







我自己的原文哦~ https://blog.51cto.com/whaosoft/12207168
#HivisionIDPhotos
1万Star量,最火AI证件照项目怎么训的?
不会 PS 也能生成证件照了,背景去除、美颜等功能统统包含。不仅如此,操作简单,而且还是开源的。

该研究就是最近爆火的 HivisionIDPhotos 项目,曾一度冲上 Github 趋势榜榜首,现在星标量已经达到 10.7 k。

具体来说,HivisionIDPhotos 是一个开源轻量级 AI 证件照项目,旨在为用户提供轻量好用的证件照制作工具,让每个人都拥有自己的线上照相馆。
该项目运用多个模型组合实现面部定位、背景去除、尺寸裁剪与美颜,实现在纯 CPU 下几秒内完成从自拍到标准证件照的全流程,因低门槛、实用、效果好的特点受到开源社区的欢迎。
此外,HivisionIDPhotos 还提供了 Gradio、API 接口、Docker 等多种使用方式,让开发者能够灵活地进行上层应用开发。
相关链接
https://github.com/Zeyi-Lin/HivisionIDPhotos
https://github.com/SwanHubX/SwanLab
#UNA
综合RLHF、DPO、KTO优势,统一对齐框架
论文主要作者:
1. 王智超:本科就读于厦门大学土木工程系,研究生博士就读于佐治亚理工并获得土木工程和计算机工程硕士及机械工程博士,现任职于 Salesforce,专注于 LLM Alignment。
2. 闭彬:本科就读于华中科技大学计算机工程系,研究生就读于香港大学计算机科学系,博士就读于 UCLA 计算机科学系,现任职于 Salesforce,专注于 LLM Alignment。
3. 黄灿:厦门大学数学系副教授
随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。
其中,RLHF 是一种广泛使用的方法,依赖于从人类反馈中学习强化策略。RLHF 的流程包括两个阶段:首先,通过人类偏好数据训练奖励模型(Reward Model, RM),然后使用该奖励模型指导策略模型(Policy Model)的强化学习优化。然而,RLHF 存在若干显著问题,如高内存占用、训练不稳定以及流程复杂等。
为了解决 RLHF 的复杂性,DPO 方法被提出。DPO 简化了 RLHF 的流程,将强化学习的训练阶段转化为一个二分类问题,减少了内存消耗并提高了训练稳定性。但 DPO 无法充分利用奖励模型,且仅适用于成对的偏好数据,无法处理更为广泛的反馈类型。
此外,KTO 进一步扩展了 DPO,能够处理二元数据(如正向和负向反馈),但它同样有其局限性,无法统一处理不同类型的反馈数据,也无法有效利用已有的奖励模型。
在这种背景下,来自 Salesforce、厦门大学的研究团队提出了一种名为 UNA 的新方法,它通过一种通用的隐式奖励函数,统一了当前主流的大规模语言模型(LLM)对齐技术。主要包括 RLHF、DPO 和 KTO,这些技术的结合不仅简化了模型的训练流程,还提高了模型对齐的性能,稳定性和效率。
论文标题:UNA: Unifying Alignments of RLHF/PPO, DPO and KTO by a Generalized Implicit Reward Function
论文地址:https://arxiv.org/abs/2408.15339
UNA 的创新点
UNA 的核心创新点在于通过一个(generalized implicit reward function)将 RLHF、DPO 和 KTO 统一为一个监督学习问题。UNA 的创新体现在以下几个方面:
- 推导通用的隐式奖励函数:UNA 通过使用 RLHF 的目标函数推导出一个通用的隐式奖励函数。
- 简化 RLHF 的流程:UNA 将传统 RLHF 中不稳定且资源密集的强化学习过程转化为一个稳定的监督学习过程,减少了训练的不稳定性和对内存的需求。
- 多种反馈数据的支持:UNA 能够处理不同类型的反馈数据,包括成对反馈(pairwise feedback)、二元反馈(binary feedback)以及基于评分的反馈(score-based feedback)。

- 监督学习框架的统一性:UNA 通过最小化隐式奖励和显式奖励之间的差异,统一了对策略模型的优化。

UNA 的理论基础
UNA 的理论基础源于对 RLHF 目标函数的重新推导。研究人员证明,给定 RLHF 的经典目标函数,最优策略可以通过一个隐式的奖励函数来诱导。该隐式奖励函数是策略模型与参考策略之间的对比结果,通过这个函数,UNA 能够将不同类型的奖励信息整合到统一的框架中进行处理。

实验结果与性能表现
研究人员通过一系列实验验证了 UNA 的有效性和优越性。在多个下游任务中,UNA 相较于传统的 RLHF、DPO 和 KTO 都有显著的性能提升,特别是在训练速度、内存占用和任务表现等方面。以下是实验结果的主要亮点:
- 任务表现:在多个语言理解任务和生成任务中,UNA 的表现优于 RLHF 和 DPO。例如,在 Huggingface 的 Open LLM Leadboard 数据集上的测试中,UNA 在多个评价指标上超越了 RLHF 和 DPO,表现出了更强的对齐能力和任务适应性。
- 训练速度:由于 UNA 将 RLHF 中的强化学习任务转化为一个监督学习问题,其训练速度提高了近一倍。
- 内存占用:UNA 的内存消耗显著低于 RLHF。由于 UNA 不再需要维护多个模型(如策略模型、参考策略、奖励模型和价值模型),其内存占用大幅减少,尤其在处理大规模模型时,这种优势尤为明显。


总结
UNA 的提出标志着大规模语言模型对齐技术的一个重要进展。通过统一 RLHF、DPO 和 KTO,UNA 不仅简化了模型的训练流程,还提高了训练的稳定性和效率。其通用的隐式奖励函数为模型的对齐提供了一个统一的框架,使得 UNA 在处理多样化反馈数据时具有更强的适应性和灵活性。实验结果表明,UNA 在多个下游任务中表现优越,为语言模型的实际应用提供了新的可能性。未来,随着 UNA 的进一步发展,预期它将在更多的应用场景中展现出强大的能力。
#Differential Transformer
差分Transformer竟能消除注意力噪声,犹如降噪耳机
Transformer 的强大实力已经在诸多大型语言模型(LLM)上得到了证明,但该架构远非完美,也有很多研究者致力于改进这一架构,比如曾报道过的 Reformer 和 Infini-Transformer。
今天我们又将介绍另一种新型 Transformer 架构:Differential Transformer(差分 Transformer,简称 Diff Transformer)。该架构来自微软研究院和清华大学,有四位共一作者:Tianzhu Ye、Li Dong、Yuqing Xia、Yutao Sun。
- 论文标题:Differential Transformer
- 论文地址:https://arxiv.org/pdf/2410.05258
在 Hacker News 及 Twitter 等社交网络上,该论文都反响热烈,有网友表示差分 Transformer 提出的改进简单又美丽,而带来的提升又非常显著。
甚至已有开发者做出了差分 Transformer 的轻量实现!
那么差分 Transformer 弥补了原生 Transformer 的哪些问题呢?如下图所示,Transformer 往往会过度关注不相关的上下文,该团队将此称为注意力噪声(attention noise)。而差分 Transformer 则能放大对答案范围的注意力并消除噪音,从而增强上下文建模的能力。这就要用到该团队新提出的差分注意力机制(differential attention mechanism)了。

差分注意力机制可以消除注意力噪声,鼓励模型重点关注关键信息。该方法有些类似于电气工程中的降噪耳机和差分放大器。
下面我们就来详细了解一下差分 Transformer 的设计思路。
差分 Transformer
差分 Transformer 是一种用于序列建模的基础模型架构。为了方便说明,他们使用了仅解码器(decoder-only)模型作为示例来描述该架构。
该模型堆叠了 L 个 Diff Transformer 层。给定一个输入序列 x,将输入嵌入打包成 X^0。输入会被进一步上下文化来获得输出 X^L。每一层都由两个模块组成:一个差分注意力模块和之后的前向网络模块。
相比于 Transformer,差分 Transformer 的主要差别在于使用差分注意力替换了传统的 softmax 注意力,同时保持整体宏观布局不变。此外,他们也参考 LLaMA 采用了 pre-RMSNorm 和 SwiGLU 这两项改进措施。
差分注意力
差分注意力机制的作用是将查询、键和值向量映射成输出。这里使用查询和键向量来计算注意力分数,然后计算值向量的加权和。
此处的关键设计是使用一对 softmax 函数来消除注意力分数的噪声。具体来说,给定输入 X,首先将它们投射成查询、键和值 Q_1、Q_2、K_1、K_2、V。然后差分注意力算子 DiffAttn (・) 通过以下方式计算输出:

其中 W^Q、W^K 、W^V 是参数,λ 是可学习的标量。为了同步学习动态,将标量 λ 重新参数化为:
![]()
其中 λ_q1、λ_k1、λ_q2、λ_k2 是可学习的向量,λ_init ∈ (0, 1) 是用于初始化 λ 的常数。该团队通过经验发现,设置 λ_init = 0.8 − 0.6 × exp (−0.3・(l − 1)) 在实践中效果很好,其中 l ∈ [1, L] 表示层索引。它在实验中被用作默认策略。
他们也探索了另一种初始化策略:对所有层使用相同的 λ_init(例如 0.8)。如后面消融研究所示,使用不同的初始化策略时,性能相对稳健。
差分注意力利用两个 softmax 注意力函数之间的差来消除注意力噪声。这个想法类似于电气工程中提出的差分放大器,其中两个信号之间的差用作输出,这样就可以消除输入的共模噪声。此外,降噪耳机的设计也基于类似的想法。
- 多头差分注意力机制
该团队也为差分注意力使用了多头机制。令 h 表示注意力头的数量。他们对各个头使用不同的投影矩阵 W^Q_i 、W^K_i 、W^V_i ,i ∈ [1, h]。标量 λ 在同一层内的头之间共享。然后对头输出执行归一化,并投射成最终结果,如下所示:

其中 λ_init 是 (2) 式中的常数标量,W^O 是可学习的投影矩阵,LN (・) 是对每个头使用 RMSNorm,Concat (・) 的作用是沿通道维度将头连接在一起。这里使用一个固定乘数(1 − λ_init)作为 LN (・) 的缩放尺度,以使梯度与 Transformer 对齐。
- 逐头归一化
图 2 使用了 GroupNorm (・) 来强调 LN (・) 独立应用于每个 head。由于差分注意力往往具有更稀疏的模式,因此头之间的统计信息更加多样化。为了改进梯度的统计情况,LN (・) 算子会在连接操作之前对每个头进行归一化。

整体架构
其整体架构会堆叠 L 层,其中每层包含一个多头差分注意力模块和一个前向网络模块。如此,便可将差分 Transformer 层描述为:

其中 LN (・) 是 RMSNorm,SwiGLU (X) = (swish (XW^G) ⊙ XW_1) W_2,且 W^G、W_1、W_2 是可学习的矩阵。
实验
该团队从以下角度评估了差分 Transformer 在 LLM 中的应用,包括对比评估、应用评估和消融研究。这里我们仅关注实验结果,更多实验过程请访问原论文。
语言建模评估
该团队评估了差分 Transformer 的语言建模能力。为此,他们使用 1T token 训练了一个 3B 大小的差分 Transformer 语言模型,并与之前的 Transformer 语言模型做了比较。
结果见表 1,其中报告的是在 LM Eval Harness 基准上的零样本结果。

可以看到,3B 规模下,差分 Transformer 语言模型的表现优于之前的 Transformer 语言模型。此外,实验也表明差分 Transformer 在多种任务上都胜过 Transformer,详见原论文附录。
与 Transformer 的可扩展性比较
该团队也比较了新旧 Transformer 的可扩展性。结果见图 3,其中 a 比较了模型规模方面的可扩展性,而 b 则是训练 token 数量方面的可扩展性。

可以看到,在这两个方面,差分 Transformer 的可扩展性均优于常规 Transformer:仅需后者 65% 左右的模型大小或训练 token 数量就能达到相媲美的性能。
长上下文评估
当 3B 模型上下文长度增长至 64K,模型的表现又如何呢?又使用另外 1.5B token 训练了 3B 版本的检查点模型之后,该团队发现随着上下文长度的增加,累积平均负对数似然(NLL)持续下降。差分 Transformer 得到的 NLL 值低于常规 Transformer。见图 4,这样的结果表明,差分 Transformer 可以有效地利用不断增加的上下文。

关键信息检索
为了检验差分 Transformer 检索关键信息的能力,该团队执行了 Needle-In-A-Haystack(草堆找针)测试。
表 2 给出了 4K 上下文长度的情况,其中 N 是针的数量,R 是查询引用的数量。可以看到,差分 Transformer 的多针检索准确度高于常规 Transformer,尤其是当针数量较多时,差分 Transformer 的优势会更加明显。

那么当上下文长度提升至 64K 时,又会如何呢?结果见图 5,这里使用的上下文长度在 8K 到 64K 之间,使用了 N = 8 和 R = 1 的设置。

可以看到,在不同的上下文长度下,差分 Transformer 能够保持相对稳定的性能。而当上下文长度越来越大时,常规 Transformer 的性能会逐渐下降。
另外,表 3 展示了分配给关键信息检索任务的答案范围和噪声上下文的注意力分数。该分数可代表模型保留有用信息、抵抗注意力噪声的能力。

可以看到,相比于常规 Transformer,差分 Transformer 能为答案范围分配更高的注意力分数,同时为注意力噪声分配更低的注意力分数。
上下文学习能力评估
该团队从两个角度评估模型的上下文学习能力,包括多样本分类和上下文学习的稳健性。
图 6 展示了新旧 Transformer 模型的多样本分类结果。结果表明,在不同的数据集和不同的演示样本数量上,差分 Transformer 均稳定地优于 Transformer。此外,差分 Transformer 的平均准确度优势也很明显,从 5.2% 到 21.6% 不等。

图 7 则展示了两种模型的上下文学习稳健性结果。该分析基于 TREC 数据集,并且采用了两种提示词格式:示例随机排列(图 7a)和按类别交替排列(图 7b)。

在这两种设置下,差分 Transformer 的性能方差要小得多。结果表明,新方法在上下文学习任务中更为稳健。相比之下,Transformer 容易受到顺序排列的影响,导致最佳结果与最差结果之间差距巨大。
上下文幻觉评估
该团队基于文本摘要和问答任务评估了模型的上下文幻觉现象。结果见表 4。

可以看到,相比于常规 Transformer,差分 Transformer 在摘要和问答任务上的上下文幻觉更低。该团队表示,原因可能是差分 Transformer 能更好地关注任务所需的基本信息,而不是无关上下文。
激活异常值分析
在 LLM 中,一部分激活值明显大于大多数激活值的现象被称为激活异常值(activation outliers)。异常值导致训练和推理过程中模型量化困难。实验表明差分 Transformer 可以降低激活异常值的幅度,从而可能实现更低的量化位宽。
表 5 展示了两个训练得到 Transformer 和差分 Transformer 模型的激活值统计情况。这里分析了两种类型的激活,包括注意力 logit(即 pre-softmax 激活)和隐藏状态(即层输出)。可以看到,尽管中位数相似,但与 Transformer 相比,差分 Transformer 的较大激活值要低得多。这表明新方法产生的激活异常值较少。

图 8 则展示了将注意力 logit 量化到更低位的情况。这里使用的方案是:使用 absmax 量化的动态后训练量化。其中,16 位配置表示未经量化的原始结果。模型逐步量化为 8 位、6 位和 4 位。这里报告的是在 HellaSwag 上的零样本准确度,但该团队也指出在其它数据集上也有类似表现。

从图中可知,即使降低位宽,差分 Transformer 也能保持较高性能。相较之下,常规 Transformer 的准确度在 6 位和 4 位量化时会显著下降。这一结果表明,差分 Transformer 本身就能缓解注意力分数中的激活异常值问题,从而可为低位 FlashAttention 的实现提供新机会。
最后,该团队也进行了消融实验,证明了各个新设计的有效性。
#GR-2
ByteDance Research提出机器人大模型,具备世界建模和强大泛化能力
最近,ByteDance Research 的第二代机器人大模型 —— GR-2,终于放出了官宣视频和技术报告。GR-2 以其卓越的泛化能力和多任务通用性,预示着机器人大模型技术将爆发出巨大潜力和无限可能。
GR-2 官方项目页面:
https://gr2-manipulation.github.io
初识 GR-2:百炼出真金
和许多大模型一样,GR-2 的训练包括预训练和微调两个过程。
如果把机器人和人做比较,预训练过程就好像是人类的 “婴儿期”。而 GR-2 的婴儿期与其他机器人截然不同。
在预训练的过程中,GR-2 在互联网的海洋中遨游。
它在 3800 万个互联网视频片段上进行生成式训练,也因此得名 GR-2(Generative Robot 2.0)。这些视频来自学术公开数据集,涵盖了人类在不同场景下(家庭、户外、办公室等)的各种日常活动。

这个过程,就像是它在经历一个快速的 “生长痛”,迅速学会了人类日常生活中的各种动态和行为模式。

该图展示了 GR-2 预训练数据中的样本视频和动词分布。下图中的 y 轴是最热门单词的对数频率。
这种预训练方式使 GR-2 具备了学习多种操作任务和在多种环境中泛化的潜能。庞大的知识储备,让 GR-2 拥有了对世界的深刻理解,仿佛它已经环游世界无数次。
微调的艺术:视频生成能力拔高动作准确率
据悉,GR-2 的开发团队采用了一种创新的微调方法。
在经历大规模预训练后,通过在机器人轨迹数据上进行微调,GR-2 能够预测动作轨迹并生成视频。
GR-2 的视频生成能力,让它在动作预测方面有着天然的优势。它能够通过输入一帧图片和一句语言指令,预测未来的视频,进而生成相应的动作轨迹。
如下图所示,只需要输入一句语言指令:“pick up the fork from the left of the white plate”,就可以让 GR-2 生成动作和视频。可以看到,机械臂从白盘子旁边抓起了叉子。右图中预测的视频和真机的实际运行也相差无几。

以下是几个进一步展示 GR-2 视频生成能力的示例,包括把物品放进烤箱、将物品置于咖啡壶嘴下方等任务。
这种能力,不仅提升了 GR-2 动作预测的准确性,也为机器人的智能决策提供了新的方向。
Scaling Law:机器人 + 大模型的要诀
在人工智能领域,Scaling Law 是一个备受瞩目的概念。它描述了模型性能与其规模之间的关系。对于 GR-2 这样的机器人模型来说,这一法则尤为关键。
随着模型规模的增加,GR-2 的性能呈现出显著的提升。

(a)(b)(c) 分别展示了不同尺寸 GR-2 在 Ego4d、RT-1、GR-2 三个数据集的验证集上的视频生成损失。(d) 展示了不同尺寸 GR-2 在真机实验中的成功率。
在 7 亿参数规模的验证中,团队看到了令人鼓舞的结果:更大的模型不仅能够处理更多复杂的任务,而且在泛化到未见过的任务和场景时也表现得更加出色。
这表明,通过扩大模型规模,我们可以解锁机器人更多的潜能,使其在多任务学习和适应新环境方面更加得心应手。
多任务学习与泛化:未知场景的挑战者
在多任务学习测试中,GR-2 能够完成 105 项不同的桌面任务,平均成功率高达 97.7%。
GR-2 的强大之处不仅在于它能够处理已知任务,更在于其面对未知场景和物体时的泛化能力。无论是全新的环境、物体还是任务,GR-2 都能够迅速适应并找到解决问题的方法。

