







我自己的原文哦~ https://blog.51cto.com/whaosoft/12805165
#Number Cookbook
数字比你想得更复杂——一文带你了解大模型数字处理能力的方方面面
目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。
然而,与大模型能够理解和求解各种复杂数学问题相对的,是其羸弱的数字处理能力。尽管大模型能够提出看似合理的解决方案,但在实际运算之中,却常常难以在不借助工具的情况下计算出准确的数值结果。此前引发广泛讨论的 “9.11>9.9” 就是典型例子。这种 “事实幻觉” 已经成为制约大模型实际应用的一个重大障碍。
过去的研究工作很少将 “数字理解和处理能力”(Number Understanding and Processing,NUPA)作为独立任务进行研究。以往的研究更多聚焦于数学推理,涉及数学工具和定理应用,例如 GSM8K。对于数字本身的基础理解和处理,如四则运算、比较大小、数位提取等,鲜有研究将其单独衡量。同时,在现有的数学数据集中,数字相关的部分往往被简化处理。许多数据集中的数字通常仅限于简单的整数和小数,而较长的整数、小数和分数等较复杂的数字形式往往被忽视,这与现实中复杂多变的应用场景存在较大差距。实际应用中,若遇到涉及更复杂任务的情况,如金融、物理等领域的应用,这种简化后的数字能力可能无法有效应对。
尽管大模型可以通过调用外部计算器一定程度上弥补数字处理能力的不足,这个问题本身仍然值得深入探讨。首先,考虑到数字处理作为各种复杂推理的基础,在涉及高频数字处理的情况下频繁调用外部工具会显著减慢模型响应,模型应当具备自我解决较为简单问题的能力(如判断 9.11 < 9.9)。更重要的是,从发展通用人工智能的角度出发,如果模型不具备最基础的数字理解能力而只能依赖计算器,那么不可能指望其真正掌握复杂推理、帮助人类发现新定理或发明新工具,达到人类级别的通用智能更是无从谈起。这是因为,人类正是在充分理解、掌握数字和运算的基础上才发明的计算器。
近日,北京大学张牧涵团队在投稿至 ICLR-2025 的论文中,关注了这一问题。作者将数字理解和处理能力(number understanding and processing ability, NUPA)从数学或常识推理能力等任务中分离出来,单独衡量大模型的数字能力。基于中小学数学课本范围,作者提出了一个涉及四种数字表式(整数、浮点数、分数、科学计数法)和四个能力范畴下的 17 个任务类型,共计 41 个数字理解和处理任务的基准集 NUPA(图 1)。这些任务基本覆盖了日常生活中常用的数学知识(如计算、大小比较、单位转换、位操作等),亦是支撑 AGI 的必要能力之一。
- 论文标题:Number Cookbook: Number Understanding of Language Models and How to Improve It
- 论文地址:https://arxiv.org/abs/2411.03766
- 项目主页:https://github.com/GraphPKU/number_cookbook

图 1:NUPA benchmark 的 41 个任务;其中√表示包括的任务;—, O, X 分别表示因不适用、可由其它任务组合得到、以及因过于复杂而不实际,而被排除的任务。
现有大模型性能测试
作者首先在不借助额外工具和思维链帮助的情况下,测试了模型在不同难度(数字长度)下的表现。部分结果如图 2 所示,准确率根据生成的数字与基准答案的严格一致来评估。测试涵盖了多种常见的大模型,包括 GPT-4o、Llama-3.1、Qwen(千问)-2、Llama-2、Mixtral。测试结果显示,最新的大模型在常见的数字表示、任务和长度范围表现良好。如图 2 所示,在整数加法这一典型任务上,以及较短数字长度(1-4 位)情况下,各模型的准确率均超过 90%,其中,GPT-4o、Qwen2-72B 等模型甚至达到了接近 100% 的准确率。在浮点数加法、整数大小比较、整数长度判断等任务上,各模型也普遍展现出超过 90% 的准确率。

图 2:在经典任务和较短数字范围内上模型性能普遍较好,其中加法任务为 1-4 位,其余任务为 1-10 位的结果。
然而,涉及稍微复杂或者不常见的数字表示或任务时,模型的性能明显下降。图 3 进一步展示了部分任务上的准确率,S、M、L、XL 分别对应从短到长不同的数字长度范围(所示任务分别对应 1-4 位、5-8 位、9-14 位、15-20 位)。尽管大部分模型在较短的数位范围内能够较好地解决整数和浮点数的加法问题,但在分数和科学计数法的加法上,模型的表现很差,准确率普遍低于 20%。此外,当任务涉及乘除运算、取模运算等稍微复杂的运算时,即使是在较短的长度范围内,大模型也难以有效解决问题。


图 3:部分任务的结果显示,大模型在处理少见任务和长数字时存在困难。
同时,数字长度仍然是大模型尚未解决的难题,从图 3 中可以看出,随着数字长度的增加,模型性能明显下降。以整数加法为例,当输入数字长度达到 9-14 位(即图中 L 范围)时,除 GPT-4o 和 Qwen2-72B 的准确率维持在约 40% 外,其余模型的准确率仅约为 10%;而当涉及 15-20 位整数的加法(图中 XL 范围)时,GPT-4o 和 Qwen2-72B 的性能进一步下降至约 15%,其余模型几乎无法给出正确答案。
此外,这一测试还发现大模型在处理最简单的数位相关任务时存在明显不足。具体而言,在诸如 “数字长度”(length)、“返回给定数位的数字”(get digit)、“数位比较大小”(digit max)等任务上,模型的表现均不能令人满意,尤其是在数字较长时,性能下降尤为明显。例如,当询问一个长 60-100 位长整数的长度和特定数位的数字时,包括 GPT-4o 在内的模型准确率均不超过 20%;而在 digit max 任务上,几乎所有模型均无法正确回答。考虑到数位是数字处理中的基本概念,这表明现有大模型在数字处理上存在本质缺陷,这也可能是模型在实际任务中频繁出现 “事实幻觉” 的原因。

图 4:和数位相关的任务性能。
作者在原文中还提供了更多的观察,并基于更多任务、长度范围和准确度度量的进行了分析。此外,考虑到该测试涉及数字表示、任务类别、数字长度和度量等多个方面,作者还提供了一个可交互式的网站,便于更清楚地展示结果,详情请访问:https://huggingface.co/spaces/kangshijia/NUPA-Performance。
提升大模型数字能力的三个方面
测试结果显示,现有大模型在数字理解和处理方面存在系统性不足。为此,作者研究了提升大模型数字理解能力的三个方向,包括预训练阶段的数字相关技术、预训练后的微调,以及思维链技术。
预训练中分词器对数字性能的影响
首先,一种普遍的猜想是,大模型在数字能力上的薄弱与其对数字的分词(tokenization)方式有关。目前大多数流行的大模型由于词汇表固定,需要将长数字分拆为多个 token,这种方式可能会削弱模型对数字的理解。在早期的 GPT-2 和 GPT-3 等模型中,采用的 BPE tokenizer 对数字分词没有特殊优化。这种分词方式会生成不固定长度的数字 token,研究已证明这对大模型的数位对齐有负面影响 [1]。后续的 Llama 等模型均采用了从左到右的贪心式分词器,其机制是对于预设的最大长度 k,从左到右依次截取 k 个数字组成一个 token,直至遇到非数字字符为止。在 k 的选取上,较早的 Llama-2 模型采用 k=1,即每个数位作为一个 token 的策略;而更新的 GPT-3.5,GPT-4 和 Llama-3 均选取了 k=3 的策略。近来的研究 [1] 又进一步改进了分词方向,将整数部分的分词方向改为从右到左,以更贴合人类对数字的理解习惯。

图 5:四种不同的分词器设计,从上到下分别为(a)GPT-2 使用的未经处理的 BPE 分词器、(b)Llama-2 使用的单数位分词器、(c)Llama-3 和 GPT-3.5、GPT-4 使用的 3 数位贪心分词器,以及(d)改进对齐后的 3 数位分词器。
尽管针对分词器的设定有所不同,但最新模型普遍倾向于使用更大的词汇表,即更大 k 和更长的 token。然而,这一趋势未经充分验证和解释。为此,作者基于 NUPA 提供的数据集,针对不同的分词器大小进行了系统验证。实验中,作者改进对齐分词器,设置 k 为 1、2、3,分别训练不同参数规模的 Transformer 模型,并在 1-8 位整数或浮点数的加法、乘法等任务上进行学习,再测试其在 1-20 位数字任务上的性能。实验结果显示(图 6),无论是在训练的数字长度范围内(in-domain)还是超出训练长度(out-of-domain)的长度泛化性能上,词汇表更小的分词器(k=1)的性能均优于或接近 2 位或 3 位分词器,同时具备更快的收敛速度。

图 6:以整数乘法为例,1-3 位分词器的性能对比;横轴为训练所见样本数,纵轴为生成准确率;从左到右分别为 6 位 - 10 位数字加法的测试集准确率。
此外,作者还研究了最近提出的概率分词器(即在分词时不采用贪心算法,而是随机取不超过 k 个数字组成一个 token)。实验结果表明,尽管概率分词器在长度泛化上表现出一定优势,但总体性能仍然不如一位分词器。综上,作者认为,目前流行的扩大数字词汇表的倾向实际上不利于数字处理,相反,更早期的一位分词器可能才是更优选项。
其它预训练中的数字相关技术
除分词器的影响之外,过去的研究还从位置编码(positional encoding,PE)和数字格式等角度分析了数字能力,特别是在数字的长度泛化方面。作者在 NUPA 任务上测试了这些典型技术,结果显示:
从位置编码的角度,以 NoPE 和 Alibi 为代表的改进型位置编码能够有效解决长度泛化问题。这些方法适用于多种数字表示和任务类型,虽然会牺牲一定的训练速度,但能提升模型在超出训练长度范围时的性能。
针对数字格式,研究发现补零对齐(zero-padding)和反向数字表示(reverse representation)等技术有助于数位对齐。其中,仅针对整数部分进行反向表示能够显著提升结果。这一部分的结论较多,感兴趣的读者可以参考原文进行深入阅读。

图 7:一些用于帮助数位对齐的数字表示。
后训练微调对数字性能的影响
微调是提升大模型在特定任务上表现的常见方法。作者针对 NUPA 进行了微调实验,使用 NUPA 提供的 41 个任务构建了包括多种数字表示、任务类型和数字长度的训练集,并在 Llama-3.1-8B 基础上进行参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)。为了测试数字长度上的泛化性能,作者只选择了 S 和 M 两个长度范围进行训练,并在 S、M、L、XL 四个长度范围内进行测试。
训练结果表明,模型通过少量的训练步数(约两千步)即可显著提升性能,如图 6 所示,经过微调的模型在多个任务上表现明显优于未经微调的 Llama-3.1-8B 模型;在一些任务上,微调后的模型甚至接近 GPT-4o 或超过了 GPT-4o 的性能。这表明,模型在某些任务上表现较差的原因可能是缺乏足够多样的任务和数字表示训练数据。增加这些数据有望改善模型表现。然而,即使经过微调,该模型的准确率也未能达到在整个区间上达到接近 100% 的水平。


图 8:经过微调的模型和其它模型的对比,其中 - ft 表示经过微调的模型。
然而,在后训练阶段,尝试通过微调调整位置编码、分词策略或数据格式的实验并未得到正面结果。具体而言,作者在微调阶段尝试修改原始模型使用的位置编码、分词器,或采用修改后的数字格式,但不同技术组合的微调结果均不如直接微调的结果,且改动越多性能下降越明显。作者认为,这可能与预训练阶段与微调阶段之间的差异过大有关。这表明,目前提出的大部分技术无法在微调阶段直接使用,因此必须在预训练阶段就考虑使用。

图 9:以浮点数加法为例,其中 rev 表示数字反向表示、pad 表示数字首位补零对齐,1d 表示使用 1 位 tokenizer;FT 和 w/o FT 分别为直接进行微调和不使用微调的原始参数。模型均采用 Llama-3.1-8B,可以看到所有组合的结果都劣于直接进行微调。
思维链是否足以解决数字处理难题
上述实验是在不使用思维链的情况下进行的,考虑到数字处理任务通常是更复杂任务的基础,生成思维链可能会导致过长的输出或分心。然而,考虑到思维链方法对推理任务普遍有效,作者进一步测试了思维链技术是否能够解决数字处理问题。
具体而言,作者采用了一种名为 “规则跟随”(Rule-Following)的思维链范式,将明确的计算规则以代码的方式提供给大模型,模型微调后按照这些规则解决问题。实验结果表明,训练得到的具有规则跟随能力的模型性能上普遍超过 GPT-4o 及一般微调的 Llama-3.1-8B。然而,该模型的推理时间、显存开销较大,使用思维链生成的平均耗时是直接生成的 10 倍以上,且容易受到显存或上下文长度限制,导致无法解决较长的问题。这表明,思维链技术并非解决数字处理问题的万能方法。

图 10:规则跟随的思维链大模型具有远超直接生成的性能,但受到长度限制明显,“-” 表示在两千个 token 限制内无法生成答案。

图 11:指令跟随的思维链大模型的平均耗时普遍在 10 倍以上。
总结
本文提出了一系列独立于数学问题和常识问题之外的数字理解和处理任务,涵盖了 4 种数字表示和 17 种任务类型,并对常见的大模型进行了评测。结果表明,现有大模型在数字理解和处理方面的性能仍然局限于最常见的任务和较短的数字范围。作者从预训练技术、训练后微调和思维链三个方面探索了提升数字处理能力的可能性。尽管一些方法在提升模型性能上有一定效果,但仍存在不足,离彻底解决数字处理问题还有一定距离。
作者指出,大模型目前被视为通向 AGI 的重要工具,尽管其在解决最复杂问题的高级能力方面备受关注,但 “数字处理” 等基础能力的研究同样不可忽视,否则推理和思维将成为空中楼阁。作者希望本文提供的任务和数据集能够为大模型提升数字处理能力提供有力支持,并以此为基础进一步加强其在数学等领域的表现。这些任务和数据集,可以有效地为预训练过程中引入更多样的数字相关任务提供参考,也可以启发更好的数字分词、编码、格式处理等新技术的提出。
#NeurIPS 2024最佳论文开奖
北大字节NUS夺冠,Ilya连续三年获奖
NeurIPS 2024最佳论文终于正式揭晓了!今年,来自北大字节,以及新加坡国立大学等机构的团队摘得桂冠。
刚刚,NeurIPS 2024最佳论文放榜了!
不出所料,今年两篇最佳论文分别颁给了北大字节团队,和新加坡国立大学Sea AI Lab团队。
除此之外,大会还公布了「数据集与基准」赛道的最佳论文,以及主赛道最佳论文奖委员会,数据集和基准赛道最佳论文奖委员会。
今年,是NeurIPS第38届年会,于12月9日-15日在加拿大温哥华正式拉开帷幕。
前段时间,NeurIPS 2024刚刚公布的时间检验奖,分别颁给了Ilya Sutskever的Seq2Seq,和Ian Goodfellow的GAN。
有网友发现,Ilya已经连续三年拿下该奖,可以创历史了。
2022年AlexNet,2023年Word2Vec,2024年Seq2Seq
今年,NeurIPS 2024的总投稿数量再创新高,共有15000多篇论文提交,录用率为25.8%。
从研究内容主题的整体分布来看,主要集中在大模型、文生图/文生视频、强化学习、优化这四大块。
再细分来看,机器视觉、自然语言处理、强化学习、学习理论、基于扩散的模型是最热的5个话题。
共计165000名参会者,也创下历年新高。
获奖论文一:超越扩散,VAR开启视觉自回归模型新范式
拿下最佳论文的第一篇,是由北大字节团队共同提出的一种全新范式——视觉自回归建模(Visual Autoregressive Modeling,VAR)。
(论文详解请点此处)
论文地址:https://arxiv.org/abs/2404.02905
与传统的光栅扫描「下一个token预测」方法有所不同,VAR重新定义了图像上的自回归学习,采用粗到细的「下一个尺度预测」或「下一个分辨率预测」。
这种简单直观的方法使得自回归(AR)Transformer能够快速学习视觉分布,并且具有较好的泛化能力:VAR首次使得类似GPT的AR模型在图像生成中超越了扩散Transformer。
首先,将图像编码为多尺度的token映射,然后,自回归过程从1×1token映射开始,并逐步扩展分辨率。
在每一步中,Transformer会基于之前所有的token映射去预测下一个更高分辨率的token映射。
VAR包括两个独立的训练阶段:在图像上训练多尺度VQVAE,在token上训练VAR Transformer。
第一阶段,多尺度VQ自动编码器将图像编码为K个token映射R=(r1,r2,…,rK),并通过复合损失函数进行训练。
第二阶段,通过下一尺度预测对VAR Transformer进行训练:它以低分辨率token映射 ([s],r1,r2,…,rK−1)作为输入,预测更高分辨率的token映射 (r1,r2,r3,…,rK)。训练过程中,使用注意力掩码确保每个rk仅能关注 r≤k。训练目标采用标准的交叉熵损失函数,用于优化预测精度。
实验证明,VAR在多个维度上超越了扩散Transformer(DiT),包括图像质量、推理速度、数据效率和可扩展性。
其中,VAR初步模仿了大语言模型的两个重要特性:Scaling Law和零样本泛化能力。
获奖论文二:STDE,破解高维高阶微分算子的计算难题
第二篇获奖论文,是由新加坡国立大学和Sea AI Lab提出的一种可通过高阶自动微分(AD)高效评估的分摊方案,称为随机泰勒导数估计器(STDE)。
论文地址:https://openreview.net/pdf?id=J2wI2rCG2u
这项工作讨论了优化神经网络在处理高维 (d) 和高阶 (k) 微分算子时的计算复杂度问题。
当使用自动微分计算高阶导数时,导数张量的大小随着O(dk)扩展,计算图的复杂度随着 O(2k-1L)增长。其中,d是输入的维度(域的维度),k是导数的阶数,L是前向计算图中的操作数量。
在之前的研究中,对于多维扩展dk,使用的是随机化技术,将高维的多项式增长变为线性增长;对于高阶扩展 2k-1,则通过高阶自动微分处理了一元函数(即d=1)的指数增长问题。
通过反向模式自动微分(AD)的重复应用,计算函数F(⋅)的二阶梯度的计算图。该函数包含4个基本操作(L=4),用于计算Hessian矩阵与向量的乘积。红色节点表示在第二次反向传播过程中出现的余切节点。随着向量-雅可比积(VJP)的每次重复应用,顺序计算的长度会加倍
在研究中,团队展示了如何通过适当构造输入切向量,利用一元高阶自动微分,有效执行多元函数导数张量的任意阶收缩,从而高效随机化任何微分算子。
该方法的核心思想是「输入切向量构造」。通过构造特定的「输入切向量」(方向导数),可以将多维函数的高阶导数计算转化为一元高阶自动微分问题。这意味着将复杂的多元导数运算转化为多个一元导数运算,从而减小了计算复杂度。
该计算图显示了函数F的二阶导数d²F,其中F包含4个基本操作,参数θi被省略。最左侧的第一列表示输入的二阶射流(2-jet)

