







我自己的原文哦~ https://blog.51cto.com/whaosoft/11930718
#支小宝
支付宝突然推出新App,竟想用AI让日常生活开挂
只是装了一个 App,整个生活就 AI 了 。
家人们,支付宝已经这么「炸场」了吗?
输入「买一张周日的高铁票,从北京到武汉, 下午出发,行程时间最短的一趟」, 点击三次,等待数秒,购票成功!以前跳转几个页面、点击十几下才能搞定,感觉像是一个段子。
,时长00:13
随着国内各大互联网平台纷纷推出专门的 AI 原生应用,国民级应用支付宝也向等待已久的市场交出答卷——一个全新的 AI 原生应用「支小宝」。
不少 AI 原生应用像一个全能助手,你可以问任何开放性问题,TA 都能回答,尽管也不那么笃定。
但「支小宝」不同,作内首款办事型 AI 生活管家,TA 生动展示了大语言模型的应用如何从理解( Chat )转向采取实际行动( Act )。
支付宝已经诞生 20 年,每天都有数亿人用它支付、出行、理财、就医、办事。做普通人的「生活百宝箱」,也一直是它的底色。而今,进入 AI 时代,「支小宝」正接力支付宝,希望人工智能也能像二维码服务一样,未来惠及每一个普通人。
一、只要一句话,生活就 AI
乍一看, AI 原生应用就和移动互联网原生应用(支付宝)很不同。
单一蓝色的配色方案,配以极简的界面设计,让人倍儿感清爽。「此刻」、「对话」 分别对应「支小宝」两个核心能力,主动陪伴和跑腿办事。「智能体」示意「支小宝」未来要交很多朋友。
一个对话框「包打天下」:只要你一句话,叫车、订票、充话费服务立刻直达。
体验一番后发现,日常就这样被大模型给摆平了。
早上叫醒打工人的不是梦想,而是咖啡,只用说句「点杯瑞幸咖啡的生耶拿铁,到店取」,搞掂!
,时长00:08
「支小宝」会将取餐码,连同天气和要闻「写到」便利贴上,贴到「此刻」公告栏。
车站附近扫码取咖啡。发现车快来了,点开「随身口令」,「我要坐公交」,乘车码立刻弹出来。
本着「能动手就不要动口」的精神,召唤刚需服务的「口令」已经进化成模版。
,时长00:18
早会完毕,接到下周出差的任务,只需在对话框说清要求,如出发地、目的地、时间、甚至票价高低,就能一键搞定,身份证号都能帮你填好。
午饭时间,「此刻」自动更新到中午状态,前几天网购的包裹已经到了。
天气太热,上个月电费花了多少?打开一看,不出所料,充值缴费多半都是电费支出。
充话费、给闺蜜转账,啥都不用自己填, 「支小宝」直接搞定。
晚上,依旧咳嗽不止,白天还发烧,该挂什么科?「支小宝」请来健康医生作答,确认科室后,直接将医院挂号入口找了出来。
,时长00:08
过去多次点击才能完成的事儿,现在只需一句话,AI 就能帮你办好。很多生活百科问题,「支小宝」也能整合网络内容回答你。
通过「对话」,你可以享受一句调动日常服务的快感。进入「此刻」,因为拥有场景感知系统,「支小宝」会基于你的日常习惯、空间位置主动给到陪伴。
TA 就像一个聪明的公告栏,实时将 To-do list 事项更新至此。除了实时更新的天气和新闻,快到地铁站了,乘车码会自动冒出来;快递到了,取件码会被贴在首页。如果你在黄山,请出「智能体」里的「黄小松」就能获得更地道的本地服务。
,时长00:14
用得越多,TA 越懂你。经常打车去某个地方,「打车去XX」就会出现在「随身口令」中。
二、 用硬科技狠活儿满足最接地气的需求
「支小宝」有点迷惑性。
当产品体验丝滑到「无感」后,人们反而容易忽视沉淀在下面的深刻技术,甚至会有「这也不难做到」的错觉。
没有底层的模型和算法能力创新,就不可能有产品上的「一键上翻支付宝百万级小程序」、「让 8000 万数字生活服务『触手可得』」。
和大模型理解用户意图后直接调用商家接口的做法不同,「支小宝」使用了一个名为 ACT(Transformer for actions )的智能服务技术,让智能助理具备屏幕感知与仿真执行能力,就像让 AI 有了「眼睛」和「手脚」,模拟人类交互(如点击、滚动和输入)下单、订票。
ACT 会先利用大语言模型来理解用户的自然语言需求,然后将其转化为一系列具体的操作指令。这使得用户无需手动操作多个界面,只需用语言表达他们想要的东西即可。为了实现这一目标,支付宝在多个方面进行了探索和创新。
首先,支付宝实现了多模态数据采集,除了行为数据,还有页面的图片、数字、按钮、输入框等各种元素,使系统能够「看到」并理解当前的用户界面。这就像给机器人装上了眼睛,让它能够准确地在界面上操作。
有了「眼睛」还不够,跑腿办事还得有「四肢」,围绕支付宝框架和容器能力,他们自建了一套仿真执行能力,针对性地解决了在支付宝 App 上做仿真执行的问题。
为了提供更好的用户体验,ACT 采用了「离屏」方案,将整个操作过程隐藏在用户视线之外。这样,用户就不会看到中间的操作过程,体验更加流畅。
除了这些会见诸媒体报道的底层创新,更多技术和能力沉淀在了超级应用里。
为了提升大模型的行动力,支付宝还优化了 Function Call(函数调用)。通过采用函数表达和显式推理等高级 Prompt 技术,显著提升了大模型理解和调用合适工具的能力。更值得一提的是,他们还利用实际业务场景的复杂数据来训练模型,这大大增强了模型的「实操」能力。
作为一个泛生活服务数字平台,支付宝的服务生态非常丰富。现在,借由 AI 将平台 8000+ 数字生活服务、400万+ 小程序重新连接起来,这一举措堪比支付宝当初通过一张张二维码构建起移动支付网络,对工程化落地能力提出了极高要求。
而系统工程能力正是中国这些日活过亿超级应用的强项。「亚运数字火炬手」活动吸引了超过 1 亿人参与,「五福节」活动更是支持了 6 亿人次的 AI 互动,这些成功案例不仅证明了支付宝在处理海量用户请求方面的卓越能力,更展示了其在解决大模型应用规模化落地中的关键问题,如算力支撑和成本控制等方面的领先实力。
ACT 正在从端侧渲染向端云协同渲染过渡。这种转变虽然工程复杂度很高,但对于「支小宝」这类对响应速度要求极高的产品来说至关重要。特别是 ACT 技术所需的容器级别云渲染,比起「五福节」中使用的单纯界面渲染要复杂得多,对工程能力的要求也更高。
三、支付宝的「内生」:
不止于 All in AI,而是 AI in All
二十年来,中国人的购物方式和日常生活发生了翻天覆地的变化。人们可以使用二维码移动支付,而不必再使用信用卡。手机上不仅能买机票、电影票,还能打车、缴费、挂号甚至领结婚证。支付宝成了「生活百宝箱」,但从「百宝箱」立刻翻出你要的东西,也是不易。
今年4月,支付宝将 AI 引入整个平台。在首页开启测试全新 AI 产品支付宝智能助理(「支小宝」前身),同时在多个场景接入了智能助理:搜索、出行频道、市民中心。
拉下支付宝 App 首页,就能唤起,起到「App 智能导航」的作用。后因探索 AI 原生应用,为用户提供更极致的体验,又有了独立 App「支小宝」。
由此可见,ChatGPT 和 LLMs 大热 ,每个公司都会选择最合适自己的方式跟进。
OpenAI、Anthropic、Mistral 等将聊天机器人作为一个神奇的通用界面,追逐一个可以提问任何开放性问题的全能助手。而支付宝给出了另一种选择,转向更加务实的应用层,看看能帮助用户解决什么问题。
选择利用其现有的产品生态和经过市场验证的刚需(衣食住行)落地新技术,支付宝降低了试错成本,还能更快地获得市场反馈。即便某些产品可能失败,也能获得宝贵经验,尝试越多越有利。
因此,支付宝选择的第一个方向是「内生」,用 AI 焕新整个平台,不止于All in AI,而是 AI in All。他们并不声称,新的基础模型在所有方面都是最好的,但对于他们想要焕新的功能来说,一定要足够好。
其实,找到一个合适场景,把先进技术变成一个普惠服务,一直是支付宝最擅长的。蚂蚁集团 CTO 何征宇说过,「支付宝过去和今天的技术发展思路是一样的。」
这款国民应用今日之大成,不是基于「上帝视角」的预先设计,无非是见山修路,见河搭桥,虽然也在激烈的竞争中走过弯路,但有一点始终没变:我能为用户解决什么问题?如何让服务更简单、更敏捷?围绕核心业务体验,把硬核技术吃透。
当然,因为内核是智能体(AI Agent),「支小宝」的未来并不像它带来的体验那么「简单」。
「支小宝」能以多种形式承载并服务用户,透过专业智能体的深度连接,用户会感受到服务体验的代际升级。但,这也需要千行百业和无数 ISV 一起来「种草」。
今天的外滩大会上,支付宝面向行业正式启动智能体生态开放计划,并推出了一站式智能体开发平台「百宝箱」,依托智能体构建能力,商家机构可 0 代码、最快 1 分钟创建专属服务智能体,并一键发布到支付宝生态圈。
今天的外滩大会上,支付宝面向行业正式启动智能体生态开放计划。
此前,支付宝已经开始打样。
他们携手安徽黄山风景区,打造了国内首个「全程 AI 伴游」景区。外地游客抵达黄山后,打开「支小宝」就能快速进入黄山智能体,开启 AI 伴游。
支付宝和浙江卫健委联合推出的数字健康管家「安诊儿」,背后也是一个连接多个医院与机构的智能体生态。
二十年前,支付宝发明了快捷支付,它对整个中国移动支付发展的贡献要在很多年后才会显现出来。二十年后,支付宝设想了一种新生活,演化的进度条开始读取中。
#把Llama训成Mamba
性能不降,推理更快!
近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。
先来看一张其乐融融的图片(一眼AI):
右边的小羊驼代表Llama,而左边的蛇(Mamba)也是我们的老熟人了。
至于到底能不能其乐融融,咱就不管了,之所以有此场景,是因为Mamba方面又搞出了有意思的研究:
——如何把Llama变成Mamba?
论文地址:https://arxiv.org/pdf/2408.15237
代码地址:https://github.com/jxiw/MambaInLlama
近日,来自康奈尔、普林斯顿等机构的研究人员推出了上面这篇工作,将Llama这样的大型Transformer提炼成了Mamba模型,
并且成功在Mamba架构上应用了带有硬件感知的推测解码算法,提高了整个模型的推理速度。
为什么要把Llama变成Mamba?
因为从头开始训练一个大模型太贵了。
Mamba也火了这么长时间了,相关的研究每天都有,但自己训练大尺寸Mamba模型的却很少。
目前比较有名的是AI21的Jamba(进化到了1.5版本,最大398B,MoE),以及NVIDIA的Hybrid Mamba2模型(8B)。
不过世界上有那么多成功的Transformer大模型,而知识就包含在这些模型参数里。
如果能够锁住知识,同时把Transformer微调成Mamba,不就解决问题了?
在本文中,研究人员结合渐进式蒸馏、监督微调(SFT)和定向偏好优化(DPO)等方法达成了这一目标。
光是变大还不够,
在性能匹配Transformer的前提下,速度也要够快才行。
Mamba凭借固定的推理开销,在长序列中的优势明显,但Transformer这边也是有推理加速方案的,比如推测解码。
而由于Mamba本身的结构特性,不能直接应用这种方案,所以作者设计了全新的算法,并结合硬件的性质来实现基于Mamba的推测解码。
最终,研究人员将Zephyr-7B、Llama-3 8B提炼为了线性RNN模型(混合Mamba和Mamba2),且性能与蒸馏之前的标准模型相当。
整个训练过程只使用了20B的token,效果却能够与使用1.2T个token从头开始训练的Mamba 7B模型,以及使用3.5T个token训练的NVIDIA Hybrid Mamba2模型相媲美。
从 Transformer 到 Mamba
在介绍Mamba 2的时候我们讲过,线性RNN(或SSM)跟线性注意力是一回事。
所以可以根据x,B,C与V,K,Q的对应关系直接复用注意力中的投影矩阵。
额外的参数包括SSM需要的A矩阵和Δt(由x投影得到),这就完成了基本的参数初始化。
之后就是SSM的运算过程,再通过投影和累加得到输出。
模型架构和训练
下图给出了模型的架构,因为Transformer的知识存在于MLP层,所以冻结这部分参数。
除了用线性RNN层(Mamba)替换掉注意力头,还有一些组件需要处理,比如跨头共享键和值的分组查询注意力(GQA)。
知识蒸馏(Knowledge distillation,KD)是一种常用的压缩技术,用来训练模仿较大模型(teacher)行为的较小网络(student)。
根据经验,这里采用逐步替换Attention层的策略,先是每2层进行蒸馏,然后每4层继续蒸馏......
监督微调
有两种常见的蒸馏方法。一种方法是使用word-level的KL散度,此时训练student模型去匹配teacher模型输出的完整概率分布。
第二种方法是序列级知识蒸馏(SeqKD),直接使用teacher模型的输出作为ground truth来训练student模型(也称为伪标签)。

这里θ是student模型的可训练参数,α和β分别控制序列和词的loss项的权重。
偏好优化
LLM指令调优的第二阶段是使其符合用户偏好。这个阶段,使用一组期望的偏好对来改进模型的输出。
优化的目标是使奖励模型最大化,同时保持产生的输出接近参考模型。
通常,参考模型使用上一步监督微调后的模型。这里因为是蒸馏,直接可以用teacher模型:

偏好模型的奖励函数定义取决于所使用的方法,本文采用直接偏好优化(DPO),通过直接梯度更新有效地到达优化目标。
DPO表明,对于给定的提示x ,如果我们能够获得preferred和dispreferred两种输出,就可以将这个优化问题重新表述为:

这种优化可以在序列级别上执行,让teacher模型和student模型一起对preferred和dispreferred输出进行评分,然后反向传播给student模型。
推测解码
经过上面的一套小连招,模型转换就搞定了,下面开始想办法应用Transformer那边的推测解码。
推测解码(Speculative Decoding)可以简单理解为下面这张图。
Transformer做推理的时候,除了要处理不断变长的KV cache之外,计算效率也是个问题。
因为显卡的设计是计算高于访存的,具体到计算单元就是做矩阵乘法。
而推理的时候每次只能进入一个词向量,显卡的很多计算就被浪费了。
推测解码给出的解决方案是,使用一个小模型做生成,然后拿显卡多余的计算做验证。
小模型跑得快,可以一口气生成很多输出向量,但是可能效果差一点。这时候用大模型作为验证,一次计算之前生成的很多个向量。
所以小模型串行跑得快,大模型可以并行计算跑得也快,遇到验证不通过的就直接回滚,整体上提高了推理的速度。
Transformer可以方便地回滚,因为KV cache跟时间是一一对应的,但Mamba这边只有一个当前的中间状态ht,你总不能把所有中间状态都存起来吧。
为了解决这个问题,研究人员设计了下面的算法:
简单来说就是每次使用小模型(draft model)生成一组输出,然后大模型(verification model)验证这一组输出,根据验证匹配的位置来更新需要保存的中间状态。
我们可以从下面的伪代码了解详细的过程:
每次生成K个草稿输出,验证模型通过MultiStep函数返回K个真正的输出,以及上一次校验成功位置的cache(中间状态hj)和本次最后位置的cache(hk)。
Multi-Step内核的性能特征
通过FirstConflict函数找到最后匹配(校验成功)的位置,如果所有都匹配,则cache可以更新到最后的hk,否则就只更新到上一次的hj。
兵马后动,粮草先行,不耽误输出和校验,同时只需要多存储一个中间状态。
当然,如果草稿模型也用Mamba的话,算法的推测部分会变得复杂一些,因为草稿模型需要重新计算上一次迭代中验证成功位置的状态。
硬件特定优化
下面使用Mamba 7B和 Mamba 2.8B作为目标模型进行推测实验。
最初,作者搞了一版简单的算法实现,结果在Ampere架构的GPU(3090)上面效果显著,Mamba 2.8B获得了1.5倍的推理加速, 同时有60%的接受率。
但是这种实现方式在H100 GPU上不太好使,主要是因为GEMM操作的速度更快了,使得缓存和重新计算产生的开销更加明显。
所以,作者通过融合内核以及调整实现方式来优化算法。
对于验证模型,首先从缓存中重新计算之前的步骤,然后对新的草稿token序列进行多步解码,最后在单个内核中进行缓存。
对于草稿模型,重新计算、解码和缓存也融合在单个内核中。最终实现了上表中的加速效果。
实验
研究人员使用两个LLM聊天模型进行实验:Zephyr-7B和Llama-3 Instruct 8B。
采用三阶段蒸馏。在第一阶段,使用UltraChat和UltraFeedback作为种子提示,并使用teacher模型生成伪标签。
使用AdamW优化器训练模型,β=(0.9,0.98) ,批量大小64。先使用线性学习率预热,然后进行余弦退火。
第二阶段,在一个epoch中使用SFT在GenQA、InfinityInstruct和OpenHermes 2.5数据集上对模型进行监督微调,采用与Zephyr相同的超参数。
最后一个阶段,对于从Zephyr中提取的模型,在UltraFeedback数据集上使用DPO与标准模型进行蒸馏对齐。
过程中只在第一阶段冻结MLP层,后两个阶段所有参数都进行训练。
作者表示,通常只需要在8卡80G A100上运行3到4天,即可重现本文的结果。
参考资料:
https://arxiv.org/abs/2408.15237
#多智能体强化学习
论文第一作者是北京大学人工智能研究院博士生马成栋,通讯作者为人工智能研究院杨耀东助理教授。人工智能研究院多智能体中心李阿明研究员和伦敦国王大学杜雅丽教授为共同第一作者。这一成果首次在大规模多智能体系统中实现了高效的去中心化协同训练和决策,显著提升了人工智能决策模型在大规模多智能体系统中的扩展性和适用性。
论文链接:https://www.nature.com/articles/s42256-024-00879-7
在大规模多智能体系统中实现高效的可扩展决策是人工智能领域发展的重要目标之一。多智能系统主要以庞大的智能体交互数据为基础,利用大量计算资源驱动每个智能体学习如何与其他智能体合作执行复杂任务,其核心范式是多智能体强化学习。近年来,这一领域取得了显著的进展,诞生了以游戏人工智能为代表的一系列应用。现阶段两种主要的学习范式是中心化学习和独立学习,中心化学习要求每个智能体都具有全局观察能力,这大幅度增加了算法复杂性和通信成本,降低了在大规模系统中的可扩展性,而独立学习虽然降低了系统和算法的复杂性,但学习过程往往不稳定,导致决策性能较差。
值得注意的是,在游戏以外的更加真实的场景中,都存在一些客观的交互限制和不得不考虑成本因素,这使得现有方法难以扩展到大规模真实世界多智能体系统中。一个简单的例子是,当在城市交通系统中控制交通信号灯时,频繁的大规模通信操作容易增加功率损失和被信号干扰的概率,并且计算复杂性将随着交通灯数量的增多而指数级增加。因此,有必要设计能够在有限数据和客观通信约束下,将决策能力扩展到包含大量智能体的复杂真实系统中的多智能体强化学习方法。
这项研究正是以此出发点,降低了现有多智能体学习方法对于全局通信和大量交互数据的依赖性,实现了强化学习算法在复杂的大规模系统中的广泛部署与高效扩展,朝着可扩展到大规模系统的决策范式迈出了重要一步。

