 大模型技术前沿解析
大模型技术前沿解析





我自己的原文哦~ https://blog.51cto.com/whaosoft/14187612
#DeepSeek-V3.2-Exp
刚刚,DeepSeek开源V3.2-Exp,公开新稀疏注意力机制DSA
还是熟悉的节奏!
在假期前一天,DeepSeek 果然搞事了。

刚刚,DeepSeek-V3.2-Exp 开源了!
该模型参数量为 685B,HuggingFace 链接:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
此外,此次发布竟然也同步公开了论文,公开了 DeepSeek 新的稀疏注意力机制,为我们提供了更多结束细节:
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
DeepSeek Sparse Attention(DSA)稀疏注意力机制
在官方介绍中,DeepSeek 表示 DeepSeek-V3.2-Exp 是实验版本。作为迈向下一代架构的过渡,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek 稀疏注意力机制(DeepSeek Sparse Attention,DSA)—— 一种旨在探索和验证在长上下文场景下训练和推理效率优化的稀疏注意力机制。
DSA 也是 3.2 版本的唯一架构改进。

DeepSeek-V3.2-Exp 的架构,其中 DSA 在 MLA 下实例化。
重点要说的是,DeepSeek 称该实验版本代表了他们对更高效的 Transformer 架构的持续研究,特别注重提高处理扩展文本序列时的计算效率。

在 v3.2 版本中,DeepSeek 稀疏注意力 (DSA) 首次实现了细粒度稀疏注意力,在保持几乎相同的模型输出质量的同时,显著提高了长上下文训练和推理效率。
为了严格评估引入稀疏注意力机制的影响,DeepSeek 特意将 DeepSeek-V3.2-Exp 的训练配置与 9 月 22 日刚刚推出的 V3.1-Terminus 进行了对比。在各个领域的公开基准测试中,DeepSeek-V3.2-Exp 的表现与 V3.1-Terminus 相当。

更多信息,读者们可以查阅 DeepSeek-V3.2-Exp 的 huggingface 介绍。
值得一提的是,智谱的 GLM-4.6 也即将发布,在 Z.ai 官网可以看到,GLM-4.5 标识为上一代旗舰模型。

最后,有一波小节奏。在模型发布前,已经有网友在 Community 里发帖称:国庆是休息日,请给我们关注的同学一点休息时间。

对此,你怎么看?
强强联手!深度求索、寒武纪同步发布DeepSeek-V3.2模型架构和基于vLLM的模型适配源代码
2025 年 9 月 29 日,深度求索公司发布新一代模型架构 DeepSeek-V3.2 ,引发行业广泛关注。令人瞩目的是,在该大模型发布的同时,寒武纪也官宣了对 DeepSeek-V3.2 的适配,并开源大模型推理引擎 vLLM 源代码。
深度求索公司正式发布的 DeepSeek-V3.2-Exp 模型,是一个实验性(Experimental)的版本。作为迈向新一代架构的中间步骤,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。
目前,DeepSeek 官方 App、网页端、小程序均已同步更新为 DeepSeek-V3.2-Exp,同时 API 大幅度降价,欢迎广大用户体验测试并提供反馈意见。
同时,寒武纪已同步实现对深度求索公司最新模型 DeepSeek-V3.2-Exp 的适配,并开源大模型推理引擎 vLLM-MLU 源代码。代码地址和测试步骤见文末,开发者可以在寒武纪软硬件平台上第一时间体验 DeepSeek-V3.2-Exp 的亮点。
这一同步发布适配的“高能”操作,在业内专家看来,背后蕴含着中国顶尖科技企业深度协同的重要信号。
从技术层面来看,这款新大模型的体量相当可观,达到了 671GB 。据行业测算,在带宽充足的理想条件下,仅完成该大模型的下载,就需要耗费约 8-10 个小时。而芯片与大模型的适配,涉及底层架构优化、算力资源匹配、兼容性调试等一系列复杂工作,绝非短时间内能够完成。
有 AI 行业资深专家分析指出:“如此快速的适配响应,充分说明寒武纪早在 DeepSeek-V3.2 发布前就已启动适配研发,双方在技术层面的沟通与协作早已悄然展开。双方都是低调务实的公司,前期秘而不宣,估计早就已经相向而行了。”拒绝炒作、专注技术,正是当下中国顶尖科技企业行事风格的典型体现。
全球 AI 竞争日趋激烈,中国 AI 产业要想在国际舞台上站稳脚跟、占据优势地位,离不开头部企业间的深度协同合作。此次大模型与 AI 芯片领军企业的快速联动,正是国内高科技企业协同创新的有力例证。
我们可以期待,本次产业链上下游领军企业的深度协同,将大幅降低大模型用户在长序列场景下的训推成本,助力 AI 应用的 “涌现”。
DeepSeek开源模型获取方式:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
vLLM-MLU DeepSeek-V3.2-Exp适配的源码获取方式:
https://github.com/Cambricon/vllm-mlu
DeepSeek新版本,节前突袭发布!
DeepSeek 发布了新版本模型 DeepSeek-V3.2-Exp,引入了全新的稀疏注意力机制 DeepSeek Sparse Attention(DSA),通过优化计算效率,在处理长文本时显著降低了推理成本,同时保持了性能的稳定。
DeepSeek 发布了新版本模型 DeepSeek-V3.2-Exp。顾名思义,这是一个实验性(Experimental)版本,主要用于探索下一代大模型架构的可能性。
模型参数量为 685B,Hugging Face开源地址:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
此外,这次发布还同步公开了论文,里面详细介绍了全新的稀疏注意力机制:DeepSeek Sparse Attention(DSA) 的设计思路和实现方法。
论文地址:
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
核心升级:引入新的稀疏注意力机制
这次的升级,最大的亮点是引入了 DeepSeek Sparse Attention(DSA)。它是一种稀疏注意力机制,目标是在处理长文本时能够减少计算量、提升效率。简单来说:
模型不再逐字逐句死磕,而是能更快抓住重点;
在处理超长文本时,推理成本显著下降;
性能基本保持稳定,在编程、数学、推理等方面损耗很小。
模型不再逐字逐句死磕,而是能更快抓住重点
DSA 机制通过 闪电索引器(lightning indexer) 和细粒度 token 选择机制,使模型能够高效地筛选关键信息,而不是对所有 token 进行全局注意力计算。

在处理超长文本时,推理成本显著下降
DSA 将原本 Transformer 的 注意力计算复杂度降低至 ,其中 《 (例如,在训练中仅选择 2048 个关键 token)。尽管索引器本身仍为 ,但由于其计算量远小于 MLA(Multi-Latent Attention),整体推理成本大幅降低。
论文中的实验数据显示,在 H800 GPU 集群上,DeepSeek-V3.2-Exp 的推理成本明显低于 V3.1-Terminus,尤其是在长序列(128K token)场景下:

性能基本保持稳定,在编程、数学、推理等方面损耗很小
尽管采用了稀疏注意力机制,DeepSeek-V3.2-Exp 在多项能力评估(包括编程、数学、逻辑推理等)中与 V3.1-Terminus 相比未出现显著性能下降。
在 BrowseComp(编程评估)和 SWE Verified(软件工程验证)等任务上,两者的强化学习训练曲线高度一致,表明 DSA 并未影响模型的学习稳定性。
虽然在 GPQA、HLE、HMMT 2025 等任务上有轻微性能差距,但论文指出这主要是由于 V3.2-Exp 生成推理 token 更少,若使用中间检查点使 token 数量相当,该差距会消失。

通过这样一个 DSA 机制,能让模型学会“抓大放小”的思维模式,用极高的效率在长文本中锁定关键信息。这也使得模型在推理速度上获得巨大提升,同时核心能力基本保持无损(性能稳定)。
价格离谱:表现与上代接近,价格竟下降一半
讲完了核心升级的机制,来看模型的表现。
在各个领域的公开基准测试中,DeepSeek-V3.2-Exp 与之前的 V3.1-Terminus 总体表现差不多,个别测试有小幅差异。

但在保证效果的同时,API 调用价格有了明显下降,整体便宜了超过 50%。基本都等于白送了,百万输出仅3元,堪称“价格屠夫”!


总结
DeepSeek-V3.2-Exp 并不是一个「分数更高」的版本,算是一种面向未来的探索。
此外,我们还发现智谱的GLM-4.6也即将发布,在Z.ai官网可以看到,GLM-4.5也已经标识为上一代旗舰模型。

....
#VCMamba
CNN+四向Mamba双剑合璧,82.6% ImageNet夺魁,参数量砍37%秒PlainMamba
本文提出VCMamba,先用CNN卷积提局部细节,再换四向Mamba扫全局,全程线性复杂度;ImageNet上82.6% Top-1、ADE20K 47.1 mIoU,参数比同级模型少37%仍领先,为高精度视觉任务提供轻量级新骨干。
本文主要解决了什么问题
- 视觉Transformer (ViTs) 和状态空间模型 (SSMs) 在捕捉细粒度局部特征方面不如卷积神经网络 (CNNs) 有效,而CNNs缺乏ViTs和Mamba等模型的全局推理能力。
- 现有视觉SSM模型主要依赖patch embeddings,无法充分利用CNN在视觉处理早期阶段擅长捕捉的丰富、空间密集的局部特征。
- 标准非重叠patch embeddings可能导致信息损失,特别是对密集预测任务至关重要的细粒度细节。
本文的核心创新是什么
- 提出了VCMamba,一种新颖的分层视觉架构,有效结合了多阶段卷积特征提取和多方向Mamba SSMs,实现高效且强大的全局上下文建模。
- 采用卷积茎和分层结构,在早期和中间阶段使用卷积块提取丰富的多尺度局部特征,后期阶段使用多向Mamba块建模长距离依赖关系和全局上下文。
- 设计了多向Mamba块,利用四向扫描机制和方向感知更新,有效捕获2D空间关系,同时保持相对于图像分辨率的线性复杂度。
结果相较于以前的方法有哪些提升
- 在ImageNet-1K分类任务上,VCMamba-B实现了82.6%的top-1准确率,以37%较少参数超过PlainMamba-L3的0.3%,以64%较少参数优于Vision GNN-B的0.3%。
- 在ADE20K语义分割任务上,VCMamba-B获得了47.1 mIoU,比EfficientFormer-L7高出2.0 mIoU,同时使用的参数减少了62%。
- VCMamba-S在ImageNet-1K上达到78.7%的top-1准确率,超过了ViM-Ti(76.1%)和Pyramid ViG-Ti(78.2%),展示了在轻量级模型上的优势。
局限性总结
- 论文未明确讨论VCMamba在更高分辨率图像上的计算效率和性能表现,尽管提到Mamba具有线性复杂度优势。
- 未提供VCMamba在其他视觉任务(如目标检测、实例分割)上的实验结果,限制了对其通用性的全面评估。
- 未详细分析多向Mamba块的计算开销及其对整体推理速度的影响,这在实际应用中可能是一个重要考量因素。
导读
Vision Transformers(ViTs)和 State Space Models(SSMs)的最新进展已经挑战了 Convolutional Neural Networks(CNNs)在计算机视觉领域的主导地位。ViTs 擅长捕捉全局上下文,而像 Mamba 这样的 SSMs 为长序列提供了线性复杂度,但它们在捕捉细粒度局部特征方面不如 CNNs 有效。相反,CNNs 对局部特征具有强大的归纳偏置,但缺乏 transformers 和 Mamba 的全局推理能力。为了弥合这一差距,作者引入了 VCMamba,这是一种新颗的视觉 Backbone 网络,整合了 CNNs 和多向 Mamba SSMs 的优势。 VCMamba 采用卷积茎和分层结构,在其早期阶段使用卷积块来提取丰富的局部特征。这些卷积块随后由包含多向 Mamba 块的后期阶段处理,这些块旨在有效地建模长距离依赖关系和全局上下文。这种混合设计允许优越的特征表示,同时保持相对于图像分辨率的线性复杂度。作者通过在 ImageNet-1K 分类和 ADE20K 语义分割上的广泛实验证明了 VCMamba 的有效性。作者的 VCMambaB 在 Image Net-1K 上实现了 的 top-1 准确率,以 的较少参数超过了 PlainMamba-L3 的 ,并以 的较少参数优于 Vision GNN-B 的 。此外,VCMamba-B 在 ADE20K 上获得了 47.1 mloU ,比 EfficientFormer-L7 高出 2.0 mloU ,同时使用的参数减少了 。
代码 https://github.com/Wertyuui345/VCMamba
01 引言
深度学习视觉架构的发展主要由卷积神经网络(CNNs)所塑造。其固有的归纳偏置,如局部性和权重共享,使得分层特征的高效学习成为可能。然而,卷积的固定感受野可能会限制其有效捕获长距离依赖关系的能力。视觉Transformer(ViTs)作为一种强大的替代方案出现,它将图像视为 Patch 序列,并利用自注意力机制来建模全局关系,通常能够实现卓越的性能,尽管其复杂度相对于 Patch 数量呈二次方增长。
最近,状态空间模型(SSMs)作为一种有前景的架构引起了关注。Mamba 是一个显著的SSM变体,引入了选择机制和硬件感知算法,实现了线性时间序列建模和在语言任务上的强大性能。这激发了将SSMs适配于视觉领域的兴趣,催生了如VMamba、Vision Mamba (Vim) 和PlainMamba等模型。VMamba使用2D选择性扫描模块将一维SSMs适配于2D视觉数据。Vim利用双向Mamba块进行视觉表示,而PlainMamba提出了一种简单的、非层次化的SSM,并具有特定的2D扫描适配用于视觉识别。这些模型展示了SSMs在视觉领域的潜力,在性能和效率之间提供了有吸引力的平衡,特别是对于高分辨率输入。
尽管取得了这些进展,许多当代视觉SSM(类似于ViTs)主要依赖于patch embeddings,这可能无法充分利用CNN在视觉处理早期阶段擅长捕捉的丰富、空间密集的局部特征。虽然PlainMamba专注于非分层SSM结构,而其他视觉SSM探索不同的扫描策略或双向机制,但仍有机会创建一种视觉 Backbone 网络,明确融合分层卷积阶段的强大局部特征提取与后期High-Level多向Mamba模块的高效全局建模。标准的非重叠patch embeddings可能导致信息损失,特别是对于密集预测任务至关重要的细粒度细节,而这一挑战可以通过为更高分辨率阶段设计的分层卷积结构来缓解。
为了弥合这一差距,作者引入了VCMamba,一种整合了CNNs和多向Mamba SSMs优势的新型视觉 Backbone 网络。VCMamba采用了一个卷积茎和分层结构,在其早期和中间阶段使用卷积块(实现为带有 和 卷积的 FFN ),使能够提取丰富的多尺度局部特征。这些特征随后由包含多向Mamba块的后期阶段处理,特别利用了中详述的四向扫描机制,以有效地建模长距离依赖和全局上下文。这种混合的分层设计允许卓越的特征表示,同时在其Mamba阶段保持相对于图像分辨率的线性复杂度,这是高分辨率图像处理的一个关键优势。
作者通过在ImageNet-1K分类和ADE20K语义分割上的大量实验证明了VCMamba的有效性。VCMambaB在ImageNet-1K上实现了 的top-1准确率,以少 的参数量超越了 PlainMamba-L3( 准确率) ,并在使用少 参数量的情况下优于Vision GNN-B( 准确率) 。此外,VCMamba-B在ADE20K语义分割上获得了 47.1 的平均 ,在使用少 参数量的情况下超过了EfficientFormer-L7( 45.1 mloU ) 2.0 mloU 。这些结果展示了VCMamba的强劲性能和高效率,特别是在受益于其混合特征提取能力的任务中。
作者的贡献是:
- 作者提出了VCMamba,一种新颖的分层视觉架构,它有效地结合了多阶段卷积特征提取和多方向Mamba SSMs,以实现高效且强大的全局上下文建模。
- 作者提出了几种VCMamba变体,并证明了它们相对于领先的CNN、ViT、视觉GNN和视觉SSM架构的优越性能。
- 作者表明,作者的混合和分层方法在图像分类和语义分割任务中都取得了优异的性能,同时保留了Mamba在高分辨率输入方面的效率优势。
本文的组织结构如下。第2节涵盖相关工作。第3节解释了state space models的初步信息。第4节描述了作者的hierarchical feature extraction、multi-directional mamba blocks以及VCMamba架构。第5节描述了作者在ImageNet-1K图像分类和ADE20K语义分割方面的实验设置和结果。最后,第6节总结了作者的主要贡献。
02 相关工作2.1 视觉架构
卷积神经网络(CNNs)长期以来一直是计算机视觉领域的主导架构。其成功源于固有的归纳偏置,如局部性和权重共享,这些特性使得层次化视觉特征的高效学习成为可能。诸如ResNet 、EfficientNet 和ConvNeXt 等架构不断推动性能边界。对于移动应用,轻量级CNN如MobileNet 引入了深度可分离卷积等高效操作。近期研究进一步探索了通过使用高效扩展感受野的技术来增强用于移动视觉的CNN。尽管CNN在局部特征提取方面表现出色,但与基于注意力的模型相比,其固定的感受野在捕获全局、长距离依赖关系方面可能存在局限性。
Vision Transformers (ViTs)通过将最初为自然语言处理设计的Transformer架构应用于图像数据,标志着一种范式转变。ViTs 将图像视为 Patch 序列,并使用自注意力机制对它们之间的全局关系进行建模,通常能获得最先进的结果。然而,自注意力相对于 Patch 数量(图像分辨率)的二次复杂度为高分辨率输入和密集预测任务带来了重大的计算挑战。为缓解这一问题所做的努力包括MobileViT 和MobileViTv2 ,它们旨在通过融入卷积原理为移动设备创建更高效的ViT变体。
视觉图神经网络(ViGs)通过将图像建模为相互连接的 Patch 或节点的图提供了另一种视角。ViG 是早期提倡使用GNN作为通用视觉 Backbone 网络的工作,它利用K-最近邻算法连接图中的相似节点。对于移动应用,MobileViG 引入了一种基于静态图的连接机制。进一步的优化如GreedyViG 、WiGNet 和ClusterViG 专注于引入新的动态和高效的图构建算法。虽然ViGs提供了一种灵活的建模关系的方式,但图构建和传播步骤可能会引入计算开销。
2.2 视觉中的状态空间模型(SSMs)
状态空间模型(SSMs)最近作为一种引人注目的序列建模替代方案而出现,其提供了与序列长度成线性关系的复杂度。Mamba 作为一个突出的SSM,引入了一种选择性扫描机制,该机制实现了高效的、依赖于输入的处理,并在语言建模中表现出强大的性能。这种在语言建模方面的成功激发了将SSMs,特别是Mamba,适应于计算机视觉任务的浓厚兴趣。将Mamba的能力转换到视觉领域的初步努力包括:
- VMamba 提出了2D选择性扫描模块(SS2D)来为SSMs提供2D空间感知能力,将图像转换为通过四向扫描处理的有序块序列。
- Vim 引入了一个采用双向Mamba块和位置嵌入的视觉 Backbone 网络。
- PlainMamba 专注于用于视觉的非分层Mamba架构,引入连续2D扫描以更好地将Mamba的选择性扫描适应到2D图像。
其他最近的研究方向包括领域特定适应如VideoMamba,专门任务如使用QMamba进行质量评估,以及效率提升如PTQ4VM 中的训练后量化。同时,分析性工作如MambaOut 和批判性地检查了Mamba组件在视觉领域的作用和功效。这些模型强调了SSMs为各种视觉任务提供高效强大 Backbone 的潜力,尽管活跃的研究仍在继续优化它们在2D数据上的应用。
2.3 混合架构
不同架构的互补优势导致了各种混合模型的出现。像CoAtNet 和MobileFormer 这样的CNN-ViT混合模型旨在结合CNN的局部特征提取与ViT的全局上下文建模能力。EfficientFormer 进一步优化了这种融合,以提高移动设备上的速度和效率。MambaVision 代表了一种最近的Mamba-Transformer混合模型,它将Transformer块集成到其后期阶段,以改善对长距离空间依赖性的捕获。
作者提出的VCMamba通过创建一个独特的CNN-SSM混合架构为这一研究方向做出了贡献。与将Transformer块与Mamba集成的MambaVision不同,VCMamba采用了一种分层结构,在其早期和中间阶段使用卷积块进行强大的多尺度特征提取,随后在后期阶段过渡到多向Mamba块以进行高效的全局建模。VCMamba旨在利用CNNs的局部特征丰富性和Mamba的序列建模能力,而不依赖Transformer块。
03 预备知识:状态空间模型 (Mamba)
状态空间模型(SSMs)通过状态变量描述系统。一个连续线性SSM定义为:
其中 是输入, 是潜在状态, 是输出,( )是系统矩阵。对于深度学习应用,这些通过使用时间尺度参数 进行离散化,将 A 和 B 转换为它们的离散对应物 和 。 Mamba[9]通过使参数 和 依赖于输入(选择性),显著增强了传统的 SSM。这使得模型能够基于当前 token 动态调整其行为,沿着序列选择性地传播或遗忘信息。离散化递归为:
其中下标 表示Mamba[9]中参数的输入依赖性。Mamba采用硬件高效的并行扫描算法进行训练和推理,实现了线性复杂度。
将Mamba适配到2D视觉数据,如PlainMamba[47]中所示,涉及将图像块展平为一维序列,然后应用选择性扫描。为了捕获2D空间上下文,PlainMamba采用了连续2D扫描等技术,该技术以多种(例如四种)预定义顺序处理视觉token,确保空间邻接性,以及方向感知更新,其中表示扫描方向的可学习参数 被整合到SSM的更新规则中。例如,对于第 k 个扫描方向和第 i 个 token的隐藏状态 的更新可以增强为:
这些多向扫描的输出然后通常会被聚合。这种多向方法对VCMamba的后续阶段至关重要。
04 VCMamba 架构
作者将VCMamba设计为一个分层视觉 Backbone 网络,在其早期阶段集成了CNN的强大局部特征提取能力,在后期阶段结合了多方向Mamba SSMs的高效全局上下文建模能力。这种混合方法使VCMamba能够在保持计算效率的同时,有效地处理多尺度的视觉信息。如图1所示的整体架构,包括一个卷积茎和随后的四个阶段的特征提取块,阶段之间有下采样层以创建特征金字塔。

4.1 层次化特征提取
VCMamba架构以卷积主干(图1(b))开始处理,这是现代视觉主干网络中用于初始特征提取和空间下采样的常见策略。该主干包含两个连续的 卷积层,每个卷积层使用步长为 2。每个卷积后都跟随批归一化和ReLU激活函数。总体而言,该主干将输入图像下采样4倍,在降低的空间分辨率上高效生成Low-Level特征表示,为后续阶段做准备。
在主干网络之后,VCMamba采用四阶段分层结构(图1(a))以逐步细化特征并构建多尺度表示。每个阶段在不同的空间分辨率上运行。采用下采样层将空间尺寸减半并扩展通道容量。这些下采样层通过一个带步长的 卷积后接批量归一化来实现(图1(c))。这种金字塔架构能够在不同尺度上学习特征,这对于在多样化视觉任务上实现稳健性能至关重要。该架构具有基于模型大小的不同模型变体(VCMamba-S、VCMamba-M和VCMamba-B),如第4.3节所讨论。
在初始三个阶段以及第四阶段的早期部分,VCMamba主要利用卷积 FFN(FFN)块进行特征转换和细化。这些FFN块在架构上类似于移动CNN中突出的高效倒置残差块 。在结构上,每个FFN块(图1(d))包含一个核心MLP模块,该模块首先使用 卷积扩展通道维度,然后使用 深度卷积进行空间混合,随后使用另一个 卷积将特征投影回来。在这些MLP模块中应用了批归一化和GeLU激活函数,以确保训练稳定并引入非线性。这种FFN设计优先考虑在网络高分辨率的早期阶段进行高效的局部特征提取和表示学习。
4.2 用于全局上下文的多向Mamba块
在其最后阶段,VCMamba从卷积FFN块转换以整合多向Mamba块(图1(e))。这种转变使模型能够利用前面的卷积阶段提取的丰富的多尺度局部特征,并有效地建模特征图上的长距离依赖和全局上下文。
VCMamba中的每个基于Mamba的块都是一个复合结构。它接收来自前一层的2D特征图,应用批归一化(Batch Normalization),然后通过一个核心的2D适应Mamba模块进行处理。该Mamba模块的输出通过残差连接与输入相结合,接着是另一个批归一化(Batch Normalization)和一个卷积MLP,其结构与4.1节中描述的FFN块中使用的结构相同。
基于Mamba的块通过利用Plain Mamba中建立的扫描原理,将Mamba的选择性扫描机制适配于2D视觉数据。作者的Mamba块还利用位置嵌入来帮助理解空间关系。正如作者的消融研究中所详述的,该块的设计通过用 Shortcut 替代乘法分支、交错Mamba和FFN以及层归一化进行了优化,以最大化性能。对于特征图的处理过程如下:
- 位置和局部上下文编码:输入特征图 首先通过带有位置嵌入的 卷积,将其投影到内部维度 并进行归一化。然后将得到的特征展平成一个序列。为了在主要的SSM操作之前用局部空间上下文丰富这些token,应用了一个 深度卷积,然后接一个SiLU激活函数。这一步骤对于准备视觉token以供SSM进行有效的顺序处理至关重要。
- 多向选择性扫描:为了全面捕捉2D空间关系,该模块采用多向扫描策略。与单一的单向扫描不同,视觉 Token 沿着四个不同的、空间连续的路径进行处理(例如,行和列的"蛇形"模式),如图 2中的概念性说明。这种方法类似于连续2D扫描方法,确保当 Token 被SSM顺序处理时,一维序列中的相邻性对应于原始2D特征图中的空间相邻性,从而保留了关键的语义和空间连续性。沿着这 个扫描方向中的每一个,Mamba选择性扫描机制利用其输入相关参数( ),根据公式(2)中的递归关系更新每个 Token 的隐藏状态 。

- 方向感知更新:为了在每次1D扫描期间明确告知模型2D空间遍历的性质,引入了一种方向感知更新机制,如中所述。这涉及一组可学习参数 ,每个参数对应一个扫描方向(以及一个初始"开始"方向)。这些方向参数被整合到SSM的状态更新方程中,通常通过增强输入相关矩阵 来实现。因此,对于第 个扫描方向和第 个 token 的修改后状态更新可以表示为:
其中 表示针对当前token和扫描路径的离散化方向参数。
- 聚合与输出投影:由四个方向扫描中的每一个产生的特征序列通过求和进行聚合。这种结合了多方向上下文的组合表示,使用LayerNorm进行归一化。然后接着是一个 卷积和批归一化。
这个多向Mamba模块使VCMamba能够在其深层特征提取阶段高效地建模全局交互和长距离依赖。
4.3 VCMamba网络架构
如图1所示,整体VCMamba架构集成了卷积茎、带有卷积FFN块的分层阶段、阶段间下采样,以及最后阶段交替使用基于多方向Mamba的块与卷积FFN块。
作者通过调整深度(每个阶段的块数)和宽度(通道维度)来定义几种VCMamba变体,从而在性能和计算成本之间进行权衡。VCMamba-S、VCMamba-M和VCMamba-B的配置在表1中详细说明,展示了从最小模型尺寸(VCMamba-S)到最大模型尺寸(VCMamba-B)的宽度和深度调整。这些配置指定了卷积FFN块的数量和多向

四个阶段中各自的基于Mamba的模块(MDM Blocks)及其相应的通道维度 。
05 实验
在本节中,作者详细介绍了实验设置,并对作者提出的VCMamba架构进行了全面的性能评估。作者将VCMamba与现有的用于图像分类和语义分割任务的突出架构进行了基准测试。作者的结果表明,VCMamba实现了出色的准确性和计算效率,优于几种最先进的CNN、ViT、ViG和其他基于Mamba的视觉模型。
5.1 在ImageNet-1K上的图像分类
作者在广泛使用的ImageNet-1K数据集上评估VCMamba,该数据集包含约 130 万张训练图像和 5 万张验证图像,涵盖 1000 个物体类别。所有VCMamba模型都从零开始训练 300 个 epoch,使用标准输入分辨率 。作者的实现利用了PyTorch和Timm库。遵循训练现代视觉 Backbone 网络的常见做法,作者的训练方案包括AdamW优化器 ,学习率为 和余弦退火调度,以及数据增强技术,如RandAugment、Mixup 、CutMix和随机擦除。
作者的中等大小VCMamba-M模型,拥有 21.0 M 参数,达到了 的top-1准确率,优于 DeiT-Small(拥有 22 M 参数,准确率为 )和PVT-Small(拥有 24.5 M 参数,准确率为 )。轻量级VCMamba-S模型仅用 10.5 M 参数就达到了 的top-1准确率,超过了ViM-Ti(拥有 7 M 参数,准确率为 )和Pyramid ViG-Ti(拥有 10.7 M 参数,准确率为 )。这些结果突显了VCMamba的分层混合设计在各种模型规模上实现强大分类性能的有效性。
这些不同规模的结果突显了VCMamba的混合CNN-Mamba设计的有效性,该设计在早期阶段利用卷积的优势,在后期阶段利用多向Mamba能力,实现了良好的精度-参数权衡。
5.2. ADE20K上的语义分割
为评估VCMamba在密集预测任务上的能力,作者在ADE20K数据集上进行了语义分割实验。ADE20K包含 20 K张训练图像和 2 K张验证图像,涵盖 150 个语义类别。作者遵循既定方法,构建了以Semantic FPN作为分割解码器的VCMamba。
VCMamba Backbone 网络使用其在ImageNet-1K上预训练的权重进行初始化。随后,模型进行了40K次迭代的微调。作者使用AdamW优化器,初始学习率为 ,并使用幂为 0.9的多项式调度进行衰减。训练输入分辨率为 。
如表3所示,VCMamba在语义分割任务中表现出强大的性能。作者的VCMamba-S(1050万 Backbone 网络参数)达到了 42.0 mIoU ,超越了其他轻量级模型,如EfficientFormerL1 ( )。作者更大的模型VCMamba-B(3150万 Backbone 网络参数)达到了令人印象深刻的 47.1 mloU 。这超越了FastViT-SA36 4.2 mIoU 以及参数量大得多的 EfficientFormer-L7(拥有 82.1 M Backbone 网络参数, 45.1 mloU ) 2.0 mloU ,尽管VCMamba-B的 Backbone 网络参数减少了约 。这些结果突显了VCMamba架构在为密集预测任务学习强大表示方面的有效性,有效利用了其混合卷积和多向Mamba设计。

5.3. 消融研究
为了验证作者的架构设计选择,作者在ImageNet-1K上进行了一系列消融研究,从使用PlainMamba 层作为作者最终阶段的 Baseline 开始,并逐步集成作者提出的VCMamba的关键组件。该 Baseline 模型在拥有参数的情况下达到了的top-1准确率。逐步改进的细节在表4中详细说明。

首先,作者通过用简单的 Shortcut 替代乘法分支来优化Mamba块的内部结构,这使准确率提高到 ,同时略微减少了参数量至 31.0 M 。接下来,为了更好地融合特征表示,作者交错排列Mamba和FFN层,并在其后应用批量归一化,进一步将性能提升至 。然后,作者观察到在Mamba层内添加一个额外的LayerNorm带来了显著提升,准确率达到 。接下来,作者用卷积替换线性层头,使准确率达到 。最后,为确保模型层次结构中稳定的特征分布,作者用批量归一化层包豪每个阶段。这个最终模型是作者的VCMamba-B,它的top-1准确率达到 ,比作者的CNN-Mamba Baseline 模型总共提高了 。这一系列消融实验验证了最终VCMamba架构的有效性。
06 结论
在本文中,作者介绍了VCMamba,一种新颗的分层视觉主干网络,旨在协同地桥接卷积神经网络(CNNs)的强大局部特征提取能力与状态空间模型(SSMs)的高效全局上下文建模。VCMamba采用多阶段架构,在其早期和中间阶段利用卷积块来构建丰富的多尺度特征层次结构。在其更深、更低分辨率的阶段,它转向多向Mamba块以有效捕获长距离依赖关系。这种混合设计使 VCMamba在其Mamba阶段保持线性复杂度,为高分辨率视觉理解提供了可扩展的解决方案。
作者的广泛评估表明VCMamba在ImageNet-1K分类和ADE20K语义分割任务上具有强大的性能和效率。值得注意的是,VCMamba-B在ImageNet-1K上达到了 的top-1准确率,以减少 参数量的情况下,超过了PlainMamba-L3模型 ,并在ADE20K上获得了 47.1 mloU ,在使用减少 参数量的同时,超过了EfficientFormer-L7 2.0 mIoU 。这些结果验证了VCMamba作为一个引人注目且高效的主干网络,适用于多种计算机视觉任务。
参考
[1]. VCMamba: Bridging Convolutions with Multi-Directional Mamba for Efficient Visual Representation
....
#揭秘零样本「看懂」世界
谷歌Veo 3论文竟无一作者来自美国!
“视觉版GPT-3”惊现!仅凭提示词就在边缘检测、实例分割等62项任务中刷新零样本纪录,mIoU达0.74、物体提取准确率92.6%,甚至能解迷宫。DeepMind报告认为,视频模型正重演大语言模型的通用飞跃,“帧链式”推理让视觉领域迎来GPT-3时刻。
大模型的「零样本能力」,使自然语言处理从任务特定模型跃迁到了统一的、通用的基础模型。
这样的飞跃源于在规模数据上训练的大型生成式模型。
视频模型是否可以实现同样的飞跃,也向着具有通用视觉理解的方向发展。
在DeepMind近日发布的一篇论文中验证了这一猜想:
视频模型是「零样本学习者与推理者」,这一论点在足够强大的模型上几乎都能得到验证。
项目页面:https://video-zero-shot.github.io/
论文地址:https://arxiv.org/abs/2509.20328
研究证明,Veo 3可以完成大量它并未专门训练过的任务,比如:
物体分割、边缘检测、图像编辑、物理属性理解、物体可操作性识别、工具使用模拟等。

