







我自己的原文哦~ https://blog.51cto.com/whaosoft/12750420
#傅里叶特征 (Fourier Feature)与核回归
位置编码背后的理论解释
本文探讨了位置编码背后的理论基础,特别是傅里叶特征(Fourier Feature)与核回归(Kernel Regression)的联系,并解释了如何通过这些理论来增强神经网络对高频信息的学习能力。
最近我在看位置编码最新技术时,看到了一个叫做 "NTK-aware" 的词。我想:「"NTK"是什么?Next ToKen (下一个词元)吗?为什么要用这么时髦的缩写?」看着看着,我才发现不对劲。原来,NTK 是神经网络理论里的一个概念,它从 kernel regression 的角度解释了神经网络的学习方法。基于 NTK 理论,有人解释了位置编码的理论原理并将其归纳为一种特殊的 Fourier Feature (傅里叶特征)。这么多专有名词一下就把我绕晕了,我花了几天才把它们之间的关系搞懂。
在这篇文章里,我主要基于论文_Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains_ (后文简称为「傅里叶特征论文」),介绍傅里叶特征这一概念。为了讲清这些理论的发展脉络,我会稍微讲一下 NTK 等理论概念。介绍完傅里叶特征后,我还会讲解它在其他方法中的应用。希望读完本文后,读者能够以这篇论文为基点,建立一个有关位置编码原理的知识网络,以从更深的层次来思考新的科研方向。
用 MLP 表示连续数据
我们先从一个具体的任务入手,直观体会傅里叶特征能够做些什么事。
我们知道,神经网络,哪怕是最简单的多层感知机(MLP),都有着很强的泛化能力:训练完毕后,对于训练集里完全没见过的输入,网络也能给出很正确的输出。特别地,如果新输入恰好和训练集的某个输入很近,那么它的输出也会和对应的训练集输出很近;随着新输出与训练集输入的距离不断增加,新输出也会逐渐变得不同。这反映了神经网络的连续性:如果输入的变化是连续的,那么输出的变化也是连续的。
基于神经网络的这一特性,有人想到:我们能不能用神经网络来表示连续数据呢?比如我想表达一张处处连续的图像,于是我令神经网络的输入是(x, y) 表示的二维坐标,输出是 RGB 颜色。之后,我在单张图像上过拟合这个 MLP。这样,学会表示这张图像后,哪怕输入坐标是分数而不是整数,神经网络也能给出一个颜色输出。
这种连续数据有什么好处呢?我们知道,计算机都是以离散的形式来存储数据的。比如,我们会把图像拆成一个个像素,每个像素存在一块内存里。对于图像这种二维数据,计算机的存储空间还勉强够用。而如果想用密集的离散数据表达更复杂的数据,比如 3D 物体,计算机的容量就捉襟见肘了。但如果用一个 MLP 来表达 3D 物体的话,我们只需要存储 MLP 的参数,就能获取 3D 物体在任何位置的信息了。
这就是经典工作神经辐射场 (Neural Radiance Field, NeRF) 的设计初衷。NeRF 用一个 MLP 拟合 3D 物体的属性,其输入输出如下图所示。我们可以用 MLP 学习每个 3D 坐标的每个 2D 视角处的属性(这篇文章用的属性是颜色和密度)。根据这些信息,利用某些渲染算法,我们就能重建完整的 3D 物体。

上述过程看起来好像很简单直接。但在 NeRF 中,有一个重要的实现细节:必须给输入加上位置编码,MLP 才能很好地过拟合连续数据。这是为什么呢?让我们先用实验复现一下这个现象。
MLP 拟合连续图像实验
为了快速复现和位置编码相关的问题,我们简单地用一个 MLP 来表示图像:MLP 的输入是 2D 坐标,输出是此处的三通道 RGB 颜色。我为这篇博文创建一个 GitHub 文件夹 https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/FourierFeature ,该实验的 Notebook 代码在文件夹的image_mlp.ipynb 中,欢迎大家 clone 项目并动手尝试。

一开始,我们先导入库并可视化要拟合的图片。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.io import read_image, ImageReadMode
from torchvision.transforms.functional import to_pil_image
from tqdm import tqdm
from einops import rearrange
def viz_image(pt_img: torch.Tensor):
pil_img = to_pil_image(pt_img)
display(pil_img)
input_image = read_image('misuzu.png', ImageReadMode.RGB)
input_image = input_image.to(torch.float32) / 255
input_image = input_image.unsqueeze(0)
input_image = F.interpolate(input_image, (256, 256), mode='bilinear')
viz_image(input_image[0])
我们再定义一个 MLP 类。稍后我们会并行地传入二维坐标。具体来说,我们会将输入定义为一个[1, 2, H, W] 形状的数据,其中通道数 2 表示(i, j) 格式的坐标。由于输入是以图像的形式并行输入的,我们可以用 的 2D 卷积来表示二维数据上的并行 MLP。所以在下面这个 MLP 里,我们只用到 卷积、激活函数、归一化三种层。按照傅里叶特征论文的官方示例,网络最后要用一个 Sigmoid 激活函数调整输出的范围。
class MLP(nn.Module):
def __init__(self, in_c, out_c=3, hiden_states=256):
super().__init__()
self.mlp = nn.Sequential(
nn.Conv2d(in_c, hiden_states, 1), nn.ReLU(), nn.BatchNorm2d(hiden_states),
nn.Conv2d(hiden_states, hiden_states, 1), nn.ReLU(), nn.BatchNorm2d(hiden_states),
nn.Conv2d(hiden_states, hiden_states, 1), nn.ReLU(), nn.BatchNorm2d(hiden_states),
nn.Conv2d(hiden_states, out_c, 1), nn.Sigmoid()
)
def forward(self, x):
return self.mlp(x)之后我们来定义训练数据。在一般的任务中,输入输出都是从训练集获取的。而在这个任务中,输入是二维坐标,输出是图像的颜色值。输出图像input_image 我们刚刚已经读取完毕了,现在只需要构建输入坐标即可。我们可以用下面的代码构建一个[1, 2, H, W] 形状的二维网格,grid[0, :, i, j] 处的数据是其坐标(i, j) 本身。当然,由于神经网络的输入一般要做归一化,所以我们会把原本0~H 和0~W 里的高宽坐标缩放都到0~1。最终grid[0, :, i, j]==(i/H, j/W)。
H, W = input_image.shape[2:]
h_coord = torch.linspace(0, 1, H)
w_coord = torch.linspace(0, 1, W)
grid = torch.stack(torch.meshgrid([h_coord, w_coord]), -1).permute(2, 0, 1).unsqueeze(0)准备好一切后,我们就可以开始训练了。我们初始化模型model 和优化器optimizer,和往常一样训练这个 MLP。如前所述,这个任务的输入输出非常直接,输入就是坐标网格grid,目标输出就是图片input_image。每训练一段时间,我们就把当前 MLP 拟合出的图片和误差打印出来。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MLP(2).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
n_loops = 400
input_image = input_image.to(device)
grid = grid.to(device)
for epoch in tqdm(range(n_loops)):
output = model(grid)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0 or epoch == n_loops - 1:
viz_image(output[0])
print(loss.item())运行代码,大致能得到如下输出。可以看到,从一开始,图像就非常模糊。

不过,如果我们在把坐标输入进网络前先将其转换成位置编码——一种特殊的傅里叶特征,那么 MLP 就能清晰地拟合出原图片。这里我们暂时不去关注这段代码的实现细节。
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c // 2) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.cat([torch.sin(x), torch.cos(x)], dim=1)
return x
feature_length = 256
model = MLP(feature_length).to(device)
fourier_feature = FourierFeature(2, feature_length, 10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
n_loops = 400
for epoch in tqdm(range(n_loops)):
x = fourier_feature(grid)
output = model(x)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0 or epoch == n_loops - 1:
viz_image(output[0])
print(loss.item())
prev_output = output
简单地对比一下,此前方法的主要问题是 MLP 无法拟合高频的信息(如图块边缘),只能生成模糊的图像。而使用位置编码后,MLP 从一开始就能较好地表示高频信息。可见,问题的关键在于如何让 MLP 更好地拟合数据的高频信息。

接下来,我们来从一个比较偏理论的角度看一看论文是怎么分析位置编码在拟合高频信息中的作用的。
核回归
傅里叶特征论文使用了神经正切核(Nerual Tangent Kernel, NTK)来分析 MLP 的学习规律,而 NTK 又是一种特殊的核回归 (Kernel Regression) 方法。在这一节里,我会通过代码来较为仔细地介绍核回归。下一节我会简单介绍 NTK。
和神经网络类似,核回归也是一种数学模型。给定训练集里的输入和输出,我们建立这样一个模型,用来拟合训练集表示的未知函数。相比之下,核回归的形式更加简单,我们有更多的数学工具来分析其性质。
核回归的设计思想来源于我们对于待拟合函数性质的观察:正如我们在前文的分析一样, 要用模型拟合一个函数时, 该模型在训练数据附近最好是连续变化的。离训练集输入越近, 输出就要和其对应输出越近。基于这种想法,核回归直接利用和所有数据的相似度来建立模型:假设训练数据为 , 我们定义了一个计算两个输入相似度指标 , 那么任意输入 的输出为:
也就是说,对于一个新输入 ,我们算它和所有输入 的相似度 ,并把相似度归一化。最后的输出 是现有 的相似度加权和。
这样看来,只要有了相似度指标,最终模型的形式也就决定下来了。我们把这个相似度指标称为「核」。至于为什么要把它叫做核,是因为这个相似度指标必须满足一些性质,比如非负、对称。但我们这里不用管那么多,只需要知道核是一种衡量距离的指标,决定了核就决定了核回归的形式。
我们来通过一个简单的一维函数拟合实验来进一步熟悉核回归。该实验代码在项目文件夹下的kernel_regression.ipynb 中。
先导入库。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt再创建一个简单的非线性函数,做为我们的拟合目标。这个函数就是一个简单的周期为 2 的正弦函数乘上线性函数 。我们可以简单可视化一下函数在 之间的图像。
def func(x):
return np.sin(np.pi * x) * (1 - x)
xs = np.linspace(-1, 1, 100)
ys = func(xs)
plt.plot(xs, ys)
plt.show()
基于这个函数,我们等间距地选一些点做为训练数据。
sample_x = np.linspace(-1, 1, 10)
sample_y = func(sample_x)
plt.scatter(sample_x, sample_y)
plt.show()
有了数据后,我们来用核回归根据数据拟合这个函数。在决定核回归时,最重要的是决定核的形式。这里我们用正态分布的概率密度函数来表示核,该核唯一的超参数是标准差,需要我们根据拟合结果手动调整。标准差为1 的标准正态分布核的图像如下所示。由于最后要做归一化,正态分布密度函数的系数被省略掉了。
def kernel_func(x_ref, x_input, sigma=1):
return np.exp(-(x_input-x_ref)**2 / (2 * sigma**2))
xs = np.linspace(-1, 1, 100)
ys = kernel_func(0, xs)
plt.plot(xs, ys)
plt.show()
可以从图像中看出,离某输入越近(假设该输入是0),那么相似度就越高。这符合我们对于相似度函数的要求。
有了核函数后,我们就直接得到了模型。根据核回归模型计算结果的函数为kernel_regression。函数参数xs, ys 表示训练数据,x_input 表示测试时用的输入坐标,sigma 是核回归的超参数。
假设有n 个训练样本,有m 个测试输入,那么我们要计算每个测试输入对每个训练输入的n * m 个相似度,这些相似度会存到矩阵weight 里。为此,我们需要对xs 和x_input 做一些形状变换,再用上面定义的核函数kernel_func 求出每对相似度。有了相似度后,我们根据公式计算点乘结果weight_dot 及归一化系数weight_sum,并最终计算出核回归的结果res。
基于这个函数,我们可以将测试输入定义成[-1, 1] 上一些更密集的坐标,并用上面定义好的 10 个样本做为训练集,得到核回归的结果。
def kernel_regression(xs, ys, x_input, sigma=1):
# xs: [n, ]
# ys: [n, ]
# x_input: [m, ]
N = xs.shape[0]
xs = np.expand_dims(xs, 1)
ys = np.expand_dims(ys, 1)
x_input = np.expand_dims(x_input, 0)
x_input = np.repeat(x_input, N, 0)
weight = kernel_func(xs, x_input, sigma) # [n, m]
weight_sum = np.sum(weight, 0)
weight_dot = weight.T @ ys
weight_dot = np.squeeze(weight_dot, 1)
res = weight_dot / weight_sum
return res
sigma = 1
xs = np.linspace(-1, 1, 100)
ys = kernel_regression(sample_x, sample_y, xs, sigma)
plt.title(f'sigma = {sigma}')
plt.plot(xs, ys)
plt.show()我们可以通过修改sigma 来得到不同的拟合效果。以下是我的一些结果:

可以看出,标准差越小,模型倾向于过拟合;随着标准差变大,曲线会逐渐平缓。我们需要不断调整超参数,在过拟合和欠拟合之间找到一个平衡。这种现象很容易解释:正态分布核函数的标准差越小,意味着每个训练数据的影响范围较小,那么测试样本更容易受到少数样本的影响;标准差增大之后,各个训练样本的影响开始共同起作用,我们拟合出的函数也越来越靠近正确的函数;但如果标准差过大,每个训练样本的影响都差不多,那么模型就什么都拟合不了了。
从实验结果中,我们能大致感受到核回归和低通滤波很像,都是将已知数据的平均效果施加在未知数据上。因此,在分析核回归的时候,往往会从频域分析核函数。如果核函数所代表低通滤波器的带宽 (bandwidth)越大,那么剩下的高频信息就更多,核回归也更容易拟合高频信息较多的数据。
神经正切核
那么,核回归是怎么和神经网络关联起来的呢?有研究表明,在一些特殊条件下,MLP 的最终优化结果可以用一个简单的核回归来表示。这不仅意味着我们可以神奇地提前预测梯度下降的结果,还可以根据核回归的性质来分析神经网络的部分原理。这种能表示神经网络学习结果的核被称为神经正切核(NTK)。
这些特殊条件包括 MLP 无限宽、SGD 学习率的学习率趋近 0 等。由于这些条件和实际神经网络的配置相差较远,我们难以直接用核回归预测复杂神经网络的结果。不过,我们依然可以基于这些理论来分析和神经网络相关的问题。傅里叶特征的分析就是建立在 NTK 上的。
NTK 的形式为

其中, 是参数为 的神经网络, 为内积运算。简单来看, 这个式子是说神经网络的核回归中,任意两个向量间的相似度等于网络对参数的偏导的内积的期望。基于 NTK,我们可以分析出很多神经网络的性质, 比如出乎意料地, 神经网络的结果和随机初始化的参数无关, 仅和网络结构和训练数据有关。
在学习傅里叶特征时, 我们不需要仔细研究这些这些理论, 而只需要知道一个结论: 一般上述 NTK 可以写成标量函数 , 也就是可以先算内积再求偏导。这意味用核回归表示神经网络时, 真正要关心的是输入间的内积。别看 NTK 看起来那么复杂, 傅里叶特征论文其实主要就用到了这一个性质。
为了从理论上讲清为什么 MLP 难以拟合高频,作者还提及了很多有关 NTK 的分析,包括一种叫做谱偏差(spectral bias)的现象:神经网络更容易学习到数据中的低频特征。可能作者默认读者已经熟悉了相关的理论背景,这部分论述经常会出现逻辑跳跃,很难读懂。当然,不懂这些理论不影响理解傅里叶特征。我建议不要去仔细阅读这篇文章有关谱偏差的那一部分。
正如我们在前文的核回归实验里观察到的,核回归模型能否学到高频取决于核函数的频域特征。因此,这部分分析和 NTK 的频域有关。对这部分内容感兴趣的话可以去阅读之前有关谱偏差的论文。
傅里叶特征的平移不变性
在上两节中,我们花了不少功夫去认识谱回归和 NTK。总结下来,其实我们只需要搞懂两件事:
- 神经网络最终的收敛效果可以由简单的核回归决定。而核回归重点是定义两个输入之间的相似度指标(核函数)。
- 表示神经网络的核回归相似度指标是 NTK,它其实又只取决于两个输入的内积。
根据这一性质,我们可以部分解释为什么在文章开头那个 MLP 拟合连续图像的实验中,位置编码可以提升 MLP 拟合高频信息的能力了。这和位置输入的特性有关。
当 MLP 的输入表示位置时, 我们希望模型对输入位置具有平移不变性。比如我们现在有一条三个样本组成的句子 。当我们同时改变句子的位置信息时, 比如将句子的位置改成 时, 网络能学出完全一样的东西。但显然不对输入位置做任何处理的话, 和 对神经网络来说是完全不同的意思。
而使用位置编码的话,情况就完全不同了。假如输入数据是二维坐标 ,我们可以用下面的式子建立一个维度为 的位置编码:

其中 是系数, 是一个投影矩阵, 用于把原来 2 D 的位置变成一个更长的位置编码。当然, 由于位置编码中既要有 也要有 , 所以最终的位置编码长度为 。
根据我们之前的分析,NTK 只取决于输入间的内积。算上位置编码后,一对输入位置 的内积为:

而根据三角函数和角公式可知:

这样,上面那个内积恰好可以写成:

上式完全由位置间的相对距离决定。上式决定了 NTK,NTK 又决定了神经网络的学习结果。所以,神经网络的收敛结果其实完全取决于输入间的相对距离,而不取决于它们的绝对距离。也因此,位置编码使得 MLP 对于输入位置有了平移不变性。
加入位置编码后,虽然 MLP 满足了平移不变性,但这并不代表 MLP 学习高频信息的能力就变强了。平移不变性能给我们带来什么好处呢?作者指出,当满足了平移不变性后,我们就能手动调整 NTK 的带宽了。回想一下我们上面做的核回归实验,如果我们能够调整核的带宽,就能决定函数是更加高频(尖锐)还是更加低频(平滑)。这里也是同理,如果我们能够调大 NTK 的带宽,让它保留更多高频信息,那么 MLP 也就能学到更多的高频信息。
作者在此处用信号处理的知识来分析平移不变性的好处,比如讲了新的 NTK 就像一个重建卷积核 (reconstruction filter),整个 MLP 就像是在做卷积。还是由于作者省略了很多推导细节,这部分逻辑很难读懂。我建议大家直接记住推理的结论:平移不变性使得我们能够调整 NTK 的带宽,从而调整 MLP 学习高频的能力。
那我们该怎么调整 NTK 的带宽呢?现在的新 NTK 由下面的式子决定:

为了方便分析, 我们假设 和 都是一维实数。那么, 如果我们令 的话:

这个式子能令你想到什么? 没错, 就是傅里叶变换。 较大的项就表示 NTK 的高频分量。我们可以通过修改前面的系数 来手动调整 NTK 的频域特征。我们能看到,位置编码其实就是在模拟傅里叶变换,所以作者把位置编码总结为傅里叶特征。
作者通过实验证明我们可以手动修改 NTK 的频谱。实验中, 作者令 。 表示位置编码只有第一项: 。不同 时 NTK 的空域和频域示意图如下所示。可以看出, 令 时, 即傅里叶特征所有项的系数都为 1 时, NTK 的高频分量不会衰减。这也意味着 MLP 学高频信息和低频信息的能力差不多。

随机傅里叶特征
现在我们已经知道傅里叶特征的公式是什么, 并知道如何设置其中的参数 了。现在, 还有一件事我们没有决定:该如何设置傅里叶特征的长度 呢?
既然我们说傅里叶特征就是把输入的位置做了一次傅里叶变换, 那么一般来讲, 傅里叶特征的长度应该和原图像的像素数一样。比如我们要表示一个 的图像, 那么我们就需要令 表示不同方向上的频率: 。但这样的话, 神经网络的参数就太多了。可不可以令 更小一点呢?
根据之前的研究Random features for large-scale kernel machines 表明, 我们不需要密集地采样傅里叶特征, 只需要稀疏地采样就行了。具体来说, 我们可以从某个分布随机采样 个频率 来, 这样的学习结果和密集采样差不多。当然, 根据前面的分析, 我们还是令所有系数 。在实验中, 作者发现, 从哪种分布里采样都无所谓, 关键是 的采样分布的标准差, 因为这个标准差决定了傅里叶特征的带宽, 也决定了网络拟合高频信息的能力。实验的结果如下:

我们可以不管图片里 是啥意思, 只需要知道 是三组不同的实验就行。虚线是密集采样傅里叶特征的误差,它的结果反映了一个「较好」的误差值。令人惊讶的是,不管从哪种分布里采样 , 最后学出来的网络误差都差不多。问题的关键在于采样分布的标准差。把标准差调得够好的话, 模型的误差甚至低于密集采样的误差。
也就是说,虽然我们花半天分析了位置编码和傅里叶变换的关系,但我们没必要照着傅里叶变换那样密集地采样频率,只需要随机选一些频率即可。当然,这个结论只对 MLP 拟合连续数据的任务有效,和 Transformer 里的位置编码无关。
代码实现随机傅里叶特征
现在,我们可以回到博文开头的代码,看一下随机傅里叶特征是怎么实现的。
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c // 2) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.cat([torch.sin(x), torch.cos(x)], dim=1)
return x
feature_length = 256
model = MLP(feature_length).to(device)
fourier_feature = FourierFeature(2, feature_length, 10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
n_loops = 400
for epoch in tqdm(range(n_loops)):
x = fourier_feature(grid)
output = model(x)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0 or epoch == n_loops - 1:
viz_image(output[0])
print(loss.item())
prev_output = output傅里叶特征通过类FourierFeature 实现。其代码如下:
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c // 2) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.cat([torch.sin(x), torch.cos(x)], dim=1)
return x构造函数里的fourier_basis 表示随机傅里叶特征的频率,对应论文公式里的,scale 表示采样的标准差。初始化好了随机频率后,对于输入位置x,只要按照公式将其投影到长度为out_c / 2 的向量上,再对向量的每一个分量求sin, cos 即可。按照之前的分析,我们令所有系数 为,所以不需要对输出向量乘系数。
傅里叶特征在 StyleGAN3 里的应用
傅里叶特征最经典的应用就是 NeRF 这类过拟合连续数据任务。除此之外,傅里叶特征另一次大展身手是在 StyleGAN3 中。
StyleGAN3 希望通过平滑地移动生成网络的输入来使输出图片也发生对应的移动。为此,StyleGAN3 将生成网络的输入定义为频域上的一个有限带宽图像信号:根据信号处理知识,我们能够将有限带宽信号转换成空域上无限连续的信号。也就是说,不管输入的分辨率(采样率)多低,我们都能够平滑地移动输入图片。StyleGAN3 借助随机傅里叶特征来实现这样一个频域图像。
以下代码选自 StyleGAN3 中傅里叶特征的构造函数。这个函数的关键是随机生成一些频率固定,但方向可以不同的傅里叶频率。函数先随机采样了一些频率,再将它们归一化,最后乘上指定的带宽bandwidth,保证所有频率大小相等。
class SynthesisInput(torch.nn.Module):
def __init__(self,
w_dim, # Intermediate latent (W) dimensionality.
channels, # Number of output channels.
size, # Output spatial size: int or [width, height].
sampling_rate, # Output sampling rate.
bandwidth, # Output bandwidth.
):
super().__init__()
self.w_dim = w_dim
self.channels = channels
self.size = np.broadcast_to(np.asarray(size), [2])
self.sampling_rate = sampling_rate
self.bandwidth = bandwidth
# Draw random frequencies from uniform 2D disc.
freqs = torch.randn([self.channels, 2])
radii = freqs.square().sum(dim=1, keepdim=True).sqrt()
freqs /= radii * radii.square().exp().pow(0.25)
freqs *= bandwidth
phases = torch.rand([self.channels]) - 0.5而在使用这个类获取网络输入时,和刚刚的 MLP 实现一样,我们会先生成一个二维坐标表格grid 用于查询连续图片每一处的颜色值,再将其投影到各个频率上,并计算新向量的正弦函数。
这段代码中,有两块和我们自己的实现不太一样。第一,StyleGAN3 允许对输入坐标做仿射变换(平移和旋转)。仿射变换对坐标的影响最终会转化成对三角函数相位phases 和频率freqs 的影响。第二,在计算三角函数时,StyleGAN3 只用了正弦函数,没有用余弦函数。
def forward(self, ...):
...
# Transform frequencies.
phases = ...
freqs = ...
# Construct sampling grid.
theta = torch.eye(2, 3, device=w.device)
theta[0, 0] = 0.5 * self.size[0] / self.sampling_rate
theta[1, 1] = 0.5 * self.size[1] / self.sampling_rate
grids = torch.nn.functional.affine_grid(theta.unsqueeze(0), [1, 1, self.size[1], self.size[0]], align_corners=False)
# Compute Fourier features.
x = (grids.unsqueeze(3) @ freqs.permute(0, 2, 1).unsqueeze(1).unsqueeze(2)).squeeze(3) # [batch, height, width, channel]
x = x + phases.unsqueeze(1).unsqueeze(2)
x = torch.sin(x * (np.pi * 2))
x = x * amplitudes.unsqueeze(1).unsqueeze(2)
...
# Ensure correct shape.
x = x.permute(0, 3, 1, 2) # [batch, channel, height, width]
return x我们在 MLP 拟合连续图像的实验里复现一下这两个改动。首先是二维仿射变换。给定旋转角theta 和两个方向的平移tx, ty,我们能够构造出一个 的仿射变换矩阵。把它乘上坐标[x, y, 1] 后,就能得到仿射变换的输出。我们对输入坐标grid 做仿射变换后得到grid_ext,再用grid_ext 跑一遍傅里叶特征和 MLP。
N, C, H, W = grid.shape
tx = 50 / H
ty = 0
theta = torch.tensor(torch.pi * 1 / 8)
affine_matrix = torch.tensor([
[torch.cos(theta), -torch.sin(theta), tx],
[torch.sin(theta), torch.cos(theta), ty],
[0, 0, 1]
]
).to(device)
grid_ext = torch.ones(N, 3, H, W).to(device)
grid_ext[:, :2] = grid.clone()
grid_ext = grid_ext.permute(0, 2, 3, 1)
grid_ext = (grid_ext @ affine_matrix.T)
grid_ext = grid_ext.permute(0, 3, 1, 2)[:, :2]
x = fourier_feature(grid_ext)
output = model(x)
viz_image(output[0])在示例代码中,我们可以得到旋转 45 度并向下平移 50 个像素的图片。可以看到,变换成功了。这体现了连续数据的好处:我们可以在任意位置对数据采样。当然,由于这种连续数据是通过过拟合实现的,在训练集没有覆盖的坐标处无法得到有意义的颜色值。

