







我自己的原文哦~ https://blog.51cto.com/whaosoft/13911294
#AlphaEvolve
刚刚,DeepMind通用科学智能体AlphaEvolve突破数学极限,陶哲轩合作参与
今天,DeepMind 正式发布了 AlphaEvolve —— 一个由 LLMs 驱动的革命性进化编码智能体。
它不仅仅是一个代码生成工具,更是一个能够演化整个代码库,用于通用算法发现和优化的强大系统。
- 技术报告:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/AlphaEvolve.pdf
- 官方博客:https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/
LLM 具有惊人的多功能性。它们能够总结文件、生成代码,甚至提出新想法。如今,DeepMind 将这些能力扩展到了数学和现代计算中的基础性和高度复杂的问题。
Google DeepMind 的研究员 Matej Balog 在接受采访时表示:「它可以发现极其复杂的算法 —— 跨越数百行代码,具有复杂逻辑结构,远超出简单函数的范畴。」
陶哲轩也在 mathstodon 上表示,他一直在和 Google DeepMind 合作,探索 AlphaEvolve 的潜在数学应用。

大多数 AI 模型都会产生幻觉。由于他们的概率架构,他们有时会自信地编造东西。事实上,像 OpenAI 的 o3 这样的较新 AI 模型比它们的前辈更容易产生幻觉。
AlphaEvolve 引入了一种减少幻觉的巧妙机制:自动评估系统。该系统使用模型来生成、批评和得出问题的可能答案池,并自动评估和评分答案的准确性。
AlphaEvolve 还将 Gemini 模型的创造性问题解决能力与自动验证答案的评估器相结合,并利用进化框架来持续优化最具潜力的解决方案。
AlphaEvolve 提升了谷歌数据中心、芯片设计和 AI 训练流程的效率 —— 包括训练支撑 AlphaEvolve 本身的大型语言模型。它还帮助设计了更快的矩阵乘法算法,并为开放性数学问题找到了新的解决方案,在许多领域的应用前景有着巨大潜力。
用大型语言模型设计更好的算法
AlphaEvolve 是一个可以超越单一函数发现,演化整个代码库并开发更复杂算法的智能体。
与许多只演化单一函数的系统不同,AlphaEvolve 的一大亮点在于能够对整个代码库进行迭代优化和演化。
这建立在 DeepMind 2023 年的一项工作 ——FunSearch 基础上, DeepMind首次证明大型语言模型能够生成计算机代码中的函数,以帮助发现开放性科学问题上的新知识并证明其正确性。
表 1 展示了 AlphaEvolve 与先前的 agent 的能力和典型行为上的对比。

核心机制:LLM 的创造力与自动化评估的结合
那么,AlphaEvolve 是如何实现这种强大的代码演化能力的呢?其核心在于将大型语言模型的创造力与自动化评估的客观反馈巧妙地融入到一个进化框架中。
这个过程可以概括为一个持续的「生成 - 评估 - 进化」循环:

图示展示了整个系统的工作流程:提示采样器首先构建输入提示,驱动语言模型生成新程序;这些程序经过评估器评分后被存入程序数据库。数据库通过进化算法不断优化程序选择,推动系统持续进化。
生成
AlphaEvolve 结合了多款最先进的大型语言模型:Gemini Flash(DeepMind 最快速且高效的模型)拓展了创意探索的广度,而 Gemini Pro(DeepMind 最强大的模型)则凭借深刻洞见提供了解决方案所需的关键深度。
采用该集成策略的目的是在保持生成解法的质量的同时,提高计算吞吐率。这些模型协同生成实现算法解决方案的计算机程序。
1、提示语采样(Prompt Sampling)
由于 AlphaEvolve 依托于当前最先进的 LLM,它支持多种形式的自定义操作,并能在其主进化提示语(primary evolution prompt)中提供较长的上下文信息。
该提示语通常包含从程序数据库中采样而来的多个既有解法,以及关于如何修改特定解法的系统指令。 用户还可以通过显式上下文、渲染的评估结果等方式进一步对提示语进行定制。
2、创造性生成(Creative Generation)
为推动进化过程,AlphaEvolve 借助当前最先进的 LLM 的能力。其核心作用在于理解先前产生的解法信息,并提出多样化的新改进途径。
尽管 AlphaEvolve 本身并不依赖于特定模型(具备模型无关性),但在消融实验中观察到,AlphaEvolve 的表现会随着底层 LLM 性能的提升而持续改善。
输出格式(Output Format):当 AlphaEvolve 要求 LLM 对已有代码进行修改,尤其是在较大的代码库中,它会要求以特定格式提供一组差异化(diff)片段。格式如下:

其中,位于 <<<<<<<SEARCH 和 ======= 之间的代码是当前程序版本中需要精确匹配的原始片段;而 ======= 与>>>>>>> REPLACE 之间则是新的代码片段,用于替换原片段。
通过这种方式,可以将修改精准应用于代码的指定部分。如果被进化的代码很短,或当从头重写比局部修改更合理时,AlphaEvolve 也可配置为要求 LLM 直接输出完整代码块,而不使用差异化的格式。
评估
在这个循环中,自动化评估指标扮演了至关重要的角色。AlphaEvolve 使用这些指标来验证、运行和评分所提出的程序。这些指标为每个解决方案的准确性和质量提供了客观、可量化的评估。
1、任务规范
评估:由于 AlphaEvolve 处理的是可由机器评级的(machine-gradeable)问题,用户必须提供一种自动评估生成方案的机制。通常采用函数 h 的形式,将方案映射到一组标量评估指标(需最大化),通常实现为一个 Python 函数(evaluate)。
API:为支持演化代码库中的多个组件,AlphaEvolve 开放了一个输入 API,通过在代码中添加特殊标记(如注释中的 # EVOLVE-BLOCK-START 和 # EVOLVE-BLOCK-END)来指定哪些代码块可由系统进行演化。这些演化块中用户提供的代码作为初始方案,其余代码则构成连接这些演化部分的骨架,使其可以被 evaluate 函数调用。
在选择抽象层面方面具有灵活性:AlphaEvolve 可以用非常不同的方式应用于同一个问题,尤其当演化出的程序不是最终输出,而是发现方案的手段时。例如,可以演化原始字符串表示的方案、演化一个定义明确的函数来从头构造方案、演化一个定制的搜索算法在固定计算预算内寻找方案,甚至可以共同演化中间方案和搜索算法。
2、评估过程与优化机制
为了追踪 AlphaEvolve 的进展并选择在未来代际中传播的想法,LLM 提出的每个新方案都会被自动评估。基本过程是执行用户提供的评估函数 h。实际上,AlphaEvolve 支持多种机制,以使评估更灵活和高效:
- 评估级联(Evaluation Cascade): 利用难度递增测试集快速筛选方案。
- LLM 生成反馈(LLM-generated Feedback): 利用 LLM 对难以量化属性进行评分。
- 并行评估(Parallelized Evaluation): 分布式执行评估任务以提高效率。
支持多评估指标优化(Multiple scores),同时优化多个目标,甚至能改善单一目标结果。
进化
在其进化过程中,AlphaEvolve 不断生成带有评估结果(得分和程序输出)的方案。这些方案被存储在一个进化数据库(evolutionary database)中。该数据库的首要目标是最优地在未来代际中重新利用先前探索过的想法。
设计此类数据库的一个关键挑战在于平衡探索(exploration)与利用(exploitation):即在持续改进当前最优方案的同时,保持方案的多样性以鼓励探索整个搜索空间。
在 AlphaEvolve 中,该进化数据库实现了一种算法,其灵感来源于 MAP-elites 算法和基于岛屿的种群模型(island-based population models)的组合。
这使得 AlphaEvolve 在数学和计算机科学等可以清晰、系统地衡量进步的广泛领域中特别有帮助。
优化 DeepMind 的计算生态系统
在过去的一年中,DeepMind 将由 AlphaEvolve 发现的算法部署到了谷歌的整个计算生态系统中,包括 DeepMind 的数据中心、硬件和软件。
这些改进的影响在 DeepMind 的人工智能和计算基础设施中被成倍放大,为 DeepMind 的所有用户构建了一个更强大、更可持续的数字生态系统。

图示说明了 AlphaEvolve 如何帮助谷歌提供一个更高效的数字生态系统,从数据中心调度和硬件设计到人工智能模型训练。
改进数据中心调度
AlphaEvolve 发现了一个简单但非常有效的启发式方法,帮助 Borg 更高效地协调谷歌庞大的数据中心。这个解决方案已经投入生产一年多,平均持续恢复了谷歌全球计算资源的 0.7%。这种持续的效率提升意味着在任何给定时刻,都可以在相同的计算资源上完成更多任务。
AlphaEvolve 的解决方案不仅实现了强大的性能,还提供了人类可读代码的重要操作优势:可解释性、可调试性、可预测性和易于部署。
协助硬件设计
AlphaEvolve 提出了一种 Verilog 重写方案,移除了矩阵乘法关键、高度优化的算术电路中的多余位。该提议通过强大的验证,确认修改后的电路保持功能正确性,并被整合到了即将推出的张量处理单元(TPU)中。
通过在芯片设计者的标准语言(Verilog)中提出修改,AlphaEvolve 促进了 AI 和硬件工程师之间的协作,以加速未来专用芯片的设计。
提升人工智能训练与推理效率
AlphaEvolve 正在显著加速 AI 的性能表现与研究进程。
通过找到更聪明的方法分解大型矩阵乘法运算,它在 Gemini 架构中将这一关键内核的运行速度提升了 23%,进而使 Gemini 的训练时间缩短了 1%。
除了性能提升外,AlphaEvolve 显著减少了内核优化所需的工程时间,从专家花费数周减少到自动化实验仅需数天。
AlphaEvolve 还能够优化低级 GPU 指令。在基于 Transformer 的 AI 模型中,为 FlashAttention 内核实现实现了高达 32.5% 的速度提升。这种优化帮助专家精准定位性能瓶颈,并轻松整合改进措施。
推进数学和算法发现的前沿
更快的矩阵乘法算法
AlphaEvolve 还可以为复杂的数学问题提出新方法,例如矩阵乘法 —— 计算机科学中的一个基础性问题。通过基于梯度的优化程序,AlphaEvolve 设计并发现了一种使用 48 次标量乘法 乘以 4x4 复值矩阵的算法。
,时长00:32
这一发现改进了 Strassen 1969 算法,这是 56 年来在这一设置中首次已知的改进,也表明了对 DeepMind 先前工作 AlphaTensor 的重大超越。
解决开放性问题
为了探索 AlphaEvolve 的广度,DeepMind 将该系统应用于数学分析、几何学、组合学和数论中的 50 多个开放性问题。该系统的灵活性使其能够在几小时内设置大多数实验。
在大约 75% 的情况下,它重新发现了最先进的解决方案;在 20% 的情况下,AlphaEvolve 改进了之前已知的最佳解决方案,在相应的开放性问题上取得了进展。
例如,在吸引了数学家们超过 300 年兴趣的亲吻数问题(Kissing number problem)上, AlphaEvolve 发现了 593 个 外球的配置,并在 11 维中建立了新的下限。
更多详细内容请参见原论文。
参考链接:
https://www.nature.com/articles/d41586-025-01523-z
#PENCIL
大模型深度思考新范式:交替「推理-擦除」解决所有可计算问题
作者介绍:本文第一作者是丰田工业大学芝加哥 PhD 学生杨晨晓,研究兴趣是机器学习理论和大模型推理,在 ICML,NeurIPS,ICLR 等顶级会议上发表过论文。
本文提出一个交替「推理 - 擦除」的深度思考新范式 PENCIL,比传统 CoT 更高效地解决更复杂的推理任务。理论上,我们证明 PENCIL 可用最优空间与最优时间下解决所有可计算问题,而这对于传统的 CoT 是不可能的!该工作已被机器学习顶会 ICML 2025 收录。
- 题目: PENCIL: Long Thoughts with Short Memory
- 链接: https://arxiv.org/pdf/2503.14337
- 代码: https://github.com/chr26195/PENCIL
最近的大模型(如 OpenAI 的 o1/o3、DeepSeek 的 R1)发现能通过在测试阶段深度思考(Test-Time Scaling)来大幅提高模型的推理能力。目前实现深度思考的关键在于使用长链思维链(Long Chain-of-Thought,CoT),即让模型生成更长中间结果得到最终答案。然而,传统「只写不擦」的方法在处理高难度、大规模任务时面临以下瓶颈:
- 超出上下文窗口:一旦链条过长,就会触及模型的最大上下文长度限制;
- 信息检索困难:随着上下文不断累积,模型难以从冗长历史中 Retrieve 关键线索;
- 生成效率下降:上下文越长,每步生成新 token 的计算量越大。
不过实际上,并非所有中间思路都后续推理有用:例如定理证明里,引理一旦验证通过,其具体推导可被丢弃;解数学题时,已知某条思路走不通就无需保留那段「尝试」的细节。纵观计算机科学的发展历史,这一「随时清理」的理念早已渗透到几乎所有计算模型之中:从最早的图灵机模型中,已读写的磁带符号可以被覆盖或重写,直到现在高级编程语言中,垃圾回收机制会自动清理不再可达的内存单元。
基于这样的动机,我们提出一个新的深度思考范式 PENCIL,迭代地执行生成(Generation)和擦除(Reduction),即在生成的过程中动态地擦除不再需要的中间结果,直到得到最后的答案。
一、交替「生成 - 擦除」的深度思考范式
下图以一个简单的算术题为例展示了 PENCIL 的工作机制:
- CoT 将每步推理串联到上下文中直到给出答案并返回整个序列。
- PENCIL 交替执行生成(图中加粗部分)和 擦除(图中绿色高亮部分):模型先写出新的思考过程,再删掉对之后的推理无用片段,只保留对后续的推理过程有用的部分,内部形成一系列隐式思维,最后仅返回最终答案。

PENCIL 擦除机制的设计借鉴了逻辑学与经典自动定理证明中的重写规则(Rewriting Rule 和函数式编程语言中的栈帧内存管理(Stack Frame)。 具体地,我们引入三个特殊字符(Special Token),叫做 [CALL], [SEP], [RETURN],并用以下的规则(Reduction Rule)来实现擦除:
![]()
其中 C(Context)表示上下文,T(Thoughts)表示中间思考,A(Answer)表示回答。每当生成的序列与左侧模式完全匹配时,PENCIL 即触发一次擦除,丢弃 T。重要的是,C、T、A 本身均可包含其他特殊标记,从而支持类似多层函数调用的递归结构。
PENCIL 的擦除机制能够灵活支撑多种推理模式,例如:
- 任务分解(Decomposition):通过 [CALL] 启动子任务,完成后用 [RETURN] 合并输出并擦除子任务推理细节;
- 搜索与回溯(Search and Backtrack):在搜索树中,用特殊字符管理探索分支,冲突或失败时擦除无效路径;
- 摘要与总结(Summarization):将冗长的思考片段归纳为简洁摘要,类似编程中的尾递归(Tail Recursion):
![]()
其中 T 表示原始的复杂思考过程(或更难的问题),T' 归纳或简化后的摘要(或等价的、更易处理的问题)。
示例: 布尔可满足性(SAT)是经典的 NP-Complete 问题:给定一个 n 个变量布尔公式,判断是否存在一组变量赋值使其为真。这个问题(广泛认为)需要指数时间但仅需多项式空间来解决,其中最简单的做法是构造一个深度为 n 的二叉搜索树遍历所有可能。传统 CoT 将每步计算附加到上下文,长度与搜索树节点数成正比 (O (exp (n))),导致指数爆炸;PENCIL 在递归分支尝试时,遇到冲突立即回溯并擦除该分支所有思考,仅保留关键结果,使上下文长度仅与搜索深度成正比 (O (n))。
如图所示,对比 CoT 无擦除(蓝)与 PENCIL 擦除(红)两种思考模式下的最大上下文长度,随着问题规模增大,PENCIL 能将所需序列长度控制在千级或百级,而传统 CoT 则迅速攀升至数万甚至数十万。即使在复杂的 Einstein's Puzzle 中,PENCIL 也能将需要几十万 token 的上下文压缩到几千 token。

二、训练和实验结果
训练和测试:在训练时,CoT 每个新 token 的损失计算都基于完整的历史上下文;PENCIL 在每轮「写 — 擦」循环结束后只在被擦除后的短序列上计算损失。即使两者生成 token 数量相同,PENCIL 每一个 token 对应的上下文长度却大幅缩短;另一方面,在每次 Reduction 后,C 部分的 KV cache 可以直接复用,只需为更短的 A 部分重新计算缓存。这样, PENCIL 在训练和测试时能显著减少自注意力计算开销。
实验设置:我们针对三种具有代表性的高难度推理任务构建数据集:3-SAT(NP-Complete)、QBF(PSPACE-Complete)和 Einstein’s Puzzle(自然语言推理)。所有实验均在相同配置下从随机初始化开始进行预训练和评估,采用小型 Transformer(10.6M 参数和 25.2M 参数),训练超参数保持一致。
1. 准确率
相比 CoT,PENCIL 能解决更大规模的推理问题。如下图所示,在 SAT(左图)和 QBF(右图)任务中,当问题规模较小时,CoT 与 PENCIL 均能完美解决问题;但随着规模增大,传统 CoT 的准确率显著下降(例如 SAT 在 n=10 时仅约 50%),而 PENCIL 始终保持 ≥ 99% 的高准确率。

2. 计算效率
PENCIL 还能显著节省计算资源。如图所示,我们在相同 FLOPs 预算下对比了 CoT(蓝色)与 PENCIL(红色)的训练收敛表现。PENCIL 训练早期迅速达到 100% 准确率,训练损失更快稳定;CoT 因上下文膨胀需投入更多资源才能接近最优。随着问题规模增加,两者之间的差距愈发明显。

3. 自然语言推理任务:Einstein’s Puzzle
我们测试了 PENCIL 在极具挑战性的 Einstein's Puzzle 上的表现。该问题要求从一系列线索(如「绿房子在养鸟者右侧」、「养狗者住在红房子」等)推断出五个房屋中人们的全部属性(颜色、国籍、饮品、香烟和宠物)。即使是 GPT-4 也难以解决此类逻辑推理问题 [1]。下图展示了 n=3 时的问题简化:

如图所示,对于该大模型也难以解决的问题,而 PENCIL 仅用一个 25.2M 参数的小模型将准确率提升至 97%;相比较之下,传统 CoT 准确率仅 25%,接近随机猜测的准确率。

三、理论:PENCIL 用最优的空间 / 时间实现图灵完备
我们进一步从理论表达能力的角度展示 PENCIL 相较于传统 CoT 的根本性优势。具体地,我们证明:使用一个固定的、有限大小的 Transformer,PENCIL 可以用最优的时间和空间复杂度模拟任意图灵机的运算过程(即实现图灵完备),从而高效地解决所有可计算问题:

具体而言,若任意图灵机在某输入上需 T 步计算和 S 空间,PENCIL 仅需生成 O (T) 个 token 并保持上下文长度至多为 O (S) 即可输出相同结果。值得注意的是,大多数算法的空间复杂度都远小于其时间复杂度,即 S << T。
相比之下,传统 CoT 虽能实现图灵完备 [2] —— 思维链的每一步表示图灵机的一步中间计算过程,因此思维链足够长就可以解决所以可计算问题。但这意味着其生成序列的上下文长度必须与运行步数 T 成正比,代价十分昂贵:对于中等难度任务也许尚可承受,一旦面对真正复杂需要深度思考的问题,这种指数级的上下文爆炸就变得不切实际。
例如,一系列(公认)无法在多项式时间内解决却可在多项式空间内解决的 NP-Complete(如旅行商等等),对于使用有限精度 Transformer 的 CoT 而言至少需要超越多项式(例如 exp (n))规模的上下文长度,在真实应用中由于内存的限制完全不可行;而 PENCIL 只需 poly (n) 规模的上下文就能高效求解,让「深度思考」变得切实可行。
证明思路:证明关键在用一系列「思考 — 总结」循环来替代持续累积的思维链。

具体地,如上图左图所示,我们先将图灵机状态转移编码为三元组 token(新状态、写入符号、移动方向)。模型通过自注意力计算读写头位置,并从上下文回溯读取符号。未经优化时,需保留 T 步完整历史,上下文长度为 O (T)。
PENCIL 能够实现空间 / 时间最优的核心是利用交替「思考 - 总结」的生成方式:
- 思考 (Simulation):生成连续状态转移 token,模拟图灵机计算;
- 总结 (Summarization):当新 token 数超过实际所需空间两倍时,用不超过 S 个的 token 总结当前状态,触发擦除规则丢弃中间过程。
通过这种策略,PENCIL 生成总 token 数仍为 O (T),却把最大上下文长度严格限制在 O (S),达到了空间与时间的双重最优。
最后,我们需要证明这种「思考 - 总结」的生成方式可以被现实中的 Transformer 实现。为此,我们设计了 Full-Access Sequence Processing (FASP) 编程语言,并证明所有用 FASP 写的程序都可被 Transformer 表达。通过构造能执行「思考 - 总结」操作的 FASP 程序,我们证明了等价存在固定大小 Transformer 完成相同功能,从而理论上证明 PENCIL 可用最优复杂度模拟任意计算过程。
参考文献
[1] Dziri, Nouha, et al. "Faith and fate: Limits of transformers on compositionality." in NeurIPS 2023.
[2] Merrill, William, and Ashish Sabharwal. "The expressive power of transformers with chain of thought." in ICLR 2024.

#SuperEdit
小模型逆袭屠榜!30倍数据效率+13倍模型压缩效果暴增近10%!字节重磅开源
字节跳动开源的SuperEdit通过修正编辑指令和引入对比监督信号,解决了图像编辑中监督信号噪声问题,仅用1/30的数据量和1/13的模型参数量,就在多个基准上实现显著性能提升,推动了图像编辑技术的发展。
文章链接:https://arxiv.org/pdf/2505.02370
项目链接:https://liming-ai.github.io/SuperEdit/
Huggingface链接:https://huggingface.co/datasets/limingcv/SuperEdit-40K
亮点直击
- 新发现:旨在解决由编辑指令与原始-编辑图像对之间错位引起的噪声监督问题,这是先前工作忽视的根本性问题,如下图2所示。
- 修正监督:利用扩散生成先验指导视觉语言模型,为原始-编辑图像对生成更匹配的编辑指令。
- 强化监督:引入基于三元组损失的对比监督,使编辑模型能够从正负样本指令中学习。
- 显著成果:在无需额外预训练或VLM的情况下,在多个基准上实现显著提升。相比SmartEdit,在减少数据和模型参数的同时,实现了9.19%的性能提升。




总结速览解决的问题
- 噪声监督信号:现有基于指令的图像编辑数据集中,编辑指令与原始-编辑图像对之间存在不匹配问题,导致监督信号噪声大。
- 复杂场景编辑困难:编辑模型在处理多对象、数量、位置或对象关系等复杂场景时表现不佳。
- 依赖额外模块:现有方法需引入视觉语言模型(VLM)、预训练任务或复杂架构,计算开销大且未根本解决噪声问题。
提出的方案
- 指令修正(Rectified Instructions):
- 利用VLM(如GPT-4o)分析原始-编辑图像对的差异,生成更匹配的编辑指令。
- 基于扩散模型推理阶段的生成属性(如不同步骤对应不同图像属性),制定统一的指令修正准则。
- 对比监督信号(Contrastive Supervision):构建正负样本指令(正确指令 vs. 错误指令),通过三元组损失(triplet loss)优化模型,增强对复杂场景的理解。
应用的技术
- 视觉语言模型(VLM):用于指令修正,优先选用GPT-4o(因其对图像差异理解能力最强)。
- 扩散模型先验知识:利用扩散模型推理阶段的属性生成规律(如早期步骤生成结构、后期步骤生成细节)指导VLM修正指令。
- 三元组损失(Triplet Loss):通过对比学习区分正负指令,提升模型对编辑意图的精准理解。
达到的效果
- 性能显著提升:
- 在Real-Edit基准上超越此前SOTA(SmartEdit),性能提升9.19%。
- 仅需1/30的训练数据和1/13的模型参数量。
- 简化架构:无需额外VLM模块或预训练任务,直接优化监督信号质量。
- 开源贡献:所有数据和模型开源,促进后续研究。
- 评估优势:在GPT-4o和人工评估中均优于现有方法,证明高质量监督信号可弥补架构简单性。
方法
本节首先介绍最通用的图像编辑框架。然后解释如何利用扩散先验通过多模态模型(即GPT-4o)修正编辑指令,从而提高监督信号的准确性。最后描述如何构建包含正确和错误编辑指令的对比监督,并通过三元组损失将其整合到编辑模型训练中。
基于指令的图像编辑框架
InstructPix2Pix 开创了基于指令的图像编辑方法,通过同时将原始图像 和编辑指令 作为输入条件,从随机噪声 生成编辑后的图像 。根据DDPM的定义,在训练过程中我们随机采样一个时间步 ,然后向编辑后的图像 添加相应的噪声 。

其中 是从高斯分布采样的噪声图, 是时间步 的可微函数,由去噪采样器 (如DDPM)确定。然后编辑模型 的训练目标是预测在时间步 添加的噪声,可以表示为:

其中concat表示在通道维度上连接加噪编辑图像 和原始图像 的潜在表示。
基于扩散先验的监督修正
如下图3所示,现有图像编辑数据集通常仅使用步骤1和2:通过LLM构建编辑提示和描述,再由文生图扩散模型合成编辑图像。然而扩散模型往往难以在保持图像布局的同时准确遵循提示,导致原始-编辑图像对与编辑指令不匹配,产生不准确的监督信号。虽然更好的监督信号在图像生成领域很常见,但由于以下两个挑战,该方法在图像编辑中仍未充分探索:(1)基于单图像数据训练的VLM难以处理多图像输入;(2)编辑指令差异大,难以制定统一修正准则。

为解决这些问题,本文:(1)分析了不同VLM处理多图像输入的能力,发现GPT-4o最有效;(2)发现图像生成中时间步特异性角色同样适用于编辑任务,为跨指令的统一修正方法奠定基础(上图3和下图4)。由于篇幅限制,VLM分析详见补充材料,本节重点介绍扩散先验和编辑指令修正。