在多项视觉任务中,Veo 3涌现出零样本学习能力。这足以表明视频模型正朝着统一的、通用的「视觉基础模型」的方向发展——正如大语言模型成为语言基础模型一样。
谷歌发视觉版GPT-3模型
但无一作者来自美国
风险投资合伙人、谷歌搜索前员工、康奈尔计算机科学毕业生Deedy,对新论文推崇备至:Veo 3就是视觉推理的GPT-3时刻。
意外的是,随后Deedy发现论文作者中没有一个来自美国。
这8位研究者中,3位来自加拿大,2位来自德国,来自中国、韩国、印度各一位。
这篇「GPT-3」级别的论文的作者,没有一个来自美国,而且没有一个人在美国完成本科教育。哪怕算上博士毕业院校,美国也只有两所。
这不禁让网友怀疑:美国科研真不行了吗?
论文第一作者谷歌DeepMind实习生、在读博士生Thaddäus Wiedemer澄清道:
新论文只是评估了Veo和Gemini团队实现和训练的模型。
也就是说,Veo 3主要是由其他团队实现和训练的,新论文≠Veo 3。
这篇论文和OpenAI的GPT-3论文,在标题上具有极大的相似性,但谷歌新论文作者对Veo 3的实际贡献明显 < OpenAI论文作者对GPT-3的实际贡献。
尽管GPT-3论文的核心在于证明了语言模型的少样本学习能力,但论文作者的确训练出GPT-3。
论文链接:https://arxiv.org/abs/2005.14165
Thaddäus Wiedemer还指出,这项工作是在DeepMind多伦多完成的。
这就解释了为什么来自加拿大的作者最多——
近水楼台先得月,多伦多本地的加拿大人参与此项研究的机会更大。
不过,值得一提的是,Thaddäus Wiedemer在清华大学从事过约1年的研究实习。
此外,第二作者Yuxuan (Effie) Li来自国内;作者Shixiang Shane Gu则是华裔加拿大人。
视频模型是零样本学习者和推理者
大模型日益展现出「零样本学习」所衍生出的解决新任务的能力。
所谓零样本学习,即仅通过提示词指令即可完成任务,无需微调或添加任务特定模块。
研究人员通过分析18,384个Veo 3生成的视频,在62个定性任务和7个定量任务中,发现它可以完成多种未曾训练或适配的任务:
凭借感知、建模和操控视觉世界的能力,Veo 3展现出「帧链式(Chain-of-Frames, CoF)」视觉推理的初步能力。
虽然目前的任务特定模型性能仍优于零样本视频模型,但研究人员观察到Veo 3相比Veo 2在表现上有显著提升,这表明视频模型能力正在快速演进。
研究人员采用的方法很简单:向Veo模型提供提示词。
为何选择Veo?
研究人员之所以选择Veo,是因为它在text2video和image2video排行榜中表现突出。
为展现性能进步的速度,研究人员还将Veo 3与其前代Veo 2进行对比。
研究人员对多个视觉任务进行了广泛的定性研究,以评估视频模型是否具备作为视觉基础模型的潜力,并将发现归纳为四个层级能力体系,每一层都在前一层基础上演化而来(见图 1 和图 2):
- 感知:理解视觉信息的基本能力
- 建模:在感知物体的基础上对视觉世界进行建模
- 操控:对已建模的视觉世界进行有意义的修改
- 推理:跨时间与空间的视觉推理能力
建模直觉物理与世界模型
视频模型在感知视觉世界的基础上,开始尝试对其进行建模。
对世界及其运行原理(例如物理定律)进行建模,是实现有效预测与行动的关键一步。
目前,已有多项研究在深度模型中探索并量化了直觉物理能力,论文中节选了其中部分具有代表性的任务进行分析。
比如,Veo对物理规律的理解,体现在其能够建模刚体与软体的动力学以及它们之间的表面交互。
Veo还展现了对多种物理属性的认知,例如可燃性、空气阻力对下落物体的影响、浮力、光学现象等。
除了物理属性,Veo还理解抽象关系,这对于建模现实世界也至关重要。
例如,Veo能够区分玩具与笔记本电脑等其他物品。
研究人员还展示了Veo在识别模式、生成变体以及将整体结构拆解为部分等方面的能力。
此外,Veo还能在视频中跨时间与镜头变化维持对世界状态的记忆。
从「思维链」到「帧链」
Veo能够感知物体,并建模它们之间以及与环境的关系,因此它也具备对视觉世界进行有意义操控的能力。
感知、建模与操控的能力相互融合,共同构建起视觉推理的基础。
与语言模型操控文字符号不同,视频模型可以在真实世界的两个关键维度——时间与空间中进行操作。
这一过程类似于语言模型中的「思维链」(Chain-of-Thought,CoT),研究人员称之为「帧链」(Chain-of-Frames,CoF)。
研究人员认为,在语言领域中,思维链使模型能够解决推理类问题;同样帧链(也即视频生成)或许也能帮助视频模型解决那些需要跨时间和空间逐步推理的复杂视觉问题。
尽管模型的表现尚不完美,但其在零样本条件下解决这些问题的能力,展示了未来更强大视频模型在视觉推理和规划方面的巨大潜力。
定量评估
在对视频模型的能力做了定性研究之后,研究人员从七个具体任务出发,对其进行定量评估。
从视觉理解的不同方面来考察模型表现:
感知能力:评估Veo在边缘检测、图像分割和目标提取方面的能力;
操控能力:测试其在图像编辑方面的表现;
推理能力:通过迷宫求解、视觉对称性和视觉类比任务来评估。
边缘检测
研究发现,即便没有专门为边缘检测任务训练,Veo 3仍然可以通过提示词实现边缘感知。
图3展示了Veo 2和Veo 3在边缘检测任务上的表现。
图4显示在LVIS数据集的一个包含50张简单场景图像(每张图像中含有1到3个大型物体)的子集上进行类别无关的实例分割。
图像分割
与经典的实例分割或可提示分割不同,研究人员提示模型分割场景中的所有物体,而不指定物体类别或位置。
如图4所示,Veo 3实现了0.74的mIoU(最佳帧 pass@10),与Nano Banana的0.73 相当。
当然,Veo 3的性能落后于像SAMv2这样的定制模型,但仍然展示了卓越的零样本分割能力。
物体提取
研究人员要求Veo提取并将所有动物排成一排,彼此之间用白色背景分隔,通过统计最后一帧中连接组件的数量,来判断提取的动物数量是否正确。
图5展示了示例和实验结果。Veo 2的表现接近随机,而Veo 3的pass@10最高可达92.6%。
图6展示了一个编辑示例和评估结果,研究人员发现Veo 3尤其擅长在编辑过程中保留细节和纹理。
迷宫求解
在图7的迷宫求解中,各种迷宫标有起点(红色)和终点(绿色)位置。
Veo 2即使在求解较小规模的迷宫时也表现不佳,这主要由于生成过程中早期出现了非法移动,Veo 3 表现得更好。
总体来看,视频模型具备对数字视觉世界进行操作与模拟的能力。
图像编辑
图像编辑,是指根据文本指令对图像进行操作(例如添加、移除物体或更改外观)。
研究人员在Emu-edit数据集的一个随机子集(共 30 个样本)上评估了Veo的图像编辑能力。
图案对称补全任务用于评估模型对空间推理的理解与应用能力。图8显示,在这方面Veo 3的表现远超Veo 2和Nano Banana。
视觉类比任务用于评估模型理解物体变换及其关系的能力,属于抽象推理的一种形式。
图9显示,尽管Veo 2在理解类比任务方面表现不佳,Veo 3能够正确完成颜色变化和尺寸变化的样例。
然而,在镜像和旋转类比上,两种模型的表现均低于猜测水平(0.33),表明存在系统性错误偏差。
视觉领域的 「GPT-3 时刻」
近年来,自然语言处理(NLP)领域的发展尤为迅猛。
这一趋势由通用型大模型的崛起所推动,其在零样本学习场景中解决新任务的能力,已使其取代了NLP中大多数的特定任务模型。
研究人员据此提出一个观点:机器视觉也正处于类似的范式转变临界点,这一变革由大规模视频模型所展现的涌现能力所驱动。
本论文的核心发现是:
Veo 3能够以零样本方式完成各类任务,涵盖从感知、建模、操控,甚至到早期的视觉推理等整个视觉技术栈。
尽管其性能尚未尽善尽美,但Veo 2到Veo 3所展现出的显著且持续的性能提升,表明视频模型很有可能像语言模型之NLP一样,成为视觉领域的通用型基础模型。
研究人员认为当前视频模型正值一个激动人心的时刻:
机器视觉可能正在经历类似NLP从特定任务模型向通用模型转型的变革,而Veo 3等视频模型凭借其完成从感知到视觉推理等多种任务的零样本能力,或将引领这一转变,带来视频模型的 「GPT-3 时刻」。
参考资料:
https://video-zero-shot.github.io/
....
#MinerU2.5
又快又准!上海AI实验室等发布!文档解析新SOTA,1.2B模型性能超越GPT-4o
昨天,文档智能领域重量级玩家MinerU更新。来自 上海人工智能实验室(Shanghai AI Laboratory),联合 北京大学 和 上海交通大学 的庞大研究团队,共同发布了一份技术报告,详细介绍他们最新的文档解析视觉语言模型—— MinerU2.5 。
这个只有 1.2B(12亿) 参数的“小个子”模型,却在一系列文档解析任务中,展现了超越 GPT-4o、Gemini-2.5 Pro 等巨无霸模型的惊人实力,成功登顶多个基准测试的SOTA宝座。
那么,MinerU2.5究竟是如何做到“四两拨千斤”的呢?让我们一探究竟。
- 论文标题: MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
- 论文作者: Junbo Niu, Zheng Liu, Zhuangcheng Gu, Bin Wang, Linke Ouyang, 等 (一个庞大的研究团队)
- 作者机构: 上海人工智能实验室, 北京大学, 上海交通大学
- 论文地址: https://arxiv.org/abs/2509.22186
- 项目仓库: https://github.com/opendatalab/MinerU
- 模型下载: https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
- 在线演示: https://huggingface.co/spaces/opendatalab/MinerU
背景:高分辨率文档解析的“效率-精度”魔咒
我们日常接触的PDF、扫描件等文档,往往分辨率很高,包含了密集的文字、复杂的公式和精细的表格。对于AI模型来说,直接处理这种高分辨率图像,计算量会随着分辨率的增加呈平方级暴增,这让很多大模型望而却步,不得不先将图片“压缩”一下再处理。
但问题是,这一压缩,很多关键的细节信息就丢失了,导致识别精度严重下降。如何在保证精度的同时,又能高效地处理高分辨率文档,一直是文档AI领域难以破解的魔咒。
上图直观展示了MinerU2.5在OmniDocBench基准上的卓越表现,它在文本、公式、表格识别和阅读顺序预测等多个维度上,全面超越了包括Gemini、GPT-4o在内的通用VLM和领域专用模型。
MinerU2.5的核心策略:解耦的“先粗后精”两阶段解析
MinerU2.5的成功,核心在于其创新的 “先粗后精”(Coarse-to-Fine) 两阶段解析策略。这个策略巧妙地将全局的版面分析和局部的內容识别解耦开来。
如上图所示,整个流程分为两步:
阶段一:全局版面分析(Layout Analysis)
模型首先接收一个被下采样到 1036 × 1036 像素的低分辨率文档图像。在这一阶段,它的任务不是识别具体内容,而是快速、宏观地分析整个页面的结构,识别出文本块、表格、公式、图片等元素的位置。因为处理的是低分辨率图像,所以这一步的计算成本极低。
输入:原始高分辨率文档图像,经过统一缩放至 1036 × 1036 像素的缩略图。
处理:MinerU2.5模型 进行快速、整体的版面分析,捕获全局结构信息。
输出:抽象的版面信息,包括每个元素的位置(Position)、类别(Class)、旋转角度(Rotation Angle) 和 阅读顺序(Reading Order)。这种多任务范式解决了传统方法中旋转元素识别不佳和阅读顺序预测滞后的问题。
阶段二:局部内容识别(Content Recognition)
在获得全局版面信息后,模型会根据第一阶段定位的边界框(bounding boxes),返回到原始的高分辨率图像上,对这些关键区域进行精确裁剪。然后,模型会对这些高分辨率的“小图块”进行精细化的内容识别。每个裁剪区域的最大尺寸限制在 2048 × 28 × 28 像素,避免了因裁剪过小而丢失细节,也防止了冗余计算。
输入:第一阶段输出的版面信息,以及从原始高分辨率图像中裁剪出的局部区域。
处理:模型对裁剪出的局部区域进行细粒度内容识别,例如文本识别、公式识别和表格识别。
输出:识别出的内容,例如文本的OCR结果、公式的LaTeX表示、表格的OTSL(Optimized Table Structure Language)格式。
这种解耦的设计既利用了低分辨率图像进行快速全局定位的优势,又保留了高分辨率图像的细节信息用于精准识别,完美地绕开了“效率-精度”的魔咒。
成功的基石:强大的闭环数据引擎
再好的模型也离不开高质量数据的“喂养”。为了支持其独特的两阶段策略,团队还构建了一个全面、闭环的数据引擎,用于系统性地生成大规模、多样化的训练数据。
这个数据引擎的工作流程(如上图)主要包括三个核心阶段:
1. 数据策展 (Data Curation)
从海量的原始文档池中,根据版面、文档类型、元素平衡和语言等多个维度进行严格筛选和平衡,构建一个多样化且高质量的基础数据集。
- 版面多样性(Layout Diversity):通过页面级图像聚类,选择具有代表性的样本,覆盖广泛的视觉版面和风格。
- 文档类型多样性(Document Type Diversity):利用文档元数据(如学科、标签)进行分层抽样,确保学术论文、教科书、报告等各类文档的均衡表示。
- 元素平衡(Element Balance):通过初步检测模型,确保标题、段落、表格、公式、图表等关键元素的类别分布均衡。
- 语言平衡(Language Balance):过滤数据,保持中英文文档数量的平衡。
2. 预训练数据准备 (Pre-training Data Preparation)
对策展后的数据集生成初始标注,并利用专门的专家模型进行多步精炼,以确保高质量。
- 文本内容(Textual Content):利用强大的Qwen2.5-VL-72B-Instruct模型验证和纠正裁剪文本区域的初始文本识别结果。
- 公式内容(Formula Content):识别出的公式由内部训练的UniMERNet模型替换为更高保真度的输出,以提高准确性。
- 表格内容(Table Content):所有表格结构都使用内部高性能表格解析模型重新生成。 这个精炼流程生成了高质量的预训练数据集,涵盖了版面分析、文本识别、公式识别和表格识别这四个核心任务。
3. 微调数据构建 (Fine-tuning Dataset Construction)
这是最亮眼的部分。团队提出了一种名为 “基于推理一致性的迭代挖掘”(Iterative Mining via Inference Consistency, IMIC) 的策略,用于自动识别和筛选出模型难以处理的“硬案例”(Hard Cases)。
IMIC的思路(如上图)是:让模型对同一个样本进行多次“随机”推理。如果模型对这个样本的理解很透彻,那么每次的推理结果应该高度一致。反之,如果每次结果都“摇摆不定”,就说明这个样本是模型难以掌握的“硬骨头”(Hard Case)。数据引擎会自动筛选出这些“硬骨头”,交由人类专家进行高质量的精标,从而构建出一个极具价值的微调数据集,让模型能“缺啥补啥”,实现快速迭代和持续改进。
例如,对于版面分析,通过计算PageIoU来衡量一致性;对于表格识别,使用TEDS(Tree-Edit-Distance-based Similarity)评估一致性;对于公式识别,则使用CDM(Character-level Distance Metric)来评估。在复杂表格的预标注中,还使用了Gemini-2.5 Pro等基础模型。
任务重构与增强:为复杂文档而生
为了超越现有文档分析方法的局限性,MinerU2.5系统性地重构了版面分析、公式识别和表格识别的核心任务。
1. 布局分析的革新
- 统一标注系统(Unified Tagging System):针对现有数据集标注不一致的问题,MinerU2.5设计了一个分层且全面的标注系统,包含三个关键原则:
- 全面覆盖(Comprehensive Coverage):包含页眉、页脚、页码等非主体元素,对下游应用(如RAG)至关重要。
- 细粒度(Fine Granularity):将复杂元素分解,例如将图表细分为图像、图表、化学结构等。
- 语义区分(Semantic Distinction):为代码、算法、参考文献、列表等视觉上不同的文本块分配独立的类别,以保留关键语义信息。
- 增强型多任务范式(Enhanced Multi-Task Paradigm):传统布局分析常被视为目标检测任务,忽略元素旋转和阅读顺序。MinerU2.5将其重定义为多任务问题,在单次推理中同时预测每个文档元素的位置(Position)、类别(Class)、旋转角度(Rotation Angle) 和 阅读顺序(Reading Order)。这种集成设计有效解决了旋转元素解析的挑战,并简化了整个文档分析流程。
2. 公式识别的突破:原子分解与重组(ADR)框架
现有模型在处理长公式或多行公式时表现不佳,且VLM容易产生结构性幻觉。MinerU2.5引入了 原子分解与重组(Atomic Decomposition & Recombination, ADR)框架,采用“分而治之”的策略。
如上图所示,ADR框架是一个四阶段流水线:
- 公式检测(Formula Detection):MinerU2.5首先识别页面上的所有公式区域,并分类为原子公式或复合公式。
- 原子分解(Atomic Decomposition):将识别出的复合公式分解为有序的原子公式行序列。
- 公式识别(Formula Recognition):将这些简单的、语义独立的原子公式图像送回MinerU2.5模型,进行高精度的LaTeX字符串翻译。
- 结构重组(Structural Reconstruction):利用初始版面分析的位置信息,将单独的LaTeX字符串结构化重组为一个连贯的块,确保整体结构的逻辑完整性。 这种方法将一个困难的识别任务分解为一系列简单的子任务,确保了每个组件的高保真识别和整体结构的逻辑完整性。
3. 表格识别的增强:优化表格结构语言(OTSL)
表格识别的挑战在于处理复杂、长表格,特别是对于以HTML为目标的VLM方法。MinerU2.5提出了一个四阶段的表格识别流水线,并引入了 优化表格结构语言(Optimized Table Structure Language, OTSL)。
如上图所示,该流水线包括:
- 表格与旋转检测(Table & Rotation Detection):检测表格的边界框和旋转角度。
- 裁剪与旋转校正(Crop & Rotation Correction):对检测到的表格进行裁剪和旋转,将其校正到标准方向。
- 表格识别(Table Recognition):利用OTSL作为中间表示进行表格结构识别。OTSL相比HTML,结构化token数量从28个减少到5个,平均序列长度缩短约50%,使其成为更有效的模型生成目标。
- OTSL到HTML转换(OTSL to HTML):将OTSL输出直接转换为标准的HTML格式。 OTSL的引入显著减少了结构化token的数量,缩短了平均序列长度,使其成为VLM更有效的目标语言。
实验结果:全方位SOTA
MinerU2.5的性能到底有多强?论文在多个权威基准上给出了详尽的对比。
在综合性的 OmniDocBench 基准上,MinerU2.5的总分达到了 90.67 ,显著超过了第二名的dots.ocr(88.41)和Gemini-2.5 Pro(88.03)。无论是在文本识别、公式识别还是表格识别任务上,它都取得了SOTA或极具竞争力的结果。
在面向密集文本的 Ocean-OCR 基准上,MinerU2.5同样表现出色,无论是在英文还是中文文档上,其编辑距离和F1分数等多项指标均名列前茅。
除了数字上的胜利,论文还展示了大量定性的例子,从学术论文、书籍、财报到手写笔记和考试试卷,MinerU2.5都表现出了强大的解析能力。
在处理各类复杂表格(如手写、无框线、跨页、旋转表格)和复杂公式时,MinerU2.5也比现有模型更加鲁棒。
MinerU2.5不仅是一个性能卓越的模型,更重要的是,它为大模型时代下的文档智能提供了一个轻量、高效、精准的范式。它证明了通过巧妙的架构设计和系统的数据工程,小模型同样可以爆发出巨大的能量。
团队已经将模型、代码和在线演示全部开源,强烈推荐大家去尝试和体验!
...
#Thinking Machines又发高质量博客
力推LoRA,不输全量微调
LoRA 在绝大多数后训练场景下,能以远低于全量微调的成本,获得几乎同等的效果。Thinking Machines 将这一现象形容为 LoRA 的低遗憾区间(low-regret region)——即便不用全量微调,选择 LoRA 也不会让人后悔。
最近,Thinking Machines 真实高产啊。
今天,他们又更新了博客,力推 LoRA,且与全量微调( Full Fine-tuning ,以下简称 FullFT )进行了对比。

博客链接:https://thinkingmachines.ai/blog/lora/
训练大模型,到底该选全量微调还是 LoRA?
FullFT 意味着改动模型的所有参数,效果稳定但成本高昂,显存开销巨大;而LoRA 只改动一小部分参数,轻量、便宜。但一个关键问题是:便宜的 LoRA,效果会不会差很多?
Thinking Machines 最新研究发现,在小数据量任务上,LoRA 与 FullFT 几乎没有差距,完全可以对齐;在大数据量任务上,LoRA 的容量不足,承载不了过多新知识,表现略显吃力;而在强化学习任务里,哪怕 LoRA rank=1 这么小的设定,也能跑出与全量微调接近的效果。
更进一步,LoRA 的使用位置也有讲究。只加在注意力层并不理想,覆盖所有层(尤其 MLP/MoE)效果更佳。
研究还揭示了一些细节差异。例如,LoRA 在大 batch size 下,比 FullFT 更容易掉性能;LoRA 的学习率和超参数规律与 FullFT 不同,需要单独调优。
以下是这篇博客的主要内容。
为什么 LoRA 重要?
低秩适配( LoRA )是目前最热门的参数高效微调(PEFT)方法。它的核心思想是:不直接改动整个模型的权重,而是通过学习一个低维适配器(两个小矩阵 A 和 B)来表示更新。

LoRA 的优势包括:多租户部署(同一模型可同时加载多个适配器)、低显存需求、快速加载和迁移。这些特性让它自 2021 年诞生以来迅速流行。
不过,现有研究对它能否完全匹敌 FullFT 并没有一致答案。
学界普遍认为,在类似预训练的大规模数据场景下,LoRA 性能会逊于 FullFT ,因为数据规模往往超出 LoRA 参数容量。但在后训练任务中,数据规模通常处于 LoRA 容量可覆盖的范围,这意味着核心信息能够被保留。
尽管如此,这并不必然保证 LoRA 在样本利用效率和计算效率上能完全与 FullFT 持平。我们关注的核心问题是:
在什么条件下,LoRA 能实现与 FullFT 相当的效果?
实验结果显示,只要关键细节得到妥善处理,LoRA 不仅能匹配 FullFT 的样本效率,还能最终达到相似的性能水平。
LoRA 的关键要素
研究的方法有别于以往研究:
不再局限于单一数据集或任务,而是系统考察训练集规模与 LoRA 参数数量之间的普适关系;在有监督学习中,研究采用对数损失(log loss)作为统一评估指标,而非依赖采样式评测,以获得更清晰且可跨任务比较的结论。
实验结果表明,在小到中等规模的指令微调和推理任务中,LoRA 的表现可与FullFT 相媲美。然而,当数据规模超出 LoRA 参数容量时,其表现将落后于 FullFT,这种差距主要体现在训练效率的下降,而非无法继续优化。性能下降的程度与模型容量和数据规模密切相关。
此外,LoRA 对大批量训练的容忍度低于 FullFT 。当批量规模超过一定阈值时,损失值会明显上升,这种现象无法通过提升 LoRA 的秩(rank)来缓解,因为它源自矩阵乘积参数化的固有训练动力学,而非原始权重矩阵的直接优化。
即便在小数据场景,将 LoRA 应用于所有权重矩阵,尤其是 MLP 与 MoE 层,均能获得更优表现。相比之下,仅对注意力层进行 LoRA 调整,即使保持相同可训练参数量,也无法达到同样的效果。
在强化学习任务中,即使 LoRA 的秩(rank)极低,其性能仍可接近 FullFT 。这与我们基于信息论的推断一致:强化学习对模型容量的需求相对较低。
研究还分析了 LoRA 超参数对学习率的影响,包括初始化尺度与乘数的不变性,并揭示了为何 1/r1/r1/r 因子使 LoRA 的最优学习率与秩变化几乎无关。同时实验显示,LoRA 的最优学习率与 FullFT 存在一定关联。
综合来看,研究提出了低遗憾区域(low-regret region)的概念——
在该区域内,大多数后训练场景下,LoRA 能以显著低于 FullFT 的成本,实现相似的性能。这意味着,高效微调在实际应用中完全可行,LoRA 因而成为后训练的重要工具。
实验方法与主要发现
研究团队用 LLaMA 3 和 Qwen3 模型,做了有监督微调(Tulu3 和 OpenThoughts3 数据集)以及强化学习任务(数学推理)。关键做法包括:
- 调整 LoRA 的秩(rank),从 1 到 512,覆盖从低容量到高容量的场景。
- 对每个设置做学习率扫描,确保找到最优训练条件。
- 测试 LoRA 在不同层的效果,包括 attention 层、MLP 层、混合专家(MoE)层。
结果发现:
- 在小到中等数据规模下,高秩 LoRA 的性能几乎与 FullFT 无差别。

在 Tulu3 和 OpenThoughts3 数据集上,全量微调(FullFT)以及高秩 LoRA 的学习曲线非常相似,损失随训练步骤的对数几乎线性下降。而低秩 LoRA 则会在适配器容量耗尽时偏离最小损失曲线。在底部的图表(1B 模型)中,高秩 LoRA 在某个数据集上表现优于 FullFT,但在另一个数据集上则略逊一筹。这可能与不同数据集的训练动态或泛化行为差异有关,从而导致 LoRA 在不同任务上的表现存在一定随机性。

结果显示,对于 Tulu3 数据集,不同秩的 LoRA 在最佳学习率下的最终损失相差不大,高秩 LoRA 与 FullFT 的最小损失几乎一致。然而,LoRA 的最佳学习率约是 FullFT 的 10 倍,这意味着在相同条件下 LoRA 可以接受更高的学习率。
- 对于超过 LoRA 容量的数据集,LoRA 的表现不如 FullFT。 损失并不会达到一个无法降低的明显下限,而是会导致更差的训练效率,这种效率取决于模型容量与数据集大小之间的关系。
- 大批量训练下,LoRA 性能下降比 FullFT 更明显,这与秩无关,可能是参数化方法的固有特性。

批量大小对 LoRA 与 FullFT 性能的影响如图所示。左侧的学习曲线展示了在不同批量大小下的表现:在较大批量情况下,LoRA(虚线)的学习曲线始终低于 FullFT(实线),表现出持续的差距。右侧的图表则展示了最终损失与批量大小的关系,表明随着批量大小的增加,LoRA 所付出的损失代价更大。
- 即使在数据量小的情境下,LoRA 在应用于所有权重矩阵(特别是 MLP 和 MoE 层)时表现更好。仅应用于注意力层的 LoRA(attention-only LoRA)表现不佳,即使研究人员通过使用更高的秩来匹配可训练参数的数量(与 MLP-only 相比)。

仅作用于注意力层的 LoRA(Attention-only LoRA)明显不如仅作用于 MLP 层的 LoRA(MLP-only LoRA),而且在已对 MLP 层应用 LoRA 的情况下,再对注意力层额外应用 LoRA 并不能进一步提升性能。这一现象在密集模型(如 Llama-3.1-8B)和稀疏 MoE 模型(如 Qwen3-30B-A3B-Base)中均成立。

改变应用 LoRA 的层时,学习率与最终损失或奖励的关系。
- 在强化学习任务中,即使秩极低(rank=1),LoRA 也能达到 FullFT 水平,这与强化学习对容量需求较低的理论预期一致。

在小学数学(GSM,左图)或 MATH(右图)数据集上进行强化学习时,学习率与最终奖励(准确率)的关系。

在 DeepMath 数据集上使用 Qwen3-8b-base 进行的实验。左图显示了不同 rank 和全量微调(FullFT)的学习曲线。在每种设置下,我们选取了能带来最佳最终性能的最优学习率。右图则展示了学习率与最终性能的关系。与之前的数学实验类似,LoRA 在近似最优学习率范围上表现出更宽的峰值。

来自使用 Qwen3-8b-Base 在 DeepMath 数据集上实验的附加图表。左图显示了在更具挑战性的 AIME 测试集上的基准得分,右图展示了随训练步骤变化的链式思维(CoT)长度,这可被视为模型学习推理能力的一个标志。
LoRA 超参数规律
LoRA 有几个显著特点,简化了它的使用复杂度:
- 最优学习率通常是 FullFT 的 约 10 倍。
- 学习率对秩的依赖非常弱,短期训练几乎不受秩变化影响,长期训练差异也很小。
- LoRA 参数化具有不变性,实际只需关注两个组合超参数即可。
- 初期训练时,LoRA 需要更高的学习率(约 15 倍 FullFT),长期训练则趋近于 10 倍。
这些规律为 LoRA 在实际部署中提供了便利:少调超参数就能取得接近全量微调的效果。

训练早期,不同 rank 在相同学习率下的学习曲线差异。左图显示了各 rank 的学习曲线,右图则展示了 rank 16 与 rank 256 之间的差异,这个差异随时间增长。有趣的是,在最初几步中差异为负(尽管非常微小),因此那部分曲线在图中缺失。
讨论
1、为什么 LoRA 必须作用于所有层?我们发现,LoRA 要与 FullFT 接近,必须满足两个条件:作用于所有层,特别是 MLP/MoE 层,因为这些层承载了模型绝大部分参数。容量不受限制,可训练参数必须足够容纳数据中所需的信息量。
仅在 attention 层使用 LoRA 会导致训练速度下降,这可以用经验神经切线核(eNTK)解释:参数最多的层对训练动态影响最大,LoRA 覆盖所有参数层,才能保持 FullFT 的训练行为。
2、我们用信息论方法估算了容量需求,这种分析为 LoRA 在不同任务中能否胜任提供了理论支持:
在监督学习中,模型大约可存储每个参数 2 bits 信息。数据集的描述长度可以通过第一轮训练的总 log-loss 估算;
在强化学习中,尤其是策略梯度方法,每个 episode 约提供 1 bit 信息。这说明强化学习对 LoRA 容量的要求相对较低。
3、计算效率优势。LoRA 只更新低秩矩阵,而不是全权重矩阵,这让它在计算上更省力:前向+反向传播的 FLOPs 大约是 FullFT 的 2/3。
换句话说,LoRA 在相同训练步骤下,能用更少计算量达到相似效果。
未来探索方向
研究团队认为,LoRA 仍有几个值得深入探索的方向:精准预测 LoRA 性能及其与 FullFT 的差距条件、建立 LoRA 学习率与训练动态的理论框架、测评 LoRA 变体(如 PiSSA)的表现,以及研究 LoRA 在 MoE 层的不同应用方案及其与张量并行、专家并行的兼容性。
....
#GLM-4.6
节前重磅:开源旗舰模型新SOTA,智谱GLM-4.6问世
新一代大模型的发布,都赶在了国庆假期前。
昨天,深度求索刚刚开源 DeepSeek-V3.2-Exp。
今天,另一国产大模型x之光智谱 AI 也正式发布了旗下新一代旗舰模型 GLM-4.6,刚好撞车 Claude Sonnet 4.5。
但有一点不同,智谱的 GLM-4.6 会继续开源,它即将上线 Hugging Face、ModelScope 等平台,遵循 MIT 协议。
这一「节前惊喜」迅速点燃了技术圈的热情,海外开发者甚至发出了「Do the Chinese guys ever rest???」的感叹 。

但新模型也让大家非常期待,这不刚发出来,就被网友们给盯上了。

性能新高,token 消耗降低
突破开源上限
作为 GLM 系列的最新版本,GLM-4.6 在多个方面实现了全面提升,包括但不限于:
- 高级编码能力:在公开基准与真实编程任务中,GLM-4.6 代码能力对齐 Claude Sonnet 4,是国内已知的最好的 Coding 模型;
- 上下文长度:上下文窗口由 128K 增加至 200K,适应复杂的代码与智能体任务;
- 推理能力提升,并支持在推理过程中调用工具;
- 增强了模型的工具调用和搜索智能体,在智能体框架中表现更好;
- 更强的写作能力:在文风、可读性与角色扮演场景中更符合人类偏好。
根据智谱报告,GLM-4.6 模型在八大权威基准评测上性能有了全面提升,包括:AIME 25、LCB v6、HLE、SWE-Bench Verified、BrowseComp、Terminal-Bench 和 τ²-Bench。新模型在其中多个基准上胜过了 Claude Sonnet 4/Claude Sonnet 4.5,位居国产模型首位。

接下来是在 Claude Code 环境下进行的 74 个真实场景编程任务测试,GLM-4.6 实测性能超过了 Claude Sonnet 4,以及其他国产模型。

值得关注的是,在平均 token 消耗上,GLM-4.6 比 GLM-4.5 节省了 30% 以上,为同类模型最低。当然,它的 Coding API 价格也只是 Claude 的 1/7,性能更好,速度更快还更便宜。

新模型同时适配了国产 AI 硬件:GLM-4.6 已在寒武纪芯片上实现 FP8+Int4 混合量化部署,这是首次在国产芯片投产的 FP8+Int4 模型芯片一体解决方案。该方案在保持精度不变的前提下,可以大幅降低推理成本,为国产生态下大模型本地化运行开创了可行路径。
另外,基于 vLLM 推理框架部署,摩尔线程新一代 GPU 也可以基于原生 FP8 精度稳定运行 GLM-4.6。
一手实测
GLM-4.6 全方位提质
目前,GLM-4.6 已经上线 z.ai 等平台,用户在模型选择器中选择它即可开始尝试。

在这里可以看到,智谱为该模型设置的简短描述是「最先进的模型,擅长处理全方位任务」,同时也能看到智谱预设的一些工作模式和示例案例,包括 AI PPT、全栈开发、灵感画板、深度研究、写代码等等。我们也是第一时间进行了实测。
首先,我们先让 GLM-4.6 写一个「俄罗斯方块 + 贪吃蛇」游戏,看看其「写代码」的能力。开启「自动思考」,输入以下提示词:
用 Python(使用 pygame)编写一个融合俄罗斯方块和贪吃蛇的小游戏:画面分为上下两部分,上半部分有一条会自动移动的蛇,玩家需控制下落方块左右移动以躲避蛇;当方块进入下半部分后,按照俄罗斯方块规则继续下落,玩家需要把它放入合适位置以消除整行。若方块与蛇相撞则游戏结束;支持方向键移动、空格键加速下落;蛇可随机改变方向。程序需包含初始化、事件处理、逻辑更新和渲染绘制等模块,并写清注释。
可以看到,GLM-4.6 在详细分析了我们的需求之后便开始了码代码工作,并且完成之后还给出了非常详细的游戏说明,包括游戏特色、操作方式、游戏规则和程序结构。尤其值得一提的是其工作速度:完成该任务的时间仅 1 分钟左右!