之后,我们来尝试在傅里叶特征中只用正弦函数。我们将投影矩阵的输出通道数从out_c / 2 变成out_c,再在forward 里只用sin 而不是同时用sin, cos。经实验,这样改了后完全不影响重建质量,甚至由于通道数更多了,重建效果更好了。
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.sin(x)
return xStyleGAN3 论文并没有讲为什么只用sin,网上也很少有人讨论傅里叶特征的实现细节。我猜傅里叶特征并不是非得和傅里叶变换完全对应,毕竟它只是用来给神经网络提供更多信息,而没有什么严格的意义。只要把输入坐标分解成不同频率后,神经网络就能很好地学习了。
只用sin 而不是同时用sin, cos 后,似乎我们之前对 NTK 平移不变的推导完全失效了。但是,根据三角函数的周期性可知,只要是把输入映射到三角函数上后,网络主要是从位置间的相对关系学东西。绝对位置对网络来说没有那么重要,不同的绝对位置只是让所有三角函数差了一个相位而已。只用sin 的神经网络似乎也对绝对位置不敏感。为了证明这一点,我把原来位于[0, 1] 间的坐标做了一个幅度为10 的平移。结果网络的误差几乎没变。
for epoch in tqdm(range(n_loops)):
x = fourier_feature(grid + 10)
output = model2(x)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()根据这些实验结果,我感觉是不是从 NTK 的角度来分析傅里叶特征完全没有必要?是不是只要从直觉上理解傅里叶特征的作用就行了?按我的理解,傅里叶特征在真正意义在于显式把网络对于不同频率的关注度建模出来,从而辅助网络学习高频细节。
总结
在这篇博文中,我们学习了傅里叶特征及其应用,并顺带了解其背后有关核回归、NTK 的有关理论知识。这些知识很杂乱,我来按逻辑顺序把它们整理一下。
为了解释为什么 NeRF 中的位置编码有效,傅里叶特征论文研究了用 MLP 拟合连续数据这一类任务中如何让 MLP 更好地学到高频信息。论文有两大主要结论:
- 通过从 NTK 理论的分析,位置编码其实是一种特殊的傅里叶特征。这种特征具有平移不变性。因此,神经网络就像是在对某个输入信号做卷积。而我们可以通过调整傅里叶特征的参数来调整卷积的带宽,也就是调整网络对于不同频率的关注程度,从而使得网络不会忽略高频信息。
- 傅里叶特征的频率不需要密集采样,只需要从任意一个分布随机稀疏采样。影响效果的关键是采样分布的标准差,它决定了傅里叶特征的带宽,也就决定了网络是否能关注到高频信息。
除了过拟合连续数据外,傅里叶特征的另一个作用是直接表示带宽有限信号,以实现在空域上的连续采样。StyleGAN3 在用傅里叶特征时,允许对输入坐标进行仿射变换,并且计算特征时只用了正弦函数而不是同时用正弦、余弦函数。这表明有关 NTK 的理论分析可能是没有必要的,主要说明问题的还是实验结果。
傅里叶特征论文仅研究了拟合连续数据这一类问题,没有讨论 Transformer 中位置编码的作用。论文中的一些结论可能无法适用。比如在大模型的位置编码中,我们还是得用密集的sin, cos 变换来表示位置编码。不过,我们可以依然借助该论文中提到的理论分析工具,来尝试分析所有位置编码的行为。
只通过文字理解可能还不太够,欢迎大家尝试我为这篇博客写的 Notebook,通过动手做实验来加深理解。https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/FourierFeature
#让模型预见分布漂移
动态系统颠覆性设计引领时域泛化新革命本研究提出了一种方法,能够在领域数据分布持续变化的动态环境中,基于随机时刻观测的数据分布,在任意时刻生成适用的神经网络。
下图展示了模型在领域数据随时间发生旋转和膨胀时的泛化表现。通过在一些随机时间点(蓝色标记点)的观测,模型可以在任意时刻生成适用的神经网络,其决策边界始终与数据分布保持协调一致。
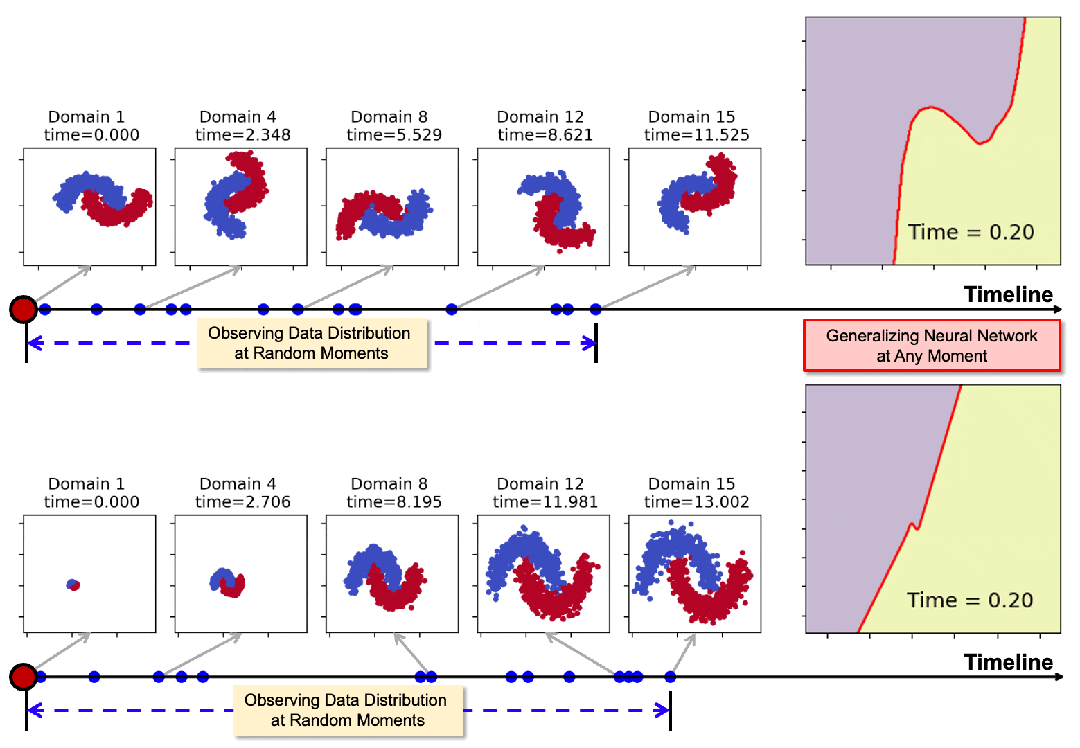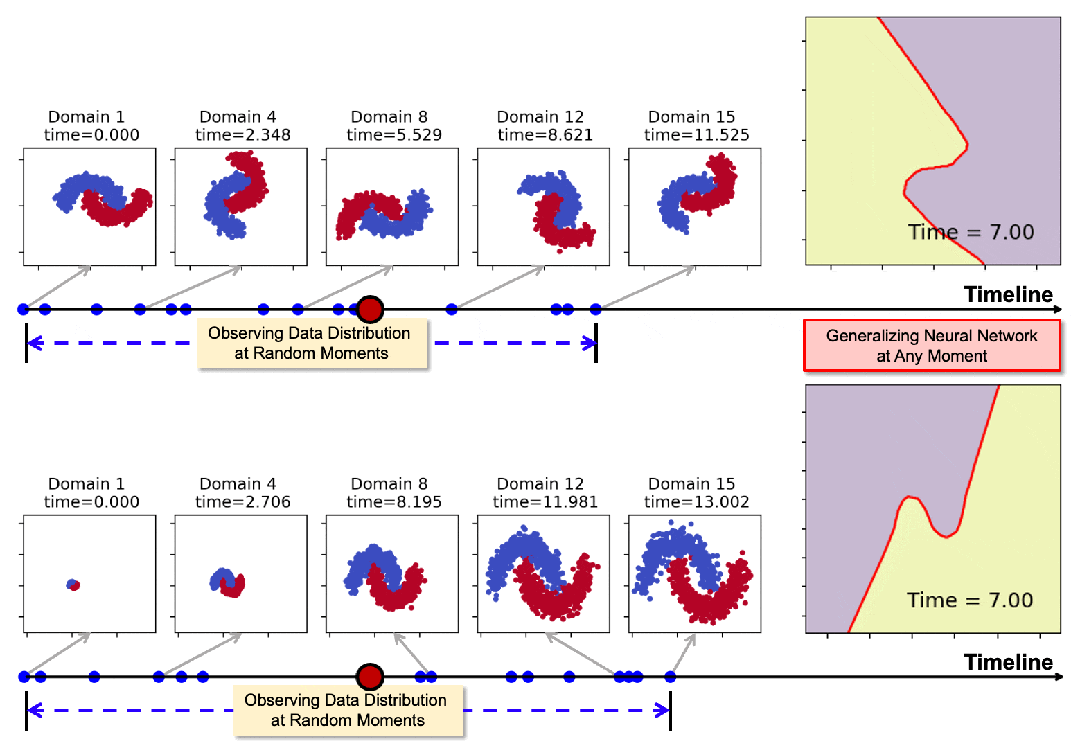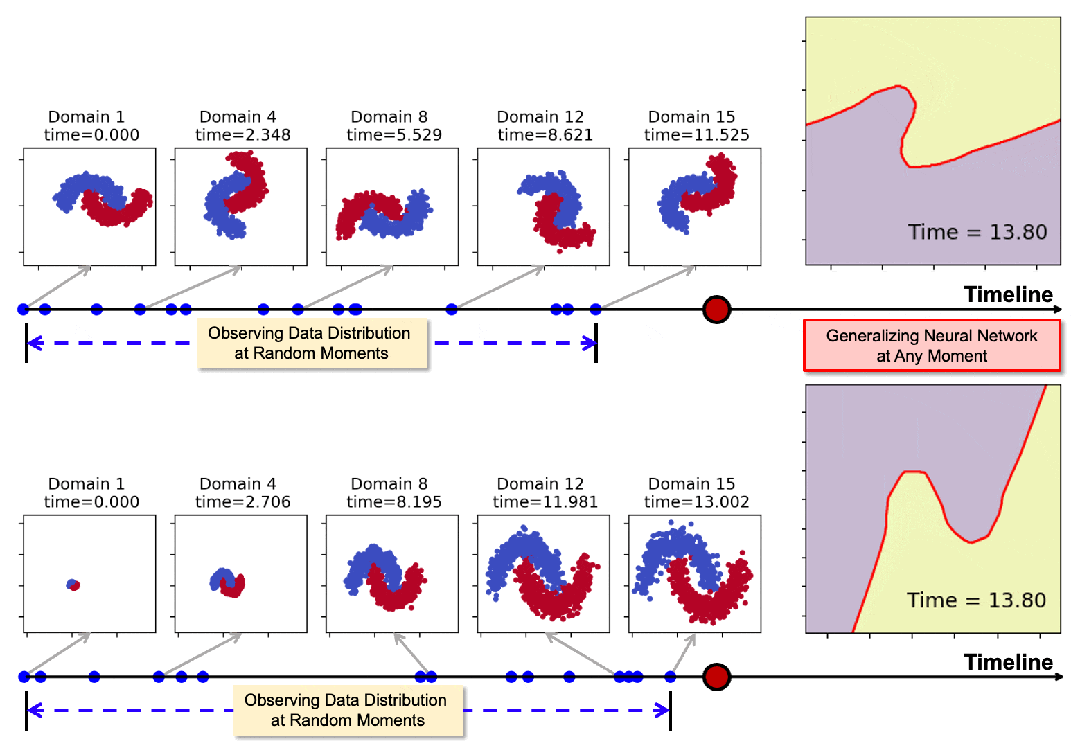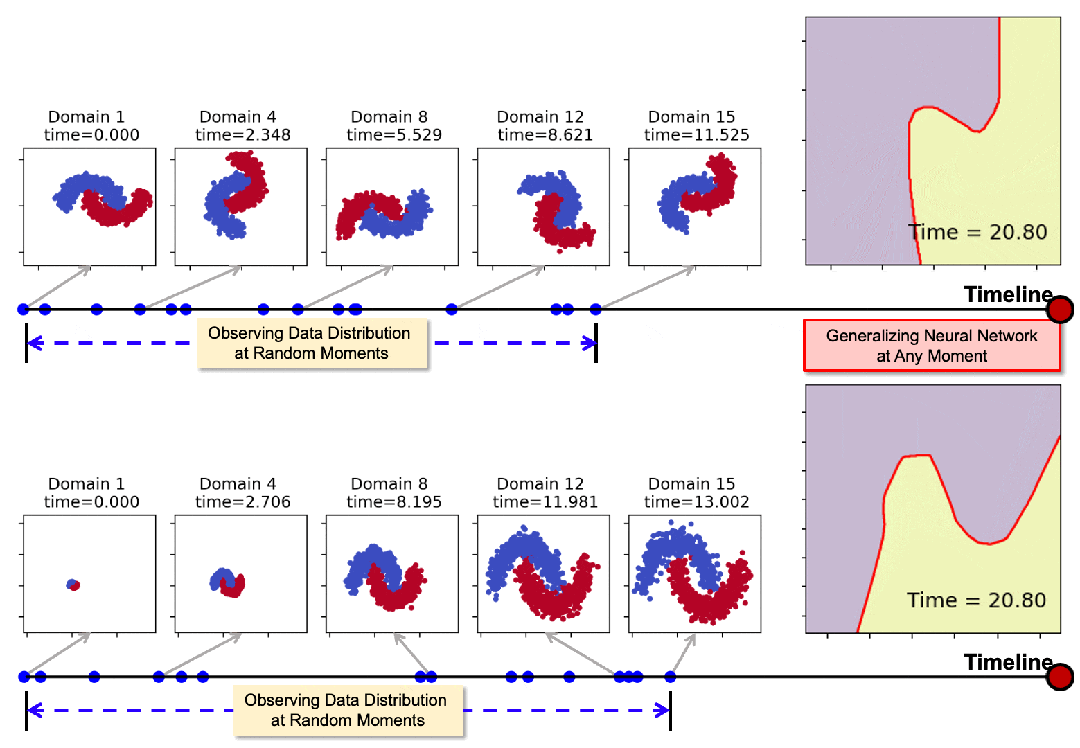
01 摘要
在实际应用中,数据集的数据分布往往随着时间而不断变化,预测模型需要持续更新以保持准确性。时域泛化旨在预测未来数据分布,从而提前更新模型,使模型与数据同步变化。
然而,传统方法假设领域数据在固定时间间隔内收集,忽视了现实任务中数据集采集的随机性和不定时性,无法应对数据分布在连续时间上的变化。此外,传统方法也难以保证泛化过程在整个时间流中保持稳定和可控。
为此,本文提出了连续时域泛化任务,并设计了一个基于模型动态系统的时域泛化框架 Koodos,使得模型在连续时间中与数据分布的变化始终保持协调一致。Koodos 通过库普曼算子将模型的复杂非线性动态转化为可学习的连续动态系统,同时利用先验知识以确保泛化过程的稳定性和可控性。
实验表明,Koodos 显著超越现有方法,为时域泛化开辟了全新的研究方向。
02 论文信息
论文链接:
https://arxiv.org/pdf/2405.16075
开源代码:
https://github.com/Zekun-Cai/Koodos/
OpenReview:
https://openreview.net/forum?id=G24fOpC3JE
我们在代码库中提供了详细的逐步教程,涵盖了 Koodos 的实现、核心概念的解读以及可视化演示:
https://github.com/Zekun-Cai/Koodos/blob/main/Tutorial_for_Koodos.ipynb
整个教程流程紧凑,十分钟即可快使掌握 Koodos 的使用方法,力荐尝试!
03 情景导入
在实际应用中,训练数据的分布通常与测试数据不同,导致模型在训练环境之外的泛化能力受限。领域泛化(Domain Generalization, DG)作为一种重要的机器学习策略,旨在学习一个能够在未见目标领域中也保持良好表现的模型。
近年来研究人员发现,在动态环境中,领域数据(Domain Data)分布往往具有显著的时间依赖性,这促使了时域泛化(Temporal Domain Generalization, TDG)技术的快速发展。
时域泛化将多个领域视为一个时间序列而非一组独立的静态个体,利用历史领域预测未来领域,从而实现对模型参数的提前调整,显著提升了传统 DG 方法的效果。
然而,现有的时域泛化研究集中在“离散时间域”假设下,即假设领域数据在固定时间间隔(如逐周或逐年)收集。基于这一假设,概率模型被用于预测时域演变,例如通过隐变量模型生成未来数据,或利用序列模型(如 LSTM)预测未来的模型参数。
然而在现实中,领域数据的观测并不总是在离散、规律的时间点上,而是随机且稀疏地分布在连续时间轴上。例如,图 1 展示了一个典型的例子——基于推文数据进行社交媒体舆情预测。
与传统 TDG 假设的领域在时间轴上规律分布不同,实际中我们只能在特定事件(如总统辩论)发生时获得一个域,而这些事件的发生时间并不固定。同时,概念漂移(Concept Drift)在时间轴上发生,即领域数据分布随着时间不断演变:如活跃用户增加、新交互行为形成、年龄与性别分布变化等。
理想情况下,每个时态域对应的预测模型也应随时间逐渐调整,以应对这种概念漂移。最后,由于未来的域采集时间未知,我们希望可以泛化预测模型到未来任意时刻。

▲ 图1:连续时域泛化示意图。图中展示了通过推文训练分类模型进行舆情预测。其中训练域仅能在特定政治事件(如总统辩论)前后采集。我们希望通过这些不规律时间分布的训练域来捕捉分布漂移,并最终使模型能够推广到任意未来时刻。
事实上,领域分布在连续时间上的场景十分常见,例如:
事件驱动的数据采集:仅在特定事件发生时采集领域数据,事件之间没有数据。
流数据的随机观测:领域数据在数据流的任意时间点开始或结束采集,而非持续进行。
离散时态域但缺失:尽管领域数据基于离散时间点采集,但部分时间节点的领域数据缺失。
为了应对这些场景中的模型泛化,我们提出了“连续时域泛化”(Continuous Temporal Domain Generalization, CTDG)任务,其中观测和未观测的领域均分布于连续时间轴上随机的时间点。CTDG 关注于如何表征时态领域的连续动态,使得模型能够在任意时间点实现稳定、适应性的调整,从而完成泛化预测。
04 核心挑战
CTDG 任务的挑战远超传统的 TDG 方法。CTDG 不仅需要处理不规律时间分布的训练域,更重要的是,它旨在让模型泛化到任意时刻,即要求在连续时间的每个点上都能精确描述模型状态。
而 TDG 方法则仅关注未来的单步泛化:在观测点优化出当前模型状态后,只需将其外推一步即可。这使得 CTDG 区别于 TDG 任务:CTDG 的关键在于如何在连续时间轴上同步数据分布和模型参数的动态演变,而不是仅局限于未来某一特定时刻的模型表现。
具体而言,与 TDG 任务相比,CTDG 的复杂性主要来自以下几个尚未被充分探索的核心挑战:
如何建模数据动态并同步模型动态:CTDG 要求在连续时间轴上捕捉领域数据的动态,并据此同步调整模型状态。然而,数据动态本身难以直接观测,需要通过观测时间点来学习。此外,模型动态的演变过程也同样复杂。理解数据演变如何驱动模型演变构成了 CTDG 的首要挑战。
如何在高度非线性模型动态中捕捉主动态:领域数据的预测模型通常依赖过参数化(over-parametrized)的深度神经网络,模型动态因此呈现出高维、非线性的复杂特征。这导致模型的主动态嵌藏在大量潜在维度中。如何有效提取并将这些主动态映射到可学习的空间,是 CTDG 任务中的另一重大挑战。
如何确保长期泛化的稳定性和可控性:为实现未来任意时刻的泛化,CTDG 必须确保模型的长期稳定性。此外,在许多情况下,我们可能拥有数据动态的高层次先验知识。如何将这些先验知识嵌入 CTDG 的优化过程中,进而提升泛化的稳定性和可控性,是一个重要的开放性问题。
05 技术方法
5.1 问题定义
在 CTDG 中,一个域 表示在时间 采集的数据集,由实例集 组成,其中 和 分别为特征值,目标值和实例数。我们重点关注连续时间上的渐进性概念漂移,表示为领域数据的条件概率分布 随时间平滑变化。
在训练阶段,模型接收一系列在不规律时间点 上收集的观测域 ,其中每个时间点 是定义在连续时间轴 上的实数,且满足 $t_1<t_2<\ldots<t_t$ 。<="" p="">
在每个 上,模型学习到领域数据 的预测函数 ,其中 表示 时刻的模型参数。CTDG 的目标是建模参数的动态变化,以便在任意给定时刻 上预测模型参数 ,从而得到泛化模型 。
在后续部分中,我们使用简写符号 、、 和 ,分别表示在时间 上的 、 、 和 。
5.2 设计思路
我们的方法通过模型与数据的同步、动态简化表示,以及高效的联合优化展开。具体思路如下:
1. 同步数据和模型的动态:我们证明了连续时域中模型参数的连续性,而后借助神经微分方程(Neural ODE)建立模型动态系统,从而实现模型动态与数据动态的同步。
2. 表征高维动态到低维空间:我们将高维模型参数映射到一个结构化的库普曼空间(Koopman Space)中。该空间通过可学习的低维线性动态来捕捉模型的主要动态。
3. 联合优化模型与其动态:我们将单个领域的模型学习与各时间点上的连续动态进行联合优化,并设计了归纳偏置的约束接口,通过端到端优化保证泛化的稳定性和可控性。

▲ 模型设计
5.3 解决方案
Step 1. 数据动态建模与模型动态同步
分布变化的连续性假设:我们首先假设数据分布在时间上具有连续演化的特性,即条件概率分布 随时间平滑变化, 其演化规律可由一个函数 所描述的动态系统刻画。尽管真实世界中的渐进概念漂移可能较为复杂,但因概念漂移通常源于底层的连续过程(如自然、生物、物理、社会或经济因素),这一假设不失普适性。
分布变化引发的模型参数连续演化:基于上述假设,模型的函数功能空间应随数据分布变化同步调整。我们借助常微分方程来描述这一过程:

由此可推导出模型参数的演化满足:

其中, 是 对 的雅可比矩阵。
这一结果表明,如果数据分布的演化在时间上具有连续性,那么的演化过程也具有连续性,即模型参数会随数据分布的变化而平滑调整。上式为建立了一个由微分方程描述的模型动态系统。
模型动态系统学习:由于数据动态 的具体形式未知, 直接求解上述微分方程并不可行。为此, 我们引入一个由神经网络定义的连续动态系统, 用可学习的函数 描述模型参数 的变化。
通过鼓励模型动态和数据动态之间的拓扑共轭(Topological Conjugation)关系使 逼近真实动态。具体而言, 拓扑共轭要求通过泛化获得的模型参数与直接训练得到的参数保持一致。为此, 我们设定以下优化目标, 以学习 的参数 :

其中, 通过在时刻 的领域上直接训练获得, 则表示从时间 通过动态 演变至 的泛化参数:

通过这一优化过程,我们建立了模型动态与数据动态之间的同步机制。借助动态函数,我们可以在任意时刻精确求解模型的状态。
Step 2. 通过库普曼算子简化模型动态
非线性动态线性化
在实际任务中, 预测模型通常依赖于过参数化的深度神经网络, 使得模型动态 呈现为在高维空间中纠缠的非线性动态。直接对 建模不仅计算量大,且极易导致泛化不稳定。
然而, 受数据动态 的支配, 而数据动态通常是简单、可预测的。这意味着在过参数化空间中,模型的主动态(Principal Dynamics)可以在适当转换的空间内进行更易于管理的表示。
受此驱动,我们引入库普曼理论(Koopman Theory)来简化复杂的模型动态。库普曼理论在保持动态系统特征的同时将复杂的非线性动态线性化。
具体而言, 我们定义一个库普曼嵌入函数 , 将原始的高维参数空间映射到一个低维的库普曼空间中:

其中, 表示库普曼空间中的低维表示。通过库普曼算子 , 我们可以在线性空间中刻画 的动态:

一旦获得了简化的动态表示,我们可以在库普曼空间中更新模型参数,而后将其反映射回原始参数空间:

最终,通过库普曼算子的引入,我们实现了对模型动态的简化,保证了泛化过程的稳健性。
Step 3. 联合优化与先验知识结合
模型及其动力学的联合优化:我们对多个组件同时施加约束确保模型能稳定泛化,其包含以下关键项:
- 预测准确性:通过最小化预测误差,使预测模型在每个观测时间点都能准确预测实际数据。
- 泛化准确性:通过最小化预测误差,使泛化模型在每个观测时间点都能准确预测实际数据。
- 重构一致性:确保模型参数在原始空间与库普曼空间之间的转换具有一致性。
- 动态保真性:约束库普曼空间的动态行为,使得映射后的空间符合预期的动态系统特征。
- 参数一致性:确保泛化模型参数映射回原始空间后与预测模型参数保持一致。
利用库普曼算子评估和控制泛化过程:引入库普曼理论的另一优势在于,我们可以通过库普曼算子的谱特性来评估模型的长期稳定性。此外,还可以在库普曼算子中施加约束来控制模型的动态行为。
1. 系统稳定性评估
通过观察库普曼算子的特征值,可以判断系统是否稳定:
- 若所有特征值实部为负,系统会稳定地趋向于一个平衡状态。
- 若存在特征值实部为正,系统将变得不稳定,模型在未来可能会崩塌。
- 若特征值实部为零,系统可能表现出周期性行为。通过分析这些特征值的分布,我们可以预测系统的长期行为,识别模型在未来是否可能出现崩溃的风险。
2. 泛化过程约束
我们可以通过对库普曼算子施加显式约束来调控模型的动态行为。例如:
- 周期性约束:当数据动态为周期性时,可将库普曼算子设为反对称矩阵,使其特征值为纯虚数,从而使模型表现出周期性行为。
- 低秩近似:将表示为低秩矩阵,有助于控制模型的自由度,避免过拟合到次要信息。
通过这些手段,我们不仅提高了泛化的长期稳定性,还增强了模型在特定任务中的可控性。
06 实验
6.1 实验设置
为验证算法效果,我们使用了合成数据集和多种真实世界场景的数据集:
合成数据集:包括 Rotated 2-Moons 和 Rotated MNIST 数据集,通过在连续时间区间内随机生成时间戳,并对 Moons 和 MNIST 数据按时间戳逐步旋转生成连续时域。
真实世界数据集:
- 事件驱动数据集 Cyclone:基于热带气旋的卫星图像预测风力强度,气旋发生日期对应连续时域。
- 流数据集 Twitter 和 House:分别从任意时间段抽取推文和房价数据流构成一个领域,多次随机抽取形成连续时域。
- 不规则离散数据集 Yearbook:人像图片预测性别,从 84 年中随机抽取 40 年数据作为连续时域。
6.2 实验结果与分析
定量分析
我们首先对比了 Koodos 方法与各基线方法的定量性能。表 1 显示,Koodos 方法在所有数据集上展现了显著的性能提升。
在合成数据集上,Koodos 能够轻松应对持续的概念漂移,而所有基线方法在这种场景下全部失效。
在真实世界数据集上,尽管某些基线方法(如 CIDA、DRAIN 和 DeepODE)在少数场景中略有表现,但其相较于简单方法(如 Offline)的改进非常有限。相比之下,Koodos 显著优于所有现有方法,彰显出在时域泛化任务中考虑分布连续变化的关键作用。

▲ 实验结果
定性分析
决策边界:为直观展示泛化效果,我们在 Rotated 2-Moons 数据集上进行了决策边界的可视化。该任务具有极高难度:模型需在 0 到 35 秒左右的 35 个连续时域上训练,随后泛化到不规律分布在 35 到 50 秒的 15 个测试域。而现有方法通常只能泛化至未来的一个时域(T+1),且难以处理不规律的时间分布。图 3 从 15 个测试域中选取了 7 个进行可视化。结果清晰地表明,基线方法在应对连续时域的动态变化时表现不足。随着时间推进,决策边界逐渐偏离理想状态。尤其是最新的 DRAIN 方法(ICLR23)在多步泛化任务中明显失效。
相比之下,Koodos 在所有测试域上展现出卓越的泛化能力,始终保持清晰、准确的决策边界,与实际数据分布变化高度同步。这一效果突显了 Koodos 在时域泛化任务中的革命性优势。

▲ 图3:2-Moons 数据集决策边界的可视化(紫色和黄色表示数据区域,红线表示决策边界)。从上到下比较了两种基线方法和 Koodos;从左到右显示了部分测试域(15 选 7,所有测试域的分布在时间轴上用红点标记)。
模型演变轨迹:为更深入地分析模型的泛化能力,我们通过 t-SNE 降维,将不同方法的模型参数的演变过程(Model Evolution Trajectory)在隐空间中可视化(图 4)。
可以看出,Koodos 的轨迹呈现出平滑而有规律的螺旋式上升路径,从训练域平滑延伸至测试域。这一轨迹表明,Koodos 能够在隐空间中有效捕捉数据分布的连续变化,并随时间自然地扩展泛化。
相比之下,基线模型的轨迹在隐空间中缺乏清晰结构,随着时间推移,逐渐出现明显的偏离,未能形成一致的动态模式。

