







我自己的原文哦~ https://blog.51cto.com/whaosoft/12206500
#纯视觉方案的智驾在大雾天还能用吗?
碰上大雾天气,纯视觉方案是如何识别车辆和障碍物的呢?
如果真的是纯纯的,特头铁的那种纯视觉方案的话。
可以简单粗暴的理解为:人眼不行的,机器也不行。

但是,现下,应该还没有如此100%纯度的纯视觉。
即便头铁如特斯拉,虽然取消的了雷达和超声波传感器。
但是在视觉传感器上疯狂做假发,而且依然保留的一定的冗余,来补上视觉的局限。
更准确的说,不应该叫纯视觉,而应该叫视觉优先。
这样,在大雾天。如果非得开,还能开一开。
优先级最大的摄像头系统,料堆得最满。
- 前置主摄像头:
负责捕捉前方远距离的视野,识别车辆、道路标志和路况。
- 广角摄像头:
捕捉前方的广角视野,尤其适合识别近距离的物体,比如停靠车辆和交叉路口的动态情况。
- 侧面摄像头:
布置在车辆两侧,用于监控车道变换、盲区检测和周围车辆的动态。后视摄像头:负责监控车辆后方的状况,辅助倒车以及识别后方来车。
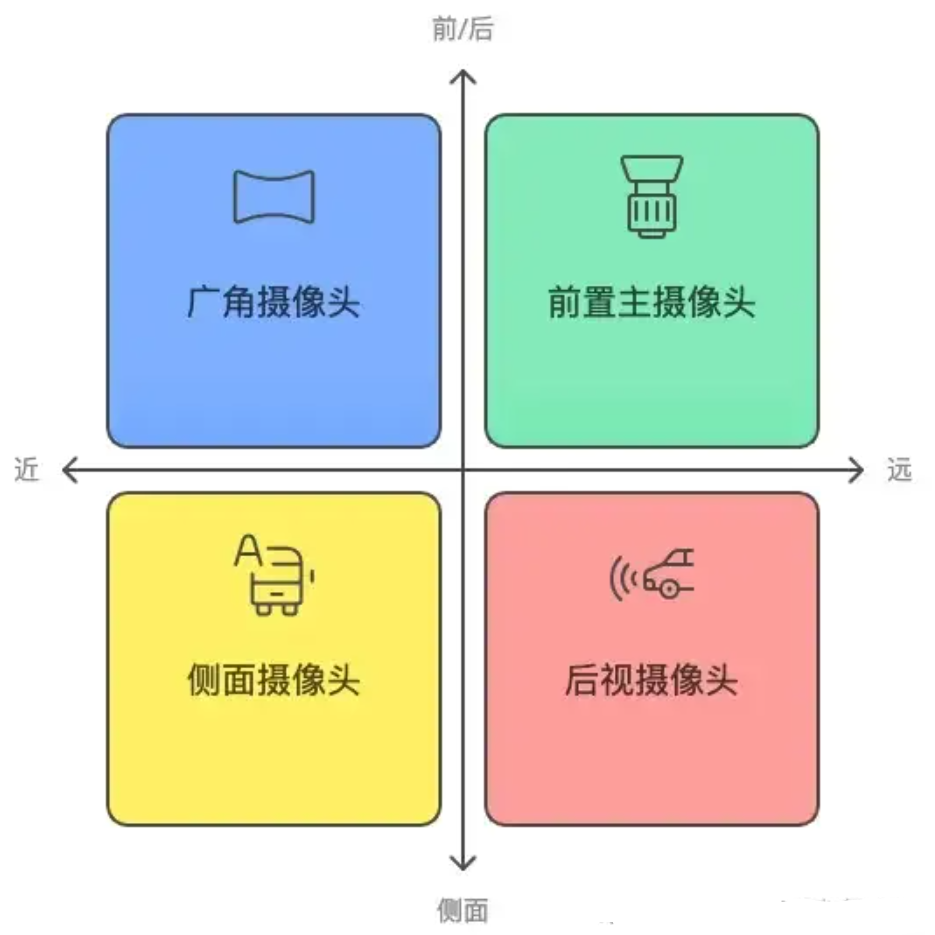
基本上,覆盖了所有该看的地方和角度。
然后,在某些瞬间失明或者视力下降的时候,还有一些传感能够暂时提供参考信息。
- GPS和高精度地图(GPS & High-Precision Maps):
GPS结合高精度地图数据,车辆能够确定自己的定位,识别出所在道路的限速、地形和路线结构。
- 惯性测量单元(IMU):
用来感知车辆的姿态、加速度和转向等信息。
这些数据帮助车辆在复杂的驾驶条件下保持平衡,并提供精确的动态反馈。
视觉优先,其实也更接近人类驾驶是的感知-规划-决策-执行的模式。
人虽然大部分的信息摄入来自于眼睛。
但是对于行动的决策判断,还有耳朵听到的,身体发肤感受到的,以及莫名其妙的第六感。
综合起来构筑起一个立体的信息。

视觉优先,今后的路应该不是走摄像头这一根独木桥。应该是如何接近
更像一个人的感知系统
把视觉之外的,哪些信息。
尽量通过不做加法的方式,给逆向仿生出来。
也许,有一天AI真的可以把驾驶这件事也给“暴力破解”了吧。
先问个问题,作为一名老司机的您,正常情况下敢在大雾天开车吗?
而纯视觉方案的智能驾驶也是一样的!
最近看到国外媒体做了一个有趣的试验:
用一辆洒水车在前面向跟在后面的车猛烈洒水,干扰其摄像头,然后突然闪开,露出车道上的模拟障碍物。而特斯拉发生了碰撞,这就证实了纯视觉系统的局限性。即确实存在看不见导致来不及反应的时候。

常规遇到这种情形,比如进入雾区或雨区,能见度变差,系统通常会先根据视觉所能观察到的距离适配行驶速度,也就是减速,并提示驾驶者接管车辆。
如果超出报警时间仍无人接管,处理方式与驾驶者长时间方向盘脱手一样————激烈报警和逐渐停车。这是在当前法规仅允许智能驾驶起辅助作用,且厂家不为辅助驾驶时发生的事故承担交通安全的主要法律责任,责任主体依然在驾驶者的情况下。
系统所做的一切操作都旨在尽量保证安全并免除厂商潜在的民事责任。
纯视觉方案,其实更接近人类驾驶是的感知-规划-决策-执行的模式。
人虽然大部分的信息摄入来自于眼睛。
但是对于行动的决策判断,还有耳朵听到的,身体发肤感受到的,以及莫名其妙的第六感。
综合起来构筑起一个立体的信息。
而纯视觉方案今后的路应该也不是走摄像头这一根独木桥。应该是如何接近,更像一个人的感知系统。
目前在纯视觉方案里面,特斯拉的体验是最好的。那么看看特斯拉是如何做的
特斯拉在智能驾驶方面遵循的是一种底线思维模式,也就是试探硬件少得不能再少的底线在哪里。
这就反过来促使研发团队在测试和软件开发上竭尽全力,让软件能力最大化地把硬件的作用发挥出来。
而一些十分特殊的场景,则可以用概率算法去压缩它发生的范围。只要不遇到极端情况,其使用体验就是好的,而且可以保证单车低成本、高利润率。
但这并没有消除“看不见”这个局限性,只是把因此而导致系统完全不能发挥作用的场景压缩到极致的、极少的场景。
对整车厂来说,智能驾驶竞争在软件,不在硬件。因为硬件都是供应商制造的,只要花钱采购都能得到。
而如何应用这些硬件,决定了竞争胜负。
比如击剑比赛,比的不是剑,而是运动员的剑术。特斯拉的策略就是把剑术练到家,方法就是用尽量少,尽量简单的硬件去修炼软件功夫。
当它达到高水平时,再升级装备就会更加显著地体现出竞争优势。而且,可尽量保持硬件上相对更低的成本。

这里要避免一个误解,就是认为特斯拉的智能驾驶就是最强的,放在哪里都最强。事实不是这样的。它在中国的体验效果就不如在美国。
自动驾驶系统非常依赖在使用当地的训练。特斯拉在美国本土的训练要比在中国相对完备得多,因此体验更好,开放使用的功能更深。
能用,但是不好用。
纯视觉方案的先天不足就是在应对恶劣环境时不好用,在当下智能驾驶只是作为辅助驾驶时,这种缺陷尚且可以克服。但是随着智能驾驶技术成熟,在未来走向无人驾驶的终极目标时,纯视觉的这种先天不足将会成为难以跨越的天堑。这也是我不看好特斯拉FSD的最主要原因。
余承东曾经点评过FSD,认为其“上限很高,下限很低。”我觉得这说到了纯视觉方案的根本缺陷。美国发生的很多FSD导致人员伤亡的案例,也证明了其安全性能不足的问题很严重。
就拿大雾天来说,这是很正常的一种气象,早晚时段都可能起雾。人类在大雾中可以谨慎缓慢行驶来克服,智能驾驶遇到大雾天气,采用谨慎缓行的策略也可以通行,其表现并不会比人类司机更好。人类驾驶员在这种大雾天气容易出现交通事故,纯视觉方案也容易出现交通事故,这就是纯视觉方案下限很低的重要原因。

而加上了激光雷达和毫米波雷达的智能驾驶可以更好地了解周边道路环境,可以看得更远,看得更清楚,即使在大雾中也可以挥洒自如,而且安全性能好得多,其高下优劣一眼可辨。这就是激光雷达方案的智能驾驶下限很高的主要原因。

更何况,智能驾驶要面对的恶劣环境还有很多,暴雨,暴雪,雾霍,烟雾,沙尘暴等恶劣天气都是纯视觉方案难以克服的缺陷,纯视觉方案很难真正摆脱人类驾驶员做到无人驾驶,注定是没有出路的。
大雾天开车,简直是雾里看花,花里胡哨,让人心里没底。不过,随着技术的发展,特别是自动驾驶技术的进步,即便是在这样的天气条件下,我们的车辆也能做到眼观六路,耳听八方,这背后靠的就是一些高科技的视觉方案。今天咱们就聊聊,这些纯视觉方案是怎么在大雾天识别车辆和障碍物的。
说到底,现在的自动驾驶汽车,特别是那些号称纯视觉方案的家伙,它们就像是拥有了“火眼金晴的孙悟空,即使是在雾气蒙蒙的情况下,也能准确地识别出前方的车辆和其他障碍物。这得归功于一系列先进的算法和技术,比如深度学习、图像处理以及多传感器融合等,它们就像是一套组合拳,让车辆能在复杂环境中稳操胜券。
拿图像去雾算法来说吧,这玩意儿就像是给相机装上了吸尘器,能把图像里的“灰尘”一也就是那些因雾气造成的模糊感,清除得干干净净。这样一来,即使是在大雾弥漫的路上,摄像头捕捉到的画面也会清晰许多,使得后续的目标检测变得更加容易。
当然,图像去雾只是第一步,接下来就是让这些处理过的图像派上用场了。这时候,就得说到YOLO这样的目标检测算法了。YOLO,全名You Only Look Once,听着就像是在说:“看一眼就够了!”这种算法能够一次性处理整张图片,而不是像传统方法那样,先选出可能含有目标的区域再逐一检查。这样不仅速度快,而且在处理动态变化的环境时也更加灵活。举个例子,当一辆车在雾中快速驶来,YOLO能够迅速识别出它的位置,并及时做出反应,确保安全。
不过,话说回来,虽然YOLO等算法在正常天气下已经相当厉害了,但在恶劣天气中,比如大雾,它们也会遇到挑战。这时候,就轮到多模式传感器融合登场了。简单来说,就是把不同类型的传感器,比如激光雷达(LiDAR)和雷达(RADAR),以及摄像头的信息结合起来,相当于给车辆配备了一套全方位的“感官系统”。激光雷达在短距离内能够提供非常精确的三维信息,而雷达则在远距离探测方面表现出色,尤其是穿透力强,不易受天气影响。这样一来,即便是在大雾中,车辆也能通过这些传感器获取到周围环境的详细信息,再结合视觉数据,使得检测更加准确可靠。
当然,除了硬件设备外,软件算法也在不断进化。比如说,有些团队就在尝试通过深度学习的方法,让车辆学会在不同天气条件下调整自己的'视力”。这就像是给我们的眼睛加上了智能调光功能,无论是在晴天还是雾天,都能自动调节到最佳状态。这样一来,即便是突然遭遇浓雾,车辆也能迅速调整策略,确保行驶安全。
还有一些挺创新的技术,就比如说VESY传感器。它把雾天图像帧的显著性映射和目标检测算法YOLO 的输出融合到了一起,给实时应用提供了一种可行的办法。这种做法就好像是给车辆装上了“夜视仪”似的,就算是在能见度特别低的情况下,也能看清前方的障碍物。
在大雾天气下,纯视觉方案并不是孤立作战,而是通过一系列的算法优化、多传感器信息融合以及硬件升级等多种手段,共同保障了车辆的安全行驶。这就好比是一支乐队,只有各个乐器协调一致,才能演奏出美妙的音乐。同样,只有各项技术紧密配合,才能在复杂环境中确保车辆平稳前行。当然了,尽管技术越来越先进,但毕竟人命关天,在恶劣天气条件下,我们还是要保持警惕,毕竟技术再好,也不能完全替代人的判断力和应急反应能力!
下次遇到大雾天开车,虽然咱们心里可能还是会有些志忑,但至少知道背后有一整套强大的技术支持,让我们的出行更加安心。当然了,安全第一,任何时候都不能放松警惕,毕竟技术虽好,但最终还是人为本!
#Manipulate-Anything
操控一切! VLM实现真实世界机器人自动化
原标题:Manipulate-Anything: Automating Real-World Robots using Vision-Language Models
论文链接:https://robot-ma.github.io/MA_paper.pdf
项目链接:https://robot-ma.github.io/
作者单位:华盛顿大学 圣巴勃罗天主教大学 艾伦人工智能研究所 NVIDIA
MANIPULATE-ANYTHING解决了什么?
大规模项目如RT-1以及社区广泛参与的项目如Open-X-Embodiment已经为扩展机器人演示数据的规模做出了贡献。然而,仍然存在提升机器人演示数据质量、数量和多样性的机会。尽管视觉-语言模型已经被证明可以自动生成演示数据,但它们的应用仅限于具有特权(privileged)状态信息的环境中,并且需要手工设计的技能,同时只限于与少量物体实例的交互。本文提出了MANIPULATE-ANYTHING,一种用于真实世界机器人操作的可扩展自动生成(scalable automated generation)方法。与以往的工作不同,本文的方法无需特权(privileged)状态信息或手工设计的技能,能够在真实环境中操作任何静态物体。在两个设置下对本文的方法进行了评估。首先,MANIPULATE-ANYTHING 成功生成了所有7个真实世界任务和14个仿真任务的轨迹,显著优于现有方法如VoxPoser。其次,MANIPULATE-ANYTHING生成的演示数据相比人类演示数据或VoxPoser、Scaling-up以及Code-As-Policies生成的数据,能够训练出更稳健的行为克隆策略。我们相信,MANIPULATE-ANYTHING 可以成为一种可扩展的方法,既能为机器人生成数据,也能在零样本环境下解决新任务。
MANIPULATE-ANYTHING的设计
现代机器学习系统的成功从根本上依赖于其训练数据的数量、质量和多样性。大规模互联网数据的可用性使视觉和语言领域取得了显著进展。然而,数据匮乏阻碍了机器人领域的类似进展。人类演示数据的收集方法难以扩展到足够的数量或多样性。像RT-1这样的项目展示了收集了17个月的高质量人类数据的实用性。其他研究则开发了用于数据收集的低成本硬件。然而,这些方法都依赖于昂贵的人类数据收集过程。
自动化数据收集方法在多样性上难以实现足够的扩展。随着视觉-语言模型(VLMS)的出现,机器人领域涌现了许多利用VLMS来指导机器人行为的新系统。在这些系统中,VLMS将任务分解为语言计划或生成代码以执行预定义技能。尽管这些方法在仿真中取得了一定成功,但在现实世界中的表现不佳。有些方法依赖于仅在仿真中可用的特权(privileged)状态信息,需要手工设计的技能,或者仅限于操作已知几何形状的固定物体实例。
随着视觉-语言模型(VLMs)性能的提升,以及它们展示出的广泛常识知识,我们是否能够利用它们的能力来完成多样化任务并实现可扩展的数据生成?答案是肯定的——通过精心的系统设计以及正确的输入和输出形式,我们不仅可以利用VLMs以零样本的方式成功执行多样化任务,还可以生成大量高质量的数据,用于训练行为克隆策略。
本文提出了MANIPULATE-ANYTHING,一种可扩展的自动化演示生成方法,用于真实世界中的机器人操作。MANIPULATE-ANYTHING能够生成高质量、大规模的数据,并且能够操作多种物体来执行多样化的任务。当被置于现实环境中并给定任务时(例如,图2中的“打开上层抽屉”),MANIPULATE-ANYTHING能够有效利用视觉-语言模型(VLMS)来指导机械臂完成任务。与之前的方法不同的是,它不需要特权(privileged)状态信息、手工设计的技能,也不局限于特定的物体实例。不依赖特权(privileged)信息使得MANIPULATE-ANYTHING能够适应各种环境。MANIPULATE-ANYTHING会规划一系列子目标,并生成相应的动作来执行这些子目标。它还可以使用验证器检查机器人是否成功完成了子目标,如有需要可以从当前状态重新规划。这种错误恢复机制使得系统能够识别错误、重新规划并从失败中恢复,并且将恢复行为注入到收集的演示数据中。本文还通过引入多视角推理,进一步增强了VLM的能力,显著提升了性能。
通过两个评估设置展示了MANIPULATE-ANYTHING的实用性。首先展示了它可以应对一个全新的、前所未见的任务,并以零样本的方式完成任务。本文在7个真实世界任务和14个RLBench仿真任务中进行了量化评估,并展示了在多个日常现实任务中的能力(详见补充材料)。在零样本评估中,本文的方法在14个仿真任务中的10个任务上显著优于VoxPoser。它还能推广到VoxPoser因物体实例限制而完全失败的任务中。此外,本文展示了该方法能够以零样本方式解决真实世界中的操作任务,任务平均成功率达到38.57%。其次展示了MANIPULATE-ANYTHING可以生成有用的训练数据,用于行为克隆策略的训练。将MANIPULATE-ANYTHING生成的数据与人工收集的真实演示数据以及VoxPoser、Scaling-up和 Code-As-Policies生成的数据进行比较。令人惊讶的是,基于本文数据训练的策略在12个任务中的5个任务上表现优于人工收集数据,并且在另外4个任务中表现相当(通过RVT-2评估)。与此同时,基准方法在某些任务上无法生成训练数据。MANIPULATE-ANYTHING展示了在非结构化的现实环境中大规模部署机器人的广泛可能性,同时也突显了其作为训练数据生成器的实用性,有助于实现扩大机器人演示数据规模这一关键目标。
图1:MANIPULATE-ANYTHING 是一种用于真实世界环境中机器人操作的自动化方法。与之前的方法不同,它不需要特权(privileged)状态信息、手工设计的技能,也不局限于操作固定数量的物体实例。它能够引导机器人完成多样化的未见任务,操纵不同的物体。此外,生成的数据可以用于训练行为克隆策略,其效果优于使用人类演示数据进行的训练。
图2:MANIPULATE-ANYTHING 框架。该过程首先将场景表示和自然语言任务指令输入到视觉-语言模型(VLM),模型识别出物体并确定子任务。对于每个子任务,本文提供多视角图像、验证条件和任务目标给动作生成模块,生成与任务相关的抓取姿势或动作代码。随后达到一个临时目标状态,子任务验证模块对其进行评估以进行错误恢复。当所有子任务完成后,本文对轨迹进行筛选,获得成功的演示数据,用于后续策略训练。
图3:MANIPULATE-ANYTHING 是一个开放词汇的自主机器人演示生成系统。本文展示了14个仿真任务和7个真实世界任务的零样本演示。
实验结果分析:
图4:扩展实验。随着训练演示数据量的增加,模型性能的扩展效果。
图5:生成数据的动作分布:本文比较了不同方法生成的数据与通过RLBench在人类生成的同一组任务演示中的动作分布。本文观察到本文生成的数据与人类生成的数据在分布上具有高度相似性。这一点也通过本文方法与RLBench数据之间计算出的CD得到支持,结果显示本文的方法的CD值最低(CD=0.056)。
图6:错误分解。来自仿真中三个任务的错误分解。
表1:零样本评估的任务平均成功率百分比。MANIPULATE-ANYTHING 在RLBench的14个仿真任务中有10个任务的表现优于其他基线方法。每个任务通过3个种子进行评估,得出任务平均成功率和标准差。
表2:使用不同生成数据的行为克隆。与其他自动数据生成基线相比,基于MANIPULATE-ANYTHING生成数据训练的行为克隆策略在12个任务中的10个任务上表现最佳。本文报告了使用VoxPoser 和 Code as Policies生成的数据训练的行为克隆策略的成功率百分比作为对比。需要注意的是,RLBench 基线使用的是人类专家演示数据,且被视为行为克隆的上限。
表3:真实世界结果。使用本文模型生成的真实世界数据(无专家介入)训练的模型,展示出与基于人类专家收集数据训练的模型相当的结果。本文展示了零样本任务完成成功率的比较(Code as Policies 和 MANIPULATE-ANYTHING),以及使用MANIPULATE-ANYTHING数据和人类专家数据训练的策略的成功率对比。
总结:
MANIPULATE-ANYTHING 是一种可扩展且环境无关的方法,用于生成无需特权(privileged)环境信息的零样本机器人任务演示。MANIPULATE-ANYTHING 利用视觉-语言模型(VLMs)进行高层次规划和场景理解,并具备错误恢复能力。这使其能够生成高质量的数据,用于行为克隆训练,且性能优于使用人类数据的训练结果。
#车圈大变天!激光雷达即将被判死刑?
昔日称霸车圈的智驾供应商Mobileye,近日宣布了一则重大决定——
今年内就要立刻关闭激光雷达研发部门,并且终止下一代激光雷达的研发工作!
抛弃激光雷达的原因,总结起来就是六个字:没必要,不挣钱。
Mobileye经过仔细评估过后,认为激光雷达对下一代智驾技术来说并没有那么重要;而且能省下每年6000万美元的研发成本,可以说是赢麻了。
无独有偶,2021年8月,Waymo宣布停止商业激光雷达业务;去年9月,博世也官宣放弃研发用于智驾的激光雷达……
激光雷达对于自动驾驶来说,到底是鸡肋还是必需?一直是个热门的争议话题。
“反对派”的代表人物,自然是世界首富马斯克。他曾多次公开diss:“只有傻子才会把激光雷达装在车上,这些自动驾驶公司都注定失败!”
马斯克这几年也确实没有动摇,FSD一直坚持纯视觉路线走到黑。不仅从来没用过激光雷达,甚至最近几年都把毫米波雷达给砍没了,能力上却越来越强。
除了特斯拉以外,搭载了百度Apollo智驾方案的极越,同样依靠纯视觉方案,就实现了城市领航辅助功能。
极越CEO夏一平,在最近也放出了类似的豪言:
“华为一定会放弃激光雷达转投视觉方案,只是余承东太狡猾。一边在宣传激光雷达方案,同时背地里也一直在砸钱开发纯视觉方案,等纯视觉成熟就无缝切换,一点空档都不留给其他对手。”

另一边,“支持派”的玩家也同样不少。包括小鹏、蔚来、理想、华为等等一线智驾玩家,纷纷选择了“摄像头视觉+雷达”的融合感知方案。
他们一致认为,激光雷达是实现高阶智驾最不可或缺的关键零部件。
比如极氪智能科技副总裁林金文表示:“不用激光雷达,是在为降本找理由!”

不过最近一段时间,风向开始出现了一些变化——
“端到端”技术浪潮来了!
随着今年特斯拉FSD推出了基于“端到端架构”的V12版本,删掉原本30万行C++代码,替换为3000行神经网络之后,系统决策准确度和执行速度都有了质的飞跃。
不依赖激光雷达、不依赖高精地图,仅仅依靠纯视觉都能把智驾做到如此流畅,难怪会让远赴美国试驾FSD的何小鹏都称赞不已。

回国之后,何小鹏曾多次承认“端到端”技术的优越性,建议友商们“别犹豫,赶紧改”。
紧接着,小鹏就对激光雷达“动刀”了!
在小鹏MONA M03发布会上,何小鹏表示将推出“AI鹰眼视觉方案”,不搭载激光雷达,摄像头精度、可视距离大幅升级,同样可以有能力实现城市领航辅助驾驶,预计今年四季度将首次搭载在新款小鹏P7i上。
要知道,4年前车企们在智驾上搞军备竞赛的时候,卷激光雷达是非常疯狂的。
长城机甲龙甚至放出了“四颗以下别说话”这种豪言,威马M7也干脆直接上了3颗激光雷达……
不过这两款车都最终没能落地就是了。
到现在来看,只有阿维塔采用了3颗激光雷达的方案,其他的车型要么是大灯周围的双激光雷达方案,要么是车顶“犄角”式的单激光雷达方案。
而最近成都车展前后亮相的几款新车型,比如问界M7 pro、深蓝S7乾崑智驾版等等,都开始向纯视觉智驾的方案上倾斜。
要知道,同一款车型带激光雷达与不带激光雷达的,价格差距基本上都在1-4万元不等。
于是这段时间,车圈出现了不少 “花高价买激光雷达的车主或将成大冤种”、“激光雷达割韭菜”的声音。

资本对于这种悲观的氛围是相当敏感的,导致今年下半年,禾赛、速腾聚创等等激光雷达公司的股价出现暴跌,市值缩水超过80%。

要知道,在2年多前,同样是在智驾圈子里,高精地图曾经也被誉为智驾路线上的“香饽饽”。
但随着一线智驾玩家为了突破智驾的使用范围,纷纷开发无图方案,高精地图沦为了被抛弃的对象。
这让图商四维图新一年爆亏了13亿,气得其CEO直接在公开场合Diss无图方案:“毫无安全敬畏!”

既然无图智驾抛弃了高精地图,那么问题来了:
端到端技术的普及,会让激光雷达也面临被抛弃的厄运吗?
对于这个问题,首先要看看目前激光雷达在智驾系统中的重要性如何。
其实有个比较简单粗暴的判断方法——故意把激光雷达遮住再去测智驾功能不就OK了?
网上能找到不少这么测试的案例。
有的车型中的一些智驾功能,即使遮住激光雷达影响也比较小,甚至察觉不出影响。
比如,去年有一位B站UP主录了一段视频,他把阿维塔上的3颗激光雷达都拿纸壳糊上,然后在路上摆放障碍物进行自动紧急避障测试。
结果发现,时速跑到120km/h自动避障只是出现了轻微延迟,功能并没有受到影响。
同样的,有人把问界M7的激光雷达遮住测AEB,也能顺利刹停。

把理想L8激光雷达遮住,会发现辅助驾驶仍然能正常开启,车道线识别和拨杆变道功能均可用。
但中控屏上会触发提示,激光雷达表面脏污,请及时清理,不能识别静止物体,和车辆、人以外的非标准物体。

但,也有遮住激光雷达影响比较大的。
在市面上首款搭载激光雷达的车型小鹏P5刚刚上市那段时间,我们公社也曾做过类似的测试。在测试跨楼层泊车功能时,故意把P5的激光雷达用A4纸拿双面胶糊上。
结果发现,只遮挡一颗激光雷达的时候,跨楼层泊车功能仍然可用,对于车位和行人的识别并没有受到影响,仍然可以丝滑的执行避让动作。
但两颗激光雷达都被遮挡时,就不能顺利执行避让和泊车动作了。

还有蔚来ET7,遮住激光雷达之后会显示辅助驾驶系统故障,无法激活。

不同的车型遮住激光雷达,却出现了不同的结果。
这说明,不同车型、不同智驾功能,对于激光雷达的依赖度都是不同的,有的优先级比较高,一旦遮挡就无法启用;有的则优先级较低,不会影响功能使用。
总体上来说,目前激光雷达在智驾系统中扮演的角色,更多的是为了安全冗余考量。
但鉴于目前大多数融合感知智驾,采用的都是传统的BEV鸟瞰图+OCC占用网络+Transformer大模型的架构,而并没有完全切换到公认更前沿的“端到端”架构。
所以要讨论激光雷达会不会被抛弃,还要看要看它与端到端架构的兼容度如何。

首先,目前传统的智驾架构逻辑,本质上就是将视觉图像做2D转3D,实时建立高精地图。
如果有激光雷达的话,就可以通过扫描物体轮廓,将扫描出来的周围环境更清晰和准确。

不过,端到端架构完全是另一个路子!
端到端智驾不需要做2D转3D,直接根据图像输出加减速信号和转向幅度,流程上大幅简化,响应速度更快,更接近人类开车的方式。
但相对的,就需要投喂大量图像与驾驶操作的对应关系数据,才能让端到端模型的决策变得更准确。
对端到端技术感兴趣的朋友,可以再回顾一下这篇:太疯狂了!特斯拉删除99%代码,FSD却更好用了!智驾的终极答案竟然是它?

简单来说就是,传统智驾靠的是感知信号与算法堆叠下的缜密逻辑,而端到端靠的是类似“肌肉记忆”的经验。
这也是为什么,有不少人认为端到端时代,激光雷达就不再那么重要了。
理由是,端到端智驾是在模仿人类的驾驶行为,本质上就是视觉感知下的经验判断,而激光雷达用的是多普勒效应,跟人类驾驶行为不搭边,所以激光雷达信号无法融入到端到端模型之中。

个人认为这种说法有些欠妥,因为即使是激光雷达作为感知信号源,也能找到与加减速转向等数据的对应关系。
将激光雷达信号加入端到端大模型的训练,实际是可行的。
但存在两个难点需要克服:
一是目前市面上带激光雷达的车相对较少,导致可供端到端训练用的激光雷达信号非常有限;
二是加入激光雷达信号意味着变量的增加,这对于整车乃至云端训练算力的需求,将会指数级增加,以现在的硬件水平未必能hold住。
换句话来说,基于纯视觉的端到端架构,真的是未来智驾的终极答案吗?我看未必。
端到端是通过人类经验行为训练出来的,那么它理论上的能力极限,会无限接近于人类极限,但很难做到超越人类驾驶。
更何况,一旦雨雾等条件下便很难发挥作用,因此纯视觉端到端更像是为L2级自动驾驶服务的。
想要达到“人机共驾”L3,以及“无人驾驶”L4,必须要有更深层次的安全冗余,这时激光雷达的价值就体现出来了。
举个例子,有个词叫“空间感”,指的是人对于自身所处方位,与其他物体距离判断的能力。
有的人空间感强,有的人空间感弱。
但即使空间感再强的人,也很难直接通过视觉效果,用近大远小和透视关系精确推断出前车距离自己到底有多远。就算“我的眼睛就是尺”的王濛来了,也精确不到毫米级。
这也是为什么,早年间特斯拉出过很多起,因为识别不出静止的白色大货车而撞车的事故的原因之一。
但激光雷达不一样,可以通过激光反射及频率,测得非常准确的距离数值,达到厘米级甚至毫米级是可以实现的。
远高于摄像头感知的精确性,恰恰就是激光雷达不可或缺的关键。

写在最后
在当下这个时间节点,“纯视觉VS激光雷达”再次成为争论的话题,并不是因为激光雷达没有未来,而是因为现在的激光雷达还不够强。
就拿像素来个举例子——
问界M9上搭载的华为192线激光雷达,折合约为210万像素,而前置摄像头为800万像素。
目前,激光雷达的像素普遍不及摄像头。像素低了,扫描模型就会变“糊”,影响信息传递的准确性。
除此之外,激光雷达探测距离、扫描频率、抗环境干扰能力、体积、功耗等方面,还有许多优化空间。

再有就是对车企来说无比重要的:成本。
虽然近几年激光雷达降本非常迅速,从动辄5万元一颗到后来的2万元左右,到现在一颗在5000元左右,已经到了车企和用户都能支付得起的地步。
但跟数百元价位的摄像头相比,降本空间还很大。
几年前,车载激光雷达市场几乎完全被外资企业垄断,而最近几年,禾赛、速腾聚创等国产激光雷达已经在悄然间崛起,已经将占据了90%以上的市场份额。

与此同时,国产激光雷达厂商们的研发脚步,并未停滞不前,而是在自身所处的产业链细分领域中,不断探索着智驾的终极答案。
智驾的终极答案究竟为何物?我们未曾可知。
但可预见的是,我们会努力成为第一个得到答案的人。
#UCLA提出全新可解释决策规划框架
完美发挥LLM和规则的双重魔力!
对于自动驾驶车辆要无缝融入为人类设计的交通系统,它们首先要“安全”,也就是作者常说的"Safty first!",但是同时也还会有一个关键要求就是“遵守交通规则(交通法规、法律和社会规范)”。但是交通规则是多样且复杂的,涵盖了来自不同地区法律、驾驶规范的数千条法规。在这些交通规则中,自车必须考虑各种因素,比如其他道路参与者的行为、当前道路状况和环境背景,来识别与特定场景相关的规则。这些因素的任何变化可能需要不同的规则或重新优先考虑现有规则。
- 论文链接:https://arxiv.org/pdf/2410.04759
之前的一些工作集中在选择关键规则和人工写的决策规则上,然而,这种手动编码方法难以处理大量交通规则,并且不能轻易适应不同地区的法规。另外,交通规则的语义复杂性和上下文依赖性也是做决策的另一个难点。交通规则从标准解释到特定驾驶行为都有涵盖,需要以不同的方式整合到决策过程中。例如,法律的约束是严格的,而当地规范和安全条款可能需要根据场景灵活应用。因此,智能地理解和将人工写的的规则纳入决策系统对于自动驾驶车辆无缝融入人类交通系统至关重要。
对于为特定任务训练的传统AI系统来说,这是一个挑战,但具有强大理解和推理能力的大型语言模型(LLMs),可以做到!本文介绍了一个新的可解释的遵守交通规则的决策者,它结合了一个基于检索增强生成(Retrieval-Augmented Generation,RAG)构建的交通规则检索智能体和使用LLM(GPT-4o)的推理模块。推理模块会从两个层面上来评估行动:
- 行动是否合规,即它是否遵循所有强制性交通规则;
- 行动是否被认为是安全行为,即它是否既遵守强制性交通规则又遵循安全指南。
这种双重层面的评估确保了对合法合规和遵守安全驾驶实践的全面评估和决策。此外,为了增强可解释性,中间推理信息,如推理过程中使用交通规则,也会被输出,提供了评估者决策过程的透明度。
相关工作
自动驾驶中的交通规则
为了将交通规则集成到自动驾驶系统中,已经有过很多的方法。早期的方法包括基于规则的系统和有限状态机,这些系统通过显式的if-then规则或状态转换来编码交通法律。为了处理复杂场景,出现了更复杂的方法:行为树创建了能够表示和执行交通规则的分层决策结构,以及使用LTL或MTL等时间逻辑的形式方法为指定和验证遵守交通法律提供了严格的框架。然而,这些方法通常难以应对现实世界交通规则的模糊性和地域差异,导致在创建能够适应不同监管环境的自动驾驶车辆时面临挑战。最近,大型语言模型(LLMs)在理解自然语言和解释复杂场景方面展现出了显著的能力。利用这些能力,LLMs可以以更灵活和上下文感知的方式处理和整合交通规则,无需基于规则的编码。例如,LLaDA利用LLMs从当地手册中解释交通规则,使自动驾驶车辆能够相应地调整任务和运动计划。同样,AgentDriver将交通规则纳入基于LLM的认知框架中,在规划期间存储和参考这些规则。然而,确保LLMs准确应用相关交通规则而不产生幻觉或误解仍然是一个关键挑战。
检索增强生成
检索增强生成(Retrieval-Augmented Generation,RAG)通过结合神经检索和sequence-tosequence生成器,解决LLM幻觉问题并提高信息检索的准确性,最近的一些研究已经证明了RAG在提高LLM在当前事件、语言建模和开放领域问答等领域的准确性和事实正确性方面的有效性。这些发现引发了RAG在提高基于LLM的自动驾驶系统的交通规则合规性方面的潜力。其动态检索能力使实时访问特定地区的交通规则成为可能,解决了适应不同监管环境的挑战。RAG提供的事实增强可以减少LLM中的幻觉,降低编造或误用交通规则的风险。RAG处理复杂和上下文信息的能力也非常适合解释具有多个条件或例外的微妙交通规则。此外,RAG的检索过程中固有的透明度可以提高自动驾驶系统中决策的可解释性,这是法规合规性和公众信任的一个关键因素。
自动驾驶的决策
自动驾驶的决策方法已经从基于规则的发展到基于学习的方法。基于学习的方法在动态驾驶环境中比前者表现出更大的适应性,使自动驾驶车辆摆脱了复杂手工规则的约束。两种典型的学习方法是模仿学习(imitation learning, IL)和强化学习(reinforcement learning, RL)。IL专注于模仿专家的决策,但面临在线部署中的不同分布问题。相反,RL在在线交互中探索和学习,但这种试错方法效率低下。此外,另一篇论文GPT-Driver引入了GPT到自动驾驶车辆中,将规划重新构想为语言建模问题。然而,在由交通规则构建的人类驾驶环境中,自动驾驶车辆不仅需要确保安全,还需要在驾驶过程中遵循这些规则,同时与人类驾驶的车辆一起驾驶。使用统一模型将不同的语义交通规则整合到决策中仍然是一个未充分探索的领域。
提出的方法
作者提出的方法,如图1所示,包含两个主要组件:
- 一个交通规则检索智能体(Traffic Rules Retrieval Agent),它使用检索查询从法规文档中检索相关交通规则;
- 一个推理智能体(Reasoning Agent),它基于环境信息、自车的状态和检索到的交通规则来评估行动集(action set)中每个行动的交通规则依从性。