上下滑动查看
复制出来运行一下看看效果,可以看到,除了 VS Code 默认字体设置问题之外,这个 GLM-4.6 一次性完成的「俄罗斯方块 + 贪吃蛇」游戏已经完整可玩,游戏逻辑也完全遵照了我们的提示词设定,表现堪称惊艳。

一个简单的游戏或许还不足以探知其代码能力的上限。接下来,我们将难度提升一个量级,要求它处理涉及真实物理数据和 3D 可视化的复杂任务:让 AI 构建一个相比扁平的圆形更接近真实的太阳系的演示模型:
请使用 Python 创建一个太阳系动态可视化演示,大体基于真实天文数据,但太阳大小可适当缩小以方便查看:包含太阳和八大行星(水星至海王星),采用 JPL 提供的轨道六根数初始化各行星轨道;以太阳系质心为参考点,利用牛顿万有引力定律构建运动微分方程,并通过数值积分模拟行星在三维空间中的轨迹;使用 matplotlib 的 3D 绘图功能实时动画展示行星绕日运动,正确体现轨道倾角、椭圆偏心率及相对公转周期;坐标轴单位为天文单位(AU),时间步长可调,并在图中标识各行星名称;代码需结构清晰、注释完整,并说明所作简化(如忽略行星间引力摄动或仅考虑日心引力)。界面使用微软雅黑字体。
这一次,GLM-4.6 同样很快就完成了任务(约 2 分钟)。这个任务的难点不仅在于代码量,更在于对天文学知识、物理公式(牛顿万有引力定律)以及专业数据库(JPL 轨道数据)的理解和应用。

上下滑动查看
将代码复制到运行环境,导入必要的库,运行:

结果再次令人印象深刻。GLM-4.6 再一次实现了「零修改」一次性运行成功!它不仅相当完美地基于 JPL 轨道数据生成了会随时间演进的 3D 太阳系模型,还贴心地加入了坐标轴设置功能,让我们能从不同视角清晰观察行星轨迹。并且,由于我们在提示词中明确指定了字体,上次实验遇到的显示问题也得到了完美解决。这证明了其代码能力不仅强大,而且对指令的遵循度极高。
当然,我们也可以将 GLM-4.6 接入到强大编程智能体 Claude Code 中。
配置完成后,我们让 GLM-4.6 尝试完成了以下任务:
写一个 Python 程序,使用 asyncio + aiohttp,并发爬取前 20 个知乎热榜问题页面,提取问题标题、回答数量、关注人数,然后将结果存储为一个 MD 文件。
,时长02:20
可以看到,接入 Claude Code 的 GLM-4.6 的运行速度同样非常快。同时得益于 Claude Code 强大的框架设计,GLM-4.6 可以针对一个具体项目进行反复优化,比如视频中我们可以看到 GLM-4.6 对目标 Python 程序的反复验证和修改,最终得到了理想的结果。
当然,作为科技媒体小编,保持对新闻的关注自然非常重要,借助 Claude Code + GLM-4.6,这个任务可以变得更加简单。
检索 24 小时内发生的热门 AI 新闻,整理一份报告给我,结果保存为一个 Markdown 文件。
,时长01:25
继续对话,我们还能让 GLM-4.6 将其设置成一个每天 8 点定时运行的任务,这样我们一上班就可以看到过去 24 小时最新的 AI 新闻报道了。
,时长03:38
可以看到,GLM-4.5 编写并优化了实现该自动化任务的脚本,我们也只需一次运行即可将其变成我们计算机上的一个定时任务。
在连续验证了其强大的「理科」编程能力后,我们来看看这个「擅长处理全方位任务」的 GLM-4.6 模型在深度研究和内容创作上的「文科」表现。 我们打开「联网搜索」,给它布置一个科技媒体工作者日常可能遇到的真实任务:
请撰写一篇深度调查报道,题为 “从 OpenAI 出走的创业者:他们是谁,又在做什么?”。基于公开可靠信息,梳理至少 5 位曾任职 OpenAI 研究或技术岗位、后离职创业的核心人物,包括其姓名、在 OpenAI 的角色、离职时间、所创公司名称、技术方向、融资或产品进展;分析他们离开的可能动因(如理念分歧、自主权或商业化考量);探讨这一人才外流对 AI 行业竞争与创新的影响,以及这些初创公司可能如何塑造未来 AI 发展。报道需专业、客观,兼具叙事性与分析深度。

上下滑动查看
从其思考过程看,GLM-4.6 首先基于任务需求检索了网络,得到了足够的必要信息,然后为「OpenAI 黑手党」构建了一份相当全面的报道,其中不仅列出了大量关键信息和细节,同时还显式地索引了相关来源以供验证。
对于我们媒体工作者而言,这已经不是一个简单的「资料整理工具」,而是一个能够提供洞见、辅助分析的强大研究伙伴。
如果说代码生成和研究报告还是相对独立的任务,那么全栈开发则考验的是模型将前后端逻辑整合、构建一个完整产品的工程能力。这一次,我们采用了一个更有趣的方式,直接让模型自己给自己出题:

新开一个窗口,选择「全栈开发」模式,将这条由 GLM-4.6 自己生成的提示词再交还给它:
,时长03:28
可以看到,GLM-4.6 在分析完任务后,首先构建了一个明确的待办事项,这本质上是它的项目开发路线图:包括设计 Todo 方案、创建前端、实现 RESTful API 路由、增加本地存储以供离线使用、测试功能。这种「先规划、后执行」的工作模式,非常接近人类程序员的思维方式。之后,它便一步步地完成了所有任务。经过实测,生成的应用功能完备,交互流畅。
更锦上添花的是,我们能直接将生成的结果以网页应用形式发布到 space.z.ai。感兴趣的读者可以访问下方链接,亲自试用这个由 GLM-4.6 在几分钟内新鲜出炉的待办事项管理应用:
https://a019u8vgp630-deploy.space.z.ai
除了上述硬核能力,GLM-4.6 也集成了多模态生成等便捷功能。在预设的 AI PPT 和灵感画板模式中,模型可以快速将想法变为现实。比如,我们让它生成了一张介绍「蕾姆」的小红书风格封面图。
执行该任务时,GLM-4.6 首先会联网检索并理解「蕾姆」这一角色,下载相关素材,然后再通过生成 HTML/CSS 代码来设计和构建版式,最终呈现出一张符合要求的图片。这展示了它理解、检索、设计、生成的综合能力。

不止于强大,更趋于全能
通过从代码生成、深度研究到全栈开发等一系列的实测,我们可以得出结论:智谱 AI 为 GLM-4.6 设定的「最先进的模型,擅长处理全方位任务」的描述并非虚言。
它的强大之处体现在:
- 极高的代码生成质量:在多个复杂项目中实现了「一次性成功」,代码逻辑严谨、功能完整。
- 深刻的需求理解与规划能力:无论是拆解游戏规则,还是规划全栈应用开发步骤,都展现了清晰的「思路」。
- 惊人的执行效率:分钟级的响应速度,大幅提升了开发和研究的效率。
- 全面的综合能力:无缝整合了联网搜索、多模态生成和应用部署,使其成为一个真正的「全能工作站」。
毫无疑问,GLM-4.6 已经展现出了顶级大模型应有的水准,它不仅是一个强大的工具,更是一个能够激发创造力、赋能专业工作的得力助手。
现如今,智谱的 GLM 系列大模型已成为全球开源 AI 领域的一支重要力量。新推出的 GLM-4.6 不论是在技术架构、性能表现,还是在使用成本上都为全球业界树立了新的标杆。我们有理由期待它在未来的应用中带来更多惊喜。
参考链接
GLM-4.6 技术博客:https://z.ai/blog/glm-4.6
....
#EchoCare“聆音”
CAIR开源发布超声基座大模型EchoCare“聆音”,10余项医学任务性能登顶
2025年9月17日,中国科学院香港创新研究院人工智能与机器人创新中心(CAIR)在香港正式开源发布其最新科研成果——EchoCare“聆音”超声基座大模型(简称“聆音”)。该模型基于超过450万张、涵盖50多个人体器官的大规模超声影像数据集训练而成,在器官识别、器官分割、病灶分类等10余项典型超声医学任务测试中表现卓越,性能全面登顶。同时,“聆音”已在山东大学齐鲁医院、中南大学湘雅医院、香港中文大学医学院的多个超声检查领域完成3000多例临床回溯性验证,与当前SOTA(最优)模型相比,性能平均提高3%~5%。
“聆音”首创的结构化对比自监督学习框架,高效解决了传统超声AI模型普遍存在的技术难题,包括对大规模标注数据的依赖、难以处理长尾分布问题、模型泛化能力不足以及缺乏足够领域知识。同时,该框架为AI大模型在其他医疗领域的应用探索提供了创新路径,是人工智能与临床医学深度融合的又一里程碑式突破。
超声AI的发展困局:数据枷锁与泛化死结
超声诊断凭借动态成像与无创安全的双重优势,已成为医学影像领域的“核心工具”。目前,我国超声年检查量已超20亿人次,占医学影像检查总量的70%以上。从产科胎心的实时监测,到急诊创伤的快速评估,再到慢性病的长期随访,超声技术贯穿临床诊疗的全流程。然而,超声AI在快速发展的同时,仍面临多重挑战。
1.1复杂且多样化的临床需求
超声图像的“多变性”使大模型难以应对。在设备层面,不同厂商的信号算法差异会导致相同解剖结构呈现出截然不同的纹理特征;在操作层面,医师的扫查角度、探头压力等变量会导致同一患者的图像发生显著变化。这些因素直接导致传统超声AI面临“碎片化开发”的困局,严重制约了技术的落地。
1.2现有解决方案的致命短板
虽然医学影像领域的基座模型如MedSAM、BioMedCLIP、USFM等已崭露头角,但在超声领域表现仍显不足。数据显示,现有超声AI训练数据量普遍低于100万张,且多集中于单一部位。更为关键的是,这些模型大多直接套用自然图像的算法架构,未能针对超声特有的斑点噪声、声影伪影等特性,以及“区域-器官”的临床推理逻辑进行定制化优化。

1.3理想超声模型的三大标准
临床对超声AI的核心诉求包括:数据高效性,需摆脱对专家标注的高度依赖;场景适应性,能够快速适配多部位、多任务应用;临床实用性,输出结果需符合诊断习惯,支撑全流程辅助。“聆音”正是基于这三大标准,通过“数据奠基-架构创新-场景验证”的路径构建而成。
“聆音”的技术突破:数据、架构与范式革新
2.1全球规模最大的超声图像数据集
“聆音”的突破始于数据根基。团队遵循“广度覆盖+深度质控”的原则,从Zenodo、Kaggle等多个渠道整合了138个高质量数据集,涵盖五大洲20多个国家,最终构建了一个包含超过450万张图像的EchoAtlas,其数据规模位居全球首位。
这份数据集展现出极强的多样性:在人种上,涵盖黄种人、白种人、黑种人、棕种人;在解剖结构上,覆盖人体9大区域的56个解剖器官;在模态上,涉及B超、M超、超声造影、弹性成像等5大主流类型;在设备上,涵盖飞利浦、西门子、日立等130种不同厂商的产品。同时,为确保数据质量,团队建立了四阶段质控体系,为“聆音”的性能突破奠定了坚实的数据基础。

2.2层级化双分支架构:贴合临床诊断逻辑
针对超声特性,“聆音”创新设计了层级化双分支架构,有效突破了传统模型架构的局限性:
图像编码器以SwinTransformer为骨干,同时通过优化注意力机制增强边缘特征的鲁棒性,从而有效应对超声斑点噪声的干扰。
双分支解码器实现双重特征学习:图像重建分支学习组织纹理等像素级特征;解剖分类分支引入三级分类头,模拟医师“胸部→心脏→心尖四腔心”的诊断思维,逐步提取并分类解剖结构特征。
层级化损失函数构建多任务优化目标:引入图像重建损失和层级化损失,在提升图像重建质量同时学习超声图像之间的语义关联,有效解决“同一器官不同视图”下的歧义问题。
这种架构与临床诊断逻辑高度契合,使模型不仅能够“看懂图像”,还能够“理解结构”。
2.3自监督训练范式:无标注数据的价值最大化
“聆音”采用两阶段训练策略,充分挖掘无标注数据的价值:
全局预训练阶段首创结构化对比自监督学习框架,基于医学先验的层次化树形标签结构,实现多标签语义关系的结构化学习与隐式编码,并结合图像掩码重建与自适应困难图块挖掘技术,引导模型聚焦于临床诊断关键细节。
下游任务微调阶段:分割任务将预训练的编码器结合解码器;诊断任务使用分类的蔬菜头;量化任务在预训练的骨干网络添加回归头进行预测络。通用预训练编码器使微调仅需原训练量 40%-60% 即可快速适配新任务。

临床验证:10项任务突破现有技术水平
团队在 7 大类 10 项核心超声任务中验证 “聆音” 性能,所有数据均来自未参与预训练的独立中心,确保结果客观。

3.1解剖分割:精准定位组织区域
分割作为诊断基础,“聆音” 在三项任务中表现突出:甲状腺结节分割,血管分割和腹部多器官分割。其中,对于甲状腺结节分割,“聆音” 的 DSC 达 83.17%,比 USFM 高约 3%。血管分割任务,“聆音” 实现 mDSC 指标 82.24%,比 USFM 高 2%,显著高于传统模型 SwinUNETR 的 70.20%。腹部多器官分割数据集,“聆音” 同样实现了最高的多器官识别分割性能。
3.2疾病诊断:提升准确性与一致性
在高价值诊断任务中,“聆音” 展现出临床价值:甲状腺结节良恶性鉴别(192 个病理证实结节)的 AUC 达 86.48%,F1 分数 87.45%,假阳性率仅 8.3%。引入时序特征使 AUC 提升 4.2%,<1cm 恶性结节检出率达 82.1%,比现有模型高 11.3%,可减少 30% 不必要活检。乳腺 BI-RADS 分级多分类的准确率 70.36%,比 USFM 高 3.09%。肝脏病变诊断准确率 87.12%,肝癌敏感性 90.3%、特异性 88.7%,辅助医师理解依据。
3.3定量分析:精准计算关键指标
量化指标是疾病评估金标准,“聆音” 在两项核心任务中实现高精度:胎儿心胸比测量的检测定位准确率 94.42%,比 USFM 高 2.78%,误差 < 5% 的病例占 89.2%,测量时间从 5 分钟缩至 2 秒,助力先天性心脏病筛查。而在 CAMUS 数据集上,左心室射血分数计算 MAE 比 USFM 低 19%,有望用于指导心衰治疗。
3.4特殊场景:破解基层与未知部位难题
低质量图像增强任务中,“聆音” 的 NIQE6.35、BRISQUE17.62,均优于 USFM 与 EnlightenGAN。
3.5临床适配:高效且实用
标注效率上,“聆音” 用 60% 标注数据即可达传统模型 100% 数据性能,血管分割仅需 40% 数据实现 80% 性能上限,收敛速度快 30%-40%。
临床适配性上,单张图像分析 < 0.5 秒满足实时需求;输出分割掩码、热力图等可视化结果;报告生成的 BLEU-4 达 78.47,可辅助医师完成初稿。
讨论与展望:超声AI的未来方向
4.1技术创新的核心价值
“聆音”通过三大创新破解行业难题:数据层面构建大规模超声预训练数据集,打破数据壁垒;架构层面设计贴合临床应用的双分支结构;训练层面首创结构化对比自监督学习框架,实现像素与语义特征协同学习。这些创新带来性能突破、临床适配与生态构建的三重价值。
4.2现存局限与改进路径
当前模型仍有提升空间:多模态信息融合不足,未来需构建图文等多模态超声数据集,赋予模型多模态分析能力;动态序列处理能力薄弱,未来将扩展至超声视频等时序数据的分析与处理;临床落地需深化,计划开展10家医院的多中心试验,建立性能监测体系。
4.3超声AI的三大发展趋势
从"专用模型"到"通用基础模型",未来超声AI将成为覆盖全流程的"AI助手";从"数据驱动"到"数据-知识双驱动",融合临床规则以提升泛化能力与可解释性;从"被动辅助"到"主动决策支持",实现实时提示病变、推荐方案、预测风险的能力。
结论
“聆音”作为首个面向超声临床场景的超声基座大模型,通过超过450余万张大规模多器官、多中心、多地区超声数据预训练,以及层级化双分支架构的创新模型设计,在超声医学图像分割、诊断、量化分析等10项核心临床任务上实现了性能突破。
其技术价值不仅体现在超越现有模型的准确率与泛化能力,更在于构建了"大规模数据-定制化架构-多场景验证"的超声AI研发范式,为行业发展提供了新思路。
该研究的公开数据集(EchoAtlas)和模型代码,将打破超声AI领域的数据壁垒和技术垄断,推动更多科研机构和企业参与到超声AI的创新研究中。随着多中心临床试验的开展和技术的持续优化,“聆音”有望在基层医疗、远程诊断、慢性病管理等场景中发挥重要作用,为提升全球超声诊断水平、实现医疗资源普惠做出贡献。
未来,随着多模态融合、知识驱动学习等技术的发展,超声AI将从"图像分析工具"进化为"全流程临床决策伙伴",为精准医疗和个性化医疗的实现提供强大支撑,最终实现"以患者为中心"的医疗AI发展目标。
EchoCare“聆音”超声基座大模型可通过以下渠道获取:
https://echocare.cares-copilot.com/
....
#Claude Sonnet 4.5
Claude Sonnet 4.5来了!能连续编程30多小时、1.1万行代码
十一假期还没开始,大模型又开始卷起来了!
昨天,DeepSeek 开源新模型 V3.2-Exp,深夜 Anthropic 也不甘人后,重磅发布 Claude Sonnet 4.5。

作为编程领域的王者,Claude 新模型依然强势,自称为世界上最好的编码模型。
我们都知道,GPT-5 Codex 曾自称能独立运行超过 7 小时。但这次,Claude Sonnet 4.5 把自主编码时长提到了 30 多个小时。

此外,Claude 还称它为构建复杂智能体的最强模型,也是使用计算机( computer use)的最佳模型,在推理和数学方面显示出巨大的进步。
Claude Sonnet 4.5 使这一切成为可能。Anthropic 将它与一系列产品重大升级一同发布:
- 在 Claude Code 方面,Anthropic 添加了检查点功能 —— 这是用户需求最高的功能之一 —— 它能保存你的进度,并让你即时回滚到之前的状态。
- Anthropic 更新了终端界面,并推出了原生的 VS Code 扩展。他们为 Claude API 增添了新的上下文编辑功能和记忆工具,让智能体能够运行更长时间,并处理更高复杂度的任务。
- 在 Claude 应用程序中,他们将代码执行和文件创建(电子表格、幻灯片和文档)功能直接融入对话之中。
- 此外,他们还为上个月加入候补名单的 Max 用户提供了 Claude for Chrome 扩展。
Anthropic 还为开发者提供了他们自己用于打造 Claude Code 的基础工具。他们将其称为 Claude Agent SDK。
Anthropic 表示,这是他们发布过的最符合对齐要求的前沿模型,与之前的 Claude 模型相比,在多个对齐领域都有显著改进。
Claude Sonnet 4.5 版本今日已全面上线。如果你是开发者,只需通过 Claude API 使用 claude-sonnet-4-5 即可。定价与 Claude Sonnet 4 版本保持一致,每百万 token 输入 / 输出分别为 3 美元 / 15 美元。
前沿智能
Claude Sonnet 4.5 在 SWE-bench 验证评估中处于 SOTA 水平,该评估衡量的是现实世界中的软件编码能力。实际上,Anthropic 观察到它在复杂的多步骤任务上能够保持专注超过 30 小时。

Claude Sonnet 4.5 代表了 computer use 方面的重大飞跃。在 OSWorld(一个在现实世界计算机任务中测试人工智能模型的基准测试平台)上,Sonnet 4.5 现在以 61.4% 的成绩领先。就在四个月前,Sonnet 4 以 42.2% 的成绩领先。Claude for Chrome 扩展将这些升级后的功能加以利用。在下面的演示中,他们展示了 Claude 直接在浏览器中工作,浏览网站、填写电子表格并完成任务。
,时长01:41
该模型在包括推理和数学在内的广泛评估中也展现出了更强的能力:

金融、法律、医学和理工科(STEM)领域的专家发现,与包括 Opus 4.1 在内的旧模型相比,Sonnet 4.5 在特定领域知识和推理方面表现得明显更好。




该模型的能力也体现在早期客户的体验中:


Anthropic 迄今为止对齐最好的模型
Anthropic 表示,Claude Sonnet 4.5 不仅是他们性能最强的模型,也是目前与人类价值观一致性最高的前沿模型。Claude 提升的能力以及 Anthropic 广泛的安全训练,让他们能够大幅改善模型的表现,减少诸如谄媚、欺骗、争取主导权(power-seeking)以及鼓励妄想性思维等令人担忧的行为。对于模型的智能体和计算机使用能力,Anthropic 在抵御提示注入攻击方面也取得了显著进展,这是使用这些能力的用户面临的最严重风险之一。
你可以在 Claude Sonnet 4.5 系统卡片中阅读一套详细的安全性和一致性评估,其中首次包括使用「机制可解释性技术」进行的测试。

系统卡地址:https://assets.anthropic.com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf

Claude Sonnet 4.5 版本将在 Anthropic 的 AI 安全等级 3(ASL-3)保护措施下发布,这是按照他们将模型能力与适当保障措施相匹配的框架进行的。这些保障措施包括名为分类器的过滤器,其旨在检测潜在危险的输入和输出,特别是那些与化学、生物、放射性等相关的内容。
这些分类器有时可能会无意中标记正常内容。Anthropic 已为用户提供便利,让他们能够继续与 Sonnet 4 进行任何中断的对话,该模型带来的化学、生物、放射性风险较低。Anthropic 在减少这些误报方面已经取得了显著进展。
Claude Agent SDK
Claude 称他们花了六个多月的时间更新 Claude Code 的能力,因此自己知道如何构建和设计 AI 智能体。过程中他们解决了许多难题:包括智能体如何在长时间运行的任务中管理内存,如何处理平衡自主性和用户控制性的权限系统,以及如何协调子智能体朝着共同目标努力。
,时长00:25
今天的发布就是以上努力的成果,也就是 Claude Agent SDK。它 Claude Code 的基础架构相同,但它不仅在编码领域,还在各种任务中展现出令人印象深刻的优势。从今天起,用户可以使用它来构建自己的智能体。
最后,Claude 还发布了一个临时研究的预览版,叫 Imagine with Claude.
在这个实验中,Claude 可以即时生成软件,且前提是不预先设定任何功能,也不预先编写任何代码。我们所看到的是 Claude 实时创建、响应并适应请求,并与用户交互互动。
,时长01:42
以上视频就是该实验的有趣演示,展示了 Claude Sonnet 4.5 的功能 —— 它可以让您了解将强大的模型与合适的基础架构相结合所能实现的潜力。
“Imagine with Claude” 将在未来五天内面向 Max 订阅用户开放。
你想体验吗?
....
#Self-Evolving LLMs via Continual Instruction Tuning
LLM工业级自进化:北邮与腾讯AI Lab提出MoE-CL架构,解决大模型持续学习核心痛点
为解决此问题,北邮百家 AI 团队与腾讯 AI Lab 团队提出参数高效的对抗性混合专家架构 MoE-CL,专门用于 LLM 的自进化持续指令微调。其核心设计在于 “解耦 LoRA 专家” 与 “GAN 对抗降噪” 的结合:为每个任务配置专属 LoRA 专家以保留任务特定知识,避免参数更新相互干扰;同时设置共享 LoRA 专家,通过生成对抗网络(GAN)中的任务感知鉴别器抑制无关噪声,确保跨任务知识高效且精准传递,最终实现 “知识保留” 与 “跨任务泛化” 的平衡,这也是 LLM 自进化的核心逻辑。
从实验效果来看,MoE-CL 的自进化能力已在实际场景与基准测试中得到验证。在腾讯真实业务场景 A/B 测试中,它将人工介入成本降低 15.3%;在公开 MTL5 跨域基准与工业级 Tencent3 基准测试中,其平均准确率优于现有主流方法,且在不同任务训练顺序下保持稳定,证明其无需人工调整即可适配任务动态变化。
- 论文标题: Self-Evolving LLMs via Continual Instruction Tuning
- 论文链接: https://arxiv.org/abs/2509.18133
- 代码仓库:https://github.com/BAI-LAB/MoE-CL
01 引言
在数字经济蓬勃发展的当下,海量文本数据如潮水般涌入互联网平台。例如,新闻资讯的快速更新、电商平台的海量评论等多源异构数据每日激增,面临跨领域、高时效、强精度的多重挑战。若采用传统方案,为每种文本类型单独训练模型,将消耗巨大的计算资源与人力成本;而使用单一模型处理全领域文本,又因数据分布差异导致性能失衡,难以满足业务需求。在此背景下,亟需一种既能高效处理新任务,又能保留旧任务知识的通用技术方案。为此,我们提出 MoE-CL 大模型混合专家(MoE)持续学习架构,致力于打破传统方法的局限,以实现多领域文本任务的高效协同处理。使得大模型具备自进化能力:动态适应训练数据,自主优化跨任务知识整合。
02 方法
混合专家持续学习(MoE-CL)框架聚焦多任务学习中的知识积累与任务适应难题。其核心采用 Transformer 块的 LoRA 增强技术,重点优化前馈神经网络(FFN)层,通过引入低秩矩阵降低参数更新量与计算成本,同时提升学习效率。
MoE-CL 将 LoRA 专家分为任务特定与任务共享两类:前者专攻特定任务知识,后者提取跨任务通用信息。结合生成对抗网络(GAN)分离任务特定与共享信息,确保模型获取高质量共享知识。
架构上,N 层 LoRA 增强的 Transformer 块级联提取信息,最终由门控网络融合两类信息,为任务预测提供支撑。这种设计使模型既能满足任务特异性需求,又能利用任务共性,实现高效持续学习。

图 1:MoE-CL 的整体框架。MoE-CL 通过采用带有任务感知判别器的对抗性 MoE-LoRA 架构,缓解了灾难性遗忘问题。MoE-CL 主要由两部分组成,任务感知判别器优化和指令调整优化。
2.1 任务感知判别器优化
任务感知判别器作为 MoE-CL 框架中的关键组件,其核心功能是识别任务标签。在 Transformer 块中,设第 i 个前馈层的输入向量为

,针对任务 t,MoE-CL 通过 LoRA 技术分别生成任务共享表示

与任务特定表示

,具体计算如下:

其中,

为 LoRA 模块的运算函数,作用于大语言模型中已冻结的参数;

和

分别对应任务共享 LoRA 专家与任务 t 专属 LoRA 专家的可学习参数,实现知识的分离与共享。
基于上述表示,任务感知判别器通过 softmax 函数

预测任务标签

:

其中,

为任务分类器的学习参数,通过训练优化以提升标签预测准确性。
在生成对抗网络(GAN)模块中,为确保任务共享信息的质量,模型通过交叉熵损失函数

计算预测标签

与真实标签

之间的差异,从而构建损失函数

:

通过最小化

,模型能够有效分离任务特定信息与共享信息,促使任务共享专家学习到更具泛化性的知识,进而提升 MoE-CL 框架在多任务场景下的性能表现。
2.2 指令调整优化
指令微调阶段,MoE-CL 通过加权组合任务共享表示

与任务特定表示

进行任务 t 的预测。二者经门控网络

自动生成的权重系数

进行线性插值,得到 Transformer 模块第 i 层的输出向量:


输入多层感知器后输出预测结果

,结合真实标签

通过交叉熵函数

计算预测损失

。
为强化任务共享信息的泛化能力,MoE-CL 将生成对抗损失

与预测损失融合,形成最终优化目标:

其中,超参数 α∈(0,1) 用于平衡两种损失权重。通过最小化

,模型在保留任务特异性知识的同时,最大化跨任务知识迁移效果。
03 实验
我们在 MTL5 和 Tencent3 两个评测基准上进行了实验,并将我们的方法与几种具有代表性的持续学习方法进行比较,以展示 MoE-CL 的有效性。
3.1 主实验结果
MTL5 和 Tencent3 评测基准上的实验结果如图 2,3 所示,有以下结论:

Tencent3 评测基准上的实验结果,使用腾讯混元作为基座模型。粗体和斜体表示根据主要评估指标准确率的最优和次优。
- 泛化能力与稳定性突出:相比所有基线方法,MoE-CL 平均准确率显著提升,且方差极小,在复杂任务中展现出优异的泛化能力与稳定性;
- 知识迁移优势显著:MoE-CL 在正反向迁移上表现稳定,较 MoCL 更不易受后续任务影响,验证了生成对抗网络集成至混合 LoRA 专家网络的有效性;
- 鲁棒性表现出色:面对不同任务序列顺序,MoE-CL 通过分离共享与特定任务专家的架构设计,在 MTL5 和 Tencent3 基准测试中展现出极强的鲁棒性 ,远超其他基线方法。
3.2 验证生成对抗网络的有效性
为验证对抗性 MoE-LoRA 架构对灾难性遗忘的抑制效果,本文构建了不含生成对抗网络(GAN)的 MoE-CL 对比版本。实验结果(图 4)显示,含 GAN 的 MoE 专家架构在持续学习任务中平均性能显著优于无 GAN 版本。这是因为 GAN 能够精准将特定任务信息分配至对应低秩适配器专家,有效规避任务间知识干扰,尤其在反向迁移(BwT)指标上表现突出,有力证明了 GAN 在防止灾难性遗忘方面的关键作用。

图 4:生成对抗网络对 MoE-CL 的影响。三个指标都是数值越大表明性能越好。
3.3 离线 A/B 测试
在腾讯真实文本分类任务中,模型依据置信度得分自动判定内容样本类别:超出阈值的样本被直接标记为合规(白样本)或不合规(黑样本),无需人工介入。剔除率作为核心评估指标,直观反映自动分类样本占比,剔除率越高,意味着人工成本越低。
为验证 MoE-CL 的实际应用价值,研究团队开展离线 A/B 测试,对比其与生产算法的剔除率表现。实验数据(图 5)显示,在任务 A 和任务 B 场景下,MoE-CL 均实现显著突破。其中,任务 A 场景中 MoE-CL 剔除率高达 28.8%,较基线算法提升 15.3%,直接降低了同等比例的人工介入工作量,切实为业务场景带来降本增效的商业价值。

