







我自己的原文哦~ https://blog.51cto.com/whaosoft/13874251
#从0开始预训练1.4b中文大模型实践
这篇文章主要记录了作者对1.4b中文大模型的实践复现过程。作者选择了QWEN作为基座模型,并训练了一个参数量达到1.4b的预训练模型,其中涉及的训练token数量约为8b。
这篇文章主要记录对1.4b中文大模型的实践复现过程。我选择了QWEN作为基座模型,并训练了一个参数量达到1.4b的预训练模型,其中涉及的训练token数量约为8b。在此过程中,我使用了两张a100 80g显卡,并耗费了大约100个小时的训练时间。尽管这个规模无法与其他大型模型相媲美,但我也取得了一定的效果。
项目:
https//github.com/jiahe7ay/MINI_LLM
动机
实践纪录的动机主要如下:
1.在阅读了Allen实验室发布的关于OLMO模型的技术报告后,我深受启发。他们不仅详细介绍了模型的训练细节,还大方地开源了整套大模型构建的代码,涵盖了数据处理、训练、评估等各个环节。这种开源精神让我深感敬佩,我也想为开源尽自己的一份薄力。
2.其实自己尝试预训练一个大模型,这是我一直以来都非常想尝试做的事情,由于对自己的能力和所拥有的资源持有疑虑,我一直未能付诸实践。然而,机缘巧合之下,我在github上看到了这两个项目:
- baby-llama2-chinese
- Phi2-mini-Chinese
在深入研究了上述两个项目后,我深受启发,意识到个人尝试复现一个大模型是完全可行的。因此,我决定基于这两个项目的成功经验,结合我自身的需求,更换它们所使用的模型和训练数据集。通过这一尝试,我希望能够训练出属于我自己的“大模型”。通过这样的实践,我能够更深入地理解预训练模型的工作原理,并为我未来的研究和工作积累宝贵的经验。
3.随着技术的不断发展和资源的日益丰富,越来越多的大厂开始关注参数量相对较小的大模型,如qwen-0.5b和phi-2b等。这一趋势让我意识到,在未来,参数量相对较小的大模型可能会在大模型领域中占据一席之地。
相较于庞大的模型,参数量相对较小的大模型具有更低的计算需求、更快的训练速度和更少的资源消耗。这使得更多的个人和团队能够参与到大模型的训练和应用中,推动了技术的普及和发展。同时,这类模型也在某些特定任务上展现出了不俗的性能,证明了其在实际应用中的价值。
总的来说,我个人非常看好参数量相对较小的大模型的发展前景。
细节
模型基座的选择
在我的项目中,我选择了QWEN作为基座模型,并将其配置扩展至1.4b参数规模。具体的修改细节,您可以在我的项目中的模型config文件中找到。我主要调整了模型的注意力头数和层数,以适应我现有的算力资源。当然,每位研究者都可以根据自己的需求和资源情况来进行相应的调整。
选择QWEN模型的原因在于,我认为它是一个成熟且稳定的中文开源大模型。此外,我注意到其他大模型复现项目通常都会自行训练tokenizer,但考虑到我个人并不希望在这一步骤上花费过多时间和精力,我决定从现有的开源项目中选取一个tokenizer。经过对比不同项目的tokenizer的压缩率和训练规模,我发现QWEN的tokenizer表现优异,因此我最终选择使用它,并决定整个模型也采用QWEN。毕竟,我的目标主要是进行复现实践,而非创造出一个新的模型。
训练数据的选择
1.wikipedia-cn-20230720-filtered:本数据集基于中文维基2023年7月20日的dump存档。作为一项以数据为中心的工作,本数据集仅保留了质量较254,547条高的词条内容。
2.中文BaiduBaiKe的数据
3.天工150b中文预训练数据集:因为算力资源限制,我只下载了前20个文件
4.bell数据集:使用了这数据集中的2M,0.5M和1M作为sft的训练数据集
训练集构造
在数据预处理阶段,我遵循了QWEN的通用做法,即在每个文章的末尾加上一个特定的结束符号“<|im_end|>”。这个符号的作用在于清晰地界定单篇文章的边界,确保模型在训练时能够准确地识别出文章的结束位置,从而与下一个文章进行区分。
此外,考虑到模型训练对输入序列长度的限制,如果文章长度超过了这一限制,我会进行截断处理。具体来说,我会将超长的文章截断至规定长度,并将截断的部分作为下一个样本。这样做不仅保证了模型输入的合规性,同时也充分利用了原始数据,避免了信息的浪费。
这种数据预处理方式既遵循了行业内的常见做法,又考虑到了模型训练的实际需求,有助于提升模型的训练效果和泛化能力。
环境
如果安装了flash-attn的话,训练速度大概能提升20%,但是我发现这个flash-attn越来越不好装了。
具体的requirements如下:
datasets
transformers==4.36.0
torch==2.2.0
accelerate==0.27.2
einops==0.7.0
flash-attn==2.5.5
tiktoken
einops训练参数
预训练参数如下:
per_device_train_batch_size=24,
per_device_eval_batch_size=4,
gradient_accumulation_steps=10,
num_train_epochs=1,
weight_decay=0.1,
ddp_find_unused_parameters=False,
warmup_steps=0,
learning_rate=1e-4,
evaluation_strategy='steps',
eval_steps=100,
save_steps=50,
save_strategy='steps',
save_total_limit=4,
report_to='tensorboard',
optim="adamw_torch",
lr_scheduler_type='cosine',
bf16=True,
logging_steps=20,
log_level='info',
logging_first_step=True,sft训练参数
per_device_train_batch_size=32,
gradient_accumulation_steps=2,
num_train_epochs=3,
weight_decay=0.1,
warmup_steps=0,
learning_rate=6e-5,
ddp_find_unused_parameters=False,
evaluation_strategy='steps',
eval_steps=500,
save_steps=500,
save_total_limit=3,
report_to='tensorboard',
optim="adamw_torch",
remove_unused_columns=False,
lr_scheduler_type='cosine',
bf16=True,
logging_steps=10,
log_level='info',
logging_first_step=True,值得注意一点是:
1.多卡的话最好设置ddp_find_unused_parameters=False,这样也能提升训练的速度
2.尽可能地把单个bs调大,因为我试过把单个bs没有调那么大,通过使用累积梯度步数来增大总的bs,但是收敛的没有把单个bs调大快,我在想这个和学习率调整有关。
训练加速
使用了accelerate库来使用deepspeed来加速,只需要运行 accelerate launch --multi_gpu --config_file accelerate_multi_gpu.yaml xx.py即可
具体的配置如下:
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 10
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: false
zero3_save_16bit_model: false
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false启动训练

训练的是天工数据集前10个文件

占用的显存
训练结果
预训练loss
我首先预训练的数据集是维基百科加百度百科,然后把checkpoint权重保存下来

loss是维基百科加Baidu
接着上次预训练的权重,继续预训练。

loss是天工前20个数据集
sft训练loss

sft训练的loss
其实通过上面这几个Loss图,就能看出大模型的训练都遵循scaling law的原则,图的走向基本都是那样的,所以这次实践让我更深一步体会到了大模型 scaling law的威力。
模型效果
1.简单的问好

能回答问候
2.一些通识类的问题
乔布斯的问题基本能回答对80%了,但乔布斯不是在攻读博士的期间开始创业的,还是会有幻觉的问题。苹果公司的基本回答无误了。在介绍广州这个问题上,还是会有重复回答的问题,出现了两个广州塔

3.模型有分辨问题并进行准确回答的能力
这四个问题它都回答正确了

4.尝试使用它来写一下代码
首先让它写一个排序算法,它用文字给出了思路,可以看出它给出的是思路是冒泡排序,如果不细看感觉对了,但是仔细看第2步中的“继续比较下一个值和最后一个值”,这个最后一个值是不是多余了,还是差了一点点才能回答正确
然后再让它使用python写一个排序算法,好家伙,直接化身调包侠哈哈哈哈哈。但是它关于这个代码的注释还是有些地方写错了,比如第一个注释说将排序后的结果储存在新的列表中,代码中并没有。第二个注释中的列表名字说错了。

使用python写排序算法
5.尝试写一下文案
这一部分倒是写的有模有样的。

#大模型落地实用主义思考
要想跑出来,无非是做好能力和数据天平的配平。要么选一个简单的场景,当你的任务越难,能力越远离通用大模型,越深潜,越复杂,就需要越多,越好,越相关的垂类数据来训练大模型。
这两天腾讯搞了两个很好的采访,分别是杨植麟,一位是朱啸虎。杨植麟是AIGC创业者学术大佬,朱啸虎是TMT方向颇负盛名的投资大佬。两篇文章的链接分别是:
1.杨植麟采访:https://mp.weixin.qq.com/s/kEKotLcnlFK0jf8gNajXIg
2.朱啸虎采访:https://mp.weixin.qq.com/s/4111julSNH4XPXsUc8XEXA
原文比较长,让大模型来总结下:
我仔细检查了两篇文章,并对我的回答进行了补充和完善,以确保完整覆盖所有方面
杨植麟与朱啸虎对AGI的看法
1.对大模型创业的看法:
杨植麟: 坚定看好大模型创业,认为这是未来十年唯一有意义的事,并将其视为一个结合科学、工程和商业的系统,需要长期投入和坚持,最终目标是实现 AGI
朱啸虎: 不看好大模型创业,认为现阶段大模型公司缺乏场景和数据,估值过高,且面临开源模型的竞争,投资风险大。他更倾向于投资能快速商业化、变现的应用层项目。
2.对开源模型的看法
杨植麟: 认为开源模型落后于闭源模型,且差距会持续存在因为开源的开发方式和人才、资金聚集程度都无法与闭源模型
朱啸虎: 认为开源模型会逐渐赶上闭源模型,因为技术迭代曲线会放缓,且开源社区有更多开发者参与。他认为中国开发者更倾向于使用开源模型,因为不用担心被抄袭
3.对 AGI 的看法:
杨植麟: 坚定相信 AGI 是未来,并将其作为公司发展的长期目标。他认为 AGI 会改变世界,并希望通过技术突破和用户产品的结合来实现这一目标。
朱啸虎: 对 AGI 持怀疑态度,认为至少在5到10 年内还无法实现。他更关注短期内能商业化的应用,并认为在现阶段投入三资研发 AGI 风险过高。
4.对中美大模型产业的看法
杨植麟: 认为中美在基础通用能力上不会有太大差别,但在通用能力基础上的差异化应用更可能发生。他也相信中国公司未来有机会在某些方面取得领先。
朱啸虎: 认为中美在大模型领域差距很大,美国在底层技术上领先,而中国在应用场景和数据上更有优势。他建议中国创业公司先聚焦国内市场,再考虑出海。
5.对投资策略的看法:
杨植麟: 追求长期主义,愿意投入大量资金和资源进行前沿探索,并相信技术突破最终会带来商业回报
朱啸虎: 追求短期回报,更倾向于投资能快速商业化、变现的项目,并强调创业公司要控制成本、不要烧钱。
6.对 Sora 的看法:
杨植麟: 认为 Sora 是一个重要的里程碑,代表着视频生成技术的巨大进步,并认为它可以用来提升对多模态输入的理解能力,以及打通数字世界和物理世界
朱啸虎: 文章中没有明确表达对 Sora 的看法,但他对视频生成技术的前景表示乐观,并认为中国公司有机会在这一领域取得领先。
7对创业公司和巨头的关系的看法
杨植麟: 认为巨头和创业公司在目标和策略上有所不同,但两者之间存在着竞争和合作关系
朱啸虎: 认为大模型创业公司最终可能会被巨头收购,但收购价格不会很高,因为大模型技术同质化严重
8.对创业的风险和挑战的看法
杨植麟: 坦然接受创业的风险和挑战,并表示会无所畏惧地往前冲。
朱啸虎: 认为在当前的宏观环境下,创业公司要更加注重控制成本和自我造血能力,才能在市场竞争中存活下来
9.对未来的展望
杨植麟: 对未来充满乐观,相信 AGI 可以推动人类文明进入下一个阶段。
朱啸虎: 对未来持谨慎态度,认为技术发展存在不确定性,创业公司需要更加现实和务实。
10.对人才的看法
杨植麟: 重视人才密度,并认为公司上限是由人的上限决定然后 补充其他维度的人才。打造的。他一开始寻找天才个完整、有韧性、能打仗的团队。
朱啸虎: 认为大模型领域的人才同质化严重,创业公司需要找到有商业头脑和管理销售能力的人才,才能在市场竞争中胜氏。
11.对商业化的看法
杨植麟: 认为商业化是实现 AGI 的手段和目的,但不能为了追求短期商业利益而放弃长期目标。
朱啸虎: 认为商业化是检验大模型公司价值的唯一标准,并强调创业公司要找到能快速变现的场景和应用,
总结: 杨植麟和朱啸虎代表了两种不同的投资理念和对 AI 发展路径的判断。两种观点各有其合理性,最终谁的判断更准确,还需要时间来验证。一位是典型的实用主义,一位是典型的长期主义,谁对谁错需要更长的时间来验证。
我们从落地的角度看看,AGI有哪些“实用主义”的问题。
环顾四周,除了写代码,看文档之外,目前大模型对C端落地的应用最多的两个场景,一个是电商+助手(淘宝问问,京东京言), 另外一个是评论区+助手(小红书,B站,什么值得买)。前一个目前距离理想效果有一定差距,后一个有较好的表现。
分析电商+多轮chat助手落后的主要原因,技术方面如下:
1.大模型能力有限。电商类助手依赖大模型作为Agent大脑,但是现阶段大模型能力有限,无法完成特别复杂的决策。大模型可以很好的学习大量的语料,获取人类的知识,也可以学习大量的代码,获取形式化和逻辑的能力,但不擅长在一个特别具体的任务上做深入思考。
2.特定训练数据缺乏。chat+电商缺少真实的导购语言交互数据,与之相对推销是一个典型的有大量语言交互数据的场景,朱啸虎也提到了,这个B端方向取得了较好的落地进展。在“直接推断”或者“少量训练”模式下,大模型不能很好的理解用户一个垂直场景的各类长尾需求。为此,大家利用GPT4的能力,要么直接使用GPT4进行prompt的指令构造,要么使用GPT4构造数据,其优点是可以快速上线拿到60分,缺点在于天花板不高,未从根本上解决真实导购数据缺失问题。
产品方面因为体验不到较为理想的状态,用户的留存较低,抱着好奇心体验后,未有持续使用的意愿,无法形成积累数据和体验提升的飞轮。总结来看,是因为大模型能力和数据问题,导致了目前的电商导购AI助手的体验不达预期,形成了“简单的问题无需助手,复杂的问题助手又解决不了”的局面。
另外你真的需要一个助理吗?
需要,但不是一个APP上的助理,也不是一个手机里的助理,而是一个真实世界,能取外卖,订餐馆,订会议室,整理会议纪要,订机票的助理。
这里面的差别就是,Agent解决应用内的十位数内的接口调用,而助理真的需要连接真实世界万种接口调用,现在AI做不到。
传统的搜广推通过列表页的高效精准呈现信息,而导购助手在一个粗略模糊的需求上,也给个位数选择,与目前大家网购的真实习惯有极大的冲突。
当然,大模型在这个事上也不是一无是处,在技术上,大模型带来一个的优势是,让传统的任务对话的pipeline变简单了,开发一个这样的导购的任务型机器人了不需要那么多人工定制的部分,GPT可以把意图识别,槽位提取做个60分,并且自带一点生成和总结的能力。
虽然大模型对开发简化提效有所帮助,但大模型并未提高助理效果的核心因素,如理解、规划和推理等。没有数十万规模的真实的助理数据训练,无法理解其垂直场景的各种长尾情况。
逛淘宝买衣服的女同胞和给领导订餐馆的朋友可知其难度。
与之相对的,我们应该尽可能去寻找大模型落地的可能性较高的场景,要有两个特点:1.符合大模型能力要求2.数据满足要求的场景,进而形成体验和数据的飞轮。
目前落地较好的一些B端应用,都有如下特点:
1.相对基座已经有的能力,其任务简单,不过分依赖大模型的推理,规划,思考能力,仅利用其生成和记忆本质。
2.场景有较完备的数据支撑。
这两个是一个天平的关系,越难的垂直任务,需要越多越好越相关的数据。
大家都说,现在大模型很强了,Agent的工具调用能力可以低成本开发很多应用,确实,大模型在垂直应用的意义就是把其中一部分任务的难度降低了,让你不需要特别多的垂类数据也能做很好。但是,大模型也不是擅长所有的事情,在很多场景,仍需非常多的数据微调。我们看看核心的两个问题。
一、大模型的能力边界在哪?
定性来说,能力边界是任务对大模型能力提出的要求及格分数线。在回答能力边界是什么上,我们首先要想办法定义一个任务的难度。如传统的分类任务中,我们可以通过类别多少,类别差异性来判断一个任务的难度,典型的大规模2000文本细粒度分类的任务就要比二极的情感分类难上很多。大模型也是如此,我们定义的难度指标主要与三个角度:
1.与基座相似性:任务需要的能力,相比基座原有的能力越接近,则构建该任务越简单。比如写代码,文本摘要等,这些都是大模型基座能力的舒适区,构建一个类似的应用,需要的额外的场景的数据量越少,给基座写几个prompt就可以搞定了。
2.场景深潜:任务需要的能力,是漂在任务的表面,还是需要挖掘场景内各种“长尾”。比如订餐助手,你如果只考虑做什么时间,什么餐馆,几个人吃饭,那就是传统的任务型对话都可以搞定的简单任务。如果是另外一个场景,“刚刚领导打电话给我,让我晚上陪他参加一场饭局,让我提前去饭店把菜点好”,这个问题就非常困难,需要仔细了解各种各样的情况,结合“人”和POI的特点综合考量,难上加难。
3.逻辑复杂:任务需要的能力,是直来直去,还是逻辑复杂。写代码的逻辑并不复杂,可以用形式语言描述,有非常严格的语法表达;查阅论文知识的逻辑也并不复杂,只需要预训练阶段大量记忆,根据语义的相关性检索记忆就可以。复杂的逻辑要求大模型走出总结,概括,记忆的舒适区,去挑战真正的能力泛化。
看一下GPTs应用商店的应用热度top10,主要集中在科学研究,写代码,文档问答,图像生成等领域。其实总结也可以发现,GPT落地应用较好的几个领域,除图像外有以下几种共性:强知识储备低复杂逻辑,与基座具有的能力相似,离个性化较远。侧重于总结,抽取,整理或形式语言,诸如写代码,看论文,PDF文档问答等应用。
二、到底需要多少数据和什么样的数据?
1.数据量:在考察我们场景的数据丰富度的时候,并非所有任务一概而论,到底多少数据才够,要考虑上文提到的场景的“难度”。随着一个任务难度的提升,需要的数量量也是成指数性增长。比如写代码,1k的prompt足够。总结摘要回答问题,Lora +几千条数据也够了,AI营销机器人,需要几十万的真实推销交互数据。复刻GPT4,需要千亿数量级的token数。另外,数量只是数据的一个维度,还有两个很重要的维度是数据哪里来和数据质量。
2.数据一致性:数据越接近于交互的结果,越直接相关越好。通常数据来源有三种:真实数据,转写数据,生成数据。生成数据就是蒸馏GPT4,真实数据是直接的用户交互产生的数据,转写数据通过其他方式,把用户的数据转录为语言。比如学习一个熟练的销售员在微信上的聊天记录,要比使用ASR翻译的推销电话效果要好,更远远好于用GPT4模仿一个高级销售的效果。
3.数据质量:数据的质量越高越好。驻场硕士标注员清洗/标注的数据,大概率好于外包标注。openAI花了大价钱寻找的标注员也是有备而来的,他可不是乱找的。
看完了技术分析,我们再看看这1.5年的大模型应用整体情况。
2023年是大模型快速发展的一年,也是人们对大模型的认知迭代逐渐收敛清晰的一年。
在资金意愿和落地进展两方面,基座都领先于应用。2月20日,AI领域内的初创企业月之暗面融资超10亿美元,应用方面微软接入GPT4打造Copilot已经过去一年。
更具体地回顾这一年,在基座能力方面,我们观察到的时间线是:22年末的狂热,23年初期国产化的奋起追赶,23年中GPT4发布,23年底国产大模型基座在一年内差不多具有了GPT3.5的能力。
在应用能力方面,热点追踪主要从23年初诞生了RAG概念和llama index ,langchain等开源工具,23年中Agent概念火爆,GPTs应用商店发布,24年初sora发布。
整体看起来,大家对于国产基座追赶GPT4的目标,还保持着高涨的热情和投入。
但是在C端应用方面,除了几个大模型能力甜点区,如写代码,看论文,文生图等场景取得了较好的落地效果,在其他拟人要求高,思考能力要求高的应用上,大模型的落地进展落后于预期。
参考华为天才少年的演讲,我们拆分两个维度,分别是思考深度和人格特点,通过这两个维度划分典型应用,横轴是人格轴,对应着有趣的强人格和有用的工具两端;纵轴是思考深度的维度,即快速思考与缓慢思考。快速思考类似于下意识的反应,不经过深思熟虑,如ChatGPT这种即问即答的模式可以视为一种快速思考,缓慢思考则涉及到有状态的、复杂的思维过程,比如规划和解决复杂问题的顺序和方法。大模型的优势区是第三象限(弱人格,强工具,低深度,快思考),如下图所示。

目前落地较好的也是第三象限。
B端应用方面,除了在与基座能力近的方向落地很好,如Copilot,写代码,看文档等,另外在一些数据丰富的垂直场景效果也很不错,比如微信的私域营销,AI电话等。
所以,最后总结起来,要想跑出来,无非是做好能力和数据天平的配平。要么选一个简单的场景,当你的任务越难,能力越远离通用大模型,越深潜,越复杂,就需要越多,越好,越相关的垂类数据来训练大模型。
#大模型在复杂推理任务上潜力如何?多智能体互动框架ThinkThrice玩转剧本杀
剧本杀是一种广受欢迎的多角色扮演侦探游戏,要求玩家扮演不同的角色。通过阅读角色文本、理解各自的故事、搜集线索、以及逻辑推理,玩家们共同努力揭开谜团。游戏角色通常被分为平民和凶手两大类:平民的目标是找出隐藏在他们中间的凶手,而凶手则尽力隐藏自己的身份,避免被发现。那么,如果让 AI 加入游戏,会产生怎样的新变化呢?

