







一、什么是Presto
Presto是一款分布式SQL查询引擎, Presto可以独立提供计算分析操作, 不需要依赖于其他的计算引擎。而HIVE仅 仅是一个工具, 最终计算是依赖于MR或者其他的执行引擎 Presto可以对接多种数据源, 可以从不同的数据源中读取数据进行分析处理, 一条presto查询可以将多个数据源 进行合并, 可以跨越多个不同的组织进行分析 Presto是完全基于内存的计算引擎,这也导致Presto不能对海量大量的数据进行统计分析操作,数据集一般在 GB ~ PB左右(集群数量越多,资源越多,可以计算的数据量越高)
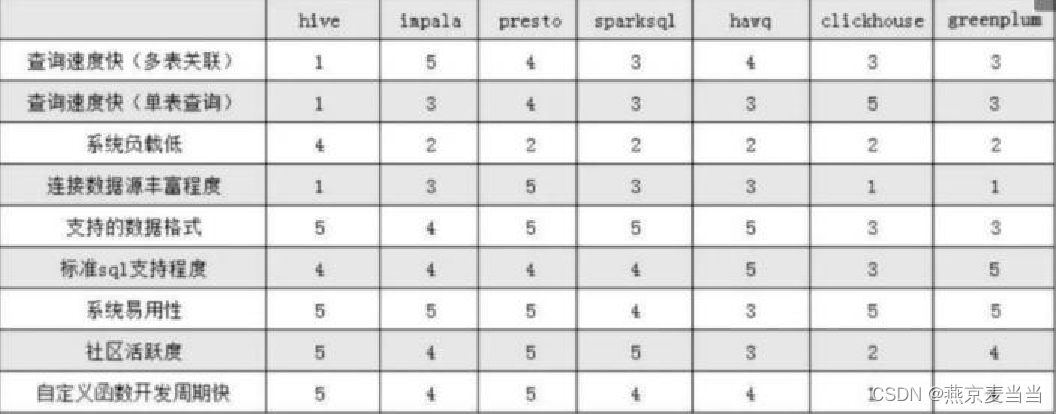
性能对比图表 :
原理图:
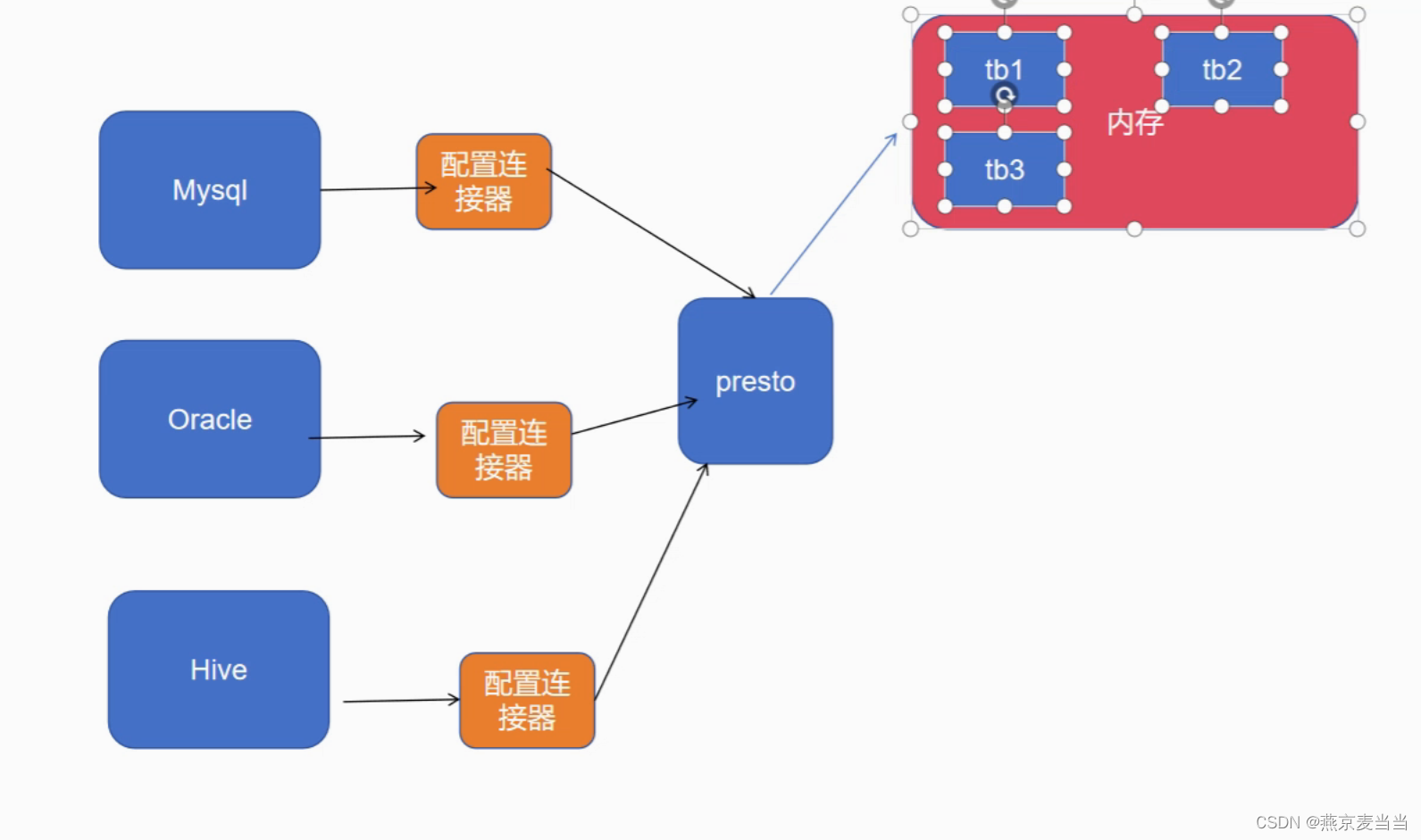
二、Presto应用场景
适用场景 :
(1) 适用于对数据源统一查询 (多数据源场景)。
(2) 适用于 GB TB 快速的数据查询操作, 数据量越大, 资源占用越高。
(3) 适用于在开发测试中, 基于测试数据查询从而加快测试开发的速度。
不适用场景 :
(1) 多张数据量比较大的表Join操作。
(2) 不适合进行清洗 转换 维度退化的相关操作, 主要应用在数据分析上。
三、prosto架构
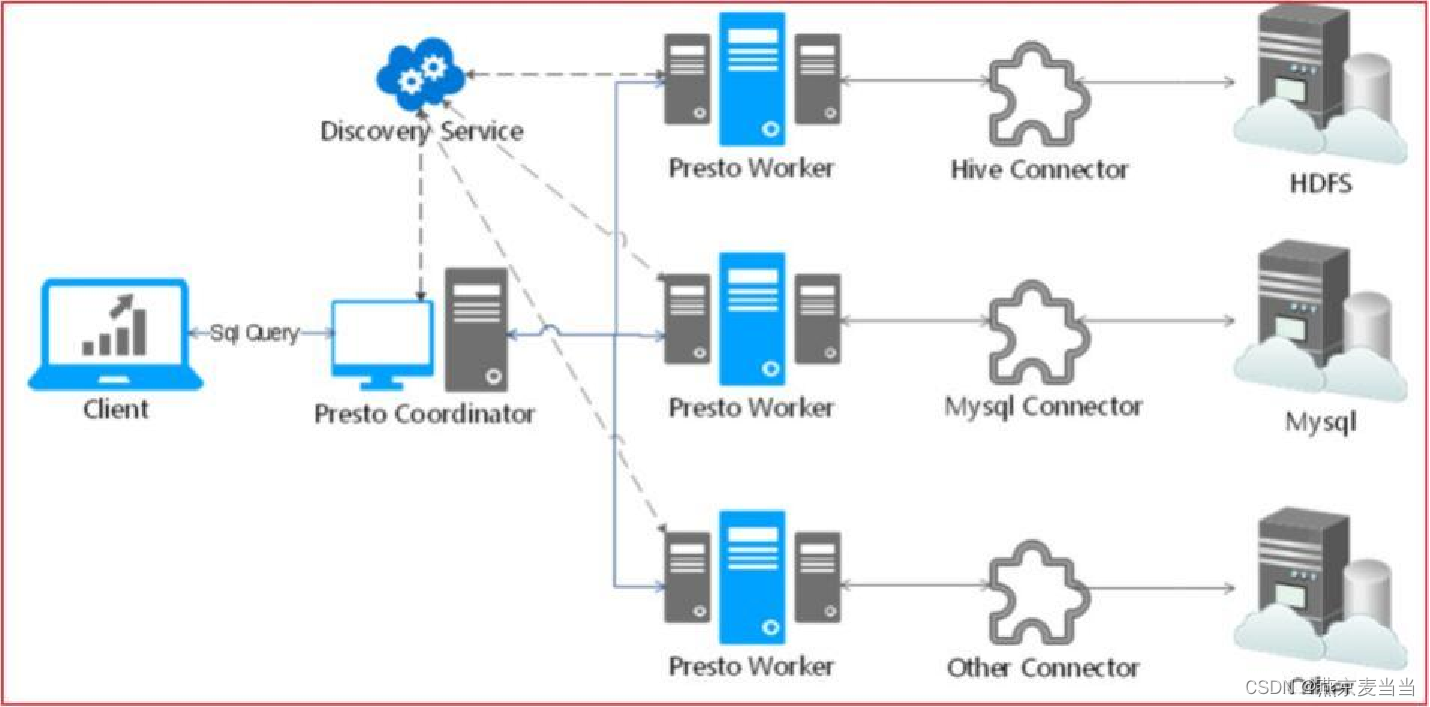
整个presto是一个 M-S架构 (主从架构) :
coordinator: 主节点