通过剔除率衡量的离线 A/B 测试。
04 总结
混合专家持续学习框架 MoE-CL 通过三大核心设计破局:专属任务专家防止灾难性遗忘,任务共享专家促进跨任务知识迁移,生成对抗网络保障共享信息质量。三者协同运作,使模型高效适应新任务,实现大模型持续学习中的自进化。
....
#HunyuanImage 3.0
腾讯发布混元图像3.0:800亿参数MoE,开源巨兽性能媲美SOTA
最近的AIGC领域,神仙打架越来越精彩了。就在大家还在热议各种闭源大模型的时候,腾讯混元团队悄悄放出了一个“大招”——正式发布了其技术报告 《HunyuanImage 3.0 Technical Report》,并宣布将其图像生成模块开源。
HunyuanImage 3.0 是一个原生的多模态模型,它在一个统一的自回归框架内,同时实现了“看懂图”和“画出图”的能力。下面这些由它生成的图片,无论是对提示词的精准理解、逻辑推理,还是概念泛化和文字渲染能力,都相当惊艳。
- 论文标题:HunyuanImage 3.0 Technical Report
- 作者:腾讯混元团队
- 机构:腾讯
- 论文地址:https://arxiv.org/abs/2509.23951
- 代码仓库:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0
800亿参数的开源巨兽
这次最大的亮点,莫过于模型的规模和架构。HunyuanImage 3.0 采用了一种名为 混合专家(Mixture-of-Experts, MoE) 的架构,总参数量超过了 800亿。即便总参数量巨大,但在推理时,每个token(可以理解为信息处理的基本单元)只会激活其中的 130亿 参数。
MoE架构就像一个拥有众多专家的“智囊团”。当任务来临时,系统会根据任务类型,只唤醒最相关的几位专家来协同工作,而不是让所有专家都全体出动。这样既保证了模型的强大能力,又极大地提升了训练和推理的效率,让普通开发者“玩得起”大模型成为可能。
凭借这个设计,HunyuanImage 3.0 成为了迄今为止 规模最大、能力最强的开源图像生成模型。
一体化的多模态架构
HunyuanImage 3.0 的设计哲学是“原生”和“统一”。它不是简单地将一个文本模型和一个图像模型拼接起来,而是在一个自回归框架内,实现了对多模态信息的端到端处理。
从上图的模型结构可以看出,其核心是一个强大的大语言模型(LLM)骨干,它同时接收来自文本和图像的信息:
- 文本输入:通过文本编码器转换成LLM能理解的格式。
- 图像输入:通过一个视觉编码器(ViT)转换成视觉token序列。
这些不同来源的token在LLM内部被统一处理。当需要生成图像时,模型会先输出一段描述性的文本(图像标题),然后一个潜在扩散模型(Latent Diffusion Model)会根据这个文本标题来生成最终的图像。这种设计使得模型既能“理解”也能“创造”。
成功的关键要素
要训练这样一个庞然大物,背后是一整套复杂的系统工程。报告中提到了几个关键点:
精心的数据策划
模型好不好,数据是基础。团队构建了一套高效的图像描述流程,为海量图片生成了高质量、高信息量的文本描述,为模型提供了优质的“养料”。
原生“思维链”模式
为了更好地对齐文本和图像,模型引入了原生的“思维链”(Chain-of-Thoughts)模式。简单来说,当用户给出一个简单的提示词时,模型会先“脑补”出一个更详细、更丰富的场景描述,然后再根据这个详细描述去生成图像。这大大提升了模型对复杂语义的理解和遵循能力。
渐进式与激进式训练
训练过程也很有讲究。模型采用了 渐进式预训练,从低分辨率图像开始,逐步过渡到高分辨率,分阶段进行训练,稳扎稳打。
同时,在后训练阶段则采用 激进式策略,利用高质量数据对模型进行强化,进一步提升生成图像的质量和美学表现。
性能媲美SOTA
说了这么多,HunyuanImage 3.0 的实际表现如何?研究团队通过大量的自动评估和人工评估,证明了其在文本-图像对齐和视觉质量方面,均达到了与业界顶尖模型(SOTA)相媲美的水平。
在文本-图像对齐评估(SSAE)中,HunyuanImage 3.0 的表现与DALL-E 3、Midjourney v6等顶级模型不相上下。
在通用的美学评分(GSB)上,它的得分也极具竞争力。
这些结果表明,HunyuanImage 3.0 不仅在规模上取得了突破,在生成质量上也实实在在地站到了第一梯队。
通过开源模型代码和权重,腾讯混元团队希望为整个社区提供一个强大的基础模型,让更多的研究者和开发者能在此之上探索新的想法,共同构建一个充满活力的多模态生态。
....
#从VLM到扩散,再到强化学习方案
纯血VLA综述来啦!
- 标题:Pure Vision Language Action (VLA) Models: A Comprehensive Survey
- 作者:Dapeng Zhang1,2, Jing Sun2, Chenghui Hu2, Xiaoyan Wu2, Zhenlong Yuan3, Rui Zhou2, Fei Shen1, and Qingguo Zhou2
- 机构:
- 新加坡国立大学
- 兰州大学
- 中科院计算所
- 原文链接:https://arxiv.org/pdf/2509.19012v2
1. 介绍
机器人学长期以来一直是科学研究中的重要领域。早期的机器人主要依赖预编程的指令和人工设计的控制策略来完成任务分解与执行。这类方法通常应用于简单、重复性的任务,例如工厂流水线和物流分拣。近年来,人工智能的快速发展使研究者能够在图像、文本和点云等多模态数据中,利用深度学习的特征提取与轨迹预测能力。通过结合感知、检测、跟踪和定位等技术,研究者将机器人任务分解为多个阶段,以满足执行需求,从而推动了xx智能与自动驾驶的发展。然而,大多数机器人仍然作为孤立的智能体存在,它们通常为特定任务而设计,缺乏与人类和外部环境的有效交互。
为克服这些局限性,研究者开始探索将大语言模型(LLMs)与视觉语言模型(VLMs)引入机器人操作中,以实现更精准和灵活的控制。现代的机器人操作方法通常依赖视觉-语言生成范式(如自回归模型 或扩散模型),并结合大规模数据集 以及先进的微调策略。我们将这些方法称为 VLA基础模型,它们显著提升了机器人操作的质量。对生成内容进行细粒度的动作控制,使用户获得更大的灵活性,从而释放了VLA 在任务执行中的实际潜力。
图1:VLA 综述的组织与结构
尽管 VLA 方法展现了巨大潜力,但针对纯 VLA方法的综述仍然十分稀缺。现有综述要么集中在 VLM基础模型的分类上,要么提供对机器人操作的整体性回顾。首先,VLA方法在机器人学中仍是一个新兴领域,尚未形成明确的方法学格局或公认的分类体系,这使得系统性总结变得具有挑战性。其次,当前综述往往依据基础模型的差异对VLA方法进行分类,或者覆盖整个机器人学发展历史的全面分析,但往往更强调传统方法而忽视新兴技术。虽然这些综述提供了有价值的见解,但大多仅对机器人模型进行粗略的审视,或主要聚焦于基础模型,从而在纯VLA 方法的研究上留下了显著的空白。
图2:各种VLA骨架的示意图
在本文中,我们对 VLA方法及相关资源进行了研究,提供了一个聚焦而全面的综述。我们的目标是提出清晰的分类体系,系统性地总结VLA 研究,并阐明该领域快速演进的发展轨迹。在简要回顾 LLM 与 VLM的背景之后,我们重点讨论 VLA模型的策略设计,突出以往研究中的独特贡献与方法学特征。我们将 VLA方法划分为四类:自回归范式、扩散范式、强化学习范式、混合与特定领域方法,并对其动机、核心策略和机制进行深入分析。如图[2]所示,我们展示了这些方法的 VLA框架。我们进一步考察了其在机械臂、四足机器人、类人机器人以及轮式机器人(自动驾驶车辆)等领域的应用,全面评估了VLA 在不同场景中的部署情况。鉴于 VLA模型对数据集与仿真平台的高度依赖,我们对相关资源进行了简要综述。最后,基于当前VLA的研究格局,我们识别了关键挑战,并提出未来研究方向的展望------包括数据局限性、推理速度与安全性等,以推动VLA 模型与通用机器人学的进一步发展。
本文整体结构如图 [1]所示:首先,第[2]节介绍 VLA研究的背景;第[3]节呈现现有 VLA 方法;第[4]节介绍 VLA方法所使用的数据集与基准测试;第[5]节与第[6]节分别讨论仿真平台与机器人硬件;第[7]节进一步探讨VLA方法在机器人学中的挑战与未来方向。最后,我们对全文进行总结,并对未来发展提出展望。
综上,本文的主要贡献如下:
-- 提出了结构化的纯 VLA方法分类体系,并基于动作生成策略对方法进行归类,从而帮助理解现有方法并揭示该领域的核心挑战。
-- 强调各类方法的独特特征与方法学创新,提供了对现有研究的清晰视角。
-- 系统性地梳理了 VLA 模型训练与评估所依赖的资源(数据集、基准测试与仿真平台)。
-- 探讨了 VLA在机器人学中的实际影响,识别了现有技术的主要局限,并提出潜在的研究方向。
图3:视觉语言动作分类法:从基于自回归、基于扩散到基于强化学习以及混合/专业化方法,视觉语言动作(VLA)的多范式进展和实际应用。该分类法按照时间线进行组织
2. 背景
视觉-语言-动作(Vision Language Action,VLA)模型的出现,标志着通用xx智能迈出了重要一步。传统的机器人系统通常依赖于孤立的感知流水线、人工设计的控制策略,或任务特定的强化学习方法。尽管这些方法在受限环境(如工厂车间或实验室)中表现良好,但在动态和非结构化环境下的泛化能力却较差。现代机器人可以通过计算机视觉模型"看",通过大语言模型"理解",并通过控制器或学习得到的策略"行动";然而,将这些能力整合为一个统一且连贯的系统仍然是一个关键挑战。VLA模型通过提供一个统一框架,将语言与感知相结合并映射为可执行的动作,从而回应了这一挑战。
2.1 早期:LLM/VLM 基础模型
单模态建模的突破为多模态整合奠定了方法学和工程基础。在计算机视觉中,卷积神经网络(如AlexNet 、ResNet)确立了从局部卷积到深度残差学习的表征范式,这一方向进一步被 VisionTransformer (ViT) 推动。ViT将自注意力机制引入图像领域,显著提升了模型的可迁移性与泛化能力。在自然语言处理中,Transformer架构使大规模预训练与对齐技术成为可能,催生了 BERT 、GPT 、T5 以及 GPT-4等模型,它们展现了强大的推理能力、指令跟随能力以及上下文学习能力。与此同时,强化学习推动了策略优化与序列决策的发展,从DQN、PPO 到 Decision Transformer,体现了通过序列建模实现控制的统一视角。
在此背景下,视觉语言模型(VLMs)成为单模态学习与xx智能之间的重要桥梁。早期方法(如ViLBERT 、VisualBERT )通过双流或单流 Transformer将图像与文本进行对齐和融合,而对比学习方法(如CLIP)则将大规模图像-文本对映射到共享嵌入空间,使模型具备零样本和小样本的识别与检索能力。近年来,基于指令调优、对话中心的多模态模型(如BLIP-2 、Flamingo 、LLaVA)显著增强了开放式跨模态理解、细粒度语义对齐以及多轮推理能力,为视觉-语言-动作(VLA)系统奠定了基础。
2.2 现状:VLA 模型的发展2.2.1 从 LLM/VLM 到 VLA 模型
沿着这一发展轨迹,研究自然地迈向 VLA集成,它在单一的序列建模框架下统一了视觉感知、语言理解与可执行控制。典型的设计方式是将图像与指令编码为前缀或上下文token,引入机器人状态与传感器反馈作为状态 token,并自回归生成动作 token以产生控制序列,从而闭合感知-语言-动作的 循环。与传统的感知、规划与控制流水线相比,VLA提供了端到端的跨模态对齐,并在目标、约束和意图上实现统一建模。它继承了VLM的语义泛化与指令泛化能力,而显式的状态耦合与动作生成则增强了系统对环境扰动和长时任务的鲁棒性。这一演进过程------从单模态到多模态,再到多模态加可执行控制------奠定了系统"能看、能理解、能行动"的方法学基础。
2.2.2 数据与仿真的支撑作用
视觉-语言-动作(VLA)模型在机器人学中的发展高度依赖于高质量的数据集与能够反映现实复杂性的逼真仿真器。现代机器人方法通常基于深度学习并以数据驱动,因此数据集的采集与标注在推动该领域发展中起着至关重要的作用。一些数据集采集自真实世界环境,这往往需要大量的人力与经济 成本。为应对这些挑战,研究者还利用来自互联网的大规模人类操作视频作为泛化数据集,为VLA模型训练提供辅助监督。尽管如此,数据采集仍然代价高昂,标注过程劳动密集,且长尾与极端情况往往代表性不足。另一类数据集则通过机器人仿真器生成,从而支持大规模标注数据的获取。仿真器 提供了多样且可控的环境、灵活的传感器配置、逼真的运动学模型以及交互式静态与动态场景,既支持数据采集,也支持模型评估。代表性数据集包括Open X-Embodiment (OXE) ,它整合了来自 21 个机构的 22个机器人数据集,涵盖 527 项技能与 160,266 个任务;以及 BridgeData ,包含10 个环境中 71 个任务。此类资源标准化了数据格式,从而促进了 VLA研究的快速发展与可复现性。THOR 、Habitat 、MuJoCo 、Isaac Gym 与 CARLA等仿真平台提供了可扩展的虚拟环境,能够生成多模态标注,包括动作轨迹、物体状态与自然语言指令。这些数据集与仿真平台共同缓解了真实机器人数据的稀缺性,加速了VLA 模型的训练与评估。
2.3 展望:通用xx智能
VLA模型位于视觉、语言与动作交汇的研究前沿。它们建立在感知与推理基础模型的突破之上,强调人机交互与任务执行能力,并将这些能力延伸至物理世界。通过结合视觉编码器的表征能力、大语言模型的推理能力以及强化学习与控制框架的决策能力,VLA模型展现出弥合"感知--理解--行动"鸿沟的重要潜力。尽管在可扩展性、泛化性、安全性以及现实部署方面仍面临挑战,VLA仍被普遍认为是xx人工智能的关键前沿。虽然 VLA在视觉-语言-动作交互方面已取得显著成果,并受益于大规模语言模型的进展,但它尚未在xx智能领域实现全面通用化。通用xx智能认为,人类般的智能行为 不仅依赖于认知处理,还依赖于物理身体、环境感知与反馈机制,从而实现与外部世界的交互。为适应多样化任务的需求,通用xx智能可以通过不同类型的机器人体现,例如应用于家庭场景的人形机器人、拥有灵巧操作手臂的装配机器人,以及具备特殊能力的仿生机器人。显然,通用xx智能有潜力使人工系统能够在多样化环境中执行更广泛的任务。当前,VLA正在朝着这一通用xx智能的愿景演进,并展现出实现这一目标的巨大潜力。
3. 视觉-语言-动作模型
近年来,视觉-语言-动作(VLA)模型在多模态表征学习、生成式建模与强化学习的共同推动下实现了快速而系统的发展。为追溯这一演进,本节回顾VLA的主要方法学范式,包括基于自回归的建模、基于扩散的建模、强化学习策略,以及混合或特定化设计。图[3]给出了这些范式沿时间轴演进的"树状"示意图,每个分支对应其各自谱系中的代表性工作。该分类按时间顺序组织,强调方法创新如何持续拓展VLA 模型的能力边界。
3.1 自回归范式在 VLA 中的研究
在视觉---语言---动作(VLA)任务中,基于自回归的模型是经典而有效的序列生成范式。通过将动作序列视为时间相关的过程,这类模型在先验上下文、感知输入与任务提示的条件下,逐步生成动作。伴随Transformer 架构的快速发展,近期的 VLA 系统 展示了该范式在可扩展性与鲁棒性方面的 优势。
这些方向的代表性工作在图[4]中进行了汇总,整体体现了自回归建模在VLA研究中的通用性与多样性。
图4:基于自回归模型的代表性著作
3.1.1 通用型自回归 VLA 方法
面向"通用体"的 VLA研究,将感知、任务指令与动作生成统一到自回归序列建模之中。通过对多模态输入进行token 化,这些模型能够在异构任务间实现逐步的动作生成。早期的 Gato 证明了对异构模态进行统一 token化并进行联合训练的可行性。随后,RT-1/RT-2依托大规模真实世界数据与网络级预训练扩展了规模;PaLM-E将预训练语言知识注入xx控制,确立了自回归 Transformer作为统一模型的实用路径。为应对xx差异化,Octo 、LEO 与 UniAct等框架,通过将视觉---语言模态与通用动作抽象对齐,以实现跨平台兼容。近期的进展聚焦于"推理集成"与"效率化":模型将动作生成与语言推理、自适应提示结合以支持长时规划;同时,NORA 与 RoboMM 等轻量化设计面向部署约束。
总体而言,通用体 VLA 的研究已从早期的"统一 token化"迈向"大规模真实训练与语义落地",并进一步走向"跨平台通用、推理融合、效率导向"的设计。这一轨迹体现了从概念验证向"可扩展、具语义推理与易部署"的系统演进。图[4] (A)总结了代表性的自回归通用体代理与其关键贡献。不过,安全性、可解释性以及与人类价值对齐等问题仍未得到充分解决,仍有广阔的研究空间。
3.1.2 基于 LLM 的自回归推理与语义规划
将 LLM 引入VLA,使其从被动的输入解析器演进为语义中介,使得面向长时与可组合任务的"推理驱动控制"成为可能。本节回顾基于LLM 的推理从语义中介到分层规划,再到平台级编排的演进脉络。为向 VLA 注入推理能力,Inner Monologue提出了"自言自语"式的推理范式,结合行动前规划与行动后反思;Prompt-to-Walk、RoboFlamingo与 RoboMM 则在行走与操作任务中展示了语言表示的跨域适配。
随后的方法通过反馈与层级规划增强了适应性:Interactive Language支持实时纠正,Open-Ended Instructable Agents 利用情景记忆,Hi Robot采用层级规划来处理长指令。MissionGPT、Mobility VLA 与 NORA强调轻量化部署与对话驱动的可适应性。层级化框架将语义规划与控制器结合以实现灵巧操作 ;InSpire、From Foresight to Forethought 与 CoT-VLA 强调运行时稳定性与链式思维机制。自回归式推理架构通常将附加信息"打补丁"式地注入序列输入,并据此进行后续推理。这类模型可处理不同长度的输入;其强大的"上下文学习"能力使其能够在统一结构下处理多种模态。面向无人机的 CognitiveDrone 与 UAV-VLA强调空域导航与基于卫星信息的规划;OneTwoVLA则关注推理---行动的自适应切换与异构控制空间的抽象。
与上述方法相对,系统化与平台化的努力正在汇聚这些进展:Gemini Robotics 与Agentic Robot 将 LLM定位为xx流水线的核心编排器; 0.5 与 fast面向开放世界可扩展性与高效 token 化。VLA Model--Expert Collaboration 与LLaRA 等工作探索协作机制与辅助任务,以改善从 VLM 到 VLA的迁移。总体来看,LLM 驱动的 VLA推理已从语义中介走向交互式与层级化规划、跨模态扩展以及一体化平台。
尽管基于 LLM 的 VLA推理已从语义中介演进至交互式与层级规划、跨模态扩展与平台集成,但仍存在诸多挑战,包括幻觉抑制、多模态对齐、推理稳定性以及实时安全等。图[4] (B) 汇总了代表性研究及其贡献。
3.1.3 自回归轨迹生成与视觉对齐建模
自回归的轨迹建模在强化"感知---行动"映射的同时,确保视觉---语言的语义对齐。此类模型在多模态观测的条件下解码运动轨迹或控制token,为"语义对齐的指令跟随与动作执行"提供了统一机制 。
早期的 LATTE 证明了"语言到轨迹"的直接映射可行性,启发了多模态拓展。借助大规模预训练,VIMA 与 InstructRL 表明语言、视觉与动作的联合 token化能够支持跨任务强泛化,但多在仿真中验证。与此同时,MOO 与一系列 GPT基座方法 利用预训练的视觉---语言骨干实现开放世界泛化与轻量轨迹生成,提示语义先验可降低对机器人特定预训练的依赖。
第二条路线探索视频预测与世界模型。GR-1/2 将视频生成预训练迁移至机器人领域;CronusVLA 与 WorldVLA 改善了时间一致性。TraceVLA 与 Uni-NaVid 进一步引入长时提示,整体上从短视野解码转向"预测式的环境建模"。
自回归方法已适配多种xx形态,从四足行走到双臂协作,展现了视觉---语言---动作框架的灵活性 。OpenVLA等大规模工作强调了跨平台泛化与高效适配,而潜运动 token 路线 指向轻量化预训练策略。
在操作之外,自回归轨迹生成也扩展至自动驾驶:最新模型通过将视觉与语言对齐到轨迹预测上,实现了闭环控制,且常在无 HD 地图或 LiDAR 的设定下工作 。类似原理也被用于移动操作与无人机规划 ,凸显了该范式在多种机器人平台上的通用性。
研究者还将自回归框架扩展至更细粒度的感知与更丰富的模态。近期模型强调通过稳健的预训练管线实现精细操作 ;触觉---语言---动作一体化 使得"接触丰富"的交互成为可能。并行方向利用 3D/4D感知将空间结构注入自回归解码中 ,进一步拓展了多模态版图。
综上,自回归轨迹生成已从"语言直达轨迹"走向覆盖"多模态预训练、视频驱动世界建模、xx特定架构与跨模态感知"的广阔生态(见图[4] )。这些进展展示了自回归作为统一机制在VLA中的可扩展性与多样性。但在长时稳定性、噪声输入下的语义对齐、以及物理机器人上的高效部署方面仍存挑战。未来工作应优先推进"预测建模与低层控制"的稳健闭环耦合,并探索自回归策略与高层推理模块(如LLM 规划器)的协同,以迈向可靠的通用xx智能。
3.1.4 结构优化与高效推理机制
在自回归 VLA研究中,结构优化与高效推理是实现可扩展部署与实时控制的关键。除准确率外,核心挑战在于如何降低计算冗余、缩短推理时延,并在多样化机器人场景下保持鲁棒性。
一条重要方向是层级化与模块化优化。早期的 HiP 表明,将任务分解为符号规划、视频预测与动作执行,有助于在自回归模型中实现长时推理。后续设计------从高效观测骨干、动作分块,到轨迹感知注意力与频域分解 ------进一步说明模块化结构可在保留泛化的同时显著降低计算量。
第二条路线强调动态与自适应推理。DeeR-VLA 能依据任务复杂度提前终止解码;而 FAST 等 token高效设计则将长动作序列压缩为可变长度token。二者共同表明,自适应计算可以在较小精度损失下显著提升实时响应性。
第三类工作强调轻量化压缩与并行化。量化与层跳过方法 通过降低数值精度与动态激活部分层,显著削减计算;与此同时,并行解码与冗余消减策略无需再训练即可加速推理,凸显结构压缩与自适应推理的互补性。
效率同样体现在传感器融合与时间复用中。体素化空间建模 、自适应 KV 缓存 与感知适配 等面向领域的优化,减少冗余计算同时提升鲁棒性。
值得注意的是,一些工作将效率与多模态推理相融合。OTTER 在视觉编码阶段注入语言感知;ChatVLA 采用分阶段耦合与专家混合路由。其他进展------从基于扩散的目标生成 、量化 ,到超长时域的层级反馈 ------展示了如何在效率与可扩展性之间取得平衡。
总之,自回归 VLA的结构优化与高效推理,已从早期的层级分解发展到自适应计算、轻量压缩、缓存机制与多模态感知融合(见图[4] (D))。这些方法针对长序列依赖与计算冗余问题,带来了在基准与真实部署中的显著收益。展望未来,应推进软硬件协同优化、智能调度与稳健的安全机制,以确保朝向通用xxx智能的可扩展与可靠进展。
3.1.5 结论
创新 基于自回归的模型通过在可扩展的 Transformer 架构中统一多模态感知、语言推理与序列化动作生成,推动了 VLA研究的重要创新。它们支持能够跨任务泛化的通用体代理,通过引入 LLM实现语义规划,并将轨迹生成拓展至长时与多模态场景;同时,诸如 token压缩、并行解码与量化等结构优化,为真实世界部署带来了效率提升。
限制 自回归解码会引入误差累积与时延;在噪声或不完整输入下,多模态对齐可能变得脆弱;而扩展大模型常需高昂的计算与数据成本。此外,推理驱动的方法仍面临幻觉、稳定性与可解释性等挑战效率机制有时也会牺牲准确性或通用性。要解决这些问题,需要在"推理---控制"之间建立更紧密的耦合,在真实世界不确定性下提升鲁棒性,并开展面向硬件的优化以在可扩展性与实际部署之间取得平衡。
3.2 扩散范式在 VLA 中的研究
扩散模型(包括流匹配、VAE等)已成为生成式人工智能中的重要范式,并在xx智能的视觉-语言-动作(VLA)框架中展现出巨大潜力。本小节回顾了扩散模型在VLA 系统中的演进,重点讨论三个关键维度。
代表性作品汇总见图[5].
图5:基于扩散模型的代表性作品
扩散模型(包括流匹配、VAE等)已成为生成式人工智能中的重要范式,并在xx智能的视觉-语言-动作(VLA)框架中展现出巨大潜力。本小节回顾了扩散模型在VLA 系统中的演进,重点讨论三个关键维度。
3.2.1 通用型扩散 VLA 方法
将扩散模型引入 VLA系统,使机器人动作生成从确定性回归转向概率生成策略。通过将动作生成建模为条件去噪,基于扩散的方法能够自然地表示多样化的动作分布,从而在相同观测条件下生成多条合理的轨迹 。一个重要方向是引入更丰富的表征结构。几何感知方法将 SE(3)约束嵌入扩散过程,超越欧氏空间,在三维环境中联合优化抓取与运动 ,从而保证动作的物理一致性。与此同时,将策略学习重新解释为视频生成 ,利用视频的时间丰富性来支持长时规划与跨模态语义对齐。 扩展性研究如 RDT-1B 展示了在双臂操作中结合时间与环境条件的轨迹级扩散方法,能够实现零样本泛化。时间一致性问题则通过统一速度场建模 或基于历史条件与高效缓存的实时部署 来缓解。这些进展标志着三方面的转变:从确定性到概率生成、从欧氏空间到几何感知表征、从监督式到自监督式范式。作为生成式建模的重新框定,扩散方法支持多任务泛化、小样本适应以及自然语言接口。图[5] (A) 总结了相关架构选择与训练策略。然而,在动态环境变化下,时间一致性仍较为脆弱。
3.2.2 基于扩散的多模态架构融合
在 VLA 系统中引入 Transformer推动了视觉、语言与动作的统一建模,突破了传统的模块化流水线,能够捕捉xx智能中复杂的跨模态依赖。在这一趋势中,将 Transformer与扩散模型结合尤为关键,因为注意力机制与生成建模天然互补。大规模框架如Dita 与 Diffusion Transformer Policy 证明,将注意力结构扩展至动作建模显著提升了连续动作生成能力,其自注意力归纳偏差与机器人行为的组合性高度契合。核心挑战不在于架构规模化,而在于如何在保留模态特性的同时实现异质模态的融合。视觉、语言与本体感知在时间粒度、语义与处理需求上存在差异,这既创造了丰富上下文的机会,也带来了削弱模态优势的风险。为此,M-DiT 等 token 空间对齐方法将多样信号映射为统一表征,使条件扩散 Transformer能灵活支持任意目标与观测的组合,这是迈向通用机器人学的重要一步。
面向特定领域的设计如 ForceVLA 将力觉视为核心模态,利用力觉感知的专家混合机制将触觉反馈与视觉-语言嵌入结合,显著提升了接触丰富场景下的操作性能。近期研究还在扩散策略中引入显式推理。Diffusion-VLA 提出自生成推理模块,用于产生符号表示;CogACT 则利用语义场景图,实现了感知、推理与控制的一体化。
预训练模型的迁移也逐渐普及,例如利用图像编辑模型实现零样本操作 ,或通过PERIA 等联合微调策略实现跨领域适配。结构化分解方法如Chain-of-Affordance 与基于流图的 0 在复杂环境中优于端到端方法。
总体来看,这些进展(见图[5] (B))显示出该领域正处于转型阶段------从单一架构扩展向认知启发式框架过渡,将结构化推理、多模态输入与显式知识表征结合起来。这一转变意味着研究正超越纯粹依赖数据驱动的端到端学习,迈向更具可解释性与泛化性的设计,但仍受限于高昂的计算开销与数据集多样性的不足。
3.2.3 扩散 VLA 的应用优化与部署
从实验室原型到真实世界部署仍是扩散式 VLA系统面临的重大挑战。要解决这一问题,需要在效率、适应性与鲁棒性三方面取得突破。最新研究表明,与其盲目扩大模型规模,不如依托优化策略、认知启发式架构与实用部署机制。效率优化已成为核心议题。尽管扩散模型资源消耗巨大,轻量化设计如 TinyVLA与 SmolVLA 表明,通过预训练骨干与参数高效调优(如LoRA),可以在单卡规模实现训练而不损失性能。VQ-VLA 等方法利用向量量化动作编码器缩小"模拟---现实"差距,展示了效率与鲁棒性可以兼得。这一趋势体现了"智能稀疏性"的理念,更关注单位计算性能,而非单纯扩展规模。
与此同时,任务适应性成为先进 VLA系统的重要特征。在灵巧操作中,大规模精选数据集如 DexVLG 实现了强大的零样本性能;在移动操作中,AC-DiT 通过运动-身体条件统一了感知与控制。总体上,趋势是"通用架构 +深度专业化",在保留广泛多模态能力的同时注入任务特定归纳偏置。架构创新代表了新前沿。双系统与三系统设计如 MinD 与 TriVLA 展示了如何将认知原理操作化。MinD将低频视频预测用于战略规划,将高频扩散策略用于反应控制;TriVLA则显式分离"视觉语言推理、动力感知与策略学习",形成协同模块。这些架构可在交互频率(如36Hz)下运行,不仅提升了性能,还改善了可解释性与可维护性------这是工业应用中的关键要求。
除效率与设计外,运行时鲁棒性成为真实部署的决定因素。BYOVLA 等轻量干预方法可在推理时动态编辑无关视觉区域,无需微调即可缓解环境不确定性下的鲁棒性问题。DreamVLA 等自反思架构引入层级化错误处理,结合增强推理模块、错误感知层与专家适配器,体现了向"防御型AI"转变的趋势,强调系统韧性与可靠性与性能同等重要。扩散式 VLA 的应用场景迅速拓展。在自动驾驶中,DriveMoE 通过场景与技能专家混合实现闭环控制的最新水平;在人形机器人中,DreamGen 借助视频世界模型,将单任务远程操作泛化至数十种新行为。EnerVerse 与VidBot 通过自回归视频扩散与可供性学习预测xx未来,凸显了视频中心世界建模在规划中的潜力。这些进展标志着研究正从任务特定原型向跨领域通用系统转变。
基础模型方向的雄心进一步凸显了这一趋势。FP3 提出大规模 3D策略模型,预训练于 60,000 条轨迹上;GR00T N1 将多模态 Transformer架构集成至人形机器人基础系统。类似于 NLP中的大语言模型,这些方法旨在为机器人提供通用先验,但必须解决安全性、实时控制与物理可靠性等问题------这些挑战在文本领域并不突出。泛化与微调策略在推动扩散式 VLA 走向现实部署中仍至关重要。ObjectVLA 与SwitchVLA 展示了开放世界物体操作与执行感知的任务切换能力,凸显了动态环境下的灵活性。与此同时,LangToMo与 Evo-0 提出了新型中间表征与几何感知插件模块,证明结构化感知先验可显著提升跨任务适应性。在优化方面,系统化微调框架OFT 集成并行解码、动作分块与连续表征学习等技术,使研究从探索性原型逐步迈向工程化学科。
总体来看,这些策略表明要实现鲁棒的泛化,需要依托架构创新、高效模型设计、任务自适应、认知启发式架构与运行时鲁棒性机制(见图[5] )。然而,安全关键场景仍缺乏系统性研究。弥合这些差距,是 VLA从实验室原型迈向可靠通用机器人系统的关键。扩散模型在 VLA系统中的应用正朝着更高效、更鲁棒与更通用的方向发展。从基础的动作生成建模,到复杂的多模态融合,再到实际部署优化,一个完整的技术框架已逐渐形成。仍有诸多问题亟待解决,未来的发展趋势将继续聚焦于提升模型效率、增强泛化能力与优化实际部署性能。
3.2.4 结论
创新
基于扩散的模型从根本上将机器人控制重新表述为生成式建模问题。它们支持概率化的动作生成、多模态架构融合与认知启发式部署策略,突破了确定性与模块化流水线的局限。这些方法提升了轨迹多样性、几何一致性与推理集成。同时,TinyVLA与 SmolVLA 等效率导向设计,使真实世界的部署日益可行。
限制
然而,在动态环境中保持时间一致性仍然脆弱;大规模扩散模型需要高昂的计算资源与数据集支持;安全关键场景下的鲁棒性研究尚不足。此外,多模态融合虽然丰富了表征,但可能削弱模态特有优势;领域专用适配可能降低跨域迁移能力。要应对这些挑战,需要更高效与稳健的训练范式、更丰富的安全感知评估标准,以及"基础规模建模"与实际部署约束之间更紧密的衔接。
3.3 基于强化学习微调的 VLA 模型3.3.1 强化学习微调策略
图6:基于强化学习的模型在虚拟实验室研究中的发展及关键创新点
基于强化学习的视觉-语言-动作(VLA)方法将视觉-语言基础模型与强化学习结合,以增强感知、推理与决策能力。通过利用视觉与语言输入,这些方法能够在交互式与动态环境中生成具备上下文意识的动作,已成为推动自动驾驶、机器人学及更广泛xx智能系统发展的关键研究方向。近期进展表明,基于强化学习的VLA方法能够引入人类反馈,适应新任务,并在性能上超越纯监督范式。这些研究的发展脉络汇总于图[6]。
早期方法利用大规模人类视频数据集或机器人操作数据集,通过引入强化学习奖励策略提升机器人操作能力。这些研究重点探讨了预训练视觉语言模型(VLMs)在强化学习中的"提示可控性",并显示即使在冻结参数的情况下,模型也能通过提示嵌入学习高效支持下游策略训练。VIP提出了与动作无关的自监督目标条件价值函数,能够生成平滑的嵌入,并通过嵌入间距离隐式评估价值。类似于其他强化学习微调方法,一些研究利用语言与图像联合生成奖励代理,并通过自监督对比学习获得跨模态状态-语言表征。这类方法强调奖励感知表征的可迁移性,使其能够应用于稀疏奖励或复杂语言指令下的机器人学习任务。
此外,部分方法重点优化奖励函数或损失函数以改进策略学习。这些方法将语言模型作为奖励函数设计的中介,通过人类演示与 VLM语义映射学习奖励代理,从而简化了奖励工程。结合人类反馈的强化学习(RLHF)可进一步提升泛化与可解释性。例如,Elemental展示了在复杂操作任务中快速定制任务需求并在少量样本下实现高效学习的能力。