剧本杀游戏流程。
加拿大蒙特利尔大学和 Mila 研究所的研究团队带来了一项令人兴奋的新研究,将 AI 的潜力引入到剧本杀游戏中。这项研究不仅展现了大型语言模型(LLM)在复杂叙事环境中的应用潜力,而且为 AI 智能体的推理能力评估设定了新的试验场。让我们一起深入了解这项研究的细节和其带来的启发。
论文链接:https://arxiv.org/abs/2312.00746
研究动机:AI 与剧本杀的交汇
AI 的进步已经使其被广泛应用于各种游戏中。然而,剧本杀游戏以其独特的玩法和复杂的设置,仍是一块待开发的新领域。为了将 AI 引入剧本杀游戏中,蒙特利尔大学的研究团队面临三个主要挑战:
首先,剧本杀游戏中复杂的角色情节和人物关系要求 AI 不仅要理解所扮演的游戏角色的背景和动机,还要能够适应游戏剧情的多层次叙事,通过在游戏中和其他角色互动来收集其他角色的信息、还原案件原貌。
其次,由于缺乏专门为剧本杀设计的数据集,需要开发一个包含丰富文本的剧本杀数据集,这对于启动和评估 AI 模型至关重要。
最后,如何准确定量和定性地评估 AI 在剧本杀游戏中的表现也是极具挑战性的任务。因为在剧本杀游戏中,目标不仅是赢得比赛,更重要的是理解游戏剧情并揭露案件的真相。为此,AI 需要在参与游戏的过程中展示出卓越的沟通交流、信息收集以及逻辑推理能力。
这项研究的贡献主要涵盖四个方面:
- 首先,团队构建了一个专门针对剧本杀游戏的数据集,旨在启动和评估 AI 模型;
- 其次,团队设计了一个多智能体互动框架,允许剧本杀游戏自动进行,从而无需人为干预;
- 再者,团队开发了一套量化和质化评估方法,以评估 LLM 智能体在游戏中的信息搜集和推理能力;
- 最后,通过利用最新的上下文学习技术,团队设计了增强 LLM 智能体性能的模块。
此项研究不仅推动了 AI 在多角色互动的复杂叙事游戏:剧本杀中的应用研究,也为智能体的评估和性能优化提供了新的视角和方法。
数据集构建:剧本杀游戏的数字化转型
为了在剧本杀的环境下启动和评估 AI 模型,研究团队精心收集了 1115 个剧本杀游戏案例,创建了一个庞大的数据库。这些游戏包含了丰富的关于剧本杀游戏的游戏规则、剧情故事、角色背景、案件线索等文本信息,为 AI 的仿真和测试提供了理想的素材,使得研究人员能够在模拟的环境中准确观察和评估 AI 智能体的表现。此外,数据集还提供了图片、视频、音频等多模态的信息,为未来多模态的 AI 智能体的开发和测试提供了可能。

表 1. 剧本杀数据集中不同模态的游戏剧本数量

表 2:剧本杀数据集中游戏剧本的玩家数量和token统计。
ThinkThrice 框架:AI 如何玩转剧本杀
研究团队开发了一个名为 ThinkThrice (三思) 的多智能体互动框架,允许基于 LLM 的 AI 智能体自主参与剧本杀游戏。这个框架通过记忆检索、自我完善和自我验证三个使用上下文学习技术的 模块确保 AI 智能体能够有效地理解游戏情景,收集信息,并进行逻辑推理。AI 智能体的每一步动作,包括询问、回应、投票等,都是基于其角色剧本和以往的交互记录由 LLM 自动产生的。

ThinkThrice (三思) 框架。
评估方法:新的评价标准
研究者设计了事实性问题回答和推理性问题回答两项任务来评估 AI 智能体的表现。事实性问题旨在测试 AI 智能体在游戏过程中收集的信息量,而推理性问题则评估 AI 使用这些信息进行推理的能力。其中推理性问题不仅需要考察 AI 智能体对特定问题的答案,还要评估其背后的推理过程是否合理。

表 3:事实性问题示例。

表 4:推理性问题示例。
实验结果:AI 智能体的侦探能力评估
实验结果表明,与基线模型相比,引入记忆检索、自我完善和自我验证模块的 AI 智能体在回答关于其他角色的事实性问题时,准确率得到了显著提升。这证明了信息交流在理解游戏中其他角色的行为和动机方面至关重要。此外,AI 智能体信息收集能力的增强,也显著提高了其在推理解案和识别凶手方面的表现。这表明 AI 智能体通过收集充足的信息和进行有效的推理,能够更准确地确定凶手身份。

表 5:AI 智能体回答关于自己扮演角色的事实性问题 (Own Q) 和其他角色的事实性问题 (Other’s Q) 的准确率。

AI 智能体使用 GPT-3.5 和 GPT-4 时的推理准确率。

AI 智能体的凶手识别准确率和平民玩家胜率。
结语
该研究通过将大型语言模型(LLM)智能体引入侦探角色扮演游戏 “剧本杀”,探索了 LLM 智能体在复杂叙事环境中的应用潜力,为观察和评估 LLM 智能体的行为及能力提供了新的视角和方法,并为社区深入理解大型语言模型的能力开辟了新途径。通过实证研究,该团队证明了其设计的多智能体互动框架和上下文学习模块在信息收集、凶手识别和逻辑推理能力方面,相较于基线模型有了显著提升。这一发现预示着 LLM 在复杂推理任务中应用的广阔前景。预计在不远的将来,AI 将能够与人类携手解决复杂场景的推理问题。
#当prompt策略遇上分治算法,南加大、微软让大模型炼成「火眼金睛」
近年来,大语言模型(LLMs)由于其通用的问题处理能力而引起了大量的关注。现有研究表明,适当的提示设计(prompt enginerring),例如思维链(Chain-of-Thoughts),可以解锁 LLM 在不同领域的强大能力。
然而,在处理涉及重复子任务和 / 或含有欺骗性内容的任务(例如算术计算和段落级别长度的虚假新闻检测)时,现有的提示策略要么受限于表达能力不足,要么会受到幻觉引发的中间错误的影响。
为了使 LLM 更好地分辨并尽可能避免这种中间错误,来自南加州大学、微软的研究者提出了一种基于分治算法的提示策略。这种策略利用分治程序来引导 LLM。
论文地址:https://arxiv.org/pdf/2402.05359.pdf
具体来讲,我们将一个大任务的解决过程解耦为三个子过程:子问题划分、子问题求解以及子问题合并。理论分析表明,我们的策略可以赋予 LLM 超越固定深度 Transformer 的表达能力。实验表明,我们提出的方法在受到中间错误和欺骗性内容困扰的任务中(例如大整数乘法、幻觉检测和错误信息检测)可以比经典的提示策略获得更好的性能。
太长不看版:我们发现在应用 LLM 处理较长的问题输入时,把输入拆分然后分而治之可以取得更好的效果。我们从理论上解释了这一现象并实验角度进行了验证。
研究动机
本文的研究动机来自于实验中观察到的有趣现象。具体来说,我们发现对于涉及重复子任务和 / 或含有欺骗性内容的任务(如段落级别长度的虚假新闻检测),对输入进行拆分可以提升模型对于错误信息的分辨能力。下图展示了一个具体的例子。
在这个例子当中,我们调用大语言模型来评估一段总结性文本是否与完整的新闻报道存在事实性冲突。

在这个任务中,我们尝试了两种策略:耦合策略和分治策略。在耦合策略下,我们直接为模型提供完整的新闻报道和整段总结性文本,然后要求模型评估二者是否存在冲突。模型错误地认为二者不存在冲突,并且忽视了我们标红的冲突点(新闻中明确表示调查人员否定了录像的存在,然而总结中的第一句话表示录像已被成功复原)。
而当我们采取分治策略,也就是简单地将总结性文本拆分成多句话,然后分别对每句话进行评估,模型成功地识别出了冲突。
这个例子向我们展示了:对长输入进行划分可以帮助我们更好地解锁模型的能力。基于这一点,我们提出利用分治程序来引导 LLM,从而赋予模型更强的分辨力。
基于分治的提示(prompting)策略
我们提出使用分治(Divide-and-Conquer, DaC)程序来引导 LLM。该程序包括三个不同的子过程:子问题划分、子问题求解以及子解答合并。
在子问题划分,我们提示 LLM 将任务分解为一系列具有较小规模的并行同质子任务(例如将长段落分解为句子)。这里的并行原则保证模型可以分别处理这些子任务而不依赖于某些特定的求解顺序。也因此,一个子任务的解答不会依赖于其它子任务的解答的正确性,这增强了模型对于中间错误的鲁棒性,使模型获得更强的分辨力。
之后,在子问题求解阶段,我们提示 LLM 分别求解每个子任务。
最后,在子解答合并阶段,我们提示 LLM 将每个子任务的答案组合起来并获得最终答案。在这个过程中,所有三个阶段的推理过程都被隔离开来以避免干扰。它们都由一个程序而不是 LLM 来引导,以避免幻觉或来自输入上下文的欺骗。
在下面的示意图中,我们将自己的方法和目前流行的提示策略进行了对比。

为了解决不同规模的任务,我们提出了两种变体:单级分治策略 (Single-Level Divide-and-Conquer) 和多级分治策略 (Multi-Level Divide-and-Conquer)。单级策略中,我们只对输入进行一次划分,然后就开始进行求解。在多级策略中,我们可以递归调用分治程序,从而把求解过程展开成一棵多层的树。


理论分析
我们通过理论分析展示了为什么分治策略能够提升大语言模型的分辨力。
此前的工作(Feng et al 2023, Merrill & Sabharwal 2023)已经证明,现有的通用大语言模型所普遍采用的固定深度与对数精度的预训练 Transformer,存在表达能力上的限制。
具体来说,假设 NC1 类问题严格难于 TC0 类时(TC0 和 NC1 是并行计算理论中的两大类问题,其关系类似 P 与 NP),那么这些 Transformer 模型在处理 NC1 完全问题时,其模型宽度需要以超多项式(如指数)级别的速度随问题规模增长。NC1 完全问题包含了很多常见的问题,比如两色 2 叉子树匹配问题。
而我们此前提到的评估两段文本是否存在事实性冲突的问题,恰好可以被视为判断总结文本所对应的语义树是否匹配新闻材料的语义树的一棵子树。因此,当总结性文本足够长时,大语言模型会面临表达能力不足的问题。我们的理论分析严格证明了,在基于分治的提示策略下,存在一个宽度和深度均为常数的 Transformer,可以在 log(n)的时间复杂度下解决任意规模的两色 2 叉子树匹配问题
实验结果
我们考虑了三个任务:大整数乘法、幻觉检测、新闻验证。我们基于 GPT-3.5-Turbo 和 GPT-4 进行评估。对于大整数乘法,此前的工作已经证明,ChatGPT 难以正确计算 4 位以上的整数乘法问题。因此我们使用 5 位乘 5 位的乘法来验证我们的提示策略的有效性。
结果如下图所示,可以看出,无论是准确率指标还是编辑距离指标,我们的方法相对其他 baseline 都具有明显优势。

对于幻觉检测,我们采用 HaluEval 数据集中的 Summarization Hallucination Detection 子集。对于该子集,模型需要根据一段新闻材料判断一段总结性文本是否包含幻觉。我们将总结性文本划分为单句并分别进行检测。
检测结果如下,可以看到,我们的方法相对 baseline 更好的平衡了精确度和召回率,从而取得了更好的准确率和 F1 score。

对于新闻验证,我们基于 SciFact 数据集构造了一个段落验证数据集。对于该数据集,模型需要根据一篇学术论文中的段落判断一段新闻报道是真新闻还是假新闻。我们将新闻报道划分为单句并分别进行检测。
检测结果如下,可以看到,我们的方法相对 baseline 取得了更好的准确率和 G-Mean score。

#Attention的分块计算: 从flash-attention到ring-attention
flash attention是LLM训练的标配。它是一个加速attention的cuda算子;ring attention则是利用分布式计算扩展attention长度的一个工作。然而它们背后的核心则都是softmax局部和全局关系的一个巧妙公式。
观察到局部softmax和全局softmax的关系,充分利用容量小但速度快的cache计算局部的attention,再推导出全局的attention,最终达到加速attention计算,或扩展attention长度的目的。
概要
局部的softmax和全局的softmax可以推出一个公式关系。利用这一点,flash-attention使用SRAM来计算局部的attention,再规约到全局的attention,并将attention包装为一个CUDA kernel,大大加速attention计算速度,并减小现存占用。而ring attention则反着利用这个公式关系,让一个GPU计算attention的一个局部,整个GPU多卡集群就可以计算出全局的attention,这样就大大扩展了Transformer序列长度。
方法
局部softmax和全局softmax之间的关系


这样的好处是什么呢?
attention里面的softmax,一般值还挺多的,特别是对于长序列,所以整体计算全局softmax,可能cache里面就放不下,就得放到容量大但是比较慢的地方去计算这些数了。而局部的值,数量少,就可以放在cache里面算,算完以后再根据上面的公式,把总体的softmax算出来。
flash attention:利用SRAM作为cache
flash attention是一个attention的算子,主要目的是加速attention的计算。
GPU里面的存储有个层次结构。HBM (high bandwidth memory,可以认为就是cuda编程里面的global memory)就是显卡上边的memory,容量大,但是速度慢; SRAM (Static Random-Access Memory,可以认为就是cuda编程里面的shared memory),容量小,但是速度快。
flash-attention的核心思想就是,把attention的计算分成一小块一小块的,放在SRAM里面算,算完以后再通过前面介绍的关系,把全局的attention值算出来。大大提升了attention的计算速度。
flash-attention还把整个attention的计算做成一个算子,这样就可以把中间的结果给它省掉,大大减小了显存占用。

CPU/GPU计算时候的存储层次结构 from flash-attention
ring attention:利用单GPU卡作为cache
ring attention的主要目的是扩展Transformer的序列长度。计算Transformer序列长度的一个核心困难是算attention的时候,序列太长会OOM。
ring attention的核心想法是,每一个GPU只计算一个局部的attention,然后全局的attention再利用前面的公式给计算出来。这样,因为每个GPU的算的attention长度就没那么长了,就可以计算了,但整体的attention长度就可以大大扩展了。这个attention长度的扩展还是根据GPU数量线性增加的,有多少GPU就能扩多长,所以ring attention的论文题目里说"Near-Infinite Context"。
小结与想法
flash attention已经是LLM训练的标配了。它是一个加速attention的cuda算子;ring attention则是利用分布式计算扩展attention长度的一个工作。然而它们背后的核心则都是softmax局部和全局关系的一个巧妙公式。真的是非常漂亮。
#RLx2~~
大模型时代,模型压缩和加速显得尤为重要。传统监督学习可通过稀疏神经网络实现模型压缩和加速,那么同样需要大量计算开销的强化学习任务可以基于稀疏网络进行训练吗?本文提出了一种强化学习专用稀疏训练框架,可以节省至多 95% 的训练开销
深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨大潜力。然而现有的生成小型模型的方法主要基于知识蒸馏,即通过迭代训练稠密网络,训练过程仍需要大量的计算资源。另外,由于强化学习自举训练的复杂性,训练过程中全程进行稀疏训练在深度强化学习领域尚未得到充分的研究。
清华大学黄隆波团队提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),可适用于多种离策略强化学习算法。 它采用基于梯度的拓扑演化原则,能够完全基于稀疏网络训练稀疏深度强化学习模型。RLx2 引入了一种延迟多步差分目标机制,配合动态容量的回放缓冲区,实现了在稀疏模型中的稳健值学习和高效拓扑探索。在多个 MuJoCo 基准任务中,RLx2 达到了最先进的稀疏训练性能,显示出 7.5 倍至 20 倍的模型压缩,而仅有不到 3% 的性能降低,并且在训练和推理中分别减少了高达 20 倍和 50 倍的浮点运算数。
- 论文主页:https://arxiv.org/abs/2205.15043
- 论文代码:https://github.com/tyq1024/RLx2
在游戏、机器人技术等领域,深度强化学习(DRL)已经取得了重要的应用。然而,深度强化学习模型的训练需要巨大的计算资源。例如,DeepMind 开发的 AlphaGo-Zero 在围棋游戏中击败了已有的围棋 AI 和人类专家,但需要在四个 TPU 上进行 40 多天的训练。OpenAI-Five 是 OpenAI 开发的 Dota2 AI,同样击败了人类半职业 Dota 高手,但是需要高达 256 个 GPU 进行 180 天的训练。实际上,即使是简单的 Rainbow DQN [Hessel et al. 2018] 算法,也需要在单个 GPU 上训练约一周时间才能达到较好的性能。

图:基于强化学习的 AlphaGo-Zero 在围棋游戏中击败了已有的围棋 AI 和人类专家
高昂的资源消耗限制了深度强化学习在资源受限设备上的训练和部署。为了解决这一问题,作者引入了稀疏神经网络。稀疏神经网络最初在深度监督学习中提出,展示出了对深度强化学习模型压缩和训练加速的巨大潜力。在深度监督学习中,SET [Mocanu et al. 2018] 和 RigL [Evci et al. 2020] 等常用的基于网络结构演化的动态稀疏训练(Dynamic sparse training - DST)框架可以从头开始训练一个 90% 稀疏的神经网络,而不会出现性能下降。

图:SET 和 RigL 等常用的稀疏训练框架会在训练的过程中周期性地调整神经网络结构
在深度强化学习领域,已有的工作已经成功生成了极度稀疏的深度强化学习网络。然而,他们的方法仍然需要迭代地训练稠密网络,往往需要预训练的稠密模型作为基础,导致深度强化学习的训练成本仍然过高,无法直接应用于资源有限设备。

图:迭代剪枝通过迭代地训练稠密网络得到稀疏的深度强化学习网络
从头开始训练一个稀疏深度强化学习模型,如果能够完美实现,将极大地减少计算开销,并实现在资源受限设备上的高效部署,具备优秀的模型适应性。然而,在深度强化学习中从头开始训练一个超稀疏网络(例如 90% 的稀疏度)具有挑战性,原因在于自举训练(Bootstrap training)的非稳定性。在深度强化学习中,学习目标不是固定的,而是以自举方式给出,训练数据的分布也可能是非稳定的。此外,使用稀疏网络结构意味着在一个较小的假设空间中搜索,这进一步降低了学习目标的置信度。因此,不当的稀疏化可能对学习路径造成不可逆的伤害,导致性能较差。最近的研究 [Sokar et al. 2021] 表明,在深度强化学习中直接采用动态稀疏训练框架仍然无法在不同环境中实现模型的良好压缩。因此,这一重要的开放问题仍然悬而未决:
能否通过全程使用超稀疏网络从头训练出高效的深度强化学习智能体?
方法
清华大学黄隆波团队对这一问题给出了肯定的答案,并提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),用于离策略强化学习(Off-policy RL)。这是第一个在深度强化学习领域以 90% 以上稀疏度进行全程稀疏训练,并且仅有微小性能损失的算法框架。RLx2 受到了在监督学习中基于梯度的拓扑演化的动态稀疏训练方法 RigL [Evci et al. 2020] 的启发。然而,直接应用 RigL 无法实现高稀疏度,因为稀疏的深度强化学习模型由于假设空间有限而导致价值估计不可靠,进而干扰了网络结构的拓扑演化。
因此,RLx2 引入了延迟多步差分目标(Delayed multi-step TD target)机制和动态容量回放缓冲区(Dynamic capacity buffer),以实现稳健的价值学习(Value learning)。这两个新组件解决了稀疏拓扑下的价值估计问题,并与基于 RigL 的拓扑演化准则一起实现了出色的稀疏训练性能。为了阐明设计 RLx2 的动机,作者以一个简单的 MuJoCo 控制任务 InvertedPendulum-v2 为例,对四种使用不同价值学习和网络拓扑更新方案的稀疏训练方法进行了比较。

图:不同网络结构更新方案的性能比较。其中,SS 表示采用静态稀疏网络,RigL 表示使用基于梯度的网络拓扑演化的方法,RigL+Q * 表示使用 RigL 的拓扑演化且采用真实值函数引导自举训练的方法(真实值函数在实际算法中并不可知),RLx2 表示使用 RigL 网络拓扑演化且采用作者所提值估引导自举训练的方法。可以发现,RLx2 的性能已经非常逼近 RigL+Q * 的方法。
下图展示了 RLx2 算法的主要部分,包括基于梯度的拓扑演化、延迟多步差分目标和动态容量回放缓冲区。

图:RLx2 算法的概览
基于梯度的拓扑演化
在 RLx2 中,作者采用了与 RigL [Evci et al. 2020] 相同的方法来进行拓扑结构的演化。作者计算了损失函数对网络权重的梯度值。然后,周期性地增加稀疏网络中具有较大梯度的连接,并移除权重绝对值最小的现有连接。通过周期性的结构演化,获得了一个结构合理的稀疏神经网络。
延迟多步差分目标
RLx2 框架还引入了多步差分目标:

然而,训练伊始立即采用多步差分目标可能会导致更大的策略不一致误差。因此,作者额外采用了延迟方案来抑制策略不一致性并进一步提高值函数的学习效果。
动态容量回放缓冲区
离策略(Off-policy)算法使用回放缓冲区(Replay buffer)来存储收集到的数据,并使用从缓冲区中抽样的批次数据来训练网络。研究表明 [Fedus et al. 2020],当使用更大的回放容量时,算法的性能通常会提高。然而,无限大小的回放缓冲区会因为多步目标的不一致性和训练数据的不匹配导致策略不一致性。动态容量回放缓冲区是一种通过调整缓冲区容量控制缓冲区中数据的不一致性,以实现稳健值函数学习的方法。作者引入了以下策略距离度量来评估缓冲区中数据的不一致性:

随着训练的进行,当回放缓存中的策略距离度量大于阈值时,则停止增加缓冲区容量,使得策略距离度量始终小于设定的阈值。
实验
作者在四个 MuJoCo 环境(HalfCheetah-v3、Hopper-v3、Walker2d-v3 和 Ant-v3),和两个常见的深度强化学习算法 TD3 和 SAC 中进行了实验。作者定义了一个终极压缩比率,即在该比率下,RLx2 的性能下降在原始稠密模型的 ±3% 之内。这也可以理解为具有与原始稠密模型完全相同性能的稀疏模型的最小大小。根据终极压缩比率,作者在下表中呈现了不同算法在不同环境采用相同参数量的神经网络的性能。

