







前面几个task分别学习了数据的加载,观察,探索性数据分析,数据清洗,特征值观察,数据的重构可视化等…今天就可以进入到数据建模部分的学习。
task5的任务分成了两个部分
数据建模
- 了解数据建模
- 使用sklearn完成分类模型的构建
模型评估
- 了解模型评估
- 使用sklearn完成模型评估
数据建模
前面我们已经处理完数据,下一步就是选择一个合适的模型,在进行模型选择之前我们需要先知道数据集最终是进行监督学习还是无监督学习,模型的选择一方面是通过我们的任务来决定的。除此外还可以根据数据样本量以及特征的稀疏性来决定。
刚开始我们总是先尝试使用一个基本的模型来作为其baseline,进而再训练其他模型做对比,最终选择泛化能力或性能比较好的模型。
任务大致可以分为三大类
| 任务 | 对应算法 |
|---|---|
| 无监督学习 | k均值聚类、主成分分析、关联规则、社会网络分析 |
| 监督学习 | 回归分析、k最近邻、支持向量机、决策树、随机森林、神经网络 |
| 强化学习 | 多臂老虎机 |
什么是无监督学习?
- 任务目标:指出数据中隐藏的模式。
之所以称为无监督学习,是因为我们并不知道要找的模式是什么,而是要依靠算法从数据集中发现模式。
什么是监督学习? - 任务目标:使用数据中的模式做预测
他们的预测都基于已有的模式
什么是强化学习?
- 任务目标:使用数据中的模式做预测,并根据越来越多的反馈结果不断改进。
无监督学习和监督学习模型在部署之后便无法更改,不同于此,强化学习模型自身可以通过反馈结果不断改进。
本次建模使用的是sklearn,他是机器学习中一个很常用的库。
下面给出一个sklearn模型算法选择的路径图
# sklearn模型算法选择路径图
Image('sklearn.png')
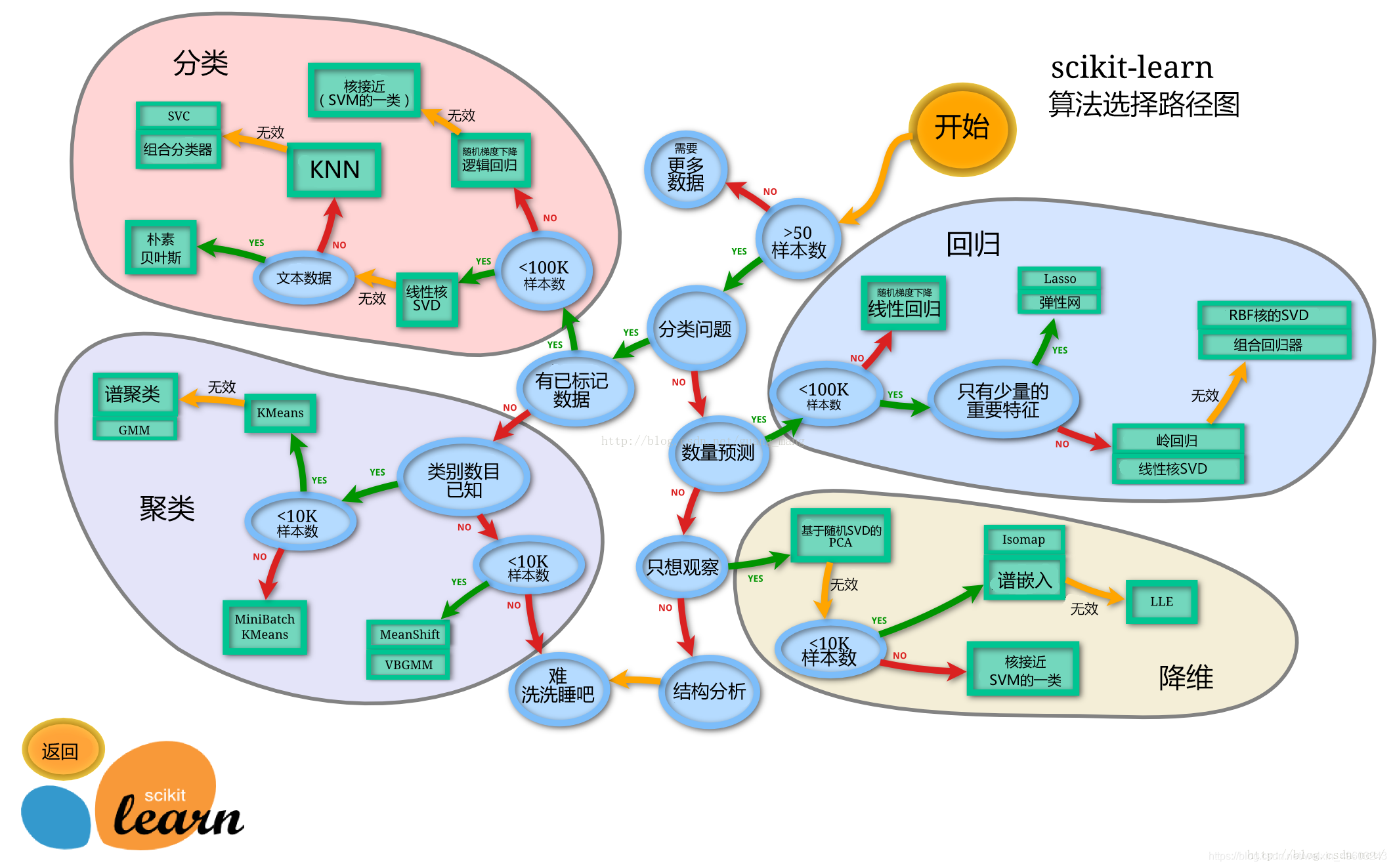
通过这个图我们能够更清晰的知道我们进行数据分析时具体需要建一个什么样的模型。
建模的流程:
- 切割数据集
在开始建模之前,还需要把数据集拆分为两个部分:训练集和测试集。在普通机器学习项目中至少需要包括这两个数据集,一个用于训练机器,确定模型。另一个用于测试模型的准确性。不仅如此还需要一个验证集,以在最终测试之前增加验证环节
【思考】划分数据集的方法有哪些?
对于数据集的划分有三种方法:留出法,交叉验证法和自助法
from sklearn.model_selection import train_test_split