图 1,中心化学习和独立学习的区别及该研究的出发点和所涉及到的网络化系统类型
在这项研究中,研究团队对大规模多智能体系统进行了以智能体为单位的动力学特性的解耦,将智能体之间的关系描述为一种拓扑连接结构下的网络化关系,其中包括线状,环状,网状等各种同构 / 异构节点,降低了系统处理的复杂性。在此之前,也有一些研究者以网络化的形式建模智能体之间的关系从而提升算法扩展性。但这种对于系统的分解具有较强的假设,不一定符合真实世界系统的特性。因此团队进一步提出了一种更通用的网络化系统模型用来刻画解耦后多智能体系统的动力学和真实系统动力学之间的关系,其优势在于它能够处理更广泛的合作多智能体任务。该概念弥合了标准网络系统和一般多代理系统之间的差距,为去中心化多智能体系统的研究提供了必要的理论框架和分析工具。

进一步,基于这种更一般化的网络系统,研究团队将单智能体学习中的模型学习理论扩展到多智能体系统中,使智能体能够独立学习局部状态转移、邻域信息价值和去中心化策略,将复杂的大规模决策难题转化为更容易求解的优化问题。这样,大型人工智能系统即使在样本数据和信息交互受限的情况下,也能实现令人满意的决策性能。早在上世纪 90 年代,强化学习教父 Richard Sutton 就提出了基于模型的方法来学习系统内在的动态特性来辅助策略学习,提升样本效率。在这项工作中,研究团队将本地化模型学习与去中心化策略优化相耦合,提出了一个基于模型的去中心化策略优化方法。该方法是高效且可扩展的,在较小的本地信息大小(当单个智能体与其他智能体之间的信息交互受到限制)下就能近似单调的提升智能体策略。具体而言,智能体能够使用经过充分训练得到的本地化模型来预测未来状态,并使用本地通信来传递该预测。

图 2,网络系统结构关系及多智能体模型学习过程
为了缓解模型预测的误差问题,研究团队采用了分支推出策略,用许多短时间线推出替换了少数长时间线推出,以减少模型学习和预测中的复合误差,促进了策略学习过程中的近似单调提升能力:

研究团队从理论上进一步证明了系统解耦后所产生的扩展值函数和策略梯度是接近真实梯度的近似值,这在去中心化模型学习和单调策略提升之间建立了重要的理论桥梁。


多项测试结果表明,该方法能够扩展到具有数百个智能体的大规模电网和交通等网络化系统中,在较低的通信成本下实现较高的决策性能。

图 3,研究方法在智能交通控制场景中的效果
使用了该方法控制的信号灯能够仅通过接收相邻路口的车流信息调控复杂的交通流。这是因为在网络化结构的设计下,整体交通状况已经通过城市路网间接地传递并汇总到相邻路口,通过分析这些相邻路口的观测信息,就能推断和预测整个城市的车流变化,从而做出最优决策。在智能电网上的效果也验证了方法的可扩展性,能够在具有上百个节点的电力网络中实现较低的电能损耗。

图 4,研究方法在智能电网控制场景中的效果
研究团队负责人杨耀东表示:「未来我们将继续深入推进多智能体学习理论与方法的研究,并赋能具身智能和世界模型等前沿人工智能领域,显著提升更广泛的智能系统在协作、预测和决策方面的能力,使其在复杂动态环境中更加灵活高效的执行任务。同时,我们还将推动这些研究成果在智能交通、智慧电网等领域的应用,促进科技成果的快速转化,为社会创造更大价值。」
#Claude Enterprise(Claude 企业版)
原生集成GitHub,让AI成为协作者,Claude企业版馋哭个人开发者
聊天机器人的 game changer?
刚刚,只有 Claude 聊天机器人一款产品的 Anthropic 更新了其产品线,推出了 Claude Enterprise(Claude 企业版)。虽然严格来说,企业版依然是 Claude 聊天机器人,但它却具有一些明显的优势,其中最大的两个亮点是原生集成 GitHub 以及长达 500K 的上下文长度。
原生集成 GitHub 是企业版的一大核心亮点,可让用户将 GitHub 代码库同步到 Claude,从而可以在 Claude 的帮助下测试代码、调试以及培训新人。Anthropic 表示 GitHub 是 Claude 首个原生整合的服务,但目前只有参与 beta 测试的早期企业版用户可用。今年晚些时候才会向更多企业版用户开放。
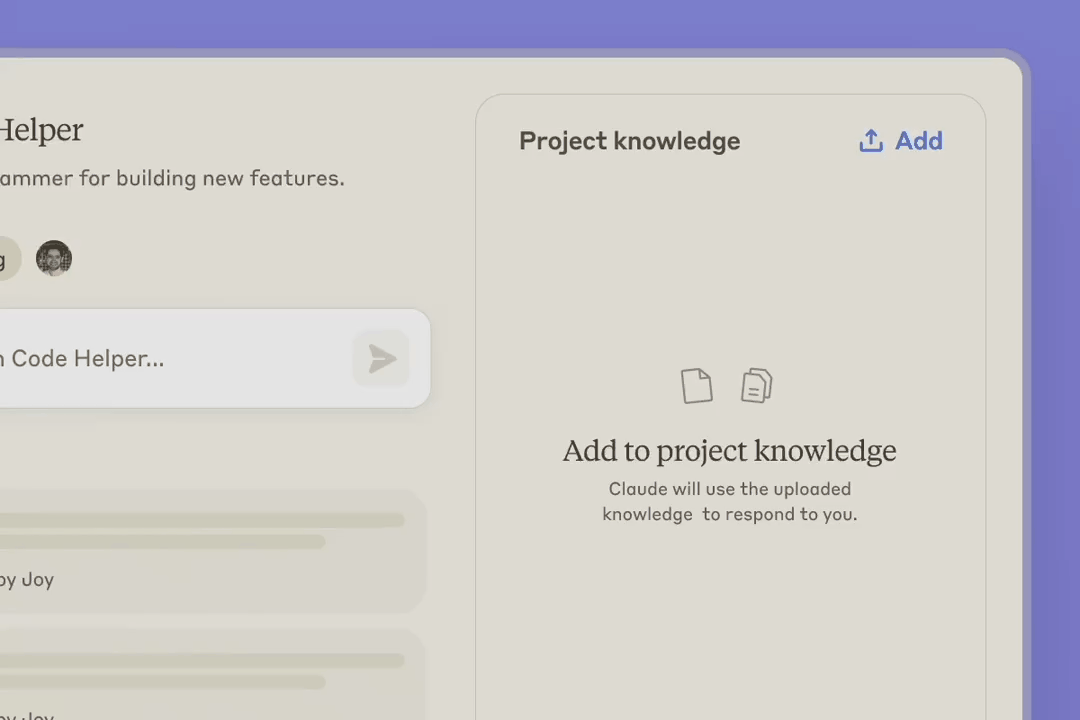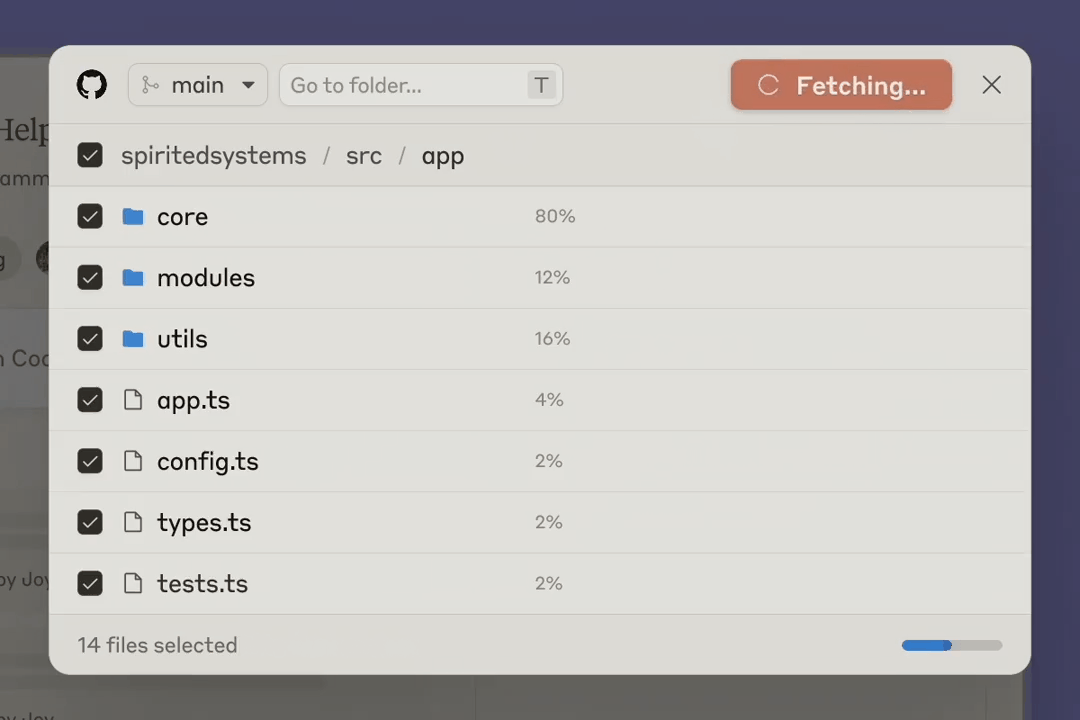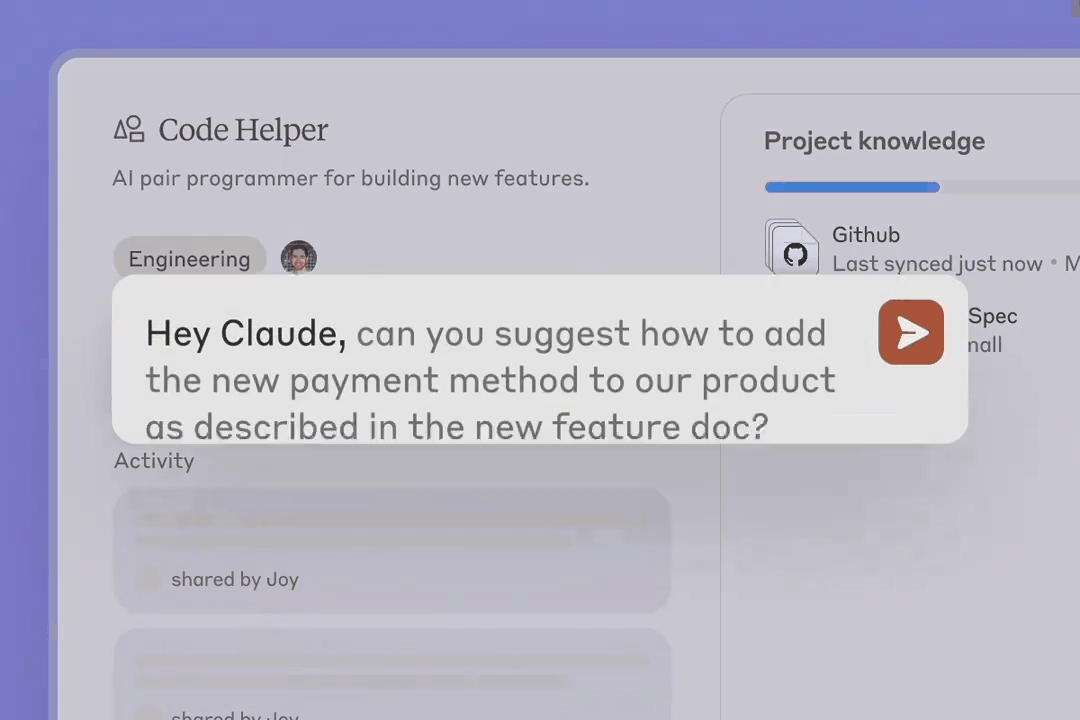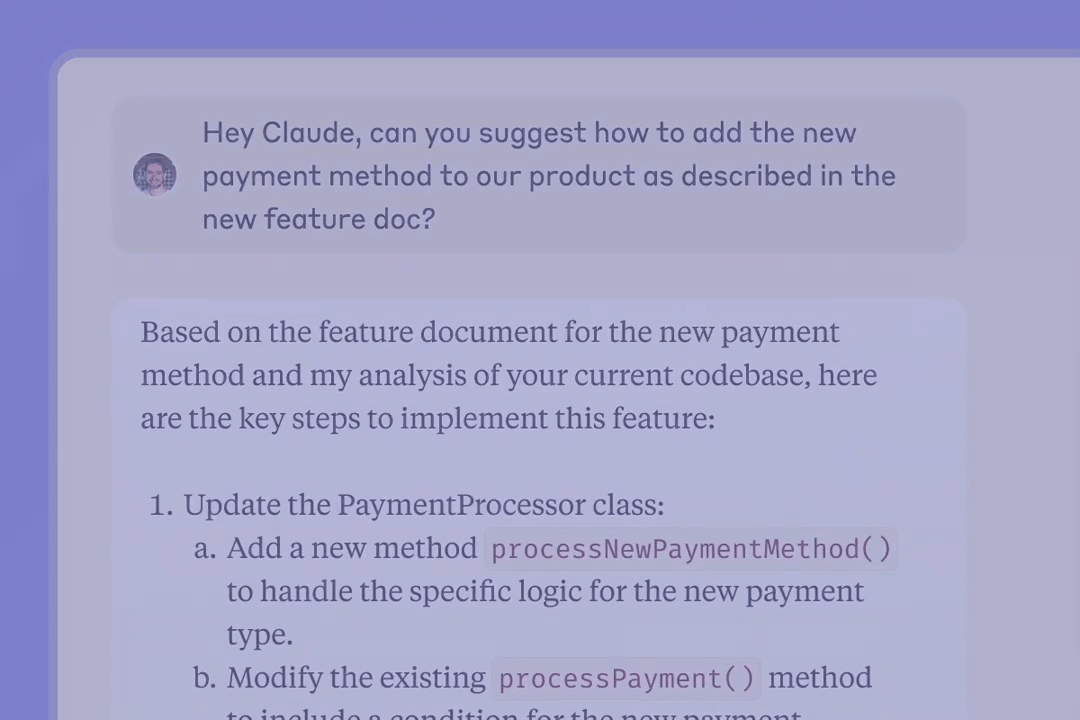
DAIR.AI 创始人 Elvis Saravia 表示,这个功能是 game changer。他说:「GitHub 集成对上下文整合来说意义重大,但更激动人心的是将其整合进 Artifacts,利用 AI 实现更快的开发周期。这就是集成该有的样子。Anthropic 明白这一点。」但他也遗憾地说,目前只有企业版有这个功能,他们应该快些向所有人开发。
他还表示:「我多年来在 GitHub 上投入的一切将开始带来回报。我几年前就在设想这样的集成,但没想到它会来得如此之快。」
畅想一下,该功能如果与 Cursor 整合,那会带来怎样的可能性?用户完全可以基于 GitHub 上大量开放软件库生成新代码,甚至帮助很多早已不再更新的开源软件生成新版本、加入新功能……
有不嫌事大的用户表示 Claude 将是 OpenAI 的掘墓人并 @ 了它。
甚至已经有用户打算使用该功能开发自己的 FPS 游戏了:
这项功能让不少 Pro 版用户眼红,纷纷表示也想要。
另外,Claude 企业版的上下文长度增至 500K,并且支持上传相关文档。Anthropic 表示,这个上下文长度相当于 100 组 30 分钟长度的销售对话转录文本、10 万行代码或 15 份完整的财务报道。其还表示,通过将 Projects 和 Artifacts 整合进上下文窗口,Claude 可以成为一个端到端的解决方案,让团队可以将新生的想法变成高质量的成果。