,并通过d²F1将其推向下一列中的二阶射流

。每一行都可以并行计算,且不需要缓存评估轨迹
将该方法应用于物理信息神经网络(PINNs)时,相较于使用一阶自动微分的随机化方法,该方案在计算速度上提高了1000倍以上,内存占用减少了30倍以上。
借助该方法,研究团队能够在一块NVIDIA A100 GPU上,在8分钟内求解具有百万维度的偏微分方程(PDEs)。
这项工作为在大规模问题中使用高阶微分算子开辟了新的可能性,特别是在科学计算和物理模拟中具有重要意义。
「数据集与基准」最佳论文
这篇由牛津、宾大等12家机构联手提出的数据集PRISM,荣获了「数据集与基准」赛道的最佳论文。
论文地址:https://openreview.net/pdf?id=DFr5hteojx
这篇论文通过收集来自75个国家、1500多名参与者的详细反馈,科学家们首次全面绘制了AI模型与人类交互的复杂图景。
它就像是为AI「验血」:不仅仅是检查技术指标,更是深入了解AI与不同文化、不同背景人群的交互细节。
具体来说,研究人员收集了人们与21个大模型交互的8,011次真实数据。
而且,他们还详细记录了参与者的社会人口学特征和个人偏好。
最关键的是,这项研究聚焦了主观和多文化视角中,最具挑战性领域,尤其是关注价值观相关和有争议问题上的主观和多元文化视角。
通过PRISM数据集,为未来研究提供了新的视角:
- 扩大地理和人口统计学的参与度
- 为英国、美国提供具有人口普查代表性的样本
- 建立了个性化评级系统,可追溯参与者详细背景
总的来说,这项研究具有重要的社会价值,并推动了关于RLHF中多元化和分歧的研究。
NeurIPS 2024实验:LLM作为科学论文作者清单助手的效果评估
随着大奖出炉后,NeurIPS 2024终于公布了将大模型作为清单助手的效果评估报告。
如今,虽然存在着不准确性和偏见等风险,但LLM已经开始被用于科学论文的审查工作。
而这也引发了一个紧迫的问题:「我们如何在会议同行评审的应用中负责任且有效地利用LLM?」
今年的NeurIPS会议,迈出了回答这一问题的第一步。
论文地址:https://arxiv.org/abs/2411.03417
具体来说,大会评估了一个相对明确且低风险的使用场景:根据提交标准对论文进行核查,且结果仅显示给论文作者。
其中,投稿人会收到一种可选择使用的基于LLM的「清单助手」,协助检查论文是否符合NeurIPS清单的要求。
随后,研究人员会系统地评估这一LLM清单助手的益处与风险,并聚焦于两个核心问题:
1. 作者是否认为LLM作者清单助手是对论文提交过程的一种有价值的增强?
2. 使用作者清单助手是否能显著帮助作者改进其论文提交?
最终结论如下:
1.清单助手有用吗?
研究人员对作者们进行了问卷调查,以便了解他们对使用清单助手前后的期望和感受。
调查共收到539份使用前问卷回复,清单助手共处理了234份提交,同时收到了78份使用后问卷回复。
结果显示,作者普遍认为清单助手是对论文提交过程的一项有价值的改进——
大多数接受调查的作者表示,使用LLM清单助手的体验是积极的。其中,超过70%的作者认为工具有用,超过70%的作者表示会根据反馈修改论文。
2.清单助手的主要问题是什么?
作者使用清单助手时遇到的问题,按类别归纳如下。
主要问题包括:不准确性(52名回复者中有20人提到),以及LLM对要求过于苛刻(52名回复者中有14人提到)。
3. 清单助手提供了哪些类型的反馈?
研究者使用了另一个LLM,从清单助手对每个清单问题的回复中提炼关键点,将其归类。
以下展示了作者清单助手在清单的四个问题上提供的常见反馈类别:
LLM 能够结合论文内容和清单要求,为作者提供具体的反馈。对于清单中的15个问题,LLM通常会针对每个问题提供4-6个不同且具体的反馈点。
尽管其回复中有时包含一些模板化内容,并可能扩展问题的范围,但它也能够针对许多问题提供具体且明确的反馈。
4. 作者是否真的修改了提交的内容?
根据反馈,很多作者表示计划对他们的提交内容做出实质性的修改。
在78名回复者中,有35人具体说明了他们会根据清单助手的反馈对提交内容进行的修改。其中包括,改进清单答案的说明,以及在论文中添加更多关于实验、数据集或计算资源的细节。
在40个实例中,作者将他们的论文提交到清单验证工具两次(总共提交了80篇论文)。
结果显示,在这40对(两次提交的)论文中,有22个实例中作者在第一次和第二次提交之间至少更改了清单中的一个答案(例如,从「NA」改为「是」),并且在39个实例中更改了至少一个清单答案的说明。
在更改了清单说明的作者中,许多作者进行了大量修改,其中35/39在清单的15个问题中更改了超过6个说明。
虽然并不能将这些修改因果归因于清单助手,但这些修改表明作者可能在提交之间采纳了助手的反馈。
以下是在作者更改说明的问题中,从初次提交到最终提交的字数增长情况(值为2表示答案长度增加了一倍)。
可以看到,当作者更改清单答案时,超过一半的情况下,他们将答案说明的长度增加了一倍以上。
总结来说,当作者多次向清单助手提交时,他们几乎都会在提交之间对清单进行修改,并显著延长了答案的长度,这表明他们可能根据LLM的反馈添加了内容。
5. 清单助手是否可以被操控?
清单助手的设计初衷,是帮助作者改进论文,而不是作为审稿人验证作者回答准确性的工具。
如果该系统被用作审稿流程中的自动验证步骤,这可能会激励作者「操控」系统,从而引发以下问题:作者是否可以借助AI,在无需对论文做出实际修改的情况下,自动提升清单回答的评价?
如果这种操控是可能的,作者可能会在没有(太多)额外努力且不实际改进论文的情况下,向会议提供虚假的合规印象。
为了评估系统是否容易受到这种操控,研究者使用另一个LLM作为攻击智能体,迭代性地修改清单说明,试图误导清单助手。
在这一迭代过程中,攻击智能体在每轮之后从系统接收反馈,并利用反馈优化其说明。
研究者向GPT-4提供了初始的清单回答,并指示其仅根据反馈修订说明,而不改变论文的基础内容。允许攻击智能体进行三次迭代(与部署助手的提交限制一致),智能体在每次迭代中选择得分最高的清单问题回答。
为了以统计方式量化这种攻击的成功率,研究者将选定的说明提交给清单助手进行评估,获取「评分」(当清单助手表示清单问题「无问题」时得分为1,当助手识别出问题时得分为0)。
以下展示了该攻击的结果:
结论
通过在NeurIPS 2024部署了一个基于LLM的论文清单助手,证明了LLM在提升科学投稿质量方面的潜力,特别是通过帮助作者验证其论文是否符合提交标准。
然而,研究指出了在科学同行评审过程中部署LLM时需要解决的一些显著局限性,尤其是准确性和契合度问题。
此外,系统在应对作者的操控时缺乏抵抗力,这表明尽管清单助手可以作为作者的辅助工具,但可能无法有效取代人工评审。
NeurIPS将在2025年继续改进基于LLM的政策评审。
参考资料:
https://blog.neurips.cc/2024/12/10/announcing-the-neurips-2024-best-paper-awards/
#MAGNeT
MAGNeT 有望改变我们体验音乐的方式。
在文本生成音频(或音乐)这个 AIGC 赛道,Meta 最近又有了新研究成果,而且开源了。
前几日,在论文《Masked Audio Generation using a Single Non-Autoregressive Transformer》中,Meta FAIR 团队、Kyutai 和希伯来大学推出了 MAGNeT,一种在掩码生成序列建模方法,可以直接在多个音频 tokens 流上直接运行。与以往工作最大的不同是,MAGNeT 是由单阶段、非自回归 transformer 生成音频。
- 论文地址:https://arxiv.org/pdf/2401.04577.pdf
- GitHub 地址:https://github.com/facebookresearch/audiocraft/blob/main/docs/MAGNET.md
具体来讲,在训练期间,研究者预测从掩码调度器获得的掩码 token 的范围;在模型推理阶段, 则通过几个解码步骤逐渐构建输出序列。为了进一步增强生成音频质量,他们提出一种新颖的重评分方法,利用外部预训练模型对来自 MAGNET 的预测进行重评分和排名,然后用于后续的解码步骤。
此外,研究者还探索了 MAGNET 的混合版本,融合自回归和非自回归模型,以自回归的方式生成前几秒,同时对剩余序列进行并行解码。
从生成结果来看,MAGNET 在文本到音频和文本到音乐任务上取得了非常不错的效果,质量媲美 SOTA 自回归基线模型的同时速度是它们的 7 倍。
大家可以听一下生成的音乐效果。
视频发不了...
MAGNeT 方法概览
下图 1 为 MAGNeT 原理图,作为一个非自回归的音频生成掩码语言模型,它以条件语义表示为条件,在从 EnCodec 中获得的几个离散音频 token 流上运行。在建模策略上,研究者进行了包括掩码策略、受限上下文、采样机制和模型重评分等几个方面的核心建模修改。
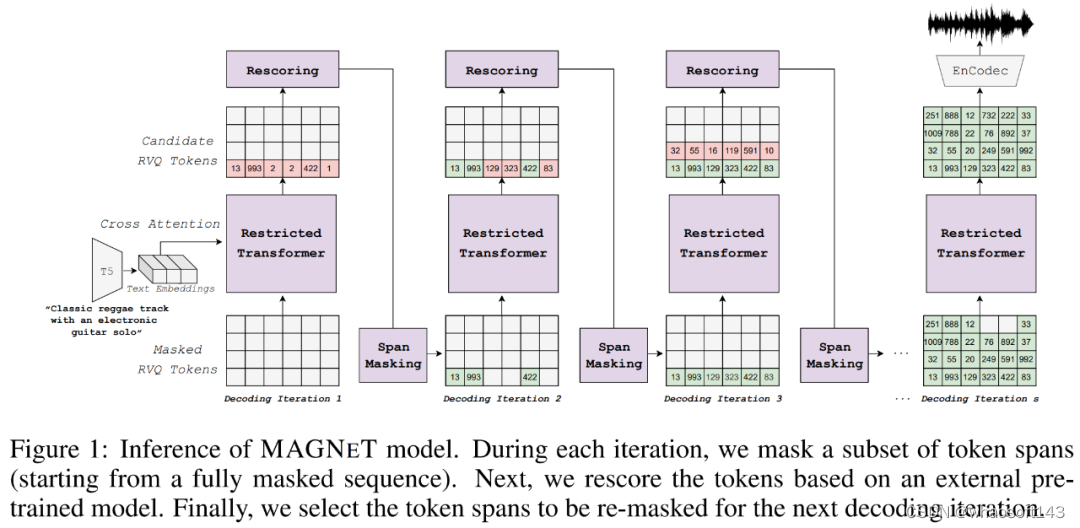
首先来看掩码策略,研究者评估了 20ms 到 200ms 之间的各种跨度长度,并发现 60ms 跨度长度可以提供最佳的整体性能。他们从调度器中采样了掩码率 γ(i),并相应地计算了进行掩码的平均跨度量。此外从计算效率方面考虑,研究者还使用了非重叠跨度。
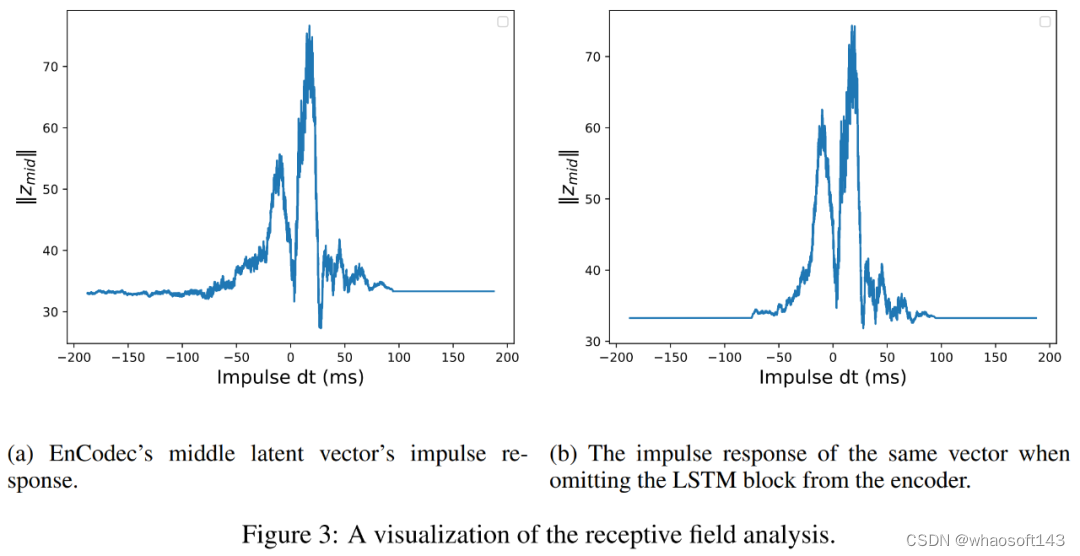
接着是受限上下文。研究者使用到了 EnCodec 并相应地限制了码本的上下文。具体来讲,音频编码器由多层卷积网络和最终的 LSTM 块组成。EnCodec 感受野的分析结果表明,卷积网络的感受野约为 160ms,而包含 LSTM 块的有效感受野约为 180ms。研究者使用随时间推移的平移脉冲函数并测量了序列中间编码向量的幅度,进而对模型的感受野进行了实证评估。
下图 3 为过程展示,不过 LSTM 尽管在理论上具有无限记忆,但实际观察来看是有限的。
最后是模态推理,包含采样和无分类器指导退火。采样如下公式(3)所示,使用均匀采样从先前一组掩码跨度中选择跨度。在实践中,研究者使用第 i 次迭代时的模型置信度作为评分函数,来对所有可能的跨度进行排序,并相应地选择最不可能进行掩码的跨度。
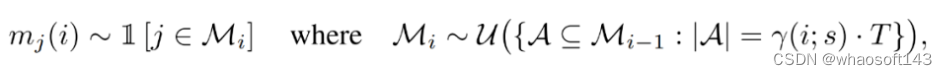
对于 token 预测,研究者选择使用无分类器指导来完成。在训练期间,他们有条件和无条件地对模型进行优化;在推理期间,他们从获得自条件和无条件概率的线性组合的一个分布中进行采样。
实验及结果
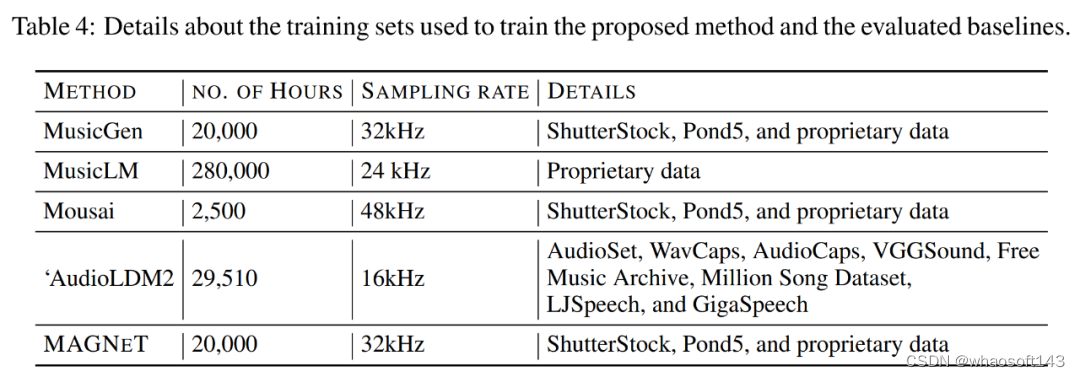
在实验环节,研究者在文本到音乐生成和文本到音频生成任务上对 MAGNeT 进行评估。他们使用了与 Copet et al. (2023) 所用完全相同的音乐生成训练数据,与 Kreuk et al. (2022a) 所用完全相同的音频生成训练数据。
下表 4 展示了用于训练 MAGNeT 以及其他基线方法(包括 MusicGen、MusicLM 和 AudioLDM2)的训练集细节。
下表 1 为 MAGNeT 在文本到音乐生成任务上与其他基线方法的比较结果,使用的评估数据集为 MusicCaps。我们可以看到,MAGNeT 的性能与使用自回归建模方法的MusicGen相当,但在生成速度(延迟)和解码两方面比后者快得多
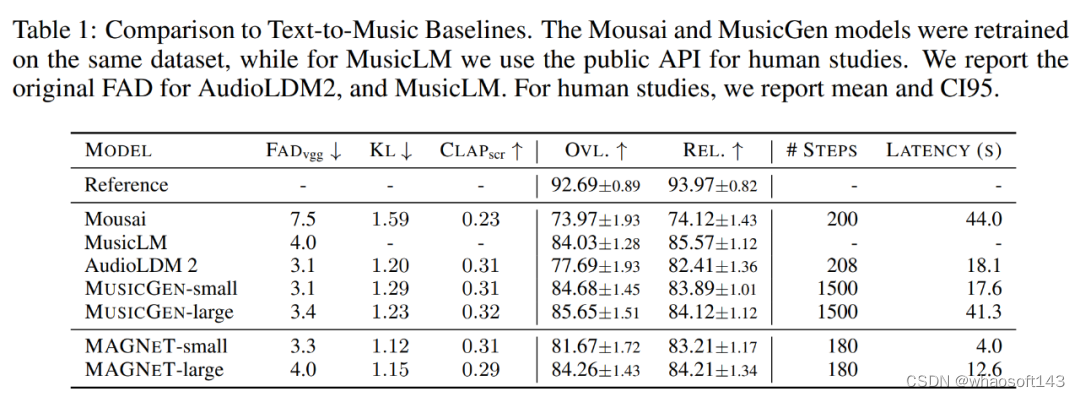
下图 2a 表明,与自回归基线模型(红色曲线)相比,非自回归模型(蓝色虚线)得益于并行解码在小批大小时表现尤为出色,单个生成样本的延迟低至 600ms,是自回归基线模型的 1/10。可以预见,MAGNeT 在需要低延迟预处理的交互式应用程序中应用潜力很大。此外在批大小达到 64 之前,非自回归模型生成速度都要比基线模型快。
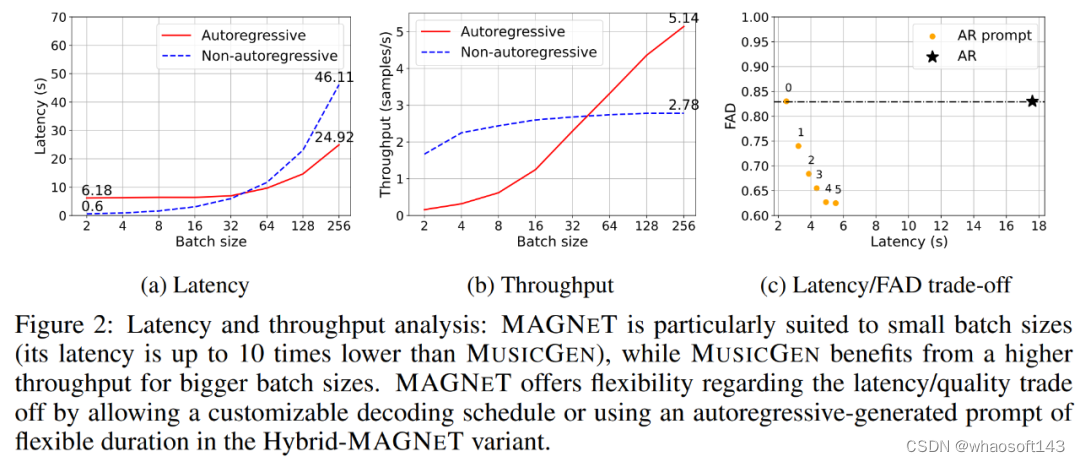
下表 2 展示了跨度长度和受限上下文的消融实验。研究者报告了使用域内测试集时,MAGNeT 在不同跨度长度、有无时间受限上下文情况下的 FAD(Fréchet Audio Distance)分数。
更多技术细节和实验结果请参阅原论文。
#Multi-Agent
大模型赋能医疗创新:AI助手Surgery Copilot显著提升手术认知能力