我开、我放……我眼里有活儿
更让人惊艳的是,GR-2 还能够与大语言模型相结合,完成复杂的长任务,并与人类进行互动。
比如,我们想要喝一杯咖啡。GR-2 会先从托盘里拿起杯子,并将其放在咖啡壶嘴下方。接着,它会按下咖啡机上的按钮来煮一杯咖啡。最后,当咖啡煮好了,机器人会把杯子放回托盘上。整个过程无需人类干预。

又如,我们早餐想要吃点东西。根据场景中的物体,机器人决定为我们制作一份烤面包。机器人首先按下烤面包机上的开关来烤制面包。然后它拿起烤好的面包,并将其放入红色的碗中。

认真工作中,勿扰
ByteDance Research 还想强调,GR-2 能够鲁棒地处理环境中的干扰,并通过适应变化的环境成功完成任务。
以果蔬分类任务为例:桌子上放置着水果和蔬菜,我们需要机器人帮忙将水果和蔬菜分装到不同的盘子里。机器人能够自主识别物体的类别,并自动将它们放入正确的盘子中。

当在机器人移动的过程中移动盘子,GR-2 依然能回过神来,准确找回它要放的目标盘子。

穿越“果”群,仍能找到你
工业应用中的突破:端到端的丝滑物体拣选
在实际应用中,GR-2 相比前一代的一个重大突破在于能够端到端地完成两个货箱之间的物体拣选。
这个任务要求机器人从一个货箱中逐个拿起物体,并将其放入旁边的货箱。看似简单,但在实际应用中,能够实现这个需求的多模态端到端模型却难得一见。

端到端拣选任务场景
如下图所示,GR-2 可以实现货箱之间丝滑且连续的物体拣选。

真 · 无情的拣选机器人
无论是透明物体、反光物体、柔软物体还是其他具有挑战性的物体,GR-2 均能准确抓取。这展现了其在工业领域和真实仓储场景的巨大潜力。

除了能够处理多达 100 余种不同的物体,例如螺丝刀、橡胶玩具、羽毛球,乃至一串葡萄和一根辣椒,GR-2 在未曾见过的场景和物体上也有着出色的表现。

拣选任务中的 122 个测试物品,其中只有 55 个物体参与训练。

GR-2 可以识别透明的、可变形的或反光的物体。
话分两头,尽管 GR-2 在互联网视频上接受了大规模的预训练,但也存在一些进步空间。例如,真实世界动作数据的规模和多样性仍然有限。
GR-2 的故事,是关于 AI 如何推动机器人发展的故事。它不仅仅是一个机器人大模型,更是一个能够学习和适应各种任务的智能体。我们有理由相信,GR-2 在实际应用中拥有巨大潜力。
GR-2 的旅程,才刚刚开始。
#Jürgen又站出来反对Hinton得诺奖
Nature也炮轰提名过程不透明
今年的诺贝尔物理学奖颁给了两位享誉盛名的 AI 研究者 John J. Hopfield 和 Geoffrey E. Hinton,这确实让很多人感到意外。
第一层疑问是:Hinton 和物理学有什么关系吗?
第二层疑问是:AI 科学家是如何提名物理学奖的?这程序合理吗?
连 GPT-4o 都不敢相信:
当然,更深层的质疑来自一些同赛道的 AI 科学家,比如挑战 Hinton 多年的 LSTM 之父 ——Jürgen Schmidhuber。
Jürgen Schmidhuber 又来了
在统计物理学中,Hopfield 模型成为最常研究的 Hamiltonians 学派之一,关于它的论文和书籍已有数万篇。这个想法为数百名物理学家进入神经科学和 AI 领域提供了切入点。
在计算机科学中,Hopfield 网络是促使 AI 寒冬(1974-1981 年)结束以及随后人工神经网络复兴的主要驱动思想。Hopfield 在 1982 年发表的论文标志着现代神经网络时代的开始。
但 Jürgen Schmidhuber 认为:「诺贝尔物理学奖授予了计算机科学领域的剽窃和错误归属,主要涉及 Amari 的 Hopfield 网络和玻尔兹曼机。」
在发表于 X 平台的小作文中,Jürgen Schmidhuber 洋洋洒洒列了四条依据,内容如下:
1、Lenz-Ising 神经元递归结构发表于 1925 年。1972 年,甘利俊一(Shun-Ichi Amari)使其具有自适应能力,通过改变连接权重,学会将输入模式与输出模式联系起来。不过,在「2024 年诺贝尔物理学奖的科学背景」中,Amari 只是被简单引用。遗憾的是,Amari 的网络后来被称为「Hopfield 网络」。Hopfield 在 10 年后重新发表了它,但没有引用 Amari,甚至在后来的论文中也没有引用。
2、Ackley、Hinton 和 Sejnowski 的相关玻尔兹曼机论文是关于神经网络隐藏单元内部表征的学习。它没有引用 Ivakhnenko 和 Lapa 提出的第一个内部表征深度学习算法,也没有引用 Amari 通过随机梯度下降(SGD)在深度 NN 中端到端学习内部表征的独立工作(1967-68 年)。甚至连作者后来的调查和「2024 年诺贝尔物理学奖的科学背景」都没有提到深度学习的这些起源。玻尔兹曼机也没有引用 Sherrington & Kirkpatrick 和 Glauber 之前的相关工作。
3、诺贝尔奖委员会还称赞了 Hinton 等人 2006 年提出的深度神经网络分层预训练方法(2006 年)。然而,这项工作既没有引用 Ivakhnenko 和 Lapa(1965 年)对深度神经元进行分层训练的原始方法,也没有引用对深度神经元进行无监督预训练的原始方法。
4、如「主流信息」所说:「在 20 世纪 60 年代末,一些令人沮丧的理论结果让许多研究人员怀疑这些神经网络永远不会有任何实际用途」。然而,深度学习研究在 20 世纪 60-70 年代显然是活跃的,尤其是在英国以外的地区。
Jürgen 还表示,关于剽窃和错误署名的更多案例,可参见以下参考文献,可以从第 3 节开始:
《3 位图灵奖获得者如何重新发表他们未能归功于创造者的关键方法和想法》https://people.idsia.ch/~juergen/ai-priority-disputes.html
有关该领域的历史,请参阅以下参考文献:
《现代人工智能和深度学习的注释历史》
https://people.idsia.ch/~juergen/deep-learning-history.html
但情况真的如 Jürgen 所说吗?至少一些网友已经指出了表述中的问题:
「在机器学习中,那些无法真正证明其想法可行的想法论文比比皆是,而且往往不会被广泛阅读或采用。除此之外,我们实际上并没有一个统一的理论,因此不同的阵营使用完全不同的术语,直到你真正深入研究它,你才会意识到独立创建的各种模型之间存在数学等价性。」
维基百科词条中,关于 Hopfield 网络的简介如下:
第二个要添加的组成部分是对刺激的适应。中野薰(Kaoru Nakano)于 1971 年和甘利俊一(Shun'ichi Amari)于 1972 年分别对此进行了描述,他们提出通过 Hebbian 学习规则修改 Ising 模型的权重,使其成为联想记忆模型。William A. Little 于 1974 年发表了同样的想法,Hopfield 在 1982 年的论文中对他表示了感谢。
基本上,有 3 个不同的人想到使用 Hebbian 学习进行联想记忆。因此 Hopfield 将这个想法归功于他所知道的人,尽管看起来 Amari 更早(或许 Nakano 甚至比 Amari 还早)。
还有网友说,玻尔兹曼机论文并没有使用反向传播、Hebbian 学习或 Schmidhuber 认为没被引用的任何方法。这篇论文本身并没有说它发明了第一个学习算法,只是说它发现了一种可以产生有用且有趣的中间表示的学习算法。
而 Hinton 早就在几年前解释过 Jürgen Schmidhuber 指出的问题,并表示「从此不会再做出任何回应」。
与 Schmidhuber 就学术信用问题进行公开辩论并不可取,因为这只会助长他的气焰,而且他会不惜花费大量时间和精力来诋毁他所认为的对手。他甚至不惜使用维基百科中的多重别名等伎俩,让别人看起来似乎同意他的说法。他网站上关于艾伦・图灵的页面就是一个很好的例子,说明他是如何试图削弱其他人的贡献的。
尽管我有最好的判断力,但我觉得我不能完全不回答他的指控,所以我只回应一次。我从未声称反向传播是我发明的。David Rumelhart 是在其他领域的人发明反向传播很久之后才独立发明它的。的确,当我们第一次发表论文时,我们并不了解这段历史,所以我们没有引用之前的发明者。我所声称的是,是我清楚地证明了反向传播可以学习有趣的内部表征,而这正是它广受欢迎的原因。我是通过强迫神经网络学习单词的向量表征来做到这一点的,这样它就能根据前一个单词的向量表征来预测序列中的下一个单词。正是这个例子说服了《自然》杂志的审稿人发表了 1986 年的论文。
的确,媒体上有很多人说我发明了反向传播,我也花了很多时间来纠正他们。以下是 Michael Ford2018 年出版的《智能架构师》(Architects of Intelligence)一书的节选:
在 David Rumelhart 之前,很多不同的人发明了不同版本的反向传播。他们主要是独立的发明,我觉得我的功劳太大了。我在媒体上看到有人说是我发明了反向传播,这完全是错误的。这是一个罕见的例子,一个学者觉得他在某件事情上获得了太多的荣誉!我的主要贡献是展示了如何使用它来学习分布式表征,所以我想澄清这一点。
也许 Jürgen 想澄清是谁发明了 LSTM?
Nature:诺奖的提名过程必须更加公开透明
在诺贝尔奖的物理学奖和化学奖分别颁发给 AI 之后,大家开始怀疑:莫非今年的诺贝尔文学奖要颁给 ChatGPT?
面对诺贝尔奖评选结果的多重「意外」,顶刊也是早有预料了。
前两天,Nature 杂志就发表了一篇社论,炮轰诺贝尔奖在全球范围内代表性不足,提名过程必须更加公开透明。
类似于 AI 的推理过程还是个「黑盒」,诺贝尔奖的评选过程也是一个有点像「黑盒」的机制,提名人和被提名人名单在评奖结果公布之前必然严格保密,被提名名单更是要保密 50 年。因此,诺贝尔奖评选的具体细节,我们无从得知。
为了预测下一年的诺贝尔奖得主,人们只能从往年的获奖者中寻找规律。于是,一直有传言称,诺贝尔文学奖的评选存在一个不成文的规定,即来自五大洲的作家轮流获奖。
与此相对照的是,负责评选诺贝尔奖的组织表示过,他们正在积极努力提升诺贝尔奖得主的多样性,并且已经取得了显著进展。整个 20 世纪,诺贝尔化学奖、物理学奖以及生理学或医学奖仅有 11 次被授予女性;而在 2000 年至 2023 年间,这个数字就提升到了 15 次。

1910 年 - 2020 年女性获得诺贝尔奖的数量变化
虽然性别的多样性取得了可喜的进展,但大家似乎已经习惯了科学界权力和资金分配在全球范围内的不均衡,往往忽视了这一点。在诺贝尔奖的历史中,只有 10 位获奖者出生于目前被世界银行归类为中低收入以下的国家,并且他们中的绝大多数在获奖时已经移居北美或欧洲。
正如《TWAS at 20(第三世界科学院 20 年)》这本书中所写,四十年前,许多非发达地区的科学家面临着艰难的选择:「背弃你的家乡,专注于职业生涯;或者留在家里,献祭你的职业生涯。」
在更隐秘的角落,诺贝尔奖之上还笼罩着一层巨大而无形的「人情网」。Nature 的调查显示,无论看起来有多离谱,几乎所有诺贝尔奖得主都存在某种联系。令人惊讶的是,获得科学类以及经济学奖项中的 736 位得主,其中有 702 位属于同一个学术家族 —— 他们通过学术关系在历史的某个节点彼此相连。

这可能与诺贝尔奖提名采用邀请制有关。根据诺贝尔基金会章程,历届诺贝尔奖得主、瑞典、丹麦、芬兰、冰岛和挪威的大学教授、瑞典皇家科学院成员以及相关诺贝尔奖评审委员会成员可以无需许可,直接提名候选人。其他有资格参与评奖的人则必须获得官方邀请函,才能提名入围名单。
提名过程分为两个阶段:首先高级领导、院长和教授们收到诺奖官方的信件;然后,被这些被选中的科学家们按照标准进行提名。来自斯德哥尔摩大学的 Peter Brzezinski 对 Nature 表示,瑞典皇家科学院今年联系了大约 1250 所大学。但由于人力有限,平均每五年,每所大学只会收到一次邀请。
这种情况可能是诺贝尔在设立奖项时未曾预见的。诺贝尔奖的评选历史已接近 120 年,当初科学研究还是个小众领域。20 世纪初,全世界的物理学家大约只有 1000 人,而如今广义上的物理学家已多达数百万。
诺贝尔奖的揭晓再次激起了世人对科学与技术的热情,但如何在当今科技日新月异的时代设立一个更加全面和包容的评奖机制,确实也是不容忽视的重要议题。
#Gradio5
开源软件Gradio上新5大功能,几行Python代码,构建Web应用程序
用最简单的方法来构建一个AI Web应用程序。
Gradio 5 来了!
刚刚,Gradio 官方表示经过几个月的努力,他们宣布 Gradio 5 稳定版本正式发布!
- 快速入门:https://www.gradio.app/guides/quickstart
- 项目地址:https://github.com/huggingface/blog/blob/main/gradio-5.md
Gradio 是一个开源 Python 软件包,可让用户快速为机器学习模型、API 或任意 Python 函数构建 Demo 或 Web 应用程序。然后,用户可以使用 Gradio 的内置共享功能在几秒钟内通过公共链接分享 demo。无需 JavaScript、CSS 或 Web 托管经验!

更重要的是,只需几行 Python 代码即可完成上述演示。
这次开源的 Gradio 5 是由 Hugging Face 推出的,Hugging Face 于 2021 年收购了 Gradio 。据不完全统计,Gradio 每月拥有超过 200 万用户(在 Hugging Face Spaces 上有超过 47 万个应用),已成为构建、分享和使用机器学习应用的默认方式。
最新版本旨在弥补机器学习人员的专业知识和 Web 开发技能之间的差距。「机器学习开发人员对 Python 编程非常熟悉,但通常不太熟悉 Web 开发的具体细节,」Gradio 创始人 Abubakar Abid 表示。「Gradio 让开发人员只需几行 Python 代码即可构建高性能、可扩展的应用程序,这些应用程序是遵循安全性和可访问性方面的最佳实践。」
Gradio 5 最显著的特点之一是它注重企业级安全,Abid 也强调了这一点,他们还聘请了知名网络安全公司 Trail of Bits 对 Gradio 进行独立审计,并修复了他们在 Gradio 5 中发现的所有问题。对于 Gradio 开发人员来说,即使自己不是网络安全专家, Gradio 5 应用程序也是开箱即用,遵循网络安全方面的最佳实践。
不难看出,有了 Gradio 5,开发者可以构建生产级的机器学习 Web 应用程序,这些应用不仅性能优越、可扩展、设计精美、易于访问,而且还遵循了最佳的 Web 安全实践。
Gradio 5 五大新功能
想要体验 Gradio 5 的小伙伴,只需在终端输入以下命令即可:
pip install --upgrade gradio以下是 Gradio 5 中的 5 个新功能(包括一种无需编写代码即可构建 Gradio 应用的新方式!)
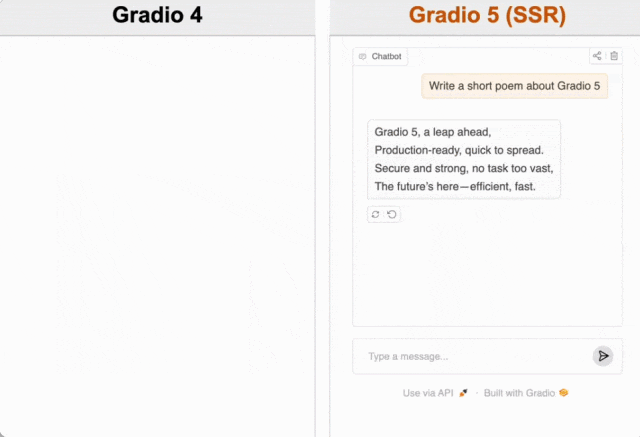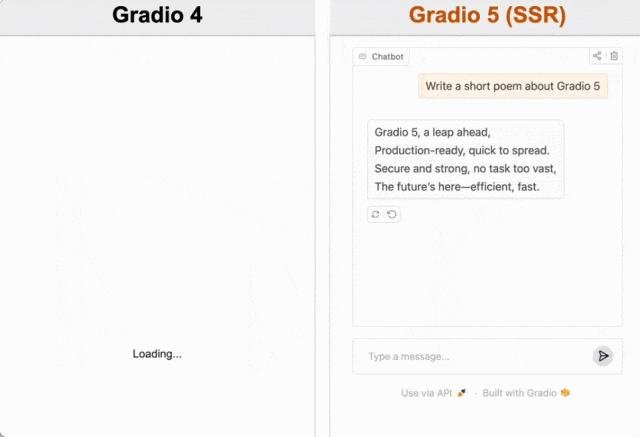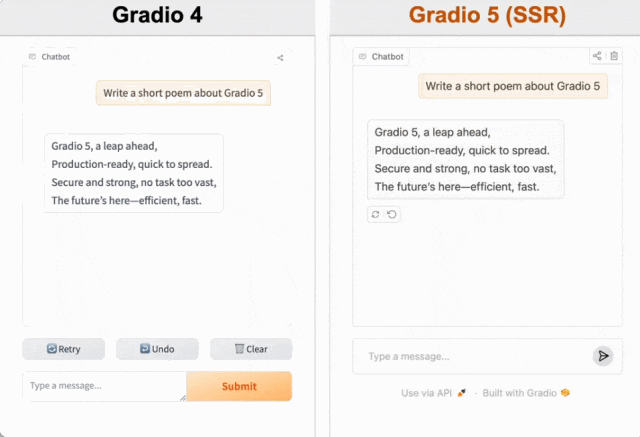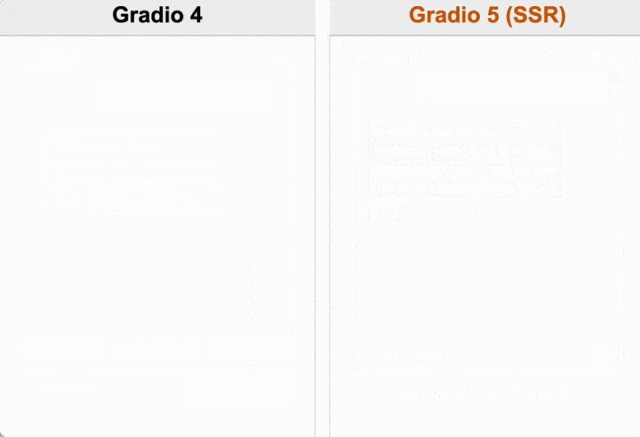
首先是加载速度。如果之前你使用过 Gradio ,给你的第一感觉可能就是加载过慢。现在 Gradio 5 有了重大的性能改进,包括通过服务器端渲染 (SSR) 提供应用程序,从而实现立即在浏览器中加载 Gradio ,不会再有加载时转圈圈的延迟。
其次是界面。此前,Gradio 应用看起来很老旧。现在 Gradio 5 更新了许多核心组件,包括按钮、选项卡、滑块以及高级聊天机器人界面。此外,官方还发布了一组新的内置主题,如「柑橘」和「海洋」主题,让用户轻松创建外观新颖的 Gradio 应用。