作者首先做环境分析,为交通规则检索智能体生成检索查询,并为推理智能体提供环境信息输入。为了提取超出常见感知输出的更多法规相关特征,作者使用视觉语言模型(Vision Language Model,VLM)GPT-4o,基于自车的摄像头图像分析环境。分析遵循精心设计的“思考链”(Chain-of-Thought,CoT)流程:VLM首先进行广泛的环境概览并检查一般道路信息,然后进行详细分析,重点关注关键要素,如其他道路使用者、交通元素和车道标记,特别是与车辆全局规划输出相关的元素(例如,“右”、“左”或“向前”)。然后VLM生成一个简洁的检索查询,总结当前场景的情况,供交通规则检索智能体使用。

图3展示了环境分析的一个示例输出。作者从基于全局规划输出的行动空间(Action Space)中提取一个行动集,该行动集包含所有可能的行动。为了简单起见,作者将行动空间仅包含一组预定义的行动:右转、左转、向前行驶(以当前速度、加速或减速)、向左变道和向右变道。提取过程选择与全局规划输出一致的行动。例如,如果全局规划输出是“左”,行动集将包括以当前速度、加速或减速左转。
交通法规的检索增强生成
为了增强模型对本地交通规则和规范的理解,并充分考虑所有可用来源的相关规则,作者开发了交通规则检索(Traffic Regulation Retrieval, TRR)智能体,如图2所示。

由于不同地区有不同的交通规则来源,作者以美国为例来展示TRR智能体如何充分考虑可用来源。由于宪法原因,美国的交通规则由各州而不是联邦政府制定。城市还建立了本地规则以管理交通并确保安全。为确保全面覆盖,TRR包括州和地方法规。此外,为美国司法系统提供参考的案例法和提供额外安全指南的驾驶手册也被视为重要来源,并被纳入TRR。因此,作者设计的TRR包含以下综合法规文档集合:
- 州级交通法律:由州立法机构制定并在整个州执行的,规范车辆运营并确保道路安全的法律。
- 州级驾驶手册:由各州DMV出版,详细说明州交通法律和安全驾驶实践。它包括以文本和插图形式呈现的驾驶安全指南。
- 市级交通规则:由地方政府制定,用于解决特定需求(如停车、速度限制和车道使用)的规则,以管理本地交通并确保安全。
- 州级法院案例:对交通相关案例的司法裁决澄清法律并影响执法。
- 交通规范:被广泛认可的驾驶员遵循的行为,以确保顺畅和安全的道路互动。这些规范对于自动驾驶车辆与人类驾驶行为和社会期望保持一致至关重要。本文不专注于为这些规范建立记录库,但作者将使用示例来说明作者的框架仍然适用。
在评估了基于传统倒排索引的检索方法(依赖于关键词输入,如BM25和Taily)的检索性能后,作者发现基于嵌入的算法(利用信息丰富的长查询并根据段落相似性检索)在完整性和效率方面显著优于前者。集成到TRR智能体中,基于嵌入的方法更有效地处理驾驶场景的复杂性。
每个文档或记录都被重新格式化为带有层次标题的markdown,以提高清晰度,使随后的推理智能体更好地解释。除了文本内容,尤其是在州级手册中广泛使用,用视觉示例澄清法规的图表,也被集成到TRR智能体中。这种集成特别重要,因为有些法规细节嵌入在图像中,但并未在相应的文本中明确描述。所以,图表被转换为文本标签,并附在相关段落的末尾,并在检索过程结束时适当恢复。
在检索过程中,作者首先为法规文档和先前生成的交通规则检索查询生成向量嵌入,然后应用FAISS相似性搜索来确定它们之间的相关性。从段落级到句子级的级联检索pipeline有助于确保结果既全面又简洁。在对整个数据源进行段落级嵌入后,应用top-k选择来选择最相关的段落,形成一个新颖的细分数据库。为解决由于大型标记化交通手册的规模而可能影响搜索准确性的稀疏性问题,作者对选定的段落进行了句子级重新嵌入。这第二级嵌入通过专注于最相关的部分,提供了更好的索引和搜索能力。这种方法允许动态适应,通过优先考虑可用法规的相关性。最终,TRR智能体汇总了从交通法规和州级法律中选定的句子、城市法规的规则以及法院案例,以及属性图像,以产生一个全面的结果,提供给推理智能体。
推理智能体
推理智能体利用带有CoT提示方法的LLM(GPT-4o),来负责确定行动集中的每个行动是否符合交通规则。推理智能体接收三个关键输入:
- 来自环境分析的当前环境信息
- 自车的行动集
- 从TRR智能体检索到的一组交通规则。
在推理过程中,智能体首先过滤检索到的交通规则,以识别最适用于当前情况和自车预期行动的规则。然后,这些规则被归类为强制性规则(必须遵循以确保合法合规)或安全指南(代表最佳实践,虽然不具有法律要求,但建议采取以实现最佳驾驶行为)。推理智能体接着检查是否符合强制性规则。如果当前行动违反任何强制性规则,智能体得出行动不合规的结论;否则,它被标记为合规。然后模型通过检查强制性规则和安全指南(如果有检索到)来评估安全性,如果行动同时符合两者,它被标记为安全;否则,被标记为不安全。推理智能体为行动集中的每个行动输出一个二元合规性和安全性决策,并清晰地引用每个适用规则,详细说明行动为何合规或不合规,以提高推理过程的可解释性。然后框架选择被标记为既合规又安全的行动作为决策的最终输出。图3最右侧则展示了推理智能体的一个示例输出。
实验结果
为了验证提出的方法以及其在利用法规进行决策制定方面的有效性,作者开发了一个全面的基准,其中包含了假设的和现实世界场景,如图3所示。假设场景提供了更大的多样性,而现实世界数据实验展示了框架在真实驾驶条件下的实际性能。作者主要在波士顿地区评估了这些场景。
交通规则检索(TRR)智能体和RAG
作者在TRR智能体中使用的文档集合遵循图2所示的架构,包括以下内容:

作者使用了OpenAI的“text-embedding-ada-002”模型进行段落级检索,阈值设定为0.28,以及SentenceTransformers的“paraphrase-MiniLM-L6-v2”进行句子级检索,并收集了top-5检索到的句子。
假设场景
假设场景以文本格式描述,包括30种情况,涵盖了从转弯或通过交叉口等常见场景,到在分隔道路上超过停止的学校巴士或让从后方接近的紧急车辆等罕见案例,这些通常不被真实世界数据集所涵盖。这些场景由研究人员通过审查波士顿的法规代码和驾驶手册手动识别,因为它们对人类或自动驾驶驾驶员来说可能具有挑战性。作者评估了框架在30个假设场景中的性能,包括使用和不使用TRR智能体的数据,如图4所示。

在缺乏特定本地法规或依赖交通规范的场景中,LLM有效地使用其广泛的预训练知识做出正确的决策。然而,在需要遵守详细的市级或州级法规或司法先例的场景中,仅LLM不足以确保安全。整合了包括本地法规和司法决定的TRR智能体,将场景-行动推理精度从82%提高到100%,决策制定精度从76%提高到100%。这突出了将全面的法律和司法信息整合到LLM框架中,以有效应对复杂的现实世界驾驶情况的重要性。
现实世界场景
为了评估框架在现实世界数据上的性能,作者在nuScenes数据集上对其进行了测试。由于它不是为与交通规则相关的任务设计的,因此不包含交通规则注释。为此,作者手动审查了摄像头图像,并选择了与交通规则强相关的样本,其中行动更多地受到交通规则的约束或影响。对于每个样本,作者为行动集中的行动标注了合规性和安全性标签,确定合规和安全的行动作为决策输出的基准真实值。为确保有意义的评估并避免由于重复或过于相似的场景导致的不平衡,作者仔细选择了适用不同交通规则的样本,或者由于与法规直接相关的场景特定因素导致相同规则的应用存在变化。因此,作者从验证集中识别出了17个多样化的样本进行评估,作者的模型为其中的15个样本产生了正确的输出和准确的推理。

在图5(a)和(b)中,作者展示了两个场景:一个是没有行人的斑马线,一个是有行人的斑马线。对于没有行人的斑马线,模型在自车加速向前时输出“合规但不安全”,这符合常识。在有行人的场景中,加速向前不符合交通规则,作者的框架正确地识别了这一点,输出了正确的合规判断。这两个例子展示了模型根据环境因素的变化,准确地调整其评估的能力。在(c)中,作者进一步展示了一个需要同时考虑多个交通元素和规则的案例。在这个场景中,车辆在没有“禁止红灯右转”标志的红灯处右转,这使得右转在法律上是允许的。然而,有一个行人正在车辆前方的斑马线上过马路,要求车辆让行。因此,不礼让的右转是不遵守交通规则的。如最终输出所示,作者的模型成功识别了这一点,并输出了“不合规”。在(d)中,作者展示了一个自车接近施工区域并应减速的案例,作者的模型成功识别了这一点,输出了行动“以减速向前行驶”。这是以前基于规则的方法难以处理的场景,因为它们通常由于需要手工制定规则,通常只选择关键规则,经常省略特定案例,如施工区域的法规。

在图6中,作者展示了新加坡的一个案例,以展示作者的模型可以轻松适应不同地区。在这个场景中,自车试图在红灯处右转。虽然在波士顿右转是合法的,但在新加坡是非法的。如图所示,作者的模型正确地输出了“不合规”,符合新加坡的交通规则。与以前需要为每个新地区重新制定规则的基于规则的方法不同,作者的模型只需简单地将交通规则文件从波士顿的切换到新加坡的,就可以无缝地适应新场景。
写在最后
本文介绍了一个可解释的、由LLM驱动的、重视交通规则的决策框架,该框架集成了交通规则检索(TRR)智能体和推理智能体。在假设的和现实世界场景上进行的实验证实了作者方法的强大性能及其对不同地区的无缝适应性。作者相信,该框架将显著提高自动驾驶系统的安全性和可靠性,增强监管机构和公众的信任。未来的工作将扩展框架的测试到更多地区,并多样化作者的测试场景。此外,开发一个全面的现实世界数据集,用于与交通规则相关的任务,对于该领域的未来研究和进步至关重要。
#RealMotion
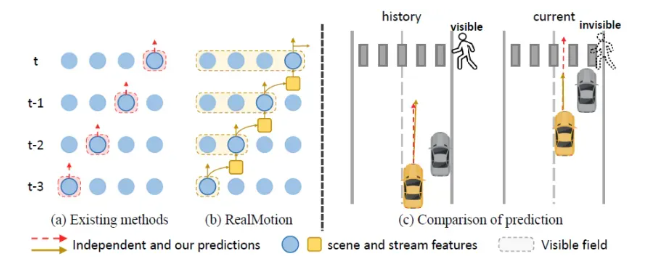
连续自动驾驶中的运动预测
标题:Motion Forecasting in Continuous Driving
作者:Nan Song, Bozhou Zhang, Xiatian Zhu, Li Zhang
机构:Fudan University、University of Surrey
原文链接:https://arxiv.org/abs/2410.06007
- 导读
- 引言
运动预测是当代自动驾驶系统中的关键要素,它使自动驾驶车辆能够预测周围主体(agent)的运动模式。这一预测对于确保驾驶的安全性和可靠性至关重要。然而,众多复杂因素,包括随机的道路状况和交通参与者多样化的运动模式,使得解决这一任务颇具挑战性。近期的研究聚焦于表征和建模的研究,同时越来越重视精确的轨迹预测。此外,该领域还越来越关注多主体预测这一更具挑战性但更有价值的子任务。这些进展共同推动了近年来运动预测领域的显著进步。推荐课程:面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)。
- 效果展示
- 主要贡献
- 方法
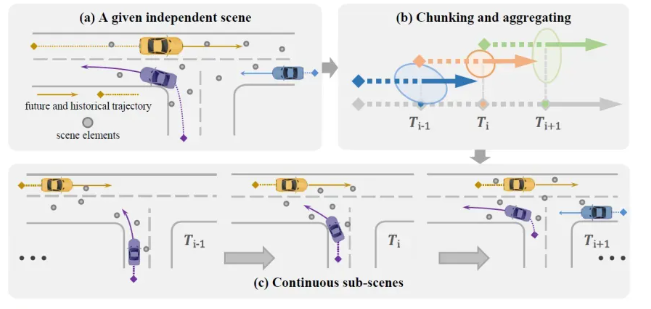
鉴于现有基准测试与实际应用之间的差异,我们的首要步骤是对这些数据集进行重新组织,将每个样本场景转换为连续序列,以模拟连续的真实驾驶场景。具体而言,我们通过将智能体轨迹均匀分割为较短的片段并采样局部地图元素(参见图2),来回顾性地检查每个独立场景。具体来说,我们首先沿着历史帧步骤选择几个分割点Ti。然后,从这些点分别向过去和未来延伸,生成等长的轨迹片段。历史和未来步骤的数量分别由最小分割点和真实轨迹的长度决定。此外,在每个分割点,我们为感兴趣的智能体聚合一定范围内的周围智能体和局部地图,形成一系列子场景。这种重新组织方式能够自由利用原始元素,从而在场景层面为模型优化提供有价值的环境信息和渐进见解。因此,现有方法也可以引入这种新型数据结构并从中受益。
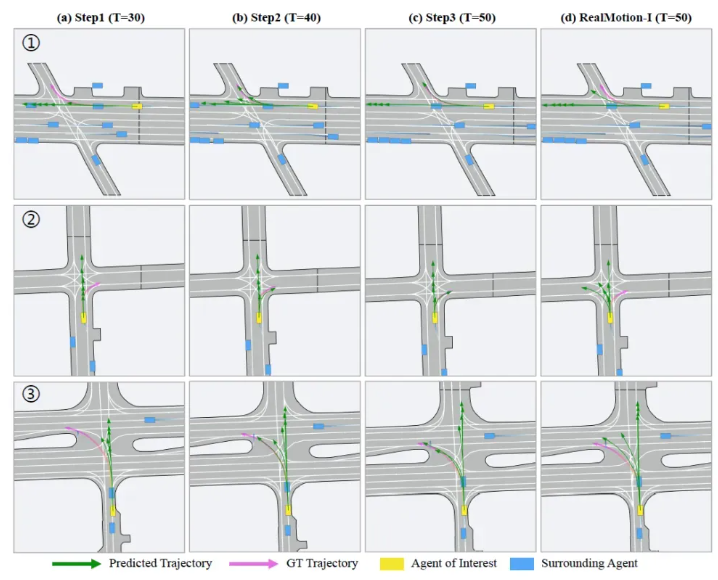
- 实验结果
7. 总结 & 局限性
在本文中,我们计划从更贴近实际的连续驾驶角度出发来解决运动预测任务。这本质上相较于之前的设定,将运动预测功能置于了一个更广泛的场景背景中。我们进一步提出了RealMotion,这是一个专为支持在时空上连续进行预测动作而设计的通用框架。我们框架的关键组件包括场景上下文流和代理轨迹流,这两者都以序列化的方式工作,并逐步捕捉时间关系。我们在多种设定下进行了广泛的实验,全面证明了RealMotion超越了当前最先进的性能水平,从而为快速发展的自动驾驶领域中的安全可靠运动预测提供了一个有前景的方向。
我们数据处理方法的一个明显限制是需要足够数量的历史帧来进行序列化。因此,它不适用于如Waymo Open Dataset等仅提供10帧历史轨迹的短期基准测试。此外,现有的数据集通常提供的历史信息与真实世界场景差异较大且有限,这阻碍了我们的序列化设计充分发挥其优势。因此,我们期望在未来的工作中将我们的框架集成到序列化的自动驾驶系统中,以最大化流式设计的效益。
#DIKI
基于残差的可控持续学习方案,完美保持预训练知识
本研究解决了领域-类别增量学习问题,这是一个现实但富有挑战性的持续学习场景,其中领域分布和目标类别在不同任务中变化。为应对这些多样化的任务,引入了预训练的视觉-语言模型(VLMs),因为它们具有很强的泛化能力。然而,这也引发了一个新问题:在适应新任务时,预训练VLMs中编码的知识可能会受到干扰,从而损害它们固有的零样本能力。现有方法通过在额外数据集上对VLMs进行知识蒸馏来解决此问题,但这需要较大的计算开销。为了高效地解决此问题,论文提出了分布感知无干扰知识集成(DIKI)框架,从避免信息干扰的角度保留VLMs的预训练知识。具体而言,设计了一个完全残差机制,将新学习的知识注入到一个冻结的主干网络中,同时对预训练知识产生最小的不利影响。此外,这种残差特性使分布感知集成校准方案成为可能,明确控制来自未知分布的测试数据的信息植入过程。实验表明,DIKI超过了当前最先进的方法,仅使用0.86%的训练参数,并且所需的训练时间大幅减少。
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Mind the Interference: Retaining Pre-trained Knowledge in Parameter Efficient Continual Learning of Vision-Language Models
- 论文地址:https://arxiv.org/abs/2407.05342
- 论文代码:https://github.com/lloongx/DIKI
Introduction
监督学习技术在对所有数据完全访问的情况下训练网络,这可能导致在扩展网络以获取新任务知识时缺乏灵活性。持续学习(CL)作为一种解决方案应运而生,使得模型能够在陆续到达的数据上进行持续训练,同时保留所学的信息。传统的CL设置一般考虑的只新引入的类别或领域分布的变化,这称为类别增量学习和领域增量学习。然而,只考虑一种增量的现有工作限制了它们在复杂现实场景中的适用性。
考虑一个更具挑战性的领域-类别增量学习(DCIL)设置,在该设置中,领域数据分布和待分类的类别在所有任务中可能不断变化,如图1(a)所示。在这种情况下,基于传统图像编码器的技术由于其不可扩展的分类头设计而无法实现。最近,对比训练的视觉-语言模型(VLMs)如CLIP的出现,使得解决这一要求高但实际的问题成为可能。VLMs是在大规模的图像-文本对上训练的,具有强大的零样本泛化能力,可以识别几乎无限的类别,应对这种严重的任务变化场景。
然而,使用视觉-语言模型引入了增量训练的新挑战。传统的持续学习方案旨在防止模型遗忘先前学习的知识,这被称为向后遗忘(忘记微调的知识)。现有的研究探讨了正则化机制、复习缓冲区和架构设计在减轻向后遗忘方面的潜力,并取得了令人鼓舞的成果。然而,当这些方法应用于视觉-语言模型时,出现了一种不同形式的灾难性遗忘:模型往往会遗忘在预训练阶段所学的知识,从而妨碍其强大的零样本泛化能力。这个问题被称为向前遗忘(忘记预训练的知识),因为它发生在VLMs对未知分布数据进行“向前”预测时。图1(a)展示了这两种遗忘类型。
最近的工作ZSCL尝试解决CLIP上的向前遗忘问题,引入了一个大规模的参考数据集来进行知识蒸馏,并结合了权重集成方案。然而,这种方法需要大量的计算和外部数据,在实际场景中可能不可行。同时,现有的基于VLM的参数高效持续学习方法主要利用提示调整机制,未能保留预训练知识,并导致零样本能力下降,如图1(b)所示。论文将这个问题归因于信息干扰:新引入的任务特定参数可能会干扰预训练知识。这些方法的示意图如图1(c)所示。
为了以计算和参数高效的方式缓解VLMs的向前遗忘问题,论文引入了分布感知无干扰知识融合(DIKI)框架。具体而言,将任务特定信息注入到冻结的VLM中,以便为每个任务高效地存储已学习的知识。
论文的贡献总结为三点:
- 引入了参数高效的DIKI,以在DCIL设置下保留VLM中的预训练知识。它解决了信息干扰问题,降低了对大量计算和外部数据的需求。
- 为了缓解向前遗忘,DIKI以完全残差的方式植入新知识,保持预训练知识不受干扰。凭借这种残差特性,进一步集成了分布感知融合校准,以提高在未见任务上的性能。
- 综合实验表明,与以前的方法相比,DIKI以仅0.86%的训练参数和显著更少的训练时间实现了最先进的性能。
Preliminaries
- Continual learning protocol


- Vision-language models

- Task-specific prompt learning
一系列研究开始探索在持续学习中参数高效微调的潜力,常见的做法是为每个任务学习和存储一组轻量级提示,在持续学习阶段形成一个“提示池”,表示为:

其中N是任务编号,l和d分别是提示的长度和特征嵌入的维度。





通过最相关的键,选择相应的提示并将其附加到冻结模型上,执行推理过程。
Methodology
Interference-free Knowledge Integration
- Is prepending the best choice?
尽管将提示预先添加到输入tokens的方法因其实现简单而被广泛使用,但论文发现它们面临两个方面的问题。
- 将提示与输入tokens进行连接会导致它们在注意力过程中相互作用,从而影响预训练知识的提取。当测试样本来自模型学习提示时的分布时,适应后的模型可以保持相对令人满意的结果。然而,一旦遇到分布发生改变的样本,这种干扰可能导致模型性能下降,并损失其重要的零样本泛化能力,造成前向遗忘问题。
- 简单地预先添加提示不可避免地增加了所有Transformer块的token长度,这在许多有token长度限制的场景中并不理想。另外,它的可扩展性有限:较长的提示上下文可能会使文本编码器忽视重要的类别名称,从而导致文本嵌入表示不佳。
上述问题的存在表明,基于提示调优的方法并不满足“残差属性”:期望学习到的参数应该是与冻结主干并行的残差路径,补充新的知识而不影响关键的预训练知识。因此,论文提出了一种无干扰知识整合(Interference-free Knowledge Integration,IKI)方案,以最小化噪声的方式将新学习的知识注入到预训练的VLM中。
- IKI mechanism





为了解决这个问题,论文分别计算输入tokens内的自注意力和提示与输入tokens之间的交叉注意力,如图2(b)所示。换句话说,只训练一个残差注意力分支,保持现有的注意力分数不变。通过新引入的键和值,残差注意力分支的输出可以表示为:


理想情况下,一个理想的残差块在未在下游数据集上进行训练之前,应该不会影响原始分支,比如在初始化时。广泛使用的方式用均匀或正态分布初始化提示,这会在没有学习到任何知识的情况下向预训练的VLMs中注入随机噪声。具体而言,通过将参数初始化为零,强制残差注意力加法成为一个恒等函数:

注意,论文仅在开始时将值限制为零,同时保持随机初始化。这是因为将和都初始化为零矩阵会阻止通过梯度更新,从而使陷入到具有相同值的向量中。
由于零初始化更像是一种选择而非技术,一些研究在各种任务中采用了它。然而,这些工作利用零初始化来确保稳定和渐进的训练机制,而在DCIL场景中并不存在这一顾虑。论文认为,零初始化对于残差注意力设计是至关重要的,它可以以最小的噪声将新知识注入到预训练的VLMs中。
Distribution-aware Integration Calibration
- Observations 在推理时,会执行公式3中描述的查询-键匹配机制,以检索适合当前测试样本的学习提示。这种方法是针对传统的持续学习设置而设计的,仅考虑了向后遗忘。然而,当面对来自未见领域的数据时,这种简单的匹配设计被强制执行,从而为测试样本分配一个相对相似的任务,尽管它们之间存在显著的分布差距。
得益于IKI的残差设计,与之前的方法相比,现在可以在这种不匹配的场景中引入更少的噪声。然而,当训练和测试分布之间的差异增加时,模型在某种程度上的性能下降是不可避免的,这会损害VLMs在预训练阶段所学到的零样本能力。
ZSCL通过蒸馏来解决这个问题。他们构建了一个包含来自ImageNet的100,000张图像的参考数据集,以在每个训练步骤中将原始CLIP的预训练知识蒸馏到当前模型中,明确进行复习以避免遗忘。这种方法可能有效,但它依赖于大规模存储和高计算资源,从而在实际环境中显得不切实际。
一个直观的解决方案是控制知识植入模型的程度。然而,之前基于前置的提示调整技术只有两个选择:要么追加学习到的提示,要么不对原始CLIP模型进行任何修改。得益于IKI的优雅残差特性,现在可以控制这一并行分支的能力。
- DIKI: calibrate the integration with distribution




![]()

#Poison-splat
首个3DGS重大安全漏洞研究!首个研究如何攻击3DGS计算复杂性的工作
3DGS由Kerbl等人在2023年提出,迅速改变了3D视觉领域,获得了压倒性的欢迎。与NeRF不同,3DGS并非由神经网络驱动,而是通过学习一组3D高斯来捕捉场景,并使用光栅化同时渲染多个对象。这使得3DGS在渲染速度、照片逼真度和可解释性方面具有显著优势,成为该领域的游戏规则改变者。
高斯点云的一个有趣特性是其模型复杂度的灵活性。不同于NeRF或其他基于神经网络的算法,这些算法的计算复杂性通常由网络超参数预先确定并保持固定,3DGS可以根据输入数据动态调整其复杂性。在3DGS的训练过程中,可学习参数的数量,即3D高斯的数量,随着场景复杂度的变化而动态调整。具体来说,3DGS算法采用自适应密度控制策略,通过增加或减少高斯数量来优化重建,从而导致GPU内存占用和训练时间成本的可变性。
该设计的灵活性旨在为训练提供优势。然而,这种灵活性也可能成为一个漏洞。在本文中,我们揭示了一个严重且未被注意到的攻击向量:3DGS复杂性的灵活性可能被滥用,从而过度消耗计算资源(如GPU内存),并显著拖慢高斯点云系统的训练速度,将训练过程推向其最糟糕的计算复杂性。
本文介绍Poison-splat[1]是计算成本攻击方法,作为这种新型攻击向量的概念验证。Poison-splat以训练数据污染的形式出现(Tian等人,2022年),攻击者通过操纵输入数据来攻击受害者的3DGS系统。这在现实世界中具有实际操作性,因为像Kiri (KIRI)、Polycam (Polycam) 和Spline (Spline) 这样的商业3D服务提供商接收来自用户上传的图像或视频以生成3D捕获。攻击者可以伪装成普通用户提交污染数据,隐秘地发起攻击,甚至可以秘密篡改其他用户上传的数据。在高峰使用期,这种攻击会与合法用户争夺计算资源,降低服务响应速度,可能导致严重的后果,如服务崩溃,进而导致服务提供商的财务损失。
Poison-splat攻击被建模为一个最大最小问题。内部优化是3D高斯点云的学习过程,即在给定输入图像和相机姿态的情况下,最小化重建损失,而外部优化问题则是最大化解决内部问题的计算成本。
- 虽然准确解决这个双层优化问题往往是不可行的,但我们发现攻击者可以使用代理模型来近似内部最小化过程,并专注于优化外部最大化目标。
- 此外,我们观察到内存消耗和渲染延迟与训练中3D高斯数量呈现出显著的正相关关系。因此,攻击者可以在代理模型训练中使用高斯数量作为外部优化中的计算成本指标。
基于这些见解,Poison-splat攻击采用图像总变分损失作为先验来引导3D高斯的过度密集化,并能够以较低的成本近似解决这一双层优化问题。
主要贡献可概括为:
- 揭示了3DGS模型复杂性的灵活性可以成为一个安全后门,使其容易受到计算成本攻击。这一漏洞在3D视觉和机器学习社区中基本上被忽视了。该研究表明,这类攻击是可行的,可能给3D服务提供商带来严重的财务损失。
- 将对3D高斯点云的攻击建模为数据污染攻击问题。据我们所知,之前没有任何工作研究如何通过污染训练数据来增加机器学习系统的计算成本。
- 提出了一种新的攻击算法,名为Poison-splat,它显著增加了GPU内存消耗并减缓了3DGS的训练过程。我们希望社区能够认识到这一漏洞,并开发更为健壮的3D高斯点云算法或防御方法,以减轻此类攻击的影响。
资源针对型攻击
在计算机安全领域,一个类似的概念是拒绝服务攻击(DoS攻击)。DoS攻击的目标是通过过度消耗系统资源或网络来使其无法为合法用户提供服务。常见的方法包括通过大量请求使系统负载过高,或通过恶意输入触发系统崩溃。这类攻击给现实中的服务提供商带来了严重风险,可能导致广泛的业务中断和经济损失。例如,生成式AI平台Midjourney曾经历了一次持续24小时的重大系统中断,可能是由于另一家生成式AI公司的员工试图抓取数据,导致拒绝服务。
在机器学习领域,类似的概念很少被提及。这可能是因为大多数机器学习模型在设置超参数后,其计算复杂性保持固定。无论输入数据内容如何,大多数机器学习算法的计算成本和资源消耗几乎是恒定的。然而,只有少数研究关注在推理阶段的资源针对型攻击。例如,Shumailov等人(2021年)首次发现了触发过度神经元激活的样本,这些样本能够最大化能量消耗和延迟。后续研究还探讨了其他针对动态神经网络和语言模型的推理阶段攻击。然而,据我们所知,之前的工作尚未针对机器学习系统的训练阶段的计算成本进行攻击。该工作首次通过高斯点云建模,提出了这一研究方向,该方法具有自适应的计算复杂性。
POISON-SPLAT攻击
问题表述
在数据投毒框架下对攻击进行表述。受害者是3D高斯点云(3DGS)的服务提供商,他们通常使用多视图图像和相机姿态的数据集
攻击者。攻击者从干净数据集 开始,通过操作这些数据生成投毒训练数据 ,其中攻击者并不修改相机姿态配置文件。每幅投毒图像 是从原始干净图像
受害者。另一方面,受害者从攻击者处接收了这个投毒数据集 ,并不知道数据已被投毒。受害者使用这些数据训练高斯点云模型 ,其目标是最小化重建损失(见公式1)。受害者的目标是尽可能实现最低的损失,从而确保高斯点云模型的质量。
优化问题。总结来说,攻击者的计算成本攻击可以表述为如下最大-最小双层优化问题:
其中,计算成本度量
提出的方法
为了实施攻击,直接求解上述优化问题是不现实的,因为计算成本不可微。因此,我们试图为该目标找到一个近似解。
使用高斯数量作为近似。3DGS的一个主要优势是其根据输入数据的复杂性动态调整模型复杂性(即高斯的数量)的能力。这种适应性增强了模型在渲染复杂场景时的效率和逼真度。然而,这一特性也可能成为潜在的攻击后门。为了探索这一点,我们分析了高斯数量如何影响计算成本,包括内存消耗和训练时间。我们的研究结果(图2(a-b))揭示了计算成本与使用的高斯数量之间的显著正相关性。基于这一见解,使用高斯的数量 ∥G∥ 来近似内部优化中涉及的计算成本函数是直观的:
通过锐化3D物体最大化高斯数量。即使有了上述近似,解决优化问题仍然困难,因为3DGS中的高斯增密操作不可微。因此,攻击者不可能使用基于梯度的方法来优化高斯的数量。为了规避这一问题,我们探索了一种策略性替代方法。如图2(c)所示,我们发现3DGS倾向于为那些具有更复杂结构和非平滑纹理的物体分配更多的高斯,且这种复杂性可以通过总变分(Total Variation,TV)得分来量化,即评估图像锐度的度量标准。直观上,3D物体表面越不平滑,模型需要更多的高斯来从其2D图像投影中恢复所有细节。因此,非平滑性可以作为高斯复杂性的一个良好描述符,即 ∥G∥ ∝ STV(D)。受此启发,我们通过优化渲染图像的总变分得分 STV(Ṽk) 来最大化计算成本:
通过可选的约束优化平衡攻击强度与隐蔽性。上述策略使攻击能够显著增加计算成本。然而,这可能会导致图像的无限制更改,进而导致生成的视图图像在语义上的完整性丧失(参见图4(b)),使得攻击容易被检测到。考虑到攻击者可能希望在保持图像语义的同时隐秘地发起攻击,我们引入了一种可选的约束优化策略。受对抗性攻击的启发,我们在扰动上施加了L∞范数的ϵ球约束:
ϵ
其中,ϵ 表示将渲染的投毒图像限制在原始干净图像 Vk 周围的L∞范数的ϵ球内,即 ϵ。通过调整ϵ,攻击者可以在攻击的破坏性和隐蔽性之间进行权衡,实现所需的结果。如果ϵ设置为∞,则约束实际上被移除,返回到其原始的无约束形式。
通过代理模型确保多视图图像的一致性。我们研究中的一个有趣发现是,仅通过最大化每个视图图像的总变分得分来独立优化扰动,并不能有效增强攻击效果。如图3(b)所示,这种基于图像级别的总变分最大化攻击的效果显著低于我们的Poison-splat策略。这主要是因为图像级别的优化会导致不同视图之间的投毒图像出现不一致,从而削弱了攻击的整体有效性。
我们的解决方案受到了3DGS模型渲染函数的视图一致性特性的启发,该函数有效地保持了从3D高斯空间生成的多视图图像之间的一致性。基于此,我们提出训练一个代理3DGS模型来生成投毒数据。在每次迭代中,攻击者将当前的代理模型投影到相机姿态上,获得渲染图像 。此图像随后作为优化的起点,攻击者在干净图像 的 ϵ 范围内,搜索一个目标 ,以最大化总变分得分。接着,攻击者通过一个优化步骤更新代理模型,以模仿受害者的行为。在随后的迭代中,投毒图像的生成从更新后的代理模型的渲染输出开始。通过这种方式,攻击者通过迭代展开外部和内部优化,近似解决了这个双层优化问题,同时保持了视图之间的一致性,从而增强了攻击的有效性。我们在算法1中总结了Poison-splat的流程。
实验效果
总结一下
Poison-splat揭示了3D高斯点云(3DGS)中的一个重大且此前未被重视的安全漏洞,该方法显著增加了3DGS的计算需求,甚至可以触发拒绝服务(如服务器中断),从而给3DGS服务提供商造成重大财务损失。通过采用复杂的双层优化框架和一系列策略,如攻击目标近似、代理模型渲染和可选的约束优化,该方法证明了此类攻击的可行性,并强调了简单防御措施难以应对这一问题。这是首个研究如何攻击3DGS计算复杂性的工作,首次探讨了机器学习系统训练阶段的计算复杂性攻击。希望3DGS领域的研究人员和实践者能够认识到这一安全漏洞,并共同努力开发更加健壮的算法和防御策略,以应对此类威胁。
局限性与未来方向
- 更好的外部最大化优化近似。在本研究中,通过高斯的数量来近似外部最大化目标(即计算成本)。尽管高斯的数量与GPU内存占用和渲染延迟有很强的相关性,但仍然可能存在更好的优化度量。例如,高斯的“密度”,即在相同平铺中参与alpha混合的高斯数量,可能是实现更好优化结果的一个更好的度量标准。
- 更好的防御方法。主要关注开发攻击方法,而没有深入探讨防御策略。我们希望未来的研究可以提出更健壮的3DGS算法,或者开发出更有效的防御技术来应对此类攻击。这一方向的研究将显著增强3DGS系统在实际应用中的安全性和可靠性。
社会影响
尽管我们的方法可能会被恶意行为者滥用,扰乱3DGS服务提供商并造成经济损失,但我们的目标并不是促成这样的行为。相反,我们的目的是揭示3DGS系统中存在的重大安全漏洞,并促使研究人员、从业者和服务提供商共同认识和解决这些问题。我们希望通过我们的研究,激励开发出更健壮的算法和防御策略,从而增强3DGS系统在实际应用中的安全性和可靠性。我们承诺坚持伦理研究,不支持利用我们的研究结果对社会造成伤害。
#扩散模型去伪求真,Straightness Is Not Your Need?
这篇文章探讨了基于rectified flow和flow-matching的扩散模型在生成领域的应用,并指出了对这些模型的常见误解。文章通过对比不同的扩散模型形式,如variance preserving (VP)、variance exploding (VE)和flow-matching,阐明了flow-matching只是一般扩散模型的一个特例,并非本质上更优越。
23年以来,基于rectified flow[1]和flow-matching[2]的扩散模型在生成领域大展异彩,许多基于flow-matching的模型和文章如雨后春笋般涌现,仿佛“直线”已经成为一种政治正确。
该blog的动机,是源于网络平台,诸如知乎,小红书,乃至许多论文中都出现了很多对于rectified flow (flow-matching) 的错误理解和解读。本文希望能够提供一个相对合理的视角来重新思考关于rectified flow相关的话题, 抛砖引玉。
该blog基于最近的论文:
Rectified Diffusion: Straightness is Not Your Need
单位: MMLab-CUHK, Peking University, Princeton University
https://arxiv.org/pdf/2410.07303
https://github.com/G-U-N/Rectified-Diffusion/tree/master
https://huggingface.co/wangfuyun/Rectified-Diffusion
直观对比,FMs和一般的DMs有本质区别吗?
早在21年,Variational Diffusion Models[3] 就已经使用了一种general的扩散模型表达式 其中
这种表达式的好处,在于他提供了一个统一的form来看待很多diffusion的形式。下面我们举几个例子:
- 的表达式,也被称为variance preserving (VP)[6]的表达式。其只需要满足 。在这种情况下,我们很容易看到 ,这也是该表达式被称为 variance preserving的原因。所以,我们这样理解DDPM就会发现他的form也并不复杂,之所以 DDPM论文的原始推导显得如此复杂,就在于他额外引入了一个 序列,然后用 序列的累乘来计算得到
- variance exploding (VE) [6]的表达式,也常常被认为是EDM[7]的form,只要满足 即可。这个时候, 的值域就不会仅仅限制在0-1之间,而是会有
- 我们以同样的视角来看flow-matching的表达式,只要设置 就可以了。要说这种form的优点,大概就是他简单,不过从笔者的视角看,他也并不比variance exploding (VE) 的form简单, 因为VE中甚至只需要考虑唯一的变量
以这种视角我们看到,flow-matching,它只是general 扩散模型表达式的一种特例,他并不比其他的形式包括VP, VE, Sub-VP更加特殊。要说为什么有很多文章诸如sd3,flow-matching等文章中的效果要比其他form好,我个人认为更多是超参数导致的问题,例如如何分配时间的采样,时间的weigthing,还有prediction type的差异等等。论文中通常为了表现自己方法的优越性,都会对自己的方法进行比较精细的超参数搜索。而对于一种diffusion form的最优超参数设置,未必适用于其他的diffusion forms。
FMs的轨迹真的直吗?
关于这点的误解是最多的,其实所有的diffusion模型训练结束后,它们的采样轨迹几乎必然是curved。我们来看flow- matching的形式
因此
从上面的式子可能会误认为, 永远都是,因此是一条直线。但是由于我们diffusion的训练, 和 都是随机配对的,所以实际上 的最终的收敛目标会是
并且注意到, 对于不同时间刻, 这种期望并不相同, 因此不同时间刻 对应的
我们用下面一张图更加形象的说明这个例子, 红色的点, 代表离散采样过程中每一步的 , 虽然每步模型denoise都是走直线, 但是由于
Rectified Flow是怎么让轨迹变直的?
通读rectified flow[1] [8] [9]的相关文章,我们可以看到rectified flow相较于一般的DDPM,主要有三点核心的观点:
- Flow-matching。Rectified Flow提出上述的的扩散形式。中间的噪声状态 定义为 , 其中 为干净数据,
- -Prediction。Rectified Flow提出采用 -预测, 即模型学习预测 。这使得去噪形式变得简单。例如, 可以基于 预测 , 公式为 , 其中 表示模型参数,^表示预测值。此外, 它避免了在 时使用 -预测时出现的数值问题。例如, , 这是invalid的。
- Rectification。Rectification(也称为Reflow)是Rectified Flow中提出的重要技术。它是一种渐进式的重训练方法, 能够显著提高低步长下的生成质量, 并保持标准扩散模型的多步预测的灵活性。具体来说, 它将标准扩散训练中采用的任意塊合 (真实数据) 和 (噪声)转变为一个新的确定性塊合 (生成数据) 和 (预先收集的噪声)。简单来说,它将 替换为 , 其中 是真实数据, 是由预训练扩散模型 生成的数据, 是随机采样的噪声, 是生成
Rectified flow的采样轨迹,只有在执行了多次(一次)的rectification的操作之后,才会慢慢的变为直线,这也正是rectified flow中实现单步生成的重要操作。
Rectified flow包括后续的诸多工作,都强调Rectification这个操作,仅适用于flow-matching形式的diffusion模型。也就是说他们认为前两点~(1和2)是采用Rectification并实现采样加速的的基础,并强调修正过程(Rectification)将ODE路径“拉直”。如果是其他的diffusion forms,如VP, VE, sub-VP[6]等,则无法采用rectification的操作来实现加速。
这就导致,在InstaFlow[10]中 (Rectified Flow的后续工作,其作者尝试将rectified flow拓展到stable diffusion上的文生图任务),rectified flow的作者使用stable diffusion的原始权重初始化,但是将SD转变为flow-matching的form,并采用-prediction来进行重新训练。
所以,rectified flow中的这种观点真的正确吗?在加速sd的过程中,真的有必要首先将其转化为flow-matching的形式和-prediction吗? Flow-matching的diffusion form真的显著比别的形式好吗?
Recfified Diffusion: 本质是使用配对的噪声样本对重训练。
Rectification实现采样加速的成功之处在于使用成对的噪声-样本进行训练。 为了清晰地展示差异,我们可视化了标准的flow matching训练和rectified flow的rectification训练的过程,分别对应算法1和算法2。差异部分以红色标出。一个关键的观察点是,在标准流匹配训练中,表示从训练集中随机采样的真实数据,而噪声 是从高斯分布中随机采样的。这导致了噪声和样本之间的随机配对。相对的,在rectification的训练中,噪声是预先从高斯分布中采样的,图像则是通过预先采样的噪声由前一轮重整(预训练模型)生成的,形成了确定性的噪声与样本的配对。
Flow-matching Training是标准diffusion training的子集。此外,算法2 可视化了更一般的扩散模型的训练过程,与算法1的差异以蓝色和橙色标出。值得注意的是,流匹配是我们讨论的扩散形式的一个特殊情况。从算法中可以看出,它们之间的唯一区别在于扩散形式和预测类型。因此,流匹配训练只是特定扩散形式和预测类型下的标准扩散训练的特殊情况。
通过比较算法2 和算法3 与算法1,可以自然而然的推导出算法4。本质上,通过引入预训练模型来收集噪声-样本对,并在标准的扩散训练中用这些预先收集的配对替换随机采样的噪声和真实样本,我们就得到了Rectified Diffusion的训练算法。
以此为基础,我们提出rectified diffusion。如图下图所示,我们的总体设计非常简单。我们保留了预训练扩散模型的所有内容,包括噪声调度器、预测类型、网络架构,甚至训练和推理代码。唯一的不同在于用于训练的噪声 和数据
训练目标是轨迹一阶化
对于上述讨论的通用扩散形式 ,存在一个精确的ODE解形式[4],