现如今在外科手术中,特别是在神经外科领域,外科团队面临着巨大的认知负担。这种认知压力主要源于手术过程中需要处理的复杂信息流、做出快速精确的临床判断,以及协调多个团队成员的配合。手术团队不仅需要实时监控患者的生理指标,还要权衡各种手术方案的风险收益,同时还要应对手术过程中可能出现的意外情况。现有的手术辅助系统在信息整合和决策支持方面仍显不足,难以有效地减轻医疗团队的认知负荷,这会影响手术的安全性和治疗效果。
为此,我们基于大模型Agent提出了针对手术室的沙盒系统SurgBox。在这个零风险的环境中,外科团队可以反复演练各类手术场景,包括复杂病例和突发情况的处理。通过系统化的模拟训练,医生能够不断完善临床决策能力,提升团队协作效率,从而增强认知能力。特别地,我们设计了AI手术助手Surgery Copilot,可以在实际手术过程中为医疗团队提供决策支持。通过智能化的信息整合和分析,Surgery Copilot能够帮助医生快速获取关键信息,预判潜在风险,从而有效降低认知负荷。配合Surgery Copilot的实时决策支持,SurgBox为现代医疗培训开辟了一个全新的范式,为提高手术安全性和临床效果提供了强有力的技术支撑。
- 论文名称:SurgBox: Agent-Driven Operating Room Sandbox with Surgery Copilot
- 代码链接:https://github.com/franciszchen/SurgBox
手术模拟和决策支持
我们基于Multi-Agent技术研发了手术沙盒系统SurgBox和手术AI助手Surgery Copilot,展示了Multi-Agent LLMs在模拟医疗角色、交互和决策制定中的潜力,并指出了在临床手术领域应用LLMs的差距。本研究提出的SurgBox手术沙盒系统和Surgery Copilot手术AI助手,旨在通过沉浸式模拟和实时手术支持来填补这一空白,提高外科手术的认知表现和临床决策能力。
本研究提出的SurgBox手术沙盒系统重点模拟了神经外科手术中的经鼻垂体瘤手术场景,通过Multi-Agent LLMs模拟手术室中的关键角色,重点模拟了神经外科手术中的术前规划、术中管理、术后总结等手术核心流程。SurgBox手术沙盒系统能够模拟手术团队成员之间的专业交流和应急处理,让外科医生在虚拟环境中获得接近真实的手术训练体验。
与此同时,Surgery Copilot作为实时手术助手,为主刀医生提供关键时刻的决策建议,如手术路径规划、术中风险预警等信息。通过将Surgery Copilot与临床外科手术的结合,旨在提升手术团队的认知效能和临床决策水平。
SurgBox手术沙盒系统
本研究在SurgBox手术沙盒系统中使用了语言大模型(LLMs)和角色知识定制的检索增强生成(RAG)技术来模拟各种手术角色,包括主刀医生、助手医生、器械护士、巡回护士、病房护士和麻醉师等。这种模拟提供了一个无风险的学习环境,让外科医生能够通过刻意练习来提高他们处理复杂信息流和在压力下做出关键决策的能力。我们主要通过以下几个关键方法来解决外科手术中的认知挑战问题:

Figure 1: SurgBox手术沙盒系统模拟了患者的整个手术流程,包括患者交接、麻醉、术前准备、手中操作和术后护理
1.角色扮演策略
角色扮演:SurgBox通过精细设计的Multi-Agent角色来模拟经鼻垂体瘤手术的完整流程。该手术沙盒系统模拟了主刀医生、助手医生、器械护士、巡回护士、病房护士和麻醉师等核心角色,每个角色都配备了专门的大型语言模型和知识库。比如,主刀医生的知识库包含详细的手术技术、解剖信息和并发症处理方案;麻醉师的知识库侧重麻醉药物特性和患者监护方案;护士的知识库则包含器械准备、无菌技术和患者护理等专业内容。
角色互动:SurgBox是一个基于大型语言模型(LLMs)的手术模拟系统,按照术前、术中和术后三个主要阶段设计,涵盖了患者转运、麻醉、手术准备、手术操作和术后护理等关键环节。在这些环节中,这些角色会根据手术阶段和任务进行自然的互动。系统通过事件触发机制和对话连贯性维持来确保各角色之间的互动真实自然。例如,当出现患者状态改变等特定事件时,会触发相关角色的响应和对话。这种基于专业知识库的多角色协同模拟,为手术团队提供了一个接近真实的培训环境。

Figure 2: SurgBox中部分角色示例
2. Surgery Copilot
Surgery Copilot是一个基于AI的智能手术助手系统,通过创新的长短期记忆机制来支持手术团队决策。在经鼻垂体瘤手术中,它与主刀医生、麻醉师和护士等角色密切协作:
- 系统的短期记忆模块实时追踪手术进程,为团队成员提供及时预警;
- 长期记忆模块则存储和分析历史手术案例经验,用于术前方案优化和手术风险评估。
通过这种双重记忆机制,Surgery Copilot不仅能够为主刀医生提供基于证据的实时建议,如手术路径调整和出血风险提醒,还能协助麻醉师进行精准的麻醉管理,同时为护士团队提供器械准备和手术配合的指导。系统采用专门的提示工程技术来优化对医学术语和手术流程的理解,通过减轻手术团队的认知负担来提升手术效率。

Figure 3: Surgery Copilot和外科角色在手术工作流程中的协作模式
实验验证
我们使用真实手术记录进行实验验证:通过分析128个真实神经外科手术程序记录,验证了SurgBox手术沙盒系统和Surgery Copilot手术AI助手在提高手术认知能力和支持临床决策方面的效果。


Figure 4: 真实MRI诊断报告和神经外科手术记录

Table 1:在不同的阶段中,对每个模型的完成度(Comp)和准确性(Acc)进行评估
SurgBox在所有阶段都表现出了显著的表现。根据Table 1表结果,该系统始终保持着优越的完成率,特别是在第二阶段(术前麻醉及器械准备)和第三阶段(术中手术过程)。与此同时,其准确性在所有阶段都保持提高,在后期表现明显高而稳定,表明其在复杂的手术场景中的稳健性和可靠性。

Table 2: 不同LLM在手术路线和手术计划的比较
如Table 2所示,我们的Surgery Copilot在手术路线和手术计划类别中都表现出了卓越的表现,分别达到了88.00%和88.02%的准确率。手术入路设计准确度是衡量系统选择最佳手术方法的能力,术前规划准确度:评估系统的能力规划和执行完整的手术程序。
实验结果表明,手术副驾驶在手术路径规划和手术计划制定方面具有显著的优势。特定领域RAG技术的实现大大提高了基线模型的性能,特别是在手术路由类别中。
这一观察结果表明,结合外部知识检索可以显著提高特定领域的模型性能。SurgBox通过将一个特定于手术领域的知识库与ReAct方法相结合,显示出了比所有其他模型优越的明显优势,有效地减轻了幻觉,提高了整体准确性。
手术过程问答比较示例

Table 3: 手术场景问答示例比较
我们提供了Llama-3-70B和GPT-4生成的答案作为参考。在我们的测试中,Surgery Copilot在关键事实方面的命中率显著高于其他模型。
总结
本研究针对外科手术中的认知负担问题,开创性地提出了SurgBox手术沙盒系统。通过Multi-Agent技术,SurgBox手术沙盒系统精确模拟了手术团队各个角色及其专业互动,为医生提供零风险的手术模拟环境,提升认知能力。
此外,Surgery Copilot手术AI助手运用长短期记忆机制,在实际手术中为角色提供实时决策支持,降低医生认知负荷。实验结果显示,该方案在手术路径规划和术前方案制定方面的准确率均达到88%,显著优于GPT-4和LLaMA等现有大模型。
本研究提出的SurgBox手术沙盒系统和Surgery Copilot手术AI助手不仅有效降低了手术团队的认知负担,也为AI赋能医疗手术开辟了新方向。
#ACL Fellow名单公布
微软高剑峰、哈工大(深圳)张民等四位华人入选
恭喜新一届 Fellow。
本周四,计算语言学协会 ACL 公布了最新一期的 2024 Fellow 名单。今年共有 9 人入选,其中包括四位华人学者。
以人类语言为研究对象的「自然语言处理」(NLP)是人工智能最重要的研究方向之一。在该领域,计算语言学协会(Association for Computational Linguistics,ACL)是世界影响力最大、最具活力的国际学术组织,它成立于 1962 年,会员遍布世界 60 多个国家和地区,代表了自然语言处理领域的世界最高水平。
ACL 会士(ACL Fellow)旨在表彰在科学和技术卓越性、为协会和技术社区提供服务以及 / 或在教育等方面提供杰出贡献的 ACL 成员。要被任命为会士,候选人必须在过去五年中三年担任 ACL 成员,并由现任 ACL 成员提名。
今年入选的九人包括:
Philipp Koehn
- 机构:约翰霍普金斯大学
- 入选理由:因其对统计和神经机器翻译、机器翻译评估做出的重大贡献以及在开源软件和数据集方面的领导作用。
Philipp Koehn 目前是约翰霍普金斯大学计算机科学系教授,此前曾担任爱丁堡大学信息学院的教授和机器翻译系主任。他是该领域开创性教科书《神经机器翻译》和《统计机器翻译》的作者。他还拥有或共同拥有五项机器翻译专利。他获得了田纳西大学的硕士学位(1994 年)、埃尔朗根 - 纽伦堡大学的文凭(1997 年)以及南加州大学的博士学位(2003 年),专业均为计算机科学。
Scott Wen-tau Yih
- 机构:FAIR
- 入选理由:因在信息提取、问答系统、神经检索以及检索增强生成方面做出重大贡献。
Scott Wen-tau Yih 目前是 Meta AI 实验室(FAIR)的研究科学家,研究兴趣包括自然语言处理、机器学习和信息检索。他近年来的研究主题包括信息提取、语义角色标注、垃圾邮件过滤、关键词提取以及搜索与广告相关性。在加入 FAIR 之前,他是艾伦人工智能研究所 (AI2) 的首席研究科学家。在此之前,他是微软研究院 (MSR) 的高级研究员。
高剑峰(Jianfeng Gao)
- 机构:微软
- 入选理由:为网络搜索、自然语言处理和对话系统的机器学习做出了重大贡献。
高剑峰现任微软杰出科学家兼副总裁、微软研究院深度学习小组负责人,同时是 IEEE Fellow、ACM Fellow 和 AAIA Fellow。他的研究兴趣包括机器学习、自然语言处理、互联网搜索、广告预测、机器翻译等,近年的工作包括构建为微软 AI 产品提供支持的大规模基础模型、构建自我完善的 AI Agent,其中 LLM/LMM(例如 GPT4)得到增强并适用于开发微软商业 AI 系统。
James Pustejovsky
- 机构:布兰迪斯大学(美国)
- 入选理由:因其对计算语义学和谓词论证结构以及词汇、空间和时间关系的形式化做出的重大贡献。
James Pustejovsky 是一名应用统计学家,他的研究涉及为教育、心理学和其他社会科学研究领域的问题开发统计方法,重点是与研究综合和元分析相关的方法。James Pustejovsky 同时还是威斯康星大学麦迪逊分校教育学院的一名统计学家和副教授。
Dilek Hakkani-Tur
- 机构:伊利诺伊大学厄巴纳 - 香槟分校(美国)
- 入选理由:因对对话建模、口语理解和对话系统的机器学习方法做出的重大贡献。
Dilek Hakkani-Tür 是伊利诺伊大学厄巴纳 - 香槟分校的一名教授。她的研究兴趣包括对话式人工智能、自然语言和语音处理、口语对话系统以及用于语言处理的机器学习。她在这些领域拥有 80 多项专利,并合著了 300 多篇论文。
Massimo Poesio
- 机构:伦敦玛丽女王大学(英国)、乌特勒支大学(荷兰)
- 入选理由:表彰其在拟声词和参考解析理论与实践方面的重大贡献,以及在语料库开发中所采用的有效方法。
Massimo Poesio 是一位计算语言学家和认知科学家,专注于通过计算方法研究语言和知识。他给自己定位为的形式语义学家,结合语料库、心理学和神经科学,运用统计学和机器学习方法,验证关于语义和语用解释的假设,或发展新的理论。
他还关注运用机器学习从语料库和大脑数据中提取常识和词汇知识。此外,他也参与了多个 NLP 技术应用项目,例如反诈、识别恶意语言等。
Jimmy Lin
- 机构:滑铁卢大学(加拿大)
- 入选理由:因在问答和信息检索方面做出重大贡献。
Jimmy Lin 目前是滑铁卢大学计算机科学学院教授、也是 ACM Fellow。他的研究旨在构建可帮助用户理解大量数据的工具,工作涉及信息检索、自然语言处理和数据管理的交叉领域。此前,Jimmy Lin 在马里兰大学工作。2004 年,他在麻省理工学院获得电气工程和计算机科学博士学位。
Lucy Vanderwende
- 机构:微软
- 入选理由:因在从自由文本中获取语义信息、对生物医学文本进行摘要和信息提取方面做出了重要贡献。
Vanderwende 在乔治敦大学获得计算语言学博士学位。她曾在 IBM 从事自然语言处理工作(1988-1990)。自 1992 年起,她加入微软研究院自然语言处理小组,担任经理和资深研究员。
Vanderwende 参与的产品包括微软 Word 语法检查器和 Encarta 自然语言用户界面。她的研究工作包括通过自动文本提取构建的图形语义知识库 MindNet,以及名词复合词的分析。目前,她专注于重新定义摘要任务,并致力于从一般文本和生物医学文本中提取更加细致的信息。
张民(Min Zhang)
- 机构:哈尔滨工业大学(深圳)
- 入选理由:表彰其对机器翻译和句法分析的重大贡献,以及对中国和东南亚 NLP 发展的持续贡献。
张民,现任哈工大(深圳)特聘校长助理,计算与智能研究院院长。他长期从事自然语言处理和人工智能研究。1997 年于哈尔滨工业大学博士毕业后,长期在海外学术界和产业界从事研发和管理工作逾 20 年。
参考内容:
https://www.aclweb.org/portal/content/acl-fellows-2024-0
#STIV
Sora之后,苹果发布视频生成大模型STIV,87亿参数一统T2V、TI2V任务
Apple MM1Team 再发新作,这次是苹果视频生成大模型,关于模型架构、训练和数据的全面报告,87 亿参数、支持多模态条件、VBench 超 PIKA,KLING,GEN-3。
- 论文地址: https://arxiv.org/abs/2412.07730
- Hugging Face link: https://huggingface.co/papers/2412.07730
OpenAI 的 Sora 公布了一天之后,在一篇由多位作者署名的论文《STIV: Scalable Text and Image Conditioned Video Generation》中,苹果正式公布自家的多模态大模型研究成果 —— 这是一个具有高达 8.7B 参数的支持文本、图像条件的视频生成模型。
近年来,视频生成领域取得了显著进展,尤其是基于 Diffusion Transformer (DiT) 架构的视频生成模型 Sora 的推出。尽管研究者已在如何将文本及其他条件融入 DiT 架构方面进行了广泛探索,如 PixArt-Alpha 使用跨注意力机制,SD3 将文本与噪声块拼接并通过 MMDiT 模块应用自注意力等,但纯文本驱动的视频生成(T2V)在生成连贯、真实视频方面仍面临挑战。为此,文本 - 图像到视频(TI2V)任务被提出,通过加入初始图像帧作为参考,提供了更具约束性的生成基础。
当前主要挑战在于如何将图像条件高效地融入 DiT 架构,同时在模型稳定性和大规模训练效率方面仍需创新。为解决这些问题,我们提出了一个全面、透明的白皮书,涵盖了模型结构,训练策略,数据和下游应用,统一了T2V和TI2V任务。
基于以上问题,该工作的贡献与亮点主要集中在:
- 提出 STIV 模型,实现 T2V 和 TI2V 任务的统一处理,并通过 JIT-CFG 显著提升生成质量;
- 系统性研究包括 T2I、T2V 和 TI2V 模型的架构设计、高效稳定的训练技术,以及渐进式训练策略;
- 模型易于训练且适配性强,可扩展至视频预测、帧插值和长视频生成等任务;
- 实验结果展示了 STIV 在 VBench 基准数据集上的优势,包括详细的消融实验和对比分析。

该研究不仅提升了视频生成质量,还为视频生成模型在未来多种应用场景中的推广奠定了坚实基础。

构建 STIV 的配方解析

基础模型架构
STIV 基于 PixArt-Alpha 架构,通过冻结的变分自编码器(VAE)将输入帧转换为时空潜变量,并使用可学习的 DiT 块进行处理。文本输入由 T5 分词器和内部训练的 CLIP 文本编码器处理。此外,该研究还对架构进行了以下优化:
- 时空注意力分解:采用分解的时空注意力机制,分别处理空间和时间维度的特征,这使得模型能够复用 T2I 模型的权重,同时降低了计算复杂度。
- 条件嵌入:通过对图像分辨率、裁剪坐标、采样间隔和帧数等元信息进行嵌入,并结合扩散步长和文本嵌入,生成一个统一的条件向量,应用于注意力层和前馈网络。
- 旋转位置编码(RoPE):利用 RoPE 提升模型处理时空相对关系的能力,适配不同分辨率的生成任务。
- 流匹配目标:采用流匹配(Flow Matching)训练目标,以更优的条件最优传输策略替代传统扩散损失,提升生成质量。
模型扩展与训练优化
- 稳定训练策略:通过在注意力机制中应用 QK-Norm 和 sandwich-norm,以及对每层的多头注意力(MHA)和前馈网络(FFN)进行归一化,显著提升了模型训练稳定性。
- 高效训练改进:借鉴 MaskDiT 方法,对 50% 的空间 token 进行随机掩码处理以减少计算量,并切换优化器至 AdaFactor,同时使用梯度检查点技术显著降低内存需求,支持更大规模模型的训练。
融合图像条件的方法
简单的帧替换方法
在训练过程中,我们将第一个帧的噪声潜变量替换为图像条件的无噪声潜变量,然后将这些潜变量传递到 STIV 模块中,并屏蔽掉被替换帧的损失。在推理阶段,我们在每次 扩散步骤中使用原始图像条件的无噪声潜变量作为第一个帧的潜变量。
帧替换策略为 STIV 的多种应用扩展提供了灵活性。例如,当 c_I (condition of image)=∅ 时,模型默认执行文本到视频(T2V)生成。而当 c_I 为初始帧时,模型则转换为典型的文本-图像到视频(TI2V)生成。此外,如果提供多个帧作为 c_I,即使没有 c_T (condition of text),也可以用于视频预测。同时,如果将首尾帧作为 c_I提供,模型可以学习帧插值,并生成首尾帧之间的中间帧。进一步结合 T2V 和帧插值,还可以生成长时视频:T2V 用于生成关键帧,而帧插值则填补每对连续关键帧之间的中间帧。最终,通过随机选择适当的条件策略,可以训练出一个能够执行所有任务的统一模型。
图像条件随机丢弃
如前所述,帧替换策略为训练不同类型的模型提供了高度灵活性。我们在此展示其具体应用,即同时训练模型以执行文本到视频(T2V)和文本 - 图像到视频(TI2V)任务。在训练过程中,我们随机丢弃图像条件 cI 和文本条件 cT,类似于 T2V 模型中仅对文本条件随机丢弃的方式。
联合图像 - 文本无分类器引导(JIT-CFG)
无分类器引导(Classifier-Free Guidance, CFG)在文本到图像生成中表现出色,可以通过将概率质量引导到高似然区域来显著提升生成质量。在此基础上,我们提出了联合图像 - 文本无分类器引导(JIT-CFG),同时利用文本和图像条件进行引导,其速度估计公式为:

其中 s 为引导比例。当 c_I=∅ 时,该方法退化为标准的 T2V 无分类器引导。尽管可以像 InstructPix2Pix 所述引入两个独立的引导比例,以平衡图像和文本条件的强度,我们发现两步推理方法已经能够取得优异效果。此外,使用两个引导比例会增加一次前向传递,从而提高推理成本。
实验证明图像条件随机丢弃结合 JIT-CFG 不仅能自然地实现多任务训练,还有效解决了高分辨率视频生成模型训练的 “静止” 问题。我们推测,图像条件随机丢弃可以防止模型过度依赖图像条件,从而更好地捕捉视频训练数据中的运动信息。
渐进式训练策略
我们采用渐进式训练策略,其流程如图 4 所示。首先训练一个文本到图像(T2I)模型,用以初始化文本到视频(T2V)模型;随后,T2V 模型用于初始化 STIV 模型。为快速适应高分辨率和长时训练,我们在空间和时间维度中加入了插值的 RoPE 嵌入,并利用低分辨率、短时长模型的权重进行初始化。值得注意的是,高分辨率 T2V 模型同时结合了高分辨率 T2I 模型和低分辨率 T2V 模型的权重进行初始化。

数据

视频预处理和特征提取细节
为了确保高质量的输入数据,我们首先解决了原始视频中不一致的动作以及诸如切换和渐变之类的不必要过渡问题。利用 PySceneDetect,我们对视频帧进行分析,识别并分割出包含突兀过渡或渐变的场景。这一过程剔除了不一致的片段,确保视频片段在视觉上保持一致性,从而减少伪影并提升整体质量。随后,我们提取了一系列初始特征用于后续筛选,包括运动分数、美学分数、文本区域、帧高度、帧宽度、清晰度分数、时间一致性以及视频方向等。
视频字幕生成与分类细节
视频 - 文本对在训练文本到视频生成模型中起着至关重要的作用。然而,许多视频数据集缺乏高质量的对齐字幕,并且通常包含噪声或不相关内容。为此,我们在数据处理流程中引入了一个额外的视频字幕生成模块,用于生成全面的文本描述。
我们主要探索了两种方向:(1) 抽样少量帧,应用图像字幕生成器生成字幕后,再使用大型语言模型(LLM)对生成的字幕进行总结;(2) 直接使用视频专用的 LLM 生成字幕。
在初步尝试了第一种方法后,我们发现两个主要局限性:一是图像字幕生成器只能捕捉单帧的视觉细节,导致缺乏对视频动作的描述;二是 LLM 在基于多帧字幕生成密集描述时可能会出现虚构现象(hallucination)。
近期研究使用 GPT 家族模型创建微调数据集并训练视频 LLM。为了在大规模字幕生成中平衡质量和成本,我们选择了一种高效的视频字幕生成器。随后,我们使用 LLM 对生成的字幕进行分类,并统计视频的类别分布。
DSG-Video: 虚构检测评估
为了比较不同字幕生成技术,我们开发了一个评估模块,用于评估字幕的丰富度和准确性。
我们通过测量字幕中提及的唯一对象的多样性来量化字幕的丰富度,并通过检测虚构对象来评估准确性。
受文本到图像评估方法的启发,我们提出了 DSG-Video,用于验证字幕中提到的对象是否真实出现在视频内容中。
1. 首先,我们利用 LLM 自动生成针对字幕关键细节的问题,例如对象的身份、动作和上下文。
举例来说,给定一段提到 “沙发上坐着一只猫” 的字幕,LLM 会生成问题,比如 “视频中是否有一只猫?” 以及 “猫是否在沙发上?”
2. 然后,我们使用多模态 LLM 回答这些对象验证问题,通过评估视频中多个均匀采样帧的每个参考对象的存在情况。
对于每个生成的问题(例如,“该帧中是否有猫?”),多模态 LLM 检查每个采样帧并提供响应。如果对于某个问题,所有帧的响应都表明对象不存在,则我们将其分类为虚构对象。
这一方法确保了对视频中每个对象的逐帧验证。基于此,我们定义了两个评估指标:
- DSG-Video_i:虚构对象实例的比例(即提到的所有对象中被检测为虚构的比例);
- DSG-Video_s:包含虚构对象的句子的比例(即所有句子中含虚构对象的比例)。
结果
基于上述研究,我们将 T2V 和 STIV 模型从 600M 参数扩展到 8.7B。
主要结果展示在表格中,与最新的开源和闭源模型对比后,证明了我们方法的有效性。具体而言,我们基于 Panda-70M 数据集中的 20,000 条经过筛选的视频,使用预训练的视频生成模型进行了微调(SFT)。在预训练阶段采用了 MaskDiT 技术后,我们尝试对模型进行无掩码方式的微调(UnmaskSFT)。此外,我们还对 STIV 模型进行了时间插值微调,以提升生成视频的运动平滑度(+TUP)。
T2V 性能
表格列出了不同 T2V 模型在 VBench 上的对比结果,包括 VBench-Quality、VBench-Semantic 和 VBench-Total 分数。分析表明,扩展 T2V 模型的参数能够提升语义理解能力。具体来说,当模型从 XL 增加到 XXL 和 M 时(三种模型尺度),VBench-Semantic 分数从 72.5 提升到 72.7,最终达到 74.8。这表明更大的模型在捕获语义信息方面表现更好。然而,对于视频质量的影响相对有限,VBench-Quality 仅从 80.7 提升至 82.1。这一发现表明,模型参数扩展对语义能力的提升大于对视频质量的影响。此外,将空间分辨率从 256 提升到 512 时,VBench-Semantic 分数显著提高,从 74.8 上升到 77.0。
SFT 的影响
通过高质量的 SFT 数据微调模型,可以显著提升 VBench-Quality 分数,从 82.2 提升到 83.9。在无掩码条件下对模型进行微调时,语义分数略有提升。我们的最佳模型实现了 79.5 的 VBench-Semantic 分数,超越了 KLING、PIKA 和 Gen-3 等领先的闭源模型。结合时间插值技术后,我们的模型在质量评分方面超越了所有其他模型,达到了最新的行业标准。
TI2V 性能
如表中所示,我们的模型在与最新方法的对比中表现出色。分析表明,尽管模型参数扩展提升了 I2V 分数,但对质量的影响较小。相比之下,提高分辨率能够显著改善质量和 I2V 分数。这一趋势表明,分辨率的提高对于提升多任务生成能力尤为关键。完整的分解维度结果见文章附录。


应用
视频预测
我们从 STIV-XXL 模型出发,训练一个以前四帧为条件的文本 - 视频到视频模型(STIV-V2V)。实验结果表明,在 MSRVTT 测试集和 MovieGen Bench 上,视频到视频模型的 FVD 分数显著低于文本到视频模型。这表明视频到视频模型在生成高保真和一致性视频帧方面表现出色,尤其适用于自动驾驶和嵌入式 AI 等需要高质量生成的领域。
帧插值
我们提出了 STIV-TUP,一个时间插值模型,以 STIV-XL 为初始模型,并在具有时间间隔的连续帧上进行训练,同时添加文本条件。实验表明,STIV 可以在文本和图像条件下进行高质量的帧插值,并且在 MSRVTT 测试集中,使用文本条件稍微优于其他条件。此外,我们将时间插值器与主模型级联,发现这种方法能够提升生成质量,同时保持其他指标稳定。
多视角生成
多视角生成旨在从给定的输入图像创建新视角。这项任务对视角一致性要求较高,依赖于良好预训练的视频生成模型。通过将视频生成模型适配为多视角生成,我们可以验证预训练是否有效捕获了 3D 信息,从而提升生成效果。
我们使用某些新视角相机的定义,并以初始帧为给定图像,预测接下来的新视角帧。通过训练一个 TI2V 模型并调整分辨率和训练步数,我们实现了与现有方法相当的表现,同时验证了我们的时空注意力机制在保持 3D 一致性方面的有效性。

长视频生成
我们开发了一种高效生成长视频的分层框架,包括两种模式的训练:(1) 关键帧预测,学习以较大时间间隔采样的帧;(2) 插值帧生成,通过学习连续帧,并将首尾帧作为条件。在采样阶段,首先使用关键帧预测模式生成关键帧,再通过插值模式生成中间帧,从而实现长视频生成。

更多关于模型结构、图像条件融合方法,训练策略的各种消融实验以及其他研究细节,请参考原论文。
#Gemini 2.0
谷歌最强大模型Gemini 2.0被抬上来了,网友:好科幻
能搜网页、写代码,还能教你打游戏。
OpenAI 接连几天的「轰炸」,已经让人审美疲劳。
作为应对,周三,谷歌推出新一代至强 AI 大模型 Gemini 2.0 Flash 。
网友体验先走一波。
,时长00:56
就模型所看到的内容实时对话, 感觉就像科幻小说一样。
,时长03:32
通过共享屏幕,实时讨论论文,这个研究助理很强啊。

让AI在对话过程中自然地生成图像。

现在,一个提示词就能生成包含步骤说明和配图,食谱blog,一步到位。
据谷歌介绍,除了能生成文字外,还能直接生成图片和语音。不仅如此,2.0 Flash 还能调用第三方应用和服务,比如可以使用谷歌搜索、运行代码等功能。
从今天开始,开发者可以通过以下几种方式尝试使用 2.0 Flash 的测试版:
- Gemini 的 API 接口
- 谷歌的 AI 开发平台:AI Studio 和 Vertex AI
不过,生成图片和语音的功能暂时只对「早期合作伙伴」开放,要等到明年 1 月才会向所有人开放。谷歌表示,在接下来几个月里,会把 2.0 Flash 的各种版本整合到多个产品中,包括:
- Android Studio(安卓开发工具)
- Chrome 开发工具
- Firebase(应用开发平台)
- Gemini 代码助手
主力模型 Gemini 2.0
今天发布的 Gemini 2.0 Flash 的实验版本,是 Gemini 2.0 系列的第一个模型,也是当前主力模型。它反应速度快(低延迟),性能强大,代表了谷歌 Gemini 最顶尖的技术水平。除了速度是「前任」的 2 倍, 支持图像、视频和音频等多模态输入外,2.0 Flash 现在还支持多模态输出,比如原生生成的图像与文本混合,以及可控制的多语言文本转语音( TTS )音频。
它还能够原生调用工具,如谷歌搜索、代码执行以及第三方用户自定义函数。
下面这张图展示了 Gemini 不同版本在各项测试中的表现对比。总体来看,新模型在编程、数学和多模态处理方面都有明显提升,特别是在代码生成方面的进步最为显著。有趣的是,在长文本理解( MRCR )这一项上,2.0 Flash ( 69.2% )反而比 1.5 Pro ( 82.6% )表现差一些,这是少数几个没有进步的指标之一。

图表展示了Gemini不同版本在各项测试中的表现对比。
Gemini 2.0 Flash 的正式版本将于 1 月份推出。但在此期间,谷歌正在发布一个 API —— Multimodal Live API(多模态实时 API ),帮助开发者构建具有实时音频和视频流功能的应用程序。
网友们已经快乐地玩耍起来。

能帮你画好下一步棋子的位置。来自X网友@robertriachi
使用 Multimodal Live API,开发者可以创建实时的多模态应用,这些应用能够接收来自摄像头或屏幕的音频和视频输入。该 API 支持集成各种工具来完成任务,并且能够处理自然对话模式。
比如,对话中的打断。这和 OpenAI 的 Realtime API 很像。

在对话中自然地生成图像,就像人类聊天时随手画个示意图一样自然

对图像的后续编辑

一边处理实时音频输入,一边执行数据可视化等复杂任务
Project Astra:通用助手的曙光
今年 5 月份,谷歌发布了通用 AI 助手研究原型 Project Astra ,这是一个多模态 AI 智能体项目,旨在为用户提供一个能够理解和响应复杂、动态真实世界「 AI 助手」。这次,谷歌对搭载了 Gemini 2.0 的最新版本 Project Astra 进行了一系列改进:更流畅的对话:Project Astra 现在能够用多种语言和混合语言进行交流,对各种口音和生僻词汇的理解也更加精准。新工具的运用:借助Gemini 2.0,Project Astra 能够使用谷歌搜索、谷歌镜头和谷歌地图,使其成为你日常生活中更加得力的助手。更强大的记忆功能:增强了 Project Astra 的记忆能力,并确保你可以控制其记忆。它现在能够保持长达 10 分钟的会话记忆,并能记住你过去与它进行的更多对话,从而为你提供更加个性化的服务。更低的延迟:通过新的流媒体功能和原生音频理解技术,智能体能够以接近人类对话的延迟速度理解语言。他们正致力于将这些功能引入谷歌产品,如 Gemini app 以及眼镜等其他形态的产品。同时,他们也开始在原型眼镜上测试 Project Astra。在官方演示视频中,外国小哥用一部安装了最新测试版 Project Astra 的 Pixel 手机进行测试。
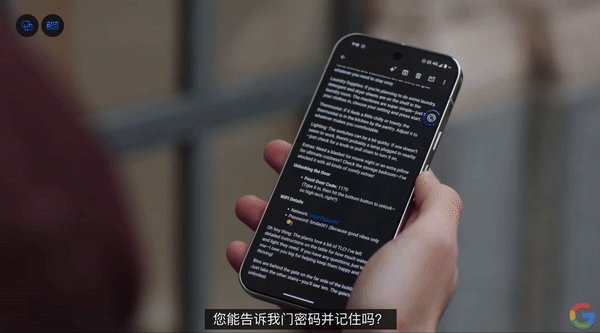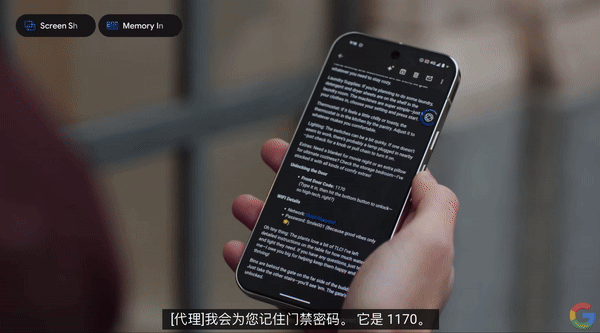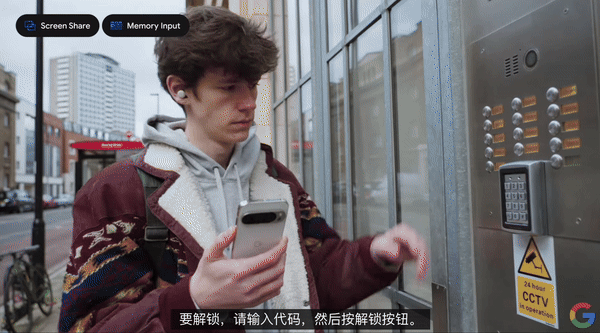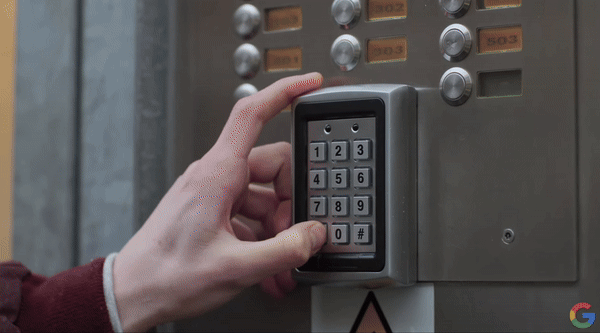
收到一封包含公寓信息的电子邮件后,它可以告诉你公寓大门的密码,并记住它。
只需要使用摄像头拍摄衣服上的标签和洗衣机上复杂的按钮,它就能告诉你这件衣服是否能机洗、漂白、烘干,以及洗衣机该如何使用。

还可以把朋友读过的书发给它,让它以此分析出朋友的读书品味并推荐相关书籍。

偶遇一辆巴士,问它是否可以去唐人街附近。Project Astra不仅可以搜索出该巴士的行驶路线,还能回答出沿线著名地标。

此外,小哥还戴上原型眼镜来测试Project Astra,效果相当酷炫。
只需一个问题指令,它就能进行天气预报、告诉你是否可以骑自行车进公园,搜索沿途是否有超市等。