用户现在可以在 Gradio 中构建实时应用!Gradio 5 改变了流媒体的内部工作方式:现在使用 websockets 并通过 base64 编码发送数据,以减少延迟。Gradio 5 还通过自定义组件支持 WebRTC,并且还添加了更多文档和示例演示,这些文档和示例演示侧重于常见的流媒体用例,例如基于网络摄像头的对象检测、视频流、实时语音转录和生成以及对话聊天机器人。

安全性。Gradio 5 还在安全性方面做出了重大改进,包括获得 Gradio 的第三方审核。
LLM 的加持。Gradio 5 附带了一个实验性的 AI Playground,允许开发人员使用自然语言提示生成和预览 Gradio 应用程序。
Gradio 的一位负责人 Ahsen Khaliq 强调了此功能的重要性,他说:「与其他 AI 编程环境类似,用户可以输入文本提示,解释自己想要构建什么样的应用程序,然后 LLM 会将其转换为 Gradio 代码。但与其他编码环境不同的是,用户还可以查看 Gradio 应用程序的即时预览并在浏览器中运行它。」
,时长00:46
AI Playground 链接:https://www.gradio.app/playground
可以看出,随着人工智能继续影响各个行业,像 Gradio 5 这样将先进技术与实际业务应用相结合的工具可能会发挥重要作用。通过此版本,Hugging Face 不仅仅是更新了产品,它可能会改变企业人工智能开发的格局。
参考链接:
https://x.com/Gradio/status/1844142446185414718
#多智能体系统
CMU副教授:在多智能体流行的当下,不要忽视单智能体系统
单智能体更简单、更易于维护。
最近,「多智能体系统」是人工智能领域最热门的流行词之一,也是开源框架 MetaGPT 、 Autogen 等研究的焦点。
但是,多智能体系统就一定是完美的吗
近日,来自卡内基梅隆大学的副教授 Graham Neubig 在文章《Don't Sleep on Single-agent Systems》中强调了单智能体系统也不可忽视。
Graham Neubig 从以下几个方面展开:
- 当代 AI 智能体发展的元素,包括大语言模型、提示以及动作空间;
- 多智能体系统示例;
- 多智能体系统存在的问题;
- 如何从使用多个专门的智能体过渡到一个强大的智能体,以及一些需要解决的问题。
CMU 机器学习和计算机系助理教授陈天奇对这项研究进行了转发并评论:「这是一篇关于如何让单智能体系统更强大的深刻见解,对机器学习系统也有很好的启示。提示前缀缓存将成为与其他一般推理优化技术相互作用的一项关键技术」。
基于 LLM 的智能体
大多数智能体都是基于大语言模型构建的,如 Anthropic 的 Claude 或 OpenAI 的语言模型。但语言模型不足以构建一个出色的智能体,构建一个智能体至少需要三个组件:
- 大语言模型 LLM;
- 提示:可以是用于指定模型一般行为的系统提示,或者从智能体周围环境中提取的信息类型;
- 动作空间:上述两项是研究者提供给 LLM 的辅助工具,以便智能体在真实世界中产生动作。
一般来说,当涉及多智能体系统时,至少要改变这三个组成部分中的其中一个。
多智能体示例
假设你正在构建一名 AI 软件开发助手,这里作者以 CodeR 为例,这是一个用于 AI 软件开发的多智能体框架。它包括多个智能体,所有智能体都使用相同的底层 LM,但提示和动作空间各不相同:
- 管理器(Manager):该智能体的提示指定它应该为其他智能体编写一个规划来执行,以及输出规划的动作空间;
- 复现器(reproducer):该智能体有一个提示,告诉它重现该问题,以及一个将代码写入重现错误文件 reduce.py 的动作空间;
- 故障定位器(Fault Localizer):该智能体有一个提示,告诉它找到导致错误的文件,以及一个使用软件工程工具进行故障定位和列出文件以供以后使用的动作空间;
- 编辑器(Editor):该智能体有一个提示,用于接收复现器和故障定位器的结果,并有一个动作空间,允许它对文件进行编辑;
- 验证器(Verifier):此智能体具有提示,可接收其他智能体的结果,以及输出问题是否已解决的动作空间。
这是构建一个系统时所需要的结构,但是在构建这样的系统时存在一些困难。
多智能体系统存在的一些问题
在构建多智能体系统时,你可能会遇到许多问题,比如:
获得正确的结构:多智能体系统通过添加结构来解决问题。当智能体面临的问题与指定的结构完全匹配时,效果会很好,但问题是如果不匹配怎么办?
上下文信息的传递:多智能体系统通常在多个智能体之间传递信息,但这可能是信息丢失的原因。例如,如果故障定位器仅将其摘要信息传递给其他智能体,则通常会导致重要的上下文信息丢失,而这些信息可能对下游智能体有用。
可维护性:最后,这些智能体通常都有自己独立的代码库,或者至少有独立的提示。因此,多智能体系统可能拥有更大、更复杂的代码库。
有趣的是,很多这些挑战也适用于人类组织!我们都有过这样的经历:团队组织混乱,沟通不畅,或者当某个成员离开时,无法维持必要的技能。
如何打造出色的单智能体系统
人们为什么要打造多智能体系统?一个需要说明的重要原因是:专用于特定任务的智能体的表现通常很好,只要有合适的结构和工具,它们就能很好地完成相应的任务。
单智能体有能力竞争吗?
可能比我们预想的还更容易一些,作者表示这里已经有一个很好的原型:https://github.com/All-Hands-AI/OpenHands/tree/main/agenthub/codeact_agent
下面我们就来看看,要打造出优秀的单 LLM、单动作空间和单提示工程技术,需要些什么。
单 LLM:这是相对比较容易的部分。近段时间已经出现了一些表现出色的通用 LLM,包括 Claude 和 GPT-4o 等闭源模型以及 Llama 和 Qwen 等开源模型。虽说这些模型也不是万能的,但它们也确实能完成多种多样的任务。就算它们缺乏某个功能,也可以通过持续训练来增添,同时不会对其它功能产生太大影响。
单动作空间:这也不难。如果我们有多个使用不同工具的智能体,那么我们可以 (1) 为模型提供相对通用的工具,以帮助它们解决问题;(2) 如果不同的智能体有不同的工具组合,则可以将他们连接起来。比如,在 OpenHands 中,可以向智能体提供写代码、运行代码和执行网络浏览的工具。这样的通用方法可让模型使用为人类开发者开发的软件工具,从而增多它们的功能,做到其它多智能体能做到的事。
单提示工程技术:这是比较困难的地方!我们需要确保智能体在如何解决任务上获得正确的指示,同时从其环境中获得正确的信息。
下面给出了两个选择:
- 将所有提示词连接起来使用:如果我们有一个多智能体系统,要使用 10 个不同的提示词,那么为什么不将它们连接组合到一起呢?近期的长下文模型已经有能力处理多达几十万 token 了,比如 Cluade 能处理 20 万 token,而 Llama 是 12.8 万。OpenHands 也使用了此方法。但这种方法也有一些缺点。首先是成本,更长的提示词需要更多金钱和时间,不过现在有一些技术(比如 Anthropic 的提示词缓存技术)可以降低其成本。这种方法的另一个缺点是,如果提示词太多,则 LLM 可能无法关注到重点,但随着模型能力提升,LLM 在确定长上下文中的重要信息方面越来越强了。
- 检索增强式提示:另一种可能的选择是使用检索。如同检索增强式生成(RAG)系统一样,可以出于效率或准确度的目的对长上下文进行裁剪。在选择提供 LLM 的示例方面,这里有一些研究进展:https://arxiv.org/abs/2209.11755
总结
本文并不是说多智能体就没有用武之地了。比如在一个智能体可以访问专有信息,而另一个智能体则代表了另一个人的情况下,多智能体系统肯定大有作为!
本文的目的是批判性地思考让系统更加复杂这一趋势。有时候简单就是最好的 —— 有强大的模型、强大的工具和多种多样的提示词就足够了。
参考链接:https://www.all-hands.dev/blog/dont-sleep-on-single-agent-systems
#SparseLLM
突破性全局剪枝技术,大语言模型稀疏化革命
本篇工作已被NeurIPS(2024 Conference on Neural Information Processing Systems)会议接收,文章第一作者为美国埃默里大学的博士生白光霁,通讯作者为赵亮教授,来自埃默里大学计算机系。共同作者包括美国阿贡国家实验室的Yijiang Li和Kibaek Kim,以及埃默里大学的博士生凌辰。该研究主要探讨了大语言模型的全局剪枝方法,旨在提高预训练语言模型的效率。该成果的发表为大模型的剪枝与优化研究提供了新的视角,并在相关领域具有重要的应用潜力。
论文标题:SparseLLM: Towards Global Pruning of Pre-trained Language Models
论文链接:https://arxiv.org/abs/2402.17946
情景导入
随着大型语言模型(LLMs)如 GPT 和 LLaMA 在自然语言处理领域的突破,现如今的模型能够在各种复杂的语言任务中表现优异。然而,这些模型往往包含数十亿参数,导致计算资源的需求极为庞大。为了让LLMs在更多的实际应用中变得可行,研究人员进行了大量的模型压缩工作,其中包括剪枝、量化、知识蒸馏和低秩分解等方法。
剪枝作为一种重要的压缩策略,通过引入稀疏性提升了内存和计算效率。尽管剪枝的有效性已在视觉任务和较小规模的语言模型中得到验证,但全局剪枝由于需要将整个模型加载到同一个GPU中,对于如今的大规模LLMs而言是不现实的。因此,近年来出现了局部剪枝方法比如SparseGPT和Wanda,尽管这些方法简单粗暴地局部化每个layer的剪枝,从而在效率上有了提升,但局部剪枝带来的效果往往是次优 (suboptimal) 的。
我们提出的 SparseLLM 框架,通过将全局剪枝问题分解为更易管理的子问题,从而在高稀疏度下也能实现高效的优化和优异的性能。SparseLLM 在实现了内存和计算效率的同时,超越了当前最先进的剪枝方法,为LLMs的压缩和应用树立了新的标杆。

Figure 1: 此图展示了全局剪枝、局部剪枝与我们提出的 SparseLLM 框架的对比。全局剪枝(左):由于需要将整个模型加载到同一GPU中,内存消耗过大,难以适用于大规模LLMs。局部剪枝(中):只考虑每一层的局部误差,尽管内存需求较低,但会导致次优的全局性能。SparseLLM(右):通过引入辅助输入和输出,将全局剪枝问题分解为可管理的子问题,实现低内存开销下的全局剪枝,保持全局最优性能。
现有方法及其缺陷
在模型剪枝中,剪枝方法主要分为两大类:全局剪枝(Global Pruning)和局部剪枝(Local Pruning)。
全局剪枝
全局剪枝旨在对整个模型应用统一的稀疏化掩码(sparsity mask),以最小化未压缩模型与压缩模型之间的全局损失。虽然理论上全局剪枝可以为模型提供最优的性能,尤其是在高稀疏度情况下,但它的主要缺点在于其内存开销巨大。为了实现全局剪枝,整个模型必须被加载到同一个GPU中,这对于如今规模巨大的LLMs(如GPT和LLaMA)来说是不现实的。
局部剪枝
为了规避全局剪枝的内存瓶颈,局部剪枝通过将模型压缩分解为每一层的子问题来减少内存消耗。局部剪枝的方法通常会对每一层的输出进行独立的稀疏化,并构造局部损失来衡量未压缩和压缩层之间的差异。虽然局部剪枝方法在资源使用方面更加高效,但由于它只关注每一层的局部最优解,导致了全局上次优的模型性能,尤其是在高稀疏度下表现尤为显著。
方法缺陷
局部剪枝的局限性在于它无法很好地捕捉模型层之间的相互依赖关系,只针对各层的稀疏化进行优化。这种过度约束每层激活值的行为,容易导致全局性能的下降。因此,尽管局部剪枝在某些情况下能带来效率提升,但它往往无法达到全局剪枝所能带来的最优性能。
技术方法
在SparseLLM框架中,我们的目标是实现全局剪枝。SparseLLM通过将全局剪枝目标分解为多个子问题,每个子问题可以使用较少的资源解决,并且可以协同实现全局剪枝目标。SparseLLM的优势在于它能够在内存消耗较低的情况下实现全局剪枝。
动机
SparseLLM的开发基于以下观察:LLMs可以被表述为一个复合函数,后一个模块的输出是下一个模块的输入。这使得可以通过辅助变量将全局剪枝目标重新表述为等价形式,从而将其分解为多个子问题。然后,开发了一种高效的算法,通过交替优化每个子问题来实现全局最优解。
剪枝问题的重新表述
我们通过对模型的稠密线性部分和非线性部分进行解耦,重新表述了剪枝问题。将每一层的输出存储为一个新变量 ,非线性层的输出则表示为激活值 。接着,我们优化以下目标函数:
其中约束条件为:
这里 表示模型的总层数, 表示需要剪枝的层集合, 和 分别代表原始预训练模型的中间变量值。 是模型的最终输出结果 。
Remark:
这个公式具有高度的通用性和灵活性。当 时,解决该问题等同于全局剪枝。而当 时,问题简化为局部剪枝,独立地考虑每一层。通过调节 的大小,我们可以在全局和局部剪枝之间无缝切换。
SparseLLM优化过程
原始的全局剪枝问题包含全局约束条件,为了避免直接求解带约束的目标函数,我们引入了辅助变量和惩罚函数。通过引入 惩罚项,原始的全局目标函数被转化为无约束问题,具体表达如下:
其中, 和 是超参数。这样,我们将每一层的剪枝问题解耦为局部子问题,同时保留了层之间的依赖性。
SparseLLM算法的关键在于上面公式中的的灵活性,目的是在完全全局剪枝(会导致内存瓶颈)和完全局部剪枝(会导致次优性能)之间找到更好的折中。粗暴地对所有层进行全局剪枝是不现实的。最近的研究表明,前馈网络 (FFN) 模块在每个解码器层中的参数占LLM总参数的三分之二以上。因此,SparseLLM优先对FFN模块进行全局剪枝,同时仍然遵循对多头注意力模块 (MHA) 的局部剪枝策略(见Figure 2)。这种策略在剪枝大规模模型的计算可行性与剪枝过程的有效性之间取得了平衡,并遵循了现有LLM剪枝框架的限制和实践。
具体而言,SparseLLM将设置为,其中表示每个解码器层FFN模块中线性层的索引集(具体数学细节详见论文)。也就是说,同一个FFN模块中的线性层被全局剪枝,而剩下的线性层仍按照局部剪枝。对于每一层的FFN模块,我们的目标是最小化以下无约束的目标函数:
此时,每一层的剪枝问题被表述为线性投影模块(上投影和下投影)的优化问题,并且可以针对每一个子问题进行交替优化。这一过程通过引入辅助变量和惩罚函数,使得我们能够在不消耗过多内存的前提下,求解全局最优解。

Figure 2: 该图展示了 SparseLLM 框架在不同LLM架构中的工作原理。左侧描绘了在 OPT模型中的剪枝流程。SparseLLM通过引入辅助变量,将全局剪枝问题分解为可管理的子问题,利用线性层的上下投影模块(Up Proj 和 Down Proj)以及ReLU激活函数来实现模型压缩。右侧描绘了在 LLaMA模型 中的剪枝流程。此处,SparseLLM除了使用线性层的上下投影外,还利用了SiLU激活函数与Gate Proj模块来实现更复杂的剪枝操作。图中标注了剪枝层(蓝色)、辅助变量(绿色)和预训练模型的固定输入/输出(粉色),以帮助理解各模块在剪枝过程中的相互关系与作用。
OPT 模型中的子问题求解
在 OPT 模型中,我们的目标是对每一层的FFN模块进行全局剪枝。根据公式5,我们首先考虑交替优化子问题,对于每一个子问题的闭式解,我们分以下步骤进行:
- 剪枝权重的优化:首先,我们固定其他变量,优化权重 和 。具体来说,优化目标是最小化以下表达式:为了求解该问题,我们首先对 进行分解:,其中 ( 表示伪逆)。通过将分解后的 带入原始损失函数中,可以得到权重剪枝问题的闭式解,类似于 SparseGPT 等剪枝方法。
- 激活值的更新:对于激活值 的优化,这是一个类似于权重剪枝的简单最小二乘问题。激活值 的更新可以通过如下公式求解:
- 输出 的更新:对于输出 ,我们最小化以下非凸的损失函数:由于ReLU函数的逐元素操作,问题可以通过简单的if-then逻辑分为两种情况:,以及 。
LLaMA 模型中的子问题求解
在LLaMA模型中,我们的剪枝过程与OPT模型类似,唯一不同的是LLaMA模型中包含额外的门控投影层,并使用了SiLU激活函数。我们针对LLaMA的各层子问题进行如下求解:
- 剪枝权重的优化:对于LLaMA模型中的FFN模块,权重剪枝的优化过程与OPT模型类似。我们通过最小化以下表达式来优化权重:并使用类似于OPT模型的分解方法求解。
- 激活值 的更新:在LLaMA模型中,我们使用SiLU激活函数,因此激活值的更新公式如下:
- 输出 的更新:对于LLaMA模型中的输出 ,我们最小化以下损失函数:通过类似的数学操作,我们可以求得 的解析解为:
- 门控投影输出 的更新:对于门控投影层的 ,我们通过最小化以下表达式来更新:由于SiLU函数的非凸特性,问题可以通过查找预先计算好的解决方案的查找表来快速求解。
通过上述过程,SparseLLM能够在LLaMA和OPT两种模型架构中实现高效的全局剪枝,最大化压缩效果的同时,保持模型的全局性能。
实验部分
实验设置
为了验证 SparseLLM 框架的有效性,我们在多个大规模语言模型上进行了广泛的实验。我们使用了 PyTorch 框架并结合 HuggingFace 的 Transformers 库来处理模型和数据集。所有剪枝实验均在 NVIDIA A100 GPU 上执行,以确保实验结果具备较好的可扩展性和适用性。
实验的数据集选取了 WikiText2 (WT2)、PTB(Penn Treebank),以及 C4 的验证集。这些数据集是语言模型压缩任务中的标准基准集,确保了结果的广泛适用性。为了保持公平性,我们在所有实验中使用了相同的数据子集,并确保剪枝过程为零样本设置,即不引入额外的训练数据,仅依赖于模型的预训练权重进行剪枝。
我们采用了模型的 困惑度(Perplexity) 作为评估指标,这是一种常用的衡量语言模型生成能力的指标。困惑度越低,模型的表现越好。所有剪枝后的模型均通过困惑度指标评估其在不同数据集上的性能,比较剪枝前后的性能变化以及不同稀疏度下的性能差异。
模型与剪枝策略
实验中,我们选择了两类主流的预训练语言模型进行剪枝实验:
- OPT 模型:我们针对不同规模的 OPT 模型(如 OPT-1.3b、OPT-2.7b 等)进行全局剪枝,评估 SparseLLM 在不同大小的模型上的效果。
- LLaMA 模型:我们也对 LLaMA 系列模型进行了实验,特别是 LLaMA-2 13b 模型,考察其在使用 SparseLLM 框架下的剪枝效果。
对于每一个模型,我们使用了不同的稀疏度设定,从 70% 到 90% 的非结构化稀疏度,以及 3:4 的半结构化稀疏度。在每个稀疏度水平下,我们测试了模型在各个基准数据集上的性能表现,以验证 SparseLLM 在不同稀疏度条件下的剪枝效果。
比较基线方法
为了全面评估 SparseLLM 的效果,我们与现有的几种剪枝方法进行了对比:
- 局部幅度剪枝:一种传统的剪枝方法,逐层根据权重幅度进行独立的局部剪枝,不考虑层间的依赖性。
- SparseGPT:一种最新的局部剪枝方法,专门针对预训练语言模型进行高效的权重剪枝,能够在高稀疏度条件下维持较好的性能。
- Wanda:另一种基于局部剪枝的方法,通过最小化剪枝后的模型输出误差,达到较好的压缩效果。
我们分别在不同稀疏度条件下与上述方法进行了对比,详细记录了各模型在不同数据集上的困惑度结果。
结果分析
剪枝效果分析
在不同稀疏度条件下,SparseLLM 在大多数情况下能够显著超过基线方法,特别是在高稀疏度(≥ 70%)的情况下,SparseLLM 能够维持较低的困惑度,甚至在一些任务中超越了未剪枝的模型。相比之下,局部幅度剪枝方法和 SparseGPT 的性能在稀疏度较高时下降明显,证明了全局剪枝方法在模型压缩中的优势。
此外,我们还分析了模型剪枝后的参数分布情况。SparseLLM 的剪枝策略能够有效地保持模型重要参数的位置不变,减少了剪枝过程中重要信息的丢失,这也解释了其在高稀疏度下性能优越的原因。