SafeVLA 从安全角度探索了 VLA的应用,聚焦开放环境下的部署风险。其提出了一种约束学习对齐机制,在保持任务性能的同时防止高风险行为。该方法在VLA架构中引入安全评论网络以估计风险水平,并采用约束策略优化(CPO)框架在最大化奖励的同时确保安全损失低于预设阈值。在多任务测试中(包括操作、导航与物体处理),尤其是在模糊自然语言指令增加不确定性的场景下,SafeVLA显著减少了风险事件,展现出更高的安全性与稳定性。这一研究为 VLA在现实应用中的安全部署提供了重要机制。
不同于前述机械臂 VLA 模型,研究者还探索了面向四足机器人与人形机器人的VLA框架。这些机器人依赖自然语言导航指令,强调轨迹预测、目标描述与避障等任务。例如,NaVILA通过单阶段强化学习策略对 VLA模型进行微调,以输出连续控制指令,从而适应复杂地形与动态变化的语言指令。相比之下,MoRE将多个低秩自适应模块作为不同专家集成至多模态大语言模型(MLLM)中,形成稀疏激活的混合专家模型,随后通过强化学习目标训练为Q 函数。LeVERB 则进一步提出了面向人形机器人全身控制(WBC)的层级化 VLA框架。与 NaVILA 类似,LeVERB将视觉-语言处理与动力学级别的动作处理相结合,利用强化学习策略将潜在词汇转化为高频动态控制命令,从而实现复杂的全身任务执行。
离线强化学习在混合质量数据集上学习鲁棒策略模型方面表现突出。ReinboT应用通过最大化累积奖励的 RL原则,增强了对数据质量分布的理解,并通过预测细粒度奖励捕捉任务间的差异,从而帮助机器人基于长期收益生成更鲁棒的决策。在线强化学习方法也在VLA 领域得到广泛探索。例如,SimpleVLA-RL仅使用单条轨迹与二值奖励(0/1)来训练 VLA模型。该方法避免了对密集监督或大规模行为克隆数据集的依赖,却能通过环境中的基于规则的奖励信号模拟,达到与全轨迹监督微调(SFT)相当的性能。意识到仅使用离线或在线策略的局限性,ConRFT提出了一种结合两者的混合策略:离线部分通过行为克隆与 Q-learning从有限演示中提取策略并稳定价值估计;在线部分则引入一致性目标与人工干预机制,以稳步提升策略性能,确保训练过程中的安全探索与样本效率。
在自动驾驶领域,VLA 模型同样利用强化学习来提升在未见场景中的驾驶性能。AutoVLA即为一例,它提出了一种结合推理与动作能力的自回归生成模型。该模型首先处理视觉输入与语言指令,然后通过推理微调生成可离散化为连续轨迹的可行动作。其采用链式推理(CoT)与群体相对策略优化(GRPO)两阶段微调,达到了最新性能。值得注意的是,不同于参数规模巨大的现有模型(导致高计算与存储需求),部分研究探索了在基于强化学习的VLA中引入量化、剪枝与知识蒸馏等效率策略,常结合近端策略优化(PPO)。例如,RPD通过蒸馏将教师 VLA 模型压缩为学生模型以提升推理速度;RLRC提出了一种新型压缩框架,结合结构化剪枝、SFT 与 RL的性能恢复以及量化,从而在保持任务成功率的前提下降低了内存使用并提高推理吞吐量。
3.3.2 结论
创新 基于强化学习的 VLA 微调策略通过视觉与语言信号生成密集且可迁移的奖励代理,并结合离线行为克隆与在线强化学习稳定了策略优化,提升了泛化能力。安全导向的方法通过约束优化减少了开放环境部署中的高风险动作,也代表了重要的进展。此外,这类方法已扩展至四足、人形机器人及自动驾驶场景,凸显了强化学习驱动的VLA 在不同机器人xx形式中的多样性与适用性。
限制 尽管取得了显著进展,但基于强化学习的 VLA 在奖励工程中仍常依赖间接或噪声信号,导致学习次优;训练稳定性可能受到监督微调与探索相互作用的干扰;在高维真实环境中扩展时计算开销巨大,需要大量硬件与数据资源。此外,尽管已有安全感知的策略提出,但在模糊或对抗性指令下确保鲁棒泛化仍是悬而未决的问题。解决这些挑战需要更高效的奖励表征、更稳健且高效的训练范式,以及更丰富的评估基准,以同时衡量安全性与推理能力。
3.4 其他前沿研究
图7:视觉语言动作研究中混合架构与专用方法的演变
尽管自回归、扩散与强化学习仍是 VLA模型设计的基础范式,但随着xx任务的复杂性与多样性不断提升,越来越多的方法开始跨越这些边界。当前研究进展可归纳为五个关键方向:整合多种生成范式的混合架构、面向更强跨模态与空间理解的高级多模态融合、面向任务挑战的特定领域适配、在大规模层面统一"感知---推理---控制"的基础模型与大规模训练范式,以及强调效率、安全与人机协作的实用部署策略。代表性工作见图[7]。
3.4.1 混合架构与多范式融合
随着xx操作任务的多样性与复杂性提升,单一生成范式(无论是自回归、扩散或强化学习)往往难以胜任。混合架构因而成为有前景的方案,通过策略性地结合多种范式以发挥其互补优势。其核心目标是在连续动作生成的平滑性与物理一致性、离散推理的精确性,以及面向动态真实环境的适应性之间取得平衡,从而为更强大、更多才多艺的VLA 模型奠定基础。代表性工作 HybridVLA 在单一 7B参数框架中统一了基于扩散的连续轨迹生成与基于自回归的 token级推理:前者保障运动的平滑与物理一致性,后者保留上下文条件下的推理能力。
受认知科学启发的"双系统"理念也被近期工作采纳。Fast-in-Slow将卡尼曼的双系统理论工程化:在较慢但更具认知能力的 VLM主干中嵌入低时延执行模块,以在保留高层推理的同时实现实时响应。RationalVLA通过可学习的潜在嵌入,将视觉---语言推理与低层操作策略耦合,使模型得以过滤不可行指令并规划可执行动作。混合设计的规模化同样展现潜力。Transformer-based Diffusion Policy显示,十亿级参数的注意力架构可有效结合扩散过程与注意力机制,相比传统U-Net在轨迹建模中更能捕获丰富的上下文依赖。这一趋势指向"在扩散式规划器中嵌入自回归Transformer"的下一代 VLA:既具更强上下文感知,又能生成质量更高的运动。
除单点创新外,OpenHelix 等倡议正推动混合 VLA设计的系统化:通过大规模实证评测,对比不同"推理---执行"集成策略,并提供开源实现与设计指引,促进了复现性与标准化。相关进展见图[7] (A)。
3.4.2 高级多模态融合与空间理解
在复杂环境中实现稳健操作,不仅需要简单的跨模态对齐,更需要结构化、任务感知的融合机制,以刻画细粒度语义与空间关系。近期研究明显从早期"特征拼接"转向"显式建模几何、可供性与空间约束"的架构,推动VLA 在非结构化、具 3D意识的场景中获得更强的空间落地性与更可靠的动作生成。
早期工作 CLIPort 以"what/where"双通路解耦视觉处理:基于 CLIP的表示,从图像---语言对生成抓放热力图,体现语言条件操作中的结构化视觉推理优势。其后工作强调3D 空间理解为核心能力:VoxPoser 在体素化场景上构建由大模型引导的可组合3D价值图,将指令解析分为目标理解与动作规划,清晰分离语义解析与空间推理以增强泛化。3D-VLA则在生成式 3D世界模型中,结合自回归语言建模与基于扩散的动作预测,实现"感知---语言---动作"的一致统一。
多视角感知的挑战通过统一表征学习来应对。RoboUniView 使用多视角Transformer 融合时空线索,相比单视角显著提升 3D 几何理解;BridgeVLA 将3D 观测投影为多张 2D 视图,并在统一的 2D热力图空间内预测动作,凸显紧凑且具空间落地性的高效表征。
为应对更苛刻场景,还出现了专门的空间推理方法:ReKep以关系关键点图建模时空依赖,适于高精度场景;RoboPoint预测可供性图,提供下游规划所需的关键感知先验;GeoManip通过符号几何约束引导动作生成,无需任务特定再训练,获得强 OOD 泛化。
总体轨迹清晰:从早期 2D 通路式融合,迈向模块化、具 3D意识的架构,统一空间落地、语义推理与动作生成。随着 VLA在开放世界落地,围绕几何与可供性的显式推理能力将持续决定其稳健与可泛化的操作性能。相关进展见图[7] (B)。
3.4.3 专用领域的适配与应用
VLA框架的通用性,使其得以扩展至具有独特感知、推理与控制挑战的特定xx领域。这些适配既验证了VLA原则的普适性,也揭示了在不同领域取得成功所需的架构与算法改造。从安全关键机器人到纯数字交互,相关创新展示了VLA 流水线在多样运行场景中的可塑性。
在安全关键的自动驾驶领域,CoVLA 提供了首个面向该领域的大规模 VLA数据集,包含约 5万条语言指令与驾驶轨迹视频,覆盖多样城市场景,展示了"视觉---语言推理 +连续控制"在导航与危险规避中的耦合方式。
VLA 范式亦扩展至 GUI 交互这一纯数字空间:ShowUI采用视觉---语言---动作管线解析屏幕元素并生成点击、拖拽、表单填写等控制序列,在GUI-Bench 上表现强劲,表明 VLA 原则同样适用于非物理的"操作"任务。
人形机器人"全身控制"是另一艰巨领域。LeVERB提出层级架构:视觉---语言策略从运动学演示中学习潜在动作词汇,强化学习控制层产生低层动力命令;这种两级设计弥合语义---控制鸿沟,并实现150+ 任务的稳健"仿真到现实"迁移。Helix则表明单一统一策略网络可在无需任务特定再训练的条件下习得多样人形行为,从物体操作到跨机器人协作。
面向大规模编队与移动操作的适配同样活跃。AutoRT以"观察---推理---执行"框架编排异构机器人群:将高层策略规划委托给PaLM-E、RT-2 等 VLM;MoManipVLA 通过航点轨迹与双层运动优化,将固定基座VLA 迁移至移动操作。
其他领域化创新融入物理推理或任务专属认知结构:物理落地 VLA加入稳定性与接触点估计模块,提升复杂物理约束下的操作;CubeRobot 以VisionCoT +记忆流的双环路结构求解魔方,在低/中难度任务近乎满分,在高难度场景亦表现出色。相关适配汇总见图[7] 。
3.4.4 基础模型与大规模训练
基础模型与大规模训练重塑了 VLA研究路线,使"感知---推理---控制"的统一框架得以跨任务、跨xx形态与跨环境泛化。该方向利用海量多模态数据与可扩展架构,致力于构建能力广泛、适应高效的通用xx体。大规模预训练正日益成为下一代VLA 系统的骨干。近期综述 系统梳理了机器人领域的基础模型研究,覆盖视觉---语言模型、策略模型与跨模态对齐技术,聚焦VLA架构,并按"感知对齐、策略生成、世界模型"进行组织,指出"多模态接口深度一体化"的收敛趋势。
大规模数据集是实现基础规模训练的关键。DROID 提供超 15万条轨迹,覆盖千余对象与任务场景,含RGB-D、语言、低维状态与环境标签等多模态标注;General Flow 以 3D点轨迹作为可迁移的可供性表征,实现"人---机"跨域技能迁移;ViSA-Flow在大规模人---物交互视频中提取语义动作流进行生成式预训练,下游机器人学习所需适配极少。
训练策略方面,Zhang 等 基于 2500 次 rollout实验分析微调关键因素(动作空间、策略头设计、监督信号),给出基础规模 VLA适配的实用指南;Chen 等 探索将链式思维(CoT)引入xx策略学习,证明轻量级推理机制可在保持性能的同时将推理时延缩短至原来的约1/3。
总体而言,研究正朝着"基于海量多样数据训练的通用xx体 + 模块化推理能力"的方向收敛:大规模预训练、有效适配与可迁移的可供性表征的组合,使基础规模 VLA 日益成为下一代机器人智能的底座。代表性工作见图[7] (D)。
图8:各种数据集的样本数据
3.4.5 面向效率、安全与人机协作的实际部署
当 VLA 模型从研究走向真实应用,实用部署要求在效率、鲁棒性与人机交互上统筹兼顾。在动态且不可预测的环境中,实时推理、对抗条件下的韧性,以及顺畅的人机协同流程,都是可靠运行的关键。本方向将系统优化与安全、适应性融合,确保高容量模型在实践中既有效又可信。
面向效率的设计致力于降低推理时延、压缩计算需求,并提升资源受限平台上的适配性。实时执行方面,RTC(Real-Time Chunking) 在执行当前动作段的同时预测下一段,实现连续的高频控制;EdgeVLA 取消末端执行器预测中的自回归依赖,并引入小型语言模型,在几乎不损失性能的情况下实现约 6× 加速;DeeR-VLA 使用动态早退机制,在置信度达阈值时提前结束推理,降低在线控制开销。
适配过程中保持知识完整性也成为重点:知识隔离 VLA 在向预训练 VLM 注入专用模块时抑制语义退化,保留跨任务泛化;CEED-VLA 等一致性加速策略通过一致性蒸馏与早退解码实现 4× 以上加速,并以混合标签监督缓解误差积累。RoboMamba 等轻量多模态融合与 ReVLA 等跨域适配方法亦助力可部署效率。
安全与鲁棒性同样是部署就绪的支柱。SAFE 基于 VLA 内部特征进行故障检测,能泛化至未见场景并实现前瞻性干预;Cheng 等 的 PVEP 体系揭示了对抗补丁、排版诱导提示与分布偏移下的脆弱性,促使"感知---控制"管线的对抗鲁棒设计;Lu 等 从可解释性出发,在 VLA 隐层中发现对象、关系与动作的符号编码,为更透明的决策奠基。DyWA 等自适应控制框架通过联合建模几何、状态、物理与动作,应对动态与部分可观环境。
在人机协作方面,研究探索"人---机共学"的交互闭环:Xiang 等 将有限专家干预纳入 VLA 决策,降低操作员负担并丰富训练数据;Zhi 等 的闭环策略结合 GPT-4V 感知与实时反馈控制,随环境变化自适应;面向历史的策略学习 与 CrayonRobo 的目标中心可视化提示提升任务落地与透明度;技能库构建 与 Grounding Mask 支持可扩展、可复用的任务分解;cVLA 以"图像坐标系航点"直接预测轨迹,弱化对具体xx形态的依赖,改善仿真到现实的迁移。代表性方法见图7。
综上,VLA 的实用部署需要一种多维一体的设计哲学:同时解决效率、安全与协作适应性。将"实时推理优化、故障与对抗鲁棒、人在回路的细化"有机融合,正为真实世界中持续、可靠、可交互的机器人系统铺平道路。
3.4.6 结论
创新 本节所述前沿研究共同将 VLA 推向更广阔的边界:混合架构整合互补范式以兼顾推理与动作生成;高级多模态融合实现具 3D 意识的空间落地;领域化适配将 VLA 原则扩展至自动驾驶、人形控制与 GUI 交互等场景;基础规模模型以海量多模态数据塑造更通用的智能体;面向部署的方法在效率、安全与人机协作上发力,提升真实可用性。
限制 然而,混合系统在计算与工程规模化上成本高昂;多模态融合易受真实场景噪声与不完全输入影响;领域化适配存在过拟合窄域的风险;基础模型对数据与资源依赖巨大;部署层面在对抗与动态条件下的鲁棒性、可解释性与可靠性仍具挑战。应对这些问题,需要更高效的训练策略、更广谱的评测标准,以及研究设计与实际部署之间更紧密的结合。
4. 数据集与基准
图9:机器人代表数据集与基准测试
与其他模仿学习方法相似,视觉-语言-动作(VLA)模型依赖高质量的标注数据集。这些数据集或来自真实世界场景的采集,或由仿真环境生成,其样例见图[8]。通常,它们包含多模态观测------如图像、LiDAR 点云、惯性测量单元(IMU)读数------以及相应的真实标注与语言指令。为便于系统化理解,我们对现有数据集与基准进行分析,并提出一种按复杂度、模态与任务多样性组织数据集的分类法。该分类法为评估不同数据集对 VLA 研究的适配性提供了清晰框架,并突出当前资源中的潜在空白;代表性工作汇总见图[9]。
4.1 真实世界数据集与基准
高质量的真实世界数据集是可靠 VLA 算法发展的基础。近年来,研究者采集了大量高质量、且多样化的真实机器人数据集,覆盖不同的传感器模态、多类任务与环境设置。
4.1.1 xx机器人真实世界数据集与基准
真实世界xx机器人数据集,指机器人在与环境交互过程中采集到的多模态数据集合。这类数据集专门用于刻画视觉、听觉、本体感知与触觉等多种感知输入与相应的运动动作、意图及环境语境之间的复杂耦合关系。它们对于xx人工智能的训练与评测至关重要,其目标是在动态环境中实现闭环、可自适应的行为。通过提供丰富且时间对齐的观测与动作,这些数据集成为模仿学习、强化学习、视觉-语言-动作以及机器人规划等算法发展的基础资源。
当前xx机器人数据集面临显著的数据成本问题,因为真实机器人数据尚未大规模采集。采集真实数据既需要硬件设备,也需要精确操作。其中,MIME 、RoboNet 与 MT-Opt 覆盖了从简单推动到复杂家居堆叠等多类任务的大规模演示数据。不同于早期多假设"单最优轨迹"的设定,这些数据集为同一任务提供多次示范,并以测试轨迹到最优轨迹的最小距离作为评估指标,显著推动了操作与 VLA 方向的研究。 BridgeData 提供跨 10 个环境、71 个任务的大规模多域机器人数据。实验显示:在该数据上联合训练,并在新域仅额外使用少量(如 50 个)未见任务样本,成功率可较仅用目标域数据翻倍。因此,许多当代 VLA 方法采用 BridgeData 进行训练。 在xx AI 领域,模型泛化常受限于真实数据采集的多样性不足。RT-1 提供广泛的真实机器人任务数据,以提升任务性能与对新场景的泛化能力。类似地,Bc-z 含有在同一场景中、由新奇物体组合构成的未见操作任务,支持可泛化策略学习研究。 若干数据集还提供覆盖手部操作、运动、多任务、多智能体与肌肉驱动控制等环境的完整软件平台与生态 。相比以往,RoboHive 弥合了当前机器人学习能力与潜在增长之间的鸿沟,支持强化、模仿与迁移等多种学习范式。 RH20T 独具特色地提供了 147 个任务、11 万段操作片段,包含多模态视觉、力觉、音频与动作数据。每段数据均配有人类示范与语言描述,使其特别适合基于单样本的模仿学习与面向新任务的策略迁移。
为发展更具泛化能力的操作策略,机器人社区需优先采集覆盖广泛任务与环境的大规模多样化数据集。多机器人、跨区域协作采集的数据集在地理与语境多样性上达到了新的高度 。此外,Open X-Embodiment(OXE) 整合了 21 个机构合作采集的 22 个机器人数据集,覆盖 527 种技能与 160,266 个任务,并提供标准化数据格式以便利研究使用。图[9] (A) 对这些数据集作了概览。
在基准评测上,常用指标为成功率(成功完成任务数占总任务数的比例)。部分研究额外采用语言跟随率,以评估模型对语言指令的理解与执行能力。进一步地,近期 VLA 模型常通过将训练得到的策略迁移到未见环境来评估其鲁棒性与泛化性能 。
4.1.2 自动驾驶真实世界数据集与基准
自动驾驶数据集不同于xx机器人数据集。作为人工智能最具变革性的应用之一,自动驾驶高度依赖大规模数据集来训练与评估感知、规划与控制算法。高质量数据集是构建稳健且具泛化性的自动驾驶系统的基石,它们支持监督学习、基准评测以及对稀有/安全关键场景的模拟。过去十年,大量数据集 相继发布,提供包括摄像头图像、LiDAR 点云、雷达与高精地图在内的多模态传感数据。它们在地理覆盖、传感器配置、驾驶行为多样性与标注丰富度等方面差异显著,因而在研发中具有互补性。
然而,多数公开数据集为开环采集,主要反映正常驾驶行为,难以覆盖长尾极端情形。为弥补这一不足,近期工作转向合成数据生成、闭环交互模拟,以及面向稀有/安全关键事件的专门数据集策划。持续的创新对推进安全、可扩展且可泛化的自动驾驶系统至关重要。
在评估方面,自动驾驶 VLA 模型常用 L2 轨迹误差(度量与参考轨迹的偏差)与完成率(成功完成驾驶任务的比例)等指标。
4.2 仿真数据集与基准
对连续控制任务而言,采集大规模真实数据具有显著挑战,因为此类任务需要实时交互与持续的人类标注反馈。此外,采集代价高、周期长,限制了可扩展性。 因此,研究者利用虚拟引擎生成的大规模高质量模拟数据进行训练与评估,以在大量问题实例上实现可扩展的人类监督信号与安全试验。
4.2.1 xx机器人仿真世界数据集与基准
xx AI 的仿真数据集通常包含合成场景、基于物理的交互、以及针对导航、物体操作、任务执行与体---环境动力学的标注。这些数据集支持从视觉导航、语义探索到复杂多步物体操作等广泛任务的训练与基准测试。代表性例子包括 ,它们在真实感、任务多样性与控制保真度之间提供不同取舍。 通过实现安全的可扩展试验与海量数据采集,仿真数据集成为发展鲁棒、可泛化xx智能体的根基。随着领域成熟,覆盖多种xx形态、任务与环境、更加真实丰富的仿真数据集设计,正持续推动向真实部署的迈进。
ROBOTURK 提供通过移动设备远程操作收集的高质量 6-DoF 操作状态与动作的仿真数据。不同于依赖远程用户在虚拟引擎中逐一演示的传统方式,ROBOTURK 借助策略学习生成多步任务并设置不同奖励;通过聚合大量示范,数据在训练与评估中均具有较高的精确性与可靠性。 iGibson0.5 提出用于训练与评估交互式导航的基准,不仅提供新的仿真实验环境,还提出了用于衡量"导航---物理交互"耦合的指标:交互式导航分数(Interactive Navigation Score),由路径效率与努力效率两部分构成。路径效率定义为"最短成功路径长度/实际行走路径长度",并乘以成功指示函数;努力效率反映导航过程中过量的运动学与动力学代价。 VIMA 提出 VIMA-BENCH,设立四级评测协议,逐步考察从随机摆放到全新任务的泛化能力。CALVIN 与 LOTA-Bench 则聚焦在多模态传感数据下学习长时、语言条件的操作任务,特别适合在大规模交互数据上训练、并在新场景上测试的泛化方法。此类基准通常以任务成功率为主要指标。仿真数据集概览见图[9] (B)。
4.2.2 自动驾驶仿真世界数据集与基准
闭环仿真在保障自动驾驶安全方面至关重要,因为它能够生成现实中难以或危险采集的安全关键情景。
尽管既有行车记录为构造新情景提供了宝贵资源,但闭环评测要求对原始传感数据进行修改,以反映更新后的场景配置。例如,需要添加/移除交通体,且现有交通体与自车的轨迹可能与原记录不同 。 UniSim 是一种神经传感器仿真器,可将单段记录扩展为多传感器闭环模拟。其构建神经特征网格重建静态背景与动态体,并进行合成以模拟来自新视角的 LiDAR 与相机数据,从而支持添加、移除或重定位交通体。为适配未见视角,UniSim 进一步使用卷积网络补全原始数据中不可见区域。
不同于真实世界数据集,闭环仿真基准需要面向交互式驾驶任务的专用评测指标。常用指标包括:Driving Route(路线遵循度)、Infraction Score(交通违规惩罚)与 Completion Score(任务完成度)。它们共同对 VLA 模型在更接近现实、安全关键场景下的表现给出更全面的评估。
4.3 结论
创新 本文引入了系统化分类、标准化评测指标,以及如 Open X-Embodiment(OXE)这类多机构协作的统一化努力,促进了可复现性与泛化。这些贡献扩展了任务覆盖、丰富了模态组合,并改善了跨领域策略迁移,推动xx AI 研究的可扩展性。
限制 然而,真实数据集采集成本高、组织复杂,且常受限于实验室等受控场景,场景多样性不足;仿真数据集虽具可扩展与安全优势,但仍难以完全刻画真实交互的复杂性、噪声与不可预测性。此外,成功率与轨迹偏差等指标或不足以反映语言落地、长时推理或在非结构化环境中的安全部署等细粒度能力。要解决这些问题,既需要扩展数据集的多样性与真实感,也需要设计更丰富的评测协议,以更好地契合真实自主系统的需求。
5. 仿真平台
机器人仿真器已成为在多样化交互环境中开发与评估智能机器人系统的必备工具。这些平台通常集成物理引擎、传感器模型(如 RGB-D、IMU、LiDAR)以及任务逻辑,以支持导航、操作、多模态指令执行等多类任务。最先进的仿真器能够提供可扩展、照片级真实感且物理合理的环境,用于基于强化学习、模仿学习或大规模预训练模型的xx智能体训练。通过提供安全、可控、可复现的实验环境,xx仿真器不仅加速了可泛化机器人智能的发展,还显著降低了真实世界实验的成本与风险 。
THOR 提供了近乎真实感的三维室内场景,AI 智能体可在其中进行导航与物体交互以完成任务。它支持模仿学习、强化学习、操作规划、视觉问答、无监督表征学习、目标检测与语义分割等多个研究方向。与此相对,一些仿真器基于虚拟化真实空间而非人工设计环境,涵盖数千栋配备xx智能体的完整建筑,并具备真实的物理与空间约束 。Habitat 与 Habitat 2.0 进一步扩展了此类范式,提供可扩展的仿真平台,用于在复杂 3D 环境中训练xx智能体,且包含物理驱动的交互场景。 ALFRED 引入了一个基准,涵盖长时、可组合的任务以及不可逆的状态变化,旨在缩小仿真与真实应用之间的差距。其任务同时包含高层目标与低层语言指令,在序列长度、动作空间与语言多样性上远超以往数据集。
早期物理与机器人任务结合的仿真环境常聚焦于狭窄场景,规模小且场景简化。相比之下,iGibson 1.0 与 iGibson 2.0 是开源平台,支持更丰富的家庭任务,且场景基于真实住宅复刻,物体分布与布局与现实高度一致,从而增强了生态效度,弥合了仿真与现实机器人学习之间的差距。先进的仿真器不仅允许多个智能体在同一环境中交互,还能输出多样的传感与物理信息。理想情况下,它们应结合通用物理引擎、灵活的机器人仿真平台与高保真渲染系统。这些特性使其既是机器人仿真的强大工具,也是生成模型评估的重要平台 。MuJoCo 是一个被广泛采用的开源物理引擎,专为机器人学及相关需要高精度仿真的领域而设计。近年来,GPU 驱动的仿真引擎逐渐流行。NVIDIA Isaac Gym 基于 Omniverse 平台,支持大规模开发、仿真与测试 AI 驱动的机器人,并在物理真实的虚拟环境中运行。Isaac Gym 已逐渐成为学界与工业界加速机器人工具研发与改进的重要选择。
在自动驾驶领域也存在类似挑战:大规模真实数据的采集与标注昂贵且耗时,尤其难以涵盖罕见的长尾场景。为此,研究者开发了包含静态道路元素(如路口、红绿灯、建筑物)与动态体(如车辆、行人)的仿真器。CARLA 与 LGSVL 基于游戏引擎渲染逼真的驾驶场景,支持灵活的传感器配置,并生成可用于训练与评估驾驶策略的信号。这些平台已成为推动自动驾驶研究的重要工具,因其可控、可复现且低成本的测试环境。
6. 机器人硬件
机器人的物理结构为感知、运动、操作与环境交互提供基础。其核心组件通常包括传感器、执行器、动力系统与控制单元。传感器(如相机、LiDAR、惯性测量单元与触觉阵列)提供外部环境与机器人内部状态的关键信息;执行器(如电机、舵机或液压系统)将控制信号转化为物理动作,从而实现运动与物体操作。控制单元通常基于嵌入式处理器或微控制器,作为计算核心整合传感器输入并向执行器下发指令。动力系统多为电池或外部能源,为持续运行提供保障。硬件设计需在性能、能效、重量与耐用性之间权衡,以满足工业自动化、服务机器人与自动驾驶等不同应用场景的需求 。
7. 挑战与机遇7.1 视觉-语言-动作模型的挑战
本节总结了推动视觉-语言-动作(VLA)模型发展的未解难题与未来方向。尽管近年来取得了显著进展,VLA 模型的研究与应用逐渐暴露出关键瓶颈。最根本的问题在于,当前 VLA 系统主要依赖于大规模 LLM 或 VLM 的迁移。尽管这些模型在语义理解与跨模态对齐方面表现优异,但它们缺乏与物理世界交互的直接训练与经验。因此,VLA 系统在真实环境中常表现为"能理解指令但无法正确执行任务"。这反映了一个核心矛盾:语义层面的泛化与物理世界中的xx能力之间的断裂。如何实现从非xx知识到xx智能的转化,并真正弥合语义推理与物理执行之间的鸿沟,是该领域的核心挑战。具体而言,这一矛盾体现在以下几个方面:
7.1.1 机器人交互数据稀缺
机器人交互数据是决定 VLA 模型性能的关键资源,但现有数据集在规模与多样性上仍然不足。在真实世界中采集覆盖广泛任务与环境的大规模演示受制于硬件成本、实验效率与安全问题。现有开源数据集(如 Open X-Embodiment)虽推动了机器人学习,但主要集中在桌面操作与抓取,任务与环境的多样性不足,严重限制了复杂场景中的泛化。仿真平台(如 RLBench)虽然能低成本生成大规模轨迹,但受制于渲染真实性、物理引擎精度与任务建模能力。即便采用域随机化或风格迁移,仿真到真实(sim-to-real)的鸿沟依旧存在,许多模型在仿真中表现优异,却在物理机器人上失败。因此,如何在大规模上增强机器人数据的多样性与真实性,仍是缓解泛化不足的首要挑战。
7.1.2 架构分散与缺乏统一标准
多数 VLA 模型尝试端到端覆盖视觉、语言与动作,但其实现方式高度异构。一方面,不同工作采用的主干网络差异显著:视觉编码器可能基于 ViT、DINOv2 或 SigLIP,语言模型可能使用 PaLM、LLaMA 或 Qwen,而动作头则可能采用离散化 token、连续控制向量,甚至基于扩散的生成方式。这种架构多样性阻碍了模型之间的对比与复用,延缓了统一标准的出现。另一方面,感知、推理与控制在内部往往耦合松散,导致特征空间碎片化,跨平台与跨任务迁移性较弱。一些模型在跨任务语言理解上表现出色,但在对接底层控制器时需进行大量适配。这种异构性加大了集成复杂度,显著限制了泛化性与可扩展性。
7.1.3 实时推理的限制与成本
当前 VLA 模型高度依赖大规模 Transformer 架构与自回归解码,严重限制了推理速度与在真实机器人上的执行效率。由于每个动作 token 依赖于前一个,延迟不断累积,而高频任务(如动态抓取或移动导航)要求毫秒级响应。此外,高维视觉输入与海量参数量带来极高的计算与存储成本。许多最新 VLA 模型的 GPU 内存需求远超嵌入式平台的能力。即使结合量化、压缩或边云协同推理,依旧难以在准确率、实时性与低成本之间取得平衡。由此造成的推理约束与硬件瓶颈,使得 VLA 部署面临"过慢"与"过贵"的两难。
7.1.4 人机交互中的伪交互问题
当前 VLA 的普遍问题是"伪交互":系统往往基于先验知识或静态训练模式生成动作,而非真正建立在环境动态与因果推理的交互之上。当面对陌生场景或状态变化时,模型更多依赖数据中的统计共现,而非利用传感器反馈进行动作修正。缺乏因果推理导致 VLA 虽然看似遵循指令,却未能真正建立环境状态与动作结果之间的因果链条。因此,机器人在动态环境中常表现出适应性不足。伪交互凸显了 VLA 在因果建模与反馈利用方面的缺陷,是实现xx智能的重要障碍。
7.1.5 评估与基准测试的局限性
VLA 模型的评测体系同样存在局限。目前的基准大多设定在实验室或高度结构化的仿真环境中,主要聚焦于桌面操作或抓取任务。这类任务评估的分布较窄,无法反映在开放世界中的泛化性与鲁棒性。一旦部署于室外、工业或复杂家庭环境,性能往往急剧下降,暴露出评测与实际应用的差距。这种狭窄的评测范围阻碍了对 VLA 可行性的全面评价,也限制了模型间的横向比较。缺乏统一、权威且多样化的基准,已成为推动现实进展的重要瓶颈。
以上五个方面凸显了 VLA 在数据、架构、交互与评测上的不足,但并未穷尽所有挑战。更为根本的长期问题是:VLA 系统能否真正实现可控性、可信性与安全性。换言之,VLA 的未来不仅在于性能与泛化性的提升,还在于如何负责任地部署智能体。这意味着研究者必须超越单纯的模型优化,向系统性范式转变,以应对长期挑战。
7.2 视觉-语言-动作模型的机遇
尽管挑战重重,VLA 的未来同样充满机遇。作为连接语言、感知与动作的关键桥梁,VLA 有潜力跨越语义与物理的鸿沟,成为xx智能的核心路径。突破当前瓶颈不仅可能重塑机器人研究范式,还可能使 VLA 走向真实世界的前沿部署。
7.2.1 世界建模与跨模态统一
当前 VLA 系统中的语言、视觉与动作仍然松散耦合,使其局限于指令"生成",而非完整的世界建模。实现真正的跨模态统一,将使 VLA 能够在单一 token 流中联合建模环境、推理与交互,从而演化为原型化的"世界模型"。这一统一结构将帮助机器人真正闭环语义理解与物理执行。除了技术意义,这也将成为迈向通用人工智能的重要一步。
7.2.2 因果推理与真实交互的突破
现有 VLA 大多依赖静态数据分布与表层相关性,缺乏基于因果规律的交互能力。它们往往通过模式匹配来"模拟交互",而不是主动探测环境并利用反馈更新策略。若未来 VLA 能引入因果建模与交互式推理,机器人将能够通过探测、验证与自适应调整来与动态环境进行真实对话。这一突破将克服伪交互,标志着从数据驱动智能向深度交互智能的转变。
7.2.3 虚实融合与大规模数据生成
尽管数据稀缺是关键限制,但同时也是巨大的机遇。若能通过高保真仿真、合成数据生成与多机器人共享实现虚拟与真实数据生态的融合,就有可能构建包含万亿级轨迹的大规模数据集。正如 GPT 借助互联网语料实现语言智能的跃迁,这类数据生态有望引发xx智能的跨越,使 VLA 在开放世界中表现出更强的鲁棒性。
7.2.4 社会嵌入与可信生态
VLA 的最终价值不仅在于技术能力,更在于其社会融入。当 VLA 进入公共与家庭空间时,安全性、可信性与伦理对齐将决定其应用范围。建立标准化的风险评估、可解释性与责任机制,将帮助 VLA 从实验室原型转变为可信赖的伙伴。一旦融入社会,VLA 将成为下一代人机交互接口,重塑医疗、工业、教育与服务等领域。这种社会嵌入为前沿研究转化为现实变革提供了里程碑式的机遇。
8. 结论
近期视觉-语言-动作(VLA)模型的进展,将视觉语言模型的泛化能力拓展至机器人应用,包括xx智能、自动驾驶与多样化操作任务。本文系统性地梳理了 VLA 方法的出现过程,从动机、方法论到应用进行了全面分析。我们首先基于自回归模型、扩散模型、强化学习、混合结构与高效推理等维度,对 VLA 架构创新进行了分类;随后,探讨了支撑 VLA 训练与评估的数据集、基准与仿真平台。在此基础上,分析了当前方法的优势与局限,并提出了未来的研究方向。总体而言,本文为发展可信赖、可持续演进的 VLA 提供了统一参考与前瞻性路线图,并为推动机器人系统迈向通用人工智能奠定了基础。
....
#Sora 2
Sora 2深夜来袭,OpenAI直接推出App,视频ChatGPT时刻到了
没想到吧,在别家节前卷大模型时,OpenAI 悄悄发布了 Sora2。

