






一、爬虫获取b站热门排行榜数据
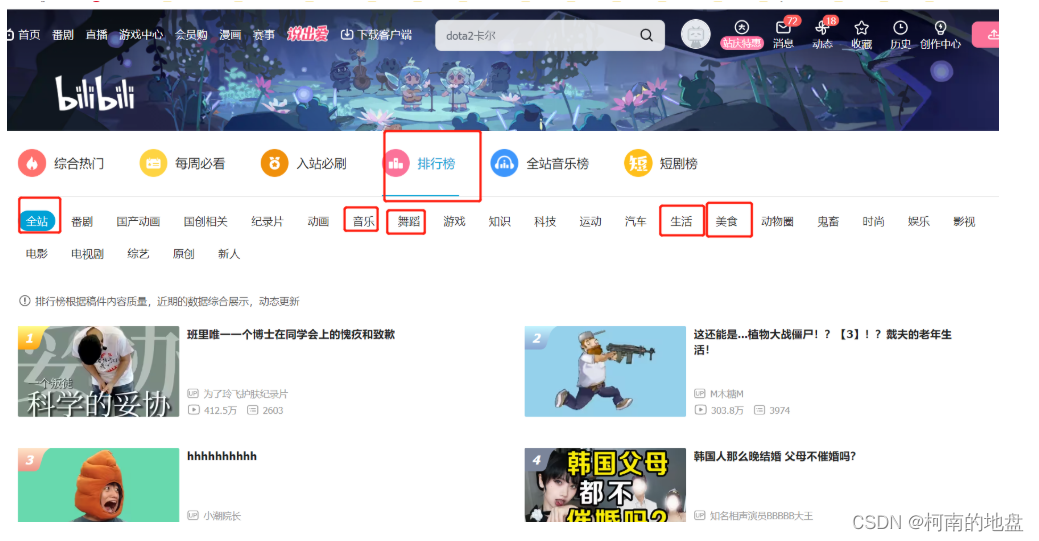
目标网站与模块如图所示:
1 导入包
import pandas
import requests #发送请求
2 目标网站
url_dict = {
'全站': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all',
'音乐': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=3&type=all',
'舞蹈': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=129&type=all',
'生活': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=160&type=all',
'美食': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=211&type=all',
}
3 请求头
headers = {
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Referer": "https://www.bilibili.com/v/popular/rank/all/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"if-modified-since": "Mon, 17 Jan 2022 08:00:21 GMT",
"if-none-match": "02a69914e93cd387f70d5b0308e1f6fe",
"origin": "https://www.bilibili.com",
"content-length": "0",
"Origin": "https://www.bilibili.com",
"Accept": "application/json, text/plain, */*",
"Upgrade-Insecure-Requests": "1"
}
这里请求头可以根据自己浏览器的headers修改。
4 核心爬虫代码
for i in url_dict.items():
url = i[1] # url地址
tab_name = i[0] # tab页名称
title_list = []
play_cnt_list = [] # 播放数
danmu_cnt_list = [] # 弹幕数
coin_cnt_list = [] # 投币数
like_cnt_list = [] # 点赞数
share_cnt_list = [] # 分享数
favorite_cnt_list = [] # 收藏数
author_list = []
video_url = []
try:
r = requests.get(url, headers=headers)
print(r.status_code)
#获取目标数据所在数据并转成字典类型
json_data = r.json()
list_data = json_data['data']['list']
for data in list_data:
title_list.append(data['title'])
play_cnt_list.append(data['stat']['view'])
danmu_cnt_list.append(data['stat']['danmaku'])
coin_cnt_list.append(data['stat']['coin'])
like_cnt_list.append(data['stat']['like'])
# dislike_cnt_list.append(data['stat']['dislike'])
share_cnt_list.append(data['stat']['share'])
favorite_cnt_list.append(data['stat']['favorite'])