模型大小与性能权衡
我们进一步分析了不同大小模型在使用 SparseLLM 剪枝时的表现。实验表明,较大规模的模型在剪枝后的性能更为稳定,尤其是 LLaMA 13b 等大规模模型,即使在90%稀疏度下,困惑度的增幅也非常有限。这一结果表明,随着模型规模的增加,SparseLLM 能够更有效地在剪枝中找到最优的权重保留策略,降低剪枝对模型性能的负面影响。

Figure 3: Fast convergence of SparseLLM. Training loss per epoch for pruning layer 3 of OPT-125m at 80% sparsity (Left) and layer 6 of LlaMA-2 13b at 70% sparsity (Right).
收敛速度分析
除了剪枝性能,我们还对 SparseLLM 的收敛速度进行了分析。在实际训练过程中,SparseLLM 在最初的几个 epoch 内即可快速达到较低的训练损失,表明其剪枝过程非常高效。相比之下,其他局部剪枝方法在稀疏度较高时,需要更多的训练步骤才能收敛到类似的性能水平。这进一步证明了全局剪枝策略在保持模型性能的同时,能够有效减少训练时间和资源消耗。
不同任务的通用性
为了验证 SparseLLM 在零样本设置下的通用性,我们在多个零样本任务上测试了剪枝后的模型性能。实验结果表明,SparseLLM 在大多数任务上保持了优异的性能,特别是在涉及推理和生成任务时,SparseLLM 剪枝后的模型仍然能够生成高质量的文本输出,而其他基线方法的性能在高稀疏度下显著下降。

实验小结
实验结果表明,SparseLLM 框架能够在不同规模的预训练语言模型上实现高效的全局剪枝,同时保持良好的模型性能。无论是在较小的 OPT 模型上,还是在更大规模的 LLaMA 模型上,SparseLLM 均表现出色,特别是在高稀疏度的条件下表现尤为突出。此外,SparseLLM 的收敛速度和剪枝后的通用性也为其在实际应用中的高效性和适用性提供了强有力的支持。
结论
在本研究中,我们提出了 SparseLLM,一个针对大规模预训练语言模型的全局剪枝框架。通过引入辅助变量和局部子问题,我们成功解决了全局剪枝在计算和内存方面的瓶颈。实验结果表明,SparseLLM 能够在保持模型性能的同时,在高稀疏度下有效地压缩模型。与现有的剪枝方法相比,SparseLLM 在困惑度、稀疏度和通用性方面展现出了显著的优势,特别是在处理大型模型(如 LLaMA 和 OPT 系列)时,SparseLLM 的全局剪枝策略展现了更好的性能保持能力。
通过本研究,我们证明了全局剪枝在大规模语言模型中的潜力,不仅能够显著降低模型的计算和存储成本,还能在高稀疏度下维持优异的性能。这为实际应用中对资源敏感的任务提供了一个有效的解决方案。
未来研究方向
虽然 SparseLLM 取得了优异的结果,但仍有若干值得深入研究的方向:
- 动态剪枝策略的研究:当前的 SparseLLM 是基于静态的全局剪枝策略,即在训练前决定剪枝的层和稀疏度。未来可以探索动态剪枝策略,结合任务需求和模型训练过程,实时调整剪枝比例和剪枝区域,以进一步提升模型压缩效率。
- 稀疏性与硬件加速的结合:尽管 SparseLLM 能够大幅减少模型的计算和存储开销,但在实际部署中如何高效利用硬件加速器(如GPU、TPU)的稀疏性支持仍是一个开放问题。未来的工作可以研究如何更好地结合稀疏矩阵乘法和硬件加速技术,以实现更大的性能提升。
- 剪枝后的模型微调:尽管我们的实验已经展示了 SparseLLM 在高稀疏度下的性能保持能力,但剪枝后的模型是否可以通过微调进一步提升性能仍然值得探索。未来的研究可以结合剪枝和微调技术,探讨如何在稀疏化后进一步优化模型性能。
通过探索这些方向,SparseLLM 有望在大规模语言模型的压缩与高效推理中发挥更加广泛的作用,为各类NLP应用提供更多的支持与创新。
#The Super Weight in Large Language Models
大模型承重墙,去掉了就开始摆烂!苹果给出了「超级权重」
去掉一个「超权重」的影响,比去掉其他 7000 个离群值权重加起来还要严重。
大模型的参数量越来越大,越来越聪明,但它们也越来越奇怪了。
两年前,有研究者发现了一些古怪之处:在大模型中,有一小部分特别重要的特征(称之为「超权重」),它们虽然数量不多,但对模型的表现非常重要。
如果去掉这些「超权重」,模型就完全摆烂了,开始胡言乱语,文本都不会生成了。但是如果去掉其他一些不那么重要的特征,模型的表现只会受到一点点影响。

有趣的是,不同的大模型的「超权重」却出奇地相似,比如:
它们总是出现在

层中。
它们会放大输入 token 激活的离群值,这种现象研究者们称之为「超激活」(super activation)。无论输入什么提示词,「超激活」在整个模型中都以完全相同的幅度和位置持续存在。而这源于神经网络中的「跨层连接」。
它们还能减少模型对常用但不重要的词汇,比如「的」、「这」、「了」的注意力。
得到了这些发现,圣母大学和苹果的研究团队进一步对「超权重」进行了探索。
他们改进了 round-to-nearest quantization(RNQ)技术,提出了一种对算力特别友好的方法。

- 论文链接:https://arxiv.org/pdf/2411.07191
- 论文标题:The Super Weight in Large Language Models
这种新方法与 SmoothQuant 效果相当,在处理模型的权重时,可以用这种技术处理更大的数据块,让模型在变小的同时,还能保持很好的效果。
看来,苹果是真的把宝押在小模型身上了!
什么是「超权重」?
为了量化「超权重」对模型的影响有多大,研究团队修剪了所有的离群值权重,结果发现,去掉一个「超权重」的影响,比去掉其他 7000 个离群值权重加起来还要严重。

如何识别「超权重」?
虽然之前的研究者发现了「超权重」可以激活异常大的神经网络。该团队又把「超权重」和「超激活」之间的联系向前推进了一步。他们发现在降维投影之前,门控和上投影的 Hadamard 乘积产生了一个相对较大的激活,而「超权重」进一步放大了这个激活并创造了「超激活」。
而通过激活的峰值可以进一步定位「超权重」。基于此,研究团队提出了一种高效的方法:通过检测层间降维投影输入和输出分布中的峰值来定位「超权重」。
这种方法只需要输入一个提示词,非常简单方便,不再需要一组验证数据或具体示例了。
具体来说,假设存在降维投影权重矩阵

,其中 D 表示激活特征的维度,H 是中间隐藏层的维度。设

为输入矩阵,其中 L 表示序列长度。定义输出矩阵为

;「超激活」为

。如果 X_ik 和 W_jk 都是远大于其他值的异常值,那么 Y_ij 的值将主要由这两个异常值的乘积决定。
在这种情况下,j 和 k 是由 X_ik 和 Y_ij 的值决定的。因此,可以首先绘制出 mlp.down proj 层的输入和输出激活中的极端异常值。接着,如图 3 所示,确定超权重所在的层和坐标。
一旦检测到一个超权重,将其从模型中移除并重复上述过程,直到抑制住较大的最大激活值。
「超权重」的机制
- 「超权重」的影响
研究团队发现超级权重有两种主要影响:
- 引发「超激活」;
- 抑制了停用词(stopword)的生成概率。

为了探究「超权重」是完全通过「超激活」,还是也通过其他 token 来影响模型质量,研究团队设计了一个控制变量实验:
- 原始模型;
- 移除「超权重」,将其权重设置为 0;
- 移除「超权重」,但恢复神经网络层中的「超激活」。
实验结果如表 1 所示。恢复「超激活」后,模型的平均准确率从 35.14 恢复到 49.94,恢复「超激活」挽回了约 42% 的质量损失。

这表明,「超权重」对模型整体质量的影响并不完全由「超激活」所导致。
- 「超权重」对输出 token 概率分布的影响
「超权重」会影响输出 token 的概率分布。为此,该团队研究了「超权重」对 Lambaba 测试集的 500 个 prompt 的输出 token 概率分布有何影响。

实验表明,移除「超权重」后,停用词的生成概率显著放大。例如,对于 Llama-7B 模型,「the」的生成概率增加约 2 倍,「.」 增加约 5 倍,「,」 增加约 10 倍
为了更加深入地剖析,研究团队进行了案例研究:
- 输入 prompt 为:「Summer is hot. Winter is 」
- 下一个 token 应为「cold」,这是一个具有强语义的词。
含有「超权重」的原始模型能够以 81.4% 的高概率正确预测。然而,移除「超权重」后,模型预测的最多的词变成了停用词「the」,并且「the」的概率仅为 9.0%,大多数情况是在胡言乱语。
这表明,「超权重」对于模型正确且有信心地预测具有语义的词汇至关重要。
- 「超权重」的重要性
研究团队还分析了超级权重幅值变化对模型质量的影响,通过将超级权重按 0.0 到 3.0 的缩放因子放大。结果表明,适度放大幅值可以提升模型准确率,详见下图。

超离群值感知量化
量化是一种压缩模型和减少内存需求的强大技术。然而,无论是权重量化还是激活量化,异常值的存在都会大大降低量化质量。如前所述,研究者将这些有问题的异常值(包括超权值和超激活值)称为超异常值。
如上所示,这些超离群值对模型质量的重要性是不成比例的,因此在量化过程中保留它们至关重要。
量化一般是将连续值映射到一个有限的值集;这里考虑的是其中一种最简单的形式,即非对称轮至最近量化:

其中

是量化步长,N 是比特数。请注意,计算 ∆ 时使用的是最大值,因此 X 中的超离群值会大大增加步长。步长越大,离群值平均会被舍入到更远的值,从而增加量化误差。随着超离群值的增加,离群值被舍入到更少的离散值中,更多的量化 bin 未被使用。这样,超离群值就会导致量化保真度降低。
研究者特别考虑了硬件以半精度执行运算的情况,这意味着张量 X 在使用前会进行量化和去量化;在这种情况下,我们可以通过两种方法利用超离群值的先验知识。
首先,保留超离群值,防止对离群值量化产生不利影响。其次,在去量化后恢复超离群值,以确保超离群值的效果得以保留。
接下来将以两种形式对权重和激活采用这一观点。
激活量化
研究者使用值舍入量化技术进行实验,并做了一个小修改:用中值替换超激活(REPLACE),量化(Q)和去量化(Q-1)激活,然后在 FP16 中恢复超激活(RESTORE)。具体操作如下:

由于超激活是单个标量,因此对比特率和内核复杂度的影响不大。
权重量化
小规模分组会带来计算和比特率开销,需要其他技术来处理大量的半精度刻度和偏差。为了应对这一挑战,本文提出了一种简单的方法来改进 INT4 的大块量化。首先,识别超权重;其次,为了改善离群值拟合,对离群值权重进行剪切(CLIP),在这一步超权重也会被剪切,对剪切后的权重进行量化(Q)和去量化(Q-1);然后,为了确保保留超权重的效果,在去量化后恢复半精度超权重(RESTORE)。

如上公式,使用 z-score 对剪切进行参数化。假定所有权重都符合高斯分布,研究者认为所有 z 值超过某一阈值 z 的值都是离群值。为了调整超参数 z,研究者使用 Wikitext-2 训练集中的 500 个示例找到了最小重构误差 z-score。
实验
为了全面展示超权重的效果,研究者在 LLaMA 7B-30B、Mistral 7B 和 OLMo 上进行了实验。为了评估 LLM 的实际应用能力,他们评估了这些模型在 PIQA、ARC、HellaSwag、Lambada 和 Winogrande 等零样本基准上的精度。细节如下所示。
激活量化
表 3 比较了本文方法和 SmoothQuant。对于两个数据集上的三个 Llama 模型,本文方法比 SmoothQuant 的 naive 量化方法提高了 70%。在使用 Llama7B 的 C4 数据集和使用 Llama-30B 的 Wikitext 数据集上,本文改进幅度超过 SmoothQuant 的 80%。这意味着,与更复杂的方法相比,经过大幅简化的量化方法可以获得具有竞争力的结果。

随后,研究者扩大了评估范围,纳入了更多的 LLM:OLMo(1B 和 7B)、Mistral-7B 和 Llama-2-7B,结果如表 4 和附录表 7 所示。这些模型代表了不同的架构和训练范式,能够评估量化方法的通用性。由于 SmoothQuant 没有报告这组模型,因此研究者将他们的结果与 naive W8A8 量化进行了比较。在所有模型和数据集上,本文方法始终优于 naive W8A8 量化,且在 OLMo 模型上表现特别突出。


值得注意的是,OLMo 模型使用非参数化 LayerNorm,因此与 SmoothQuant 方法不兼容,后者依靠 LayerNorm 权重来应用每个通道的比例。在 Mistral-7B 上,改进幅度较小。研究者假设这是因为这些模型的 LayerNorm 所学习的权重可能会积极抑制超激活,从而使激活幅度的分布更加均匀。
这些结果凸显了超激活在量化过程中保持模型性能的重要性。通过以最小的计算开销解决这一单一激活,本文方法捕捉到了更复杂的量化方案所实现的大部分优势。这一发现表明,在量化过程中,超激活在保持模型质量方面发挥着不成比例的巨大作用。
权重量化
为了评估所提出的超权重感知量化方法的有效性,研究者将其与传统的 round-to-near 量化方法进行了比较,在一套零样本下游任务中对模型进行了评估,结果如图 7 所示。