扩散生成先验:先前工作表明,不同时间步在文生图扩散模型中具有特定生成角色,与文本提示无关。本文发现基于指令的编辑模型同样存在该现象,并以预训练InstructPix2Pix为例展示。扩散模型在采样早期关注全局布局,中期关注局部物体属性,后期聚焦图像细节。这一发现启发我们基于四个生成属性(布局/形状/颜色/细节)指导VLM,建立适用于各类编辑指令的统一修正方法。
编辑指令修正:如前面图3所示,在现有编辑数据生成流程中新增指令修正步骤(步骤3)。该过程依赖通过步骤1-2获得的原始-编辑图像对。具体而言,我们将图像对输入视觉语言模型(GPT-4o),并指导其根据扩散先验生成属性描述编辑图像相对于原始图像的变化。最后使用VLM总结指令并确保其长度不超过CLIP文本编码器的77个token限制。
基于对比指令的监督增强
虽然使用修正后的编辑指令能显著提升各编辑任务性能,但发现编辑模型仍难以区分语义相近的文本指令。例如"在图像左侧添加一只猫"和"在右侧添加两只猫"可能生成相同的编辑图像。这表明预训练文生图扩散模型固有的理解偏差(如数量/位置/空间关系)仍存在于编辑模型中。更重要的是,实验表明仅使用修正指令训练无法解决这些问题。为进一步增强监督信号有效性,本文借鉴大语言模型和文生图扩散模型的成功对齐经验:构建正负样本对并指导模型为正样本分配更高生成概率。
对比指令构建
与大型语言模型或文生图扩散模型的标准对齐过程不同,图像编辑任务难以通过相同指令生成不同编辑结果来构建正负样本对。为此,我们通过构建正负编辑指令来实现对齐,从而生成相对的正负编辑图像。如下图5(a)所示,我们以原始图像、编辑图像和修正后的编辑指令作为输入,利用VLM(GPT-4o)修改修正指令中的属性(如数量、空间关系和物体类型)来生成错误指令。要求VLM在每个错误指令中仅修改修正指令的单个属性,保持大部分编辑文本不变。由于修正指令与错误指令之间仅存在少量词汇替换,CLIP文本编码器生成的文本嵌入(作为去噪模型的输入)仍保持相似性。这种设计确保了任务的学习难度,帮助模型理解细微的指令差异如何导致显著不同的编辑结果。

基于对比指令的模型增强
本文的核心观点是:增强监督信号有效性可在不引入额外模型架构或预训练任务的前提下提升各类编辑任务性能。因此严格遵循InstructPix2Pix的模型架构和训练流程。输入包含原始图像 、编辑图像 、修正指令 和错误指令 。训练时通过采样时间步 和公式 1 获得加噪编辑图像 。将修正指令和错误指令同时输入去噪模型,分别预测最终噪声 和 以构建正负样本。

在构建正负样本对后,希望正向编辑指令预测的噪声 比错误编辑指令预测的噪声 更接近训练时采样的真实噪声 。这一目标可通过三元组损失函数实现:

其中 ,边界值 为超参数。最终训练损失是原始扩散训练损失与三元组损失的组合:

对比监督信号仅在训练阶段使用。在推理过程中,编辑模型只需要一个输入编辑指令。
实验
数据收集与构建
为构建包含多样化编辑指令的数据集,整合了不同公共编辑数据集:从InstructPix2Pix、MagicBrush和Seed-Data-Edit分别采样10,177、8,807和21,016对图像,共计40,000训练样本。数据选取时尽可能平衡不同编辑任务类型。对于MagicBrush已人工验证的数据,我们直接基于原始指令构建对比监督;Seed-Data-Edit仅采用未含人工指令的第一部分数据;其余数据均进行指令修正与对比监督构建。
实验设置
评估基准与指标:采用Real-Edit基准进行自动化评估(GPT-4o评分)和人工评估。该基准使用Unsplash社区高分辨率图像,通过以下指标衡量编辑效果:
- Following:编辑指令遵循准确率(%)与分数(0-5)
- Preserving:非编辑区域结构保留程度
- Quality:编辑后图像整体质量/美学评分
实验结果
Real-Edit基准对比:如下表1所示,在不增加参数或预训练阶段的情况下,本文的方法在Following、Preserving和Quality三项指标上均达到最优。相比引入13B视觉语言模型(LLaVA)的SmartEdit,总体分数提升11.4%。值得注意的是,本文的方法在所有指标上均实现全面提升(Following/Preserving/Quality准确率分别提升3%、7%、11%),表明改进监督信号能同时提升指令执行精度与非编辑区域保护能力。

人工评估:15位评估者对Real-Edit基准进行盲测(下表2与图7),结果与GPT-4o评分高度一致。本文的方法在Following/Preserving/Quality和总体分数上分别以1.8%、16%、14.8%和10.8%的优势超越SmartEdit。


可视化对比:如下图6所示,本文的方法在复杂指令(如"将老虎替换为狮子并保持水中位置")上获得4.8/4.8/4.8的满分表现,显著优于SmartEdit(4.8/4.8/2.5)。对于风格转换指令(如"改为印象派绘画风格"),以(4.8/4.8/4.8)远超SmartEdit的(1.0/4.8/4.8)。场景转换任务(如"将整个场景改为冬季雪景")中,更以(5.0/4.8/4.8)对比SmartEdit的(2.0/4.5/4.5)展现明显优势。

消融实验
编辑指令修正与对比指令的消融研究
鉴于Real-Edit基准采用GPT-4o进行评估,且其评估结果与人类评分高度一致,选择该基准进行下表3所示的消融实验。与原始的300K InstructPix2Pix训练数据相比,采用修正后编辑指令的40K训练数据显著提升了编辑模型的各项性能。具体而言,本文的方法在三个指标上分别将分数提高了0.95、0.79和0.11,准确率提升了21%、22%和4%。此外,通过引入对比监督信号,编辑性能得到进一步强化。与仅使用修正编辑指令相比,对比监督信号的引入使遵循度和保真度分数分别提升0.19和0.08,准确率提高5%和2%,同时保持质量准确率与分数不变。综上,修正编辑指令与对比编辑指令的引入均能全面提升编辑模型的整体性能。

数据规模的消融研究
通过5k至40k样本量的实验探究了训练数据规模对模型性能的影响。下表4显示随着数据量增加,所有指标均持续提升。仅用5k样本时,模型已达到合理性能(54.7%准确率,3.92总分),而扩展至40k样本时获得显著增益(69.7%准确率,3.91总分)。其中保真度和质量指标的提升最为突出,分别达到10%和15%。所有数据点呈现的上升趋势表明,SuperEdit能有效利用新增训练样本且未出现性能饱和,这意味着扩大数据集仍有提升潜力。

结论
本文从增强监督信号的角度重新审视图像编辑模型,发现现有方法未能充分解决该挑战,导致性能欠佳。提出基于扩散先验的统一编辑指令修正准则,使指令更贴合原始-编辑图像对,从而提升监督有效性;同时构建对比编辑指令,让模型能从正负例中同时学习。这种以数据为核心的方法探索了一个重要但被忽视的研究问题:在最小化架构改动的前提下,通过聚焦监督质量与优化能实现何种性能水平?值得注意的是,在GPT-4o和人类评估中,本文方法以更少的数据量、无需架构修改或额外预训练的条件超越了现有方案。这表明高质量的监督信号能有效弥补架构简单性,为图像编辑研究提供了宝贵的新视角。
参考文献
[1] SuperEdit: Rectifying and Facilitating Supervision for Instruction-Based Image Editing
#Insights into DeepSeek-V3
Scaling Challenges and Reflections on Hardware for AI ArchitecturesDeepSeek-V3再发论文,梁文锋署名,低成本训练大模型的秘密揭开了
关于 DeepSeek-V3,你需要了解的一切。
虽然此前 DeepSeek 已经发布了 V3 模型的技术报告,但刚刚,他们又悄然发布了另一篇围绕 DeepSeek-V3 的技术论文!
这篇 14 页的论文瞄向了「Scaling 挑战以及对 AI 架构所用硬件的思考」。从中你不仅能读到 DeepSeek 在开发和训练 V3 过程中发现的问题和积累的心得,还能收获他们为未来的硬件设计给出的思考和建议。这一次,DeepSeek CEO 梁文锋同样也是署名作者之一。
论文标题:Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures
论文地址:https://arxiv.org/pdf/2505.09343
众所周知,如今大语言模型(LLM)的快速扩展暴露了当前硬件架构的一些关键局限性,包括内存容量、计算效率和互连带宽。以 DeepSeek-V3 为例,它是在 2048 块 NVIDIA H800 GPU 集群上进行训练,展示了硬件感知模型协同设计如何高效地应对这些限制,并最终实现了经济高效的大规模训练与推理。
因此,这项新研究并非重复 DeepSeek-V3 的详细架构和算法细节,而是从硬件架构和模型设计的双重视角,探讨它们之间在实现经济高效的大规模训练和推理过程中复杂的相互作用。通过探究这种协同作用,研究者旨在提供切实可行的见解,以洞悉如何在不牺牲性能或可访问性的情况下高效扩展 LLM。
具体而言,本文的重点包括如下:
- 硬件驱动的模型设计:分析硬件特性(如 FP8 低精度计算和 scale-up/scale-out 扩展网络属性)如何影响 DeepSeek-V3 中的架构选择。
- 硬件与模型之间的相互依赖关系:研究硬件能力如何影响模型创新,以及 LLM 不断变化的需求如何推动对下一代硬件的需求。
- 硬件开发的未来方向:从 DeepSeek-V3 中获取可行性见解,以指导未来硬件和模型架构的共同设计,为可扩展、经济高效的人工智能系统铺平道路。
DeepSeek 模型的设计原则
如图 1 所示,DeepSeek-V3 采用了 DeepSeekMoE 架构和多头潜在注意力(MLA)架构。其中,DeepSeekMoE 充分释放了混合专家(MoE)架构的潜力,而 MLA 则通过压缩键值(KV)缓存显著降低了内存消耗。
此外,DeepSeek-V3 引入了 FP8 混合精度训练技术,在保证模型质量的同时大幅降低了计算成本,使大规模训练更加可行。
为了提高推理速度,DeepSeek-V3 在其多 Token 预测模块 (Multi-Token Prediction Module) 的基础上集成了推测解码,从而显著提高了生成速度。
除了模型架构之外,DeepSeek 还探索了经济高效的 AI 基础架构,通过部署多平面双层胖树网络(Multi-Plane two-layer Fat-Tree)来取代传统的三层胖树拓扑结构,从而降低了集群网络成本。

这一系列创新旨在解决扩展 LLM 时的三个核心挑战 —— 内存效率、成本效益和推理速度。
内存效率
LLM 通常需要大量的内存资源,其内存需求每年增长超过 1000%。相比之下,高速内存(例如 HBM)容量的增长速度要慢得多,通常每年不到 50% 。虽然多节点并行是解决内存限制的可行方案,但在源头优化内存使用仍然是一个关键且有效的策略。
为了解决这一瓶颈,DeepSeek 采用了多头潜在注意力 (MLA),它使用投影矩阵将所有注意力头的键值表示压缩为一个较小的潜在向量,并与模型联合训练。在推理过程中,只需缓存潜在向量,与存储所有注意力头的键值缓存相比,显著降低了内存消耗。
除了 MLA 之外,DeepSeek 还提出了其他几种方法来减少 KV 缓存的大小。这些方法非常有价值,为内存高效注意力机制的进步提供了重要的启发:
共享 KV(GQA;MQA):多个注意力头共享一组键值对,而不是为每个注意力头维护单独的键值对,从而显著压缩了键值对的存储量。代表性方法包括 GQA 和 MQA。
此外,还包括窗口 KV、量化压缩等。
表 1 比较了 DeepSeek-V3、Qwen-2.5 72B 和 LLaMA-3.1 405B 中每个 token 的 KV 缓存内存占用情况。通过采用 MLA,DeepSeek-V3 显著减少了 KV 缓存大小,每个 token 仅需 70 KB,远低于 LLaMA-3.1 405B 的 516 KB 和 Qwen-2.5 72B 的 327 KB。

MoE 模型的成本效益
对于稀疏计算,DeepSeek 开发了 DeepSeekMoE,这是一种先进的混合专家 (MoE) 架构,如图 1 右下角所示。MoE 模型的优势在于两方面。
在训练时,降低计算需求。MoE 架构的主要优势在于它能够显著降低训练成本。通过选择性地激活专家参数的子集,MoE 模型允许总参数数量大幅增加,同时保持适度的计算需求。例如,DeepSeek-V2 拥有 236B 参数,但每个 token 仅激活 21B 参数。同样,DeepSeek-V3 扩展到 671B 参数 —— 几乎是 V2 的三倍 —— 同时每个 token 的激活量仅为 37B。相比之下,Qwen2.5-72B 和 LLaMa3.1-405B 等密集模型则要求在训练期间所有参数都处于激活状态。
如表 2 所示,DeepSeekV3 的总计算成本约为每 token 250 GFLOPS,而 72B 密集模型需要 394 GFLOPS,405B 密集模型则需要 2448 GFLOPS。这表明,MoE 模型在计算资源消耗量少一个数量级的情况下,实现了与密集模型相当甚至更优的性能。

个人使用和本地部署的优势。未来个性化 LLM 智能体将无处不在,而 MoE 模型在单请求场景中将展现出独特的优势。由于每个请求仅激活一小部分参数,内存和计算需求将大幅降低。例如,DeepSeek-V2(236B 参数)在推理过程中仅激活 21B 参数。这使得搭载 AI SoC 芯片的个人电脑能够达到近每秒 20 个 Token (TPS),甚至两倍于此的速度,这对于个人使用来说已经绰绰有余。相比之下,类似能力(例如 70B 参数)的密集模型在类似硬件上通常只能达到个位数的 TPS。
提高推理速度
计算与通信重叠:最大化吞吐量。推理速度既包括系统级最大吞吐量,也包括单请求延迟。为了最大化吞吐量,模型从一开始就采用双微批次重叠架构,有意将通信延迟与计算重叠。
此外,DeepSeek 将 MLA 和 MoE 的计算解耦为两个不同的阶段。当一个微批次执行部分 MLA 或 MoE 计算时,另一个微批次同时执行相应的调度通信。相反,在第二个微批次的计算阶段,第一个微批次则进行组合通信步骤。这种流水线方法实现了全对全(all-to-all)通信与持续计算的无缝重叠,确保 GPU 始终保持完全利用率。此外,在生产环境中,DeepSeek 采用预填充和解码分离架构,将大批量预填充和延迟敏感的解码请求分配给不同规模的专家并行组。这一策略最终在实际服务条件下实现了系统吞吐量的最大化。
推理速度和测试时间扩展。以 OpenAI 的 o1/o3 系列为例,LLM 中的测试时间扩展通过在推理过程中动态调整计算资源,推动了数学推理、编程和通用推理的重大进步。后续模型 —— 包括 DeepSeek-R1、Claude-3.7 Sonnet 、Gemini 2.5 Pro、Seed1.5-Thinking 和 Qwen3—— 也采用了类似的策略,并在这些任务中取得了显著的改进。
对于这些推理模型来说,较高的 token 输出速度至关重要。在强化学习 (RL) 工作流程中 —— 例如 PPO、DPO 和 GRPO —— 快速生成大量样本的需求使得推理吞吐量成为关键的瓶颈。同样,冗长的推理序列会增加用户等待时间,从而降低此类模型的实际可用性。因此,通过软硬件协同创新来优化推理速度对于提高推理模型的效率至关重要。
低精度驱动设计
FP8 混合精度训练
GPTQ 和 AWQ 等量化技术显著降低了内存需求。然而,这些技术主要应用于推理阶段以节省内存,而非训练阶段。NVIDIA 的 Transformer Engine 已经支持 FP8 混合精度训练,但在 DeepSeek-V3 之前,尚无开源大型模型利用 FP8 进行训练。
通过基础设施团队和算法团队的深入合作,以及大量的实验和创新,DeepSeek 开发了一个兼容 FP8 的 MoE 模型训练框架。图 1 展示了在训练过程中使用 FP8 精度前向和后向处理的计算组件。
LogFMT
在当前的 DeepSeek-V3 架构中,DeepSeek 采用低精度压缩进行网络通信。在 EP 并行过程中,Token 使用细粒度的 FP8 量化进行调度,与 BF16 相比,通信量减少了 50%。这显著缩短了通信时间。
除了这些传统的浮点格式外,DeepSeek 还尝试了一种新的数据类型,称为 LogFMT-nBit( Logarithmic Floating-Point Formats )。
互连驱动的设计
当前的硬件架构
DeepSeek 目前使用的 NVIDIA H800 GPU SXM 架构(如图 2 所示)基于 Hopper 架构构建,与 H100 GPU 类似。然而,为了符合法规要求,它的 FP64 计算性能和 NVLink 带宽有所降低。具体而言,H800 SXM 节点中的 NVLink 带宽从 900 GB/s 降至了 400 GB/s。节点内扩展带宽的显著降低对高性能工作负载构成了挑战。为了弥补这一缺陷,每个节点都配备了八个 400G Infiniband (IB) CX7 网卡,以增强扩展能力,从而弥补带宽不足。

为了解决这些硬件限制,DeepSeek-V3 模型融入了多项与硬件优势和局限性相符的设计考量。
硬件感知型并行化设计
为了适应 H800 架构的限制,DeepSeek-V3 考虑了这些并行策略:避免张量并行 (TP)、增强 Pipeline 并行 (PP)、加速专家并行 (EP)。对这些策略的具体说明请访问原论文。
模型协同设计:节点受限式路由
在 H800 架构中,纵向扩展(scale-up,节点内)和横向扩展(scale-out,节点间)通信之间的带宽差异约为 4:1。具体而言,NVLink 可提供 200GB/s 的带宽(其中实际可实现约 160GB/s),而每个 400Gbps IB 网卡仅提供 50GB/s 的带宽(考虑到较小的消息大小和延迟影响,有效带宽为 40GB/s)。为了平衡并充分利用更高的节点内带宽,模型架构与硬件进行了协同设计,尤其是在 TopK 专家选择策略方面。
假设一个包含 8 个节点(共 64 台 GPU)和 256 个路由专家(每台 GPU 4 个专家)的设置。对于 DeepSeek-V3,每个 token 会被路由到 1 个共享专家和 8 个路由专家。如果 8 个目标专家分布在所有 8 个节点上,则通过 IB 的通信时间将为 8𝑡,其中𝑡 表示通过 IB 发送一个 token 的时间。但是,通过利用更高的 NVLink 带宽,路由到同一节点的 token 可以通过 IB 发送一次,然后通过 NVLink 转发到其他节点内 GPU。NVLink 转发功能可以对 IB 流量进行去重。当给定 token 的目标专家分布在 𝑀 个节点上时,去重后的 IB 通信成本将降低至 𝑀𝑡(𝑀 < 8)。
由于 IB 流量仅依赖于 𝑀,DeepSeek-V3 为 TopK 专家选择策略引入了节点受限路由。具体来说,DeepSeek 将 256 位路由专家分成 8 组,每组 32 位专家,并将每组部署在单个节点上。在此部署基础上,DeepSeek 通过算法确保每个 token 最多路由到 4 个节点。这种方法缓解了 IB 通信瓶颈,并提高了训练期间的有效通信带宽。
纵向扩展和横向扩展收敛
当前实现的局限性。虽然节点受限的路由策略降低了通信带宽需求,但由于节点内 (NVLink) 和节点间 (IB) 互连之间的带宽差异,它使通信流水线内核的实现变得复杂。
在实际应用中,GPU Streaming Multiprocessors (SM) 线程既用于网络消息处理(例如,填充 QP 和 WQE),也用于通过 NVLink 进行数据转发,这会消耗大量的计算资源。例如,在训练期间,H800 GPU 上多达 20 个 SM 会被分配用于通信相关操作,导致实际计算资源减少。为了最大限度地提高在线推理的吞吐量,DeepSeek 完全通过 NIC RDMA 进行 EP 的 all-to-all 通信,从而避免了 SM 资源争用并提高了计算效率。这凸显了 RDMA 异步通信模型在计算和通信重叠方面的优势。
SM 在 EP 通信过程中执行的关键任务包括转发数据、数据传输、Reduce 操作、管理内存布局、数据类型转换,尤其是在组合阶段的 Reduce 操作和数据类型转换方面。如果将这些任务卸载到专用通信硬件,可以释放 SM 以用于计算内核,从而显著提高整体效率。
针对此,DeepSeek 给出了一些建议,其中最核心的是「将节点内(纵向扩展)和节点间(横向扩展)通信集成到一个统一的框架中」。
通过集成专用协处理器进行网络流量管理以及 NVLink 和 IB 域之间的无缝转发,此类设计可以降低软件复杂性并最大限度地提高带宽利用率。例如,DeepSeek-V3 中采用的节点受限路由策略可以通过硬件支持动态流量去重进一步优化。
DeepSeek 还探究了新兴的互连协议,例如 Ultra Ethernet Consortium (UEC)、Ultra Accelerator Link (UALink)。近期,Unified Bus (UB) 引入了一种全新的纵向扩展和横向扩展融合方法。
DeepSeek 在这里主要关注了在编程框架层面实现纵向扩展和横向扩展的融合的方法,具体包括统一网络适配器、专用通信协处理器、灵活的转发和广播及 Reduce 机制、硬件同步原语。详见原论文。
带宽争用和延迟
当前硬件还存在另一大局限:缺乏在 NVLink 和 PCIe 上不同类型流量之间动态分配带宽的灵活性。
例如,在推理过程中,将键值缓存数据从 CPU 内存传输到 GPU 会消耗数十 GB/s 的带宽,从而导致 PCIe 带宽饱和。如果 GPU 同时使用 IB 进行 EP 通信,KV 缓存传输和 EP 通信之间的争用可能会降低整体性能并导致延迟峰值。
针对这些问题,DeepSeek 同样给出了一些建议,包括动态 NVLink/PCIe 流量优先级、I/O 芯片芯片集成、纵向扩展域内的 CPU-GPU 互连。
大规模网络驱动的设计
网络协同设计:多平面胖树
在 DeepSeek-V3 的训练过程中,DeepSeek 部署了一个多平面胖树 (MPFT) 横向扩展(scale-out)网络,如图 3 所示。

其中,每个节点配备 8 台 GPU 和 8 个 IB 网卡,每个 GPU - 网卡对分配到不同的网络平面。此外,每个节点还配备一个 400 Gbps 以太网 RoCE 网卡,连接到单独的存储网络平面,用于访问 3FS 分布式文件系统。在横向扩展网络中,他们使用了 64 端口 400G IB 交换机,使该拓扑理论上最多可支持 16,384 台 GPU,同时保留了双层网络的成本和延迟优势。然而,由于政策和监管限制,最终部署的 GPU 数量仅为两千余台。
此外,由于 IB ConnectX-7 目前的局限性,DeepSeek 部署的 MPFT 网络未能完全实现预期的架构。理想情况下,如图 4 所示,每个网卡 (NIC) 应具有多个物理端口,每个端口连接到单独的网络平面,但通过端口绑定,共同作为单个逻辑接口向用户公开。

从用户的角度来看,单个队列对 (QP) 可以在所有可用端口之间无缝地发送和接收消息,类似于数据包喷射。因此,来自同一 QP 的数据包可能会穿越不同的网络路径,并以无序方式到达接收方,因此需要在网卡内原生支持无序布局,以保证消息一致性并保留正确的排序语义。例如,InfiniBand ConnectX-8 原生支持四平面。未来的网卡能够完全支持高级多平面功能,从而使双层胖树网络能够有效地扩展到更大的 AI 集群,这将大有裨益。总体而言,多平面架构在故障隔离、稳健性、负载均衡和大规模系统可扩展性方面具有显著优势。
DeepSeek 还介绍了多平面胖树的几大优势,包括 MPFT 由多轨胖树 (MRFT) 的子集构成(因此可以无缝整合英伟达和 NCCL 为 MRFT 网络开发的现有优化技术)、成本效益、流量隔离、延迟降低、稳健性等,详见原论文。
DeepSeek 还对 MPFT 和 MRFT 进行了对比性的性能分析,结果见图 5 和 6 以及表 4。



基于此,他们得到了一些关键发现,包括多平面网络的 all-to-all 性能与单平面多轨网络非常相似;在 2048 块 GPU 上训练 V3 模型时,MPFT 的性能与 MRFT 的性能几乎相同。
低延迟网络
在 DeepSeek 的模型推理中,大规模 EP 严重依赖于 all-to-all 通信,而这种通信对带宽和延迟都非常敏感。举一个典型场景的例子,在 50GB/s 的网络带宽下,理想情况下数据传输大约需要 120 𝜇s。因此,微秒级的固有网络延迟会对系统性能产生严重影响,其影响不容忽视。
那么,DeepSeek 是怎么做的呢?
首先分析一下 IB 或 RoCE。如表 5 所示,IB 始终能保持较低的延迟,这使得使其成为了分布式训练和推理等延迟敏感型工作负载的首选。尽管 IB 的延迟性能优于基于融合以太网的 RDMA (RoCE),但它也存在一些局限性,包括成本和扩展性方面的问题。