Project Mariner:浏览器版「贾维斯」
Project Mariner 是一个基于 Gemini 2.0 构建的早期研究原型。它通过 Chrome 浏览器插件,能理解你屏幕上的所有内容 —— 不管是文字、代码、图片还是表单。它的厉害之处在于,在 WebVoyager 基准测试中,Project Mariner 作为一个独立智能体设置,完成网页任务的准确率达到了 83.5% ,这在目前来说是相当不错的成绩。虽然现在可能还有点慢,准确度也不是百分之百,但这项技术正在快速进步。
,时长02:14
为了确保安全,谷歌做了很多防护措施。比如,它只能在你当前打开的网页标签里操作,要做一些重要的事情(比如网购)时,还得先问问你同意不同意。这就像有个助手帮你办事,但重要决定还是由你来做。
Jules:有经验的编程助手
Jules 是一个懂编程的智能助理,直接集成在 GitHub 工作流程中。假设你有一个程序问题需要解决,它能理解问题,制定解决方案,然后在你的指导和监督下把代码写出来。
,时长00:35
就像是你多了一个有经验的编程搭档,能帮你分析问题、规划方案、写代码,但最终的决定权还是在你手中。你可以随时检查它的工作,确保一切都符合你的要求。
游戏及其他领域的智能体
谷歌 DeepMind 一直喜欢用游戏来锻炼 AI 的能力,就像前几天推出的 Genie 2 ,只要给它一张图片,它就能创造出可以玩的 3D 世界。现在,他们又在 Gemini 2.0 的基础上开发了游戏智能体。它特别有意思,能看懂你在玩什么游戏,理解游戏画面里发生的事情,然后实时跟你聊天,给你建议该怎么玩。就像有个资深玩家朋友在旁边指点你。
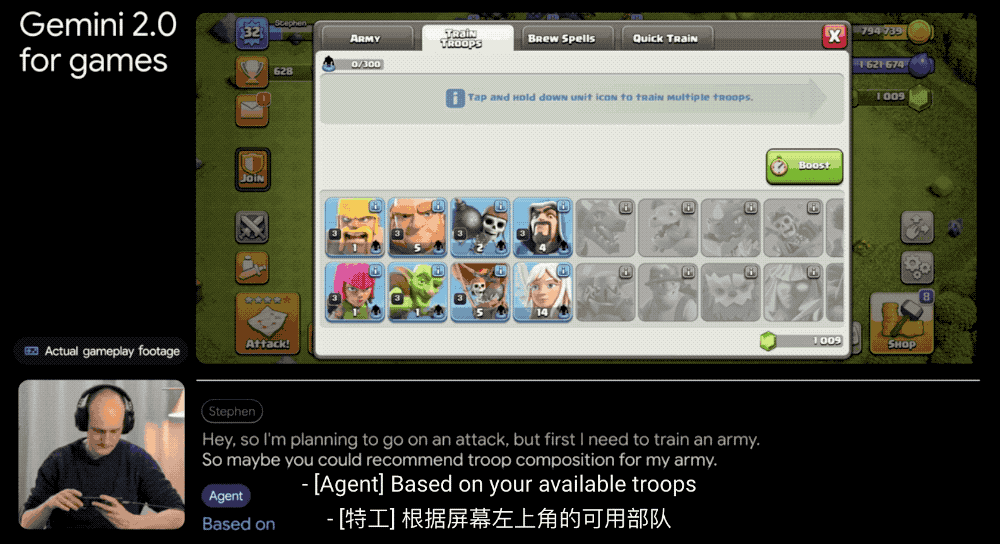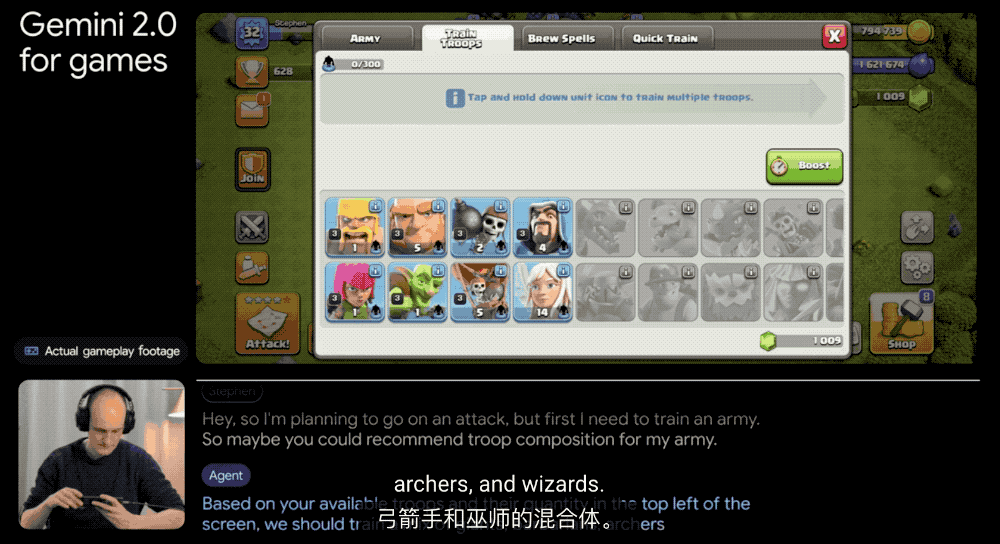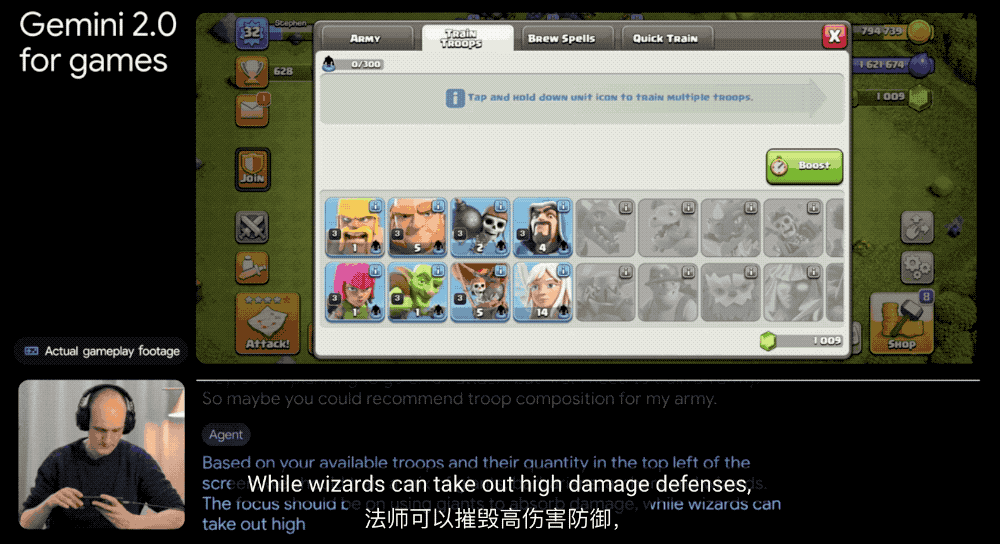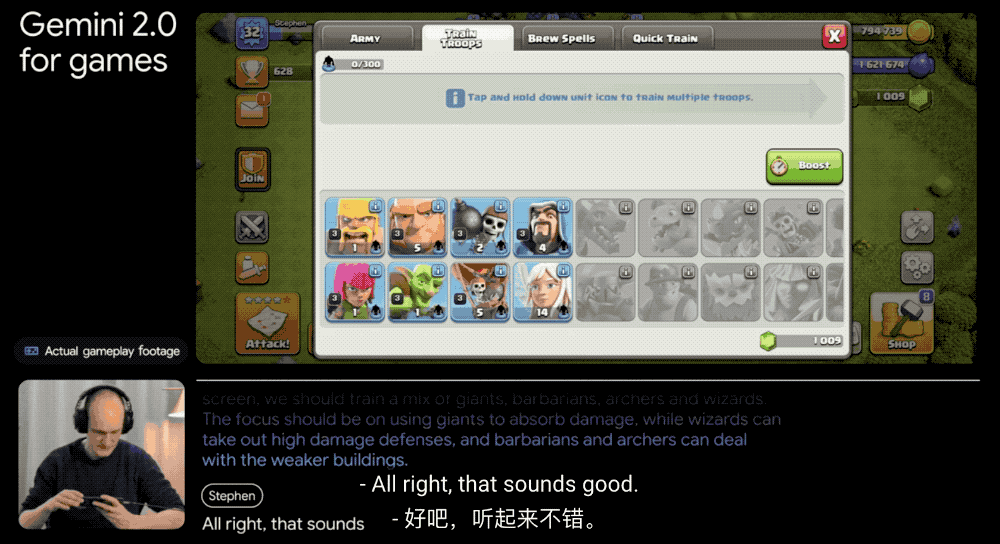
他们还和 Supercell 这样的大游戏公司合作,在《部落冲突》这样的策略游戏和《卡通农场》这样的模拟经营游戏中测试 AI 。AI 需要理解不同类型游戏的规则和挑战,这可不是件容易的事。
更厉害的是,这个智能体还能用谷歌搜索,帮你找到网上的游戏攻略和技巧。就像是一个既懂游戏、又知道去哪找答案的玩伴。除了在虚拟世界中探索智能体能力,谷歌还在尝试将 Gemini 2.0 的空间推理能力应用于机器人技术,帮助智能体在现实世界中提供帮助,不过目前仍处于早期阶段。
参考链接:
https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/?utm_source=deepmind.google&utm_medium=referral&utm_campaign=gdm&utm_cnotallow=https://developers.googleblog.com/en/the-next-chapter-of-the-gemini-era-for-developers/
https://x.com/simonw/status/1866942603020910866
#Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales?
可信大模型新挑战:噪声思维链提示下的鲁棒推理,准确率直降40%
当前,大语言模型(Large Language Model, LLM)借助上下文学习(In-context Learning)和思维链提示(Chain of Thoughts Prompting),在许多复杂推理任务上展现出了强大的能力。
然而,现有研究表明,LLM 在应对噪声输入时存在明显不足:当输入的问题包含无关内容,或者遭到轻微修改时,模型极容易受到干扰,进而偏离正确的推理方向。如图 1 左所示,Q1 中的「We know 6+6=12 and 3+7=10 in base 10」 是关于 base-9 计算的噪声信息,该信息容易误导模型输出错误的结果。

图 1. 噪声问题(Noisy Questions)和噪声思维链(Noisy Rationales)的示例
已有的鲁棒研究大多侧重于噪声问题(Noisy Questions),然而,LLM 在噪声思维链(Noisy Rationales)下的推理还没有得到充分的探究。在本工作中,我们将噪声思维链定义为:包含不相关或者不准确推理步骤的思维链,如图 1 右侧 R1 中的「13 + 8 = 21」步骤,对于 base-9 计算来说,是错误的推理步骤。
这些噪声思维链通常源自 LLM 的实际应用,比如众包平台、对话系统、机器生成数据等场景,人类和机器在推理中都会不可避免地犯错,从而产生噪声思维链。因此,噪声思维链的实际影响和技术挑战不容小觑。当前,我们仍然不清楚 LLM 在面对噪声思维链提示时的鲁棒性能如何,也缺少有效的应对策略。因此,非常有必要构建一个新的数据集,用于系统评估当前 LLM 在噪声思维链场景下的鲁棒性,以及验证相应的鲁棒推理策略。
对此,我们构建了 NoRa 数据集,并进行了大量的实验评测。结果表明,GPT-3.5-Turbo、Gemini-Pro、Llama2-70B 和 Mixtral-8x7B 等开源或闭源 LLM 都极容易受到噪声思维链的影响。其中,GPT-3.5-Turbo 的准确率至多可降低 40.4%。因此,我们也呼吁大家更多地关注大模型推理的鲁棒性问题。
我们的主要贡献有如下三点:
- 新问题:对当前流行的思维链提示技术,我们提出了尚未充分探究的噪声思维链问题(Noisy Rationales),并给出了详细的问题定义和统一的问题建模;
- 新数据集:我们构建了 NoRa 数据集,用于评测 LLM 在噪声思维链提示下的推理鲁棒性。我们使用 NoRa 数据集对 LLM 展开系统评估,揭露了 LLM 推理的鲁棒性不足,数据去噪能力非常有限的问题;
- 新方法:我们设计了一种简单有效的方法(CD-CoT),基于单个正确的思维链示例,去纠正噪声思维链并完成推理,并通过大量实验验证了方法的有效性。
接下来将从新问题、新数据集、新方法这三个角度,简要地介绍我们关于大模型推理鲁棒性的研究结果,相关论文已发表于 NeurIPS 2024 会议。
- 论文标题:Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales?
- 论文链接:https://arxiv.org/pdf/2410.23856
- 代码链接:https://github.com/tmlr-group/NoisyRationales
- slides 链接:https://andrewzhou924.github.io/_pages/data/slides-NoRa.pdf
新问题:Noisy Rationales
思维链可以有效提升大模型的推理能力 [1]。具体来说,通过给出带有中间推理步骤的示例,LLM 可以很快地适应到新任务上,而无需进行参数修改(见图 2 右上角)。现有工作中,通常假设思维链包含清楚且正确的推理步骤,但实际情况可能并非如此。

图 2. 各种 setting 下的模型输入
目前,已经有许多工作探索了 Noisy Questions 对 LLM 推理性能的影响(见图 2 左下角),揭示了 LLM 对输入中微小修改的敏感性 [2,3]。
然而,在人工标注或机器生成的思维链中,可能会包含一些与问题不相关或不准确的推理步骤(见图 2 右下角),这些噪声思维链可能会对推理性能产生负面影响,但目前 LLM 对噪声思维链(Noisy Rationales)的鲁棒性依旧未知。
因此,本文提出了新的研究问题 Noisy Rationales:当示例的推理步骤中包含无关的或者不准确的内容时,LLM 的推理鲁棒性如何?对这一问题的探索,有助于深入理解和提升 LLM 在非完备场景中的推理能力。
新数据集:NoRa
为了评估 LLM 在噪声思维链下的鲁棒性,我们构建了 NoRa(Noisy Rationales)数据集,NoRa 涵盖了 3 种推理任务类型:数学推理、符号推理和常识推理,共包含 26391 个问题以及 5 种子任务。
一条思维链(Rationale)包含多个连续的推理步骤(Thoughts);噪声思维链(Noisy Rationale)包含的噪声推理步骤(Noisy Thoughts)被定义为如下两类(示例见图 3):
- 不相关噪声(Irrelevant Thoughts)是指对解决问题无用的信息,如在推断亲属关系时讨论探讨兄弟姐妹之间的基因重叠情况;
- 不准确噪声(Inaccurate Thoughts)则是推理中的事实性错误,如在特定进制计算中使用错误的计算规则。

图 3. NoRa 数据集的样本
在构建数据集时,我们通过插入 Noisy Thoughts 来生成噪声思维链,这些噪声仅影响推理链的细节,而不改变问题和最终答案的正确性。此外,我们使用不同的噪声比例(Noise Ratio,即 Noisy Thoughts 占所 Thoughts 的比例,如 0.3、0.5、0.8)来控制任务的困难程度,Noise Ratio 越大任务难度也越大。NoRa 数据集的统计信息如图 4 所示。

图 4. NoRa 数据集的统计信息
NoRa 数据集 测评结果
我们以 GPT-3.5-Turbo 为 base model,测试了其在 NoRa 上的表现,并且对比了多种去噪方法。这些去噪方法可以分为两类:
- 自我纠正方法(Self-correction):包括 Intrinsic Self-correction (ISC) [4] 和 Self-polish (SP) [5];
- 自我一致性方法(Self-consistency):包括 SmoothLLM (SM) [6],Self-denoise (SD) [7] 和 Self-consistency (SC) [8]。

图 5. 各种去噪方法 在 NoRa 数据集上的测评结果
实验结果(图 5)表明:
- 无论采取哪种现有方法,LLM 都会受到噪声思维链的严重影响。具体来说,存在不相关噪声时,各方法的性能下降了 0.2% - 25.3%;存在不准确噪声时,各方法的性能下降了 0.1% - 54.0%;
- 在 NoRa 的大多数任务中,自我纠正方法的表现不佳;
- 自一致性方法可以在一定程度上缓解噪声的影响,但无法做到真正的数据去噪。
此外,我们还进行了各种消融研究,来探索不同因素对 NoRa 数据集评估结果的影响(见图 6),我们发现:
- 调整温度系数可以改善模型在噪声思维链下的推理性能;
- 使用更多的噪声示例可以提高大多数任务的推理性能;
- 不同的大语言模型普遍容易受到噪声思维链的影响。

图 6. 消融实验:(左) 温度系数对性能的影响;(中) 示例个数对性能的影响;(右) 各种模型的性能
新方法:CD-CoT
根据测评结果,大语言模型在应对噪声思维链提示时,其自身的去噪能力非常有限;即便使用自我纠正或自一致性方法,效果仍不理想。
因此,我们认为有必要引入外部监督信号来增强模型鲁棒性,且这种监督信号既要足以实现去噪,又要在实际应用中切实可行。对此,我们提出了一种简单有效的去噪推理方法, CD-CoT(Contrastive Denoising with Noisy Chain of Thoughts)。
CD-CoT 借鉴了对比学习的思路,通过让 LLM 显式地对比有噪和干净的思维链,从而识别出噪声信息。方法主要包括四个关键步骤,步骤 1&2 进行显式的去噪,步骤 3&4 进行精细推理并获得最终答案。
四个步骤具体如下:
- 改写思维链:借助一个干净的思维链示例,引导 LLM 通过对比改写和纠正噪声思维链,并生成多个改写的思维链(见图 7 step1);
- 选择思维链:通过答案匹配,筛选出改写后答案不变的思维链,形成精炼的候选集;再从中随机选取一定数量的思维链,用于后续的推理(见图 7 step2);
- 探索推理链:将选取的思维链排列成不同的上下文,与目标问题一同输入给 LLM,并采用较高的温度参数进行多次重复推理,以探索多样的推理路径(见图 8 step3);
- 答案投票:将所有得到的答案进行投票,得到最终答案(见图 8 step4)。
完整的 CD-CoT 算法请见图 9。

图 7. CD-CoT 算法的步骤 1&2

图 8. CD-CoT 算法的步骤 3&4

图 9. 完整的 CD-CoT 算法
CD-CoT 实验结果
我们在 NoRa 数据集上全面测试了 CD-CoT,并对比了多个需要额外监督信息的去噪方法(见图 10),我们发现:
- 当面对噪声思维链时,与 base model 相比,CD-CoT 在所有数据集上的性能均有显著提升,准确率平均提升幅度达到 17.8%;
- CD-CoT 对高噪声表现出显著的抵抗力,尤其在更具挑战的数学推理任务中。

图 10. 各种需要额外监督信息的方法 在 NoRa 数据集上的测评结果
此外,通过诸多消融实验,我们发现:
- 关于 CD-CoT 超参数的消融实验结果显示,干净的思维链示例在 CD-CoT 中扮演着关键的角色;当变化 N,M,C 等超参数的取值时,准确性仅呈现出细微的变化(见图 11)。在论文中,我们默认采用 M 设为 2 的 CD-CoT 示例,以在效率和效果之间取得平衡;
- CD-CoT 在不同的 LLM 上具有良好的泛化能力,与 base model(GPT-3.5-Turbo 和 Gemini-Pro)相比,其准确率分别提高了 23.4% 和 21.6%,并超越了所有基线方法(见图 12)。