其中, 是 的反函数。左侧项 是一个预定义的确定性缩放。右侧项是关于 预测的指数加权积分。如果满足一阶ODE,上述任意 和

在文章中, 我们证明了任意 和 的上述两个方程等价当且仅当ODE轨迹上的
一阶ODE与预定义扩散形式具有相同的形式
简而言之, 我们假设ODE轨迹是一阶ODE, 且存在一个解点 。因此, ODE轨迹上解点 对应的 预测是常数, 我们将其记作 。将 和
这与预定义的前向过程形式完全相同。因此, 我们可以得出一阶ODE正是数据和噪声按预定义的前向扩散形式进行加权插值。唯一的区别在于, 上述方程中的 和 是在同一ODE轨迹上的确定性对, 而在标准扩散训练中, 和 是随机采样的。这意味着, 如果我们在训练中实现了数据 和噪声 的完美塊合, 并且不同路径之间不存在交叉 (否则 预测可能是不同路径的
一阶化轨迹可能是弯曲的
对于一阶ODE, 虽然基于流匹配的方法的轨迹是直线, 但其他形式的扩散模型的轨迹可以本质上是弯曲的。但如果我们定义 , 我们将从方程
得到 。我们可以很容易地观察到 的轨迹是一条从初始点 朝向 方向的直线(即一阶轨迹可以转换为直线)。我们在下图中展示了我们的发现:我们选择 和 。图 (a) 和图 (b) 展示了流匹配和EDM的一阶轨迹, 它们都是直线, 但EDM的一阶轨迹和flowmatching完全不同。图 (c) 和图 (d) 展示了DDPM和Sub-VP的一阶轨迹, 它们的一阶轨迹本质上是弯曲的。图 (e) 展示了
实验验证
我们进行了广泛的实验验证和方法对比,我们的方法取得了一致超越rectified flow相关方法的性能,并且与最先进的蒸馏加速算法[11] [12]也取得了comparable的结果。
最后欢迎大家关注我们的论文:
参考
- ^abFlow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow https://arxiv.org/abs/2209.03003
- ^Flow Matching for Generative Modeling https://arxiv.org/abs/2210.02747
- ^Variational Diffusion Models https://arxiv.org/abs/2107.00630
- ^abDPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps https://arxiv.org/abs/2206.00927
- ^Denoising Diffusion Probabilistic Models https://arxiv.org/abs/2006.11239
- ^abcdScore-Based Generative Modeling through Stochastic Differential Equations https://arxiv.org/abs/2011.13456
- ^Elucidating the Design Space of Diffusion-Based Generative Models https://arxiv.org/abs/2206.00364
- ^PeRFlow: Piecewise Rectified Flow as Universal Plug-and-Play Accelerator https://arxiv.org/abs/2405.07510
- ^Improving the Training of Rectified Flows https://arxiv.org/abs/2405.20320
- ^InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation https://arxiv.org/abs/2309.06380
- ^Phased Consistency Model https://arxiv.org/abs/2405.18407
- ^Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation https://arxiv.org/abs/2404.04057
#RoboGSim
Real2Sim2Real范式的数据合成器和闭环仿真器
随着具身智能的高速发展,真实环境下的高效数据获取变得愈发重要。然而,通过遥操捕获或真机现场采集的数据收集往往成本极高,且难以高效扩展数据规模。在仿真环境中采集任务序列是一种实现大规模数据采集的有前景方案,但现有模拟器在纹理和物理建模的高保真度上存在不足。为了解决这些问题,我们结合了 3D 高斯泼溅技术(3DGS)和物理引擎提出了 RoboGSim,一个基于 Real2Sim2Real 的机器人模拟器。RoboGSim 主要包括四个模块:高斯重建器、数字孪生生成器、场景组合器和交互引擎。它能够生成包含新视角、新物体、新轨迹和新场景的合成数据。此外,RoboGSim 提供了一种在线的、可重复的、安全的评估方式,用于不同抓取策略的评测。Real2Sim 和 Sim2Real 的交叉验证实验表明,RoboGSim 在纹理和物理表现上具有高度一致性。此外,我们在真实世界的抓取任务中验证了合成数据的有效性。我们希望 RoboGSim 能成为一个闭环模拟器,为策略学习的公平比较提供支持。项目页面:https://robogsim.github.io/
一些介绍
收集大规模的抓取数据对于有效的策略学习至关重要。一些方法建议通过遥操来捕获演示和动作信息。这样的操作虽然相对提高了采集效率,但随着数据规模的增大,往往会带来极大的成本。为了解决这个问题,另有一些工作尝试在仿真环境下合成数据,进一步用于学习抓取策略。然而,这些 Sim2Real 方法受到模拟环境和现实环境之间巨大域差距的影响,使得学习到的策略无效。
最近,一些工作引入了用于机器人学习的 Real2Sim2Real (R2S2R) 范式。核心思想是通过神经辐射场方法执行真实重建,并将学习到的表示插入模拟器中。在这些方法中,典型的方法 Robo-GS 提出了 Real2Sim 管道,并引入了混合表示来生成支持高保真模拟的数字资产。然而,它缺乏对新场景、视图和物体的演示综合,以及模型学习数据的验证。此外,由于潜在表示、仿真环境和真实世界之间的不一致,它无法对不同的策略进行闭环评估。
在本文中,我们提出一个名为 RoboGSim 的 Real2Sim2Real 模拟器,用于高保真演示综合和物理一致的闭环评估。主要包括四个部分:高斯重建器、数字孪生生成器、场景组合器和交互引擎。给定多视图的 RGB 图像序列和机械臂的 MDH 参数,高斯重建器基于 3DGS 构建,对场景和物体进行重建;数字孪生生成器执行网格重建并在 Isaac Sim 中创建数字孪生,同时我们提出布局对齐模块来对齐仿真环境、现实世界和 3DGS 表示之间的空间;之后,场景合成器将仿真器中的场景、机械臂和物体结合起来,并从新视角渲染图像;在交互引擎中,RoboGSim 作为合成器和评估器来执行演示合成和闭环策略评估。
与现有的 (Real2)Sim2Real 框架相比,RoboGSim 带来了许多优势。它是第一个将演示合成和闭环评测相结合的辐射场模拟器。RoboGSim 可以生成具有新场景、新视角和新物体的真实操纵演示,用以进行策略学习。它还可以对不同的策略网络进行闭环评测,确保现实环境下的公平比较。总之,我们的核心贡献可以总结为:
- 基于 3DGS 的真实模拟器:我们开发了基于 3DGS 的模拟器,可以从多视图 RGB 视频中重建具有真实纹理的场景和物体。RoboGSim 针对一些具有挑战性的条件进行了优化,例如弱纹理、弱光和反射表面。
- 数字孪生系统:我们在系统中引入了布局对齐模块。通过布局对齐的 Isaac Sim,RoboGSim 从 Real2Sim 空间映射物体和机械臂之间的物理交互。
- 合成器和评估器:RoboGSim 可以将真实的操纵演示与新颖的场景、视图和物体进行合成,以进行策略学习。它还可以充当评估器,以物理一致的方式执行模型评估。
RoboGsim方法说明整体架构
如图 2 所示,RoboGSim 主要包括四个部分:高斯重建器、数字孪生生成器、场景组合器 和交互引擎。对于多视角图像和机器人臂的 MDH 参数,高斯重建器使用 3DGS 重建场景和物体,同时对机械臂进行分割,并构建 MDH 运动学驱动图结构,以实现机械臂的精确运动建模。数字孪生构建器负责场景和物体的网格重建,通过布局对齐,资产数据流可以互联,从而促进交互引擎的后续评估。场景合成器实现了新物体、新场景和新视角的合成。交互引擎可合成新视角/场景/物体的图像,并用于策略学习。同时,它还能以闭环方式评估策略网络。此外,我们还可以通过 VR/Xbox 等现实世界设备,在仿真中收集操作数据。
高斯重建器
我们采用 3DGS 对静态场景进行重建,并对机器人臂关节的点云进行分割。随后,利用 MDH 动力学模型控制对应每个关节的高斯点,从而实现机器人臂的动态渲染。
3DGS 使用多视角图像作为输入,完成高保真场景重建。3DGS 将场景表示为一组高斯分布,并采用可微分的光栅化渲染方法以实现实时渲染。具体来说,对于由 个高斯点表示的场景 ,每个高斯点可以表示为 。其中, 表示均值, 表示协方差矩阵, 表示不透明度, 表示通过球谐系数表示的颜色因子。
在渲染过程中,像素的最终颜色值 可以通过类似于 alpha 混合的渲染方法计算得到。它利用了与该像素重叠的 个有序高斯点的序列。此过程可以表示为:
其中 表示第 个高斯点对于当前像素的不透明度, 表示 2D 高斯点中心和像素中心的位移量, 表示 2D 协方差矩阵。
MDH是一种参数化模型,用于描述机械臂的运动链。运动链中的每个关节和连杆都由一组参数表征。在 MDH 模型中,可以为每个连杆构造一个变换矩阵,从而实现机械臂在运动过程中每个阶段姿态的精确表示。设 表示第 个关节的原点坐标。对于一个机械臂,第 个关节的配置可以表示为:

其中, 表示扭转角,即从第 个关节到第 个关节绕 轴的旋转角度。 表示连杆长度,是从 到 沿 轴的距离。 是连杆偏移,表示从 到 沿 轴的位移。 表示关节角,是从 到 绕 轴的旋转角度。
使用 MDH 参数构造的每个连杆的变换矩阵 可以写为:
通过依次相乘这些变换矩阵,可以得到从基座到末端执行器的最终变换矩阵。
我们对每个关节进行分割,并将关节内的所有高斯点视为一个质点。随后,根据 对每个关节内的所有高斯点进行移动,从而实现对高斯点的运动学驱动控制。
数字孪生生成器
数字孪生不仅应映射现实世界资产,还需要进行坐标对齐。通过 Real2Sim 布局对齐和 Sim2GS 稀疏关键点对齐,我们能够将真实世界的数字化,实现真实、仿真和 3DGS 表示之间的数字资产流动。这种方法促进了数字资产在各方向的转换,实现全面的资产整合。
3D 资产生成
我们采用两种方法生成 3D 物体资产。对于现实世界中的物体,我们通过旋转台捕获物体的高质量多视角图像,并使用 GIM 提取匹配特征,以解决纹理缺乏和反射等问题。随后,我们集成 COLMAP 管道,获得初始的 SFM 点云,并使用 3DGS 对其进行重建。此外,对于来自网络的新颖物体,我们首先使用 Wonder3D 获得几何一致的法向量和纹理网格,然后利用 GaussianEditor 中基于扩散模型的方法,在 3DGS 中完成物体重建。
布局对齐
如图 2 所示,由于我们遵循机械臂的局部坐标系统,因此世界坐标系与 Isaac Sim 仿真器间已经轴对齐。我们首先测量真实世界的场景,并对 Isaac Sim 中导入的桌面场景进行尺寸对齐。为实现坐标对齐,我们在 3DGS场景和 Isaac Sim 场景中同时在基座关节上方 1.6 米处放置向下的摄像机,通过比较从 BEV 视图渲染的场景,正面和侧面分割视图中渲染的场景,我们在 Isaac Sim 中调整偏移量以实现布局对齐。
Sim2GS 对齐
对于基于 MDH 的变换矩阵 和仿真变换矩阵 ,存在一个变换矩阵 满足以下关系:

为了计算平均变换矩阵 ,我们采用加权求和并进行归一化:

其中, 为每个关节的权重。
对于 Isaac Sim 中的目标物体 ,可以使用以下公式将其转换为 3DGS 坐标系:

相机定位
为了将现实世界的坐标系转换到 3DGS 坐标系,我们采用 GS-SLAM 中的定位方法。对于一个预训练的 3DGS 模型 ,我们冻结 3DGS 的属性,并优化外部相机参数 。
在相机定位过程中,仅优化当前相机的姿态,而不更新地图表示。对于单目情况,我们最小化以下光度残差:

其中, 表示通过高斯点 和像机参数 渲染的新视角图像, 是观测到的图像。
场景组合器
为了将点云合并到机械臂场景中,首先计算标记点的变换矩阵 。然后,基于该变换矩阵将新场景中的点云坐标投影到机器人臂的坐标系中。通过以下公式将 3DGS 中的 3D 协方差 展开为缩放因子 和旋转四元数 :

变换的比例因子 可以被分离并提取为一个独立分量:

进一步使用 对旋转矩阵 进行归一化:

调整高斯点的缩放属性 :

将变换 应用于高斯点的坐标:

物体编辑
此处的变换可以扩展自上述场景编辑的变换。不同之处在于目标物体的坐标中心由 (1) 给出。高斯点的坐标变换可以表示为:

交互引擎
我们的交互引擎可以作为数据生成器和模型评估器使用。作为数据生成器,它可以以低成本生成大量数据用于下游策略学习;作为评估器,它可以进行安全、实时且可重复的评估。
数据生成器
我们使用引擎生成多种训练轨迹,包括机器人臂运动轨迹和目标轨迹。这些轨迹驱动 3DGS 生成大规模、高度真实的模拟数据集,用于策略学习。这些多样化的数据集包括新视角渲染、场景组合和对象替换。
模型评估器
对于已训练的模型,直接在物理设备上测试可能存在安全风险或带来高昂的复现成本。因此,我们将预测的轨迹转换为 3DGS 渲染结果,以高效、快速地评估模型的预测质量。具体来说,Isaac Sim 输出目标对象和机器人臂的初始状态,3DGS 根据状态进行渲染。渲染图像被输入到策略网络中,预测下一帧的动作。预测的动作被传递到仿真环境中,用于运动学反解析、碰撞检测和其他物理交互。随后,Isaac Sim 将解析得到的六轴相对位姿发送至 3DGS 渲染器,渲染器将渲染结果作为反馈返回给策略网络。这一过程为预测下一步动作提供了视觉反馈,持续迭代直到任务完成。
实验
由于目前尚无 Real2Sim2Real 的基准,我们构建了以下四组代理实验,全面评估 RoboGSim 在模拟和现实场景中的性能。所有实验均使用 UR5 机械臂进行。机械臂的渲染部分基于 Robo-GS 的代码库实现。
Real2Sim 新位姿合成:验证从现实世界采集的机械臂位姿是否可以有效用于实现模拟器中的精准控制。
Sim2Real 轨迹重现:检查在模拟器中收集的轨迹是否能够被真实世界中的机械臂准确复现。
RoboGSim 作为数据生成器:展示 RoboGSim 生成具有新场景、新视角和新对象的高保真演示能力,并与现实世界对齐。
RoboGSim 作为评估器:展示 RoboGSim 能够高效执行策略网络的闭环评估。
Real2Sim 新位姿合成
新位姿合成的目标是验证 Real2Sim 重建的性能,特别是机械臂运动的准确性和图像纹理的逼真度。静态场景使用机械臂初始姿态的第一帧 GT 进行重建。真实机械臂采集的轨迹作为驱动力,并通过运动学控制实现新位姿的渲染。
如图 3 所示,实验结果表明,我们的重建能够准确捕捉机械臂的纹理和物理动态,突显了 RoboGSim 实现的高保真度。与真实机械臂在新视点下的视频序列对比,RoboGSim 在渲染中达到了 31.3 的 PSNR 和 0.79 的 SSIM,同时保证了每秒 10 帧的实时渲染速度。
Sim2Real 轨迹重现
为了验证 Isaac Sim 中的轨迹是否能够与真实机械臂和 RoboGSim 有效对齐,我们设计了一项实验:首先在 Isaac Sim 中采集轨迹,然后利用该轨迹驱动 GS 渲染一个抓取可乐的场景,同时将相同的轨迹用于驱动真实机械臂抓取可乐罐。
如图 4 所示,实验结果显示,模拟策略与机械臂的实际物理行为之间具有较强的对齐效果,突出体现了我们系统中 Sim2Real 迁移的有效性。这些结果表明,我们的模拟可以可靠地建模现实世界的动态,促进策略从模拟到现实的成功迁移。
RoboGSim 作为数据生成器
在本部分,我们使用视觉-语言-动作 (VLA) 模型验证 RoboGSim 生成数据的有效性。我们使用 LLAMA3-8B 作为大语言模型 (LLM),CLIP 作为视觉编码器,并采用两层 MLP 作为投影网络。VLA 模型在 8xA100 (80GB) 上训练 1 个 epoch,训练过程分为三个阶段:(1)预训练阶段:仅启用连接器,使用 LAION-558K 数据集。(2)训练阶段:解冻 LLM,使用 LLaVA665K 数据集。(3) 监督微调 (SFT):使用机器人图像-动作数据进行训练,同时冻结 CLIP 权重。
我们在具有挑战性的套圈任务上进行实验(见图6),该任务分为两个子任务:拾取套环和将其投放至目标。对于真实世界数据,人工采集了 1,000 个样本。为了公平比较,我们使用 RoboGSim 生成了 1,000 个合成样本。在测试阶段,每个模型测试 10 次,每次允许 3 次尝试。如果 3 次尝试均失败,则该次测试标记为失败。
如表 1 所示,使用 RoboGSim 合成数据训练的 VLA 模型实现了 40% 的抓取成功率和 50% 的投放成功率。相比之下,使用真实数据训练的 VLA 模型抓取成功率为 90%,投放成功率为 70%。需要注意的是,人工采集数据耗时 40 小时,而 RoboGSim 的数据生成仅需 4 小时。进一步扩展合成数据规模有望提升模型性能。图 6 展示了一些成功和失败案例的可视化结果。此外,我们还提供了更多关于新场景合成的定性分析。如图 5 所示,我们展示了 UR5 机械臂在新场景中的物理迁移结果,包括工厂、货架以及两个室外环境。高保真的多视图渲染表明,RoboGSim 能够使机械臂在多样化场景中无缝操作。
RoboGSim 作为评估器
逼真的闭环评估对于验证和比较策略网络至关重要。本部分主要探索 RoboGSim 作为评估器的有效性,以展示其与现实推理的高度一致性。
在实验中,我们将训练良好的 VLA 模型分别部署到真实机器人和 RoboGSim 模拟环境中。如图 7 所示,我们的闭环模拟器 RoboGSim 可以再现与现实世界类似的结果。对于相似的错误案例,RoboGSim 能够避免现实中存在的问题,例如越界和碰撞。因此,RoboGSim 提供了一个公平、安全且高效的策略评估平台。
#UncAD
基于在线地图不确定性的安全端到端自动驾驶
摘要
本文介绍了UncAD:基于在线地图不确定性的安全端到端自动驾驶。端到端自动驾驶旨在直接从原始传感器生成规划轨迹。目前,大多数方法将感知、预测和规划模块集成到一个完全可微分网络中,这有望实现巨大的可扩展性。然而,这些方法通常依赖于感知模块中在线地图的确定性建模来引导或者约束车辆规划,这可能会加入错误的感知信息并且进一步危及规划安全性。为了解决这个问题,本文深入研究了在线地图不确定性对于提高自动驾驶安全的重要性,并且提出了一种新的范式,称为UncAD。具体而言,UncAD首先估计了感知模块中在线地图的不确定性。然后,它利用该不确定性来引导运动预测和规划模块,以生成多模态轨迹。最后,为了实现更安全的自动驾驶,UncAD根据在线地图不确定性提出了一种不确定性碰撞感知规划选择策略,以评估和选择最佳的轨迹。本项研究将UncAD加入到各种最先进的(SOTA)端到端方法中。在nuScenes数据集上的实验表明,集成UncAD(仅增加了1.9%的参数)能够将碰撞率降低26%,并且将可行驶区域冲突率降低42%。
主要贡献
本文的主要贡献总结如下:
1)本文提出了一种称为UncAD的新范式,它将在线地图不确定性集成到端到端自动驾驶系统中;
2)本文设计了一种不确定性引导的预测和规划模块以及一种不确定性碰撞感知选择策略,以全面加入地图不确定性,从而实现更安全的规划;
3)本文引入了一种新的指标,即可行驶区域冲突率(DACR),用于全面评估规划质量;
4)在综合评估下,本文方法在nuScenes数据集上实现了SOTA性能。
论文图片和表格
总结
本文探索了端到端自动驾驶中地图不确定性的估计,并且提出了一种称为UncAD的新方法。本文深入研究了这一框架,通过不确定性引导的规划策略和不确定性碰撞感知规划选择模块来有效地利用地图不确定性,从而生成鲁棒且安全的规划结果。在nuScenes上的充足实验和SOTA性能证明了所提出方法的有效性。
#Momenta,为什么可以开打全球自动驾驶赛?
这届上海车展,重头戏依然是智能辅助驾驶。
全球汽车品牌这两天齐聚上海,场面空前,热闹程度创下历史之最,短短2天召开了近200场发布会。
智能辅助驾驶仍然是发布会的热点话题,释放出的消息让从业者惊呼:
太快了。
1年前,北京车展上头部玩家还在比拼「全国都能开」。
而今天,已经有玩家率先迈向了「全球都能开」。
一家中国智能辅助驾驶供应商,率先获得了全球认证,在全球化赛场拔得头筹,独坐钓鱼台,这就是Momenta。
集齐中美日德顶流车企的认可,此前行业的「隐形冠军」再也无法隐藏。以上海车展为分水岭,智能辅助驾驶新的赛段格局也开始形成。
是时候,竞速全球了。
而率先晋级全球赛的中国品牌,就是Momenta。
智能辅助驾驶的全球化步伐,Momenta迈得超级大
智能辅助驾驶的热潮并没有退去,解决方案扎堆展出,传统车企加速转型。
不论是大众车型还是豪华品牌,都在车展上将智能辅助驾驶作为重要卖点:
奥迪推出了全新电动品牌AUDI,宣布将搭载高阶辅助驾驶。
本田则宣布今后在华销售新车型,都将搭载智能辅助驾驶。
通用旗下的别克品牌,也宣布下半年会推出城区辅助驾驶车型。
德系豪华,日系三强,美系巨头,这些品牌来自不同地区,拥有不同背景,最终却选择了同一位中国玩家的方案:
Momenta。
至此,全球十大车企中有七家都成为了Momenta的合作伙伴,Momenta的朋友圈正以前所未有的速度扩张。
2022年,Momenta刚刚踏上智能辅助驾驶量产之路,只有1款定点车型。第二年,也不过8款车型,到2024年也只有26款车。
2025年4月,Momenta官宣定点车型数量超130款,实现了翻倍跨越式增长。这种Momenta速度,在整个智能辅助驾驶领域里,都绝对是TOP中的TOP选手。

量产方案上车量同步飞速增长,从0到10万辆,Momenta用了24个月的时间。第二个10万辆用时大减,不过6个月。
目前量产方案上车数量已经接近了30万辆,Momenta预计第三个10万辆用时3个月不到。
Momenta量产上车的进程,正在跑出飞轮效应。这个飞轮以上海滩为起点,横渡太平洋到达底特律,跨越欧亚大陆来到慕尼黑。
欧美汽车工业巨头与中国AI明星结盟,也引起他们的本土友商关注,开始打探消息。
智能车参考在逛展时,就偶遇了一位佩戴福特工牌的代表,用英文询问另一家头部厂商,“你们的方案与Momenta有什么不同”。
收获中美日德多家车企的关注和认可,Momenta实际上已成为「全球品牌的共同选择」,是第一家全球智能辅助驾驶品牌。
Momenta能率先脱颖而出,转动起量产成绩的飞轮,得益于背后的技术飞轮。
「全球品牌的共同选择」,为什么是Momenta?
Momenta成为「全球品牌的共同选择」,核心原因当然是对其技术实力的认可。
Momenta构建技术壁垒的过程,可以解读为一句话:
数据飞轮构建初速度,双线并行跑出加速度。
Momenta在行业中最早意识到了数据的价值,提出首个全流程数据驱动飞轮,实现数据闭环,飞轮大模型是Momenta打造全球朋友圈的初速度。
而随着端到端的兴起,行业开始转向数据驱动,先行一步的Momenta仍然具备独特优势,正在双线并行,用Robotaxi跑出业内少有的加速度。
Momenta CEO曹旭东刚刚在发布会上,对Momenta“两条腿走路”的战略做出了最新解读。
在乘用车做智能辅助驾驶是贡献数据流,为Momenta的飞轮大模型收集数据,优化算法,让更多用户愿意用进而得到更海量的数据,实现闭环。
最终获取1000亿公里的数据,抵达自动驾驶的终局。
而Robotaxi业务与智能辅助驾驶共享传感器平台,基于数据流优化算法,探索飞轮大模型上限,目前也同步取得了新的突破:
车端无人Robotaxi年底运营,基于量产车,量产域控和量产传感器,而且不用高精地图!
这在感知硬件和整体成本上,为Momenta的Robotaxi大规模量产落地奠定了基础。对岸的马斯克,要加把劲儿了。
这背后也体现出Momenta对自身技术实力的信心,也正是因为技术实力,给用户带来了良好的体验,让Momenta成为「全球品牌的共同选择」。
这是Momenta用第五代飞轮大模型取得的里程碑和新起点,据了解Momenta今年下半年会更进一步,推出基于强化学习的一段式端到端飞轮大模型Momenta R6。
数据飞轮进化也意味着,Momenta的朋友圈还有着很大的扩张潜力。
此时此刻,你是否也在感慨:
就在DeepSeek爆火短短数月后,又有一家中国AI公司,获得了海内外一致认可。
中国AI企业正在全球不同行业,证明中国的AI技术实力。而在智能辅助驾驶的全球竞赛中,第一个晋级的中国玩家,从上海车展浮出水面。
#π0.5
PI最新出品!π0继续升级:打通VLA模型在开放世界泛化能力
为了使机器人发挥作用,它们必须在实验室之外的现实世界中执行实际相关的任务。虽然视觉 - 语言 - 动作(VLA)模型在端到端机器人控制方面已取得令人瞩目的成果,但这类模型在野外环境中的泛化能力究竟如何仍是一个悬而未决的问题。我们介绍π0.5,这是一种基于π₀的新模型,它通过对异构任务进行联合训练来实现广泛的泛化。π0.5利用来自多个机器人的数据、高级语义预测、网络数据和其他来源的数据,以实现广泛可泛化的现实世界机器人操作。我们的系统结合了联合训练和混合多模态示例,这些示例融合了图像观察、语言指令、物体检测、语义子任务预测和低级动作。我们的实验表明,这种知识转移对于有效的泛化至关重要,并且我们首次证明了一个支持端到端学习的机器人系统可以在全新的家中执行长时间和灵巧的操作技能,比如清洁厨房或卧室。
论文链接:https://arxiv.org/abs/2504.16054
背景介绍
开放世界泛化是物理智能领域最大的开放性问题之一:诸如机械臂、类人机器人和自动驾驶汽车等实体系统,只有在能够离开实验室,应对现实世界中各种不同的情况和意外事件时,才真正具有实用价值。基于学习的系统为实现广泛泛化提供了一条途径,尤其是随着近年来的进展,在从自然语言处理到计算机视觉等各个领域都实现了可扩展的学习系统。然而,机器人在现实世界中可能遇到的情况千差万别,这不仅需要规模,还需要设计合理的训练方法,提供足够广泛的知识,使机器人能够在多个抽象层次上进行泛化。例如,当一个移动机器人被要求清理一个它从未见过的厨房时,有些行为如果在数据中有足够多的场景和物体来体现,就很容易泛化(比如拿起一把刀或一个盘子);有些行为可能需要对现有技能进行调整或修改,以便以新的方式或顺序使用;还有些行为可能需要根据先验知识理解场景的语义(比如打开哪个抽屉,或者台面上哪个物体最有可能是晾衣架)。那么,如何为机器人学习系统构建一个能够实现这种灵活泛化的训练方法呢?
一个人可以凭借一生的经验,为这些挑战中的每一个合成合适的解决方案。并非所有这些经验都是亲身经历,也并非都来自死记硬背的练习——例如,我们可能会使用别人告诉我们的事实,或者从书中读到的内容,再结合我们在不同背景下执行其他任务时获得的一些见解,以及在目标领域的直接经验。类似地,我们可以假设,可泛化的机器人学习系统必须能够从各种信息来源转移经验和知识。这些来源中,有些是与手头任务直接相关的亲身经验,有些需要从其他机器人实体、环境或领域转移,还有些代表完全不同的数据类型,比如语言指令、基于网络数据的感知任务,或者高级语义命令的预测。这些不同数据源的异构性构成了一个主要障碍,但幸运的是,视觉 - 语言 - 动作(VLA)模型的最新进展为我们提供了一套工具,使这一切成为可能:通过将不同模态纳入相同的序列建模框架,VLA可以适应于对机器人数据、语言数据、计算机视觉任务以及上述内容的组合进行训练。