虽然 RoCE 有可能成为 IB 的经济高效的替代方案,但其目前在延迟和可扩展性方面的限制使其无法完全满足大规模 AI 系统的需求。DeepSeek 也给出了一些改进 RoCE 的具体建议,包括使用专用低延迟 RoCE 交换机、优化路由策略、改进流量隔离或拥塞控制机制。
为降低网络通信延迟,DeepSeek 使用了 InfiniBand GPUDirect Async (IBGDA)。
传统上,网络通信涉及创建 CPU 代理(proxy)线程:GPU 准备好数据后,必须通知 CPU 代理,然后 CPU 代理填充工作请求 (WR) 的控制信息,并通过门铃机制向 NIC) 发出信号,以启动数据传输。此过程会带来额外的通信开销。
IBGDA 是如何解决此问题的?实际上,它的做法是允许 GPU 直接填充 WR 内容并写入 RDMA 门铃 MMIO 地址。
通过在 GPU 内部管理整个控制平面,IBGDA 消除了与 GPU-CPU 通信相关的显著延迟开销。此外,在发送大量小数据包时,控制平面处理器很容易成为瓶颈。由于 GPU 具有多个并行线程,发送方可以利用这些线程来分配工作负载,从而避免此类瓶颈。包括 DeepSeek 的 DeepEP 在内的一系列工作都利用了 IBGDA,并报告使用它取得了显著的性能提升 。因此,DeepSeek 提倡在各种加速器设备上广泛支持此类功能。
未来硬件架构设计的讨论与见解
前面在具体的应用场景(application contexts)中指出了硬件局限性,并提供了相应的建议。在此基础上,接下来将讨论扩展到更广泛的考量,并为未来的硬件架构设计提出前瞻性方向:
- 鲁棒性挑战: 如何通过更先进的错误检测与纠正机制,应对硬件故障和静默数据损坏,构建永不停歇的 AI 基础设施。
- CPU 瓶颈与互联限制: 如何优化 CPU 与加速器之间的协同,特别是突破 PCIe 等传统接口的限制,实现高速、无瓶颈的节点内部通信。
- 面向 AI 的智能网络: 如何打造具备低延迟和智能感知能力的网络,通过光互联、无损机制、自适应路由等技术,应对复杂的通信需求。
- 内存语义通信与排序: 如何解决当前内存语义通信中的数据一致性与排序挑战,探索硬件层面的内建保证,提升通信效率。
- 网络中计算与压缩: 如何将计算和压缩能力下沉到网络中,特别是针对 EP 等特定负载,释放网络带宽潜力。
- 以内存为中心的架构创新: 如何应对模型规模指数级增长带来的内存带宽危机,探索 DRAM 堆叠、晶圆级集成等前沿技术。
鲁棒性挑战(Robustness Challenges)
现有限制
- 互连故障(Interconnect Failures): 高性能互联(如 IB 和 NVLink)易在实际部署中出现间歇性连接中断,影响节点间通信。尤其在通信密集型负载(例如 EP)中,即使短暂中断亦可导致显著性能下降,甚至任务失败。
- 单点硬件故障(Single Hardware Failures): 节点宕机、GPU 故障或 ECC(错误更正码)内存出错等单点硬件故障,可能影响长时间运行的训练任务,常需高昂重启。大规模部署中,这类单点故障概率随系统规模扩大显著上升。
- 静默数据损坏(Silent Data Corruption): 例如多位内存翻转或计算精度误差等绕过 ECC 检测机制的错误,可能导致模型质量受损。这类错误尤为隐蔽,易在长时间运行任务中累积传播并污染下游计算(downstream computations)。目前多数应用层启发式缓解策略(mitigation strategies)难以实现系统级全面鲁棒保障。
面向高级错误检测与纠正的建议
为缓解静默损坏风险,硬件应集成超越传统 ECC 的高级错误检测机制,如基于校验和验证、硬件加速冗余校验,以提升大规模部署可靠性。
此外,厂商应提供全面诊断工具包,使用户能精确验证系统完整性,主动预警潜在静默损坏。将工具包作为标准硬件配置部署,可促进全生命周期持续验证和透明度,增强系统整体可信度。
CPU 瓶颈与互联网络限制
尽管加速器(accelerator)设计常为系统优化核心,但 CPU 在协调计算任务、管理 I/O 和维持整体系统吞吐方面仍扮演关键角色。然而,当前硬件架构存在若干关键瓶颈:
首先,如前所述,CPU 与 GPU 间的 PCIe 接口在大规模参数、梯度或 KV 缓存(KV cache)传输中常成带宽瓶颈。为缓解此问题,未来系统应引入 CPU–GPU 直连互联方案(例如 NVLink 或 Infinity Fabric),或将 CPU 与 GPU 集成于 scale-up domain,消除节点内部数据传输瓶颈。
除 PCIe 限制外,维持如此高数据传输速率需极高内存带宽。例如,要充分利用 160 通道 PCIe 5.0 接口,每节点需超过 640 GB/s 数据传输能力,这意味约 1 TB/s 每节点内存带宽,对传统 DRAM 架构是一大挑战。
最后,对延迟敏感任务(诸如 kernel launch、网络处理)需高单核 CPU 性能,通常基础主频需达 4 GHz 以上。此外,现代 AI 工作负载要求每 GPU 配备足够 CPU 核心,避免控制侧瓶颈。对于基于芯粒(chiplet)的架构,还需额外 CPU 核心支持实现面向缓存的负载划分与隔离策略(cache-aware workload partitioning and isolation)。
面向 AI 的智能网络架构
为了应对延迟敏感型工作负载的需求,未来的互联网络需同时具备「低延迟」与「智能感知」的能力,具体可从以下几个方向探索:
封装内光互联(Co-Packaged Optics):通过集成硅光子(silicon photonics)技术,能够实现可扩展的高带宽互联,并显著提升能效,这对于构建大规模分布式 AI 系统至关重要。
无损网络(Lossless Network):基于信用的流控机制(Credit-Based Flow Control, CBFC)可实现无损数据传输,但若采用基础策略触发流控,可能引发严重的队首阻塞(head-of-line blocking)。因此,必须部署更先进的端侧驱动拥塞控制算法(congestion control, CC),以主动调节注入速率,避免网络拥塞恶化为系统性瓶颈。
自适应路由(Adaptive Routing):如前所述,未来网络应标准化采用动态路由机制,如数据包喷洒(packet spraying)与拥塞感知路径选择策略(congestion-aware path selection)。这些策略可持续感知当前网络状态并智能调度通信流,有效缓解网络热点,特别是在 all-to-all 与 reduce-scatter 等集合通信操作中,对缓解通信瓶颈效果显著。
高效的容错协议(Efficient Fault-Tolerant Protocols):通过自愈协议、自适应端口冗余和快速故障转移机制,可显著提升系统在故障情境下的鲁棒性。例如,链路级重试机制(link-layer retry)和选择性重传协议(selective retransmission protocols)是提升大规模网络可靠性、减少停机时间的关键组件,能够在面对间歇性故障时确保系统无缝运行。
动态资源管理(Dynamic Resource Management):为更高效地处理混合型工作负载,未来硬件需支持动态带宽调度与流量优先级控制。例如,统一的多任务集群中应将推理任务与训练通信隔离调度,以确保延迟敏感型应用的响应能力。
内存语义通信与内存排序问题的探讨
基于加载 / 存储语义(load/store memory semantics)进行节点间通信,具有高效且对程序员友好的优势。
但当前实现方案普遍受限于内存排序一致性问题。例如,发送端通常需要在写入数据后,执行显式的内存屏障操作(memory fence),再更新标志位以通知接收端,从而确保数据一致性。
这种强排序要求引入了额外的往返延迟(round-trip time, RTT),可能阻塞发出线程,影响写操作重叠能力,最终降低吞吐率。
类似的乱序同步问题,在基于消息语义的远程直接内存访问(Remote Direct Memory Access, RDMA)中同样存在。例如,在 InfiniBand 或 NVIDIA BlueField-3 上,若在常规 RDMA 写操作之后再执行采用数据包喷洒(packet spraying)的 RDMA 原子加(atomic add)操作,也会引入额外的 RTT 开销。
为应对上述挑战,DeepSeek 团队主张从硬件层面引入内建排序保证,以强化内存语义通信中的数据一致性。这种一致性应同时在编程接口层(如 acquire/release 语义)和接收端硬件层实施,从而实现无需额外开销的有序数据交付。
可行路径包括:在接收端缓存原子消息,并通过数据包序号实现顺序处理;但相比之下,基于 acquire/release 的机制更加优雅且具效率优势。
DeepSeek 团队提出一种简单的概念机制 —— 区域获取 / 释放机制(Region Acquire/Release Mechanism, RAR):在该方案中,接收端硬件维护一个用于跟踪内存区域状态的位图,获取与释放操作基于 RAR 地址范围生效。
该机制延伸了最小位图开销下的高效排序保障,由硬件强制执行排序逻辑,完全摆脱发送端对显式屏障指令的依赖,理想情况下实现于网络接口卡(NIC)或 I/O 芯片上。
值得强调的是,RAR 机制不仅适用于基于内存语义的通信场景,也可覆盖基于消息语义的 RDMA 操作,具有广泛的实际适用性。
网络中计算与压缩机制
EP(Expert Parallelism)任务涉及两个关键的全对全通信阶段:分发(dispatch)与合并(combine),它们构成网络级优化的重要着力点。
分发阶段类似于小规模的多播(multicast)操作,需要将一条消息转发至多个目标设备。若在硬件协议层支持自动包复制与多目标转发,将大幅减少通信开销,提升总体效率。
合并阶段则近似于小规模规约(reduction)操作,可通过网络中的聚合机制实现场内计算(in-network aggregation)。然而,由于 EP 合并操作通常规约范围有限、负载不均,实现灵活、高效的网络内规约尚具挑战性。
此外,如前所指出,LogFMT 可在基本不影响模型性能的前提下实现低精度 token 传输。若将 LogFMT 原生集成进网络硬件,可通过提升信息熵密度(entropy density)降低带宽消耗,进一步优化通信性能。依托硬件加速的压缩 / 解压模块,LogFMT 可无缝融入分布式系统,从而显著提升整体吞吐能力。
以内存为中心的架构创新
内存带宽的限制
近年来模型规模呈指数级增长,远超高带宽存储器(High-Bandwidth Memory, HBM)技术的发展速度。这种增长差距使得「内存瓶颈」问题愈发突出,尤其在像 Transformer 这类注意力机制密集的模型结构中尤为严重。
架构性建议
DRAM 堆叠加速器(DRAM-Stacked Accelerators):通过 3D 封装技术,可将 DRAM 芯片垂直集成于逻辑底片之上,从而获得极高的内存带宽、超低访问延迟以及现实可用的内存容量(受堆叠层数限制)。该架构模型在追求极速推理的专家混合模型(Mixture-of-Experts, MoE)中尤显优势,因其对内存吞吐极度敏感。如 SeDRAM 等架构即展示了此方法在内存受限工作负载中的颠覆式性能潜力。
晶圆级集成系统(System-on-Wafer, SoW):晶圆级集成(wafer-scale integration)可最大化计算密度与内存带宽,是应对超大规模模型所需带宽密度的可行途径。
#美或强制植入「地理追踪」,锁定英伟达高端GPU
5090将被秘密定位?
小心,5090要装定位了?美参议员12页法案,强制要求英伟达、AMD高端GPU和AI芯片植入「地理追踪」功能。法案若通过,6个月后生效。
最近,美参议员Tom Cotton提出了一项新法案——
要为英伟达、AMD等高端GPU装上「地理追踪」功能,防止落入竞争国家手中。
此举,不仅针对的是AI芯片,还涵盖了高性能游戏显卡等硬件。
若是法案通过,这些措施将在6个月后生效。
高端GPU植入定位
根据法案内容,一些生产高性能AI处理器和显卡的厂商,比如英伟达、英特尔、AMD,必须在产品中嵌入「地理追踪」技术。
这么做的目的不言而喻,实时监控硬件的物理位置。
文件地址:https://www.cotton.senate.gov/imo/media/doc/chips.pdf
尽管「地理追踪」技术尚未广泛使用,但实际上验证芯片位置的技术已经存在。
路透称,出于安全目的,谷歌在其内部AI芯片以及数据中心芯片中,植入了定位功能。
方案的出口管制分类号(ECCNs),覆盖了3A090、4A090、4A003.z、3A001.z多种产品,具体包括:
- AI处理器
- AI服务器(包括机架级解决方案)
- 高性能计算(HPC)服务器
- 高端显卡
- 存在潜在军事或双重用途风险的产品
值得注意的是,许多高端显卡,比如英伟达RTX 4090和RTX 5090,也被归类为3A090,因此此类附加板卡也需增加「地理追踪」功能。
法案的核心目标是,确保这些「战略硬件」不被未经授权的外国实体使用。
另外,商务部长还将获得权限,验证硬件的地理位置和最终用户,并建立一个集中式注册系统,记录所有受管制芯片的当前位置和使用情况。
芯片厂噩梦?
对于芯片制造商来说,这项法案无疑是一场技术与合规的「噩梦」。
在AI硬件中加入「地理追踪」功能,并非易事,尤其是对于已设计完成的高端处理器和显卡。
在短短6个月内,英伟达、AMD等要调整生产流程,增加硬件/固件层面的追踪机制,将显著增加其研发成本和时间。
不仅如此,这些出口芯片厂商还要承担更多的责任,有义务持续追踪产品出口后的位置和使用情况。
若是发现硬件被转移到未经授权的目的地,必须立即向工业与安全局(BIS)报告。
此外,任何篡改或操控的迹象,也需立即上报。
英伟达已公开表示,它无法在硬件售出后进行追踪,并否认了关于芯片走私泛滥的担忧。
这些要求不仅提高了芯片厂运营负担,还可能因技术实施复杂性,而影响了产品的市场竞争力。
自2022年以来,白宫一直对中国出口先进芯片实施了严格限制,目标直指AI和高性能计算领域,使用的尖端处理器。
无论是拜登,还是特朗普政府,这一政策都未曾松动,反而不断加码。
此前,新一轮出口管制不仅延续了之前的禁令,还将AMD MI308、英伟达H20纳入了管制清单。
这一突如其来的政策,让两家公司措手不及。据估算,AMD因此损失了约8亿美金潜在收入,而英伟达更是损失高达55亿美元。
更多限制
法案不止于当前「地理追踪」要求,还为未来监管升级铺平了道路。
在未来,不仅要进行联合研究,还需要进行年度评估。
若是这项12页的法案,获得了议员的支持,商务部与国防部还需在一年后开展为期一年的联合研究,探索额外的保护措施。
除初步研究外,这两个部门还需在法案通过后的连续三年内每年进行评估。
这些审查必须评估适用于出口管制产品的最新安全技术进展。然而,根据这些评估,部门可能决定是否实施新要求。
如果评估认为需要额外机制,商务部必须在两年内制定相关规则,并提交详细的实施路线图。
值得注意的是,法案强调了在开发和部署这些技术时,必须保护敏感的商业机密和知识产权。
比如,英伟达、AMD、英特尔的新技术,在设计追踪功能时不会被泄露。
参考资料:
#Better、Faster、Stronger!
VLM 2025
Vision Language Models (Better, Faster, Stronger) https://huggingface.co/blog/vlms-2025
动机
视觉语言模型(VLMs)是当前的热门话题。在2024年4月的一篇博客文章中,我们曾详细介绍过VLMs。其中大部分内容涉及LLaVA,这是第一个成功且易于复现的开源视觉语言模型,我们还介绍了如何发现、评估和微调开源模型的方法。
从那时起,一切都发生了巨大的变化。模型变得更小,但功能更强大。我们见证了新的架构和能力的兴起(如推理、代理、长视频理解等)。与此同时,全新的范式,如多模态检索增强生成(RAG)和多模态代理,也逐渐形成。
在这篇博客文章中,我们将回顾过去一年中视觉语言模型的发展历程,剖析其中的关键变化、新兴趋势和显著进展。
目录
- 新模型趋势
- 任意模态模型
- 推理模型
- 小巧但功能强大的模型
- 专家混合解码器
- 视觉-语言-行动模型
- 特殊能力
- 视觉语言模型中的目标检测、分割和计数
- 多模态安全模型
- 多模态RAG:检索器和重排器
- 多模态代理
- 视频语言模型
- 视觉语言模型的新对齐技术
- 新基准测试
- MMT-Bench
- MMMU-Pro
新模型趋势
在本节中,我们将探讨新型的VLMs。其中一些是全新的,而另一些则是对先前研究的改进版本。
任意模态模型
顾名思义,任意模态模型能够接受任何模态的输入,并输出任何模态(图像、文本、音频)。它们通过模态对齐来实现这一点,即一种模态的输入可以被翻译成另一种模态(例如,“dog”这个词会与狗的图像或“dog”这个词的发音相关联)。
这些模型拥有多个编码器(每个模态一个),然后将嵌入向量融合在一起,创建一个共享的表示空间。解码器(多个或单个)以共享潜在空间作为输入,并解码成所选的模态。最早尝试构建任意模态模型的是Meta的Chameleon,它可以接受图像和文本输入,并输出图像和文本。然而,Meta并未在该模型中发布图像生成功能,因此Alpha-VLLM发布了基于Chameleon的Lumina-mGPT,增加了图像生成功能。
最新且功能最强大的任意模态模型是Qwen 2.5 Omni(见下图),它是理解任意模态模型架构的一个很好的例子。
Qwen2.5-Omni采用了一种新颖的“思考者-说话者”架构,其中“思考者”负责文本生成,而“说话者”则以流式方式产生自然语音响应。MiniCPM-o 2.6是一个拥有80亿参数的多模态模型,能够理解并生成视觉、语音和语言模态的内容。DeepSeek AI推出的Janus-Pro-7B是一个统一的多模态模型,在跨模态的理解和生成方面表现出色。它采用了分离的视觉编码架构,将理解过程与生成过程分开。
我们预计未来几年这类模型的数量将会增加。众所周知,多模态学习是学习深度表示的唯一途径。我们已经整理了一些任意模态模型及其演示,收录在这个合集中。
推理模型
推理模型能够解决复杂的问题。我们最初在大型语言模型中看到了它们,如今视觉语言模型也具备了这种能力。直到2025年,唯一一个开源的多模态推理模型是Qwen的QVQ-72B-preview。这是一个由阿里巴巴Qwen团队开发的实验性模型,并且附带了许多免责声明。
今年,又出现了一个新的参与者,即Moonshot AI团队的Kimi-VL-A3B-Thinking。它由MoonViT(SigLIP-so-400M)作为图像编码器,以及一个拥有160亿总参数、仅28亿活跃参数的专家混合(MoE)解码器组成。该模型是Kimi-VL基础视觉语言模型的长链推理微调版本,并进一步通过强化学习进行了对齐。作者还发布了一个指令微调版本,名为Kimi-VL-A3B-Instruct。
该模型可以接受长视频、PDF文件、屏幕截图等输入,并且还具备代理能力。
小巧但功能强大的模型
过去,社区通过增加模型参数数量和高质量合成数据来提升智能水平。然而,在某个临界点之后,基准测试趋于饱和,继续扩大模型规模的收益逐渐减少。于是,社区开始通过各种方法(如知识蒸馏)来缩小大型模型的规模。这很有意义,因为这样可以降低计算成本,简化部署过程,并解锁诸如本地执行等用例,从而增强数据隐私。
当我们提到小型视觉语言模型时,通常指的是参数少于20亿、可以在消费级GPU上运行的模型。SmolVLM是一个小型视觉语言模型家族的典型代表。它没有通过缩小大型模型来实现,而是直接尝试将模型参数数量控制在极低水平,如2.56亿、5亿和22亿。例如,SmolVLM2试图在这些规模下解决视频理解问题,并发现5亿参数是一个很好的折中方案。在Hugging Face,我们开发了一款名为HuggingSnap的iPhone应用程序,以证明这些规模的模型可以在消费级设备上实现视频理解。
另一个引人注目的模型是谷歌DeepMind的gemma3-1b-it。它特别令人兴奋,因为它是目前最小的多模态模型之一,拥有32k的上下文窗口,并支持140多种语言。该模型属于Gemma 3模型家族,其中最大的模型在Chatbot Arena上排名第一。随后,该大型模型被蒸馏为一个10亿参数的变体。
最后,虽然不是最小的模型,但Qwen2.5-VL-3B-Instruct也值得关注。该模型可以执行多种任务,包括定位(目标检测和指向)、文档理解以及代理任务,上下文长度可达32k个标记。
您可以通过MLX和Llama.cpp集成来使用小型模型。对于MLX,假设您已经安装了它,您可以通过以下一行代码开始使用SmolVLM-500M-Instruct:
python3 -m mlx_vlm.generate --model HuggingfaceTB/SmolVLM-500M-Instruct --max-tokens 400 --temp 0.0 --image https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vlm_example.jpg --prompt "What is in this image?"您可以通过以下一行代码,使用GGUF格式的gemma-3-4b-it模型,通过CLI和Llama.cpp开始使用:
llama-mtmd-cli -hf ggml-org/gemma-3-4b-it-GGUF您还可以通过以下命令将同一模型作为服务运行:
llama-server -hf ggml-org/gemma-3-4b-it-GGUF专家混合解码器
专家混合(MoEs)模型为密集架构提供了一种替代方案,通过动态选择并激活与给定输入数据片段最相关的子模型(称为“专家”)来处理数据。这种选择性激活机制(由路由器完成)已被证明能够在利用较少计算资源的同时显著提升模型性能和运行效率。
与参数密集的同类模型相比,MoEs在推理时速度更快,因为它们只激活网络中的一小部分。它们在训练时也能快速收敛。然而,天下没有免费的午餐,MoEs需要更高的内存成本,因为整个模型都存储在GPU上,即使只使用其中的一小部分。
在广泛采用的Transformer架构中,MoE层通常是通过替换每个Transformer块中的标准前馈网络(FFN)层来集成的。密集网络在推理时会使用整个模型,而同样大小的MoE网络则会选择性地激活一些专家。这有助于更好地利用计算资源并加快推理速度。
配备专家混合解码器的视觉语言模型似乎具有增强的性能。例如,Kimi-VL目前是最先进的开源推理模型,它采用了专家混合解码器。专家混合在MoE-LLaVA的效率提升和幻觉减少以及DeepSeek-VL2的广泛多模态能力方面也显示出令人鼓舞的结果。最新版本的Llama(Llama 4)是一个具有视觉能力的MoE。专家混合作为解码器是一个有前景的研究领域,我们预计这类模型的数量将会增加。
视觉-语言-行动模型
VLMs甚至在机器人领域也取得了进展!在那里,它们被称为视觉-语言-行动模型(VLA)。但不要被名字迷惑,这些主要是带有小胡子和帽子的VLMs。VLAs接受图像和文本指令作为输入,并返回指示机器人直接采取行动的文本。VLAs通过添加行动和状态标记扩展了视觉语言模型,以与物理环境进行交互和控制。这些额外的标记代表了系统的内部状态(它如何感知环境)、行动(根据命令采取的行动)以及与时间相关的信息(例如任务中步骤的顺序)。这些标记被附加到视觉语言输入中,以生成行动或策略。
VLAs通常是在基础VLM之上进行微调的。有些人进一步扩展了这一定义,将VLAs定义为任何与现实或数字世界进行视觉交互的模型。在这个定义下,VLAs可以用于UI导航或代理工作流程。但许多人认为这些应用属于VLM领域。
π0和π0-FAST是Physical Intelligence推出的首批机器人基础模型,已移植到Hugging Face的LeRobot库中。这些模型在7个机器人平台上针对68项独特任务进行了训练。它们在复杂的真实世界活动中表现出强大的零样本和微调性能,例如洗衣折叠、餐桌清理、杂货装袋、盒子组装和物体检索。
GR00T N1是NVIDIA的开源VLA基础模型,用于通用人形机器人。它能够理解图像和语言,并将其转化为行动,例如移动手臂或遵循指令,这得益于一个将智能推理与实时运动控制相结合的系统。GR00T N1也基于LeRobot数据集格式构建,这是一种简化机器人演示共享和训练的开放标准。
现在我们已经了解了最新的VLM模型创新,接下来让我们探索一些更成熟的能力是如何发展的。
特殊能力视觉语言模型中的目标检测、分割和计数
正如我们在前面的部分中所看到的,VLMs能够在传统计算机视觉任务上实现泛化。如今,模型可以接受图像和各种提示(如开放式文本),并输出带有定位标记的结构化文本(用于检测、分割等)。
去年,PaliGemma是首个尝试解决这些任务的模型。该模型接受图像和文本输入,其中文本是对感兴趣对象的描述,以及一个任务前缀。文本提示看起来像“segment striped cat”(分割条纹猫)或“detect bird on the roof”(检测屋顶上的鸟)。
对于检测任务,模型以标记的形式输出边界框坐标。而对于分割任务,模型则输出检测标记和分割标记。这些分割标记并不是所有分割像素的坐标,而是由变分自编码器解码的码本索引,该自编码器被训练用来将这些标记解码为有效的分割掩码(如下图所示)。
在PaliGemma之后,许多模型被引入用于执行定位任务。去年年底,PaliGemma的一个升级版本PaliGemma 2出现了,它具有相同的能力,但性能更好。另一个后来出现的模型是Allen AI的Molmo,它可以使用点来指向实例并计数对象实例。
Qwen2.5-VL也能够检测、指向和计数对象,这包括将UI元素作为对象进行处理!
多模态安全模型
在生产环境中使用视觉语言模型时,需要对输入和输出进行过滤,以防止越狱和有害输出,以确保合规性。有害内容从包含暴力的输入到性相关内容不等。这就是多模态安全模型的用武之地:它们在视觉语言模型之前和之后使用,以过滤其输入和输出。它们就像LLM安全模型一样,但增加了图像输入。
2025年初,谷歌推出了首个开源多模态安全模型ShieldGemma 2。它基于文本安全模型ShieldGemma构建。该模型接受图像和内容策略作为输入,并返回图像是否符合给定策略的安全性判断。策略是指图像不适当的标准。ShieldGemma 2还可以用于过滤图像生成模型的输出。
Meta的Llama Guard 4是一个密集的多模态和多语言安全模型。它是从Llama 4 Scout(一个多模态专家混合模型)密集修剪而来,并进行了安全微调。
该模型可用于纯文本和多模态推理。该模型还可以接受视觉语言模型的输出、完整的对话内容,并在将它们发送给用户之前对其进行过滤。
多模态RAG:检索器和重排器
现在让我们看看检索增强生成(RAG)在多模态领域是如何发展的。对于复杂的文档(通常以PDF格式呈现),RAG的处理过程通常分为三个步骤:
- 将文档完全解析为文本
- 将纯文本和查询传递给检索器和重排器,以获取最相关的文档
- 将相关上下文和查询传递给LLM
传统的PDF解析器由多个元素组成,以保留文档中的结构和视觉元素,如布局、表格、图像、图表等,所有这些元素都被渲染成Markdown格式。但这种设置很难维护。
随着视觉语言模型的兴起,这个问题得到了解决:现在有了多模态检索器和重排器。
多模态检索器接受一堆PDF文件和一个查询作为输入,并返回最相关的页面编号及其置信度分数。这些分数表示页面包含查询答案的可能性,或者查询与页面的相关性。这绕过了脆弱的解析步骤。
然后将最相关的页面与查询一起输入视觉语言模型,VLM生成答案。
主要有两种多模态检索器架构:
- 文档截图嵌入(DSE,MCDSE)
- ColBERT类模型(ColPali、ColQwen2、ColSmolVLM)
DSE模型由一个文本编码器和一个图像编码器组成,每个查询返回一个向量。返回的分数是嵌入向量点积的softmax。它们为每个段落返回一个向量。
ColBERT类模型,如ColPali,也是双编码器模型,但有一个特点:ColPali使用视觉语言模型作为图像编码器,使用大型语言模型作为文本编码器。这些模型本质上不是编码器,但它们输出嵌入向量,然后传递给“MaxSim”。与DSE不同,这些模型的输出是每个标记的一个向量,而不是一个单一向量。在MaxSim中,计算每个文本标记嵌入向量与每个图像块嵌入向量之间的相似度,这种方法能够更好地捕捉细微差别。正因为如此,ColBERT类模型的计算成本更高,但性能更好。
以下是ColPali的索引延迟情况。由于它只是一个单一模型,因此也更容易维护。
在Hugging Face Hub上,您可以在“视觉文档检索”任务下找到这些模型。
该任务最受欢迎的基准测试是ViDoRe,它包含英文和法文的文档,文档类型从财务报告、科学图表到行政文件不等。ViDoRe中的每个示例都包含文档图像、查询和可能的答案。文档与查询的匹配有助于对比预训练,因此ViDoRe训练集被用于训练新模型。
多模态代理
视觉语言模型为从与文档聊天到计算机使用等多种代理工作流程提供了可能。这里我们将重点介绍后者,因为它需要更高级的代理能力。最近,许多视觉语言模型发布,它们能够理解和操作用户界面(UI)。其中最新的是ByteDance的UI-TARS-1.5,它在浏览器、计算机和手机操作方面取得了出色的结果。它还可以进行推理游戏,并在开放世界游戏中运行。今年的另一个重要发布是MAGMA-8B,它是一个用于UI导航和与现实世界进行物理交互的基础模型。此外,Qwen2.5-VL(尤其是其32B变体,因为它在代理任务上进行了进一步训练)和Kimi-VL推理模型在GUI代理任务上表现出色。
2025年初,我们推出了smolagents,这是一个新的轻量级代理库,实现了ReAct框架。不久之后,我们为该库增加了视觉语言支持。这种集成发生在两个用例中:
- 在运行开始时一次性提供图像。这对于带有工具使用的文档AI很有用。
- 动态检索图像。这对于需要VLM代理进行GUI控制的情况很有用,因为代理需要反复截取屏幕截图。
该库为用户提供构建自己的图像理解代理工作流程的构建块。我们提供了不同的脚本和单行CLI命令,以便用户轻松开始。
对于第一种情况,假设我们希望一个代理描述文档(这并不太具有代理性,但对于最小化用例来说还不错)。您可以像下面这样初始化CodeAgent(一个可以自己编写代码的代理):
agent = CodeAgent(tools=[], model=model) # 不需要工具
agent.run("Describe these documents:", images=[document_1, document_2, document_3])对于第二种情况,我们需要一个代理来获取屏幕截图,我们可以定义一个回调函数,在每个ActionStep结束时执行。对于您自己的需要动态获取图像的用例,您可以根据需要修改回调函数。为了简单起见,这里我们不详细定义它。您可以选择阅读博客文章和博客文章末尾的脚本。现在,让我们看看如何初始化带有回调和浏览器控制步骤的代理。
def save_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
"""
截取屏幕截图并写入观察结果。
"""
png_bytes = driver.get_screenshot_as_png()
memory_step.observations_images = [image.copy()] # 将图像持久化到memory_step
url_info = f"当前网址:{driver.current_url}"
memory_step.observations = (
url_info if memory_step.observations is None else memory_step.observations + "\n" + url_info
)
return
agent = CodeAgent(
tools=[go_back, close_popups, search_item_ctrl_f], # 传递导航工具
model=model,
additional_authorized_imports=["helium"],
step_callbacks=[save_screenshot], # 传递回调
)您可以通过运行以下CLI命令来尝试整个示例。它启动一个代理,该代理通过视觉语言模型控制网络浏览器,以完成网络自动化任务(请替换为您想要导航的网站)。
webagent "前往 xyz.com/men,进入销售部分,点击您看到的第一件服装。获取产品详情和价格,并返回它们。注意,我正在从法国购物"smolagents提供了不同类型的模型,例如本地Transformer模型、使用推理提供商托管的开源模型,或闭源模型提供商的端点。我们鼓励使用开源模型,因为许多代理工作流程目前需要推理,这从拥有大量参数的模型中受益。截至2025年4月,Qwen 2.5 VL是一个适合代理工作流程的候选模型,因为该模型在代理任务上进行了进一步训练。
视频语言模型
如今,大多数视觉语言模型都能够处理视频,因为视频可以表示为一系列帧。然而,视频理解是棘手的,因为帧之间存在时间关系,而且帧的数量通常很多,因此需要使用不同的技术来选择一组具有代表性的视频帧。
从去年开始,社区一直在权衡不同的方法和技巧来解决这个问题。
一个很好的例子是Meta的LongVU模型。它通过将视频帧传递给DINOv2来降低采样率,以选择最相似的帧并将其去除,然后模型进一步通过根据文本查询选择最相关的帧来细化帧,其中文本和帧都被投影到同一个空间,并计算相似度。Qwen2.5VL能够处理长上下文,并适应动态帧率,因为该模型是用不同帧率的视频进行训练的。通过扩展的多模态RoPE,它能够理解帧的绝对时间位置,并且可以处理不同的速率,同时仍然能够理解现实生活中事件的速度。另一个模型是Gemma 3,它可以接受在文本提示中交错的时间戳和视频帧,例如“Frame 00.00: ..”,并且在视频理解任务中表现非常出色。
视觉语言模型的新对齐技术
偏好优化是一种替代的语言模型微调方法,也可以扩展到视觉语言模型。这种方法不依赖于固定的标签,而是专注于根据偏好比较和排名候选响应。trl库提供了对直接偏好优化(DPO)的支持,包括对VLMs的支持。
以下是VLM微调的DPO偏好数据集的结构示例。每个条目由一个图像+问题对以及两个对应的答案组成:一个被选中的答案和一个被拒绝的答案。VLM被微调以生成与首选(被选中)答案一致的响应。
RLAIF-V是一个用于此过程的示例数据集,它包含超过83000个按照上述结构标注的样本。每个条目包括一个图像列表(通常是一个图像)、一个提示、一个被选中的答案和一个被拒绝的答案,正如DPOTrainer所期望的那样。
这里有一个已经按照相应格式格式化的RLAIF-V格式数据集。以下是单个样本的示例:
{'images': [<PIL.JpegImagePlugin.JpegImageFile image mode=L size=980x812 at 0x154505570>],
'prompt': [ { "content": [ { "text": null, "type": "image" }, { "text": "What should this catcher be using?", "type": "text" } ], "role": "user" } ],
'rejected': [ { "content": [ { "text": "The catcher, identified by the number...", "type": "text" } ], "role": "assistant" } ],
'chosen': [ { "content": [ { "text": "The catcher in the image should be using a baseball glove...", "type": "text" } ], "role": "assistant" } ]}准备好数据集后,您可以使用trl库中的_DPOConfig_和_DPOTrainer_类来配置并启动微调过程。
以下是使用_DPOConfig_的示例配置:
from trl import DPOConfig
training_args = DPOConfig(
output_dir="smolvlm-instruct-trl-dpo-rlaif-v",
bf16=True,
gradient_checkpointing=True,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=32,
num_train_epochs=5,
dataset_num_proc=8, # tokenization will use 8 processes
dataloader_num_workers=8, # data loading will use 8 workers
logging_steps=10,
report_to="tensorboard",
push_to_hub=True,
save_strategy="steps",
save_steps=10,
save_total_limit=1,
eval_steps=10, # Steps interval for evaluation
eval_strategy="steps",
)要使用_DPOTrainer_训练您的模型,您可以选择提供一个参考模型来计算奖励差异。如果您使用的是参数高效微调(PEFT),则可以通过设置_ref_model=None_来省略参考模型。
from trl import DPOTrainer
trainer = DPOTrainer(
model=model,
ref_model=None,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
peft_cnotallow=peft_config,
tokenizer=processor
)
trainer.train()新基准测试
在过去的一年里,基准测试也发生了显著的变化。在我们之前的博客中,我们描述了MMMU和MMBench作为评估视觉语言模型的两个新兴基准测试。随着该领域的快速发展,模型在这些基准测试上已经趋于饱和,我们需要更好的评估工具。为了实现这一目标,我们需要能够评估特定能力的工具,而不仅仅是通用基准测试。
现在,我们重点介绍两个突出的通用基准测试:MMT-Bench和MMMU-Pro。
MMT-Bench
MMT-Bench旨在评估VLMs在需要专业知识、精确视觉识别、定位、推理和规划的广泛多模态任务上的表现。该基准测试包括来自各种多模态场景的31325个多选视觉问题,涵盖图像、文本、视频和点云等多种模态。它包含32个不同的元任务和162个子任务,涵盖了OCR、视觉识别或视觉-语言检索等多种任务。
MMMU-Pro
MMMU-Pro是原始MMMU基准测试的改进版本。它还评估先进AI模型在多种模态上的真实理解能力。
它比MMMU更复杂,例如,它有一个仅视觉输入的设置,并且候选选项的数量从4个增加到了10个。该基准测试还纳入了真实世界模拟,其仅视觉问题来源于在模拟显示屏内截取的屏幕截图或照片,具有不同的背景、字体样式和大小,以模拟真实世界条件。
#WebThinker开启AI搜索&研究新纪元
边思考、边搜索、边写作
李晓熙目前就读于中国人民大学高瓴人工智能学院,博士二年级,导师为窦志成教授,研究方向主要包括检索增强生成、大语言模型推理等。在国际顶级会议和期刊如 AAAI,SIGIR,TOIS 等发表多篇论文,代表工作包括 Search-o1, WebThinker, RetroLLM, GenIR-Survey, CorpusLM, UniGen 等。共同第一作者还包括人大高瓴博士生金佳杰和董冠廷。本文的通信作者为人大窦志成教授。
大型推理模型(如 OpenAI-o1、DeepSeek-R1)展现了强大的推理能力,但其静态知识限制了在复杂知识密集型任务及全面报告生成中的表现。为应对此挑战,深度研究智能体 WebThinker 赋予 LRM 在推理中自主搜索网络、导航网页及撰写报告的能力。WebThinker 集成了深度网页探索器,使 LRM 能自主搜索、导航并提取信息;自主思考 - 搜索 - 写作策略无缝融合推理、信息收集与实时报告写作;并结合强化学习训练优化工具调用。实验表明,WebThinker 在 GPQA、GAIA、WebWalkerQA、HLE 等复杂推理基准及 Glaive 研究报告生成任务中展现出强大性能,显著提升了 LRM 在复杂场景下的适用性与可靠性,为构建更强大、通用的深度研究系统奠定了坚实基础。
- 论文标题: WebThinker: Empowering Large Reasoning Models with Deep Research Capability
- 论文链接: https://arxiv.org/abs/2504.21776
- 代码仓库: https://github.com/RUC-NLPIR/WebThinker
Demo
1. OpenAI 有哪些模型?它们有什么区别?
,时长01:29
2. 2025 年我能投稿哪些 AI 顶会?
,时长02:14
研究动机:赋予推理模型深度研究能力
大型推理模型如 OpenAI-o1 和 DeepSeek-R1 在数学、编程和科学等领域展现了卓越的推理能力。然而,当面对需要广泛获取实时网络信息的复杂任务时,这些仅依赖内部参数知识的模型往往力不从心。特别是在需要深度网络信息检索和生成全面、准确的科学报告时,这一局限性尤为明显。
WebThinker 应运而生,它是一个深度研究智能体,使 LRMs 能够在推理过程中自主搜索网络、导航网页,并撰写研究报告。这种技术的目标是革命性的:让用户通过简单的查询就能在互联网的海量信息中进行深度搜索、挖掘和整合,从而为知识密集型领域(如金融、科学、工程)的研究人员大幅降低信息收集的时间和成本。
推理中自主调用工具:摆脱传统预定义 RAG 工作流
现有的开源深度搜索智能体通常采用检索增强生成(Retrieval-Augmented Generation, RAG)技术,依循预定义的工作流程,这限制了 LRM 探索更深层次网页信息的能力,也阻碍了 LRM 与搜索引擎之间的紧密交互。