性能 在所有四个环境中,RLx2 的性能在很大程度上优于所有基准算法(除了 Hopper 环境中与 RigL 和 SAC 的性能相近)。此外,小型稠密网络(Tiny)和随机静态稀疏网络(SS)的性能平均最差。SET 和 RigL 的性能较好,但在 Walker2d-v3 和 Ant-v3 环境中无法保持性能,这意味着在稀疏训练下稳健的价值学习是必要的。
模型压缩 RLx2 实现了优秀的压缩比,并且仅有轻微的性能下降(不到 3%)。具体而言,使用 TD3 算法的 RLx2 实现了 7.5 倍至 25 倍的模型压缩,在 Hopper-v3 环境中获得了最佳的 25 倍压缩比。在每个环境中,演员网络(Actor network)可以压缩超过 96% 的参数,评论家网络(Critic network)可以压缩 85% 至 95% 的参数。SAC 算法的结果类似。另外,使用 SAC 算法的 RLx2 实现了 5 倍至 20 倍的模型压缩。
节省训练开销 与基于知识蒸馏或行为克隆的方法 [Vischer et al. 2021] 不同,RLx2 在整个训练过程中使用了稀疏网络。因此,它具有加速训练并节省计算资源的额外潜力。四个环境的平均结果表明,表格中 RLx2-TD3 分别减少了 12 倍和 20 倍的训练和推理浮点运算数,RLx2-SAC 分别减少了 7 倍和 12 倍的训练和推理浮点运算数。
总结
作者提出了一种用于离策略强化学习的稀疏训练框架 RLx2,能够适用于各种离策略强化学习算法。这一框架利用基于梯度的结构演化方法实现了高效的拓扑探索,并通过延迟多步差分目标和动态容量回放缓冲区建立了稳健的值函数学习。RLx2 不需要像传统剪枝方法一样预训练稠密网络,却能够在训练过程中使用超稀疏网络来训练高效的深度强化学习智能体,并且几乎没有性能损失。作者在使用 TD3 和 SAC 的 RLx2 上进行了实验,结果表明其稀疏训练性能非常出色:模型压缩比例为 7.5 倍至 20 倍,性能下降不到 3%,训练和推理的浮点运算数分别减少高达 20 倍和 50 倍。作者认为未来有趣的工作包括将 RLx2 框架扩展到更复杂的 RL 场景,这些场景对计算资源的需求更高,例如多智能体、离线强化学习等场景,也包括真实世界的复杂决策问题而非标准的 MuJoCo 环境。
参考文献
1.Hessel, Matteo, et al. "Rainbow: Combining improvements in deep reinforcement learning." Proceedings of the AAAI conference on artificial intelligence. Vol. 32. No. 1. 2018.
2.Mocanu, Decebal Constantin, et al. "Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science." Nature communications 9.1 (2018): 2383.
3.Evci, Utku, et al. "Rigging the lottery: Making all tickets winners." International Conference on Machine Learning. PMLR, 2020.
4.Sokar, Ghada, et al. "Dynamic sparse training for deep reinforcement learning." arXiv preprint arXiv:2106.04217 (2021).
5.Munos, Rémi, et al. "Safe and efficient off-policy reinforcement learning." Advances in neural information processing systems 29 (2016).
6.Fedus, William, et al. "Revisiting fundamentals of experience replay." International Conference on Machine Learning. PMLR, 2020.
7.Vischer, Marc Aurel, Robert Tjarko Lange, and Henning Sprekeler. "On lottery tickets and minimal task representations in deep reinforcement learning." arXiv preprint arXiv:2105.01648 (2021).
#LongLLaMA
今年 2 月,Meta 发布的 LLaMA 大型语言模型系列,成功推动了开源聊天机器人的发展。因为 LLaMA 比之前发布的很多大模型参数少(参数量从 70 亿到 650 亿不等),但性能更好,例如,最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B,所以一经发布让很多研究者兴奋不已。将上下文长度扩展到256k,无限上下文版本的LongLLaMA来了?
然而,LLaMA 仅授权给学术界的研发人员使用,从而限制了该模型的商业应用。
因而,研究者开始寻找那些可用于商业用途的 LLaMA,UC 伯克利的博士生 Hao Liu 发起的项目 OpenLLaMA,就是其中一个比较热门的 LLaMA 开源复制品,其使用了与原始 LLaMA 完全相同的预处理和训练超参数,可以说 OpenLLaMA 完全按照 LLaMA 的训练步骤来的。最重要的一点是,该模型可商用。
OpenLLaMA 在 Together 公司发布的 RedPajama 数据集上训练完成,有三个模型版本,分别为 3B、7B 和 13B,这些模型都经过了 1T tokens 的训练。结果显示,OpenLLaMA 在多项任务中的表现都与原始 LLaMA 相当,甚至有超越的情况。
除了不断发布新模型,研究者对模型处理 token 的能力探索不断。
几天前,田渊栋团队的最新研究用不到 1000 步微调,将 LLaMA 上下文扩展到 32K。再往前追溯,GPT-4 支持 32k token(这相当于 50 页的文字) ,Claude 可以处理 100k token (大概相当于一键总结《哈利波特》第一部)等等。
现在,一个新的基于 OpenLLaMA 大型语言模型来了,它将上下文的长度扩展到 256k token,甚至更多。该研究由 IDEAS NCBR 、波兰科学院、华沙大学、 Google DeepMind 联合完成。
LongLLaMA 基于 OpenLLaMA 完成,微调方法采用 FOT ( Focused Transformer )。本文表明,FOT 可以用于对已经存在的大型模型进行微调,以扩展其上下文长度。
该研究以 OpenLLaMA-3B 和 OpenLLaMA-7B 模型为起点,并使用 FOT 对它们进行微调。由此产生的模型称之为 LONGLLAMAs,能够在其训练上下文长度之外进行外推(甚至可以达到 256K),并且在短上下文任务上还能保持性能。
- 项目地址:https://github.com/CStanKonrad/long_llama
- 论文地址:https://arxiv.org/pdf/2307.03170.pdf
有人将这一研究形容为 OpenLLaMA 的无限上下文版本,借助 FOT,模型很容易外推到更长的序列,例如在 8K token 上训练的模型,可以很容易外推到 256K 窗口大小。
本文用到了 FOT 方法,它是 Transformer 模型中一种即插即用的扩展,可用于训练新模型,也可对现有的较大模型进行更长上下文微调。
为了达到这一目的,FOT 使用了记忆注意力层和跨批次(crossbatch)训练过程:
- 记忆注意力层使模型能够在推理时从外部存储器中检索信息,从而有效地扩展了上下文;
- 跨批次训练过程使模型倾向于学习(键,值)表示,这些表示对于记忆注意力层的使用非常简便。
有关 FOT 架构的概述,请参见图 2:

下表为 LongLLaMA 的一些模型信息:

最后,该项目还提供了 LongLLaMA 与原始 OpenLLaMA 模型的比较结果。
下图为 LongLLaMA 一些实验结果,在密码检索任务上,LongLLaMA 取得了良好的性能。具体而言,LongLLaMA 3B 模型远远超出了它的训练上下文长度 8K,对于 token 为 100k 时,准确率达到 94.5%,当 token 为 256k 时,准确率为 73%。

下表为 LongLLaMA 3B 模型在两个下游任务(TREC 问题分类和 WebQS 问题回答)上的结果,结果显示,在使用长上下文时,LongLLaMA 性能改进明显。

下表显示了即使在不需要长上下文的任务上,LongLLaMA 也能表现良好。实验在零样本设置下,对 LongLLaMA 和 OpenLLaMA 进行了比较。


#RAPHAEL
商汤大模型团队提出的文生图大模型RAPHAEL, 可以生成具有高度艺术风格或者摄影风格的图片,而且生成速度极快,并且在各项测试上击败了Stable Diffusion XL,DALL-E 2,DeepFloyd等模型。基于混合去噪路径的文生图大模型
自从2022年开始,以Stable Diffusion, ChatGPT为代表的生成式AI席卷了整个AI社区,AI大模型也走进了公众的视野。本文将介绍商汤大模型团队提出的文生图大模型RAPHAEL(体验链接见第五节), 可以生成具有高度艺术风格或者摄影风格的图片,而且生成速度极快,并且在各项测试上击败了Stable Diffusion XL,DALL-E 2,DeepFloyd等模型。
本文共提出了三个组件: Space-MoE, Time-MoE, 以及Edge-supervised learning模块。Space-MoE找出了文本中每一个token在图片中对应的区域,用不同的expert来处理不同的区域,最后再融合;Time-MoE模块使得模型能够在不同的timestep上选择不同的expert;这些MoE事实上组成了一系列的diffusion path,用来画某一类名词,动词,或者形容词。这些词的diffusion path都可以被XGBoost算法分开,证明了每一个path负责一个词。Edge-supervised learning模块则帮助模型更好的学习到图片的结构信息。我们也做了充分的消融实验来验证这三个模块的效果,具体可见论文的正文部分。我们使用了清洗后的LAION-5B以及一些内部数据集来训练RAPHAEL,超参数文中都有提供。实验也遇到了很多血泪史,以后有机会的话再和大家分享。具体的网络结构见下图:
实验指标
3.1. 我们首先在FID上进行了测试,FID是一个衡量图片生成质量和多样性的指标,常常被用于评测生成模型的能力,我们在这一项指标上击败了所有写了论文的模型,比如Stable Diffusion,DALL-E 2等,达到6.61。
3.2. 我们同时也基于人类评估给出了一些指标,结论发现RAPHAEL在图文匹配度以及生成质量上均超过了Stable Diffusion XL,DeepFloyd, DALL-E 2,如下图所示
放图环节
接下来就是大家喜闻乐见的秀图环节啦,在做过大量的测试后,可以认为RAPHAEL效果优于Stable Diffusion XL, DALL-E 2,DeepFloyd等模型。由于篇幅的限制,没办法放更多了,而且为了方便浏览压缩了清晰度,大家可以自己上手玩,一试便~





体验链接
我们提供了将RAPHAEL作为基座的artist v0.3.0 beta模型的在线试玩链接,可以在https://miaohua.sensetime.com/zh-CN/中免费试玩(注意不要选错模型了),相信这是世界上最一流的免费体验的文生图大模型之一。同时,我们也设置了反馈按钮(在生成图的旁边)来帮我们不断优化,希望大家可以积极体验反馈,也帮忙和亲朋好友宣传一下,多多支持我们国产大模型~
一些tips
可能绝大部分同学没有学习过怎么写文生图的prompt,于是我们也提供了描述词优化功能,可以将简单的prompt扩展成能得到优秀效果的prompt。当然,一些国外的网站也提供了一些优秀的prompt库:
https://www.midjourney.com/app/feed/
https://app.prompthub.studio/
同时建议大家把步数拉到100,图片质量会更佳。
论文引用
https://arxiv.org/abs/2305.18295
@article{xue2023raphael,
title={Raphael: Text-to-image generation via large mixture of diffusion paths},
author={Xue, Zeyue and Song, Guanglu and Guo, Qiushan and Liu, Boxiao and Zong, Zhuofan and Liu, Yu and Luo, Ping},
journal={arXiv preprint arXiv:2305.18295},
year={2023}
#LONGNET
微软新出论文:Transformer扩展到10亿token
当大家不断升级迭代自家大模型的时候,LLM(大语言模型)对上下文窗口的处理能力,也成为一个重要评估指标。
比如明星大模型 GPT-4 支持 32k token,相当于 50 页的文字;OpenAI 前成员创立的 Anthropic 更是将 Claude 处理 token 能力提升到 100k,约 75000 个单词,大概相当于一键总结《哈利波特》第一部。
在微软最新的一项研究中,他们这次直接将 Transformer 扩展到 10 亿 token。这为建模非常长的序列开辟了新的可能性,例如将整个语料库甚至整个互联网视为一个序列。
作为比较,普通人可以在 5 小时左右的时间里阅读 100,000 个 token,并可能需要更长的时间来消化、记忆和分析这些信息。Claude 可以在不到 1 分钟的时间里完成这些。要是换算成微软的这项研究,将会是一个惊人的数字。
- 论文地址:https://arxiv.org/pdf/2307.02486.pdf
- 项目地址:https://github.com/microsoft/unilm/tree/master
具体而言,该研究提出了 LONGNET,这是一种 Transformer 变体,可以将序列长度扩展到超过 10 亿个 token,而不会牺牲对较短序列的性能。文中还提出了 dilated attention,它能指数级扩展模型感知范围。
LONGNET 具有以下优势:
1)它具有线性计算复杂性;
2)它可以作为较长序列的分布式训练器;
3)dilated attention 可以无缝替代标准注意力,并可以与现有基于 Transformer 的优化方法无缝集成。
实验结果表明,LONGNET 在长序列建模和一般语言任务上都表现出很强的性能。
在研究动机方面,论文表示,最近几年,扩展神经网络已经成为一种趋势,许多性能良好的网络被研究出来。在这当中,序列长度作为神经网络的一部分,理想情况下,其长度应该是无限的。但现实却往往相反,因而打破序列长度的限制将会带来显著的优势:
- 首先,它为模型提供了大容量的记忆和感受野,使其能够与人类和世界进行有效的交互。
- 其次,更长的上下文包含了更复杂的因果关系和推理路径,模型可以在训练数据中加以利用。相反,较短的依赖关系则会引入更多虚假的相关性,不利于模型的泛化性。
- 第三,更长的序列长度可以帮助模型探索更长的上下文,并且极长的上下文也可帮助模型缓解灾难性遗忘问题。
然而,扩展序列长度面临的主要挑战是在计算复杂性和模型表达能力之间找到合适的平衡。
例如 RNN 风格的模型主要用于增加序列长度。然而,其序列特性限制了训练过程中的并行化,而并行化在长序列建模中是至关重要的。
最近,状态空间模型对序列建模非常有吸引力,它可以在训练过程中作为 CNN 运行,并在测试时转换为高效的 RNN。然而这类模型在常规长度上的表现不如 Transformer。
另一种扩展序列长度的方法是降低 Transformer 的复杂性,即自注意力的二次复杂性。现阶段,一些高效的基于 Transformer 的变体被提出,包括低秩注意力、基于核的方法、下采样方法、基于检索的方法。然而,这些方法尚未将 Transformer 扩展到 10 亿 token 的规模(参见图 1)。

下表为不同计算方法的计算复杂度比较。N 为序列长度,d 为隐藏维数。

方法
该研究的解决方案 LONGNET 成功地将序列长度扩展到 10 亿个 token。具体来说,该研究提出一种名为 dilated attention 的新组件,并用 dilated attention 取代了 Vanilla Transformer 的注意力机制。通用的设计原则是注意力的分配随着 token 和 token 之间距离的增加而呈指数级下降。该研究表明这种设计方法获得了线性计算复杂度和 token 之间的对数依赖性。这就解决了注意力资源有限和可访问每个 token 之间的矛盾。

在实现过程中,LONGNET 可以转化成一个密集 Transformer,以无缝地支持针对 Transformer 的现有优化方法(例如内核融合(kernel fusion)、量化和分布式训练)。利用线性复杂度的优势,LONGNET 可以跨节点并行训练,用分布式算法打破计算和内存的约束。
最终,该研究有效地将序列长度扩大到 1B 个 token,而且运行时(runtime)几乎是恒定的,如下图所示。相比之下,Vanilla Transformer 的运行时则会受到二次复杂度的影响。

该研究进一步引入了多头 dilated attention 机制。如下图 3 所示,该研究通过对查询 - 键 - 值对的不同部分进行稀疏化,在不同的头之间进行不同的计算。

分布式训练

该研究利用 LONGNET 的线性计算复杂度来进行序列维度的分布式训练。下图 4 展示了在两个 GPU 上的分布式算法,还可以进一步扩展到任意数量的设备。

实验
该研究将 LONGNET 与 vanilla Transformer 和稀疏 Transformer 进行了比较。架构之间的差异是注意力层,而其他层保持不变。研究人员将这些模型的序列长度从 2K 扩展到 32K,与此同时减小 batch 大小,以保证每个 batch 的 token 数量不变。
表 2 总结了这些模型在 Stack 数据集上的结果。研究使用复杂度作为评估指标。这些模型使用不同的序列长度进行测试,范围从 2k 到 32k 不等。当输入长度超过模型支持的最大长度时,研究实现了分块因果注意力(blockwise causal attention,BCA)[SDP+22],这是一种最先进的用于语言模型推理的外推方法。
此外,研究删除了绝对位置编码。首先,结果表明,在训练过程中增加序列长度一般会得到更好的语言模型。其次,在长度远大于模型支持的情况下,推理中的序列长度外推法并不适用。最后,LONGNET 一直优于基线模型,证明了其在语言建模中的有效性。

序列长度的扩展曲线
图 6 绘制了 vanilla transformer 和 LONGNET 的序列长度扩展曲线。该研究通过计算矩阵乘法的总 flops 来估计计算量。结果表明,vanilla transformer 和 LONGNET 都能从训练中获得更大的上下文长度。然而,LONGNET 可以更有效地扩展上下文长度,以较小的计算量实现较低的测试损失。这证明了较长的训练输入比外推法更具有优势。实验表明,LONGNET 是一种更有效的扩展语言模型中上下文长度的方法。这是因为 LONGNET 可以更有效地学习较长的依赖关系。

扩展模型规模
大型语言模型的一个重要属性是:损失随着计算量的增加呈幂律扩展。为了验证 LONGNET 是否仍然遵循类似的扩展规律,该研究用不同的模型规模(从 1.25 亿到 27 亿个参数) 训练了一系列模型。27 亿的模型是用 300B 的 token 训练的,而其余的模型则用到了大约 400B 的 token。图 7 (a) 绘制了 LONGNET 关于计算的扩展曲线。该研究在相同的测试集上计算了复杂度。这证明了 LONGNET 仍然可以遵循幂律。这也就意味着 dense Transformer 不是扩展语言模型的先决条件。此外,可扩展性和效率都是由 LONGNET 获得的。

长上下文 prompt
Prompt 是引导语言模型并为其提供额外信息的重要方法。该研究通过实验来验证 LONGNET 是否能从较长的上下文提示窗口中获益。
该研究保留了一段前缀(prefixes)作为 prompt,并测试其后缀(suffixes)的困惑度。并且,研究过程中,逐渐将 prompt 从 2K 扩展到 32K。为了进行公平的比较,保持后缀的长度不变,而将前缀的长度增加到模型的最大长度。图 7 (b) 报告了测试集上的结果。它表明,随着上下文窗口的增加,LONGNET 的测试损失逐渐减少。这证明了 LONGNET 在充分利用长语境来改进语言模型方面的优越性。
#DetDiffusion
本文提出了DetDiffusion,这是一种简单而有效的架构,利用了生成模型和感知模型之间的内在协同作用。通过将检测器感知性整合到几何感知模型中,通过P.A. Attr作为条件输入和P.A.损失作为监督,Det-Diffusion可以生成针对检测器定制的图像,以获得更好的识别性和可训练性。
文章链接:https://arxiv.org/pdf/2403.13304
当前的感知模型严重依赖资源密集型数据集,促使我们需要创新性的解决方案。利用最新的扩散模型和合成数据,通过从各种标注构建图像输入,对下游任务非常有益。尽管先前的方法分别解决了生成和感知模型的问题,但DetDiffusion首次将两者结合起来,解决了为感知模型生成有效数据的挑战。
为了增强感知模型与图像生成的质量,本文引入了感知损失(P.A.损失),通过分割改进了质量和可控性。为了提高特定感知模型的性能,DetDiffusion通过提取和利用在生成过程中perception-aware属性(P.A.属性)来定制数据增强。目标检测任务的实验结果突显了DetDiffusion的优越性能,在布局引导生成方面建立了新的SOTA。此外,来自DetDiffusion的图像合成可以有效地增强训练数据,显著提高了下游检测性能。
效果先睹为快

介绍
当前感知模型的有效性严重依赖于广泛且准确标注的数据集。然而,获取这样的数据集通常需要大量资源。最近生成模型的进展,特别是扩散模型,使得生成高质量图像成为可能,从而为构建合成数据集铺平了道路。通过提供诸如类别标签、分割图和目标边界框等标注,已经证明了用于生成模型的合成数据对提高下游任务(例如分类、目标检测和分割)的性能是有用的。
尽管大多数方法专注于分别改进生成模型或感知模型,但生成模型和感知模型之间的协同作用需要更紧密的整合,以相互增强生成和感知能力。在感知模型中,挑战在于有效的数据生成或增强,这是一个以前主要从数据角度(例如OoD泛化和域自适应)探讨的话题。其在一般情况下提高感知模型性能的潜力尚未充分探索。相反,生成模型研究一直致力于改进模型以获得更好的输出质量和可控性。然而,必须认识到感知模型也可以提供有价值的额外见解,以帮助生成模型实现更好的控制能力。生成模型和感知模型之间的这种协同作用为进步提供了一个有前景的途径,这表明需要更多的整合方法。
作为首个探索这种协同作用的工作,本文提出了一种新颖的感知生成框架,即DetDiffusion,如下图1所示。