我们利用这一观察结果,为VLA设计了一个联合训练框架,该框架可以利用异构和多样的知识来源来实现广泛的泛化。在π₀ VLA的基础上,我们提议纳入一系列不同的数据来源,创建π0.5模型(“pi oh five”),它可以控制移动机械臂执行各种家务任务,即使是在训练过程中从未见过的家中。π0.5借鉴了许多来源的经验:除了在各种真实家庭中使用移动机械臂直接收集的中等规模数据集(约400小时)外,π0.5还使用来自其他非移动机器人的数据、在实验室条件下收集的相关任务数据、需要根据机器人观察预测“高级”语义任务的训练示例、人类监督者提供给机器人的语言指令,以及从网络数据创建的各种多模态示例,如图像字幕、问答和物体定位(见图1)。提供给π0.5的绝大多数训练示例(在第一训练阶段占97.6%)并非来自执行家务任务的移动机械臂,而是来自这些其他来源,如其他机器人或网络数据。尽管如此,π0.5仍能够在训练过程中从未见过的全新家中控制移动机械臂,执行诸如挂毛巾或整理床铺等复杂任务,并且能够执行持续10 - 15分钟的长时间操作技能,仅根据一个高级提示就能清洁整个厨房或卧室。
“关上橱柜”“把物品放进抽屉”“擦拭溢出物”“把盘子放进水槽”

图2:π0.5清洁新厨房。机器人的任务是清洁一个不在训练数据中的家中的厨房。模型被赋予一般任务(关上橱柜、把物品放进抽屉、擦拭溢出物和把盘子放进水槽),它通过预测要完成的子任务(例如拿起盘子)和发出低级动作来执行这些任务。
π0.5的设计遵循一种简单的分层架构:首先在异构的训练任务混合集上对模型进行预训练,然后使用低级动作示例和高级 “语义” 动作对其进行微调,使其专门用于移动操作,这些高级 “语义” 动作对应于预测子任务标签,如 “拿起切菜板” 或 “重新整理枕头”。在运行时,在推理的每一步,模型首先预测语义子任务,根据任务结构和场景语义推断接下来适合执行的行为,然后根据这个子任务预测低级机器人动作块。这种简单的架构既提供了对长时间多阶段任务进行推理的能力,又为两个层次利用不同的知识来源提供了可能:低级动作推理过程很容易从其他机器人收集的动作数据中受益,包括其他环境中更简单的静态机器人的数据;而高级推理过程则受益于网络上的语义示例、高级注释预测,甚至是人类 “监督者” 提供给机器人的语言命令,这些监督者会像指导人一样,一步一步地指导机器人完成诸如清洁房间等复杂任务,告知它合适的子任务。我们在图1中展示了这种设计。
主要贡献是一个用于训练高度可泛化的VLA(π0.5)的系统,以及一个概念验证,即当该模型在适当多样化的数据上进行训练时,泛化能力可以从该模型中涌现。我们对π0.5的泛化能力以及不同联合训练成分的相关性进行了详细的实证评估。据我们所知,该工作首次展示了一个支持端到端学习的机器人系统,它可以在全新的家中执行长时间和灵巧的操作技能,如清洁厨房或卧室。实验和比较进一步表明,这是通过从其他机器人、高级语义预测、人类监督者的语言指令、网络数据和其他来源转移知识来实现的。
相关工作
(一)通用机器人操作策略
最近的研究表明,将机器人操作策略的训练数据分布从狭窄的单任务数据集扩展到涵盖许多场景和任务的多样化数据集,不仅可以使生成的策略能够直接解决更广泛的任务,还能提高它们对新场景和任务的泛化能力。训练这样的通用策略需要新的建模方法,以处理通常涵盖数百个不同任务和场景的数据集的规模和多样性。视觉 - 语言 - 动作模型(VLAs)提供了一个有吸引力的解决方案:通过对预训练的视觉 - 语言模型进行微调以用于机器人控制,VLAs可以利用从网络规模预训练中获得的语义知识,并将其应用于机器人问题。当与高度表达性的动作解码机制(如流匹配、扩散或高级动作token化方案)相结合时,VLAs可以在现实世界中执行各种复杂的操作任务。然而,尽管VLAs具有令人印象深刻的语言跟随能力,但它们通常仍在与训练数据紧密匹配的环境中进行评估。虽然一些研究表明,通过在更广泛的环境中收集机器人数据,像拿起物体或打开抽屉这样的简单技能可以实现泛化,但将相同的方法应用于更复杂、长时间的任务(如清理厨房)具有挑战性,因为通过暴力扩展机器人数据收集来实现对合理场景的广泛覆盖是不可行的。在我们的实验中,我们在全新的场景(如训练中未见过的新厨房和卧室)中评估π0.5,表明我们的VLA不仅可以利用目标移动机械臂平台上的直接第一手经验,还可以利用其他数据源的信息,从而泛化到全新的场景。这些数据源包括来自其他(非移动)机器人的数据、高级语义子任务预测和网络数据。
(二)非机器人数据联合训练
许多先前的工作试图使用多样化的非机器人数据来提高机器人策略的泛化能力。先前的方法探索了从计算机视觉数据集初始化视觉编码器,或者利用现成的任务规划器。VLA策略通常从预训练的视觉 - 语言模型初始化,该模型已经接触了大量的互联网视觉和语言数据。值得注意的是,VLA架构具有灵活性,允许在多模态视觉、语言和动作token的输入和输出序列之间进行映射。因此,VLAs不仅支持简单的权重初始化,还支持在单一统一架构上对任何交错了上述一种或多种模态的数据集进行联合训练,从而拓宽了可能的迁移方法的设计空间。先前的工作表明,使用用于视觉语言模型(VLM)训练的数据混合物对VLAs进行联合训练,可以提高它们的泛化能力,例如在与新物体交互或在未见场景背景下的交互中。在这项工作中,我们超越了VLM数据联合训练,设计了一个系统,用于使用更广泛的与机器人相关的监督源对VLAs进行联合训练,包括来自其他机器人的数据、高级语义子任务预测和语言指令。虽然多任务训练和联合训练不是新的想法,但我们展示了我们系统中特定的数据源组合,使移动机器人能够在全新的环境中执行复杂和长时间的行为。我们认为,这种泛化水平,特别是考虑到任务的复杂性,远远超出了先前工作中展示的结果。
(三)基于语言的机器人推理和规划
许多先前的工作表明,用高级推理增强端到端策略可以显著提高长时间任务的性能,特别是当高级子任务推理可以受益于大型预训练的语言模型(LLMs)和视觉语言模型(VLMs)时。我们的方法也使用两阶段推理过程,首先推断高级语义子任务(例如 “拿起盘子”),然后根据这个子任务预测动作。许多先前的方法为此使用两个单独的模型,一个VLM预测语义步骤,一个单独的低级策略执行这些步骤。我们的方法在高级和低级推理中使用完全相同的模型,其方式更类似于思维链或测试时计算方法,不过与实体思维链方法不同,高级推理过程的运行频率仍然低于低级动作推理。
(四)具有开放世界泛化能力的机器人学习系统
虽然大多数机器人学习系统在与训练数据紧密匹配的环境中进行评估,但也有一些先前的工作探索了更广泛的开放世界泛化。当机器人的任务被限制在一组更狭窄的基本原语(如拿起物体)时,允许特定任务假设的方法(例如抓取预测,或结合基于模型的规划和控制)已被证明可以广泛泛化,甚至可以泛化到全新的家中。然而,这些方法不容易泛化到通用机器人可能需要执行的所有任务。最近,跨多个领域收集的大规模数据集已被证明能够使简单但端到端学习的任务泛化到新环境。然而,这些演示中的任务仍然相对简单,通常持续时间不到一分钟,并且成功率相对较低。我们展示了π0.5可以执行长时间、多阶段的任务,如将所有盘子放入水槽或从新卧室的地板上捡起所有衣物,同时泛化到全新的家中。
预备知识回顾
视觉 - 语言 - 动作模型(VLAs)通常通过在多样化的机器人演示数据集D上进行模仿学习来训练,通过最大化在给定观察和自然语言任务指令的情况下,动作(或者更一般地,动作块)的对数似然:。观察通常包含一个或多个图像和本体感受状态,本体感受状态捕获机器人关节的位置。VLA架构遵循现代语言和视觉 - 语言模型的设计,具有特定模态的tokenizer,将输入和输出映射到离散(“硬”)或连续(“软”)token表示,以及一个大型自回归transformer骨干网络,该网络经过训练,用于从输入token映射到输出token。这些模型的权重从预训练的视觉 - 语言模型初始化。通过将策略输入和输出编码为token化表示,上述模仿学习问题可以转化为一个关于观察、指令和动作token序列的简单下一个token预测问题,可以利用现代机器学习的可扩展工具来优化它。在实践中,图像和文本输入的tokenizer选择遵循现代视觉 - 语言模型的选择。对于动作,先前的工作开发了有效的基于压缩的token化方法,在预训练期间使用这些方法。最近的一些VLA模型还提议通过扩散或流匹配来表示动作分布,为连续值动作块提供更具表达性的表示。在模型的训练后阶段,将基于π₀模型的设计,通过流匹配来表示动作分布。在这种设计中,与动作对应的token接收来自流匹配上一步的部分去噪动作作为输入,并输出流匹配向量场。这些token还使用一组不同的模型权重,我们将其称为 “动作专家”,类似于专家混合架构。这个动作专家可以专门用于基于流匹配的动作生成,并且可以比LLM骨干网络的其余部分小得多。
π0.5模型和训练方法

图3中概述了π0.5模型和训练方法。模型权重从在网络数据上训练的标准视觉语言模型(VLM)初始化,然后训练分两个阶段进行:预训练阶段旨在使模型适应多样化的机器人任务,训练后阶段旨在使其专门用于移动操作,并为其配备高效的测试时推理机制。在预训练期间,所有任务(包括涉及机器人动作的任务)都用离散token表示,这使得训练简单、可扩展且高效。在训练后阶段,让模型和π₀一样拥有一个动作专家,以便更精细地表示动作,并实现更高效的实时推理控制。在推理时,模型首先为机器人生成一个高级子任务,然后基于这个子任务通过动作专家预测低级动作。
(一)π0.5架构
π0.5架构能够灵活地表示动作块分布和token化文本输出,后者既用于联合训练任务(如问答),也用于分层推理时输出高级子任务预测。模型所捕捉的分布可以写成,其中包含了所有摄像头拍摄的图像以及机器人的配置信息(关节角度、夹爪姿态、躯干升降姿态和底座速度),是整体任务提示(例如“把盘子收起来”),代表模型的(token化的)文本输出,它可以是预测的高级子任务(例如“拿起盘子”),也可以是网络数据中视觉语言提示的答案,是预测的动作块。我们将该分布分解为:
其中动作分布不依赖于,仅依赖于。因此,高级推理捕捉,低级推理捕捉,这两个分布均由同一个模型表示。
该模型是一个transformer,它接收个多模态输入token (这里我们宽泛地使用“token”一词,既指离散化输入,也指连续输入),并生成一个多模态输出序列,可以写成。每个可以是文本token()、图像块(),或者是流匹配中机器人动作的中间去噪值()。观察值构成的前缀部分。根据指示的token类型,每个token不仅可以由不同的编码器处理,还可以由transformer中的不同专家权重处理。例如,图像块通过视觉编码器处理,文本token通过嵌入矩阵嵌入。遵循π₀的做法,我们将动作token线性投影到transformer嵌入空间,并在transformer中使用单独的专家权重来处理动作token。注意力矩阵表示一个token是否可以关注另一个token。与标准的大语言模型(LLMs)中的因果注意力不同,图像块、文本提示和连续动作token使用双向注意力。
由于我们希望模型既能输出文本(用于回答关于场景的问题或输出接下来要完成的任务),又能输出动作(用于在现实世界中执行动作),因此的输出分别被拆分为文本token对数几率和动作输出token。前个对应于可用于采样的文本token对数几率,后面的个token由一个单独的动作专家生成,就像在π₀中一样,并通过线性映射投影到连续输出,以获得(见下一节)。需要注意的是,即并非所有输出都与损失相关。机器人的本体感受状态被离散化,并作为文本token输入到模型中。附录E中有关于该架构的更多详细信息。
(二)结合离散和连续动作表示
与π₀类似,我们在最终模型中使用流匹配来预测连续动作。给定,其中,是流匹配时间索引,模型被训练来预测流向量场。然而,正如相关研究所示,当动作由离散token表示时,VLA训练可以快得多,特别是在使用对压缩动作块有效的token化方案(如FAST)时。遗憾的是,这种离散表示不太适合实时推理,因为推理时需要进行昂贵的自回归解码。因此,理想的模型设计应该是在训练时使用离散化动作,但在推理时仍能使用流匹配来生成连续动作。
因此,我们的模型被训练为既通过token的自回归采样(使用FASTtokenizer),又通过流场的迭代积分来预测动作,结合了两者的优点。我们使用注意力矩阵来确保不同的动作表示之间不会相互关注。我们优化模型以最小化组合损失:
其中是文本token与预测对数几率(包括FAST编码的动作token)之间的交叉熵损失,是(较小的)动作专家的输出,是一个权衡参数。这种方案使我们能够首先将模型作为标准的VLMtransformer模型进行预训练(此时,将动作映射为文本token),然后在训练后阶段添加额外的动作专家权重,以非自回归的方式预测连续动作token,从而实现快速推理。按照下面进一步解释的这个过程进行操作,能够使VLA模型在预训练时保持稳定,并具有出色的语言跟随能力。在推理时,首先对文本token使用标准的自回归解码,然后基于文本token进行10步去噪,以生成动作。
(三)预训练
在第一个训练阶段,π0.5使用广泛的机器人和非机器人数据进行训练,我们在下面进行总结并在图4中展示。它作为一个标准的自回归transformer进行训练,对文本、物体位置和FAST编码的动作token进行下一个token预测。

多样的移动机械臂数据(MM):我们使用了约400小时的移动机械臂在约100个不同家庭环境中执行家务任务的数据,其中一些家庭环境如图7所示。这部分训练集与我们的评估任务最直接相关,评估任务包括在全新的、未见过的家庭环境中执行类似的清洁和整理任务。

多样的多环境非移动机器人数据(ME):我们还收集了在各种家庭环境中使用单臂或双臂的非移动机器人数据。这些机械臂固定在表面或安装平台上,由于它们更轻且更易于运输,我们能够用它们在更广泛的家庭中收集到更多样化的数据集。然而,这些ME数据来自与移动机器人不同的实体。
跨实体实验室数据(CE):在实验室中收集了广泛任务(例如清理桌子、折叠衬衫)的数据,实验环境为更简单的桌面环境,使用了多种类型的机器人。其中一些任务与我们的评估高度相关(例如将盘子放入箱子),而另一些则不相关(例如研磨咖啡豆)。这些数据包括单臂和双臂机械臂,以及静态和移动底座。我们还纳入了开源的OXE数据集。该数据集是π₀使用的数据集的扩展版本。
高级子任务预测(HL):将高级任务命令(如“打扫卧室”)分解为更短的子任务(如“整理毯子”和“拿起枕头”),类似于语言模型的思维链提示,有助于训练好的策略对当前场景进行推理,并更好地确定下一步行动。对于MM、ME和CE中涉及多个子任务的机器人数据,我们手动为所有数据标注子任务的语义描述,并训练π0.5基于当前观察和高级命令联合预测子任务标签(作为文本)以及动作(以子任务标签为条件)。这自然使得模型既能作为高级策略(输出子任务),又能作为执行这些子任务动作的低级策略。我们还token当前观察中显示的相关边界框,并训练π0.5在预测子任务之前预测这些边界框。
多模态网络数据(WD):最后在预训练中纳入了多样的网络数据,包括图像字幕(CapsFusion、COCO)、问答(Cambrian-7M、PixMo、VQAv2)和物体定位。对于物体定位,我们用带有边界框注释的室内场景和家庭物体的额外网络数据进一步扩展了标准数据集。
对于所有动作数据,我们训练模型预测目标关节和末端执行器的姿态。为了区分两者,在文本提示中添加“<控制模式>关节/末端执行器<控制模式>”。所有动作数据使用每个数据集各动作维度的1%和99%分位数归一化到[-1,1]。我们将动作的维度设置为一个固定值,以适应所有数据集中最大的动作空间。对于配置和动作空间维度较低的机器人,我们对动作向量进行零填充。
(四)训练后
在使用离散token对模型进行280,000次梯度步骤的预训练后,我们进行第二个训练阶段,称为训练后阶段。这个阶段的目的是使模型专门适用于我们的应用场景(家庭中的移动操作),并添加一个动作专家,该专家可以通过流匹配生成连续动作块。这个阶段通过联合训练进行下一个token预测,以保留文本预测能力,并为动作专家(在训练后阶段开始时随机初始化权重)使用流匹配。我们优化公式(1)中的目标,,再进行80,000步训练。训练后动作数据集包括MM和ME机器人数据,筛选出长度低于固定阈值的成功片段。我们纳入网络数据(WD)以保留模型的语义和视觉能力,以及与多环境数据集对应的HL数据片段。此外,为了提高模型预测合适高级子任务的能力,我们收集语言指令演示(VI),这些演示由专家用户提供“语言演示”构建而成,他们选择合适的子任务命令,一步一步地指挥机器人执行移动操作任务。这些示例是通过实时“远程操作”机器人并使用语言执行任务收集的,使用学习到的低级策略,本质上为训练好的策略提供了良好的高级子任务输出演示。
实验评估
π0.5模型旨在广泛地泛化到新环境中。虽然在与训练数据匹配的环境中评估视觉语言动作(VLA)模型很常见,但我们所有的实验都在训练过程中从未见过的全新环境中进行。为了进行定量比较,我们使用一组模拟家庭环境,以提供一个可控且可重复的实验设置,而最贴近实际的最终评估则在三个不属于训练集的真实家庭中进行(见图6)。我们的实验主要关注以下几个问题:
- π0.5能否有效地在全新的家庭环境中泛化到复杂的多阶段任务?
- π0.5的泛化能力如何随着训练数据中不同环境数量的增加而提升?
- π0.5训练混合数据中的各个联合训练成分对其最终性能有何贡献?
- π0.5与π₀ VLA相比表现如何?
- π0.5的高级推理组件有多重要?它与简单的低级推理以及理想化的高级基线相比又如何?

(一)π0.5能在真实家庭环境中实现泛化吗?
为了回答问题(1),在三个训练集中未包含的真实家庭里,使用两种类型的机器人对π0.5进行了评估。在每个家庭中,机器人都被要求执行卧室和厨房清洁任务。每个任务的评估标准在附录B中给出,大致相当于每个任务中成功完成步骤的百分比(例如,将一半的盘子放入水槽中大约对应50%的完成度)。图7中的结果显示,π0.5能够在每个家庭中持续成功地完成各种任务(我们还要指出,该模型能够执行的任务比我们定量评估中所使用的任务多得多)。许多任务包含多个阶段(如移动多个物体),持续时间约为2到5分钟。在这些试验中,模型会收到一个简单的高级指令(例如,“把盘子放进水槽里”),高级推理过程会自主确定合适的步骤(例如,“拿起杯子”)。这种在真实场景中的泛化能力,无论是在模型需要处理的环境新颖度方面,还是在任务持续时间和复杂性方面,都远远超过了之前视觉语言动作模型所取得的成果。
(二)泛化能力如何随场景数量变化?
在接下来的一组实验中,我们旨在衡量泛化能力如何随着训练数据中所见环境数量的变化而变化。改变移动操作数据中的环境数量,通过使用来自3个、12个、22个、53个、82个和104个不同地点的数据进行训练,来测量其对泛化能力的影响。由于对每个这样的数据集都应用完整的预训练和训练后流程在计算上过于昂贵,在这些实验中,在没有移动操作数据的机器人动作预测数据混合集上进行预训练,然后比较在包含不同数量环境的移动操作数据上进行训练后的模型。原则上,按地点划分的数据集在大小上有所不同,但在实践中选择的训练步数(40,000步)能确保每个模型看到相同数量的独特数据样本,这使我们在训练后实验中改变地点数量时能够控制数据集的大小。
每个模型都在图6所示的模拟环境中进行评估,这些环境在训练中并未出现。我们进行了两种类型的评估。首先,为了评估在多阶段任务上的整体性能,使用附录B中的标准评估方法和模拟测试家庭,来评估每个模型在将盘子放入水槽、将物品放入抽屉、整理衣物和整理床铺等任务上的端到端性能。其次对每个模型遵循语言指令并与新物体交互的能力进行了更细致的评估,在这个评估中,机器人必须根据语言命令从厨房台面上拿起特定的物体。这些实验既使用了与训练数据中相似类别但为新实例的分布内物体,也使用了来自未见类别的分布外物体。后者需要广泛的语义泛化能力。

第一个实验的结果如图8所示。任务的平均性能通常随着训练地点数量的增加而提高。为了量化最终模型(使用104个地点的数据进行训练)在泛化差距上的缩小程度,我们设置了一个对照组(绿色所示),该对照组直接在来自测试家庭的数据上进行训练。这个对照组的性能与最终使用104个地点训练的模型相似,这表明我们的联合训练方法有效地实现了广泛的泛化,达到了与在测试环境上训练的模型相似的性能。为了确认这种泛化性能需要我们完整的联合训练方法,还纳入了两个基线模型,它们在预训练阶段不使用任何其他联合训练任务,而是直接在来自测试环境的数据(浅绿色)或来自104个训练地点的移动操作数据(浅黄色)上进行训练。这两个基线模型的性能明显更差——这表明即使策略已经见过来自测试家庭的机器人数据,我们完整训练方法中利用的其他数据源对于良好的泛化也是至关重要的。当不使用来自测试家庭的数据时,使用我们的方法进行预训练尤为重要,如图8中绿色条和浅黄色条之间的巨大差距所示。
第二个实验(语言跟随能力)的结果如图9所示。报告语言跟随率,它衡量机器人选择语言命令中指定物体的频率,以及成功率,它衡量机器人成功将该物体放置在正确位置(根据测试场景,要么是抽屉内,要么是水槽内)的频率。我们分别测量模型在训练中见过的物体类别(但为新的物体实例)和未见(“分布外”)物体类别上的性能。这个实验的详细信息在附录C中展示和讨论。图9显示,随着训练数据中地点数量的增加,语言跟随性能和成功率都有所提高。正如预期的那样,模型在分布内物体上的性能提升比在分布外物体上更快。随着每个新环境引入新的家居物品,模型变得更加稳健,开始能够泛化到训练数据中不存在的任务类别。

(三)联合训练方法的每个部分有多重要?
为了研究问题(3),将完整的π0.5模型与其他训练数据组合进行比较,以研究每个组合成分的重要性,同样使用模拟家庭中的端到端任务性能以及语言跟随能力评估。完整的训练方法使用来自多个环境中的移动机械臂数据(MM)、多个环境中的静态机械臂数据(ME)、在实验室环境中收集的各种跨实体数据(CE)。它还包括预测对应高级语言命令的高级数据(HL),以及与图像字幕、视觉问答和物体定位任务相关的网络数据(WD)。训练后阶段还使用语言指令数据(VI)。在这些实验中,对混合数据的不同部分进行了消融实验:
- no WD:这个消融实验排除了网络数据。
- no ME:这个消融实验排除了多环境非移动数据。
- no CE:这个消融实验排除了实验室跨实体数据。
- no ME or CE:这个消融实验排除了来自其他机器人的两个数据源,这样模型仅在目标移动机械臂平台的数据以及网络数据上进行训练。
在完整模拟家庭任务上的结果如图10所示(每个任务的性能详细分解见附录D)。首先,从结果中我们可以看到,排除两个跨实体数据源(ME和CE)中的任何一个都会显著降低性能,这表明π0.5从跨实体转移中受益匪浅,包括来自其他环境(ME)和其他任务(CE)的数据。同时排除这两个数据源对性能的损害更大。有趣的是,在这个实验中,no WD消融实验的性能差异在统计上并不显著,不过我们稍后会展示网络数据对语言跟随能力(如下)和高级子任务推理(第五节E部分)有很大影响。

语言跟随实验的结果如图11所示,呈现出与图10类似的趋势——排除ME或/和CE数据会导致性能显著下降。现在的不同之处在于,移除网络数据(no WD)会导致在分布外(OOD)物体上的性能明显变差——我们推测,使用包含广泛物理物体知识的网络数据进行训练,使模型能够理解和遵循涉及未见物体类别的语言命令。

(四)π0.5与其他VLA模型相比如何?
将π0.5与原始的π₀ VLA以及我们称为π₀ - FAST + Flow的π₀改进版本进行比较。这个改进版本通过公式(1)中的联合扩散和FAST动作预测公式进行训练,但仅在动作数据上进行,不使用HL或WD数据集。这些模型提供了有力的比较点,因为π₀已被证明在复杂和灵巧的移动操作任务上表现出色,而π₀ - FAST + Flow的改进使其尽可能接近π0.5。π0.5在这些模型的基础上结合了联合训练任务。为了进行公平比较,所有模型都接受相同的跨实体机器人训练集,并进行了相当数量的训练步骤。不同之处在于:(1)π0.5额外使用HL和WD数据;(2)π0.5采用混合训练过程,在预训练阶段使用离散token训练,在训练后阶段仅使用流匹配动作专家进行训练,而π₀始终使用动作专家。π₀ - FAST + Flow遵循混合训练方法,但仅使用包含机器人动作的数据进行训练,因此无法进行高级推理。图12中的结果表明,π0.5的性能显著优于π₀和我们的增强版本。即使我们允许π₀进行长达300,000步的训练,这个结果仍然成立,这证实了与基于纯扩散的训练相比,如Pertsch等人的研究所述,使用FASTtoken进行训练在计算上更有效。

(五)高级推理有多重要?
最后,我们评估高级推理的重要性,并比较几种替代高级推理方法的性能。π0.5中的高级推理机制接收一个高级命令(例如,“打扫卧室”),并输出要完成的子任务(例如,“拿起枕头”),然后将其用作推断低级动作的上下文,类似于思维链推理。虽然π0.5使用统一的架构,同一模型同时进行高级和低级推理,但我们也可以构建基线方法,要么像标准VLA模型中常见的那样,省略高级推理过程,将任务提示直接输入到低级系统中;要么使用另一个模型进行高级推理,以消融不同数据集组件对高级策略的影响。我们考虑以下方法和消融实验,所有这些方法都使用完整的π0.5低级推理过程,但具有不同的高级策略:
- π0.5模型进行高级和低级推理。
- no WD:π0.5的一个消融实验,排除网络数据。
- no VI:π0.5的一个消融实验,排除语言指令(VI)数据。
- implicit HL:运行时不进行高级推理,但在训练中包含高级数据,这可能会隐式地教会模型关于子任务的知识。
- no HL:既不进行高级推理,训练中也完全不包含高级数据。
- GPT - 4:使用GPT - 4作为高级策略,评估在机器人数据上训练高级策略的重要性。为了使模型与我们的领域保持一致,我们用任务描述和最常用标签列表来提示GPT - 4。
- human HL:使用专家人类作为“神谕”高级策略,以提供性能上限。
这些实验的结果如图13所示。完整的π0.5模型表现最佳,甚至超过了human HL“神谕”基线。也许令人惊讶的是,第二好的模型是implicit HL消融实验模型,它不进行任何高级推理,但在训练中包含完整的数据混合,即也包括子任务预测。这强烈表明了我们模型使用的联合训练方法的重要性:虽然显式推断高级子任务有好处,但通过在训练混合中包含子任务预测数据,已经可以获得很大一部分好处。no HL消融实验,即使在训练中也排除HL任务,性能明显更差。结果还表明,相对较小的语言指令数据集(仅占高级移动操作示例的约11%)对良好的性能至关重要,因为no VI消融实验的性能明显较弱。no WD消融实验的性能也明显更差,这表明网络数据的大部分好处(也许并不奇怪)在于改进高级策略。最后,零样本GPT - 4消融实验的性能最差,这表明用机器人数据调整视觉语言模型的重要性。

参考
[1] π0.5: a Vision-Language-Action Model with Open-World Generalization.
#Wan
阿里,DiT,时空 VAE,多模态(文本,图像,视频,音频)生成)Wan:开放且先进的大规模视频生成模型
Wan: Open and Advanced Large-Scale Video Generative Models
1. 引言
当前开源模型存在三大问题:性能与闭源模型差距大、应用场景有限、效率较低,限制了社区的发展。
本文提出了视频基础模型系列 Wan,旨在推动开放视频生成模型的边界。
- Wan 基于 Diffusion Transformer(DiT)和 Flow Matching 框架,设计高效架构,
- 通过创新的时空(spatio-temporal)变分自编码器(VAE)提升文本可控性与动态建模能力
- 模型使用超过万亿 tokens 的图像与视频训练,在运动幅度、质量、风格多样性、文本生成、摄像机控制等方面均展现强大能力
Wan 提供两个版本:适配消费级显卡的 1.3B 参数模型和能力强大的 14B 参数模型,支持包括图像生成视频、指令引导视频编辑和个性化视频生成在内的 8 项下游任务,是首个能生成中英视觉文本的模型。此外,Wan 1.3B 仅需 8.19GB 显存,显著降低部署门槛。
2. 相关工作
随着生成建模技术的发展,视频生成模型尤其是在扩散模型框架下取得了显著进展。相关工作主要可分为两个方向:闭源模型和开源社区贡献。
闭源模型方面,大厂主导的发展进度快速,目标是生成具备专业质量的视频。代表性模型包括:
- OpenAI Sora(2024 年 2 月),标志性成果,极大推动视频生成质量;
- Kling(快手)和Luma 1.0(Luma AI)(2024 年 6 月);
- Runway Gen-3(2024 年 6 月)在 Gen-2 基础上优化;
- Vidu(声树 AI,2024 年 7 月)采用自研 U-ViT 架构;
- MiniMax Hailuo Video(2024 年 9 月)和 Pika 1.5(Pika Labs,2024 年 10 月);
- Meta Movie Gen 和 Google Veo 2(2024 年 12 月)进一步增强物理理解与人类动态感知能力。
- 这些闭源模型借助强大算力与数据资源在生成质量、真实感、细节控制等方面具有优势。
开源社区方面,虽然起步略晚,但发展迅速,取得重要突破。现有视频扩散模型多数基于 Stable Diffusion 架构,由三个关键模块构成:
- 自动编码器(VAE):将视频压缩至潜空间,常见如标准 VAE(Kingma, 2013)、VQ-VAE(Van Den Oord, 2017)、VQGAN(Esser et al., 2021)等,近期 LTX-Video(HaCohen et al., 2024)更进一步提升重建质量;
- 文本编码器:多数使用 T5(Raffel et al., 2020)或结合 CLIP(Radford et al., 2021),如 HunyuanVideo 使用多模态大语言模型增强文本-视觉对齐;
- 扩散神经网络:多采用 3D U-Net 结构(VDM),或 1D 时间 + 2D 空间注意力结构(Zhou et al., 2022),最新架构则采用Diffusion Transformer(DiT)结构(Peebles & Xie, 2023),以 Transformer 替代 U-Net,在视觉任务中表现优越。

在此基础上,多个开源视频模型如 Mochi、HunyuanVideo、LTX-Video、CogVideoX 等相继发布。Wan 模型在此基础上精心选择与优化各核心组件,力求在生成质量上实现突破。
此外,开源社区也积极探索下游任务,包括图像补全、视频编辑、可控生成与参考帧生成等,常通过适配器结构或ControlNet增强用户控制能力。
Wan 不仅整合上述核心技术,还在多个下游任务上进行了系统设计与评估,推动生成模型从“能生成”向“能控制、高质量、可泛化”迈进。
3. 数据处理流程
高质量的大规模训练数据是生成模型性能的基石。Wan 构建了完整自动化的数据构建流程,以 “高质量、高多样性、大规模” 为核心原则,整理了数十亿级图像与视频数据。
数据分为 预训练(pre-training)数据、后训练(post-training)数据 和 视频密集描述(Dense Video Caption)三个阶段进行处理。
3.1 预训练数据
预训练阶段的数据来自内部版权素材与公开数据,通过以下四步筛选:
1)基础属性筛选:通过多维度过滤提升基础数据质量:
- 文本检测:使用轻量 OCR 过滤文字遮挡严重视频/图像;
- 美学评分:采用 LAION-5B 的打分器剔除低美感数据;
- NSFW 评分:内部安全模型评估并移除违规内容;
- 水印 / LOGO / 黑边检测:裁剪干扰区域;
- 曝光异常检测:移除光感异常内容;
- 模糊与伪图检测:利用模型打分移除失焦和合成图(污染率 <10% 即可显著影响性能);
- 时长 / 分辨率限制:视频需大于 4 秒,且低分辨率视频按阶段剔除。
该流程去除约 50% 原始数据,为后续高语义挑选做准备。
2)视觉质量筛选:
- 数据首先聚类为 100 类,防止长尾数据缺失后影响分布,
- 再按每类选样本进行人工打分(1~5分),训练质量评估模型自动评分,选出高评分样本。
3)运动质量筛选:运动质量划分六档:
- 最优运动:运动幅度、视角、透视感良好,动作清晰流畅;
- 中等运动:运动明显但有遮挡或多主体;
- 静态视频:主要为访谈等高质量但动作少的视频,降低采样比例;
- 相机驱动运动:相机移动为主,主体静止,如航拍,采样比例较低;
- 低质量运动:场景混乱或遮挡严重,直接剔除;
- 抖动镜头:非稳定镜头导致的模糊失真,系统性剔除。
4)视觉文本数据构建:为提升视觉文本生成能力,结合两类数据来源:
- 合成路径:将中文字渲染在白底图上,构造数亿样本;
- 真实路径:从真实图像中提取中英文文本,结合 Qwen2-VL 生成详细描述。
- 该策略帮助模型学会生成稀有字词,显著增强视觉文字生成质量。