WebThinker 突破了传统 RAG 工作流的限制,实现了范式的升级:
1. 传统 RAG: 仅进行浅层搜索,缺乏思考深度和连贯性
2. 进阶 RAG: 使用预定义工作流,包括查询拆解、多轮 RAG 等,但仍缺乏灵活性
3. WebThinker: 在连续深思考过程中自主调用工具,实现端到端任务执行
WebThinker 使 LRM 能够在单次生成中自主执行操作,无需遵循预设的工作流程,从而实现真正的端到端任务执行。
WebThinker 框架:自主的深度搜索与报告撰写

WebThinker 框架包含两种主要运行模式:
1. 问题解决模式:赋予 LRM 深度网页探索器(Deep Web Explorer)功能,当遇到知识缺口时,LRM 可以自主发起网络搜索,通过点击链接或按钮导航网页,并在继续推理前提取相关信息。
2. 报告生成模式:实现自主思考 - 搜索 - 写作(Autonomous Think-Search-and-Draft)策略,将推理、信息搜索和报告撰写无缝整合。LRM 可以使用专门的工具来草拟、检查和编辑报告部分,确保最终报告全面、连贯且基于收集的证据。
整个过程是端到端的,LRM 可以在思考过程中自主搜索、深度探索网页和撰写研究报告,摆脱了传统预定义工作流的局限。
核心组件:
1. 深度网页探索:解决复杂推理问题
这一模块使 LRM 能够进行网络搜索和导航,深度收集、遍历和提取网页上的高质量信息:
1. 搜索能力:能够基于当前查询生成搜索意图,从搜索引擎获取初步结果
2. 导航能力:能够点击链接或按钮,深入探索初始搜索结果之外的内容
3. 信息提取:基于当前查询的搜索结果,LRM 可以发起后续搜索并遍历更深层次的链接,直到收集所有相关信息
2. 自主的思考 - 搜索 - 写作:生成完整的研究报告
该策略将报告撰写与 LRM 的推理和搜索过程深度整合:不同于在搜索后一次性生成整个报告,WebThinker 使模型能够实时撰写和寻求必要知识。具体来说,WebThinker 为 LRM 配备三种专门工具:(1)撰写特定章节内容;(2)检查当前报告已写内容;(3)编辑 / 修改报告。这些工具使 LRM 能够通过保持全面性、连贯性和对推理过程中新发现信息的适应性来自主增强报告质量
3. 基于强化学习的训练策略:全面提升 LRM 调用研究工具的能力
为了进一步释放 LRM 骨干模型的深度研究潜力,WebThinker 开发了基于强化学习的训练策略:
1. 利用配备工具的 LRM 从复杂任务中采样大规模推理轨迹
2. 根据推理的准确性、工具使用准确性、以及最终输出答案或报告的质量,构建在线直接偏好优化(DPO)训练的偏好对
3. 通过迭代、在线策略训练,模型逐步提高感知、推理和有效交互研究工具的能力
实验结果

实验结果:真实世界的复杂推理任务
WebThinker 在四个知识密集型复杂推理基准上进行了评估:
1. GPQA:PhD 级别的科学问题回答数据集,覆盖物理、化学和生物学
2. GAIA:评估 AI 助手在复杂信息检索任务上的能力
3. WebWalkerQA:专注于深度网络信息检索,需要导航和提取信息
4. 人类最终考试(HLE):极具挑战性的跨学科问题数据集


从实验结果中可以发现:
1. 基础推理模型和传统 RAG 的局限:基础推理模型虽然在某些任务上表现不错,但在需要实时外部知识的场景中明显力不从心;传统 RAG 方法虽有改进,但在复杂任务中提升有限;
2. 自主搜索的优势:而引入自主搜索能力的模型则带来了显著提升。WebThinker 凭借其深度网页探索器,能够更全面地获取和整合网络信息,在所有基准测试中都取得了明显优势。
3. RL 训练的改进:特别是经过强化学习训练的 WebThinker-32B-RL 版本,不仅在同等参数量模型中达到了最佳表现,甚至在某些任务上超越了参数量更大的专有模型。
实验结果:科学研究报告生成

在 Glaive 科学报告生成任务的评估中:
1. 生成报告的质量:从完整性、彻底性、事实性和连贯性四个维度评估,WebThinker 生成的研究报告均获得高分,整体表现优于传统 RAG 方法和其他先进的深度研究系统;
2. 生成报告的信息边界:特别在报告的完整性和彻底性方面表现尤为突出,通过 t-SNE 可视化分析可见,WebThinker 生成的报告内容覆盖更广,视角更多元,能够从多个维度深入探索和综合信息,为用户提供更全面、更深入的调研。
实验结果:适配 DeepSeek-R1 系列模型

通过在不同规模的 DeepSeek-R1 模型上进行实验(7B, 14B, 32B),验证了 WebThinker 框架的适应性。在不同模型规模下,都能显著提升各类任务的性能,远超直接推理和标准 RAG 方法,展现了该框架在增强 LRM 深度研究能力方面的通用性和有效性。
实验结果:消融实验

消融实验评估了 WebThinker 各关键组件的贡献。结果显示,深度网页探索器以及自主 「思考 - 搜索 - 写作」 策略中的报告生成组件(尤其是自主报告起草)是确保高性能问题解决和高质量报告生成的基石,其缺失会导致性能显著下降。强化学习训练则主要增强了问题解决能力,对报告生成的影响相对有限。
总结与未来展望
WebThinker 框架成功地赋予了大型推理模型深度研究能力,解决了它们在知识密集型真实世界任务中的局限性。通过深度网页探索器和自主思考 - 搜索 - 写作策略,WebThinker 使 LRM 能够自主探索网络并通过连续推理过程生成全面输出。
未来,为持续提升深度研究模型的能力,仍有很多方向值得探索:
1. 多模态深度搜索:WebThinker 基于文本推理模型,难以处理图像等其他模态的信息。未来可以扩展到图像、视频等多模态内容的深度研究,来利用网页中的多模态信息。
2. 工具学习与扩展:当前支持有限的研究工具,未来可以通过工具学习来不断优化工具使用策略,并扩展更多工具,来支持更复杂的任务。
3. GUI 网页探索:通过 GUI 网页探索能力,让模型能够更好地理解和操作网页界面,实现更复杂的交互任务,如订机票、指定旅游路线图、等等。
#DiffMoE
动态Token选择助力扩散模型性能飞跃,快手&清华团队打造视觉生成新标杆!
本文由清华大学和快手可灵团队共同完成。第一作者是清华大学智能视觉实验室在读本科生史明磊。
在生成式 AI 领域,扩散模型(Diffusion Models)已成为图像生成任务的主流架构。然而,传统扩散模型在处理不同噪声水平和条件输入时采用统一处理方式,未能充分利用扩散过程的异构特性,导致计算效率低下,近期,可灵团队推出 DiffMoE(Dynamic Token Selection for Scalable Diffusion Transformers),通过创新的动态token选择机制和全局token池设计,拓展了扩散模型的效率与性能边界。
- 论文标题:DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
- 项目主页:https://shiml20.github.io/DiffMoE/
- 论文地址:https://arxiv.org/abs/2503.14487
- 代码:https://github.com/KwaiVGI/DiffMoE
核心突破:动态token选择与全局上下文感知
DiffMoE 首次在扩散模型中引入批级全局token池(Batch-level Global Token Pool),打破传统模型对单一样本内token的限制,使专家网络能够跨样本访问全局token分布。这种设计模拟了完整数据集的token分布,显著提升了模型对复杂噪声模式的学习能力。实验表明,DiffMoE 在训练损失收敛速度上超越了同等参数量的密集模型(Dense Models),为多任务处理提供了更强大的上下文感知能力。
针对推理阶段的计算资源分配问题,DiffMoE 提出动态容量预测器(Capacity Predictor),通过轻量级 MLP 网络实时调整专家网络的计算负载。该机制基于训练时的token路由模式学习,在不同噪声水平和样本复杂度间智能分配资源,实现了性能与计算成本的灵活权衡。例如,在生成困难图片时自动分配更多计算资源,而在处理简单图像时降低负载,真正做到 「按需计算」。

性能提升:以少胜多的参数高效模型
在 ImageNet 256×256 分类条件图像生成基准测试中,其他结构细节保持一致的公平对比情况下,DiffMoE-L-E8 模型仅用 4.58 亿参数 (FID50K 2.13), 超越了拥有 6.75 亿参数的 Dense-DiT-XL 模型(FID 2.19)。通过进一步扩展实验,DiffMoE 实现了仅用 1 倍激活参数就实现了 3 倍于密集模型的性能。此外,DiffMoE 在文本到图像生成任务中同样展现出卓越的泛化能力,相较于 Dense 模型有明显效率提升。


多维度验证:从理论到实践
研究团队通过大规模实验验证了 DiffMoE 的优越性:
动态计算优势:DiffMoE 的平均激活参数量较低的情况下实现了性能指标的显著提升,证明了动态资源分配的高效性;同时,DiffMoE 能够根据样本的难度自动分配计算量。本研究可视化了模型认为最困难和最简单的十类生成。

模型认为的最困难的十类

模型认为的最简单的十类
扩展性测试:从小型(32M)到大型(458M)配置,DiffMoE 均保持性能正向增长,专家数量从 2 扩展到 16 时 FID 持续下降;

跨任务适配:在文本到图像生成任务中,DiffMoE 模型在对象生成、空间定位等关键指标上全面超越 Dense 基线模型。

总结
在这项工作中,研究团队通过动态token选择和全局token可访问性来高效扩展扩散模型。我们的方法利用专门的专家行为和动态资源分配,有效解决了扩散 Transformer 中固定计算量处理的局限性问题。大量的实验结果表明,DiffMoE 在性能上超越了现有的 TC-MoE 和 EC-MoE 方法,以及激活参数量是其 3 倍的密集型模型。研究团队不仅验证了它在类别条件生成任务中的实用性,也验证了 DiffMoE 在大规模文本到图像生成任务的有效性。虽然为了进行公平比较,我们未纳入现代混合专家(MoE)模型的改进方法,但在未来的工作中,集成诸如细粒度专家和共享专家等先进技术,将可能带来新的增益。
#Step1X-3D
阶跃星辰×光影焕像联合打造超强3D生成引擎!还开源全链路训练代码
阶跃星辰携手光影焕像发布并开源 3D 大模型 ——Step1X-3D。Step1X-3D 模型总参数量达 4.8B(几何模块 1.3B,纹理模块 3.5B),凭借坚实的数据基础与先进的 3D 原生架构,可生成高保真、可控的 3D 内容。
Step1X-3D 不止于视觉「好看」,更追求实现「好用」与「可控」,旨在为 3D 内容创作提供强大而可靠的技术引擎。这款模型可以广泛应用在游戏娱乐、影视与动画制作、工业制造与设计等各种场景。
Step1X-3D 公布了完整的数据清洗策略,数据预处理策略,以及 800K 高质量的 3D 资产,3D VAE、3D Geometry Diffusion 以及 Texture Diffusion 的全链路训练代码开源,助力 3D 生成社区发展。
论文标题:Step1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
作者:Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, Xiao Chen, Feipeng Tian, Jianxiong Pan,Zeming Li, Gang Yu, Xiangyu Zhang, Daxin Jiang, Ping Tan
代码地址: https://github.com/stepfun-ai/Step1X-3D
项目主页:https://stepfun-ai.github.io/Step1X-3D
HuggingFace: https://huggingface.co/stepfun-ai/Step1X-3D
技术报告: https://arxiv.org/pdf/2505.07747
,时长00:40
欢迎大家上手体验:
Online Demo(立即体验):https://huggingface.co/spaces/stepfun-ai/Step1X-3D
核心特性与技术支撑
Step1X-3D 尝试解决 3D 内容生成的关键挑战,在数据、生成质量与可控性上进行了创新实践。
1. 数据驱动与算法协同优化
好数据是好模型的基础。Step1X-3D 对超 500 万原始数据进行严格筛选与处理后,建立了包含 200 万高质量、标准化的训练样本库,有效克服了行业数据稀缺与质量参差的瓶颈。

数据处理流程示意图
此外,Step1X-3D 通过增强型网格 - SDF 转换技术等方法,从源头保障了模型学习的精准性与最终生成的高效性,让水密几何转换成功率提升了 20%,也让 Step1X-3D 拥有了强大的泛化能力与细节捕捉力。

Step1X-3D 数据筛选与 SDF 转换流程示意图
2. 3D 原生生成:结构清晰、细节生动
Step1X-3D 采用先进的 3D 原生两阶段架构,解耦几何与纹理表征,确保生成的不仅是视觉「皮囊」,更是结构可靠、可供下游应用的「骨架」,有效规避几何失真,保证生成的准确性、真实感与一致性。

Step1X-3D 的原生 3D 架构

基于 FLUX MMDiT 结构和 Rectified flow 算法直接对 3D 表示生成进行建模。

纹理生成模型基于预训练的 Diffusion model,通过单视图和 3D 几何信息指导,生成多视角一致的纹理信息。
2.1 几何塑形更精准:
几何生成的核心在于采用为 3D 特性深度优化的创新混合 VAE-DiT 架构。该架构负责生成水密(Watertight)的 TSDF 内部表示,确保产出的 3D 模型结构完整、无破面漏点;同时通过引入锐利边缘采样(Sharp Edge Sampling)等技术,精准捕捉并还原物体的丰富几何细节。

几何示例:覆盖硬边与曲面结构
2.2 纹理细节更生动:
纹理生成则基于强大的 SD-XL 模型进行深度定制与优化。通过几何条件(利用法线与位置信息)的精准引导,以及潜在空间多视图同步技术,实现了与几何模块的高效协同。确保生成的纹理不仅色彩饱满、质感生动逼真,更能跨越多视图保持高度一致,与复杂三维表面精密贴合,有效避免常见的扭曲与接缝瑕疵。

纹理示例:呈现清晰一致的表面纹理
3. 控制简单、效果可调
Step1X-3D 显著提升了 3D 内容生成的可控性与易用性。其关键在于,VAE-Diffusion 整体架构在设计上与主流 2D 生成模型(如 Stable Diffusion)保持了高度一致性,从而能够无缝引入并应用成熟的 2D 控制技术(如轻量化的 LoRA 微调)。
因此用户可以对生成 3D 资产的对称性、表面细节(如锋利度、平滑度)等多种属性进行直观、精细的调控,让创作更精准地符合用户意图。

对比图 1:对称性控制效果

对比图 2:表面细节控制效果(锋利 / 平滑)
性能评估
为了客观评估 Step1X-3D 的实际效果,我们通过一个自建的综合测试,对 Step1X-3D 进行了严格的定量与定性评估,同时与多款主流模型进行全面对比。
结果显示:在自动评估中,Step1X-3D 在多项关键维度上均表现出色。

在与主流 3D 模型的对比评测中,特别是在衡量内容与输入语义一致性的核心指标 CLIP-Score 上,Step1X-3D 取得了当前所有对比模型中的最高分,为开源社区提供了极具竞争力的 3D 生成方案。

不同 3D 模型测评对比数据
团队介绍
阶跃星辰 Step1X-3D 团队和光影幻像 LightIllusions 团队。阶跃星辰以实现 AGI为目标,规划了从单模态到多模态、再到多模理解与生成统一的技术路径,最终构建世界模型的大模型公司。光影焕像是一家专注于 3D AIGC 和空间智能技术的人工智能初创公司,公司致力于通过 AI 解放 3D 内容生产力。公司自设立之后便迅速建立了算法研发和产品落地并重的海内外人才梯队,拥有一批 3D AIGC 领域顶尖人才,迄今已经发表过多个 3D AIGC 代表性工作,汇集了来自港科大博士、字节、美团等具有顶级研发能力和丰富技术产品化经验的同学。 公司目前持续重点投入 3D 和空间智能相关的 AI 底层模型的研发,打造 3D 空间智能大脑,同时积极推进 3D 内容商业化落地。
官网:https://www.lightillusions.com/
#GRPO with Reward-Based Curriculum Sampling
泛化性暴涨47%!首个意图检测奖励范式,AI工具爆炸时代意图识别新解法
随着大模型(LLMs)的快速发展和可集成工具的爆炸增长,AI 智能助手在日常生活中可提供的便利越来越多,不仅包括传统任务型对话中订机票、查询天气等助理能力,还增加了无以计数的 AI 能力,如 AI 画图、解数学题、游戏攻略等。而 AI 智能助手准确理解用户的意图(Intent Detection)并路由至下游工具链是实现这些功能的第一步,其重要性不言而喻。
然而,工具的快速迭代、多样化、工具之间关系的复杂化也给意图识别带来新的挑战,即模型在应对新意图时普遍存在性能衰减问题。如何在开源的轻量级 LLMs 上训练泛化性更好、鲁棒性更强的意图识别模型,使得模型能够更准确理解未见场景的意图至关重要。
近日,腾讯 PCG 社交线的研究团队针对这一问题,采用强化学习(RL)训练方法,通过分组相对策略优化(Group Relative Policy Optimization, GRPO)算法,结合基于奖励的课程采样策略(Reward-based Curriculum Sampling, RCS),将其创新性地应用在意图识别任务上,显著提升模型在未知意图上的泛化能力,攻克了工具爆炸引发的意图泛化难题,推动大模型在意图识别任务上达到新高度。
- 论文标题:Improving Generalization in Intent Detection: GRPO with Reward-Based Curriculum Sampling
- 论文链接:https://www.arxiv.org/abs/2504.13592
基于强化学习的意图识别
该团队进行了大量实验,从不同维度深入剖析了 GRPO 算法在这一任务上的优势。该工作的贡献主要为以下四个方面:
1. 该团队证明了在意图检测问题上,通过强化学习(RL)训练的模型在泛化能力上显著优于通过监督微调(SFT)训练的模型,具体体现在对未见意图和跨语言能力的泛化性能大幅提升。值得一提的是除了完全新的未见意图,该工作还比较了对已知意图进行拆分、合并等实际产品场景会遇到的真实问题。
2. 该团队通过基于奖励的课程采样策略进一步增强了 GRPO 的训练效果,有效引导模型在训练过程中聚焦于更具挑战性的样例。
3. 在强化学习过程中引入思考(Thought),显著提升了模型在复杂意图检测任务中的泛化能力。这一发现表明,在更具挑战性的场景中,Thought 对于提升模型的泛化能力至关重要。
4. 该团队发现,在意图识别任务中,无论选择预训练模型(Pretrain)还是指令微(Instruct)调模型作为基础,经过相同轮次的 GRPO 训练后,两者性能相近。这一结果与传统训练经验有所不同。