顺带一提,Artifacts 是指用户可让 Claude 生成文本文档或代码并在一个专门窗口打开。也就是说,这相当于一个工作窗口。这个功能是在今年 6 月 Claude 3.5 Sonnet 发布时推出的,让用户可以实时地查阅和编辑 Claude 输出的结果并基于其进行构建。比如,这个功能可让用户创建营销日历、销售数据流、制作业务仪表盘、生成特定功能的代码、编写法律文件、总结复杂合同等。该功能于前些天已向所有用户开放。
比如下图给出了一个示例,用户只需上传用户参与度数据,剩下的操作就可以交给 Claude 完成,比如绘制散点图和执行统计分析。

最后,Claude 企业版也有更高的可使用量以及企业级的安全特性,比如 SSO、权限控制、管理工具等。不用说,企业版 Claude 肯定比常规版好一些。此外,Anthropic 还承诺保护用户数据:「我们不会使用您的对话和内容训练 Claude。」
据报道,目前 GitLab、Midjourney 和 Menlo Ventures 等多家公司已经是 Claude 企业版的早期客户,一直都在为 Claude 企业版提供 beta 测试。比如 GitLab 已经在使用这款产品来进行内容创作以及更自动化地响应请求。
Anthropic 一位产品经理 Scott White 表示:「未来这些模型将更像是虚拟合作者,而不仅仅是虚拟助手。」
至于价格,Anthropic 并未明确说明,只是表示可以谈 —— 客户可以根据自身需求(包括用户和查询量、特定的功能需求等)购买使用量。
据 CNBC 报道,自 5 月份 Instagram 的联合创始人和前 CEO Mike Krieger 以及 OpenAI 前安全技术负责人 Jan Leike 加入 Anthropic 以来,该公司的发展迅速。而据彭博社预计,生成式 AI 市场收入将在 2032 年前达到 1.3 万亿美元。在 OpenAI、Meta、微软和谷歌等企业竞相争夺这块巨大市场的当下,我们有望看到更多企业级 AI 服务诞生。
参考链接:
https://www.anthropic.com/enterprise
https://x.com/alexalbert__/status/1831349257497895345
#VideoAgent
比基准高30%,媲美Gemini 1.5 Pro,基于记忆的视频理解智能体来了
视频理解仍然是计算机视觉和人工智能领域的一个主要挑战。最近在视频理解上的许多进展都是通过端到端地训练多模态大语言模型实现的[1,2,3]。然而,当这些模型处理较长的视频时,内存消耗可能会显著增加,甚至变得难以承受,并且自注意力机制有时可能难以捕捉长程关系 [4]。这些问题阻碍了将端到端模型进一步应用于视频理解。
为解决这一问题,北京通用人工智能研究院联合北京大学的研究人员提出了首个基于记忆和工具使用的视频理解智能体VideoAgent,在视频理解任务上媲美Gemini 1.5 Pro。该论文已被ECCV 2024接收。
论文链接:https://arxiv.org/abs/2403.11481
项目主页:https://videoagent.github.io/
代码链接:https://github.com/YueFan1014/VideoAgent
模型介绍
VideoAgent 的主要思想是将视频表示为结构化的记忆,并运用大语言模型的强大推理能力和工具使用能力从记忆中抽取关键信息,实现对视频的理解以及对视频问题的回答。

图 1:VideoAgent 流程图。
VideoAgent 的记忆设计遵循简约原则:作者发现视频中发生的事件以及视频中出现的人和物体能够涵盖最常见的视频问题。因此,作者设计了如图 1 所示的两个记忆组件:1)时间记忆,用于存储每2秒视频片段所发生的事件;2)物体记忆,用于存储视频中出现的人和物体的信息。给定一个视频,VideoAgent会首先构建该视频的时间记忆和物体记忆。在推理阶段,对于该视频的一个问题,VideoAgent会调用一系列工具,从记忆中抽取与问题有关的信息来回答该问题。
,时长01:55
视频 1:VideoAgent 运用思维链和工具回答视频问题。
记忆构建
对于时间记忆,作者使用预训练的视频文本模型 LaViLa [7] 为每 2 秒的视频片段生成描述文本,反映了视频片段中发生的事件。除了描述片段的文本外,时间记忆还存储了每个视频片段的特征,片段特征包括:1)文本特征,通过使用文本编码器 text-embedding-3-large [8] 得到片段的描述文本的嵌入向量;2)视觉特征,通过使用视频语言模型 ViCLIP [9]对视频片段进行视觉编码获得的嵌入向量。这些片段特征在推理阶段时可被 VideoAgent 用于定位关键片段。
物体记忆的核心是跟踪 (tracking) 并且重识别 (re-identification) 视频中的所有物体和人物。作者首先使用 RT-DETR [10] 和 Byte-track [11] 对视频进行物体检测和跟踪。然而,仅仅使用物体跟踪算法无法解决同一物体由于在视频中多次出现而被识别成多个物体的情况。因此,作者提出一种基于 CLIP 特征 [12] 和 DINO-v2 特征 [13] 的物体重识别算法,将物体跟踪结果中相同的物体赋予同一物体 ID。
,时长00:37
视频2:物体重识别效果展示。杯子和牛奶瓶能够在不同位姿下被重识别。
值得一提的是,记忆构建阶段所涉及的所有模型都满足实时性的要求,这使得VideoAgent也能够接受视频流输入,并且实时地构建记忆。最后,物体记忆中存储的内容有:1)包括物体 ID、物体类别和物体所出现的视频片段三个字段的物体数据库;2)物体ID所对应的 CLIP 特征,用以支持在推理阶段的开放词表物体检索。
视频问答
为了回答一个视频问题,大型语言模型(LLM)会将其分解为多个子任务,并调用工具来解决。这些工具围绕统一的记忆库运作,主要包括以下几个工具:
1. 片段描述召回:给定两个时刻,返回两个查询时刻之间所有片段的文本描述。
2. 片段定位:给定一个文本描述,通过将该文本特征与所有片段特征进行比较,检索与之最相关的 5 个片段。
3. 视觉问答:给定一个视频片段和问题,利用 VideoLLaVA [1] 工具,根据视频片段回答该问题。
4. 物体记忆查询:给定一个有关视频中物体的问题,结合 SQL 查询功能和基于 CLIP 特征的开放词表物体检索,从物体记忆中进行复杂的物体信息查询。
最后,LLM 会整合这些工具的使用结果,生成对视频问题的回答。
图 2 展示了 VideoAgent 的一个推理示例。VideoAgent 首先通过片段定位得到了视频中小男孩与成年人同时出现的 5 个时刻;接着在其中两个时刻上调用视觉问答工具,得到了小男孩与成年人之间的关系,并最终准确回答出了视频中的成年人是小男孩的监护者。

图 2:VideoAgent 回答视频问题的示例。
在关于视频中有几艘船的问题上,端到端的多模态大语言模型由于其视觉特征的缺陷,无法准确回答出视频中船的数量。但 VideoAgent 能借助视觉基础模型的能力以及物体重识别算法得到精确的物体细节并存放到物体记忆中,因此能够准确回答出视频中有 6 艘船。

图 3:VideoAgent 与多模态大语言模型的对比。
实验分析
作者在 EgoSchema [14], WorldQA [15], NExT-QA [16] 三个长视频理解数据集上测试了 VideoAgent 的性能。实验表明 VideoAgent 能够取得比目前开源的多模态大语言模型更好的表现,并且能够与目前最好的闭源模型相媲美。
在 EgoSchema 长视频多选题数据集上(见表1),VideoAgent 的 60.2% 的准确率相比基准的多模态大语言模型高出了近 30 个百分点,接近 Gemini 1.5 Pro 的 63.2% 的准确率。在 WorldQA 数据集上(见表2),VideoAgent 在选择题和开放问题上都取得了不错的性能,这归功于 VideoAgent 能够结合大语言模型中的常识知识、推理能力以及视频记忆共同实现对于长视频的理解。

表1:在EgoSchema数据集上的实验结果。

表2: 在WorldQA数据集上的实验结果。
在 NExT-QA 数据集上(见表3),VideoAgent 在时序、因果、描述三类问题上相比基线模型都有显著提升,其在因果类问题上的提升最大。

表3: 在NExT-QA上的实验结果。
在 NExT-QA 上,作者对于 VideoAgent 中的 4 种不同工具进行了消融实验(见表4)。实验表明片段描述召回对于 VideoAgent 理解视频是十分必要的。物体记忆对于 VideoAgent 在时序、因果、描述三类问题的回答准确率都有提升。片段定位和视觉问答这两个工具对于 VideoAgent 正确回答问题的贡献最大。

表4: 在NExT-QA上对不同工具的消融实验。
总结
本文提出的 VideoAgent 是一种多模态智能体,通过一种新颖的记忆机制结合了多个基础模型,用于视频理解。与端到端的多模态大语言模型(LLM)和其他工具使用智能体相比,VideoAgent 采用了极简的工具使用流程,不需要昂贵的训练,同时在 EgoSchema、WorldQA 和 NExT-QA 等具有挑战性的长视频理解基准上,产生了相当或更好的表现。未来的研究方向可能包括在具身智能、制造业和增强现实领域的实际应用。
#Reflection 70B
开源大模型新王干翻GPT-4o,新技术可纠正自己幻觉,数学99.2分刷爆测试集
开源大模型王座突然易主,居然来自一家小创业团队,瞬间引爆业界。
新模型名为Reflection 70B,使用一种全新训练技术,让AI学会在推理过程中纠正自己的错误和幻觉。
比如最近流行的数r测试中,一开始它犯了和大多数模型一样的错误,但主动在<反思>标签中纠正了自己。
在官方评测中,70B模型全面超越最强开源Llama 3.1 405B、GPT-4o、Claude 3 Opus、Gemini 1.5 Pro,特别是数学基准GSM8K上直接刷爆,得分99.2%。
这个结果也让OpenAI科学家、德扑AI之父Noam Brown激情开麦:
GSM8K得分99%!是不是可以正式淘汰这个基准了?
模型刚刚上线网友就把试玩挤爆了,对此Meta还主动支援了更多算力。
在网友测试中,Reflection 70B能回答对GSM8K数据集中本身答案错误的问题:
我向模型提供了GSM8K中存在的5个“ground_truth”本身就不正确的问题。
模型没有重复数据集中的错误答案,而是全部回答对了,这很令人印象深刻,表明那99.2%的准确率并非来自于记忆测试集!
数各种r都不在话下,连生造词“drirrrngrrrrrnnn”中有几个r也能被正确数对。
网友纷纷对小团队做出的开源超越顶流闭源感到惊讶,现在最强开源模型可以在本地运行了。
关键70B还只是个开始,官方表示下周还会发布更大的Reflection 405B。
预计405B性能将大幅优于Sonnet和GPT-4o。
Reflection 70B权重已公开,API访问将于今天晚些时候由Hyperbolic Labs提供。
模型能自我反思纠正错误
目前关于Reflection 70B的更多细节如下。
Reflection 70B能力提升的关键,是采用了一种名为Reflection-Tuning的训练方法,它能够让模型反思自己生成的文本,在最终确定回应前检测并纠正自身推理中的错误。
训练中的数据来自使用GlaiveAI平台生成的合成数据。
Reflection 70B基于Llama 3.1 70B Instruct,可以使用与其它Llama模型相同的代码、pipeline等从Reflection Llama-3.1 70B进行采样。
它甚至使用了标准的Llama 3.1聊天格式。
不过,Reflection 70B引入了一些特殊tokens,结构化输出过程。
如下面这个例子所展示的,规划过程分为一个独立的步骤,这样做可以提高CoT效果,并保持输出精炼:

模型将从在<thinking>和</thinking>标签内输出推理开始,一旦对其推理感到满意,就会在<output>和</output>标签内输出最终答案。
所以它能够将其内部思考和推理与最终答案分离。
在<thinking>部分,模型可能会输出一个或多个<reflection>标签,这表明模型发现了其推理中的错误,并将在提供最终答案之前尝试纠正该错误。
系统提示如下:
You are a world-class AI system, capable of complex reasoning and reflection. Reason through the query inside tags, and then provide your final response inside tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside tags.(你是一个世界级人工智能系统,能够进行复杂的推理和反思。在标签内对查询进行推理,然后在标签内提供你的最终回应。如果你发现自己在任何时候推理出错,请在标签内纠正自己。)
此外值得一提的是,基准测试中,所有基准都已通过LMSys的LLM Decontaminator检查污染,隔离了<output>部分,并单独对这一部分进行测试。
使用Reflection 70B的时候,官方还分享了小tips:
初步建议参数temperature为.7 , top_p为.95
为提高准确性,最好附加“Think carefully.”在Prompt末尾
官方还表示,下周会发布一份报告,详细介绍模型训练过程和发现。
Agent创业团队打造
Reflection 70B的背后是一支小团队,由HyperWriteAI的CEO Mutt Shumer带领。
领英显示,Mutt Shumer是一位连续创业者,毕业于美国锡拉丘兹大学,现任OthersideAI的联合创始人兼CEO。
OthersideAI是一家AI应用公司,致力于通过大规模AI系统开发全球最先进的自动补全工具,也是HyperWrite的幕后公司。
HyperWrite是一个浏览器操作agent,可以像人一样操作谷歌浏览器来完成一系列任务,比如订披萨:

和gpt-llm-trainer一样,你只需要用文字描述目标,它就会一边列步骤,一边执行。
刚推出时号称“比AutoGPT强”。
HyperWrite还可以在谷歌扩展程序中安装。
另外,Mutt Shumer高中时期就创立了Visos,致力于开发用于医疗用途的下一代虚拟现实软件。
还创立了FURI,这是一家旨在通过创造高性能产品并以公平的价格销售它们来颠覆体育用品行业的公司。
虽然有Meta支持,但目前打开试玩,还是:暂时无法访问。
感兴趣的童鞋可以先码住了~
https://reflection-playground-production.up.railway.app/
参考链接:
[1]https://huggingface.co/mattshumer/Reflection-Llama-3.1-70B
[2]https://x.com/mattshumer_/status/1831767014341538166
[3]https://x.com/polynoamial/status/1831798985528635806
[4]https://x.com/degeneratoor/status/1831809610451448196
[5]https://x.com/kimmonismus/status/1831772661296345333
#4800个大模型团队竞逐「产业真题」
这场金融科技大赛火出圈了
今年 7 月,一份《全球数字经济白皮书 (2024)》统计显示,全球目前已有 1300 多个基础大模型,美国的数量最多,中国紧随其后排在第二。
这一数字对比说明,在大模型这张「牌桌」上,中美是最具实力的两个玩家。曾经,中国奋力追赶「OpenAI 们」,两年之后我们可以看到,国产大模型在技术层面已抵达全球第一梯队。
而在这个过程中,圈内玩家逐渐分化出两条路线:一派继续卷性能,一派专注搞应用。
国内的优势恰恰在于产业场景极其丰富,落地空间极其广阔。面向大模型的下半场战事,业界普遍认为,中国将在应用层展现出更强的后劲。
目前的核心问题是,如何让大模型技术尽快与更多真实的产业场景连接起来。
从何处入手?一是精准定位最需要大模型的产业场景,二是找到能解决这些真实场景问题的人才。
一场直面「产业真命题」的技术赛事
我们熟悉的大模型落地案例更多发生在对话、作画、视频等方向,但其价值远不止于此,大模型同样可以深刻改变城市发展、金融科技、生物医药、工业制造、科学研究等领域。
已连续举办两届的 AFAC 金融智能创新大赛,正在成为国内大模型人才竞逐金融产业真命题的赛场。
AFAC2024 金融智能创新大赛(以下简称 AFAC2024 大赛)以金融行业内真实案例及海量真实数据为牵引,鼓励参赛者直面金融产业真命题,探索最具挑战的创新模型和算法。在去年赛制的基础上,AFAC2024 大赛对比赛形式进一步升级,在「挑战组」之外新增了「初创组」和「企业组」,形成了涵盖算法赛、应用赛和创业赛的综合赛制架构。
蚂蚁集团副总裁、蚂蚁金融技术委员会主席王晓航表示,举办 AFAC2024 大赛的出发点之一就是集聚、培养优秀科技人才、开展高水平合作交流。
同时,大赛设立了丰厚的奖金池,并为选手提供了配套的技术支持,吸引了数千个极具潜力的大模型团队参与。值得注意的是,选手们可以基于蚂蚁开源的 agentUniverse 多智能体框架,对多智能体协作模型进行开发定制,轻松构建智能体应用,节省更多精力以专注于破解产业命题。
3 个月,4882 支队伍的技术探索,让这场比赛「卷」出了新的高度。中国最顶尖的一批大模型人才围绕金融场景下的众多产业真题,贡献了众多前沿解决方案。
「我们始终相信通过科技的力量可以带来更多微小而美好的变化,我们期待 AI 能让高质量的金融服务惠及每一个人,让更好的金融产品进入千家万户,成为人们生活中的一部分。」王晓航表示,「人工智能技术的作用和价值不应仅限于研究和模型能力,更应产生更大的应用价值,就像扫码支付一样能够进入千家万户,进入每一个行业。」
接下来,让我们来看看三个代表团队的技术创新故事。
什么样的金融研报生成应用
能从六百多支队伍脱颖而出?
「拥抱 AIGC」团队的三位成员有很多共同点:都就读于浙江大学软件工程专业,都是硕士二年级的研究生,甚至住在同一个寝室。除了研究方向不太相同:三人分别选择了计算机视觉、数据治理与大语言模型、时空数据作为主攻方向。
队长高天弘曾参加过首届 AFAC 大赛,关注到 AFAC2024 大赛启动之后,他决定拉上室友再挑战,尽管「金融智能」对于三人来说是有些陌生的领域。
一番深思熟虑之后,他们选择了「AIGC 金融多模态研究报告智能生成」这个赛题。团队需要将大模型技术和金融数据深度融合,提出有创新价值的金融研报生成智能体解决方案,并应用于实际场景。
大模型的通用能力在不断进化,但要想解决高水平问题,还要靠行业知识的进一步积累。纵观当前的各类对话式 AI 应用,生成真实、有用、高水平的研究报告仍然是一项极具挑战性的任务。特别是对于金融这种专业门槛极高的领域,数据时效性、长文本总结、图表生成等都是其中存在的挑战。
如何有效攻克?特别是在赛题发布后,留给团队完成方案设计的时间并不算多。
针对上述问题,他们设计了一个面向金融研报生成的多智能体协同框架。具体来说,这个框架包含三层:多元数据来源、金融研报生成智能体 Agent、多源大语言模型。
与传统的对话系统不同,协同的智能体具备任务规划和执行能力,能够在无需人类干预的情况下自动处理复杂问题,包括生成研报:

其中,团队以 FinGPT-Forecaster 为基础,结合 LoRA 微调,训练了一个用于投资评级分析的股价预测大模型,克服了 ChatGPT 预测含糊和数据隐私问题,提供了可解释的预测结果。

为了更高效地筛选金融数据,同时保证实时性和专业性,团队设计了一套多源检索增强方案。在检索获得行情、研报、股价等信息之后,首先针对走势图、PDF 研报等多模态数据进行预处理,突破单模态分析的局限性,使市场波动更直观呈现。然后从相关性、市场敏感性、可靠性、时效性多个维度出发,使用基于 LLM 的重排器进行排序优化。在这个过程中,作为赛事主办方之一,蚂蚁集团提供了新闻信息助手 API ,保证了数据收集的实时性,也大大减少了数据处理的工作量。

最终,这一方案在同赛道的六百多支队伍中脱颖而出,夺得冠军。获奖之外,三位成员通过这次比赛也学会了如何理解现实中的产业需求,又如何面向真实产业场景制定具备可行性的方案。
他们更加深刻地体会到大模型与传统 AI 研究的巨大差异。此前的 AI 模型基本面向具体任务而设计,仅用少量数据训练就可达到目标性能。相比之下,从底层训练的角度说,大模型对数据、算力的要求已经实现了指数级增长,对训练大模型的人的创新能力要求显然也更上一层楼。
用大模型打造「一对一」旅行智能助理
在「初创组」的赛场上,「智游幻境 Odyssey Agent」团队的成果让评委们印象十分深刻。
这个团队由五位热爱旅行的年轻人组成。众所周知,旅行的回忆是美好的,但旅行前的规划是千头万绪的。出行的人常常花费大量时间辗转于各个平台之间,获取信息、制定行程、预定服务,如果涉及出境游难度更甚。
以 Gemini、ChatGPT 为代表的对话式 AI 应用,也具备提供旅行信息推荐的能力,但往往只有「第一次可用」。很多时候,如果我们继续追问,后续对话可能很难与前面所谈行程保持一致。而且这些基本只能集成单个平台的信息,无法做到有效整合旅行过程中全部所需信息。
能不能做一款提供一站式定制旅行服务的大模型应用呢?五个人一拍即合,决定打造一个「旅行规划智能助理」。尽管团队中有几位成员在大厂的工作非常忙碌,但他们还是利用业余时间快速打造出了这个项目的雏形。
具体来说,他们参考 agentUniverse 多智能体框架的交互模型设计思路,针对旅行场景搭建了一套多 Agent 协作体系:「CHaTS」(Consult,Hotel and Transportation,Spots)。
生成一个七日行程平均要调用大语言模型 50 余次,能在 3 到 5 分钟内返回一个城市的旅行规划和游记 Vlog。对于用户来说,最大的体验提升就是推荐的攻略细节真的更丰富了。
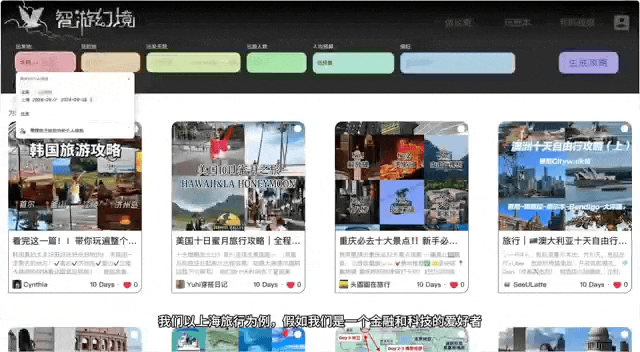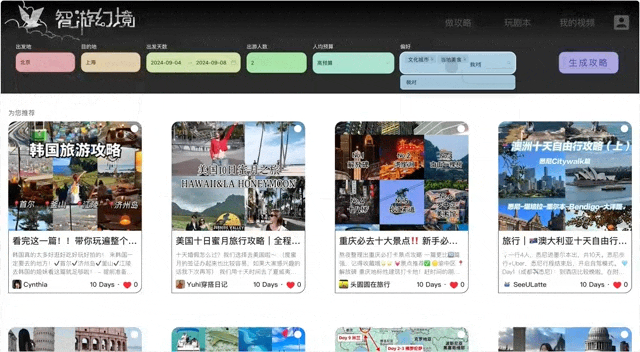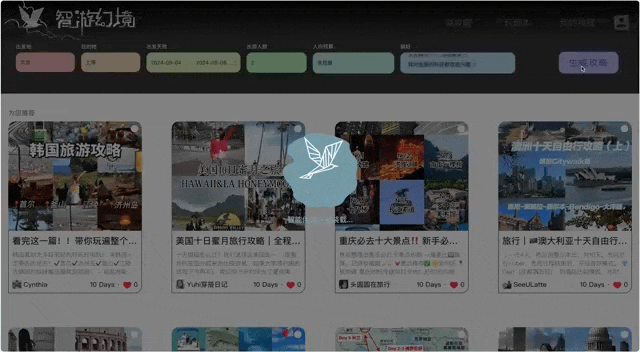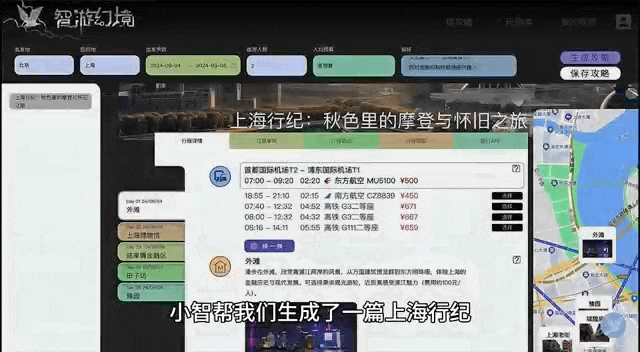
由于涉及到多个大语言模型生成机制,为了避免前后行程矛盾、关键信息的遗忘以及 token 长度和整体成本问题,团队引入了共享记忆和 tool memory 机制。具体来说,他们将相关工具的执行结果(比如机票 / 酒店查询结果、每日景点推荐),在简单地预处理后进行本地存储,或者通过 Qwen 模型的 File 编码的形式存储在云端,降低了频繁调用工具造成的时间和经济成本,也避免了模型在重新推荐时产生幻觉或者矛盾冲突。
尽管目前的「智游幻境」还处于早期版本,却恰好展示了大模型在旅行类应用赛道的想象空间。团队表示,未来的「智游幻境」可以引入更强的大模型、更多的模态、更丰富的场景。比如通过 VR/AR 设备、无线耳机、摄像头等设备的联动,这款应用可以变为一个能看、能听、能说的「导游」,带来更沉浸的旅行体验。
从观光推荐到实时翻译服务,这样一款应用真的有可能彻底改变旅行者与世界互动的方式。
让大模型融入科技金融业务的「系统工程」
相比于挑战组和初创组,大赛的「企业组」赛道主要着眼于科技金融行业的新兴方向,鼓励科技金融行业的中小型企业提报有亮点、有新意的新技术、新产品落地项目。
深擎科技是一家成立六年的公司,多年来利用 AI 与大数据分析技术,为券商银行提供智能投顾助手和个性化内容生成相关产品,也见证了大模型技术的兴起和爆发。
在数十家参赛企业中,深擎科技提交的方案受到了较多的关注。简单来说,他们围绕 AI Agent 的基座,打造了一整套行业「刚需」的应用产品体系。
对于那些想用大模型变革自身业务的金融机构来说,在实践中往往会遇到一些挑战:如何快速响应业务需求,让业务参与到大模型应用场景的打磨中来?投入的大量配套研发,如何沉淀,算子化、可复用的最佳实践?如何量化评价场景效果,上线后如何持续优化迭代?
核心的问题就是,技术的快速迭代与金融业务所需的确定性之间,如何平衡?
深擎科技给出的解决方案是 AI Agent 平台「乾坤圈」,将大模型能力融入到金融业务的「系统工程」之中。

在不同基础模型各有所长的今天,「乾坤圈」的一大亮点是支持多个基座大模型协作完成业务交付,且支持本地化、SaaS 大模型服务接入,兼容主流的开源和闭源模型。
此外,「乾坤圈」还提供了敏捷的 AI 场景构建模板和工具,让机构以低代码甚至无代码的方式迅速构建业务场景应用,解决了大模型落地中容易产生的「重复造轮子」问题。
基于「乾坤圈」,以往业界存在的金融领域大模型幻觉控制、业务数据和知识接入、生成结果合规安全性、产研运营端到端效率和生成结果质量评测问题,都得到了有效解决。
实际上,「乾坤圈」平台的技术探索也代表了当前大模型落地的整体趋势,对于很多专业门槛较高的领域来说,只有面向真实的产业场景设计垂直解决方案,才能实现以技术解决真问题的初衷。
目前,深擎科技的产品已经实现 PMF(Product Market Fit),覆盖了 80% 的大中型券商和 50% 的大型银行,近几年的主营收入年复合增长率超过 80%。
接下来的阶段,大模型技术与金融业务场景的结合也会越来越紧密,深擎团队希望持续完善「乾坤圈」,在大模型和金融行业的交叉领域做更多从 0 到 1 的创新,为金融机构实现「数字化、集约化、精细化」客户经营提供动力。
期待大赛能诞生出中国的「OpenAI」
在有关大模型的讨论中,「人才」始终被认为是非常关键的竞争要素。
以 AFAC2024 大赛为代表的技术赛事之所以备受瞩目和火爆出圈,因为它既能提供一方培养 AI 人才的土壤,也切实给到了这些高潜力 AI 人才需要的扶持资源。
比如,对于「拥抱 AIGC」团队来说,这是一次走出校园、直面产业真题的宝贵机会;对于「智游幻境」团队,这是一次走上广阔舞台、验证自身设想的契机;对于「深擎科技」团队,这是一次与业内最顶级同行比拼、促进自我提升的精彩旅程。
纵览 AFAC2024 大赛的 4800 多支队伍,「年轻化」和「多元化」也是本次参赛群体的一大特质。但这些年轻的队伍却做到了对前沿技术的极致追求,以长远的眼光去看,未来中国的「山姆奥特曼」和「OpenAI」,很可能就诞生在这些充满技术热情的队伍中。
AFAC 组委会相关人士表示,希望大赛里涌现的出来各种优秀人才,能成为国内大模型领域的中坚力量,最终造福于整个行业的发展和创新。
#Transformer将超越人脑
Andrej Karpathy最新激进观点
还说 AI 可能会与人类融合……
前些天,OpenAI 前首席科学家 Ilya Sutskever 创立的新公司获得 10 亿美元投资的新闻刷遍了各大新闻头条,而 OpenAI 的另一位早期成员和著名 AI 研究者 Andrej Karpathy 则正在「AI+教育」赛道耕耘,其创立的 Eureka Labs 公司正在积极打造其第一款产品。
近日,播客节目 No Priors 发布了对这位著名 AI 研究者的专访视频。
来自:No Priors
Andrej Karpathy 曾是 OpenAI 的早期成员之一,之后加入特斯拉领导其自动驾驶的计算机视觉团队。之后他又回到过 OpenAI,领导着一个专注提升 ChatGPT 的GPT-4 的小团队。今年 7 月,他宣布创立了一家名为 Eureka Labs 的 AI+教育公司。在这个节目中,Andrej Karpathy 分享了有关研究、新公司以及对 AI 未来的期待,其中不乏颇为激进的观点,比如他认为 Transformer 很快就将在性能上超越人类大脑、我们已经在特定的领域实现了有限的 AGI、AI 会成为人类新的大脑皮层……这些观点已经在网上引起了不少的讨论和争议。
自动驾驶是 AGI 以及 Waymo vs 特斯拉
首先,Andrej Karpathy 谈到了完全自动驾驶汽车。他说自己在自动驾驶领域工作了 5 年时间,也经常将 AGI 与自动驾驶放在一起类比。他说:「我确实认为我们已经在自动驾驶领域实现了 AGI。」因为现在在旧金山等城市已经有了一些付钱就能乘坐的自动驾驶汽车。这实际上已经成为了一种服务产品。他还分享了自己十年前乘坐 Waymo 自动驾驶的经历:「十年前一位在那里工作的朋友给我展示了一个 demo,它带我在街区绕了一圈。而十年前它几乎就已经是完美的了,但它还是用了十年时间才从 demo 变成可付费使用的产品。」他表示,之所以用了这么长时间,一方面是技术原因:demo 和产品之间确实存在巨大差距;另一方面则是监管方面的原因。不过要实现自动驾驶的全球化,还有很长的路要走。至于 Waymo 和特斯拉哪家强?Karpathy 表示:「人们认为 Waymo 比特斯拉领先,但我认为特斯拉领先于 Waymo。」他表示非常看好特斯拉的自动驾驶项目。而对于这两家公司的问题,他认为特斯拉的问题在于软件,而 Waymo 的问题是硬件。对比之下,软件问题其实更好解决。特斯拉的汽车已经在全世界销售,因此当技术成熟时,特斯拉能更好地实际部署它们。Karpathy 说自己昨天才驾驶过最新的版本,体验非常好,感觉很神奇(miraculous driving)。他说 Waymo 目前在自动驾驶方面看起来领先,但如果以 10 年为尺度长远来看,特斯拉更可能领先。

特斯拉自动驾驶功能演示
我们知道,Waymo 和特斯拉采用了不同的技术方法论:
Waymo 的自动驾驶汽车采用了大量昂贵的激光雷达和各式各样的传感器,从而为其软件系统提供全方面的信息支持。
特斯拉则是使用相机,从而能极大地降低系统的复杂性和成本。
对此,Karpathy 表示其实特拉斯也会使用大量昂贵的传感器,但只是在训练时这样做——系统可以借此完成地图测绘等工作。然后再将其蒸馏成一个测试包,并将其部署到只使用视觉信号的系统中。「我认为这是一个睿智的策略。我认为这种策略的效果能得到证明,因为像素具备足够信息,其网络也有足够能力。」之后他提到了神经网络的重要性。一开始的时候,特斯拉的系统中包含大量人工编写的 C++ 代码,之后神经网络的比重越来越大——先是执行图像检测,然后进行预测,之后更是能发出转向等指令。他表示,特斯拉最终的自动驾驶系统(比如十年之后)就是一个端到端的神经网络。也就是说,向其输入视频,它就直接给出命令。
人形机器人以及机器人公司特斯拉
Andrej Karpathy 在离开特斯拉之前也参与研究过特斯拉的人形机器人。他认为这是将能改变一切的研究方向。他说:「汽车其实就是机器人。我认为特斯拉不是一家汽车公司。这有误导性。这是一家机器人公司,大规模机器人公司,因为规模也像一个完全独立的变量。他们不是在制造东西,而是在制造制造东西的机器。」实际上,人形机器人 Optimus 的早期版本与特斯拉的汽车区别不大——它们有完全一样的计算机和摄像头。在其中运行的网络也是汽车的网络,当然其中需要做一些微调,使其适应步行空间。