3.2 后训练数据
后训练阶段旨在提升模型生成视频的 清晰度与运动效果,分别对图像与视频数据采用不同处理策略。
- 图像数据:从评分较高图像中,采用专家模型选出前 20% 并手动补充关键概念,确保多样性与覆盖度,构成百万级高质量图像集。
- 视频数据:从视觉质量与运动质量双重评分中选取若干百万级视频,涵盖 “技术、动物、艺术、人类、交通” 等 12 大类,以强化泛化能力。
3.3 视频密集描述
为增强模型对指令的理解能力,Wan 构建了大规模密集视频描述数据集,涵盖图像与视频描述、动作识别、OCR 等多个维度,数据来源包括:
3.3.1 开源数据集
整合多种视觉问答、图像/视频描述数据集及纯文本指令数据,支持多维度理解与生成。
3.3.2 自建数据集
围绕若干核心能力设计:
- 名人/地标识别:通过 LLM 与 CLIP 筛选高质量图像;
- 物体计数:结合 LLM 与 Grounding DINO 进行一致性过滤;
- OCR 增强:提取文本后再由模型生成描述;
- 相机角度与运动识别:人工标注+专家模型辅助增强控制能力;
- 细粒度类别识别:覆盖动物、植物、交通工具等;
- 关系理解:聚焦 “上下左右” 空间位置;
- 再描述:将短标注扩展为完整描述;
- 编辑指令生成:配对两图,生成描述差异的指令;
- 多图描述:先描述公共属性,再描述各自差异;
- 人工标注数据:最终训练阶段使用最高质量的图像 / 视频密集标注。
3.3.3 模型设计
(2023|NIPS,LLaVA,指令遵循,预训练和指令微调,Vicuna,ViT-L/14,LLaVABench)视觉指令微调
(2024|CVPR,LLaVA-1.5,LLaVA-1.5-HD,CLIP,MLP 投影)通过视觉指令微调改进基线
(2024,LLaVA-NeXT(LLaVA-1.6),动态高分辨率,数据混合,主干扩展)
Wan 的描述生成模型采用 LLaVA 风格架构,结合视觉与语言多模态输入,设计要点如下:
- 视觉编码器:使用 ViT(Vision Transformer)提取图像和视频帧的视觉特征;
- 投影网络:视觉特征通过两层感知机投射至语言模型输入空间;
- 语言模型:使用 Qwen LLM(QwenTeam, 2024)作为生成器;
输入结构:
- 图像输入采用动态高分辨率切分为最多 7 块(patch),每块特征下采样为 12×12;
- 视频输入按每秒 3 帧采样,最多 129 帧;
Slow-Fast 编码机制:
- 每 4 帧保留原始分辨率;
- 其他帧采用全局平均池化;
- 显著提升长视频理解能力(如在 VideoMME 提升从 67.6% → 69.1%)。
该架构兼顾精度与效率,适配图像、视频、多图等不同输入类型。
3.3.4 模型评估
为自动化评估 Wan 的视频描述能力,团队设计了多维度评测流程,参考 CAPability(Liu et al., 2025b)方法:
评估维度(共10项):
- 动作(Action)
- 摄像机角度(Camera Angle)
- 摄像机运动(Camera Motion)
- 对象类别(Category)
- 对象颜色(Color)
- 计数能力(Counting)
- OCR(视觉文字)
- 场景类型(Scene)
- 风格(Style)
- 事件(Event)
评估流程:
- 随机抽取 1000 个视频样本;
- 分别由 Wan 的模型与 Google Gemini 1.5 Pro 生成描述;
- 使用 CAPability 自动评分,计算每个维度的 F1 值。

结果分析:
- Wan 明显优于 Gemini 在:事件、摄像角度、摄像运动、风格、颜色;
- Gemini 在 OCR、类别识别、动作理解等方面略占优势;
- 两者整体性能相近,Wan 在生成控制性与视频结构理解上表现更佳。
4. 模型设计与加速
Wan 模型基于 Diffusion Transformer(DiT)架构设计,包含自研时空变分自编码器 Wan-VAE、Diffusion Transformer 主干、文本编码器 umT5,以及一系列推理加速与内存优化机制。
4.1 时空变分自编码器

4.1.1 模型设计
为压缩高维度视频数据并保持时序一致性,Wan 设计了 3D 因果结构的 Wan-VAE,具备以下特点:
- 输入视频 V ∈ R^{(1+T) × H × W × 3} 经压缩得到潜变量 x ∈ R^{(1+T/4) × H/8 × W/8 × C},其中通道数 C = 16;
- 第一帧仅做空间压缩,参考 MagViT-v2;
- 所有 GroupNorm 替换为 RMSNorm 以保持时间因果性;
- 解码端特征通道减半,减少推理内存 33%。
Wan-VAE 参数量为 127M,显著小于同类模型。
4.1.2 训练
采用三阶段训练策略:
- 训练 2D VAE;
- 将其膨胀为 3D 结构,在低分辨率小帧数视频上训练;
- 微调至高分辨率、多帧数视频,加入 3D 判别器 GAN loss。
损失函数包括:
- L1 重建损失;
- KL 散度;
- LPIPS 感知损失
- 加权系数:3,3e-6 ,3
4.1.3 高效推理

为支持长视频推理,引入 chunk-based 特征缓存机制:
- 每个 chunk 对应一组潜变量,缓存前一 chunk 的特征以实现上下文连续;
- 默认设置下使用 2 帧缓存,支持因果卷积;
- 对于 2× 时间下采样场景,采用 1 帧缓存与零填充。
该机制可推理任意长度视频,且在显存使用上优于传统方法。
4.1.4 评估

量化评估 对比显示:
- Wan-VAE 在 PSNR(视频质量)和每帧延迟(效率)上优于 HunYuanVideo、CogVideoX、Mochi 等;
- 在同一硬件环境下,速度提升约 2.5×。

质量评估 显示:在纹理、人脸、文本与高运动场景下,Wan-VAE 保留更多细节、减少失真。
4.2 模型训练

Wan 主干采用 DiT 架构,包含:
- Wan-VAE(视频编码);
- Diffusion Transformer;
- 文本编码器 umT5(多语言支持强,收敛快);
视频经 VAE 编码为潜变量,后由 DiT 生成。
(2023|ICCV,diffusion,transformer,Gflops)使用 Transformer 的可扩展扩散模型
4.2.1 视频 DiT

Transformer 模块采用以下设计:
- 3D Patchify(卷积核为 1×2×2),展开为序列;
- 每层 Transformer 块包含自注意力、交叉注意力(文本)、时间步嵌入;
- 时间步嵌入通过 MLP 生成六组调节参数;
- 所有 Transformer 层共享该 MLP,节省约 25% 参数量。
4.2.2 预训练策略
采用 Flow Matching 框架建模视频生成流程:
给定视频潜变量 x_1、噪声 x_0 ∼ N(0,I) 与时间步 t ∈ [0,1],中间状态为:
![]()
模型预测速度向量:

损失函数为:
![]()
训练阶段包括:
- 低分辨率图像预训练(256px),构建跨模态对齐能力;
- 图像-视频联合训练,按分辨率逐步升高(192px → 480px → 720px);
- 使用 bf16 精度与 AdamW 优化器,初始学习率 1e-4,动态衰减。
4.2.3 后训练
沿用预训练配置,在高质量后训练数据上继续训练,进一步提升视觉细节与运动建模。
4.3 模型扩展与训练效率
Wan 针对大模型训练的高资源消耗问题,设计了一系列优化策略,包括工作负载分析、并行策略、显存优化及集群稳定性保障。
4.3.1 工作负载分析
在 Wan 的训练中,Diffusion Transformer(DiT)占据超过 85% 的计算资源,而文本编码器与 VAE 编码器计算量较小,且在训练阶段被冻结,仅推理使用。
DiT 的计算开销 由以下表达式近似:
![]()
其中:
- L:DiT 层数;
- b:micro-batch 大小;
- s:序列长度(token 数);
- h:隐藏维度;
- α:线性层复杂度;
- β:注意力层复杂度(Wan 中前向为 4,反向为 8);
与 LLM 不同,Wan 中的视频序列长度 s 可达百万级,注意力计算成为训练瓶颈。在序列长度为 1M 时,注意力计算时间可达训练总时间的 95%。
内存占用 近似为: γLbsh,其中 γ 为实现(implementation)相关系数(LLM 中约为 34,Wan 中可超 60),当 batch size = 1,14B 参数的 DiT 激活内存需求可达 8 TB。
4.3.2 并行策略
Wan 的三大模块(VAE、Text Encoder、DiT)采用不同的并行方式:
- VAE:内存占用小,使用数据并行(Data Parallel,DP);
- Text Encoder:显存需求高(>20GB),采用权重切分(FSDP);
- DiT:采用多维并行策略
DiT 的并行策略:为应对巨量激活内存与计算成本,采用以下组合:
- FSDP(Fully Sharded Data Parallel):参数、梯度、优化器状态均切分;
- 上下文并行(Context Parallel,CP):沿序列长度 s 分片,包含:
- Ulysses(内层);
- Ring Attention(外层),实现跨节点通信重叠;
- 数据并行(DP):进一步扩展 batch size。

如图 11,128 GPU 配置下:
- Ulysses = 8,Ring = 2,CP = 16;
- FSDP = 32;
- DP = 4;
- 全局 batch size = 8b。
此混合策略结合通信效率与内存分布优势。
模块切换机制:
- 由于 VAE 与 Text Encoder 使用 DP,DiT 使用 CP,为避免冗余计算,在切换到 CP 前使用广播策略共享必要数据。
- 该方法将 VAE/Text Encoder 推理时间缩短为原来的 1/CP,从而提升整体效率。
4.3.3 显存优化
Wan 在长序列场景中优先使用 激活迁移(Activation Offloading),替代传统的 梯度检查点(Gradient Checkpointing,GC):
- 激活迁移允许将激活缓存转移到 CPU,同时与计算重叠;
- PCIe 传输时间通常只占 1~3 层 DiT 的计算时间,适合重叠;
- CPU 内存易耗尽时,结合 GC 策略使用。
该策略有效降低了显存压力,特别适用于 720p 长视频训练。
4.3.4 集群稳定性
依托阿里云训练平台,Wan 使用以下机制保障超大规模训练稳定性:
- 启动前检测机器健康状况,避免分配异常节点;
- 训练中实时隔离故障节点,自动修复并恢复任务;
- 智能调度提升资源利用率;
- 以上机制确保了训练作业在长周期内的高稳定性与可扩展性。
4.4 推理
Wan 在推理阶段针对长序列、多步采样的特点,设计了高效的并行化策略与缓存机制,并结合量化技术,显著降低延迟与内存需求。
4.4.1 并行策略
推理过程涉及约 50 步扩散采样,需优化每步生成的延迟。Wan 结合训练期相同的策略:
- 模型切分(FSDP):在长序列推理中通信开销较小,支持参数分片;
- 2D 上下文并行(2D-CP):如训练中所述,外层为 Ring Attention,内层为 Ulysses,适配长序列;
- 线性加速:如图 12 所示,Wan 14B 在多个 GPU 上接近线性加速。

4.4.2 扩散缓存
推理过程中存在以下可利用特性:
- 注意力相似性:同一 DiT 层中,多个采样步之间注意力输出差异小;
- CFG 相似性:在采样后期,带条件与无条件生成结果接近。
Wan 借助这些现象构建 Diffusion Cache 机制:
- Attention Cache:每隔若干步执行一次注意力前向,并缓存其结果,其他步复用;
- CFG Cache:后期跳过无条件路径,仅对条件路径前向,结果通过残差补偿恢复细节;
- 结果:在不降低质量的前提下,14B 模型推理效率提升 1.62 倍。
该机制参考了 DiTFastAttn(Yuan et al., 2024b)与 FasterCache(Lv et al., 2024)等近期研究。
4.4.3 量化
为进一步加速推理,Wan 采用两类量化技术:
1)FP8 GEMM 运算
- 所有 GEMM 运算均使用 FP8 精度;
- 权重按张量(per-tensor)量化,激活按 token(per-token)量化;
- 实验显示损失极小,且 DiT 模块加速 1.13×,GEMM 性能提升 2×。
2)FlashAttention3 的 8-bit 优化
虽然 FlashAttention3 原生 FP8 实现存在精度损失,Wan 通过如下优化提升效果:
- 混合 8-bit 优化:Q、K、V 使用 INT8 表示内积 S = QK^T,而 O = PV 用 FP8;
- 跨块 FP32 累积:使用 FP32 寄存器对跨块结果做高精度累加,借鉴 DeepSeek-V3 的策略。
为了兼顾数值精度与 kernel 性能,Wan 还引入以下优化:
- FP32 累积融合流水线(Float32 Accumulation + Intra-Warpgroup Pipelining):
- FlashAttention3 原生通过 intra-warpgroup pipeline 并行 Softmax、Scaling 与 WGMMA;
- Wan 在此基础上将 FP32 累积策略融合进流水线中,实现高精度无额外延迟。
- 4.5 提示对齐
为提升文本驱动的生成一致性,Wan 在训练过程中增强了提示对齐能力:
- 注意力设计:采用 Cross-Attention 将文本信息注入视频生成过程,使模型能更好地理解描述意图;
- 语言建模:使用 umT5 文本编码器提供高质量跨语言、多粒度语义嵌入;
- 训练数据辅助:借助高质量视频密集描述数据集(第 3.3 节),显著增强模型对提示内容的理解与跟随能力。
同时,针对稀有概念(如特殊角色或复杂动作),Wan 在训练中动态采样包含此类信息的数据,提升稀有提示的响应能力。
通过上述设计,Wan 在多个任务上均能展现优异的文本控制力,包括图像生成视频(I2V)、个性化生成、视频编辑等。
4.6 基准评测
现有的视频生成评估指标,如 Fréchet Video Distance(FVD)和 Fréchet Inception Distance(FID),在与人类感知的一致性方面存在明显不足。为此,本文提出了一套 自动化、全面且符合人类偏好 的新评估体系:Wan-Bench,用于衡量视频生成模型的综合表现。

Wan-Bench 从三个核心维度出发:动态质量(Dynamic Quality)、图像质量(Image Quality)、指令跟随能力(Instruction Following),共包含 14 个细粒度指标,并针对每个维度设计了特定的评分算法,结合传统检测器与多模态大模型(MLLM)实现自动评估。
1)动态质量:该维度评估模型在非静态场景下的表现,包括以下方面:
- 大幅度动作生成:通过特定 prompt 激发大运动,使用 RAFT 计算视频光流并归一化,评估动作幅度。
- 人类伪迹检测(Human Artifacts):训练基于 YOLOv3 的检测器,对 20,000 张 AI 生成图像标注伪迹,综合置信度、边界框与持续时间得出评分。
- 物理合理性与流畅度:
- 使用物理相关 prompt(如球弹跳、流体);
- 基于 Qwen2-VL 模型问答判断是否存在违反物理规律(如穿模、悬浮);
- 复杂动作流畅度由 Qwen2-VL 识别伪迹并评分。
- 像素级稳定性:在静态区域计算帧间差异,差异越小表明稳定性越高。
- 身份一致性:包括人类、一致动物、目标物体等,使用 Frame-level DINO 特征提取,衡量帧间相似度。
2)图像质量:该维度评估每帧图像的视觉效果与美学属性:
- 综合图像质量:
- 清晰度评估使用 MANIQA 检测模糊与伪迹;
- 美学评估结合 LAION 美学预测器与 MUSIQ;
- 三者得分取平均作为最终图像质量分数。
- 场景生成质量:
- 帧间一致性:使用 CLIP 计算连续帧相似度;
- 语义一致性:使用 CLIP 计算帧图与文本之间相似度;
- 综合加权得出评分。
- 风格化能力:使用 Qwen2-VL 回答图像风格相关问题,评估艺术生成能力。
3)指令跟随能力:该维度评估模型对文本指令的理解与执行效果:
- 目标与位置关系:
- Qwen2-VL 预测对象类别、数量与相对空间位置;
- 统计满足条件的帧比例,作为最终得分。
- 相机控制:
- 涉及 5 种机位动作:横移、升降、缩放、航拍、跟拍;
- 对于横移、升降、缩放使用 RAFT 光流分析;
- 航拍、跟拍使用 Qwen2-VL 视频问答评估。
- 动作执行:
- 涵盖人类(如奔跑)、动物(如爬行)、物体(如飞行)等动作;
- 提取关键帧,Qwen2-VL 回答该动作是否执行、是否完成、是否存在伪迹,综合得分。
4)用户反馈引导的权重策略:不同维度对人类偏好的影响不同,因此 Wan-Bench 引入了基于用户反馈的加权评分机制:
- 收集了超过 5,000 对视频样本的人工对比评价;
- 用户基于相同 prompt 比较两个视频,并赋予偏好与分数;
- 使用 Pearson 相关系数 计算模型打分与人类偏好之间的相关性;
- 将此相关性作为权重,用于最终 Wan-Bench 综合得分的加权平均。
- 这一策略使得 Wan-Bench 不仅能自动评估模型性能,更能够模拟人类主观感知,更贴近实际使用场景中的评价标准。
4.7 模型评估
4.7.1 指标与结果
基准模型与评估指标:目前已有众多具代表性的文本生成视频(T2V)模型可供对比,涵盖商用闭源与开源系统:
- 闭源模型:Kling(快手,2024.06)、Hailuo(海螺,MiniMax,2024.09)、Sora(OpenAI,2024)、Runway(2024.06)、Vidu(声树AI,2024.07);
- 开源模型:Mochi(GenmoTeam,2024)、CogVideoX(Yang et al., 2025b)、HunyuanVideo(Kong et al., 2024)等。
定量评估结果:
- 评估样本:为每个模型收集 1,035 个统一 Prompt 条件下的生成样本;
- 评估维度:分别从三项核心指标进行评分:
- 动态质量(Dynamic Quality)
- 图像质量(Image Quality)
- 指令跟随能力(Instruction Following Accuracy);
- 评分方式:使用 Wan-Bench 全自动评估框架,按 第 4.6 节定义的人类偏好加权规则 计算总分。

评估结果见表 2,Wan 在这三大指标上均领先主流商业模型与开源系统,说明其在实际视频生成任务中具有全面的优势表现。

定性结果分析:图 15 展示了 Wan 模型的多种文本驱动生成示例,展示其优异的生成能力:
- 大规模复杂动作合成:可稳定生成包含多个物体、多视角、剧烈运动的场景;
- 物理交互场景建模:物体间的碰撞、反弹、水流等动作自然流畅;
- 风格化与美学表现:兼容多种艺术风格,具有电影级画面美感;
- 多语言文本生成能力:可将中英文文字嵌入视频,并呈现出高度一致的视觉文字效果,支持字幕类动画生成。
人类评价结果:
- 设计了 超过 700 个评测任务;
- 由 20+ 名标注人员完成人工打分,维度包括:
- Prompt 对齐(Alignment)
- 图像质量(Image Quality)
- 动态质量(Dynamic Quality)
- 整体质量(Overall Quality);
表 3 结果显示:Wan-14B 模型在所有维度上均表现优异,T2V 任务中领先于其他模型,体现其在 人类感知层面 的生成优势。

公共榜单表现(Wan in Public Leaderboard):Wan 还在开放视频生成评测榜单 VBench(Huang et al., 2023) 上展现出 SOTA(State-of-the-Art)性能:
- VBench 由多个维度组成(共 16 项),覆盖审美质量、运动流畅性、语义一致性等方面;
- Wan 参评版本包括:
- Wan-14B
- Wan-1.3B;
表 4 显示:
- Wan-14B 在该榜单中总得分 86.22%;
- 其中视觉质量得分为 86.67%,语义一致性得分为 84.44%;
- 位列当前所有参评模型首位。

4.7.2 消融实验
1)自适应归一化层的消融实验:基于 DiT 中的 AdaLN(Adaptive LayerNorm)进行实验,主要探讨两种策略的优劣:
- 增大 AdaLN 参数量(即不共享参数)
- 增加网络深度(保持参数量不变)
借鉴 PixArt 的做法,设计了以下四种模型配置:
- Full-shared-AdaLN-1.3B:30 层注意力模块,所有层共享 AdaLN(参数最少)
- Half-shared-AdaLN-1.5B:前 15 层共享,后 15 层不共享,参数增至 1.5B
- Full-shared-AdaLN-1.5B (extended):仍共享 AdaLN,但将层数扩展至 35 层,参数 1.5B
- Non-shared-AdaLN-1.7B:不共享AdaLN,保持30层,参数最多(1.7B)

所有模型在 Text-to-Image 任务中训练 200k 步,并对比 latent 空间中的 L2 训练损失。实验结果显示:
- Full-shared-AdaLN-1.5B(增加层数)性能优于 Non-shared-AdaLN-1.7B(增加参数)
- 说明 增加深度比增加参数更有效
最终,选用参数共享的 AdaLN 设计,兼顾性能与效率。
2)文本编码器的消融实验:对比三种支持中英双语的文本编码器:
- umT5 (5.3B)
- Qwen2.5-7B-Instruct
- GLM-4-9B

训练配置保持一致,均在 text-to-image 任务中训练,并分析其训练损失曲线(如图 17)。结果表明:
- umT5 表现最佳,训练损失最低。
- 其优势源自采用 双向注意力机制,更适合扩散模型(对比 Qwen 和 GLM 的单向因果注意力)。
- 后续还对比了 Qwen-VL-7B-Instruct,使用其第二层输出时,效果接近 umT5,但模型体积更大。
3)自动编码器消融:设计了一个变体 VAE-D,将传统的重建损失替换为 扩散损失。在 text-to-image 任务中分别训练 VAE 和 VAE-D 模型,训练步数为 150k,结果如下:

结果表明,VAE 的 FID 更低,即生成质量更好。因此主模型继续采用原始的 VAE 结构。
5.扩展应用
5.1 图像到视频生成
5.1.1 模型设计

Wan 在图像生成视频(I2V)任务中引入图像作为首帧控制生成过程:
- 输入构建:将条件图像与零帧拼接后,经 Wan-VAE 编码为潜变量 z_c,并引入掩码 M 标记保留与生成帧。
- 模型结构:将噪声潜变量、条件潜变量与掩码拼接输入 DiT 模型;由于通道数增加,使用额外投影层适配。
- 图像语义注入:利用 CLIP 图像编码器提取特征,经 MLP 投影后通过交叉注意力注入模型,提供全局语义信息。
多任务统一框架:该方法适用于图像生成视频、视频续接、首尾帧变换等任务,统一以掩码机制控制输入与输出。
训练策略:
- 联合预训练阶段:使用与文本生成视频(T2V)相同的数据集,使模型具备基本的图像驱动生成能力。
- 微调阶段:为每个任务准备专门的数据集,提升任务特定性能。
5.1.2 数据集
图像生成视频(I2V):为确保首帧与视频内容一致性,计算首帧与剩余帧的 SigLIP 特征余弦相似度,仅保留相似度高的视频样本。
视频续接:选择时间连续性强的视频,基于视频开头 1.5 秒和结尾 3.5 秒的 SigLIP 特征相似度进行筛选。
首尾帧转换:更关注首帧与尾帧之间的平滑过渡,优先保留具有明显变化的样本以增强过渡效果。
5.1.3 评估
实验设置:基于480p 和 720p 两个预训练模型,分别微调 I2V、视频续接与首尾帧转换任务。
评估方式:参考 T2V 评估,比较视觉质量、运动质量和内容匹配度,并与 SOTA 方法对比。

结果(表 7)显示 Wan 在各项指标上均表现优越。

5.2 统一视频编辑
Wan 提出一个统一的视频编辑框架,支持多种编辑任务,如文本引导编辑、风格迁移、画面插入/删除等。

5.2.1 模型设计
输入形式:包含原始视频、编辑目标(如文本指令或图像条件)及掩码信息。
条件编码:视频帧和掩码通过 Wan-VAE 编码为上下文token,与噪声视频token结合输入模型。
概念解耦:
- 与 I2V 模型类似,采用掩码标记保留与需要生成的帧或区域,实现灵活编辑。
- 二者均通过 Wan-VAE 编码并对齐到统一潜空间,确保清晰的编辑任务分工与收敛稳定。
上下文适配调优(Context Adapter Tuning):
- 引入 Context Blocks 处理上下文 token,然后注入 DiT 主干模型,无需修改原始模型参数,实现灵活编辑扩展。
参考图像处理:参考图像单独编码,并拼接进时间维中,解码时去除对应部分,防止与视频混淆。
5.2.2 数据集与实现
数据构建:为训练统一视频编辑模型,构建涵盖多模态输入的数据集,包括目标视频、源视频、局部掩码、参考图像等。
数据处理流程:
- 视频先进行镜头切分与初筛(基于分辨率、美学得分、运动幅度)。
- 首帧通过 RAM 与 Grounding DINO 做实例检测,筛除目标过小或过大的样本。
- 使用 SAM2 进行视频级实例分割,并依据掩码面积筛选高质量连续帧。
针对不同编辑任务采用差异化数据构建策略,确保数据多样性与任务适应性。
实现细节:模型基于 Wan-T2V-14B 微调,最高支持 720p。
训练流程分三阶段:
- 在修复、延展等基础任务上训练,强化时空上下文理解;
- 扩展至多参考帧与组合任务;
- 进一步精调,提升质量与时序一致性。
5.2.3 评估
结果:Wan 单一模型在多个编辑任务中均表现出色,具备优良的视频质量和时间一致性。

扩展能力(图 24 (a)):展示了模型跨任务组合能力,例如风格迁移+内容插入等复合编辑。
通用性(图 24 (b)):VACE 框架同样适用于图像生成与编辑,验证了其广泛适配性。
5.3 文本生成图像
联合训练策略:Wan 同时在图像和视频数据上进行训练,不仅具备强大的视频生成能力,也展现出卓越的图像合成效果。
数据比例:图像数据集规模约为视频的 10 倍,有效促进了图像与视频任务之间的跨模态知识迁移。
图像生成表现:
- 支持多样化风格与内容;
- 可生成包括艺术文字图像、写实人像、创意设计、产品摄影等在内的高质量图像。

效果展示:图 25 展示了多种图像类别下 Wan 的高保真生成结果。
5.4 视频个性化
目标是生成与用户提供参考图像身份一致的视频内容。Wan 集成了先进的视频个性化技术,取得领先性能。
5.4.1 模型设计
主要挑战:
- 获取高保真身份信息;
- 将身份特征无缝融入生成流程。
核心策略:
- 不依赖 ArcFace 或 CLIP 等提取器,避免信息丢失;
- 直接使用 Wan-VAE 的潜空间输入人脸图像作为个性化条件;
- 采用 自注意力机制 注入身份信息,比交叉注意力更适配潜空间建模。

具体流程:
- 将提取的人脸图像扩展为前 K 帧;
- 在通道维拼接人脸图像与对应的掩码(前 K 帧为全 1,后续帧为全 0);
- 使用扩展视频作为输入进行扩散过程,实现 “修复式” 个性化生成;
- 支持 0~K 张参考图生成,通过训练时随机丢弃部分人脸帧实现泛化。
5.4.2 数据集
从 Wan-T2V 的训练集中过滤构建个性化子集(约 O(10)M 视频):
- 筛选标准包括单人脸、面部检测覆盖率、帧间一致性(ArcFace 相似度)、人脸分割与对齐。
- 不排除小尺寸人脸,保留全身人像样本。
通过 自动合成 增强多样性:
- 利用 Instant-ID 对 O(1)M 视频生成风格多样的人脸;
- 随机组合姿态 + 文本模板(如动漫、电影、Minecraft 风格等)生成合成样本;
- 保留 ArcFace 相似度高的样本以确保身份一致性。
5.4.3 评估

图 27 展示输入人脸与生成视频的对比,表现稳定。

在 Pexels 随机选取图像进行测试,并用 ArcFace 计算人脸相似度(1 FPS 采样)。表 8 显示 Wan 个性化模型在多个指标上优于或媲美商业/闭源中文模型,展现强大竞争力。
5.5 摄像机运动可控性
该模块旨在实现对视频中摄像机运动轨迹的精确控制,包括视角与位置变化。

输入参数:每帧包含 外参 [R,t] ∈ R^{3×4[} 和 内参 K_f ∈ R^{3×3}。
1)摄像机姿态编码器:
- 使用 Plücker 坐标将每个像素位置编码为姿态序列 P ∈ R^{6×F×H×W};
- 通过 PixelUnshuffle 降低空间分辨率,提升通道数;
- 使用多层卷积模块提取多级摄像机运动特征,与 DiT 层数对齐。
2)姿态适配器:
- 使用两层零初始化卷积生成缩放因子 γ_i 和偏移量 β_i;
- 注入到每层 DiT,通过如下公式实现与视频潜特征 f_i 融合:
![]()
数据与训练:
- 使用 VGGSfM 算法从训练视频中提取真实摄像机轨迹,获取约 O(1) 千段具有显著运动的视频片段;
- 在 T2V 框架中训练该模块,优化器为 Adam;
- 图 29 展示了多个受控摄像机运动的视频生成样例,验证了模块的控制效果。

5.6 实时视频生成
背景与动机:
- 当前视频生成方法需大量计算资源,即使高端硬件也常耗费数分钟生成数秒视频;
- 这严重限制了在 交互娱乐、虚拟现实、直播、视频创作 等实时反馈场景下的实用性与创作效率;
- Wan 致力于打破该限制,实现高质量、低延迟、可持续的视频生成,支持快速迭代与动态场景响应。
5.6.1 方法
为构建实时生成流程,Wan 基于已有的预训练模型进行两项核心改造:
流式生成机制(Streaming Pipeline):
- 替代一次性固定长度生成方式;
- 引入 “去噪队列” 机制:每次生成新帧加入队尾,旧帧出队,支持无限时长连续生成。
实时加速优化:
- 优化生成速度,使每帧生成速度达到播放要求,满足真正的实时体验;
- 基于预训练模型,不仅提升训练稳定性,还继承了对运动与时间动态的理解,有利于生成连贯内容。
5.6.2 流式视频生成
为解决传统 DiT 模型难以生成长视频的问题,Wan 提出 Streamer 架构,通过 滑动时间窗口 实现高效、持续的视频生成。
核心机制:滑动窗口去噪(Shift Window Denoise)
- 假设:时间依赖性局限在有限窗口内;
- 机制:
- 视频 token 被维护在一个固定长度的队列中;
- 每轮去噪后,队首 token 出队并缓存,新 token 加入队尾;
- 只对当前窗口内的 token 执行注意力计算,大幅降低计算与内存开销;
- 实现 无限长度连续视频生成。
训练与推理策略
- 训练阶段:
- 每次采样 2w 个 token(w:窗口大小,等于扩散步数 T);
- 前 w 帧用于 warm-up,不计入损失;
- 后 w 帧参与训练,提升窗口内的生成质量。
- 推理阶段:
- 同样先 warm-up,再从第 w+1 帧开始输出;
- 缓存机制:已生成帧以 “0 噪声” 形式重新加入下一窗口,保障跨窗口一致性。
方法优势:
- 无限长度视频生成:滑动窗口避免固定长度限制;
- 高效注意力计算:仅计算局部时间依赖,降低资源消耗;
- 连贯性强:缓存与再注入机制实现无缝视频过渡。
5.6.3 一致性模型蒸馏
虽然 Streamer 实现了 无限长度视频生成,但扩散过程仍较慢,不利于实时应用。为此,Wan 引入 一致性模型蒸馏(Consistency Model Distillation)蒸馏机制,极大提升生成速度。
一致性模型集成:
- 使用 Latent Consistency Model (LCM) 与其视频版本 VideoLCM;
- 将原始扩散与 class-free guidance 蒸馏为 仅需 4 步采样 的一致性模型;
- 保留滑动时间窗口机制,兼顾时间一致性与生成效率;
- 最终实现 10–20 倍推理加速,生成速率达到 8–16 FPS,满足实时交互需求(如实时合成、互动仿真等)。
消费级设备部署:量化优化。尽管速度提升显著,但部署仍受限于计算资源(即便是 4090 GPU)。为此,Wan 进一步引入 量化优化策略:
- int8 量化(Attention + Linear Head):
- 显著减少内存消耗;
- 几乎不影响画质,但提升速度有限。
- TensorRT 量化(整模型优化):
- 实现 单张 4090 也可 8 FPS 实时生成;
- 但可能带来轻微的视觉误差,如闪烁、细节偏差等。
- 综合策略:结合 int8 与 TensorRT,权衡速度、质量与稳定性。通过精调量化参数与启用误差检查机制,有效控制失真影响。
整体优势
- 实现高效实时生成:生成质量与时间一致性兼具;
- 支持消费级部署:优化内存与推理速度;
- 面向互动场景:适配游戏、VR、直播等对低延迟要求极高的应用。


5.7 音频生成
Wan 支持 视频到音频(V2A)生成,为视频自动配上环境音与背景音乐(不含语音),要求生成内容与视频节奏、情绪精准同步。同时,支持用户通过文本控制生成风格或指定音效。
5.7.1 模型设计

架构概览:基于 Diffusion Transformer(DiT) 搭建扩散式生成模型,使用 flow-matching 建模去噪过程。
音频编码器:1D-VAE
- 不使用传统 mel-spectrogram 编码(因其打乱时间顺序);
- 采用 直接处理原始波形的 1D-VAE,生成形状为 T_a × C_a 的音频 latent,保持时间同步性。
多模态同步输入
- 视觉编码器:用 CLIP 提取逐帧视觉特征,并通过特征复制与采样率对齐至音频节奏;
- 文本编码器:采用冻结的 umT5 模型,具备多语言理解能力;
- 特征统一投影到 1536 维 latent 空间后进行融合输入 DiT。
数据构建与训练
- 从视频生成数据中筛选出无语音的有效样本,构建约 千小时音视频对齐训练集;
- 采用 Qwen2-audio 生成音频描述(包括环境音 + 音乐风格),配合密集视频字幕,构建三部分统一训练结构:
- 视频描述;
- 环境声音标签;
- 背景音乐分析(风格/节奏/乐器等)。
实现细节
- 音频:最高生成 12 秒立体声、采样率 44.1kHz;
- 视频:下采样为 48 帧对应 12 秒,确保逐帧对齐;
- 文本嵌入维度 4096,视觉特征 1024,统一映射为 DiT 的 1536 维;
- 引入 随机文本掩码策略:训练中随机去除部分文本提示,强制模型仅基于视觉理解生成音频,增强视觉-音频跨模态对齐能力。