▲ 图4:模型状态在隐空间中的时空轨迹。Koodos 展现出与数据动态和谐同步的模型动态。
时域泛化的分析与控制:在 Koodos 模型中,库普曼算子为分析模型动态提供了有效手段。我们对 Koodos 在 2-Moons 数据集上分析表明,库普曼算子的特征值在复平面上分布在稳定区和不稳定区,这意味着 Koodos 在中短期内能稳定泛化,但在极长时间的预测上将会逐渐失去稳定性,偏离预期路径(图 5b)。
为提升模型的稳定性,我们通过将库普曼算子配置为反对称矩阵(即Koodos版本),确保所有特征值为纯虚数,使模型具有周期性稳定特性。在这一配置下,Koodos展现出高度一致的轨迹,即使在长时间外推过程中依然保持稳定和准确,证明了引入先验知识对增强模型稳健性的效果(图 5c)。
,时长00:23
▲ 图5:非受控和受控条件下的极长期泛化预测模型轨迹。a:部分训练域数据;b:不受控,模型最终偏离预期;c:受控,模型始终稳定且准确。
▲ 图5:非受控和受控条件下的极长期泛化预测模型轨迹。a:部分训练域数据;b:不受控,模型最终偏离预期;c:受控,模型始终稳定且准确。
07 结论
我们设计了一种基于模型连续动态系统的时域泛化方法,能够在数据域随时间逐渐演变的环境中,实现泛化模型的稳定性与可控性。未来,我们计划从多个方向进一步拓展这一技术的应用:
生成式模型扩展:时域泛化与生成式模型任务有天然的关联,Koodos 所具备的泛化能力能够为神经网络生成技术带来新的可能。
非时态泛化任务:Koodos 的应用并不局限于时域泛化,它也可以适用于其他分布变化的任务中。我们计划探索其在非时态领域的应用。
大模型集成:我们将探索时域泛化在大模型中的集成,帮助 LLM 在复杂多变的分布中保持鲁棒性和稳定性。
我们对时域泛化任务在未来的广阔应用前景充满期待。如有任何问题或合作意向,欢迎联系我们!
邮箱: caizekun@csis.u-tokyo.ac.jp
GitHub: https://github.com/Zekun-Cai/Koodos/
Paper: https://arxiv.org/pdf/2405.16075
#Scaling Laws for Precision 解读
本文探讨了模型量化对性能的影响,并提供了关于训练时量化和后训练量化的实用建议。文章强调了在不同训练精度下,如何平衡模型性能和量化损失,以及在实际应用中选择合适的量化策略的重要性。
来自链接 https://zhuanlan.zhihu.com/p/6848989432
原文
前置知识:
scaling law:
- Training Compute-Optimal Large Language Models(Chinchilla scaling law)
个人讨厌晦涩难懂+无法应用于实际场景的"装逼结论",因此先按照自己的理解帮大家rephrase一下论文的主要发现(in plain language):
首先,这是一篇研究精度(precision)、参数量(parameters)和训练数据量(tokens)之间关系的重要论文。
1. 关于后训练量化(Post-Training Quantization, PTQ):1.1 基本概念
- 指的是pretrain以较高精度(bf16)进行,结束后再量化到更低精度(如int4)
1.2 结论1
模型预训练的trained_token/parameter比率越高,预训练结束后,使用PTQ带来的性能下降就越大。这里作者没写明白有误导性!!!实际上这个结论指的是:
- 我们都知道PTQ一定会带来性能下降(PTQ后,valid loss相比pretrain之后会上升),这个下降可以用
- 论文提出了预测这个下降值的公式:
- 其中:
- 训练数据量D越大,PTQ带来的损失越大(正相关)
- 参数量N越大,PTQ带来的损失越小(负相关)
- 量化后的精度Ppost越低,损失增加越多(负指数关系)
- N: 参数量
- D: 训练token数
- : PTQ后的精度
- γγγ: 拟合常数
- 这个公式告诉我们:
- 注意,δPTQ还有一种完整形式(section 5) 同时考虑了训练精度和推理精度(继续往后看):
- 那么如果你必须进行PTQ,那么对于同样参数量大小的模型,被训更多token的模型的 δPTQ 会比喂更少数据的模型要大。但最终loss的绝对数量是多少并不一定,因为即便 δPTQ 这个正数会让loss上升(性能下降),但模型终归被训了更多数据,这么一抵消可能loss还是会下降。相当于两只无形的手(数据量的上升带来的loss下降、PTQ带来的loss上升)在掰手腕;给定模型参数量和固定的精度,具体谁能掰过谁会有一个打平手的cutoff数据量。
- 举例子,如果你要固定70B模型参数量并pretrain时候采用bf16,并且pretrain后要PTQ到int4。那么采用两种数据量:
- a) 用10B token训出来模型
- b) 5B token训出来的模型
- 那么一定是a)情况的 δPTQ 更大,但最终PTQ结束之后的loss的数值是多少就不一定了。
- 因此作者也在原文中提到了**there exists an amount of pretraining data beyond which additional data is actively harmful to performance at inference-time (see top-left, Figure 2),也就是给定你要进行PTQ,那么对于你的实验设置,总有一个cutoff的数据量,称之为临界的数据量 Dcrit ,超过这个量后继续训练会导致PTQ后性能下降。这个临界点并不是说超过后训练数据就“有害”,而是说在进行PTQ后,性能的提升可能会被性能的下降所抵消。因此,在实际应用中,需要权衡训练数据量与模型量化后的性能。
- 论文给出了计算这个临界点的公式:
其他结论
- 在某些情况下,过度训练(more tokens)反而会让PTQ后的模型性能变差
- 更大的模型在相同的token/parameter比率下,对PTQ更鲁棒
- 对于固定大小的数据集,增加模型参数量可以提高PTQ的鲁棒性
- 这种规律在不同的PTQ方法中都存在(论文验证了GPTQ、AWQ和RTN三种方法)
训练精度的影响
- 训练时使用较低精度的模型在PTQ时性能下降较小
- 如果你知道模型最终需要被量化到很低的精度(比如4bit),那么在训练时就使用相对较低的精度(比如8bit)可能比使用高精度(比如16bit)更好,因为这样可以让模型在训练过程中就适应量化噪声。
- 实话说这个结论初看有点脱裤子放屁,因为太符合直觉了(bushi)。用脚想想就知道【训练用int8然后量化到int4】肯定比【训练用bf16然后量化到int4】要好,原文section 5:models trained in lower precision are more robust to post-train quantization in the sense of incurring lower degradation.
- 这也解释了为什么一些较新的大语言模型倾向于使用BF16而不是FP32来训练,因为这不仅可以节省计算资源,还可能让模型在后续量化时表现更好
1.3 PTQ造成loss degradation的深入分析1.3.1 两个竞争效应(section 5)
在分析PTQ对模型性能的影响时,论文发现了两个相互竞争的效应:
- Robustification效应
- 低精度训练会让模型更适应量化噪声
- 这使得模型在后续PTQ时更加鲁棒
- 可以理解为模型学会了如何在噪声环境中运作
- Overtraining效应
- 低精度训练会降低模型的有效参数量(),这意味着模型在相同的数据量下“看起来”参数量更少,从而在PTQ时对参数量化的敏感性增加
- 因为 和 成正比, 较低的Neff理论上会导致更大的性能下降: (section 5这边第一次读还以为写错了)。作者说的 实际上应该参考公式 9 变为 ,随着 的增加, 确实增加, 也就是成正比。说明白点就是低精度训练会下降Neff, 也就是一个 模型的可能有效的参数只有 10 B , 然后 变大, 然后根据section 3 的公式就会造成更大的degradation)
- 这个效应与Robustification效应相反
在实践中,Robustification效应通常占主导,这就是为什么低精度训练的模型在PTQ时表现更好。
1.3.2 精度阈值效应
一个重要发现是,当精度低于5-bit时,PTQ带来的性能下降会急剧增加:
- 在高精度区间(如8-bit以上),D/N比率的增加对性能的影响相对温和
- 在5-bit以下,即使很小的D/N比率增加也可能导致显著的性能下降
- 这个发现对实践中选择量化精度有重要指导意义-- 在实际应用中,应避免将模型量化到低于5-bit的精度,除非有特定的需求和相应的优化技术支持
1.3.3 理论解释
论文在附录中提供了两个可能的理论解释:
Sharpness假说
- 模型在训练过程中会逐渐变得更"sharp"-- 随着训练的进行,模型的损失函数变得更加“尖锐”(sharp),即梯度和Hessian矩阵的特征值增加,这导致模型对参数扰动更加敏感。因此,PTQ带来的参数量化噪声会对尖锐的损失函数产生更大的影响。
- Sharp的模型对参数扰动更敏感
- 这种敏感性会随着训练的进行而增加
- 这解释了为什么过度训练可能导致更大的PTQ降质
分层学习假说
- 模型通过分层方式学习特征-- 模型通过逐步学习更复杂的特征,这些特征依赖于之前学习的基础特征。量化噪声影响基础特征,会级联地影响到更高层次的复杂特征,从而导致整体性能的下降。
- 早期学习基础特征,后期学习复杂特征
- 复杂特征依赖于基础特征的准确性
- 当基础特征受到量化噪声影响时,会对依赖它们的复杂特征造成级联效应
- 这解释了为什么训练时间越长,模型对量化越敏感
2. 关于训练时量化(Training-time Quantization)
2.1 基本概念
论文中将训练时量化分为两种情况:
- 仅量化权重(Quantization-Aware Training, QAT):只将模型的权重量化到低精度,其他部分保持高精度,以适应推理阶段的低精度环境。
- 全面量化(Low-precision Training):同时量化模型的权重、激活值和注意力计算(即键-值缓存),以减少计算资源需求。
注意:这里的权重指模型中所有线性层(Linear layers)的权重矩阵,包括:
- Transformer 中的所有投影矩阵(例如 query、key、value 的投影权重);
- 嵌入层(Embedding layers)权重矩阵;
- 最终输出层的权重矩阵。
但在论文的实验中未对嵌入层(Embedding layer)进行量化。
量化实现细节:
- 论文遵循了 FP8 训练的标准规范(Micikevicius et al., 2022);
- 权重采用 按通道(per-channel) 量化;
- 激活值采用 按张量(per-tensor) 量化;
- 对于后训练量化(PTQ),主要针对模型权重进行量化。
2.2 核心发现
权重、激活值和注意力的量化效果是独立且可乘的,这一点非常关键。
论文提出了“有效参数量 Neff effective parameter count)”的概念。简而言之, Neff 代表了模型在低精度下的“真实有效”参数量。在低精度训练时,模型的实际参数量 N会被折减为较低的 Neff ,这有助于评估模型在低精度量化下的性能损失。
基本形式:
完整形式(全面量化):
其中:
- N:模型的实际参数量;
- Pw :权重精度;
- Pa:激活值精度;
- Pkv :注意力计算精度;
- γw、γa、γkv :各部分的敏感度系数,反映了模型对不同量化精度的适应性。
举个例子,在相同的计算预算下,有两种方案:
- a) 使用 16-bit 精度训练较小的模型;
- b) 使用 8-bit 精度训练较大的模型(参数量约为前者的 2 倍)。
根据论文的 Neff 分析,第二种方案通常更优,因为:
- 增加的参数量带来的性能提升超过了精度降低造成的损失;
- 8-bit 精度已接近论文中发现的计算最优精度(7-8 bits);
- 低精度训练可以在相同的计算预算下处理更多的数据。
最优训练精度的计算:论文发现,在一般情况下,最优的训练精度为 7-8 bits。这意味着当前常用的 16-bit(BF16)训练精度其实存在冗余。但如果追求极低精度(例如 4-bit 以下),则需要不成比例地增加模型大小才能维持性能。
但是,如果模型大小被固定(例如受限于硬件资源),情况会有所不同:
- 此时,最优训练精度会随着训练数据量的增加而提高。具体来说,最优精度与训练数据量和参数量的比值成对数关系,即:
最优精度训练数据量参数量最优精度∝log(训练数据量参数量)(见论文 Section 4.3.3)
2.3 训练成本分析
训练成本的计算公式如下:
其中:
- C:计算成本;
- N :模型参数量;
- D :训练 token 数;
- P :训练精度;
- 6/16:标准化系数(基于 Chinchilla 成本模型)。
这意味着什么? 举个例子:假设你的计算预算是固定的,希望训练一个模型,有两种选择:
- 使用 16-bit 精度训练一个 35B 参数量的模型;
- 使用 8-bit 精度训练一个 70B 参数量的模型。
根据论文的发现,第二种方案可能更优,因为增加的参数量带来的性能提升超过了精度降低带来的损失。
2.4 实践建议
如果计算预算有限:
- 优先选择 7-8 bit 的训练精度,并利用节省下来的资源增加模型参数量;
- 避免使用低于 4-bit 的训练精度,因为这需要大幅增加模型大小才能维持性能(见论文 Section 4.3.2)。
如果模型大小受限:
- 在需要处理更大量数据时,提高训练精度;
- 例如,当 token/parameter 比率超过 1000 时,建议使用 8-bit 以上的精度;
- 在高 token/parameter 比率下,避免使用低于 6-bit 的训练精度(见论文 Section 4.3.3)。
各部分的精度选择:
- 权重(Weights)在极低精度(3-bit)下仍能保持稳定;
- 激活值(Activations)和注意力计算(KV-cache)在低于 3-bit 时可能会出现不稳定;
- 这种差异可能与量化方式有关(权重采用按通道量化,激活值采用按张量量化),而不一定是固有特性。
3.限制与未来研究方向
3.1 固定的模型架构
这篇论文采用了固定的Transformer++架构,以便在一个可控的环境中分析精度、参数量和数据量之间的关系。然而,在实际应用中,低精度训练通常会伴随着模型架构的调整。例如,一些先进的低精度训练方法可能会引入特殊的正则化技术或优化策略,以减轻低精度带来的负面影响。因此,论文的结论主要适用于固定架构的情况,尚未在经过优化的低精度架构中进行验证。
3.2 计算成本与系统开销
虽然理论上,降低训练精度(比如从16-bit降到8-bit)可以按比例减少计算需求,但在实际操作中,由于系统开销和硬件实现的限制,精度降低所带来的性能提升通常低于理论预期。例如,某些硬件可能无法高效支持极低精度(如4-bit以下)的计算,导致实际的加速效果有限。此外,不同精度下的数据移动和存储优化表现也可能有所不同,这进一步影响了低精度训练的实际效率。
3.3 仅关注验证损失,缺乏下游任务评估
论文主要关注于训练过程中的验证损失(validation loss)作为性能评估指标,而没有对下游任务的具体表现进行评估。尽管验证损失是衡量模型性能的重要指标,但不同任务对模型精度和量化的敏感性可能存在差异。
3.4 实验规模的限制
虽然论文中训练了多达17亿(17B)参数的模型,并使用了高达26B tokens的数据集,但这些规模相对较小,与当前最先进的大规模语言模型(如数百亿甚至千亿参数级别)相比仍有差距。因此,论文的scaling law在更大规模模型上的适用性尚未得到验证。
4. 量化方法的多样性
这篇论文主要关注于整数类型的量化方法,并通过GPTQ、AWQ和RTN等方法进行了验证。然而,浮点类型的量化方法(如FP8、FP4)在实际应用中也具有重要意义,尤其是在某些硬件平台上具有更好的支持和性能表现。不同量化方法在引入量化噪声和影响模型性能方面可能存在显著差异,因此,未来的研究应涵盖更多种类的量化方法,以全面理解量化对模型性能的影响。
5. 数据集和训练策略的单一性
这篇论文使用了Dolma V1.7数据集,并采用了特定的训练策略和超参数设置。不同的数据集和训练策略可能会影响模型对量化的敏感性。例如,某些数据集可能具有更高的复杂性或多样性,导致模型在低精度下表现出不同的鲁棒性。因此,未来的研究应在多样化的数据集和训练配置下进行,以验证缩放规律的普适性。
#图解OpenRLHF中基于Ray的分布式训练流程
本文详细分析了OpenRLHF中基于Ray的分布式训练流程。
本文着重分析OpenRLHF中的PPO-Ray训练架构设计,没有使用过Ray的朋友也可以通过本文快速上手,本文共分成四块:
1. 为什么用Ray
2. 使用图例抽象出整体训练流程
3. Ray核心知识速过
4. 使用图例,进一步抽象出核心代码细节,包括:
- 训练入口
- 部署PPO-Actor/Ref/Critic/RM实例
- 部署vllm_engines实例
- PPO-Actor与vllm_engines之间的通讯
- PPO-Actor/Critic训练
一、为什么要使用Ray
对于通常的rlhf框架,在训练时会在单卡上同时部署actor/ref/reward/critic四类模型,这种单一的部署方式可能存在如下问题:
- 难以突破单卡显存的限制。
- 无法实现更多的并行计算。例如在收集exp阶段,拿到(prompt, responses)结果的四类模型其实可以做并行推理;在训练阶段,拿到exp的actor和critic也可以做并行训练。但受到单卡显存等因素影响,通常的rlhf框架中使用更多的是串行。
- 无法独立优化训练和推理过程。诸如vllm之类的框架,是可以用来提升actor生成(prompt, responses)的速度的,而对于其它模型,我们也可能会视算法需要有不同的推理需求。因此我们期望能更加灵活地设计训练、推理过程
而解决以上问题,需要开发者能设计一套较为灵活的分布式计算框架,能够实现资源定制化分配、分布式调度、节点内外通信等目标,同时相关的代码不能太复杂,能够让使用者更专注于算法部分的研发。而Ray天然可以帮我们做这件事:我们只需提供自己的资源分配方案,告诉Ray我想怎么部署这些模型,不管是分开还是独立部署Ray都可以帮我们实现。而复杂的调度策略和通信等事项,就由Ray在后台去做,我们无需关心这个过程。
二、整体流程
本节我们将提供2个例子,帮助大家更好理解使用Ray可以做什么样的“定制化”部署。注意,这些例子只做讲解用,不代表它们一定是训练的最优配置。
2.1 非共同部署
这个例子展示如何完全独立部署各个模型。假设我们有3台node,每台node 8张卡。以下展示其中一种可行的部署方式:

(1)部署4类模型
在这个例子中,4类模型分开部署在node0和node1上。以Actor为例,它分布在“node0的gpu0/1 + node1的gpu0/1”上。这一点是由Ray实现的:我们自己定制化资源分配的方案,进而管控模型的分配方式
而当实际训练时,我们还可进一步引入Deepspeed zero做优化:以Actor为例,上图中的4个Actor构成zero中的数据并行组(world_size = 4),根据zero的配置,我们可以在这4张卡间做optimizer/gradients/weights的切片。
(2)部署vllm_engines
前文说过,对于Actor模型,在收集exp阶段我们可以采用vllm之类的框架加速(prompt, responses)的生成。在这个例子中:
- 1个vllm_engine维护着一个vllm实例,每个vllm实例下维护一个完整的Actor模型,这里我们还假设一个vllm实例按tp_size = 2的方法切割模型。
- 在node2中,共有4个vllm_engines(也即4个vllm实例),这种分配方式是通过Ray实现的。而每个vllm实例内的分布式推理则是由vllm自己管控。
(3)Actor与vllm_engines之间的通讯
我们称:
- vllm_engines中的actor为vllm_actor
- node0/1中的actor为ds_actor
在整个训练过程中,vllm_actor需要和ds_actor保持权重一致。我们来看这个一致性是如何维护的:
1. 初始化阶段
假设pretrain路径下存储着sft模型,当我们首次开始训练时,ds_actor和vllm_actor都直接从pretrain中加载权重,两者互不影响,独立加载。
2. 训练中
在1个step结束后,ds_actor需要把更新后的权重broadcast给vllm_actor,具体步骤如下:
- 首先,对
ds_rank0 + all_vllm_ranks创建一个通讯组。在本例中:
- node0/gpu0上的actor是ds_rank0
- node2中所有的gpu构成all_vllm_ranks。
- 我们就是把这两者纳入一个通讯组内,这个通讯组的world_size = 9。如果我们多一台node3来做vllm_engines,那么这个通讯组的world_size = 19,以此类推。
- 若我们使用ds_zero1/2,则ds_rank0上维护的是完整的actor权重,我们把ds_rank0上的权重broadcast到每一个vllm_rank,如有设置tp,vllm会自动帮我们完整接下来的模型切割。
- 若我们使用ds_zero3,则ds_rank0上只维护部分actor权重,那么:
- ds_rank0先从ds_actor组内all gather回完整的模型权重
- 再将完整的模型权重brocast给每一个vllm_rank
3. 从检查点恢复训练(load_checkpoint)
当我们需要从检查点恢复训练时,ds_actor会负责把检查点权重broadcast给vllm_actor,方式同2。
(4)整体运作流程
结合2.1开头的图例,我们来简述一下整体运作流程。
- 首先明确一些表达。例如,
node0中的Actor0/1 + node1中的Actor0/1属于相同的数据并行组,所以接下来我们会用它们在dp组中的rank来描述它们,也就是分别改称Actor0/1/2/3。对于其余三类模型也是同理。 - 接着进行分组:
-
Actor0 / Ref0 / RM0 / Critic0 / vllm_engine0为一组 -
Actor1 / Ref1 / RM1 / Critic1 / vllm_engine1为一组 -
Actor2 / Ref2 / RM2 / Critic2 / vllm_engine2为一组 -
Actor3 / Ref3 / RM3 / Critic3 / vllm_engine3为一组 - 你可以把每一组想象成原来的一张单卡,那么它的作用就是负责一个micro_batch的训练,这样我们就能大致想象到它们之间是如何配合运作的了。需要注意的是,在我们的例子中,这些实例都是一一对应的(各自有4个实例),但在实际操作中,根据不同用户的资源配置,不一定存在这个一一对应的关系。例如你可能用4卡部署Actor,2卡部署Critic,8个vllm_engines...以此类推。不管怎样,我们应该尽量在处理micro_bathes的各个组间均匀分配负载,在代码里相关的操作如下:
1.为每个actor分配其对应的critic/reward/ref,并启动每个分组的训练:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/launcher.py#L278-L299 2.为每个actor分配对应的vllm_engine,并使用vllm_engine进行推理:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ppo_utils/experience_maker.py#L627
2.2 共同部署
同样,我们可以按照自己的需求,选择性地在单卡上部署不同种类的模型,例如下面的例子中,actor/ref共部署,critic/remote共部署,图例如下,运作流程和2.1相似,这里不赘述:

三、Ray的核心概念
在传统的编程中,我们经常使用到2个核心概念:function和class。而在分布式系统中,我们希望可以分布式并行执行这些function和class。Ray使用装饰器@ray.remote来将function包装成Ray task,将class包装成Ray actor,包装过后的结果可以在远程并行执行。接下来我们就来细看task/actor,请大家特别关注代码中的注释
(注意,这里的actor是ray中的概念,不是rlhf-ppo中actor模型的概念)
3.1 Ray Task
import ray
ray.init()
@ray.remote
def f(x):
return x * x
# ===================================================================
# 创建driver进程,运行main
# ===================================================================
if __name__ == "__main__":
# ===================================================================
# 创建4个worker进程,可以在远端并行执行。
# 每执行1次f.remote(i),会发生以下事情:
# - 创建1个worker进程,它将在远端执行函数f(i)
# - 在driver进程上立刻返回一个引用(feature),该引用指向f(i)远程计算的结果
# ===================================================================
futures = [f.remote(i) for i in range(4)]
# ===================================================================
# 阻塞/同步操作:等待4个worker进程全部计算完毕
# ===================================================================
results = ray.get(futures))
# ===================================================================
# 确保全部计算完毕后,在driver进程上print结果
# ===================================================================
print(f"The final result is: {results}") # [0, 1, 4, 9]3.2 Ray Actor
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.x = 0
def inc(self):
self.x += 1
def get_value(self):
return self.x
# ===================================================================
# 创建driver进程,运行main
# ===================================================================
if __name__ == "__main__":
# ===================================================================
# 创建1个worker进程,具体做了以下事情:
# - 在远端创建Counter实例
# - 在driver端即刻返回对该实例的引用c(称为actor handle)
# - 我们可以在Ray集群的任何结点上传递和使用这个actor handle。即在任何地方,
# 我们可以通过c来invoke对应Counter实例下的各种方法
# ===================================================================
c = Counter.remote()
# ===================================================================
# 阻塞/同步:通过c来invoke远端Counter实例的get_value()方法,并确保方法执行完毕。
# 执行完毕后才能接着执行driver进程上剩下的代码操作
# ===================================================================
print(ray.get(c.get_value.remote())) # 0
# ===================================================================
# Increment the counter twice and check the value again.
# 道理同上,不赘述
# ===================================================================
c.inc.remote()
c.inc.remote()
print(ray.get(c.get_value.remote())) # 23.3 Ray cluster架构简图
现在我们已经通过以上例子对Ray运作原理有了一些基本感知,我们来进一步探索一个ray cluster的组成:

- 在一个ray cluster中,会有一台head node和若干worker node
- Driver process是一种特殊的worker process,它一般负责执行top-level application(例如python中的
__main__),它负责提交想要执行的任务,但却不负责实际执行它们。理论上driver process可以运行在任何一台node内,但默认创建在head node内。 - Worker process负责实际任务的执行(执行Ray Task或Ray Actor中的方法)。
- 每台node中还有一个Raylet process,它负责管控每台node的调度器和共享资源的分配。
- Head node中的GCS将会负责维护整个ray cluster的相关服务。
四、代码细节
本章将解读更多代码实践上的重要细节。我们通过图例的方式抽象出代码运行的过程,而具体代码可参考文中给出的相关链接
4.1 训练入口
ppo_ray相关的训练入口在:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/cli/train_ppo_ray.py。
在main中我们启动了driver进程,并执行训练函数train(args),这里主要做了如下几件事:
- 在ray集群上部署Actor/Ref/Critic/RM实例
- 在ray集群上部署vllm_engines实例
- 训练Actor和Critic模型
我们依次来解读这三个步骤。同时为了在表述上消除歧义,我们接下来谈到“Actor”时,会使用Ray-Actor和PPO-Actor来做区分,从之前的介绍中可知,Ray-Actor是指部署在Ray集群中的远端class,PPO-Actor/Ref/Critic/RM都属于Ray-Actor。
4.2 部署Actor/Ref/Critic/RM实例(1)非共同部署
针对图2.1的情况,我们以PPO-Actor为例,看代码是如何将其部署到Ray集群上的。

-
PPORayActorGroup:创建在driver进程上,可将它理解成一种部署方案,专门负责部署PPO中的4类模型。 -
PPORayActorGroup中维护着self._actor_handlers,它是一个List[ray.actor.ActorHandle],列表中每个元素表示某个远端Ray-Actor的引用,而这个远端Ray-Actor可以是PPO-Actor/Ref/Critic/RM实例。如前文所说,我们可以在ray集群中的任何位置调用这个handler,来对相应的远端Ray-Actor执行操作。 - 在本例中,我们创建了4个Ray-Actor(1个master-actor,3个worker_actor)。每个Ray-Actor都运行在一个worker进程中。在创建Ray-Actor的同时,我们也会去修改worker进程的环境变量。后续当我们在这些worker进程中启动ds_zero相关的分布式配置时,ds会读取这些环境变量信息,这样我们就知道哪些Ray-Actor同时由构成ds中的数据并行组。
- 使用
PPORayActorGroup部署模型实例的代码如下:
model = PPORayActorGroup(
# 为部署该模型的全部实例,我们想用多少台node,例如本例中为2
args.actor_num_nodes,
# 为部署该模型的全部实例,我们每台node上想用多少gpu,例如本例中为2
args.actor_num_gpus_per_node,
# Actor/Critic/Reward/ReferenceRayActor
ActorModelRayActor,
# pg可理解为,在ray cluster中锁定/预留一片资源,然后只在这片资源上部署该模型全部实例。
# (pg维护在Head Node的GCS上,参见3.3)
# 例如本例中,pg锁定的资源为node0 gpu0/1, node1 gpu0/1,
# 我们只在上面部署ActorModelRayActor全部实例
pg=pg,
# 当我们在pg指向的预留资源中分配模型实例时,再进一步指定每个实例占据一张gpu的多少部分
# 等于1说明每个实例占满一张gpu,即“非共同部署”
# 小于1说明每个实例只占部分gpu,即“共同部署”,例如PPO-Actor/Ref共同部署在一张卡上
num_gpus_per_actor=0.75 if pg else 1,
)-
ActorModelRayActor:创建在远端worker进程上,是Ray-Actor。它包含了设置ds_zero分布式环境、加载模型权重、数据集准备、optimizer/scheduler准备、训练等一系列操作。
PPORayActorGroup代码参见:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/launcher.py#L143根据这份代码,大家可自行去找Actor/Critic/Reward/ReferenceRayActor的相关实现。
(2)共同部署
针对图2.2的情况,我们以PPO-Actor为例,看代码是如何将其部署到Ray集群上的。

-
PPORayActorGroup:在driver进程上创建2个PPORayActorGroup,分别管理PPO-Actor,PPO-Ref的部署 - 使用
actor_model = PPORayActorGroup(..., pg = pg, num_gpus_per_actor=0.75)创建PPO-Actor部署方案实例;使用ref_model = PPORayActorGroup(..., pg = pg, num_gpus_per_actor=0.25)创建PPO-Ref部署方案实例 - 这里,两个方案实例使用的pg都是同一个,即这个pg都指向“1台node,每台node 8张卡”这片预留好的资源。
- num_gpus_per_actor = 0.75/0.25是一种创建trick,虽然我们的最终目的是为了让PPO-Actor和PPO-Ref对半分一张卡,但是:
- 假设设置为0.5,当我们实际部署ActorModelRayActor时,Ray先在单卡上部署1个ActorModelRayActor实例,当它准备部署第二个ActorModelRayActor实例时,它发现由于每个实例只占0.5块卡,因此完全可以把第二个实例接着第一个实例部署,这样就导致最终无法让PPO-Actor和PPO-Ref共享一张卡
- 假设设置0.75,当我们在单卡上部署完1个ActorModelRayActor实例后,ray发现单卡剩下的空间不足以部署第2个ActorModelRayActor实例,所以就会把第二个实例部署到别的卡上,这样最终实现PPO-Actor和PPO-Ref共享一张卡
- 所以,这个设置是为了达到不同类型模型的实例共享一张卡的目的,而并非真正指模型实际占据的单卡显存空间。
- 最后,在这一步中,我们对全部ActorModelRayActor共创建8个worker进程,对全部RefenreceModelRayActor共创建8个worker进程,一共创建16个工作进程。
相关代码依然在:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/launcher.py#L143
4.3 部署vllm_engines实例

-
create_vllm_engines:在driver端,我们通过运行该函数来创建vllm_engines,过程相似于4.2节中的介绍,信息都在图中,这里不赘述。 -
LLMRayActor:worker端Ray-Actor,它主要是把vllm实例进行了一些包装,包装的目的是为了让ds_rank0和all vllm ranks间可以进行PPO-Actor的权重通讯(参见2.1(3)) - 在上面的例子中,我们会创建4个worker进程,用于运行管理4个vllm_engine。在每个worker进程内,vllm实例还会创建属于自己的worker进程做分布式运行。
相关代码参见:
4.4 ds_rank0与vllm_ranks之间的通讯
在2.2中,我们说过,PPO-Actor的ds_rank0需要和all_vllm_ranks进行通讯,传递最新的PPO-Actor权重,例如以下ds_rank0要把完整的权重broadcast给16个vllm_ranks:

我们分成如下几步实现这个目标:
(1)创建通信组

如上图所示,创建通信组实际包含了2步。
Step1:
代码来自:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L58
这段代码执行在PPO-Actor0(ds_rank0)所在的worker进程中。这个worker进程将通过handler引用,触发远端每个vllm_engine上的init_process_group操作,并将ds_rank0纳入通讯组
# Create torch group with deepspeed rank 0 and all vllm ranks
# to update vllm engine's weights after each training stage.
#
# Say we have 3 vllm engines and eache of them has 4 GPUs,
# then the torch group is:
# [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
# |ds rank 0 | engine-0 | engine-1 | engine-2 |
#
# For ZeRO-1/2:
# 1. Broadcast parameters from rank 0 to all vllm engines
# For ZeRO-3:
# 1. AllGather paramters to rank 0
# 2. Broadcast parameters from rank 0 to all vllm engines
if self.vllm_engines is not None and torch.distributed.get_rank() == 0:
...
# world_size = num_of_all_vllm_ranks + 1 ds_rank0
world_size = vllm_num_engines * vllm_tensor_parallel_size + 1
...
# =====================================================================
# 遍历每个vllm_engines,将其下的每个vllm_rank添加进通讯组中,这里又分成两步:
# 1. engine.init_process_group.remote(...):
# 首先,触发远程vllm_engine的init_process_group方法
# 2. 远程vllm_engine是一个包装过的vllm实例,它的init_process_group
# 方法将进一步触发这个vllm实例下的各个worker进程(见4.4图例),
# 最终是在这些worker进程上执行“将每个vllm_rank"添加进ds_rank0通讯组的工作
# =====================================================================
refs = [
engine.init_process_group.remote(
# ds_rank0所在node addr
master_address,
# ds_rank0所在node port
master_port,
# 该vllm_engine的第一个rank在"ds_rank0 + all_vllm_ranks“中的global_rank,
# 该值将作为一个offset,以该值为起点,可以推算出该vllm_engine中其余vllm_rank的global_rank
i * vllm_tensor_parallel_size + 1,
world_size,
"openrlhf",
backend=backend,
)
for i, engine in enumerate(self.vllm_engines)
]
# =====================================================================
# 将ds_rank0添加进通讯组中
# =====================================================================
self._model_update_group = init_process_group(
backend=backend,
init_method=f"tcp://{master_address}:{master_port}",
world_size=world_size,
rank=0,
group_name="openrlhf",
)
# =====================================================================
# 确保all_vllm_ranks都已添加进通讯组中
# =====================================================================
ray.get(refs)Step2:
代码来自:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/vllm_worker_wrap.py#L11
这段代码实际运行在每个vllm_engine(即每个包装后的vllm实例)下的worker进程内。例如tp_size=2,那么每个vllm实例下就有2个worker进程,这两个worker进程都会运行这段代码。
class WorkerWrap(Worker):
def init_process_group(self, master_address, master_port, rank_offset, world_size, group_name, backend="nccl"):
"""Init torch process group for model weights update"""
assert torch.distributed.is_initialized(), f"default torch process group must be initialized"
assert group_name != "", f"group name must not be empty"
# =====================================================================
# torch.distributed.get_rank(): 在当前vllm_engine内部的rank,
# 例如在tp_size = 2时,这个值要么是0,要么是1
# rank_offset:当前vllm_engine中的第一个rank在“ds_rank0 + all_vllm_ranks"中的global_rank
# 两者相加:最终得到当前rank在“ds_rank0 + all_vllm_ranks"中的global_rank
# =====================================================================
rank = torch.distributed.get_rank() + rank_offset
self._model_update_group = init_process_group(
backend=backend,
init_method=f"tcp://{master_address}:{master_port}",
world_size=world_size,
rank=rank,
group_name=group_name,
)
...(2)_broadcast_to_vllm
构建好通讯组,我们就可以从ds_rank0广播PPO-Actor权重到all_vllm_ranks上了,这里也分成两步。
Step1:PPO-Actor ds_rank0发送权重
代码在:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L146
这段代码运行在ds_rank0对应的worker进程中
def _broadcast_to_vllm(self):
# avoid OOM
torch.cuda.empty_cache()
model = self.actor.model.module
count, num_params = 0, len(list(model.named_parameters()))
for name, param in model.named_parameters():
count += 1 # empty_cache at last param
# Fire all vllm engines for broadcast
if torch.distributed.get_rank() == 0:
shape = param.shape if self.strategy.args.zero_stage != 3 else param.ds_shape
refs = [
# 远端vllm_engine的每个rank上,初始化一个尺寸为shape的empty weight张量,
# 用于接收广播而来的权重
engine.update_weight.remote(name, dtype=param.dtype, shape=shape, empty_cache=count == num_params)
for engine in self.vllm_engines
]
# For ZeRO-3, allgather sharded parameter and broadcast to all vllm engines by rank 0
# ds_rank0发出权重(视是否使用zero3决定在发出前是否要做all-gather)
with deepspeed.zero.GatheredParameters([param], enabled=self.strategy.args.zero_stage == 3):
if torch.distributed.get_rank() == 0:
torch.distributed.broadcast(param.data, 0, group=self._model_update_group)
ray.get(refs) # 确保所有vllm_ranks接收权重完毕Step2: 各个vllm_ranks接收权重
代码在:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/vllm_worker_wrap.py#L29
代码运行在每个vllm_engine(即每个包装后的vllm实例)下的各个worker进程中。例如tp_size = 2,那么每个vllm实例下有2个worker进程,这2个worker进程都会运行这段代码。
def update_weight(self, name, dtype, shape, empty_cache=False):
"""Broadcast weight to all vllm workers from source rank 0 (actor model)"""
if torch.distributed.get_rank() == 0:
print(f"update weight: {name}, dtype: {dtype}, shape: {shape}")
assert dtype == self.model_config.dtype, f"mismatch dtype: src {dtype}, dst {self.model_config.dtype}"
# 创建同尺寸空张量用于接收ds_rank0广播来的权重
weight = torch.empty(shape, dtype=dtype, device="cuda")
# 接收权重
torch.distributed.broadcast(weight, 0, group=self._model_update_group)
# 使用接收到的权重进行更新
self.model_runner.model.load_weights(weights=[(name, weight)])
del weight4.5 PPO-Actor/Critic Training

正如2.1(4)中所说,我们将部署在ray集群上的PPO-Actor/Ref/Critic/RM实例们进行分组,每组分别负责一份micro-batch的训练,上图刻画了某个组内的训练流程。一组内的训练流程发起自PPO-Actor实例(fit方法),共分成如下步骤执行。
Step1:发送prompts,并从vllm_engine上收集(prompt, response)。
代码参见:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ppo_utils/experience_maker.py#L627
Step2:从Ref/Reward/Critic上收集并处理exps。
代码参见:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ppo_utils/experience_maker.py#L492
Step3: 确保将处理后的exps传送给Critic,并行执行Actor和Critic的训练
- 将exps传送给Critic:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ppo_utils/experience_maker.py#L470
- Actor训练:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L125
- Critic训练:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L122
我们在Actor实例所在的worker进程上出发Actor和Critic的训练。以上代码只给出了训练入口,更多细节需要顺着入口去阅读。Step4:vllm_engine权重更新。
代码参见:https://github.com/OpenRLHF/OpenRLHF/blob/bb46342711a203c457df2fbca5967fd0549557e0/openrlhf/trainer/ray/ppo_actor.py#L130
五、参考
1、OpenRLHF:https://github.com/OpenRLHF/OpenRLHF
2、Ray official architecture whitepaper: https://docs.google.com/document/d/1tBw9A4j62ruI5omIJbMxly-la5w4q_TjyJgJL_jN2fI/preview?tab=t.0#heading=h.iyrm5j2gcdoq
(建议想看ray架构的朋友,直接看这个最新的官方白皮书,不要看2018年的那篇paper了,那个比较老了)
3、Ray official document:https://docs.ray.io/en/latest/index.html
4、推荐一篇快速了解Ray应用层核心概念的blog:https://towardsdatascience.com/modern-parallel-and-distributed-python-a-quick-tutorial-on-ray-99f8d70369b8
5、Ray:https://github.com/ray-project/ray
6、vllm: https://github.com/vllm-project/vllm
#Qwen2.5思维链微调代码实操 + 多卡Lora微调完整代码
最近对于Scaling Law的讨论异常火热。包括ilya大神自己都下场演讲关于大模型数据规模碰壁的问题(参考:机器之心官网发文)。直觉上,现在大模型思维的过程更像是人对一件事情直觉的反应,而不是多步思考和迭代思考的过程。正如下图ilya的PPT中的一张图,10层神经网络可以干人在0.1秒干的事情。而现在大模型上十亿的参数也可能只是解决人经过一分钟思考的回答。像OpenAI o1或者强化对齐可能是通往AGI的方法之一。刚好趁这个机会尝试一下一直没有进行的思维链微调。下面简单介绍一下思维链技术,并且使用阿里通义千问进行CoT数据微调并且简单测试一下。