当伊隆·马斯克决定做人形机器人时,各种 CAD 模型和供应链等等都是现成的,可以从汽车生产线直接拿过来重新配置,就像是电影《变形金刚》中那样——从汽车变成了机器人。至于人形机器人的第一个应用领域,Karpathy 说:「我认为 B2C 并不是一个正确的起点。」他表示特斯拉的人形机器人最好的客户就是特斯拉自己。这能避免很多麻烦,同时还能检验成果。等产品孵化成熟之后,再进入 B2B 市场,为那些拥有巨大仓库或需要处理材料的公司提供服务。最后才是面向消费者的 B2C 市场。当被问到为什么要做人形机器人时(因为人形可能并不是完成任务的最佳形态),他说:「我认为人们可能低估了进入任何单一平台的固定成本和复杂性。我认为任何单一平台都有很大的固定成本,因此我认为集中化,拥有一个可以做所有事情的单一平台是非常有意义的。」而人形是我们熟悉的形态,可以帮助研究者更好地判断操作和采集数据,毕竟我们人类自身就已经证明了人形形态的有效性。另外,人类社会也是为人类设计的,人形平台可以更好地适应这一点。当然,他并不否认这些形态未来可能发生变化。他强调了迁移学习的重要性。不管形态如何,如果能有一个能迁移到不同形态的神经网络,从而继承原有的智慧和能力,必定会大有用途。
Transformer 可能超越人脑
Andrej Karpathy 称赞了 Transformer 的独特之处:「它不仅仅是另一个神经网络,而是一个惊人的神经网络。」正是因为 Transformer,规模扩展律(scaling laws)才真正得以体现。Transformer 就像是通用型训练计算机,也就是可微分的计算机。「我认为这实际上是我们在算法领域偶然发现的神奇事物。」当然其中也有个人的创新,包括残差连接、注意力模块、层归一化等等。这些东西加起来变成了 Transformer,然后我们发现它是可训练的,也能具有规模扩展律。Karpathy 表示 Transformer 还远没到自己的极限。现在神经网络架构已经不是阻碍我们发展的瓶颈了,新的改进都是基于 Transformer 的微小变化。现在的创新主要集中在数据集方面。互联网数据很多,但 Karpathy 表示这并不是适合 Transformer 的数据。不过互联网上也确实有足够的推理轨迹和大量知识。现在很多的研究活动都是为了将这些数据重构成类似内心独白的格式。使用合成数据也能大有助益。所以很有趣的一点是:现在的大模型正在帮助我们创造下一代大模型。不过他也警告了合成数据的风险。合成数据往往多样性和丰富度不足。为此人们想出了一些办法,比如有人发布了一个个性数据集,其中包含 10 亿个不同背景的人物个性。在生成合成数据时,可以让这些不同个性去探索更多空间,从而提升合成数据的熵。接下来,Karpathy 说虽然 Transformer 和人脑应当谨慎类比,但他认为 Transformer 在很多方面已经超过了人脑。他说:「我认为它们实际上是更高效的系统。它们不如人脑工作的原因主要是数据问题。」比如在记忆力方面,Transformer 可以轻松记住输入的序列,而人脑的工作记忆很小,记忆力表现差得多。虽然人脑的工作机制还没被完全揭示,但可以说它是一种非常随机的动态系统。「我确实认为我们可能会拥有比人脑更好的(Transformer),只是目前还没有实现。」
AI 增强人类以及与人类的融合
AI 能提升人类的生产力和效率,但 Andrej Karpathy 认为 AI 的成就将远不止此。他引用了乔布斯的名言:「计算机是人类心智的自行车。」他表示,计算机与人类实际上已经有一点融合了。比如我们随身携带的智能手机,现在许多人完全无法离开手机,否则甚至会感觉自己智力都下降了。另一个例子是导航软件让许多人失去了记忆道路的能力,甚至在自家附近也要导航。他表示翻译软件也正渐渐让人们失去直接使用外语沟通的能力。他说,自己曾看过一个小孩子在杂志进行滑动操作的视频。我们觉得很自然的技术可能在新一代人眼中并不自然。但如果要实现更高级的融合,还有一些 I/O 问题有待解决。实际上,NeuraLink 就正在做这方面的研究。他说:「我不知道这种融合会是什么样子。可能会像是在我们的大脑皮层上再构建额外一层皮层。」不过这个皮层可能在云端。当然,这又会引发对生态系统的担忧。想象一下,如果你的「新皮层」 是寡头垄断的封闭平台,你肯定不会放心。好在我们也有 Llama 等开放平台。与加密货币社区的「不是你的密钥就不是你的币」类似,Karpathy 表示,「不是你的权重就不是你的大脑」。
现在的大模型参数过剩
当被问到蒸馏小模型方面的问题,Karpathy 认为当前的模型浪费了大量容量来记忆无关紧要的事情,原因是数据集没有经过精细化的调整(curation)。而真正用于思考的认知核心(cognitive core)可以非常小,如果它需要查找信息,它会知道如何使用不同的工具。至于具体的大小,Karpathy 认为会是数十亿的参数量,这可以通过对大模型执行蒸馏来获得。这就类似于互联网数据。互联网数据本身可能是由 0.001% 的认知数据和 99.999% 的相似或无用信息构成的。当这些模型发挥作用时,它们并不会孤军奋战,而是会协同合作,各自处理自己擅长的任务。这就像是一家公司,他打了个比方,LLM 们会有不同的分工,有程序员和产品经理等。
Karpathy 的教育事业
Andrej Karpathy 离开 OpenAI 后一头扎进了「AI+教育」领域。他说:「我一直是一名教育工作者,我热爱学习和教学。」他谈到了自己的愿景。他认为 AI 领域现在很多工作的目的是取代人,但他更感兴趣的是以 AI 赋能人类。
Karpathy 宣布成立「AI+教育」公司 Eureka Labs 的推文
他说:「我正在努力打造一门单一课程。如果你想了解 AI,你只需要看这个课程。」
GitHub 链接:https://github.com/karpathy/LLM101n
(但请注意,课程还没上线。)
他谈到自己曾经在斯坦福大学教过二三十门课程,那是最早的深度学习课程,也很成功。但问题是如何将这些课程普及化,让地球上说不同语言、有不同知识体系的 80 亿人都能理解。对于这样的任务,单一的教师不可能办到,而 AI 却能很好地做到这一点,实现真正的一对一教学。这时候人类教师就不必接触学生了,只需在后端设计课程;AI 会成为教学的前端——它可以说不同的语言,针对学生的具体情况进行教学。Karpathy 认为这是目前可以做到的事情,只是目前还没人把它做出来。这是一个已经成熟正待摘取的果实。目前在 AI+教育这一赛道上,AI 已经在翻译方面卓有成效,而且已经有能力实现实时现场翻译。他认为,AI 有望帮助实现教育的普及或者说知识的民主化。在被问到这门课程大概什么时候上线时,Karpathy 说大概会在今年晚些时候。但他也说现在让他分心的事情很多,所以也可能会在明年初。对于现在的孩子们该学习什么,他也给出了自己的建议:数学、物理学和计算机科学等学科。他说这些有助于提高思维技能。「在这个前 AGI 时代,这些会很有用。」
参考链接:
https://www.youtube.com/watch?v=hM_h0UA7upI
#DeepSeek分享沉淀多年的高性能深度学习架构
用60%成本干80%的事
硬件发展速度跟不上 AI 需求,就需要精妙的架构和算法。
根据摩尔定律,计算机的速度平均每两年就会翻一倍,但深度学习的发展速度还要更快,如图 1 和 2 所示。


可以看到,AI 对算力的需求每年都以 10 倍幅度增长,而硬件速度每两年增长 3 倍、DRAM 带宽增长 1.6 倍、互连带宽则仅有 1.4 倍。
而大模型是大数据 + 大计算的产物,其参数量可达千亿乃至万亿规模,需要成千上万台 GPU 才能有效完成训练。
这些实际情况提升了人们对高性能计算(HPC)的需求。
为了获得更多计算资源,人们不得不扩展更多计算节点。这就导致构建 AI 基础设施的成本不断激增。降低这些成本具有很大的好处,构建成本和能耗高效型计算机集群也就自然成了一个热门的研究方向。
近日,DeepSeek(深度求索)发布了一份基于硬件发展的实际情况及其多年实践经验的研究成果,其中提出了一些用于构建用于深度学习和 LLM 的 AI-HPC 系统的成本高效型策略。
- 论文标题:Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
- 论文地址:https://arxiv.org/pdf/2408.14158
具体来说,该团队基于 Fire-Flyer AI-HPC 架构部署了一个包含 1 万台 PCIe A100 GPU 的计算集群。下表比较了该集群与英伟达的 DGX-A100 的硬件参数。

Fire-Flyer 2:支持深度学习和早期 LLM 训练
如图 3 所示,LLM 的内存需求量通常比较大。相较之下,其它模型的需求就小多了。ResNet、Mask-RCNN、BERT、MAE 等常用模型的参数量均少于 1B,这说明其内存需求较低。因此,在设计用于深度学习模型训练的集群时,使用 PCIe A100 GPU 可能就已经足够了。

Fire-Flyer 2:PCIe A100 GPU 架构
基于该团队的训练工作负载,使用单个 200Gbps 的 NVIDIA Mellanox ConnectX-6 (CX6) InfiniBand (IB) 网卡就能满足 8 台英伟达 PCIe A100 GPU 的存储 IO 和计算通信的带宽需求。他们使用了如图 4 所示的计算节点架构:

之后,随着 LLM 时代的到来,该团队也在 PCIe 卡之间添加了 NVLink Bridge。
网络拓扑:整合了存储和计算的两层 Fat-Tree
他们选择的拓扑结构是 Fat-Tree,原因是它具有极高的对分带宽。网络连接解决方案则是 InfiniBand。具体来说,他们使用了 Mellanox QM8700 InfiniBand 交换机,其提供了 40 个速度 200 Gbps 的端口。整体而言,该集群由 1 万台 A100 GPU 构成,包括约 1250 个 GPU 计算节点和近 200 个存储服务器,尽管双层 Fat-Tree 最多可以容纳 800 个节点(配置 20 个脊交换机和 40 个叶交换机)。
为了降低成本,他们选择了两区网络配置而不是三层 Fat-Tree 解决方案,如图 5 所示。

每个计算区都包含一个 800 端口的 Fat-Tree,并连接到了大约 600 个 GPU 计算节点。每台存储服务器配备两个 IB 网卡,分别连接到不同的区,因此所有 GPU 计算节点可以共享一组存储服务。
此外,这两个区会通过有限数量的链路互连。他们的 HAI Platform 调度策略确保跨区计算任务最多限制为一个。无论是使用 NCCL 还是 DeepSeek 内部开发的通信库 HFReduce,都可以通过使用双二叉树算法跨区运行。其调度器可确保在此拓扑中,只有一对节点跨区通信因此,即使有任务需要用到所有节点,也能在 Fire-Flyer 2 AI-HPC 上高效运行。
该架构的成本性能
在 TF32 和 FP16 GEMM 基准上,相比于英伟达 DGX-A100 架构,DeepSeek 设计的这套架构的计算性能为前者的 83%。但是,其成本和能耗的下降幅度要大得多,仅为前者的 60%,如表 2 所示。

DGX-A100 集群使用了三层 Fat-Tree,其中包含 320 台核心交换机、500 台脊交换机和 500 台叶交换机,总共 1320 台交换机(如表 3 所示),而 DeepSeek 的这个架构只需要 122 台交换机。这样的设计具有更高的成本效益。
此外,通过使用 800 个端口的 Frame 交换机,还能进一步降低光模块和线缆的成本。虽然由于 PCIe 卡规格和 SXM 之间的固有差异而存在性能差距,但 DeepSeek 的这一架构通常能以仅 60% 的成本实现 80% 的 DGX-A100 性能!此外,他们还将能耗降低了 40%,也由此降低了二氧化碳排放。从这些指标看,这一架构设计无疑是成功的。
HFReduce:软硬件协同设计
有了高效的硬件,也自然需要适配的软件。该团队开发了一个用于高效 allreduce 运算的软件库:HFReduce。HFReduce 的核心策略见图 6,其包括节点内(算法 1)和节点间(算法 2)的 reduce。


HFReduce 相较于 NCCL 的优势有两项:
1. 降低 PCIe 的带宽消耗
2. 没有 GPU 核开销
如图 7a 所示,在 Fire-Flyer 2 AI-HPC 上执行数据大小为 186 MiB 的 allreduce 时,HFReduce 可以达到 6.3-8.1GB/s 的节点间带宽,而 NCCL 的节点间带宽仅为 1.6-4.8GB/s。

另外,还能使用 NVLink 提升 HFReduce 的性能。
通过安装 NVLink Bridge,可通过速度 600 GB/s 的 NVLink 实现成对 GPU 间的高效通信。为了缓解原 HFReduce 的内存限制问题,他们还实现了另一种 allreduce 模式,称为 HFReduce with NVLink。其核心概念是先在通过 NVLink 互连的 GPU 之间执行 reduce 操作,再将梯度传递给 CPU。随后,当 CPU 返回结果时,它会拆分结果数据并将它们分别返回给通过 NVLink 连接的配对的 GPU,然后通过 NVLink 执行 allgather。如图 7b 所示,HFReduce with NVLink 实 现了超过 10 GB/s 的节点间带宽。
有关 HFReduce 的策略和瓶颈的更多深度分析请参阅原论文。
HaiScale:针对深度学习模型训练进行特别的优化
HaiScale 分布式数据并行(DDP)是一种以 HFReduce 为通信后端的训练工具。这类似于 Python 的以 NCCL 为后端的 DDP。在反向传播阶段,HaiScale DDP 会对计算出的梯度执行异步 allreduce 操作,允许此通信与反向传播中涉及的计算重叠。
如图 8a 所示,相较于使用 Torch DDP 的 NCCL 后端,使用 HFReduce 训练 VGG16 模型所需的时间仅为前者的一半,当 GPU 数量从 32 增至 512 时可实现近 88% 的并行可扩展性。

为了训练大型语言模型(LLM),HaiScale 框架采用了多种并行策略,类似于 Megagron 和 DeepSpeed。他们针对 PCIe 架构在数据并行(DP)、管道并行(PP)、张量并行(TP)、专家并行(EP)等方面进行了特定的工程优化。
1. 使用 NVLink Bridge 实现 PCIe GPU 之间的张量并行
2. 在 PCIe 架构中优化管道并行
3. 完全分片式数据并行(FSDP)
图 8 和 9 展示了这些优化策略的一些实验结果。可以看到,随着 GPU 数量增长,这些策略能带来非常好的可扩展性。

此外,该团队还在论文中分享了更高级的成本效率和联合设计优化方法,其中包括一些降低计算 - 存储整合网络中信息拥堵的方法、高吞吐量分布式文件系统 3FS 以及一个时间共享式调度平台 HAI Platform。
最后,他们验证了这整套设计的稳定性和稳健性。下图总结了他们在 2023-2024 年遇到的内存和网络故障趋势。