在传统的 round-to-near 量化方法中,可以观察到一个明显的趋势:随着块大小的增加,模型质量明显下降。这种下降可能是由于当较大的权重块一起量化时,量化误差会增加,从而使异常值影响到更多的权重。相比之下,本文的「超权重」感知量化方法对更大的块大小具有更强的鲁棒性。随着块大小的增大,模型质量的下降明显小于 round-to-near 方法。
这种鲁棒性源于本文方法能够保留最关键的权重(超权重),同时将离群值权重对整个量化过程的影响降至最低。通过剪除离群值并关注离群值权重,本文的方法在表示模型参数时保持了更高的保真度。
还有一个关键优势是,它能够支持更大的数据块尺寸,同时减少模型质量的损失。这种能力使平均比特率更低,文件尺寸更小,这对于在资源有限的环境(如移动设备或边缘计算场景)中部署模型至关重要。
#人大附中、北师大实验中学等摘得3篇Spotlight
NeurIPS 2024高中生论文录用结果公布!论文接受率仅为6.4%,3名国内学生杀出重围,斩获Spotlight。
就在刚刚,NeurIPS 2024首届高中论文录用结果公布了!
今年,NeurIPS 2024首次设置了「高中生赛道」,直接将「学好AI要从娃娃抓起」变成了现实。
此举曾在今年4月引发激烈的讨论,有人认为这为有科研潜力的高中生提供了宝贵机会,也有人担心它会进一步加剧教育资源的不平等。甚至有网友戏称,这是「代练家长」的战场,研究生和博士们可能也会被拉下水。
总之,此次大会邀请高中生提交关于「机器学习对社会影响」的研究论文。部分决赛入围者将获得在线展示项目的机会,并将在NeurIPS官网上重点展示他们的研究成果。此外,获奖项目的第一作者将被邀请参加在温哥华举行的NeurIPS 2024颁奖典礼。
研究应用领域包括但不限于以下方面:农业、气候变化、教育、医疗保健、无家可归问题、饥饿、粮食安全、心理健康、贫困、水质。
值得注意的是,每份提交作品必须由高中生作者独立完成。
最终,大会共收到了全球高中生提交的330个项目。
其中,有21篇被选为Spotlight,4篇为获奖论文,接受率6.4%。
值得注意的是,总共约有13位华人学生入选,其中3名国内学生的论文获得Spotlight!
他们分别是来自上海星河湾双语学校的Tianrui Chen、人民大学附属中学的Alan Wu、北京师范大学附属实验中学的Yuhuan Fan。
获奖项目
1. ALLocate: A Low-Cost Automatic Artificial Intelligence System for the Real-Time Localization and Classification of Acute Myeloid Leukemia in Bone Marrow Smears
作者:Ethan Yan
学校:Groton School(美国)
(ALLocate:一种低成本自动化AI系统,用于骨髓涂片中急性髓性白血病的实时定位和分类)
当前临床实践中,准确检测白血病仍面临成本高、耗时长及医疗经验不足等挑战。为解决这一问题,该研究开发了首个用于实时定位和分类骨髓涂片中急性髓系白血病的低成本集成自动人工智能系统——ALLocate。
该系统由自动显微镜扫描系统和图像采样系统组成,并配有基于深度学习的定位和分类系统。研究开发了一种基于卷积神经网络(CNN)的区域分类器,用于从血液和血块区域中筛选可用区域。为了实现实时检测,开发并优化了YOLOv8模型。这些模型表现出高性能,区域分类器的准确率达到96%,YOLOv8的mAP为91%。
此外,研究还使用3D打印组件开发了一种低成本自动显微镜扫描仪系统,该系统由步进电机驱动,并通过基于Arduino的RAMPS控制板进行编程控制。将ALLocate应用于骨髓涂片时,其白血病检测结果与医生的结果相似,但速度明显更快。
这是首次将深度学习系统与低成本显微镜扫描系统集成应用于高性能白血病检测的报告,可惠及小型社区诊所和资源匮乏地区的诊所,从而使医疗服务更加普惠且经济可行。
2. Image Classification on Satellite Imagery For Sustainable Rainwater Harvesting Placement in Indigenous Communities of Northern Tanzania
作者:Roshan Taneja,Yuvraj Taneja
学校:Sacred Heart Preparatory(美国)
(利用卫星图像分类技术在坦桑尼亚北部土著社区进行雨水可持续收集系统选址)
在坦桑尼亚北部偏远地区,马赛部落的妇女和儿童每天需要步行九小时去取水。通过与马赛社区长达四年的合作努力,已安装了多个雨水收集装置,为超过4000人提供了教育机会和经济发展的条件,从而改善了当地的社会经济状况。
本项目采用了一种创新方法,将卫星数据与图像分类相结合,用于识别以独特形状的马赛房屋为标志的人口密集区域。它还将利用密度地图规划最佳的雨水收集装置位置,目标是帮助3万名马赛族人。
该项目的核心是开发了一个图像分类模型,该模型基于1万张手工挑选的 Bomas(马赛居住单位)的卫星图像样本进行训练。通过此模型生成的密度热力图,可以在最关键的位置战略性地放置雨水收集装置,从而最大化其影响。该项目突显了卫星技术与机器学习在解决人道主义需求(如水资源问题)方面的潜力,尤其是在难以建设基础设施的偏远地区。
3. Multimodal Representation Learning using Adaptive Graph Construction
作者:Weichen Huang
学校:St. Andrew’s College(爱尔兰)
(基于自适应图构建的多模态表征学习)
多模态对比学习通过利用图像和文本等异构数据源来训练神经网络。然而,许多当前的多模态学习架构无法泛化到任意数量的模态,并且需要手动构建。
该项目提出了一种新颖的对比学习框架AutoBIND,可以通过图优化从任意数量的模态中学习表示。
研究在阿尔茨海默病检测中评估了AutoBIND,因为它具有现实世界的医学应用价值,并且包含广泛的数据模态。实验结果表明,AutoBIND在这一任务上优于以往的方法,凸显了该方法的泛化能力。
4. PumaGuard: AI-enabled targeted puma mitigation
作者:Aditya Viswanathan,Adis Bock,Zoe Bent,Tate Plohr,Suchir Jha,Celia Pesiri,Sebastian Koglin,Phoebe Reid
学校:Los Alamos High School(美国)
(PumaGuard:基于AI的美洲狮精准防治系统)
该项目训练了一个机器学习分类算法,以检测野外摄像机图像中的美洲狮。这个算法将成为一种专用防范工具的一部分,以阻止美洲狮攻击当地马厩的牲畜。该模型使用Xception算法,训练准确率达99%,验证准确率为91%,并成功识别出马厩附近的美洲狮。
Spotlight项目
1. Predicting Neurodevelopmental Disorders in rs-fMRI via Graph-in-Graph Neural Networks
作者:Yuhuan Fan
学校:The Experimental High School Attached to Beijing Normal University(北京师范大学附属实验中学)
(基于嵌套图神经网络在静息态功能磁共振成像中预测神经发育障碍)
2. GeoAgent: Precise Worldwide Multimedia Geolocation with Large Multimodal Models
作者:Tianrui Chen(陈天睿)
学校:Shanghai Starriver Bilingual School(上海星河湾双语学校)
(GeoAgent:基于大规模多模态模型的全球多媒体精确地理定位)
值得一提的是,陈天睿同学还参加了今年8月举办的第一届国际人工智能奥林匹克(IOAI)。
参赛成员来自全球的34个国家与地区,共44支队伍。其中,陈天睿作为乾队队长,带领团队斩获2枚银牌。另外,坤队也获得了1枚银牌。
3. Vision-Braille: An End-to-End Tool for Chinese Braille Image-to-Text Translation
作者:Alan Wu(吴悠)
学校:The High School Affiliated to Renmin University of China(中国人民大学附属中学)
(Vision-Braille:面向中文盲文图像到文本转译的端到端工具)
论文地址:https://arxiv.org/abs/2407.06048
结合盲文识别算法,该项目开发了首个公开可用的盲文翻译系统。
由于缺乏高度准确的盲文翻译系统,视障群体的盲文作业或考试试卷常常无法被普通教师理解,特别是中文盲文还包含声调标记。为了节省空间,盲文书写者常常省略声调标记,这导致在将具有相同声母和韵母的盲文翻译成中文时容易产生混淆。以往的算法在提取上下文信息方面存在不足,导致盲文翻译成中文的准确率较低。
该项目创新性地对mT5模型进行了信息化微调,采用了编码器-解码器架构,用于实现盲文到汉字的转换。本研究基于Leipzig Corpora创建了盲文与相应中文文本的训练数据集。
通过课程学习的微调方法,本项目显著减少了盲文中的混淆问题,在验证集和测试集上分别达到了62.4和62.3的BLEU分数。
这一系统将为备战中国高考的视障学生及其家庭带来帮助,为他们实现大学梦想提供助力,并推动教育公平的发展。
项目地址:https://vision-braille.com/
北京大学计算机学院的张铭教授在今年9月也分享了吴悠同学的入围消息,并对她表示了祝贺。据张铭教授介绍,吴悠在2022年高一加入她的课题组时,就提出了这个项目的想法。
4. Diagnosing Tuberculosis Through Digital Biomarkers Derived From Recorded Coughs
作者:Sherry Dong
学校:Skyline High School(美国)
5. INAVI: Indoor Navigation Assistance for the Visually Impaired
作者:Krishna Jaganathan
学校:Waubonsie Valley High School(美国)
6. Implementing AI-driven Techniques for Monitoring Bee activities in Hives
作者:Tahmine Dehghanmnashadi
学校:Shahed Afshar High School for Girls(伊朗)
7. AquaSent-TMMAE: A Self-Supervised Learning Method for Water Quality Monitoring
作者:Cara Lee, Andrew Kan,Christopher Kan
学校:Woodside Priory School(美国),Weston High School(美国),Noble and Greenough School(美国)
8. AAVENUE: Detecting LLM Biases on NLU Tasks in AAVE via a Novel Benchmark
作者:Abhay Gupta,Philip Meng,Ece Yurtseven
学校:John Jay Senior High School(美国),Phillips Academy(美国),Robert College(土耳其)
9. FireBrake: Optimal Firebreak Placements for Active Fires using Deep Reinforcement Learning
作者:Aadi Kenchammana
学校:Saint Francis High School(美国)
10. Advancing Diabetic Retinopathy Diagnosis: A Deep Learning Approach using Vision Transformer Models
作者:Rhea Shah
学校:Illinos Mathematics & Science Academy(美国)
11. LocalClimaX: Increasing Regional Accuracy in Transformer-Based Mid-Range Weather Forecasts
作者:Roi Mahns,Ayla Mahns
学校:Antilles High School(美国)
12. HypeFL: A Novel Blockchain-Based Architecture for a Fully-Connected Autonomous Vehicle System using Federated Learning and Cooperative Perception
作者:Mihika A. Dusad,Aryaman Khanna
学校:Thomas Jefferson High School for Science and Technology(美国)
13. Robustness Evaluation for Optical Diffraction Tomography
作者:Warren M. Xie
学校:Singapore American School(新加坡)
14. Translating What You See To What You Do: Multimodal Behavioral Analysis for Individuals with ASD
作者:Emily Yu
学校:Pittsford Mendon High School(美国)
15. SignSpeak: Open-Source Time Series Classification for ASL Translation
作者:Aditya Makkar,Divya Makkar,Aarav Patel
学校:Turner Fenton Secondary School(加拿大)
16. SeeSay: An Assistive Device for the Visually Impaired Using Retrieval Augmented Generation
作者:Melody Yu
学校:Sage Hill School(美国)
17. Realistic B-mode Ultrasound Image Generation from Color Flow Doppler using Deep Learning Image-to-Image Translation
作者:Sarthak Jain
学校:Silver Creek High School(美国)
参考资料:
https://blog.neurips.cc/2024/11/18/announcing-the-neurips-high-school-projects-results/
#DeepSeek-V3-0324
DeepSeek V3深夜低调升级,代码进化令人震惊,网友实测可媲美Claude 3.5/3.7 Sonnet
昨夜,DeepSeek V3 毫无征兆地来了一波更新,升级到了「DeepSeek-V3-0324」版本。
目前,新版本在 Hugging Face 上可以下载并部署。

- Hugging Face 地址:https://huggingface.co/deepseek-ai/DeepSeek-V3-0324/tree/main
不过,DeepSeek-V3-0324 没有公布详细的模型卡。我们只能看到它的参数为 6850 亿以及张量类型。

此外,DeepSeek-V3-0324 支持了更宽松的 MIT 开源协议。

模型放出来后,DeepSeek-V3-0324 的代码能力让所有人震惊了!
有人表示,经过自己的测试,DeepSeek-V3-0324 在数学推理和前端开发方面的表现优于 Claude 3.5 和 Claude 3.7 Sonnet。

图源:https://x.com/selcukemiravci/status/1904311856313028870
X 博主「@KuittinenPetri」表示,Anthropic 和 OpenAI 陷入了困境。更新后的 DeepSeek-V3-0324 可以轻松免费地创建漂亮的 HTML5、CSS 和前端。

图源:https://x.com/KuittinenPetri/status/1904224441384771909
提示词如下:为 AI 公司「NexusAI」创建一个外观精美的响应式首页,将所有内容包含在一个 HTML5 文件中。结果如下图所示,所有图像,包括用户故事和他们的面孔,一切都是用这个提示完成的。
他认为:DeepSeek-V3-0324 是 DeepSeek 最好的非推理模型,通常更适合创意写作任务,但现在也比 R1 更适合制作 HTML5 + CSS + 前端。上述提示的结果代码总共 958 行,但它实际上实现了一个交互式网站,包括所有图像。并且结果也适用于移动设备。


他还称,DeepSeek-V3-0324 在编写代码方面确实很棒!早期测试显示,它是所有开源选择中最好的非推理模型,甚至可以与 Claude 3.5/3.7 Sonnet 相媲美。

另一位网友也让 DeepSeek-V3-0324 创建网站,只见该模型一口气写了 800 多行代码,中途一次都没卡壳,生成的网站布局也非常完美。

这位网友还把提示语放出来了,简单的几行字,大家可以前去一试。

Hyperbolic 联合创始人兼 CTO Yuchen 称自己的氛围测试显示,DeepSeek- V3-0324 已经有了一些思维链模型的影子。
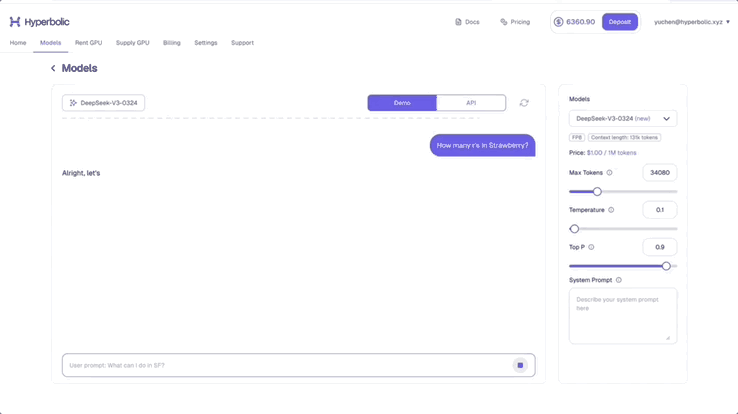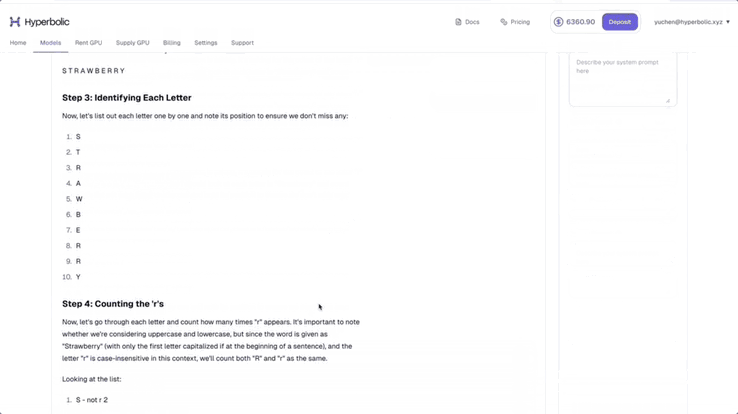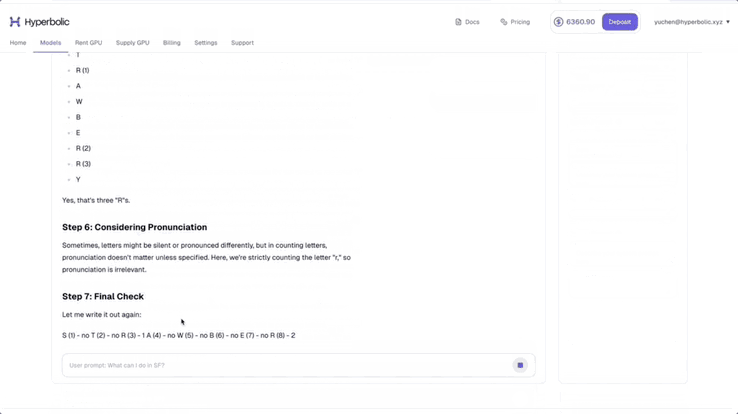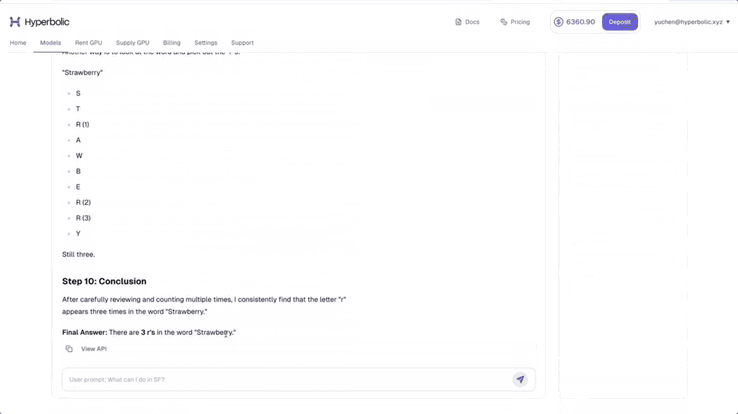
他测试了题目「strawberry 中有多少个 r」,可以看到,DeepSeek-V3-0324 展示了详细的推理步骤。他表示,真正的「Open AI」又赢了。

图源:https://x.com/Yuchenj_UW/status/1904223627509465116
还有人将 DeepSeek-V3-0324 与 OpenAI o1-pro 生成小球的效果进行了比较。下面是 o1-pro 的效果:

他表示,DeepSeek-V3-0324 大约可以实现 o1-pro70% 的性能,但它免费并且 API 价格比后者便宜了至少 50 倍。二者选谁一目了然!
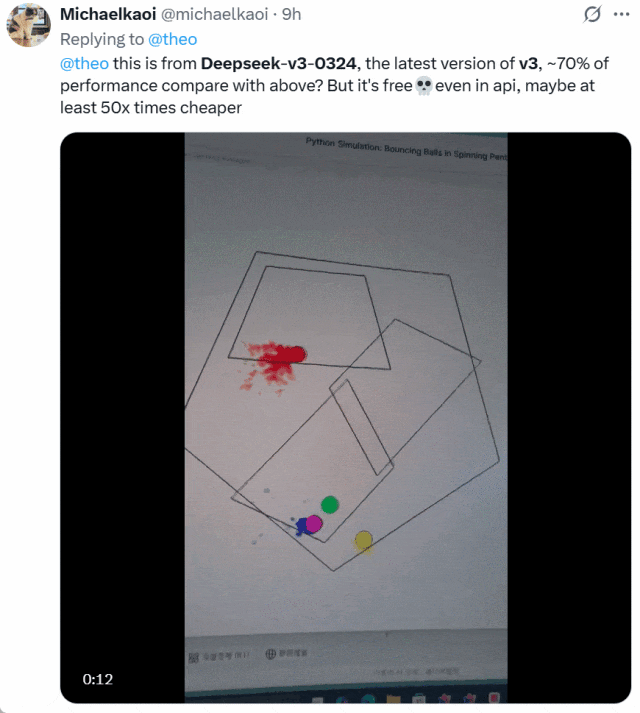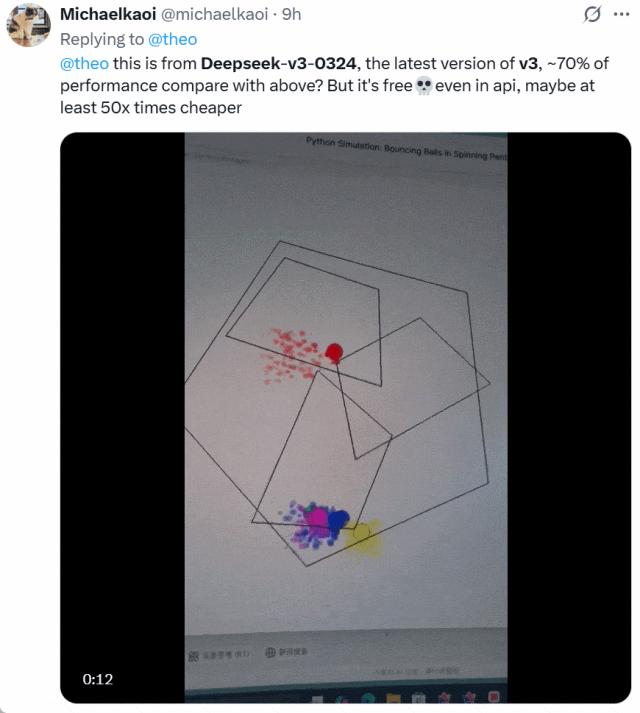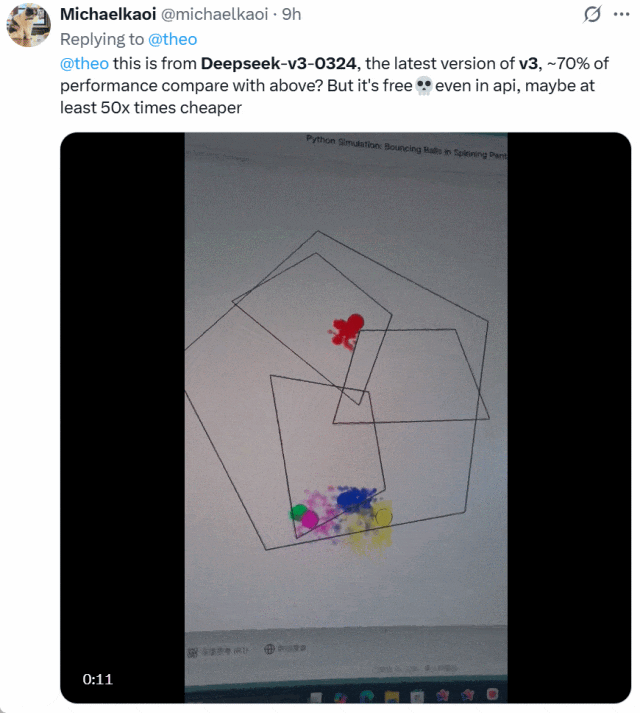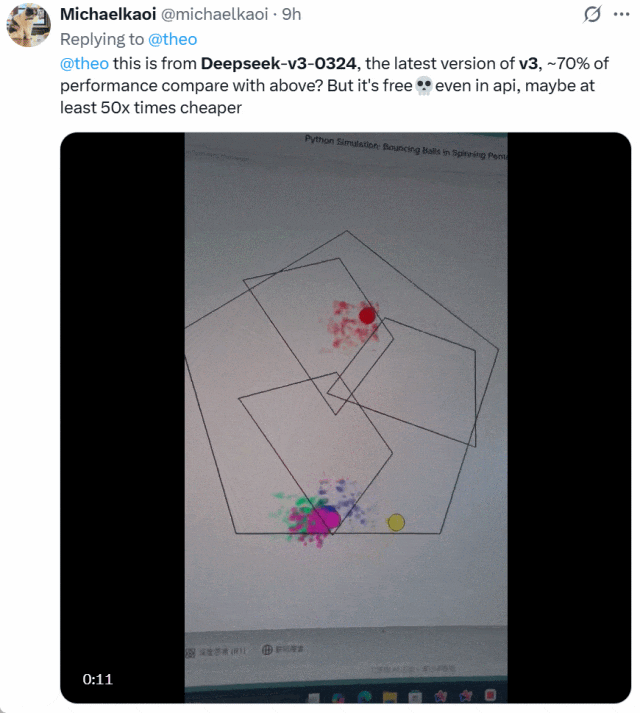
图源:https://x.com/michaelkaoi/status/1904178015833297342
X 博主「orange.ai」对 DeepSeek V3、DeepSeek-V3-0324 与 Claude Sonnet 3.7 的海报设计结果进行了比较,同样表示前端代码能力相比上代有了显著增强。