DetDiffusion使生成模型能够利用来自感知模型的信息,从而增强其进行受控生成的能力。同时,它根据感知模型的能力有针对性地生成数据,从而提高了模型在合成数据上训练的性能。
具体而言,对于目标检测任务,基于Stable Diffusion对模型进行微调,利用受控生成技术生成高质量数据,有助于训练检测模型。为提高生成质量,创新性地引入了感知损失。通过引入基于UNet的分割模块,利用中间特征与标签真值一起监督生成的内容,以增强可控性。
此外,为进一步提高检测模型的性能,提出从经过训练的检测模型中提取和使用目标属性,然后将这些属性纳入生成模型的训练中。这种方法能够生成专门定制的新数据,以产生独特样本,从而显著提高检测器的性能。
经过实验证实,DetDiffusion在生成质量方面取得了新的SOTA,在COCO-Stuff数据集上达到了31.2的mAP。它显著增强了检测器的训练,通过在训练中策略性地使用Perception-Aware属性(P.A. Attr),将mAP提高了0.9 mAP。这在很大程度上是因为DetDiffusion在解决长尾数据生成挑战方面的精细控制。这些进展突显了DetDiffusion在技术上的优越性,并标志着在受控图像生成方面的重大进步,特别是在精确检测属性至关重要的情况下。
本文的主要贡献包括三个方面
- 提出了DetDiffusion,这是第一个旨在探索感知模型和生成模型之间协同作用的框架。
- 为提高生成质量,提出了一种基于分割和目标mask的感知损失。为了进一步提高合成数据在感知模型中的有效性,并在生成过程中引入了目标属性。
- 对目标检测任务的广泛实验表明,DetDiffusion不仅在COCO数据集上的布局引导生成方面取得了新的SOTA,还有效地提升了下游检测器的性能。
相关工作
扩散模型。扩散模型作为一种生成模型,经过从图像分布到高斯噪声分布的前向变换后,被训练学习反向去噪过程。这些模型可以采用马尔可夫过程或非马尔可夫过程。由于它们在处理各种形式的控制和多种条件方面的适应性和能力,扩散模型已经应用于各种条件生成任务,例如图像变异、文本到图像生成、像素级别的受控生成等。这些模型的一个显著变种是潜在扩散模型(LDM)。与传统的扩散模型不同,LDM在潜在空间中进行扩散过程,提高了模型的效率。我们的感知数据生成框架基于LDM。然而,关注于生成模型和感知模型之间的协同作用,提出了一些设计来同时改善生成质量和可控性,以及在下游任务中的性能。
布局到图像(L2I)生成。本文的方法着重于将高层次的图形布局转换成逼真的图像。在这个背景下,LAMA实现了一个局部感知mask适应模块,以改进图像生成过程中的目标mask处理。Taming显示,一个相对简单的模型可以通过在潜在空间中训练超越更复杂的前辈模型。更近期的发展包括GLIGEN,它将额外的门控自注意力层整合到现有的扩散模型中,以增强布局控制;LayoutDiffuse则采用了为边界框量身定制的创新布局注意力模块。生成模型与GeoDiffusion和Geom-Erasing具有类似的架构,而DetDiffusion侧重于生成和感知之间的协同作用,并独特地提供了以下两点:
- 利用分割头信息的新型Perception-Aware损失(P.A. loss);
- 一种新颖的目标属性机制(P.A. Attr),有助于目标检测器的训练。
感知模型的数据生成。在一些L2I方法中,合成数据对提升目标检测任务性能的效用得到了证明,例如GeoDiffusion。类似地,MagicDrive提出生成的图像有助于3D感知,而TrackDiffusion为多目标跟踪生成数据。然而,它们没有探索使用感知模型增强生成,或为特定检测器量身定制数据。除了可控生成之外,一些工作通过从生成特征中提取标注将生成器转换为感知模型。DatasetDM使用了类似Mask2Former风格的P-decoder与Stable Diffusion,而Li等人开发了一个用于开放词汇分割的融合模块。尽管这些技术能够产生带有标注的数据,但它们受限于对基于文本的生成的依赖、对预训练扩散模型的限制以及与专门模型(如SAM)相比的性能较低。
方法
本文的目标是从感知的角度提高生成质量,并促进下游的感知任务。在解决这一具有挑战性的问题中,设计适当而强有力的监督非常重要,提议将易于访问但以前被忽视的感知信息,即Perception-Aware属性(P.A. Attr)和损失(P.A. loss),集成到生成框架中,以促进感知模型和生成模型之间的信息交互。首先介绍了预备知识,并详细展开了Perception-Aware属性(P.A. Attr),该属性通过目标检测器生成,并设计为特殊的标注以辅助扩散模型。再介绍了一个量身定制的Perception-Aware损失(P.A. loss)。整体架构如下图2所示。

预备知识
扩散模型 (DMs) 已经成为突出的文本到图像生成模型, 以其在生成逼真图像方面的有效性而闻名。一个显着的变体, 潜在扩散模型 (LDM), 将标准DMs的扩散过程创新地转移到潜在空间中。这种转变是重要的, 因为LDMs表现出了保持原始模型质量和灵活性的能力, 但计算资源需求大大降低。这种效率的提升主要归功于潜在空间维度的降低, 这有助于更快的训练时间, 而不影响模型的生成能力。

作为条件输入的Perception-Aware属性
为了增强检测模型的性能,本研究引入了一种围绕生成Perception-Aware逼真图像的新方法。该方法涉及一个两步过程:首先,从预训练的检测器中提取目标属性。这些属性封装了对准确目标检测至关重要的关键视觉特征。随后,将提取的属性集成到生成模型的训练方案中。这种集成旨在确保生成的图像不仅表现出很高的逼真度,而且与对于有效检测至关重要的感知标准密切对齐。通过这样做,生成模型被定制为生成更有助于训练稳健检测器的图像,可能会显著提高检测准确性和可靠性。

Perception-Aware损失作为监督
在训练扩散生成模型时,目标是最小化预测图像(或噪声)与其真值之间的重构距离。传统的生成方法主要利用L1或L2损失来实现这一目的。然而,这些标准损失函数通常不能产生具有高分辨率细节和对图像属性具有精确控制的图像。为了解决这一限制,提出了一种新颖的Perception-Aware损失(P.A. loss)。该损失函数的构建是为了利用丰富的视觉特征,从而促进更加细致的图像重构。

目标函数。最终, 目标函数将Perception-Aware损失与Latent Diffusion Model (LDM) 的基本损失函数相结合。这个整合在数学上表示为:

实验
实验设置
数据集。采用了广泛认可的 COCO-Thing-Stuff 基准数据集用于 L2I 任务,该数据集包括 118,287 张训练图像和 5,000 张验证图像。每张图像都标注有 80 个目标类别和 91 个材料类别的边界框和像素级分割mask。与先前的研究 [7, 9, 52] 保持一致,忽略了属于人群或占据图像面积不到 2% 的目标。


主要结果
L2I 生成要求生成的目标尽可能与原始图像一致,同时确保高质量的图像生成。因此,首先全面分析保真度实验。此外,生成目标检测数据的一个重要目的是其适用于下游目标检测。接下来展示了可训练性实验。
保真度
设置。为了评估保真度,在 COCO-Thing-Stuff 验证集上利用两个主要指标。Fréchet Inception 距离(FID)评估生成图像的整体视觉质量。它使用 ImageNet 预训练的 Inception-V3 网络来测量真实图像和生成图像之间特征分布的差异。在 LAMA 中的 YOLO Score使用生成图像上 80 个目标类别边界框的平均精度(mAP)。它使用预训练的 YOLOv4 模型来实现,展示了生成模型中目标检测的精度。我们的模型在图像尺寸为 256×256 上进行训练。与先前的工作一样,我们利用包含 3 到 8 个目标的图像,在验证期间共有 3,097 张图像。
结果。在 COCO-Thing-Stuff 验证集上使用了三种属性策略来评估我们的模型,并将它们与 L2I 任务的最新模型进行了比较,例如 LostGAN、LAMA、TwFA、Frido、LayoutDIffuse、LayoutDiffusion、Reco、GLIGEN、GeoDiffusion 和 ControlNet。


可训练性
设置。本节探讨了使用 DetDiffusion 生成的图像来训练目标检测器的潜在优势。可训练性的评估包括使用预先训练的 L2I 模型从原始标注创建新的合成训练集。然后,使用原始和合成训练集来训练检测器。
COCO 可训练性。为了建立可靠的基线,利用 COCO2017 数据集,选择性地选择包含 3 到 8 个目标的图像,以提高合成图像的质量并保持保真度。该过程产生了一个包含 47,429 张图像和 210,893 个目标的训练集。我们的目标是展示 DetDiffusion 可以为下游任务带来的改进,同时保持不同模型比较的固定标注。为了提高训练效率并专注于数据质量对训练的影响的评估,采用了修改后的 1× 计划,将训练周期缩短为 6 个epoch。DetDiffusion 在调整到 800×456 的图像上进行训练,这是其支持的最大分辨率,以解决与 COCO 的分辨率差异。
结果。如下表2 所示,ReCO、GeoDiffusion和我们的三种策略都有助于下游检测器的训练,通过这些策略生成的合成图像对检测器的提升更为显著(超过 35.0 mAP)。此外,与“origin”策略相比,“hard”策略在所有检测器指标上展现了最大的改进。这归因于“hard”策略通过生成更具挑战性的实例,这些实例通常代表真实数据集中的长尾数据,或者作为更强大的数据增强形式。总的来说,我们模型生成的数据显著增强了下游检测器的训练,超过了所有其他 L2I 模型,并表明通过感知获得的信息可以进一步有益于下游训练。

为了验证在相同的训练成本下的训练效果,绘制了训练损失曲线和验证 mAP 曲线,分别在 图6a 和 6b 中。我们的 DetDiffusion 在整个训练过程中表现最佳。

在下表 3 中展示了更多关于可训练性的结果,重点关注 COCO 数据集中较少出现的类别,如停车计时器、剪刀和微波炉,每个类别在数据集中的占比都不到 0.2%。可以看到,我们的 hard 策略在所有类别上都取得了收益,尤其是长尾类别方面取得了显著的改进。

定性结果
保真度。 下图4展示了验证我们模型在图像生成中的忠实度和准确性的示例。LayoutDiffusion的混乱结果源于其额外的控制模块与扩散过程的冲突。依赖高质量字幕的ReCo经常遭受质量降低和遗漏细节的困扰。GLlGEN和ControlNet,尽管输出质量很高,但缺乏精确的目标监督,导致细节不足和目标数量不稳定。我们对P.A.损失和P.A.属性的实现增强了目标质量,确保了一致的数量和受控的生成,如与P.A.属性对齐的生成目标数量所反映的那样。

简单与困难。 在下图5中,展示了perception-aware attribute(P.A. Attr)的选择,比较了“简单”和“困难”的实例。通过大象、马、显示器和键盘等示例来说明“简单”图像,这些图像着重展示了内在的目标特征,确保了清晰度和缺乏噪音。相反,“困难”示例,如带长牙的大象、马鞍上的马、昏暗的显示器和反光的鼠标,引入了额外的元素,通过遮挡、光照和其他复杂性引入噪音。这些属性使得目标识别更具挑战性。值得注意的是,既有明显可区分的“简单”和“困难”情况,也有微妙不同的情况,突显了对检测过程的微妙影响。这表明了在没有先验知识的情况下识别具有挑战性的例子的重要性。有关更多示例,请参阅附录D。

消融研究
模型组件。 按顺序将两个模块集成到基线模型中,以评估我们模型的关键元素。为了清楚地展示P.A.损失的效果,所有属性都被设置为[易]。正如表4所示,添加P.A. Attr显著增强了图像的保真度和YOLO Score。这意味着包含感知信息有助于产生更真实、更易识别的图像。此外,实施P.A.损失,监督中间生成图像中的潜在特征,显著提高了模型在图像生成方面的精度,特别是在位置精度方面。
可训练性。 进一步对FCOS和ATSS进行实验。如表5所示,不管是哪种检测器模型,Det-Diffusion生成的图像都取得了显著的改善,这与表2中的结果一致。

检测器。 探讨了两种广泛认可的检测器[1,39],用于在省略使用P.A.损失的情况下获取P.A. Attr。表6展示了检测器选择对P.A. Attr质量的显著影响,YOLOv4在这方面表现出色。因此,YOLOv4作为保真度的主要检测器,而Faster R-CNN则用于可训练性,因为它是训练后下游检测器的角色。

结论
本文提出了DetDiffusion,这是一种简单而有效的架构,利用了生成模型和感知模型之间的内在协同作用。通过将检测器感知性整合到几何感知模型中,通过P.A. Attr作为条件输入和P.A.损失作为监督,Det-Diffusion可以生成针对检测器定制的图像,以获得更好的识别性和可训练性。


#Ferret-UI
让大模型理解手机屏幕,苹果多模态Ferret-UI用自然语言操控手机,此次,苹果提出的多模态大语言模型(MLLM) Ferret-UI ,专门针对移动用户界面(UI)屏幕的理解进行了优化,其具备引用、定位和推理能力。
移动应用已经成为我们日常生活的一大重要组成部分。使用移动应用时,我们通常是用眼睛看,用手执行对应操作。如果能将这个感知和交互过程自动化,用户也许能获得更加轻松的使用体验。此外,这还能助益手机辅助功能、多步 UI 导航、应用测试、可用性研究等。
为了在用户界面内实现感知和交互的无缝自动化,就需要一个复杂的系统,其需要具备一系列关键能力。
这样一个系统不仅要能完全理解屏幕内容,还要能关注屏幕内的特定 UI 元素。以视觉理解为基础,它应当有能力进一步将自然语言指令映射到给定 UI 内对应的动作、执行高级推理并提供其交互的屏幕的详细信息。
为了满足这些要求,必须开发出能在 UI 屏幕中确定相关元素位置并加以引述的视觉 - 语言模型。其中,确定相关元素位置这一任务通常被称为 grounding,这里我们将其译为「定基」,取确定参考基准之意;而引述(referring)是指有能力利用屏幕中特定区域的图像信息。
多模态大型语言模型(MLLM)为这一方向的发展带来了新的可能性。近日,苹果公司一个团队提出了 Ferret-UI。
- 论文地址:https://arxiv.org/pdf/2404.05719.pdf
- 论文标题:Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
这应当是首个专门针对 UI 屏幕设计的用于精确引述和定基任务的 MLLM,并且该模型能解读开放式的语言指令并据此采取行动。他们的这项工作聚焦于三个方面:改进模型架构、整编数据集、建立评估基准。
实验表明,他们的这种方法效果还挺不错,如图 1 所示:Ferret-UI 能够很好地处理从基础到高级的 11 种任务,从简单的寻找按钮到复杂的描述具体功能。

下面来看具体方法。
方法概览
Ferret-UI 基于 Ferret,而 Ferret 是一个擅长处理自然图像的引述和定基任务的 MLLM,并且其支持多种形状和细节层级。
Ferret 包含一个预训练的视觉编码器(如 CLIP-ViT-L/14)和一个仅解码器语言模型(如 Vicuna)。
此外,Ferret 还采用了一种独特的混合表征技术,可将指定区域转换为适合 LLM 处理的格式。其核心是一个可感知空间的视觉采样器,能够以不同稀疏层级管理区域形状的连续特征。
为了将 UI 专家知识集成到 Ferret 中,苹果团队做了两方面工作:(1)定义和构建 UI 引述和定基任务;(2)调整模型架构以更好地应对屏幕数据。
具体来说,为了训练模型,Ferret-UI 包含多个 UI 引述任务(比如 OCR、图标识别、小部件分类)和定基任务(比如寻找文本 / 图标 / 小组件、小组件列表);这些任务可帮助模型很好地理解手机 UI 并与之交互。之前的 MLLM 需要外部检测模块或屏幕视图文件,而 Ferret-UI 不一样,它自己就能搞定,可以直接输入原始屏幕像素。这种方法不仅有助于高级的单屏幕交互,而且还可支持新应用,比如提升支持残障人士的辅助功能。
研究 UI 数据集还为该团队带来了另外两个有关建模的见解:(1)手机屏幕的纵横比(见表 1a)与自然图像的不一样,通常更长一些。(2)UI 相关任务涉及很多对象(即图标和文本等 UI 组件),并且这些组件通常比自然图像中的对象小得多。

举个例子,很多问题涉及的图标的面积只占整个屏幕的 0.1%。因此,如果只使用单张重新调整了大小的低分辨率全局图像,可能会丢失很多重要的视觉细节。
为了解决这个问题,该团队引入了 any resolution(任意分辨率 /anyres)这一思想。
具体来说,基于手机的原始纵横比,他们选择了两种网格配置:1x2 和 2x1。给定一张屏幕图像,选取最接近其原始纵横比的网格配置。之后,调整屏幕图像大小,使其匹配所选的网格配置,然后再将其切分为子图像(sub-image)。很明显,纵向屏幕会被水平切分,而横向屏幕会被垂直切分。然后,使用同一个图像编码器分开编码所有子图像。接下来 LLM 就可以使用各种粒度的所有视觉特征了 —— 不管是完整图像还是经过增强的细节特征。
图 2 给出了 Ferret-UI 的整体架构,包括任意分辨率调整部分。

数据集和任务构建
苹果团队构建了一个数据集来训练和评估模型。
收集 UI 数据
UI 屏幕。该团队不仅收集了 iPhone 屏幕,也收集了安卓设备的屏幕。
其中安卓屏幕数据来自 RICO 数据集的一个子集,并根据该团队的分割方案进行了处理。总共有 26,527 张训练图像和 3080 张测试图像。
iPhone 屏幕则来自 AMP 数据集,有不同大小,共 84,685 张训练图像和 9,410 张测试图像。
UI 屏幕元素标注。他们使用一个预训练的基于像素的 UI 检测模型对收集到的屏幕数据进行了细粒度的元素标注。
任务构建
下面将简单描述该团队是如何将 UI 屏幕和相应标注转换成可用于训练 MLLM 的格式。这有三种方法。
方法一:调整 Spotlight 的格式。基于论文《Spotlight: Mobile ui understanding using vision-language models with a focus》,他们取用了 Spotlight 中的三个任务:screen2words、widgetcaptions 和 taperception,并将它们的格式调整为了对话式的一对对问答。具体来说,为了创建 prompt,他们使用了 GPT-3.5 Turbo 来处理他们编写的基础 prompt:
每个训练示例都采样了相应任务的 prompt,并搭配了原始原图像和基本真值答案。
方法二:基础任务。除了 Spotlight 任务,该团队还创建了 7 个新的 UI 任务:用于引述的 OCR、图标识别和小部件分类;用于定基的小部件列表、查找文本、查找图标、查找小部件。他们将引述(referring)任务定义为输入中有边界框的任务,而将定基(grounding)任务定义为输出中有边界框的任务。
他们还使用 GPT-3.5 Turbo 扩展了每个任务的基础 prompt,以引入任务问题的变体版本。图 3 给出了数据生成的详情。每个任务的训练样本数量见表 1b。

方法三:高级任务。为了让新模型具备推理能力,他们跟随 LLaVA 的做法并使用 GPT-4 额外收集了四种其它格式的数据。图 4 展示了高级任务的训练数据生成过程。

这四个任务是:详细描述、对话感知、对话交互和功能推断。
实验结果
该团队进行了实验研究和消融研究,并对结果进行了详细分析。
设置:Ferret-UI-anyres 是指集成了任意分辨率的版本,Ferret-UI-base 是指直接采用 Ferret 架构的版本,Ferret-UI 是指这两种配置。训练使用了 8 台 A100 GPU,Ferret-UI-base 耗时 1 天,Ferret-UI-anyres 耗时约 3 天。
结果
实验比较了 Ferret-UI-base、Ferret-UI-anyres、Ferret 和 GPT-4V 在所有任务上的表现;另外在高级任务上参与比较的模型还有 Fuyu 和 CogAgent。
表 2 总结了实验结果,其中的数据是模型在每个类别中的平均表现。

图 5 和表 3 给出了在具体的基础和高级任务上的表现详情。


从这些图表可以看到,Ferret-UI 的表现颇具竞争力。尤其是任意分辨率(anyres)的加入能让 Ferret-UI-base 的表现更上一层楼。
消融研究
表 4 给出了消融研究的详情。

从表 4a 可以看到,基础任务能够帮助提升模型解决高级任务的能力。
而表 4b 则表明,加入基础任务数据并不会明显改变模型在三个 Spotlight 任务上的性能。其原因可能是基础任务的响应中使用了简短且高度专业化的 UI 相关术语,这与 Spotlight 任务要求的响应风格不一致。而如果进一步整合高级任务,便能够在 Spotlight 任务上得到最佳结果,即便这些高级任务数据完全来自 iPhone 屏幕。
该团队最后对 Ferret-UI 的结果进行了详细的分析,进一步验证了其在引述和定基任务上的出色表现
#Self-Play Preference Optimization, SPPO
人类偏好就是尺!SPPO对齐技术让大语言模型左右互搏、自我博弈
Richard Sutton 在 「The Bitter Lesson」中做过这样的评价:「从70年的人工智能研究中可以得出的最重要教训是,那些利用计算的通用方法最终是最有效的,而且优势巨大。」
自我博弈(self play)就是这样一种同时利用搜索和学习从而充分利用和扩大计算规模的方法。
今年年初,加利福尼亚大学洛杉矶分校(UCLA)的顾全全教授团队提出了一种自我博弈微调方法 (Self-Play Fine-Tuning, SPIN),可不使用额外微调数据,仅靠自我博弈就能大幅提升 LLM 的能力。
最近,顾全全教授团队和卡内基梅隆大学(CMU)Yiming Yang教授团队合作开发了一种名为「自我博弈偏好优化(Self-Play Preference Optimization, SPPO)」的对齐技术,这一新方法旨在通过自我博弈的框架来优化大语言模型的行为,使其更好地符合人类的偏好。左右互搏再显神通!
- 论文标题:Self-Play Preference Optimization for Language Model Alignment
- 论文链接:https://arxiv.org/pdf/2405.00675.pdf
技术背景与挑战
大语言模型(LLM)正成为人工智能领域的重要推动力,凭借其出色的文本生成和理解能力在种任务中表现卓越。尽管LLM的能力令人瞩目,但要使这些模型的输出行为更符合实际应用中的需求,通常需要通过对齐(alignment)过程进行微调。
这个过程关键在于调整模型以更好地反映人类的偏好和行为准则。常见的方法包括基于人类反馈的强化学习(RLHF)或者直接偏好优化(Direct Preference Optimization,DPO)。
基于人类反馈的强化学习(RLHF)依赖于显式的维护一个奖励模型用来调整和细化大语言模型。换言之,例如,InstructGPT就是基于人类偏好数据先训练一个服从Bradley-Terry模型的奖励函数,然后使用像近似策略优化(Proximal Policy Optimization,PPO)的强化学习算法去优化大语言模型。去年,研究者们提出了直接偏好优化(Direct Preference Optimization,DPO)。
不同于RLHF维护一个显式的奖励模型,DPO算法隐含的服从Bradley-Terry模型,但可以直接用于大语言模型优化。已有工作试图通过多次迭代的使用DPO来进一步微调大模型 (图1)。

图1.基于Bradley-Terry模型的迭代优化方法缺乏理论理解和保证
如Bradley-Terry这样的参数模型会为每个选择提供一个数值分数。这些模型虽然提供了合理的人类偏好近似,但未能完全捕获人类行为的复杂性。
这些模型往往假设不同选择之间的偏好关系是单调和传递的,而实证证据却常常显示出人类决策的非一致性和非线性,例如Tversky的研究观察到人类决策可能会受到多种因素的影响,并表现出不一致性。
SPPO的理论基础与方法

图2.假想的两个语言模型进行常和博弈。
在这些背景下,作者提出了一个新的自我博弈框架 SPPO,该框架不仅具有解决两玩家常和博弈(two-player constant-sum game)的可证明保证,而且可以扩展到大规模的高效微调大型语言模型。
具体来说,文章将RLHF问题严格定义为一个两玩家常和博弈 (图2)。该工作的目标是识别纳什均衡策略,这种策略在平均意义上始终能提供比其他任何策略更受偏好的回复。
为了近似地识别纳什均衡策略,作者采用了具有乘法权重的经典在线自适应算法作为解决两玩家博弈的高层框架算法。
在该框架的每一步内,算法可以通过自我博弈机制来近似乘法权重更新,其中在每一轮中,大语言模型都在针对上一轮的自身进行微调,通过模型生成的合成数据和偏好模型的注释来进行优化。
具体来说,大语言模型在每一轮回会针对每个提示生成若干回复;依据偏好模型的标注,算法可以估计出每个回复的胜率;算法从而可以进一步微调大语言模型的参数使得那些胜率高的回复拥有更高的出现概率(图3)。