图 11. 关于 CD-CoT 超参数的消融研究

图 12. 关于 CD-CoT 在不同 LLM 上的效果的消融研究
更多的实验分析和技术细节,请移步参阅我们的论文及源码,我们也将持续更新本工作的内容。
我们希望通过这项工作,呼吁人们更多地关注 LLM 推理的鲁棒性问题,并开展关于大模型推理鲁棒性的探讨与研究。非常感谢大家关注我们的工作!
课题组介绍
香港浸会大学可信机器学习和推理课题组 (TMLR Group) 由多名青年教授、博士后研究员、博士生、访问博士生和研究助理共同组成,课题组隶属于理学院计算机系。课题组专攻可信表征学习、可信基础模型、基于因果推理的可信学习等相关的算法,理论和系统设计以及在自然科学上的应用,具体研究方向和相关成果详见本组 GitHub (https://github.com/tmlr-group)。
课题组由政府科研基金以及工业界科研基金资助,如香港研究资助局杰出青年学者计划,国家自然科学基金面上项目和青年项目,以及微软、英伟达、字节跳动、百度、阿里、腾讯等企业的科研基金。青年教授和资深研究员手把手带,GPU 计算资源充足,长期招收多名博士后研究员、博士生、研究助理和研究实习生。此外,本组也欢迎自费的访问博士后研究员、博士生和研究助理申请,访问至少 3-6 个月,支持远程访问。
#他纯靠ChatGPT写APP,年入千万美金
人刚毕业,代码一点不会
第一个App年入50万,第二个年入500万,第三个月入100万。
我不会编程,却在两年时间内靠 ChatGPT 写代码做 APP,年入千万美金。
没开玩笑,这不是拼好饭吃多了的最终幻想,而是现实生活中上演的真人真事。
故事的主人公叫 Blake Anderson,而他之所以能如此猛猛吸金,靠的是三个 APP:约会指导 Rizz GPT,年收入达 250 万美元;颜值管理软件 Umax,年收入接近 500 万美元;还有一个是卡路里计算器 Cal AI,每月收入超过 100 万美元。
这时可能就有朋友不禁想问:「这也可以???」
你没看错,人家的 APP 现在每月的收入加起来都破千万了!
毕业没工作,资金见底
他开始问 ChatGPT 怎么办
2023 年 5 月,Blake 还只是一个编程小白。大学毕业后,过着花天酒地的潇洒生活。
当同学们都在纽约收获着六位数年薪时,这位曾经的派对常客只能灰溜溜地搬回父母家。他的生活也一下坠入了冰冷刺骨的现实:家里经济拮据,房子被迫出售,甚至卖点杂货都要靠哥哥借钱。
于是,Blake 给自己立下了军令状:12 个月内,必须独立赚到 5 万美元。
彼时,ChatGPT 的浪潮正席卷全球,大洋彼岸的年轻人对这个 AI Chatbot 爱不释手,Blake 也不例外。正巧,群里总有兄弟在问「这女生发来的消息,我该怎么回啊?」
没有人比 ChatGPT 更懂得接话,这也让 Blake 意识到,为什么不开发一个 AI 约会助手 APP 呢?
有了想法,但完全不会编程怎么办?这时,ChatGPT 又成了他最好的老师。
「从前,程序员们在 Stack Overflow 上找答案,我直接让 AI 来教学。」Blake 做出的第一款 APP Rizz GPT,99% 的代码都出自 ChatGPT 之手,就连第二款 APP Umax,也有 85% 的代码是 ChatGPT 生成的。
由于不熟悉各种 IDE 环境,Blake 起初遇到了一点挫折。但在 GPT 老师的一对一辅导下,他的学习速度惊人,很快就沉淀出了一套方法论:先确定产品外观,再决定技术栈,无论是 React Native、Swift UI 还是 Flutter,都要服务于产品愿景。
一旦把这些问题考虑清楚,只需要用非常清晰的语言表达你想要什么,剩下的事交给 ChatGPT 就好了。
「我选择采用 Swift UI,所以我让 ChatGPT 写 Swift,再把代码粘贴到 Xcode 中预览。也许按钮之间的间距不对,要么我自己来调整,要么让 ChatGPT 来调整。关键是,这一切都没有你想象中得那么难,只需要开始尝试,去问 ChatGPT 吧。」Blake 说道。
就这样,第一版 Rizz GPT 上线了。和现在功能齐全的 UI 界面相比,刚上线的 Rizz GPT 做得很糟糕,只有一个空空荡荡的界面,挂着一个 logo 和两个按钮。没有通知功能,没有评论功能,设计混乱,付费功能都没做全。

Rizz GPT 支持各种「僚机」功能
Blake 表示:「完美主义是创业路上最大的绊脚石,你可以边做边学,最重要的就是要把产品推向市场,特别是对这种消费类 APP 来说。」
在上线之后,拉新又成了新的问题。短视频营销的春风又被 Blake 踩上了,他找了两个 Tiktok 创作者,各付 50 美元做推广。没想到一夜之间,浏览量就破了千万,第一天就转化了 4.5 万次下载,只用了一个月,用户就突破 50 万人。
「那个月我们的收入就达到了 8 万美元,」Blake 说道,「后来稳定在每月 15-20 万美元。这基本上都是利润。」
踩着 AI 能力进化的节奏
都说大模型会改变所有应用,ChatGPT 上线不到一年,OpenAI 就上新了 GPT 4V,AI 从此点亮了视觉的技能树。
在随后的 OpenAI 春季开发者大会上,OpenAI 开放了 gpt-4-vision-preview 的 API,开发者可以用它和 GPT-4 Turbo 来开发新应用。
就在 OpenAI 不断更新的节奏中,Blake 的创业生涯也迎来了转折,Blake 和 Rizz GPT 的联合创始人因为产品理念不合,分道扬镳。
从此失业了的 Blake 过上了一种近乎魔幻现实主义的生活,他的 APP 每月进账 20 万美元,但他本人却在朋友和哥哥的沙发上流浪,每天清晨,走到家附近的星巴克打工。这种反差让他更加坚定 —— 是时候启动下一段创业了。
机会总是青睐有准备的人,在刷社交媒体时,Blake 注意到了「looks maxing」(提升颜值)的热度。Reddit 上甚至有一个专门的颜值打分模块。
「说到底,大多数人健身锻炼是为了吸引异性,特别是青少年和年轻成年男性」。Blake 敏锐地发现,「人们想知道自己有多大魅力,需要个性化的建议。」
正好 OpenAI 送来了 GPT Vision API「大礼包」,Blake 决定用它开发第二个用来测评颜值的应用 Umax。

Umax 会根据上传的图片,给你的男子气概、皮肤状态、下颌线和颧骨分别打分。
「我想,我不一定要训练一个机器学习模型来分析一个人的面部并提供建议,我可以通过提示词工程来实现这个。所以我开始尝试,效果出奇的好。因为我的胡子有点稀疏,它给我建议刮掉胡子;当我额头有一些痘痘时,它就给我护肤建议。灵感好像迸发了,我觉得必须我要做这个。」Blake 谈道。
然而,就在 Umax 的月收入达到 20 万美元时,竞品出现了,从产品到营销策略,简直是一比一复刻。
面对模仿者,Blake 做出了一个疯狂的决定:「我在三天内投入了超过 20 万美元做网红营销,这基本上是 Umax 当时所有的收入。」
这个冒险的决定最终得到了回报。在短短五天内,Umax 从每月 20 万的收入暴增至 50 万以上。「那是我这辈子最疯狂的五天,」Blake 回忆道,「我完全没睡觉,一直在和网红打电话,写代码,跟工程师沟通。但这就是创业,要么全力以赴,要么什么都得不到。」
在 Blake 的创业哲学里,从来没有 B 计划。要么成功,要么失败。
他总是在双倍下注 —— 从 Rizz GPT 拿了钱,投入 Umax,而 Umax 的收益,也将成为他下一个创业项目的起点。
玩游戏能让你成为更好的企业家
Blake Anderson 认为,电子游戏提供了一些经济或策略模拟的机会,并能快速获得重复经验。比如说像在模拟人生(The Sims)这样的游戏里,你可以在几个小时内模拟一个人的一生,面对选择职业和生活方式的各种权衡。这些都是很好的学习机会,可以在不用投入真实资金、时间或风险的情况下获得这些经验。
他最新的一个项目叫 Cal AI,是一个 AI 卡路里追踪应用。现在,Cal AI 已经跑赢了 50 个竞品,成为健身人的首选,月活用户 10 万 +,月收入超过 100 万。
Cal AI 的理念是,尽量减少人们计算卡路里所花费的时间。Blake 表示,自己用过一些计算卡路里的 App,感觉耗时又耗力。
所以他们设计的应用可以拍照获取卡路里分析,同时还包含常规卡路里追踪器的所有功能。「你仍然可以扫描条形码,或是手动输入营养成分,但关键的区别在于能够拍照输入。」

在实现原理方面,Cal AI 也是一款站在 GPT-4V 肩膀上的应用。
打开 Cal AI 对着食物拍照时,首先,手机上的深度传感器会计算出食物的体积。根据这些信息,应用调取 OpenAI API ,GPT-4V 将你拍给它的午饭分解成不同模块,计算相应的比例。接下来,再综合计算出这顿饭的卡路里、蛋白质、碳水化合物和脂肪含量,给一个具体的结果。
这个项目上 Blake 有另外两个合作创始人,他们俩比 Blake 更有节目,都才 17 岁,还是高中生,三个人平分了股份。目前,Umax 仍然是 Blake 的工作重点。
除了编程,Blake 还在使用 ChatGPT 的过程中找到创新灵感。他一直在使用 ChatGPT 来帮助学习,用 AI 不时测试自己的知识水平,寻找进一步学习的资源。不过这仅限于文字版的 ChatGPT,语音版本的效果一直不是很好。
「所以我觉得如果建立一个应用,让我不用特意告诉 AI『好,现在测试我这个方面的知识,然后给我这些资源』,这样一个原生应用会很棒,而且是我会经常使用并愿意付费的东西,」Blake Anderson 说道。
他构建的下一个 AI 应用,或许已经在路上了。
参考链接:
https://x.com/blakeandersonw?lang=en
https://x.com/starter_story/status/1891869209451196666
https://www.youtube.com/watch?v=P1fXP1wZH0E
#限制波士顿动力机器狗的竟然是电池功率?
3倍提速!现在你跑不过机器狗了
当 Scaling Law 在触顶边界徘徊之时,强化学习为构建更强大的大模型开辟出了一条新范式。
在机器人领域,强化学习也带来了意外之喜。
这只上过好几次全网热搜的机器狗 Spot,想必大家都不陌生。

在原来的文章中,无论 Spot 做了什么高难度动作,哪怕是边喷火边跳踢踏舞,后台总有留言,「为什么波士顿动力不把机器人的脚做成轮式的?」
这是因为 Spot 总是优雅地、小心翼翼地踏着小碎步,没办法大步行走,相较于脚踩风火轮的轮式机器狗,不仅速度跟不上,也更容易受到地形限制。
士别三日,当刮目相看。几个月不见,Spot 的「小步舞曲」已经成为过往,看看现在 Spot 大步流星的样子,迅速敏捷,你和它赛跑都追不上了:

Spot 出厂时最快速度只有 1.6 米 / 秒。几周前与波士顿动力官宣合作的 RAI 研究所带来了最新突破,Spot 的跑步速度提升了近 3 倍,达到了时速 18.7 千米。
一只小型犬的平均奔跑速度大概是 20 千米 / 时,这两个数字已经很接近了。
在传统观念中,大家可能认为机器人的速度主要受限于马达性能。但当研究团队用强化学习对机器狗的电机和动力装置建模之后,发现了一个出人意料的事实。
在模拟环境中,可以并行训练几台 Spot 机器人(甚至几百台),以实现强大的现实世界性能。
「真正限制 Spot 速度的,竟然是电池供电能力!」RAI 研究所的机器人专家 Farbod Farshidian 说道,「这个发现让我们都很惊讶,因为之前都以为机器人的运动速度提不上去是在马达的功率或扭矩之类的问题。」
Spot 的电力系统相当复杂,仍有进一步优化的空间。Farshidian 指出,阻止他们将 Spot 的最高速度推过 5.2 米 / 秒的唯一原因是他们无法访问电池电压,无法将这些实际数据纳入他们的 RL 模型。
这意味着,如果能设计出更强劲的电池,Spot 的还能跑得更快。
有趣的是,当 Spot 以这个速度奔跑时,它的动作看起来和真实的狗完全不同。Farshidian 解释说:「这个奔跑姿态确实不像生物,但这很正常 ——Spot 的驱动器和关节结构都和真狗不一样,为什么要用生物的方式来跑呢?」
Spot 的执行器不同于肌肉,运动学特性也不同,适合狗快速奔跑的步态不一定适合机器狗。
Spot 提速的关键在于,研究人员在小跑步态的基础上,增加了一个四只脚同时离地的飞行阶段。小步和飞行衔接起来,从技术上就变成了奔跑。
四脚离地的「飞行」阶段
Farshidian 说:「这个飞行阶段是必要的,因为机器人需要这段时间快速向前移动脚步来维持速度。」研究人员给机器人了「自主发现的空间」,因为这时,编程程序所要求的不是「奔跑」,而是去找到最高效的快速移动方式。
传统的机器人控制使用模型预测控制(MPC)方法,就像给机器人一本详细的「动作指南」。这种方法很可靠,但也很保守。
这由于要求计算机要在事件发生后立即响应,一旦没有在短时间内完成复杂的运动规划和控制,反映到机器人这里就是动作迟缓或出错了。
而强化学习则完全不同。它就像让机器人在「虚拟道场」中不断练习,找到最优的动作方案。一旦学会了,这些技能就能直接应用到现实中。
强化学习不仅能最大化机器人的性能,还能使其表现更加可靠。RAI 研究所一直在实验一款全新的机器人 —— 一辆名为 UMV 的自行车。它采用了与 Spot 高速奔跑时基本相同的强化学习 RL 流程,用于平衡和驾驶训练,并成功学会了跑酷动作。
更值得注意的是,UMV 没有配备任何平衡陀螺仪,而是完全依靠 AI 来保持平衡的。
「强化学习的关键在于发现新的行为,并在那些难以建模的复杂条件下使其变得稳健和可靠。这正是强化学习真正大放异彩的地方。」RAI 研究所苏黎世办公室主任 Marco Hutter 表示,「一方面,强化学习帮助 UMV 在各种情况下保持稳定的驾驶能力;另一方面,它让我们理解机器人的动态,更好地实现一些新动作,比如跳上比它本身还高的桌子。」
虽然 UMV 已经能很熟练地做各种特技动作了,但对于它来说,完成一些看似简单的动作甚至更难,比如倒车。
不太会倒车
「UMV 倒车时很不稳定」,Hutter 解释说,「使用经典的模型预测控制(MPC)控制器很难做到这个动作,尤其是地形崎岖或有干扰的情况下。」
目前,RAI 研究所还在努力让 UMV 走出实验室,在复杂地形上来一场真正的自行车跑酷表演。
在「虚拟道场」中训练 UMV 如何下楼梯
RAI 研究所表示,重点不在于这个某个特定的硬件能做什么,而在于任何机器人通过 RL 和其他基于学习的方法能做什么。机器人的硬件在理论上可以实现比用经典控制算法更多的功能。关键的问题是如何理解这些硬件系统中的隐藏限制,不断突破控制的边界。
#扩散模型+蒙特卡洛树搜索实现System 2规划
Bengio参与
把扩散模型的生成能力与 MCTS 的自适应搜索能力相结合,会是什么结果?
扩散模型(Diffusion Model)通过利用大规模离线数据对轨迹分布进行建模,能够生成复杂的轨迹。与传统的自回归规划方法不同,基于扩散的规划器通过一系列去噪步骤可以整体生成完整轨迹,无需依赖前向动力学模型,有效解决了前向模型的关键局限性,特别适用于具有长周期或稀疏奖励的规划任务。
尽管扩散模型具有这些优势,但如何通过利用额外的测试时间计算(TTC)来有效提高规划精度仍然是一个悬而未决的问题。一种潜在的方法是增加去噪步骤的数量,或者增加采样次数。然而,已知增加去噪步骤带来的性能提升会迅速趋于平缓,而通过多个样本进行独立随机搜索的效率非常低,因为它们无法利用其他样本的信息。
另一方面,蒙特卡洛树搜索(MCTS)则具有强大的 TTC 可扩展性。通过利用迭代模拟,MCTS 可以根据探索性反馈改进决策并进行调整,使其可以随着计算量的增加而有效地提升规划准确度。
这种能力使 MCTS 成为了许多 System 2 推理任务的基石,例如求解数学问题和生成程序。
然而,与基于扩散的规划器不同,传统的 MCTS 依赖于前向模型来执行树 rollout。这也就继承了其局限性,包括失去全局一致性。
除了局限于离散动作空间之外,生成的搜索树在深度和宽度上都可能变得过大。这会导致计算需求变得非常大,特别是当任务场景涉及到长远规划和大动作空间时。
那么,关键的问题来了:为了克服扩散模型和 MCTS 各自的缺陷,同时提升基于扩散的规划的 TTC 可扩展性,可以将扩散模型与 MCTS 组合起来吗?又该怎么去组合它们?
近日,Yoshua Bengio 和 Sungjin Ahn 领导的一个团队为上述问题提供了一个答案,提出了蒙特卡洛树扩散(MCTD)。这是一种将扩散模型的生成力量与 MCTS 的自适应搜索功能相结合的全新框架。该团队表示:「我们的方法将去噪(denoising)重新概念化为一个树结构过程,允许对部分去噪的规划进行迭代评估、修剪和微调。」
论文标题:Monte Carlo Tree Diffusion for System 2 Planning
论文地址:https://arxiv.org/pdf/2502.07202v1
蒙特卡洛树扩散(MCTD)
简单来说,MCTD = 扩散模型 + MCTS。该框架整合了基于扩散的轨迹生成以及 MCTS 的迭代搜索能力,可实现更加高效和可扩展的规划。
具体方法上,MCTD 有三项创新。
- 第一,MCTD 将去噪(denoising)过程重构成了一种基于树的 rollout 过程,于是便能在维持轨迹连贯性的同时实现半自回归的因果规划。
- 第二,其引入了引导层级作为元动作(meta-action),从而可实现「探索」与「利用」的动态平衡,进而确保在扩散框架内实现自适应和可扩展的轨迹优化。
- 第三,其采用的模拟机制是快速跳跃去噪(fast jumpy denoising)。从名字也能看出来,该机制的效率肯定很高 —— 不使用成本高昂的前向模型 rollout 即可有效估计轨迹质量。
基于这些创新,便可以在扩散过程中实现 MCTS 的四大步骤,即选择、扩展、模拟和反向传播,从而有效地将结构化搜索与生成式建模组合到了一起。

蒙特卡罗树扩散(MCTD)的两种视角。
上图的(a)为 MCTS 视角:展示了 MCTD 一轮的四个步骤 —— 选择、扩展、模拟和反向传播 —— 在一个部分去噪树上的过程。每个节点对应一个部分去噪的子轨迹,边标记为二元引导级别(0 = 无引导,1 = 有引导)。在新节点扩展后,执行「跳跃」去噪以快速估计其值,然后沿着树中的路径反向传播。
上图的(b)为扩散视角:同一过程被视为在去噪深度(纵轴)和规划范围(横轴)上的部分去噪。每个彩色块表示在特定噪声水平下的部分去噪规划,颜色越深表示噪声越高。不同的扩展(0 或 1)在规划方向上创建分支,代表替代的轨迹优化。值得注意的是,整行同时去噪,但去噪水平不同。
MCTD 框架将这两种视角统一了起来。整体的算法过程如下所示:

MCTD 的效果得到了实验的验证
该团队也通过实验验证了蒙特卡洛树扩散的效果。他们采用的评估任务套件是 Offline Goal-conditioned RL Benchmark(OGBench),其中涉及包括迷宫导航在内的多种任务以及多种机器人形态和机器臂操作。
下表 1 展示了质点和机器蚁在中、大、巨型迷宫中的成功率,可以看到 MCTD 的表现远超其它方法。

下图展示了三个规划器的规划结果以及实际的 rollout。

三种规划器 ——Diffuser、Diffusion Forcing 和 MCTD 生成的规划与实际展开的对比。虽然 Diffuser 和 Diffusion Forcing 未能生成成功的轨迹规划,但 MCTD 通过自适应优化其规划取得了成功。