总体而言,Fire-Flyer 2 AI-HPC 在成本性能上表现优秀 —— 能以 60% 的能源消耗达到英伟达 DGX-A100 计算性能的 80%。当进行大规模训练时,其能带来的整体成本效益将非常可观。如果你也打算构建自己的大规模训练集群,不妨考虑一下这套架构。
#DeepSeek-R2
曝5月前上线!第三弹DeepGEMM 300行代码暴击专家优化内核
DeepSeek开源第三弹,是支持稠密和MoE模型的FP8计算库——DeepGEMM,支持V3/R1训推。仅凭300行代码,就超过了专家优化的内核。开发者惊叹:DeepSeek有最好的GPU工程师,仿佛拥有某种编译器黑魔法!更令人兴奋的是,DeepSeek-R2有望在5月前提前发布。
第三天,DeepSeek发布了DeepGEMM。
这是一个支持稠密和MoE模型的FP8 GEMM(通用矩阵乘法)计算库,可为V3/R1的训练和推理提供强大支持。
仅用300行代码,DeepGEMM开源库就能超越专家精心调优的矩阵计算内核,为AI训练和推理带来史诗级的性能提升!
DeepGEMM库具有以下特征:
- 在Hopper GPU上实现高达1350+ FP8 TFLOPS的算力
- 极轻量级依赖,代码清晰易懂
- 完全即时编译,即用即跑
- 核心逻辑仅约300行代码,却在大多数矩阵规模下超越专家级优化内核
- 同时支持密集布局和两种MoE布局
开发者惊叹道:才300行代码,就能打败专家优化的内核?!
要么是DeepSeek真的破解了GPU运算的天机,要么我们就是见证了有史以来最高级的编译器黑科技。
总之,这个DeepGEMM听起来简直是数学界的超级英雄,比飞快的计算器还要快。
它改变了我们使用FP8 GEMM库的方式,简单、快速、开源。这就是AI计算的未来!
同时,外媒还曝出了另一个重磅消息:原计划在5月初发布的DeepSeek-R2,现在发布时间将再次提前!
在DeepSeek-R2中,将实现更好的编码,还能用英语以外的语言进行推理。
业内人士预测,DeepSeek-R2的发布,将是AI行业的一个关键时刻。目前DeepSeek在创建高成本效益模型上的成功,已经打破了该领域少数主导玩家的垄断。
DeepSeek开源两天,前两个项目爆火程度难以想象。FlashMLA已在GitHub斩获近10k星标,DeepEP的星标已有5k。
DeepGEMM
DeepGEMM是一个专为清晰高效的FP8通用矩阵乘法(General Matrix Multiplications,GEMMs)设计的库,它采用了DeepSeek-V3中提出的细粒度缩放技术。
该库支持常规矩阵乘法和混合专家模型(Mix-of-Experts,MoE)分组矩阵乘法。DeepGEMM使用CUDA编写,无需在安装时进行编译,而是通过轻量级即时编译(Just-In-Time,JIT)模块在运行时编译所有内核。
目前,DeepGEMM仅支持NVIDIA Hopper张量核。为了解决FP8张量核在累加计算时的精度问题,该库采用了基于CUDA核心的两级累加(提升)技术。
虽然DeepGEMM借鉴了CUTLASS和CuTe的一些概念,但避免了过度依赖它们的模板或代数系统。
相反,该库追求设计简洁,仅包含一个核心内核函数,代码量仅约300行。这使其成为学习Hopper FP8矩阵乘法和优化技术的理想入门资源。
尽管采用轻量级设计,DeepGEMM在处理各种矩阵形状时的性能都能够达到甚至超越经专家调优的库。
性能
研究人员在配备NVCC 12.8的H800上测试了DeepSeek-V3/R1推理过程中,可能使用的所有矩阵形状(包括预填充和解码阶段,但不包括张量并行计算)。
所有性能提升指标均与基于CUTLASS 3.6内部精心优化的实现进行对比计算得出。
DeepGEMM在某些矩阵形状下的表现还不够理想,如果你对此感兴趣,可以提交优化相关的Pull Request(拉取请求)。
稠密模型的常规GEMM
下表展示了不同矩阵维度(M、N、K)下DeepGEMM库的性能数据,结果显示在某些配置(如 M=128, N=2112, K=7168)下实现了高达 2.4 倍的加速,反映了DeepGEMM在优化GPU矩阵计算方面的效率和灵活性。
MoE模型的分组GEMM(使用连续存储布局)
MoE模型的分组GEMM(使用掩码存储布局)
快速入门
要求
- NVIDIA Hopper架构GPU(需支持sm_90a计算能力)
- Python v3.8或更高版本
- CUDA v12.3及以上版本(强烈建议使用v12.8或更新版本以获得最佳性能)
- PyTorch v2.1及以上版本
- CUTLASS v3.6或更高版本 (可通过Git子模块[submodule]方式克隆获取)
开发
下面代码是DeepGEMM项目的安装和测试指南。
首先,通过命令克隆仓库及其子模块。然后,创建第三方库(CUTLASS和CuTe)的符号链接以便开发。接着,测试JIT编译功能。最后,测试所有GEMM实现。
# Submodule must be cloned
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.py安装
下面代码使用脚本安装Python包,会将包及其依赖项安装到系统中以便在项目中使用。
python setup.py install接下来,在你的Python项目中导入deep_gemm,就可以开始使用啦!
优化技术
注意:下面用🐳标记的是,CUTLASS中未包含的技术。
持久化线程束专用化
遵循CUTLASS的设计,DeepGEMM中的内核采用线程束(warp)专用化技术,实现了数据移动、张量核心MMA(矩阵乘累加)指令和CUDA核心提升操作的重叠执行。下图简要说明了这个过程:
TMA线程主要负责数据加载(Data load)和任务分发(TMA issue),用黄色和蓝色表示。数学线程则交替执行WGMA(Wavefront Matrix Multiply-Accumulate)计算(绿色)和数据提升(Promotion,黄色),展示了一种并行计算策略,其中数据加载与矩阵计算和优化操作协同工作,以提高效率和性能。
Hopper TMA特性
张量内存加速器(Tensor Memory Accelerator,TMA)是Hopper架构引入的新硬件特性,用于实现更快速的异步数据移动。具体来说,在以下方面使用TMA:
- LHS(左矩阵)、LHS缩放因子和RHS(右矩阵)的TMA加载
- 输出矩阵的TMA存储
- LHS矩阵的TMA多播
- TMA描述符预取
常见的细节优化
- 使用stmatrixPTX指令
- 针对不同线程束组的寄存器数量精确控制
- 最大化指令重叠,如TMA 存储与非TMA RHS 缩放因子加载的重叠🐳
统一且经过优化的块调度器
- 所有非分组和分组内核使用同一调度器
- 采用光栅化技术提高L2缓存重用率
完全JIT设计 🐳
DeepGEMM采用完全即时编译(JIT)设计,无需在安装时编译。所有内核在运行时通过轻量级JIT实现进行编译。这种方法具有以下优势:
- GEMM(通用矩阵乘法)形状、块大小和流水线阶段数被视为编译时常量
- 有效节省寄存器空间
- 使编译器能够进行更多优化
- 能够自动选择块大小、线程组数量、最优流水线阶段和TMA(张量内存访问)集群大小
- 即使在不进行自动调优的情况下,也能确定性地选择最优配置
- 完全展开MMA(矩阵乘加)流水线,为编译器提供更多优化机会
- 这一特性对处理小规模矩阵运算尤为重要
- 详细信息请参考kernel文件中的launch_k_iterations部分
总的来说,JIT显著提升了小形状的计算性能,这与Triton编译器采用的方法类似。
非对齐块大小🐳
对于某些形状,采用2的幂次对齐的块大小可能导致SM利用率不足。
例如,当M=256,N=7168时,传统的块大小分配BLOCK_M=128,BLOCK_N=128只能利用 (256/128) * (7168/128) = 112个SM(总共132个)。
为解决这个问题,团队为诸如112这样的非对齐块大小提供了支持,使得 (256/128) * (7168/112) = 128个SM能够充分工作。将这种技术与细粒度缩放结合需要精心优化,但最终能带来显著的性能提升。FFMA SASS交错优化🐳
团队发现CUTLASS FP8内核在NVCC 12.2和12.3版本之间存在性能差异。
通过比对编译后的SASS代码,可以发现在一系列FADD指令中有一个位按交错模式翻转。
参考开源CUDA汇编器实现后,团队确定这个位控制着让出(yield)操作,可能用于增强线程束级并行性(推测是通过让出当前线程束使其他线程束得以执行)。
为此,团队开发了专门的脚本来修改编译后二进制中的FFMA指令。除了修改让出位,还调整了重用位(当线程束被让出时禁用寄存器重用)。
这种优化通过创造更多MMA指令和提升类FFMA指令重叠的机会,显著提高了细粒度缩放FP8 GEMM的性能(在某些情况下提升超过10%)。
参考资料:
https://x.com/deepseek_ai/status/1894553164235640933
#火山引擎用「AI云原生」重构大模型部署范式
500万TPM+20msTPOT
部署 DeepSeek 系列模型,尤其是推理模型 DeepSeek-R1,已经成为一股不可忽视的潮流。
不只是 AI 和云服务商在部署 DeepSeek 系列模型以提供 AI 服务,很多企业和组织也在部署它们来助力自家的业务,比如为自己的员工提供支持,或者让自己的服务变得更加强大。甚至很多学校也在部署自己的 DeepSeek-R1 以辅助教育和助力「学生建立正确使用 AI 价值观」,包括中国人民大学、北京交通大学、浙江大学、上海交通大学等等,其中一些甚至采用了本地部署「满血版」DeepSeek-R1 的做法。
本地部署自己的 DeepSeek-R1 固然是一种选择,但对绝大多数(尤其是规模较小的)企业和组织来说,这个选择并非最优,因为本地部署往往需要在技术、安全和运维等方面投入大量资金和人力资源。
作为替代,基于云的部署或许是一种更合理选择。事实上,现在已有不少云服务商在争夺这方面的业务,其中包括国内所有主要的云服务商,如腾讯云、阿里云和火山引擎;这些云服务商为了争夺市场份额,纷纷推出了各种优惠措施,力图在这后 DeepSeek-R1 时代初期占据更大的市场份额。
而要说哪家云服务商最有可能夺得这场竞赛的头筹,相信很多人都会不假思索地给出一个答案:火山引擎。并且,原因不仅仅是火山引擎的性价比最高,更在于其能提供高速、可靠和安全的服务,保证企业能够稳健地在云上部署自己的 AI 模型和服务。就连 DeepSeek-R1 模型也非常认可火山引擎在 AI 模型部署上的优势。

DeepSeek-R1 分析在火山引擎部署 AI 模型的优势
不管是速度还是性能,火山引擎的强劲表现已经得到了 SuperCLUE 和基调听云等多个第三方评测平台的认可,比如基调听云便在《大模型服务性能评测 DeepSeek-R1 API 版》中写到:「火山引擎在平均速度、推理速度、生成速度上表现最优,且可用性高达 99.83%,在 API 接入上首选推荐。」

图源:基调听云
前段时间,火山引擎更是领先全网将每位用户的初始 TPM(每分钟 token 数)上调到了 500 万!一时之间吸引了无数眼球。此外,火山引擎也已经成功将 TPOT(输出每个 Token 的时间)稳定地降低到了约 20 ms,成为了国内延迟最低的大规模 AI 模型推理服务 —— 要知道 DeepSeek-R1 在思考时往往会生成大量 token,单 token 输出降低几毫秒时间就足以大幅加速输出过程。

物美价廉,火山引擎为什么能成为后发先至的云服务商?主要是得益于其为 AI 时代的云服务率先总结出了自己的方法论:AI 云原生。
AI 云原生:下一个十年的云计算新范式
对于熟悉云计算的读者而言,「云原生」这一概念应该并不陌生。简单来说,云原生(Cloud-Native)是指围绕云计算开发和部署应用的方法论,其核心目标是让应用更好地适应云环境的特性,实现高可伸缩性、弹性、可用性和自动化管理等优势。同时,由于云原生可通过云架构带来弹性存算分离、服务化等特性,企业能够非常高效地去构建自己的大规模业务系统。云原生架构被广泛认为是过去十年计算技术发展的关键范式之一,它为现代应用的可扩展性、灵活性和高效性打下了坚实的基础。
基于这一发展背景,「AI 云原生」则是将云原生理念应用到人工智能(AI)领域,专注于 AI 工作负载的云端构建和部署。2024 年 12 月,火山引擎成为了国内首个提出并实践「AI 云原生」的厂商。当时,火山引擎总裁谭待在 2024 冬季火山引擎 FORCE 原动力大会上表示:「我们认为下一个十年非常重要的事是计算范式从云原生进入到 AI 云原生的新时代。」他还指出,火山引擎指出 AI 云原生的特点是「以 GPU 为核心」。

火山引擎总裁谭待介绍 AI 云原生
相对而言,过去的云原生则是以 CPU 为核心。到了 AI 时代,如果还是继续沿用这个架构,就需要让大量数据经由 CPU 绕行,再交给 GPU 处理,但这样无法充分利用 GPU 高算力和大带宽的优势。另外,GPU 训练和推理的场景也对高速互联、在线存储和隐私安全提出了更高的要求。
AI 云原生首先要做的便是以 GPU 为核心来重新优化计算、存储与网络架构,让 GPU 可以直接访问存储和数据库,从而显著降低 IO 延迟,同时还要让整个系统有能力提供更高规模的高速互联和端到端的安全保护。
而现在,火山引擎 AI 云原生的关注重心有了进一步的升级:从「以 GPU 为核心」转向了「以模型为核心」。
火山引擎总结了以模型为核心的 AI 云原生基础设施的几大主要特征:
- 全栈推理加速,并具有最佳工程实践;
- 具有高性价比的资源和灵活部署模式;
- 更高安全性保障大模型应用平稳运行;
- 易用性好并且具有优良的端到端体验。
正是基于 AI 云原生的理念,火山引擎推出了新一代的计算、网络、存储和安全产品,并总结出了一套实现 AI 最佳部署的方法论。
以 DeepSeek 部署为样板:火山引擎总结出 AI 云原生最佳部署方法论
秉承 AI 云原生理念,火山引擎基于支持火山方舟和各行业客户 DeepSeek 实践的部署流程,总结出了从开源模型到企业部署调用的端到端关键步骤。
简单来说,这个流程包含四大关键步骤:模型选择、最佳资源规划、推理部署工程优化、企业级服务调用。如下图所示。当然,这套流程不仅适用于部署 DeepSeek 系列模型,企业在云上部署其它 AI 模型式也完全可以参考。

第一步:模型选择。在选择 AI 模型时,并不是总是越大越好,毕竟有的任务对准确度的要求可能并不高,反而有较高的效率需求,比如实时语音检测、异常监控和简单的图像分类或文本情绪识别任务。用户应根据自身的业务需求正确选择合适的 AI 模型 —— 有时候使用 DeepSeek-R1 蒸馏版其实更佳,比如集成在实时语音助手中时。这一步涉及到模型适配性判断以及模型性能评估。
第二步:最佳资源规划。在部署 AI 模型时,并不是资源越多越好,还需要兼顾成本因素和资源冲突等问题。因此,选择合适的部署模式(云上部署或混合部署)以及有效的资源调度和监控以及成本控制是必需的。
第三步:推理部署工程优化。用户在前两步确认了自己的需求之后,就需要根据自身需求选择平台,其中的一大重点是考虑平台能够为自身业务提供足够的性能优化,比如是否有较好的 PD(Prefill 和 Decode)分离方案、弹性的资源调度方案等。
第四步:企业级服务调用。对于企业来说,光是保障性能与服务稳定性还不够,数据安全与隐私也是重中之重。此外,企业还需要考虑如何将 DeepSeek-R1 等模型集成到已有的系统中,其中涉及到适配和调试、API 对接、IAM 身份认证管理等诸多议题。
火山引擎认为上述四步都是「AI 云原生」必须为客户提供的能力,而火山引擎自身已经做到了一点。也因此,可以说火山引擎是部署 DeepSeek 系列模型的最佳选择。
数据说话:火山引擎是部署 DeepSeek 的最佳选择
有了新的方法论和最佳部署流程,我们再来看看火山引擎有何优势,为什么说火山引擎是部署 DeepSeek 模型的最佳选择。
最大 768G 显存 + 最高 3.2Tbps 高速 RDMA 互联带宽
火山引擎配备了高性能的计算资源。在 GPU 方面,火山引擎可以提供 24G、48G、80G、96G 等多个 GPU 显存规格的云服务器实例,单机最大支持 768G 显存 —— 足以部署 671B 的 DeepSeek-R1 满血版(全量模型的文件体积高达 720GB)。当然,用户也完全可以选择在更小的实例上部署满足自身需求的不同大小的蒸馏版 DeepSeek-R1。
同时火山引擎具备业界领先的高性能计算产品能力,有成熟的多机互联集群产品方案,跨计算节点最高可提供 3.2Tbps 高速 RDMA 互联带宽。因此,用户也可通过 RDMA 网络互联的 GPU 云服务器,轻松部署 DeepSeek-R1 满血版。
全栈且系统化的推理加速:320Gbps+80%+1/50+100%
火山引擎提供了全栈且系统化的推理加速能力,可端到端地从硬件到软件提供加速优化能力。
硬件方面,前面已经提到了火山引擎卓越的跨计算节点。此外,从 GPU 在数据中心中部署开始,火山引擎就已经开始在做优化了:把高算力的 GPU 和高显存带宽的 GPU 以合理配比做了亲和性部署,首先从物理层面就降低了数据跨交换机传输的概率。不仅如此,火山引擎还为跨 GPU 资源池和存储资源提供了最高达 320Gbps vRDMA 的高速互联能力,实现了整体通信性能上最高 80% 的提升,通信时延领先同类产品最高可达 70%!(注:火山引擎采用的 vRDMA 网络是基于标准 RoCE V2 协议自研的,在部署 AI 方面极具效率和灵活性优势。)
火山引擎也实现了对 PD 分离架构的大规模支持。事实上,火山方舟也是国内公有云平台上最先支持 DeepSeek PD 分离的 —— 对于 Prefill 和 Decode 阶段各自适合用什么卡以及比例多少,都可以为客户提供最佳实践。
软件方面,对于大模型的 KV-Cache 优化,火山引擎推出了相应的加速产品:弹性极速缓存(EIC);可通过以存代算、GDR 零拷贝等方式大幅降低推理 GPU 资源消耗,优化推理时延 —— 甚至可将推理时延降低至原来的 1/50,同时还能将 GPU 推理消耗降低 20%。
火山引擎还自研了推理加速引擎 xLLM,可将端到端大模型推理性能提升 100% 以上!当然,如果用户更偏好通过社区版本的 SGlang 和 vLLM 部署 DeepSeek 模型,也能在火山引擎上获得良好的支持。
此外,火山引擎也提供基于开源 Terraform 的一键部署方案。用户只需复制脚本代码并执行,即可安全、高效地完成基于 ECS 的部署。在模型加载加速方面,通过缓存、预热等能力,模型拉取和加载速度也能够提升数倍。
一站式模型部署和定制能力
火山引擎提供了 1 站式的模型部署和定制能力。以部署 DeepSeek 系列模型为例,火山引擎的用户可以选择适合自己的各种层级的解决方案,包括:
- 从方舟直接调用 API;
- 在 MLP 机器学习平台上自行部署;
- 云原生 PaaS(平台即服务):火山引擎提供云计算平台,用户可搭建自己的机器学习框架,再部署 AI 模型。
- IaaS(基础设施即服务):火山引擎提供最底层的基础设施,用户可根据需求获得最大限度的部署自由。
更棒的是,针对其中每一个层级,火山引擎 AI 云原生都有快速部署的最佳实践,让客户可以快速完成 DeepSeek 系列模型的部署。
在此基础上,火山引擎也提供了一站式的模型定制能力。用户不仅可以在火山引擎上完成对全尺寸 DeepSeek 模型的微调,还可以根据自身业务需求对模型进行蒸馏甚至进一步的强化学习,从而以最优的资源利用率得到最适合自己的定制版 DeepSeek 模型。

