







Python 爬虫编码问题
今天本来想写个小爬虫,在返回数据页面时发现全是乱码,尝试使用两种常用的解决编码问题的方式
response.encoding = 'utf-8' # 根据网页编码进行更改
response.encoding = response.apparent_encoding
发现还是不行,于是尝试不带 headers 访问,结果不乱码了;问题出在 headers 头里
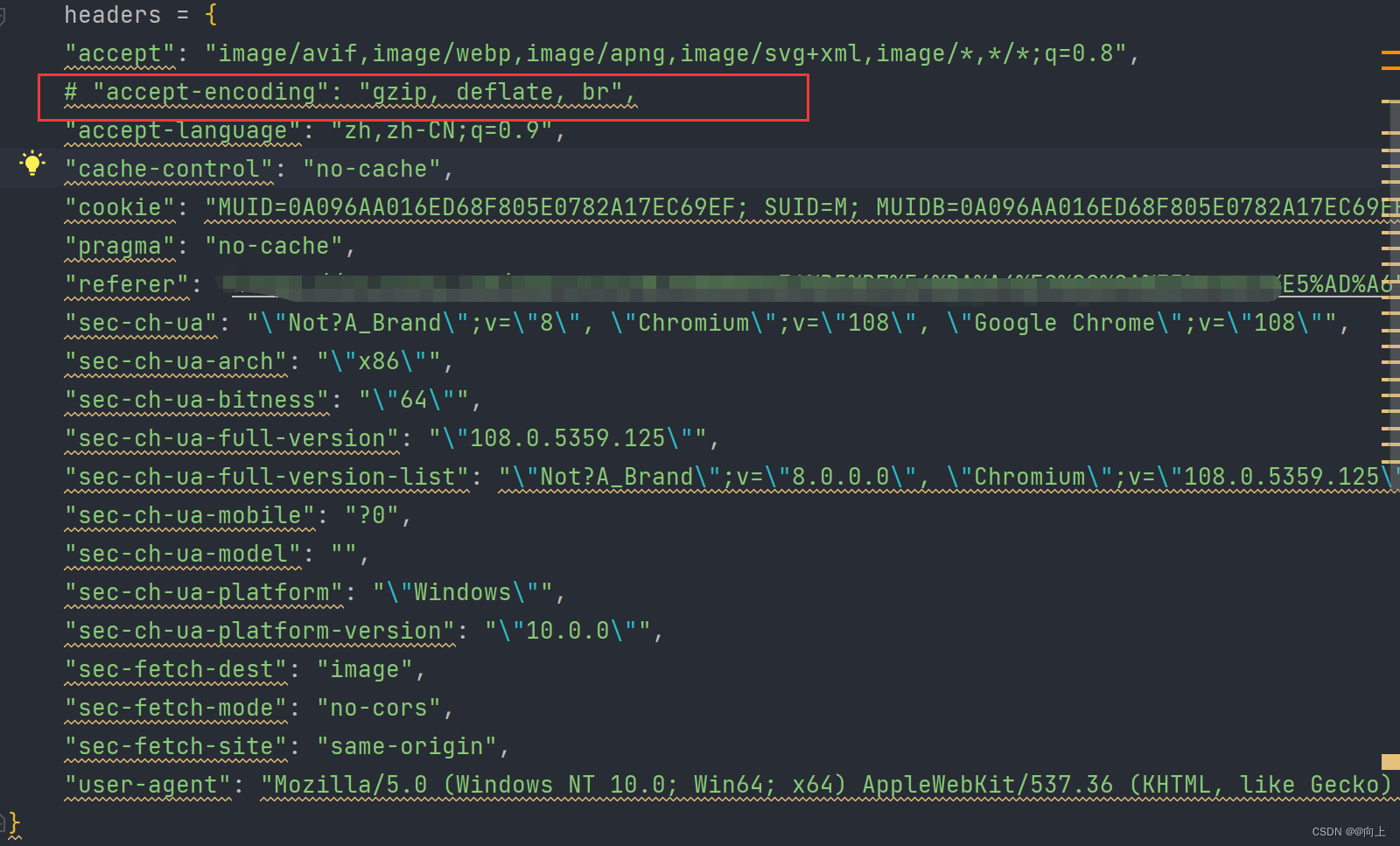
一条一条进行删除测试 终于发现问题的源头
accept-encoding": “gzip, deflate, br”
就是这个东西
将这个东西进行删除或者注释,返回的数据就正常了
后来百度了一波,发现网上对这个东西解释
普通浏览器访问网页,之所以添加"Accept-Encoding" = “gzip,deflate,br”,那是因为,浏览器对于从服务器中返回的对应的gzip压缩的网页,会自动解压缩,所以,其request的时候,添加对应的头,表明自己接受压缩后的数据。
而在我们编写的代码中,如果也添加此头信息,结果就是,返回的压缩后的数据,没有解码,而将压缩后的数据当做普通的html文本来处理,当前显示出来的内容就是乱码了。















 4137
4137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