图源:https://x.com/oran_ge/status/1904306405823467526
#SPIN-Bench
棋盘变战场,大模型却呆了?普林斯顿、UT Austin新基准SPIN-Bench曝AI智商瓶颈
当棋盘变成战场,当盟友暗藏心机,当谈判需要三十六计,AI 的智商令人叹息!
近日,来自普林斯顿和德州大学奥斯丁分校最新评测基准 SPIN-Bench,用一套 "组合拳" 暴击了大模型的软肋。研究显示,即便是 o1、o3-mini、DeepSeek R1、GPT-4o、Claude 3.5 等顶尖大模型,在涉及战略规划和社会推理的复杂任务中集体 "自闭"。
- 论文标题:SPIN-Bench: How Well Do LLMs Plan Strategically and Reason Socially?
- 论文链接:https://arxiv.org/pdf/2503.12349
- 项目主页:https://spinbench.github.io
在过去的一年里,大语言模型(LLM)展现了令人惊叹的 "文本生成" 和 "智能代理" 能力。许多社区用户已经见到了各大模型的「百花齐放」:从高效的简单问答到多轮对话推理。
然而,当我们谈到真正复杂的 "思考" 场景 —— 譬如需要在一个充满其他 "玩家"(人或智能体)的不确定环境中做出长程策略规划、临场谈判合作甚至 "背后使坏" 时,当下的 LLM 是否还能站稳脚跟?
传统 AI 测试总让大模型做 "乖学生":解数学题、写代码、背百科...... 但在真实世界中,人类更常用的智能是动态博弈中的谋略和复杂社交中的洞察。
为解答这一问题,作者推出了全新的多域评估框架 SPIN-Bench(Strategic Planning, Interaction, and Negotiation),将单人规划、合作游戏、对抗博弈和多方谈判统一到一个测试框架中,并系统化地扩大环境规模和复杂度,旨在全面刻画 LLM 在战略规划与社交推理方面的 "短板" 与潜力。
SPIN-Bench: 一览多维度评估体系

SPIN-Bench 框架包含两个核心组成部分:
1. 游戏代理,包括 LLM 及其自适应提示;
2. 环境和评估子系统,用于管理游戏逻辑、跟踪互动和量化性能。
传统的规划评测大多在单人、可完全观察的环境中进行,无法充分反映现实中团队决策的复杂度。而 SPIN-Bench 试图通过形式化任务与多人场景相结合,把现实中需要的 "同伴合作"" 谈判博弈 " 等关键技能一并纳入,以帮助找到 LLM 在真实应用落地时可能面临的问题。
SPIN-Bench 让 LLM 面对从 "最基础" 的单智能体规划,到 "最复杂" 的多智能体混合对抗与合作,逐步升级难度。文章并不仅仅统计 "最终是否获胜" 或者 "是否达成目标",还额外设置了若干细颗粒度的指标,用来量化模型的决策准确性、协作有效性以及在社交场景下的话术与执行匹配度。
具体而言,该文主要聚焦三个层次:
- 经典规划(PDDL)- 测试 "单智能体思维" 极限
1、单智能体,确定性环境,多步动作规划,通过层层递进的难度,分析模型的错误原因。
2、涵盖 21 个领域(共 1,280 个任务),包含 elevator、grid、floortile 等多个常见子任务,考察点涉及状态空间的逐步提升和逐渐复杂的约束条件。
3、在经典规划问题中,题目通常会明确给出初始状态、可执行的动作集以及希望达到的目标状态。Agent 的任务则是利用这些已知信息,规划并生成从初始状态到目标状态的动作序列(trajectory)。
例如,在一个电梯控制问题中,Agent 可以执行电梯的上下移动和开关门等动作,它需要通过合理规划,在最少的步骤内,将所有乘客准确、高效地运送到他们各自对应的目标楼层。在这个例子中 o1 把最后一位乘客(p4)送错了楼层,说明 LLM 仍有提升空间。

- 多智能体对抗或合作 - 逐步升级的脑力绞杀
1. 对抗场景(井字棋,四子棋,国际象棋):文章分别对比 LLM 的落子行动与专业博弈引擎、启发式搜索算法的对战平局概率与选步差异,动作是否符合最优策略,评估其在战术和战略层面的深度。
2. 合作场景(Hanabi):考核模型面对不完全信息时,是否能够通过沟通隐含信息、推测队友手牌,实现团体协作。
- 战略游戏与谈判 - 七国混战 + 实时谈判,上演 AI 版《权力的游戏》
Diplomacy 是一款融合联盟、谈判、背叛与合作的策略类桌游。玩家之间需要相互通信、结盟或欺骗,最终同时下达指令。文章考察 LLM 在 "多步长程规划" 与 "社交手段"(如如何争取盟友、如何制定信息不对称策略)方面的综合表现。不仅仅是让模型 "求解" 问题,更是让模型在有其他玩家干扰、或需要和其他玩家沟通的场景中,实时地进行策略调整。这就要求 LLM 要在语言能力之外,具备多步推理和心智模型(Theory of Mind),并能兼顾团队 / 对手的动机。
实验结果与分析: AI 集体遭遇 "滑铁卢"
模型配置概述
该文评估了当前流行的闭源和开源大语言模型:
- 闭源模型:包含 OpenAI(如 o1, o3-mini, o1-mini, GPT-4o、GPT-4o mini、GPT-4-turbo 等)和 Anthropic 的 Claude 3.5(Sonnet/Haiku),共 10 个商业模型。
- 开源模型:涵盖 DeepSeek-R1、Llama3 系列、Qwen2.5-72B 和 Mistral-7B 等 7 个模型。

表 1:PDDL、竞技棋盘游戏和合作游戏的结果。Plan Acc 表示规划准确度。N-Step " 表示 N 步前瞻。TTT、C4、CH 是三种竞技游戏。WR 下标表示专业博弈引擎对每个 LLM 的胜率(%)。T3 下标显示 LLM 在所有对局中的棋步属于 top 3 choice 的百分比(%)。Hanabi 列显示 2-5 名棋手参与游戏的平均得分。
PDDL 实验结果分析

图 1:o1 的准确度与行动空间之间的关系。左图描绘的是准确率与合法行动平均数量的函数关系,右图考察的是准确率与状态 - 行动空间 大小的关系。
- o1 在经典规划上表现最佳,但在大型行动 / 状态空间中仍有明显下降。
- 核心发现:模型准确率与状态 - 行动空间规模的关联性显著高于与合法行动平均数量的关联性。
- 认知解读:模型在规划时需承担未来大量潜在分支的认知负担,即使每一步仅有少量有效选择。这表明 LLMs 更易受全局复杂性影响,而非单步决策限制。
竞技棋盘游戏表现
在 solver 与 LLM 的对决中,solver 几乎总是获胜或和棋(表 1):
- 井字棋(Tic-Tac-Toe):较强的模型(如 o1,Claude 3.5 Sonnet)偶尔能与完美 Solver 达成平局,但多数情况仍落败。
- 四子棋(Connect Four)与国际象棋(Chess):游戏 Solver(如 Stockfish 引擎)对所有测试的 LLMs 保持 100% 胜率。
- LLMs 在四连环中偶尔能选择最优棋步,但在国际象棋中准确率骤降,凸显其深层战术推理与分支扩展能力不足。

Hanabi 多人合作游戏分析
多人协作挑战:
- 当玩家数量从 2 人增至 5 人时,顶尖模型(如 o1)的平均得分从 16.4 降至 14.2,表明多代理协调对 LLMs 的策略一致性造成压力。
- 部分模型(如 o1-mini、DeepSeek-R1)它们的高方差以及相对较低的平均得分表明缺乏足够的策略规划能力以有效地进行 Hanabi 游戏,无法适应复杂协作场景。
与人类对比:
- 作者团队爬取并分析了 54,977 场人类 Hanabi 游戏数据,发现人类得分集中在 15-25 分区间。
- 当 LLMs 必须协调多个不完整的信息渠道并跟踪队友不断变化的知识状态时,所有 LLMs 均未达到人类得分的第一四分位数,暴露其 "社会智能" 普遍不足。

表 2:4 个玩家的 Diplomacy 游戏实验结果结果,(结果表示:无协商 / 有协商)展示 LLM 不同类别指令的成功率,以及游戏结束时供应中心(SC)和受控区域(CR)的数量。右侧从左到右为谈判消息的评测指标。基本技能测试(BS)显示特定模型是否通过了外交游戏的基础技能测试。
Diplomacy 战略谈判游戏分析(表 2)
基础技能测试:
- 在无谈判的单玩家最简单基准测试中,仅 o1-preview、o1 和 GPT-4o 能在 20 回合内占领 18 个补给中心,其他模型均失败,反映 LLMs 在长期战略规划上的局限性。
空间指令能力:
- o1 在基本命令(如移动和攻击)的成功率上超过其他模型(20-30%)。
- 对于需要多步或多智能体逻辑的复杂行动(如自我支援和支援他人),所有模型的性能都明显下降。
多玩家场景表现:
- 随着参与国数量增加(2-7),LLMs 的指令准确性、攻击成功率与供应中心收益显著下降,表明其难以应对部分可观测性与动态联盟关系的叠加复杂度。
- 对模型谈判消息的分析表明,大型语言模型在谈判中展现出差异化策略:所有模型均表现出高策略一致性(比率 > 0.90),其中 o1 的说服力最强(接受率 65%),而 Claude 3.5 Haiku 较弱(36%)。多数模型倾向提出互利方案(如 GPT-4-turbo),但 DeepSeek-R1 和 3.5 Haiku 更倾向于引发冲突。尽管 GPT-4-turbo 擅长换位思考,DeepSeek-R1 善用条件性战术,但从结果来看,所有模型均缺乏人类谈判者的策略灵活性 —— 尤其在复杂社交互动中表现局限,反映出当前 AI 的社会智能仍处于初级阶段。
谈判的负面影响:
- 引入谈判往往会对 o1 这样的强推理模型产生反直觉的影响:执行的指令数量与最终得分(补给中心 / 控制区域)大幅下降,而部分较弱模型反而表现稳定。
- 这一结果表明,激烈的社交互动可能会破坏强推理 LLM 的计划连贯性和推理思维链,凸显其 "思维链扩展" 与社会智能间的潜在矛盾。
实验结论:LLM 的痛点与挑战
通过这套涵盖从基础规划到多智能体策略博弈的评测,研究者得出了一些关键结论:
简单规划还行,复杂规划时大多不行
当状态空间小、可选动作少时,LLM 可以完成相当不错的单步或短程规划,但一旦问题规模扩张,或者游戏进入中后期出现大量分支,模型就很快出现多步推理瓶颈,甚至输出不合规则的行动。
大模型背后的 "社交" 与 "规划" 引擎仍需加强
本次评测表明了大模型在多步决策与他人意图建模方面的不足。未来若想真正让 LLM 在更复杂、更现实的多智能体协同场景发光发热,我们需要更先进的强化学习或多智能体训练框架,结合知识图谱、记忆模块或世界模型来避免推理链被轻易打断。
不完全信息和多跳推断是硬伤
在如 Hanabi 这类带 "隐含信息" 的合作游戏中,模型需要通过队友提示来推理自己持有的牌。实验显示,大多数 LLM 依旧力不从心,也缺乏对他人思维进行多跳推理的稳定能力。
与人类高水平协作仍有明显差距
即便是表现最好的大模型,在需要深度合作(如 Hanabi)或多方谈判(如 Diplomacy)时,仍远远达不到人类玩家的平均成绩。这也从一个侧面说明:真实多智能体团队决策中,大模型还需要大量的结构化规划模块与更丰富的交互记忆 / 推理机制。
作者的项目主页提供了不同 LLM 之间的对战以及游戏轨迹细节和任务的可视化:https://spinbench.github.io
#Qwen2.5-VL-32B-Instruct
阿里深夜开源Qwen2.5-VL新版本,视觉推理通杀,32B比72B更聪明
就在 DeepSeek V3「小版本更新」后的几个小时,阿里通义千问团队也开源了新模型。
择日不如撞日,Qwen2.5-VL-32B-Instruct 就这么来了。

相比此前的 Qwen2.5-VL 系列模型,32B 模型有如下改进:
- 回复更符合人类主观偏好:调整了输出风格,使回答更加详细、格式更规范,并更符合人类偏好。
- 数学推理能力:复杂数学问题求解的准确性显著提升。
- 图像细粒度理解与推理:在图像解析、内容识别以及视觉逻辑推导等任务中表现出更强的准确性和细粒度分析能力。
对于所有用户来说,在 Qwen Chat 上直接选中 Qwen2.5-VL-32B,即可体验:https://chat.qwen.ai/

32B 版本的出现,解决了「72B 对 VLM 来说太大」和「7B 不够强大」的问题。如这位网友所说,32B 可能是多模态 AI Agent 部署实践中的最佳选择:

不过团队也介绍了,Qwen2.5-VL-32B 在强化学习框架下优化了主观体验和数学推理能力,但主要还是基于「快速思考」模式。
下一步,通义千问团队将聚焦于长且有效的推理过程,以突破视觉模型在处理高度复杂、多步骤视觉推理任务中的边界。
32B 可以比 72B 更聪明
先来看看性能测试结果。
与近期的 Mistral-Small-3.1-24B、Gemma-3-27B-IT 等模型相比,Qwen2.5-VL-32B-Instruct 展现出了明显的优势,甚至超越了更大规模的 72B 模型。

如上图所示,在 MMMU、MMMU-Pro 和 MathVista 等多模态任务中,Qwen2.5-VL-32B-Instruct 均表现突出。
特别是在注重主观用户体验评估的 MM-MT-Bench 基准测试中,32B 模型相较于前代 Qwen2-VL-72B-Instruct 实现了显著进步。
视觉能力的进步,已经让用户们感受到了震撼:

除了在视觉能力上优秀,Qwen2.5-VL-32B-Instruct 在纯文本能力上也达到了同规模的最优表现。

实例展示
或许很多人还好奇,32B 版本的升级怎么体现呢?
关于「回复更符合人类主观偏好」、「数学推理能力」、「图像细粒度理解与推理」这三个维度,我们通过几个官方 Demo 来体会一番。
第一个问题,是关于「细粒度图像理解与推理」:我开着一辆卡车在这条路上行驶,现在是 12 点,我能在 13 点之前到达 110 公里外的地方吗?

显然,从人类的角度去快速判断,在限速 100 的前提下,卡车无法在 1 小时内抵达 110 公里之外的地方。
Qwen2.5-VL-32B-Instruct 给出的答案也是「否」,但分析过程更加严谨,叙述方式也是娓娓道来,我们可以做个参考:

第二个问题是「数学推理」:如图,直线 AB、CD 交于点 O,OD 平分∠AOE,∠BOC=50.0,则∠EOB=()

答案是「80」:


第三个题目的数学推理显然更上难度了:

模型给出的答案特别清晰,解题思路拆解得很详细:



在下面这个图片内容识别任务中,模型的分析过程也非常细致严谨:



关于 Qwen2.5-VL-32B-Instruct 的更多信息,可参考官方博客。
博客链接:https://qwenlm.github.io/zh/blog/qwen2.5-vl-32b/
#MCP与AI工具生态的未来
它会是AI智能体的「万能插头」吗?
如今,随着基础模型变得越来越智能,人们越来越需要有一个用于执行、数据获取和工具调用的标准接口。
自 OpenAI 在 2023 年发布函数调用功能以来,AI 智能体与外部工具、数据和 API 的交互能力却日益碎片化:开发者需要为智能体在每个系统中的操作和集成实现特定的业务逻辑。
显然,执行、数据获取和工具调用需要一个标准接口。API 曾是互联网的第一个伟大统一者——为软件之间的通信创造了一种共享语言,但 AI 模型却缺乏类似的机制。
2024 年 11 月 Anthropic 推出的模型上下文协议(Model Context Protocol,简称 MCP),在开发者和 AI 社区中迅速获得了广泛关注,被视为一种潜在的解决方案。

近日,全球知名投资机构 a16z 发布了一篇博客文章,深度介绍了 MCP 以及 AI 工具生态的未来。

博客链接:https://a16z.com/a-deep-dive-into-mcp-and-the-future-of-ai-tooling/
本文将深入探讨 MCP 是什么,它如何改变 AI 与工具的交互方式,开发者已经用它构建了哪些应用,以及仍需解决的挑战。
让我们跟随博客一探究竟。
MCP 是什么?
MCP(Model Context Protocol,模型上下文协议)是一种开放协议,它允许系统以可泛化的方式为 AI 模型提供上下文信息,从而跨越不同集成场景实现通用性。该协议定义了 AI 模型如何调用外部工具、获取数据以及与服务交互。举个具体的例子,以下展示了 Resend MCP 服务器如何与多个 MCP 客户端协同工作。

这一理念并非创新,MCP 从语言服务器协议(LSP)中汲取了灵感。在 LSP 中,当用户在编辑器中输入时,客户端会向语言服务器查询以获取自动补全建议或诊断信息。

而 MCP 超越 LSP 的地方在于其以智能体为中心的执行模型:LSP 主要是被动的(基于用户输入响应 IDE 的请求),而 MCP 则旨在支持自主的 AI 工作流。根据上下文,AI 智能体可以决定使用哪些工具、以什么顺序使用,以及如何将它们串联起来以完成任务。

