以及使用上述定义的函数获得的角度来找到这一点。
由于我们正在获取眼睛臀部和脚踝的坐标,因此我们知道当一个人平躺(倒下)时,他的眼睛、臀部和脚踝之间的角度在 170 到 180 度的范围内。因此,我们可以简单地提出一个条件,当角度在 170 -180 度之间时,我们可以说一个人摔倒了。
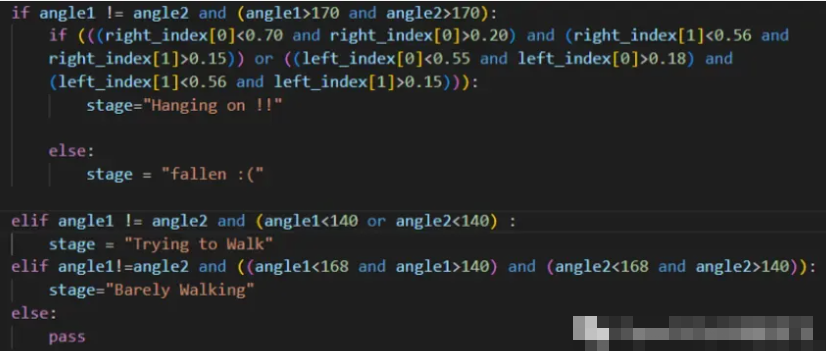
现在你的脑海中可能会出现一个问题,即如何确定这个人是否真的摔倒了,或者他是否只是躺在床上,因为在这两种情况下,角度都在相同的范围内。
我们也会回答它,所以请继续阅读:)
【5】如何区分床和地板?
我们将再次使用从 OpenCV 获得的坐标,然后使用它来找到床的坐标,然后在检查跌倒条件时引入一个新条件,即当受试者的坐标与床坐标一致时,这意味着一个人在床上时自然是安全的。这种情况将排除跌倒的情况,程序将显示安全。只有当此条件变为假时,才会检查跌倒条件和其他步行和尝试步行条件。

因此,通过引入带有床坐标的单一条件,我们也解决了上述问题。
【6】让我们在屏幕上打印结果:
现在打印摔倒和安全等的结果;我们可以很容易地使用 cv2 中的 putText 函数来显示保存在变量 stage 中的文本。
该函数的示例用法如下所示:
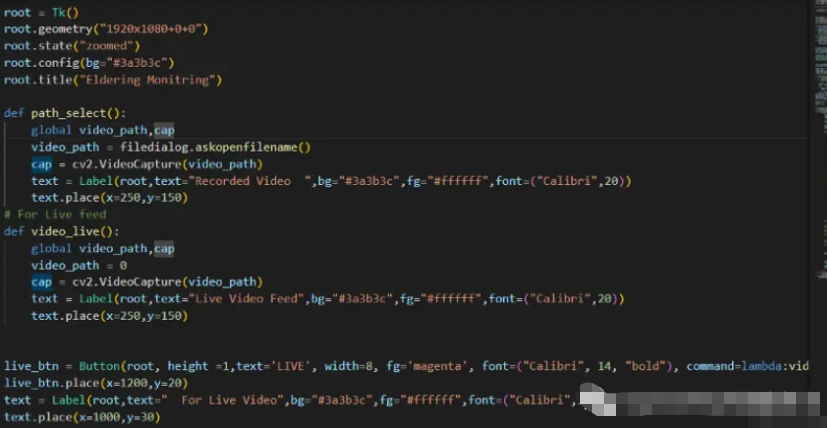
cv2.putText(image, ‘Condition: ‘, (15,12), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1, cv2.LINE_AA)【7】添加图形用户界面:
我们还可以添加一点 GUI 来进一步增加整个程序的外观并使其更加用户友好。实现最简单 GUI 的代码片段示例如下:
最终效果:




完整代码下载链接:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