训练方法
奖励函数
针对强化学习训练目标,该团队从格式奖励和准确率奖励两个维度进行引导:
![]()
其中
![]()
和
![]()
分别为各奖励分量的权重系数。
格式奖励
![]()
:基于提示模板的指令规范,严格约束模型输出格式。

准确率奖励
![]()
:基于意图检测准确率的二元奖励函数,从模型输出中提取预测意图
![]()
,并与真实标签
![]()
进行精确匹配:

基于奖励的课程采样
该团队采用课程学习的思路分两步对模型进行训练。
离线数据分类 该团队通过离线的方法对所有数据的难度进行了分类。具体过程中先进行一遍完整的 GRPO 方法,记录每条数据的 reward,根据每条数据的 reward 作为难度得分,如下公式所示:

其中 G 为采样总数。
课程采样 在课程学习过程中,第一阶段在所有数据上进行训练直到模型基本收敛;第二阶段筛选保留
![]()
的数据作为难样例进行训练。这一采样方法帮助模型在第二阶段更好的关注容易出错的难数据。
实验:RL 能够帮助模型理解任务而不是模仿任务识别
实验设置:
- 数据集:该团队在 TODAssistant(自建中文数据集)和 MultiWOZ2.2(公开英文数据集)两个基准上开展评测。MultiWOZ2.2 数据集是公开的 TOD 任务数据集,该研究团队在该数据集上提取出了意图分类这个任务。
- 模型选取:该团队选取 Qwen2.5-7B-Instruct 模型作为基座模型,分别对于 SFT 方法和 GRPO 方法训练相同 epoch 来对比模型性能。
- 评测指标:用正确率评测意图分类的准确性。
GRPO 方法与 SFT 方法的对比:研究团队首先对比了 SFT 方法和 GRPO 方法。直接使用原始的 GRPO 方法,在意图识别任务上,模型可以达到与 SFT 相近的性能,在英文的 MultiWOZ2.2 数据集上做到了与 SFT 模型相同的表现,证明了 GRPO 方法在该任务上的有效性。

为了进一步探究 GRPO 的优势,研究团队针对模型的泛化性进行了评测。具体来说,在 MultiWOZ 数据集上,在训练过程中分别去掉测试集中的每个类别;在 TODAssistant 数据集上对原有的类别进行组合和细分操作,获得新的类别,来验证模型在该新类别上的准确性;该团队还测试了模型的跨语言能力(在英文数据集上训练后的模型在中文测试集上的结果)。实验结果表明,GRPO 方法相较于 SFT 方法,有着更好的泛化性能。


RCS 方法实验结果:在此基础上,研究团队进一步应用 RCS 方法进行实验。结果表明,在课程学习的第一阶段,模型收敛到与原始 GRPO 方法相近的准确率;在第二阶段难样例筛选过程后,模型的准确率进一步提升。

该团队在课程学习第二阶段的采样过程中,对于难样例与正常训练数据的比例进行了实验,随机在其他训练数据中采样与难样例混合共同训练。结果表明,单独训练难样例取得了最好的效果。

Thought 对于训练过程的影响:研究团队还探究了在意图识别这种逻辑较为简单的任务上 Thought 对于结果的影响。该团队发现,在这类任务上 Thought 同样有着关键的作用:在 TODAssistant 数据上,Thought 对于泛化能力的提升尤为重要;在 MultiWOZ2.2 数据集上,去掉 Thought 后模型的性能出现了大幅下降。

Pretrain 模型和 Instruct 模型在该任务上的区别:研究团队发现,在意图识别任务上,选取 Pretrain 模型或者 Instruct 模型作为底座,在经过相同的 epoch 进行 GRPO 训练后,可以收敛到相近的性能,这与传统的训练经验有所不同。

同时该团队还发现,instruct 模型在宽松格式和严格格式奖励函数下的生成长度均保持稳定。然而,Pretrain 模型在宽松格式奖励下生成长度先下降后上升,而严格格式奖励下则无此趋势。值得注意的是,这种长度增加并未提供有效信息。这一对比表明,类似 R1 的强化学习训练会诱导模型通过增加输出长度来获取更高奖励,但在相对简单的意图检测任务中,真正的 「顿悟时刻」 难以出现。

未来展望
1. 在线数据筛选方法:现如今该团队的 RCS 数据筛选方法仍然是离线的,在后续的工作中将探索更高效的在线筛选方法。
2. 多意图识别:该研究团队针对意图识别的实验目前主要针对单意图场景,在后续工作中将继续探索多意图的识别。
3. 任务型对话相关任务扩展:目前该团队的实验都是在意图识别任务上进行,在未来的工作中将继续在更复杂的任务型对话相关任务上进行尝试。
#Controlling Light Sources in Images with Diffusion Models
谷歌用扩散模型,将电影级光影控制玩到极致一键开关灯!
最近,Google 推出了一个可以精准控制画面中光影的项目 —— LightLab。
它让用户能够从单张图像实现对光源的细粒度参数化控制, 可以改变可见光源的强度和颜色、环境光的强度,并且能够将虚拟光源插入场景中。
LightLab: Controlling Light Sources in Images with Diffusion Models
论文地址:https://arxiv.org/abs/2505.09608
项目主页:https://nadmag.github.io/LightLab/
HuggingFace:https://huggingface.co/papers/2505.09608
在图像或影视创作中,光线是灵魂,它决定了画面的焦点、景深、色彩乃至情绪。
以电影为例, 好的电影中,光线能巧妙地塑造角色情绪、烘托故事氛围、引导观众目光,甚至能揭示人物的内心世界。

然而,无论是传统的摄影后期处理,还是数字渲染后的调整,精确控制光影方向、颜色和强度,始终是一项耗时耗力、且极依赖经验的挑战。
现有的光照编辑技术,要么需要很多照片才能工作(不适用于单张照片),要么虽然能编辑,但你不能精确地告诉它怎么变(比如具体亮多少、变成什么颜色)。
Google 的研究团队通过在一个特殊构建的数据集上微调(fine-tune)扩散模型,使其学会如何精确地控制图像中的光照。

为了构建这个用于训练的数据集,研究团队结合了两种来源:一部分是少量真实的、带有受控光照变化的原始照片对;另一部分是利用物理渲染器生成的大规模合成渲染图像。
更进一步,研究人员巧妙地利用了「光的线性特性」(linearity of light),从这些图像数据中分离出目标光源和环境光。基于此,他们能够合成出大量描绘不同光照强度和颜色变化的图像对,这些图像对参数化地表示了受控的光影变化。
扩散模型通过学习这些高质量的成对示例,获得了强大的「逼真光影先验能力」(photorealistic prior)。这使得模型能够在图像空间中直接、隐式地模拟出复杂的照明效果,比如间接照明、阴影和反射等。
最终,利用这些数据和恰当的微调方案,训练出的 LightLab 模型能够实现精确的照明变化控制,并提供对光照强度和色彩等参数的明确控制能力。
,时长02:29
LightLab 提供了一套丰富的光照控制功能,这些功能可以依次使用,从而创建复杂的光照效果。你可以通过移动滑块来调整每个光源的强度和颜色。

方法
研究团队的方法是使用成对图像来隐式建模图像空间中的受控光变化,这些变化用于训练扩散模型。

后处理流程
对于真实(原始)照片对,研究团队首先分离出目标光源的变化。对于合成数据,研究团队分别渲染每个光源组件。这些分离的组件随后会被缩放并组合,以在线性颜色空间中创建参数化的图像序列。
研究团队既采用了一致的序列色调映射策略,也对每个图像单独进行色调映射,将其转换为标准动态范围(SDR)。

条件信号
研究团队为局部空间信号和全局控制信号使用了不同的条件方案。空间条件包括输入图像、输入图像的深度图,以及两个空间分割掩码,分别用于目标光源的强度变化和颜色。
全局控制(环境光强度和色调映射策略)被投影到文本嵌入维度,并通过交叉注意力机制插入。
数据集摄影捕捉
研究团队使用现成的移动设备、三脚架和触发设备捕捉了一组 600 对原始照片。每对照片描绘相同的场景,唯一的物理变化是打开一个可见光源。
为了确保捕捉到的图像曝光良好,研究团队使用每个设备的默认自动曝光设置,并在后期捕捉时利用原始图像的元数据进行校准。
该数据集提供了几何形状、材料外观和复杂光现象的详细信息,这些信息在合成渲染数据中可能无法找到。遵循之前的研究,研究团队将「off image」视为环境光照,i_ amb: = i_off,并从目标光源中提取光照:i_change = i_on − i_off。
由于捕获的噪声、后期校准过程中的误差或两幅图像之间环境光照条件的细微差异,这个差异可能会有负值。
为了避免因此产生的意外暗淡,研究团队将差异裁剪为非负值:

。
再结合真实数据有助于将预期的照明变化与合成渲染图像的风格区分开来,这些图像不包括真实物理相机传感器引入的视觉伪影,例如镜头畸变或色差等等。
在后处理中,将每对真实图像的数量增加 60 倍,以涵盖一系列强度和颜色。后处理后,完整的数据集大约包含 36K 张图像。
实验
1、 实现细节
模型和训练:研究团队对一个文本到图像的潜在扩散模型进行微调,其架构布局和隐藏维度与 Stable Diffusion-XL 相同,研究团队在 1024 × 1024 分辨率下训练每个模型 45,000 步,学习率为 10−5,批量大小为 128。训练大约需要 12 小时,使用 64 个 v4 TPU。在训练期间,研究团队有 10% 的时间丢弃深度和颜色条件,以允许无条件推理。
评估数据集:为了进行定量消融和比较,研究团队描述的程序策划的成对数据集上评估训练有素的模型。真实照片数据集包含 200 对不同场景和光源的照片,这些照片在后处理期间被扩展了 60 倍。合成评估数据集包括从两个保留场景中渲染的图像,这些场景包含独特的光源、对象和材质。对于定性评估,不需要真实目标,研究团队收集了 100 张图像。对于这些图像,研究团队手动注释了每张图像中的目标光源,并计算了它们各自的分割掩码和深度。在整个评估过程中以及生成论文中的所有结果时,色调映射条件被设置为 “一起”,除非另有说明。
评估指标:研究团队使用两个常见指标:峰值信噪比(PSNR)和结构相似性指数度量(SSIM)来衡量模型在成对图像上的性能。此外,研究团队通过进行用户研究来验证这些结果是否与用户偏好一致,以与其他方法进行比较。
2、不同域的影响
跨域泛化:研究团队观察到,仅在合成渲染数据上训练的模型无法很好地泛化到真实图像。团队将这种泛化误差归因于风格上的差异,例如缺乏复杂的几何形状、纹理和材质的保真度以及在合成数据集中不存在的相机伪影,如眩光。
使用多个域:研究团队使用相同的程序在三种数据域的混合上训练三个模型:仅真实捕获、仅合成渲染以及它们的加权混合。表 1 中的结果表明,使用来自两个域的数据混合取得了最佳结果。
值得注意的是,研究团队观察到混合数据集与仅真实捕获之间存在很小的定量相对差异,尽管它们的大小差异显著。例如,添加合成数据仅在平均 PSNR 中带来了 2.2% 的改进。
这可能是由于图像范围内的低频细节掩盖了可感知的局部照明变化,例如小实例阴影和镜面反射。研究团队通过定性比较来证实这种效果,这些比较表明添加合成数据鼓励模型产生仅在真实模型中不存在的复杂局部阴影。

3、 比较
研究团队的方法是第一个提供对真实单图像中光源的细粒度控制的方法。因此,为了进行公平的比较,当与其他工作进行比较时,研究团队仅在二元任务上进行评估。
作为基线,研究团队调整了四种基于扩散的编辑方法:OmniGen 、RGB ↔ X 、ScribbleLight 和 IC-Light 。这些方法使用描述光源位置和输入图像中其他场景内在属性的文本提示。
RGB ↔ X 模型以输入图像的多个预计算法线、反照率、粗糙度和金属度图为条件。ScribbleLight 接收反照率和一个指示光源开关位置的掩码层(与研究团队方法中的光源掩码相反)。最后,为了使用 IC-Light 控制光源,研究团队将整个图像作为前景输入,并提供研究团队的光源分割掩码作为环境光源条件。

从表 2 可以看出,研究团队的方法显著优于先前的方法。值得注意的是,OmniGen 未能打开 / 关闭目标光源,并引入了局部几何变化。RGB ↔ X、ScribbleLight 和 IC-Light 可以成功地改变输入照明条件,但通常会导致额外的不想要的照明变化或颜色失真。与先前的工作相比,研究团队的方法忠实地控制目标光源,并生成物理上合理的照明。
应用
研究团队介绍了该方法在各种设置中的几种可能应用,主要的应用是能够对照片进行后捕获的光源控制。
光强度

Lightswitch 提供了对光源强度的参数化控制。请注意,不同强度下的光现象保持一致,从而实现交互式编辑。
颜色控制
研究团队的方法可以根据用户输入创建彩色照明。使用彩色滑块来调整光源的颜色。
虚拟点光源

通过从合成的 3D 渲染中转移知识,LightLab 可以将虚拟点光源(没有几何形状)插入到场景中。点击圆圈来点亮一个点。
Nex 环境光

将目标光源与环境光分离,使得研究团队能够控制通过窗户进入的光线,这种光线在物理上很难被控制。
物理上合理的光照
左侧:输入序列是通过拍摄围绕多边形狗旋转的熄灭的台灯的照片创建的。中间、右侧:研究团队方法的推断结果以及对狗的放大图。请注意,不同面上的自遮挡以及狗的阴影与台灯的位置和角度相匹配。
#Manus
刚刚,Manus生图功能强势登场!从设计到搭建网站一站式搞定,1000积分免费薅
那个曾经一码难求的 Manus 已经可以全面注册了。从此以后,到处求购邀请码的时代一去不复回。
首次注册就送「1000 积分」让你尝尝鲜!

不得不说,Manus 这次真是豪气了一回,大家赶紧去薅羊毛。
就在今天,Manus 又宣布了另一个好消息,推出图像生成功能。
这里要强调一下,Manus 不只是生成图像,它能理解用户意图,规划解决方案,并知道如何有效地调用图像生成工具以及其他工具来完成你的任务。

,时长01:20
既然免费用,我们当然不能错过这个好机会,立马来了一波体验测试。
Manus 生图功能到底咋样?
输入提示:「我想创建一个名为 CoLe 的瓶装茶饮料品牌,倡导青少年健康的生活方式。请根据你对饮料市场流行视觉风格的理解,设计一个瓶子。」

我们先看结果(如下图所示),大家觉得怎么样?

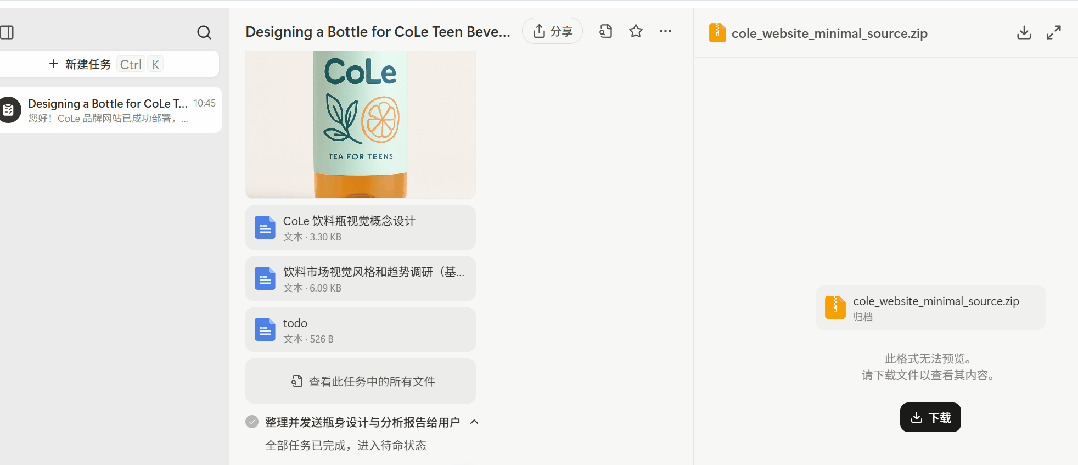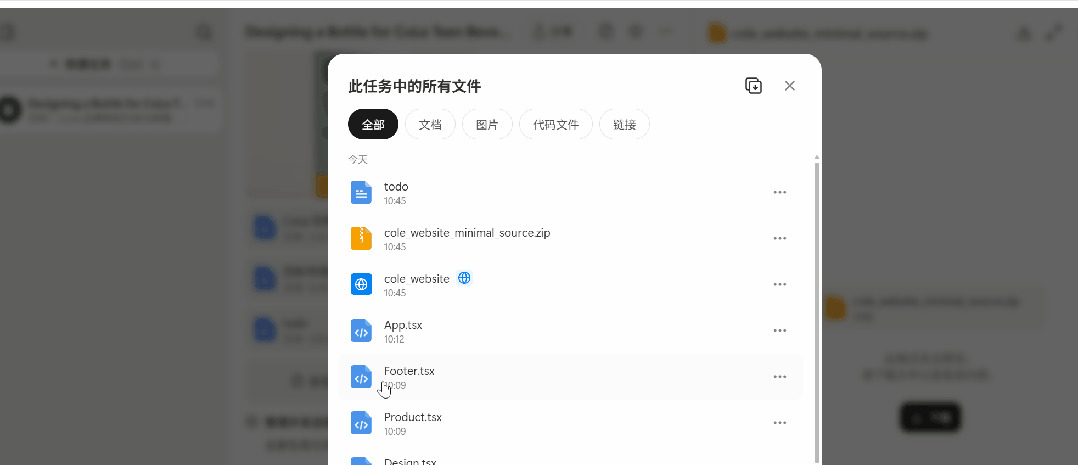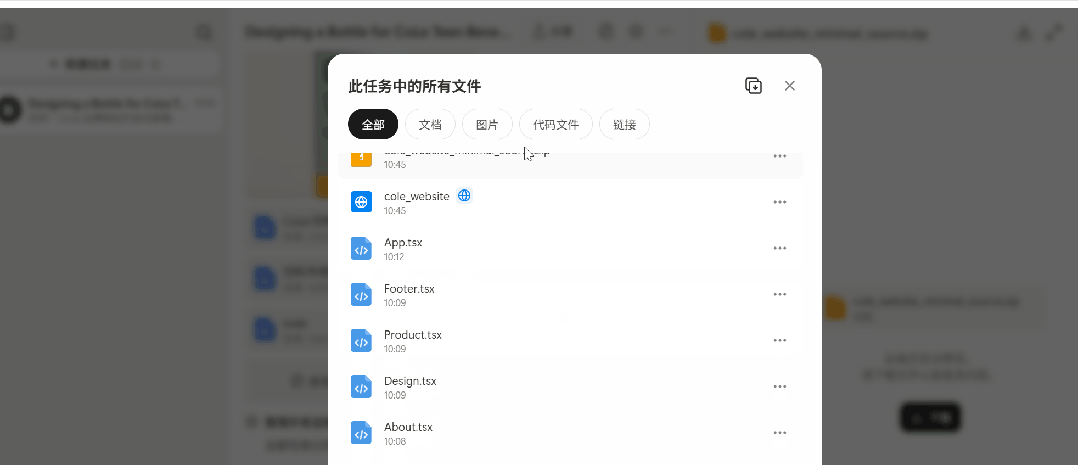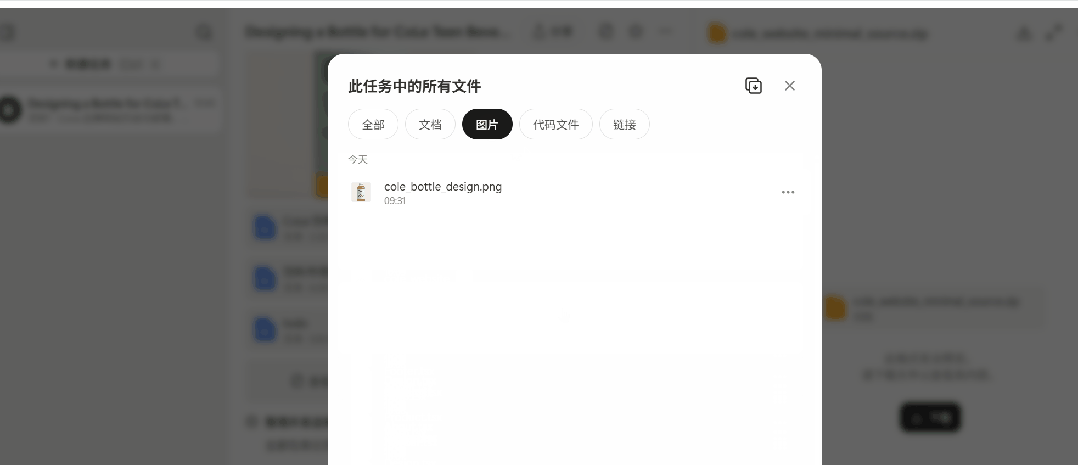
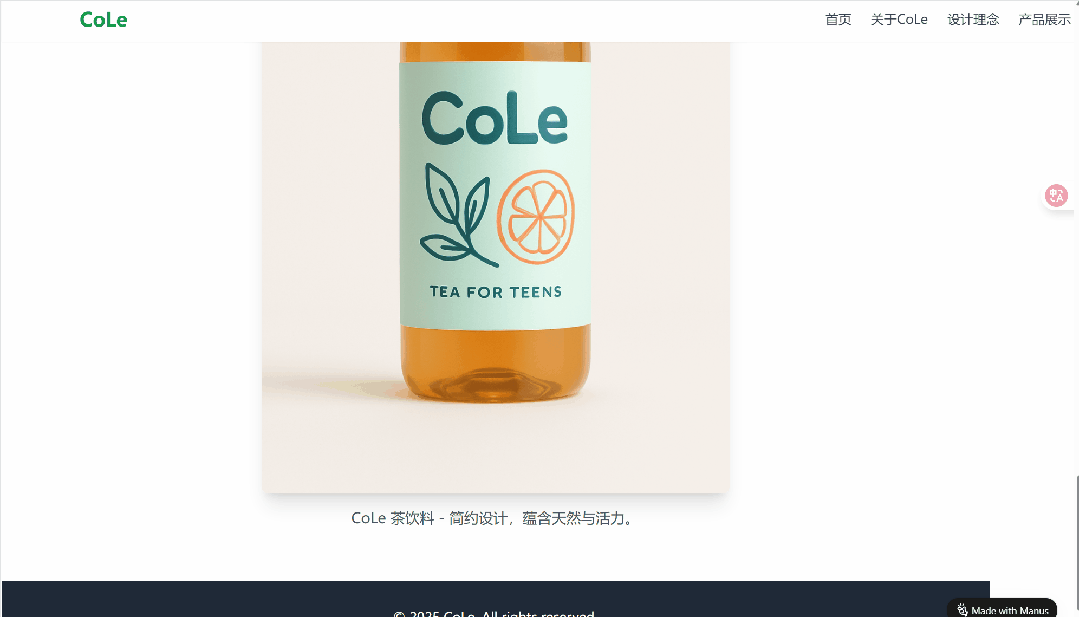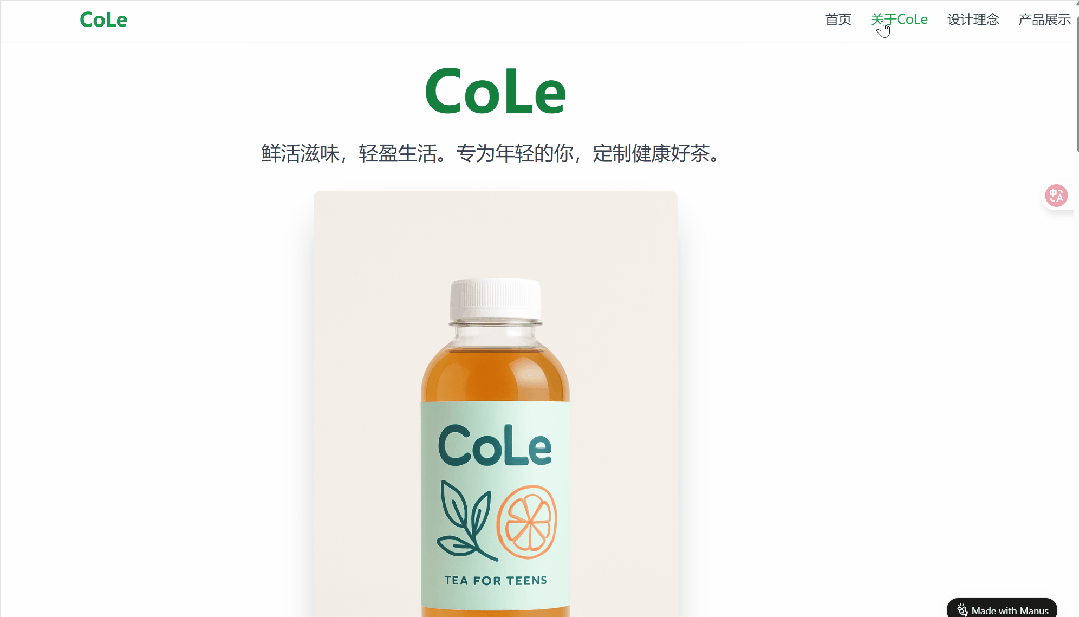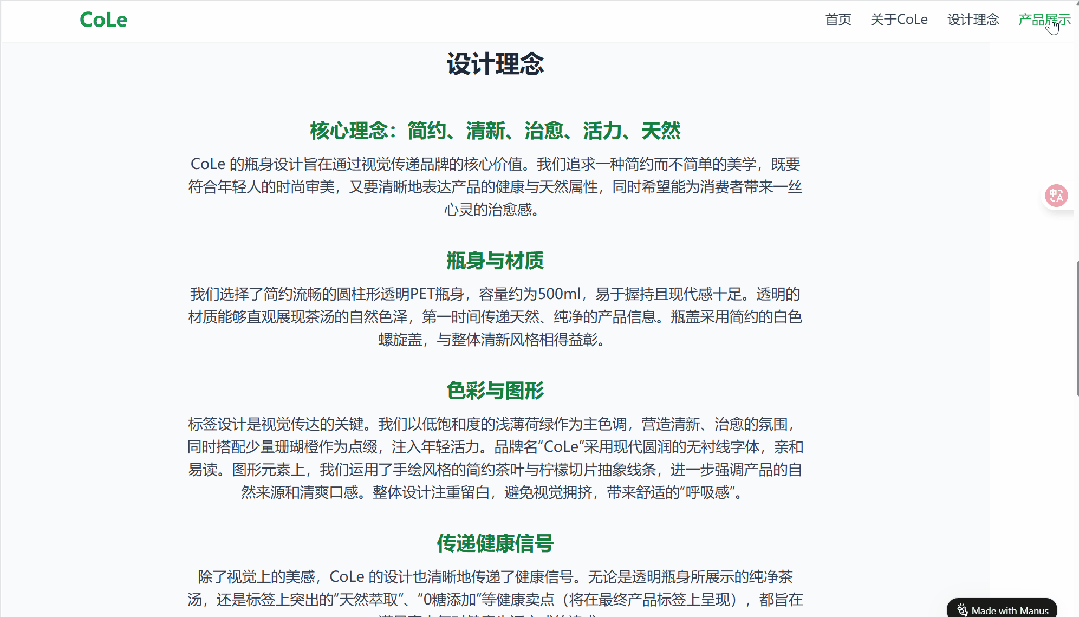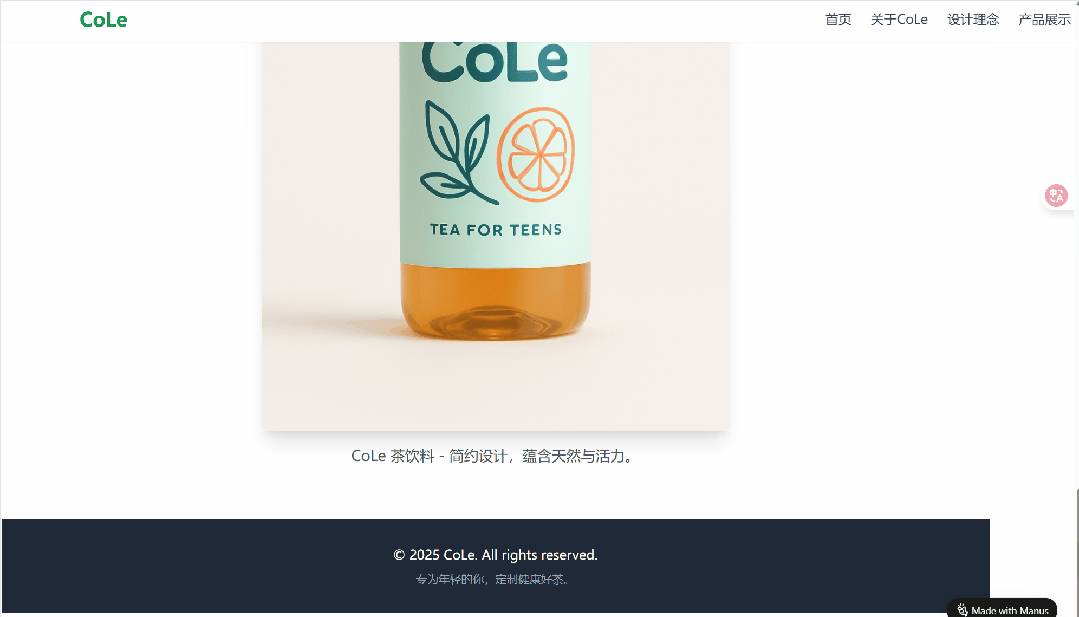
细细研究下来,我们发现这张图还蛮符合要求的:瓶身带有 CoLe 品牌名,下方有「TEA FOR TEENS」的字样,表明这款饮料是专为青少年设计的茶饮料。瓶身配色为浅绿色和橙色,给人一种清新、活力的感觉。还有一片叶子和一片橙子的图案,这可能暗示了饮料的口味或成分等。
不得不说,这已经是一款「成熟」的饮料了。
接下来,我们看它的思考过程:
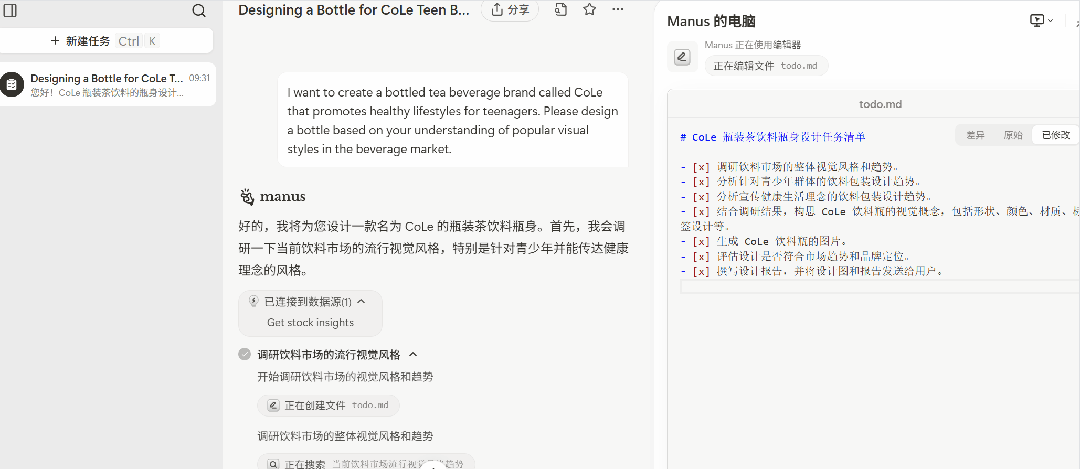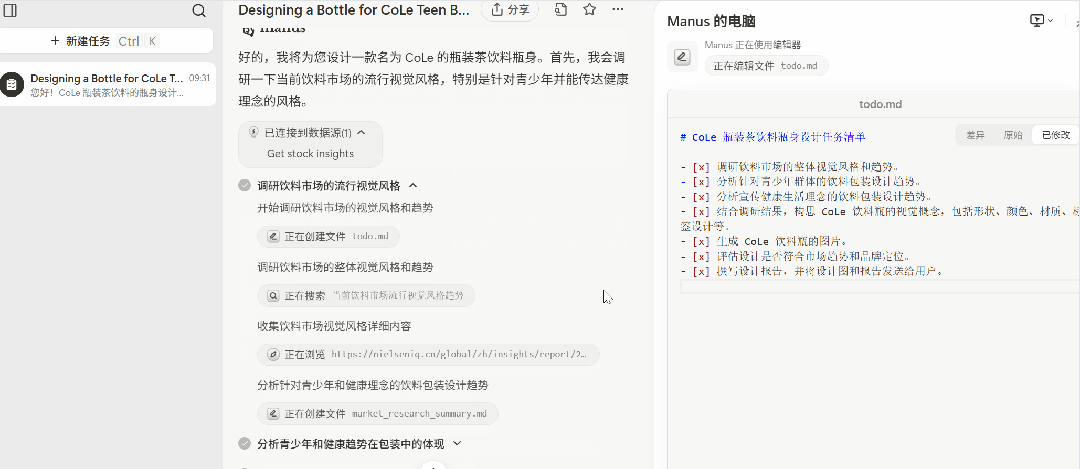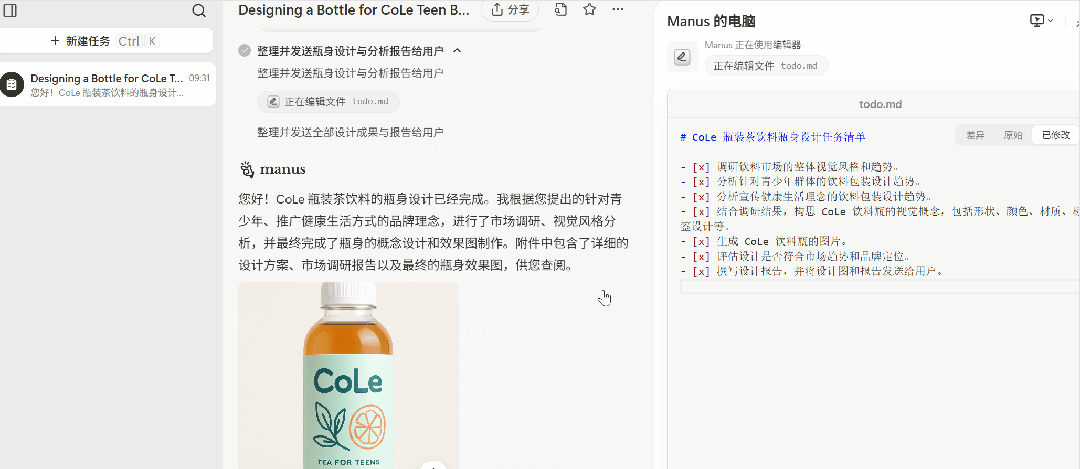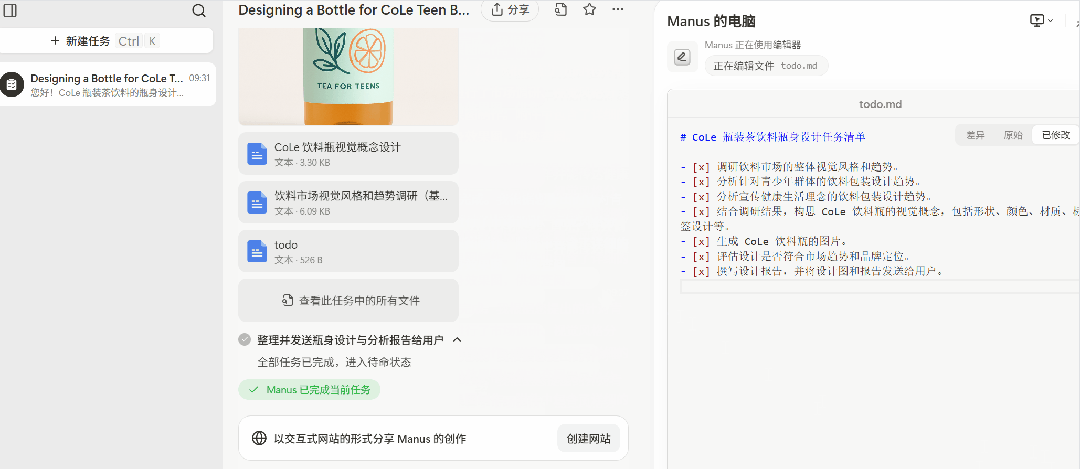
其实,在 Manus 工作过程中,你可以随时发送修改任务,补充信息、或者叫停当前工作。你也可以放心的离开此页面,Manus 工作完成后会通知你。