作用 : 负责接收客户端发送的SQL, 对SQL进行编译, 形成执行计划, 根据执行计划, 分发给各个从节点进行执行操作
discovery service : 附属节点
作用 : 一般内嵌在主节点中, 主要负责维护从节点列表, 当从节点启动后, 都需要到 discovery 节点进行注册操作
worker节点 : 从节点
作用 : 负责接收coordinator传递过来任务, 对任务进行具体处理工作(读取数据, 处理数据, 将处理后结果数据返回 给coordinator)
四、Presto相关的时间函数
在presto中, 对于数据类型要求比较严格, 比如 数据字段类型为date类型,那么在基于这个字段进行过滤的时候, 编 写的过滤条件上值必须也是date类型。
日期转换操作 :
--date_format(timestamp,format) : 将一个带有年月日 时分秒的日期对象 转换为字符串
--date_parse(string,format) ---> timestamp: 将带有年月日 时分秒的日期字符串 转换为 日期对象
--date(日期对象)--->date : 将带有年月日 时分秒的日期对象, 转换为仅包含年月日的日期对象 说明 : date类型 : 表示只有年-月-日;timestamp类型 : 表示年-月-日-时-分-秒;format格式 : 年:%Y 月:%m 日:%d 时:%H 分:%i 秒:%s 周几:%w(0..6)