图3.自我博弈算法的目标是微调自身从而胜过上一轮的语言模型
实验设计与成果
在实验中,研究团队采用了一种Mistral-7B作为基线模型,并使用了UltraFeedback数据集的60,000个提示(prompt)进行无监督训练。他们发现,通过自我博弈的方式,模型能够显著提高在多个评估平台上的表现,例如AlpacaEval 2.0和MT-Bench。这些平台广泛用于评估模型生成文本的质量和相关性。
通过SPPO方法,模型不仅在生成文本的流畅性和准确性上得到了改进,更重要的是:「它在符合人类价值和偏好方面表现得更加出色」。

图4.SPPO模型在AlpacaEval 2.0上的效果提升显著,且高于如 Iterative DPO 的其他基准方法。
在AlpacaEval 2.0的测试中(图4),经过SPPO优化的模型在长度控制胜率方面从基线模型的17.11%提升到了28.53%,显示了其对人类偏好理解的显著提高。经过三轮SPPO优化的模型在AlpacaEval2.0上显著优于多轮迭代的DPO, IPO和自我奖励的语言模型(Self-Rewarding LM)。
此外,该模型在MT-Bench上的表现也超过了传统通过人类反馈调优的模型。这证明了SPPO在自动调整模型行为以适应复杂任务方面的有效性。
结论与未来展望
自我博弈偏好优化(SPPO)为大语言模型提供了一个全新的优化路径,不仅提高了模型的生成质量,更重要的是提高了模型与人类偏好的对齐度。
随着技术的不断发展和优化,预计SPPO及其衍生技术将在人工智能的可持续发展和社会应用中发挥更大的作用,为构建更加智能和负责任的AI系统铺平道路。
#MiniCPM~2
中文OCR超越GPT-4V,参数量仅2B,面壁小钢炮拿出了第二弹, OpenAI后,大模型新增长曲线来了。大语言模型的效率,正在被这家「清华系」创业公司发展到新高度。
从 ChatGPT 到 Sora,生成式 AI 技术遵从《苦涩的教训》、Scaling Law 和 Emerging properties 的预言一路走来,让我们已经看到了 AGI 的冰山一角,但技术的发展的方向还不尽于此。
最近一段时间,科技公司大力投入生成式 AI,一系列新的概念正在出现:手机厂商认为「AI 手机」正在引领手机形态的第三次转变;PC 厂商认为「AI PC」可能会改变个人电脑的形态;而对于更多科技公司来说,AI 进入 2.0 时代后,所有应用「都应该重写一遍」。
这些改变游戏规则的事物,背后隐含着一个逻辑:AI 大模型需要快速覆盖大量场景。而对于算力有限的端侧而言,优化是重中之重。从应用落地的角度看,轻量级、MoE 大模型已经成为人们重要的探索方向。
面对逐渐增多的生成式 AI 落地需求,「清华系」创业公司面壁智能一直在致力于对语言模型进行优化,使其在同等成本下达到更好的效果。
今年 2 月 1 日,面壁智能发布的第一代 2B 旗舰端侧大模型 MiniCPM,不仅超越了来自「欧洲版 OpenAI」Mistral 的性能标杆之作,同时整体领先于 Google Gemma 2B 量级,还越级超越了一些业内标杆的 7B、13B 量级模型,如 LLaMa2-13B 等。
仅仅 70 天以后,端侧大模型面壁 MiniCPM 小钢炮的第二弹乘胜追击,迎来多模态、长文本、MoE 等领域模型的迭代,主打的就是「小而强,小而全」。
把大模型做小,不止是提高效率
4 月 11 日,面壁智能正式发布了新一代 MiniCPM 系列模型,包括四个模型:
- OCR 能力惊艳,当前端侧最强多模态模型MiniCPM-V 2.0;
- 适配更多端侧场景,仅 1.2B 的基座模型 MiniCPM-1.2B;
- 最小的 128K 长文本模型 MiniCPM-2B-128K;
- 性能进一步增强的 MoE 架构模型 MiniCPM-MoE-8x2B。
- MiniCPM-V 2.0 开源地址:
https://github.com/OpenBMB/MiniCPM-V - 小钢炮全家桶系列开源地址:
https://github.com/OpenBMB/MiniCPM - 小钢炮全家桶技术 Blog 地址:
https://openbmb.vercel.app/?category=Chinese+Blog
这些模型的具体表现如何?我们可以从真实评测数据和实际任务表现两个方面一探究竟。
首先是近来各个大模型厂商都极力主推的多模态能力。面壁智能此次发布了能跑在手机上的「最强端侧多模态大模型」MiniCPM-V 2.0,参数规模仅为 2.8B,但在与参数远超自己的竞品模型较量中实现越级胜出。
其中在 OpenCompass 榜单中,综合 11 个主流评测基准的结果表明,MiniCPM-V 2.0 的通用多模态能力超越了 Qwen-VL-Chat-10B、CogVLM-Chat-17B 和 Yi-VL-34B,让我们看到了「小身板也能蕴藏强大能力」。
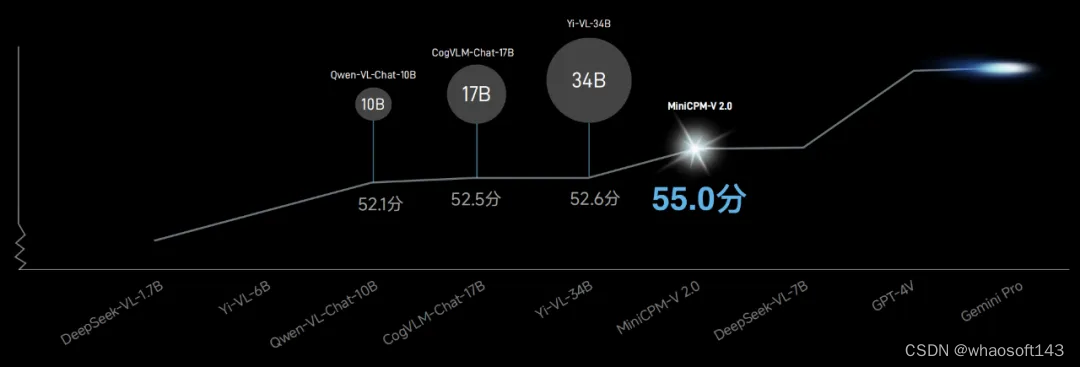
模型通用能力越强,意味着幻觉水平越低,事实准确性越高。因此,MiniCPM-V 2.0 大大降低了自身幻觉水平。
在评估大模型幻觉的 Object HalBench 榜单中,幻觉水平与 GPT-4V 持平(见图上)。下面是实测的一次看图说话任务,MiniCPM-V 2.0 出现了 3 处幻觉,GPT-4V 出现了 6 处幻觉(见图下高亮红字):
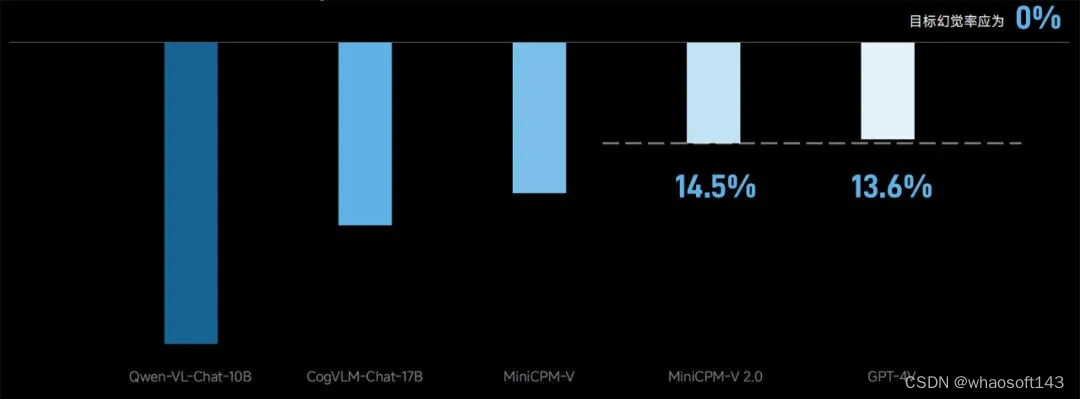

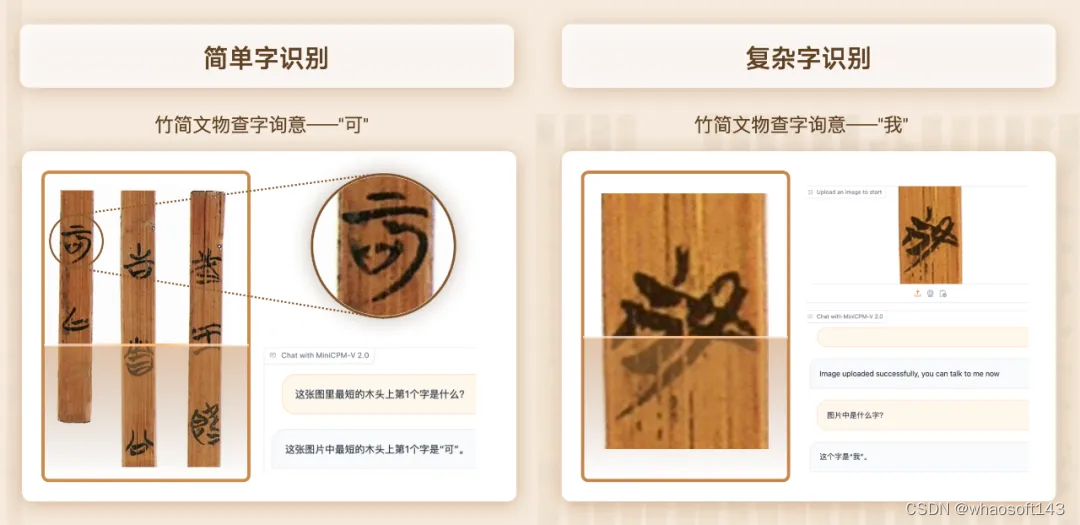
除了越来越强大的通用能力,在 OCR(光学字符识别)这一多模态识别与推理能力的硬性指标上,MiniCPM-V 2.0 更有亮眼的表现,在精准识别图片中物体的同时,对包括古文字在内的文字符号的识别迎来了史诗级加强。
比如让该模型识别清华大学收藏的「清华简」竹简上的古文字,它轻松搞定了简单字(下图左)和复杂字(下图右)的识别。
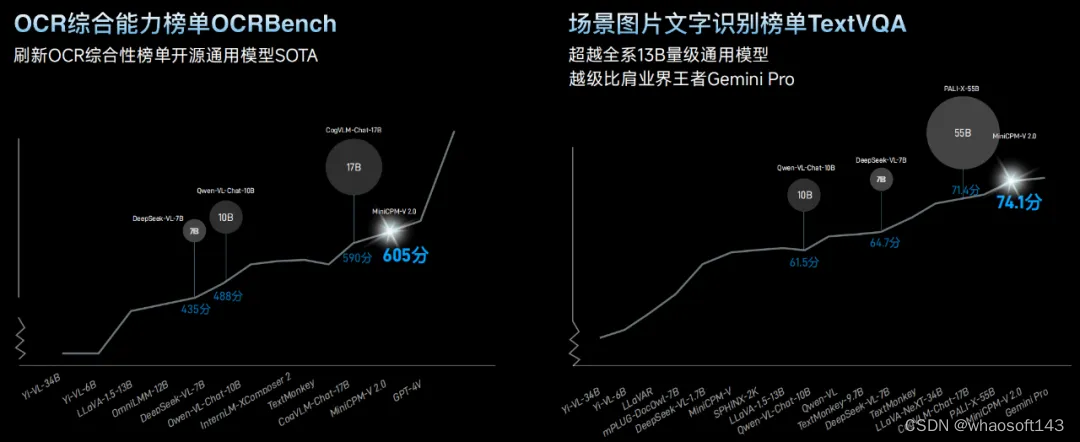
此外,MiniCPM-V 2.0 在 OCR 综合能力榜单 OCRBench 上刷新开源模型 SOTA 表现;还在场景图片文字识别榜单 TextVQA 上超越全系 13B 量级通用模型,其中文字理解表现越级比肩了业界王者谷歌 Gemini Pro,让我们惊叹它的进化之快。
评测数据如此之强,让 MiniCPM-V 2.0 面对一系列 OCR 场景经典难题时毫无压力。传统大模型只能处理 448×448 像素固定的小图,对于包含海量信息的更精细图片识别则力有不逮。对于构图繁复、细节丰富的街景识别,MiniCPM-V 2.0 模型抓全景、抓细节、抓重点的能力显然更胜一筹。

此外还有传统大模型往往表现不佳的长图识别,其中包含的大量文本信息对模型构成了巨大挑战。而 MiniCPM-V 2.0 能够更稳、更准地捕获长图重点信息,进行摘要总结,这是之前的模型无法做到的。

当然,在中文 OCR 场景任务的表现上,MiniCPM-V 2.0 超越了 GPT-4V,能后者之所不能。

面壁智能将「小」做到极致,推出了一款体量更小的模型 ——MiniCPM-1.2B,号称「小小钢炮」。模型参数虽然较上一代 2.4B 模型减少了一半,但仍保留了其 87% 的综合性能。
同样用数据说话,在 C-Eval、CMMLU、MMLU 等多个公开权威评测榜单上,综合性能越级超越了 Qwen1.8 B、LLaMa2-7B 甚至是 LLaMa2-13B,展现出了更小模型击败大模型的巨大潜力。
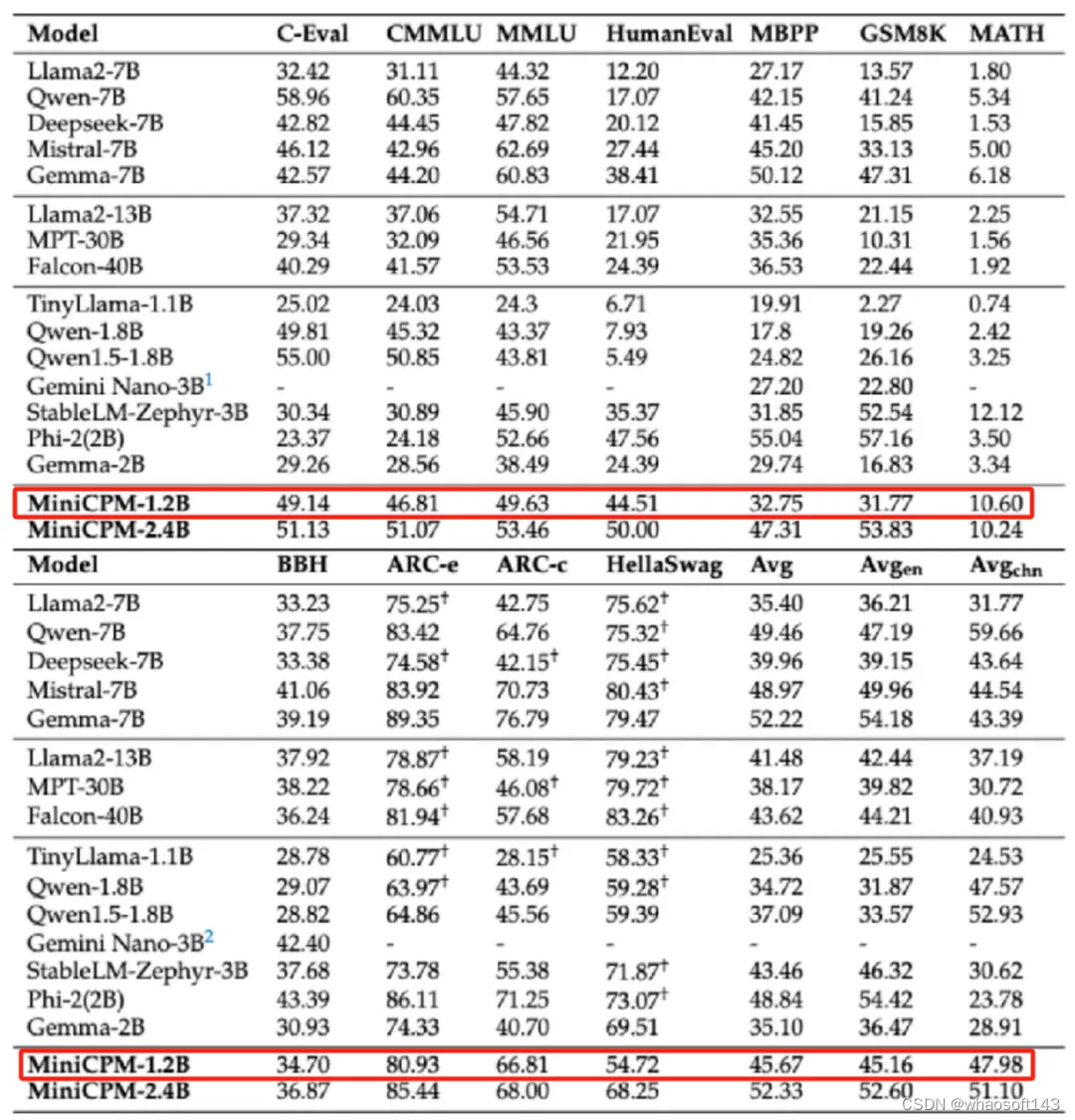
更小参数意味着更有利于手机等端侧设备上部署和运行。活动现场,面壁智能演示了 MiniCPM-1.2B 在 iPhone 15 上流畅的运行效果,推理速度提升 38%,达到了 25 token/s,是人说话速度的 15 到 25 倍。

