







一、DataX介绍
官网: DataX/introduction.md at master · alibaba/DataX · GitHub
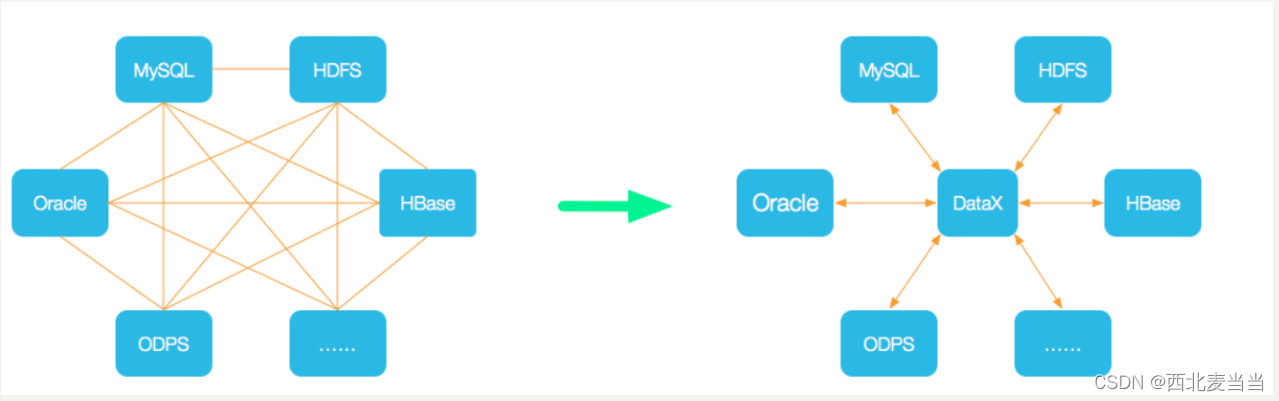
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的
离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
DataX 的特点包括:
支持多种数据源和数据目的地:DataX 支持各种常见的数据源和数据目的地,包括关系型数据库、NoSQL 数据库、数据仓库、云存储等。
可扩展性:DataX 提供了可扩展的插件机制,用户可以根据需要自定义插件来支持新的数据源或数据目的地。
高性能:DataX 被设计为高性能的数据处理工具,在处理大规模数据时能够提供较高的性能和吞吐量。
易用性:DataX 提供了简单易用的配置方式,用户可以通过配置文件来定义数据处理任务,而无需编写复杂的代码。
二、Datax架构说明
DataX 的架构设计灵活而可扩展,通过调度器、执行器、任务配置、插件等组件的协同工作,实现了高效、可靠的数据交换和处理功能。
DataX 是一个分布式数据交换系统,其架构设计主要包括以下几个关键组件:
调度器(Scheduler):调度器负责协调和管理数据交换任务的执行。它接收用户提交的数据交换任务,并将任务分配给可用的执行器进行处理。调度器还负责监控任务的执行状态,并在需要时重新调度失败的任务或处理异常情况。
执行器(Executor):执行器是实际执行数据交换任务的组件。它负责根据调度器分配的任务执行数据抽取(Extract)、转换(Transform)、加载(Load)等操作。执行器可以部署在集群中的多台机器上,以实现并行处理和提高任务执行的效率。
任务配置(Job Configuration):任务配置包括用户定义的数据交换任务的配置信息,如数据源、数据目的地、数据转换规则等。任务配置通常采用简单的配置文件或数据流程图的形式进行定义,以便于用户理解和管理。
数据源和数据目的地(Data Source & Data Sink):数据源是数据交换任务的来源,可以是关系型数据库、文件系统、NoSQL 数据库等;而数据目的地是数据交换任务的目标,通常是用来存储处理后的数据。DataX 提供了丰富的插件来支持各种常见的数据源和数据目的地。
插件(Plugin):插件是 DataX 的核心组件之一,用于实现不同类型数据源和数据目的地的读写操作以及数据转换功能。DataX 提供了丰富的插件体系,用户可以根据需要选择合适的插件来支持特定的数据源或数据目的地。
资源管理器(Resource Manager):资源管理器负责管理执行器所需的资源,如内存、CPU 资源等。它可以根据任务的执行情况动态调整资源分配,以实现资源的高效利用和任务的平衡执行。

三、Datax数据处理流程
DataX 的数据处理流程包括任务配置、任务提交、调度和分配、数据抽取、数据转换、数据加载、任务监控和报告等多个阶段,通过这些阶段的协同工作,实现了高效、可靠的数据交换和处理功能。
DataX 的数据处理流程通常可以分为以下几个阶段:
任务配置:用户首先需要定义数据交换任务的配置信息。这包括指定数据源和数据目的地的类型、连接信息、数据转换规则等。任务配置可以通过简单的配置文件或者可视化工具进行定义。
任务提交:一旦任务配置完成,用户将任务提交给 DataX。这通常通过命令行工具或者调度系统的 API 进行提交。
调度和分配:调度器接收到用户提交的任务后,会根据任务的优先级和资源情况将任务分配给可用的执行器。如果任务需要在特定的时间点执行,调度器也会相应地进行调度安排。
数据抽取(Extract):执行器首先从数据源中读取数据。这可能涉及到连接数据库、读取文件、调用 API 等操作,具体的操作取决于数据源的类型和配置。
数据转换(Transform):一旦数据被抽取到内存中,执行器会根据用户定义的转换规则对数据进行处理和转换。这包括数据清洗、格式转换、字段映射等操作,以确保数据符合目标格式和要求。
数据加载(Load):处理后的数据将被加载到目标数据存储中。这可能涉及到写入数据库、上传文件、推送到消息队列等操作,具体的操作取决于数据目的地的类型和配置。
任务监控和报告:在整个数据处理流程中,调度器会监控任务的执行状态和进度,并及时报告任务的执行情况给用户。这可以帮助用户及时发现和解决任务执行中的问题。
任务完成:一旦任务执行完成,用户可以查看任务的执行结果,并根据需要进行后续的数据分析、挖掘等操作。

核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
四、DataX使用说明
DataX 是一个强大的数据交换工具,用于实现数据抽取、转换和加载(ETL)任务。下面是一个简要的 DataX 使用说明:
1. 安装 DataX
首先,您需要安装 DataX。您可以从 DataX 的官方 GitHub 仓库中获取源代码,并按照官方文档提供的安装说明进行安装。另外,也可以通过直接下载 DataX 的发布版本进行安装。
2. 编写任务配置文件
接下来,您需要编写数据交换任务的配置文件。配置文件通常使用 JSON 或者其他类似的格式进行编写。在配置文件中,您需要指定数据源、数据目的地、数据转换规则等信息。
3. 提交任务
一旦配置文件编写完成,您可以使用 DataX 提供的命令行工具或者调度系统的 API 进行任务提交。提交任务时,需要指定配置文件的路径以及其他必要的参数。
4. 监控任务执行
一旦任务提交成功,DataX 将会开始执行任务。您可以使用 DataX 提供的监控和日志查看工具来监控任务的执行状态和进度。这些工具通常会提供任务执行日志、报告和统计信息,帮助您了解任务的执行情况。
5. 调优和优化