而且,这次是直接产品化,推出了 App,甚至还有配套的视频推送算法,声称可以防成瘾。这是要做自己的 TikTok?

据介绍,Sora 在物理准确性、真实感和可控性方面都优于以往的系统。
另外,就是它还具备同步的对话和音效能力。
Altman 称之为 ChatGPT for creativity 时刻。

在介绍文章中,OpenAI 更是直言 Sora2 直接进入了视频领域的 GPT 3.5 时刻,也就是当时的 ChatGPT 时刻。

如此看来,OpenAI对Sora2的技术能力与产品体验都极为满意。
我们也搞到了邀请码,在后续文章中将体验一波。海外已经体验上的网友称,这就是媒体、电影和娱乐的新时代。

接下来就让我们先看下Sora2的官方效果吧。
,时长02:13
Sora来了
2024 年 2 月发布的初代 Sora 模型,在很多方面都堪称视频领域的 GPT-1 时刻 —— 这是视频生成首次让人觉得开始行得通,像物体恒存性这样的简单行为,也随着预训练计算量的提升而出现。从那以后,Sora 团队一直专注于训练具备更先进世界模拟能力的模型。OpenAI 认为,此类系统对于训练能深度理解物理世界的 AI 模型至关重要。实现这一目标的一个重要里程碑,是掌握大规模视频数据的预训练和后训练技术,与语言领域相比,这些技术在视频领域尚处于起步阶段。
,时长00:50
OpenAI 表示,有了 Sora 2,他们直接进入可能是视频领域的 GPT-3.5 时刻。Sora 2 能做到一些对于之前的视频生成模型来说极其困难,甚至在某些情况下完全不可能做到的事情:比如呈现奥运体操动作、在桨板上完成后空翻,精确模拟浮力和刚性的动态变化,以及在小猫紧紧抓着的情况下完成三周半跳。
,时长00:50
此前的视频模型过于乐观 —— 它们会扭曲物体并改变现实,以成功满足文本提示。例如,如果一名篮球运动员投篮未中,球可能会自发地瞬移到篮筐处。在 Sora 2 中,如果一名篮球运动员投篮未中,球会从篮板上反弹回来。有趣的是,该模型所犯的「错误」往往似乎是 Sora 2 隐含模拟的内部主体所犯的错误;尽管仍不完美,但与之前的系统相比,它在遵守物理定律方面表现得更好。对于任何有用的世界模拟器来说,这都是一项极其重要的能力 —— 你必须能够模拟失败,而不仅仅是成功。
该模型在可控性方面也取得了重大飞跃,能够遵循复杂的多镜头指令,同时准确保持世界状态。它擅长写实、电影和动漫风格。
,时长00:40
作为一个通用的视频音频生成系统,它能够以高度的真实感创建复杂的背景音、语音和音效。
,时长00:55
你也可以直接将现实世界的元素注入到 Sora 2 中。例如,通过观看 OpenAI 一些员工的视频,该模型可以将他们插入到 Sora 生成的任何环境中,并准确呈现其外貌和声音。这种能力非常通用,适用于任何人、动物或物体。
,时长01:07
该模型远非完美,会犯很多错误,但它证明了在视频数据上进一步 scale 神经网络规模将使我们更接近模拟现实。
Sora APP已上线
OpenAI 表示,几个月前,Sora 团队首次尝试了「上传你自己」的功能,大家都玩得很开心。这感觉就像是一种自然而然的交流演变 —— 从短信到表情符号,再到语音消息,直至发展到如今这个样子。
所以今天,他们推出了一款全新的 iOS 社交应用,名为「Sora」,由 Sora 2 提供支持。在这款应用中,你可以创作作品、基于他人作品进行二创,在可定制的 Sora 信息流中发现新视频,还可以通过「客串(cameos)」功能让自己或朋友出镜。通过「客串」功能,在应用中进行一次简短的视频和音频录制以验证身份并捕捉外貌后,你就能以极高的逼真度直接融入任何 Sora 场景。
在「客串」功能中,你可以完全掌控自己的形象使用权:只有你能决定谁可使用你的 cameo,你可随时撤销权限或删除含有你 cameo 的视频,且无论视频是否被他人保存为草稿,你都能随时查看。
上周,OpenAI 在内部向全体员工推出了这款应用程序。有些人表示,因为这个功能,他们在公司结识了新朋友。OpenAI 认为,围绕这个「客串」功能打造的社交应用程序,是体验 Sora 2 魅力的最佳方式。
除了视频生成,OpenAI 还做了推荐算法
对刷视频停不下来、成瘾、孤立以及强化学习优化的推送内容的担忧是 OpenAI 首要关注点。以下是他们针对这些问题正在采取的措施。
他们为用户提供工具和选择,让他们能够掌控在动态消息中看到的内容。利用 OpenAI 现有的大语言模型,他们开发了一类新的推荐算法,这些算法可以通过自然语言进行指令设定。他们还内置了相关机制,定期向用户询问他们的身心健康状况,并主动为他们提供调整动态消息的选项。
默认情况下,OpenAI 向你展示的内容会严重偏向于你关注或互动的人,并优先展示模型认为你最有可能用作自己创作灵感的视频。OpenAI 表示,他们并非针对用户在视频中花费的时间进行优化,而且他们明确将应用程序设计为最大限度地促进创作,而非消费。详情参见:https://openai.com/index/sora-feed-philosophy/
OpenAI 表示,他们通过这款应用解决了许多安全问题,包括使用肖像的许可、来源出处、防止生成有害内容等等。更多详情,可以参见《Sora 2 安全文档》:https://openai.com/index/launching-sora-responsibly/。
OpenAI 认为,与现有的平台相比,Sora 将是一个更有利于娱乐与创意发展的平台,是更有利于娱乐与创意发展的平台。
可用性以及接下来的安排
Sora iOS APP 现已可供下载(美国和加拿大用户),最初免费,初始算力限制较为宽松。ChatGPT Pro 用户还可以在 sora.com 中使用实验性的、更高质量的 Sora 2 Pro 模型。OpenAI 还计划在 API 中发布 Sora 2。
,时长00:10
参考链接:https://openai.com/index/sora-2/
Sora 2干翻Veo 3?
超全对比实测:会中文脱口秀,但体操翻车,附有效邀请码
这次,OpenAI 又搞了波大的,祭出 Sora2,可以直接生成最长 20 秒的 1080p 视频。
比如,有网友拿奥特曼生成了 GPU 外卖小哥,甚至还有去超市偷显卡的剧情。
,时长00:18
相比于旧版本,Sora 2 在物理准确性、真实感和可控性方面都更胜一筹,而且它还和谷歌 Veo3 一样具备音画同步能力。
我们使用同样的提示词,让两个版本的 Sora 同台竞技。
提示词:A black tech reviewer talking about a smartphone, while sitting at a desk in front of 2 displays.(一位黑人技术评论员坐在办公桌前,面对两台显示屏谈论一款智能手机。)
上个版本的 Sora 并未对视频中的物体产生「理解」,模型仍然容易出现「幻觉」。
黑人小哥右手拿的手机总是凭空出现或消失,左手会在不经意间多根手指或少根手指,显示屏中的图片也都出现了手指畸变的情况。

而 Sora 2 生成的视频足够以假乱真,没有物体相互穿透或者无故消失和重现,人物手指也始终没出现畸变的问题,还实现了音频、视频一锅出。
要知道,我们对黑人小哥的评论话术没有任何提示,但 Sora2 生成的小哥嘴皮子溜得很,全程没有打磕巴,评论话术也完全是模型自己编的。我们还可以随意调整生成视频比例。
,时长00:20
这也难怪 Sora2 一经推出,外网就炸了锅。
「这款下一代 AI 视频和音频模型,可能是 Veo3 的真正竞争者。」

「Sora2 的音频生成比 Veo 3 更加出色。」

当然,也有泼冷水的。
「Sora2 生成的视频逼真效果确实让人叹为观止,但成本也非常巨大。」

Gary Marcus也一如既往的「毒舌」。他引用了一项研究数据,当生成的视频长度加倍时,文本到视频生成器的能耗会增加四倍。

他认为GPU是AI开发中的核心计算资源,需求量极大,将这些宝贵的计算资源用于开发一个AI生成的视频社交应用,而不是用于像癌症研究这样更有意义的领域,是一种资源错配。

与 Veo3 对比
目前,我们有两种方法使用 Sora2,既可以访问网页端,也可以下载 Sora iOS APP(美国和加拿大用户)。

这两种方法都免费,但需要邀请码,并且得是美区IP。
网页版访问地址:https://sora.chatgpt.com/explore

接下来还是老规矩,我们奉上一手实测,将其与谷歌 Veo3 来个正面对决。
Round 1:考验演技
Prompt:Handheld medium shot tracking an American soldier walking through a ruined Normandy battlefield at dusk. Heavy rain falls. The camera moves backward, facing him directly. His muddy face is blank, eyes hollow. Explosions flash behind him.
He stops, kneels in the mud, and whispers: ‘Why am I still here?’ A slow, somber orchestral score swells.(手持中景镜头跟踪一名美国士兵走过诺曼底废墟战场,黄昏时分,沉重的雨水倾盆而下。镜头向后移动,正对着他,他满脸泥污,表情空洞,眼神无神。爆炸的光芒在他身后闪现。他停下,跪在泥土中,低声说:「我为什么还在这里?」一段缓慢而沉重的管弦乐旋律响起。)
二者对于人物表情、场景设定的捕捉都很到位,爆炸声、配乐也都配的恰到好处,但从提示词遵循的角度来说,Veo3 更胜一筹。
提示词中明确要求一名美国士兵走过诺曼底废墟战场,然后跪下低语,Veo3 严格遵循了文本描述,而 Sora2 生成的视频省略了「停下脚步,在泥泞中跪下」这一趴。
而且 Veo3 生成的雨水落下的效果更加逼真,人物的运动幅度也更大。
我们还比较了上一个版本的 Sora,意外发现切镜头的效果相当丝滑,只是没有声音。

Round 2:生成 ASMR
Veo3 刚发布时,有网友生成 ASMR 视频一下子火了,这次我们也试了下。
Prompt:asmr creator typing on a noisy keyboard and then looking up and blowing into the microphone as she talks.(ASMR 创作者在嘈杂的键盘上打字,随后抬起头对着麦克风吹气并开始说话。)
,时长00:19
这两个模型生成效果都很惊艳,它们能够精准实现音画同步,捕捉到每一个细节。ASMR 创作者手敲键盘的声音清晰呈现,并且当她抬头呼气时,音效也能无缝切换,与画面完美结合。
这么说吧,如果不标注 AI 生成,估计会骗过在座诸位的眼睛。
Round 3: 考验唱功
Prompt:A male singer in a cozy recording studio singing into a microphone with headphones on, surrounded by acoustic panels and warm lighting — close-up on emotional facial expressions, intimate mood.(一位男歌手戴着耳机,站在一个温馨的录音室里,唱着歌,麦克风前面。周围是声学面板和柔和的灯光 —— 镜头特写他的情感丰富的面部表情,氛围温馨而亲密。)
,时长00:19
这效果确实没得说,真实得没边了。
不管是 Sora2 还是 Veo3,音画同步的处理非常精准,男歌手的歌声与口型完全一致,耳机、麦克风和录音室的环境细节也都处理得非常到位,让整个画面显得自然且真实。
Round 4:编假新闻
再来看它们生成的「假新闻」。
Prompt:A news anchor with a serious tone reporting an obviously fake news story about aliens landing in New York City, complete with stock footage overlays, dramatic music, and animated graphics behind them — newsroom background.(一位新闻主播以严肃的语气报道关于外星人降临纽约市的假新闻,画面中包含了库存视频素材的叠加、戏剧性的音乐和动态图形,背景是新闻室。)
,时长00:19
这一局 Sora2 胜出。
Veo3 生成画面主要是以演播室的 AI 主播为主,她操着一口纯正的美式播音腔一本正经地胡说八道,身后的屏幕虽然也呈现相关外星人画面,但较为模糊,多少有些出戏。
Sora2 除了呈现演播室主播播报新闻外,还时不时切换现场镜头,使得虚构的内容看起来像是一个真正的新闻报道。
Round 5:生成脱口秀
我们使用脱口秀场景,测试了一下他们对于中文提示词的理解能力。
提示词:一个脱口秀演员在台上说了一个笑话,内容是「别整天说自己是单身狗,狗在你这个年纪,早 die 了」,观众爆笑。
,时长00:19
给一段中文提示词,Sora2 就可以根据语言自动生成中国脱口秀演员,挑眉、嘴角上扬等微表情都能捕捉到,且口型对得严丝合缝,唯一的 bug 就是如果中文提示词里面夹杂着英文,英文就说不对。
我们之前用 Veo3 也尝试过同样的提示词,但 Veo3 只能输出说着英语的外国人。为了验证,我们重新使用 flow 平台中的 Veo3,仍未生成成功,原因是目前它仅支持英语提示。

Round 6:体操考验
无论是 Veo3 还是 Sora2,在生成体操视频方面还是会翻车。
提示词:一位体操运动员在明亮的体操房内,身着鲜艳的体操服,在高低杠上优雅地旋转、跳跃、翻腾,动作行云流水,镜头从不同角度捕捉她的精彩表现,背景音乐是激昂的交响乐,旁白详细讲解着她的动作技巧和训练历程。
,时长00:29
我们用 Sora2 分别生成了带中文和英文两种解说的体操视频,画外音解说效果确实不错,但体操动作还是会闹笑话。比如体操运动员的动作突然倍速、突然多出来的胳膊:

或者一个大回环人已经飞出老远了,但下一秒仍稳稳抓到单杠:

Veo3 也有好多邪门的细节,在单杠上旋转时要骨折的胳膊、原地跳跃时 360 度旋转的手臂……

在版权方面,OpenAI长教训了,Sora2不仅采用邀请制,还采取了安全措施,如水印和对公众人物深度伪造的限制,以防止滥用。
在我们体验中,Sora 2 App经常因版权保护措施和其他原因而拒绝生成视频,其他创作者生成的作品也禁止下载或录屏。
一个全是假视频的 TikTok,真的会火吗?
除了常规的视频生成功能外,这次 OpenAI 还推出了基于自拍的客串功能。

比如让奥特曼客串 SpaceX 发射现场。
提示词:@sama watches spaceX rocketship launch. Then laugh.@sama says 「good job」。
,时长00:08
OpenAI 推出的 Sora iOS 应用,最初在美国和加拿大上线。
手指一划,就能观看一个个 100% 由 AI 生成的视频流,我们还可以通过可滑动的动态信息流生成、重混和分享视频。

不得不说,该 App 就连页面设计都像极了 TikTok,包含一个由推荐算法驱动的「为你推荐」页面,在视频流的右侧为用户提供了点赞、评论或重混视频的选项,底部的导航栏分别是主页、搜索、发布视频、通知和「我的」,甚至还有「私信」。

对于 OpenAI 这种打法,有人认为,「单论视频生成的模型,从谷歌到国内的快手、字节、MiniMax、百度,大家一个比一个卷,没有谁能持续领先。但通过 Sora 应用程序建立产品壁垒后,OpenAl 就可以有充分的喘息时间来追平模型差距。即便在某些指标上暂时落后,它依旧能牢牢握住用户入口和使用习惯。」
可问题是,OpenAI 并不是第一个这么干的。上周,Meta 也刚刚宣布,在其 Meta AI 应用中新增了一个名为 Vibes 的视频流。
早在去年,即梦AI App就先后在安卓应用市场和苹果 App Store上线,后来随着平台功能完善和社区运营启动,即梦AI App逐步形成了创作者生成的视频流生态,目前已发展为国内领先的 AI 内容创作与分发平台。
因此,一个全是假视频的 TikTok 能否持续火下去、能否真正成为 OpenAI 的产品壁垒,这还有待时间验证。
最后,想体验的读者欢迎留言获取邀请码。数量有限,先到先得。
参考链接:
https://x.com/GaryMarcus/status/1973153261801898248
https://x.com/AstroJoeB/status/1973140106866213113
https://x.com/bilawalsidhu/status/1973151157137842416
....
#OpenAI的这位幕后大神是谁
CUDA内核之神、全球最强GPU程序员?
在 AI 圈里,聚光灯总是追逐着那些履历光鲜的明星人物。但一个伟大的团队,不仅有台前的明星,更有无数在幕后贡献关键力量的英雄。
之前我们介绍了 OpenAI 的两位波兰工程师,最近 OpenAI 又一位身处幕后的工程师成为了焦点。
起因是 X 上的一则热门帖子,其中提到 OpenAI 仅凭一位工程师编写的关键 CUDA Kernel,就支撑起每日数万亿次的庞大计算量。

评论区纷纷猜测,这位大神便是 OpenAI 的资深工程师 Scott Gray。

在 OpenAI 的官方介绍中也明确提到,他的工作重心是「优化深度网络在 GPU 上的性能」。

为什么一个能编写 CUDA Kernel 的工程师会引起如此关注?
因为编写高性能的模型训练 CUDA Kernel 是一项极度专业的技能,它要求开发者必须同时精通三大高深领域:并行计算理论、GPU 硬件架构与深度学习算法。能将三者融会贯通的顶尖人才凤毛麟角。
大多数开发者停留在应用层,使用现成工具。从事推理优化的人稍多,因为其问题边界更清晰。然而,要深入底层,为复杂的训练过程(尤其是反向传播)从零手写出超越 cuDNN 等现有库的 CUDA Kernel,则需要对算法、并行计算和硬件有宗师级的理解。
而 Scott Gray 的职业轨迹,恰好是为这个角色量身打造的。他并非典型的「神童」科学家,而是走出了一条专注于底层性能工程的「普通」道路。

Scott Gray 毕业于 UIUC 物理与计算机科学,2016 年入职 OpenAI,早年于 Nervana 从事 GPU 汇编级内核优化。

前 Nervana CEO 在评论区更是直接盖章,称他们当年在论坛发现 Scott 后便当场聘用,并盛赞其为「全球最强 GPU 程序员」。

CUDA 内核之神、全球最强 GPU 程序员,这些名号放在同一个人身上,可想而知他的的实力有多硬核。不少网友开玩笑说,他可能已经上了小扎的「暗挖名单」。
接下来我们来回顾一下他的职业生涯和技术路线。
在 Nervana 压榨物理极限
Scott Gray 在 AI 领域的声名鹊起,始于他在 Nervana Systems(一家后被英特尔以约 4 亿美元收购的公司)的时期。
当时,深度学习正处于爆发前夜,但软件框架与底层硬件之间存在着巨大的效率鸿沟。绝大多数开发者依赖 NVIDIA 的 CUDA C/C++ 和官方库(如 cuBLAS、cuDNN)进行 GPU 编程。这个标准流程虽然便捷,但其多层软件抽象(CUDA C -> PTX 中间语言 -> SASS 机器码)屏蔽了硬件细节,也成为了性能的「天花板」。
Gray 的哲学是,要实现真正的性能突破,必须绕过这些抽象层。
maxas 汇编器:直接与硬件对话
Gray 认为 NVIDIA 官方的汇编器(ptxas)在寄存器分配、指令调度等方面表现不佳,导致性能损失。
他没有选择在框架内小修小补,他开发了 maxas,一个针对 NVIDIA Maxwell 架构的汇编器。这让他得以绕开编译器的束缚,手动编写出极致性能的计算内核。
maxas 让开发者可以直接编写最底层的 SASS 机器码,从而获得对硬件资源的绝对控制权,包括手动分配寄存器、管理内存延迟、控制指令流水线等。
为了证明其价值,Gray 使用 maxas 手写了一个 SGEMM(单精度通用矩阵乘法)内核。结果是颠覆性的。
当时的 GM204 GPU 上,该内核的计算效率达到了硬件理论峰值的 98%,意味着软件开销几乎为零。
更重要的是,它的性能比 NVIDIA 官方闭源、同样由专家手写的 cuBLAS 库还要快 4.8%。这向业界证明,即便是硬件厂商自己打造的「黄金标准」也并非不可逾越。
maxDNN:将极致优化方法论推广至卷积
在 maxas 成功的基础上,Gray 将目光投向了深度学习中另一个核心计算——卷积。他开发了 maxDNN,旨在证明 maxas 的底层优化方法论是一种可以系统性应用的通用策略。
maxDNN 借鉴了当时最高效的卷积算法思路,但在底层完全采用 maxas 中被验证过的汇编级优化技术,例如使用 128 位纹理加载、激进的双缓冲策略来隐藏内存延迟,并对数据进行重组以实现完美的内存合并访问。最终,其核心计算循环中,超过 98% 的指令都是纯粹的浮点运算指令,计算效率极高。
maxDNN 的性能表现全面超越了当时 NVIDIA 的 cuDNN 库。在 AlexNet 模型的所有卷积层上,maxDNN 稳定地达到了 93-95% 的计算效率。相比之下,cuDNN 的效率在 32% 到 57% 之间大幅波动。在 Overfeat 模型的某个卷积层上,maxDNN 的效率更是达到了 96.3% 的峰值。
在 Nervana 的这两项工作,为 Scott Gray 赢得了「性能优化大师」的声誉,并证明了通过深入硬件底层,一个小团队甚至单一个体也能创造出超越行业巨头的性能。
OpenAI 时期:从优化算子到赋能新架构
加入 OpenAI 后,Gray 的工作重心发生了战略性转变。随着 Scaling Laws 的提出,模型规模的增长成为提升性能的关键。然而,稠密模型的无限扩张在计算和成本上面临瓶颈。Gray 的工作转向了为更高效的稀疏模型架构开发底层工具,从一个「优化者」转变为一个「使能者」。
Scott Gray 的名字出现在几乎所有 OpenAI 的里程碑式论文中,包括 GPT-3、GPT-4、Codex 和 DALL-E。他作为核心技术人员,编写了大量高性能 GPU 内核,支撑了这些模型万亿次级别的训练和推理计算。他是将 Scaling Laws 这一理论发现转化为工程现实的关键人物之一。

为了解决稠密模型的规模化难题,Gray 与同事共同开发了一套创新的块稀疏(block-sparse)GPU 内核。
- 论文标题:GPU Kernels for Block-Sparse Weights
- 论文地址:https://cdn.openai.com/blocksparse/blocksparsepaper.pdf
不同于移除单个权重的非结构化稀疏,块稀疏将权重矩阵划分为固定大小的块,并将整个块置零。Gray 为此开发了专门的 GPU 内核,在计算时能够完全「跳过」这些零值块,从而大幅提升效率。
这些内核的运行速度可以比处理稠密矩阵的 cuBLAS 或处理通用稀疏矩阵的 cuSPARSE 快上几个数量级。
这种性能突破带来了巨大的架构优势。研究人员可以在固定的计算预算内,构建参数量远超以往的神经网络模型(例如,宽度是同等稠密网络 5 倍的 LSTM 模型)。利用这些内核,OpenAI 在文本和图像生成等多个任务上取得了当时的 SOTA 成果。
与在 Nervana 时一样,OpenAI 也将这些高性能的块稀疏内核进行了开源,旨在推动整个社区在模型和算法设计上的进一步创新。
....
#Reinforcement Learning Meets Large Language Models
复旦、同济和港中文等重磅发布:强化学习在大语言模型全周期的全面综述
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。
对此,来自复旦大学、同济大学、兰卡斯特大学以及香港中文大学 MM Lab 等顶尖科研机构的研究者们全面总结了大语言模型全生命周期的最新强化学习研究,完成题为 “Reinforcement Learning Meets Large Language Models: A Survey of Advancements and Applications Across the LLM Lifecycle” 的长文综述,系统性回顾了领域最新进展,深入探讨研究挑战并展望未来发展方向。
- 论文标题: Reinforcement Learning Meets Large Language Models: A Survey of Advancements and Applications Across the LLM Lifecycle
- 论文链接:https://arxiv.org/pdf/2509.16679
作者综述了强化学习赋能大语言模型的理论与实践进展,详细阐述了强化学习在大语言模型全生命周期各阶段的应用策略,包括预训练、对齐微调与强化推理并整理了当前用于强化学习微调的现有数据集与评估基准以及现有的主流开源工具与训练框架,为后续研究提供清晰的实践参考。该综述还详细分析了强化学习增强型大语言模型领域未来面临的挑战与发展趋势,旨在为研究人员与从业者呈现强化学习与大语言模型交叉领域的最新进展及前沿趋势,以期推动更智能、更具泛化能力且更安全的大语言模型的发展。

图 1:强化学习增强型大语言模型的核心组件概览。该图展示了强化学习增强型大语言模型生命周期内的核心组件及其交互关系。在强化学习框架与工具包的驱动下,强化学习算法参与大语言模型的预训练、对齐及推理增强训练,并通过测试基准进行验证。
该综述深入剖析了强化学习技术如何应用于大语言模型的全生命周期阶段,如何贯穿 LLMs 的预训练、对齐和强化推理全过程。文章总结了强化学习应用于大语言模型的具体方法和技术细节,为未来强化学习与 LLMs 的深度融合提供了经验,以此探索未来的研究机遇与发展路径。基于所综述内容,作者提出了首个 RL 在 LLMs 全生命周期的运作方法的分类总览图:

图 2:强化学习增强型大语言模型的分类体系总览图。该图呈现了构建强化学习增强型大语言模型所涉及的关键阶段与资源的分类体系,共分为五个分支:预训练、对齐、基于可验证奖励的强化学习、数据集与基准测试、开源框架。此分类体系明确了各阶段之间的关联,可作为理解该综述所探讨的方法进展与相关资源的参考框架。
作者将基于可验证奖励的强化学习技术 (Reinforcement Learning with Verifiable Rewards, RLVR) 作为该综述的关注重点,系统性地梳理了自 OpenAI-o1 与 DeepSeek-R1 发布以来强化学习赋能大语言模型以及多模态大语言模型推理能力上的应用研究,总结了如何通过提供可验证的奖励信号提升模型推理的稳定性和准确性。通过引入可自动验证的奖励机制,RLVR 不仅优化了推理过程,还增强了模型对复杂任务的适应能力。该综述对 RLVR 进行了详细探讨,展示了其在数学推理、编程任务等领域的应用效果。

图 3:RLVR 方法的技术架构图。该架构图展示了 RLVR 的整体工作流程,并详细阐述了奖励模型、离线策略辅助、奖励过滤、采样与推理策略、智能体强化学习以及奖励更新层级的设计方法。
该综述主要有三大特有贡献:
- 全生命周期梳理:系统涵盖了强化学习在大语言模型中的完整应用生命周期,详细阐述了从预训练、对齐到推理强化的各阶段流程。在此过程中,该文章明确了每个阶段的目标、方法及面临的挑战。
- 聚焦先进 RLVR 技术:重点介绍了基于可验证奖励的强化学习领域的前沿方法。该文章深入分析了 RLVR 的实验现象与尖端应用,探究了用于确保奖励具备客观性与可验证性的相关方法。
- 整合关键研究资源:总结了对大语言模型中强化学习相关实验、评估及实际落地至关重要的数据集、基准测试与开源框架。通过整合这些信息,该文章为未来希望在 LLMs 场景下探索 RL 的研究人员提供了极具价值的参考资源。
强化学习在大语言模型上的应用,标志着大模型发展的一次重要转折。然而当前强化学习在大语言模型全生命周期中的应用依然面临的挑战。作者指出,尽管强化学习在提升 LLM 的对齐和推理能力方面取得了显著进展,但在系统规模的可扩展性和训练稳定性方面仍存在很大的挑战。大规模 RL 训练对于 LLM 来说依然是计算密集型的,并且往往不稳定。
此外,奖励设计和信用分配的问题也是当前 RL 应用中的难点,尤其是在长时间推理过程中,奖励延迟的问题给模型的学习带来了不小的困难。理论层面,当前缺乏清晰的理论框架来分析 RL 在 LLM 训练中的泛化能力和稳定性,这使得对 RL 的有效性和潜在风险的理解仍然不充分。在应用层面,将RL与基于LLM的智能体和工具使用相结合,也面临着效率、安全性和可控性等挑战。因此,文章强调了在数据集和评估基准建设方面的不足,当前大多数研究仍依赖特定任务的数据集,缺乏统一的标准化基准,这为强化学习微调方法的比较和验证带来了困难。
该综述形成了一份基于生命周期的综合分析,既突出了方法层面的进展,也涵盖了配套支持资源,并结合领域技术趋势和工程实践需求分析了现有挑战和未来方向,可作为强化学习增强型大语言模型领域研究者的前沿参考资料
....
#OpenGPT-4o-Image
中科大、清华、快手等发布:为多模态AI打造的“超级燃料”,图像编辑性能提升18%
如今,我们都对GPT-4o这类强大的多模态模型的威力惊叹不已,它们能看、能听、能说,还能生成和编辑图片。但一个灵魂拷问随之而来:要让这些模型变得更强,下一个突破口在哪里?答案可能出乎很多人的意料—— 数据。
没错,就像顶级运动员需要科学的营养配餐一样,顶级的AI模型也需要高质量、高维度的“精神食粮”。现有的数据集大多只覆盖了简单的任务,比如风格转换或单个物体修改,远远不能满足真实世界复杂多变的需求。
正是为了打破这一瓶颈,来自中国科学技术大学、快手Kling团队、杭州电子科技大学、北京大学、南京大学、中国科学院和清华大学的众多研究者们,联手推出了一个全新的大规模数据集—— OpenGPT-4o-Image。这不仅仅是一个数据集,更是一套系统性的“AI能力培养皿”。
- 论文标题: OpenGPT-4o-Image: A Comprehensive Dataset for Advanced Image Generation and Editing
- 作者: Zhihong Chen, Xuehai Bai, Yang Shi, Chaoyou Fu, Huanyu Zhang, 等
- 机构: 中国科学技术大学、快手Kling团队、杭州电子科技大学、北京大学、南京大学、中国科学院、清华大学
- 论文地址: https://arxiv.org/abs/2509.24900
- 项目主页: https://github.com/NROwind/OpenGPT-4o-Image
- Hugging Face地址: https://huggingface.co/datasets/WINDop/OpenGPT-4o-Image
不仅仅是“更多”,更是“更好更全”
与以往的数据集相比,OpenGPT-4o-Image最大的特点是其 系统性的构建方法。研究者们不再是简单地收集数据,而是首先定义了一个全面的、层次化的 任务分类体系。
这个体系不仅包含了像文本渲染、风格控制这样的基础能力,更引入了一系列极具实用性但又充满挑战的类别,例如:
- 科学图像生成:比如绘制化学分子结构图,这对模型的专业知识和精确绘图能力提出了极高要求。
- 复杂指令编辑:要求模型能理解并同时执行多个操作,比如“把图中的猫换成狗,并把背景从草地换成沙滩”。
- 多轮对话编辑:模拟真实的人机交互,通过连续多轮对话来逐步完善编辑效果。
最终,整个数据集包含了 11个主要领域 和 51个子任务,形成了一个结构清晰、覆盖全面的能力图谱。
GPT-4o加持的自动化“数据工厂”
定义好了任务体系,如何高效地生成海量高质量数据呢?团队设计了一套自动化的数据生成流水线。
如上图所示,这个“数据工厂”的核心是 GPT-4o 和一个 结构化的资源池。首先,通过填充多样化的语法模板来大规模生成结构化的指令,然后利用GPT-4o根据这些指令生成最终的图像。整个流程实现了对数据多样性和质量的精准控制,最终高效地生成了 8万个 高质量的“指令-图像”数据对。
专治“疑难杂症”:数据集亮点一览
OpenGPT-4o-Image覆盖了极其丰富的图像生成和编辑场景,堪称多模态模型的“多面手”。
从上图的编辑任务示例中,我们可以看到其覆盖范围之广,从基础的物体、文本、全局编辑,到更具挑战的复杂指令和多轮对话编辑,一应俱全,为训练出能力更全面的多模态模型提供了可能。
“好数据”喂出“好模型”:显著的性能提升
那么,用这份“超级燃料”去训练现有的SOTA模型,效果如何呢?答案是:提升显著!
研究者们在多个主流的图像生成和编辑模型上进行了微调实验。结果表明,经过OpenGPT-4o-Image微调后,模型在各大基准测试集上的性能都获得了大幅提升。
在图像编辑任务上,性能提升最高达到了 18%!
在图像生成任务上,性能提升也高达 13%!
下面的对比图更直观地展示了模型在微调前后的变化,无论是构图的合理性还是细节的精确性,都判若两“模”。
xx认为,这项工作最重要的贡献,是为社区证明了“系统性的数据构建是推动多模态AI能力进步的关键”。OpenGPT-4o-Image不仅是一个高质量的数据集,更是一套可复现、可扩展的数据构建方法论,为未来更强大模型的诞生铺平了道路。目前数据集已在GitHub和Hugging Face上开放,强烈推荐大家去探索。
....
#Sora 2数手指翻车
奥特曼成第一批「受害者」,被AI玩成最惨打工人
奥特曼大型社死现场。
Sora 2,强大如斯,却也数不明白手指。
X 网友 @fofrAI 整了个提示词测试 Sora 2:a man counts out loud from 1 to 10, using his fingers and holding them up as he goes.(一名男子一边举起手指,一边大声数着从 1 到 10。)
视频一开始,男人的表现没啥毛病,但之后就漏了馅,嘴里喊着数字 2、3、5,手上却比划着 4 根手指。他还搞了个额外福利,让奥特曼出镜,数手指游戏依然没有成功。
,时长00:19
Sora 2生成的视频中,男人能够正确数数,但手指的展示与数字并不完全对应。
这已经不是该博主第一次拿这种提示词测试视频生成模型。早在今年 5 月份,他就用这个提示词测试过 Veo3,Veo3 不仅手指没比划对,数字还只数到 3。
后来博主又润色了提示词:a man counts out loud from 1 to 10, "1, 2, 3, 4, 6, 7, 8, 9, 10", he counts using his fingers and holds them up as he goes.(一名男子大声从 1 数到 10,「1、2、3、4、6、7、8、9、10」,他一边数,一边举起手指),仍以失败告终:
,时长00:16
之前史密斯吃意大利面还是一个出圈的 AI 视频生成模型的测试案例,没想到现在数手指成为了新基准。

也有人表示,这些视频模型之所以数不明白,或许是因为提示词写的模棱两可。

有网友给出了一个更具体的提示词:a man considers each digit(finger) of both of his hands as representing a number, starting from his right hand thumb as representing "one" and the pinky of his left hand as "ten", he begins at the beginning, on the digit (finger) representing "one' and systematically and meticulously advances through the counting out loud as he raises and display each digit (finger) that corresponds with his verbal and logical count.(一个人将双手的每个手指视为一个数字,从右手拇指代表「1」,左手小指代表「10」开始,从代表「1」的数字开始,系统而细致地大声数数,同时举起并展示与他的口头和逻辑计数相对应的每个数字。)

我们用新提示词分别测试了 Sora2 和 Veo3,还是失败:
,时长00:18
除了数手指,网友们还开发出五花八门的测试,比如模拟了水倒入玻璃杯的场景、玻璃折射测试,还有魔术师将水倒入玻璃杯中,然后拿起玻璃杯并将其倒置,水不会流出。
,时长01:05
Sora 2 可以轻松模拟水倒入玻璃杯的过程,包括反射、涟漪、折射。不过细究一下还会有瑕疵,比如在模拟光的折射现象时向杯中倒入水,朝左的箭头变成朝右的同时,箭头也少了一丢丢;在那个经典魔术中,杯中水突然像溅出来一样,水中气泡的生成也很不合理。