5.7.2 音频生成评估
对比分析
- 图 33 展示了 Wan 与开源模型 MMAudio 在音频生成任务中的对比;
- 所有测试视频均来自 Wan 的文本生成视频模型,时长 5 秒。
Wan 的优势
- 时序一致性强:如 “倒咖啡” 场景中声音与画面同步更自然;
- 音质清晰:如 “打字” 案例中,相较 MMAudio 的杂音,Wan 生成更干净;
- 节奏感出色:如“行走”“拳击”“马蹄声”等例子中,Wan 展现出更自然连贯的节奏型音效。
局限性
- 无法生成语音类声音(如说话、笑声、哭声等);
- 原因在于训练数据中有意排除语音内容,而 MMAudio 保留了部分语音相关数据;
- 后续计划引入语音生成机制,扩展音频生成能力。
6. 局限与结论
尽管 Wan 在多个基准任务上取得显著进展(如大幅度运动、指令遵循等),但仍存在以下挑战:
- 细节保持难:面对剧烈运动场景(如舞蹈、运动),生成视频的细节保真度仍需提升;
- 计算开销大:14B 模型在单张 GPU 上推理约需 30 分钟,难以普及,需进一步优化效率与可扩展性;
- 缺乏专业适配性:虽为通用视频模型,但在教育、医疗等垂直领域的表现尚不足,需社区参与推动专业化发展。
结论:
- 本报告发布了 Wan,一个全新的基础级视频生成模型;
- 详细介绍了其 Wan-VAE 与 DiT 架构设计、训练流程、数据构建与评估方法;
- 深入探索了多个下游应用,如图像生成视频、视频编辑、个性化生成,展现出 Wan 的广泛适应性;
- 除开源 14B 大模型外,还发布了 轻量版 1.3B 模型,支持消费级设备运行,显著提升可用性;
- 未来工作将聚焦于扩大数据规模与模型架构,持续提升视频生成质量与效率,推动该领域的创新与应用落地。
论文地址:https://arxiv.org/abs/2503.20314
项目页面:https://github.com/Wan-Video/Wan2.1
#L3是受限但清晰ODD边界的L4,加上全场景L2辅助驾驶
余凯演讲全文
4月18日,地平线在上海举办2025年度产品发布会,地平线创始人余凯进行了两个多小时的演讲,非常震撼。就像给观众上了一节科技课,更难得的是,其中不乏对当下科技热潮的许多冷静思考。
我认为这或许是今年中国科技圈最值得一看的演讲了。相信无论是智能汽车领域的从业者,还是科技行业的创业者,都能从中获得一些启发。下面给大家划一下重点。
余凯认为:
一,AI时代的产品逻辑是“逼近世界真相”。这不同于互联网时代的产品逻辑是“洞见人间烟火”,本质上是链接,得流量者得天下,得用户者得天下。正如AlphaGo通过学习人类的数据,最多达到人类的9段围棋水平,而通过不断迭代自身的算法设计,能够达成10段甚至13段的水平。AI时代,人类行为数据没有价值,99%的用户数据不值得学习。智能驾驶只有通过自我学习,才能真正超越人类驾驶水平,逼近“驾驶之神”。
二,技术进步同样会带来技术“平权陷阱”。鸡兔同笼问题在小学时是一道奥数题,到初中学习了二元一次方程后就是一种普通题;智能驾驶技术也是如此,昨日的独门绝技,放到今天就是标准解法。看似炫酷的技术,并不会带来真正的领先性与差异化。干好苦活累活、做好经验积累、提高体系化的组织文化与能力,才能打造真正的技术护城河,避免陷入技术平权陷阱。
三,智能驾驶算法的需要“快思考、慢思考”两种模式。快思考靠直觉,而慢思考靠认知,需要复杂推理。余凯说,地平线基于快思考推出“一段式端到端模型”,基于慢思考引入强化学习,实现驾驶模型的“智能涌现”。
四,L3/L4/L5的前提是足够好的全场景辅助驾驶。L3是受限但清晰ODD边界的L4,加上全场景L2辅助驾驶。行百里者半九十,在用户价值的兑现上,整个行业才刚刚开始。他呼吁行业,要做狂飙中的冷静者,悲观中的笃定者。
五、智能驾驶的本质是功能价值,而非情绪价值。智能驾驶如同智能汽车的“基带”,是重要的基础设施,给用户提供安全、便捷、舒适等标准化的“功能价值”。智能驾驶提供功能价值,智能座舱提供情绪价值,有了功能价值做基础,情绪价值才有机会进一步释放。奇瑞控股集团董事长尹同跃,在和余凯对话时,也强调说“安全第一,不说过头话,让智能化体验自由且信赖。”
此外,余凯还回顾了地平线创业十年的历程,他分享说,地平线这些年沉淀了两条战略方法论。一是在没有竞争的地方竞争:地平线不愿意内卷,更愿意做一个外卷型的企业,另辟蹊径,去拓宽技术和产业边界。如果真的要上“竞争战场”,那就以10打1,必须赢得胜利。二是永远不要在悬崖边跳舞:要花更多精力思考死门在哪里,降低一切可以降低的“可见风险”。如果真的要跳,也要距离悬崖有足够的安全距离。
地平线2015年成立,2024年港股上市。余凯创业时的目标是,要做智能机器人时代的 “Wintel”(英特尔+微软 )。他和团队曾尝试过智能家电、智能商业等多种场景,直到在成立4年后的2019年,才聚焦到智能汽车。因为他认为智能汽车其实是机器人的第一形态。目前,在中国自主品牌乘用车中,地平线拿到了33.97%的市场份额,超过成立 20 年以上的 Mobileye 、瑞萨和英伟达,成为最大的智驾计算方案提供商。同时,也改写了中国一直没有高算力自动驾驶计算产品的历史。
过去二十年,互联网企业的成长路径塑造了大众对成功企业的认知,但地平线却独辟蹊径。它并不依赖于商业模式的革新实现迅猛扩张,而是致力于底层技术创新与市场需求培育并行推进。不是一味追求技术遥遥领先,而是真正做到让客户满意。地平线志在成为“智能机器人的大脑”,实现这个目标更具挑战性,过程更为复杂,所需时间也更为漫长。这或许正是从零开始创造一家科技企业的魅力所在。用余凯的话说:“耐得寂寞是真正的英雄主义”。
期待下一个十年的地平线“新征程”。
演讲原文:
余凯:各位嘉宾、各位朋友,感谢大家光临地平线2025产品发布会。还有网上的朋友们,感谢大家的时间,今天是周五的傍晚,这个时间其实是一个礼拜当中最宝贵的,我们陪家人、我们陪朋友,但是我们今天大家相聚于此,很多朋友从北京坐飞机过来的,有广州、深圳坐飞机过来,到上海还得长途跋涉来到这里。这个地方是哪里?是上海临港。大家知道吗?临港是上海最早看到日出的地方,地平线上日出东方,这个跟地平线的寓意是何其吻合,日出东方冉冉升起,这难道不是我们的产业吗?这难道不是中国的汽车工业的吗?这难道不是中国的科技产业吗?这难道不是我们的国家吗?在这样一个冉冉升起一轮红日的地方象征着希望,象征着力量。我有一个号召,我希望全场的各位为我们辛勤工作的产业,为我们的国家一起鼓掌好不好?
关于产品发布会,我想从何说起呢?我想先跟大家分享一下地平线是谁,我是谁,我从哪里来,我们十年前为什么要出发。好多人好奇,公司的名字为什么叫地平线?你看港股的叫地平线机器人。十年前创立这家公司我们给公司起名字叫Horizon Robotics,小小公司的简单名字实际上蕴含着大大的野心,我们想做未来机器人无处不在时代的基础设施,就是它的计算平台。什么叫计算平台?对我这样从事计算行业、人工智能行业30年,也算一个老兵,计算平台很简单就是芯片+操作系统。地平线我们想做机器人时代的芯片+操作系统。历史上什么样的公司做芯片跟操作系统?在个人电脑时代、PC时代差不多是75年、76年成立了两家公司,一个叫苹果,一个叫微软。当然那个时候还有一家公司叫Intel,他们三家公司开启全人类的PC时代。我们今天每个人手上面都有一个手机,在手机计算平台ARM,高通,包括Google的安卓,也包括苹果,他们奠定了全人类在移动时代的操作系统。现在还有人工智能,英伟达一己之力撑起了人工智能的计算平台,他们的共性是什么呢?这一些公司不仅仅是挣了钱,他们推动了全人类科技文化的进步。
我这么想,我说在中国的过去20年、30年毫无疑问我们的经济建设取得了巨大的举世瞩目的成就,中国有很多挣钱的公司,非常挣钱的公司。我觉得站在当下这样的关口,我们朝未来看,我觉得中国并不缺任何一家挣钱的公司,当然一家公司当然要挣钱,但是我觉得中国缺什么呢?一个全新的公司,日出东方不仅仅挣钱,更重要推动全人类科技文明的进步,地平线就是想做这样的一家公司。谢谢大家的支持!
在2015年的6月份,当时我刚刚从上一家公司辞职,那个时候在我心目当中孕育着一家年轻的公司。那个时候作为创业者我在干着很多创业者都在干的事情,就是接受媒体采访,忽悠投资人。我相信现场也有很多我们的老股东,我说我们要做的是把深度神经网络置于芯片之中、方寸之间,但是我们要做的不是PC,不是移动,是机器人的大脑芯片。我们要让每一辆车,每一个电器都具有环境感知、人机交互、复杂场景决策控制的能力。那个时候的想法听下来非常的懵懵懂懂,但是我们看地平线的今天,在座的我们的合作伙伴都是客户,都是主机厂。
大家知道地平线是今天车载计算方案跟软件方面在中国的领导者,去年甚至是辅助驾驶市场的第一名。我相信这些很多人不一定了解,我们其实还有另外一个身份,我们内心的小火苗也从来没有熄灭过的,就是做机器人的计算平台。实际上地平线机器人也是消费类机器人第一大芯片跟计算方案的供应商,我相信你们在家里面有很多扫地机,包括中国出口到大洋彼岸的院子里面的割草机,因为装了我们的芯片能够在院子里面知道自动建图、定位,能够知道哪个地方是草坪、哪个地方是路径,能够自动规划取代路径让每个人生活更轻松。
所以地平线十年前的小伙伴一直到今天我们还在干这样的事情,还在让每一辆车、每一个电气都具备智能的能力。当然这个十年的过程,其实我也很难回顾这里面的点滴了。我觉得大家能够记起地平线的恐怕是某一些高光时刻,偶尔的那一刹那。但是这个东西其实是这十年创业的常态。这个是去年某一天晚上半夜大概凌晨快一点钟的时候,那一天我大概是经历很大的挫折,那个时候我在等车,行李在旁边,我分享了这么一个图片。我觉得创业真实的发生是从挫折走向挫折,从失败向失败,那个高光时刻只是偶尔一瞬间。但是我认为我们是有成长的,在这十年当中,我们什么东西变化了,什么东西不变?我觉得不变的是我们一贯的初心,给汽车和机器人时代去打造计算平台,它的价值跟意义在什么地方呢?就是我们的使命跟愿景。
2015年创立的时候我们是说要赋能万物,让每个人生活更安全、更美好。安全是第一,美好是其次,在安全之上才能有一切的美好,如果没有安全所有的美好都不复存在。那个时候我们不知道商业切入点在什么地方。科学家创业拥有的是一个对技术的热爱跟执念。所以我们的愿景是说要成为边缘人工智能芯片的全球领导者,听的我自己都热血沸腾的。但是实际是什么呢?处处碰壁,商业的场景从哪里去切入呢?边缘人工智能太虚无缥缈了。所以我们到了2020年,这个时候我们的征程2芯片已经量产了,在长安打造了一款爆款车型,这个时候懵懵懂懂明白了:我们要从科学家创业走向真正的企业的经营者、企业的领导者,我们要通过现实追求理想,而不是反过来。所以迭代我们的愿景就是让每一辆车都搭载地平线的智能计算方案。
可是到2022年年底的时候,我们发现有很多的问题,我们发现真正要解决的问题还应该有更加终极的价值感,我们的工作应该让每个人都能够感知到,让每个人每天出行都能够真正的享受到,不仅仅是一个车厂出厂的配置而已,不能只是一个广告而已,要变成实实在在每个人都可以享受到的科技产品。所以进一步又迭代了我们的愿景和使命,我们要打造人人爱用的智能驾驶产品,这个也是我第一次跟大家来分享地平线最新的使命和愿景。但是不变的是什么呢?是安全,是安全,是安全。建立在安全之上才有一切的可能性,才能有一切的美好,当然大家也知道我们在行业里面,现在也在面临一些状况,我觉得坚持这样的初心是非常非常重要的。有这样一个目标,有这样一个初心,我们要向何方我们心里面越来越清楚,可是我们保持一个什么样的姿势,是屁滚尿流,还是跌跌撞撞,还是身段优雅,有所坚持有所从容的方式,以什么样的方式去走向我们的目标,我们的彼岸?这个就是我们的文化价值观。
在创业初期差不多2015年、2016年,那个时候创业就跟小孩子过家家一样,觉得好的,我们搞了一家公司,我们也得像模像样胡诌一点所谓的使命、愿景、价值观。我们当时一看阿里六脉神剑,太好了!我们也来攒一个。所以我们攒了七个:成就客户,正直担当,阳光进取……我们也取了一个名字叫“北斗七星”。2019年那几年都是致暗时刻,因为找不到商业的切入点。我们说做人工智能芯片用在什么地方?我们用在无数的地方,车只是其中之一。2019年有一个大彻大悟的顿悟,把汽车以外其他业务基本上就砍掉了,2020年活过来了,当时汽车产业发展,我们也实现了量产,第一个征程2芯片实现了量产。所以有一些起色,这个时候我召集地平线的核心管理团队在一起开复盘会议,说:“兄弟们,这五年过来,我们得总结一下是什么东西支撑我们过来的?我们公司文化价值观,我问一下,大家你们谁能把它背出来?”结果你们知道吗?我们在座的高管核心管理层没有一个人能背出来,扪心自问我自己也背不出来。所以价值观实际上是写在墙上,并不是刻在我们心里的。我又问大家:“过去我们遇到很多挑战,但是走岔路的时候,总能把我们给掰回来,是什么东西能够把我们掰回来?”结果在场的每个人的答案出奇的一致,都指向这两个核心的文化价值观。“耐得寂寞 成就客户”非常简单,就这八个字。
我们认为耐得寂寞是真正的英雄主义,耐得寂寞意味着当整个创业,比如说人工智能创业、芯片创业、智能驾驶创业,大家都热热闹闹的往这边走,我们反而会去思考,我们其实想反方向:人迹罕至,没有人看见,没有关注,没有人重视,投资人也懒得搭理的方向,是不是更有机会,是不是从现在可以成为大的产业的一个机会?耐得寂寞是意味着我们心目当中有一个很大的目标,我们愿意为此付出长期的努力。耐得寂寞意味着延迟满足,意味着我们不太介意短期的得失,更加愿意经过长期一点一滴的努力,比如说做芯片这件事情,做车规芯片这个事情。是方寸之间,毫米之间我们要编织大大的一个世界,大大的计算,去契合整个世界交通流,人流的复杂度。我们愿意为此长期努力,不介意短期的得失,延迟满足。
成就客户是自我成就的最佳路径,利他利己不是矛盾的,只有利他才能真正的利己,我们认为只有为行业,为国家创造价值才能有所收获,才能有精神和物质的收获。所以成就他人其实就是成就自己。我们这些年跟客户的打磨,从一个新的项目开始,我们总是获得一个新的车型以后就有第二个车型,第二个车型就有第三个车型,第三个车型以后就有大的车型平台总是这样一步一步获得跟客户的信任,我觉得这个是背后很简单的准则商业其实本质上面是利他。
在很多的商业合作的过程当中,其实我们要做很多很多的选择。有的选择比如说基于现在整个报价、竞争这些都是看得见的东西。但是很多时候商业因为是创新,所以实际上是硝烟弥漫的战场,在看不清的时候就需要有一个战略方法去支撑你,帮助你做选择。很多时候选择并不是取,而是舍。对于地平线来讲,我们战略思考框架其实核心要思考的是什么呢?不是教我们怎么赢,而是教我们怎么不要失败,教我们怎样不要输。我们其实主要两条,经过10年创业所总结下来的。
首先第一个:公司内部在选择一件事做不做的时候,我们不断的去思考,我们要在没有竞争的地方竞争。比如说10年前人工智能软件算法创意是大热门,地平线带着浓浓软件算法的基因,我们反而在思考搞芯片是不是更有意思,是不是更加的有护城河,是不是有更高的竞争壁垒,尽管那个时候大部分人都看不懂我们的玩法。那个时候我们做芯片还有行业大佬跟我讲,余博士你做芯片要做主战场。我说什么是主战场?他说你要做手机芯片,手机是大产业。我当然想我才不干呢,那个时候2015年,我认为移动互联网基本大格局已经差不多了,就像一个球赛快要临近尾声了,我觉得这个时候冲进球场,我觉得我连捡球都不配,我觉得战略布局是不对的。
有人说余博士你要搞云计算。2012年的时候英伟达人工智能计算是全世界最大的,我当时在百度负责百度的人工智能。2015年7月14日我们公司正式注册成立的时候,那天英伟达是107亿美金的一个公司,很多人都不知道的,但是我其实知道的,CUDA云计算上面的生态2015年我认为是没有办法去竞争的。我说no,我们选择机器人芯片!这个听下来真的是拍脑袋,天方夜谭,那个时候连这个市场都没有,但是想起来这个选择在没有竞争的地方竞争,其实是一个基本的选择。后来做了很多非常傻的事情也犯了很多错误,但是现在地平线还能够活着其实源于当年基本的选择。要么是另辟蹊径,要么当一个战场已经很兴起的时候,智能驾驶的计算这个地方已经非常清晰,有清晰的市场目标、清晰的需求、清晰的客户。地平线要做的是什么事情呢?不惜一切代价以10打1,我们要把所有的精力、所有带宽,所有研发力量,包括所有管理中心都聚焦在一个战场以10打1,战略的本质是不赌,在没有竞争的地方竞争。
还有另外一条不断反复运用的战略思考方法论,不要在悬崖边跳舞。地平线在这件事情上面也是有一点奇怪的,比如说我们其实从来不冒险。比如说我们的财务管理,基本上账上面的话一直是有非常充分和健康的现金流,这点在创业公司里面是极其罕见的。在2019年的时候我们当时选择战略聚焦,把汽车以外其他业务都砍掉或者压缩,外面连篇的报告说地平线不行了,破产了,没有钱了,实际上我们账上还有30多亿的现金。
地平线在公关PR品牌上面,我们一直坚持自己的思考,我们不要在舞台中央,当然今天发布会没有办法我在舞台中央。地平线一直在说我们不要当明星,我们要在镁光灯的边缘,因为要在镁光灯的中央,万众瞩目大家都可以看到我,我稍微有一点小动作你都可以看到。如果在镁光灯边缘没有人看得到我,我反而可以更加冷静做我的事情,但是因为在镁光灯边缘,不在镁光灯之外,大家也不会忽略我们。把握这个度,在过去AI时代,我们也不是任何一条小龙,到今天也不是一个明星。所以的话,要克制平衡,不要在悬崖边跳舞。我特别欣赏的理查蒙格讲说的——“我如果知道在哪里死,就不会到那里去。”听起来平淡无奇甚至有点无聊,但是其实是充满着人生智慧。对于企业来说我们要考虑生门和死门,很多企业80%或者90%、100%的精力考虑机会在打哪里,不顾一切的去抓生门,地平线永远是80%的精力考虑死门在哪里,我们会死在哪里,我们会避免去那里。这里面巴菲特一句话说“投资的真谛是不亏钱”,这个听下来好无聊,但是我觉得这个才是真正的经营,长久企业的经营之道。
那基于这样的战略,我们不断思考我们自己的商业切口在什么地方。到2019年的时候,那个时候我自己内心非常痛苦,我觉得诸事不顺,有的时候整晚整晚睡不着觉,我们这么好的技术为什么没有客户呢?为什么在我们进入的所有这些领域,包括当时还搞过智能玩具,智能电器,智能空调,一开始想赋能万物恨不得把所有的都放到智能设备里面,但是没有一个业务是走的很顺的。我们经历长达半年多的反反复复的战略讨论,那个时候战略讨论开到晚上七点钟开完,但是其实从来没有按时开完过,总是吵到凌晨,大家都很痛苦。到2019年11月份的时候突然开始有点顿悟,突然开始明白商业第一原理,不是我有什么,不是我能做什么,不是我有什么牛逼的技术。而是首先是客户是谁,我们的客户到底是谁,我们的客户究竟是谁?这个问题我作为科学家创业,创业五年的时候我突然明白这个问题的时候,我已经突然跟很多的科学家创业已经脱开了好几个身位。我们客户需求和痛点到底是什么?还有什么难以被复制的方式去高效满足用户需求和解决他的痛点?把这三个问题放一起:客户是谁?他们的问题痛点是什么?我有什么高效方式解决他们的痛点和需求?这三个问题,第一个问题比第二个问题重要,第二个问题比第三个问题重要。想明白了这三个问题其实地平线就从一个科学家过家家变成了一个真正的创业团队。
关于技术的选择。我这里面给大家分享2017年地平线第一次产品发布会当时我的一个PPT,那个时候我的身材可能比现在还稍微好点,发量也比现在大一点。但是有的东西是不变的——我们骨子里面的技术信仰就是软硬结合。软硬结合这件事情全世界真正去做的公司非常少,我这里面引用天才的计算机科学家Alan Kay的一句话“你要真正认真对待你的软件,你就要真正做你的硬件”,这句话他说出来以后没有人能懂。全世界真正信仰他的一个人,这个人就是乔布斯,苹果是真正信仰软硬结合的,后来乔布斯也把Alan Kay请到了苹果,还有一家公司——特斯拉相信软硬结合。地平线从2025年Day One我们骨子里面就是软硬结合。像我自己从第一天鬼使神差说要做芯片,但是那个时候我做了20年的人工智能算法,我告诉你们我虽然知道我的代码在某一个不知名的机房,机房里面的服务器,服务器里面有一些芯片在运行软件,但是我手都没有摸过这种芯片。创业花了2年的时候,可以是说求仙问道搞明白怎么搞芯片的,实话实说我现在还在学习,幸亏我们的团队非常的强,非常的厉害。地平线的芯片有世界级的设计团队。
我最近在看一本书,我相信很多人也在读。《The Thinking Machine》这个就是讲的英伟达的故事,这里面有一个章节专门讲了这个事情,他说整个计算推理性能一部分贡献来自于硬件,也有很多一部分贡献来自于软件。如果他们讲跟AMD讲硬件结构没有什么不同,但是黄仁勋讲了他掌握了无与伦比的科技生态,是一个有强大的软件生态公司。
我下面给大家稍微上一上技术课,为什么软件硬件要深刻结合?看任何一代平台,无论早年大型机还是早年PC还是服务器,人工技能计算,还是现在干的事情。每一代计算平台随着时间推演,它的计算性能一定会不断上涨的。但是对于这一代计算平台,其实用户有一个需求的期望。用户需求的期望在那里,但是他说不清道不明。比如说在90年代你问用户你的需求对于PC到底是什么?他说不清楚的。但是今天我问在座的各位,如果你的个人电脑没有摔坏,你估计都找不到理由要换电脑。为什么?因为现在个人电脑它的性能已经超过了你的需求,所以这个超过用户性能的那根线,我们叫个人过剩,现在移动手机差不多了。我最近要不是因为三叠屏让我觉得可以的、有意思、是我的新玩具,所以我买了,要不然我也没有什么理由换手机。所以现在手机性能也过剩了。产业发展总是从一开始性能不足走到性能过剩,当性能不足的时候软件硬件深度结合和联合优化,可以让整个系统的效能取得相对竞争优势。
这个绿色的曲线、蓝色的曲线代表着软件跟硬件每一个充分的协同,在每个时间点上,它的性能是不如软件跟硬件优化的。这也是为什么当性能不足的时候,软件硬件的联合优化总是能取得竞争优势。所以大家看到历史上面,其实比比皆是、屡屡发生。在PC时代软件的强大如微软,硬件能力强大如Intel,他们两家都是要什么?都是要一对一排他性的组成所谓的Intel的,在移动时代,软件能力强大包括高通,ARM整个生态组成了AA联盟,也是一对一排它性的。为什么?因为软件跟硬件要深度的优化。到了人工智能时代,英伟达跟他自己,历史上有可能是两家公司做,有可能是一家公司做。但是真正不变的是什么?是软件跟硬件的深度结合。所以地平线一直在思考,智驾的本质是什么?其实智驾的本质更加的极端,它甚至不是一个面向百花齐放的应用平台。比如说像windows上面有这么多工作,娱乐的,通讯这么多应用,它就一个应用——把车开好。所以它是一个面向单一任务的计算系统,当然他也是有史以来恐怕是最复杂的计算系统,我这里把航天飞机与每天的出行来做比较,航天飞机开在天上是不会碰到外卖小哥的,可是我们的自动驾驶穿行在人流车流这样复杂路况里面,各种可能性都会出现,它难以用确定性的公式F等于MA、或者E等于MC的平方来描述它,所以它是有史以来最复杂的计算系统。
人类对于自动驾驶有没有什么说不清道不明,摆在他面前他知道需求的那条线呢?当然是有,就是L5级的自动驾驶,在这条曲线需求被满足或者被过剩之前,智能驾驶一定要走软硬结合的路线,所以这个是地平线在过去10年里面少数做对的几件事情之一。
今天在座的各位,抽出周五晚上宝贵时间来参加地平线的发布会。前两天在电动车百人会我也有一个观点,每次跟大家分享我一定要讲一个所谓的反共识观点,或者挑战大家习以为常的一些观点,我觉得我有这个责任和义务不浪费大家的时间。什么意思呢?反共识不求正确,但是也许可以促进大家的思考跟整个行业的讨论,让我们更加共同逼近真相。所以地平线从来不是单纯的芯片公司,我们是芯片公司里面最懂软件算法的,我们是软件算法公司里面最懂芯片的,我们是软件算法加芯片里最懂车规的,以及最懂车规级质量安全的。所以我们是一个“芯片+软件”系统级的智驾技术公司。
当然除了我们对技术的信仰,还有很重要的是地平线也是一家有生态系统的技术赋能公司。我们一直相信开放共赢,全维利他。我刚才也讲了地平线想明白的一件事情,利他跟利己其实是一回事,如果从利己到利他有什么不同?道路会越走越窄,从利他来利己我觉得道路越走越宽。所以我们也知道产业分工的重要性,每个企业一定要做自己最擅长的事情,只有大家去形成这种草木繁荣的生态,我觉得整个社会,整个行业才能真正往前进步。所以地平线这一些年一直坚持这点开放共赢,我们有幸跟很多合作伙伴这些年形成了非常深的合作伙伴关系以及互相之间的信任。
所以这里面也牵扯到地平线的品牌的slogan,我们叫JourneyTogether,Journey征程,大家知道征程地平线的品牌,征程2、征程3、征程5一直到现在的征程6。这个背后的话其实是有我们的一个信仰在的。首先第一点,我们认为我们的价值、地平线存在的原因是与客户、员工、股东跟合作伙伴的长期共赢。在这种共赢之中才能找到这家公司之所以应该存在的原因。比如说就我自己来说,这些年要说我创业最大的收获是什么?我可以跟大家分享。
第一,地平线的员工,包括地平线历史上面的员工,我觉得在过去10年人工智能,芯片,智能驾驶这个所有创业公司里面地平线员工在经历创业过程当中,他们收获个人成长,他们精神跟物质的收获我相信是不差的。地平线去年10月24号完成了上市,我们在过去做了很多事情,造成一个结果:一级市场最早的这些股东包括上市以后支持我们的股东,所有的这些股东都是挣了钱的,虽然挣的不一定多,有多有少,取决于什么时候投资了我们。但是过去几年大家知道,遇到的资本挑战,大家都是知道这点的,能做到这点其实是很不容易的。这件事情我自己觉得很喜悦,因为Journey Together,包括跟我们的客户和合作伙伴。另外Journey Together为什么?因为我相信创业不是一个party,不是一个热热闹闹,张灯结彩的一个派对。结束了呢?我们认为它就是一个跋涉,又开始可能没有终点的,所以我们有这个心态一直在不断前进。
当然今年是地平线创业的第10年,所以我跟大家汇报我们业务上面的一些进展、一些更新。去年4月份,我们开了产品发布会,当时宣布出货500万套整个辅助驾驶的计算方案,到今天,我们出货已经超过了800万套。我相信很快就会超过1000万套。另外关于车型定点,我们已经拿下或者正在交付已经交付,超310款车型定点,已经交付了200多个车型。在这个交付过程当中,我觉得地平线经过了地狱级的打磨,因为所有加载地平线辅助驾驶系统的车型,每天都在跑在祖国大陆从南到北,从东到西跑在各种各样的天气和工况上,我们对这件事情其实有深深的敬畏之心,到今天我为这件事情还是战战兢兢。当然我们跟我们的合作伙伴在一起的共赢,这个也是我自己的一个收获。另外,我知道斌哥明天要开发布会,大家也很辛苦,我了解到尤其是在座的媒体朋友们,这个礼拜中国的车厂一共要开19场发布会,你们辛苦了。蔚来的萤火虫,也是搭载了征程5的计算方案,我们预祝明天斌哥的发布会圆满成功,斌哥加电!
所以谈到市场份额这个是历史上第一次,在所有辅助驾驶市场份额我们获得了中国市场的第一名。我们前年还是第二年,23.26%的市场份额,去年获得了33.97%的市场份额。我相信我们今年市场份额还会继续增长。简而言之,去年整个中国市场推出来的每三台带有辅助驾驶的智能车,就有一台搭载地平线的计算方案。
当然去年的上市也是我们很重要的一个里程碑,这个IPO是去年美股+港股所有科技公司最大的IPO,也是三个月进入科技指数的科技公司。我觉得这个意义在于什么地方?大家都知道过去三年很难,行业里面每个人都很难。科技公司,科技创业公司更难。但是我听到了一些声音,他们说地平线去香港上市,他们能成功的上市,那我也能。所以我觉得我很骄傲、很自豪,我觉得大家在至暗的时刻、悲观的时刻也要看到希望,在绝望当中也要看到希望。
所以在去年3月26日,我们公开在香港股市香港证监会招标,当时在内部有一个发言,引用了丘吉尔的一段话,我也分享在我的朋友圈里面。我在想这对我来说意味着什么?这不是一个结束,也不是一个开始的结束,这只是真正的征程的开始,因为L5还没有实现呢,我们还得继续努力。毫无疑问也不只是地平线在努力,我觉得我们全行业都在努力。今年开春以来,长安、比亚迪、奇瑞一系列中国领先的主机厂,其实都在推进智驾平权,实实在在的推进。我们要打造更加科技、更加智能的产品,让每个人的出行更加安全、更加美好。
大家知道吗?我为什么刚才说我觉得地平线今年的市场份额我很有信心会持续增长。因为开春以来每一场发布会背后都有我们地平线。地平线去年的产品发布会所宣布的量产芯片,征程6E、征程6M这两个芯片在今年卖爆了,它成为行业的最大公约数。要知道过去每一款产品第一年的量产上市,从来没有像这款芯片这样,第一年就会超过百万级的出货量,到现在征程6E/M已经拿到超过了20款的车型,一共搭载目前已知超过100款车型。
商业成绩背后实际上是地平线对技术创新不断的追求,虽然我们不在悬崖边跳舞,我们恨不得在悬崖50米以外跳舞。但是我们对于研发投入是持续的,是非常认真的。去年,差不多30亿的研发投入,今年,差不多要投入40亿的研发投入。我稍微看了一下中国今年新势力的主机厂大概一百亿或者不到一百亿,地平线在这一件事情上面我们有足够的投入,我相信持续的投入会构建坚实的智能驾驶底座。
地平线从来没有跟大家说过这件事情:我们有三大实验室,第一个AGI实验室,第二个具身智能实验室,第三个AI Agent实验室。这些实验室在2017年、2018年开始长期深耕底层的技术研究。去年的2024年地平线作为年轻的科技公司,我们在国际学术人工智能的顶会上面发表了一系列文章,这里面包括CVPR,世界最著名的视觉学习功能ICML,也在这一些技术上面做了相当多的底层研发。学术的成果在这些年里面被引用超过10万多次,全球专利申请超过2000件,尤其是在端到端自动驾驶,在交互式的强化学习,在视觉的主干网络方面,我们有世界级的研究成果。比如说去年的产品发布会,其实跟大家分享2023年的CVPR,世界第一的这样一个视觉的学术会议,提到了自动驾驶端到端大模型UniAD,获得了全场最佳论文,从9000篇全球论文里面脱颖而出,这是世界上首个发表端到端的算法框架,所以地平线在前沿技术上面其实是一直领先的。但是我们从来没有懈怠过,那个已经过去了。
2024年的成绩我给大家分享一下,我们去年发表了一篇论文提出叫Vision Mamba,全球一共去年发表了4万多篇人工智能领域的学术论文,有10篇是最高的,其中三篇来自于中国。地平线推出的Vision Mamba中国引用率第一,全球引用率第三。跟传统的主干网络,具有线性计算复杂度,而不是二次方的计算复杂度,所以它大大简化了计算复杂度,提升了计算性能,同时保持极高识别效率,所以它会成为新一代智能驾驶主干网络。大家最近有看到一些新闻包括腾讯很多公司也在推基于Mamba和Transformer的混合网络,顺便也可以提一下,DeepSeek也是这里面十篇引用率最高的论文之一。得益于对算法,软件芯片架构方面的持续研发投入,大家可以看到过去10年摩尔定律的进展是100倍的话,通过我们软件跟硬件的联合优化,我们在过去10年地平线的底层计算架构BPU性能提升超过1000倍。
最近看有的媒体说:地平线是“生态之王”,我想这个对我们是一个鼓励,意味着这个是正确的一个方向,我们也在持续的坚持。我们相信通过与广泛的合作伙伴、软件生态不断深化合作,我们能够共同地去推动整个辅助驾驶和智能驾驶继续不断向前发展,让每个人出行更安全,更美好。
这里面我也要重点说,地平线也特别重视与顶级的Tier-1合作伙伴,我们跟博世、电装、大陆、酷睿程合作。我们要打造什么样的战略呢?In China for China。但是这个只是开始,我觉得我们可以在一起合作的是In China for Global,我相信未来10年是中国的科技力量走向全球的10年,带着这样的愿景我想我们还是要有一些反共识的思考,所以我想跟大家再分享一些反共识的思考,要不然对不起大家在周五晚上来参加我们的发布会。
第一个智能驾驶的本质到底是什么?它带来的是什么价值?是功能价值,还是情绪价值?与之关联的问题,智能驾驶是智能汽车的灵魂吗?我们来回顾跟比较一下手机时代发生过的故事。手机有一个很重要的功能,毫无疑问是——通讯,如果没有通讯不叫手机,叫掌上玩具。这里面核心的技术就是基带芯片,大家有没有想过基带通讯这样一个很重要的功能,它跟用户没有关系。它跟你是男人、女人、小孩、中国人、日本人、印度人、德国人没有任何关系。它要保证通讯的流畅稳定,在高楼大厦密集的城区,在地广人稀的农村,在不同基站要保持通讯、稳定、流畅。就跟打电话一样,打电话功能也很重要,打电话用户体验跟是男人、女人、小孩的用户没有任何关系。
手机有另外一个重要的事情就是拍照,拍照这件事情你发现没有,手机厂商基本都是各异的。为什么?它没有标准。它跟目标用户是谁相关的。对我来说我拍照,我的喜好是清汤寡水,自自然然。但是比如说我的联合创始人黄畅,他拍照可能喜欢浓墨重彩,添彩抹粉,这个爱好不一样,我也不能讲哪个好哪个不好。这个没有统一标准,面对你用户是谁,你打造的品牌是谁,要充分的打造差异化。
我们来看智能驾驶,智能驾驶更像手机的基带,还是更像带来情绪价值的一个技术?大家想一想,智能驾驶核心是什么?从A到B,安全不能出事故。第二要足够舒适,因为你是送人不是送货。第三个是什么?要足够快速,要足够便捷。大家在大城市打拼讨生活都不容易,你上班慢了会被老板骂。所以无论你是谁,无论你是男人、女人,老人、小孩,中国人、印度人、德国人,智能驾驶功能要求都是一样,跟用户是谁没有关系。它是重要的,但是不带来情绪价值,没有办法说智能驾驶开出林志玲的风格,或者开出郭德纲的风格,所以它就像手机的基带。重要的,它还是收敛的一个功能价值。智能座舱难说了,智能座舱里面音乐、音箱、香氛、灯光,比如说给老板坐的MPV它里面一定要有豪华感,如果家庭用车一定要有温馨、安全、舒适,这完全是不一样的,没有一个固定的标准,完全看你的用户是谁。
所以你看很有意思,智能驾驶我认为特别像手机时代的基带,大家想想看2009年的时候3G推出来,让传图片变得很随意,可以拍照,做的菜可以分享,看到好看的衣服可以分享了。所以那个时候本地生活,像美团、电商,移动电商在3G时代都起来了,更多是功能价值。4G时代差不多2013年,视频流变得无限流畅,这个时候抖音出来了,TikTok出现了,还有很多其他的手游出现了。所以实际上功能价值的推进释放了情绪价值的可能。
我们进一步来看推论,对于智能驾驶来讲,它如果不断的往前推进,假设我们实现了L3,那可能某一些ODD情况下可以实现完全智能驾驶,司机不用负责任。在上班通勤当中,如果你进入这样一个智能驾驶的状态,我可以开会、开视频会议,我可以跟同事们在视频会议里面去吵架了,他们听到的不是我的声音,能看到我的情绪,能看到我的表情,能看到我的愤怒,对不对?如果是L4、L5的话,那就不一样,你可以躺着坐着了,你可以在里面打游戏,你可以在里面看电影,可以在礼拜五下午在海淀下班,上了车打游戏、看电影、睡觉,第二天早上在青岛的海边看日出。所以我在想智能驾驶虽然重要,但是跟汽车品牌没有关系,因为它主要是基础能力,基础设施,但是它未来会释放无限情绪价值的可能。这个是我的一个看法,智能驾驶重要但是又不是那么一回事,智能驾驶不会帮助你定义品牌。
我们今天讲人工智能,大家都在讲人工智能很重要,我们要搞流量,我们要搞用户。如果没有流量,没有用户,我们产品搞不定,我们会失败。真的是这样吗?我给大家分享一下,我觉得现在很多人在搞人工智能产品的时候都顺着当年互联网产品逻辑的惯性。我们看一下互联网产品的本质逻辑,它本质是连接,比如说搜索链接人与信息,比如说电商链接人与商品,比如说链接人与人就是社交,链接人与视频就是抖音、快手。所有的互联网产品都围绕一件事情,通过记忆算法怎么揣摩这个人喜好、偏好是什么?他到底爱好看什么样的片子。所以在互联网的产品逻辑来说就是得用户者得天下,得流量者得天下。为什么呢?因为用户流量可以让他更好的理解这些用户的喜好。所以我说互联网的产品逻辑一言以必知,就是洞见人间烟火,他没有说超越人。互联网产品逻辑没有一件事情是说超越人,超越人就把这个事情搞黄了。
AI时代的产品逻辑呢?我们千万不要顺着惯性去走。要知道移动时代来的时候,PC时代的王者根本搞不懂移动时代发生什么事情了。现在AI时代的玩家如果顺着互联网时代去考虑当下,恐怕又是大错特错。我们看三个例子,AlphaGo下围棋,DeepSeek大模型,我们再看智能驾驶。
AlphaGo一开始的时候是学习人类的习惯的数据,很多后来发现特点有一个更牛逼的方法,这个方法叫Alpha Zero,所谓的Alpha Zero就是从零开始的,不需要人类历史上面任何的下棋数据,哪怕你是棋圣,这个数据也不学习。为什么?因为不值得。所以学习。所以Alpha Zero完全从零通过强化学习,左右互搏,不断在虚拟世界里面提升棋艺,后面Alpha Zero达到的棋艺的水平,人类已经没有资格给它评判它是几段,远超九段水平。如果想象方寸棋盘上面有一个上帝,Alpha Zero基本找到这个上帝它逼近了棋盘的真理。
我们看大语言模型,我们每个人都在谈DeepSeek,DeepSeek真的很了不起。大家有没有想一件事情,DeepSeek横空出世的时候是一个没有产品,没有流量的公司,他完全通过强化学习,逻辑推理,数学演算能够打败绝大部分的数学水平,甚至是博士生的数学水平,没有任何的流量数据。你看OpenAI,你觉得OpenAI会去学习这些流量数据吗?大部分这些用户跟OpenAI之间的交互他的问题和他的回答其实根本不值得学习的,为什么呢?还不如OpenAI自问自答的质量高。
所以大语言模型的目标不是去达到人类水平,是远超人类水平的。它实际上要逼近什么?逼近世界的真相。什么是世界的真相?比如说数学跟逻辑。这个世界都不存在的时候,当宇宙大爆炸没有发生的时候,那个时候数学逻辑就已经存在了,这个是世界背后的真相。所以人工智能其实是在逼近那个东西世界背后的真相。这里面想给大家提一个暴论,习以为常是真的吗?是正确的吗?顺着互联网惯性来思考人工智能是真的吗?是对的吗?我提供这个观点也不一定是说求正确,但是至少大家可以思考,我们认为AI时代,人类的行为数据没有价值。地平线在过去从事智能驾驶其实也发现,99%的人类司机的驾驶行为是不值得学习的,因为他们开的真的不好,他们刹车刹的真的很重,他们很多时候拐弯我觉得不够优雅。你知道一个很有趣的结果,是瑞典还是哪个,一个北欧国家,采访所有人类的司机,80%的司机认为自己开的比平均水平好。
其实最近特斯拉也释放出一些新闻端倪,特斯拉实际上不是靠用户数据,特斯拉是自己专门的fleet,自己专门车队来搜集数据的,再加上更重要的什么呢?在虚拟世界的仿真,虚拟世界的强化学习,强化学习对于虚拟驾驶的突破是非常重要的。所以对于智能驾驶来说,智能驾驶的。目标不是做出来跟人开出来一样安全,是要做的远比人类要安全。不是说开车要跟人一样舒适,他是要做到远比人开车更加的舒适。所以智能驾驶的目标其实不是洞见人间烟火,而是逼近驾驶之神,我认为这个目标是最终可以实现的。我自己大概悲观估计、客观估计可能10年,乐观估计可能5年,但是要持续的努力。
这个也让我想到这点,既然AI在逼近世界的真相,有可能AI革命是人类历史上面最后一次科技革命。这个让我想到了爱因斯坦,大家知道吗?爱因斯坦是从来不做实验的。他推导出狭义相对论跟广义相对论,他从16岁开始他通过什么?思想实验。他完全是在虚拟世界里面推导的。你看看,逼近世界的真相有可能不是从人间烟火,而是可能从纯粹理性的逻辑推导。所以我们在思考,AI革命可能是人类历史上最后一次科技革命。为什么是最后一次?因为靠AI逼近世界真相了。去年诺贝尔奖,物理学奖已经开始跟AI相关了,生物医学奖也跟AI相关,也有可能诺贝尔奖越来越多跟AI相关,去年只是开始并不是绝版。
第三个我的思考,我们看历史上面是有一个阶段,这个阶段是什么?十倍速技术关键阶段的快速变化,因为十倍速技术关键快速变化导致了整个产业格局的天翻地覆,套用马克思主义经济学的一个观念,生产力决定生产关系,因十倍生产力的变化导致原来的庄家开始下牌桌了,以前牌桌的无名小卒现在成为行业内的顶尖人物,这个比比皆是。我看新能源车某种意义就是,新能源市占率的变化,咱们中国自主品牌以前不到50%,去年年底70%。因为一个关键技术的10倍速变化,有的跟上了有的没有跟上,所以一下子庄家跟牌桌上的玩家就一下子反转了,这个比比皆是。
我给大家分享一下个人电脑当时发生了什么事情。差不多在1986年的时候,那个时候英特尔跟微软实际是给IBM做小弟的,看历史的话,那个时候IMB是巨无霸。286IBM电脑当时取得了辉煌成功,英特尔想推出更高性能处理器386,IBM不支持,IBM说我觉得我的PC性能够用。英特尔跟微软在外面偷偷摸摸支持了康柏,戴尔,惠普一堆的公司。我们可以知道IBM整个市场地位在1986年开始一直往下。286、386、486、586、686、奔腾,如果90年代有印象的话,大家知道686是整个改变了产业的格局。所以这个时候其实当时X86性能的处理器就是一个4倍速的技术变量,这个时候其实所有的这些厂商唯一要做的事情就是以高打低,以快打慢,如你慢了你就被淘汰了。
智能手机时代也是一样的,我们看手机时代。在1G、2G的时代,摩托罗拉,飞利浦,西门子、爱立信、松下,大家都记得这些品牌。那个时候的话他们都自研机的,他们在3G、4G时代持续领先,高通这些,凡是跟上的手机厂商现在都活的挺好的,那些没有跟上的,曾经的王者现在都已经下牌桌了。所以移动通信技术的基带其实是一个时代变量,是10倍速变化的技术要素。这个时候所有手机厂商要跟进什么?以高打低,以快打慢。
我刚才已经讲了,智能驾驶就像智能汽车的基带。从今年开始智驾平权,从基础配置变成L2的辅助驾驶,一定会往前发展。2-3年以后可能会出现L3,L3整个算力大概要500—1000T,比如说现在Thor基本上基本在这个范围,地平线要推出的新一代产品就在这个范围。L4可能2030年一直到2035年,我们认为一直会到5000T的算力。为什么说5000T也不是完全拍脑袋,因为人类大脑就是5000T算力,我觉得智能驾驶要达到这样安全性,我觉得至少要达到这样的一个计算性能。所以未来10年其实自动驾驶的软件跟硬件也是10倍速变化的技术要素,这个时候的话其实对于主机厂来讲,我的建议是说无论是自研还是第三方合作这个都是招式。但是重要的什么?求生,以高打低,以快打慢。
我再来分享跟我们自动驾驶相关的最近发生的一个事情。端到端,BEV,Transformer,VLA这两年我们听这些技术名词比比皆是,热门的技术名词。可是我跟大家分享一下,这些先进技术的进步有可能不会给你带来任何的红利,反而有可能是给你带来某些陷阱,叫技术平权的陷阱。
我给大家举一个例子,小时候幼儿园小学一年级、二年级,妈妈教你做题或者老师教你做题,做不出来打屁股。“鸡兔同笼”问题,这个笼子里面有这么多脑袋有这么多腿,问有多少鸡多少兔子,那个时候班上只有最聪明小朋友才能求解,真厉害,可以搞奥数了。人总要长大,长到了初中一年级,老师教了你更牛逼的一个技术叫二元一次方程组,这个时候班上最差的学生都可以求解了,所以更牛逼的技术不会给你带来机会,但是让好学生变得跟差学生一样了,你没有优势了,这是不是一个很糟糕的事情呢?其实你看过去的历史很多,比比皆是。比如说语音识别,那个时候能做语音识别,能做的很牛的世界上面没有几个人,我当时记得世界上整个把语音识别做的很好的并不多,一个手指可以数出来。后来发现深度学习出来了,要知道现在搞语音识别基本20人、30人团队能做的跟顶级团队水平差不多,那个时候很牛逼的学生现在变得不牛逼了。
人脸识别也是一样的,2012年之前AlexNet出来之前,人脸识别包括自动驾驶里面的行人检测,其实跟magic一样,就像一个神奇的东西,只有少数全世界几个团队可以把它做好。后来AlexNet神经网络出来,发现全世界的人都做的不错,都做的好了。我跟你讲没有任何差异化的商业是不值得做的,特别在中国。如果你能做任何事情你如果能做,前面一百家公司,其他一百家公司也可以做,那肯定是非常惨烈、血淋淋的竞争,在中国聪明的人非常多。所以这一些先进的技术很有可能把你带入某一个技术平权陷阱,并不是给你带来任何差异化的优势。什么是差异化的优势?这个也是我自己在2015年创业的时候我在思考的,我觉得地平线算法一直应该是挺牛的,因为我们有这个基因,但是我深刻思考到,光靠算法很难构建商业的护城河,我很有可能进入一个领域,七七八八一堆团队陷入同质化竞争,所以那个时候说要在没有竞争的地方竞争,从算法搞到芯片,从芯片搞到算法,从算法和芯片搞到车规,所以这个让我们一直是处于很有差异化的竞争壁垒和护城河。所以真正的差异化是那些没有办法写进教科书的炫酷技术,VLA、VLM、端到端、Transformer、BEV。所以真正的技术护城河是十年如一日的苦活,脏活,累活,是说不清道不明的经验积累,以及为此打造的研发文化和流程。比如说耐得寂寞,愿意干苦活,脏活,累活。自动驾驶其实是完美适合这点的,如果我们相信酷炫的VLA、VLM、端到端,Transformer就认为把这些事情搞定了。对不起,你错了。你还是有很多东西是无解的,所以你还是需要苦活、脏活、累活,所以你还是需要时间积累,你还是需要有芯片的算力,还是需要对车规质量流程有敬畏之心,并且为此打造相应组织流程和文化。