author_list.append(data['owner']['name'])
# score_list.append(data['score'])
video_url.append('https://www.bilibili.com/video/' + data['bvid'])
# print('*' * 10)
except Exception as e:
print("爬取失败:{}".format(str(e)))
#创建dataframe保存数据
df = pd.DataFrame(
{'视频标题': title_list,
'视频地址': video_url,
'作者': author_list,
'播放数': play_cnt_list,
'弹幕数': danmu_cnt_list,
'投币数': coin_cnt_list,
'点赞数': like_cnt_list,
'分享数': share_cnt_list,
'收藏数': favorite_cnt_list,
})
#print(df.head())
#将数据保存到本地
df.to_csv('B站TOP100-{}.csv'.format(tab_name), index=False,encoding='utf_8_sig') # utf_8_sig修复乱码问题
print('写入成功: ' + 'B站TOP100-{}.csv'.format(tab_name))
代码执行完毕后,爬取到的数据会保存到py文件所在目录下。
二、数据分析部分
1、模块导入
#导入numpy,pandas库,用于读取csv文件,并对所读取的数据进行处理
import pandas as pd
import numpy as np
#导入matplotlib库,绘制图像
import matplotlib.pyplot as plt
#读取数据集到phone_data中
import seaborn as sns
import jieba
from collections import Counter
from wordcloud import WordCloud
data_meishi=pd.read_csv('B站TOP100-美食.csv')
data_quanzhan=pd.read_csv('B站TOP100-全站.csv')
data_shenghuo=pd.read_csv('B站TOP100-生活.csv')
data_wudao=pd.read_csv('B站TOP100-舞蹈.csv')
data_yinyue=pd.read_csv('B站TOP100-音乐.csv')
plt.rcParams['font.family'] = 'SimHei'
2、数据分析与可视化
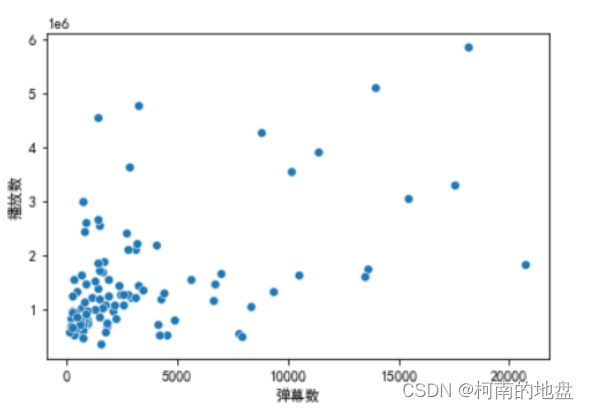
2.1 弹幕数与播放数的散点图
#弹幕数与播放数的散点图
sns.scatterplot(x='弹幕数', y='播放数', data=data_quanzhan)
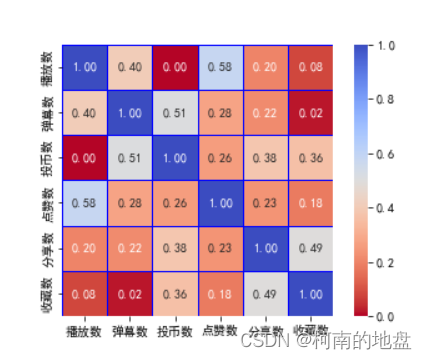
2.2 全站数据特征相关性分析
cor = data_quanzhan.corr(method='spearman')
sns.heatmap(cor,
annot=True, # 显示相关系数的数据
center=0.5, # 居中
fmt='.2f', # 只显示两位小数
linewidth=0.5, # 设置每个单元格的距离
linecolor='blue', # 设置间距线的颜色
vmin=0, vmax=1, # 设置数值最小值和最大值
xticklabels=True, yticklabels=True, # 显示x轴和y轴
square=True, # 每个方格都是正方形
cbar=True, # 绘制颜色条
cmap='coolwarm_r', # 设置热力图颜色
)
plt.ion() #显示图片
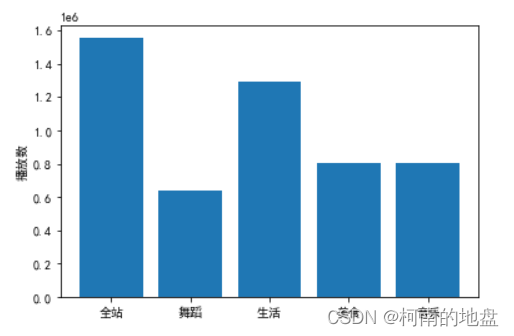
2.3 各板块数据播放量均值对比图
