






机器学习
机器学习是人工智能的一个分支,它使用算法和统计模型来使计算机系统自动地从经验数据中学习,并不断改进其性能。简单来说,机器学习是一种通过训练计算机程序来识别和预测模式的方法。
在机器学习中,计算机程序会根据提供的数据进行学习,然后使用这些学习结果来做出决策或者预测未来事件。这个过程包括了数据采集、清理、处理、训练模型、评估模型和预测等步骤。
本文主要是本人在进行模型调参之前进行的资料搜集
模型评估与调整——学会评估模型的性能并调整超参数以获得更好的性能。了解交叉验证、网格搜索等技术。
神经网络:
循环神经网络RNN
深度神经网络DNN
卷积神经网络CNN
生成对抗网络GAN
卷积神经网络常用的基础组网模块
卷积(Convolution):
卷积核(kernel) 填充(padding) 步幅(stride) 感受野(Receptive Field) 多输入通道、多输出通道和批量操作
池化(Pooling)
激活函数
批归一化(Batch Normalization)
丢弃法(Dropout)
池化:
平均池化(Average Pooling)
最大池化
空间金字塔池化(Spatial Pyramid Pooling,SPP)
全局平均池化(Global Average Pooling,GAP)
全局最大池化(Global Max Pooling)
NetVLAD池化
随机池化
重叠池化
RoI池化
激活函数:
Sigmoid函数
Tanh函数
ReLU函数
LReLU
PReLU
ELU
swish
hswish
归一化方法:
批归一化(Batch Normalization)
层归一化(Layer Normalization, LN)
组归一化(Group Normalization, GN)
实例归一化(Instance Normalization, IN)
其中N知batch size、H和W分别表示特征图的高度和宽度、C表示特征图的通道数,蓝色像素表示使用相同的均值和方差进行归一化:
编辑
添加图片注释,不超过 140 字(可选)
LN:对[C,W,H]维度求均值方差进行归一化,即在通道方向做归一化,与batch size大小无关,在小batch size上效果可能更好
GN:先对通道方向进行分组,然后每个组内对[Ci,W,H]维度进行归一化,也与batch size大小无关
IN:只对[H,W]维度进行归一化,图像风格化任务适合使用IN算法
丢弃法(Dropout):
DropConnect
Standout
Gaussian Dropout
Spatial Dropout
Cutout
Max-Drop
RNNDrop
循环Drop
飞桨中提供两种方法:
downscale_in_infer
训练时以比例r随机丢弃一部分神经元,不向后传递它们的信号;预测时向后传递所有神经元的信号,但是将每个神经元上的数值乘以(1−r)。
upscale_in_train
训练时以比例p随机丢弃一部分神经元,不向后传递它们的信号,但是将那些被保留的神经元上的数值除以 (1−p);预测时向后传递所有神经元的信号,不做任何处理。
优化器:
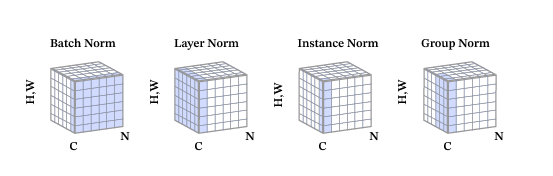
四种主流优化算法
SGD
Momentum
AdaGrad
Adam
编辑切换为居中
添加图片注释,不超过 140 字(可选)
SGD: 随机梯度下降算法,每次训练少量数据,抽样偏差导致的参数收敛过程中震荡。
Momentum: 引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)往往更喜欢稍重篮球。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,学习率随着梯度变化而适应,解决AdaGrad学习率急剧下降的问题。
Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这是当前广泛应用的算法。
学习率:
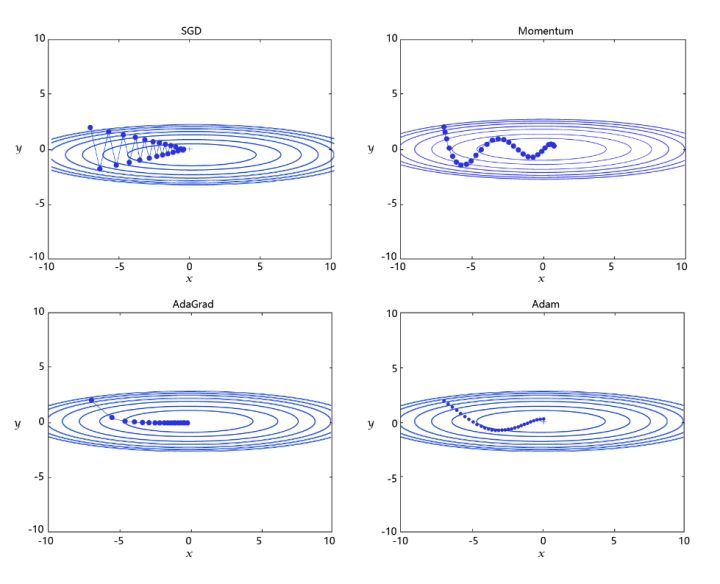
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。
学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如 图2 左图所示。
学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如 图2 右图所示。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
正则化项:
为了防止模型过拟合,在没有扩充样本量的可能下,只能降低模型的复杂度,可以通过限制参数的数量或可能取值(参数值尽量小)实现。具体来说,在模型的优化目标(损失)中人为加入对参数规模的惩罚项。当参数越多或取值越大时,该惩罚项就越大。通过调整惩罚项的权重系数,可以使模型在“尽量减少训练损失”和“保持模型的泛化能力”之间取得平衡。泛化能力表示模型在没有见过的样本上依然有效。正则化项的存在,增加了模型在训练集上的损失。
飞桨支持为所有参数加上统一的正则化项,也支持为特定的参数添加正则化项。前者的实现如下代码所示,仅在优化器中设置weight_decay参数即可实现。使用参数coeff调节正则化项的权重,权重越大时,对模型复杂度的惩罚越高。
目标检测基本概念:
Anchor:
Anchor-Based
Anchor-Based方法又可以分为两阶段检测算法和单阶段检测算法。
Anchor-Based使用Anchor提取候选目标框,然后在特征图上的每一个点,对Anchor进行分类和回归。两阶段检测算法先使用Anchor在图像上产生候选区域,划分前景和背景,再对候选区域进行分类并预测目标物体位置。典型的两阶段检测算法是R-CNN系列(Fast R-CNN、Faster R-CNN等),经典的Faster R-CNN通过RPN(Region Proposal Network)学习候选区域(Region Propposal, RP),再对候选区域进行分类和回归,输出最终目标框和类别。基于先产生候选区域再检测的两阶段模型通常具有较优的精度,但是预测速度较慢。
此外,Anchor-Based还有一些单阶段模型,这类模型在产生候选区域的同时即可预测出物体类别和位置,不需要分成两阶段来完成检测任务。典型的单阶段算法是YOLO系列(YOLOV2、YOLOv3、YOLOv4、PP-YOLO、PP-YOLOV2等)。单阶段算法摒弃两阶段算法中的RPN产生候选区域这一步骤,将候选区域和检测两个阶段合二为一,使得网络结构更加简单,检测速度快。
但是Anchor-Based方法在实际应用中存在一些缺点,比如:手工设计Anchor需要考虑Anchor的数量、尺寸(长宽比);在特征图上像素点密集滑动会生成的检测框会存在大量负样本区域,就需要考虑正负样本不均衡的问题;Anchor的设计导致网络超参数变多,模型学习比较困难;更换不同的数据集需要重新调整Anchor。
Anchor-Free
因此研究者提出了Anchor-Free方法,不再使用预先设定Anchor,通常通过预测目标的中心或角点,对目标进行检测。包含基于中心区域预测的方法(FCOS、CenterNet等)和基于多关键点联合表达的方法(CorNert、RepPoints等)。Anchor-Free算法不再需要设计Anchor,模型更为简单,减少模型耗时,但是精度也比Anchor-Based方法精度低。
模型结构:
R-CNN
SSD
YOLO(1, 2, 3……7)
R-FCN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









