







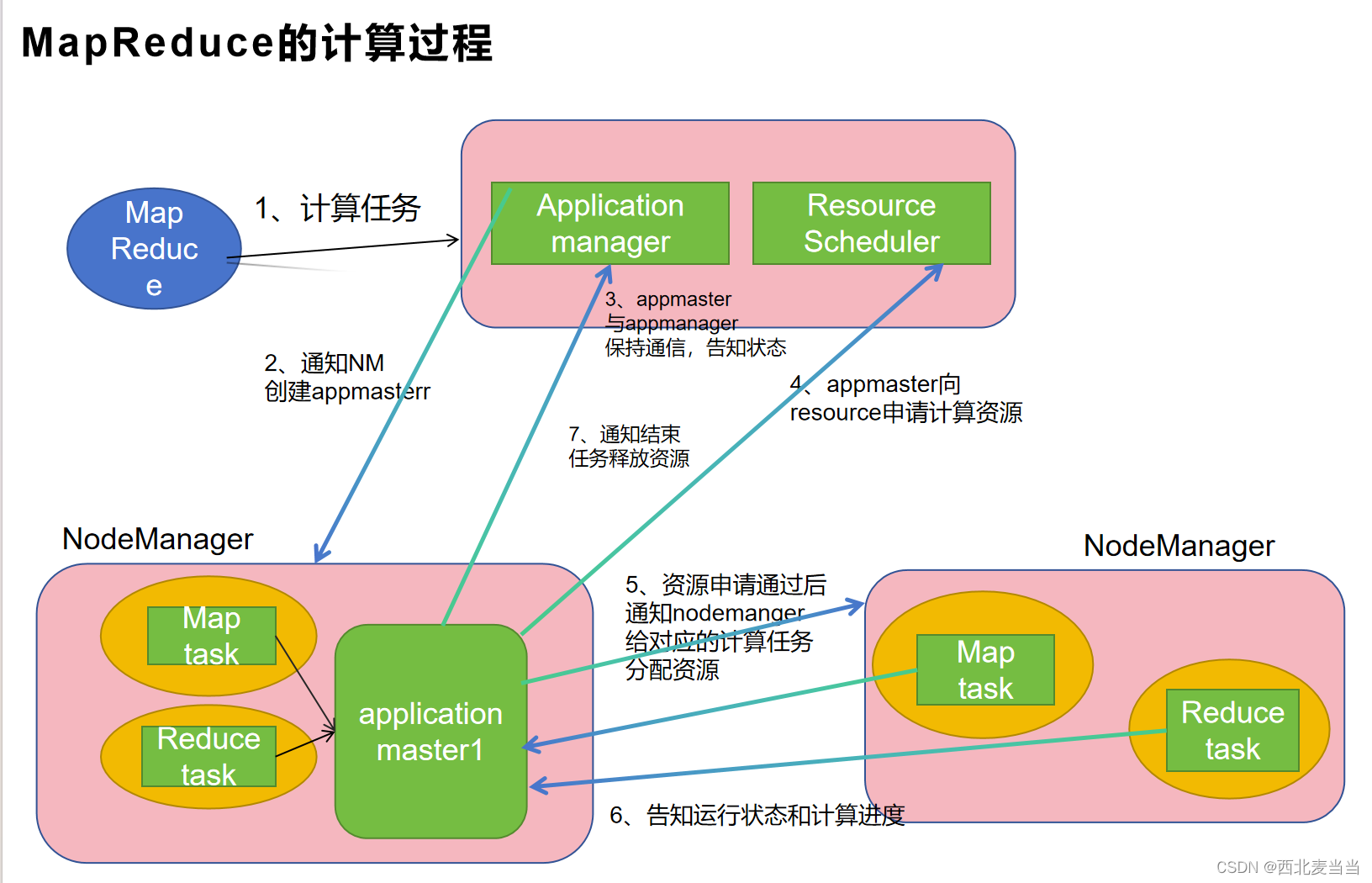
MapReduce的计算过程
MapReduce是一种编程模型和处理大规模数据集的方法。它通常用于分布式计算环境中,能够将数据处理任务分解成独立的部分,分配给多台计算机进行并行处理。这个模型由Google提出,并在开源领域中得到了广泛的应用和实现。MapReduce模型包含两个主要阶段,MapReduce的优点在于它的可伸缩性和容错性。它可以处理非常大的数据集,并且能够在计算过程中处理节点故障等问题,保证整个计算任务的完成。Hadoop是最著名的MapReduce实现之一,它是一个开源的分布式计算框架,用于在大规模集群上运行MapReduce作业。
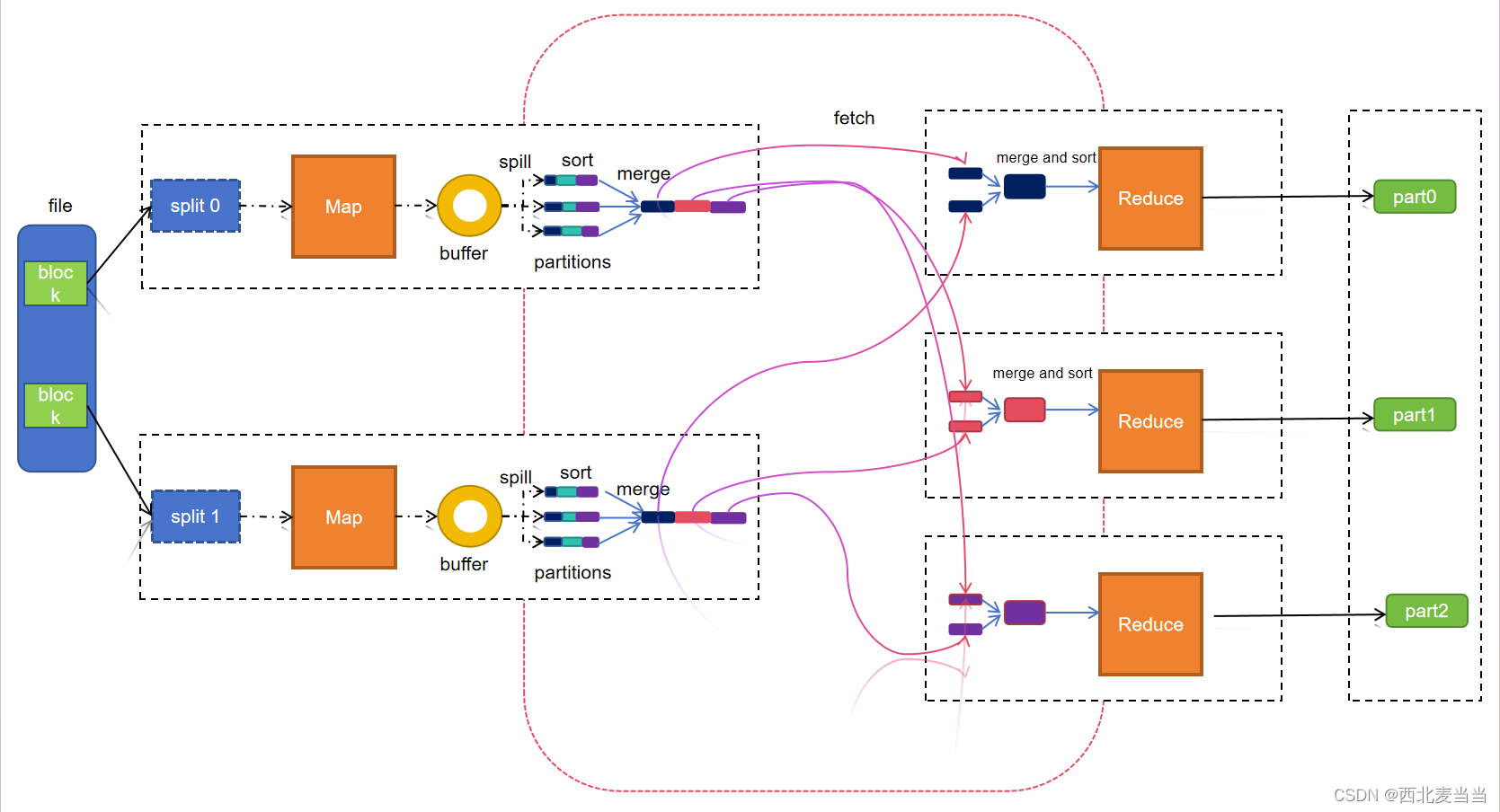
一、计算流程
Map阶段
1.按照块数量进行split的块数据读取
2.split切割后的数据传递给对应的map进行处理,会对数据转为kv (张三,1) (李四,2)
3.map将处理的后的数据写入buffer缓存区
4.对缓冲区内的数据进行spill溢出(读取缓冲区内的数据)
5.对读取的数据进行分区,将数据拆分多份
6.对每份拆分的数据进行排序 sort
7.将拆分的数据写入不同的文件
8.在将每次溢出的数据合并merge在一起,保存同一文件,文件是临时文件,计算后会删除
Reduce阶段
1.根据的分区数创建出多个reduce
2.每个reduce从不同的map中fetch获取相同分区的文件数据
3.在将fetch后的文件合并,对合并后的数据进行排序
4.reduce对合并后的文件数据进行计算
5.reduce对结果输出到hdfs的目录下
二、图形化流程















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