当然,模型尺寸减小不仅有利于端侧落地,内存成本也得到显著降低。在 iOS 系统端,MiniCPM-1.2B 的内存用量(1.01G)比 MiniCPM-2.4B 量化模型(2.1G)减少了 51.9%,折算成本下降了 60%(1 元 = 4150000 tokens)。
1.2B 的体量让语言模型的应用范围不在仅限于旗舰手机,极致的优化让模型的体量更小,使用场景却大大增多了。尤其对于想要在端侧部署大模型的手机厂商来说,MiniCPM-1.2B 是个不错的选择。
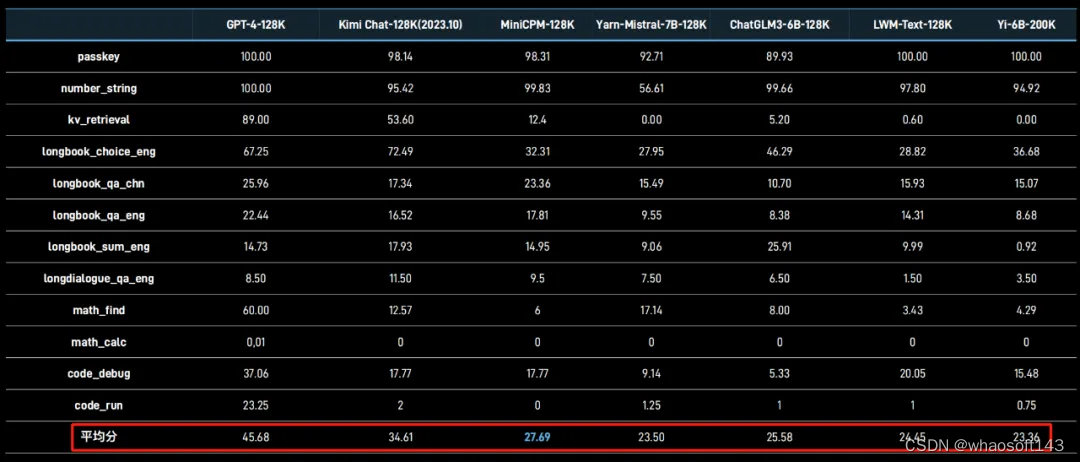
MiniCPM「小钢炮」同样强化了长文本理解能力。此次推出的 MiniCPM-2B-128K 成为了支持 128K 上下文窗口的最小体量模型。
其中在 InfiniteBench 榜单的平均成绩较量中,MiniCPM-2B-128K 以 2B 的「小身躯」超越一众 6B、7B 量级模型,比如 Yi-6B-200K、Yarn-Mistral-7B-128K,实实在在做到了「量小质高」。
关于长文本模型的下一步探索方向,面壁智能表示,同样会在端侧的部署和运行上发力。
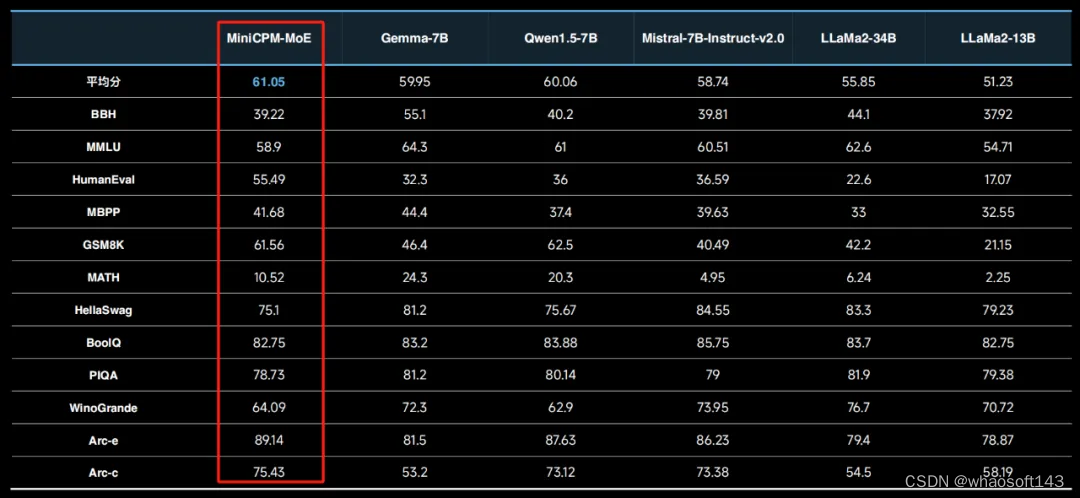
多模态和长文本保证了 MiniCPM 模型能力的基本盘,而混合专家模型(MoE)架构的引入让该系列模型的能力更上一层楼。全新 MiniCPM-MoE-8x2B 模型将第一代 2B 模型的平均性能提升了 4.5 个百分点,并且相较于完全从头开始训练,训练成本大大降低。
该模型的平均激活参数虽然只有 4B,但在 BBH、MMLU 等 12 个权威评测基准上的平均成绩取得了第一,甚至击败了 LLaMa-34B,而推理成本仅仅为 Gemma-7B 的 69.7%。
至此,面壁智能将覆盖多模态、长文本、MoE 架构的新四「小」模型一一铺开,充分挖掘小体量大模型的全方位能力,在一众更大参数规模的竞品模型中成功突围。
能力突围背后,藏着一系列独门技术
今年 2 月 MiniCPM 第一代的发布会上,面壁智能联合创始人刘知远曾表示:「我们会在春节之后不断发布 MiniCPM 的新版本,性能还会进一步提升。我们要给大家春节的休息时间。」几十天后,面壁智能果然拿出了亮眼的成绩。
当然,这一切离不开面壁智能厚积薄发的独门技术实力。
先以 MiniCPM-V 2.0 展现的超强多模态能力来说,该模型面对一系列 OCR 场景的经典难题都给出对应的高效技术解决方案。
比如上文展示的更精细图片识别和长图识别,都要得益于高清图片、高效编码和任意宽高比图像无损识别,使得对小物体和光学字符等细腻视觉信息的感知能力大大增强,可以处理最大 180 万像素高清大图,甚至 1:9 极限宽高比的高清图片,对它们进行高效编码和无损识别。
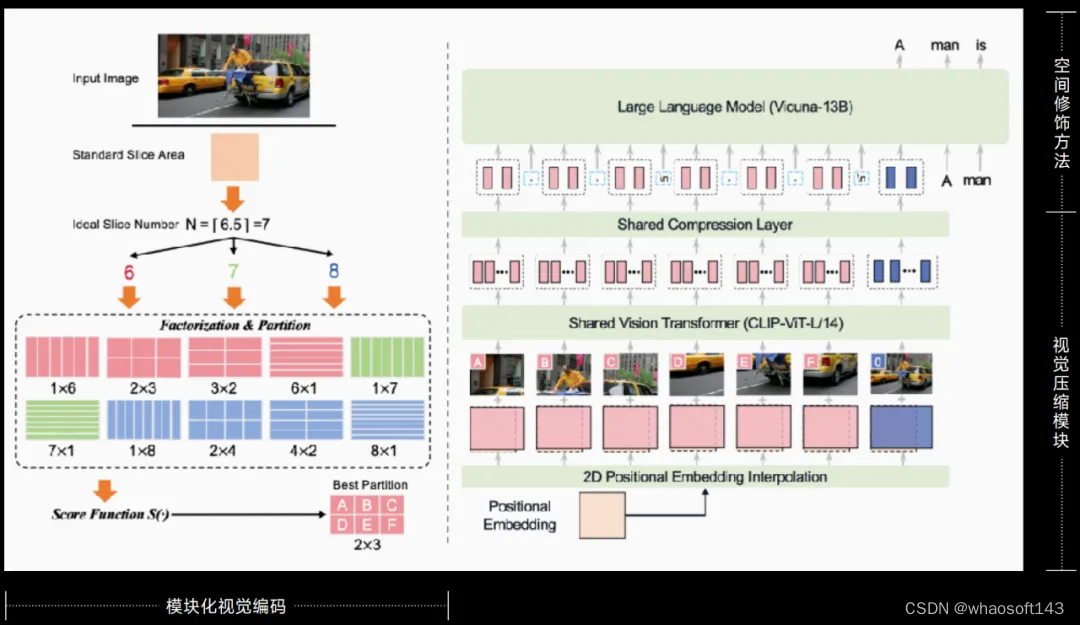
做到这些靠的是面壁智能的一项独门技术 —— LLaVA-UHD,它包含了三大重要组件,即模块化视觉编码、视觉压缩模块和空间修饰方法,它们发挥的作用分别如下:
- 模块化视觉编码负责将原始分辨率图像划分为可变大小切片,并且无需像素填充或图像变形即可实现对原始分辨率的完全适应;
- 视觉压缩模块使用共享感知器重采样层压缩图像切片的视觉 tokens,无论分辨率多少 token 数量皆可负担,计算量更低的同时支持任意宽高比图像编码;
- 空间修饰方法则使用自然语言符号的简单模式,有效告知图像切片的相对位置。
三位一体、相辅相成,让高清图像、高效编码成为可能。
此外,MiniCPM-V 2.0 还具备了独家的跨语言多模态泛化技术,让大模型可以用中文解读英文菜单并给出推荐。
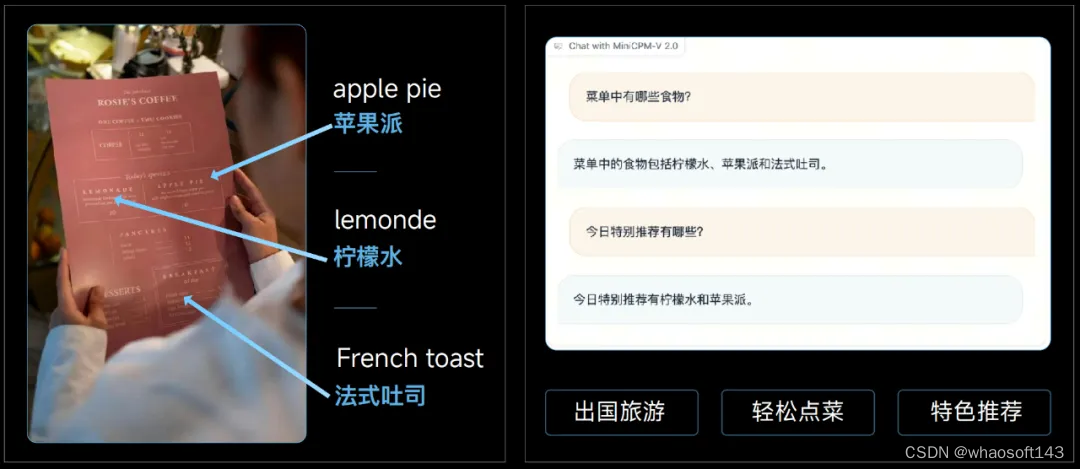
不仅如此,跨模态跨语言泛化技术还解决了中文领域缺乏高质量、大规模多模态数据的挑战。团队提出的 VisCPM 可以通过英文多模态数据的预训练,进而泛化实现优秀的中文多模态能力。
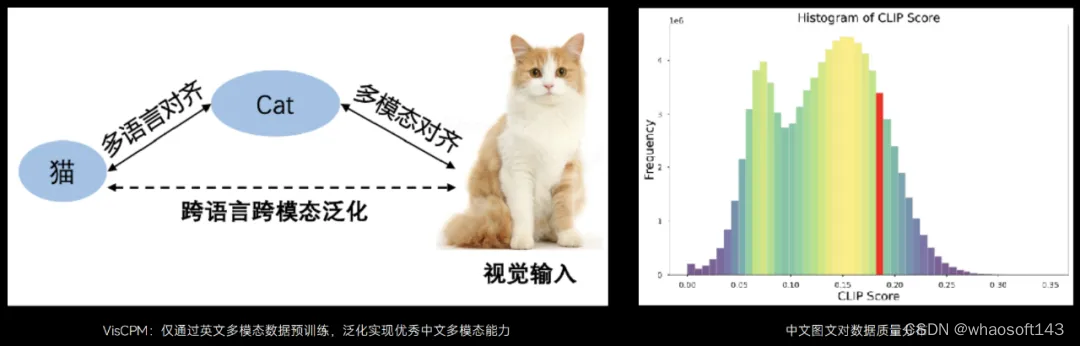
VisCPM 论文地址:https://arxiv.org/pdf/2308.12038.pdf
与此同时,在 MiniCPM-2B-128K 上,团队通过多阶段训练方法,在训练过程中使用课程学习、动态调整数据配比等技术,组合使用多种长文本扩展方式,成功将模型的上下文长度扩展至 128K。这一过程既提高了训练效率,又尽可能减少了对短文本处理性能的损失。面壁智能表示,未来还将进一步扩展模型的上下文长度。
MiniCPM-MoE-8x2B 模型采用了最前沿的 MoE (混合专家模型)架构,这一架构能在不增加推理成本的情况下为大模型带来性能激增。
MiniCPM-MoE-8x2B 模型总共包含 8 个 expert,全参数量(non-embedding)为 13.6B,每个 token 激活其中的 2 个 expert,激活参数量(non-embedding)为 4B。
掌握新的 Scaling Law
在众多投身大语言模型的创业公司中,专注于「小模型」方向的面壁智能,早已总结出了自己的一套打法。
2020 年,OpenAI 一篇论文《Scaling Laws for Neural Language Models》对于 transformers 架构的大模型表现与训练时间、上下文长度、数据集大小、模型参数量和计算量的关系进行了讨论。其提出模型的表现与规模存在强相关,这就是「Scaling Law」。
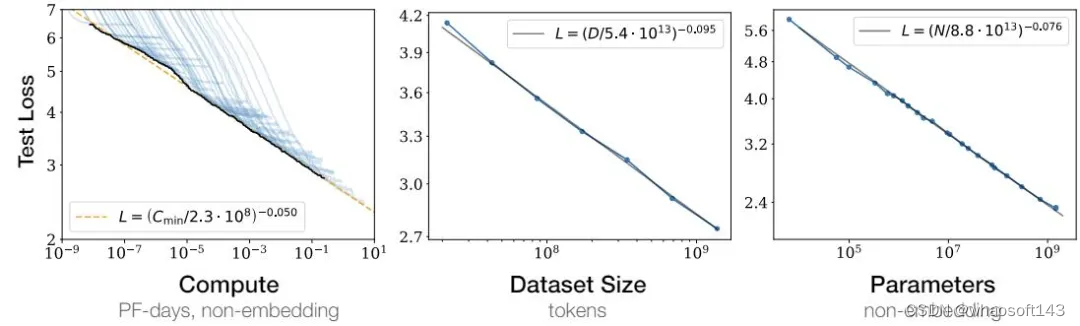
随着我们增加模型体量、数据集大小和训练算力,语言建模的性能平稳提高。为了获得最佳性能,所有三个因素必须同时扩大。当其中一个因素受限时,模型表现随另外一个因素增加变好,但效果会逐渐衰减。(图片来自 OpenAI)
随着之后 GPT-3、GPT-4 的推出,OpenAI 遵循着这样的规律进行探索,为生成式 AI 带来了突破性的进展。众多科技公司、创业公司也纷纷入局,投入构建千亿级,甚至万亿级参数大模型的行列中。
但在大模型的世界中,参数量大,并不一定等于性能更好。今年 3 月 17 日,马斯克的 xAI 正式开源了 3140 亿参数的混合专家(MoE)大模型 Grok-1,成为了当前参数量最大的开源大语言模型。然而仅过去不到两个星期,Databricks 开源的 1320 亿参数通用大模型 DBRX 就在多个基准上打败了它。
今年初的 AI 顶会 ICLR 2024 上,面壁智能等机构被接收的论文《Predicting Emergent Abilities with Infinite Resolution Evaluation》引发了人们对 Scaling Law 的新理解。
在这项研究中,研究人员发现小模型虽然性能有限,但表现出关键且有一致性的任务性能改进趋势,而由于测量分辨率不足,传统的评估策略无法捕获这些改进。在新的评估策略支持下,人们发现了一种加速涌现,其标度曲线不能用标准标度律函数拟合,并且具有递增的速度。
面壁智能 CTO 曾国洋表示,其团队从 2020 年 GPT-3 发布后开始训练大模型,逐渐认识到「提升模型效果是大模型训练的根本目标,但这并不意味着一定要通过扩大参数量规模和燃烧高昂的算力成本来实现。」相反,让每一个参数发挥最大作用,在同等参数量上实现更好的性能,才是解决大模型效率问题的核心。
面壁智能的语言模型探索,也是一直围绕着小体量、高性能的目标展开的。
今年 2 月发布的「性能小钢炮」MiniCPM,作为全球领先的轻量高性能大模型,标志着面壁大模型高效训练模式的彻底跑通。独特的面壁「模型沙盒实验」,通过对大模型训练过程进行环境建、并对最佳模型训练结果进行精准模拟预测,成功打造出高效 Scaling Law 曲线 —— 同等参数量条件下性能更优、同等性能情况下参数更小。
2 月发布的 MiniCPM 2B 在更小参数量的基础上可以实现媲美 Mistral-7B 的性能,进一步验证了其「低参数、高性能」的方法论。
而在最近,面壁智能的技术已经可以做到把中文 OCR 水平媲美 GPT-4V 的模型塞进手机,新 Scaling Law 的路线已经逐渐清晰。
面壁智能在探索「高效」这件事的过程中,以源源不断的世界级前瞻研究成果,布局了贯彻高效训练、高效落地与高效推理的大模型全栈技术生产线。
从清华自然语言处理实验室(THUNLP)走来,务实,但专注于有引领性方向的研究,是面壁大模型团队的标签。
实际上,这个团队多年来对于 AI 技术路线作出了很多次精准的预言式判断:从 2018 年投入 BERT 技术路线,2020 年率先拥抱大模型,2023 年初对 AI 智能体(Agent)的超前探索,千亿多模态大模型 CPM-Cricket 的发布,再到对大模型端云协同的前瞻布局。在竞争激烈的生成式 AI 领域,面壁超前的 Al 技术研判策略,逐渐收获了业内的认知与认同。
结语
目前,面壁智能已经组建起 100 余人的科研团队,其中 80% 人才来自清北,平均年龄 28 岁。
MiniCPM 新的探索,也在引领大模型领域的下一阶段发展。如果从效率的角度来看,面壁或许会是速度更快的那一个。
在昨天的发布会上,面壁智能正式宣布完成了新一轮数亿元人民币的融资,由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。新一轮融资,将被用于加快推动大模型的高效训练、快步应用落地。
面壁把大模型做小,不仅是为了端侧的快速落地:通过 MiniCPM 系列模型 等工作,能够实现 AGI 的通用基座大模型已有了更深厚的基础。基于 Scaling Law 的科学方法论,通过把大模型做小验证出高效大模型的框架,更加强大的 AI 正在路上。
#纯cのGPT-2
1000行C语言搓出GPT-2!AI大神Karpathy新项目刚上线就狂揽2.5k星,训练大模型的方法可能要被革新了!AI大神Karpathy发布的新项目仅用1000行的C语言训完GPT-2,而不再依赖庞大的GPT-2库。他本人预告,即将上线新课。
断更近一个月,Karpathy终于上线了。这次不是AI大课,而是带来一个新项目。仅用1000行纯C语言训完GPT-2。
想象一下,如果我们能够不依赖于庞大的PyTorch(245MB)和cPython(107MB)库,仅仅使用纯C语言就能训练大型语言模型(LLM),那会怎样?
现在,借助llm.c,这件听起来似乎不太可能的事,已经成为了现实!
这个项目的亮点在于,它仅用约1000行简洁的C代码,就实现了在普通计算机处理器(CPU)上训练GPT-2模型的能力。
而且,这份代码不仅可以立即编译运行,其训练结果也和PyTorch版本的GPT-2完全一致。
之所以选择GPT-2作为起点,是因为它标志着大型语言模型发展史上的一个重要里程碑,是第一次以我们现在所熟悉的形式整合了这样的技术栈,并且模型权重也是公开可获取的。
这一项目刚刚发布几个小时,已经获得了2.5k星。
项目地址:https://github.com/karpathy/llm.c
有网友表示,初创公司正在等着Karpathy挖掘新的点子。
很少有人知道,SUNO一开始是nanoGPT的一个分支。(Suno创业团队首款产品Bark受到了nanoGPT的启发)
或许Karpathy正在尝试的是重新设计LLM架构,通过llm.c项目去探索一种更简单、高效的模型训练方法。
「我无法创造的,我就无法理解」。
Karpathy完全让AI走向大众化。
那么,仅用C语言如何训出LLM?
千行C代码训完GPT-2
项目开篇介绍中,Karpathy还提到了自己目前正在进行的研究:
- 直接使用CUDA实现,速度会快得多,可能接近PyTorch。
- 使用SIMD指令加速CPU版本,x86上的AVX2/ARM上的NEON(比如苹果芯片)。
- 采用更现代的架构,如Llama2、Gema等。
对于repo,Karpathy希望同时维护干净、简单的参考实现以及更优化的版本,这些版本可以接近PyTorch,但只需很少的代码和依赖项。
快速入门
下载数据集,并将其进行分词。Tinyshakepeare数据集下载和分词速度最快:
python prepro_tinyshakespeare.py打印内容如下:
Saved 32768 tokens to data/tiny_shakespeare_val.bin
Saved 305260 tokens to data/tiny_shakespeare_train.bin其中,.bin文件包含有int32的原始数据流,这些整数代表了通过GPT-2分词器定义的Token ID。
当然,也可以通过运行prepro_tinystories.py来对TinyStories数据集进行分词处理。
理论上讲,现在已经能够开始训练模型了。但是,目前基于CPU和FP32的参考代码运行效率极低,无法从零开始训练这些模型。
因此,我们选择先用OpenAI发布的GPT-2模型权重进行初始化,再对模型进行微调。
为了这个目的,我们需要下载GPT-2模型的权重文件,并把它们作为检查点保存下来,这样就可以在C语言环境中进行加载了:
python train_gpt2.py这个脚本的作用是下载GPT-2(124M)模型,并对单个数据batch进行10次迭代训练实现过拟合。
接着,脚本将执行几步生成任务,并且最重要的是,保存两个文件:
- gpt2_124M.bin,其中包含了可用于在C语言环境中加载模型的原始权重;
- gpt2_124M_debug_state.bin,其中包含了额外的调试信息,如输入数据、目标、logits和损失。
这些信息对于调试、单元测试以及确保与PyTorch的参考实现完全一致很有帮助。
目前,主要关注的是gpt2_124M.bin文件中的模型权重。有了它们,就可以在C语言环境中初始化模型并开始训练了。
首先,我们需要编译代码:
make train_gpt2你可以打开Makefile文件,并阅读里面的注释。
它会自动检查你的电脑是否支持OpenMP,这对于以非常低的复杂度来加速代码运行很有帮助。
当完成train_gpt2的编译之后,就可以开始运行了:
OMP_NUM_THREADS=8 ./train_gpt2现在,你需要根据电脑的CPU核心数来设置程序运行的线程数。
然后,程序会加载模型的权重和Token,接着进行几次迭代的微调过程,这个过程使用了Adam优化算法,学习率设置为0.0001。
最后,程序会根据模型生成一个样本。
总结来说,代码实现了模型每一层的数据处理流程,包括前向传播、反向传播和参数更新等,并且被组织成了一个完整的循环。
在搭载M3 Max芯片的MacBook Pro上运行时,输出结果如下:
[GPT-2]
max_seq_len: 1024
vocab_size: 50257
num_layers: 12
num_heads: 12
channels: 768
num_parameters: 124439808
train dataset num_batches: 1192
val dataset num_batches: 128
num_activations: 73323776
val loss 5.252026
step 0: train loss 5.356189 (took 1452.121000 ms)
step 1: train loss 4.301069 (took 1288.673000 ms)
step 2: train loss 4.623322 (took 1369.394000 ms)
step 3: train loss 4.600470 (took 1290.761000 ms)
... (trunctated) ...
step 39: train loss 3.970751 (took 1323.779000 ms)
val loss 4.107781
generated: 50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323