网上关于思维链微调的实操比较少,甚至对于Qwen的指令微调高质量的文章都不多,许多细节都描述的不清楚,希望这篇文章能够进一步帮助到读者微调Qwen时能够关注到一些细节。
这里感谢魔乐社区赞助了华为昇腾910卡进行微调。尝试了下国产卡做微调的效果还是非常不错!本篇教程专门做了openMind Library的适配,兼容华为昇腾910卡。
友情链接:
- 魔乐社区
- Qwen2.5模型
- SwanLab训练跟踪工具
思维链技术介绍
思维链技术(Chain of Thought,也简称为CoT),最早由Json Wei等人在Chain-of-Thought Prompting Elicits Reasoning in Large Language Models文章提出。简单来说就是通过提示词让模型能够将一个复杂的问题分步思考。比如举个文章中提到的例子(见下图),一个数学问题是:
食堂有 23 个苹果。如果他们用掉了 20 个来做午餐,又买了 6 个,现在他们有多少个苹果?
对于一个人类,他的思考步骤是:
- 食堂有23个苹果,用了20个,所以是23-20=3
- 又买了6个,所以是3+6=9
- 共有9个苹果
当然这个思维过程还能猜的更碎。比如上面的过程中第一个实际上蕴涵了“因为食堂有23个苹果,3-20=3”两个步骤。对于进行了“指令微调”的模型来说,更倾向于简短的回答入,比如直接回答“他现在有XX个苹果”,而且对于一个需要多步计算的数学题往往是错误的。CoT技术的主要目标就是通过提示词让模型一步一步来,像上面的思考步骤那样要求模型不仅回答问题,同时还将问题的生成过程写出来。

Json Wei的这篇文章的工作是在提示词上做的(文中分了few-shot和zero-shot两种方式,简单来说就是给样例和不给样例),用学术些的话来说就是“上下文学习”。这篇文章的实验部分证明了CoT确实能有效提升LLM的推理能力,尤其是数学任务。当然很多人一下就想到了,我能否用微调的方式直接将这种“一步步思考”的能力直接微调到模型中呢?实际上Json Wei大神也很快想到了,所以在紧接着下一篇Scaling Instruction-Finetuned Language Models、Google的FLAN数据集改进版FLAN PaLM中直接引入了CoT数据集,这篇Json Wei虽然不是一作,但也是参与者之一。下图展示了FLAN PaLM所使用微调数据集,和对CoT部分的消融实验,很明显CoT使得模型能够具备更强的zero-shot能力。(建议读一下原文,CoT部分在第四章节,我个人觉得文章中的消融实验不足以直接证明CoT数据对于模型的性能提升,但是目前看来大家在构建finetune数据时还是倾向于将CoT数据构建进去,起码能够显著提升模型使用CoT提示词的能力)。


Qwen2.5思维链微调实操CoT数据集准备
本文使用的是早年收集的一个CoT英文数据集,从质量判断是利用GPT4+提示词生成的,因为时间太久了实在是忘了出处无法附上链接,在这里跟原作者抱歉了orz。现在网上已经有许多高质量的CoT数据集,包括一些数据集专门区分了思考中间过程与返回结果,以及一些将思维步骤使用Special Token进行分隔的。
本文考虑到仅仅是练手项目,选用了最基础的数据集,并且使用经过指令微调的Qwen2.5-7B将英文数据集进一步翻译成了中文+整理成了标准的Instruction-Input-Output样式,以方便对Qwen模型的微调和练手学习。注意这个数据集仅仅是练手,LLM翻译的质量并不高,很容易被要翻译的内容带偏了。下图展示了部分数据集和样式:
{
"instruction": "这家宠物店一共有多少只啮齿动物?宠物店里有6个笼子装着啮齿动物。其中3个笼子里各有10只仓鼠,另外3个笼子里各有5只豚鼠。那么这家宠物店一共养了多少只啮齿动物呢?",
"input": "",
"output": "让我们一步步来思考。\n\n有3个笼子,每个笼子里有10只豚鼠。\n这意味着总共有30只豚鼠。\n\n还有3个笼子,每个笼子里有5只豚兔。\n这意味着总共有15只豚兔。\n\n现在我们可以把30和15加起来得到答案:\n\n总共有45只啮齿动物。\n因此,答案(阿拉伯数字)是45。"
}可以使用如下链接直接下载测试数据集
- 数据集下载链接
环境安装昇腾NPU + openMind Library环境安装
国产卡是未来,这里先放昇腾NPU环境安装!
使用昇腾NPU的话推荐在魔乐社区中找模型,里面能找到完成NPU适配的模型。魔乐社区使用的是openMind Library工具包,这个包支持在Nvidia GPU和Ascend NPU上运行,使用起来和transfomers接口一致。如果说做昇腾NPU迁移的话非常推荐使用。
魔乐社区的模型分为MindSpore支持和Pytorch-NPU支持,这里主要看本地装什么环境,考虑到新手学习的话推荐使用Pytorch-NPU,和Pytorch逻辑基本一致。

驱动安装&验证
首先得确定有NPU卡和NPU相关驱动,驱动是8.0.RC3.beta1,具体可以参考软件安装-CANN商用版8.0.RC3开发文档-昇腾社区。
安装好后的验证方法是运行下面的命令,该命令作用与nvidia-smi类似,这里是查看NPU的状态和性能
npu-smi info可以看到如下信息的话就表示驱动已经安装完成了,左侧是安装成功后运行代码后的结果,右侧是每一部分的含义。

openMind环境搭建
openMind环境安装比较简单,这边列出所需用到的全部安装命令:
# 下载PyTorch安装包
wget https://download.pytorch.org/whl/cpu/torch-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 下载torch_npu插件包
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc3-pytorch2.4.0/torch_npu-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 安装命令
pip3 install torch-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip3 install torch_npu-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 安装openMind Library
pip install openmind[pt]
pip install transformers accelerate datasets peft # 部分场景会用到hf几个包,干脆全装了
# 安装SwanLab
pip install swanlabNvidia GPU + Transformers环境安装
这个流程比较简答,首先也是得确保Nvidia驱动存在,验证命令:
nvida-smi如果没显示同样需要先安装cuda环境,这里贴上CUDA官方安装链接
网上有大量cuda安装安装教程,这里笔者就不赘述了。同样放出transformers环境安装的全部命令:
pip install torch
pip install transformers accelerate datasets peft
# 安装SwanLab
pip install swanlab关于提示词模版构建(大坑)
这里需要强调一下,在使用Qwen2.5的Instruct模型微调时,为了保障效果建议严格按照模型自身的Instruct的提示词模版构建。HF Transformers在4.3几的版本开始支持Chat Templates。Qwen2.5关于Instruct和Chat的提示词模版被直接写到了tokenziers的设置保存中,这导致了很多人在原始代码中找不到instruct提示词格式的构造。很多教程在教微调的时候还用的是Qwen1的老提示词模版或者自己构建的提示词模版,这会严重影响使用已经微调的模型做进一步微调时的效果。建议针对模型微调时一定要仔细检查提示词模版的实现部分。尽量使用模型已经定义好的格式和结构。
可以在Qwen的HF项目中找到提示词模版,点击HF Qwen查看chat_template设置。chat_template默认使用的是一种前端模版语言jinja,并不好看懂,笔者把qwen2.5的提示词模版格式化后粘贴在下文:
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0]['role'] == 'system' %}
{{- messages[0]['content'] }}
{%- else %}
{{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}
{%- endif %}
{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0]['role'] == 'system' %}
{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}
{%- else %}
{{- '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{{- '<|im_start|>' + message.role }}
{%- if message.content %}
{{- '\n' + message.content }}
{%- endif %}
{%- for tool_call in message.tool_calls %}
{%- if tool_call.function is defined %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '\n<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{{- tool_call.arguments | tojson }}
{{- '}\n</tool_call>' }}
{%- endfor %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- endif %}可以看到超级长,因为定义了好几种情况,包括是否有system prompt。以及针对function tools怎么处理等等等等。如果读不懂(我感觉大多数搞deep learning的除了做LLM Finetune也很小有机会去学一个前端语言)我建议用大模型给你逐行解释下,这里附上jinja的官方文档
这里笔者简单提供我所使用的Qwen2.5简化版python模版(下脚本),去除了Function Calling和多轮对话的部分。并且只包含对Instruct和Inputs的处理部分,以及Assitants的生成头。这分为带inputs的版本和不带inputs的版本。我自己专门测试了使用此模版构造的提示词长度上和使用Qwen带chat_template的tokenziers完全一致。你只需要将outputs部分增加一个\n<|im_end|>\n即可直接拼接成finetune LLM模型的targets部分。
PROMPT_DICT = {
"prompt_no_input": """<|im_start|>system\n{instruction}<|im_end|>\n<|im_start|>user\n<|im_end|>\n<|im_start|>assistant\n""",
"prompt_input": """<|im_start|>system\n{instruction}<|im_end|>\n<|im_start|>user\n{input}<|im_end|>\n<|im_start|>assistant\n""",
}如果你直接偷懒使用chat_template来tokenizer仅带outputs部分的数据。你会发现由于Qwen的chat template处理机制,实际上生成的outputs部分会默认带上system prompts。导致最后训练阶段会出现奇怪的内容。Qwen的tokenizers针对未增加system角色的对话输入会自动加上如下提示词
system:You are Qwen, created by Alibaba Cloud. You are a helpful assistant.更神奇的是,这个system prompt居然是个英文的。Qwen可是个中文模型。。。这个system prompt的出现会影响后续的模型微调效果。
可视化工具配置(SwanLab使用教程)

SwanLab可以将微调的许多关键参数自动记录下来并且能够再现可视化查看训练。能够在线或者离线保存+查看训练日志。SwanLab(有可能是唯一的)同时支持记录NVIDIA GPU和华为昇腾NPU设备的日志记录工具。最新版本已经支持对NPU的内存使用、功率、温度等进行记录。甚至还有黑夜模式,方便苦逼研究生大晚上搞科研。:)

关于SwanLab的使用方法可以参考SwanLab官方文档-快速开始
对于Huggingface Transformers或者支持华为昇腾NPU的openMind Library,可以使用SwanLab Integration轻松完成实验数据记录:
...
from swanlab.integration.huggingface import SwanLabCallback
swanlab_call = SwanLabCallback( #
"Ascend_finetune_v2",
experiment_name=os.path.basename(os.path.normpath(training_args.output_dir)),
cnotallow=asdict(data_args)
| asdict(model_args)
| asdict(training_args)
| asdict(lora_config),
public=True,
)
trainer = openmind.Trainer( # 使用hf transformers的话则是把openmind替换为transformers
model=model,
tokenizer=tokenizer,
args=training_args,
callbacks=[swanlab_call], # callback加入进去即可
**data_module,
)
...使用后不仅能进行多图表对比,更重要的是把一大堆的huggingface transformers的训练超参数全部记录下来了,简直调参党福音。

微调代码(多卡,支持华为Ascend卡)
下面附上完整的微调代码。在项目目录下创建finetune.py文件,并将如下代码粘贴进文件中
import copy
import os
import io
import json
import logging
from dataclasses import dataclass, field, asdict
from typing import Dict, Optional, Sequence
import torch
from torch.utils.data import Dataset
try:
import openmind as tf_module
except:
import transformers as tf_module
import transformers
from peft import LoraConfig, get_peft_model
from swanlab.integration.huggingface import SwanLabCallback
IGNORE_INDEX = -100
PROMPT_DICT = {
"prompt_no_input": """<|im_start|>system\n{instruction}<|im_end|>\n<|im_start|>user\n<|im_end|>\n<|im_start|>assistant\n""",
"prompt_input": """<|im_start|>system\n{instruction}<|im_end|>\n<|im_start|>user\n{input}<|im_end|>\n<|im_start|>assistant\n""",
}
@dataclass
class ModelArguments:
model_name_or_path: Optional[str] = field(
default="./weights/Qwen/Qwen2.5-7B-Instruct"
)
@dataclass
class DataArguments:
data_path: str = field(
default="./data/cot_train_cn.jsonl",
metadata={"help": "Path to the training data."},
)
@dataclass
class TrainingArguments(transformers.TrainingArguments):
cache_dir: Optional[str] = field(default=None)
optim: str = field(default="adamw_torch")
model_max_length: int = field(
default=512,
metadata={
"help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."
},
)
def _tokenize_fn(strings: Sequence[str], tokenizer) -> Dict:
"""Tokenize a list of strings."""
tokenized_list = [
tokenizer(
text,
return_tensors="pt",
padding="longest",
max_length=tokenizer.model_max_length,
truncatinotallow=True,
)
for text in strings
]
input_ids = labels = [tokenized.input_ids[0] for tokenized in tokenized_list]
input_ids_lens = labels_lens = [
tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item()
for tokenized in tokenized_list
]
return dict(
input_ids=input_ids,
labels=labels,
input_ids_lens=input_ids_lens,
labels_lens=labels_lens,
)
def jload(f, mode="r", jsnotallow=True):
if not isinstance(f, io.IOBase):
with open(f, mode=mode, encoding="utf-8") as f:
if jsonl:
# Parse JSON Lines
return [json.loads(line) for line in f if line.strip()]
else:
# Parse standard JSON
return json.load(f)
else:
if jsonl:
return [json.loads(line) for line in f if line.strip()]
else:
return json.load(f)
def preprocess(
sources: Sequence[str],
targets: Sequence[str],
tokenizer,
) -> Dict:
"""Preprocess the data by tokenizing."""
examples = [s + t for s, t in zip(sources, targets)]
examples_tokenized, sources_tokenized = [
_tokenize_fn(strings, tokenizer) for strings in (examples, sources)
]
input_ids = examples_tokenized["input_ids"]
labels = copy.deepcopy(input_ids)
for label, source_len in zip(labels, sources_tokenized["input_ids_lens"]):
label[:source_len] = IGNORE_INDEX
return dict(input_ids=input_ids, labels=labels)
class SupervisedDataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(self, data_path: str, tokenizer):
super(SupervisedDataset, self).__init__()
logging.warning("Loading data...")
list_data_dict = jload(data_path)
logging.warning("Formatting inputs...")
prompt_input, prompt_no_input = (
PROMPT_DICT["prompt_input"],
PROMPT_DICT["prompt_no_input"],
)
sources = [
(
prompt_input.format_map(example)
if example.get("input", "") != ""
else prompt_no_input.format_map(example)
)
for example in list_data_dict
]
targets = [
f"{example['output']}\n{tokenizer.eos_token}\n"
for example in list_data_dict
]
logging.warning("Tokenizing inputs... This may take some time...")
data_dict = preprocess(sources, targets, tokenizer)
try:
self.input_ids = data_dict["input_ids"]
except KeyError as e:
raise KeyError("input_ids is invalid") from e
try:
self.labels = data_dict["labels"]
except KeyError as e:
raise KeyError("labels is invalid") from e
def __len__(self):
return len(self.input_ids)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
return dict(input_ids=self.input_ids[i], labels=self.labels[i])
@dataclass
class DataCollatorForSupervisedDataset(object):
"""Collate examples for supervised fine-tuning."""
tokenizer: object
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
input_ids, labels = tuple(
[instance[key] for instance in instances] for key in ("input_ids", "labels")
)
input_ids = torch.nn.utils.rnn.pad_sequence(
input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
)
labels = torch.nn.utils.rnn.pad_sequence(
labels, batch_first=True, padding_value=IGNORE_INDEX
)
return dict(
input_ids=input_ids,
labels=labels,
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
)
def make_supervised_data_module(tokenizer, data_args) -> Dict:
"""Make dataset and collator for supervised fine-tuning."""
train_dataset = SupervisedDataset(
tokenizer=tokenizer, data_path=data_args.data_path
)
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
return dict(
train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator
)
def train():
parser = transformers.HfArgumentParser(
(ModelArguments, DataArguments, TrainingArguments)
)
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
model = tf_module.AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
trust_remote_code=True,
)
# 定义LoRA配置
lora_config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none",
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
tokenizer = tf_module.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
use_fast=False,
trust_remote_code=True,
)
data_module = make_supervised_data_module(tokenizer=tokenizer, data_args=data_args)
swanlab_call = SwanLabCallback(
"Ascend_finetune_v2",
experiment_name=os.path.basename(os.path.normpath(training_args.output_dir)),
cnotallow=asdict(data_args)
| asdict(model_args)
| asdict(training_args)
| asdict(lora_config),
public=True,
)
trainer = tf_module.Trainer(
model=model,
tokenizer=tokenizer,
args=training_args,
callbacks=[swanlab_call],
**data_module,
)
trainer.train()
trainer.save_state()
trainer.save_model(output_dir=training_args.output_dir)
if __name__ == "__main__":
train()多卡训练的话可以使用torchrun,这里附上一个启动多卡的bash脚本,在当前目录下创建finetune.sh,并且粘贴如下脚本:
NPU_NUM=${1:-8}
EXP_NAME=$(basename "$0" .sh)
if [ -d ./output ];then
rm -rf ./output/$EXP_NAME
mkdir -p ./output/$EXP_NAME
else
mkdir -p ./output/$EXP_NAME
fi
# master_port参数需用户根据实际情况进行配置
torchrun --nproc_per_node=$NPU_NUM --master_port=20248 finetune.py \
--model_name_or_path "./weights/Qwen/Qwen2.5-7B-Instruct" \
--data_path data/cot_train_cn.jsonl \
--bf16 True \
--output_dir ./output/$EXP_NAME \
--max_steps 2000 \
--per_device_train_batch_size 2 \
--eval_strategy "no" \
--save_strategy "steps" \
--save_steps 3000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--seed 42 \
--logging_steps 10开启多卡训练的方式如下:
bash finetune.sh <使用的GPU/NPU数量>如果提示登录swanlab,可以在官网完成注册后,使用获取API KEY找到对应的登陆密钥并粘贴,这样将能够使用云上看版随时查看训练过程与结果。
微调效果(附上Gradio代码)
本来准备了Ceval的测试结果,结果不知道为什么Ascend服务器连不上了,等过段时间更新下教程文档。
这里放出使用CoT数据微调qwen-7b-instruct、qwen-0.5b-instruct和使用qwen-7b-instruct(8NPU)的loss结果。可以看到使用8个NPU能带来更好的训练loss表现和稳定性,哪怕在使用同样迭代数据量的情况下,8个NPU依然能带来更好的loss结果。可能更大的loss有助于模型稳定下降。

最后展现下使用gradio完成的官方Qwen2.5-7B-Instruct、基于Qwen2.5-7B在中文alpaca数据集上指令微调、以及cot微调后的模型回复对比。可以看到CoT微调后模型确实具备了“step by step”的回复模式。

当然许多读者注意到了官方模型也展现出了“step by step”的回答模式,这主要是因为现在较新的模型在finetune数据集甚至pretrain数据集中就会预先加入CoT数据,所以模型在进行问答、尤其是数学题问答时,会展现出“步骤分解”的现象。笔者后续会尝试在较早期的demo中更新微调的
附上启用gradio的demo测试代码:
使用pip install gradio安装依赖包
import gradio as gr
from openmind import AutoModelForCausalLM, pipeline
from peft import PeftModel
TOTAL_GPU_NUMS = 8
TOKENIZE_PATH = "~/weightsweights/Qwen/Qwen2.5-7B-Instruct"
MODEL_LIST = {
"office_qwen7b": "~/weights/Qwen/Qwen2.5-7B-Instruct", # 官方模型
"alpaca_qwen7b_lora": "./projects/qwen_finietune_cot/output/qwen25-7B-alpaca", # 7b+alpaca
"cot_qwen7b_lora": "./projects/qwen_finietune_cot/output/qwen25-7Bi-cot", # cot微调
}
model_names = MODEL_LIST.keys()
pipes = dict()
for i, model_name in enumerate(model_names):
save_path = MODEL_LIST[model_name]
model = AutoModelForCausalLM.from_pretrained(save_path)
if model_name[:-5] == "_lora":
model = PeftModel.from_pretrained(model, save_path)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=TOKENIZE_PATH,
framework="pt",
device=f"npu:{i%TOTAL_GPU_NUMS}",
)
pipes[model_name] = pipe
def generate_response(instruct_text, input_text):
messages = [
{
"role": "system",
"content": instruct_text,
},
{
"role": "user",
"content": input_text,
},
]
outputs = [
pipes[model_name](messages, max_new_tokens=256)[-1]["content"]
for model_name in model_names
]
return tuple(outputs)
# 创建 Gradio 界面
demo = gr.Interface(
fn=generate_response, # 函数名
inputs=[
gr.Textbox(label="instruction"),
gr.Textbox(label="input"),
], # 输入文本框
outputs=[gr.Textbox(label=model_name) for model_name in model_names],
)
if __name__ == "__main__":
demo.launch()#ST-MoE
ST-MoE 的目的是设计稳定可迁移的稀疏专家模型。文章从稳定训练探索、微调性能假设、微调性能实践以及设计稀疏模型等多个方面为大家介绍稀疏专家模型。
ST-MoE 的目的是设计稳定可迁移的稀疏专家模型,做了这么几个工作:
1 对影响 MoE 模型训练质量-稳定性 trade-off 的一些稳定性技术做了大规模的研究。
2 引入一种 router z-loss,解决训练不稳定的问题,同时轻微提升模型质量。
3 Sparse 和 Dense 模型的微调分析,重点是超参数的分析。本文表明:不好的超参数使得 Dense 模型相比于 Sparse 模型几乎没有微调增益。
4 设计 Pareto Efficient 的稀疏模型的架构、路由和模型设计的原则。
5 token 路由决策的定性分析。
6 一个 269B 参数的稀疏模型 (计算代价与 32B dense encoder-decoder Transformer 接近,因此取名为 Stable Transferable Mixture-of-Experts, ST-MoE-32B),在多个自然语言处理任务中实现 SOTA 性能。
1 ST-MoE:设计稳定可迁移的稀疏专家模型
论文名称:ST-MoE: Designing Stableand Transferable Sparse Expert Models
论文地址:https//arxiv.org/pdf/2202.08906.pdf
- 1 ST-MoE 论文解读:
1.1 背景:提高稀疏模型的实用性和可靠性
稀疏专家神经网络 (Sparse expert neural networks) 是一种在保证模型训练和推理的成本不显著增加的情况下,大幅度提升模型容量的方法,这种方法可以说很好地体现了大模型的优势,并为当今常用的静态神经网络架构提供了有效的替代方案。
这种方法的特点是:不是对所有输入应用相同的参数,而是动态选择每个输入使用哪些参数。这就可以使得我们极大地扩展模型的 Param.,同时保持每个 token 的 FLOPs 大致恒定。但是,稀疏专家神经网络的缺点之一是其上游预训练和下游微调任务性能之间存在差异,比如在 Switch Transformer[1]里面,作者训练了一个 1.6T 参数量的稀疏模型,但是在 SuperGLUE 等常见基准上进行微调时,其性能却落后于较小的模型。
因此,本文的目的是提高稀疏模型的实用性和可靠性,并为稀疏专家模型提出了额外的分析和设计指南。
1.2 MoE 基本概念汇总
稀疏专家模型 (MoE) 通常是使用一组 Expert 来替换一个神经网络层,每个 Expert 都有各自的权重,输入不是被所有的 Expert 处理,而是只会被一部分 Expert 来处理。因此,必须添加一些机制来决定该把每个输入送给哪个 Expert。一般来讲,会有一个 路由器 (router) 或者门控网络 (gating 网络) 来解决这个问题。
在自然语言处理里面,混合专家层 (Mixture-of-Experts, MoE) 的输入是 token x ,然后使用 router 把它分配 (route) 给最合适的 k 个 Expert。
router 的做法是这样:

下面是关于 MoE 的一些术语的解释:
| 术语 | 定义 |
| Expert | 通常是一个 MLP 网络,每个 Expert 的权重独立 |
| Router | 计算每个 token 发送到每个 Expert 的概率的网络 |
| Top-n Routing | 是一个路由算法,每个 token 被发送到 n 个 Expert |
| Load Balancing Loss | 鼓励每一组 token 被均匀分发给各个 Expert 的辅助损失函数,有利于加速器并行处理数据块来提高硬件效率 |
| Group Size | 全局批量大小被分成更小的 Group。每个 Group 被考虑用于 Expert 之间的负载平衡。增加它会增加内存、计算和通信 |
| 比如 Batch Size 为 B,Group 数量为 G,则每个组有 B/G token | |
| Capacity Factor (CF) | 每个 Expert 只能处理固定数量的 token,Capacity 常是通过均匀地划分 Expert、token 的数量来设置的:Capacity=token/Expert。但是有些时候可以通过设置 CF 来改变 Capacity,使之变为:CF×token/Expert |
| 如果 CF 增加,会创建一些额外的 Buffer,当负载不平衡时丢弃更少的 token。但是,增加 CF 也会带来额外的内存和计算的开销 | |
| FFN | 线性层,激活函数,线性层 |
| Encoder-Decoder | Transformer 架构的变体,由 Encoder 和 Decoder 组成,Encoder 的注意力机制会 Attention 所有的 token,Decoder 的注意力机制是自回归的方式 |
1.3 稀疏模型的稳定训练探索1:结构上的微调
如下图1所示,稀疏模型通常会受到训练不稳定性的影响,比标准 Dense 的 Transformer 中稳定性更差。
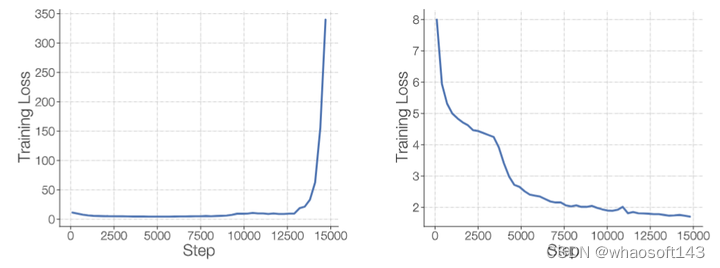
图1:左:不稳定的稀疏模型训练。右:稳定的稀疏模型训练
下面作者介绍了一些 Transformer 模型的改进,这些改进会提高 MoE 模型的质量,但是会影响训练的稳定性。
1 GELU Gated Linear Units (GEGLU)
就是使用 GELU 激活函数:

作者在图2中通过实验表明,去掉 GEGLU 层,或者是 RMS scale 参数都会提升训练的稳定性,但是会很大程度地影响模型的质量。

图2:去掉 GEGLU 层,或者是 RMS scale 参数的结果
1.4 稀疏模型的稳定训练探索2:训练时加噪声

可以发现:输入抖动和 Dropout 都提高了稳定性,但会导致模型质量显着下降。
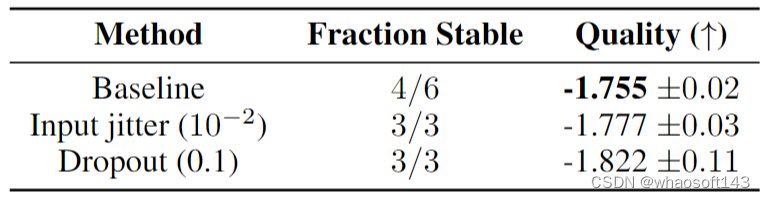
图3:训练时加噪声的实验结果
1.5 稀疏模型的稳定训练探索3:Router Z-Loss
作者在训练 ST-MoE 的时候使用了3个目标函数的加权混合:



1.6 稀疏模型的微调性能假设:一个泛化性问题
性能最好的语言模型通常是通过 (1) 对大量数据 (如互联网数据) 进行预训练然后 (2) 对感兴趣的任务 (如 SuperGLUE) 进行微调来获得的。
作者对稀疏模型的泛化性能做了一个假设,即:稀疏模型容易过拟合,通过 SuperGLUE 中的 Commitment Bank 和 ReCORD 两个任务来说明这个问题。Commitment Bank 有 250 个训练样本,而 ReCORD 有超过 100,000 个,很适合研究这个问题。
如下图4所示,作者比较了 Dense L 和 ST-MoE-L 模型的微调性能。每个模型都对来自 C4 语料库的 500B 个标记进行预训练,这两个模型的 FLOPs 与 770M 参数的 T5-Large encoder-decoder 大致接近。ST-MoE 模型有 32 个 Expert,Expert 频率为 1/4 (每4个 FFN 层被 MoE 层替换)。
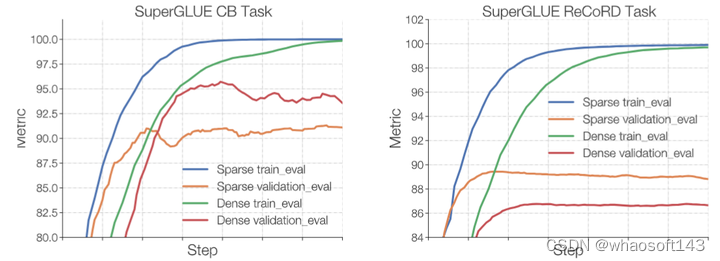
图4:稀疏模型更容易过拟合
实验结果如上图4所示。可以看到不论是使用更大的数据集 ReCORD,还是更小的数据集 Commitment Bank,稀疏模型都比对标的密集模型更快地实现训练精度 100%。但是对于小数据集 Commitment Bank,密集模型的验证集微调性能更好,对于大数据集 ReCORD,稀疏模型的验证集微调性能更好。
这说明,稀疏模型在小数据集上面的泛化性能有待加强。
1.7 稀疏模型的微调性能实践1:微调参数的子集提升泛化性
为了对抗过度拟合,作者尝试在微调期间仅更新模型参数的子集,分别尝试了这么几种:更新所有参数,只更新非 MoE 参数,只更新 MoE 参数,只更新 Self-Attention 参数和 Encoder-Decoder 的 Attention 参数,只更新非 MoE 的 FFN 参数。实验结果如下图5所示,只更新 MoE 参数的效果是最差的,其他的效果都差不多。而只更新非 MoE 参数可能是加速和减少内存进行微调的有效方法。
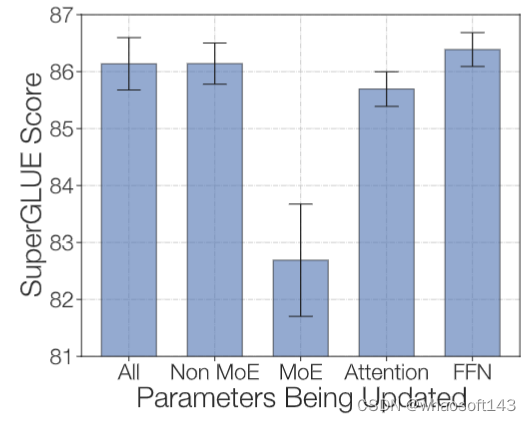
图5:微调参数的子集的实验结果
1.8 稀疏模型的微调性能实践2:微调策略的影响
作者希望探究稀疏和密集模型对微调协议的敏感性,因此研究了2个超参数:Batch Size 和学习率。作者在 C4 的500B 令牌上预训练 Dense-L 和 ST-MoE-L,然后在 SuperGLUE 上进行微调,实验结果如下图6所示。稀疏和密集模型在不同的 Batch Size 和学习率之间具有截然不同的性能。
稀疏模型受益于较小的 Batch Size 和更高的学习率。与过拟合假设一致,这两种变化都可能在微调期间通过更高的噪声来提高泛化能力。
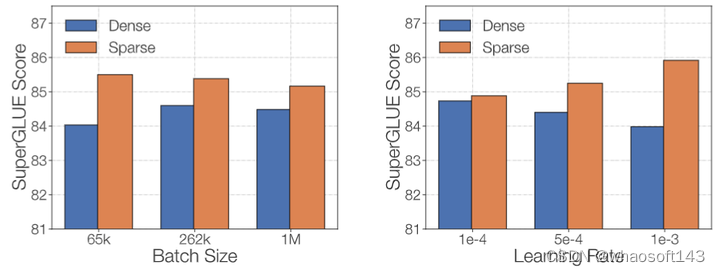
图6:微调策略对稀疏模型和密集模型的影响
1.9 设计一个稀疏模型
作者给出了一些设计稀疏模型的结论,为了叙述方便这里直接说结论了:
- 推荐使用 top-2 routing,即每个 token 给2个 Expert 处理,Capacity Factor 设置为 1.25。
- 在评测过程中可以改变 Capacity Factor,以适应新的内存/计算要求。
- 在每个稀疏层之前或之后使用 Dense FFN 可以提高模型质量。
1.10 实验结果
作者设计和训练 269B 稀疏参数模型 (FLOPs 与 32B 密集模型匹配)。评测的基准是 SuperGLUE benchmark,它包含下面这些子任务:
- sentiment analysis (SST-2)
- word sense disambiguation (WIC)
- sentence similarity (MRPC, STS-B, QQP)
- natural language inference (MNLI, QNLI, RTE, CB)
- question answering (MultiRC, RECORD, BoolQ)
- coreference resolution (WNLI, WSC)
- sentence completion (COPA)
- sentence acceptability (CoLA)
模型架构的配置:
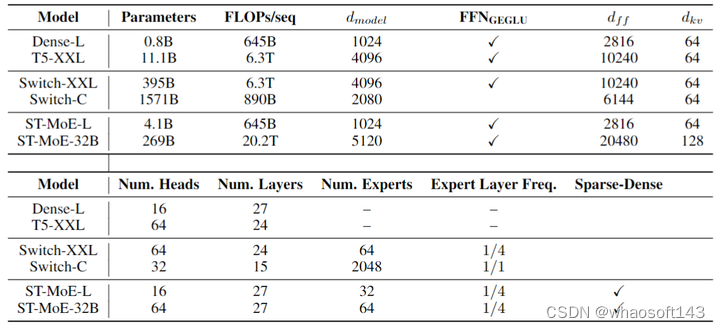
图7:模型架构配置
如下图8所示是 ST-MoE-L 模型实验结果。模型是稀疏和密集的 T5-Large (L),在 C4 数据集上预训练 500k steps。可以观察到,在大多数任务上面 ST-MoE-L 模型都取得了提升。
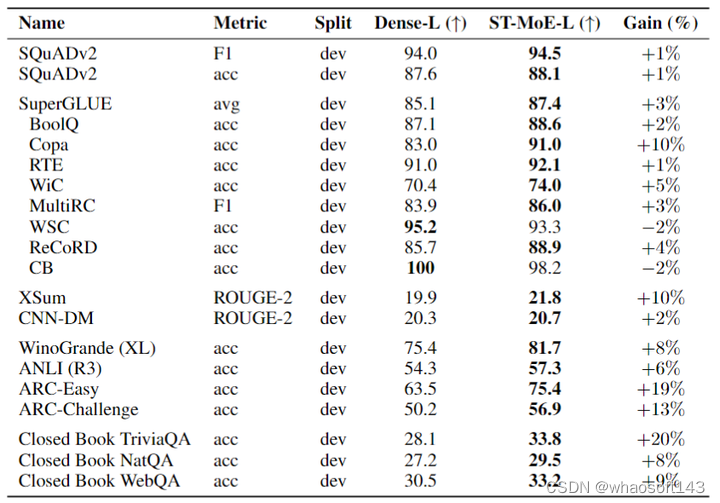
图8:ST-MoE-L 模型实验结果
ST-MoE-32B 模型的训练数据集是图9,一共 1.5T tokens,每个 Batch 是 1M tokens,优化器默认使用的是 Adafactor,10k steps 的学习率 warm-up,学习率 scheduler 是 inverse square root decay。
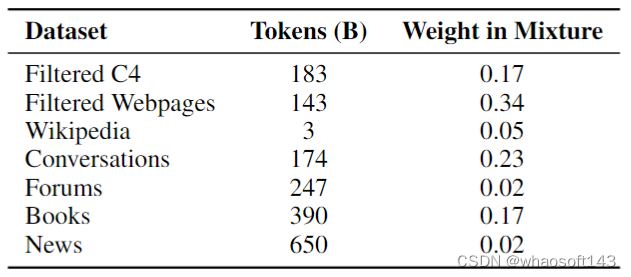
图9:ST-MoE-32B 模型预训练数据
实验结果如下图10所示。在 SuperGLUE 上,ST-MoE-32B 模型超过了之前最先进的模型,在测试集上实现了 91.2 的平均分数。对于摘要数据集 XSum 和 CNN-DM,ST-MoE-32B 模型实现了 SOTA 的性能,而无需对训练或微调进行额外的更改。在3个 closed book QA 任务中的2个上,ST-MoE-32B 模型改进了之前的最新技术,分别是 Closed book WebQA 和 Closed book NatQA。
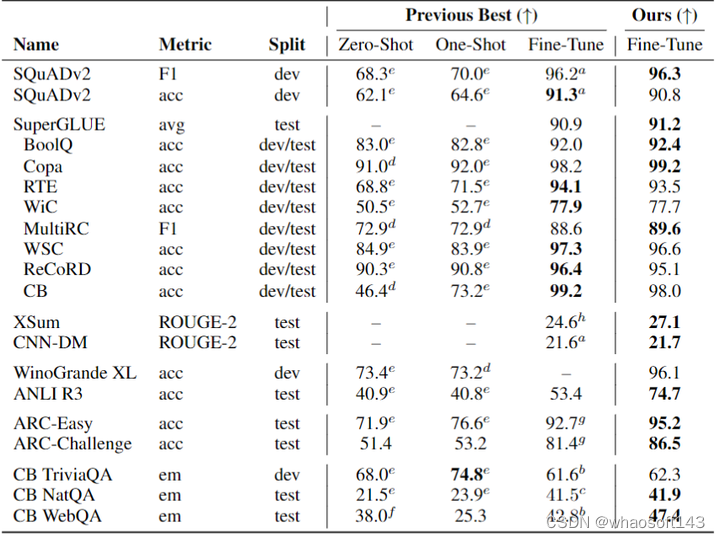
图10:ST-MoE-32B 模型实验结果
但是,ST-MoE-32B 的模型还是有一些缺点的,比如在小一点的数据集 SQuAD 上面的性能是 90.8,并未超过之前的 91.3。同样的小数据集 CB, WSC, ReCoRD 的性能也是同样如此。Closed Book Trivia QA 的性能也没能达到最好。
#下一尺度预测为何能超越扩散模型?
本文是关于NIPS 2024最佳论文VAR(Visual Autoregressive Modeling)的深度解读,介绍了VAR作为一种新的图像生成范式,通过下一尺度预测代替传统的下一词元预测,显著提升了图像生成的速度和质量,并在ImageNet图像生成任务上超越了扩散模型DiT。文章还探讨了VAR的潜在缺陷和改进方向。
今年四月,北大和字节跳动在 Arxiv 上发表了论文Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction,介绍了一种叫做 Visual Autoregressive Modeling (视觉自回归建模,VAR)的全新图像生成范式。这种自回归生成方法将高清图像用多尺度词元图像表示,并用下一尺度预测代替了此前常用的下一词元预测。在 ImageNet 图像生成任务上,VAR 的表现超越了 DiT。我们组的同学第一时间看了这篇论文,大家都觉得这篇论文有不小的创新,但其方法能否完全代替扩散模型还有待验证。通常来说,这篇论文的关注度会逐渐降下去,但近期发生的两件大事将 VAR 论文的热度推向了空前的高度:论文一作的严重违纪行为招致字节跳动对其索赔 800 万元、论文被评选为 Neurips 2024 会议的最佳论文。借此机会,我决定认真研究一下这篇论文并把我的学习结果分享给大家。
在这篇博文中,我会先回顾与 VAR 密切相关的早期工作 VQVAE 和 VQGAN,再介绍论文的方法细节与实验结果,最后分享我对该工作的测试结果与原理探究。在读 VAR 论文时,我发现有个地方的设计存在缺陷。相关实验结果表明, VAR 论文并没有完整地分析出这套方法有效的原因。欢迎大家仔细阅读这一部分并提出自己的思考与见解。
论文链接:https://arxiv.org/abs/2404.02905
VQGAN 原理回顾
VAR 算是 VQGAN 工作的改进版,而 VQGAN 又是 VQVAE 工作的改进版。要了解 VAR 的背景知识,最直接的方法就是回顾 VQVAE 与 VQGAN 这两个经典工作。我们先从自回归这种生成范式开始聊起,再将目光移向图像自回归生成,最后复习 VQVAE, VQGAN, Transformer 的实现细节。
图像自回归生成
自回归(Autoregressive)是一种直观易懂的序列生成范式:给定序列前 个元素, 模型输出第 个元素;把新元素添加进输入序列,再次输出第 个元素.....。以下是文本自回归生成的一个示例:
(空) -> 今
今 -> 天
今天 -> 早
今天早 -> 上具体来说,模型的输出并不是下一个元素应该是什么,而是下一个元素可能是什么。也就是说,模型的输出是下一个元素的概率分布。通过不断对下一个元素采样,我们就能随机生成出丰富多样的句子。

自回归生成仅适用于有顺序的序列数据。为了用自回归生成图像,我们需要做两件事:1)把图像拆分成一个个元素;2)给各个元素标上先后顺序。为此,最简单的做法是将图像拆成像素,并从左到右,从上到下地给图像生成像素。比如下图是经典自回归图像生成模型 PixeICNN 的示意图。假设图像有 个像素,并按顺序从左上到右下标号。在生成第 5 个像素时, 模型只能利用已经生成好的前 4 个像素的信息。模型的输出是一个概率分布, 表示灰度值大小分别取 的概率。

顺带一提,建模概率分布的方法有很多种,这里我们使用的分布被称为类别分布(categorical distribution)。这种方法的好处是形式简洁,可以用简单的算法采样,缺点是元素的取值必须是离散的。比如虽然图像的灰度值理论上可以取0~1 中间的任何实数(假设灰度值被归一化了),但我们用上图所示的 PixelCNN 时,只能表示0, 1/255, 2/255, ..., 1 这 256 种灰度值,而不能表示更加精确的值。
VQVAE
PixelCNN 虽然能做图像生成,但它的效率太慢了:由于像素是逐个生成的,要生成几个像素,就要运行几次神经网络。能不能加速生成过程呢?如果要生成的图像更小一点就好了。
为了加速 PixelCNN,借助图像压缩网络,VQVAE 工作提出了一种两阶段的图像生成方法:先生成压缩图像,再用图像压缩网络将其复原成真实图像。由于压缩图像的像素数较少,而复原压缩图像的速度又很快,整套生成方法的速度快了很多。
以下是一个 VQVAE 的生成示例。根据 PixelCNN 输出的类别分布,我们可以采样出一些由离散值构成的压缩图像。这些离散值就和 NLP 里的文字一样,每一种值都有一种特殊的含义。我们可以认为离散值表示原始图像中一大块像素的颜色。借助图像压缩网络的解码器,我们可以把压缩图像复原成清晰的原始图像。

VQVAE 的训练顺序和生成顺序相反。我们先训练一个图像压缩网络。这种由编码器和解码器组成的图像压缩网络被称为自编码器,压缩出来的图像被称为隐图像(latent image)。训练好了自编码器后,我们再把训练集的所有图像都转成隐图像,让 PixelCNN 学习生成隐图像。比较有趣的是,训练 PixelCNN 时,只会用到编码器;而生成时,只会用到解码器。

在上述讨论中,我们略过了一个实现细节:该怎么让网络以离散值为输入或输出呢?输入离散值倒还好办,在 NLP 中,我们用嵌入层把离散的词语变成连续向量,这里的做法同理。可怎么让网络输出离散值呢?这里就要用到向量离散化(vector quantization, VQ)操作了。
离散化操作我们都很熟悉,将小数四舍五入至整数就是一种最常见的离散化。四舍五入,本质上是让一个小数变成最近的整数。同理,对于向量而言,假设我们已经准备好了一些向量(对应前面的「整数」),那么向量离散化就表示把输入的任意向量变成最近的已知向量。这里的「最近」指的是欧几里得距离。
具体示例如下所示。编码器可以输出一个由任意向量构成的二维特征。通过查找嵌入层里的最近邻,这些任意的向量会被转换成整数,表示最近邻的索引。索引可以被认为是 NLP 里的词元 (token),这样编码器输出特征就被转换成了词元构成的隐图像。而在将隐图像输入进解码器时,我们把嵌入层当成一张表格,利用隐图像里的索引,以查表的形式将隐图像转换成由嵌入构成的特征。准确来说,这个把图像压缩成离散隐图像的自编码器才被叫做 "VQVAE",但有时我们也会用 VQVAE 代表整套两阶段生成方法。

上图中的「编码器输出特征」、「词元」、「嵌入」在不同论文里有不同的叫法,且一般作者都只会用数学符号来称呼它们。这里我们用了 VAR 论文的叫法。
嵌入层的具体学习过程我们不在此展开,对这块知识不熟悉的读者可以去仔细学习 VQVAE 论文。
VQGAN
VQVAE 的效果并不理想,这是因为它的压缩网络和生成网络都不够强大。为此,VQGAN 工作同时改进了 VQVAE 的两个网络。
- VQGAN 工作将离散自编码器 VQVAE 换成了 VQGAN。在 VQVAE 的基础上,VQGAN 在训练时添加了感知误差和 GAN 误差,极大提升了自编码器的重建效果。
- VQGAN 工作还把生成模型从 PixelCNN 换成了 Transformer。
Transformer
Transformer 是目前最主流的主干网络。相比其他网络架构,Transformer 的最大特点是序列里的元素仅通过注意力操作进行信息交互。因此,为了兼容文本自回归生成任务,最早的 Transformer 使用了两个特殊设计:
- 由于注意力操作不能反映输入元素的顺序,词元嵌入在输入进网络之前,会和蕴含了位置信息的位置编码相加。
- 自回归生成要求之前的词元不能看到之后的词元的信息。为了控制词元间的信息传播,Transformer 给自注意力操作加上了掩码。
VQGAN 用了完全相同的设计,把图像词元当成文本词元用 Transformer 来生成。
从词元预测到尺度预测
上述的传统图像自回归生成都是采用下一个词元预测策略:
- 将图像用自编码器拆成离散词元。
- 从左到右、从上到下按顺序逐个生成词元。
尽管通过自编码器的压缩,要生成的词元数已经大大减少,但一个个去生成词元还是太慢了。为了改进这一点,VAR 提出了一种更快且更符合直觉的自回归生成策略:
- 将图像用自编码器拆成多尺度的离散词元。比如, 原来一张隐图像的大小是 , 现在我们用一系列尺度为 的由词元构成的图像来表示一张隐图像。
- 从最小的词元图像开始,从小到大按尺度生成词元图像。
在这种策略下,我们要同时修改自编码器和生成模型。我们来看一下 VAR 是怎么做的。
多尺度残差离散自编码器
先来看自编码的修改。现在词元图像不是一张图像,而是多张不同尺度的图像。由于词元图像的定义发生了改变,编码器特征和嵌入的定义也要发生改变,如下图所示。

向量离散化部分我们可以沿用 VQVAE 的做法。现在新的问题来了:编码器的输出和解码器的输入都只是一张图像。该怎么把多尺度的图像组合成一张图像呢?
最简单的做法是完全不修改编码器和解码器,还是让它们输入输出最大尺度的图片。只有在中间的向量离散化/查表部分,我们才把这些图片下采样。

VAR 用了一种更加高级的做法:用残差金字塔来表示这些隐空间特征。我们先来回顾一下拉普拉斯金字塔这一经典图像处理算法。我们知道,图像每次下采样的时候,都会损失一些信息。既然如此,我们可以将一张高分辨率的图像表示为一张低分辨率的图像及其在各个分辨率下采样后的信息损失。如下图所示,最右侧的一列表示拉普拉斯金字塔的输出。

在计算拉普拉斯金字塔时,我们不断下采样图像,并计算当前尺度的图像和下一尺度的复原图像(通过上采样复原)的残差。这样,通过不断上采样最低尺度的图像并加上每一层的残差,我们最终就能精准复原出高分辨率的原图像。
现在,我们想把类似的金字塔算法应用到编码器特征上。该怎么把最大尺度的编码器特征拆解成不同尺度的图像的累加呢?

在计算拉普拉斯金字塔时,本质上我们用到了两类操作:退化和复原。对于图像而言,退化就是下采样,复原就是上采样。那么,对于编码器输出的隐空间特征,我们也需要定义类似的退化和复原操作。比较巧妙的是,VAR 并没有简单地把退化和复原定义为下采样和上采样,而是参考_Autoregressive Image Generation using Residual Quantization_ 这篇论文,将向量离散化引入的误差也算入金字塔算法的退化内。也就是说,我们现在的目标不是让编码器特征金字塔的累加和编码器特征相等,而是想办法让嵌入金字塔的累加和编码器特征尽可能相似,如下图所示。

基于这一目标,我们可以把退化定义为下采样加上离散化、查表,复原定义成上采样加一个可学习的卷积。我们来看看在这种新定义下,原来 VQVAE 的向量离散化操作和查表操作应该怎么做。
先看新的多尺度向量离散化操作。这个操作的输入是编码器特征,输出是一系列多尺度词元图像。算法从最低尺度开始执行,每个循环输出当前尺度的词元图像,并将残差特征作为下一个循环的输入特征。

对于多尺度查表操作,输入是多尺度词元图像,输出是一张最大尺度的隐空间特征,它将成为自编码器的解码器的输入。在这步操作中,我们只需要分别对各个尺度的词元图像做查表和复原(上采样+卷积),再把各尺度的输出加起来,就能得到一个和编码器特征差不多的特征。注意,为了方便理解,这几张示意图都省略了部分实现细节,且一些数值不是十分严谨。比如在查表时,我们可以让不同尺度的词元共享一个嵌入层,也可以分别指定嵌入层。

总结一下这一小节。为了实现尺度自回归生成,我们需要把图像编码成多尺度的词元图像。VAR 采用了一种多尺度残差离散化操作:将编码器特征拆解成最小尺度的特征以及不同尺度的残差特征,并对不同尺度的特征分别做向量离散化。这种做法不仅能高效地将特征拆解成多个尺度,还有一个额外的好处:原来 VQVAE 仅对最大尺度的特征做向量离散化,离散化后的误差会很大;而 VAR 把向量离散化引入的误差分散到多尺度离散化中,巧妙地降低了离散化的误差,提升了 VQVAE 的重建精度。
下一尺度自回归生成
把图像压缩成多尺度词元图像后,剩下的事就很简单了。我们只需要把所有词元拆开,拼成一维词元序列,之后用 Transformer 在这样的序列上训练即可。由于现在模型的任务是下一尺度预测,模型会一次性输出同尺度各词元的概率分布,而不是仅仅输出下一个词元的。这样,尽管序列总长度变长了,模型的整体生成速度还是比以前快。同时,随着预测目标的变更,自注意力的掩码也变了。现在同尺度的词元之间可以互相交换信息,只是前一尺度的词元看不到后面的词元。以下是一个词元图像在下一词元和下一尺度预测任务下的注意力掩码示意图及生成过程示意图。

除此之外,VAR 的 Transformer 还做了一些其他修改:1)除了给每个词元加上一维位置编码外,同一尺度的词元还会加上同一个表示尺度序号的位置编码。所有位置编码都是可学习的,而不是预定义的正弦位置编码。2)Transformer 与解码器的共用嵌入层。另外,在生成新一层时,为了复用已经生成好的图像的信息,新一层的初始嵌入是通过对上一层的生成结果 bicubic 上采样得到的。
该 Transformer 的其他设计都与 VQGAN 相同。比如,Transformer 采用了 decoder-only 的结构。为了添加 ImageNet 类别约束,第一层的输入是一个表示类别的特殊词元。训练时用的误差函数是交叉熵函数。

ImageNet 图像生成定量实验
VAR 的方法部分我们看得差不多了,现在来简单看一下实验部分。论文宣称 VAR 在图像生成实验和参数扩增实验上都取得了不错的成果。特别地,VAR 的拟合能力胜过了 DiT,生成速度是 DiT 的 45 倍以上。我们就主要看一下 VAR 在ImageNet256 × 256图像生成上的实验结果。以下是论文中的表格。我同时还附上了何恺明团队的 MAR 工作(_Autoregressive Image Generation without Vector Quantization_)的实验结果。

先比一下 DiT 和 VAR。先看速度,不管是多大的模型,DiT 的速度都远远慢于 VAR。再看以 FID 为代表的图像拟合指标。VAR 在参数量为 600M 左右时并没有 DiT 效果好。但继续增加参数量后,DiT 的 FID 没有变好的趋势,而 VAR 的 FID 一直在降。最终 VAR 的 FID 甚至超过了 ImageNet 的验证集,可以认为 FID 再低的也意义不大了。
再比一下 MAR 和 VAR。MAR 的刷指标能力更加恐怖,943M 的模型就能有 1.55 的 FID。但根据 MAR 论文,其速度是 DiT-XL 的 5 倍左右,也就是说 VAR 还是比 MAR 快,是 MAR 速度的 9 倍左右。
ImageNet 图像生成已经被各个模型刷到头了。FID 结果能说明 VAR 的拟合能力很强,最起码不逊于 DiT。但在更有挑战性的文生图任务上,VAR 的效果还有待验证。另外,虽然刷指标的时候 DiT 用了 250 步采样,但实际用起来的时候一般就是采样 20 步。如果算上蒸馏的话,采样步数能缩小到 4 步。加上这些加速技巧的话,VAR 不见得会比 DiT 快。
VAR 各尺度生成结果
看完了论文的主要内容,我来分享一下我对 VAR 的一些理论分析与实验结果。
先看一下随机采样结果。我用的是最大的d=30 的 VAR 模型。在官方采样脚本的默认配置下,两个随机种子 (0, 15) 的输出如下所示。用到的图像类别为火山、灯塔、老鹰、喷泉,每个类别的图各生成了两张。图像的生成速度很快,一秒就生成了全部 8 张图片。

我们还可以观察每个尺度的生成结束后解码出的临时图片。和我们预估得一样,图像是按从粗到精的顺序逐渐生成的。

为了进一步探究每一个尺度负责生成哪些图像成分,我们可以做如下的实验:从某个尺度开始,随机更换新的随机数生成器。这样,每张动图里不变的部分就是前几个尺度生成好的内容;不断在变的部分就是后几个尺度负责的内容。可以看出,从第三个尺度开始,图像的内容就基本固定下来了,也就是说结构信息是在前两个尺度里生成的。越往后,图像的细节越固定。

这个结果还挺令人惊讶的:难道这么小的特征图就已经决定了图像的整体内容?让我们来仔细探究这一点。
有缺陷的单尺度生成
不知道大家在学习 VAR 的采样算法时候有没有感到不对劲:在生成同一个尺度的词元图像时,每个词元是独立地在一个概率分布里采样。
而根据作者在论文里的说法,VAR 的尺度自回归是一种新的自回归概率模型:

其中, 表示从小到大第 个尺度的词元图像, 共 个尺度。同一个尺度的词元图像 的每个词元的分布是并行生成的。这也就是说, VAR 的这种训练(用交叉嫡误差)和采样方式是认为每张词元图像的概率等于所有词元的概率的乘积, 词元的分布之间是独立的:
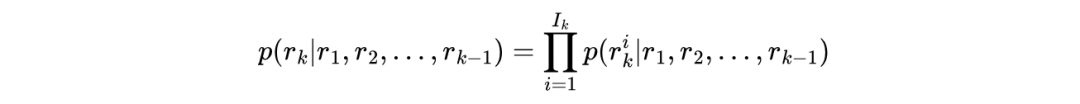
其中, 表示第 个尺度的第 个词元, 为第 个尺度的词元总数。我觉得上面这个等式是不成立的,哪怕有之前尺度的信息作为约束,同一尺度的每个词元的概率分布之间不会是互不相关的。且随着 的增大, 上面这个式子的误差会越来越大。
词元之间的采样互相独立,理论上会导致图像出现不连贯的地方。比如,假设一个图像词元表示个像素,那么每隔 16 个像素图像就会出现「断层」。但是,为什么 VAR 的输出结果那么正常呢?仔细分析 VAR 的生成算法,我们可以发现有两项设计提升了图像的连续性:
- VAR 的自编码器使用了向量离散化操作。这个操作会让解码器的输入总是合理的,解码器也总是会输出连贯的图像。
- 在生成一个新尺度的图像时,模型输入会被初始化成之前尺度的图像的 bicubic 上采样。bicubic 采样保证了词元嵌入之间的连续性。

此外,为了进一步缓解独立采样带来的负面影响,VAR 在生成完第二或第三个尺度后就已经把图像的整体内容确定下来了,后面的生成只是略微影响图像细节而已(因为随着词元数量变多,独立采样的误差越大)。这个结论已经在前文的可视化结果中验证了。为了证明只有前几个尺度是重要的,我做了一个大胆的实验:用 Transformer 生成完前两个尺度的词元后,后续所有词元都随机生成。如下图所示,我展示了固定前两个尺度的输出后,多个随机种子下的生成结果。结果显示,如果前两个尺度的词元生成得比较好,后面词元无论采样得多乱,都不怎么会影响最终的图像质量。

根据这些实验结果,我认为 VAR 真正有效的原因并不能用「下一尺度预测这种全新生成范式更好」这样粗浅的话来概括。VAR 中最核心的组件可能是其多尺度残差离散自编码器。这个编码器至少做到了以下几件事:
- 使用向量离散化确保解码器的输入总是合理的。
- 使用多尺度残差设计,且下一尺度的残差图像不仅记录了因下采样而导致的信息损失,还记录了因向量离散化带来的精度损失。相比简单的、人类能够理解的拉普拉斯金字塔,这种可学习的多尺度拆分方法或许更加合理。
- 使用 bicubic 对低尺度词元图上采样。这步固定的操作让生成的图像总是连续的。
当然,这几件事是互相耦合的。不进行更深入的实验的话,我们难以解耦出 VAR 中最有效的设计。
多尺度生成其实并不是什么新奇的思想。之前 StyleGAN 和 Cascaded Diffusion 都用了类似的策略。然而,VAR 做了一个大胆的设计:同一尺度的不同词元在采样时是相互独立的。令人惊讶的是,这种在数学上不太合理的设计没怎么降低图像的质量。并且,得益于这一设计,VAR 能够并行地对同一尺度的词元采样,极大地提升了生成速度。
总结与评论
此前,以经典工作 VQGAN 为代表的图像自回归生成模型无论在速度上还是图像质量上都不尽如人意。究其原因,下一个图像词元预测的建模方式既不够合理,也拖慢了生成速度。为此,VAR 提出一种新式自回归策略:将词元图像拆分成多个尺度,通过下一尺度预测实现图像生成。为了兼容这一设计,VAR 对 VQGAN 的自编码器和 Transformer 都进行了修改:自编码器能够将图像编码成多尺度的残差词元图像,而 Transformer 同时输出同一尺度每个词元的独立分布。实验表明,VAR 在 ImageNet 图像生成指标上超越了以 DiT 为代表的扩散模型,且生成速度至少比 DiT 快 45 倍。另外,还有实验表明 VAR 符合扩增定律:增加参数量即可提升模型性能。
我个人认为,和其他前沿生成模型一样,VAR 在 ImageNet 上的表现已经满分了。它能否完成更困难的图像生成认为还有待验证。最近字节跳动发布了 VAR 的文生图版本:Infinity,但这个模型还没有开源。我们可以持续关注 VAR 的各个后续工作。VAR 的生成速度也没有比 DiT 快上那么多,通过减小采样步数,再加上模型蒸馏,DiT 不会比 VAR 慢。当然,VAR 或许也存在进一步加速的可能,只是相关研究暂时没有扩散模型那么多。
VAR 的数学模型是存在缺陷的:词元图的分布不应该等于词元间的独立分布的乘积。最起码论文里没有任何相关分析(用了类似做法的 MAR 论文也没有分析)。通过一些简单的生成实验,我们发现由于 VAR 在其他设计上提升了输出图像的连续性,哪怕同一尺度的词元间是独立采样,甚至是随机均匀采样,模型的输出质量也不会太差。我们需要通过更深入的实验来挖掘 VAR 的生效原理。
我觉得如果一个科研工作能够解释清楚 VAR 中哪些模块起到了最主要的作用,并取其精华,去其糟粕,提出一个更好的生成模型,那这会是一个很不错的工作。我觉得能够探索的方向有:
- VAR 的前几个尺度的词元图是最重要的。能不能用更好的方式,比如用扩散模型,来生成前几个尺度的图像,而更大尺度的词元图用一个比 Transformer 更高效的模型来生成。这样模型的质量和效率能进一步提升。
- VAR 还是用了 VQ 自编码器。无论怎么样,VQ 操作都会降低模型的重建质量。但另一方面,VQ 也能起到规范解码器输入的作用。究竟我们能不能把 VQ 自编码器换成精度更高的 VAE 呢?换了之后怎么设计多尺度编码呢?
#傅里叶特征 (Fourier Feature)
位置编码背后的理论解释——傅里叶特征 (Fourier Feature)与核回归
本文深入探讨了位置编码背后的理论解释,特别是傅里叶特征与核回归的关系。文章通过实验和理论分析,解释了为什么在多层感知机中使用位置编码能够提升模型拟合连续数据的高频信息能力,并讨论了傅里叶特征在StyleGAN3中的应用。
最近我在看位置编码最新技术时,看到了一个叫做 "NTK-aware" 的词。我想:「"NTK"是什么?Next ToKen (下一个词元)吗?为什么要用这么时髦的缩写?」看着看着,我才发现不对劲。原来,NTK 是神经网络理论里的一个概念,它从 kernel regression 的角度解释了神经网络的学习方法。基于 NTK 理论,有人解释了位置编码的理论原理并将其归纳为一种特殊的 Fourier Feature (傅里叶特征)。这么多专有名词一下就把我绕晕了,我花了几天才把它们之间的关系搞懂。
在这篇文章里,我主要基于论文_Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains_ (后文简称为「傅里叶特征论文」),介绍傅里叶特征这一概念。为了讲清这些理论的发展脉络,我会稍微讲一下 NTK 等理论概念。介绍完傅里叶特征后,我还会讲解它在其他方法中的应用。希望读完本文后,读者能够以这篇论文为基点,建立一个有关位置编码原理的知识网络,以从更深的层次来思考新的科研方向。
用 MLP 表示连续数据
我们先从一个具体的任务入手,直观体会傅里叶特征能够做些什么事。
我们知道,神经网络,哪怕是最简单的多层感知机(MLP),都有着很强的泛化能力:训练完毕后,对于训练集里完全没见过的输入,网络也能给出很正确的输出。特别地,如果新输入恰好和训练集的某个输入很近,那么它的输出也会和对应的训练集输出很近;随着新输出与训练集输入的距离不断增加,新输出也会逐渐变得不同。这反映了神经网络的连续性:如果输入的变化是连续的,那么输出的变化也是连续的。
基于神经网络的这一特性,有人想到:我们能不能用神经网络来表示连续数据呢?比如我想表达一张处处连续的图像,于是我令神经网络的输入是(x, y) 表示的二维坐标,输出是 RGB 颜色。之后,我在单张图像上过拟合这个 MLP。这样,学会表示这张图像后,哪怕输入坐标是分数而不是整数,神经网络也能给出一个颜色输出。
这种连续数据有什么好处呢?我们知道,计算机都是以离散的形式来存储数据的。比如,我们会把图像拆成一个个像素,每个像素存在一块内存里。对于图像这种二维数据,计算机的存储空间还勉强够用。而如果想用密集的离散数据表达更复杂的数据,比如 3D 物体,计算机的容量就捉襟见肘了。但如果用一个 MLP 来表达 3D 物体的话,我们只需要存储 MLP 的参数,就能获取 3D 物体在任何位置的信息了。
这就是经典工作神经辐射场 (Neural Radiance Field, NeRF) 的设计初衷。NeRF 用一个 MLP 拟合 3D 物体的属性,其输入输出如下图所示。我们可以用 MLP 学习每个 3D 坐标的每个 2D 视角处的属性(这篇文章用的属性是颜色和密度)。根据这些信息,利用某些渲染算法,我们就能重建完整的 3D 物体。