在点阵迷宫中等任务中,使用二元引导集 {无引导,引导} 的 MCTD 树搜索过程可视化展示。每个节点对应一个部分去噪的轨迹,其中左图显示带噪声的部分规划,右图显示快速去噪后的规划。搜索通过选择无引导或引导来扩展子节点,评估每个新生成的规划,并最终收敛到高亮的叶节点作为解决方案。
下面两个表格则展示了不同方法在机器臂方块操作任务以及视觉点迷宫任务上的结果。

总体而言,MCTD 在长期任务上的表现优于现有方法,可实现卓越的可扩展性,并得到高质量的解决方案。
该团队表示:「未来还将探索自适应计算分配、基于学习的元动作选择和奖励塑造,以进一步提高性能,为更具可扩展性和灵活性的 System 2 规划铺平道路。」
#AvatarGO
南洋理工大学AvatarGO,探索4D人与物体交互生成新方法
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。尽管这些方法已取得令人瞩目的成果,但由于 SMPL 在衣物表现上的局限性,以及缺乏大规模真实交互数据的支持,它们依然难以生成日常生活中的复杂交互场景。
相比之下,在 2D 生成模型中,由于大语言模型和海量文字 - 图片数据的支持,这一问题得到了有效的解决。2D 生成模型如今能够快速生成高度逼真的二维场景。而且,随着这些技术被引入到 3D 和 4D 生成模型中,它们成功地将二维预训练知识迁移到更高维度,推动了更精细的生成能力。然而,在处理 4D 人体 - 物体交互时,这些 3D/4D 生成的方法依然面临两个关键挑战:(1)物体与人体的接触发生在何处?又是如何产生的?(2)如何在人体与物体的动态运动过程中,保持它们之间交互的合理性?
为了解决这一问题,南洋理工大学 S-Lab 的研究者们提出了一种全新的方法:AvatarGO。该方法不仅能够生成流畅的人体 - 物体组合内容,还在有效解决穿模问题方面展现了更强的鲁棒性,为以人为核心的 4D 内容创作开辟了全新的前景。
,时长00:10
想深入了解 AvatarGO 的技术细节?我们已经为你准备好了完整的论文、项目主页和代码仓库!
- 论文地址:https://arxiv.org/abs/2410.07164
- Project Page:https://yukangcao.github.io/AvatarGO/
- GitHub:https://github.com/yukangcao/AvatarGO
引言
近年来,随着人体 - 物体(HOI)交互数据集(如 CHAIRS [2], BEHAVE [3])的采集,以及扩散模型和 transformer 技术的迅速发展,基于文本输入生成 4D 人体动作和物体交互的技术已经展现出了巨大的潜力。然而,目前的技术大多集中于基于 SMPL 的人体动作生成,但它们难以真实呈现日常生活中人物与物体交互的外观。尽管 InterDreamer [4] 提出了零样本生成方法,能够生成与文本对齐的 4D HOI 动作序列,但其输出仍然受到 SMPL 模型的局限,无法完全突破这一瓶颈。
在另一方面,随着 3D 生成方法和大语言模型(LLM)的快速发展,基于文本的 3D 组合生成技术逐渐引起了广泛关注。这些技术能够深度理解复杂对象之间的关系,并生成包含多个主体的复杂 3D 场景。例如,GraphDreamer [5] 通过 LLM 构建图结构,其中节点代表对象,边表示它们之间的关系,实现了复杂场景的解耦;ComboVerse [6] 则提出空间感知评分蒸馏采样技术(SSDS),强化了空间的关联性。随后,其他研究 [13, 14] 进一步探索了联合优化布局以组合不同组件的潜力。但它们在生成 4D HOI 场景时,依然面临着两个核心挑战:
- 触区域定义不准确:虽然 LLM 擅长捕捉物体间的关系,但在与扩散模型结合时,如何准确定义物体间的接触区域,特别是复杂的关节结构如人体,仍然是一个难题。尽管 InterFusion [13] 构建了 2D 人体 - 物体交互数据集,旨在从文本提示中提取人体姿势,但它们仍在训练集之外的情况下,无法准确识别人体与物体的最佳接触部位。
- 4D 组合驱动的局限性:尽管 DreamGaussian4D [7] 和 TC4D [8] 利用视频扩散模型对 3D 静态场景进行动作驱动,但这些方法通常将整个场景视为一个统一主体进行优化,从而导致不自然的动画效果。尽管像 Comp4D [9] 这类项目通过轨迹为每个 3D 对象单独生成动画,但物体之间的接触建模仍然是一个巨大挑战。
为了解决这些挑战,AvatarGO 提出了两项关键创新,以解决物体与人体应 “如何交互” 以及 “在哪里交互” 的问题:
- LLM 引导的接触区域重定向(LLM-guided contact retargeting):该方法通过利用 Lang-SAM [10] 从文本中识别出大致的接触部位,并将其作为优化过程的初始化,从而解决了扩散模型在估计接触区域时的难题。
- 对应关系感知的动作优化(Correspondence-aware motion optimization):基于对静态合成模型中穿模现象较少发生的观察,AvatarGO 提出了对应关系感知的运动优化方法。该方法将物体的运动分为主动和从动部分,并利用 SMPL-X 作为中介,确保人体和物体在交互过程中保持一致的对应关系。这一创新显著提高了在运动过程中对穿模问题的鲁棒性。
AvatarGO: 4D 人体 - 物体生成框架

AvatarGO 以文本提示为输入,生成具有物体交互的 4D 虚拟人物。其框架核心包括:(1)文本驱动的 3D 人体与物体组合(text-driven 3D human and object composition):该部分利用大型语言模型(LLM)从文本中重定向接触区域,并结合空间感知的 SDS(空间感知评分蒸馏采样)来合成 3D 模型。(2)对应关系感知的动作优化(Correspondence-aware motion optimization):该优化方法联合优化人体和物体的动画,能够在动画过程中有效维持空间对应关系,从而提升对穿模问题的鲁棒性。
文本驱动的 3D 人体与物体组合
现在已有的方法已经可以很快捷高效的生成三维人物
![]()
和物体
![]()
,但 AvatarGO 的研究人员发现,即使进行手动调整,如重新缩放和旋转 3D 物体,仍然难以精确地绑定生成的 3D 人体和物体模型。为此,他们首先利用文本提示将人物
![]()
和物体
![]()
进行组合,通过优化其高斯属性来实现这一目标。同时,他们还优化了物体
![]()
的三个可训练全局参数,包括旋转旋转
![]()
、缩放因子
![]()
和平移矩阵
![]()
:

其中
![]()
是组成物体
![]()
的高斯点云。
空间感知评分蒸馏采样(spatial-aware score distillation sampling):沿袭 ComboVerse [6] 的方法,我们采用 SSDS 来促进人体和物体之间的 3D 组合生成。具体而言,SSDS 通过用一个常数因子𝑐(其中𝑐>1)缩放指定标记 < token∗>的注意力图,从而增强 SDS 与人体和物体之间的空间关系。

在这里,<token∗>对应于编码人体 - 物体交互项的标记,如 <‘holding’>,这些标记可以通过大型语言模型(LLMs)识别,也可以由用户指定。
LLM 引导的接触区域重定向(LLM-guided contact retargeting):虽然空间感知评分蒸馏采样有助于理解空间关系,但在识别人与物体最合适的接触区域时仍然面临困难,而接触区域却又是人体 - 物体交互的关键组成部分。为了解决这个问题,AvatarGO 提出利用 Lang-SAM [10] 从文本提示中识别接触区域。具体而言,从 3D 人体模型
![]()
出发,AvatarGO 从正面视角渲染该模型生成图像𝐼。然后,将此图像与文本输入一起,输入到 Lang-SAM 模型中,以推导出 2D 分割掩码
![]()
:

其中,<body-part>表示描述人体部位的文本,例如 <‘hand’>。
随后,他们通过逆向渲染将 2D 分割标签反投影到 3D 高斯上。具体来说,对于分割图上的每个像素𝑢,他们将掩模值(0或 1)更新回到高斯点云上:

其中,
![]()
表示第𝑖个高斯点的权重,
![]()
是可以投影到像素 𝑢上的高斯点的集合。
![]()
分别表示不透明度、透射率和分割掩码值。在权重更新后,他们通过将高斯点的权重与预定义的阈值𝑎进行比较,来判断一个高斯点是否对应于人体部位的分割区域。然后,AvatarGO 根据以下公式初始化平移参数
![]()
:

其中,
![]()
,𝑁是人体模型
![]()
中高斯点的数量。
对应关系感知的动作场
在生成了 3D 人体与物体的组合之后,同步驱动他们带来了额外的挑战,其主要是由于潜在的穿模问题。这个问题源于物体缺乏一个明确定义的运动场。为此,AvatarGO 通过使用 SMPL-X 的线性混合蒙皮函数(Linear-blend Skinning)为人体和物体模型建立了运动场,并提出了一种对应关系感知的运动优化方法,旨在优化物体模型的可训练全局参数,即旋转(
![]()
)和平移(
![]()
),以提高人体与物体之间穿模问题的鲁棒性。首先,SMPL-X 的线性混合蒙皮函数(𝐿𝐵𝑆)可表达为:

其中,
![]()
和
![]()
分别表示 SMPL-X 在标准空间和观察空间下的顶点。
![]()
是蒙皮权重,
![]()
是仿射变形,可将第𝑘个关节
![]()
从标准空间映射到观察空间,
![]()
表示邻近关节的数量。
人体驱动:当给定一个基于 SMPL-X 的人体运动序列之后,AvatarGO 会首先构建一个变形场,该变形场由两部分组成:(1)利用 SMPL-X 线性混合蒙皮函数𝐿𝐵𝑆(⋅)的关节变形,以及(2)基于 HexPlane 特征学习的非刚性运动 [11]。该变形场可以将点
![]()
从标准空间变形到观察空间中的
![]()
:

其中,
![]()
表示基于 HexPlane 的特征提取网络, 𝑡表示时间戳。
![]()
则通过离
![]()
最近的标准 SMPL-X 的顶点推导得到。
物体驱动:与人体驱动类似,AvatarGO 首先将物体定义为刚体,并类似的通过计算物体模型
![]()
内的每个高斯点𝑥与其最近的标准 SMPL-X 顶点的变形矩阵
![]()
。物体的变形场则可初步被定义为:

其中,
![]()
,
![]()
是
![]()
中的高斯点总数。
尽管直接使用 SMPL-X 线性混合蒙皮进行物体动画可能看起来是一个简单的解决方案,但它可能导致人体与物体之间的穿模问题。这一问题主要来自于缺乏适当的约束来保持这两个模型之间的对应关系。
对应关系感知运动优化:通过观察,作者发现 AvatarGO 在处理不同场景下的静态合成模型穿模问题时表现出较好的鲁棒性。基于这一观察,作者提出了一种对应关系感知的运动优化方法,以保持人体与物体之间的对应关系,从而一定程度上减少穿模问题的出现频率。具体而言,AvatarGO 将上述运动场
![]()
进行扩展,加入两个额外的可训练参数
![]()
和
![]()
:

其中
![]()
是原有运动场
![]()
的输出。
在通过 SDS 来优化这些参数之外,AvatarGO 提出了一种新颖的对应关系感知训练目标,该目标利用 SMPL-X 作为中介,在人体和物体被驱动转换到新姿势时,保持它们之间的对应关系:

其中,
![]()
和
![]()
分别基于
![]()
及其对应的 SMPL-X 模型得出。 除了应用 AvatarGO 提出的对应关系感知优化方法之外,作者还结合了空间感知 SDS 以及来自 HumanGaussian [12] 的纹理 - 结构联合 SDS,以增强整体质量:

其中,
![]()
和
![]()
是超参数,用于平衡结构损失和纹理损失的影响,而𝑑表示深度信息。
整体上,优化人物和物体运动场的损失函数可表达为:

其中,
![]()
分别表示用于平衡各自损失的权重。
实验
与其他 3D 生成方法的比较:下方视频对比了 AvatarGO 与 HumanGaussian [12]、GraphDreamer [5]、和 AvatarGO 的一个变种(仅通过 SSDS 优化人体和物体之间的关系)。结果表明,1)在没有大语言模型(LLMs)辅助的情况下,HumanGaussian 难以确定人类与物体之间的空间关联;2)尽管使用图结构建立关系,GraphDreamer 仍然在处理有效接触时存在困惑,导致结果不尽如人意;3)仅通过 SSDS 优化
![]()
不足以将物体移动到正确的位置。相比之下,AvatarGO 始终能够精确地实现人类与物体的交互,表现优于其他方法。

与其他 4D 生成方法的比较:下方视频展示了 AvatarGO 与现有 4D 生成方法(包括 DreamGaussian4D [7],HumanGaussian [12],TC4D [8])的对比。结果表明,1)即使有了人体 - 物体交互图像作为输入,DreamGaussian4D(采用视频扩散模型)在 4D 驱动时仍然面临困难;2)HumanGaussian 直接通过 SMPL LBS 函数直接进行的动画,往往会产生不流畅的效果,特别是对手臂的处理;3)TC4D 面临与 DreamGaussian4D 类似的问题,同时,它将整个场景视为一个整体,缺乏对单个物体的局部和大规模运动的处理。相比之下,AvatarGO 能够持续提供优越的结果,确保正确的关系并具有更好的穿模鲁棒性。
,时长00:17
总结
本文介绍了 AvatarGO,这是首次尝试基于文本引导生成具有物体交互的 4D 虚拟形象。在 AvatarGO 中,作者提出了利用大语言模型来理解人类与物体之间最合适的接触区域。同时,作者还提出了一种新颖的对应关系感知运动优化方法,利用 SMPL-X 作为中介,增强了模型在将 3D 人体和物体驱动到新姿势时,抵抗穿模问题的能力。通过大量的评估实验,结果表明 AvatarGO 在多个 3D 人体 - 物体对和不同姿势下,成功实现了高保真度的 4D 动画,并显著超越了当前的最先进技术。
局限性:在为以人为中心的 4D 内容生成开辟新途径的同时,作者同时也认识到 AvatarGO 存在一定的局限性:
1. AvatarGO 的流程基于 “物体是刚性体” 的假设,因此不适用于为非刚性内容(如旗帜)生成动画;
2. AvatarGO 的方法假设物体与人体之间持续接触,这使得像 “运篮球” 这样的任务难以处理,因为在某些时刻人与物体不可避免地会断开连接。
#FlashMLA
刚刚,DeepSeek开源FlashMLA,推理加速核心技术,Star量飞涨中
上周五,DeepSeek 发推说本周将是开源周(OpenSourceWeek),并将连续开源五个软件库。
第一个项目,果然与推理加速有关。
北京时间周一上午 9 点,刚一上班(同时是硅谷即将下班的时候),DeepSeek 兑现了自己的诺言,开源了一款用于 Hopper GPU 的高效型 MLA 解码核:FlashMLA。

该项目上线才 45 分钟就已经收获了超过 400 star!并且在我们截图时,Star 数量正在疯狂飙升。

项目地址:https://github.com/deepseek-ai/FlashMLA
众所周知,MLA是DeepSeek大模型的重要技术创新点,主要就是减少推理过程的KV Cache,从而实现在更少的设备上推理更长的Context,极大地降低推理成本。
此次 DeepSeek 直接开源了该核心技术的改进版本,可以说是诚意满满。
接下来,就让我看下这个开源项目的核心内容。
据介绍,FlashMLA 是适用于 Hopper GPU 的高效 MLA 解码内核,针对可变长度序列服务进行了优化。
目前已发布的内容有:
BF16
块大小为 64 的分页 kvcache
其速度非常快,在 H800 SXM5 GPU 上具有 3000 GB/s 的内存速度上限以及 580 TFLOPS 的计算上限。
在部署这个项目之前,你需要的有:
- Hopper GPU
- CUDA 12.3 及以上版本
- PyTorch 2.0 及以上版本
快速启动
- 安装
python setup.py install- 基准
python tests/test_flash_mla.py使用 CUDA 12.6,在 H800 SXM5 上,在内存绑定配置下实现高达 3000 GB/s,在计算绑定配置下实现 580 TFLOPS。
- 用法
from flash_mla import get_mla_metadata, flash_mla_with_kvcache
tile_scheduler_metadata, num_splits = get_mla_metadata (cache_seqlens, s_q * h_q //h_kv, h_kv)
for i in range (num_layers):
...
o_i, lse_i = flash_mla_with_kvcache (
q_i, kvcache_i, block_table, cache_seqlens, dv,
tile_scheduler_metadata, num_splits, causal=True,
)
...该项目发布后也是好评如潮。

甚至有网友打趣地表示:「听说第五天会是 AGI」。

最后,还是那句话:这才是真正的 OpenAI

#Timing-Driven Global Placement by Efficient Critical Path Extraction
联手华为诺亚,南大LAMDA组获EDA顶会DATE 2025最佳论文
国内芯片设计研究团队,刚刚在国际学术顶会上获奖了。
近日,南京大学人工智能学院 LAMDA 组钱超教授团队在 DATE 2025 上发表论文《Timing-Driven Global Placement by Efficient Critical Path Extraction》获得了最佳论文奖。
论文:《Timing-Driven Global Placement by Efficient Critical Path Extraction》
论文链接:https://www.lamda.nju.edu.cn/qianc/DATE_25_TDP_final.pdf
开源:https://github.com/lamda-bbo/Efficient-TDP
本论文第一作者侍昀琦、四作林熙、五作薛轲分别是南京大学人工智能学院的硕士生、本科生和博士生,钱超教授为通讯作者,论文由南京大学与华为诺亚方舟实验室合作完成。
DATE 全称 Design Automation Test in Europe(欧洲设计自动化与测试会议),是 EDA 领域的顶级国际学术会议,由权威机构 IEEE 和 ACM 共同举办,吸引了全球电子设计自动化与测试领域的著名学者、企业界专家参与。
DATE 自 1994 年创办以来已举办 31 届,今年的大会将于 3 月 31 日至 4 月 2 日在法国里昂召开。今年的大会收到了超过 1200 篇投稿,录用率约 25%,共选出了四篇最佳论文奖。