在任务执行过程中,您可能需要对任务进行调优和优化,以提高任务的性能和效率。您可以根据任务执行日志和统计信息,对任务的配置进行调整,或者调整执行环境的资源配置,以达到更好的执行效果。
6. 完成任务
一旦任务执行完成,您可以根据需要对处理后的数据进行后续的分析、挖掘等操作。您可以从数据目的地中获取处理后的数据,并将其用于您的业务应用中。
4.1、DataX MysqlReader
4.1.1、介绍
MysqlReader插件实现了从Mysql读取数据。在底层实现上,MysqlReader通过JDBC连接远程Mysql数据库,并执行相应的sql语句将数据从mysql库中SELECT出来。
不同于其他关系型数据库,MysqlReader不支持FetchSize.
4.1.2、原理
简而言之,MysqlReader通过JDBC连接器连接到远程的Mysql数据库,并根据用户配置的信息生成查询SELECT SQL语句,然后发送到远程Mysql数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。
对于用户配置Table、Column、Where的信息,MysqlReader将其拼接为SQL语句发送到Mysql数据库;对于用户配置querySql信息,MysqlReader直接将其发送到Mysql数据库。
4.1.3、配置
--配置一个从Mysql数据库同步抽取数据到本地的作业:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
--配置一个自定义SQL的数据库同步任务到本地内容的作业:
{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"connection": [
{
"querySql": [
"select db_id,on_line_flag from db_info where db_id < 10;"
],
"jdbcUrl": [
"jdbc:mysql://bad_ip:3306/database",
"jdbc:mysql://127.0.0.1:bad_port/database",
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false,
"encoding": "UTF-8"
}
}
}
]
}
}4.1.4、参数说明
jdbcUrl
描述:描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。之所以使用JSON数组描述连接信息,是因为阿里集团内部支持多个IP探测,如果配置了多个,MysqlReader可以依次探测ip的可连接性,直到选择一个合法的IP。如果全部连接失败,MysqlReader报错。 注意,jdbcUrl必须包含在connection配置单元中。对于阿里集团外部使用情况,JSON数组填写一个JDBC连接即可。
jdbcUrl按照Mysql官方规范,并可以填写连接附件控制信息。具体请参看Mysql官方文档。
必选:是
默认值:无
username
描述:数据源的用户名
必选:是
默认值:无
password
描述:数据源指定用户名的密码
必选:是
默认值:无
table
描述:所选取的需要同步的表。使用JSON的数组描述,因此支持多张表同时抽取。当配置为多张表时,用户自己需保证多张表是同一schema结构,MysqlReader不予检查表是否同一逻辑表。注意,table必须包含在connection配置单元中。
必选:是
默认值:无
column
描述:所配置的表中需要同步的列名集合,使用JSON的数组描述字段信息。用户使用*代表默认使用所有列配置,例如['*']。
支持列裁剪,即列可以挑选部分列进行导出。
支持列换序,即列可以不按照表schema信息进行导出。
支持常量配置,用户需要按照Mysql SQL语法格式: ["id", "`table`", "1", "'bazhen.csy'", "null", "to_char(a + 1)", "2.3" , "true"] id为普通列名,`table`为包含保留字的列名,1为整形数字常量,'bazhen.csy'为字符串常量,null为空指针,to_char(a + 1)为表达式,2.3为浮点数,true为布尔值。
必选:是
默认值:无
splitPk
描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
目前splitPk仅支持整形数据切分,
不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错!如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
必选:否
默认值:空
where
描述:筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。在实际业务场景中,往往会选择当天的数据进行同步,可以将where条件指定为gmt_create > $bizdate 。注意:不可以将where条件指定为limit 10,limit不是SQL的合法where子句。
where条件可以有效地进行业务增量同步。如果不填写where语句,包括不提供where的key或者value,DataX均视作同步全量数据。必选:否
默认值:无
querySql
- 描述:在有些业务场景下,where这一配置项不足以描述所筛选的条件,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项之后,DataX系统就会忽略table,column这些配置型,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用select a,b from table_a join table_b on table_a.id = table_b.id