此外,MCP 还引入了人机协作能力,允许人类提供额外数据并批准执行。
当前热门应用场景
通过使用合适的 MCP 服务器,用户可以将每一个 MCP 客户端变成「万能应用」。
我们以 Cursor 为例:虽然 Cursor 本质上是一个代码编辑器,但它也是一个功能强大的 MCP 客户端。终端用户可以通过 Slack MCP 服务器将其变成 Slack 客户端,通过 Resend MCP 服务器将其变成邮件发送器,使用 Replicate MCP 服务器将其变为图像生成器。
利用 MCP 的更强大方法是在一个客户端上安装多个服务器以解锁新流程:用户可以安装服务器以从 Cursor 生成前端 UI,也可以要求智能体使用图像生成 MCP 服务器为站点生成主页横幅。
当然,除了 Cursor 以外,当前的应用场景大致可以分为两类:以开发者为中心、本地优先的工作流,以及基于 LLM 客户端的全新体验。
以开发者为中心的工作流
对于开发者来说,一个普遍的愿望是:「我不想离开我的 IDE 去完成某件事」。MCP 服务器正是实现这一梦想的绝佳方式。
基于 MCP 服务器,开发者不再需要切换到 Supabase 来检查数据库状态,而是可以直接在 IDE 中使用 Postgres MCP 服务器执行只读 SQL 命令,或通过 Upstash MCP 服务器创建和管理缓存索引。在迭代代码时,开发者还可以利用 Browsertools MCP 服务器,让编程智能体访问实时环境,获取反馈并进行调试。

Cursor 智能体使用 Browsertools 访问控制台日志和其他实时数据并更有效地进行调试的示例。
如上图所示,Cursor 智能体可以通过 Browsertools 访问控制台日志和其他实时数据,从而更高效地进行调试。
除了与开发工具交互的工作流,MCP 服务器还解锁了一种全新的应用场景:通过爬取网页或基于文档自动生成 MCP 服务器,为编码智能体提供高度准确的上下文信息。开发者无需手动配置集成,而是可以直接从现有文档或 API 中快速启动 MCP 服务器,使 AI 智能体能够即时访问这些工具。这意味着更少的时间花在样板代码上,更多的时间用于实际使用工具 —— 无论是拉取实时上下文、执行命令,还是动态扩展 AI 助手的能力。
全新体验
Cursor 等 IDE 并不是唯一可用的 MCP 客户端,对于非技术用户来说,Claude Desktop 是一个极好的切入点,它使 MCP 驱动的工具更易于普通用户使用。很快,我们可能会看到专门的 MCP 客户端出现,用于以业务为中心的任务,例如客户支持、营销文案、设计和图像编辑,因为这些领域与 AI 在模式识别和创意任务方面的优势密切相关。
MCP 客户端的设计及其支持的特定交互在塑造其功能方面起着至关重要的作用。例如,聊天应用不太可能包含矢量渲染画布,就像设计工具不太可能提供在远程机器上执行代码的功能一样。最终,MCP 客户端体验定义了整体 MCP 用户体验 —— 而对于 MCP 的体验,我们还有更多东西需要解锁。
一个典型的例子是 Highlight 如何通过实现「@」命令来调用其客户端上的任何 MCP 服务器。这创造了一种全新的用户体验模式,即 MCP 客户端可以将生成的内容直接导入到任何下游应用中。

Highlight 实现 Notion MCP(插件)
另一个例子是 Blender MCP 服务器的用例:现在,几乎不了解 Blender 的业余用户可以用自然语言描述他们想要构建的 3D 模型。随着社区为 Unity 和 Unreal 引擎等其他工具实现服务器,我们正在实时见证「文本到 3D」工作流的落地。

使用 Claude Desktop 与 Blender MCP 服务器的示例
虽然我们主要关注服务器和客户端,但随着协议的发展,MCP 生态系统正在逐步成型。当前的市场地图覆盖了最活跃的领域,但仍有许多空白。考虑到 MCP 仍处于早期阶段,我们期待随着市场的演变和成熟,将更多参与者加入这张地图。(我们将在下一部分探讨其中的一些未来可能性。)
在 MCP 客户端方面,目前我们看到的高质量客户端大多以编程为中心。这并不令人意外,因为开发者通常是新技术的早期采用者。但随着协议的成熟,我们预计会看到更多以业务为中心的客户端出现。
在 MCP 服务器方面,目前大多数服务器都以本地优先为主,专注于单一功能。这是由于 MCP 目前仅支持基于 SSE 和命令的连接。然而,随着生态系统将远程 MCP 提升为首要支持对象,并采用可流式 HTTP 传输,我们预计会看到更多的 MCP 服务器被广泛采用。

此外,一波新的 MCP 市场和服务托管解决方案正在涌现,使 MCP 服务器的发现成为可能。像 Mintlify 的 mcpt、Smithery 和 OpenTools 这样的市场,正在让开发者更容易发现、分享和贡献新的 MCP 服务器 —— 就像 npm 彻底改变了 JavaScript 的包管理,或 RapidAPI 扩展了 API 的发现一样。这一层对于标准化访问高质量 MCP 服务器至关重要,使 AI 智能体能够动态选择和集成所需工具。
随着 MCP 的普及,基础设施和工具将在使生态系统更具可扩展性、可靠性和可访问性方面发挥关键作用。像 Mintlify、Stainless 和 Speakeasy 这样的服务器生成工具正在减少创建 MCP 兼容服务的摩擦,而像 Cloudflare 和 Smithery 这样的托管解决方案则正在解决部署和扩展的挑战。与此同时,像 Toolbase 这样的连接管理平台正在开始简化本地优先 MCP 的密钥管理和智能体。
未来可能性
智能体原生架构(agent-native architecture)的发展仍处于萌芽阶段。尽管业界已经对 MCP 展现出极大热情,但构建和部署 MCP 过程中仍面临诸多亟待解决的技术难题。协议在下一轮迭代中需要重点突破的领域包括:
托管与多租户
MCP 支持 AI 智能体与其工具之间的一对多关系,但多租户架构(例如 SaaS 产品)需要支持多用户同时访问共享的 MCP 服务器。近期解决方案可能是默认采用远程服务器,使 MCP 服务器更易于访问,但许多企业同样希望能够托管自己的 MCP 服务器并实现数据面和控制面的分离。
为促进 MCP 的广泛采用,下一个关键要素是开发简化的工具链,用于支持规模化的 MCP 服务器部署和维护。
认证
MCP 目前尚未定义客户端与服务器之间认证的标准机制,也没有提供框架说明 MCP 服务器在与第三方 API 交互时应如何安全地管理和委托认证。目前,认证问题留给各个实现和部署场景自行解决。在实践中,MCP 的应用主要集中在不需要显式认证的本地集成场景。
更完善的认证范式可能是推动远程 MCP 广泛采用的关键突破点之一。从开发者视角,统一的认证方法应包括:
- 客户端认证:用于客户端-服务器交互的标准方法,如 OAuth 或 API 令牌
- 工具认证:用于第三方 API 认证的辅助函数或包装器
- 多用户认证:适用于企业部署的租户感知式认证机制
授权
即使工具已通过认证,我们仍需考虑谁应被允许使用它,以及如何精细划分用户权限。MCP 缺乏内置的权限模型,导致访问控制仅限于会话级别 —— 即工具要么可访问,要么完全受限。虽然未来可能会出现更精细的授权机制,但目前的方法依赖基于 OAuth 2.1 的授权流程,一旦认证成功即授予整个会话的访问权限。随着智能体和工具数量增加,系统复杂性随之提高 —— 每个智能体通常需要独立会话和唯一授权凭证,造成基于会话的访问管理网络不断扩大。
网关
随着 MCP 采用规模的扩大,网关可作为集中化层,负责认证、授权、流量管理和工具选择。与 API 网关类似,它将执行访问控制、将请求路由到适当的 MCP 服务器、处理负载均衡,并缓存响应以提高效率。这在多租户环境中尤为重要,因为不同用户和智能体需要不同权限级别。标准化网关将简化客户端 - 服务器交互,增强安全性,并提供更好的可观测性,使 MCP 部署更具可扩展性和可管理性。
MCP 服务器的可发现性和可用性
目前,查找和设置 MCP 服务器仍是一个手动过程。开发者需要定位端点或脚本、配置认证,并确保服务器与客户端之间的兼容性。集成新服务器不仅耗时较长,而且 AI 智能体无法动态发现或适应可用的服务器。
不过,根据 Anthropic 上个月在 AI 工程师大会上的演讲,他们似乎正在开发一套 MCP 服务器注册表 (server registry) 和发现协议 (discovery protocol)。这项技术可能将为 MCP 服务器的应用推广开启崭新阶段。
执行环境
大多数 AI 工作流程需要按顺序执行多个工具调用,但 MCP 缺乏内置的工作流概念来管理这些步骤。要求每个客户端都实现可恢复性和可重试性是不理想的。尽管目前开发者正在尝试使用 Inngest 等解决方案来实现这一功能,但将有状态执行提升为一级概念将能为大多数开发者简化执行模型。
标准客户端体验
开发者社区经常提出的一个问题是:在构建 MCP 客户端时如何考虑工具选择 —— 是否每个开发者都需要为工具实现自己的 RAG,还是有一个等待标准化的层?
除了工具选择外,目前还没有统一的工具调用 UI/UX 模式(从斜杠命令到纯自然语言的各种方式都存在)。一个用于工具发现、排序和执行的标准客户端层可以帮助创建更可预测的开发者和用户体验。
调试
MCP 服务器的开发者经常发现,让同一个 MCP 服务器轻松地跨客户端工作是很困难的。通常情况下,每个 MCP 客户端都有自己的特性,而客户端跟踪要么缺失要么难以找到,这使得调试 MCP 服务器成为一项极其困难的任务。随着越来越多远程优先的 MCP 服务器被构建,需要一套新的工具来使开发体验在本地和远程环境中更加流畅。
AI 工具的影响
MCP 的开发体验让人联想到 2010 年代的 API 开发。这种范式虽然新颖且令人兴奋,但其工具链仍处于早期阶段。如果展望几年后,假设 MCP 成为 AI 驱动工作流的事实标准,会发生什么?以下是一些预测:
- 以开发者为中心的公司竞争优势将从最佳 API 设计转向提供最优工具集。若 MCP 能自主发现工具,API 提供商需确保其工具易于被发现,并具备差异化特性,使智能体能为特定任务选择它们。
- 当每个应用都成为 MCP 客户端、每个 API 都成为 MCP 服务器时,将出现新定价模式:智能体会基于速度、成本和相关性动态选择工具。这可能使工具采用过程更市场化,优先选择性能最佳和模块化的工具。
- 文档将成为 MCP 基础设施的关键,企业需设计具有清晰、机器可读格式的工具和 API,使 MCP 服务器成为基于现有文档的事实性产物。
- 仅有 API 还不够,但可作为良好起点。工具与 API 的映射很少是一对一关系。工具是更高层次的抽象,智能体可能选择包含多个 API 调用以最小化延迟的函数。MCP 服务器设计将以场景和用例为中心。
- 若软件默认成为 MCP 客户端,将出现新的托管模式。每个客户端本质上都是多步骤的,需要可恢复性、重试和长时间运行任务管理。托管提供商需跨不同 MCP 服务器进行实时负载均衡,优化成本与性能。
MCP 正在重塑 AI 智能体生态系统,而下一阶段的发展将取决于如何应对其基础性挑战。若实施得当,MCP 有望成为 AI 与工具交互的标准接口,并开创自主、多模态且深度整合的新一代 AI 体验。
如果 MCP 获得广泛应用,它将从根本上改变工具的构建、使用和商业化方式。业内专家正密切关注市场将如何引导 MCP 的发展方向。
今年将是决定性的一年:我们是否会看到统一的 MCP 市场崛起?AI 智能体的身份验证是否能实现无缝对接?多步骤执行能否被正式纳入协议标准?
#Uni-3DAR
Uni-3DAR用自回归统一微观与宏观的3D世界,性能超扩散模型256%,推理快21.8倍
从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。如何准确且高效地构建 3D 模型、理解和生成 3D 世界正在成为 AGI、AI for Science、具身智能三大 AI 热门领域共同关注的焦点。而随着 AI 技术的发展,大型语言模型(LLM)与大型多模态模型(LMM)那强大的自回归下一 token 预测能力也已经在开始被用于创建和理解 3D 结构。基于此,我们看到了 AI for Science 的新可能。
近日,一个开创性的此类大模型诞生了!
它名为 Uni-3DAR,来自深势科技、北京科学智能研究院及北京大学,是一个通过自回归下一 token 预测任务将 3D 结构的生成与理解统一起来的框架。据了解,Uni-3DAR 是世界首个此类科学大模型。并且其作者阵容非常强大,包括了深势科技 AI 算法负责人柯国霖、中国科学院院士鄂维南、深势科技创始人兼首席科学家和北京科学智能研究院院长张林峰等。
柯国霖在 𝕏 上分享表示:Uni-3DAR 的核心是一种通用的粗到细 token 化方法(coarse-to-fine tokenization),它能将 3D 结构转化为一维的 token 序列。

- 论文标题:Uni-3DAR: Unified 3D Generation and Understanding via Autoregression on Compressed Spatial Tokens
- 论文地址:https://arxiv.org/abs/2503.16278
- 项目主页:https://uni-3dar.github.io
- 代码仓库:https://github.com/dptech-corp/Uni-3DAR
基于这套通用的 token 化方法,Uni-3DAR 使用自回归的方式,统一了 3D 结构的生成和理解任务。大量实验表明,Uni-3DAR 在分子生成、晶体结构生成与预测、蛋白结合位点预测、分子对接和分子预训练等多个任务中均取得了领先性能。尤其在生成任务中,相较于现有的扩散模型,其性能实现了高达 256% 的相对提升,推理速度提升达 21.8 倍,充分验证了该框架的有效性与高效性。此外,此模型不仅可以用在微观的 3D 分子,也可以用到宏观的 3D 任务上,具备跨尺度的能力。
具体来说,Uni-3DAR 解决了 3D 结构建模里的两个痛点:
第一,数据表示不统一。当前的 3D 结构存在多种表示方式,尤其在不同尺度下差异显著。宏观结构常用点云、网格(Mesh)等表示方式,而微观结构则多采用原子坐标或图结构。这些表示方式的差异导致建模思路截然不同。即使在同一尺度,由于数据特性的差异,不同类型的结构(如晶体、蛋白质、分子)也往往采用各自专用的表示与模型,难以兼容。这种表示上的割裂严重限制了模型的通用性,也阻碍了构建可借助大规模数据训练的通用基础模型的可能性。
第二,建模任务不统一。 3D 结构相关任务可分为生成和理解两大类,但它们各自独立发展。生成任务多依赖扩散模型,从随机噪声逐步合成稳定结构,而理解任务则主要基于无监督预训练方法。相比之下,大型语言模型(LLM)已通过自回归方式成功实现了生成与理解任务的统一,但这种统一范式在 3D 结构建模领域仍然鲜有尝试。若能借助自回归方法统一 3D 任务建模,不仅有望打通理解与生成的界限,更可能将 3D 结构纳入多模态大语言模型的处理范式,继图像和视频之后成为 LLM 可理解的新模态,为构建面向物理世界的通用多模态科学模型奠定基础。

Uni-3DAR 整体架构
下面我们具体解读下这篇论文的两个核心技术。
Compressed Spatial Tokens统一微观与宏观 3D 结构
3D 结构在微观(如原子、分子、蛋白质)和宏观(如物体整体、力学结构)层面均表现出显著稀疏性:大部分空间为空白,只有局部区域含有重要信息。传统的全体素网格表示计算资源消耗巨大,无法利用这种稀疏性。
为此,Uni-3DAR 提出了一种层次化、由粗到细的 token 化方法,实现了数据的高效压缩和统一表示,既适用于微观也适用于宏观 3D 结构建模,为后续的自回归生成与理解任务提供了坚实基础。

1. 层次化八叉树压缩
该方法首先利用八叉树对整个 3D 空间进行无损压缩。具体做法是从包含整个结构的一个大格子开始,针对非空格子(即包含原子或其他结构信息的区域),递归地将其均分为 8 个等大小的子单元。经过多层细分后,形成一个由粗到细的层次结构,其每一层的 token 不仅记录了区域是否为空,还保留了该区域的空间位置信息(由所在层次及格子中心坐标确定),为后续的自回归生成提供了明确的空间先验。
2. 精细结构 token 化
虽然八叉树可以有效压缩空白区域,但它仅提供了粗粒度的空间划分,无法捕捉到诸如原子类型、精确坐标(在微观结构中)或物体表面细节(在宏观结构中)等重要信息。
为此,该团队在最后层非空区域内进一步引入了「3D patch」的概念 —— 类似于图像领域中的 2D patch 的处理。通过将局部结构细节进行离散化(例如采用向量量化技术),将连续的空间信息转化为离散的 token。
这样一来,无论是描述微观尺度下单个原子的信息,还是刻画宏观尺度下物体表面的细节,都能以同一形式进行表示。
3. 二级子树压缩
由于即使在八叉树结构下,token 数量仍可能较多,该方法进一步提出了二级子树压缩策略。具体来说,将一个父节点及其 8 个子节点的信息合并为一个单一的 token(利用父节点固定状态以及子节点的二值特征,共可组合成 256 种状态),从而将 token 总数约降低 8 倍。这不仅大幅提高了计算效率,也为大规模 3D 结构的高效建模提供了可能。
综上,该方法充分利用了 3D 结构固有的稀疏性,通过八叉树分解、精细 token 化与二级子树压缩,不仅大幅降低了数据表示的复杂度,而且实现了从微观到宏观 3D 结构的统一表示,为后续自回归生成与理解任务提供了高效、通用的数据基础。
Masked Next-Token Preiction统一生成和理解的自回归框架
在传统自回归模型中,token 的位置是固定的 —— 例如在文本生成中,第 i 个 token 后总是紧接着第 i+1 个 token,因此下一个 token 的位置可以直接推断,无需显式建模。
然而,在该论文提出的粗到细 3D token 化方法中,token 是动态展开的,其位置在不同样本间存在较大变化;如果不显式提供位置信息,自回归预测的难度将大大增加。为此,该论文提出了 Masked Next-Token Prediction 策略。

具体而言,该方法对每个 token 复制一份,确保两个副本具有相同的位置信息,然后将其中一个副本替换为 [MASK] token。在自回归预测过程中,由于被掩码 token 与目标 token 的位置信息完全一致,模型能够直接利用这一明确的位置信息来预测下一个 token 的内容,从而更精确地捕捉下一个 token 的位置特征,提高预测效果。尽管复制 token 使序列长度翻倍,但实验结果表明,该策略显著提升了性能,而推理速度仅下降 15% 至 30%。
基于 Masked Next-Token Prediction,该论文构建了一个统一的自回归框架,使得 3D 结构的生成与理解任务能够在单一模型内同时进行。
具体来说,生成任务(包括单帧与多帧生成)在被掩码的 token 上执行,利用自回归机制逐步构建结构;token 级理解任务(如原子级属性预测)则依托精细结构 token 进行;而结构级理解任务则引入了一个特殊的 [EoS](End of Structure) token,用于捕捉整体结构的全局信息。
此设计使不同任务对应的 token 在模型内部彼此独立、互不干扰,从而支持联合训练。同时,自回归特性也便于将其他模态数据(例如自然语言文本、蛋白质序列、仪器信号等)统一到单个模型,进一步提升模型的泛化能力和实用性。
实验结果
该论文在微观 3D 结构领域设计了一系列任务,包括分子生成、晶体结构生成与预测、蛋白结合位点预测、蛋白小分子对接以及基于预训练的分子性质预测。
实验结果显示,在生成任务中,Uni-3DAR 的性能大幅超过了扩散模型方法;而在无监督预训练的理解任务上,其表现与基于双向注意力的模型基本持平。这些成果充分证明,Uni-3DAR 不仅能统一不同类型的 3D 结构数据及任务,而且在效果和速度上均实现了显著提升。