# 一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用,x是清洗好的数据,y是我们要预测的存活数据'Survived'
X = data
y = train['Survived']
# 对数据集进行切割
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 查看数据形状
X_train.shape, X_test.shape
sklearn中的train_test_split函数,是机器学习中拆分数据集的常用工具。
| 参数 | 作用 |
|---|---|
| stratify | 依据标签y,按原数据y中各类比例,分配给train和test,使得train和test中各类数据的比例与原数据集一样 |
| random_state | 用于数据集拆分过程的随机化设定。如果指定了一个整数,那么这个数叫做随机化种子,每次设定固定的种子能够保证得到同样的训练集和测试集,否则进行随机分割 |
| train_data | 所要划分的样本特征集 |
| train_target | 所要划分的样本结果 |
| test_size | 样本占比,可以为浮点、整数或None,默认为None,若为浮点时,表示测试集占总样本的百分比,若为整数时,表示测试样本样本数,若为None时,test size自动设置成0.25 |
| train_size | 可以为浮点、整数或None,默认为None,若为浮点时,表示训练集占总样本的百分比,若为整数时,表示训练样本的样本数,若为None时,train_size自动被设置成0.75 |
【思考】什么情况下切割数据集的时候不用进行随机选取?
在数据集本身已经是随机处理之后的,或者说数据集非常大,内部已经足够随机,此时不需要进行随机选取。或者数据集是时序类型的,需要按照时间顺序来排列。
- 建立模型
创建基于线性模型的分类模型
最常见的两种线性分类算法是Logistic回归(logistic regression)和线性支持向量机(linear support vector machine,线性SVM)
给出一段示例代码:
from sklearn.lin 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3472
3472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