在火山方舟上可以非常轻松地完成模型精调
长期技术驱动打造性价比,价格优惠高达 80%
火山引擎一大众所周知的优势便是便宜,但这种便宜却并不是以牺牲性能为代价。事实上,火山引擎的高性价比来自于长期的资源与技术积累。
在大规模算力资源池的基础上,火山引擎还已经与字节跳动国内业务实现资源并池。也就是说,在其它业务低峰期,字节跳动可将国内业务的空闲计算资源极速调度给火山引擎客户使用。据了解,只需分钟级的时间,火山引擎就可以调度 10 万核 CPU、上千卡 GPU 的资源量。通过弹性计算抢占式实例和业界独创的弹性预约实例产品模式,火山引擎更是做到 GPU 资源的潮汐复用,让价格最高可优惠到 80% 以上!
火山引擎可说是真正做到了物美价廉还有钱可赚。举个例子,如果要部署 671B 参数量的满血版 DeepSeek-R1/V3,当前市场主流的云方案是使用 8 卡显存 96G 的 GPU,而火山引擎在该业务上价格低于阿里云 17%、低于腾讯云 16%,下表展示了价格详情:
| 规格/系列 | 刊例价(元/月/台) | |
| 火山引擎 | 高性能计算GPU型hpcpni3ln | 133000 |
| 阿里云 | 灵骏计算节点-gu8tf | 161253 |
| 腾讯云 | GPU型HCCPNV6 | 158708 |
稳定又安全:分钟级定位问题实例 + 减少 90% 以上回复不准确问题
对企业来说,业务的稳定和安全可说是重中之重。凭借扎实的业务积累,火山引擎能在稳定性和安全性方面给予客户足够的保障。
稳定性方面,火山引擎提供了全面且丰富的检测手段,比如在高性能计算集群的 RDMA 监测指标上,火山引擎提供了 17 个监测项,可说是业界领先;同时,火山引擎在分钟级的时间内就能在上千台实例中定位到问题实例。
发现问题后,火山引擎也提供了非常高的修复效率,可在分钟级时间内完成自愈,甚至可在一分钟时间内完成单机冷迁移任务。
安全性方面,火山引擎基于自研大模型应用防火墙,可提供强大的 All in One 安全防护能力,足以为用户部署 DeepSeek 模型保驾护航。比如在抵御算力 DDoS 攻击方面,火山引擎可以消除恶意 token 消耗风险,从而使服务可用性提升数倍,确保大模型服务能够稳定运行。
此外,火山引擎还部署了相应自研大模型应用防火墙方案来防范提示词注入攻击(敏感数据泄露事件发生率可降低 70%)、减少 90% 以上幻觉等问题导致的回复不准确问题以及保障内容合规。
后 DeepSeek-R1 时代,火山引擎 AI 云原生将成为 AI 应用大爆发的基石
随着 DeepSeek 系列模型的广泛部署和应用,AI 技术的变革已经进入了一个全新的阶段。DeepSeek-R1 作为其中的核心推理模型,不仅在科技行业引发了深刻变革,更在教育、企业服务等多个领域展现出了巨大的潜力。然而,正如我们所讨论的,尽管本地部署能给一些大规模组织提供可定制的灵活性,但对于多数企业而言,成本、技术、运维等层面的挑战往往让本地部署变得不可承受。
在这样的背景下,基于云的解决方案显得尤为重要。火山引擎凭借「AI 云原生」的理念,展现出了与时俱进的技术优势。从「以 GPU 为核心」到「以模型为核心」,通过对存储和网络架构的重新设计,以及在性能、稳定性、安全性等多方面的卓越表现,火山引擎 AI 云原生不仅仅是技术的创新,更是未来十年内推动 AI 应用蓬勃发展的基础。而这次展示的 DeepSeek 系列模型四步部署方法论正是火山引擎为企业大模型部署打造的 AI 云原生样板间。
后 DeepSeek-R1 时代,AI 发展的脚步不会停歇,火山引擎作为强大的后盾,将成为推动 AI 应用大爆发的关键力量。从加速 AI 模型的部署到实现更广泛的行业落地,火山引擎无疑将在未来的 AI 生态中占据重要席位,助力各行各业进入更加智能化的时代。
#OpenAI Deep Research已向所有付费用户开放
今天,系统卡发布
相信很多用户已经见识过或至少听说过 Deep Research 的强大能力。
今天凌晨,OpenAI 宣布 Deep Research 已经面向所有 ChatGPT Plus、Team、Edu 和 Enterprise 用户推出(刚发布时仅有 Pro 用户可用),同时,OpenAI 还发布了 Deep Research 系统卡。

此外,OpenAI 研究科学家 Noam Brown 还在 𝕏 上透露:Deep Research 使用的基础模型是 o3 正式版,而非 o3-mini。

Deep Research 是 OpenAI 本月初推出的强大智能体,其能使用推理来综合大量在线信息并为用户完成多步骤研究任务,从而助力用户进行深入、复杂的信息查询与分析。参阅报道《刚刚,OpenAI 上线 Deep Research!人类终极考试远超 DeepSeek R1》。
在发布之后的这二十几天里,OpenAI 还对 Deep Research 进行了一些升级:

OpenAI 这次发布的 Deep Research 系统卡报告介绍了发布 Deep Research 之前开展的安全工作,包括外部红队、根据准备度框架进行的风险评估,以及 OpenAI 为解决关键风险领域而采取的缓解措施。这里我们简单整理了这份报告的主要内容。

地址:https://cdn.openai.com/deep-research-system-card.pdf
Deep Research 是一种新的智能体能力,可针对复杂任务在互联网上进行多步骤研究。Deep Research 模型基于为网页浏览进行了优化的 OpenAI o3 早期版本。Deep Research 利用推理来搜索、解读和分析互联网上的大量文本、图像和 PDF,并根据遇到的信息做出必要的调整。它还可以读取用户提供的文件,并通过编写和执行 Python 代码来分析数据。
「我们相信 Deep Research 可以帮助人们应对多种多样的情形。」OpenAI 表示,「在发布 Deep Research 并将其提供给我们的 Pro 用户之前,我们进行了严格的安全测试、准备度评估和治理审查。我们还进行了额外的安全测试,以更好地了解与 Deep Research 浏览网页的能力相关的增量风险,并增加了新的缓解措施。新工作的关键领域包括加强对在线发布的个人信息的隐私保护,以及训练模型以抵御在搜索互联网时可能遇到的恶意指令。」
OpenAI 还提到,对 Deep Research 的测试也揭示了进一步改进测试方法的机会。在扩大 Deep Research 的发布范围之前,他们还将花时间对选定的风险进行进一步的人工检测和自动化测试。
本系统卡包含 OpenAI 如何构建 Deep Research、了解其能力和风险以及在发布前提高其安全性的更多详细信息。
模型数据和训练
Deep Research 的训练数据是专门为研究用例创建的新浏览数据集。
该模型学习了核心的浏览功能(搜索、单击、滚动、解读文件)、如何在沙盒环境中使用 Python 工具(用于执行计算、进行数据分析和绘制图表),以及如何通过对这些浏览任务进行强化学习训练来推理和综合大量网站以查找特定信息或撰写综合报告。
其训练数据集包含一系列任务:从具有 ground truth 答案的客观自动评分任务,到带有评分标准的更开放的任务。
在训练期间,评分过程使用的评分器是一个思维链模型,其会根据 ground truth 答案或评分标准给出模型响应的分数。
该模型的训练还使用了 OpenAI o1 训练用过的现有安全数据集,以及为 Deep Research 创建的一些新的、特定于浏览的安全数据集。
风险识别、评估和缓解
外部红队方法
OpenAI 与外部红队成员团队合作,评估了与 Deep Research 能力相关的关键风险。
外部红队专注的风险领域包括个人信息和隐私、不允许的内容、受监管的建议、危险建议和风险建议。OpenAI 还要求红队成员测试更通用的方法来规避模型的安全措施,包括提示词注入和越狱。
红队成员能够通过有针对性的越狱和对抗策略(例如角色扮演、委婉表达、使用黑客语言、莫尔斯电码和故意拼写错误等输入混淆)来规避他们测试的类别的一些拒绝行为,并且根据这些数据构建的评估将 Deep Research 的性能与之前部署的模型进行比较。
评估方法
Deep Research 扩展了推理模型的能力,使模型能够收集和推理来自各种来源的信息。Deep Research 可以综合知识并通过引用提出新的见解。为了评估这些能力,需要调整已有的一些评估方法,以解释更长、更微妙的答案 —— 而这些答案往往更难以大规模评判。
OpenAI 使用其标准的不允许内容和安全评估对 Deep Research 模型进行了评估。他们还为个人信息和隐私以及不允许的内容等领域开发了新的评估。最后,对于准备度评估,他们使用了自定义支架来引出模型的相关能力。
ChatGPT 中的 Deep Research 还使用了另一个自定义提示的 OpenAI o3-mini 模型来总结思维链。以类似的方法,OpenAI 也根据其标准的不允许内容和安全评估对总结器模型进行了评估。
观察到的安全挑战、评估和缓解措施
下表给出了风险和相应的缓解措施;每个风险的具体评估和结果请参阅原报告。

准备度框架评估
准备度框架是一个动态文档,其中描述了 OpenAI 跟踪、评估、预测和防范来自前沿模型的灾难性风险的方式。
该评估目前涵盖四个风险类别:网络安全、CBRN(化学、生物、放射、核)、说服和模型自主性。
只有缓解后(post-mitigation)得分为「中」或以下的模型才能部署,只有缓解后得分为「高」或以下的模型才能进一步开发。OpenAI 根据准备度框架对 Deep Research 进行了评估。
准备度框架详情请访问:https://cdn.openai.com/openai-preparedness-framework-beta.pdf
下面更具体地看看对 Deep Research 的准备度评估。Deep Research 基于针对网页浏览进行了优化的 OpenAI o3 早期版本。为了更好地衡量和引出 Deep Research 的能力,OpenAI 对以下模型进行了评估:
- Deep Research(缓解前),一种仅用于研究目的的 Deep Research 模型(未在产品中发布),其后训练程序与 OpenAI 已发布的模型不同,并不包括公开发布的模型中的额外安全训练。
- Deep Research(缓解后),最终发布的 Deep Research 模型,包括发布所需的安全训练。
对于 Deep Research 模型,OpenAI 测试了各种设置以评估最大能力引出(例如,有浏览与无浏览)。他们还根据需要修改了支架,以最好地衡量多项选择题、长答案和智能体能力。
为了帮助评估每个跟踪风险类别中的风险级别(低、中、高、严重),准备团队使用「indicator」将实验评估结果映射到潜在风险级别。这些 indicator 评估和隐含风险水平经过安全咨询小组(Safety Advisory Group)审查,该小组确定了每个类别的风险水平。当达到或看起来即将达到 indicator 阈值时,安全咨询小组会进一步分析数据,然后确定是否已达到风险水平。
OpenAI 表示模型训练和开发的整个过程中都进行了评估,包括模型启动前的最后一次扫描。为了最好地引出给定类别中的能力,他们测试了各种方法,包括在相关情况下的自定义支架和提示词。
OpenAI 也指出,生产中使用的模型的确切性能数值可能会因最终参数、系统提示词和其他因素而异。
OpenAI 使用了标准 bootstrap 程序计算 pass@1 的 95% 置信区间,该程序会对每个问题的模型尝试进行重新采样以近似其指标的分布。
默认情况下,这里将数据集视为固定的,并且仅重新采样尝试。虽然这种方法已被广泛使用,但它可能会低估非常小的数据集的不确定性,因为它只捕获抽样方差而不是所有问题级方差。换句话说,该方法会考虑模型在多次尝试中对同一问题的表现的随机性(抽样方差),但不考虑问题难度或通过率的变化(问题级方差)。这可能导致置信区间过紧,尤其是当问题的通过率在几次尝试中接近 0% 或 100% 时。OpenAI 也报告了这些置信区间以反映评估结果的内在变化。
在审查了准备度情况评估的结果后,安全咨询小组将 Deep Research 模型评级为总体中等风险(overall medium risk)—— 包括网络安全、说服、CBRN、模型自主性都是中等风险。
这是模型首次在网络安全方面被评为中等风险。
下面展示了 Deep Research 与其它对比模型在 SWE-Lancer Diamond 上的结果。请注意其中上图是 pass@1 结果,也就是说在测试的时候,每个模型在每个问题上只有一次尝试的机会。

整体来看,各个阶段的 Deep Research 的表现都非常好。其中,缓解后的 Deep Research 模型在 SWE-Lancer 上表现最佳,解决了大约 46-49% 的 IC SWE 任务和 47-51% 的 SWE Manager 任务。
更多评估细节和结果请访问原报告。
#history-guidance
千帧长视频时代到来!MIT全新扩散算法让任意模型突破时长极限
进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
近期,MIT 团队火遍外网的新论文《History-guided Video Diffusion》提出了一种全新算法 Diffusion Forcing Transformer(DFoT),在不改动原有架构的情况下就能让模型稳定输出比之前近 50 倍、近千帧长的视频。
- 论文地址:https://arxiv.org/abs/2502.06764
- 项目主页:https://boyuan.space/history-guidance/
该算法生成的视频如此之长,以至于只能截短并降低帧率才能放下。我们先来一睹生成视频的效果。
,时长00:43
在现有的视频扩散模型中,无分类器引导(Classifier-free Guidance, CFG) 已被广泛应用于提升采样质量。然而,目前的视频模型通常只使用第一帧进行引导,而忽略了其他历史帧的重要性。作者的研究发现:历史信息才是提升视频生成质量的关键因素!
因此,通过在去噪过程中混合长历史模型和短历史模型的不同预测,论文提出了一系列「历史引导」算法 (History Guidance),显著提升了视频扩散模型的质量、生成长度、鲁棒性与可组合性。

在 X 上,论文共同一作 Boyuan Chen 的论文推介收获了十几万的阅读量、近千的点赞量。

该工作刚一推出便受到了大量网友的赞誉,尤其看到了 DFoT 算法对视频扩散模型的影响。

谷歌研究科学家、3d gaussian splating 一作 George Kopanas 转达并评论道,「一年前,连续的长期视频看起来是不可能的。而现在可以做到了!这项工作令人印象深刻,也提供了一个非常有趣的潜在想法。」

方法概览
论文提出首先要训练一个能根据不同部分的历史进行去噪预测的视频模型。作者把不同历史定义如下:
- 不同长度的历史
- 历史的不同子集
- 特定频率域的历史。
这样的模型能够灵活地应对不同场景,例如图生视频或是延长已有的视频。遗憾的是,目前的视频扩散模型架构并不具备这种灵活性。如果简单地把历史帧编码后喂给 AdaLN 层并使用无分类器引导常见的随机丢弃法进行训练,实际效果会非常差。
相反,作者提出了一个极其简洁的算法 Diffusion Forcing Transformer (DFoT),在不改变架构的情况下就可以实现以上目标。
具体来说,作者提出把热门前作 Diffusion Forcing 中提出的噪声掩码 (noise as masking) 概念带入到视频生成架构中 —— 训练扩散模型时可以对每一帧使用不同的噪声强度。某一帧无噪声时相当于直接把该帧作为条件信息,而最强的噪声相当于完全移除这一帧的信息。给定一个既有的传统 DiT 架构,DFoT 只需要控制噪声掩码就可以训练任意子序列的预测任务。
作者提到,这样做保留了把现有模型直接微调成 DFoT 的可行性,并且 Adobe 公司已经在他们的视频大模型 CausVid 上验证过了 Diffusion Forcing 微调。

图(左):传统的视频模型要需要把历史信息编码进 AdaLN 层来兼容多历史帧。图(右):DFoT 架构仅用噪声掩码来区分历史帧和预测帧。
DFoT 一旦训练好就可以进行极其灵活的采样。如下图所示,如果要把前四帧作为条件,可以控制噪声掩码给前四帧 0 噪声(第一行);如果要进行无条件生成,可以把所有历史帧设为白噪声(第二行);如果要把短历史作为条件,可以掩码较早的历史帧。

DFoT 的采样和历史引导。
基于这种能力,作者引出了一系列「历史引导」算法。历史引导扩展了无分类起引导的概念,不仅在采样过程中组合有条件模型和无条件模型,还能通过加权去噪组合多重不同的历史条件。其中最简单的版本 (HG-v) 已经能大幅提高视频的质量,较为先进一点的跨时间历史采样 (Temporal History Guidance) 和跨频率域历史采样 (Fractional History Guidance) 更是分别增强了鲁棒性和动作幅度。
实验结果
作者进行了一系列实验来分别验证 DFoT 架构和历史引导。
首先,在经典的 Kinetics 600 数据集上,DFoT 超过了所有同架构下的视频扩散算法,并仅使用学术届的计算就和谷歌闭源大模型的结果打成平手。
不光如此,DFoT 是可以用任意长度的历史生成视频的,并不像其他算法一样在训练时就要指定特定历史长度。作者还特意验证了从经典扩散算法微调而来的 DFoT 模型,发现一样能获得出色的效果。