mean_list = [data_quanzhan['播放数'].mean(),data_wudao['播放数'].mean(),data_shenghuo['播放数'].mean(),data_meishi['播放数'].mean(),data_yinyue['播放数'].mean()]
name_list=['全站','舞蹈','生活','美食','音乐']
plt.bar(name_list,mean_list)
plt.ylabel('播放数')
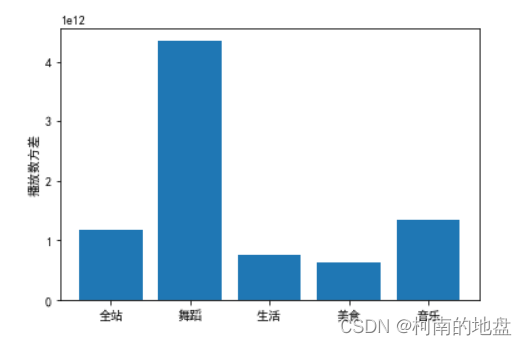
2.4 各板块数据播放量方差对比图
var_list = [data_quanzhan['播放数'].var(),data_wudao['播放数'].var(),data_shenghuo['播放数'].var(),data_meishi['播放数'].var(),data_yinyue['播放数'].var()]
plt.bar(name_list,var_list)
plt.ylabel('播放数方差')
2.5 全站数据标题词云分析
# 文本预处理
data_quanzhan['视频标题'] = data_quanzhan['视频标题'].apply(lambda x: ' '.join(jieba.lcut(x))) # 分词
# 读取停用词
with open('./停用词表.txt', 'r', encoding='utf-8') as f:
stop_words = f.read().split('\n')
data_quanzhan['视频标题'] = data_quanzhan['视频标题'].apply(lambda x: ' '.join([word for word in x.split() if word not in stop_words])) # 去除停用词
# 统计单词出现频率
words = []
for comment in data_quanzhan['视频标题']:
words += comment.split()
word_count = Counter(words).most_common(100)
# 转成字典
dct = {k:v for k, v in word_count}
print(dct)
# 生成词云图
font_path = r'C:\Windows\Fonts\msyh.ttc' # 指定微软雅黑字体路径
wordcloud = WordCloud(width=800, height=600, background_color='white',font_path=font_path).generate_from_frequencies(dct)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
这里需要在网上搜一个停用词表,并下载到本地,网上的停用词表有很多,找一个下就行了,名字保存为停用词表.txt

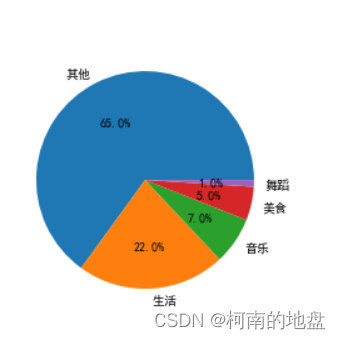
2.6 各个模块在全站模块中所占的比例
def panduan(x):
if x in data_meishi['作者'].tolist():
return '美食'
elif x in data_shenghuo['作者'].tolist():
return '生活'
elif x in data_yinyue['作者'].tolist():
return '音乐'
elif x in data_wudao['作者'].tolist():
return '舞蹈'
else:
return '其他'
data_quanzhan['类别'] = data_quanzhan['作者'].apply(panduan)
data_pie = data_quanzhan['类别'].value_counts()
plt.pie(data_pie.values,labels=data_pie.index,autopct="%3.1f%%")
plt.show()


















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