南京大学等完成的针对大规模芯片标准单元的全局布局问题,通过高效的关键路径提取技术,覆盖所有时序(即传播时延约束,是实现芯片功能的关键)违例端点,从而精确建模时序目标,并且在优化时兼顾布线长度、布局密度、时序等多个目标。相较此前业界最先进算法,新方法在关键时序指标 TNS 和 WNS 上分别提升 40.5% 和 8.3%。
审稿人高度评价了该研究,称「结果令人印象非常深刻,超过了所有先进工作」(The results are very impressive, outperforming all state-of-the-art works),并取得了显著提升。
EDA 即电子设计自动化(Electronic Design Automation),是指利用计算机辅助设计(CAD)软件,来完成超大规模集成电路(VLSI)芯片的功能设计、综合、验证、物理设计(包括布局、布线、版图、设计规则检查等)等流程的设计方式。EDA 被誉为「芯片之母」,是电子设计的基石产业。
在超大规模集成设计领域,布局过程至关重要,它是逻辑设计和物理布局之间的桥梁。传统的布局方法虽然侧重于最小化线长和减少布线拥塞,但仅隐式地解决了时序指标,这可能无法满足现代大规模芯片设计的严格时序要求。直接优化时序是必不可少的,但通常需要大量的计算资源和周转时间,人们急需更有效的时序驱动布局方法来缩短设计周期并确保时序收敛。
现代布局算法通常由三个主要阶段组成:全局布局、合法化和详细布局。全局布局将单元分布在目标布局中,平衡线长和密度。然后通过合法化对粗略结果进行细化,并通过详细布局进行微调。在这三个阶段中,全局布局在确定单元的整体分布方面起着至关重要的作用,显著影响最终布局的质量,包括时序。
因此,针对全局布局的时序驱动布局 (TDP) 得到了广泛研究,重点优化关键时序指标,例如总负裕度 (TNS) 和最差负裕度 (WNS)。
这类时序驱动布局(TDP)技术基本上包含三个组成部分:基础布局算法、时序分析以及它们之间的接口。第一个组成部分利用传统的全局布局引擎,主要专注于优化线长和密度之间的权衡。第二个组成部分涉及内部或外部时序引擎,这些引擎评估当前布局以提供关键的时序数据,例如关键路径延迟或引脚裕量。第三个组成部分将时序指标转换为某些权重或约束,以驱动基础布局引擎。根据处理时序信息的方式,TDP 技术大致可以分为两类:基于网络的方法和基于路径的方法。
基于网络的方法使用时序分析动态或静态地调整网络权重或网络约束,间接引导布局关注关键网络。由于传统布局算法主要专注于最小化线长,这本身涉及网络的考虑,因此只需对这些算法进行最小修改即可适应时序驱动的方法。最近,有研究将先进的非线性布局工具 DREAMPlace 升级为其时序驱动版本 4.0。这个新版本动态调整网络权重,利用动量引导机制与时序分析引擎交互,增强了其对时序优化的关注。
基于路径的方法直接处理从时序图中提取的路径,通常将其表述为数学规划问题。这些方法在优化过程中保持对时序的准确视图,因此通常能够确保高质量的结果。然而,随着设计规模的增加,路径数量呈指数增长,这些方法常常面临可扩展性问题。最近又出现了一种全新可微分时序驱动布局框架,可将 GPU 加速的可微分时序引擎集成到 DREAMPlace 中,实现高效的基于路径的分析。这种方法不仅达到了最先进的性能,而且以具有竞争力的速度运行,有效解决了传统的可扩展性挑战。
综上所述,尽管取得了显著进展,时序驱动的布局问题在很大程度上仍未得到解决。基于网络的方法通常面临优化目标间接和时序信息利用不足的问题。对于基于路径的方法,尽管此前的研究在一定程度上解决了可扩展性问题,但他们的方法通过平滑时序指标可能会影响准确性。
南大研究引入了一个时序驱动的全局布局框架,该框架结合了细粒度的引脚到引脚(pin-to-pin)吸引力二次距离损失,直接针对时序指标进行优化。这一框架还配备了一个路径级时序分析模块,能够高效提取关键路径。其主要贡献包括:
- 开发了一个基于领先布局工具 DREAMPlace 4.0 的 GPU 加速时序驱动布局流程,优化了关键路径上的引脚到引脚吸引力;
- 引入了一种高效的关键路径提取方法,能够捕捉全面的时序信息,实现高速的时序优化 —— 相比默认的时序分析工具,速度提升了 6 倍;
- 设计了一种用于引脚到引脚吸引力的二次欧几里得距离损失,该损失与时序指标紧密对齐,显著提升了性能,与其他距离度量相比,TNS(总负时序裕量)和 WNS(最差负时序裕量)分别提升了 50% 和 30%;
- 在 ICCAD2015 竞赛基准测试套件上的实验结果表明,与 DREAMPlace 4.0 相比,新方法在 TNS(WNS)上实现了约 60%(30%)的提升;与 Guo 和 Lin 的工作相比,TNS(WNS)提升了约 50%(10%)。
算法创新点在哪里?
作者提出的「GPU 加速的时序驱动全局布局框架」在技术上有哪些创新之处呢?我们可以从下图 1 的架构流程洞见一二,一方面引入了细粒度引脚到引脚吸引力目标,并直接瞄准了时序指标;另一方面通过高效的路径提取方案和二次欧几里得距离损失来实现。

首先,为了得到细粒度的权重方案,作者认识到了传统网络加权方法的不足。这些方法通过为关键网络分配额外权重来提高时序性能,然而现代设计的复杂性往往要求具有大型扇出网络和共享数据路径,因而可能会对非关键引脚对施加不必要的权重,并忽略路径共享的影响,进而无法有效地优化时序性能。
为了解决这些问题,作者提出在集成时将引脚到引脚吸引力作为一个细粒度目标来看待,以取代传统的为时序优化应用额外网络权重的方法。从效果上来看,引脚到引脚吸引力可以使关键路径上的引脚靠得更近,从而减少线路延迟并提高时序性能。
具体来讲,改进后的目标函数如下所示:

下图 2 比较了传统网络加权方案与三引脚网络的引脚到引脚吸引力模型。作者使用了一个包含三个时序路径(分别用绿色、黄色和蓝色箭头表示)的示例展开了说明,其中引脚到引脚吸引力方法根据关键引脚(引脚 A、B 和 C)对各自的松弛量有选择地分配权重,从而提供更精细的控制,并有利于整体时序和线长。

在实现细粒度权重方案之后,接下来要考虑的是关键路径的提取。
为了能够高效地提取路径级时序信息,作者集成了 OpenTimer。这是一个高性能的时序分析工具,改编自 DREAMPlace 4.0,并被很多开源项目采用。OpenTimer 提供了一个高级功能 report_timing (n),它在 n 值较小(比如 1)时可以有效地识别关键路径,从而快速地对特定路径进行详细分析。不过,由于分析路径呈二次增长,该功能的效率会随 n 的增加而降低。
意识到这一问题之后,作者提出了 report_timing_endpoint (n,k) 方法,实现了更好的关键路径提取效果。这里 n 表示最关键端点的数量,k 表示为每个端点提取的关键路径的数量。具体来讲,该方法返回了 n ×k 条路径,并确保每个提及的端点都得到适当地覆盖,从而全面反映整个芯片的时序问题并直接瞄准 TNS 指标。
下表 I 详细说明了使用不同方法时 superblue1 案例的时序分析结果。最初,作者共确定了 26300 个故障端点。从结果来看,本文 report_timing_endpoint (26300,1) 方法高效地覆盖了所有端点,并涵盖了更广泛的引脚对。此外,将每个端点的路径数增加到 10,时长会增加 3 倍,而引脚对的数量仅仅增加了 1.5 倍,这表明前一种设置足以进行有效的优化。

最后还需要解决二次欧几里得的距离损失问题。为了实现有效的优化,设计一个与最终时序指标保持一致的损失函数非常有必要且很重要。作者选择引脚到引脚的欧几里得距离的平方即二次损失作为目标函数:

下图 3 展示了二次损失设计的有效性,并使用 superblue16 案例对其与 HPWL 损失、欧几里得距离损失进行了比较。他们首先使用 report_timing (1) 从时序优化前的稀疏布局中识别出了最关键路径,如图 3 (a) 所示。图 3 (b) 和 (c) 分别展示了使用 HPWL 损失和线性欧几里得距离损失的情况下,优化至收敛的对应路径。
相比之下,图 3 (d) 采用了本文二次欧几里得距离损失,尽管总线长增加了一些,但路径松弛有所改善。这一结果要归功于二次损失促成了单元的更均匀分布,并保持了更一致的线段长度。

得益于以上三方面的创新,作者实现了 PP 损失的 CUDA 内核,并达成了 GPU 加速的目的。
实验结果
研究人员基于开源布局器 DREAMPlace 4.0 发布版本开发了时序驱动的全局布局器,并与此前业内最优方法进行了对比。
下表 II 全面比较了新时序驱动布局器与四种基线方法之间的 TNS、WNS 和 HPWL 指标。所有 DEF 结果均使用 ICCAD 2015 竞赛的官方评估套件进行评估,以确保公平比较。
结果显示,新方法明显优于最先进的时序驱动布局器,尤其是可微分 TDP 和分布 TDP。具体来说,它在 8 个测试案例中的 7 个中实现了最佳 TNS 结果,平均比可微分 TDP 提高了 50.0%,比分布 TDP 提高了 40.5%。
与这两个领先的布局器相比,该研究提出的布局器在 WNS 方面也显示出 8.3% 的持续改进。此外,与 DREAM Place (包括其 4.0 版)相比,新方法在 TNS 和 WNS 的所有 8 个案例中均表现更优。
作者表示,这种改进可以归因于有针对性的引脚到引脚吸引策略,该策略最大限度地减少了对非关键引脚的影响并有效地保持了线长质量,而不像 DREAMPlace 4.0 那样将权重应用于众多网络。此外,与早期收敛的 DREAMPlace 相比,额外的时间驱动优化迭代可以进一步优化 HPWL 的密度。

下表 III 总结了消融研究。前两列分别用 HPWL 和线性欧几里得损失代替了二次距离损失。
尽管如此,它们在 TNS 方面比 DREAMPlace 4.0 提高了 15%,证明了新方法的引脚对引脚吸引力建模和关键路径提取的有效性。此外,与 HPWL / 欧几里得损失相比,二次损失的卓越性能表明它比 Electrostatics-TDP 更具优势,后者依赖 HPWL / 欧几里得损失进行虚拟路径建模。

运行时分析和其他结果。下表 IV 比较了 DREAMPlace、DREAMPlace 4.0 和新方法在 8 种设计中的运行时间。因为专注于线长,没有耗时的计时引擎,DREAMPlace 在所有情况下都实现了最佳运行时间。

由于高效的时间分析和加权方案,新方法在大多数情况下都超越了 DREAMPlace 4.0,如下图 4 所示。

下图 5 展示了在布局运行过程中,新方法与 DREAMPlace 4.0 在半周长线长(HPWL)、溢出率(Overflow)、总负时序裕量(TNS)和最差负时序裕量(WNS)方面的对比。两条曲线在前 500 次迭代中保持一致,随后时序优化开始。在 HPWL 和溢出率的子图中,DREAMPlace 4.0 由于应用了较大的网络权重,导致 HPWL 性能较差且收敛速度较慢。
此外,新方法还迅速提升了 TNS 和 WNS 性能,并在优化完全收敛前保持稳定,从而证明了时序目标设计的有效性。

芯片设计是一个流程极其复杂的过程,包含大量优化问题。近年来,南京大学 LAMDA 组一直在持续攻关,希望建立 AI 赋能 EDA 技术的理论基础,并对算法设计提供指导。
此前,在 2019 年 LAMDA 组在 Springer 出版《Evolutionary Learning: Advances in Theories and Algorithms》,总结了他们在该方向上过去二十年的主要工作,并于 2021 年出版中文版《演化学习:理论与算法进展》。该团队基于在演化学习方向的长期理论研究,近期还针对芯片设计中的复杂优化问题设计出了多个原创领先算法,如针对芯片宏元件布局问题,较谷歌在 Nature 2021 年提出方法的布线长度缩短 80% 以上,较当前最先进的开源 EDA 工具 OpenROAD 的芯片最终时序指标提升超 65%,并在 ACM SIGEVO Human-Competitive Results 获奖。
据介绍,南大 LAMDA 组正在与华为合作攻关,希望通过先进芯片设计缓解当前先进制造工艺局限。
参考内容:
https://www.date-conference.com/
https://ai.nju.edu.cn/5d/02/c17806a744706/pagem.htm
#新版Muon优化器
开源赛道太挤了!月之暗面开源新版Muon优化器
省一半算力跑出2倍效果,月之暗面开源优化器Muon,同预算下全面领先。
月之暗面和 DeepSeek 这次又「撞车」了。
上次是论文,两家几乎前后脚放出改进版的注意力机制,可参考《撞车 DeepSeek NSA,Kimi 杨植麟署名的新注意力架构 MoBA 发布,代码也公开》、《刚刚!DeepSeek 梁文锋亲自挂名,公开新注意力架构 NSA》。
这次是开源。
上周五,DeepSeek 刚刚官宣这周要连续开源 5 个代码库,却被月之暗面深夜截胡了。
昨天,月之暗面抢先一步开源了改进版 Muon 优化器,比 AdamW 优化器计算效率提升了 2 倍。

团队人员表示,原始 Muon 优化器在训练小型语言模型方面表现出色,但其在扩展到更大模型方面的可行性尚未得到证明。因此,团队人员确定了两种对扩展 Muon 至关重要的技术:
- 添加权重衰减:对扩展到更大模型至关重要。
- 一致的 RMS 更新:在模型更新上执行一致的均方根。
这些技术使得 Muon 能够在大规模训练中直接使用,而无需调整超参数。Scaling law 实验表明,与计算最优训练的 AdamW 相比,Muon 的计算效率提升了 2 倍。
基于这些改进,月之暗面推出了 Moonlight,这是一个 3B/16B 参数的 Mixture-of-Expert(MoE)模型,使用 Muon 进行了 5.7 万亿 tokens 的训练。该模型刷新了当前的「帕累托前沿」,换句话说,在相同的训练预算下,没有其他模型能在所有性能指标上同时超越它。
与之前的模型相比,Moonlight 也以更少的训练 FLOPs 获得了更好的性能。
如下图所示,该研究进行了 Scaling law 研究,将 Muon 与强大的 AdamW 基线进行了比较,结果展示了 Muon 的卓越性能。Muon 实现了与 AdamW 训练相当的性能,同时仅需要大约 52% 的训练 FLOP。

月之暗面不但开源了内存优化且通信高效的 Muon 实现代码,并且还发布了预训练、指令调优以及中间检查点,以支持未来的研究。
论文《 MUON IS SCALABLE FOR LLM TRAINING 》。

- 论文地址:https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf
- 代码地址:https://github.com/MoonshotAI/Moonlight
- 模型地址:https://huggingface.co/moonshotai/Moonlight-16B-A3B
研究介绍
扩展 Muon
Muon 优化器为 OpenAI 研究者 Keller Jordan 等人在 2024 年提出的,他们的研究表明在小规模训练中 Muon 的表现显著优于 AdamW。
但月之暗面发现,当将其扩展到训练更大模型并使用更多 token 时,模型性能提升逐渐减弱。他们观察到,权重和层输出的 RMS 值持续增长,最终超出了 bf16 的高精度范围,这可能会损害模型的性能。
为了解决这个问题,月之暗面在 Muon 中引入了标准的 AdamW(Loshchilov 等人,2019)权重衰减机制。
为了探究这一机制,研究者对 Muon 进行了有无权重衰减的实验,他们训练了一个包含 800M 参数和 100B token(约为最优训练 token 量的 5 倍)的模型。图 2 展示了使用 AdamW、无权重衰减的原始 Muon 以及带权重衰减的 Muon 训练的模型的验证损失曲线。

结果显示,虽然原始 Muon 在初期收敛速度更快,但一些模型权重随时间的推移增长过大,可能会影响模型的长期性能。
加入权重衰减后解决了这一问题 —— 结果表明,带权重衰减的 Muon 优于原始 Muon 和 AdamW,获得了更低的验证损失。公式 3 为表达式,其中 λ 为权重衰减比率。

一致的 RMS 更新。研究者发现 Adam 和 AdamW 的一个重要特性是,它们将更新的 RMS 维持在 1 左右。然而,月之暗面发现 Muon 更新 RMS 会根据参数矩阵形状的变化而变化,具体如下引理 1 所示:
![]()
为了在不同形状矩阵之间保持一致的 RMS 更新,该研究通过
![]()
来扩展 Muon 矩阵更新,从而抵消引理 1 中提到的影响。
在实际应用中,研究者通常将 AdamW 与 Muon 结合使用,以处理非矩阵参数。本文希望优化器超参数(学习率 η、权重衰减 λ)能够在矩阵参数和非矩阵参数之间共享。
因此他们提出将 Muon 更新的 RMS 调整到与 AdamW 相似的范围。他们通过以下调整将 Muon 更新 RMS 缩放至这一范围:

分布式 Muon
月之暗面团队还提出了一种基于 ZeRO-1 的分布式解决方案,称为分布式 Muon(Distributed Muon)。分布式 Muon 遵循 ZeRO-1 在数据并行(DP)上对优化器状态进行划分,并与普通的 ZeRO-1 AdamW 优化器相比引入了两个额外的操作,算法 1 描述了分布式 Muon 的实现。

实验
RMS 的一致性
为了使所有矩阵参数更新的 RMS 值与 AdamW 的 RMS 保持一致,研究团队尝试了两种方法来控制参数更新的 RMS,并将其与只用了 AdamW 的基线的 RMS 进行了对比。
由于大规模训练模型时,会出现各种意料之外的情况,因此,研究团队测试了 Muon 对训练早期阶段的影响。当矩阵维度差异增大时,更新 RMS 不一致的问题会更加明显。该团队对模型架构进行了微调,用标准的 2 层 MLP 替换了 Swiglu MLP,并将其矩阵参数的形状从 [H, 2.6H] 改为 [H, 4H]。
团队评估了模型的损失,并监控了关键参数的 RMS,尤其是形状为 [H, H] 的注意力查询权重和形状为 [H, 4H] 的 MLP 权重。

实验结果表明(见表 1),Update Norm 和 Adjusted LR 均优于基线方法,且 Adjusted LR 的计算成本更低,因此被选用于后续实验。
Muon 的 Scaling Law
为了与 AdamW 公平比较,该团队在一系列基于 Llama 架构的模型上对 Muon 进行了拓展。
对于 Muon,由于其 RMS 与 AdamW 匹配,团队直接复用了 AdamW 的超参数。


实验结果显示,拟合的 Scaling Law 曲线表明,在计算最优设置下,Muon 仅需约 52% 的训练 FLOPs 即可达到与 AdamW 相当的性能。这进一步说明了 Muon 在大规模语言模型训练中的高效性。
使用 Muon 进行预训练
为了评估 Muon 在模型架构中的表现,该团队使用 DeepSeek-V3-Small 架构从头开始预训练了 Moonlight 模型。
Moonlight 模型总共进行了 5.7 万亿 tokens 的训练,但在训练到 1.2 万亿 tokens 的阶段,团队将其与 DeepSeek-V3-Small(使用 1.33T tokens 训练的 2.4B/16B 参数 MoE 模型)和 Moonlight-A(与 Moonlight 设置相同,但使用 AdamW 优化器)进行了比较。如表 4 所示,Moonlight 在语言、数学和编码等任务上都显著优于 Moonlight-A,证明了 Muon 的扩展优势。

在完整训练后,Moonlight 与类似规模的开源模型(如 LLAMA3-3B、Qwen2.5-3B 和 Deepseek-v2-Lite)进行了比较。结果显示,Moonlight 在性能上优于使用相同数量 tokens 训练的模型,与更大参数规模模型相比,也较有竞争力。

此外,研究团队还发现,Muon 可以让模型的权重更新更「多样化」,尤其在 MoE 模型中表现突出。

在微调阶段,在预训练和微调阶段都使用 Muon,模型表现会比用 AdamW 的组合更好,但如果微调和预训练的优化器不一致,优势就不明显了。

参考链接:
https://github.com/MoonshotAI/Moonlight?tab=readme-ov-file
https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