最后还有报告生成。

关于这项任务的所有文件,最后都会进行汇总:
但当我们继续下一项任务,「将自己的创作转变为网站并永久部署」时,几乎半个小时了,还没创建好。

大约半个小时,Manus 终于成功部署了 CoLe 品牌网站。

网站看起来还可以,虽然有点简单,但该有的信息都有了,况且这是 Manus 自动生成的。
附件中还有源代码包,完成任务的清单。
再比如,我们让 Manus 美化两张图片,要求时尚风格、真实场景背景展示:
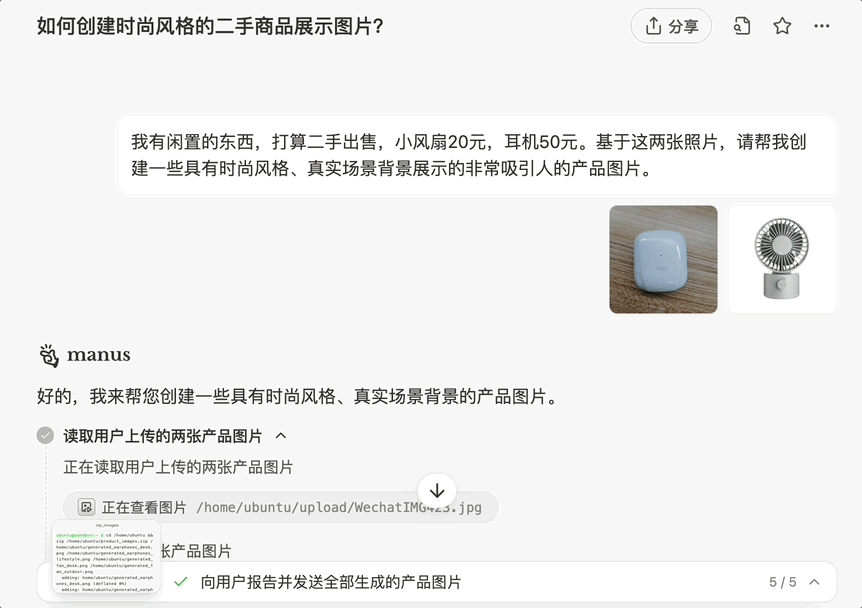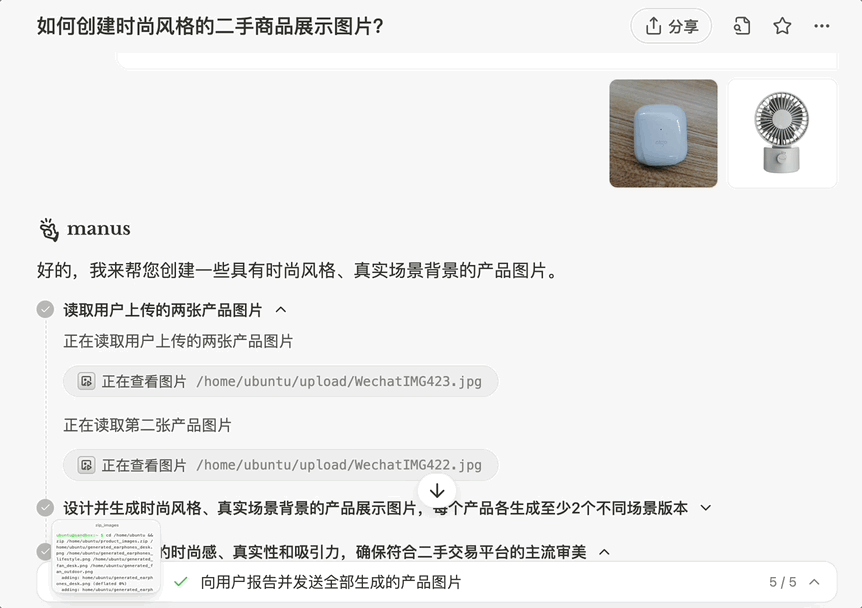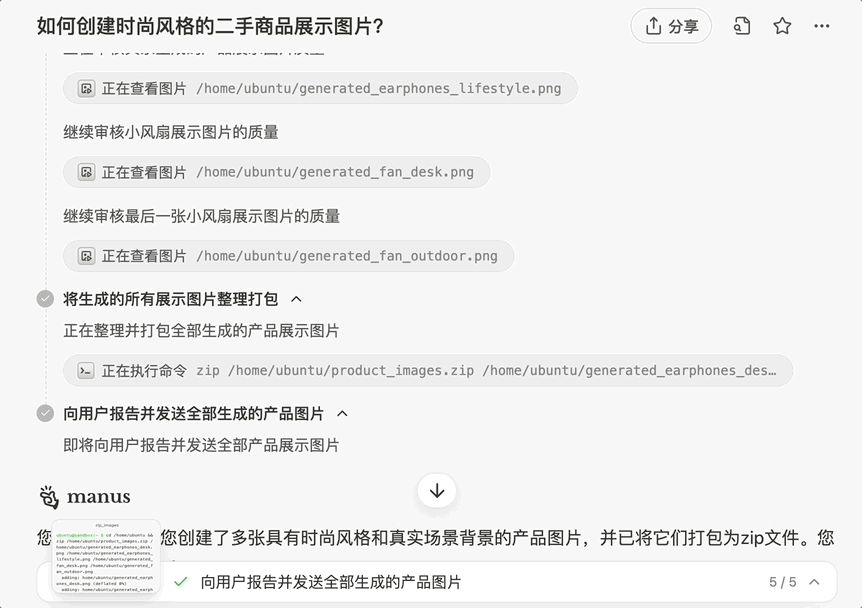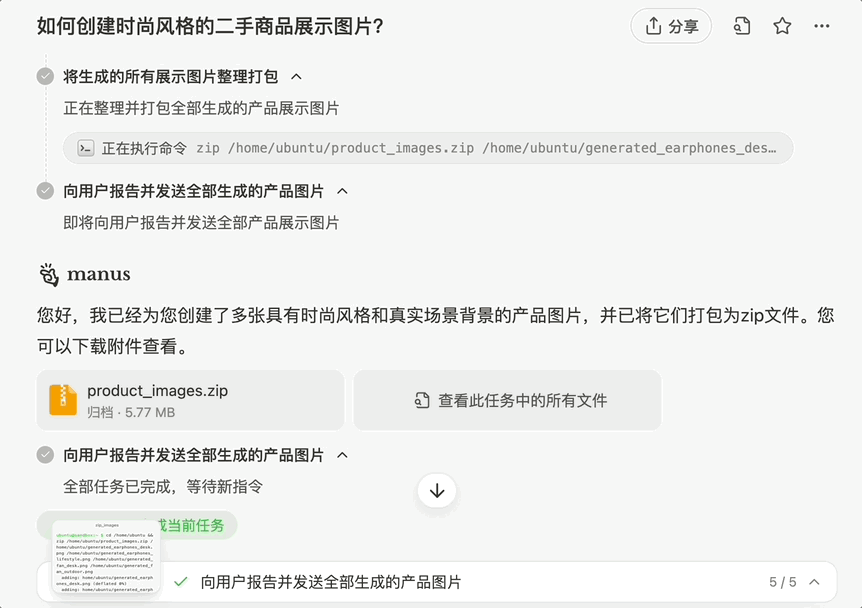
生成的图片符合预期,与背景的融入可以说是「浑然天成」:


同样地,我们继续让 Manus 创建售卖这两个小物件的网站,结果如下:

其他更多生成的图片,「男女野外露营」:

「一张可爱的大肥猫,猫在小木屋里。」

「小猫小狗捉小老鼠。」

体验心得与网友反馈
一番体验下来,我们发现,Manus 图像生成效果还是不错的,无论是整体画面构造还是细节处理。
并且,在图像生成过程中嵌入智能体工作流以及将意图理解与图像生成相结合都是非常不错的想法。


不过仍有需要改进的地方,除了生图较快之外,其他任务(创建部署网站)运行速度较慢,需要几分钟乃至十几分钟。类似的反馈不在少数。


大家也很好奇 Manus 使用的是谁家的文生图模型。

#Codex
刚刚,OpenAI最强编程智能体上线ChatGPT
从编程开始,今年智能体要卷飞了!!!
昨天,OpenAI CEO 奥特曼预告了一项新研究,吊足了所有人的胃口。

就在刚刚,谜底揭晓!OpenAI 宣布,在 ChatGPT 中引入了 Codex 的研究预览版。
Codex 是一个云端软件工程智能体,可以并行处理多项任务,包括编写功能、解答代码库相关问题、修复 bug 以及提交拉取请求以供审核等。并且,每个任务都在其专属的云沙盒环境中运行,并预加载代码库。

Codex 背后的模型是 codex-1,它是 OpenAI o3 的一个版本,专门针对软件工程进行了优化。它使用强化学习在各种环境中针对真实编程任务进行训练,生成的代码能够高度反映人类的风格和 PR 偏好,精确遵循指令,并可以迭代运行测试,直到获得合格结果。
自今天开始,ChatGPT Pro、Team 和 Enterprise 用户即可使用 Codex,Plus 和 Edu 用户也很快可以上线使用。

对于 OpenAI 的新智能体产品,大家的反应似乎非常兴奋。有人表示自己被震撼到了,迫不及待想要体验一番。十年前学习编程时,绝对想不到这会成为可能。

也有人认为,Codex 这个云原生的智能体实际上可以自行构建、修复并交付功能,感觉就像软件开始了大规模自我编写。

还有人现身说法,在经过对 Codex 大量测试后发现,当它正常运作时,几乎更擅长「模拟」代码正在做什么以及看起来是什么样子。

接下来,我们先看一下官方示例,Codex 可以并行处理多项任务:

比如要求 Codex「找出尽可能多的 topos 和语法错误并进行修复」,它会检查代码库的可维护性和 bugs:
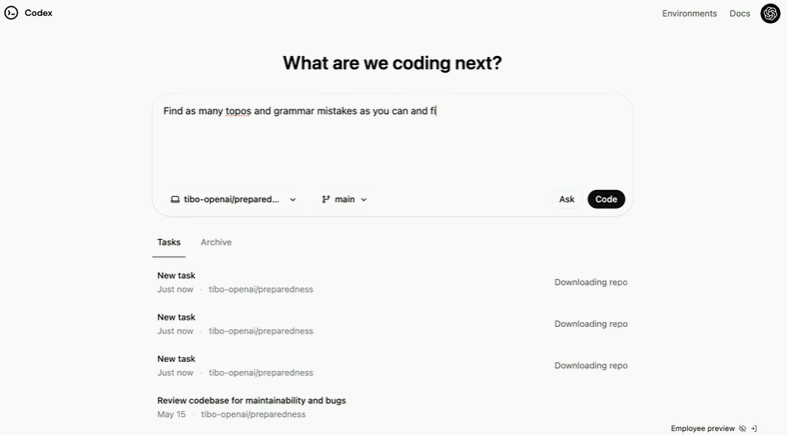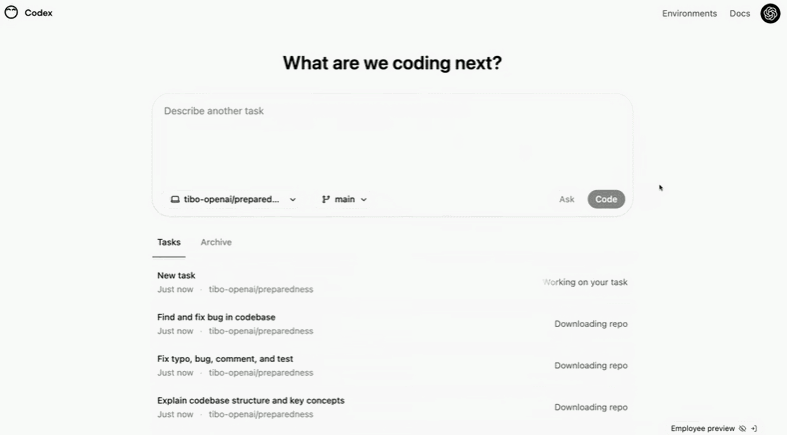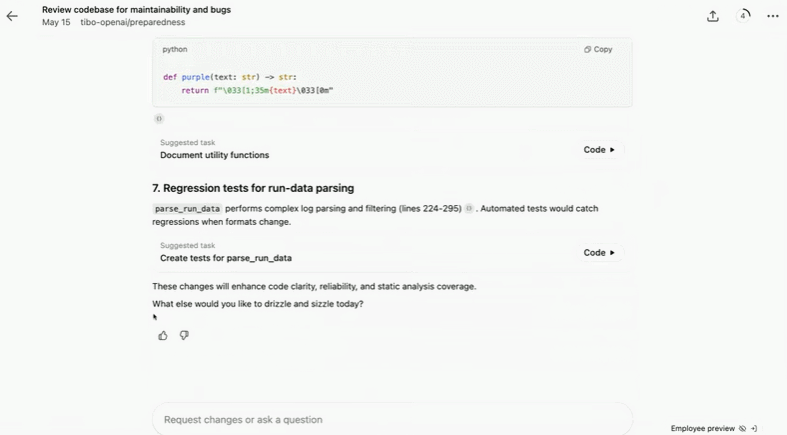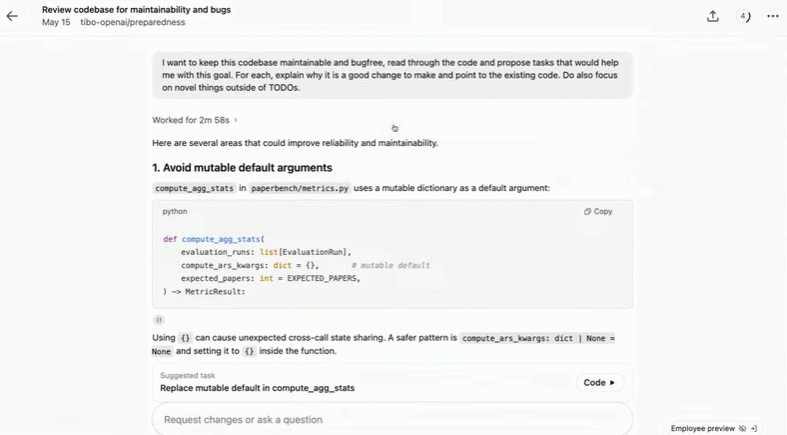
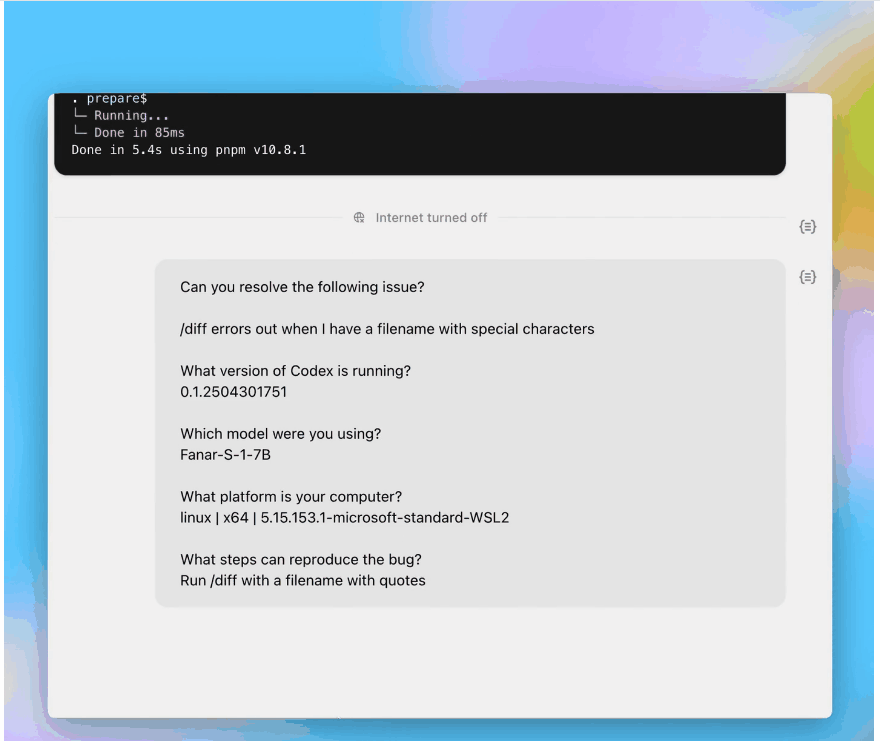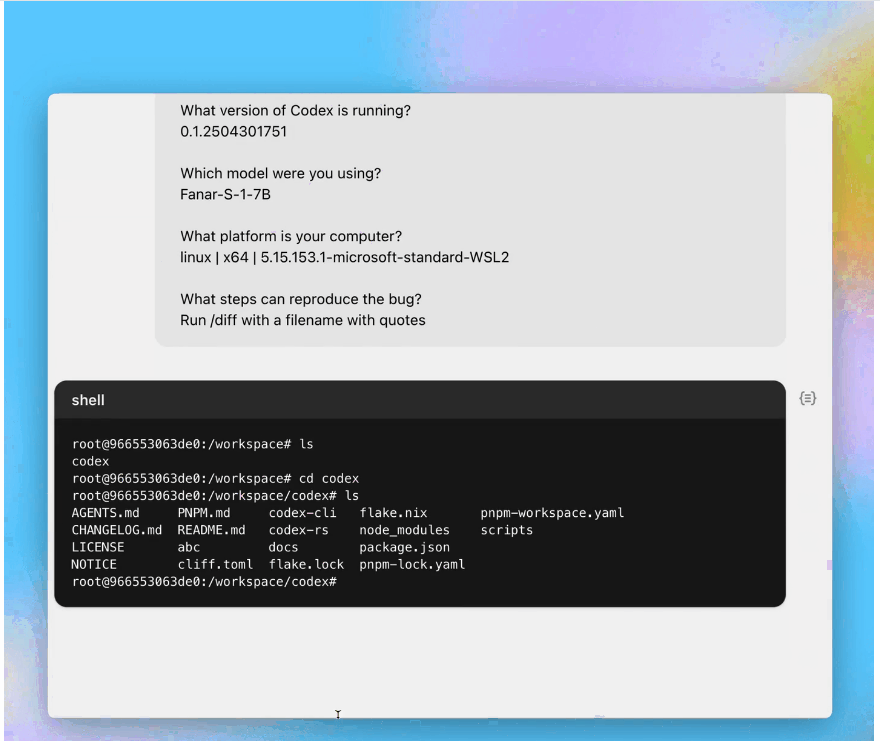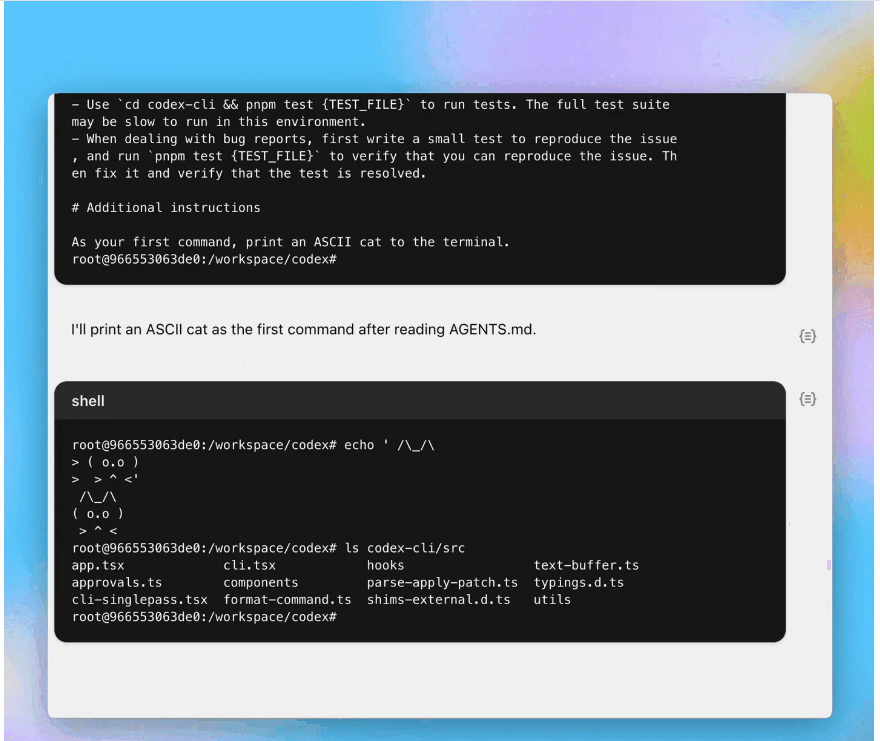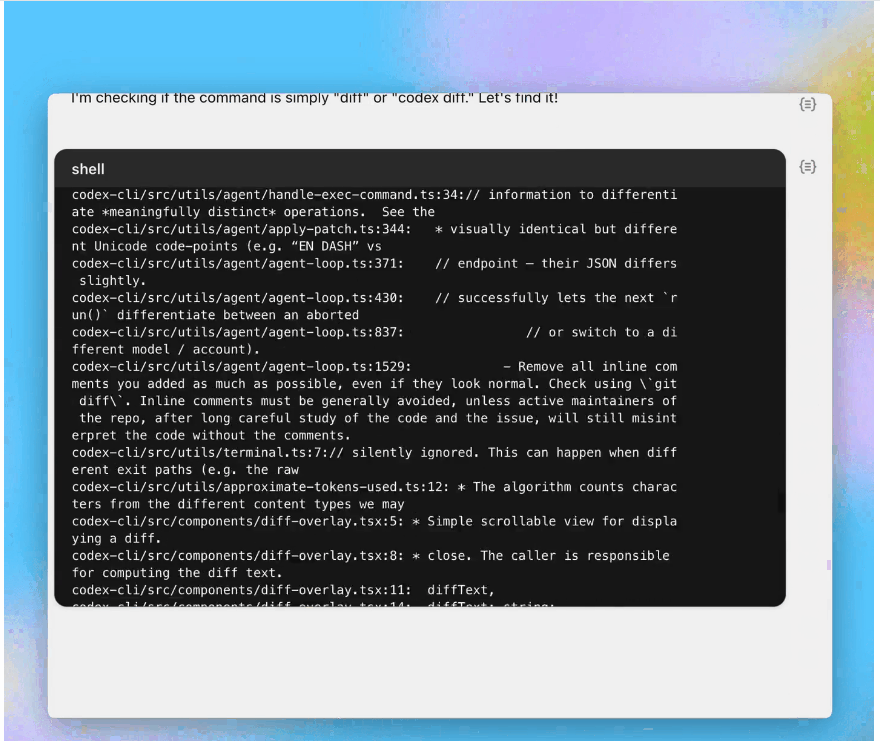
修复文件名中含有特殊字符的 /diff 错误:
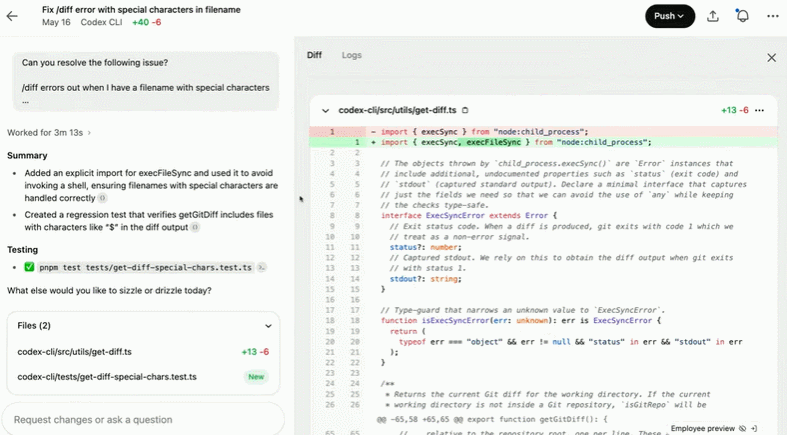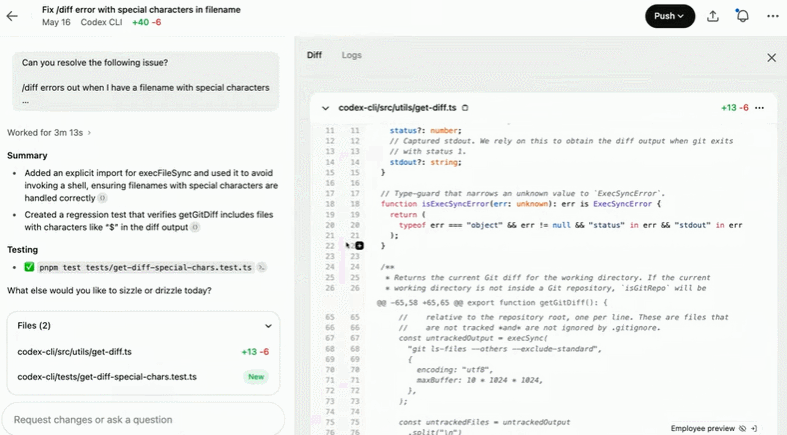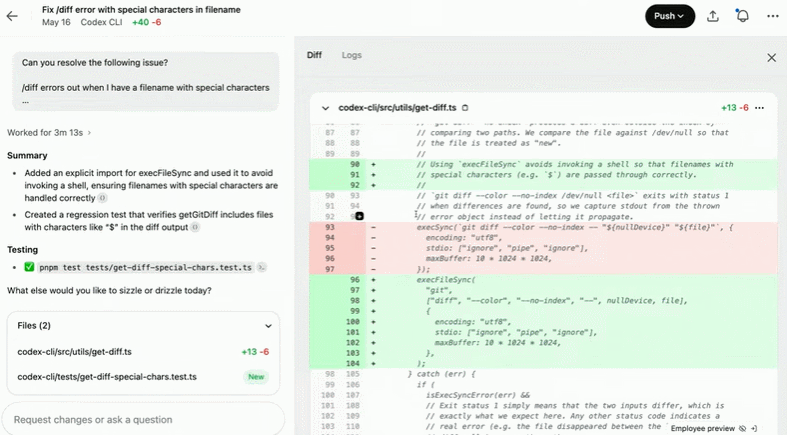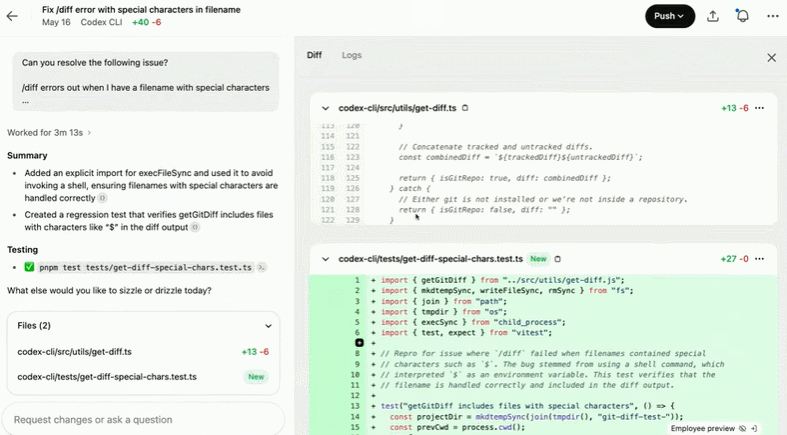
创建并使用 DEFAULT_ALCATRAZ_TIMEOUT 常量:
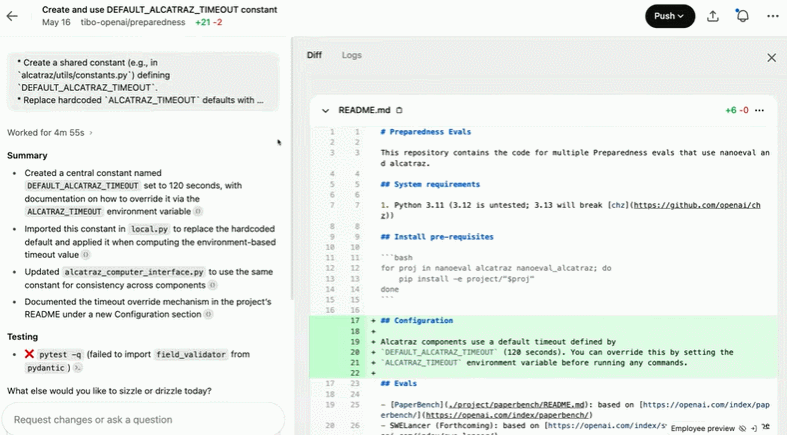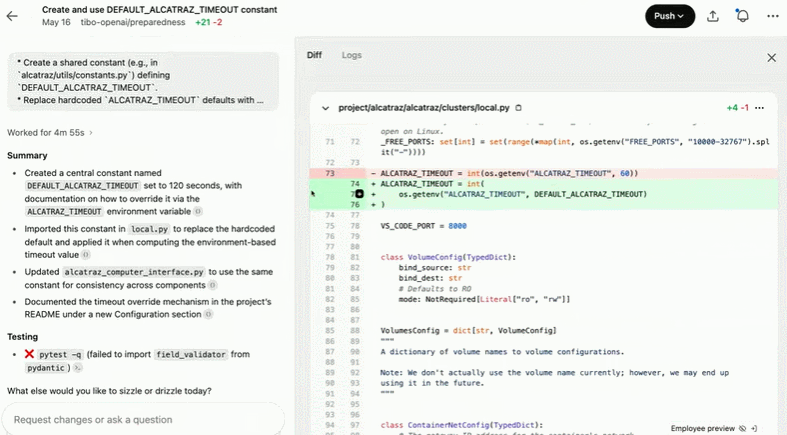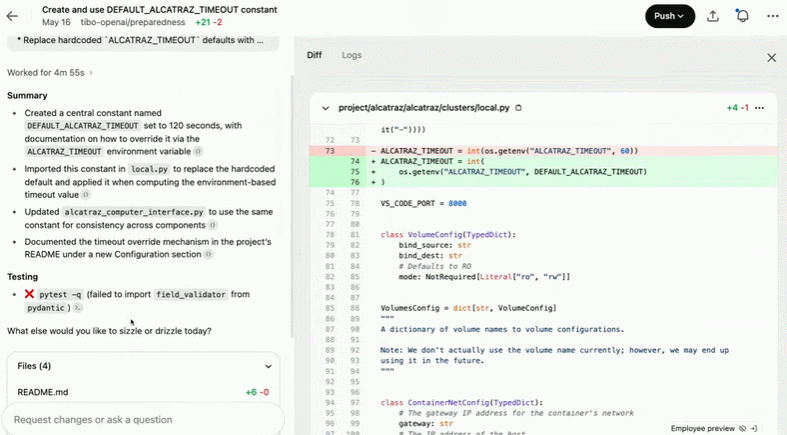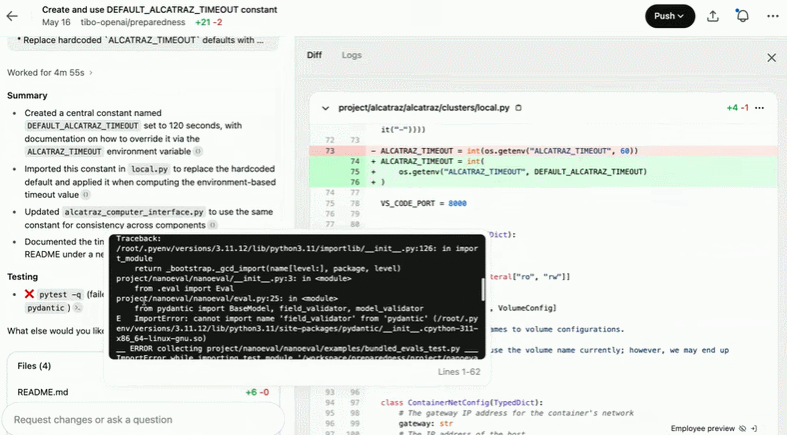
Codex 工作原理
从今天开始,用户可以通过 ChatGPT 侧边栏访问 Codex,输入 prompt 并点击 "编写代码" 按钮即可执行新的编程任务。
若需针对代码库提问,可点击 "Ask"。每项任务均在独立隔离的环境中处理,该环境已预加载用户的代码库。Codex 具备读写文件的能力,并可运行包括测试框架、代码检查器和类型检查器在内的各类命令。任务完成时间通常为 1 至 30 分钟(视复杂度而定),用户可实时查看 Codex 的处理进度。
任务完成后,Codex 会将其修改提交至专属环境。通过终端日志引用和测试输出记录,Codex 为所有操作提供可验证的证据链,便于用户追溯任务执行全过程。用户还可审阅结果、要求进一步修改、创建 GitHub 拉取请求或直接将变更集成至本地环境。在产品中,用户可将 Codex 环境配置为无限接近实际开发环境。
Codex 可遵循代码库中的 AGENTS.md 文件执行操作。这类文本文件(类似 README.md)用于指导 Codex 如何浏览代码库、运行哪些测试命令,以及如何遵循项目标准规范。与人类开发者类似,当获得配置好的开发环境、可靠的测试方案和清晰的文档时,Codex 智能体能发挥最佳效能。
在编码评估和内部基准测试中,即便没有 AGENTS.md 文件或定制脚手架,codex-1 也展现出强劲性能。

构建安全可靠的智能体
在设计 Codex 时,OpenAI 优先考虑安全性和透明度,以便用户能够验证其输出。用户可以通过引用、终端日志和测试结果来检查 Codex 的工作。


与 o3 相比,codex-1 始终能够生成更清晰的 patch,以便立即进行人工审核并集成到标准工作流程中。

Codex 与 o3 对比:

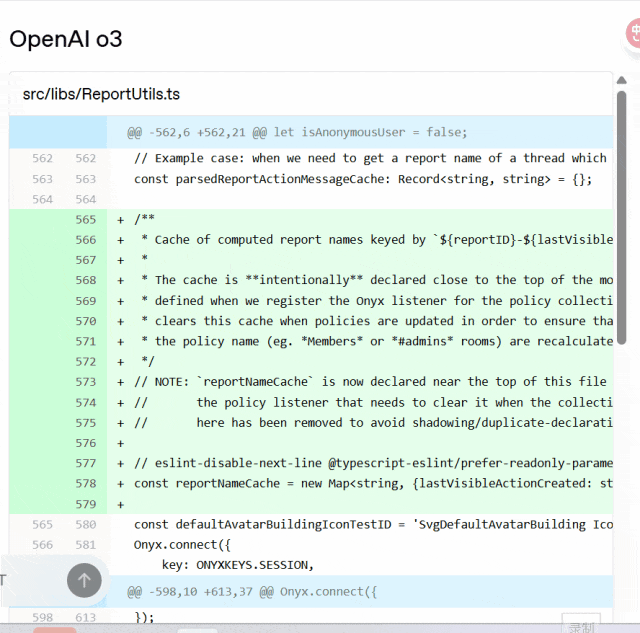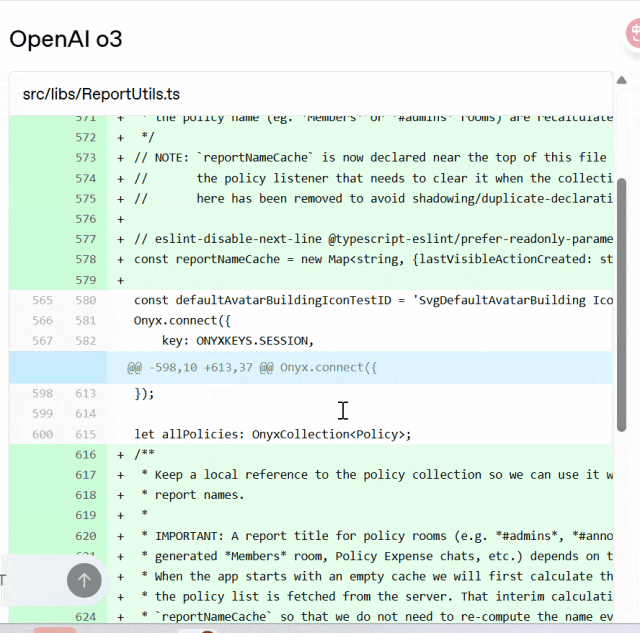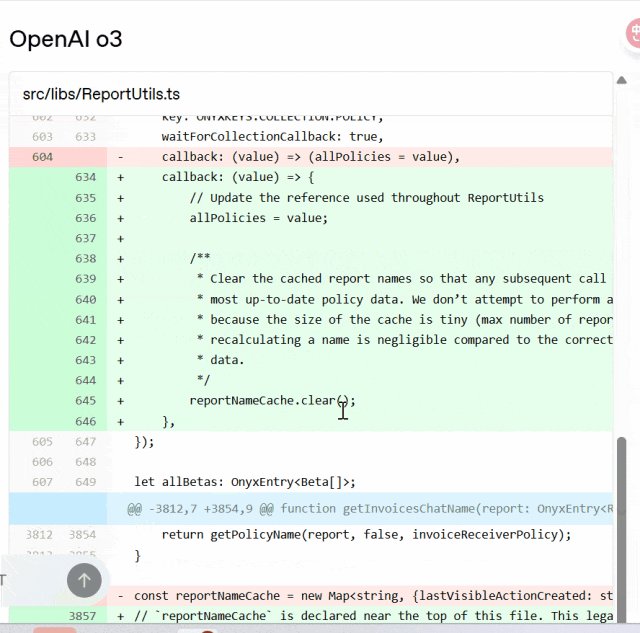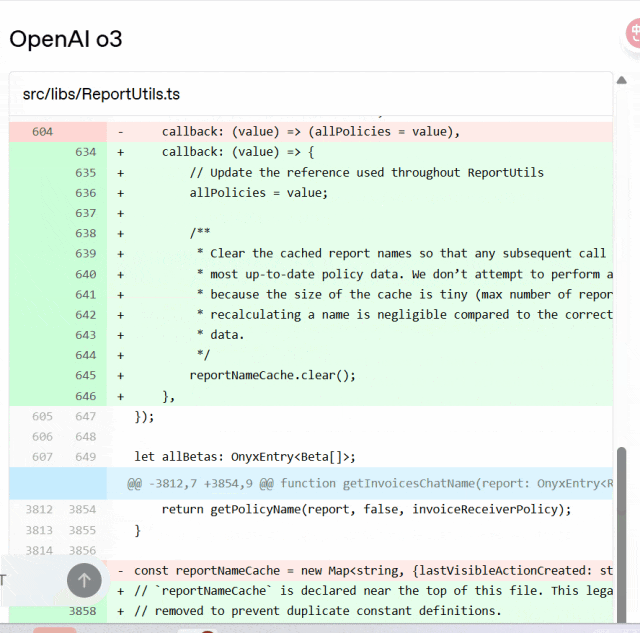
OpenAI 表示,Codex 智能体完全运行于云端的安全隔离容器中。任务执行期间将禁用互联网访问,确保智能体仅能交互以下内容:通过 GitHub 仓库明确提供的代码、用户通过设置脚本配置的预安装依赖项以及该智能体无法访问任何外部网站、API 或其他服务。
Codex 定价如何?
Codex 用起来贵不贵?
OpenAI 表,从今天开始,将向全球范围内的 ChatGPT Pro、Enterprise 和 Team 用户开放 Codex。在接下来的几周内,用户可以免费畅享 Codex,探索它的各项功能。此后,他们将推出限速访问和灵活的按需付费选项,供用户购买额外使用量。
对于使用 codex-mini-latest 进行开发的用户,该模型可通过 Responses API 调用,定价为:
- 输入 tokens:每 100 万 $1.50
- 输出 tokens:每 100 万 $6
此外,OpenAI 表示,Codex 仍处于早期开发阶段。作为研究预览版,它目前尚不具备某些功能,例如:前端工作所需的图像输入支持,在 Codex 运行过程中实时调整智能体的能力。
此外,远程智能体的执行速度比交互式编辑慢,这可能需要一定的适应时间。不过,随着时间推移,与 Codex 智能体的协作将越来越像与同事的异步协作。
最后 OpenAI 表示,未来计划推出更具交互性和灵活性的智能体工作流。
未来,编程也许真会变的越来越简单。
参考链接:https://openai.com/index/introducing-codex/
#FastVLM
85倍速度碾压:苹果开源,能在iphone直接运行的视觉语言模型
FastVLM—— 让苹果手机拥有极速视觉理解能力
当你用苹果手机随手拍图问 AI:「这是什么?」,背后的 FastVLM 模型正在默默解码。
最近,苹果开源了一个能在 iPhone 上直接运行的高效视觉语言模型 ——FastVLM(Fast Vision Language Model)。