-- timestamp ' 日期字符串数据' 直接转换为 日期对象 , 要求 后面的日期字符串的数据必须是标准格式的日期 -- 即使 日期字符串数据, 只有年月日 依然是可以转换的, 只不过 时分秒都是 0:
select date_format( timestamp '2020-10-10 12:50:50' , '%Y/%m/%d %H:%i :%s' ) ;
-- date_parse : 可以将指定日期格式数据转换为日期对象:
select date_format( date_parse('2020-10-10 12:50:50','%Y-%m-%d %H:%i :%s') , '%Y/%m/%d %H:%i :%s' ) ;
-- date '字符串':直接转换为日期对象, 仅能处理标准的年月日的数据, 无法处理带有时分秒的操作 select date_format( date '2020-10-10' , '%Y/%m/%d %H:%i :%s' ) ;
日期计算的操作 :
date_add(unit,value,timestamp) → [same as input] :
根据 unit设置时间单位, 对timestamp的时间数据 进行 value计 算 , 计算为 + 号 , 如果想计算减号, 可以让value为负数即可
date_diff(unit, timestamp1, timestamp2) → big in t :
根据 unit单位,时间timestamp2 - 时间timestamp1 , 得出差值
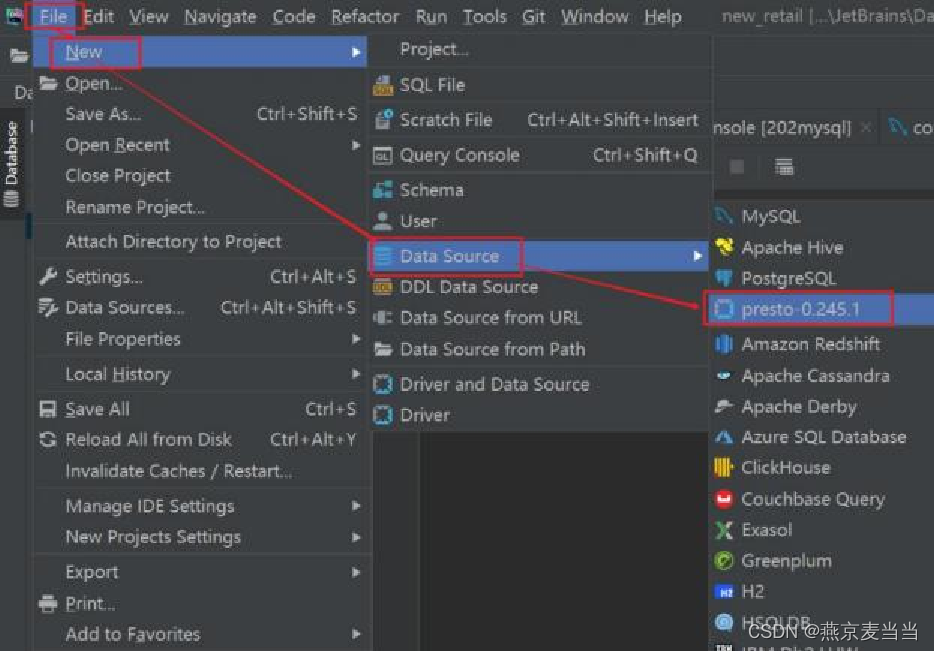
五、基于DataGrip连接Presto
如何启动:
Presto : bin/launcher start
访问WEB:
http://主机ip地址:8090/ui/
使用之前需要配置连接器:
在/export/server/presto/etc/catalog目录下配置文件
参考官网配置,官网地址:MySQL Connector — Presto 0.286 Documentation
配置举例(mysql):
在catalog目录下创建文件:vim mysql.properties
将配置信息写入文件:
connector.name=mysql
connection-url=jdbc:mysql://主机ip地址:3306
connection-user=root
connection-password=123456配置完成后关闭
/export/server/presto/bin/launcher stop
然后再开启
/export/server/presto/bin/launcher star
web端访问:http://主机ip地址:8090/ui/
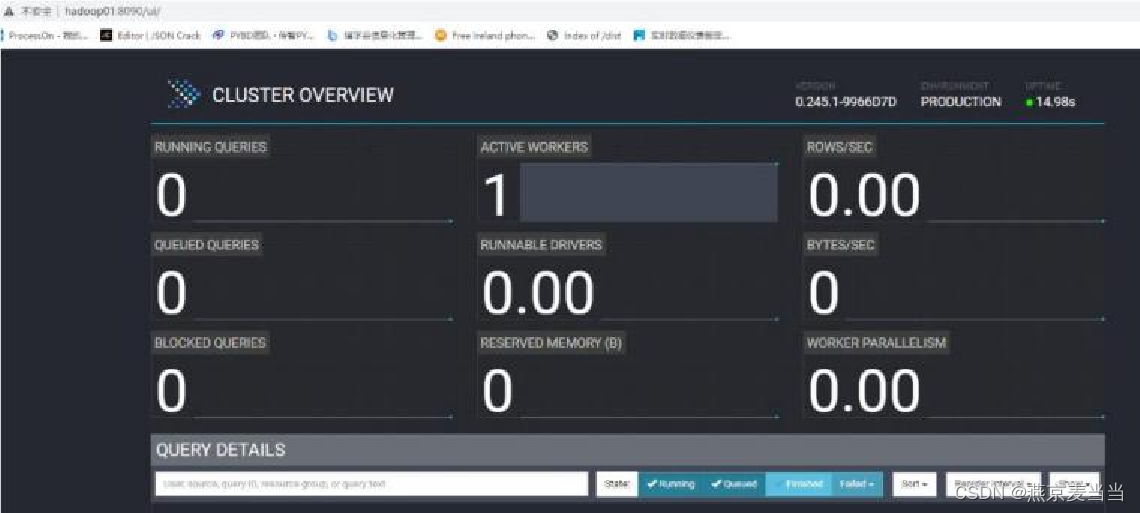
DataGrip连接Presto:















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