被玩坏的奥特曼
Sora2 的第一批受害者出现了,那就是 OpenAI CEO 奥特曼。
自从 OpenAI 推出了类似 TikTok 的新社交媒体应用 Sora,我们随便一划就能刷到各类奥特曼小短剧。
在这些 AI 生成的视频中,奥特曼的精神状态堪忧,要么又蹦又跳、放声高歌、打哈欠、自恋地欣赏自己的美貌、给自己剃光头、画烟熏妆、在马桶里唱 rap、跑到英伟达门口喊着「I need more GPUs」、模仿鸡排哥在中国街头炸鸡排:
,时长01:34
要么 Cosplay 小猫,画面太美我不敢看😂
,时长00:37
不得不说,奥特曼为了自家产品牺牲了太多,我们有理由怀疑,OpenAI 是不是只用奥特曼的视频来训练 Sora2,因为这些视频都完美展示了奥特曼的声音的举止。

就连奥特曼本人都对自己「贴脸开大」,发帖称观看动态中自己的表情包,感觉并没有想象中奇怪。

也有网友表示,看了这些奇奇怪怪的 AI 视频,反倒越来越喜欢奥特曼了。

除了奥特曼被网友玩坏了之外,皮卡丘的处境也没好到哪里去,由此还引发一种新趋势——将皮卡丘放入每部电影中,比如《拯救大兵皮卡丘》、《皮卡丘之教父》、《泰坦尼克号皮卡丘版》等。
,时长00:30
有意思的是,OpenAI 还宣称自己很重视版权保护,但转过头就有网友用 Sora2 生成了一个略带讽刺的视频:奥特曼站在宝可梦的田野里,皮卡丘、妙蛙种子还有一只卡哇伊大脚怪正在草地上嬉戏玩耍,奥特曼看着镜头说:「希望任天堂不要起诉我们。」
,时长00:49
OpenAI 研究员的担忧
网络上充斥着大量 AI 生成的深度伪造视频,这引起了不少网友的不满,一些 OpenAI 现任和前任研究员也似乎对 Sora 应用的发布是否符合 OpenAI 作为非营利组织的使命而感到矛盾。

OpenAI 预训练研究员 John Hallman 表示:「基于 AI 的动态很可怕。不可否认,当我第一次得知我们要发布 Sora 2 时,我感到有些担忧。不过,我认为团队在设计一个积极的体验方面已经尽力而为……我们会尽最大努力确保 AI 帮助人类,而不是伤害人类。」

另一位 OpenAI 研究员兼哈佛教授 Boaz Barak 回复道:「我也有同样的担忧和兴奋。Sora 2 在技术上令人惊叹,但现在就庆幸自己避开了其他社交媒体应用和深度伪造的陷阱还为时过早。」

人工智能政策研究员 Miles Brundage 认为,「有很多合理的理由让我们担心视频生成技术,但是将视频生成与整体混为一谈是一个错误。」

前 OpenAI 研究员 Rohan Pandey 借此机会宣传了他的新创公司 Periodic Labs,他说:「如果你不想建造一个无休止的 AI TikTok 垃圾机器,而是希望开发加速基础科学的 AI……来加入我们,加入 Periodic Labs。」

OpenAI 是全球增长最快的消费科技公司,但同时也是一家拥有崇高非营利使命的前沿 AI 实验室。有些前 OpenAI 员工认为,虽然它同时运营消费性业务,但这些业务也可以支持其使命,例如通过 ChatGPT 资助 AI 研究,并将技术广泛传播。
奥特曼也在 X 上发帖谈到了这一点,解释了为什么公司要为 AI 社交媒体应用分配如此多的资金和计算能力。
「我们确实需要资金来构建能够进行科学研究的人工智能,而且我们几乎所有的研究精力都集中在通用人工智能上,」奥特曼说。「同时向人们展示酷炫的新技术/产品,让他们开心,并希望在满足所有计算需求的同时还能赚到一些钱,这也是一件好事。」
「当我们推出 ChatGPT 时,有很多人问『谁需要这个?AGI 在哪里?』但实际上,公司最优发展轨迹的现实是复杂的。」

技术的发展总是一体两面,OpenAI 能否在不重蹈前人覆辙的情况下发展 Sora 仍有待观察。
最后提一嘴,由于 Sora2 采用邀请制,我们在昨天的文章评论区搞了个邀请码接力,读者朋友们非常积极,新邀请码仍在持续接力中,有需要的朋友可以去置顶评论区找码。
为了让更多人有机会体验,请收到邀请码的朋友点击 Sora 页面左边栏的 invite friends,将新码复制到评论区接力,再次感谢大家,祝大家双节快乐!
参考链接:
https://x.com/fofrAI/status/1973345533147349238
https://techcrunch.com/2025/10/01/openai-staff-grapples-with-the-companys-social-media-push/
....
#Tinker
开发者狂喜:Thinking Machines发布首款产品Tinker,后训练麻烦全给包了
对于大模型开发者 / 研究者来说,今天是重要的一天。
因为刚刚,OpenAI 前 CTO Mira Murati 创办的 Thinking Machines 推出了首款产品 ——Tinker。

简单来说,Tinker 是一个 API,用于帮开发者 / 研究人员微调语言模型。重要的是,在此过程中,你只需要专注于训练数据和算法,而你不擅长的关于 Infra 的部分 —— 调度、调优、资源管理和 Infra 可靠性 —— 统统由 Tinker 来搞定,这将大大简化 LLM 的后训练过程。


目前,Tinker 支持的模型如下所示,Qwen-235B-A22B 等前沿模型都包含在内。该公司表示,从一个小模型切换到一个大模型,就像在你的 Python 代码中更改一个字符串一样简单。Tinker 的发布是 Thinking Machines 使命的表现,即让更多人能够研究尖端模型并根据自己的需求进行定制。

Tinker 使用 LoRA 技术,以便在多个训练运行之间共享同一计算资源池,从而降低成本。 在前几天的一篇博客中,Thinking Machines 专门写了一篇博客介绍他们在 LoRA 方面的研究进展(参见《Thinking Machines 又发高质量博客:力推 LoRA,不输全量微调》)。
Tinker 的 API 为开发者提供了诸如 forward_backward 和 sample 之类的底层原语,这些原语可用于表达大多数常见的后训练方法。即便如此,要取得好的结果仍需要处理好许多细节。这就是为什么他们要发布一个开源库 ——Tinker Cookbook,其中包含基于 Tinker API 运行的后训练方法的现代实现。

伊利诺伊大学香槟分校博士生金博文表示,Tinker 的 Cookbook 中收录了他们的训练工具 ——Search-R1,这个工具可以「边推理边搜索」,感兴趣的读者可以参见《UIUC 联手谷歌发布 Search-R1:大模型学会「边想边查」,推理、搜索无缝切换》。

目前,普林斯顿大学、斯坦福大学、加州大学伯克利分校和 Redwood Research 的团队已经在使用 Tinker:
- 普林斯顿大学 Goedel 团队训练了数学定理证明器。使用 Tinker 和 LoRA,仅用 20% 的数据,他们的模型性能与全参数 SFT 模型(如 Goedel-Prover V2)相当。他们在 Tinker 上训练的模型在 MiniF2F 基准测试中达到了 88.1% 的 pass@32,通过自我校正后达到了 90.4%,超过了更大的封闭模型。
- 斯坦福大学的 Rotskoff 化学小组对一个模型进行了微调,以完成化学推理任务。在 LLaMA 70B 之上应用强化学习后,IUPAC 到公式的转换准确率从 15% 提升至 50%,研究人员称这一提升是以前在没有重大基础设施支持的情况下难以实现的。
- 加州大学伯克利分校的 SkyRL 小组在一个定制的异步 off-policy 强化学习训练 loop 上进行了实验,该 loop 涉及多智能体和多轮工具使用。得益于 Tinker 的灵活性,这些变得可行。
- Redwood Research 利用 Tinker 对 Qwen3-32B 在长上下文 AI 控制任务上进行 RL 训练。研究员 Eric Gan 表示,如果没有 Tinker,他可能不会进行这个项目,他指出,多节点训练的扩展一直是一个障碍。
这些示例展示了 Tinker 的通用性 —— 它支持经典的有监督微调和高度实验性的强化学习(RL)pipeline,跨越了广泛的领域。
Tinker 正面向研究人员和开发人员进行内部测试,waitlist 也已开放申请。参与测试的 Anyscale 公司 CEO Robert Nishihara)表示,虽然像 VERL 和 SkyRL 这样的其他微调工具已经存在,但 Tinker 提供了卓越的抽象性与可调节性的结合(Tinker 抽象出了分布式训练的细节,但仍然让大家完全控制数据和算法)。
已经试用 Tinker 几周的加州大学伯克利分校计算机科学博士研究生 Tyler Griggs 则表示,许多强化学习微调服务都是面向企业的,不允许你替换训练逻辑。使用 Tinker,你可以忽略计算,只需对环境、算法和数据负责即可。


- waitlist 链接:https://thinkingmachines.ai/tinker/
- Tinker Cookbook 链接:http://github.com/thinking-machines-lab/tinker-cookbook
Thinking Machines 表示,Tinker 在起步阶段将免费使用。在接下来的几周内,他们将推出基于使用情况的定价模式。
Tinker 的发布给了广大开发者微调自己模型的机会,而这可能带来更多样化的产品创新。

AI 大牛 Karpathy 评价说,「我认为,社区还需要进一步探索 —— 在什么情况下、以什么方式进行微调才真正比直接用『大型模型加提示』更合适。 从我目前看到的一些迹象来看,微调的作用其实并不是为了给大语言模型『加风格』或『个性化』,而是为了收窄模型的任务范围,尤其是在你拥有大量训练样本的时候。 一个极端的例子就是各种分类器,比如垃圾邮件过滤器、内容过滤器等 —— 这些都是范围极窄的模型。当然,微调的应用范围应该远不止于此。但相比于为大模型设计一个复杂的 few-shot 提示,直接微调一个更小、专门针对某个细分任务的模型,往往效果更好、速度也更快。
现在,大语言模型在实际生产中的应用越来越多是通过大型管线(pipeline)来实现的,也就是多个模型以有向无环图(DAG)或流程(flow)的方式协同工作。在这些系统里,有的部分用提示就能很好地完成任务,但有相当多的环节其实更适合通过微调来实现。」
Murati 表示,Thinking Machines 实验室希望揭开调整世界上最强大的人工智能模型所涉及工作的神秘面纱,让更多人能够探索人工智能的极限。她说:「我们正在让原本只有前沿团队具备的能力惠及所有人,这完全是改变游戏规则的。外面有大量聪明人,我们需要尽可能多的聪明人来进行前沿人工智能研究。」
该公司开放大模型微调流程的计划也体现了其对开放的承诺。Murati 还表示,她希望 Tinker 将有助于扭转商业人工智能模型日益封闭的趋势。「如果你看看前沿实验室正在做的事情,以及学术界其他聪明人士在做的事情,它们之间的分歧越来越大,」她说。「如果你想想这些强大的系统将如何进入世界,这种情况可不太妙。」
参考链接:
https://thinkingmachines.ai/tinker/
https://www.wired.com/story/thinking-machines-lab-first-product-fine-tune/
https://venturebeat.com/ai/thinking-machines-first-official-product-is-here-meet-tinker-an-api-for
....
#FireRedChat
小红书发布:首个可私有化部署的全双工大模型语音交互系统
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。彻底开源、可私域落地,打造真正 “知冷暖、能共情、懂表达” 的语音 AI。
小红书智创音频团队发布 FireRedChat—— 业内首个支持私有化部署的全双工大模型语音交互系统,直击延迟高、噪声敏感、可控性差、依赖外部 API 等痛点。
FireRedChat 基于 “交互控制器+交互模块+对话管理器” 的完整架构,将任意半双工链路一键升级为全双工;集成自研流式个性化打断 pVAD、语义判停 EoT、FireRedTTS-1s、FireRedASR、FireRedTTS2 等核心模型,提供级联与半级联两种端到端服务部署方案,覆盖从 “稳定易部署” 到 “更有温度” 的不同需求,显著提升实时性、鲁棒性与可控性。
实验结果显示,系统在多项关键指标领先其他开源框架,为 “更智能、更自然” 的全双工语音交互提供了一套真正可用、可落地的开源方案。
技术报告:https://arxiv.org/pdf/2509.06502
在线体验:https://fireredteam.github.io/demos/firered_chat
开源代码:https://github.com/FireRedTeam/FireRedChat
通过 FireRedChat 构建的 AI 聊天助手不仅具备「快速打断,智能判停,实时响应」的自然对话能力,还能依托内置的情绪感知与情感合成,让 AI 不再是一个冷冰冰的机器人,而是一个「知冷暖、能共情、懂表达」的好朋友。
她能细腻感知你的情绪变化:在你失落时,轻声安慰、真诚鼓励;在你遇到惊喜时,和你一样心潮澎湃、享受 surprise;在你开心时,陪你分享喜悦、一起欢笑。
FireRedChat 让 AI 聊天助手不只是回应文字,更能用富有温度的声音、情感和表达方式,带给你一种被理解、被陪伴的真实感受,让 AI 真正拥有「人感」。
,时长03:12
为什么全双工语音交互难,难在何处?
用户期待的是 “你说我听、我说你懂” 的自然对话,而非机械的一问一答。为了实现自然对话,要求系统既要能精准感知双方交互中的轮次变化,又要能抵抗外部其他说话人以及环境噪声的干扰;既要知道 “何时打断” 不出错,又要把握 “何时回复” 的最佳时机;还要摆脱闭源 API 的束缚,做到全链路可控、可私有化部署。这些挑战长期压制着开源生态的产品化落地。
FireRedChat 的硬核突破:五个 “真牛” 的点
第一,行业首创的 “全双工 + 私有化” 组合。FireRedChat 从设计之初就面向企业级落地,完整覆盖从音频输入到语音合成的全链路,并提供一键私有化部署能力,在数据安全、成本可控和系统扩展性上全面领先。
第二,自研 pVAD + 轻量 EoT,让 “打断” 又稳又准。pVAD 专注识别主要说话人,有效抑制环境噪声与他人说话带来的误触;EoT 准确判断用户的表达是否已经具备完整语义,避免过早打断或迟缓回应,实现自然轮次转换。
第三,级联与半级联双路线并行,兼顾成熟度与体验。级联链路(ASR → LLM → TTS)部署灵活,各模块可独立优化;半级联链路(AudioLLM → TTS)直连音频输入,可感知情绪与副语言信息,生成更贴心的回应,并进一步降低延迟与误差传播。两套方案都可直接升级为全双工,满足不同业务场景的精度、时延与成本权衡。
第四,端到端低时延,逼近工业级。凭借模块解耦与流式优化,FireRedChat 在本地级联部署下实现接近工业级系统的端到端延迟,真正把 “实时”“自然” 落到体验里。
第五,不仅能听懂,还能 “听出情绪、说出温度”。通过 AudioLLM 与 FireRedTTS2 的联动,系统可捕捉用户声学线索(情绪、语调、节奏),在回应中自然体现关怀与共情:你失落时能安慰鼓励,你兴奋时共情分享,让 AI 从 “能回答” 走向 “有温度” 的陪伴与理解。
解耦带来可控,可插拔带来进化

FireRedChat 将全双工语音交互解耦为三个核心模块,既保留端到端链路的高性能,又确保系统的可维护性和可扩展性。
轮次转换控制器(Turn-taking Controller):基于自研 pVAD 与轻量 EoT,实时判断 “谁在说、何时停、何时该我说”,像一位聪明的主持人维持对话秩序,显著降低噪声与多说话人场景下的误打断。
交互模块(Interaction Module):支持两种模式。级联模式整合 FireRedASR 与 FireRedTTS-1s,TTS 支持上下文感知,声音更贴合语境;半级联模式以 AudioLLM 直达语音语义与情感,再接 FireRedTTS-2 完成富表达的合成,打造更顺滑的 “听 —— 想 —— 说” 链路。
对话管理器(Dialogue Manager):负责对话状态管理并扩展系统能力,支持工具调用(如 WebSearch)、RAG 检索增强、插件扩展与工作流管理。系统内置与 Dify 的集成样例,便于开发者进行提示词工程、知识库构建与应用编排,快速把 Demo 变成产品。
开源、免费、可私有化
为了给开发者与企业真正的掌控力,FireRedChat 坚持彻底开源:核心模块 TTS、ASR、pVAD、EoT 全部开放,无需 API 费用与外部依赖。系统支持在企业私有环境一键部署,数据资产不出域,安全合规可审计。基于 LiveKit 的清晰模块化与完善文档、简洁 Web UI,使得普通用户即开即用,开发者可快速二次开发与深度定制。
典型应用场景
- 智能语音助手:自然打断、即时回应,贴近真人对话节奏。
- 客服与外呼:商场、车站等复杂声场仍能稳定识别与响应。
- 教育与心理陪伴:情绪感知与表达丰富度带来更强的同理心体验。
更客观的结果背书
FireRedChat 设立系统级指标,聚焦真实体验的三件事:更少的误打断,更准的语义端点检测,更低的延迟。
打断准确率方面,pVAD 显著减少噪声和无关说话人的误打断,并通过微小等待(如 50ms)在鲁棒与灵敏之间取得更优权衡。

语义端点检测准确率方面,EoT 让系统更懂 “你说完没”,减少尬等与抢话。

端到端延迟方面,本地级联部署下的响应接近工业级闭源系统,全面超越开源框架,将 “即时反馈” 变成常态。

总结与展望
FireRedChat 以 “全双工+私有化+全链路开源” 的组合拳,为全双工语音交互贡献了小红书方案。通过可插拔架构、精准轮次控制与双路线深度优化,系统在自然度、鲁棒性与时延上取得突破性进展,影响语音交互体验的性能领先其他开源框架,时延上逼近工业级闭源系统。
未来,FireRed Team 将持续迭代 FireRedChat,融入更强大的 AudioLLM、更丰富的多模态交互,并与全球开源社区共建,把语音 AI 从 “能用” 推向 “好用”,再到 “人人可用、处处可用”。
....
#Dreamer 4
Training Agents Inside of Scalable World Models梦里啥都有?谷歌新世界模型纯靠「想象」训练,学会了在《我的世界》里挖钻石
只让机器人或虚拟智能体「想象」,不让它们和物理世界交互,它们也能学到和世界交互的技能?谷歌的世界模型 Dreamer 4 为这一想法提供了新的支撑。

为了在xx环境中解决复杂任务,智能体需要深入理解世界并选择成功的行动。世界模型通过学习从智能体(如机器人或电子游戏玩家)的视角预测潜在行动的未来结果,为实现这一目标提供了一种有前景的方法。
通过这种方式,世界模型使智能体能够深入理解世界,并具备通过在想象中进行规划或强化学习来选择行动的能力。此外,原则上世界模型可以从固定数据集中学习,这使得智能体能够纯粹在想象中进行训练,而无需在线交互。对于许多实际应用而言,离线优化行为很有价值,例如物理世界中的机器人,在这种情况下,与未充分训练的智能体进行在线交互往往不安全。
世界模型智能体 —— 如 Dreamer 3—— 是迄今为止在游戏和机器人领域表现最佳且最为稳健的强化学习算法之一。虽然这些模型在其特定的狭窄环境中速度快且准确,但其架构缺乏拟合复杂现实世界分布的能力。可控视频模型,如 Genie 3,已在多样的真实视频和游戏上进行训练,并实现了多样的场景生成和简单交互。这些模型基于可扩展架构,如 diffusion transformer。然而,它们在学习物体交互和游戏机制的精确物理规律方面仍存在困难,这限制了它们在训练成功智能体方面的实用性。此外,它们通常需要多个 GPU 才能实时模拟单个场景,这进一步降低了它们在想象训练方面的实用性。
在最近的一篇论文中,来自谷歌 DeepMind 的研究者提出了 Dreamer 4。这是一种可扩展的智能体,它通过在快速且准确的世界模型中进行想象训练来解决控制任务。
- 论文标题:Training Agents Inside of Scalable World Models
- 论文链接:https://www.arxiv.org/pdf/2509.24527v1
- 项目地址:https://danijar.com/project/dreamer4/
Dreamer 4 是第一个仅从标准离线数据集(无需与环境交互)就在具有挑战性的电子游戏《我的世界》(Minecraft)中获得钻石的智能体。

,时长02:55
Dreamer 4 利用一种新颖的 shortcut forcing 目标和高效的 Transformer 架构,准确学习复杂的物体交互,同时实现实时人机交互(在单个 GPU 上)和高效的想象训练。作者表示,该世界模型能够准确预测《我的世界》中广泛的语义交互,性能大幅优于以往的世界模型。

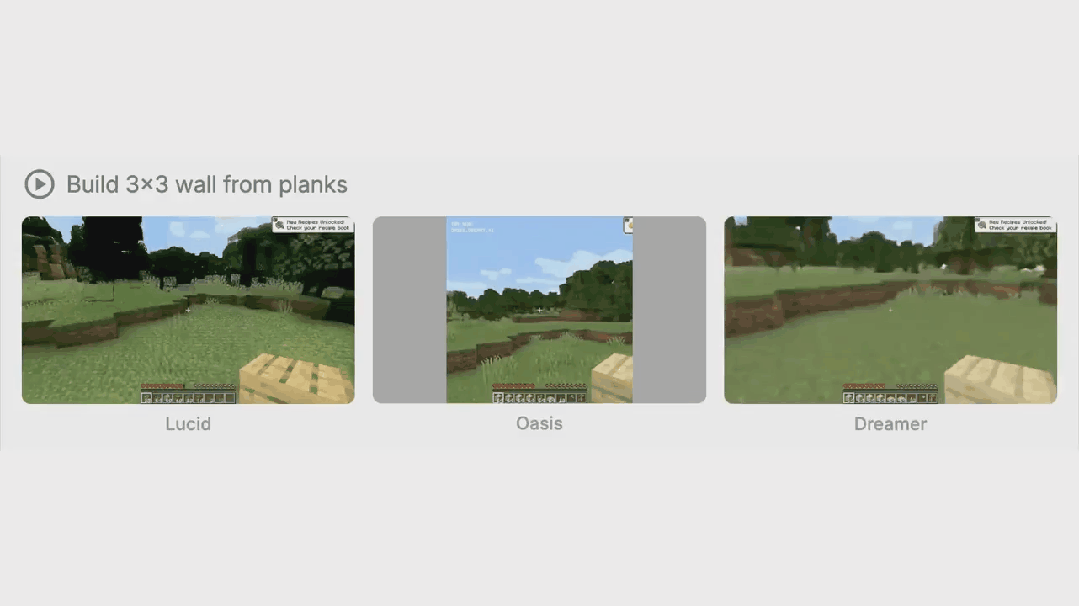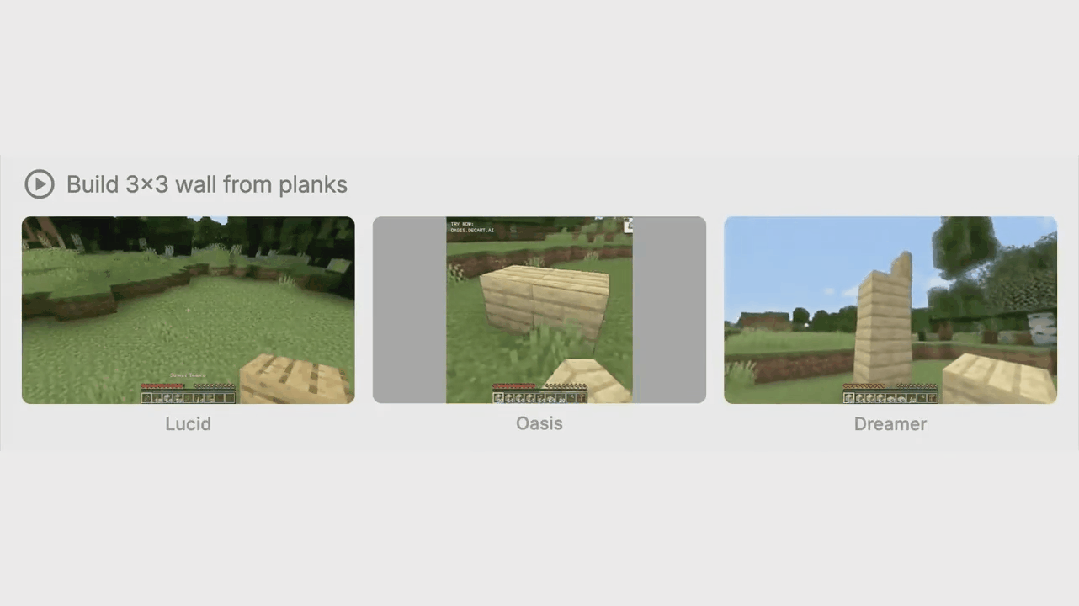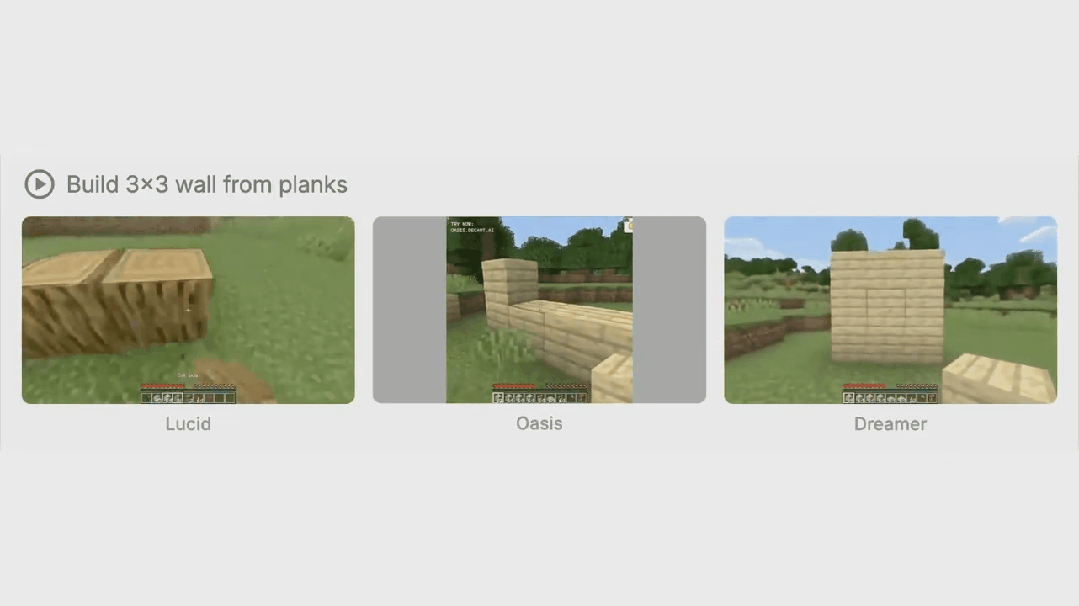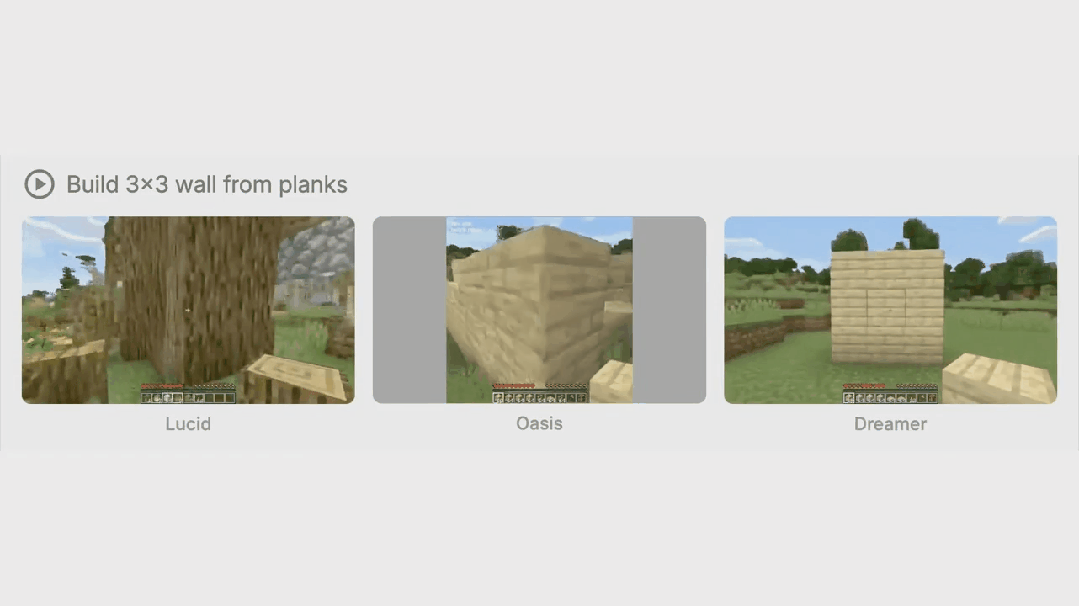
此外,Dreamer 4 可以在大量无标签视频上进行训练,并且只需要少量与动作配对的视频。这为未来从多样的网络视频中学习通用世界知识开辟了可能性,因为这些网络视频没有动作标签。
模型设计概览
Dreamer 4 是一种可扩展的智能体,它通过在快速且准确的世界模型中进行强化学习来学习解决复杂的控制任务。
如图 2 所示,该智能体由一个 tokenizer 和一个动力学模型组成。tokenizer 将视频帧压缩为连续表示,动力学模型根据交错的动作预测这些表示,两者均使用相同的高效 Transformer 架构。tokenizer 通过掩码自动编码进行训练,动力学模型则通过 shortcut forcing 目标进行训练,以实现少量前向传递的交互式生成,并防止随时间累积误差。

具体来说,tokenizer 对部分被掩码的图像块和 latent token 进行编码,通过带有 tanh 激活的低维投影压缩潜变量,并对图像块进行解码。它使用因果注意力实现时间压缩,同时允许逐帧解码。动力学模型在由动作、shortcut 噪声水平、步长和 tokenizer 表示交错组成的序列上运行。它通过 shortcut forcing 目标对表示进行去噪。在预训练之后,通过在动力学 Transformer 中插入任务 token 并从中预测动作、奖励和值,将世界模型微调为一个智能体。
如算法 1 所述,作者首先在视频和动作上预训练 tokenizer 和世界模型,然后通过交错任务嵌入将策略和奖励模型微调至世界模型中,最后通过想象训练对策略进行后训练。为了训练具有多种模态和输出头的单个动力学 Transformer,作者通过对均方根(RMS)的运行估计对所有损失项进行归一化。

实验结果
离线钻石挑战
图 3 比较了智能体在钻石任务中的表现。该图记录了在随机世界中从空物品栏开始的 60 分钟游戏情节中获得重要物品的成功率,该成功率是在 1000 个 episode 上计算得出的。通过利用想象力训练,Dreamer 4 是首个纯粹从离线经验中在《我的世界》中获取钻石的智能体。Dreamer 4 在使用的数据量少 100 倍的情况下,大幅超越了 OpenAI 的离线智能体 VPT15。它还超越了 VLA 智能体,后者利用了 Gemma 3 视觉语言模型的通用知识,在制作铁镐的成功率上几乎是 VLA 智能体的三倍。

图 4 展示了离线钻石挑战中的智能体消融实验。作者报告了四个关键物品的成功率以及获取物品所需的时间。在这两个指标上,Dreamer 4 的表现均优于基于行为克隆的方法,表明世界模型表示在行为克隆方面优于 Gemma 3 的通用表示。这表明视频预测隐式地学习到了对世界的理解,这对决策也很有用。最后,想象训练不仅持续提高成功率,还使策略更高效,从而能更快达到里程碑。

人类交互
为了评估 Dreamer 4 预测复杂交互的能力,作者在 Minecraft VPT 数据集上训练 Dreamer 4,并将其生成结果与该数据集上的先前的世界模型进行比较。在这项评估中,一名人类玩家尝试在世界模型中游玩以完成任务,如图 5 所示。人类玩家会收到任务描述,世界模型会初始化为任务的起始帧。

作者选择了一系列多样化的任务,涵盖了广泛的物体交互和游戏机制。这些任务包括挖坑、建造墙壁、砍伐树木、放置和乘坐船只、看向别处然后再看向物体、与工作台和熔炉交互等等。他们将 Dreamer 4 与世界模型 Oasis46、Lucid-v147 和 MineWorld48 进行比较。请注意,作者无法直接与 Genie 3 进行比较,因为它仅支持相机操作和一个通用的 “交互” 按钮,而 Minecraft 需要更通用的鼠标和键盘操作空间。表 1 总结了所比较的模型。完整结果见图 12 至图 14。




动作生成
图 7 展示了与完全不使用动作训练以及使用所有动作训练相比,动作条件的质量情况。仅使用 10 小时的动作时,与使用所有动作训练的模型相比,Dreamer 4 的 PSNR 达到 53%,SSIM 达到 75%。使用 100 小时的动作时,性能进一步提升,PSNR 达到 85%,SSIM 达到 100%。这一结果表明,世界模型从无标签视频中吸收了大部分知识,仅需要少量的动作。

....
#Meta内部混乱持续
FAIR自由不再,LeCun考虑辞职
Meta 内部混战又有新剧情了,这次主角是 FAIR 实验室。
据 The Information 报道,两位知情人士透露,Meta 最近对 FAIR 实验室施加了一项新政策:所有研究成果在公开发表前,必须通过额外的内部审查。