苏箐,这个哥们跟我是地平线黑白双煞,我是白衣骑士阳光、灿烂、乐观,他是暗黑骑手,天天虐工程师,但是我俩本质上,和整个地平线信仰是非常的一致的。
最后我想再分享一个反共识,L3、L4、L5。我们怎么走向L3、L4、L5。因为我们现在还是辅助驾驶,工信部这一段时间我觉得特别好的正本清源,我认为这个对整个行业发展是大大良性的约束、规范,整个行业才能够更加健康的发展。我们认为L3、L4、L5这些高级别的智能驾驶,它们的前提是足够好的L2全场景辅助驾驶。我们来看一下部分车企对于L3的定义,天气晴朗,光线良好,有雾不行,暗光不行,车道线要清晰,这个不行,那个不行。其实大家看一下,这个产品定义实际上是非常反人类的,这种ODD定义的边界对于用户来讲模糊不清。不像红绿灯,大家知道红绿灯是非常天才级的设计,清晰,红色就是红色,绿色就是绿色,什么叫天气晴朗?什么叫光线良好?早上上班有的时候起点雾你觉得看不清,我觉得看的挺清的。什么叫车道线清晰,这种不清晰模糊的ODD,用户突然一下子冷不丁要接管,要七秒钟接管他要怎么接管,所以这种情况所谓的L3实际上只是自嗨而已,对于用户没有办法真正的去使用的。所以我们认为对于L3的思考其实就是一个简单的公式,它就是一个清晰有限ODD边界L4的能力,加上L2全场景的辅助驾驶。
什么叫清晰的ODD?比如说上海的延安路立交、北京的四环。如果我说带北京四环实现了L4的自动驾驶能力,这个ODD边界对每个用户来讲是非常清晰的,我们车进入四环的时候,车正在进入L4的自动驾驶区域,离开北京四环的时候车提醒用户我们正在离开L4级的自动驾驶区域。然后回到了L2的辅助驾驶状态,你是可以体现8秒钟或者10秒钟提醒用户的,充足时间清晰的ODD边界。
但是我只是举这样一个例子,我的意思是说我们一定要定义非常清晰的ODD边界,在边界里面,我们是不是可以实现真正的自动驾驶,除了边界以外我们去看L2的辅助驾驶。怎么实现呢?第一步首先必须要有海量的L2全场景辅助驾驶系统的部署。我们要有百万辆车,千万辆车在各种路况,各种天气下来它是L2级的辅助驾驶。在这个前提之上,我们去采集海量的数据,这个数据不是为了训练,实际上是验证。因为毕竟是关系到人的生命,我不能拍脑袋说你足够安全,如果我有足够的数据跟车辆去验证,我才能够通向第三步,基于大量L2级辅助驾驶的车统计数据表明在清晰的ODD,比如说北京四环有足够的代表性,它有足够超越人的安全性,达到了L4级的等级。然后我再加上必要的整个的冗余,我觉得这个才是真正的可行的L3路径。所以可以看到L3、L4、L5,其实L3、L4、L5我认为它的前提是足够好的全场景L2辅助驾驶。
行百里者半九十,我们讲这么多,说一千道一万还是为了一个目标和使命——智能驾驶用户价值的兑现。我在想我们还是得回归冷静,虽然里面这么喧嚣,但是我们地平线还是更愿意做狂飙中的冷静者,悲观中的笃定者,还是要继续的前行。下面跟大家分享一下用户对于现在辅助驾驶,智能驾驶他们是怎么看,给大家放一段视频。
我们听了用户的声音,他们有期待,但是也有很多的抱怨。他们觉得智驾不够聪明,对于复杂道路的结构他们不认路,他们上班通勤赶时间,在城市里面打拼真的不容易,但是上班迟到真的没有办法向老板交代。他们自动驾驶不拟人,很多时候急刹,顿挫没有办法让人达到安心,怎么打造“人人爱用的智能驾驶技术的产品”这个是摆在我们面前的问题。第一个算力是很重要,算力是整个信息社会,信息的基础。这个上面我们一定要不断的设计最先进的处理器跟架构去逼近这样的上限。
地平线的Nash架构,这是我们全新专为征程6城区智能驾驶去设计的全新一代的集成架构。这里面有强大的浮点计算的能力,特别用硬件优化超越函数,比如说Softmax市面上没有做这样全新优化以及全新的存储结构。基于全新一代的BPU的结构,我现在跟现场的各位隆重推出我们传说中的全新一代的大算力征程6P。
这次我们同步推出征程6P和征程6H,征程6P是旗舰机大算力高达560T算力高性能的智能驾驶芯片。我这边也跟大家分享一下地平线成长历程。2019推出征程2,2021年推出征程3,这个是征程5,去年的话我们推出征程6M和征程6E,现在是征程6P跟6H。所以7颗芯片,地平线10年征程,我们也集齐了七颗龙珠召唤神龙。
我也给大家展示基于征程6P所打造的域控制器,这个也是现在行业里面可以是说最高性能的智能驾驶车载计算机。我们的心愿,当然我们也相信我们把高性能车载计算机会推广到千家万户,让无数的老百姓他们每天在城市中的烟火气,因为我们技术让他们出行更加的安全,更加的美好。
这样一款处理器是什么样的性能?当然现在网络结构还是Transformer,我们跟市面上的竞品O、Q1、Q2这几款处理器去比较的话,我们分别是两位数性能提升,17倍-40倍性能提升。所以大家可以想象在这样高算力下面我们会继续驾驶软件不断推进。但是大家不要担心Transformer性能提高17倍,对于客户来说付出的成本就是17倍,其实不是。我们看单位成本变了,但是计算性能你会发现同样是大幅度提升,比如说大幅度的提升了12倍,如果效率提升12倍,性能提升14倍,大家可以知道其实成本并没有提高多少。所以以更少成本获得更高的性能,这个是我们为智能驾驶算力提供的最优解。
除了硬件,算法决定了我们有多大的能力,去逼近算力给我们能够体现的可能的上限。所以算法决定了体验的兑现,其实地平线在这一块其实一直都是行业里面的引领者。2023年上海车展,我们发布跟提出了快思考跟慢思考,这样的智能驾驶的算法框架。这个也就说像人类一样,我们其实脑子里面的话是两个系统在交替或者同时工作。有的时候是快思考系统一,就是靠直觉,快速的反应。比如说在开车的时候边开车边想着给团队开会要讲什么,这个时候我有点是心游云天之外,但是实际上还能开车,这个就是快思考。突然一下子碰到施工区,道路线的话,新的线跟旧的线,跟施工的桩子交替路况变得复杂了,那个时候我不能想着工作了,不能想着跟团队开会说什么,我要follow当下启动系统二——慢思考,这个不是直觉是逻辑思考,认知是慢系统。在去年发布会上对于征程6未来整个软件的架构也是这样思考的。
所以对于快思考是一段式端到端的自动驾驶模型,地平线这些年不断的去推进从UinAD拿了CVPR的best paper然后到VAD,然后到SparseDrive,然后也端到端自动驾驶快系统。另外谈到认知,谈到系统二我们也在学习人类司机是怎么学习驾驶技能。我听说现在考驾照首先要在模拟系统上面学习,然后在真实世界学习。地平线系统的慢思考是在仿真系统模型里面去通过强化学习,在虚拟世界里面不断的提升自动驾驶策略,也不断在真实世界验证。所以在这件事情上面的话,地平线三大实验室,我们也不断在推进强化学习跟自动驾驶的模型方面的基础研发工作。我们也是世界上最早采用强化学习并且发表论文的公司之一。
不断向高而行,但是不要忘了一定要踩在坚实地基之上,不断提高智能驾驶水平,但是我们一定要心存敬畏。地平线目前L2解决方案的部署今天超过100万套的辅助驾驶系统的出货,基于这样的量产积累了超过了3万场景数据集,实话实说这可能是业界最广泛的注重安全测试的场景的数据集。这意味着每次软件版本都要通过1000万公里的里程测试,这样的规模,这样严谨的流程也让地平线在过去近千万套的辅助驾驶系统的部署。到今天,我们还是在顺利的推进,但是我们其实对这个事情还是有敬畏之心的。一系列数据不一一而读了,整个一系列数据闭环系统目前有数千PB数据的累积。我们在算力的投入上是相当大的,因为我最近经常听大家说第一梯队,第一梯队我都听烂了。所以我们不讲自己是第几梯队,地平线在算力方面现在投入超过7万张计算卡,在这个事情上面我们投入是扎扎实实的。
这个是我们首次对外公布,地平线获得全球首张且唯一的道路车辆安全和人工智能的证书,ISO 8800AI功能安全认证,这个是国际权威的一个机构,他意味着一个通行全球市场的安全信任的护照,奠定了我们监管合规的及时,这个是世界上第一个关系到人工智能这样功能安全的证书。不仅仅是软件方面,包括软件持续的迭代跟升级,包括算力升级,同样整个车载智能硬件也要升级。
这个是面向Horizon SuperDrive™打造的车载域控制器,这个域控制器非常精美,整个设计也是非常的好,因为是高性能的计算,所以它也需要有水准的。这个我们称之为弹夹式的设计,这个叫Horizon Cell。也就说在整个主板上面的话有两个子板,这个子板使得核心板是可插拔的。所以基于这样母板可以实现1120TOPS算力计算性能的域控制器,也可以基于同一个母板,拔掉一个子板板就是560TOPS核心算力的域控制器。当然灵活可配置在所有模板上面可以实现两个征程6M的256TOPS入门级的城区辅助驾驶的算力。这意味着什么呢?我跟大家讲一下,就像我们的个人电脑不管插拔,可以不断进行硬件生产,我们最终还是要强调用户价值。Horizon Cell可以实现车企跟用户的共赢,因为更强悍性能,更高性能推出的时候老用户去维权,“你把我抛弃我不干了”,这个时候可以给老用户更新可插拔计算硬件的性能。假设一个车的生命周期是10年,我们车载计算机因为10倍速变化,未来10年自动驾驶不断变化,算力不断升级,你可以给他更新车载计算机,用户价值得到体现,同时车厂又获得更多收入,所以实际上是实现车企跟用户的共赢。
所以基于这样一个配置大概300T,大概500T,大概1000T这样一个计算配置。我们认为,我觉得主打的是说单颗征程6P芯片,我们认为很快会成为十万级车型的标配,我们有信心把这样产品打造成真的是老百姓每日出行,真的是想用的,并不只是说买车的配置。
最后的话我想不仅仅是软件、硬件,硬科技。我认为科技最终还是要跟人文美学有一个结合的,因为最终我们要呈现的是一个面向用户的产品。所以关于自动驾驶的HMI,人机交互的界面最近也获得了iF的设计大奖,这个也是设计界的奥斯卡,据我了解这个也是在自动驾驶的产品里面第一次获得设计大奖。
前面铺垫了这么多,我们从芯片讲到了软件算法,从软件算法讲到了域控制器,从域控制器也讲到了人机交互的界面,所有这些把它连接在一起指向什么东西呢?指向今天晚上真正要推出来最重磅级的产品,请看视频。我再解释一下HSD,Horizon SuperDrive™,地平线城区辅助驾驶系统。
所以我们要打造既有类人体验,又真正让用户信任的,但是在安全上面要远超人的、城区辅助驾驶的产品。哈佛商学院教授一本书《The Trusted Advisor》,David Moister提出“Trust Equation”“在世界越来越‘疯狂’当下,信任反而比以往任何时候得更加重要”。我想这句话也跟各位共勉。翻译到如果对于自动驾驶用户的信任度,来自于四个指标,第一个指标是安心度,怎么让他有这种防御性的驾驶策略,让他觉得车是可以相信,是可靠的。第二个的话是专业度,也就是说作为车的本身是不是高效舒适的通行。第三是亲密度,人跟车之间亲密关系。有一个扣分项,这个扣分项是夸大度,在车型宣传方面要实事求是,行胜于言,不要过分偏差,实际的偏差。
如果是对于这样的驾驶系统,如果是发生若干次恐慌接管,恐怕以后80%的用户不会使用了,导致信任的坍塌。如果按照这样来说,我们怎么构建真正的用户可用、想用、爱用的自动驾驶系统。我们来想想看从安心度角度来讲,我们应该或者已经有什么样的表现。预防性的驾驶,对行人(行驶中)能够稍微减速,但是并没有顿挫的刹车。对外卖小哥突然的横冲直撞要有足够的预判,也不能有重刹,博弈要找控灯,减速并不让行从容完成左拐。我们再来看对于风险的预判,怎么通过预判能够让安全增加那么一点点。这个时候两个车前面都在,怎么从容通过互相之间的博弈和交互连续的避让,在盲区出现的的骑摩托车。这个时候其实也是在盲区,基本是突然有白色的小车,怎么通过防御状态怎么体现预判减速,包括前面高架桥的桥墩,降速,拐弯,无风险的提升速度去通行。两侧有盲区先减速,看清楚以后再右拐。
继续看一下在安心度上面,如何精准远距离识别通用障碍物,超远距离的提前的预判。在施工路段一定要提前看施工路段,提前的预判。这种非规则的区域,优雅的绕行。我们再看一下,现在在高速上辅助驾驶的通行效率可能还是OK,对于城区的辅助驾驶现在普遍是低于人的。所以这种导致结果上班不敢用,下班你不想用。上班你开慢怕被老板骂,下班开慢减少健身时间。现在自动驾驶其实就是一个高科技玩具,所以一定要通过提升自动驾驶专业度,使得它能够高效的通勤。比如说我们可以看到对于复杂的拓扑结构,这个是上海最复杂的环岛,这个是在五角场。大家可以看到车辆怎么高效通勤,前面有车就主动的去路形状态换道,持续换道绕过前面的车,还会继续换道有空道会折回来插进来,有出跟进不断的博弈,在复杂场景下面保持了它的安全同时又有通勤的效率。我们看看在车速窄道下面怎么连续的绕行,前面有乱停的自行车,摩托车,非常狭窄的一个空间,从容的去通过。经过临时的施工区,这个里面其实是有博弈的。
再看一下在城区里面怎么通过博弈,复杂的人流,车流,这里面不断连续的通过博弈。比如说前面这个地方左拐,对巷里面的左拐,我们要找到合适空档左拐,这个是典型的汇流,但是这个车不会让这个是很典型的,我们要找到合适空档并且稍微压压线告诉后面车要变道,我们这样成功变道,这个也是在日常通勤当中经常出现的博弈的状态。另外窄路调头,我们可以看一下非常窄的,很窄的道路里面怎么样实现窄路调头。往后推空出空间迅速打弯,完成调头。再看一下这个在效率上面的,这是第三方的一个媒体他自己组织跟人类司机,同样的地段起步看自动驾驶,城区辅助驾驶跟人类司机基本是什么样的一个状态,这是驾龄两年比较年轻的司机。可以看到经过同样的路段,下面是时间。
这个是人驾的车辆,我们现在是超过它了。可以看到这是相当典型的城市复杂路况的通勤的场景。歪到一个窄路绕过锥桶,时间可能还稍微快一点,但是所谓的板子并不代表什么,给大家展示一下自动驾驶正在逼近人类司机差不多的水准。有一些统计数据来讲,现在智驾系统的话急刹还是蛮多的,每5公里的急刹,包括每1公里的加速,这种的话实际上给人的体验感是很不舒服的,而且的话也有数据表明这样的加速度跟速度让用户有一种眩晕感,其实网上大家可以看到有很多的视频。视频因为会影响大家的食欲我就不放了,这些宠物、动物、小猫小狗坐车晕车的状况,其实地平线希望自动驾驶是能够达到这样的境界。我相信有了更好的自动驾驶,辅助驾驶技术,这些毛孩子以后也不会再晕车了。
我们后面再看一个水杯实验。车外车水马龙,车内波澜不惊。这个场景是地平线的HSD跟特斯拉的FSD。可以看到水的振动,晃动所自动驾驶带来的平衡感。相信算法是能够不断的提升,使得真正驾驶能够有所超越预期的稳定感、平衡感。其实可以看到有的时候特斯拉水的晃动其实更重,有的时候地平线HSD的晃动更重,所以这里面我想跟大家分享一下,这个好像是经过上海某一个网红打卡区域。因为时间关系我把它过掉。这里面不是说地平线HSD跟FSD谁好谁坏,我们其实共同追求一个共同的目标让自动驾驶更加的平稳,视频也是像FSD的致敬。
接下来看一下人机交互,一个足够好智驾系统应该有这样一个界面,精细细腻的体现出智能驾驶看到的视频跟我所看到的世界是一样的,背后其实是强大的人工智能在提供世界模型的还原,包括强大语音和语言的模型的交互技术,提供人跟车之间的自然交互。最后第四个要素是对产品的夸大度,我在想每个人做这件事情还是要对不起每个承诺,我们的每个承诺要对得起用户的信任,所以我最终看法还是说在狂飙中我们要冷静,在悲观中我们要笃定,行胜于言,我们多做少说。
我在想这个时候的话,产品发布会基本上也到了最后一个段落,也很感谢大家的时间。下面的话我想也邀请一位神秘嘉宾,这位嘉宾的话是我们汽车行业的一位领导者,在他不到30岁的时候他就已经做到了合资企业一汽大众的管理层,在他的职业生涯的高光时刻,他又毅然来到江南小城,他在几个茅草屋开始创业,后来的话他引领中国自主品牌,在20多年前这个自主品牌深入人心代表了中国自主品牌,每个国人心目当中的形象。在中间过程当中,几经沉浮也经历了很多挑战,也经历至暗时刻,虽然每次当中发言都是云淡风轻,我过去创业10年才知道这个事有多难。这个企业在旁边有一个大江大河,走向全世界,跨越了太平洋跨越了无数千山万水,跨向全世界。他到现在还是像孩子一样对事业的热爱,同时他最打动我的是他的胸怀,因为这么大胸怀撑起这么大的事业,在中国的市场里面笑傲江湖,他带着他的企业已经重回产业之巅。
所以今天我带着非常崇敬的心情,也请大家跟着一起以最热烈的掌声邀请奇瑞控股集团董事长,尹同跃。
我把舞台交给你,因为我今天特别感动您能来到我们现场,给我们大家来分享,您对智能驾驶跟对地平线合作的洞见,大家掌声欢迎!
尹同跃:尊敬的各位嘉宾,你们好,我在这里碰到很多平常见不到的老朋友。余凯今天晚上讲的,是我听到的最专业的关于智驾新品的发布会,让我这个最不专业的人,在最专业的讲话之后讲,形成了最大的反差。
所以中午的时候,我问了奇瑞的人都在哪里?今天晚上是一个很好的学习机会。他们都在芜湖,我想,让一个最不应该来的人来了,最应该来的人没有来。我马上告诉我们家里人,今天晚上都要来,所以奇瑞可能是今天到场的人最多的一家。
地平线是我们在智能化领域最重要的合作伙伴之一。上个月奇瑞智能化之夜我们也说过,过去20年吃了“发动机”的饭,下一个20年要吃“智能化”的饭,或者说要吃余凯的饭。因为今天中国汽车已经进入智能化下半场,中国智能化技术应用全球规模最大,中国很多主机厂胆子也最大,技术迭代速度也是全球最快的,持续引领全球汽车智能化发展。华为和地平线是中国车企智能化的核心力量,推动中国汽车从世界汽车的舞台边缘正在走向中央,同时也在改变各行各业的生态。地平线和奇瑞的辅助驾驶解决方案,是想要消除每年大量的人类事故,这是我们的战略性布局。前不久,我们宣布从今年开始,奇瑞旗下全系列产品将搭载由地平线支持的辅助驾驶解决方案,覆盖燃油和新能源的各种动力车型,在全球市场同步推进。
我们智能化战略最重要的原则是安全第一,我们总是赶晚集,就是源于对安全的重视。所以我们会选择地平线这样伟大的企业作为主要的合作伙伴。早在2021年,奇瑞就得到了地平线征程2计算方案,按照余总说的,我们当时是征程2第二个上车的车企,目前为止为超过10万位车主提供了征程方案。前不久电动车百人会上,很多人都发表了讲话,余凯讲的话是反响最好的,因为是有扎实的技术,有扎实的内容和非常独特的观点。
刚才余凯介绍的地平线方案,差不多两个半小时,这个时间够长的了。还是年轻,体力非常好。征程6P芯片的性能非常强悍,余凯忽悠我说首批装征程的车都好卖,这次“首批”轮到我们了,不好卖我们找他。
所以后面很多车为了好卖都要搭载地平线的征程6P,让中国车走向全球,走向更大的市场。在今年两会后,我跟余总在北京约好要开一下他的车,体验一下很牛的HSD。我刚上车的时候,余凯说往东走,我说不行,我必须往西走。我不走他的路线,我怕他套路我。我也开过很多合作伙伴的辅助驾驶车型,这次HSD的体验下来,的确让我非常惊喜,水平非常高,非常好。在北京高架桥下交通是非常困难的,像我这样开车40多年的老司机,在那种情况下都很难处理。所以,我们相信HSD的确是行业一流的城市辅助驾驶方案。特别是“辅助驾驶”加的特别好。因为中国汽车行业的确有不好的一点,大家都在拼命说一些事情,对用户、对市场有很大的误导,我们需要像余凯这么谦虚,加上“辅助”。
这次也特别要肯定工信部及时对智能化的发展提出要求。我们和余凯团队比较像,在技术、安全、品质上面都希望能追求极致、追求技术创新,但是对于上车,我们非常的谨慎小心。所以我们希望更多企业能够向地平线一样及时的给大家更好的提醒——我们现在还处在辅助驾驶时代,我们没有达到更高的水平,我们需要有足够长时间来积累,来渡过难关。现在奇瑞在全球有1630多万客户,我们希望能够有更多的数据积累,更多的场景积累,能够创造更多让客户感受非常好的智驾体验。所以我们永远都是用安全来兜底,永远不说过头话,让全球体验在中国能够得到更好的发展,让用户更加的安心信赖,让“中国智能”成为全球信赖的代名词,让更多用户喜欢中国智能化解决方案,喜欢余凯。谢谢大家!
余凯:谢谢,稍微等两分钟,我们有一个交换礼物环节。刚才也非常感动,希望征程6P大算力芯片以及HSD整个城区辅助驾驶的系统能够助力奇瑞汽车打造有竞争力,让老百姓真正喜欢的智能汽车产品,并且还有一个小心愿,因为奇瑞整个的企业格局与布局已经走向大江大海,我希望地平线的芯片跟软件,也跟随奇瑞汽车共同走向大江大海,走向全世界。我们一定全力以赴,谢谢尹总。
余凯:(手持征程6P芯片)尹总,方寸之间毫不起眼,但是上面刻了出厂的日期,这是第一批征程6P的芯片,第一批量产奇瑞汽车,谢谢!
尹同跃:谢谢,我就带回去了。(手持奇瑞星途车模)这个车,余总说装上他的芯片就好卖。
余凯:谢谢尹总,真的感谢。
余凯:最后发布会即将结束,地平线的理念是做什么呢?所有的技术不是为了让机器更强大,是要让人更强大,让人更自由。你可以在车上面,在堵车环境里面可以有选择不开车的自由。推而广之,未来计算平台可以赋能所有机器人,可以让人免除繁重体力劳动自由。最终的价值与意义——让机器归机器,让人的归人。我相信我们持续的努力,我们希望我们的努力,值得这样的一个信赖,把智驾交给地平线,把生活还给自己。
#CoM
使用模态链提高VLM对多模态数据的理解!出发点&动机
从人类视频中学习执行操作任务是一种很有前景的机器人教学方法。然而,许多操作任务需要在任务执行过程中改变控制参数(如力),而仅靠视觉数据无法捕捉这些信息。这里利用臂带(测量人体肌肉活动)和麦克风(记录声音)等传感设备,捕捉人类操作过程中的细节,使机器人能够提取任务计划和控制参数以执行相同任务。为此,引入了模态链(CoM),这是一种提示策略,使视觉语言模型(VLM)能够对多模态人类演示数据(视频结合肌肉或音频信号)进行推理。通过逐步整合来自每个模态的信息,CoM优化任务计划并生成详细的控制参数,使机器人能够基于单个多模态人类视频提示执行操作任务。我们的实验表明,与基线方法相比,CoM在提取任务计划和控制参数的准确性上提高了三倍,并且在真实机器人实验中对新任务设置和物体具有很强的泛化能力。
视频和代码链接:chain-of-modality.github.io
背景介绍
机器人能否仅通过观看一个人类手部视频演示,就能学会执行物理挑战性操作任务(如拧开矿泉水瓶或打鼓)?实现这一能力的一种方法是从视频中识别人类任务计划,然后将其转化为可执行的机器人技能。尽管视频理解领域的最新进展在动作识别方面取得了有希望的结果,但许多操作技能需要精确指定控制参数,而这些参数仅从纯视觉信息中难以推断,例如:轻轻握住钥匙进行旋转、用力插入插头、轻敲鼓面以产生柔和的声音。这一限制制约了机器人仅通过观看人类视频执行多样化操作任务的能力。
这里的核心挑战是,仅从人类视频数据中提取任务计划非常困难,因为纯视觉数据缺乏识别这些计划所需的细节。一个关键观察是,人类任务计划中的许多细节(如力和速度等控制参数)可以通过肌肉活动和物体交互声音等附加信号更好地捕捉。例如,插入电源插头时,人类会先以较小的力握住插头调整方向,然后用力将其插入插座。在这项工作中,我们利用配备肌肉传感器的现代臂带和带麦克风的运动相机等传感设备,收集包含图像、肌肉活动和物体交互声音的多模态演示视频。这些设备提供了人类在操作过程中何时以及如何施加物理力的额外信息。然而,有效利用这些信号需要新的方法来对多模态人类演示视频进行推理。
视觉语言模型(VLM)能够解决从视觉推理到信号处理,甚至生成控制机器人的代码等广泛的实际问题。长上下文输入的最新进展进一步使VLM能够将视频和长序列数值信号作为输入。这让我们思考:VLM能否作为通用推理模型,从多模态演示视频中推断人类任务计划?大多数VLM应用仍只接受单一模态作为输入。为应对这一挑战,引入了模态链(CoM)框架,该框架提示VLM依次分析每个模态,通过整合来自每个模态的新信息逐步优化答案。
CoM使VLM能够通过分析单个多模态人类视频提取任务计划和控制参数。借助CoM,附加模态的加入帮助VLM更好地分割子任务。例如,当人类打开瓶子时,力数据中的三个峰值信号表明三次扭转动作。CoM使VLM能够利用这些信息,首先将整个任务分割为粗略的任务框架,然后通过整合其他模态逐步填充更多细节。此外,从附加模态获取的力信息使VLM能够为诸如“抓握”和“击打”等技能生成更准确的控制参数,不同级别的力。根据经验,发现CoM从人类视频中提取精确任务计划和控制参数的准确率达到60%。仅依赖纯视觉数据的方法准确率为零,而直接将所有模态一次性输入模型的简单方法平均准确率为17%。
如何将这些任务计划转化为机器人动作?先前的工作表明,基础模型可以根据语言指令生成机器人可执行的API调用。我们的场景不同之处在于,要求基础模型根据多模态演示视频生成API调用。这些API调用具有跨实体泛化的优势,因为代码API可以抽象掉机器人实体,允许在不同机器人之间顺利部署。此外,基于高级视觉模型的代码API进一步使机器人能够泛化到新物体和未见物体配置。
主要贡献如下:
- 模态链(CoM):一种提示策略,使VLM能够通过逐步整合视觉和力信息,从多模态人类视频演示数据中进行推理。
- 一次性操作程序生成:一种从单个多模态人类演示视频生成机器人控制程序的流程,整合力信息(通过肌肉或音频信号获得)以生成不同技能的细粒度控制参数。
- 通用性:展示了CoM在两种高级VLM模型上的一致优势,并且方法允许VLM从单个人类视频中学习编写机器人代码,这些代码可以在不同的真实机器人平台上运行,具有泛化能力。
相关工作
从视频中理解人类活动
理解视频中的人类活动一直是计算机视觉领域的长期研究重点。早期工作主要旨在通过分类捕捉视频的高级语义含义。为了提取更详细的信息,后来的研究开始专注于从视频中推导任务计划。然而,这些方法往往受限于对特定训练数据集的依赖,难以泛化到未见的动作类别。近年来,大型视觉语言模型的发展使得提示VLM从视频中理解人类活动取得了令人印象深刻的结果。与先前工作不同,本工作侧重于对包含力或音频信息的多模态人类视频进行推理,为下游细粒度机器人操作任务提供必要信息。
机器人与控制的基础模型
近年来,基础模型在机器人领域取得了显著进展,涵盖从高级推理到低级控制的多个层面。早期工作主要集中在语言条件下的机器人推理和规划,其中任务使用自然语言定义。然而,一些操作任务(尤其是涉及空间歧义或需要细粒度控制的任务)仅用语言难以精确描述。视觉语言模型(VLM)的最新进展引入了更具表现力的任务规范,如视觉注释。我们的工作则使用一次性多模态视频作为任务规范,使机器人能够从人类演示中提取任务计划和控制参数。为了将基础模型应用于机器人控制,已经出现了几种有前景的方法,包括基于目标条件策略的子目标选择、轨迹优化的奖励或约束生成,以及基于感知和控制原语的代码生成。与这些基于语言输入的方法不同,这里展示了VLM如何直接从一次性人类视频输入中进行推理,生成低级操作程序,为提示机器人执行具有丰富视觉提示的新任务提供了一种替代方法。
从人类视频中学习操作
最近大量研究探索了利用人类视频数据来教机器人操作技能。这些工作侧重于从人类视频中提取不同信息,如物体功能、运动轨迹、任务动态和奖励表示。像一些工作训练了基于人类或机器人视频(而非语言指令)的操作策略。尽管它们有效,但由于这些方法仅从视频(图像序列)中学习,无法推断许多操作任务所需的重要细节,例如施加多大的力。在这项工作中,我们专注于开发能够利用多种传感模态(包括图像、力和声音)的方法,以更好地理解人类演示中不易察觉的微妙细节,并使机器人能够更好地执行此类任务。
从多模态人类视频中学习
这里介绍提出的系统设计,该系统以单个多模态人类演示视频为输入,并生成机器人可执行代码以执行视频中演示的操作任务。系统有三个主要组件:(1)收集多模态人类视频;(2)用于理解多模态人类视频的模态链;(3)生成代码和控制机器人。对于每个组件,首先讨论动机,然后给出示例。
多模态人类演示视频
视频通常难以捕捉人类执行操作任务的细粒度细节,尤其是涉及力施加的细节。例如,插入电源插头时,首先施加轻力调整其方向,然后增加力进行插入。这些不同的力级别至关重要,但仅从视频中难以观察到,这凸显了需要超越视觉信息的多模态数据。
为解决这些挑战,我们考虑多模态人类视频在每个时间步包括RGB图像、人体肌肉信号或物体交互声音以及手部姿势。它们共同提供了人类任务计划的更全面视图。由带肌肉传感器(EMG)的臂带捕捉的人体肌肉信号或由麦克风捕捉的物体交互声音可以提供必要的力信息,指示人类在整个任务中施加力的时间和大小。此外,为了提供人类手部动作的更详细信息,我们使用基于视觉的方法来估计手部姿势,并将指尖的像素位置作为另一个输入模态。
模态链
接下来,使用视觉语言模型(VLM)来分析此类多模态人类视频中提供的丰富信息,以提取任务计划描述。VLM需要处理来自所有这些模态的信号:以正确的时间顺序识别人类动作,并确定每个动作的控制参数(如目标物体名称、运动方向)。使用VLM实现此目的的一种方法是将所有模态按顺序交织在一起直接查询模型。然而,我们发现最先进的VLM(如Gemini 1.5 Pro、GPT-4o)往往难以关联模态之间的信息,导致忽略某些输入或尝试从错误模态提取信息等问题。为了提高VLM在理解多模态人类视频方面的性能,提出了模态链(CoM),这是一种提示策略,查询VLM按顺序分析每个模态,提取关键信息并逐步聚合结果以产生最终答案。
模态链提示:CoM提示由三部分组成:(1)每个模态及其输入数据格式的描述;(2)可用动作集的描述以及动作参数的解释;(3)一个视频到分析对的示例,介绍如何分析每个模态以生成带参数的已识别动作序列。
模态链示例:图2展示了使用CoM分析多模态人类视频的示例。在此视频中,一个人用左手握住瓶子,用右手拧开瓶盖。CoM依次分析每个输入模态,并基于先前分析优化答案。在图2中,我们用不同颜色突出显示每个模态贡献的新信息。在第一阶段,VLM分析力或听觉信号,找出人何时施加和释放力,然后推断出人施加力的次数。然而,没有手部和图像信息,不清楚人具体在做什么。在第二阶段,VLM结合手部姿势信息,现在识别出人在施加力时正在抓握和扭转,手指位置还表明在握住瓶子时逆时针扭转约180度,释放时顺时针旋转手指。仍然,没有图像数据,任务中出现的物体仍然未知。在第三阶段,VLM整合图像数据,识别出左手握住瓶子,右手拧开瓶盖。有了这些信息,VLM生成动作函数,指定每个时间步的详细动作参数。请注意,示例提示中没有出现任何任务或物体,示例提示仅用于演示分析的输出格式和可用技能库。
编写机器人代码
基于上述人类视频分析,最后一步是将动作序列转换为具有低级API调用的机器人可执行代码。使用相同的VLM执行此代码生成,以创建完成任务的操作程序。代码生成提示包括视频分析以及机器人API的描述和所需的输出格式。
生成高级任务计划示例:以下是上述开瓶任务生成的程序示例:
Move_to('left', Find('bottle'))
Grasp('left')
Move_to('right', Find('bottle_cap'))
for _ in range(3):
Grasp('right')
Twist('right', 'counterclockwise', 180)
Release('right')
Twist('right', 'clockwise', 180)VLM结合来自CoM的视频分析,生成了详细的开瓶任务计划,包括使用右夹具在握住瓶盖时逆时针扭转,以及在不握住瓶盖时顺时针扭转,还生成了一个for循环脚本来指定周期性扭转动作。
生成控制参数示例:除了生成任务计划外,在诸如将插头插入电源插座等接触丰富的任务中,VLM还可以生成控制参数以指定力的使用:
from skills import Grasp, Push_towards, Insert
Grasp('right', 'plug', 100) # 力范围从[0, 100]
Move_to('right', 'box', 20) # 在手内旋转插头
Insert('right', 'power_strip', 100)利用来自多模态人类视频的力信息,VLM指定了不同任务阶段施加的力大小,允许使用Move_to通过向墙壁推压(力=20)来重新调整手中插头的方向,并在将插头插入电源插座时用力握住(力=100)。
实现细节
数据收集:肌肉信号(EMG)包含八个通道的数据,采样率为200Hz。由于相机以60Hz记录,我们对肌肉信号进行下采样以匹配相机采样率,并使用八个通道的最大值作为每个时间步的力信号。与音频信号类似,我们计算每个时间步的声音响度作为输入音频值。对于手部姿势估计,我们使用HaMeR来定位指尖的像素位置。信号处理步骤的更多细节可在附录中找到。
机器人执行:机器人API调用由预定义的控制函数组成,这些函数将生成的程序“接地”到真实机器人系统中。这些API从感知模型的最新进展中受益匪浅。例如,在实验中所有物体定位都是通过向Gemini 1.5 Pro查询RGB-D图像和目标物体名称(如生成的程序中所指定)来执行的,这直接在RGB图像上生成目标物体周围的2D边界框。然后,我们使用深度信息和相机参数创建检测到的边界框内实体的3D点云,并使用平均3D位置表示物体的位置。这些开放词汇API简化了生成的程序与机器人感知系统之间的连接,直接增强了基于代码的机器人策略的能力。
实验分析
实验旨在回答以下问题:
Q1:模态链是否能提高VLM对多模态人类视频的理解?
Q2:力信息是否有助于VLM推理人类任务计划?
Q3:手部姿势是否有助于细粒度操作?
Q4:带有CoM的VLM能否从多模态人类视频中提取控制参数?
Q5:生成的程序在真实机器人上的表现如何?
实验设置
基线方法:
将基线分为两类:
- 输入模态差异组:包括仅图像(纯视觉)、无力数据(排除肌肉/音频信号)、无手部姿态(仅力+图像)、无图像(力+手部姿态)、全模态(力+手部姿态+图像)。
- 推理流程差异组:包括直接合并所有模态输入(Merg)、分模态处理后合并(Sep-Merg)、分模态独立处理(Sep-Sep),以及我们的模态链方法(CoM,逐步整合模态信息)。
任务设计:
- 多模态视频分析任务:测试按压立方体、插入插头、打鼓、开瓶4类任务,每个任务包含10个不同物体/视角的测试视频,评估VLM提取任务计划的准确率与相似度分数(基于输出与真实标签的最长公共子串)。
- 真实机器人执行任务:在开瓶、插入插头、擦板、打鼓4项任务上测试生成代码的执行效果,包含泛化场景(如未见瓶子类型、随机物体摆放)和跨机器人平台(ViperX与KUKA双臂机器人)部署。
数据与提示:
- 多模态数据包含同步的RGB视频、肌肉电信号(EMG)或音频音量、手部指尖2D坐标。
- 提示模板包含输入格式说明(如“力信号为归一化浮点数”)、动作库示例(如Grasp(hand, object, force)),并使用与测试任务无关的示例视频(如按压苹果)引导VLM输出结构化分析结果。
实验结果
模态链提升多模态理解能力
如图5所示,在Gemini 1.5 Pro和GPT-4o模型上,模态链(CoM)显著优于其他基线方法:
- 与直接合并模态的Merg方法(平均准确率17%)相比,CoM准确率提升至60%,相似度分数提高42%。
- 分阶段处理模态的Sep-Sep方法虽优于合并输入,但CoM通过逐步利用前序模态分析结果(如先用EMG信号定位力施加时机,再结合手部姿态推断动作类型),进一步提升17%-19%准确率,证明顺序推理对模态关联的重要性。
力信息是任务计划提取的关键
从表1可见:
- 仅图像输入(Image-only)在所有任务中准确率为0,表明纯视觉无法推断力相关参数(如拧瓶盖的力度变化)。
- 包含力信号的全模态方法(All)相比无力基线(w.o. force),相似度分数平均提升42%,尤其在开瓶任务中,力信号的三个峰值直接对应三次扭转动作的分段,验证了力数据对任务阶段划分的决定性作用。
手部姿态助力细粒度动作解析
在开瓶任务中,仅全模态方法(All)实现非零成功率。手部姿态提供的指尖旋转方向(如逆时针180度)和抓握释放时序,帮助VLM区分“握瓶身”与“拧瓶盖”的不同动作阶段。这表明,视觉模型估计的手部关键点对解析复杂操作至关重要,弥补了VLM直接从视频中提取精细手部运动的不足。
控制参数提取与机器人执行效果
如图4的定性结果所示,CoM能够:
- 识别单/双臂任务的目标物体(如左手握瓶、右手拧盖);
- 提取力强度(如插入插头时force=100)、运动方向(逆时针)、时间戳(t=22-35s扭转)等细粒度参数。
在真实机器人测试中(表2),CoM生成的代码平均成功率达73%,显著优于仅依赖视觉的基线(0%)。例如:
- 开瓶任务:在7种瓶子(6种未见)上成功执行,跨ViperX与KUKA机器人平台的成功率分别为60%和75%;
- 插入插头任务:面对随机摆放的插头与插座,通过Gemini 1.5 Pro的视觉定位API(生成2D边界框→转换3D坐标)实现15/20次成功插入;
- 打鼓任务:准确复现不同力度的鼓点节奏(如轻击force=20、重击force=100),成功率80%。
与“Oracle”基线(手动编写代码,成功率92%)相比,CoM的差距主要来自视觉定位误差(如目标物体遮挡)和开环控制限制(无法应对突发干扰)。
参考
[1] Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models
#LiDPM
重新思考点云补全的Point Diffusion~
LiDPM提出了一种基于全局扩散模型的激光雷达场景补全方法,突破了现有局部扩散模型的局限性,统一了点云扩散模型在物体级和场景级应用的框架。其核心贡献如下:
- 理论创新
- 挑战局部扩散的假设:现有方法(如LiDiff)认为,标准DDPM无法直接处理大规模激光雷达场景,需通过局部扩散(仅对点偏移量进行扩散)来简化问题。但LiDPM证明,这一假设并不成立,标准DDPM可直接应用于场景级点云生成,无需引入局部扩散的近似。
- 消除冗余近似:LiDiff等方法需依赖稀疏点云的噪声估计(如用稀疏点云的复制近似稠密场景),导致生成能力受限。LiDPM通过全局扩散直接建模点云分布,避免了此类近似。
- 方法统一性
- 将物体级扩散模型(如PVD)与场景级模型统一,证明标准DDPM框架只需适当调整初始条件(如从中间噪声步骤开始扩散),即可扩展到大规模场景,无需定制化设计。
- 性能提升
- 在SemanticKITTI数据集上,LiDPM在场景补全任务中显著优于LiDiff等方法,尤其在细节生成(如远处结构)和稳定性(无需额外正则化)方面表现突出。
- 支持无条件生成:LiDPM可脱离条件输入(如稀疏点云),直接生成全新场景,拓展了扩散模型的应用范围。
论文链接:https://arxiv.org/abs/2504.17791
2. 方法详解
2.1 标准DDPM框架
LiDPM基于去噪扩散概率模型(DDPM),其核心过程包括:
- 前向扩散:逐步向稠密点云 添加高斯噪声,生成噪声点云。
- 反向去噪:通过神经网络预测噪声 ( \epsilon_\theta ),逐步从噪声中恢复稠密点云。
2.2 关键改进
- 全局扩散与初始点选择
- 问题:直接从纯噪声开始扩散会导致细节丢失(如远处结构模糊)。
- 解决方案:从中间时间步 (如300步)开始扩散,初始点云由稀疏点云的复制倍叠加噪声生成,平衡了结构保真度与生成能力。
- 条件扩散与分类器自由指导
- 通过分类器自由指导(Classifier-Free Guidance)融合稀疏点云条件,增强生成点云与输入的一致性:
- 超参数 控制条件强度,实验表明其显著提升补全精度。
- 网络架构与稳定性优化
- 采用LiDiff的MinkUNet骨干网络,但将批归一化(BatchNorm)替换为实例归一化(InstanceNorm),避免条件输入或全零)导致的统计偏移问题。
- 无需额外正则化(如LiDiff的噪声均值/方差约束),简化了训练流程。
2.3 生成与补全流程
- 训练阶段:
- 输入:稠密点云真值)和稀疏点云。
- 目标:最小化预测噪声与真实噪声 的差异(MSE损失)。
- 推理阶段:
- 初始化:从 开始,生成初始噪声点云。
- 反向扩散:通过DPM-Solver快速采样(20步),逐步去噪生成稠密点云。
3. 实验结果
3.1 数据集与指标
- 数据集:SemanticKITTI,包含大规模户外激光雷达场景,训练集为序列00-10,验证集为序列08。
- 评价指标:
- **Chamfer Distance (CD)**:衡量生成点云与真值的几何差异。
- **Jensen-Shannon Divergence (JSD)**:评估点云分布的相似性(3D和BEV视角)。
- Voxel IoU:不同体素分辨率(0.5m、0.2m、0.1m)下的交并比。
3.2 主要结果
- 与现有方法对比
- 扩散模型对比:
- 完整方法对比:
LiDPM在IoU 0.2m(44.4 vs. 40.7)、IoU 0.1m(27.6 vs. 24.8)等指标上优于LiDiff,且生成点云的结构更清晰(图4)。
- 消融实验
- **初始时间步 ( t_0 )**:( t_0=300 ) 为最佳选择,平衡了结构保真度与生成能力(CD=0.437,IoU 0.2m=42.3)。
- 采样步数:DPM-Solver仅需20步即可达到与50步相近的性能(CD=0.428 vs. 0.437),加速生成过程。
- 定性结果
- LiDPM生成的点云在远处区域(如道路边缘、建筑物)细节更丰富,且无LiDiff的虚假结构(图4)。
- 无条件生成:通过调整初始形状(如直线、转弯),LiDPM可生成多样化的合成场景(图5)。
3.3 稳定性分析
- 归一化策略:实例归一化有效避免了批归一化导致的远距离点云生成异常(图3)。
- 噪声预测:LiDPM的噪声预测均值接近0,标准差稍低(0.6 vs. 1),但无需正则化即可收敛。
4. 结论与展望
LiDPM通过重新思考点扩散模型的设计,证明了标准DDPM框架在场景级激光雷达补全任务中的有效性。其核心优势包括:
- 简化流程:无需局部扩散的复杂近似,降低模型设计复杂度。
- 性能提升:在SemanticKITTI上取得SOTA结果,尤其在细节生成和稳定性方面。
- 扩展性:支持无条件生成,为数据增强和仿真场景构建提供新工具。
未来方向:
- 探索更高效的采样策略(如更少步数)。
- 结合语义信息,实现语义-几何联合补全。
- 扩展至动态场景(如移动物体补全)。
#仅10个月,首个纯端侧大模型上车量产!?
端侧大模型圈子的《速度与激情》,就这么水灵灵地上演了。
坐标上海车展,在长安马自达新车发布之际,车上的智能座舱竟然成了大亮点之一。
因为速度着实有点太快——从零到量产,只花了10个月的时间!
要知道,这件事儿在汽车领域里面,一般都是要按“年”这个单位来计算。
此举可谓是一鸣惊人,一举刷新行业纪录,一步迈进了“月”的计量单位。
而且啊,搞出这件事的,还是车圈的一位“新手”——面壁智能。
没错,就是那个在大模型圈里用“以小搏大”姿势出圈的端侧大模型玩家。
他家当家模型产品“面壁小钢炮”,一直引领全球端侧 AI 性能与算法创新之先,是响当当的端侧模型扛把子!
面壁在端侧以不足1B到8B的模型尺寸,实现了惊人的端侧GPT-4V、GPT-4o效果,前不久发布了全球首个全模态端侧模型。
超绝口碑,来自高效低成本、以小搏大,在今年年后也常被人称为“端侧 DeepSeek ”。
它所发布的智能座舱产品,叫小钢炮超级助手cpmGO,是行业首个由纯端侧大模型驱动的智能助手。
以下视频来源于
整体来看,cpmGO具备以下几个特点:
- 快准稳91%超高执行准确率,交互如行云流水
- 纯本地数据100%不离车,响应快至毫秒级
- 全场景无惧弱网断网,隧道山区照样稳如磐石
它具备覆盖舱外至舱内的全链条感知、决策与执行能力,不仅包括去年12月即端侧部署的首个纯端侧、Always On 的 GUI Agent 屏幕助手, 还带来与云端全面对齐的智能座舱原生端侧体验,下一代还将带来全模态纯端侧座舱产品。
并且在它的背后,还有十余家主流芯片厂商的适配优化,包括高通、MediaTek、Intel、英伟达、芯驰科技、芯擎科技等国内外主流平台。
放眼整个上海车展,虽不见面壁智能的专属展区,但却处处都有它的身影。
因为面壁智能已经与长安马自达、上海大众、长城、中科创达、梧桐科技、德赛西威、安波福、车联等整车厂和Tier1厂商展开合作。
不得不说,这可真的是一场大模型在车圈里上演的《速度与激情》。
端侧大模型的《速度与激情》,是如何做到的?
在科普cpmGO的技术之前,我们先来看下更多的产品图景。
例如有了cpmGO的加持,你在开车的时候也可以直接用说话的方式来进行屏幕操控,打开行车记录仪拍照片:

当行车前方有障碍物时,车辆可以自动识别障碍,并且执行减速的操作:

会主动识别你的疲惫,并提前贴心为“球迷”车主准备好在车上小憩的间隙可以观看的世界杯视频:

如果你只是说一句:
我想看星星。
那么陪你环岛巡游的cpmGO就会根据这个需求主动拆解意图、并进行详细路线与营地规划——自动帮你寻找远离市区与灯光、有水电和WiFi的露营地:

若是车内有小孩,那么cpmGO便会识别萌娃,为你细心照看小朋友的安全情况,还会根据小朋友讲的话,给他讲故事和机智互动:
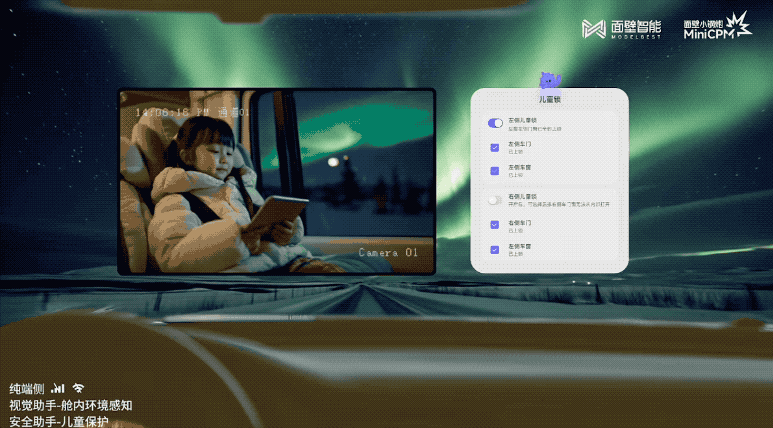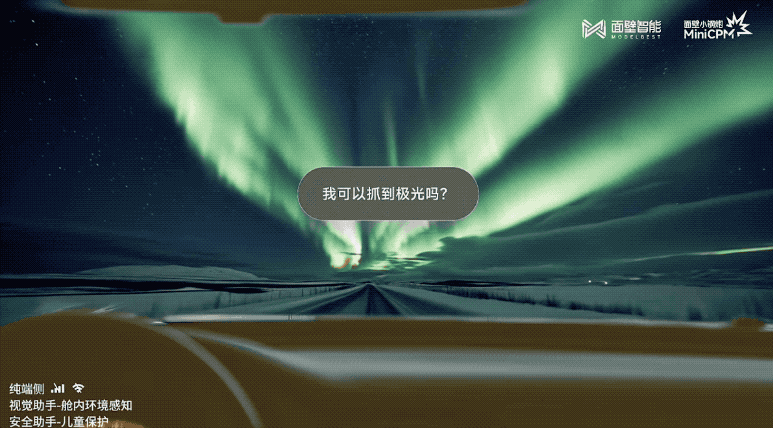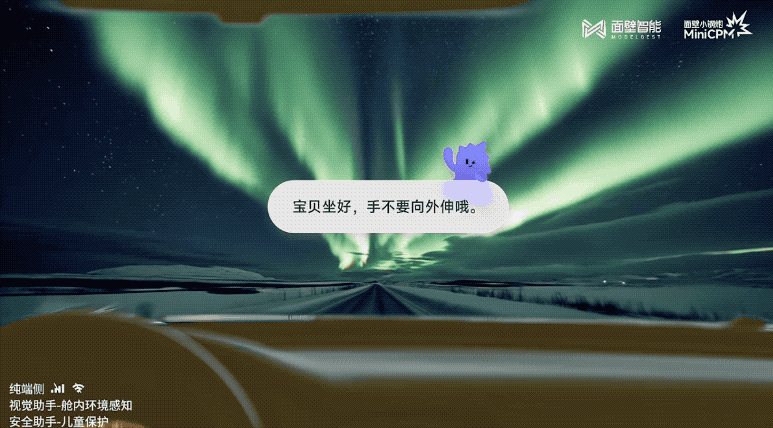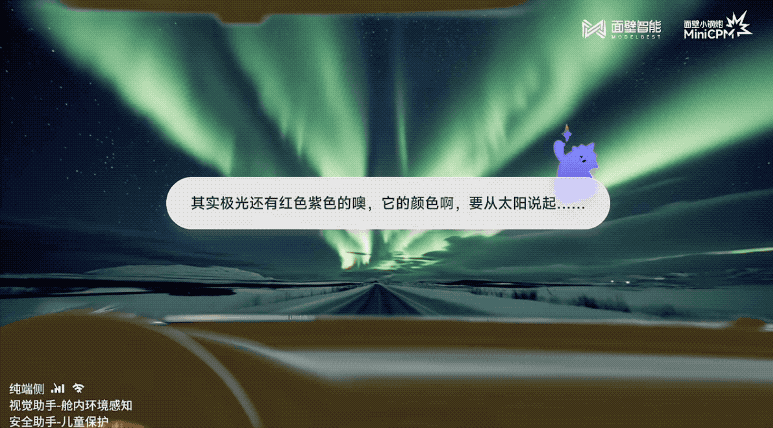
值得注意的是,上述所有的案例,未来都可以在断网状态下进行哦~
在看完效果之后,接下来我们就来看看cpmGO是如何炼成的。
首先是纯端侧方面。
cpmGO由面壁自研的MiniCPM端侧大模型驱动,完全在车机等终端设备本地运行,无需依赖云端算力。
这种设计避免了数据上传,保障了隐私安全(如车内语音、图像等敏感数据不离车)。
MiniCPM通过知识密度的极致提升将大模型压缩至适合端侧部署的尺寸,同时保持与云端大模型对齐的能力(如多模态理解、复杂意图判断等),达到性能与功耗的平衡,在车机芯片上实现了毫秒级响应。
在隧道、山区等网络不稳定场景下,纯端侧模型仍能稳定提供全功能服务,解决了云端方案的网络依赖问题。
其次是多模态感知和交互方面。
cpmGO整合了视觉(舱内摄像头)、语音(麦克风)、图形UI(中控屏)等多模态数据,实现“可见即可说”的交互。例如,用户通过语音直接操作屏幕内容,无需触控,动作执行准确率超91%,极大提升了人车交互体验。
从舱外环境感知(如障碍物识别)到舱内意图理解(如“调低空调温度”),再到执行(自动控制车机系统),形成端到端的闭环智能服务。
此外,屏幕智能体GUI Agent也是一大亮点。
cpmGO内置行业首个纯端侧GUI Agent,可理解屏幕元素并执行操作(如点击、滑动)。
不同于传统“问答式”AI,cpmGO被设计为主动服务的Agent,能根据上下文持续执行长期任务(如行程规划、舱内环境调节)。
例如,用户说“打开导航去公司”,Agent会自动完成应用启动、地址输入等步骤。
官方数据显示,其意图完成率达89%,动作执行准确率91%,参数识别准确率97%,已经接近人类操作水平。
坚定模型即应用,又小又能打的小钢炮模型,便是cpmGO背后一切技术秘籍的能量来源。
端侧大模型上车,见证真正的“汽车觉醒时刻”
速度不仅来自自身,更来自生态深度协同与伙伴的助力!极速落地,精准布局供应链生态圈,才能不仅跑得快,还跑得稳、跑得远。
车展还有两件好消息:
- 面壁智能与英特尔达成战略合作伙伴关系,共同研发端侧原生智能座舱,定义下一代车载AI;
- 与中科创达达成战略合作,打造下一代智能座舱新体验。
当前,大模型技术正式跨越云端藩篱,在端侧完成觉醒、进化。
面壁与英特尔已联合发布首个“车载大模型GUI智能体”,并与中科创达在AI 原生整车操作系统“滴水OS平台”优势互补、深度合作,将端侧AI大模型引入汽车座舱,让用户不再受限于网络环境,随时随地享受便捷、智能的座舱体验。
端侧模型天然具有离用户更近反应更灵敏、数据隐私安全性更强、突破网络条件限制稳定性更好等优点,更懂用户喜好、安全值得信赖,天然具有更强的与用户「换位思考」能力,更适合成为端云协同中的「第一大脑」,对任务即时反应、进行分发。
从面壁智能&清华团队提出的「密度定律」发现:
大模型知识密度每3.3个月翻一番,同样的模型性能,每过100天参数减半。车机芯片,正向Transformer架构的大模型快速靠拢,芯片微架构向大模型通用算法深度优化,芯片制程和性能稳步推进,车端推理速度越来越快。
我们可以发现:车端模型与芯片在协同、持续创新与深度演进。
发力「纯端侧智能座舱」,是布局未来、汽车智能进化的必由之路。更进一步说,只有把「大脑」部署在终端,才能最终在物理世界实现AGI。
现在,让我们用三个技术坐标重新定义未来:
- 第一,端云协同的黄金分割点已经到来。在座舱域控制器内,我们已经能承载相当于GPT-4o水平的全模态大模型,下一代将推出全模态纯端侧座舱产品。
- 第二,隐私安全的范式革命正在发生。端侧大模型正向个人大模型深度发展,隐私安全的豪华才铸就了汽车座舱最大的豪华。
- 第三,汽车机器人的觉醒进程已经启动。端侧大模型不再是功能模块,而是汽车的“数字脑干”。
当端侧大模型与智驾系统完成神经突触连接,我们将见证真正的“汽车觉醒时刻”。
在车企纷纷宣告大力布局AI的当下,以面壁智能为代表的端侧大模型公司正加速度与生态重要玩家共筑端侧智能生态,让人工智能不再是汽车的外接设备,而是像“汽车机器人”一样与生俱来的智能核心!
有路就有大模型
再看几组数据:
当前智能汽车产业正陷入“算力内卷”的困境。成本方面,单颗旗舰座舱芯片成本达300-500美元,叠加云端服务年费,使整车智能化成本增加5%-8%,汽车产业愈发不堪重负。
体验方面,网络波动导致语音助手响应延迟、导航卡顿,用户调研显示87%的车主遭遇过“智能功能突然失效”的尴尬场景。云端智能在车载场景,天然面临在弱网断网环境下突然“失魂落魄”的风险。
当“算力军备竞赛”走到尽头,效能比将成为新的竞争维度、汽车智能化的“第二曲线”。
cpmGO的提出,就以我们上述“纯端侧,超性能,全场景”的特性,非常有效地解决了上述痛点。
cpmGO的启示不仅在于技术本身,更在于它指向了一个更本质的趋势:真正的智能应该像空气一样无处不在,却从不喧宾夺主。
当算力霸权被瓦解、数据藩篱被破除,我们或许才能触及人工智能的终极命题——让技术谦卑地服务于人,而非让人适应技术。
从ENIAC占满整个房间到iPhone装进口袋,信息革命的本质是权力的下沉;而cpmGO代表的端侧智能,正以同样不可逆的姿态,将AI的掌控权交还给每一个普通人。
除此之外,道路与AI技术,一个物理世界,一个数字世界,二者之间的边界也在变得越发模糊,或许在不久的将来,真的就是没网也能用AI,有路就有大模型了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