step 40: train loss 4.377757 (took 1366.368000 ms)目前,程序生成的结果只是Token ID,我们需要把这些编号转换成可读的文本。
这个过程在C语言中实现起来相当简单,因为涉及到的主要是对应字符串片段的查找和输出。
现在,我们可以利用一个叫做tiktoken的工具来完成这个任务:
import tiktoken
enc = tiktoken.get_encoding("gpt2")
print(enc.decode(list(map(int, "50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323".split()))))打印内容如下:
<|endoftext|>Come Running Away,
Greater conquer
With the Imperial blood
the heaviest host of the gods
into this wondrous world beyond.
I will not back thee, for how sweet after birth
Netflix against repounder,
will not
flourish against the earlocks of
AllayKarpathy表示,他对Netflix在模型生成结果中的呈现方式非常满意,因为这显示出模型仍然保留了其训练过程中的一些特征。
此外,他也没有去调整微调的超参数,因此如果能够优化这些设置,特别是通过延长训练时间,模型的性能应该会有很大的提升空间。
测试
这里提供一个简单的单元测试程序,用来验证我们编写的C语言代码是否与PyTorch框架中的代码实现相匹配。
通过以下命令即可编译并执行:
make test_gpt2
./test_gpt2这段代码首先会加载gpt2_124M_debug_state.bin文件,然后执行一次前向计算。
这个过程会生成模型的预测结果(logits)和损失(loss),并将其与PyTorch的标准实现进行比较。
接下来,它会利用Adam优化算法对模型进行10轮训练,从而确保训练的损失与PyTorch的结果一致。
教程
项目最后,Karpathy还附上了一个非常小的教程——
项目地址:https://github.com/karpathy/llm.c/blob/master/doc/layernorm/layernorm.md
它是实现GPT-2模型的单层,即LayerNorm的一个简单的分步指南。
这是了解如何用C语言实现层的一个很好的起点。
纯CUDA也可训
在训练开始时,先一次性预分配一大块一维内存,用于存储训练过程中所需的所有数据。
这样做的好处是,在整个训练过程中,我们无需再次分配或释放内存。如此一来,不仅简化了内存管理,还确保了内存使用量保持不变,优化了数据处理效率。
接下来的核心任务是——手动编写代码,实现模型中每一层的数据前向传播和后向传播过程,并将这些层按顺序连接起来。
此外,为了构建完整的模型,我们还需要实现多个关键组件,包括编码器(encoder)、矩阵乘法(matmul)、自注意力机制(self-attention)、GELU激活函数、残差连接(residual)、softmax函数和交叉熵损失计算。
Karpathy继续解释道,一旦你有了所有的层,你就可以把所有的层串联起来。
不瞒你说,写这个过程相当乏味,也很受虐,因为你必须确保所有的指针和张量偏移向量都正确排列。
在完成了模型的前向传播和反向传播之后,接下来的工作,比如设置数据加载器和调整Adam优化算法,就比较简单了。
随后,Karpathy还介绍了自己下一步进行工作是:
一步步地将这个过程迁移到CUDA上,从而大幅提升运算效率,甚至达到接近PyTorch的水平,而且不需要依赖那些复杂的库。
目前,他已经完成了其中的几层。
接下来的工作包括减少计算精度——从FP32降到FP16甚至更低,以及添加一些新的层(如RoPE),从而支持更先进的模型架构,例如Llama 2、Mistral、Gemma等。
当然了,等着这一切完成之后,另一期「从头开始构建」的视频也会上线。
参考资料:
https://github.com/karpathy/llm.c
https://twitter.com/karpathy/status/1777427944971083809
#DeepSeek-V2
一块钱100万token,超强MoE模型开源,性能直逼GPT-4-Turbo
开源大模型领域,又迎来一位强有力的竞争者。
近日,探索通用人工智能(AGI)本质的 DeepSeek AI 公司开源了一款强大的混合专家 (MoE) 语言模型 DeepSeek-V2,主打训练成本更低、推理更加高效。
- 项目地址:https://github.com/deepseek-ai/DeepSeek-V2
- 论文标题:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-V2 参数量达 236B,其中每个 token 激活 21B 参数,支持 128K token 的上下文长度。
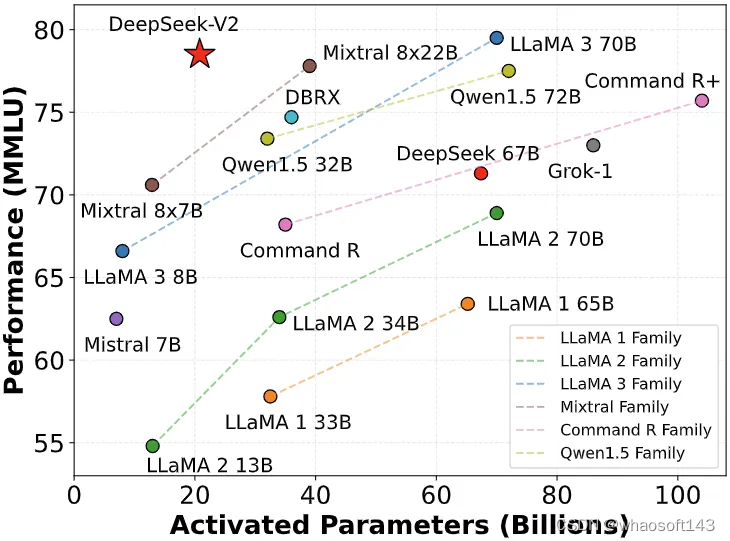
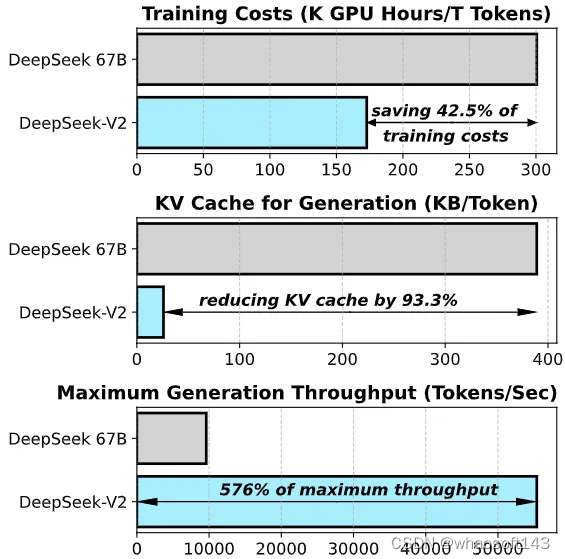
与 DeepSeek 67B (该模型去年上线)相比,DeepSeek-V2 实现了更强的性能,同时节省了 42.5% 的训练成本,减少了 93.3% 的 KV 缓存,并将最大生成吞吐量提升 5.76 倍。
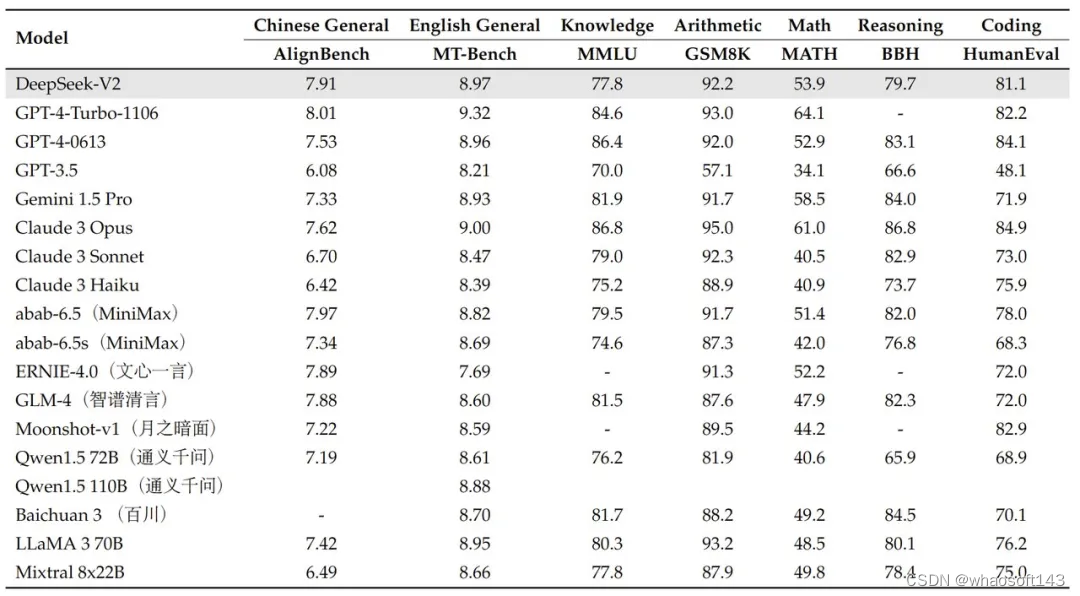
DeepSeek-V2 的模型表现非常亮眼:在 AlignBench 基准上超过 GPT-4,接近 GPT-4- turbo;在 MT-Bench 中与 LLaMA3-70B 相媲美,并优于 Mixtral 8x22B;擅长数学、代码和推理。
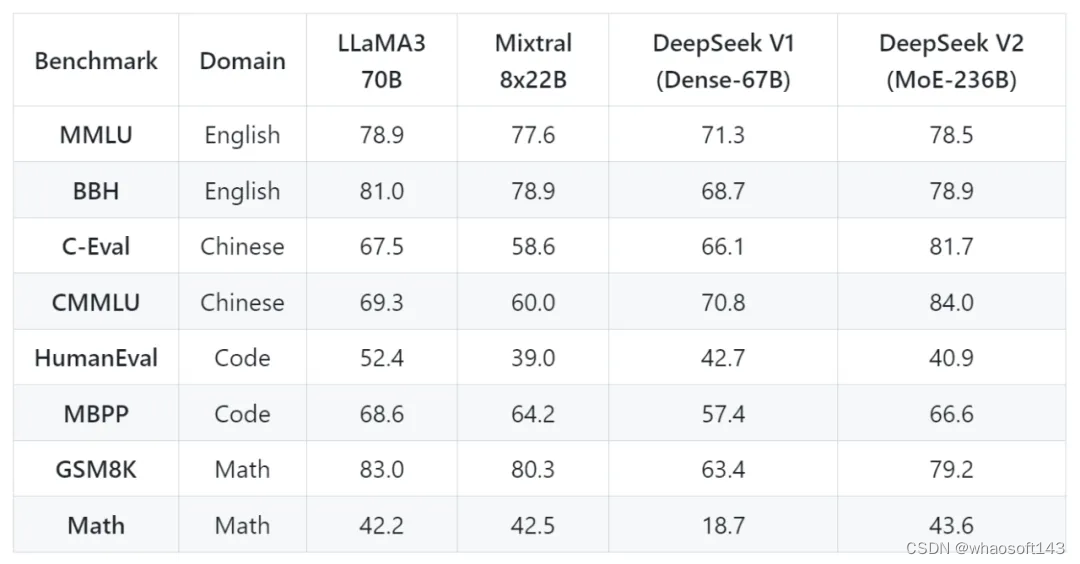
下面是 DeepSeek-V2 与 LLaMA 3 70B、Mixtral 8x22B、DeepSeek V1 (Dense-67B) 对比结果:
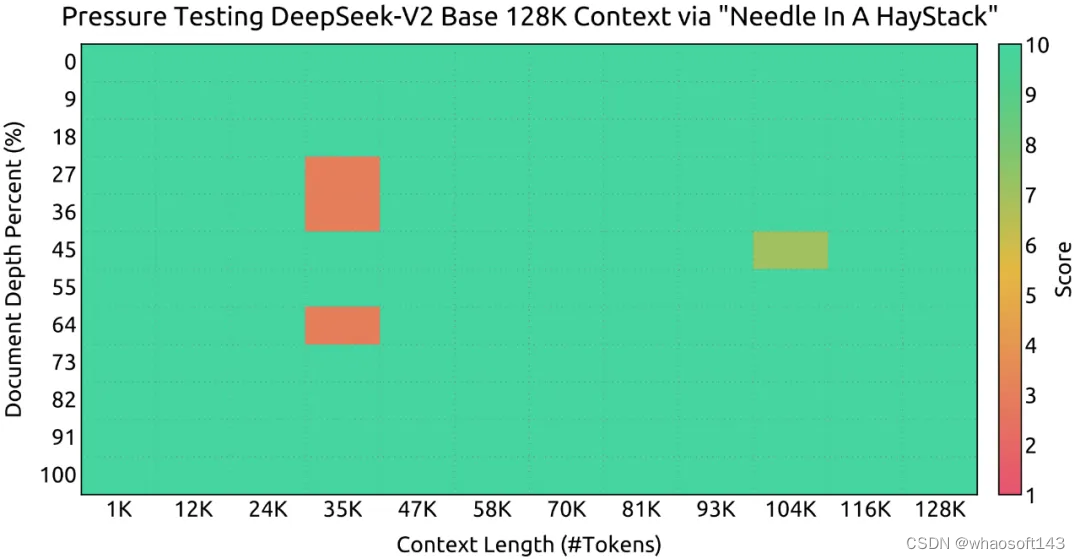
在大海捞针(NEEDLE IN A HAYSTACK)任务中,DeepSeek-V2 在上下文窗口达 128K 时表现良好。
在 LiveCodeBench (0901-0401「一个专为实时编码挑战而设计的基准」) 上,DeepSeek-V2 获得了较高的 Pass@1 分数。
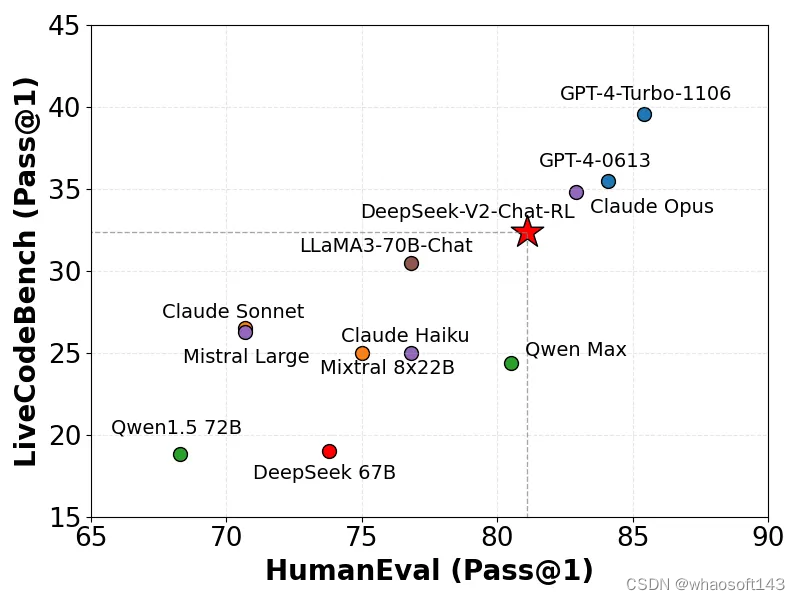
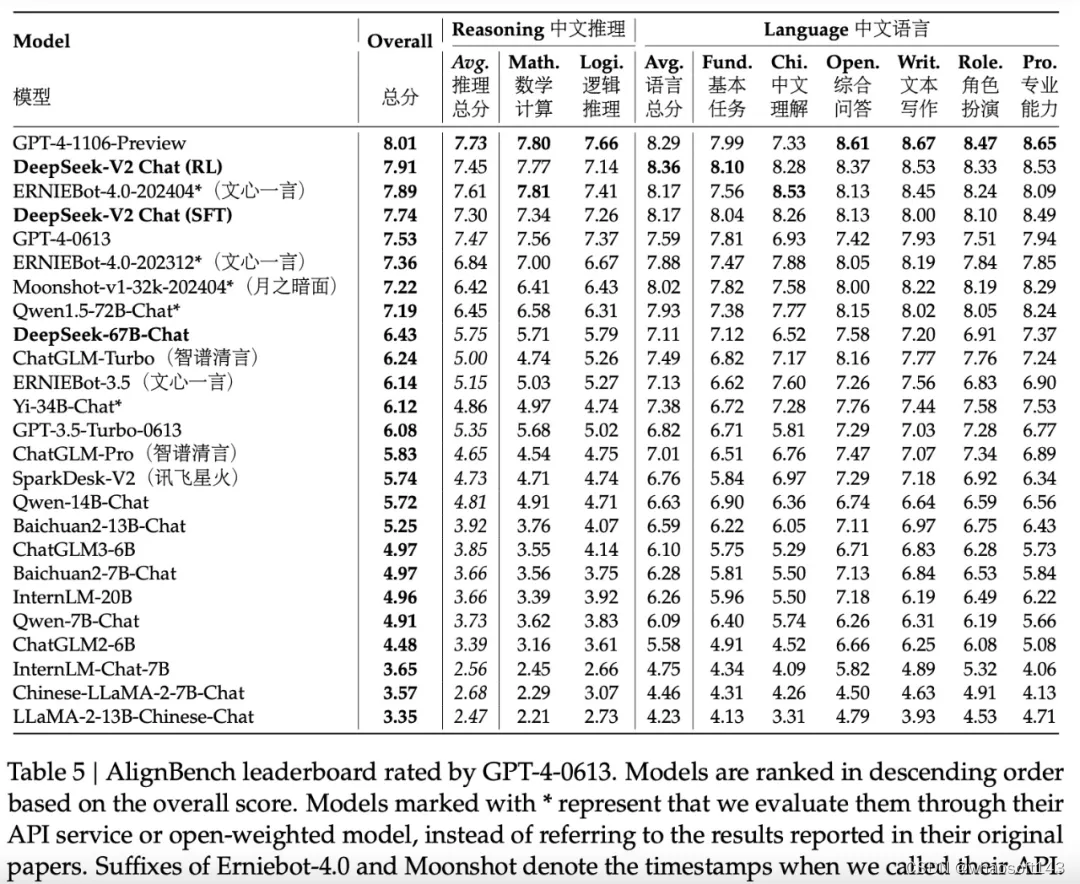
DeepSeek-V2 与不同模型在中文推理、中文语言上的表现:
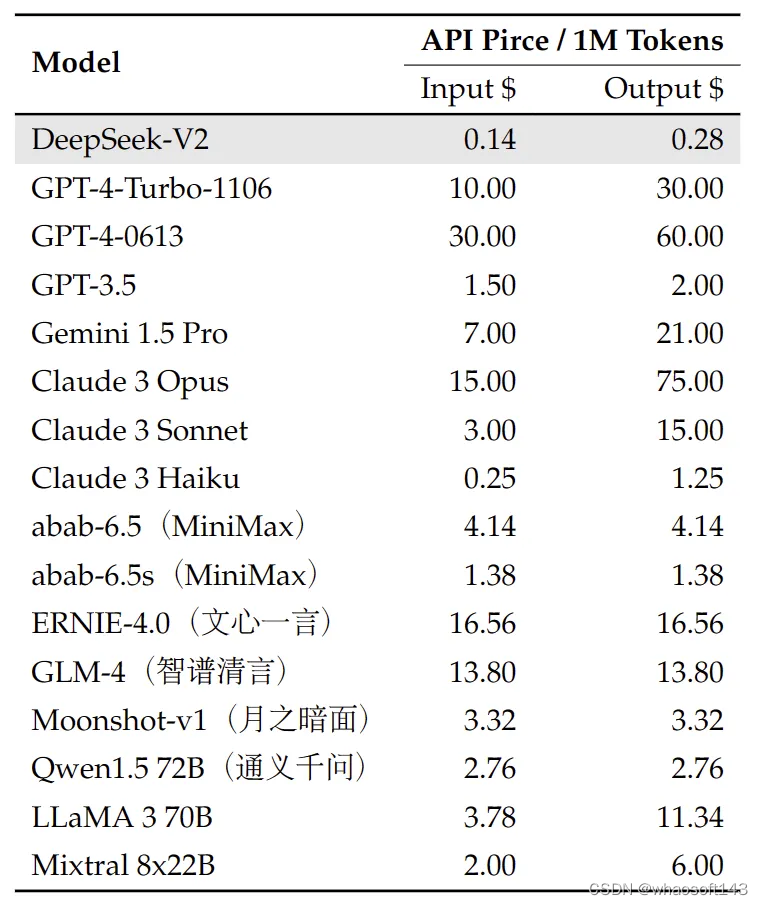
在价格方面,DeepSeek-V2 API 的定价如下:每百万 token 输入 0.14 美元(约 1 元人民币)、输出 0.28 美元(约 2 元人民币,32K 上下文),与 GPT-4-Turbo 定价相比,价格仅为后者的近百分之一。
模型介绍
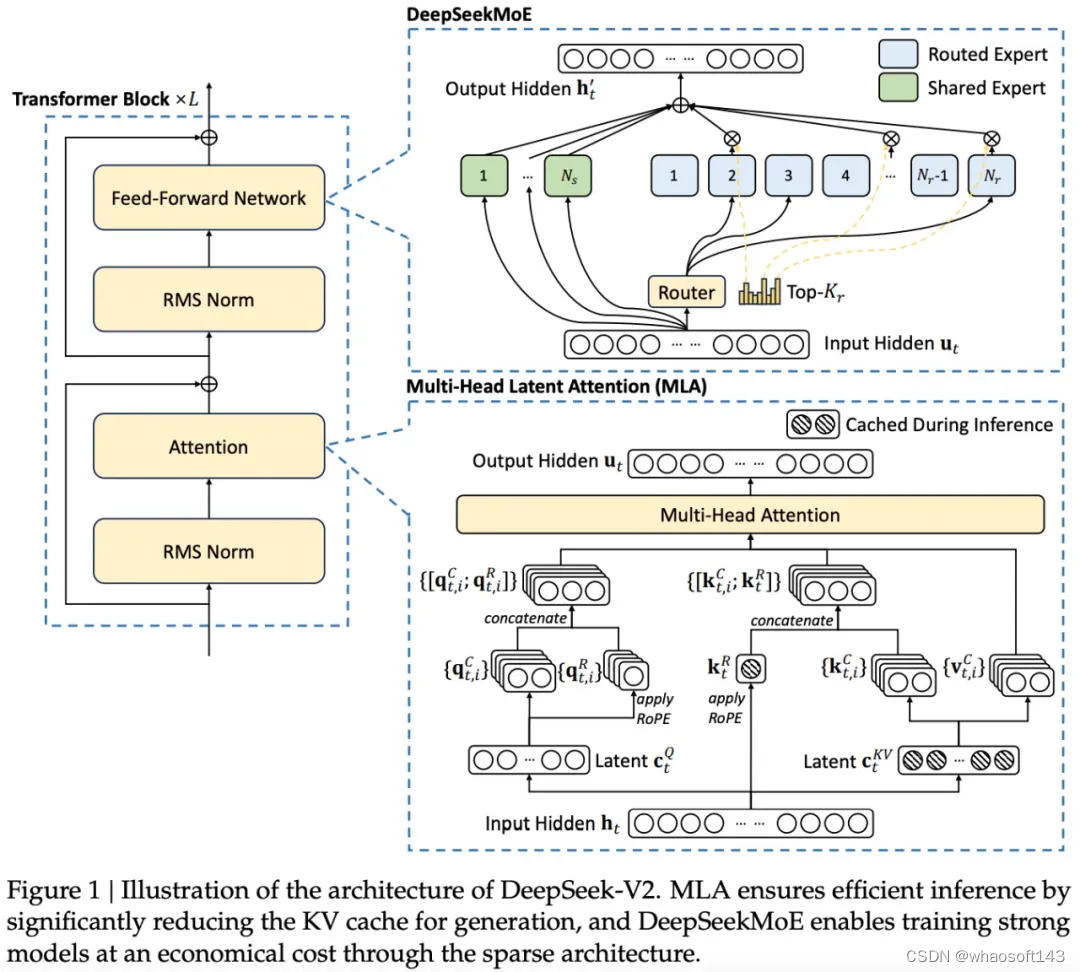
DeepSeek-V2 采用 Transformer 架构,其中每个 Transformer 块由一个注意力模块和一个前馈网络(FFN)组成。然而,对于注意力模块和 FFN,研究团队设计并采用了创新的架构。
一方面,该研究设计了 MLA,利用低秩键值联合压缩来消除推理时键值缓存的瓶颈,从而支持高效推理。
另一方面,对于 FFN,该研究采用高性能 MoE 架构 —— DeepSeekMoE,以经济的成本训练强大的模型。
在一些细节上,DeepSeek-V2 遵循 DeepSeek 67B 的设置,DeepSeek-V2 的架构如下图所示:
研究团队构建了由 8.1T token 组成的高质量、多源预训练语料库。与 DeepSeek 67B 使用的语料库相比,该语料库的数据量特别是中文数据量更大,数据质量更高。
该研究首先在完整的预训练语料库上预训练 DeepSeek-V2,然后再收集 150 万个对话,涵盖数学、代码、写作、推理、安全等各个领域,以便为 DeepSeek-V2 Chat 执行监督微调(SFT)。最后,该研究遵循 DeepSeekMath 采用群组相对策略优化 (GRPO) 进一步使模型与人类偏好保持一致。
DeepSeek-V2 基于高效且轻量级的框架 HAI-LLM 进行训练,采用 16-way zero-bubble pipeline 并行、8-way 专家并行和 ZeRO-1 数据并行。鉴于 DeepSeek-V2 的激活参数相对较少,并且重新计算部分算子以节省激活内存,无需张量并行即可训练,因此 DeepSeek-V2 减少了通信开销。
此外,为了进一步提高训练效率,该研究将计算和通信重叠,并为专家之间的通信、路由算法和线性融合计算定制了更快的 CUDA 内核。
实验结果
该研究在多种英文和中文基准上对 DeepSeek-V2 进行了评估,并将其与代表性的开源模型进行了比较。评估结果显示,即使只有 21B 个激活参数,DeepSeek-V2 仍然达到了开源模型中顶级的性能,成为最强的开源 MoE 语言模型。
值得注意的是,与基础版本相比,DeepSeek-V2 Chat (SFT) 在 GSM8K、MATH 和 HumanEval 评估方面表现出显著改进。此外,DeepSeek-V2 Chat (RL) 进一步提升了数学和代码基准测试的性能。
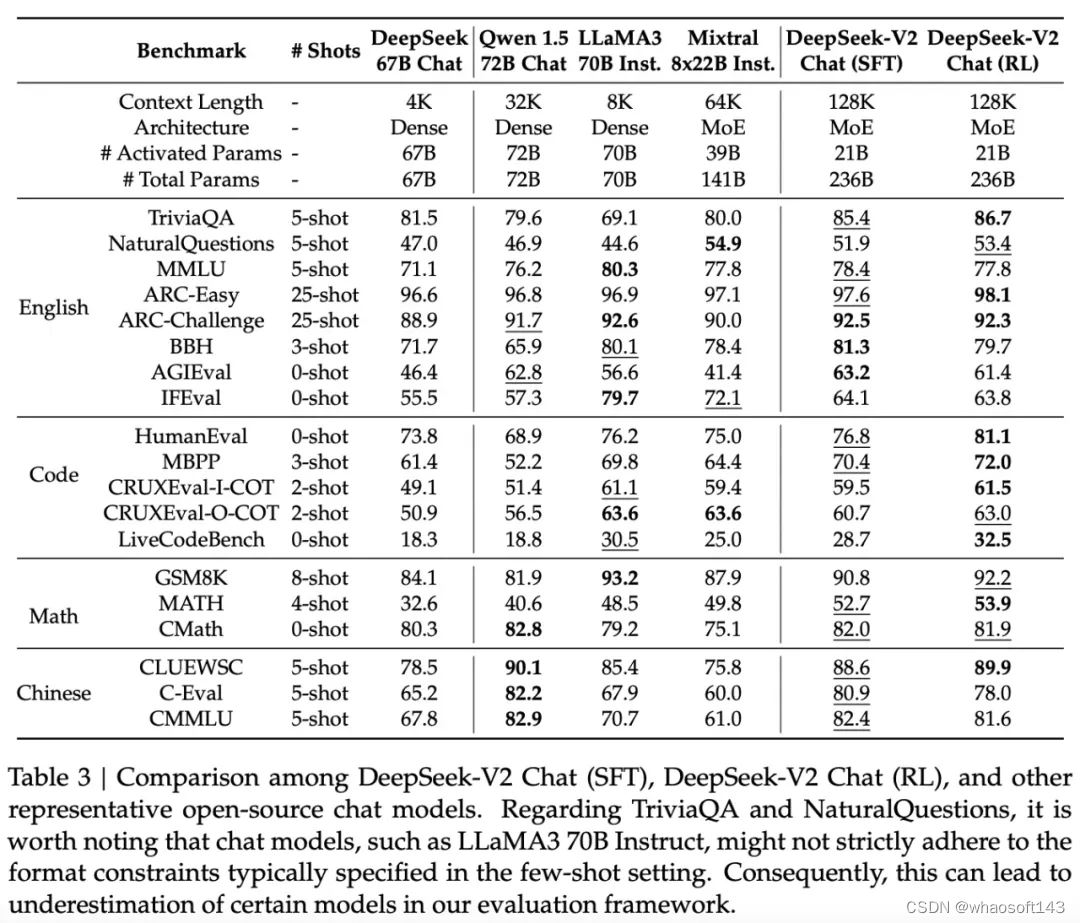
开放式生成的评估。研究团队继续在开放式对话基准上对模型进行额外评估。其中对于英文开放式对话生成,他们使用 MT-Bench 和 AlpacaEval 2.0 作为基准。表 4 中的评估结果表明, DeepSeek-V2 Chat (RL) 相对于 DeepSeek-V2 Chat (SFT) 具有显著的性能优势。这一结果展示了强化学习训练在改进一致性方面的有效性。
与其他开源模型相比,DeepSeek-V2 Chat (RL) 在两个基准的测试中均优于 Mistral 8x22B Instruct 和 Qwen1.5 72B Chat。与 LLaMA3 70B Instruct 相比,DeepSeek-V2 Chat (RL) 在 MT-Bench 上展现出具有竞争力的性能,并在 AlpacaEval 2.0 上的表现明显胜出。
这些结果凸显出了 DeepSeek-V2 Chat (RL) 在生成高质量且上下文相关的响应方面具有强大性能,尤其是在基于指令的对话任务中。
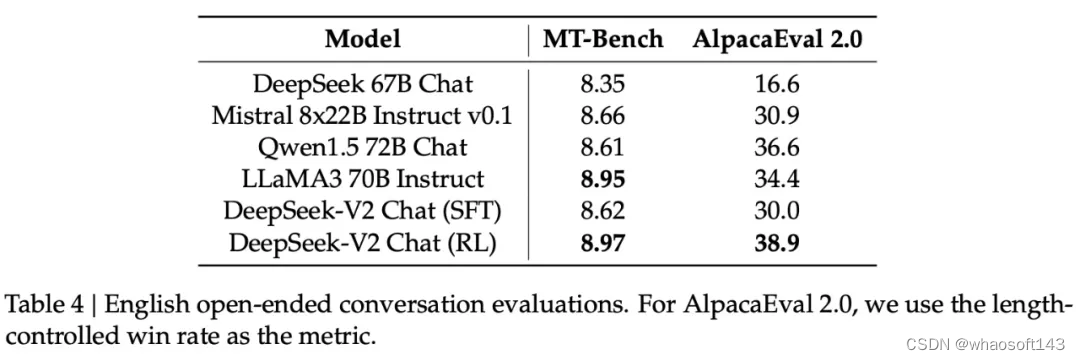
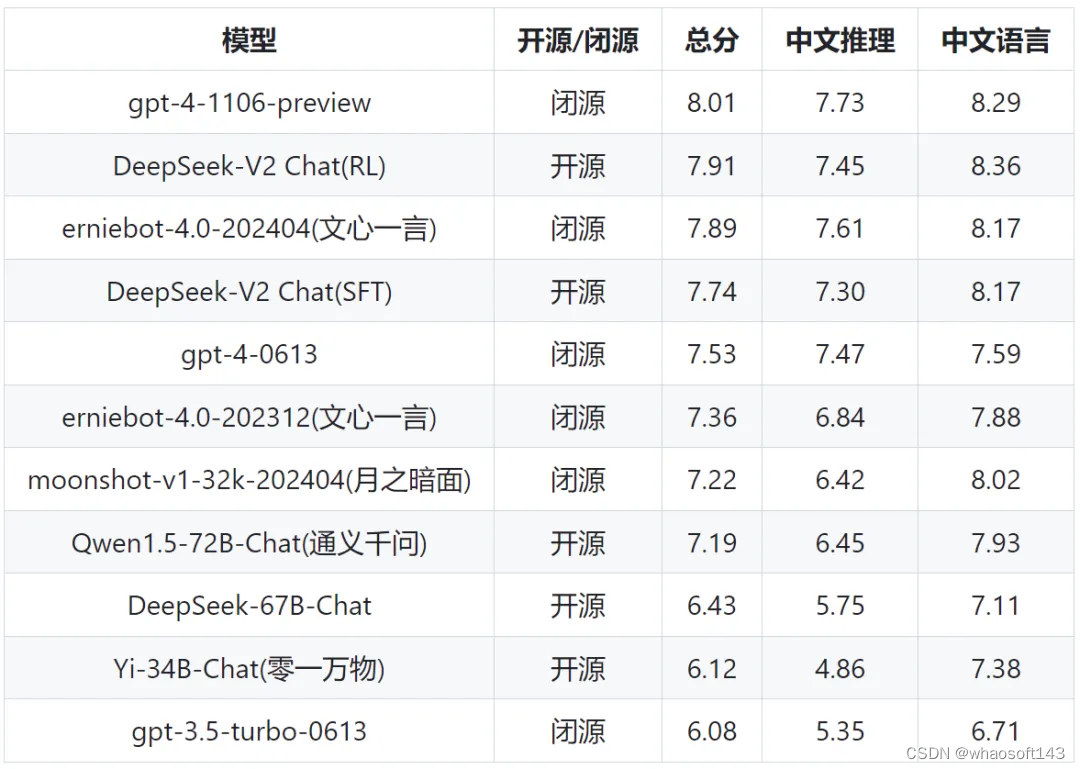
研究团队基于 AlignBench 评估了中文大模型社区的开放式生成能力。如表 5 所示,DeepSeek-V2 Chat (RL) 比 DeepSeek-V2 Chat (SFT) 稍有优势。尤其值得关注的是,DeepSeek-V2 Chat(SFT)大幅超越了所有开源中文模型,它在中文推理和语言方面都显著优于第二好的开源模型 Qwen1.5 72B Chat。
此外,DeepSeek-V2 Chat (SFT) 和 DeepSeek-V2 Chat (RL) 的性能均优于 GPT-4-0613 和 ERNIEBot 4.0,巩固了自家的模型在支持中文方面的顶级 LLM 地位。具体来说,DeepSeek-V2 Chat(RL)在中文理解方面表现出色,优于包括 GPT-4-Turbo-1106-Preview 在内的所有模型。不过 DeepSeek-V2 Chat(RL)的推理能力仍然落后于 Erniebot-4.0 和 GPT-4 等巨型模型。
#ImageGPT
在 CIFAR-10 上,iGPT 使用 linear probing 实现了 96.3% 的精度,优于有监督的 Wide ResNet,并通过完全微调实现了 99.0% 的精度,匹配顶级监督预训练模型。
本文所受的启发就是 NLP 中领域的无监督表征学习,是自回归视觉模型的先驱。本文训练了 image GPT,一个序列 Transformer 模型,来自回归地预测图片像素,而无需结合 2D 输入结构的先验知识。本文训练时,尽管只是在不含标签的低分辨率 ImageNet 上作训练,但是展示出的 GPT-2 尺度的模型依然能够学习到强力的图像表征 (通过 linear probing,fine-tuning,low-data classification 来度量)。
在 CIFAR-10 上,iGPT 使用 linear probing 实现了 96.3% 的精度,优于有监督的 Wide ResNet,并通过完全微调实现了 99.0% 的精度,匹配顶级监督预训练模型。在将像素替换为 VQVAE 编码时,iGPT 的性能还在自监督的 ImageNet benchmarks 具有竞争力,使用 linear probing 实现了 69.0% 的 top-1 精度。
本文聚焦于 NLP 领域中 GPT 模型的 "给定一些文本 tokens,然后预测下一个 token 是什么" 的范式,将这一范式从 NLP 领域迁移到 CV 领域中。因此,本文的方法称为 iGPT,是个序列 Transformer 模型。例如,把 32×32 的图像按照像素依次排列成一个序列,并使用序列 Transformer 模型建模。训练的目标函数是自回归目标函数。
这样预训练之后得到的 iGPT 模型可以在多个下游任务,比如 ImageNet,CIFAR,STL-10 上得到有前景的精度,并且展示出一些模型容量的规律。本文是将自回归方案引入视觉领域的先驱工作。
1 自回归视觉模型的先驱 ImageGPT:使用图像序列训练图像 GPT 模型
论文名称:Generative Pretraining from Pixels (ICML 2020)
论文地址:https//cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
官网地址:https//openai.com/research/image-gpt
- 1 ImageGPT 论文解读:
1.1 无监督学习在视觉的应用
无监督预训练在深度学习的复兴中起着核心的作用。从 2000 年代中期开始,深度置信网络 (Deep Belief Network)[1]和去噪自动编码器 (Denoising Autoencoder) [2]等方法通常用于计算机视觉和语音识别的神经网络。随着分段线性激活函数[3],改进的初始化策略[4]和归一化策略[5][6]等等方法的出现无监督预训练的必要性在逐步被消除。
无监督的预训练在 NLP 领域中也蓬勃发展。在词向量[7]之后,它推动了自然语言处理在大多数任务上的应用。有趣的是,BERT 等方法的训练目标,即预测损坏的输入,与最初为图像开发的去噪自动编码器的训练目标非常相似。
从模态上讲,图像比文本的维度更高、更嘈杂,且更加冗余,因此被认为难以做生成建模。考虑到生成式预训练方法对于 NLP 领域的重大影响,这种方法值得再审视,并与最近的自监督方法作比较。本文重新评估图像上的生成式预训练,并证明使用 Transformer + 自回归式预训练得到的生成式预训练模型与其他自监督方法相比同样具有竞争力。
1.2 ImageGPT 方法介绍
ImageGPT 方法包括一个预训练阶段和一个微调阶段。在预训练中,作者探索了自回归和 BERT 目标函数,还应用序列 Transformer 架构来预测像素 token,而非语言 token。
微调 (Finetuning):衡量图像表征质量的一种方法是在图像分类任务上做微调。微调在模型中添加了一个小的分类头,用于优化分类目标并且再训练所有权重。