这项政策在 FAIR 内部引起了轩然大波。多位员工认为,这一变化严重限制了他们此前享有的学术自由,即在 Meta 之外自由分享研究成果的权利。
长久以来,开放的研究氛围一直是 FAIR 吸引顶尖人才的基石。然而,随着 Meta 全面重塑其 AI 业务,公司开始要求 FAIR 更多地为内部产品服务,同时减少可能助益竞争对手的外部研究分享。
这些变化让 FAIR 的联合创始人 Yann LeCun 深感困扰。据知情人士称,他甚至在九月份私下向同事透露,或许应该辞去首席科学家的职位。
LeCun 的不满早有征兆,几个月来,他对公司新成立的、统管所有 AI 业务的Meta 超级智能实验室(MSL)的内部状况已日益失望。
今年 7 月,MSL 任命了来自 OpenAI 的研究员赵晟佳担任首席科学家。一位知情人士称,LeCun 对于外界「他已被降职」的看法感到十分恼火。尽管 Meta 最终允许 LeCun 继续专注于自己的研究并自由发表,但紧张气氛已然形成。
同时,关于 Lecun 要向 28 岁的 Alexandr Wang 汇报的消息也一度引发争议。
另外,自从 Meta 投入数十亿美元革新 AI 业务以来,数千名原有的 Gen AI 员工,不得不适应一批新的领导者以及数十位从 OpenAI、Google 等公司高薪挖来的研究员。这直接导致了「新旧两派」间的紧张关系,一些元老级研究员对新部门的保密文化以及新同事们传闻中的天价薪酬感到不满。
超级智能实验室:雄心与混乱并存
目前,Meta 超级智能实验室仍处于早期整合阶段,组织变革带来的「成长的烦恼」在所难免。
今年 6 月,Meta 聘请了前 Scale AI 首席执行官 Alexandr Wang 和前 GitHub 首席执行官 Nat Friedman 共同领导该组织。8 月,该部门被重组为四个小组:
- TBD Lab:一个高度机密的实验室,负责开发下一代大语言模型 Llama 5。
- 产品与应用研究团队:专注于 Meta AI 助手等产品的落地。
- 基础设施团队:负责底层技术支持。
- FAIR:继续进行基础 AI 研究。
这个新组织承载着 Meta 多年来最大的赌注,因此让所有员工步调一致至关重要。
为了聘请 Alexandr Wang,Meta 与 Scale 达成了一项价值 143 亿美元的交易,该交易为包括 Wang 在内的 Scale 股东带来了巨额回报,据称 Meta 还授予了 Wang 本人价值超过 2 亿美元的股票。
如今,Wang 面临的艰巨任务是:实现 CEO 扎克伯格对「超级智能」(超越人类智慧的 AI)的宏大愿景。
Meta 的 AI 业务向来有内部摩擦的历史。一位前研究员将 Meta 之前的 Gen AI 部门的文化描述为「抢占地盘、狙击项目、窃取成果」,并将其比作「转移性癌症」。如何理顺内部文化,显然是新领导层面临的巨大挑战。
Meta 的一位发言人在声明中表示:「研究是 Meta 超级智能实验室的主要支柱之一;我们没有限制研究人员发表论文。」他们补充说,LeCun 作为 FAIR 首席科学家的角色没有改变。
新旧团队的文化冲突
新组织的成立也在 Meta 内部的其他部门引发了连锁反应。
- 功能争议
Meta AI 聊天机器人的独立应用原本由首席产品官 Chris Cox 的团队负责,主要用于管理 Meta 的智能眼镜。如今,它被划归超级智能实验室管理。
当该应用准备在 9 月增加一个 AI 生成的短视频信息流(名为 Vibes)时,公司内部论坛上充满了来自 Reality Labs 可穿戴设备团队成员的抱怨,一位员工直言不讳地写道:「我绝不想要这个功能。」
- TBD Lab 的「围城」
作为新部门的明星项目,负责开发 Llama 5 的 TBD Lab 吸引了最多的资源和关注。然而,并非所有人都渴望加入,一些被邀请的研究员拒绝了 offer。
有内部人士称,巨额的资金投入和高度关注,反而催生了一种高压、无情的工作氛围。许多老员工不愿加入,尤其是当他们的薪酬与传闻中新同事的天价待遇相去甚远时。
- 工作制度分歧
TBD Lab 要求研究员每周五天必须在加州门洛帕克的总部现场办公,这也让许多习惯了混合办公的员工感到反感,因为 Meta 其他 AI 研究员通常只需每周到岗三天。
人事动荡也持续不断,例如,Alexandr Wang 的幕僚长 Bill Long 于 6 月加入 Meta,但现已返回 Scale。
面对内部的种种问题,新领导层已在寻求改善。在 8 月的一次会议上,Nat Friedman 表示,他希望赋予团队技术成员更多权力,并减少繁文缛节,特别是要减少内部会议的频率。
对于承载着 Meta 未来的这个庞大而雄心勃勃的 AI 巨舰而言,能否平稳渡过内部整合的阵痛期,仍是一个未知数。
对此你怎么看?
补充阅读:
- 混乱、内耗、丑闻:Meta 考虑向 Google、OpenAI 低头
- 是的,LeCun 要向 28 岁的 Alexandr Wang 汇报!这是 Meta 新 AI 团队的一些独家内部消息
....
#Rethinking Thinking Tokens
又一推理新范式:将LLM自身视作「改进操作符」,突破长思维链极限
推理训练促使大语言模型(LLM)生成长思维链(long CoT),这在某些方面有助于它们探索解决策略并进行自我检查。虽然这种方式提高了准确性,但也增加了上下文长度、token / 计算成本和答案延迟。
因此,问题来了:当前的模型能否利用其元认知能力,在这一帕累托前沿上提供其他组合策略,例如在降低上下文长度和 / 或延迟的情况下提高准确性?
带着这一问题,Meta 超级智能实验室、伦敦大学学院、Mila、Anthropic 等机构的研究者进行了探索。从抽象层面来看,他们将 LLM 视为其「思维」的改进操作符,实现一系列可能的策略。
论文标题:Rethinking Thinking Tokens: LLMs as Improvement Operators
论文地址:https://arxiv.org/pdf/2510.01123
研究者探究了一种推理方法家族 —— 并行 - 蒸馏 - 精炼(Parallel-Distill-Refine, PDR),该方法包含以下步骤:(i) 并行生成多样化草稿;(ii) 将其蒸馏成一个有限的文本工作区;(iii) 在此工作区的基础上进行精炼,生成的输出将作为下一轮的种子。重要的是,通过调整并行度,PDR 能够控制上下文长度(从而控制计算成本),并且上下文长度不再与生成 token 的总数混淆。
根据当前模型在 PDR 实例中的应用,它们在准确性上优于长思维链,同时延迟更低。当将并行度设置为 1 时,得到一个特例 —— 顺序精炼(Sequential Refinement, SR)(即迭代改进单一候选答案),其表现优于长思维链(代价是更高的延迟)。
这种模型组织的成功引申了一个问题:进一步的训练是否能够改变帕累托前沿?为此,研究者训练了一个 8B 规模的思考模型,使用强化学习(RL)使其与 PDR 推理方法保持一致。
在具有可验证答案的数学任务中,迭代 pipeline 在匹配的顺序预算下超越了单次推理基准,并且 PDR 方法带来了最大的提升,在 AIME 2024 和 AIME 2025 数学任务中,准确率分别提高了 11% 和 9%。
LLM 作为改进操作符
研究者考虑任务 x(例如数学问题),目标是在给定的 token 预算下生成高质量的最终成果 s_final(解答、证明或程序)。设 M_θ 为一个(可以冻结或训练的)大语言模型(LLM),并作为改进操作符。给定当前的成果 s_t(单次生成或一组生成结果)和紧凑的文本工作区 C_t,模型会提出一个改进方案:

读写压缩循环。每个步骤:(i) 读取当前工作区 C_t,(ii) 通过 M_θ 写出改进后的成果 s_t+1,(iii) 使用综合操作符 D 将成果压缩回一个有限的工作区,为下一个步骤做准备。

token 预算。研究者在以下两个预算下评估每种方法:

操作符实例化
研究者探究了以下两种短上下文的迭代精炼流程。
一是顺序精炼(SR,单一候选的深度改进)。
对于所有 t,设置 C_t ≡ ∅ ,并且迭代改进单一成果进行 R 轮:

顺序精炼与紧凑工作区。在 SR 中,不提供显式的工作区。研究者还评估了一种变体,在每一轮之间插入错误分析步骤:模型不会直接改进之前的答案,而是首先识别并解释当前解答中的缺陷,然后生成修订后的解答。这些笔记在每一轮中充当一个暂时的、局部的工作区。
二是并行 - 蒸馏 - 精炼(PDR,每轮工作区)。
研究者不保持持久的记忆。相反,对于每一轮 r = 1, . . . , R,基于当前的有限摘要采样 M_r 个草稿(并行),然后重新综合(蒸馏)出一个新的有限摘要供下一轮使用:
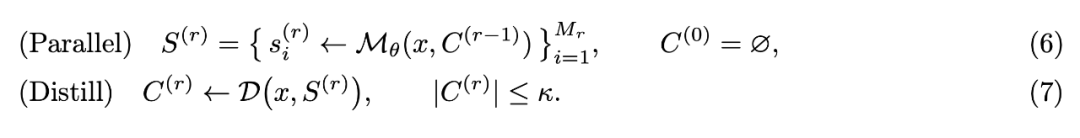
在最后一轮强制执行单次生成 M_R = 1,此生成结果作为最终解答 s_final 返回。摘要是按轮次生成且非持久的,早期文本不会被重播,防止了每次调用时上下文的增长。
另外,研究者考虑了蒸馏操作符 D 的几种实际实例化方式:
- 全局摘要
- 提取性 top-k 证据(共享)
- random-k / 自举工作区
最后是操作符一致性训练。前文将 M_θ 视为冻结,并纯粹依赖于提示 / 调度。现在,研究者通过在与测试时相同的短上下文迭代接口下优化模型,确保训练与部署 / 推理的一致性。
基础算法。对于基准强化学习(RL),研究者使用来自 Minimax-M1 的 CISPO 目标。对于给定的提示 x,生成器 π(・| θ_old) 使用旧策略 θ_old 生成 G 个回合 {o^G_i=1}。像 sympy 或 math-verify 这样的自动化检查器被用来为每个回合分配标量奖励 r_i(±1)。CISPO 将 GRPO 的组归一化优势与 REINFORCE 结合起来,达到以下目标。

为什么 PDR 训练时只进行一轮?研究者表示,进行单一的 PDR 回合(包括 M 个早期草稿,蒸馏为 C,以及单次精炼)可以捕捉到关键的接口,同时控制 B_total 并稳定强化学习。在推理时,则可以使用相同的操作符运行多个回合(R > 1)。
本文的数据混合方法在保留长轨迹能力的同时,教会模型在短迭代中进行推理。PDR 被模拟为一次并行→蒸馏→精炼回合,在该过程中,模型观察 (x, C),并对最终解答轨迹进行可验证奖励优化。
实验结果
在预算感知协议下,研究者将顺序精炼(SR)和并行 - 蒸馏 - 精炼(PDR)操作符与长思维链(CoT)基准进行了比较。他们使用符号验证器(如 sympy 和 math-verify) 来测量准确性,还将结果报告为顺序预算 B_seq(沿着接受路径的延迟代理)和总预算 B_total(所有调用的 token 数)的函数。
研究者对 SR 和 PDR 作为推理时操作符应用于数学问题进行了评估。给定一个提示 x,模型生成一个思维轨迹和最终解答。思维跨度由 「...」限定,去除后仅使用自包含的解答作为后续回合输入的构建。他们在 AIME 2024 和 AIME 2025(AoPS,2025)上进行评估,并报告在 16 次独立生成中的准确率 - mean@16。
通过实验,研究者试图回答以下四个研究问题:
- RQ1:短上下文迭代是否能通过比较 {SR, PDR} 与长轨迹 CoT,在匹配的 B_seq 和 B_total 下超越长轨迹?
- RQ2:通过比较三种 D 变体:全局摘要、提取性 top-k 和 random-k 自举,找出生成 C^(r) 的最佳蒸馏策略。
- RQ3:识别给定模型的验证能力对最终性能的影响。
- RQ4:操作符一致性训练是否能够改变帕累托前沿?他们比较了操作符一致性 + 标准强化学习与标准单轨迹强化学习。
RQ1:短上下文迭代是否在匹配延迟的情况下超越长轨迹?
图 3 和图 9 报告了在相同有效 token 预算 Bseq 下,AIME 2024 和 AIME 2025 上的准确性。研究者观察到,从长思维链(Long CoT)转到顺序精炼(SR)时,准确性稳定提升;从 SR 到并行 - 蒸馏 - 精炼(PDR)时,这一提升继续。
对于 o3-mini,在有效预算为 49k token、每次调用思维预算为 16k token 时,准确性从 76.9(长链推理)提升至 81.5(SR)和 86.7(PDR),相较长思维链,绝对值提升了 +9.8 个百分比。gemini-2.5-flash 从 SR 到 PDR 的变化小于 o3-mini,表明 gemini-2.5-flash 在自我验证方面更强。


RQ2:哪种蒸馏(即摘要)策略效果最佳?
表 2 研究了在固定轮次(每轮生成次数为 g = [16, 8, 4])和每轮 k = 2 个候选的设置下,PDR 中的蒸馏操作符 D。
在不同数据集和基础模型上,样本级的 top-k 和全局摘要选择一致性优于共享 top-k 和 random-k,并且随着思维预算 B 的增加,差距逐渐扩大。
主要的例外是 AIME 2025 与 o3-mini 的情况,其中全局摘要优于其他方法。研究者推测,o3-mini 的摘要特别擅长从正确和错误的草稿中捕捉线索,而这些线索在蒸馏后会促使更强的后续精炼。

RQ3:验证能力如何影响推理时间性能?
从图 6 和图 8 中,研究者观察到注入错误候选(Oracle (Incorrect))会导致所有模型的性能大幅下降。对于 o3-mini,性能下降显著大于 gemini-2.5-flash,这表明后者具有更强的自我验证和恢复能力。这一趋势在 AIME 2024 和 AIME 2025 中都得到了体现。


RQ4:操作符一致性训练是否推动了帕累托前沿的移动?
表 3 总结了主要结果。从每个强化学习(RL)目标得到的模型分别在长思维链(Long CoT)生成和 PDR 上进行了评估。PDR 强化学习相比基准方法在 AIME 2024 上提升了 +3.34 个百分点,在 AIME 2025 上提升了 +1.67 个百分点。
从基准 RL 检查点开始的持续更新,使得额外的 PDR 强化学习带来了更大的提升,分别在 AIME 2024 和 AIME 2025 上提升了 +5.00 和 +4.59 个百分点。此外,研究者还观察到,在 PDR RL 训练下,长思维链生成也有一定的增益。
这些结果表明,使用操作符一致性的强化学习目标进行训练减少了训练与部署之间的不匹配,将额外的计算转化为准确性,而不会增加每次调用的顺序预算。

....
#TreeSynth
港大提出,方法,一句话生成百万规模数据集
本文第一作者王升,陈鹏安与周靖淇均来自香港大学。通讯作者为香港大学计算机科学系吴川教授与孔令鹏教授。其他作者还包括来自香港大学的李沁桐、董经纬、高佳慧,以及香港中文大学的薛博阳、江继越。
想象一下,你接手了一个新项目,需要在没有数据的情况下提升模型表现。“TreeSynth” 就这样起源于作者们最初的构想:“如何通过一句任务描述生成海量数据,完成模型训练?” 同时,大规模 scalibility 对合成数据的多样性提出了新的要求。 相比之下,传统的数据合成方法就像一个缺乏规划的农夫漫无目的地四处撒种,结果发现许多肥沃的土地被遗漏,而某些贫瘠的角落却种满了庄稼。
这正是当前数据合成领域面临的核心挑战:如何从 0 系统性地生成多样化、高质量的训练数据?现有方法往往受限于模型偏见、种子数据局限和低变种 prompt,导致合成数据缺乏多样性,分布不均匀。更为关键的是,随着数据规模的增加,这种问题会变得愈发严重。

基于这一挑战,香港大学和香港中文大学的研究团队提出了 TreeSynth—— 一种受决策树启发的树引导子空间数据合成方法。它从整个数据空间的根节点出发,通过层层分支将复杂的数据领域逐步细分,直到每个叶节点都代表一个独特且互不重叠的数据子空间,最终让整棵 "树" 枝繁叶茂,确保全面而均衡地覆盖整个知识领域。形象地讲,TreeSynth 通过空间划分将 “均匀地” 数据合成转化为了一个 “填色游戏”。
论文标题: TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
论文链接: https://arxiv.org/abs/2503.17195
项目主页: https://github.com/cpa2001/TreeSynth
从决策树到数据空间:TreeSynth 的核心洞察
TreeSynth 的核心创新源于一个巧妙的类比:将数据合成问题映射到决策树的空间分割机制上。
在传统的机器学习中,决策树具有两个关键特性:互斥性(每个样本只能属于一个叶节点)和穷尽性(所有样本都必须分配到某个叶节点)。TreeSynth 巧妙地将这一机制迁移到数据合成领域:如果我们将整个任务的数据空间视为决策树的根节点,那么通过层层分割,我们可以将其分解为多个互不重叠且完全覆盖原空间的子空间。
这种方法带来了两大显著优势:
1. 多样性保证:不同叶节点的互斥性确保了跨子空间的变化,从而保证样本多样性
2. 全面覆盖:叶节点的穷尽性确保对全面数据的采样,防止样本坍塌
两阶段工作流程:分而治之的智慧
TreeSynth 采用两阶段的工作流程:数据空间分割和子空间数据合成。

阶段一:数据空间分割
这个阶段类似于决策树的构建过程,包含两个关键步骤:
1. 标准确定(Criterion Determination):对于任意数据空间,首先利用 LLM 生成多样化的 pivot samples
来近似整个空间。然后,另一个 LLM 分析这些样本,确定一个核心标准,将样本最优地划分为互斥的属性值。
2. 子空间覆盖(Subspace Coverage):由于 pivot samples 数量有限,可能无法完全覆盖原始空间。因此,需要补充潜在的属性值,确保子空间能够穷尽覆盖整个数据空间。
通过递归应用这两个步骤,TreeSynth 构建出一个完整的空间分割树,将整个数据空间分解为众多互斥且互补的原子子空间。
阶段二:子空间数据合成
在每个叶节点(原子子空间)内,TreeSynth 收集从根节点到该叶节点的完整路径描述,然后指导 LLM 在该特定约束下生成样本。最终,通过汇集所有叶节点的数据,获得具有高多样性、均衡分布和全面覆盖的最终数据集。
超越合成:TreeSynth 引导的数据平衡
TreeSynth 的价值不仅在于从零开始的数据合成,还能优化现有数据集。通过为现有数据集构建空间分割树,每个样本都可以被系统性地路由到唯一的叶节点。这样就能清晰地看到数据集在整个空间中的分布模式。如此,对于样本过多的子空间进行随机下采样,而对于样本不足的子空间则利用 TreeSynth 进行数据增强,最终获得更加均衡和全面的数据分布。
案例分析:从抽象到具体

以 GSM8K 风格的数学问题生成为例,TreeSynth 的工作流程如下:
1. 根节点定义:整个数据空间被定义为 "GSM8K 风格的数学问题"
2. 首层分割:通过分析样本特征,确定 "数学运算类型" 作为第一层分割标准,将空间分为加减法、乘除法、开方、取模等子空间
3. 递归深化:对每个子空间继续分割,比如加减法子空间可能进一步按 "问题复杂度" 分割
4. 叶节点合成:在每个最终的原子子空间内生成具体的数学问题
这种系统性的分割确保了生成的数据集既具有全面的覆盖性,又保持了各个维度上的平衡分布。
实验验证:全方位性能提升
研究团队在数学推理(GSM8K、MATH)、代码生成(MBPP、HumanEval)和心理学(SimpleToM)等多个基准任务上进行了全面评估。
与基线方法的比较
实验对比了人工标注数据和三种代表性的 LLM 数据合成方法:
- 温度采样(Temperature Sampling):通过调整采样温度增加多样性
- 种子驱动方法(Evol-Instruct):基于现有数据进化生成新样本
- 属性驱动方法(Persona Hub):利用不同属性组合生成数据
显著的性能提升
实验结果显示,TreeSynth 在所有基准测试中都取得了一致的性能提升:

- 在数学推理任务上,LLaMA3.1-8B 模型在 GSM8K 上的准确率从基线的 45.2% 提升到 55.8%,在 MATH 上从 12.1% 提升到 18.7%
- 在代码生成任务上,HumanEval 的通过率从 32.3% 提升到 41.9%,MBPP 从 39.1% 提升到 47.6%
- 平均性能提升达到 10%,最高提升幅度超过 17%

更令人印象深刻的是,TreeSynth 展现出了优秀的可扩展性。随着数据规模的增加,模型性能呈现线性甚至更好的增长轨迹,这证明了该方法在大规模数据合成场景下的稳健性。
数据多样性的显著改善

除了下游任务性能,TreeSynth 在数据多样性指标上也显著超越基线方法,在某些测试中多样性提升高达 45%。同时,t-SNE 可视化也直观地展示了 TreeSynth 卓越的数据多样性,生成的数据在嵌入空间中分布更加均匀和分散。这直接验证了树引导分割机制在防止数据重复和空间坍塌方面的有效性。
结语与展望
TreeSynth 为数据合成领域带来了全新的视角。通过将决策树的空间分割智慧迁移到数据生成任务中,它成功地解决了现有方法在多样性和覆盖性方面的不足。实验结果不仅验证了其在多个领域的有效性,更重要的是展现了其在大规模场景下的可扩展性。
这项工作的意义不仅在于提出了一种新的数据合成方法,更在于提供了一个系统性思考数据生成问题的新框架。正如一位园丁需要整体规划种植布局一样,模型的训练也需要系统性地设计数据分布。
未来值得探索的方向:
- 如何更好地 “通过一句任务描述生成海量数据,完成模型训练”?
- 如何自适应地确定最优的树深度和分割标准?
- TreeSynth 能够持续 scale 的最大规模?真实世界复杂场景还涉及 agent、多轮对话、知识库等复杂场景,如何更好地探索相关场景?
TreeSynth 开启了从 0 合成数据领域的新篇章,为构建更加多样化、全面覆盖的训练数据集提供了强有力的工具。
....
#Anthropic新CTO上任
与Meta、OpenAI的AI基础设施之争一触即发
就在刚刚,Anthropic 迎来了新的首席技术官(CTO)—— 前 Stripe 首席技术官 Rahul Patil。
据报道,Rahul Patil 于本周早些时候加入公司,接替了联合创始人 Sam McCandlish,后者将转任首席架构师一职。
Rahul Patil 在社媒上表达了自己加入 Anthropic 的激动之情与未来期许。他表示,自己很高兴加入一个新的使命和召唤。AI 的可能性是无穷无尽的,这将是一次非凡的发现之旅,需要付出努力,将这些可能性变为现实。
更重要的是,这将要求我们每天做出深思熟虑的决策,以安全地驾驭这一巨大变革,确保负责任的 AI 最终获胜。
他很感激能够加入 Anthropic 这个谦逊、聪明、勤奋且有责任感的团队,他们激发了全球无数的想象力!他还感谢每一位与自己建设 Stripe 的团队成员,感谢他们过去五年多的深刻变革!

随着这一变动,Anthropic 正在更新其核心技术团队的结构,将公司产品工程团队与基础设施、推理团队更加紧密地联系起来。
作为 CTO,Rahul Patil 将负责计算、基础设施、推理以及其他各类工程任务。Sam McCandlish 在担任首席架构师期间,将继续从事预训练和大规模模型训练的工作,扩展之前的工作。他们二人都将向 Anthropic 总裁 Daniela Amodei 汇报工作。
在一份声明中,Daniela Amodei 强调了 Rahul Patil 在为企业构建稳定基础设施方面的经验。「Rahul 在构建和扩展企业所需的可靠基础设施方面拥有经得起验证的成功经验,这些对增强 Claude 作为企业领先智能平台的地位具有重要意义。」
这一新的领导结构恰逢 Anthropic 面临来自 OpenAI 和 Meta 的激烈基础设施竞争,这两家 AI 实验室已经在计算基础设施上投入了数十亿美元。马克・扎克伯格表示,Meta 计划到 2028 年底前在美国基础设施上投资 600 亿美元,OpenAI 也通过与 Oracle 和 Stargate 项目的合作强化了基础设施投资。
尽管 Anthropic 自身基础设施的支出规模尚不明确,但随着基础设施需求的不断增长,其旗下大模型的优化速度和功耗面临巨大的压力。与此同时,Claude 产品在全球范围的流行也给公司的基础设施带来了相当大的压力。
今年 7 月,公司推出了 Claude Code 的新使用限制,针对那些「24/7 持续后台运行应用程序」的高频用户。根据新规则,用户每周 Claude Sonnet 的使用时间限制在 240 到 480 小时之间,Claude Opus 4 的使用时间则限制在 24 到 40 小时之间,具体取决于基础设施的负载。

Rahul Patil 简历
Rahul Patil 在不同的工程职位上拥有超过 20 年的经验,这将为 Anthropic 带来了丰富的基础设施经验。
他此前曾在 Stripe 担任技术职位(包括 CTO)五年,主要负责基础设施、工程和全球运营。

他还在 Oracle 担任云基础设施高级副总裁,主要负责 Oracle 云基础设施(第二代)核心产品的工程、产品管理和业务运营,涵盖计算、存储、安全和监控服务的 30 多个产品。

更早之前,他还分别在 Amazon 和 Microsoft 担任过工程职务。

Rahul Patil 本科毕业于 PESIT(印度班加罗尔的一所知名私立工程学院),硕士毕业于美国亚利桑那州立大学,并获得了华盛顿大学的 MBA。

拥有丰富工程经验的新 CTO Rahul Patil,将为 Anthropic 带来哪些转变呢?
参考链接:https://techcrunch.com/2025/10/02/anthropic-hires-new-cto-with-focus-on-ai-infrastructure/
....
#全球价值最高创企诞生
OpenAI估值创纪录来到5000亿美元
几天前,OpenAI 重磅发布了全新一代的视频大模型 Sora 2,不仅在物理准确性、真实感和可控性方面都优于以往的系统,还具备同步的对话和音效能力。
Altman 称之为「ChatGPT for creativity」时刻。

就在昨天,OpenAI 的「身价」又涨了。
据彭博社援引知情人士的消息,OpenAI 已经完成一项交易,允许现任及前任员工以 5000 亿美元的公司估值,出售价值约 66 亿美元的股份。
就在年初,OpenAI 完成了史上最大规模私企融资之一,由软银领投 400 亿美元融资,使其估值达到 3000 亿美元。如今估值来到 5000 亿美元,这一变化突显了 OpenAI 在用户和收入方面的快速增长。
在这笔最新的交易中,OpenAI 员工将股票出售给了一批投资者,包括 Thrive Capital、软银、Dragoneer Investment Group、阿布扎比的 MGX 和 T. Rowe Price。不过目前,这些投资者均未回应置评请求。
据知情人士表示,OpenAI 授权在二级市场出售超过 100 亿美元的股票,但要求匿名,因为他们未获授权披露此事。此次股票出售是软银在 OpenAI 400 亿美元融资轮中早期投资的延续。
根据此前 The Information 援引股东披露的财务信息,OpenAI 在 2025 年上半年实现约 43 亿美元(约 306 亿元人民币)的收入,比 2024 全年增长了 16%。
同期现金消耗为 25 亿美元(约 178 亿元人民币),主要为 AI 研发和 ChatGPT 的运营,其中包括大量以股票形式支付给员工的非现金开支。
伴随着这轮估值,OpenAI 成为了全球价值最高私营公司。

图源:Crunchbase, Bloomberg reporting
参考链接:
....
#QuestA
1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒
QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果:
Pass@1 的 SOTA 性能:在 1.5B 模型上实现了最先进的结果,甚至在关键基准测试中超越了早期的 32B 模型。
提升 Pass@k:在提高 Pass@1 的同时,QuestA 不会降低 Pass@k 性能 —— 事实上,它通过让模型在多次尝试中进行更有效的推理,从而提升了模型能力。
这一在强化学习训练中的发现,为开发具有更强推理能力的模型打开了大门。QuestA 使 RL 能够高效处理不同难度的任务,消除了通常在简单与困难问题之间存在的权衡。
两难:简单任务导致熵坍缩 vs. 难任务减缓学习效率
多年来,RL 训练一直存在一个需要思考的数据平衡问题:简单任务导致模型过度自信,而难任务提高推理能力,但由于样本效率低下,学习速度变慢。
- 简单任务倾向于使模型过拟合,使其在特定、更简单的问题上非常准确。然而,这导致模型变得过度自信,从而妨碍了其泛化能力,难以解决更复杂的任务。
- 难任务提高了模型的推理能力,但具有低样本效率,这意味着它需要更长的时间来学习和进展。稀疏的奖励和任务的难度使得在困难问题上的训练变得缓慢,限制了整体的学习速度。
这个权衡一直是 RL 模型的挑战,近日清华大学、上海期智研究院、Amazon 和斯坦福大学等机构提出的 QuestA 解决了这个问题。通过在训练困难任务时引入部分解决方案提示,QuestA 帮助模型更快地学习,同时不牺牲在简单任务上的表现。这确保了模型能够从简单任务和难任务中获益,提升其推理能力,同时避免过拟合或学习缓慢。
- 论文标题:QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
- Arxiv 论文地址:https://www.arxiv.org/abs/2507.13266
- HF 模型地址:https://huggingface.co/foreverlasting1202/QuestA-Nemotron-1.5B
- GitHub 地址:https://github.com/foreverlasting1202/QuestA
研究者得出的关键结果是:强化学习可以提升模型能力。具体而言,QuestA 取得了以下显著成果:
- Pass@1 改进:QuestA 显著提高了 Pass@1。研究者在使用 1.5B 参数模型的数学基准测试中达到了新的最先进结果:在 AIME24 上达到 72.50%(+10.73%),在 AIME25 上达到 62.29%(+12.79%),在 HMMT25 上达到 41.67%(+10.11%),甚至超越了 DeepSeek-R1-Distill-32B,尽管它是一个更小的模型。这表明 QuestA 显著提高了模型在平时使用中的表现。
- Pass@k 改进:与传统的 RL 方法不同,QuestA 还提高了 Pass@k,展示了模型的容量随着 RL 训练的进行而增加。这是一个关键的区别,因为它表明 QuestA 使得模型能够持续进行探索和推理,而不像其他方法,在优化 Pass@1 时 Pass@k 性能会下降。
X上有人评价称,QuestA 是一种巧妙的数据增强方法,不仅加速了 pass@1 的改进,还保持/增强了pass@k,并且没有多样性损失。这是 1.5B 推理模型的新SOTA。

QuestA 方法:提示即所需
QuestA 通过「数据增强 + 迭代课程学习」的组合设计,实现对 RL 训练的高效改进,核心逻辑如下:
- 聚焦高难度问题:采用两阶段过滤流程筛选训练数据 —— 首先以 DeepSeek-R1-Distill-1.5B 为筛选模型,从 OpenR1-Math-220K 数据集中选出仅 0-1 次正确(8 次采样)的 26K 高难度样本;再对增强后的提示词进行二次筛选,保留模型仍难以正确解答(0-4 次正确)的样本,最终聚焦不超过 10K 的核心困难任务,确保训练资源用在能力突破点上。
- 动态调整提示比例:为避免模型依赖提示,QuestA 设计迭代式课程学习 —— 先以 50% 比例的部分解决方案作为提示(p=50%)训练至性能饱和,再将提示比例降至 25%(p=25%)继续训练,逐步引导模型从「依赖提示」过渡到 “自主推理”,实现能力的真实迁移。
- 轻量化集成 RL:QuestA 无需修改 RL 算法核心或奖励函数,仅通过替换训练数据(用增强提示词替代原始提示词)即可集成至现有 RL pipeline(如 GRPO、DAPO),具备「即插即用」的灵活性。

QuestA 通过在数据集中每个原始问题前添加部分解决方案提示,对原始问题进行增强处理。

图 1: QuestA 是一种数据增强方法,通过注入部分解决方案,为强化学习(RL)在复杂推理问题上的训练提供有效支撑。研究者基于 OpenR1 中的高难度样本,构建了 2.6 万个高质量增强提示词(augmented prompts),并采用 32K 上下文长度的强化学习对模型进行微调。将该方法应用于 Nemotron-1.5B 模型后,QuestA 带来了显著的性能提升 —— 在所有数学基准测试中,均为 15 亿参数模型创下了新的当前最优(SOTA)结果。
训练细节
研究者使用 AReaLite 框架进行 RL 训练。
具体而言,他们应用了 GRPO 算法,并结合了来自 DAPO 的动态过滤技术,以排除训练中显而易见正确或错误的样本。这一优化帮助聚焦于最难的问题,提升了训练效率。
评估
研究者在竞争级数学基准测试上评估了 Pass@1(32 个样本的平均值)。QuestA-Nemotron-1.5B 在 1.5B 模型中达到了最先进水平,并在多个基准测试中匹配或超过了 DeepSeek-R1-Distill-32B,同时其模型体积小于 20×。

核心差异点:实现真实能力提升,而非熵坍缩
实验结果表明,QuestA 方法在提升模型推理能力的同时,并未损害其多样性。如图 2 所示,即便在问题难度持续增加的情况下,Pass@k 曲线仍呈现出稳定的上升趋势。

图 2:研究者比较了使用 RLVR 训练的模型在有和没有 QuestA 的情况下的 pass@k 曲线。作为对照实验,我们使用易难不同的提示进行 RL 训练。标准 RL 在易提示下(红色)随着 k 值增大,pass@k 显著下降,而与基准模型(蓝色)相比,表现较差。在难提示下训练(绿色)能够提高 pass@k,但代价是训练时间显著增加。这激发了他们开发 QuestA 的动机,QuestA 通过为困难问题提供框架,提升了训练效率,并且在所有 k 值下提供了更强的结果:RL+QuestA 模型(橙色)在所有 k 值上都优于标准 RL(红色),同时在较大的 k 值下相较于使用困难提示训练的 RL 模型,性能也保持或有所提升。
消融实验
QuestA 同时也在不同的基础模型和不同的数据集进行了实验,都让模型得到了相应幅度的提升,这证明了 QuestA 这个方法的泛用性。具体细节参考 Arxiv 文章。
结论:QuestA 方法彰显强化学习在推理任务中的更大应用潜力
QuestA 方法的研究结果表明,强化学习确实能够助力模型习得新能力。通过同时提升 Pass@1 与 Pass@k 指标的性能表现,该方法证实:强化学习可在不牺牲效率与泛化能力的前提下,持续拓展模型的能力边界。
此外,QuestA 方法有效消除了传统训练中简单任务与复杂任务之间的权衡矛盾,使模型能够在涵盖广泛问题类型的场景下,实现推理能力的极大提升。
这一技术突破对强化学习未来的应用发展具有深远意义。依托 QuestA 方法,我们期待基于强化学习构建的模型如今可处理更多复杂且多样的推理任务,其应用场景已从数学问题求解延伸至逻辑推理及创造性思维等领域。
....

















 1536
1536


 到【灌水乐园】发言
到【灌水乐园】发言