当用户配置querySql时,MysqlReader直接忽略table、column、where条件的配置,querySql优先级大于table、column、where选项。
必选:否
默认值:无
4.2、DataX MysqlWriter
4.2.1、介绍
MysqlWriter 插件实现了写入数据到 Mysql 主库的目的表的功能。在底层实现上, MysqlWriter 通过 JDBC 连接远程 Mysql 数据库,并执行相应的 insert into ... 或者 ( replace into ...) 的 sql 语句将数据写入 Mysql,内部会分批次提交入库,需要数据库本身采用 innodb 引擎。
MysqlWriter 面向ETL开发工程师,他们使用 MysqlWriter 从数仓导入数据到 Mysql。同时 MysqlWriter 亦可以作为数据迁移工具为DBA等用户提供服务。
4.2.2、原理
MysqlWriter 通过 DataX 框架获取 Reader 生成的协议数据,根据你配置的
writeMode生成
insert into...(当主键/唯一性索引冲突时会写不进去冲突的行)replace into...(没有遇到主键/唯一性索引冲突时,与 insert into 行为一致,冲突时会用新行替换原有行所有字段) 的语句写入数据到 Mysql。出于性能考虑,采用了PreparedStatement + Batch,并且设置了:rewriteBatchedStatements=true,将数据缓冲到线程上下文 Buffer 中,当 Buffer 累计到预定阈值时,才发起写入请求。
4.2.3、配置
--这里使用一份从内存产生到 Mysql 导入的数据。
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19880808,
"type": "long"
},
{
"value": "1988-08-08 08:08:08",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?useUnicode=true&characterEncoding=gbk",
"table": [
"test"
]
}
]
}
}
}
]
}
}4.2.4、参数说明
jdbcUrl
描述:目的数据库的 JDBC 连接信息。作业运行时,DataX 会在你提供的 jdbcUrl 后面追加如下属性:yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true
注意:1、在一个数据库上只能配置一个 jdbcUrl 值。这与 MysqlReader 支持多个备库探测不同,因为此处不支持同一个数据库存在多个主库的情况(双主导入数据情况) 2、jdbcUrl按照Mysql官方规范,并可以填写连接附加控制信息,比如想指定连接编码为 gbk ,则在 jdbcUrl 后面追加属性 useUnicode=true&characterEncoding=gbk。具体请参看 Mysql官方文档或者咨询对应 DBA。必选:是
默认值:无
username
描述:目的数据库的用户名
必选:是
默认值:无
password
描述:目的数据库的密码
必选:是
默认值:无
table
描述:目的表的表名称。支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。
注意:table 和 jdbcUrl 必须包含在 connection 配置单元中必选:是
默认值:无
column
描述:目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: "column": ["id","name","age"]。如果要依次写入全部列,使用
*表示, 例如:"column": ["*"]。**column配置项必须指定,不能留空!** 注意:1、我们强烈不推荐你这样配置,因为当你目的表字段个数、类型等有改动时,你的任务可能运行不正确或者失败 2、 column 不能配置任何常量值必选:是
默认值:否
session
描述: DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
必须: 否
默认值: 空
preSql
描述:写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,请使用
@table表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, ... datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:"preSql":["delete from 表名"],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称必选:否
默认值:无
postSql
描述:写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
必选:否
默认值:无
writeMode
描述:控制写入数据到目标表采用
insert into或者replace into或者ON DUPLICATE KEY UPDATE语句必选:是
所有选项:insert/replace/update
默认值:insert
batchSize
描述:一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
必选:否
默认值:1024















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