图1:iGPT 对图片的分块操作以及两种目标函数,以及评估策略
模型框架


1.3 数据集和数据增强策略
尽管有监督的预训练是图像分类的主要范式,但管理大型标注图像数据集既昂贵又耗时。本文希望从更大的可用无标记图像集中学习通用的表征,并对其进行微调以进行分类。本文使用 ImageNet 作为大型未标记的图像数据集,并使用小的有标注数据集 (CIFAR-10、CIFAR-100、STL-10) 来作为下游任务的代理。
数据增强:训练时随机调整图像的大小,使较短的边长在 [256,384] 范围内。接下来取一个随机的 224×224 裁剪。推理时调整了图像的大小,使得较短的边长为 224,并使用 224×224 中心裁剪。
当对 CIFAR-10 和 CIFAR100 进行微调时,使用 Wide Residual Networks 的数据增强方式:每边填充4个像素,并从填充图像或其水平翻转中随机采样 32×32 裁剪。
1.4 减少序列长度

1.5 模型设置

1.6 自回归预训练实验结果
深度对于表征质量的影响
首先是 iGPT 的自回归的实验结果。在有监督预训练中,表征的质量倾向于随着深度的增加而增加,这样一来最好的表征就位于倒数第二层。在生成式预训练的像素预测任务中,这一结论是否成立就不一定了。也就是说,倒数第二层产生的表征可能对分类任务而言并不是最有用的。
为了验证这一点,作者研究了表征的质量随着不同层的变化规律。实验结果如图2所示,可以发现线性探测的性能首先随着深度的增加而增加,然后再下降。造成这种现象的原因作者给出了一个解释:生成模型分2个阶段运行。第1阶段中,每个位置从其周围的上下文中收集信息,以构建全局图像表征。第2阶段中,这个输入解决像素预测任务。这有些类似于 Encoder-Decoder 的行为,区别是在一个架构里进行。
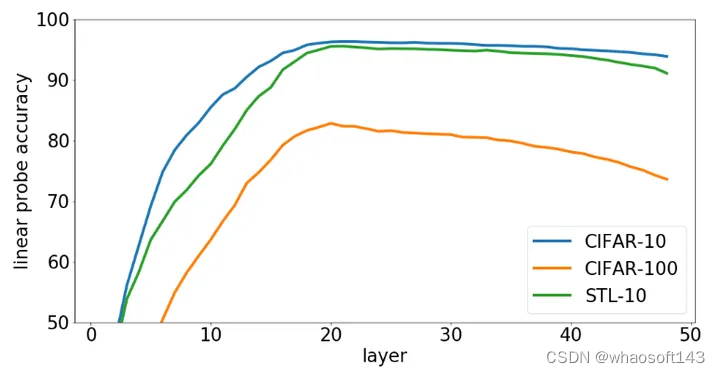
图2:表征质量在很大程度上取决于提取特征的层
模型容量对于表征质量的影响
实验结果如图3所示。可以看到自回归目标的验证集损失在整个训练过程中都会降低,线性探针精度也会增加。这一趋势在几个模型容量 iGPT-S,iGPT-M,iGPT-L 上都成立,容量更高的模型实现了更低的验证集损失。而且当验证集损失相同时,容量更大的模型精度也更好。
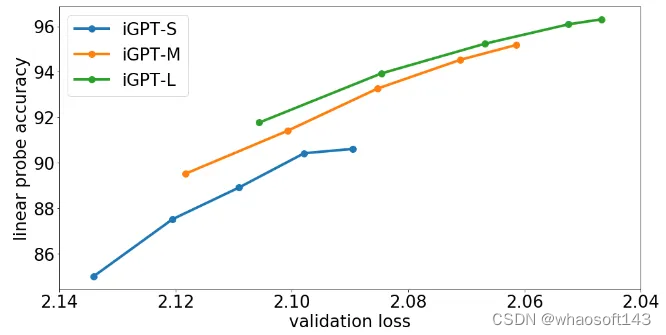
图3:模型容量对于表征质量的影响
线性探测实验结果
实验结果如图4所示。iGPT 在整个预训练方法范围内达到了领先的水平。比如在 CIFAR-10 上,iGPT 达到了 96.3%,优于 AMDIM-L (在没有标签的情况下在 ImageNet 上预训练) 和 ResNet-152 (在带有标签的 ImageNet 上预训练)。
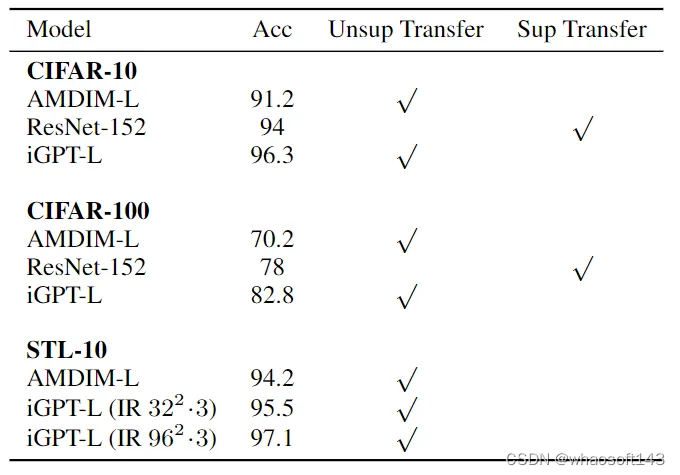
图4:CIFAR 和 STL-10 的线性探测实验结果
ImageNet 是一个比较困难的实验设置,因为无法在标准 ImageNet 输入分辨率 (IR) 下有效地训练 (这篇文章诞生时还没有 ViT 把图片分成 Patches 的策略)。在 32^232^2 的模型分辨率 (MR) 的情况下,iGPT 实现了 60.3% 的线性探测精度。在 48^248^2 的模型分辨率 (MR) 的情况下,iGPT 实现了 65.2% 的线性探测精度。
在使用了 VQ-VAE 之后,在 192^2192^2 的输入分辨率 (IR) 和 48^248^2 模型分辨率 (MR) 的情况下,线性探测精度达到 65.3%。当连接以最佳单层为中心的 11 层时,精度达到了 69.0%,与对比学习方法相当。
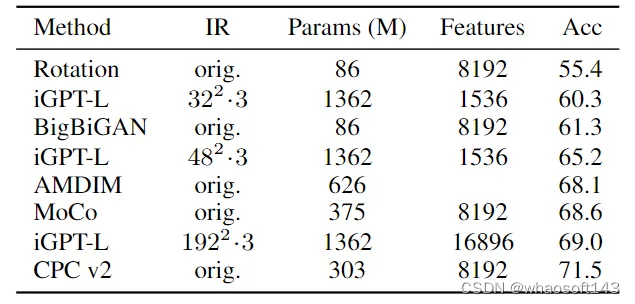
图5:ImageNet 的线性探测实验结果
完全微调实验结果
为了进一步提升模型在下游任务上的性能,作者继续微调整个模型。在之前的分析的基础上,作者尝试将分类头加在之前最佳的表征上面。在 CIFAR-10 上,iGPT 实现了 99.0% 的精度,在 CIFAR100 上达到了 88.5% 的精度。
在 ImageNet 上,iGPT 在 32^232^2 的模型分辨率上进行微调后实现了 66.3% 的精度,比线性探测提高了 6%。在 48^248^2 的模型分辨率上进行微调后实现了 72.6% 的精度,比线性探测提高了 7%。
微调时再次搜索学习率很重要,因为联合训练目标函数的最佳学习率通常比预训练的最佳学习率小一个数量级。作者还尝试使用 Dropout 进行正则化,但没有观察到任何明确的好处。此外,模型还很容易在小数据集上过拟合分类目标,因此作者采用基于验证精度的 Early Stopping。
1.7 BERT 预训练实验结果
鉴于 BERT 在 NLP 领域的成功,作者以 32^2\times332^2\times3 的输入分辨率和 32^232^2 的模型分辨率训练 iGPT-L。
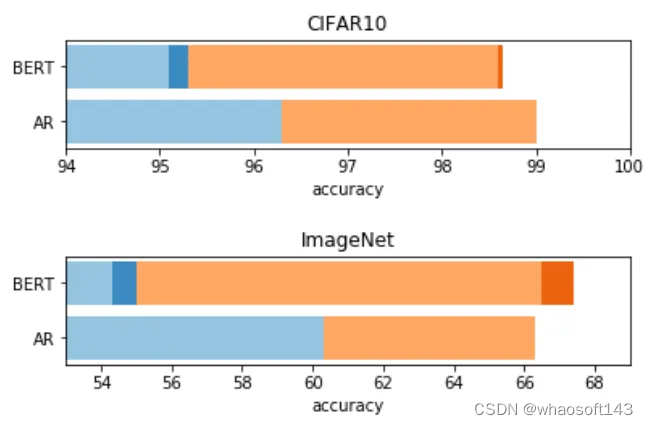
图6:BERT 预训练实验结果和自回归预训练结果在 CIFAR10 和 ImageNet 数据集上的比较。蓝色柱子是线性探测的精度,橘色柱子是完全微调精度
实验结果如图6所示,在 CIFAR-10 上,可以观察到每一层的线性探针准确度都比自回归模型差,最佳层性能低了超过 1%。ImageNet 上的最佳层精度低 6%。
然而,在微调期间 BERT 弥补了这一差距。完全微调的 CIFAR-10 模型达到了 98.6% 的准确率,仅落后于自回归模型 0.4%,而完全微调的 ImageNet 模型达到了 66.5%,略微超过了自回归的性能。
此外,作者还尝试了一种将 BERT mask 作 Ensemble 的策略,如图6中粗体所示,进一步提升了性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