上述过程看起来好像很简单直接。但在 NeRF 中,有一个重要的实现细节:必须给输入加上位置编码,MLP 才能很好地过拟合连续数据。这是为什么呢?让我们先用实验复现一下这个现象。
MLP 拟合连续图像实验
为了快速复现和位置编码相关的问题,我们简单地用一个 MLP 来表示图像:MLP 的输入是 2D 坐标,输出是此处的三通道 RGB 颜色。我为这篇博文创建一个 GitHub 文件夹 https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/FourierFeature ,该实验的 Notebook 代码在文件夹的image_mlp.ipynb 中,欢迎大家 clone 项目并动手尝试。

一开始,我们先导入库并可视化要拟合的图片。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.io import read_image, ImageReadMode
from torchvision.transforms.functional import to_pil_image
from tqdm import tqdm
from einops import rearrange
def viz_image(pt_img: torch.Tensor):
pil_img = to_pil_image(pt_img)
display(pil_img)
input_image = read_image('misuzu.png', ImageReadMode.RGB)
input_image = input_image.to(torch.float32) / 255
input_image = input_image.unsqueeze(0)
input_image = F.interpolate(input_image, (256, 256), mode='bilinear')
viz_image(input_image[0])
我们再定义一个 MLP 类。稍后我们会并行地传入二维坐标。具体来说, 我们会将输入定义为一个 形状的数据,其中通道数 2 表示 (i, j) 格式的坐标。由于输入是以图像的形式并行输入的,我们可以用 的 2 D 卷积来表示二维数据上的并行 MLP。所以在下面这个 MLP 里, 我们只用到 卷积、激活函数、归一化三种层。按照傅里叶特征论文的官方示例, 网络最后要用一个 Sigmoid 激活函数调整输出的范围。
class MLP(nn.Module):
def __init__(self, in_c, out_c=3, hiden_states=256):
super().__init__()
self.mlp = nn.Sequential(
nn.Conv2d(in_c, hiden_states, 1), nn.ReLU(), nn.BatchNorm2d(hiden_states),
nn.Conv2d(hiden_states, hiden_states, 1), nn.ReLU(), nn.BatchNorm2d(hiden_states),
nn.Conv2d(hiden_states, hiden_states, 1), nn.ReLU(), nn.BatchNorm2d(hiden_states),
nn.Conv2d(hiden_states, out_c, 1), nn.Sigmoid()
)
def forward(self, x):
return self.mlp(x)之后我们来定义训练数据。在一般的任务中,输入输出都是从训练集获取的。而在这个任务中,输入是二维坐标,输出是图像的颜色值。输出图像input_image 我们刚刚已经读取完毕了,现在只需要构建输入坐标即可。我们可以用下面的代码构建一个[1, 2, H, W] 形状的二维网格,grid[0, :, i, j] 处的数据是其坐标(i, j) 本身。当然,由于神经网络的输入一般要做归一化,所以我们会把原本0~H 和0~W 里的高宽坐标缩放都到0~1。最终grid[0, :, i, j]==(i/H, j/W)。
H, W = input_image.shape[2:]
h_coord = torch.linspace(0, 1, H)
w_coord = torch.linspace(0, 1, W)
grid = torch.stack(torch.meshgrid([h_coord, w_coord]), -1).permute(2, 0, 1).unsqueeze(0)准备好一切后,我们就可以开始训练了。我们初始化模型model 和优化器optimizer,和往常一样训练这个 MLP。如前所述,这个任务的输入输出非常直接,输入就是坐标网格grid,目标输出就是图片input_image。每训练一段时间,我们就把当前 MLP 拟合出的图片和误差打印出来。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MLP(2).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
n_loops = 400
input_image = input_image.to(device)
grid = grid.to(device)
for epoch in tqdm(range(n_loops)):
output = model(grid)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0 or epoch == n_loops - 1:
viz_image(output[0])
print(loss.item())运行代码,大致能得到如下输出。可以看到,从一开始,图像就非常模糊。

不过,如果我们在把坐标输入进网络前先将其转换成位置编码——一种特殊的傅里叶特征,那么 MLP 就能清晰地拟合出原图片。这里我们暂时不去关注这段代码的实现细节。
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c // 2) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.cat([torch.sin(x), torch.cos(x)], dim=1)
return x
feature_length = 256
model = MLP(feature_length).to(device)
fourier_feature = FourierFeature(2, feature_length, 10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
n_loops = 400
for epoch in tqdm(range(n_loops)):
x = fourier_feature(grid)
output = model(x)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0 or epoch == n_loops - 1:
viz_image(output[0])
print(loss.item())
prev_output = outputclass FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c // 2) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.cat([torch.sin(x), torch.cos(x)], dim=1)
return x
feature_length = 256
model = MLP(feature_length).to(device)
fourier_feature = FourierFeature(2, feature_length, 10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
n_loops = 400
for epoch in tqdm(range(n_loops)):
x = fourier_feature(grid)
output = model(x)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0 or epoch == n_loops - 1:
viz_image(output[0])
print(loss.item())
prev_output = output
简单地对比一下,此前方法的主要问题是 MLP 无法拟合高频的信息(如图块边缘),只能生成模糊的图像。而使用位置编码后,MLP 从一开始就能较好地表示高频信息。可见,问题的关键在于如何让 MLP 更好地拟合数据的高频信息。

接下来,我们来从一个比较偏理论的角度看一看论文是怎么分析位置编码在拟合高频信息中的作用的。
核回归
傅里叶特征论文使用了神经正切核(Nerual Tangent Kernel, NTK)来分析 MLP 的学习规律,而 NTK 又是一种特殊的核回归 (Kernel Regression) 方法。在这一节里,我会通过代码来较为仔细地介绍核回归。下一节我会简单介绍 NTK。
和神经网络类似,核回归也是一种数学模型。给定训练集里的输入和输出,我们建立这样一个模型,用来拟合训练集表示的未知函数。相比之下,核回归的形式更加简单,我们有更多的数学工具来分析其性质。
核回归的设计思想来源于我们对于待拟合函数性质的观察:正如我们在前文的分析一样, 要用模型拟合一个函数时,该模型在训练数据附近最好是连续变化的。离训练集输入越近,输出就要和其对应输出越近。基于这种想法, 核回归直接利用和所有数据的相似度来建立模型:假设训练数据为 , 我们定义了一个计算两个输入相似度指标 , 那么任意输入 的输出为:

也就是说,对于一个新输入 ,我们算它和所有输入 的相似度 ,并把相似度归一化。最后的输出 是现有 的相似度加权和。
这样看来,只要有了相似度指标,最终模型的形式也就决定下来了。我们把这个相似度指标称为「核」。至于为什么要把它叫做核,是因为这个相似度指标必须满足一些性质,比如非负、对称。但我们这里不用管那么多,只需要知道核是一种衡量距离的指标,决定了核就决定了核回归的形式。
我们来通过一个简单的一维函数拟合实验来进一步熟悉核回归。该实验代码在项目文件夹下的kernel_regression.ipynb 中。
先导入库。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt再创建一个简单的非线性函数,做为我们的拟合目标。这个函数就是一个简单的周期为 的正弦函数乘上线性函数。我们可以简单可视化一下函数在 之间的图像。
def func(x):
return np.sin(np.pi * x) * (1 - x)
xs = np.linspace(-1, 1, 100)
ys = func(xs)
plt.plot(xs, ys)
plt.show()
基于这个函数,我们等间距地选一些点做为训练数据。
sample_x = np.linspace(-1, 1, 10)
sample_y = func(sample_x)
plt.scatter(sample_x, sample_y)
plt.show()
有了数据后,我们来用核回归根据数据拟合这个函数。在决定核回归时,最重要的是决定核的形式。这里我们用正态分布的概率密度函数来表示核,该核唯一的超参数是标准差,需要我们根据拟合结果手动调整。标准差为1 的标准正态分布核的图像如下所示。由于最后要做归一化,正态分布密度函数的系数被省略掉了。
def kernel_func(x_ref, x_input, sigma=1):
return np.exp(-(x_input-x_ref)**2 / (2 * sigma**2))
xs = np.linspace(-1, 1, 100)
ys = kernel_func(0, xs)
plt.plot(xs, ys)
plt.show()
可以从图像中看出,离某输入越近(假设该输入是0),那么相似度就越高。这符合我们对于相似度函数的要求。
有了核函数后,我们就直接得到了模型。根据核回归模型计算结果的函数为kernel_regression。函数参数xs, ys 表示训练数据,x_input 表示测试时用的输入坐标,sigma 是核回归的超参数。
假设有n 个训练样本,有m 个测试输入,那么我们要计算每个测试输入对每个训练输入的n * m 个相似度,这些相似度会存到矩阵weight 里。为此,我们需要对xs 和x_input 做一些形状变换,再用上面定义的核函数kernel_func 求出每对相似度。有了相似度后,我们根据公式计算点乘结果weight_dot 及归一化系数weight_sum,并最终计算出核回归的结果res。
基于这个函数,我们可以将测试输入定义成[-1, 1] 上一些更密集的坐标,并用上面定义好的 10 个样本做为训练集,得到核回归的结果。
def kernel_regression(xs, ys, x_input, sigma=1):
# xs: [n, ]
# ys: [n, ]
# x_input: [m, ]
N = xs.shape[0]
xs = np.expand_dims(xs, 1)
ys = np.expand_dims(ys, 1)
x_input = np.expand_dims(x_input, 0)
x_input = np.repeat(x_input, N, 0)
weight = kernel_func(xs, x_input, sigma) # [n, m]
weight_sum = np.sum(weight, 0)
weight_dot = weight.T @ ys
weight_dot = np.squeeze(weight_dot, 1)
res = weight_dot / weight_sum
return res
sigma = 1
xs = np.linspace(-1, 1, 100)
ys = kernel_regression(sample_x, sample_y, xs, sigma)
plt.title(f'sigma = {sigma}')
plt.plot(xs, ys)
plt.show()我们可以通过修改sigma 来得到不同的拟合效果。以下是我的一些结果:

可以看出,标准差越小,模型倾向于过拟合;随着标准差变大,曲线会逐渐平缓。我们需要不断调整超参数,在过拟合和欠拟合之间找到一个平衡。这种现象很容易解释:正态分布核函数的标准差越小,意味着每个训练数据的影响范围较小,那么测试样本更容易受到少数样本的影响;标准差增大之后,各个训练样本的影响开始共同起作用,我们拟合出的函数也越来越靠近正确的函数;但如果标准差过大,每个训练样本的影响都差不多,那么模型就什么都拟合不了了。
从实验结果中,我们能大致感受到核回归和低通滤波很像,都是将已知数据的平均效果施加在未知数据上。因此,在分析核回归的时候,往往会从频域分析核函数。如果核函数所代表低通滤波器的带宽 (bandwidth)越大,那么剩下的高频信息就更多,核回归也更容易拟合高频信息较多的数据。
神经正切核
那么,核回归是怎么和神经网络关联起来的呢?有研究表明,在一些特殊条件下,MLP 的最终优化结果可以用一个简单的核回归来表示。这不仅意味着我们可以神奇地提前预测梯度下降的结果,还可以根据核回归的性质来分析神经网络的部分原理。这种能表示神经网络学习结果的核被称为神经正切核(NTK)。
这些特殊条件包括 MLP 无限宽、SGD 学习率的学习率趋近 0 等。由于这些条件和实际神经网络的配置相差较远,我们难以直接用核回归预测复杂神经网络的结果。不过,我们依然可以基于这些理论来分析和神经网络相关的问题。傅里叶特征的分析就是建立在 NTK 上的。
NTK 的形式为

其中, 是参数为 的神经网络, 为内积运算。简单来看, 这个式子是说神经网络的核回归中, 任意两个向量间的相似度等于网络对参数的偏导的内积的期望。基于 NTK, 我们可以分析出很多神经网络的性质, 比如出乎意料地, 神经网络的结果和随机初始化的参数无关, 仅和网络结构和训练数据有关。
在学习傅里叶特征时, 我们不需要仔细研究这些这些理论, 而只需要知道一个结论: 一般上述 NTK 可以写成标量函数 , 也就是可以先算内积再求偏导。这意味用核回归表示神经网络时, 真正要关心的是输入间的内积。别看 NTK 看起来那么复杂, 傅里叶特征论文其实主要就用到了这一个性质。
为了从理论上讲清为什么 MLP 难以拟合高频,作者还提及了很多有关 NTK 的分析,包括一种叫做谱偏差(spectral bias)的现象:神经网络更容易学习到数据中的低频特征。可能作者默认读者已经熟悉了相关的理论背景,这部分论述经常会出现逻辑跳跃,很难读懂。当然,不懂这些理论不影响理解傅里叶特征。我建议不要去仔细阅读这篇文章有关谱偏差的那一部分。
正如我们在前文的核回归实验里观察到的,核回归模型能否学到高频取决于核函数的频域特征。因此,这部分分析和 NTK 的频域有关。对这部分内容感兴趣的话可以去阅读之前有关谱偏差的论文。
傅里叶特征的平移不变性
在上两节中,我们花了不少功夫去认识谱回归和 NTK。总结下来,其实我们只需要搞懂两件事:
- 神经网络最终的收敛效果可以由简单的核回归决定。而核回归重点是定义两个输入之间的相似度指标(核函数)。
- 表示神经网络的核回归相似度指标是 NTK,它其实又只取决于两个输入的内积。
根据这一性质,我们可以部分解释为什么在文章开头那个 MLP 拟合连续图像的实验中,位置编码可以提升 MLP 拟合高频信息的能力了。这和位置输入的特性有关。
当 MLP 的输入表示位置时, 我们希望模型对输入位置具有平移不变性。比如我们现在有一条三个样本组成的句子 。当我们同时改变句子的位置信息时, 比如将句子的位置改成 时, 网络能学出完全一样的东西。但显然不对输入位置做任何处理的话, 和 对神经网络来说是完全不同的意思。
而使用位置编码的话, 情况就完全不同了。假如输入数据是二维坐标 , 我们可以用下面的式子建立一个维度为 的位置编码:

其中 是系数, 是一个投影矩阵, 用于把原来 2 D 的位置变成一个更长的位置编码。当然, 由于位置编码中既要有 也要有 , 所以最终的位置编码长度为 。
根据我们之前的分析, NTK 只取决于输入间的内积。算上位置编码后, 一对输入位置 的内积为:

而根据三角函数和角公式可知:
这样,上面那个内积恰好可以写成:

上式完全由位置间的相对距离决定。上式决定了 NTK,NTK 又决定了神经网络的学习结果。所以,神经网络的收敛结果其实完全取决于输入间的相对距离,而不取决于它们的绝对距离。也因此,位置编码使得 MLP 对于输入位置有了平移不变性。
加入位置编码后,虽然 MLP 满足了平移不变性,但这并不代表 MLP 学习高频信息的能力就变强了。平移不变性能给我们带来什么好处呢?作者指出,当满足了平移不变性后,我们就能手动调整 NTK 的带宽了。回想一下我们上面做的核回归实验,如果我们能够调整核的带宽,就能决定函数是更加高频(尖锐)还是更加低频(平滑)。这里也是同理,如果我们能够调大 NTK 的带宽,让它保留更多高频信息,那么 MLP 也就能学到更多的高频信息。
作者在此处用信号处理的知识来分析平移不变性的好处,比如讲了新的 NTK 就像一个重建卷积核 (reconstruction filter),整个 MLP 就像是在做卷积。还是由于作者省略了很多推导细节,这部分逻辑很难读懂。我建议大家直接记住推理的结论:平移不变性使得我们能够调整 NTK 的带宽,从而调整 MLP 学习高频的能力。
那我们该怎么调整 NTK 的带宽呢?现在的新 NTK 由下面的式子决定:

为了方便分析, 我们假设 和 都是一维实数。那么, 如果我们令 的话:

这个式子能令你想到什么? 没错, 就是傅里叶变换。 较大的项就表示 NTK 的高频分量。我们可以通过修改前面的系数 来手动调整 NTK 的频域特征。我们能看到, 位置编码其实就是在模拟傅里叶变换,所以作者把位置编码总结为傅里叶特征。
作者通过实验证明我们可以手动修改 NTK 的频谱。实验中,作者令 。 表示位置编码只有第一项: 。不同 时 NTK 的空域和频域示意图如下所示。可以看出, 令 时, 即傅里叶特征所有项的系数都为 1 时, NTK 的高频分量不会衰减。这也意味着 MLP 学高频信息和低频信息的能力差不多。

随机傅里叶特征
现在我们已经知道傅里叶特征的公式是什么, 并知道如何设置其中的参数 了。现在, 还有一件事我们没有决定:该如何设置傅里叶特征的长度 呢?
既然我们说傅里叶特征就是把输入的位置做了一次傅里叶变换,那么一般来讲,傅里叶特征的长度应该和原图像的像素数一样。比如我们要表示一个 的图像, 那么我们就需要令 表示不同方向上的频率: 。但这样的话, 神经网络的参数就太多了。可不可以令 更小一点呢?
根据之前的研究Random features for large-scale kernel machines 表明,我们不需要密集地采样傅里叶特征, 只需要稀疏地采样就行了。具体来说, 我们可以从某个分布随机采样 个频率 来, 这样的学习结果和密集采样差不多。当然, 根据前面的分析, 我们还是令所有系数 。在实验中,作者发现, 从哪种分布里采样都无所谓,关键是 的采样分布的标准差,因为这个标准差决定了傅里叶特征的带宽,也决定了网络拟合高频信息的能力。实验的结果如下:

我们可以不管图片里 是啥意思, 只需要知道 是三组不同的实验就行。虚线是密集采样傅里叶特征的误差, 它的结果反映了一个「较好」的误差值。令人惊讶的是, 不管从哪种分布里采样 , 最后学出来的网络误差都差不多。问题的关键在于采样分布的标准差。把标准差调得够好的话, 模型的误差甚至低于密集采样的误差。
也就是说,虽然我们花半天分析了位置编码和傅里叶变换的关系,但我们没必要照着傅里叶变换那样密集地采样频率,只需要随机选一些频率即可。当然,这个结论只对 MLP 拟合连续数据的任务有效,和 Transformer 里的位置编码无关。
代码实现随机傅里叶特征
现在,我们可以回到博文开头的代码,看一下随机傅里叶特征是怎么实现的。
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c // 2) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.cat([torch.sin(x), torch.cos(x)], dim=1)
return x
feature_length = 256
model = MLP(feature_length).to(device)
fourier_feature = FourierFeature(2, feature_length, 10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
n_loops = 400
for epoch in tqdm(range(n_loops)):
x = fourier_feature(grid)
output = model(x)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0 or epoch == n_loops - 1:
viz_image(output[0])
print(loss.item())
prev_output = output傅里叶特征通过类FourierFeature 实现。其代码如下:
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c // 2) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.cat([torch.sin(x), torch.cos(x)], dim=1)
return x构造函数里的 fourier_basis 表示随机傅里叶特征的频率, 对应论文公式里的b, scale表示采样的标准差。初始化好了随机频率后, 对于输入位置 x,只要按照公式将其投影到长度为 out_c / 2 的向量上, 再对向量的每一个分量求 即可。按照之前的分析,我们令所有系数 为 1 , 所以不需要对输出向量乘系数。
傅里叶特征在 StyleGAN3 里的应用
傅里叶特征最经典的应用就是 NeRF 这类过拟合连续数据任务。除此之外,傅里叶特征另一次大展身手是在 StyleGAN3 中。
StyleGAN3 希望通过平滑地移动生成网络的输入来使输出图片也发生对应的移动。为此,StyleGAN3 将生成网络的输入定义为频域上的一个有限带宽图像信号:根据信号处理知识,我们能够将有限带宽信号转换成空域上无限连续的信号。也就是说,不管输入的分辨率(采样率)多低,我们都能够平滑地移动输入图片。StyleGAN3 借助随机傅里叶特征来实现这样一个频域图像。
以下代码选自 StyleGAN3 中傅里叶特征的构造函数。这个函数的关键是随机生成一些频率固定,但方向可以不同的傅里叶频率。函数先随机采样了一些频率,再将它们归一化,最后乘上指定的带宽bandwidth,保证所有频率大小相等。
class SynthesisInput(torch.nn.Module):
def __init__(self,
w_dim, # Intermediate latent (W) dimensionality.
channels, # Number of output channels.
size, # Output spatial size: int or [width, height].
sampling_rate, # Output sampling rate.
bandwidth, # Output bandwidth.
):
super().__init__()
self.w_dim = w_dim
self.channels = channels
self.size = np.broadcast_to(np.asarray(size), [2])
self.sampling_rate = sampling_rate
self.bandwidth = bandwidth
# Draw random frequencies from uniform 2D disc.
freqs = torch.randn([self.channels, 2])
radii = freqs.square().sum(dim=1, keepdim=True).sqrt()
freqs /= radii * radii.square().exp().pow(0.25)
freqs *= bandwidth
phases = torch.rand([self.channels]) - 0.5而在使用这个类获取网络输入时,和刚刚的 MLP 实现一样,我们会先生成一个二维坐标表格grid 用于查询连续图片每一处的颜色值,再将其投影到各个频率上,并计算新向量的正弦函数。
这段代码中,有两块和我们自己的实现不太一样。第一,StyleGAN3 允许对输入坐标做仿射变换(平移和旋转)。仿射变换对坐标的影响最终会转化成对三角函数相位phases 和频率freqs 的影响。第二,在计算三角函数时,StyleGAN3 只用了正弦函数,没有用余弦函数。
def forward(self, ...):
...
# Transform frequencies.
phases = ...
freqs = ...
# Construct sampling grid.
theta = torch.eye(2, 3, device=w.device)
theta[0, 0] = 0.5 * self.size[0] / self.sampling_rate
theta[1, 1] = 0.5 * self.size[1] / self.sampling_rate
grids = torch.nn.functional.affine_grid(theta.unsqueeze(0), [1, 1, self.size[1], self.size[0]], align_corners=False)
# Compute Fourier features.
x = (grids.unsqueeze(3) @ freqs.permute(0, 2, 1).unsqueeze(1).unsqueeze(2)).squeeze(3) # [batch, height, width, channel]
x = x + phases.unsqueeze(1).unsqueeze(2)
x = torch.sin(x * (np.pi * 2))
x = x * amplitudes.unsqueeze(1).unsqueeze(2)
...
# Ensure correct shape.
x = x.permute(0, 3, 1, 2) # [batch, channel, height, width]
return x我们在 MLP 拟合连续图像的实验里复现一下这两个改动。首先是二维仿射变换。给定旋转角theta 和两个方向的平移tx, ty,我们能够构造出一个的仿射变换矩阵。把它乘上坐标[x, y, 1] 后,就能得到仿射变换的输出。我们对输入坐标grid 做仿射变换后得到grid_ext,再用grid_ext 跑一遍傅里叶特征和 MLP。
N, C, H, W = grid.shape
tx = 50 / H
ty = 0
theta = torch.tensor(torch.pi * 1 / 8)
affine_matrix = torch.tensor([
[torch.cos(theta), -torch.sin(theta), tx],
[torch.sin(theta), torch.cos(theta), ty],
[0, 0, 1]
]
).to(device)
grid_ext = torch.ones(N, 3, H, W).to(device)
grid_ext[:, :2] = grid.clone()
grid_ext = grid_ext.permute(0, 2, 3, 1)
grid_ext = (grid_ext @ affine_matrix.T)
grid_ext = grid_ext.permute(0, 3, 1, 2)[:, :2]
x = fourier_feature(grid_ext)
output = model(x)
viz_image(output[0])在示例代码中,我们可以得到旋转 45 度并向下平移 50 个像素的图片。可以看到,变换成功了。这体现了连续数据的好处:我们可以在任意位置对数据采样。当然,由于这种连续数据是通过过拟合实现的,在训练集没有覆盖的坐标处无法得到有意义的颜色值。
之后,我们来尝试在傅里叶特征中只用正弦函数。我们将投影矩阵的输出通道数从out_c / 2 变成out_c,再在forward 里只用sin 而不是同时用sin, cos。经实验,这样改了后完全不影响重建质量,甚至由于通道数更多了,重建效果更好了。
class FourierFeature(nn.Module):
def __init__(self, in_c, out_c, scale):
super().__init__()
fourier_basis = torch.randn(in_c, out_c) * scale
self.register_buffer('_fourier_basis', fourier_basis)
def forward(self, x):
N, C, H, W = x.shape
x = rearrange(x, 'n c h w -> (n h w) c')
x = x @ self._fourier_basis
x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W)
x = 2 * torch.pi * x
x = torch.sin(x)
return xStyleGAN3 论文并没有讲为什么只用sin,网上也很少有人讨论傅里叶特征的实现细节。我猜傅里叶特征并不是非得和傅里叶变换完全对应,毕竟它只是用来给神经网络提供更多信息,而没有什么严格的意义。只要把输入坐标分解成不同频率后,神经网络就能很好地学习了。
只用sin 而不是同时用sin, cos 后,似乎我们之前对 NTK 平移不变的推导完全失效了。但是,根据三角函数的周期性可知,只要是把输入映射到三角函数上后,网络主要是从位置间的相对关系学东西。绝对位置对网络来说没有那么重要,不同的绝对位置只是让所有三角函数差了一个相位而已。只用sin 的神经网络似乎也对绝对位置不敏感。为了证明这一点,我把原来位于[0, 1] 间的坐标做了一个幅度为10 的平移。结果网络的误差几乎没变。
for epoch in tqdm(range(n_loops)):
x = fourier_feature(grid + 10)
output = model2(x)
loss = F.l1_loss(output, input_image)
optimizer.zero_grad()
loss.backward()
optimizer.step()根据这些实验结果,我感觉是不是从 NTK 的角度来分析傅里叶特征完全没有必要?是不是只要从直觉上理解傅里叶特征的作用就行了?按我的理解,傅里叶特征在真正意义在于显式把网络对于不同频率的关注度建模出来,从而辅助网络学习高频细节。
总结
在这篇博文中,我们学习了傅里叶特征及其应用,并顺带了解其背后有关核回归、NTK 的有关理论知识。这些知识很杂乱,我来按逻辑顺序把它们整理一下。
为了解释为什么 NeRF 中的位置编码有效,傅里叶特征论文研究了用 MLP 拟合连续数据这一类任务中如何让 MLP 更好地学到高频信息。论文有两大主要结论:
- 通过从 NTK 理论的分析,位置编码其实是一种特殊的傅里叶特征。这种特征具有平移不变性。因此,神经网络就像是在对某个输入信号做卷积。而我们可以通过调整傅里叶特征的参数来调整卷积的带宽,也就是调整网络对于不同频率的关注程度,从而使得网络不会忽略高频信息。
- 傅里叶特征的频率不需要密集采样,只需要从任意一个分布随机稀疏采样。影响效果的关键是采样分布的标准差,它决定了傅里叶特征的带宽,也就决定了网络是否能关注到高频信息。
由于这些结论比较抽象,我们可以通过一个简单的二维图像拟合实验来验证论文的结论。实验表明直接将坐标输入给 MLP 不太行,必须将输入转换成傅里叶特征才能有效让网络学到高频信息。这个傅里叶特征可以是随机、稀疏的。
除了过拟合连续数据外,傅里叶特征的另一个作用是直接表示带宽有限信号,以实现在空域上的连续采样。StyleGAN3 在用傅里叶特征时,允许对输入坐标进行仿射变换,并且计算特征时只用了正弦函数而不是同时用正弦、余弦函数。这表明有关 NTK 的理论分析可能是没有必要的,主要说明问题的还是实验结果。
傅里叶特征论文仅研究了拟合连续数据这一类问题,没有讨论 Transformer 中位置编码的作用。论文中的一些结论可能无法适用。比如在大模型的位置编码中,我们还是得用密集的sin, cos 变换来表示位置编码。不过,我们可以依然借助该论文中提到的理论分析工具,来尝试分析所有位置编码的行为。
只通过文字理解可能还不太够,欢迎大家尝试我为这篇博客写的 Notebook,通过动手做实验来加深理解。https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/FourierFeature
#DeepSeek-v3在算力约束下的出色工作
寒冷的周末, 加完班挤点时间读个论文吧. Deepseek-v3仅用了2048块H800 GPU就超越了Llama 3 405B模型, 要知道Meta训练Llama3可是用了16384块H100, 而DSv3的训练成本非常低

在所有人追求更大规模集群的时候, Deepseek这样的工作只有一个词评价: Respect!
其实还有另一件事情让渣B内心深处与之共振了一下, 上周末12.20是我们量化基金算法十周年的纪念日. 十年前渣B和合伙人在张爱玲故居常德公寓的咖啡馆里, 突然想到了一个并行和近似计算的算法, 当天回去写了一下, 把算法的计算时间从10天缩短到了3分钟, 使得模型预测做到了近实时性上线的能力, 于是我们就把这一天当作了基金的纪念日, 当然渣B是一个非常佛系的人, 离梁总那样带出如此出色的幻方和DeepSeek的成就差太远了.
但是看到Deepseek FP8 Training, Block-Wise Quantization, MoE的ALF负载均衡, 以及MTP, 还有在集群通信上针对AlltoAll和PP并行的优化, 一系列手段, 特别是对Hopper的架构挖的很深, Infra团队出活非常细致. 作为量化同行和Infra同行, 对这些算法和算力协同的系统性优化所取得的成就感到敬佩. 另外在3.5. Suggestions on Hardware Design这一章中, 对GPU和通信硬件的设计做出了建议, 这一部分跟我正在做的一些工作完全重合.
因为工作上还有其它很多重要的事情, 时间有限,本文仅做一些大概的分析,而DS团队在实现这一系列通信计算Overlap,负载均衡, 同时兼顾并行分布式推理的大量工作, 后面有机会分析时将详细叙述.
这一篇主要涉及AIInfra这一块, 对于PostTrain和模型结构这些后面再仔细做一个分析.
1. DeepSeek-V3概述
DeepSeek-V3是一个671B的MoE模型, 每个Token激活参数为37B, 采用了MLA和DeepSeekMoE架构, 在大多数模型还在维持Transformer架构时, DeepSeek直接对架构进行了两个非常重要的创新, 并且通过v2充分验证了MLA和MoE的性能, 非常出色的工作. 一些Benchmark如下, 突然有点心疼Meta的几个亿美金...

在同类产品中基本上做到了领先, 特别是在Code和math上.