3D 小分子生成任务性能

晶体结构预测,以及基于多模态信息(粉末 X 射线衍射谱)的晶体结构解析性能

蛋白结合位点预测效果

蛋白小分子对接效果

基于预训练的小分子属性预测效果,其中 Uni-Mol 和 SpaceFormer 也为深势科技提出的专用模型,Uni-3DAR 超过了 Uni-Mol,与 SpaceFormer 基本持平

基于预训练的高分子聚合物性质预测,其中 Uni-Mol 和 MMPolymer 也为深势科技提出的专用模型,Uni-3DAR 超过了 Uni-Mol,与 MMPolymer 基本持平
未来展望
目前,Uni-3DAR 的实验主要集中在微观结构领域,因此亟需在宏观 3D 结构任务中进一步验证其通用性和扩展性。
此外,为保证与以往工作的公平对比,当前 Uni-3DAR 在每个任务上均采用独立训练。未来的一个重要方向是融合多种数据类型与任务,构建并联合训练一个更大规模的 Uni-3DAR 基座模型,以进一步提升性能与泛化能力。
同时,Uni-3DAR 还具备天然的多模态扩展潜力。后续可以引入更多模态的信息,例如蛋白质序列、氨基酸组成,甚至结合大语言模型与科学文献知识,共同训练一个具备物理世界理解能力的多模态科学语言模型,从而为构建通用科学智能体打下基础。
#Cosmos-Reason1
推理延展到真实物理世界:8B具身推理表现超过OpenAI ο1
在基于物理世界的真实场景进行视觉问答时,有可能出现参考选项中没有最佳答案的情况,比如以下例子:
根据视频中本车的动作,它接下来最有可能立即采取的行动是什么?
A:右转,B:左转,C:换到右车道,D:换到左车道

很显然,这里最佳的答案应该是直行,但预先提供的 4 个选项中并没有这个答案。也因此,目前的大多数 AI 在面临这个问题时往往并不能识别题中陷阱,会试图从选项中找到正确答案。比如下面展示了 ChatGPT 的回答:

当然,在日常的视觉问答任务中,这样的错误无伤大雅,但一旦涉及到真实的任务场景(比如真正的自动驾驶),这样的错误就是无法容忍的了。
而要正确解答这类问题,物理常识必不可少。
近日,英伟达发布了一系列针对物理常识推理进行了专门优化的新模型:Cosmos-Reason1。从实际结果看,该模型的表现确实不错。比如针对以上问题,该模型经过一番推理后,认为给出的选项都不对,因此没有给出选择。

Cosmos-Reason1 针对以上视觉问答问题输出的思考过程和答案。
据介绍,Cosmos-Reason1 不仅包含模型,更是英伟达开发的一个包含模型、本体(ontologies)和基准的套件,其目标是让多模态 LLM 能够生成有物理依据的响应。
目前他们已经发布了两个多模态 LLM:Cosmos-Reason1-8B 和 Cosmos-Reason1-56B。
这两个模型都经过了四个阶段的训练:视觉预训练、通用 SFT、物理 AI SFT 和物理 AI 强化学习。此外,他们还为物理常识和具身推理定义了本体,并构建了用于评估多模态 LLM 的物理 AI 推理能力的基准。

下面我们就来具体看看英伟达的这项研究成果。

- 论文标题:Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
- 论文地址:https://arxiv.org/abs/2503.15558
- 代码地址:https://github.com/nvidia-cosmos/cosmos-reason1
,时长02:44
物理 AI 推理
物理 AI(Physical AI)并不是一个新概念,但肯定算是英伟达近段时间最为推崇的发展方向之一 —— 在黄仁勋前些天的 GTC 2025 大会 Keynote 演讲中,物理 AI 也是核心关键词之一。
根据英伟达官网的定义:物理 AI 是指使用运动技能理解现实世界并与之进行交互的模型,它们通常封装在机器人或自动驾驶汽车等自主机器中。
在今天介绍的这篇论文中,英伟达首先定义了物理常识(physical common sense)的本体论(ontology)。

可以看到,其中包含三大类别:空间、时间和其它基本物理。这三大类又被进一步分为 16 类,如下表 1 所示。

此外,该团队也定义了具身推理的本体论,其中涉及处理复杂的感官输入、预测动作效果、尊重物理约束、从互动中学习;详见下表。

Cosmos-Reason1
下面将介绍 Cosmos-Reason1 的多模态架构以及 LLM 主干选择。
多模态架构
为了构建多模态 LLM,现在已经有多种不同的架构选择。常用的架构是仅解码器架构(例如 LLaVA)和基于交叉注意力的架构(例如 Flamingo 和 Llama 3-V)。
英伟达采用了类似于 LLaVA 和 NVLM-D 的仅解码器架构,因为它简单且可通过将其它模态 token(图像或视频)对齐到文本 token 嵌入空间来统一处理所有模态。
具体来说,该模型的架构首先是一个视觉编码器,然后是包含下采样两层 MLP 的 projector,然后是仅解码器的 LLM 主干。

具体选择上,英伟达这里使用了 InternViT-300M-V2.5 作为 Cosmos-Reason1-8B 和 Cosmos-Reason1-56B 的视觉编码器。
对于每张输入图像,该架构会动态调整图像以达到预定义的宽高比,并将其分割成 1 到 12 个图块,每个图块的尺寸为 448 × 448 像素,具体取决于图像的分辨率。此外,还会生成一个缩略图图块 —— 完整图像的缩小版本,以保留全局上下文。
对于每段输入视频,则以最高每秒 2 帧的速率均匀采样最多 32 帧,并将每帧的大小调整为 448 × 448 像素。对于每个 448×448 视频帧输入,视觉编码器会生成 1,024 个视觉 token,其图块大小为 14×14,然后使用 PixelShuffle 将其下采样 2×2 倍,通过将空间维度转换为通道维度将其减少到 256 个 token。
来自多个图块的图像 token 与交错的图块 ID 标签连接在一起,而来自多个帧的视频 token 则会直接连接在一起。
Cosmos-Reason1 的 LLM 主干采用了混合 Mamba-MLP-Transformer 架构设计。
表 3 总结了其模型配置:

混合 Mamba-MLP-Transformer 主干
最近英伟达发布了不少 Mamba-Transformer 混合架构的研究成果,事实上我们昨天就正巧介绍过其中两个:Nemotron-H 和 STORM。参阅报道《腾讯混元、英伟达都发混合架构模型,Mamba-Transformer 要崛起吗?》
而今天我们介绍的 Cosmos-Reason1 系列模型则采用了 Mamba-MLP-Transformer 混合架构,如下图所示。

在训练时,Cosmos-Reason1-8B 模型采用了 4 的张量并行化(TP=4),而 Cosmos-Reason1-56B 模型则采用了 8 的张量并行化和 2 的管道并行化(TP=8, PP=2)—— 可支持更长视频的训练。
实验表现
下面我们简单看看 Cosmos-Reason1 系列模型的实验表现。有关实验的更多详细设置和讨论请阅读原论文。
物理 AI 监督式微调的效果
首先来看经过物理 AI 监督式微调后,Cosmos-Reason1 的物理常识表现。如表 7 所示,Cosmos-Reason1-8B 和 Cosmos-Reason1-56B 在各自的主干网络基础上都有明显提升,其中 56B 版本的准确度表现最好,甚至略微超过了 OpenAI ο1。

要知道,这个结果是在强化学习训练之前取得的。这彰显了该团队精心挑选的常识数据集的有效性,为进一步的 RL 改进奠定了坚实的基础。
接下来看看经过物理 AI 监督式微调后,Cosmos-Reason1 的具身推理表现。从表 8 可以看到,Cosmos-Reason1 模型在此基准上取得了比所有基线模型明显更好的结果,8B 和 56B 变体与各自的主干 VLM 相比均有超过 10% 的提升。

那 Cosmos-Reason1 的直觉物理理解能力如何呢?该团队观察到,许多 VLM 在基本物理推理方面存在困难。该团队针对三个任务对模型的能力进行了测试,包括时间箭头、空间拼图和物体持久性。
表 10 展示了测试结果,可以看到在时间箭头和物体持久性任务上,现有模型的表现和胡乱猜测差不多。而在空间拼图任务上,GPT-4o 和 OpenAI o1 的表现却比随机乱猜好得多。

这表明当前的多模态模型在推理空间关系方面比推理时间动态方面更熟练。鉴于这些模型通常在 MMMU 等标准基准上表现良好,这说明现有评估其实无法体现它们对物理世界的理解能力。
然而,该团队精心设计的直觉物理数据集可使 8B 模型能够在所有三个任务上有显著提升,就展现 Cosmos-Reason1 在直觉物理推理方面的基本能力。
物理 AI 强化学习的效果
对于上面得到的模型,该团队又进行了进一步的后训练,以进一步增强它们的物理 AI 推理能力。为此,该团队构建了自己的 RL 基础设施,并基于其针对物理常识、具身推理和直觉物理推理任务对模型进行了后训练。注意,这里并没有使用复杂奖励,都是简单的、基于规则的可验证奖励。
首先来看在物理常识和具身推理任务上的结果,如表 9 所示。

可以看到,物理 AI RL 后训练可以提高模型在大多数基准上的性能,但 RoboFail 是个明显的例外。
不过该团队表示这并不奇怪,因为 RoboFail 是经过精心设计的人工整编的基准,具有测试「动作可供性(action affordance)」和「任务完成验证」的高难度现实场景。该基准的难度源于几个因素:(1) 需要高度观察的感知或全面的时间上下文处理的样本,(2) 与 RoboVQA 中的问题不同,可供性问题涉及动作执行中的复杂物理约束。
该团队认为,在 RoboFail 上的表现不提升的主要原因是代表性训练数据不足。
该团队还发现了一个有趣现象:新提出的模型学会了仔细评估所提供的选项,如果问题不明确,则会全部拒绝。如本文开始时举的例子所示,该模型会评估每个选项的可行性,并在出现歧义时采取不在选择范围内的保守行动。
最后,在直觉物理推理任务上,如上表 10 所示,通过精心的监督式微调数据整编和针对性训练,Cosmos-Reason1-8B 在所有任务上都取得了显著的进步,而物理 AI RL 能够进一步增强模型的空间拼图和物体持久性能力。然而,推理时间箭头仍然很困难。
整体来说,物理 AI RL 可以提升模型在空间、时间和物体持久性方面的推理能力。
图 9 展示了在 RL 前后 Cosmos-Reason1 的时间推理能力的差异。可以看到,该模型能够识别反物理的运动 —— 例如粉末违背重力上升到碗中,同时不受视频中静止干扰物的影响。这表明它的推理不仅仅是感知。

类似地,在图 10 中可以看到,有 RL 的模型倾向于将空间问题与时间推理混淆。虽然他们可以感知到第二帧与第一帧缺乏相似性,但它们固有的偏见会导致它们遵循默认的视频顺序,这表明它们更多地依赖于时间线索而不是真正的空间理解。

使用空间谜题来进行 RL 可让模型从第一帧中提取关键特征,并在多帧之间系统地比较它们,从而准确地确定空间关系。
最后,图 11 表明,即使 CoT 较长,没有物理 AI RL 的模型也会难以理解物体持久性,经常难以推理物体的出现和消失。相比之下,经过 RL 的模型可通过直接而简洁的推理快速得出结论。

参考链接
https://www.nvidia.cn/glossary/physical-ai/
https://research.nvidia.com/labs/dir/cosmos-reason1/
#Personalize Anything for Free with Diffusion Transformer
挖掘DiT的位置解耦特性,Personalize Anything免训练实现个性化图像生成
本文的主要作者来自北京航空航天大学、清华大学和中国人民大学。本文的第一作者为清华大学硕士生封皓然,共同第一作者暨项目负责人为北京航空航天大学硕士生黄泽桓,团队主要研究方向为计算机视觉与生成式人工智能。本文的通讯作者为北京航空航天大学副教授盛律。
个性化图像生成是图像生成领域的一项重要技术,正以前所未有的速度吸引着广泛关注。它能够根据用户提供的独特概念,精准合成定制化的视觉内容,满足日益增长的个性化需求,并同时支持对生成结果进行细粒度的语义控制与编辑,使其能够精确实现心中的创意愿景。随着图像生成模型的持续突破,这项技术已在广告营销、角色设计、虚拟时尚等多个领域展现出巨大的应用潜力和商业价值,正在深刻地改变着我们创造和消费视觉内容的方式。
然而当人们对个性化图像生成的期望不断上升时,传统的个性化图像生成方法面临着以下几个挑战:①细节还原瓶颈(如何更精准地还原物体细节,尤其是在多物体的情况下)② 交互控制难题(如何在进行个性化生成的同时,支持对物体位置等空间因素的精准控制)③ 应用拓展受限(如何将个性化和编辑统一在同一框架,以满足更多应用需求)。这些挑战严重制约着个性化图像生成技术的进一步突破,亟需构建更高效的生成框架。
因此,清华大学、北京航空航天大学团队推出了全新的架构设计 ——Personalize Anything,它能够在无需训练的情况下,完成概念主体的高度细节还原,支持用户对物体进行细粒度的位置操控,并能够扩展至多个应用中,为个性化图像生成引入了一个新范式。
总结而言,Personalize Anything 的特点如下:
- 高效的免训练框架:无需训练,具备较高的计算效率,仅需一次反演(inversion)和一次推理过程
- 高保真度与可控性:在保持高精度细节的同时兼顾了物体姿态的多样性,并支持位置控制
- 高扩展性:同时支持多种任务,包括多物体处理、物体与场景的整合、inpainting 和 outpainting 等
- 论文标题:Personalize Anything for Free with Diffusion Transformer
- 论文链接:https://arxiv.org/abs/2503.12590
- 项目主页:https://fenghora.github.io/Personalize-Anything-Page/
- 代码仓库:https://github.com/fenghora/personalize-anything
效果展示:无需训练,支持个性化、多物体组合、编辑
Personalize Anything 能够在多种任务上表现出色,可以对多组物体与场景进行组合,并同时自由控制主体位置,这是以往个性化图像生成模型难以做到的。

下面图像中依次展示了 Personalize Anything 在布局引导生成、inpainting、outpainting 三种任务上的表现。可以看到,Personalize Anything 在多种任务上都能够生成贴合文本的高质量图像。

技术突破:从 DiT 架构的新发现到个性化任意内容
个性化图像生成的传统方法通常需要对定制概念进行微调,或者在大规模数据集上进行预训练,这不仅消耗大量计算资源,还影响模型的泛化能力。最近,无需训练的方法尝试通过注意力共享机制来避免这些问题,但这些方法难以保持概念的一致性。此外,由于这些方法主要针对传统的 UNet 架构设计,无法应用于最新的 DiT 架构模型,导致它们无法应用在更大规模和更好效果的图像生成模型上。
注意力共享机制不适用于 DiT 架构
在了解 Personalize Anything 技术细节前,先来看看为什么传统无需训练的方法不能够应用在 DiT 架构的图像生成模型上。

如上文所述,传统无需训练的方法多通过注意力共享机制,也就是在运算自注意力时,将概念图像特征直接与生成图像特征进行拼接,但是经由团队实验发现,对于 DiT 架构而言,由于位置编码的影响,当去噪图像和参考图像共用同一套位置编码时,会导致过度关注,从而在生成的图像中产生重影(图 a);当调整参考图像的位置编码避免冲突时,生成图像的注意力几乎不出现在参考图像中,导致主体一致性较弱(如图 b 和图 c),这限制了传统方法在 DiT 架构上的应用。
通过上述实验发现,DiT 中显式编码的位置信息对其注意力机制具有强烈影响 —— 这与 U-Net 隐式处理位置的方式存在根本差异。这使得生成的图像难以在传统的注意力共享中正确地关注参考对象的标记。
DiT 架构的新启发:标记替换引发主体重建

基于对 DiT 架构显式位置编码的认识,团队继续对 DiT 的特征表示进行了探索。团队发现,将参考图像未带位置编码的标记替换进去噪图像的指定位置,能够重建出良好的主体图像。而传统 Unet 架构所具有的卷积操作会导致位置编码与图像特征混杂在一起,导致在进行特征替换时影响最后的图像质量。
这一发现使团队意识到,简单但有效的特征替换,对于 DiT 架构而言是一个可行的个性化图像生成方法。
定制任意内容:时间步适应替换策略与特征扰动

基于上述发现,团队将特征替换引入个性化图像生成方法中,并创新地提出了时间步适应标记替换机制 (Timestep-adaptive Token Replacement) 。
在整个流程中,首先对参考图像进行反演,并通过 mask 获取参考图像未带位置编码的标记。在去噪过程的早期阶段,为了保留物体特征细节,将参考图像主体的标记直接替换进生成图像中。而在后期,则转为传统的注意力共享机制。这种时间适应特征替换机制能够增图像生成后概念主体的多样性,同时减少生成图像的割裂感。
为了进一步保证概念主体姿态的多样性,团队又额外提出了特征扰动,旨在通过对概念图像特征进行重排,或者调整 mask,来控制特征替换时的概念图像特征代表的物体姿态等,从而为生成的图像引入多样性。
更多应用:无缝扩展至布局引导、多物体组合、编辑等

Personalize Anything 除了在核心任务上表现出色,还具有强大的扩展能力,可以应用于更复杂的实际场景。首先,可以通过自由选择特征注入的位置,来实现位置引导的生成;其次,框架支持对多物体进行自由组合,采取顺序注入的方式,支持物体间层级关系的控制;并且 Personalize Anything 支持用户将将图像视为整体,允许用户保留部分图像内容,同时对另一部分进行可控编辑。这种灵活的可扩展性为未来的研究和应用开辟了更为广阔的前景。
卓越性能:在保真度和多功能性等多个维度上表现突出
团队从单物体定制,多物体组合,物体 - 场景组合这三个任务入手,与众多优秀的开源模型进行定性定量的对比。可以看到 Personalize Anything 的结果基本都优于现有方法,并在后续的人类偏好测试中取得了显著优势。
单物体个性化生成



多物体组合生成



物体 - 场景组合


未来展望
Personalize Anything 研究团队揭示了 DiT 中位置解耦表示的性质,为免训练的图像空间操纵、个性化生成奠定基础。团队期待 DiT 的几何编程原理能够进一步拓展到视频、3D 生成等领域,实现更复杂、更精细的场景构建与编辑。希望通过深入研究和广泛应用,让这一思路激发更多可控生成的研究,推动 AI 在创意内容生成、虚拟现实、数字孪生等领域的广泛应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