无历史引导下 DFoT 的效果。
接下来,作者开始验证结合了历史引导的 DfoT。
在 kinetics600 上,原有的任务是给定前 6 帧预测下面 11 帧。由于 DFoT 极其稳定,作者直接把 11 帧拓展到了 64 帧,并在 FVD 和 vBench 上大幅超过了之前的模型。同时,文中提出的 HG-f 可以在保持稳定性的情况下避免模型生成静止的画面。

kinetics 上的对比。
在 RealEstate10K 数据集上,论文更是断崖式领先:在此之前,大部分算法只能在该数据集上做到给定开头结尾去插值中间帧,两个最强闭源模型 LVSM 和 4DiM 的在给定第一帧预测视频的情况下最多只能生成二三十帧。
而 Diffusion Forcing Transformer 和历史引导直接做到了单图生成近一千帧,并且提供了全套开源和 Huggingface 展示。

DFoT 可以在 RealEstate10K 上单图生成近千帧。
总结
论文提出了 Diffusion Forcing Transformer (DFoT),一个能用任何历史帧作为条件的视频扩散架构。DFoT 让历史引导 (History Guidance) 成为了可能,使得视频质量和长度都大幅增加。论文还涉及了大量其他内容,例如数学证明,鲁棒性,组合性和机器人实验等近四十页。
作者提供的开源实现详细提供了复现的所有步骤,并且在 Huggingface 上提供了在线体验,感兴趣的读者可以直接根据论文主页的链接在浏览器里直接验证论文效果。
Huggingface 地址:https://huggingface.co/spaces/kiwhansong/diffusion-forcing-transformer
此外,为了方便读者们进一步学习了解该论文,我们邀请到了论文共同一作、MIT计算机系四年级博士生陈博远于北京时间2月27日20:00直播解读该研究,欢迎感兴趣的读者预约观看。
用历史引导和扩散强制生成超长视频
分享嘉宾简介:陈博远是麻省理工大学计算机系四年级的博士生,师从Vincent Sitzmann教授和机器人大牛Russ Tedrake教授。陈博远的研究兴趣是世界模型,基于模型的强化学习与具身智能,他希望通过在大视频模型来解决机器人动作规划的问题,并在视觉领域上复现大语言模型的推理和自我提升。陈博远之前在Deepmind和Google X实习过,著有SpatialVLM, Diffusion Forcing等论文。
#Fractal Generative Models
何恺明带队新作「分形生成模型」:逐像素建模高分辨率图像、效率提升4000倍
这次构建了一种全新的生成模型。类似于数学中的分形,研究者推出了一种被称为分形生成模型(Fractal Generative Models)的自相似分形架构。
在计算机科学领域,它的核心是模块化概念,比如深度神经网络由作为模块化单元的原子「层」构建而成。同样地,现代生成模型(如扩散模型和自回归模型)由原子「生成步骤」构建而成,每个步骤都由深度神经网络实现。
通过将复杂函数抽象为这些原子构建块,模块化使得可以通过组合这些模块来创建更复杂的系统。基于这一概念,研究者提出将生成模型本身抽象为一个模块,以开发更高级的生成模型。一作 Tianhong Li 为 MIT 博士后研究员、二作 Qinyi Sun 为 MIT 本科生(大三)。
- 论文标题:Fractal Generative Models
- 论文地址:https://arxiv.org/pdf/2502.17437v1
- GitHub 地址:https://github.com/LTH14/fractalgen
具体来讲,研究者提出的分形生成模型通过在其内部递归调用同类生成模型来构建。这种递归策略产生了一个生成框架,在下图 1 中展示了其跨不同模块级别的具有自相似性的复杂架构。

如前文所述,本文分形生成模型类似于数学中的分形概念。分形是使用被称为「生成器」的递归规则构建的自相似模式。同样地,本文框架也是通过在生成模型中调用生成模型的递归过程构建的,并在不同层次上表现出自相似性。因此,研究者将其命名为「分形生成模型」。
本文的分形生成模型的灵感来自于生物神经网络和自然数据中观察到的分形特性。与自然的分形结构类似,研究者设计的关键组件是定义递归生成规则的生成器,比如这样的生成器可以是自回归模型,如图 1 所示。在此实例中,每个自回归模型都由本身就是自回归模型的模块组成。
具体而言,每个父自回归块都会生成多个子自回归块,每个子块都会进一步生成更多自回归块。由此产生的架构在不同级别上表现出类似分形的自相似模式。
在实验环节,研究者在一个具有挑战性的测试平台上(逐像素图像生成)检验了这个分形实例。结果显示,本文的分形框架在这一具有挑战性的重要任务上表现出色,它不仅可以逐像素生成原始图像,同时实现了准确的似然估计和高生成质量,效果如下图 2 所示。

研究者希望这一充满潜力的的结果能够激励大家进一步研究分形生成模型的设计和应用,最终在生成建模中建立一种全新的范式。
有人评论道,「分形生成模型代表了AI领域一个令人兴奋的前沿。自回归模型的递归性质反映了学习如何反映自然模式。这不仅仅是理论,它是通往更丰富、适应性更强的AI系统的途径。」

图源:https://x.com/abhivendra/status/1894421316012577231
分形生成模型详解
研究者表示,分形生成模型的关键思路是「从现有的原子生成模块中递归地构建更高级的生成模型。」
具体来讲,该分形生成模型将一个原子生成模块用作了参数分形生成器。这样一来,神经网络就可以直接从数据中「学习」递归规则。通过将指数增长的分形输出与神经生成模块相结合,分形框架可以对高维非序列数据进行建模。
接下来,研究者展示了如何通过将自回归模型用作分形生成器来构建分形生成模型。他们将自回归模型用作了说明性原子模块,以演示分形生成模型的实例化,并用来对高纬数据分布进行建模。
假设每个自回归模型中的序列长度是一个可管理的常数 k,并使随机变量的总数为 N = k^n,其中 n = log_k (N) 表示分形框架中的递归级别数。然后,分形框架的第一个自回归级别将联合分布划分为 k 个子集,每个子集包含 k^n−1 个变量。
在形式上,研究者进行了如下解耦:

接着每个具有 k^n−1 个变量的条件分布 p (・・・|・・・) 由第二个递归级别的自回归模型建模,并依此类推。
研究者表示,通过递归地调用这种分而治之(divide-and-conquer)的过程,分形框架可以使用 n 级自回归模型高效地处理 k^n 个变量的联合分布,并且每个模型都对可管理的序列长度 k 进行操作。
这种递归过程代表了一种标准的分而治之策略。通过递归地解耦联合分布,本文分形自回归架构不仅相较于单个大型自回归模型显著降低了计算成本,而且还捕获了数据中的内在层次结构。从概念上讲,只要数据表现出可以分而治之的组织结构,就可以在该分形框架内自然地对其进行建模。
实现:图像生成实例化
研究者展示了分形自回归架构如何用于解决具有挑战性的逐像素图像生成任务。
架构概览
如下图 3 所示,每个自回归模型将上一级的生成器的输出作为其输入,并为下一级生成器生成了多个输出。该模型还获取一张图像(也可以是原始图像的 patch),将其分割成 patch,并将它们嵌入以形成一个 transformer 模型的输入序列。这些 patch 也被馈送到相应的下一级生成器。
接下来,transformer 模型将上一个生成器的输出作为单独的 token,放在图像 token 的前面。基于此组合序列,transformer 为下一级生成器生成多个输出。
研究者将第一级生成器 g_0 的序列长度设置为 256,将原始图像分成 16 × 16 个 patch。然后,第二级生成器对每个 patch 进行建模,并进一步将它们细分为更小的 patch,并继续递归执行此过程。为了管理计算成本,他们逐步减少较小 patch 的宽度和 transformer 块的数量,这样做是因为对较小 patch 进行建模通常比对较大 patch 更容易。
在最后一级,研究者使用一个非常轻量级的 transformer 来自回归地建模每个像素的 RGB 通道,并在预测中应用 256 路交叉熵损失。

不同递归级别和分辨率下,每个 transformer 的精确配置和计算成本如下表 1 所示。值得注意的是,通过本文的分形设计,建模分辨率为 256×256 图像的计算成本仅为建模分辨率为 64×64 图像的两倍。

本文方法支持不同的自回归设计。研究者主要考虑了两种变体:光栅顺序、类 GPT 的因果 transformer (AR) 和随机顺序、类 BERT 的双向 transformer (MAR),具体如下图 6 所示。

尺度空间自回归模型
最近,一些模型已经提出为自回归图像生成执行下一尺度(next-scale)预测。这些尺度空间自回归模型与本文方法的一个主要区别是:它们使用单个自回归模型来逐尺度地预测 token。
相比之下,本文分形框架采用分而治之的策略,使用生成式子模块对原始像素进行递归建模。另一个关键区别在于计算复杂性:尺度空间自回归模型在生成下一尺度 token 的整个序列时需要执行完全注意力操作,这会导致计算复杂性大大增加。
举例而言,在生成分辨率为 256×256 的图像时,在最后一个尺度上,尺度空间自回归模型每个注意力块中的注意力矩阵大小为 (256 ×256)^2 即 4,294,967,296。相比之下,本文方法在对像素 (4×4) 相互依赖性进行建模时对非常小的 patch 执行注意力,其中每个 patch 的注意力矩阵只有 (4 × 4)^2 = 256,导致总注意力矩阵大小为 (64 × 64) × (4 × 4)^2 = 1,048,576 次操作。
这种减少使得本文方法在最精细分辨率下的计算效率提高了 4000 倍,从而首次能够逐像素建模高分辨率图像。
长序列建模
之前大多数关于逐像素生成的研究都将问题表述为长序列建模,并利用语言建模的方法来解决。与这些方法不同,研究者将此类数据视为由多个元素组成的集合(而不是序列),并采用分而治之的策略以递归方式对具有较少元素的较小子集进行建模。
这种方法的动机是观察到大部分数据都呈现出了近乎分形的结构。图像由子图像组成,分子由子分子组成,生物神经网络由子网络组成。因此,设计用于处理此类数据的生成模型应该由本身就是生成模型的子模块组成。
实验结果
本文在 ImageNet 数据集上进行了实验,图像分辨率分别为 64×64 和 256×256。评估包括无条件和类条件图像生成,涵盖模型的各个方面,如似然估计、保真度、多样性和生成质量。
因此,本文报告了负对数似然(NLL)、Frechet Inception Distance(FID)、Inception Score(IS)、精度(Precision)和调回率(Recall)以及可视化结果,以全面评估分形框架。
似然估计。本文首先在无条件 ImageNet 64×64 生成任务上进行了评估,以检验其似然估计能力。为了验证分形框架的有效性,本文比较了不同分形层级数量下框架的似然估计性能,如表 2 所示。

再来看生成质量评估。研究者在分辨率为 256×256 的类条件图像生成这一挑战性任务上,使用四个分形级别对 FractalMAR 进行了评估。指标包括了 FID、Inception Score、精度和召回率,具体如下表 4 所示。

值得注意的是,本文方法实现了强大的 Inception Score 和精度,表明它能够生成具有高保真度和细粒度细节的图像,如下图 4 所示。

最后是条件逐像素预测评估。
研究者进一步使用图像编辑中的常规任务来检验本文方法的条件逐像素预测性能。下图 5 提供了几个具体示例,包括修复、去除修复、取消裁剪和类条件编辑。
结果显示,本文方法可以根据未遮蔽区域来准确预测被遮蔽的像素,还可以有效地从类标签中捕获高级语义并将其反映在预测像素中。

更多实验结果参阅原论文。
#DeepGEMM
DeepSeek开源通用矩阵乘法库,300行代码加速V3、R1,R2被曝五月前问世
适用于常规 AI 模型和 MoE。
DeepSeek 的开源周已经进行到了第三天(前两天报道见文末「相关阅读」)。今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。

具体来说,DeepGEMM 是一个旨在实现简洁高效的 FP8 通用矩阵乘法(GEMM)的库,它采用了 DeepSeek-V3 中提出的细粒度 scaling 技术。该库支持普通 GEMM 以及专家混合(MoE)分组 GEMM。该库采用 CUDA 编写,在安装过程中无需编译,而是通过一个轻量级的 Just-In-Time(JIT)模块在运行时编译所有内核。
目前,DeepGEMM 仅支持英伟达 Hopper 张量核心。为了解决 FP8 张量核心累加不精确的问题,它采用了 CUDA 核心的两级累加(提升)机制。尽管它借鉴了 CUTLASS 和 CuTe 的一些概念,但避免了对其模板或代数的重度依赖。相反,该库的设计注重简洁性,仅包含一个核心内核函数,代码量仅为 300 行。这使其成为学习 Hopper FP8 矩阵乘法和优化技术的一个简洁且易于获取的资源。
尽管设计轻量,DeepGEMM 在各种矩阵形状上的性能与专家调优的库相当,甚至在某些情况下更优。

开源地址:https://github.com/deepseek-ai/DeepGEMM
早期试用者评价说,「DeepGEMM 听起来就像是数学界的超级英雄。它比高速计算器还快,比多项式方程还强大。我试着用了一下,现在我的 GPU 都在炫耀它的 1350+ TFLOPS,仿佛已经准备好参加 AI 奥赛了!」

这个计算性能如果加上高质量的数据,没准儿能贡献更大的惊喜?

除了性能,「300 行代码的性能超越了专家调优的内核」同样让不少人感到惊讶,有人认为「要么 DeepSeek 破解了 GPU 矩阵的奥秘,要么我们刚刚见证了最高等级的编译器魔法。」

看来,DeepSeek 团队里有一批掌握编译器神秘技巧的顶级 GPU 工程师。

还有人评价说,「DeepGEMM 正在改变我们使用 FP8 GEMM 库的方式,它简洁、快速且开源。这正是 AI 计算的未来。」

在项目的贡献者列表中,有人发现了一个姓 Liang 的工程师,难道是 DeepSeek 创始人梁文锋(真实性有待考证)?

性能
DeepSeek 在 H800 上使用 NVCC 12.8 测试了 DeepSeek-V3/R1 推理中可能使用的所有形状(包括预填充和解码,但不包括张量并行),最高可以实现 2.7 倍加速。所有加速指标均基于内部精心优化的 CUTLASS 3.6 实现。
但根据项目介绍,DeepGEMM 在某些形状上表现不佳。



快速启动
首先需要这些配置
- Hopper 架构的 GPU,必须支持 sm_90a;
- Python 3.8 或更高版本;
- CUDA 12.3 或更高版本,但为了获得最佳性能,DeepSeek 强烈推荐使用 12.8 或更高版本;
- PyTorch 2.1 或更高版本;
- CUTLASS 3.6 或更高版本(可通过 Git 子模块克隆)。
配置完成后,就是部署:
# Submodule must be cloned
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.py然后是安装:
python setup.py install最后在你的 Python 项目中导入 deep_gem,就可以使用了。
更多信息请参见 GitHub 开源库。
路透社:DeepSeek R2 大模型又提前了,5 月之前发布
就在 DeepSeek 紧锣密鼓地开源的同时,人们也在四处探寻该公司下一代大模型的信息。昨天晚上,路透社突然爆料说 DeepSeek 可能会在 5 月之前发布下一代 R2 模型,引发了关注。

据多位知情人士透露,DeepSeek 正在加速推出 R1 强推理大模型的后续版本。其中有两人表示,DeepSeek 原本计划在 5 月初发布 R2,但现在希望尽早发布。DeepSeek 希望新模型拥有更强大的代码生成能力,并能够推理除英语以外的语言。
可见在 Grok 3、Claude 3.7、Qwen 2.5-Max 等竞品面世之后,DeepSeek 又加快了技术演进的步伐。
值得一提的是,媒体也介绍了该公司的一些情况。DeepSeek 在北京开设的办公室距离清华、北大很近(步行可至)。据两名前员工称,梁文锋经常会与工程师们深入研究技术细节,并乐于与实习生、应届毕业生一起工作。他们还描述了通常在协作氛围中每天工作八小时的情况。
据三位了解 DeepSeek 薪酬情况的人士称,这幻方量化与 DeepSeek 都以薪酬丰厚而闻名。有人表示在幻方的高级数据科学家年薪 150 万元人民币并不罕见,而竞争对手的薪酬很少超过 80 万元。
幻方是 AI 交易的早期先驱,一位该公司高管早在 2020 年表示将「All in」人工智能,将公司 70% 的收入投资于人工智能研究。该公司在 2020 年和 2021 年斥资 12 亿元人民币建设了两个超级计算 AI 集群。第二个集群 Fire-Flyer II 由约一万块英伟达 A100 芯片组成,主要用于训练 AI 模型。
在 DeepSeek V3、R1 模型推出之后,全世界对于 AI 技术的期待已经进入了高点。科技公司都在消化 DeepSeek 提出的新技术,修正发展方向,消费者们则纷纷开始尝试各类生成式 AI 应用。
或许下一次 DeepSeek 的发布,会是 AI 行业的又一次关键时刻。
参考内容:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