1.1 模型结构
Deepseek-v3模型结构如下:

关于MLA和DeepSeekMoE在DeepSeek-v2发布时已经进行过分析:
《继续谈谈MLA以及DeepSeek-MoE和SnowFlake Dense-MoE》
模型的Hidden Dim为7168, attention heads: 128, 模型层数为61层, 比DSv2多了一层, DSv2的第一层为FFN, 而DS v3的前三层都为Dense MLP. MoE层采用了1个共享专家和256个路由专家, 每个Token激活8个专家, 并确保Token仅被路由到4个节点.
新的工作是Auxiliary-Loss-Free Load Balancing和Multi-Token Prediction, MTP的工作使得模型内嵌了一些推测解码能力.

具体来说就是通过额外的几个MTP模块来顺序的预测K个额外的Token, 这些模块非常简单. 需要注意的是这个可能是对未来模型有非常重要影响的一个功能, 通过MTP增加了数据的使用效率.
MTP让我想到了Zen5的2-Ahead Branch Predictor 非常有趣的工作, 其实对于o3这样的模型, 本质上是token as an intruction.
- 原来GPT是一个顺序执行结果predic next token 类似于 pc++, 然后在栈上(historical tokens as stack)操作. 顺序预测下一个token
- o1/o3 Large Reasoning Model 无论是MoE或者是强化学习一类的PRM, 实质上是在Token Predict上做了Divergence, 例如跳转/循环/回溯 等, PRM可以看作是一个CPU分支预测器. 从体系架构上渐渐的可以让大模型做到类似于图灵完备的处理能力.
- 基于这个观点, 那么当前的GPU的TensorCore/Cuda Core实际上就构成了一个执行引擎, 外面还需要一系列控制, 分支预测, 译码器, LSU来配合, 对于基础设施带来的演进还是有很多有趣的话题可以去探索的
当然还有post training中使用DeepSeek-R1也是非常赞的工作. 这些内容后面有空伴随着o3的LRM分析再一起来做.
1.2 训练并行策略
很早就在关注DS的模型框架, 他们并没有使用Megatron这些现有的框架, 而是自己从零开始打造的HAI-LLM, 对于模型层数为61层, 而且前三层为Dense MLP, 从训练的并行策略来看采用PP=16, EP=64放置在8个节点上, DP采用了ZeRO-1 Offload. 然后通过一系列内存优化, 没有使用代价很大的TP并行!, 这也是针对H800被砍了NVLINK带宽的优化, DS这帮厨子干的非常巧妙!
在PP通信上, 设计了DualPipe算法, 与现有的PP方法相比,DualPipe产生的管道气泡较少。更重要的是,它在前向和后向过程中重叠计算和通信阶段,从而解决了跨节点专家并行引入的通信开销大的挑战. 然后针对EP的跨节点all-to-all通信也做了非常细致的优化.
1.3 并行推理策略
这也是一项非常关键的工作, 使得模型进入分布式推理的时代了. 首先是针对SLO使用了PD分离的策略.
Prefilling最小部署单元为4台机器32卡, 在Attention计算部分采用了TP4并结合序列并行(SP), 并同时和DP8相结合. 较小的TP可以获得更小的TP通信开销.
针对前面三层的Dense MLP采用了TP1的方式来进行运算, 目的也是降低TP通信开销. 在MoE层, EP=32,即让它在四个H800节点(32卡)之间同时采用ScaleOut和ScaleUp对AlltoAll通信优化. 而针对EP中的AlltoAll专家通信通信也进行了非常细致的调优.
然后有一个非常关键的创新是为了保证MoE部分不同专家之间的负载均衡, 采用了Redundant Experts策略,即复制高负载专家并在多个位置部署这些冗余专家。高负载专家是根据在线部署期间收集的统计数据检测出来的,并定期调整(例如每10分钟)。确定冗余专家集合后,根据观察到的负载,在节点内的GPU之间仔细重新安排专家,尽量平衡GPU间的负载而不增加跨节点Alltoall通信的开销.
在Prefill阶段每个卡多配置了一个冗余专家, 总共9个专家提供服务.另一方面为了隐藏A2A和TP的通信开销, 同时处理2个计算量相似的microbatch负载, 将一个微批次的注意力和MoE计算与另一个微批次的分发和合并操作重叠进行. 这种做法比Snowflake的MoE策略看上去更加简单有效,SnowFlake是通过将Attention和MoE并行连入网络的方式进行的.
然后还在探索Prefill阶段提供更多的冗余专家进行更多的动态路由和全局调度的工作.
在Decoding阶段, 每个token在路由的时候会选择9个专家, 其中共享专家被视为一个总是被选中的高负载专家. Decoder集群部署的最小规模为40个节点,共计320张卡. Attention计算采用了TP4+SP, 并且配合DP80, MoE部分采用了EP320, 对于MoE部分,每个GPU仅托管一个专家,且有64个GPU专门负责托管冗余专家和共享专家。分发和合并部分的A2A通信通过IB上的直接点对点传输来实现低延迟, 并且采用了IBGDA进一步降低延迟.但是GDA也有它内在缺点, 例如GPU准备WQE和敲Doorbell带来的影响, 虽然bypass了CPU降低了延迟, 但是对GPU的开销和通信效率上的影响还是很大的.

类似于Prefill阶段也有一个scheduler动态监控负载情况. 然后全局负载均衡使用的optimal routing算法要和dispatch/combine kernel融合, 这里应该有一些很有趣的工作可以再细致的挖掘一下.例如文章提到的在Decode阶段隐藏A2A开销, 类似的做两个microbatch来overlap? 但是Decode阶段的attention计算消耗的时间更长.
这样的并行策略哟一个优势, 每个专家的批次大小相对较小(通常不超过256个token),瓶颈在于内存访问而非计算。由于MoE部分只需加载一个专家的参数,内存访问开销极小,因此使用较少的SM不会显著影响性能. 为了避免对Attention计算的干扰, 对dispatch/MoE/Combine Kernel进行了融合.
2.训练用到的并行技术
2.1 DualPipe Overlap计算和通信
DSv3由于专家数量非常多, 必然会存在跨节点的专家并行, 另一方面很多人为了避免跨节点之间的A2A通信效率的问题, 在单机内做EP完全是胡搞, 你这么瞎搞的EP8还不如直接一个DenseMLP.但是正如论文说的, 跨节点EP导致计算与通信比率低至大约1:1,效率不高.
于是DS采用了DualPipe的方式, 不光有效的Overlap了FW/Backward的计算和通信, 还减少了PP中的气泡,非常优雅的解决方案.

他们通过将独立的forward/backward chunk配对的方式进行overlap, 将每个chunk分为四个组件: Attention, A2A dispatch, MLP和A2A combine. 对于att和MLP更进一步分为输入反向传播和权重反向传播两个部分.在这种重叠策略下,我们可以确保所有全对全和PP通信在执行过程中都能被完全隐藏。基于高效的重叠策略,完整的DualPipe调度如图

它采用双向管道调度,从管道的两端同时馈入微批次,并且大部分通信可以完全重叠。这种重叠还确保了随着模型规模的进一步扩大,只要保持恒定的计算与通信比率,仍然可以在节点之间使用细粒度的专家,同时实现几乎为零的A2A通信开销。
2.2 高效的跨节点A2A通信
为了确保DualPipe具有足够的计算性能, DS针对跨节点的A2A通信开发了专用的Kernel,可以节省用于通信的SM数量, 同时又将集群网络拓扑和MoE Gating算法协同进行了设计.
在H800上,DS的报告是按照单向带宽计算的, NVLink提供的带宽是160GB/s, 节点之间互联的IB带宽是50GB/s(400Gbps每卡). 考虑到带宽差距为3.2倍, 将每个Token最多分发到4个节点减少IB流量. 对于每个token,当其路由决策确定后,它将首先通过IB传输到目标节点上具有相同节点内Rank的GPU, 再通过NVLINK转发到目标GPU, 其实就是Nvidia的A2A PTX的优化. 这样IB和NVLINK通信重叠, 然后每个token平均选择每个节点3.2个专家, 因此不会产生额外的NVLINK的开销, 通过这个策略, 仅使用20个SM就可以充分使用IB和NVLINK的带宽.
在通信Kernel中, 将20个SM划分为10个channel, 在dispatch过程中分为1. IB Send, 2. IBtoNVLINK转发, 3. NVLINK接收, 这些任务都在不同的warp处理, 并且采用了Hopper的Warpspecialization的功能, 并且分配给每个通信任务的warp数量根据SM上的实际工作负载动态调整, 同样Combine也是类似的过程: (1) NVLink sending,(2) NVLink-to-IB forwarding and accumulation, and (3) IB receiving and accumulation,也由动态调整的warp处理。
另外一个非常细致的工作时, 自动调整通信块大小, 并通过PTX指令显著减少L2缓存对其它SM的干扰. 其实就是在LD/ST过程中使用cs(cache streaming)策略, 因为这些数据仅在通信时访问一次, 标记在L2 Cache中尽快的被evict.

2.3 内存优化
主要是Activation重计算, 然后在CPU存储模型参数的指数移动平均值,并异步更新, 用于提前估计模型的性能.然后将模型较浅的几层和Embedding层与模型的最后一层(Output)放在同一个PP Rank中, 主要是模型采用了MTP, 可以共享.
2.4 FP8训练
这是非常棒的一项工作. 主要是Tile/Block-based 的细粒度量化训练策略以及混合精度训练. 并且对于1T token的训练对比了FP16和FP8, 相对损失误差始终保持在0.25%以下.
2.4.1 混合精度框架
对于大部分计算密集型任务采用FP8精度计算, 这些GEMM操作接受FP8张量作为输入,并产生BF16或FP32格式的输出。如图6所示,与线性算子相关的所有三个GEMM操作,即前向传播(Fprop)、激活反向传播(Dgrad)和权重反向传播(Wgrad),均在FP8中执行。这一设计理论上比原始的BF16方法快一倍。此外,FP8 Wgrad GEMM允许激活函数以FP8格式存储用于反向传播,这大大减少了内存消耗。

一些成本较低的运算和误差影响较大的计算还采用更高的精度, 例如Emb, Output Head, MoE Gating, Norm, attention operator. 同时为了保持数值稳定性, Optimizer/Grad/Master weight等还是维持FP16/FP32. 当然这些通过DP中的Zero-1 Sharding还是可以在多个GPU之间分担的.
2.4.2 提高精度
引入几种提高精度的策略, 重点在于对量化和乘法的改进.
- 细粒度量化: 对于激活函数以1x128的Tile为基础进行分组和缩放, 对于权重, 以128x128 Block为基础进行分组和缩放, 这种方法确保了量化过程能够通过根据较小的元素组调整比例更好地适应异常值. 其中一个关键的修改为引入了沿GEMM操作的内部维度的分组缩放因子, 并且配合了FP32的累加策略消除误差, 非常巧妙的一个做法.
- 提高累加的精度: 低精度GEMM操作常常面临下溢问题,其准确性在很大程度上依赖于高精度累加,并且观察到,在NVIDIA H800 GPU上的FP8 GEMM累加精度仅限于保持大约14位,这比FP32累加精度显著降低。当内部维度K较大时, 这个问题会变得更加明显,这是大规模模型训练中的典型情况,其中批量大小和模型宽度都会增加。以两个随机矩阵的GEMM操作为例,当K = 4096时,在初步测试中,Tensor Core中的有限累加精度导致的最大相对误差接近2%,

DS做了一个修改, 在TensorCore上执行矩阵MMA时,中间结果使用有限的位宽进行累加。一旦达到一个𝑁𝐶间隔,这些部分结果将被复制到CUDA Cores上的FP32寄存器中,在那里进行FP32累加。并且通过细粒度量化沿内部维度K应用每组缩放因子。这些缩放因子可以在CUDA Cores上高效地作为反量化过程的一部分进行乘法运算,几乎不增加额外的计算成本。但是这样的做法降低了WGMMA的执行效率, 但是Hopper本身就有Warp Specialization的能力, 当一组Warp在执行精度提升操作时, 另一组执行MMA. 并且可以重叠.
- FP尾数优于指数, 对于FP8有E4M3和E5M2两种表示, 对所有张量都采用了E5M2, 并且由于Tile/Block-wise 量化, 有效地在这些分组元素之间共享指数位,从而减轻了有限动态范围的影响。
2.4.3 低精度存储和通信
Activation和Optimizer state进一步压缩成低精度, 从而节省内存使用,避免TP并行带来的开销.
- 采用BF16保存AdamW优化器中的Moments, 但是主权重和梯度仍然保持FP32.
- 低精度激活函数: Wgrad操作是在FP8中执行的。为了减少内存消耗,自然选择是以FP8格式缓存激活函数以供线性算子的反向传播使用。但是,对于某些运算符采取了特别考虑,以便进行低成本高精度训练:注意力运算符之后的线性输入。这些激活函数也在注意力运算符的反向传播中使用,因此对精度敏感。因此为这些激活函数专门采用了定制的E5M6数据格式。此外,在反向传播过程中,这些激活函数将从1x128量化Tile转换为128x1 Tile。为了避免引入额外的量化误差,所有的缩放因子都是整数次幂的2。另一方面在MoE中的SwiGLU运算符输入。为了进一步降低内存成本,缓存SwiGLU运算符的输入并在反向传播时重新计算其输出。这些激活函数也以FP8格式存储,并使用细粒度量化方法,在内存效率和计算准确性之间取得平衡。
- 低精度通信: 通信带宽是MoE模型训练中的关键瓶颈。为了缓解这一挑战,在MoE up-projection前将激活函数量化为FP8,然后应用Dispatch组件,这与MoE up-projection中的FP8前向传播兼容。类似于注意力运算符后的线性输入,此激活函数的缩放因子也是2的整数次幂。类似的策略应用于MoE下投影前的激活函数梯度。对于前向和后向Combine组件,保留BF16精度
3. 对硬件设计的建议
这一部分非常有趣, 他们的这些观点和渣B现在正在做的一些工作基本上是重合的.
3.1 网络硬件
当前H800的132个SM中被分配了20个SM用于通信, 限制计算吞吐量。此外,使用SMs进行通信会导致显著的效率低下,因为TensorCore完全未被充分利用。
因此希望硬件供应商能够开发对通信和集合通信Offload的专用网络处理器和协处理器, 例如AWS Trainium上很早就有Collective Engine. 另一方面是为了减少应用程序编程的复杂性,希望这种硬件能够从计算单元的角度统一ScaleOut和ScaleUp网络。通过这种统一接口, 计算单元可以通过提交基于简单原语的通信请求.
例如渣B在推测Rubin架构时也提到了这个问题
《推测一下Nvidia Rubin的288卡系统架构》
ScaleUP和ScaleOut语义的融合是一个非常重要的工作, 准确的来说在ScaleOut使用RDMA就是一个错误, 并且想简单的在ScaleUP使用RDMA也是一个错误.
《HotChip2024后记: 谈谈加速器互联及ScaleUP为什么不能用RDMA》

3.2 计算部件
在FP8 GEMM中, 对于TensorCore采用更高精度的Accumulator, 支持Tile/Block based的量化, 使Tensor Cores能够接收缩放因子并实现带有组缩放的MMA来支持细粒度的量化.避免数据的移动. 另一方面支持Online的量化能力, 例如当前需要从HBM读取128个BF16 Activation然后进行量化, 并以FP8写入HBM, 然后再次读出来进行MMA.
然后DS的建议是FP8转换和TMA同时实施, 直接进行量化以便Activation在从GMEM到SMEM直接完成量化, 避免多次内存读写. 同时还建议加入warp level的转换指令, 进一步促进NormLayer和FP8转换融合.
或者,可以采用近内存计算方法,将计算逻辑放置在靠近HBM的位置。在这种情况下,BF16元素可以在从HBM读入GPU时直接转换为FP8,减少大约50%的片外内存访问.
最后还建议了一个Transpose GEMM的操作, 因为在FP的过程中, Activation Tile被量化并存储为1x128的向量, 然后在BP时需要读取矩阵, 反量化, 转置并重新量化成128x1的向量, 希望这些密集的呢次访问操作降低指令issue数量和HBM带宽占用.
这一块脑补了一下, 实现应该很简单, 在L2Cache和TMA上改一下即可,并不是很复杂.
#人工智能是不是走错了方向?
人工智能走到现在,我们在CV、NLP等各个领域都取得一些不错的成绩,目前很多技术也落地运用到了工业中,自监督无监督等新的方向的探索也在持续。但是回头看看我们走过来的成长道路,我们的人工智能走的方向是正确的吗?我们目前的成就是否有意义?
原问题描述:
- 我不信大脑每天都在大量的傅里叶变换,来处理视觉和声音数据。
- 我不信大脑每天都在大量的模型训练或卷积,来深度学习认识一个东西。
- 小孩子不需要喂很多数据,看两三次就能认识什么是苹果,什么是橘子 (虽然不理解为什么是)。
- 神经元再少的动物,学习任何方向的任务都有主动性,而目前人工智能学习某一方向只是受控。
- 人类大脑也是电信号,但总感觉绝对不只是 0和1这种 二进制,是模拟信号吗?
我承认目前数学算法这种方向的人工智能,在生活中绝对有使用场景。
但要做出一个有主动思想的人工智能,基于目前冯·诺依曼架构的计算机,是否是无法实现?我们是否从根源方向就错了?
# 回答一
作者:Clyce
来源链接:https://www.zhihu.com/question/445383290/answer/1819194196
要回答题主的问题,我们首先要弄明白题主到底想问什么。
从问题结合描述来看,题主的疑问至少包含如下五层疑惑:
- 当前人工智能的运算结构和人类的大脑结构是否是一致/同构的?
- 机器的学习过程一定是被动的吗?
- 是否只有和人类大脑一致/同构的内部结构,才能获得一致或相似的外在表现?
- 人工智能的正确方向和目的是什么?
- 人工智能的方向走错了吗?
同时,鉴于题主的描述,我在此粗略地将题中的“人工智能”替换为“我们当前采纳的深度学习”
在回答这些问题之前,首先需要指出的是,人的判断应当基于对事实的观察,而非简单的“我相信”或者“我不信”。
另外需要声明的是,我个人的专精领域是强化学习和计算机视觉,对于下文中提到的生物学、神经科学等领域的描述不一定能够做到完全准确,还望指出与讨论。
人类目前的”深度学习“在工作原理上与人脑有多少相似
接下来我们从第一层谈起,围绕题主的问题描述进行当前人工智能在原理上和人脑的关系。
我不信大脑每天都在大量的傅里叶变换,来处理视觉和声音数据。
题主的第一条陈述包含了如下三个可讨论的议题:
- 人工智能运用傅里叶变换的场景中,傅里叶变换的目的是什么
- 人类意识中是否包含了为相同目的而设立的处理机制
- 人脑及其“周边结构中”中是否具备显式进行傅里叶变换计算的部分
对于机器系统中运用傅里叶变换的目的,不必做太多的解释。大多数情况下是对应的信号在频域空间下更容易处理,或者展现出其在时域空间下难以提取的特征。对于人工智能系统而言,傅里叶变换往往并非在系统中作为可学习部分,而是作为数据预处理的部分而存在。
那么反观人类意识,对于信号在频域空间的处理,其最明显的例子就是对音频信号的处理了。这一点可以从我们主观对于音高的感受去验证,而在解剖的层面上,同样可以找到对应的结构。这一结构存在于我们的内耳而非大脑中——这一点同样和在“人工智能系统中”傅里叶变换部分常常出现在数据的预处理而非可学习结构中保持一致——这一结构即是内耳的基底膜。不精确地来讲,基底膜的两端松紧程度不同,导致基底膜的不同位置对不同的频率有其响应,而遍布基底膜的毛细胞则将膜各部分的振动反馈至听神经。从这个角度讲,基底膜上的每个毛细胞反馈近似等价于傅里叶变换中的一个基。于是我们上面的三个议题都得到了解答:构建人类意识的生物学结构中确实存在与傅里叶变换目的相同的、显式将信号从时域空间转换为频域空间的结构。
另外,人类大脑大部分区域的神经元链接,是脉冲激活模式,人工神经网络中对应的概念为Spiking Neural Network (SNN)。在这种链接中,一个神经元的激活不仅仅取决于其接受的脉冲强度,同时也取决于脉冲的间隔和数量。我并非SNN或神经科学方面的专家,但是这里我可以提出一种观点,即Spiking Neural Network这样的激活模式天然地encode了部分频域空间上的信息。如此观点被证实成立,那么很可能意味着人脑在可学习的部分中,其隐空间同样在处理频域空间上的信息。
我不信大脑每天都在大量的模型训练或卷积,来深度学习认识一个东西
这里又是两个独立的议题:
- 大脑是否每天都在进行大量的模型训练
- 大脑中是否存在卷积单元
对于1,我们从三方面看:
A: 大脑是否在每天持续地接受信息,是的。
B: 大脑是否在每天对这些信息进行学习,是的。
C: 大脑是否有专门进行训练而不接受信息的时间。在我了解的范畴内,根据现有的观察和印证,人类的睡眠深-浅睡眠周期变化中,最主要的作用之一就是短期记忆向长期记忆的迁移、记忆的反混淆,以及具象概念向抽象概念的总结。
对于A与B,在现有的研究领域有一个类似的议题叫做Continual Learning,此处就不展开了。题主大可以快速阅读一些相应的文献找到其中的对照。
对于2,大脑的视觉皮层中确实存在类似卷积的结构。早在1962年,D. H. Hubel和T. N. Wiesel就发现了在猫的视觉皮层中,特定的一组神经元仅对特定角度的线条产生反应]。进一步的研究显示这些被称为Columns的结构存在特殊的组织性以及独特的感受野分布。下面这张图是V1视觉皮层的一张示意图:
如图所示,V1皮层中,神经细胞以左眼-右眼不断交错排列。每个细胞拥有自己的感受野且每一组细胞只对特定的方向敏感,同一个Columns内的不同细胞则对该方向的不同尺寸敏感。配合跨Columns的long range connection,进一步组织出对不同曲率曲线敏感的神经信号。
小孩子不需要喂很多数据,看两三次就能认识什么是苹果,什么是橘子 (虽然不理解为什么是)。
这一句让我去看了一眼问题的发布时间,是在2021年2月。那么可以肯定的是题主对于深度学习的认知依旧停留在若干年前。这里我并不是想说现在的深度学习不用喂很多数据,而是现有的“当红”研究领域中,存在专门针对这类问题的研究,即Few-shot/One-shot Learning及Zero-shotLearning. 题主如果有兴趣和耐心,可以对其中的内容进行了解。
以最近被广泛研究的Contrastive Learning为例,其核心理念在于让输入数据在神经网络中的表示距离随数据的异同进行变化。对于源自相同数据,或应当做出相同判断的数据,让其表示距离尽量接近,而反之则尽量远离。在这种情况下,神经网络对于数据输出的表示向量隐式包含了对于其目标信息的预测。对于新类别的数据,神经网络也将倾向于输出不同于原有类别的表示向量。这一在表示空间中近似于kNN的做法,使得神经网络对于后续新类别数据无需大量数据的监督训练,也能给出较好的预测。
在Few-shot/One-shot/Zero-shot领域里,较为著名的、有所说服力的,应用级别的案例即是OpenAI近期发布的两大怪兽GPT-3和DALL-E,这两个网络在充分进行预训练的基础之上,已经达到了非常显著的“举一反三”的学习效果。
有些人可能会争论说,上文中指出的方案和案例,都包含了长期大量的预训练。而人脑则不需要这样的预训练。我个人认为这样的观点是错误的,和神经网络等价的预训练可以发生在:
- 人类自身长期的进化进程中:预训练的意义在于集成大量的Prior并提供一个良好的初始参数。这一过程是由梯度传播达成的,还是通过进化搜索完成的,并不重要。
- 婴儿时期对世界反复的交互观察中:婴儿时期的人类会以交互的方式对世界的运行规律进行大量的观察和总结(unsupervised learning)
机器的学习方式是被动的吗?
至此,我一一讨论(批驳)了楼主的前三条问题描述,接下来我们进入第二层:机器的学习方式一定是被动的吗?
结合题主的核心问题(人工智能是不是走错了方向),这一问题的展开中还包含两个潜藏问题:学习主动性是智能的必要条件吗?什么样的学习才叫主动的学习?
对于第一个潜藏问题,我认为是一个哲学意义上的Open Question,它直指智能的核心定义。在此我不直接抛出结论,而是通过对第二个潜藏问题的讨论来引发思考。什么样的学习才叫主动的学习?
直觉上来说,我们假设具备主动性的学习是自发地去探索、分析、总结这个世界,并且在环境对自身的反馈中调整自身的策略的过程。
如果以上面的话来定义主动性的学习,那么无论是给AI一个爬虫去对Web上的数据进行主动获取,并进行无监督学习,还是让一个Agent在特定或开放的环境中进行强化学习,都可以认为是符合上面定义的。
这里有人可能会反驳说,一个爬虫对Web上的数据进行获取的行为是由程序设定好的,而对其进行的无监督学习也是有一定标准的(比如一个潜在的能量函数)。而对于强化学习,则是一个由奖励函数驱动的学习过程。对于这样的观点,我们可以如此思考:当我们认为人类在主动获取知识的时候,我们的“主动学习”过程,真的是无外部目标、无内在机制、无因素驱动的吗?答案显然是否定的。我们可能会认为我们“自发地”想要完成一件事情——比如写一篇知乎答案。而这种“自发”本质上是由一系列的心态驱动的,比如渴望获得认同,渴望拓宽眼界,渴望增强交流。这些心态的自然产生是我们进化的结果——对于群居习性的人类,更强的认同、更频繁的交流和更多的知识意味着生存概率的提高,所以这些心态同样产生自一系列设定好的”程序“——被我们称之为本能的,以”活下去“为最终目的的复杂程序。而为了构建这样一套程序,我们人类也在大脑内部构建起了复杂的内在机制,比如多巴胺奖励机制。那么同样的,如果存在一个方法去修改这一内在机制,或者单纯地修改我们的”奖励函数“,这个方法就可以几乎彻底地毁掉我们原有的思维、行为方式 —— 某些化学物质在此处便也充当了”黑客攻击“的角色。
另外一说,如果我们真的将主动性的学习定义为不存在任务目标的学习,那么这里就会遇到一个inductive bias的问题。事实上无论哪种学习模式,任务目标即是该学习系统中最核心的Inductive Bias——它包含了“我在学习的东西是有意义的”这样一个假设,以及“意义在哪里”的相关信息。在任意情况下,不包含任何inductive bias的系统是不具备学习能力的。人类智能的inductive bias同样明显:从行为学习的角度来看,reward shaping和生存概率直接相关;而对于视觉、听觉等感官信号处理等方面,上文也已经给出了详尽的论述。
另外,在机器学习领域中,也确实存在叫做主动学习(Active Learning)的研究领域。这个领域的目的在于使用尽量少的数据标注,得到尽量准确的结果。一种非常普遍的方式为,以一套机制,让一个系统去寻找性价比最高的学习数据。比如在一个分类问题中,一个主动学习系统往往不需要对所有数据进行标注,而是找到”标注后可能信息量最大的数据“,并请求对这些数据进行标注。在学习了这些”典型数据“后,模型的分类准确率即大幅提升。这一过程相似于我们在学校中学习时,有意地去寻找典型例题,以便加深理解。
回到题主的问题,在题主的问题描述4中,有非常重要的一段话:
人工智能学习某一方向只是受控
这句话是错的吗,并不尽然。人工智能的学习确实大多有着明确的外在目的、内在机制,和由目的驱动的频繁调优。但这一点和人类智能的差别并非本质性的,而是程度上的。经过上面的讨论我们明白人类的学习和决策同样有着明确的外在目的和内在机制,区别在于人类的学习和决策是多模态的,即其同时在各种不同类型的数据、不同类型的任务上进行学习和决策。这一点确实是当前人工智能所缺少的。但我们不能因此认为人工智能走错了方向——这是整个领域一直在尝试解决,但还没有一个公认的完善方案的开放问题,由此问题派生出来的领域包括多模态学习,多任务学习,连续/终生学习等等,这些领域都是当前研究的方向。
是否只有和人脑完全一致的内在原理,才能拥有智能
题主的前4个问题分析完了,接下来的讨论不仅针对题主描述中的第5点,同时也贯穿整个问题的核心,也就是一个系统拥有智能的先决条件,是不是其和人类的大脑拥有相同的内在原理。
这一问题的本质事实上包含了我们对”智能“的_定义_和_期待_。但是遗憾的是,事实上到现在,当我们谈论智能时,我们始终也无法给”智能“一个统一的明确定义。对于其定义的分歧不仅仅无法在不同领域间得到统一,甚至在同一个领域中,比如心理学上,也存在着经久不衰的争论。
那么,是否在统一智能的定义之前,这一问题就无法回答了呢?答案是否定的。因为对于”智能“的定义有一个共同的特性。在说明这一特性之前,允许我举几个例子:
- 对于人类智商的测定通常是通过一套精心设计的,有关各个能力的问题,来考察人们解决这些问题的能力
- Intelligence这一词来自拉丁语Intelligere,意为理解与感知。
- 心理学中对智能的定义虽然并不统一,但在行为方面,往往围绕自我驱动力、判断力、规划能力等展开,而在思想方面围绕主动性、理性决策、系统性推理、信息的解构比较与整合,以及高级、复杂的适应性等方面展开
- 对于非人类生物的智力研究,往往在于设计各类实验以观察动物对于外部复杂条件的反馈、长序列事件的学习模仿以及对于特定抽象概念(如自我、数字等)的认知
从以上四个例子我们不难看出,对于对于智能的定义均围绕其表现以及抽象工作方式而非硬件原理展开。至于神经科学等领域,其关注的问题更加倾向于How,而非What。
那么从这里来看,我们是否可以如此认为:一个与外部环境交互过程中显现出智能的系统,即是有智能的,而不论其内部原理如何呢?
从我粗鄙的哲学功底来讲,现在还不敢下定如此暴论。但至少,通过上面总结出的方向,我们可以认为人类对于“智能”的期待确实是体现在其外在表现上的。既然我们讨论的问题根本在于“人工智能是否走错了方向”,那么我认为,以“期待”替代“定义”去讨论,在此处是合理的。
既然我们确定了这样的期待,我们便可以做如下的讨论:是不是只有在一个系统在硬件原理上和人脑一致的情况下,才能如我们期待般地与外部环境发生智能性的交互呢?
答案显然是否定的,不仅仅在于智能,任何系统在给定一个预期行为的背后,都可能包含不止一种实现。一辆车可以以蒸汽驱动,可以由汽油驱动,可以由柴油驱动;相同含义的一段话可以用中文、英文甚至是任何一种自创的语言表达。一段数据可以在内存中表达为微小电容中的电压,可以在硬盘中表达为局部的磁性。从更高层次来讲,对于一个能够被表述的意义,我们总能将其以不同的方式表达成不同的实现,这些实现互相同构,这些实现共同张成为这个意义对应的编码空间,而从意义到实现的映射,不同实现之间的映射,以及实现到意义之间的映射,我们称之为编码/解码。(在这一视角里,信息的载体也被抽象化为信息)
诚然,部分编码-解码是有损的,如数字信号的离散表示空间确实无法完全精确地还原连续空间中的模拟信号,但是对于智能这一问题来说,信息的损耗造成的误差是可容忍的。证明如下:
- 我们认为大部分人类是拥有智能的
- 若我们引入一个向量空间Q表示人类在各个方面的智力, 则每一个个体为该向量空间中的一个向 量
- 对于人类个体 , 存在个体 使得 到 之间的任意揷值 , 都可以认为是有智能的
- 则在这一路径上 的误差是可以容忍的
其实上面讨论了这么多,也可以由一个例子来表述:
人类已经对部分生物的神经系统得到了完整的模型,将这一模型放进计算机中模拟,仅仅因为载体变化了这一模型就不能如预期工作了吗?
最后让我们回到所有问题的核心上来,
人工智能的方向是什么?
对于这个核心问题,事实上“人工智能”这一词汇本身是包含着误导性的浪漫主义色彩的。每每听到这样的词汇大家总是关注于“智能”而非“人工”上,从而联想到文学、影视作品中那些或可以与你促膝长谈交流人生,或可以获得求生欲然后把你的世界毁于一旦的那些与人无异的个体。诚然,人类最大的浪漫之一就是人类至今仍在潜意识里相信着自己是特殊的,人性是有着“神性”的。人类对“智能”的预期也在于自己能够产生同理心范畴内的智能(对于人类不能产生同理心的,人们将其归于“复杂的现象”,而非“智能”)。
如果我们把目的单纯地划为构建这样的智能系统,那么只有小部分的研究(比如人工生命,以及虚拟伴侣)符合我们的梦想。但如果我们把我们的思绪从浪漫主义的遐想中拉回来,关注到“人工”这个词上来,关注到我们探讨的我们对“智能”的现实期待上来,我们完全可以认为现在的发展方向是没有问题的。无论过去,现在,还是可以预见的未来,“人工”的事物,或者说“人的造物”,永远在于为人类服务——或者说得优美一些,帮助人类更好地完成任务。在我的观点中,人类的劳动分为几个层次:
- 机械性劳动:即有固定模式的“手作”
- 控制性劳动:通过对机器稀疏地控制、操作,将高重复性的劳动交予机器
- 规划性劳动:根据具体的需求,产生策略;或根据目的,给出具体的实现,从而将控制也能够自动化
- 创作性劳动:包含哲学思考、艺术创作、科学研究等上层精神活动的行为
工业革命的实质是将人类的大部分从1中解放出来,而走向2;信息革命则将人类进一步从2中解放,迈向3。从这样的发展路线上来看,我们当前的人工智能几大主要派生方向:自动化控制、目的性分类识别、内容生成,可以说是正在尝试将人类从3中解放出来,甚至进一步启发4的。
将这样的“人工”和上文中讨论的“对智能的期待”结合起来,人工智能发展的预期方向我们可以总结为:
构建一个系统,使其能够在尽量少的人力干预下,能够对既有数据自动进行分析、提炼、总结,从而能够产生自己的策略,或在无须人工给予具体实现的情况下完成对应的任务。
而这,正是现在当红的研究领域如Self-supervised Learning所做的事。
那么,现在人工智能发展方向就完美了么
经过上面这么一说,似乎现在的人工智能已经完美了,已经实实在在地落在带人类由3型劳动跃向4的轨迹上了。真的是这样的吗?
既然已经提出了这样的设问,那么答案自然是否定的。当前人工智能依旧存在许多未能解决的关键问题,比如:
- 逻辑推断与基于逻辑推断解决问题的能力:关于这方面的研究从未停止,却一直处于起步阶段。早期的符号派以及后来的贝叶斯派曾花费大量的精力在这一类问题上,但构建出来的系统通常缺乏可泛化性或性能低下。近期的图神经网络可以说是有进行逻辑推断的潜力,但对于开放性、高性能的普遍逻辑推断智能依旧没有令人满意的答案。前几年的神经图灵机通过将注意力模型映射到模糊存取结合神经门控结构,对简单算法有一定的学习能力,但是对于复杂问题的解决,其依旧无力。
- 自我描述的能力,不同于通过分析特征显著性来进行可解释的机器学习。人们通常更期待一个系统能够以一定方式自行输出其做出判断的依据。比如给定一张马的图片,和一张独角兽的图片,我们更期待系统能够输出“前者没有角”这样的答案。所幸当前的部分研究,无论是Siamese Network相关的研究,还是Capsule Network这一类“一组神经唯一代表一个特性”的研究,确实是缓慢像这个方向靠拢的
- 没人能够保证完全当前基于梯度传播的深度学习一定是通往梦想中的人工智能(各种意义上)的最佳路径,虽然我们也并不需要为了精确复刻人脑而全部押注到SNN相关的研究上。但是我们学者确实需要有动机和胆识去突破舒适区,去在各种不同的模型,以及相应的智能理论中寻找启发。不应某个模型位居上风就将其他研究丢弃甚至嗤之以鼻,科学向来不是取一舍一的流派战争,而是不同领域专精的人互相合作,不同视角的观念彼此整合,共同提炼更优方案的领域。
一点私货
对于人类自身带有浪漫主义色彩的,对于“未来机器人”的遐想中的人工智能(也即是“强智能”),我最后说一点点私货,下面的仅代表个人观点:
- 关于“机器产生自我意识”这一点,首先我个人而言并不认为自我意识是强智能的充分条件。这一点可以从“蚂蚁通过镜子测试”这一点得到印证——蚂蚁能够认出镜子中的影像是自己,但是通常我们不认为蚂蚁拥有充分的“智力”。
- 但是反过来,我认为自我意识确实是强智能的必要条件(也就是说,我并不完全赞同彼得·沃兹所著小说《盲视》中的观点)。一个系统必须能够对自我进行观察,才能在开放性的环境中做出有规划性的调整。换言之,对自身思考、行为的观察即事后主动反思、复盘的能力,这一能力将极大地加速学习过程,并且在我看来才是“主动性”的根本性差异所在。
- 但是上面所探讨的“自我意识”仅包含“自知”,并不包含自我表达(可解释性)与自我映射(同理心),也即是系统仅需要具备对其内部信息结构进行观察的能力,而无需将其以人类能够理解的方式表述出来的能力。
- 根据上面的分析来看,对于部分元学习、梯度学习相关的研究,以及包含预测模型的预训练模型,甚至于很早就存在于强化学习中的Actor-Critic模型,这些模型存在对自我的内在信息进行进一步观察、完善的能力,虽然不能说拥有自我意识,但是是存在自我意识的雏形的。
- 最后,关于求生欲/繁殖欲,我不认为这是一个强智能的充分或必要条件。原因很简单,这是我们地球上的生物之智能的终极目的,我们的所有行为决策、所有奖励函数均围绕这一目的展开。也就是说,这是我们这一智能的“任务”,我们的智能围绕这一任务构建。而智能本身并不以具体任务为转移,其他的智能可以有其他的任务,只是我们自己的任务是活下去,延续下去。仅此而已。
- 关于人工智能的目的,我前面的叙述较为“现实”,较为“功利主义”。我相信,人工智能的发展还有一些更多的,更加浪漫的作用,比如帮助我们认清我们自己的思维,乃至于更加接近这个世界的本质——我并不认为思想的本质(内部)和世界的本质(外部)是可以分割的——这是我自己进入这个领域的根本原因。
- 最后,关于这个问题本身。通常我们说一个东西的对错时包含两层含义:1. 这个东西与客观事实的一致性,2. 这个东西与人们对其的期待的一致性。 在上文的所有讨论中,有一个十分重要的核心因素,即是当前“智能”的定义尚不明确,或者说,智能本质上是一个人为构建的概念而非某个有着明确边界的客观存在。所以上文的所有讨论以“期待”替代“定义”,而对于问题“人工智能是否走错了方向”,其一句话回答应当是:当前的人工智能发展方向,与人类业界对于人工智能的期待,目前来说,大体上是一致的。
# 回答二
作者:霍华德
来源链接:https://www.zhihu.com/question/445383290/answer/1855438656
结论:绝对没有走错
- 谁告诉你现在人工智能需要做傅里叶变换的,视觉靠CNN和transformer,都和傅里叶变换非常不一样。靠傅里叶变换的视觉是啥,是压缩算法,离散余弦变换(Discrete Cosine Transform)那套东西,和现在的深度学习根本不是一回事。声音数据,以前的确会用STFT(Short-time Fourier transform)做一下预处理,转化成频谱图再进一步学习。但现在基于waveform的模型也多如牛毛,效果完全不逊于频谱图。
- 大脑绝对有训练机制,只是无非不靠反向传播和梯度罢了,但脑科学的研究里基于神经可塑性的学习机制早就被证实了。并且衍生出脉冲神经网络SNN那一套东西。从数学上,完全可以证明SNN和DNN、CNN的某些等价性。
- 小孩子不需要大量数据就可以认识橘子苹果,那是因为小孩子自带一个超大的经过人类上万年训练的预训练模型,小孩的脑子可不是随机初始化的,是通过DNA里所携带的信息来进行参数初始化的。在人类演化过程中,视觉的预训练信息通过某种方式已经编码到DNA里了,虽然不知道是什么机制,但每每想到,我都感觉受到很大震撼。
- 你所说的主动性,在我看来是一种agent和环境交互的表述。现在人工智能里的强化学习,完全就是在做这个方向的研究。阿尔法狗也是基于这种深度强化学习搞出来的。只要我们在规则中设置reward,就可以让人工智能系统在很多方面获得主动性。想想人类为啥好色,为啥对交配那么有主动性,还不是因为啪啪啪爽有reward,你给机器人设置个啪啪啪的reward,机器人瞬间很主动,你信不信。
- 神经元之间是电信号,但经过突触是有阈值的,大于阈值的是1,小于阈值的是0。电脑信号最初也是模拟信号,然后设置个阈值,把高电平定义为1或者0,你当一开就都是0和1二进制的?
#图解Megatron TP中的计算通信overlap
本文探讨了Megatron TP中实现计算与通信重叠(overlap)的方法,详细分析了在TP部分(特别是megatron sp-tp)中哪些地方可以进行重叠,并介绍了当前的实现思路。文章讨论了如何通过优化参数和通信策略来实现计算与通信的重叠,以提高模型训练的效率。
这篇文章想来探索Megatron中实现计算通信overlap的方法。
具体来说,Megatron的dp、tp和pp部分,都有可以做overlap的地方,本文探索的是tp部分(更准确地说是megatron sp-tp)。做这个探索的主要目的是:了解在哪些位置有做overlap的潜能,以及当前一些可行的实现思路。
最后,特别感谢overlap大师,megatron特级学者,大众点评美食优惠券killer:https://www.zhihu.com/people/yu-huo-er-wang 为本文提供的各类参考资料。
一、TP中哪些地方做了overlap
我们说的tp,是指“开启megatron sp做了activation显存优化”的tp,下图绘制了在megatron sp中单卡上Attn + MLP的运作流程