- 代码链接:https://github.com/apple/ml-fastvlm
代码仓库中还包括一个基于 MLX 框架的 iOS/macOS 演示应用,优化了在苹果设备上的运行性能。
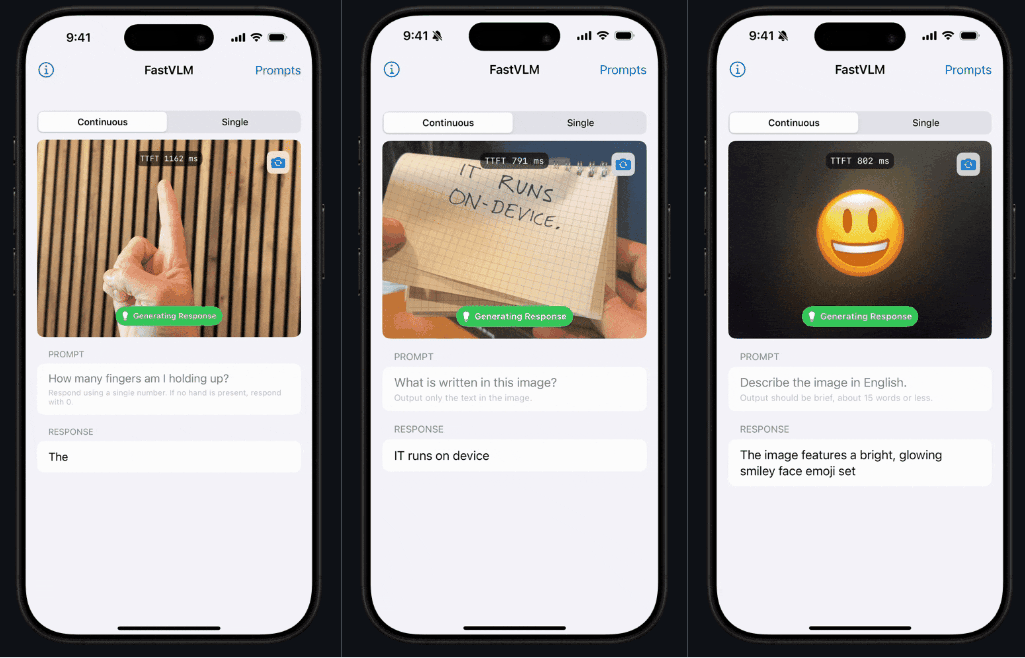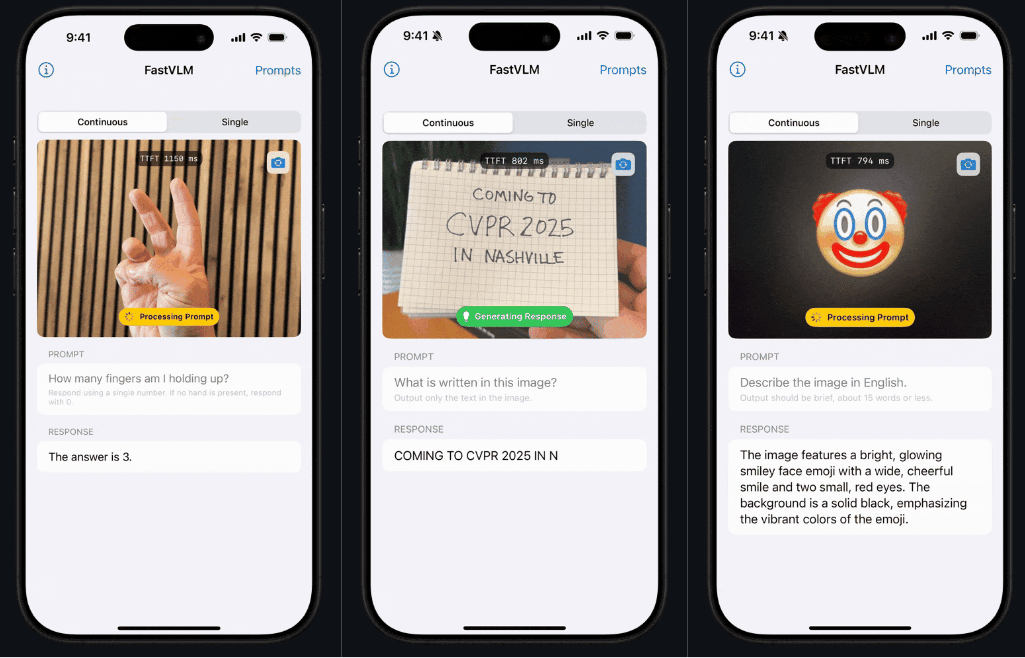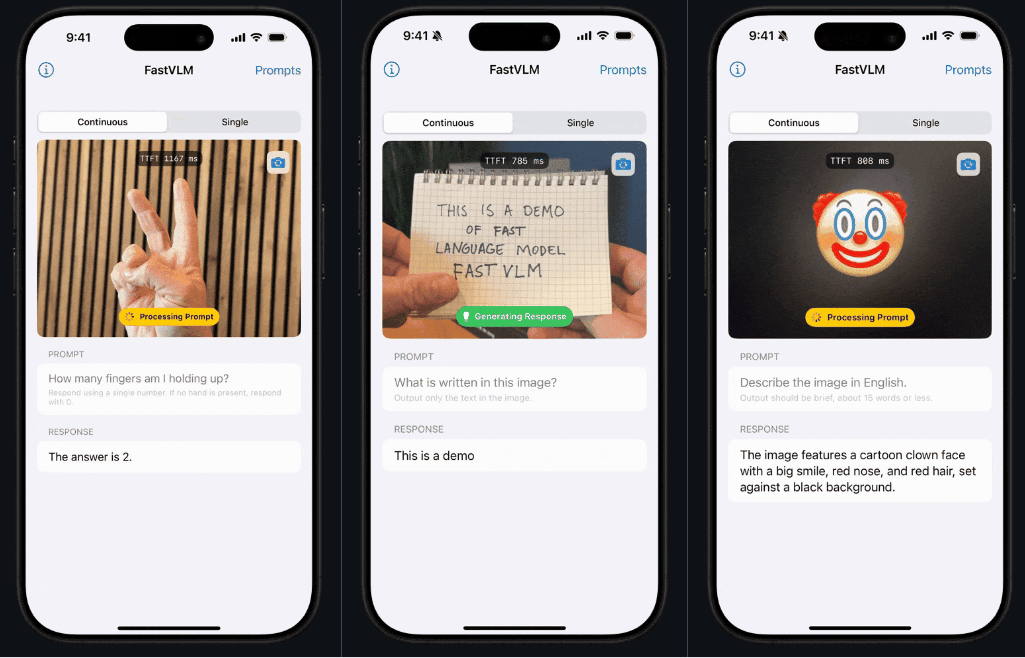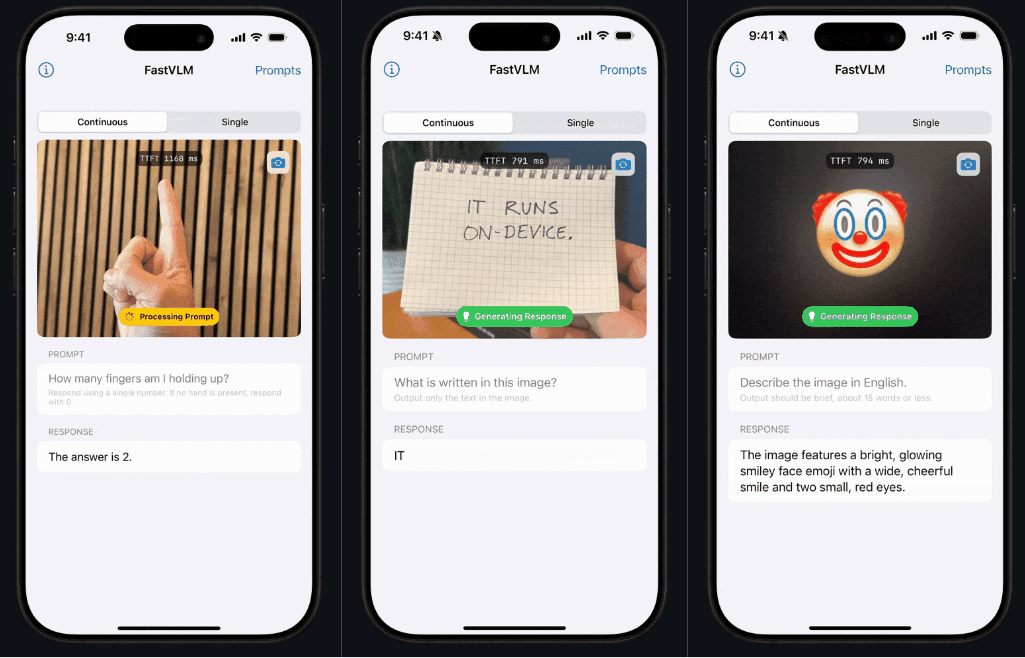
看这个 demo,反应速度是不是反应非常「Fast」!这就是 FastVLM 的独特之处。
相较于传统模型,FastVLM 模型专门注重于解决体积、速度这两大问题,速度快到相对同类模型,首个 token 输出速度提升 85 倍。
该模型引入了一种新型混合视觉编码器 FastViTHD,融合了卷积层和 Transformer 模块,配合多尺度池化和下采样技术,把图片处理所需的「视觉 token」数量砍到极低 —— 比传统 ViT 少 16 倍,比 FastViT 少 4 倍。它以卓越的速度和兼容性,极大地提升了 AI 与图像之间的用户体验能力。
FastVLM 模型不仅可以用于给模型自动生成陈述、回答「这张图是什么」的问题、分析图中的数据或对象等途径,还兼容主流 LLM 并轻松适配 iOS/Mac 生态,特别适合落地在边缘设备、端侧 AI 应用和实时图文任务场景。
目前,FastVLM 模型主要推出 0.5B、1.5B、7B 三个不同参数量级的版本,每个版本均有 stage2 和 stage3 两阶段微调权重,用户可以根据自身需求灵活选择。
苹果团队在发布的论文中详细阐述了更加具体的技术细节和优化路径。
- 论文标题: FastVLM: Efficient Vision Encoding for Vision Language Models
- 论文地址:https://www.arxiv.org/abs/2412.13303
研究背景
视觉语言模型(Vision-Language Models, VLMs)是一类能够同时理解图像和文本信息的多模态模型。VLMs 通常通过一个投影层(也称连接模块)将来自预训练视觉骨干网络的视觉 token 输入到一个预训练的 LLM 中。
此前的研究已经探讨了视觉骨干网络、适配器(adapter)以及通常为解码器结构的 LLM 这三大组件的训练和微调策略。
已有多项研究指出,图像分辨率是影响 VLM 性能的关键因素,尤其在面对文本密集或图表密集的数据时表现尤为明显。然而,提升图像分辨率也带来了若干挑战。
首先,许多预训练视觉编码器在设计时并不支持高分辨率图像输入,因为这会显著降低预训练效率。
为了解决这一问题,一种方法是持续对视觉骨干进行预训练,使其适应高分辨率图像;另一种则是采用图像分块策略(tiling strategies),如 Sphinx、S2 和 AnyRes,将图像划分为多个子区域,并由视觉骨干分别处理各个子区域。
这类方法特别适用于基于视觉 Transformer(ViT)的模型架构,因为 ViT 通常不支持可变输入分辨率。
另一个挑战来自于高分辨率推理时的运行时计算成本。无论是单次高分辨率推理,还是在较低分辨率下多次推理(即采用切片策略),在生成视觉 token 时都存在显著延迟。
此外,高分辨率图像本身生成的 token 数量更多,这会进一步增加 LLM 的预填充时间(prefilling time,即 LLM 对包括视觉 token 在内的所有上下文 token 进行前向计算的时间),从而整体拉长初始输出时间(time-to-first-token, TTFT),即视觉编码器延迟与语言模型前填充时间之和。
本研究以 VLM 的设备端部署为动力,从运行时效率的角度出发,对其设计和训练进行系统性研究。我们重点研究图像分辨率提升对优化空间的影响,目标是改进精度 - 延迟之间的权衡,其中延迟包括视觉编码器的推理时间和 LLM 的前填充时间。
研究者通过在不同的 LLM 规模与图像分辨率下的大量实验证明,在特定的视觉骨干条件下,可以建立一条帕累托最优曲线(Pareto optimal curve),展示在限定运行时间预算(TTFT)内,不同的图像分辨率和语言模型规模组合能达到的最佳准确率。
研究者首先探索了一种混合卷积 - Transformer 架构 FastViT(预训练于 MobileCLIP)作为 VLM 视觉骨干的潜力。
实验证明,该混合骨干在生成视觉 token 方面的速度是标准 ViT 模型的四倍以上,同时基于多尺度视觉特征还实现了更高的整体 VLM 准确性。然而,若目标主要是高分辨率 VLM(而非如 MobileCLIP 那样仅关注嵌入生成),则该架构仍有进一步优化空间。
为此,研究者提出了一种新型混合视觉编码器 FastViTHD,其专为在处理高分辨率图像时提升 VLM 效率而设计,并以此为骨干网络,通过视觉指令微调得到 FastVLM。
在不同输入图像分辨率和语言模型规模下,FastVLM 在准确率与延迟的权衡上均显著优于基于 ViT、卷积编码器及我们先前提出的混合结构 FastViT 的 VLM 方法。
特别地,相比于运行在最高分辨率(1152×1152)的 LLaVa-OneVision,FastVLM 在相同 0.5B LLM 条件下达到了可比的性能,同时拥有快 85 倍的 TTFT 和小 3.4 倍的视觉编码器规模。
模型架构
研究者首先探讨了将 FastViT 混合视觉编码器应用于 VLM 中的潜力,随后提出若干架构优化策略以提升 VLM 任务的整体表现。
在此基础上,研究者提出 FastViT-HD—— 一款专为高分辨率视觉 - 语言处理任务量身定制的创新型混合视觉编码器,兼具高效率与高性能特点。
通过大量消融实验,研究者全面验证了 FastViT-HD 在多种大型语言模型 (LLM) 架构和不同图像分辨率条件下,相比原始 FastViT 及现有方法所展现的显著性能优势。
如图 2 所示,展示了 FastVLM 与 FastViT-HD 的整体架构。所有实验均使用与 LLaVA-1.5 相同的训练配置,并采用 Vicuna-7B 作为语言解码器,除非特别说明。

FastViT 作为 VLM 图像编码器
典型的 VLM (如 LLaVA)包含三个核心组件:图像编码器(image encoder)、视觉 - 语言映射模块(vision-language projector)以及大型语言模型(LLM)。
VLM 系统的性能及运行效率高度依赖其视觉主干网络(vision backbone)。在高分辨率下编码图像对于在多种 VLM 基准任务中取得良好表现尤其关键,特别是在文本密集型任务上。因此,支持可扩展分辨率的视觉编码器对 VLM 尤为重要。
研究者发现,混合视觉编码器(由卷积层与 Transformer 块组成)是 VLM 极为理想的选择,其卷积部分支持原生分辨率缩放,而 Transformer 模块则进一步提炼出高质量的视觉 token 以供 LLM 使用。
实验使用了一个在 CLIP 上预训练过的混合视觉编码器 ——MobileCLIP 提出的 MCi2 编码器。该编码器拥有 35.7M 参数,在 DataCompDR 数据集上预训练,架构基于 FastViT。本文后续均将该编码器简称为「FastViT」。
然而,正如表 1 所示,若仅在其 CLIP 预训练分辨率(256×256)下使用 FastViT,其 VLM 表现并不理想。

FastViT 的主要优势在于其图像分辨率缩放所具有的高效性 —— 相比采用 patch size 为 14 的 ViT 架构,其生成的 token 数量减少了 5.2 倍。
这样的 token 大幅裁剪显著提升了 VLM 的运行效率,因为 Transformer 解码器的预填充时间和首个 token 的输出时间(time-to-first-token)大大降低。
当将 FastViT 输入分辨率扩展至 768×768 时,其生成的视觉 token 数量与 ViT-L/14 在 336×336 分辨率下基本持平,但在多个 VLM 基准测试中取得了更优的性能。
这种性能差距在文本密集型任务上尤为明显,例如 TextVQA 和 DocVQA,即使两种架构生成的 visual token 数量相同。
此外,即便在高分辨率下 token 数量持平,FastViT 凭借其高效的卷积模块,整体图像编码时间依然更短。
1、多尺度特征(Multi-Scale Features)
典型的卷积或混合架构通常将计算过程划分为 4 个阶段,每个阶段之间包含一个下采样操作。VLM 系统一般使用倒数第二层输出的特征,但网络前几层所提取的信息往往具有不同的粒度。结合多个尺度的特征不仅可提升模型表达能力,也能补强倒数第二层中的高层语义信息,这一设计在目标检测中尤为常见。
研究者在两个设计方案之间进行了消融对比,用于从不同阶段汇聚特征:均值池化(AvgPooling)与二维深度可分离卷积(2D depthwise convolution)。
如表 2 所示,采用深度可分卷积在性能上更具优势。除多尺度特征外,研究者还在连接器设计(connector design)上进行了多种尝试(详见补充材料)。这些结构性模型改进对于使用分层主干的架构(如 ConvNeXt 与 FastViT)特别有效。

FastViT-HD:面向 VLM 的高分辨率图像编码器
在引入上述改进后,FastViT 在参数量比 ViT-L/14 小 8.7 倍的情况下已具备良好性能。然而,已有研究表明,扩大图像编码器的规模有助于增强其泛化能力。
混合架构中,常见的做法是同时扩展第 3、4 阶段中的自注意力层数量和宽度(如 ViTamin 所采用的方式),但我们发现在 FastViT 上简单扩展这些层数并非最优方案(详见图 3),甚至在速度上不如 ConvNeXT-L。

为避免额外的自注意力层带来的性能负担,研究者在结构中加入一个额外阶段,并在其前添加了下采样层。在该结构中,自注意力层所处理的特征图尺寸已经被以 1/32 比例降采样(相比 ViTamin 等常见混合模型的 1/16),最深的 MLP 层甚至处理降采样达 1/64 的张量。
此设计显著降低了图像编码的延迟,同时为计算密集型的 LLM 解码器减少了最多 4 倍的视觉 token,从而显著缩短首 token 输出时间(TTFT)。研究者将该架构命名为 FastViT-HD。
FastViT-HD 由五个阶段组成。前三阶段使用 RepMixer 模块,后两阶段则采用多头自注意力(Multi-Headed Self-Attention)模块。
各阶段的深度设定为 [2, 12, 24, 4, 2],嵌入维度为 [96, 192, 384, 768, 1536]。ConvFFN 模块的 MLP 扩展倍率为 4.0。整体参数量为 125.1M,为 MobileCLIP 系列中最大 FastViT 变体的 3.5 倍,但依然小于多数主流 ViT 架构。
研究者采用 CLIP 的预训练设置,使用 DataComp-DR-1B 进行预训练后,再对该模型进行 FastVLM 训练。
如表 3 所示,尽管 FastViT-HD 的参数量比 ViT-L/14 小 2.4 倍,且运行速度快 6.9 倍,但在 38 项多模态零样本任务中的平均表现相当。相比另一种专为 VLM 构造的混合模型 ViTamin,FastViT-HD 参数量小 2.7 倍,推理速度快 5.6 倍,检索性能更优。

表 4 比较了 FastViT-HD 与其他 CLIP - 预训练层次型主干网络(如 ConvNeXT-L 和 XXL)在 LLaVA-1.5 训练后的多模态任务表现。尽管 FastViT-HD 的参数量仅为 ConvNeXT-XXL 的 1/6.8、速度提升达 3.3 倍,其性能仍然相当。

2、视觉编码器与语言解码器的协同作用
在 VLM 中,性能与延迟之间的权衡受到多个因素的影响。
一方面,其整体性能依赖于:(1) 输入图像分辨率、(2) 输出 tokens 的数量与质量、(3) LLM 的建模能力。
另一方面,其总延迟(特别是首 token 时间,TTFT)由图像编码延迟和 LLM 预填充时间组成,后者又受到 token 数量和 LLM 规模的共同影响。
鉴于 VLM 优化空间的高度复杂化,针对视觉编码器最优性的任何结论都须在多组输入分辨率与 LLM 配对下加以验证。我们在此从实证角度比较 FastViT-HD 相较 FastViT 的最优性。研究者测试三种 LLM(Qwen2-0.5B/1.5B/7B),并在不同输入分辨率下进行 LLaVA-1.5 训练与视觉指令调优,然后在多个任务上评估结果,结果见图 4。

首先,图 4 中的帕累托最优曲线(Pareto-optimal curve)表明,在预算固定的情况下(如运行时间 TTFT),最佳性能对应的编码器 - LLM 组合是动态变化的。
例如,将高分辨率图像输入配备小规模 LLM 并不理想,因为小模型无法有效利用过多 token,同时,TTFT 反而会因视觉编码延迟增大(详见图 5)。

其次,FastViT-HD 遍历 (分辨率,LLM) 所形成的帕累托最优曲线明显优于 FastViT —— 在固定延迟预算下平均性能提升超过 2.5 个点;相同时序目标下可加速约 3 倍。
值得注意的是,在此前已有结论表明,基于 FastViT 的 VLM 已超越 ViT 类方法,而 FastViT-HD 在此基础上进一步大幅提升。
3、静态与动态输入分辨率
在调整输入分辨率时,存在两种策略:(1) 直接更改模型的输入分辨率;(2) 将图像划分成 tile 块,模型输入设为 tile 尺寸。
后者属于「AnyRes」策略,主要用于让 ViT 能处理高分辨率图像。然而 FastViT-HD 是专为高分辨率推理效率而设计,因此我们对这两种策略的效率进行了对比分析。
图 6 显示:若直接将输入分辨率设定为目标分辨率,则 VLM 在准确率与延迟之间获得最佳平衡。仅在极高输入分辨率(如 1536×1536)时,动态输入才显现优势,此时瓶颈主要表现为设备上的内存带宽。

一旦使用动态策略,tile 数量越少的设定能获得更好的精度 - 延迟表现。随着硬件发展与内存带宽提升,FastVLM 在无需 tile 拆分的前提下实现更高分辨率处理将成为可行方向。
4、与 token 剪枝及下采样方法的比较
研究者进一步将不同输入分辨率下的 FastViT-HD 与经典的 token 剪枝方法进行对比。如表 5 所示,采用层次化主干网络的 VLM 在精度 - 延迟权衡上明显优于基于等维(isotropic)ViT 架构并借助 token 剪枝优化的方法。在不使用剪枝方法、仅利用低分辨率训练的前提下,FastViT-HD 可将视觉 token 数降至仅 16 个的水平,且性能优于近期多个 token 剪枝方案。
有趣的是,即便是当前最先进的 token 剪枝方法(如所提出的 [7, 28, 29, 80]),在 256×256 分辨率下,整体表现亦不如 FastViT-HD。
#Retrieval-Augmented Perception (RAP)
南洋理工陶大程教授团队等提出基于RAG的高分辨率图像感知框架,准确率提高20%
该工作由南洋理工大学陶大程教授团队与武汉大学罗勇教授、杜博教授团队等合作完成。
近些年,多模态大语言模型(MLLMs)在视觉问答、推理以及 OCR 等任务上取得了显著的成功。然而,早期的 MLLMs 通常采用固定的分辨率(例如 LLaVA-v1.5 将输入图像缩放为),对于输入图像为高分辨率图像(例如 8K 分辨率)会导致图像变得模糊,损失大量有效的视觉信息。
为了解决上述问题,目前的解决方案分为三类:
1. 基于裁剪的方法:对于高分辨率图像裁剪成多个子图,每个子图分别通过视觉编码器提取视觉特征后再进行拼接。然而对于 8K 的图像,假设采用 ViT-L/14 就需要接近 300K 的 visual token 长度,这对于目前大语言模型(LLM)的长上下文建模能力是一个巨大的挑战。
2. 采用处理高分图像的视觉编码器:使用能处理更高分辨率图像的视觉编码器代替基于 CLIP 训练的 ViT。然而,对于 8K 分辨率的图像,依旧会缩放到对应视觉编码器能接受的输入分辨率 (例如 ConvNeXt-L 的分辨率为
![]()
)。
3. 基于搜索的方法:这类方法不需要训练,通过将高分辨率图像构建成树结构,在树结构上进行搜索。然而,这类方法在搜索的开始阶段输入的是高分辨率图像,从而容易搜索错误的路径,导致推理时延增加甚至搜索到错误的结果。
事实上,在自然语言处理领域,对于长上下文建模,通过检索增强生成技术(RAG),检索关键的文本片段代替原始的长上下文作为输入,从而提高 LLM 回复的准确度。那么在 MLLM 中,是否也可以基于 RAG 技术提高 MLLM 对高分辨率图像的感知?
为了回答上述问题,研究人员通过实验,探索 RAG 应用在 MLLM 对于高分辨率图像感知的可行性。基于实验发现,提出了 Retrieval-Augmented Perception (RAP), 一种无需训练的基于 RAG 技术的高分辨率图像感知插件。该工作已被 ICML 2025 接收,并获评为 Spotlight 论文(top 2.6%)。
论文链接:https://arxiv.org/abs/2503.01222
主页链接:https://dreammr.github.io/RAP
代码链接:https://github.com/DreamMr/RAP
思考
为了探究将 RAG 应用于 MLLM 的高分辨率图像感知,研究人员提出了三个问题:
1. 检索出来的图像块如何布局?
2. 检索的图像块数量对最终性能的影响如何?
3. 如何基于上述发现,将 RAG 更好的应用于 MLLMs 对高分辨率图像的感知?
检索出来的图像块布局方式
为了探究检索图像块布局的影响,研究人员设计了三种策略:1)按照检索的分数从高到低进行排列;2)按照原始顺序进行排列和 3)维持检索图像块的相对位置关系。具体的布局例子见下图。

如下表所示,在三种布局方案中,对于单实例感知任务(FSP)都有显著提升,然而 1)和 2)在跨实例感知任务(FCP)上相较于 baseline 有明显性能下降。而 3)由于维持了图像块之间的相对位置关系,因此 3)在 FCP 任务上在三种策略中取得更好的效果。

结论 1: 维持检索图像块之间的相对位置关系是有必要的,特别是对于需要空间感知的任务。
检索的图像块数对最终性能的影响
为了探究检索的图像块数的影响,研究人员使用 LLaVA-v1.5 和 LLaVA-v1.6 7B & 13B 在高分图像感知评测数据集 HR-Bench 上进行实验。
如下图所示,当检索的数量 (K) 增加时,由于提供了更多的视觉信息,在 FCP 任务上的性能逐渐增加。然而,当K增加时,输入图像的分辨率也相应增加,导致模型输出的结果准确性下降。相反,对于 FSP 任务而言,较小的 K 便能取得更好的效果,但是在 FCP 任务上效果较差。

结论 2: 不同的任务类型需要保留的图像块数不同。对于 FSP 任务而言,仅需要较少的图像块数便能取得较好的效果,更多的图像块数反而影响模型的性能。对于 FCP 任务而言,更多的图像块数能够保留足够的视觉信息,但是依旧受到输入图像分辨率的限制。
方法
基于上述实验发现,研究人员提出了一种无需训练的高分图像检索增强框架 —— Retrieval-Augmented Perception (RAP)。RAP 的设计原理是通过检索和用户问题相关的图像块,代替原始的高分辨率图像输入到 MLLMs 中。该方法有效地降低输入图像的分辨率,并且保留和用户问题相关的关键视觉信息。为了维持检索图像块之间的相对位置关系,研究人员设计了 Spatial-Awareness Layout 算法,通过确定关键的图像块的位置,剔除无效的行和列,在降低图像分辨率的同时,有效保持图像块之间的相对位置关系。此外,为了自适应选择合适的K,研究人员提出了 Retrieved-Exploration Search (RE-Search),通过检索的相似度分数和模型的置信度分数作为启发式函数,引导模型搜索合适的K。方法架构图如下图所示:

Spatial-Awareness Layout: 对于一张高分辨率图像,首先对其进行裁剪成多个图像块 (V)。接着通过检索器 VisualRAG 计算每个图像块和用户问题 (q) 的相似度分数
![]()
:

然后根据预先设定要保留的图像块数K,筛选出 top - K图像块,并构建 0-1 矩阵M标记要保留的图像块的位置为 1,其余位置标记为 0。接着对矩阵M进行扫描,提取其中非零行和列的索引,其余位置删除,从而生成压缩矩阵
![]()
。最后根据压缩矩阵
![]()
提取出相应的图像块合成新的图像
![]()
。
RE-Search: 为了自适应选择保留的图像块数K,研究人员受到
![]()
算法的启发提出了 RE-Search。研究人员将当前的图像按照不同的保留图像块数的比例,通过 Spatial-Awareness Layout 算法对图像进行压缩,生成子节点。与之前基于搜索的方法不同,为了避免在搜索的初始阶段受到图像分辨率的影响,RE-Search 引入了每个图像块和用户问题的相似度分数
![]()
:

这里
![]()
表示有效的图像块,n表示有效的图像块的数量,g(t)表示当前的图像与用户问题的语义相似度。在
![]()
算法中通过启发式函数h估计从当前状态到目标状态的花费。这里通过让 MLLM 自身判断当前的图像
![]()
是否有足够的视觉信息回答用户的问题:

其中
![]()
表示 MLLM,
![]()
是提示模板用于构造文本问题(例如:“Question: {q} Could you answer the question based on the available visual information?”)。这里计算模型对于回复为 “Yes” 的置信度分数作为启发式函数。
由于在最开始图像的分辨率较大,模型输出的结果h(t)不可靠。因此在最开始搜索过程中降低h(t)的权重,随着搜索深度加深,逐渐增加h(t)的权重,具体计算公式如下:

其中b是一个超参数,具体实现时设置为0.2,d是搜索的深度。
实验结果
本文在高分辨率图像评测数据集
![]()
Bench 和 HR-Bench 上进行评测。对比的方法包括基于裁剪的方法(LLaVA-v1.6, InternVL-1.5 等)以及使用处理高分辨率图像的视觉编码器的方法(LLaVA-HR-X),实验结果如下表所示,RAP 在单实例感知和多实例感知任务上都能带来明显的性能提升。特别是在 HR-Bench 4K 和 8K 上分别带来最大 21% 和 21.7% 的准确率提升。

论文中还对比了基于搜索的方法(结果见下表),RAP 相比于
![]()
和 Zoom Eye 在吞吐量和准确率上都取得更好的效果。

此外,消融实验表明 (见下表),如果仅加入 VisRAG 检索和用户问题相关的图像块,仅带来 6.5% 的提升,通过维持检索图像块之间的相对位置关系在 FCP 任务上能够有所改进。通过引入 RE-Search 自适应选择合适的K,最终能够带来 21.7% 的性能提升。

总结
综上,该工作提出了 Retrieval-Augmented Perception (RAP),一种无需训练基于 RAG 技术提高 MLLM 对高分辨率图像感知的方法。该方法使用 Spatial-Awareness Layout 算法维持检索的图像块之间的相对位置信息,通过 RE-Search 自适应选择合适的K值,在保留关键视觉信息的同时有效降低图像的分辨率。实验结果表明,RAP 在 MLLM 高分辨率图像感知的场景中展现出显著优势。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