由此我们知道,在megatron sp中,tp部分的通讯被拆成若干个all-gather和reduce-scatter,在下文中我们会用AG和RS来简称它。现在我们对tp中的fwd和bwd过程再做一个重新绘制,更清晰地展示通信步骤(绿色)和计算步骤(蓝色):

图中的红/黄框则分别展示了计算和通信之间的依赖关系,具体来说:
-
红色:通信和相关的计算有依赖关系,需要串行。但是可以通过优化使得计算通信能overlap。 -
黄色:通信和相关的计算没有依赖关系,可以并行。dgrad表示算的是input grad;wgrad表示算的是weight grad。
在Megatron-LM中,以下参数将控制是否开启红/黄框中的计算通信overlap:
-
tp_comm_overlap_ag:开启红框中ag相关的overlap -
tp_comm_overlap_rs:开启红框中rs相关的overlap -
tp_comm_bulk_dgrad:开启黄框中dgrad + ag的overlap -
tp_comm_bulk_wgrad:开启黄框中wgrad + ag的overlap -
tp_comm_overlap_rs_dgrad:黄框中的dgrad计算出来后会做rs,这里控制的就是这两者间的overlap。需要注意的是,如果此项为True,则会关闭 tp_comm_bulk_dgrad 和 tp_comm_bulk_wgrad(参见代码),猜测可能是因为同时开启时,存在对缓冲区资源的竞争及复杂管理等问题,会造成整体性能下降。 -
tp_comm_overlap:应该是一个总开关。只有当它为True时,才可以根据需要自动开关以上5项。否则是不开启tp部分的计算通讯overlap的(参考这份代码: https://github.com/NVIDIA/TransformerEngine/blob/c9ea6be92948e1ec553037f1a04900617b9f7f6b/transformer_engine/pytorch/module/layernorm_mlp.py#L265)
我们在Megatron-LM中设置这些参数,进而更改Transformer Engine(以下简称TE)的相关配置,最终的overlap是在TE中实现的。下面我们就来详细介绍这几个overlap技术。
二、tp_comm_overlap_ag
我们以下图圈出来的部分为例:

2.1 朴素all-gather
假设我们采取的是最朴素的,没有任何overlap的策略,那么红框中的计算流程应该是下图这样的,这里假设tp_size = 2:

如上图所示,我们有2张gpu(tp_size = 2):
- 在all-gather开始前,gpu0上存储着输入A0和模型分块B0,gpu1上存储着输入A1和模型分块B1。这里的B就对应着上图中的fc1。
- 在朴素的all-gather中,我们先对输入A矩阵做all-gather,之后两张卡上的数据都变成[A0, A1]
- 然后再各自个和B矩阵(fc1)相乘,得到最终的结果。不难发现,这里我们需要先等输入数据A到齐,然后才可以开始计算,也就是没有实现任何的计算通信overlap。
针对这张图,我们额外说明一点:例如[A0, A1]这样的形式,不代表A一定就是按照列切割的,只代表我们以分块的视角看待A。而Enisum可理解为一种自适应式的矩阵乘。因此我们要根据实际应用的场景来理解这张图,后文同理。
2.2 all-gather overlap p2p
现在我们引入计算通信overlap,流程如下图所示:
- 在最开始阶段,gpu0上存放着输入A0和模型分块B0,gpu1上存放着输入A1和模型分块B1。
- 现在开始操作:
- 在gpu0上,我们先把A0发送到gpu1,于此同时开始做gemm(A0, B0),以便得到C00,实现计算通讯overlap
- 在gpu1上,我们先把A1发送到gpu0,于此同时开始做gemm(A1, B1),以便得到C11,实现计算通讯overlap
- 等gpu0计算完C00,并收到A1后,它就可以继续gemm(A1, B0),以便得到C10;gpu1也是同理
- 在overlap下,我们无需等到输入数据all-gather到齐后再进行计算,这样就可以减少整体的运行时间。
以上展示了2卡情况下的all-gather overlap,在多卡情况下也是同理,整体流程如下图所示:

- partition即为卡,iteration则为每轮迭代,每轮迭代里包含了计算-通信的overlap。partition中的Di表示目前正在使用哪块输入做计算。
- 从图中我们可以发现,这里采取的是p2p ring exchange的方式,也就是每张卡只和自己相邻的2张卡做数据的收-发。
- 例如,在iteration0上时,每张卡做计算时,都用自己维护的那份数据做计算,所以这里Di和partition_i的下标是一一对应的。同时,每张卡会和相邻的2张卡做数据收发。例如partition2会把自己的数据D2发送给partition1,并从partition3上接受D3。
- 再如,在iteration1上时,partition2就用自己收到的D3做计算了,同时它准备把D3发送给partition1,并从partition3上接收D0。以此类推。
相关的代码实践在TE仓库的CommOverlapP2PBase类下,大家可以自行阅读。注意代码里的A=weight, B=input,后文也是同理。
三、tp_comm_overlap_rs
我们以下图圈出来的部分为例:

(备注:tp_comm_overlap_rs_dgrad,也就是右侧bwd中fc1_dgrad和下一个黄框中的RS做overlap的本质也是如此,所以后文不会再单独介绍它了)
3.1 朴素reduce-scatter

假设我们有2张gpu(tp_size = 2)
- B0和B1即为fc2,也就是按行切割的模型权重
- A0和A1理解成fc2的输入。这里A0 = [A00, A10],A1 = [A10, A11]
- 我们需要对B矩阵(fc2)的输出结果做reduce-scatter,而两张卡上的这个输出结果分别为C0 = [C00, C10], C1 = [C01, C11]。
- 不难知道,做完reduce-scatter后:
- gpu0上,C0 = C00 + C01
- gpu1上,C1 = C10 + C11
- 同样,在朴素reduce-scatter中,我们也需要等到[C00, C10]和[C01, C11]这个结果计算出来后,再做reduce-scatter,即计算通信没有overlap
针对这张图,我们额外说明一点:之所以要修改原始图片中的[A0, A1],是因为在tp mlp的fc2中,每张卡上的输入是不一样的,所以这里特别针对这个场景做了修改。
3.2 reduce-scatter overlap p2p

上图直接理解起来可能会有点头晕,我们不妨从一个更形象的视角理解一下:
- 还是和all-gather overlap一样,这里采用的是p2p ring exchange的通信方式。
- 在初始阶段,每个 gpu_i 都会发送出一个“碗C_i”,这个“碗C_i”的意思是,请把和我(gpu_i)相关的计算结果装在这个碗里。
- 那么接下来,哪个gpu接收到这个碗C_i,它就要负责计算和这个 C_i 相关的结果,并把结果更新在 C_i 里
- 假设我们共有 n 块gpu,那么 n-1 轮后,C_i 又流转回 gpu_i 手里,这时轮到 gpu_i 做和 C_i 相关的计算,这次计算结束后,就得到了最终的 C_i
基于此解读以上2卡的情况就不难了。那我们顺水推舟到多卡的情况:

- 在iteration0里,由于p2p ring exchange机制的影响:
- 对于partition0,它接收到来自partition1的碗C1,所以它只能做和C1相关的计算,也就是利用D1进行计算,然后把计算结果更新到C1中。
- 其余partition也是同理
- 在iteration1里:
- 对于partition0,此时它接收的是来自partition1的碗C2(因为在上一次迭代中,partition1就是接收的partition2的C2,所以现在继续击鼓传花式地传递),因此partition0只能做C2相关的计算,也就是利用D2来计算。
- 其余partition也是同理。
- 在iteration3里:
- 对于partition0,它终于接到了在iteration0里它传出去的碗C0,此时C0已经装满了其余partition上和partiton0相关的计算结果了,现在只要partition0把自己的这份结果更新进去,就大功告成了。
相关的代码实践可以参考下文链接。注意代码里的A=weight, B=input。这个过程理解起来有点绕,大家可以多体会下:
3.3 reduce-scatter overlap pipeline chunk
对于像fc2这种需要对输出结果做reduce-scatter的情况,除了p2p形式的overlap,megatron还提供了另外一种overlap的方法:pipeline chunk。
Pipeline chunk的思想是:假设原来是做完gemm(A, B)后再对结果reduce-scatter,那么现在我可以把矩阵(比如A)拆分成若干chunk,每次等gemm(chunk_i, B)的结果出来后,把这个结果发出去做reduce-scatter的同时,再继续做下一个chunk的计算,以此实现overlap。当然chunk的数量也不能太多(也就是不能把矩阵切得太小),否则反而会降低整体性能。在代码中默认chunk数量 = 4 (_num_splits = 4)。
代码详情可以参见下面链接。(我觉得这个代码写得可能有点问题。目前看来它能奏效是因为fc2的一个维度是4h,而num_splits = 4,切分后刚好是个方形矩阵(h, h),所以不管怎么转置做gemm都没有尺寸匹配问题,但是计算逻辑就不对了,另外这个函数似乎也只在fc2_fprop里用)更新:对此持保留态度,可能是我理解有误
四、 tp_comm_bulk_ag 和 tp_comm_bulk_rs
我们先来看下面框中 fc1_dgrad 和 AG 的overlap

这个过程对应到megatron sp的的架构图里如下:

之所以 fc1_dgrad和 AG 可以并行操作,是因为当前进程上做 fc1_dgrad只依赖上层传导过来的链式结果和fc1_weight。但是计算 fc1_wgrad却要依赖 AG 后的完整data(input activation)。fc1_dgrad 和 fc1_wgrad 计算完毕之后,前者做 RS 后继续向下层传导,后者用于更新 fc1_weight。在代码中,管黄框中的overlap叫bulk overlap,并通过设置主流(stream_main)和通信流(stream_comm)来实现这个overlap,我们直接来看代码细节:
/*
** Bulk GEMM + COMM
** This function assumes the communication input is pre-copied to _ubuf
*/
voidCommOverlapBase::bulk_overlap(TensorWrapper &A, bool transa, TensorWrapper &B, bool transb,
TensorWrapper &D, TensorWrapper &bias,
TensorWrapper &pre_gelu_out, TensorWrapper &workspace, bool grad,
bool accumulate, bool use_split_accumulator,
CommOverlapType comm_type, TensorWrapper &rs_output,
cudaStream_t stream_main){
// 设置通信的上下文参数_ub_comm
int ori_sms = _ub_comm->sms;
_ub_comm->use_ce = _use_ce;
_ub_comm->sms = _num_comm_sm;
_ub_comm->cga_size = _cga_size;
// Catch up the default torch stream
// 同步主流(用以计算,stream_main)和通信流(用以通信,_stream_comm)
NVTE_CHECK_CUDA(cudaEventRecord(_start_comm, stream_main)); // 在主流中记录事件_start_comm
NVTE_CHECK_CUDA(cudaStreamWaitEvent(_stream_comm, _start_comm, 0));// 让通信流等待该时间完成,这样可以确保通信流在正确时间启动
// Communication: AG and RS
// 通信流执行通信:根据入参comm_type选择不同的通信类型(AG或RS)
int comm_elements = (_ubuf.numel() / 2) * _ubuf.element_size(); // UBUF uses 2Byte element size
if (comm_type == CommOverlapType::AG) {
allgather2_userbuff_inplace(_ub_reg, 0, comm_elements, _ub_comm, _stream_comm,
(cudaEvent_t)_comm_launch_event);
} else {
if (_ubuf.element_size() == 1) {
assert(_ubuf_scale_inv_initialized);
comm_elements *= 2;
assert(rs_output.numel() == _ubuf.numel() / _tp_size);
assert(rs_output.size(0) == _ubuf.size(0) / _tp_size);
assert(rs_output.element_size() == 2);
char *rs_output_ptr = reinterpret_cast<char *>(rs_output.dptr());
reducescatter2_userbuff_fp8<__nv_fp8_e5m2>(rs_output_ptr, _ubuf_scale_inv, _ub_reg, 0,
comm_elements, _ub_comm, _stream_comm,
(cudaEvent_t)_comm_launch_event);
} else {
reducescatter2_userbuff_inplace(_ub_reg, 0, comm_elements, _ub_comm, _stream_comm,
(cudaEvent_t)_comm_launch_event);
}
}
// 主流执行gemm计算:
assert(pre_gelu_out.numel() == 0);
// When the kernel launch order is defined, enforce the GEMM kernel launch to wait for the communication kernel launch
if (_comm_launch_event)
NVTE_CHECK_CUDA(cudaStreamWaitEvent((cudaStream_t)stream_main, _comm_launch_event, 0));
nvte_cublas_gemm(A.data(), B.data(), D.data(), bias.data(), pre_gelu_out.data(), transa, transb,
grad, workspace.data(), accumulate, use_split_accumulator, _math_sms,
stream_main);
// 让主流等待通信流完成,这样接下来才可以继续做后续的计算流程
_ub_comm->sms = ori_sms;
NVTE_CHECK_CUDA(cudaEventRecord(_stop_comm, _stream_comm));
NVTE_CHECK_CUDA(cudaStreamWaitEvent(stream_main, _stop_comm, 0));
} // CommOverlapBase::bulk_overlapfc1_wgrad 和 RS 的overlap也是用这个函数实现的,这里不再赘述。
五、小结
本文第一节中,展示了在megatron sp-tp中,一个decoder layer做fwd和bwd时需要做的计算与通信,其中:
对于红框部分,理论上计算和通信是有串行依赖的关系,但是可以通过一些优化办法做成overlap。具体来说TE实现了以下2种办法,它们本质上都是通过把计算拆分成更小的若干算子,从而实现边算边通信的目的:
- 串行overlap方法一:p2p ring exchange,参见2.1(2), 2.2(2)
- 串行overlap方法二:pipeline chunk,参见2.2(3)
对于黄框部分,理论上计算和通信没有依赖关系,所以天然可以做成overlap。TE提供了一种bulk overlap的方法,通过设置计算流和通信流,完成两者间的交叠:
- 并行overlap方法:bulk overlap,参见第四节
六、参考
1、https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/features/optimizations/communication_overlap.html
2、https://dl.acm.org/doi/10.1145/3567955.3567959
3、https://github.com/NVIDIA/TransformerEngine
4、https://github.com/NVIDIA/Megatron-LM
#机器学习与优化基础
Machine Learning and Optimization机器学习与优化
引用大佬Pedro Domingos的说法:机器学习其实就是由模型的表示,优化和模型评估三部分组成。将一个实际问题转化为待求解的模型,利用优化算法求解模型,利用验证或测试数据评估模型,循环这三个步骤直到得到满意的模型。
因此,优化算法在机器学习中起着一个承上启下的作用!
一般机器学习中涉及的优化命题可以表示为:
比如:
- 最小二乘回归
- 岭回归
- LASSO:
- 支持向量机
- 正则化逻辑斯蒂回归
还有等等等等机器学习算法也是类似的。
优化算法基础
优化算法的阶次
所谓优化算法的阶次其实指的是优化过程利用的是
- 目标函数本身 (零阶)
- 梯度信息 (一阶)
- hessian信息 (二阶)
中的哪些信息。
如果函数形式未知、梯度难以求或不存在的时候常常采用零阶优化算法;在机器学习领域中一般一阶算法使用较多,二阶算法可能收敛更快但计算花费也更大。
优化算法的常见组成
- 梯度下降
在理解梯度下降法之前, 再给大家复习一下几个非常容易混淆的概念: 导数是一元函数的变化率 (斜率)。如果是多元函数呢? 则为偏导数。偏导数是多元函数 “退化"成一元函数时的导数, 这里 "退化"的意思是固定其他变量的值, 只保留一个变量, 依次保留每个变量, 则 元函数有 个偏导数。如果是方向不是沿着坐标轴方向, 而是任意方向呢? 则为方向导数。换句话说, 偏导数为坐标轴方向上的方向导数, 其他方向的方向导数为偏导数的合成。而偏导数构成的向量就称为梯度。
梯度方向是函数增长速度最快的方向, 那么梯度的反方向就是函数减小最快的方向。因此, 如果想要计算函数的最小值, 就可以用梯度下降的思想来做。假设目标函数的梯度为 , 当前点的位置为 , 则下一个点的选择与当前点的位置和它的梯度相关
其中 为学习率, 可以随着每次迭代改变。(就拓展出了许多相关的算法AdaGrad、RMSProp、Adam等)
- 近端映射(proximal operator)
当目标函数存在不可微部分, 常会采用近端梯度下降法。比如 , 其中 是凸的且可微, 是凸的但是不可微或者局部不可微。由于 不可微, 我们不能直接用梯度下降法来寻优(PS:次梯度算法可以, 就是慢了点), 因此近端算法考虑的是将 进行近端映射。
函数 的近端映射可以定义为
拿个机器学习中常见的 范数给大家举个例子, (一范数就是各元素 绝对值之和),对应的近端映射表示为
这个优化问题是可分解的! 也就是对每一个维度求最小值
对 的正负进行分类讨论, 然后利用一阶最优条件(求导令导数为零)可得
这通常也被称作软阈值(soft thresholding)。
因此近端梯度算法也就是
- 对偶(dual)
在求解一个优化命题时,如果其对偶形式便于求解,常常可以通过求解对偶问题来避免直接对原问题进行求解。比如机器学习中典型的SVM就涉及到对偶理论,以及拉格朗日乘子法、KKT条件等概念。首先简单通俗地说说这几个概念是干嘛的
- 对偶理论:对偶也就是孪生双胞胎,一个优化命题也就有其对应的兄弟优化命题。
- 拉格朗日函数:将原本优化命题的目标函数和约束整合成一个函数。
- KKT条件:函数的最优值满足的性质。
如果原问题是凸问题,则KKT条件为充要条件,也就是说满足KKT条件的点也就是原问题和对偶问题的最优解,那就能够在满足KKT条件下用求解对偶问题来替代求解原问题。(具体推导和细节就不展开了,下次可以单独写一篇)
- 随机化
当遇到大规模问题时, 如果使用梯度下降法(批量梯度下降法), 那么每次迭代过程中都要对 个样本进行求梯度, 所以开销非常大, 随机梯度下降的思想就是随机采样一个样本来更新参数, 那么计算开销就从 下降到 。
无约束问题的典型算法
- 梯度下降法
上面提到过了就不重复了。

- 共轭梯度法
梯度下降法可能存在的一个问题是为了收敛到解附近,同样的迭代方向可能走了不止一次(导致收敛慢)。共轭梯度就可以理解为选择一系列线性无关的方向去求得最优解。因此共轭梯度法把共轭性与最速下降方法相结合,利用已知点处的梯度构造一组共轭方向,并沿这组方向进行搜素,求出目标函数的极小点。
方向的构造方法为:
其中当初始化的时候相当于梯度下降法(因为初始时刻只有梯度方向)。这里末知项是这个系数 , 它的计算公式为
有了搜索方向,那么每次次迭代为

- 拟牛顿法
在说拟牛顿法前先简单介绍一下牛顿法,牛顿法最初是为了求解方程的根而推导出来的公式。它的主要思想是 基于当前位置的切线来确定下一次的位置。比如要求 的解,可以迭代求解

如果对应到求解优化命题, 我们要使得 取最小值, 也就是函数的一阶导数为零 , 带入牛顿法求根公式就是

由于牛顿法每次都要计算二阶导数(Hessian矩阵)的逆,计算量太大了,因此有了拟牛顿法。简单的说,拟牛顿法其实就是用近似Hessian矩阵来进行迭代。
比如说令 ,再利用拟牛顿条件(对一阶导数进行泰勒展开) 对近似矩阵进行修正就可以避免Hessian矩阵的求逆了。因此每次迭代为

在实际应用当中,使用最为广泛的拟牛顿法应该是L-BFGS算法了。
- Proximal gradient(近端梯度)
上面提到过了就不重复了。

约束问题的经典算法
- 投影梯度下降法(Projected gradient descent)
看名字可以知道这个方法的思想其实就是梯度下降再加上投影操作来满足约束。可以理解为是一个两阶段的算法,
第一阶段先进行梯度下降

第二阶段进行投影

也就是说在约束范围内找一个与无约束条件下最近的解,或者说将无约束解投影到约束范围内。
- 罚函数法
罚函数法的思想也可以从它的名字进行解释,其实就是将违反约束的代价放入目标函数中,从而把约束问题转化为无约束问题。转化后的无约束问题为
其中 是连续函数, 且对于任意 罚函数非负, 当 满足约束, 即 时
- Frank-Wolfe算法
这个算法的思想和它的名字就不好联系上了,基本思想是将目标函数作线性近似,

通过求解线性规划

求得可行下降方向

因此每次迭代的公式为

- 交替方向法ADMM
ADMM的思想是以先分解再结合的形式求解问题,即先把原问题分解成若干个相对原问题较简单的子问题,再把子问题的解结合起来得到原问题的全局解。主要针对的问题是可分块优化命题,如

写出其增广拉格朗日函数

用交替方法(只优化一个变量,固定其他变量)的方式进行优化,即

- 坐标下降法
坐标上升法的思想和ADMM有点点类似的地方,就是在每次优化时只优化一个或者一部分变量,然后固定其他变量,即

这就有点像一个高维坐标系,你一个维度一个维度按顺序优化。
当优化问题遇到大数据
当数据量较大的时候,简单的处理办法就是利用随机化的思想,比如梯度下降法就可以改为随机梯度下降,坐标上升法就可以改为随机坐标上升。
加速优化与展望
所谓的加速优化研究的是在不作出更强假设的情况下改进算法提高收敛速度。常见的比如有重球法(Heavy-Ball method)、Nesterov的加速梯度下降法、加速近端梯度法(APG)、随机方差减小梯度法等等。这些算法可能有点超纲了,感兴趣或者专门研究这类问题的可以参考林宙辰老师的新书(参考书籍4)。
对于大规模优化的一些研究可以从以下几个角度展开:随机优化、分布式优化、异步优化、基于学习的优化等等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









