







目录
全文检索
什么是全文检索?
我们看chatGPT怎么回答的:

简单来说:全文检索就是一种通过对文本内容进行全面索引和全面搜索的技术。
全文检索原理
在全文检索中,首先需要对文本数据进行预处理,包括分词和去除停用词等操作。这些步骤有助于将文本数据转换为适合建立索引的格式,并提高搜索的效率和准确性。然后,对预处理后的文本数据建立索引,通常使用倒排索引来实现。倒排索引会记录每个单词在文档中的位置信息以及其他相关的元数据,比如词频和权重。
当用户发起搜索请求时,搜索引擎会根据用户提供的关键词或短语,在建立好的索引中查找匹配的文档。搜索引擎会根据索引中的信息计算文档的相关性,并按照相关性排序返回搜索结果。为了提高搜索结果的质量和范围,用户可以通过不同的搜索策略和过滤条件进行精确控制。
通过优化文本预处理、索引建立和搜索算法,全文检索系统能够快速准确地处理大规模的文本数据,并为用户提供满足其需求的相关搜索结果。
倒排索引
正排索引(Forward Index)和倒排索引(Inverted Index)是全文检索中常用的两种索引结构,它们在索引和搜索的过程中扮演不同的角色。
正排索引(正向索引):
正排索引是一种索引结构,它按顺序排列并编号文档,每个文档包含完整的文本内容以及其他相关属性或元数据,比如标题、作者、发布日期等。通过正排索引,可以根据文档编号或其他属性快速访问文档的内容。
在MySQL中,通过ID查找就是一种典型的正排索引的应用。MySQL中的每个表通常都会有一个自增的主键ID,通过这个ID可以直接访问表中的某条记录。这种方式效率高,特别适用于快速定位和检索特定记录的场景。
正排索引适用于需要对整个文档进行检索和展示的情况,但对于包含大量文本内容的数据集来说,正排索引的存储和查询效率可能会受到限制。因为每个文档都包含完整的内容,所以随着文档数量的增加,存储和查询的成本也会相应增加。
为了优化正排索引的性能,可以考虑采用压缩技术、分区存储、索引列的选择等方法。此外,对于大规模文本数据集,还可以考虑使用倒排索引等其他索引结构来提高检索效率。
倒排索引(反向索引)
倒排索引是一种针对文本数据建立的索引结构,它将每个单词或短语映射到包含该单词或短语的文档列表中。倒排索引的建立过程通常包括以下步骤:
-
文档预处理:对文档进行分词处理,去除停用词和其他无关信息,以便得到单词或短语的序列。
-
建立倒排索引:遍历预处理后的文档集合,对每个单词或短语建立倒排索引。倒排索引记录了每个单词或短语出现在哪些文档中以及出现的位置信息。
-
索引优化:对倒排索引进行优化,包括压缩、排序、缓存等操作,以提高查询效率和减少存储空间。
通过倒排索引,可以快速地根据关键词或短语找到包含这些词语的文档,并确定它们的相关性。这使得倒排索引适用于在大规模文本数据中进行关键词搜索和相关性排序的场景。倒排索引能够快速定位文档,提高搜索效率,并为用户提供相关的搜索结果。在实际应用中,对倒排索引的构建和优化能够有效地提升搜索引擎的性能和用户体验。
如下示例:
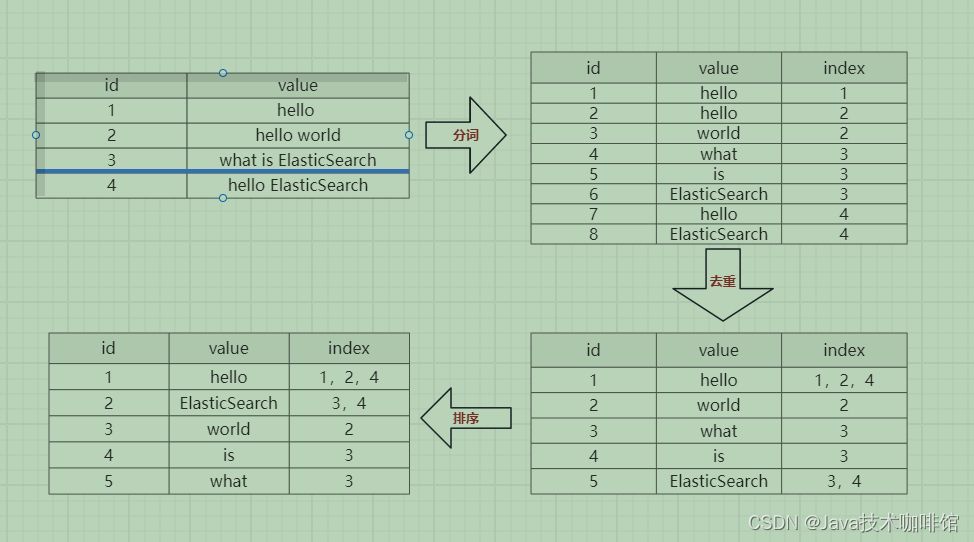
Elasticsearch介绍
官网:Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,Elasticsearch 会集中存储您的数据,让您飞快完成搜索,微调相关性,进行强大的分析,并轻松缩放规模。
Elasticsearch应用:

Elasticsearch与常用DB对比:
| Elasticsearch | Solr | MongoDB | MySQL | |
| DB类型 | 搜索引擎 | 搜索引擎 | 文档数据库 | 关系型数据库 |
| 基于何种框架开发 | Lucene | Lucene | ||
| 基于何种开发语言 | Java | Java | C++ | C、C++ |
| 数据结构 | FST、Hash等 | B+ Trees | ||
| 数据格式 | Json | Json/XML/CSV | Json | Row |
| 分布式支持 | 原生支持 | 支持 | 原生支持 | 不支持 |
| 数据分区方案 | 分片 | 分片 | 分片 | 分库分表 |
| 业务系统类型 | OLAP | OLAP | OLTP | OLTP |
| 事务支持 | 不支持 | 不支持 | 多文档ACID事务 | 支持 |
| 数据量级 | PB级 | TB级~PB级 | PB级 | 单库3000万左右 |
| 一致性策略 | 最终一致性 | 最终一致性 | 最终一致性 即时一致性 | 即时一致性 |
| 擅长领域 | 海量数据全文检索 大数据聚合分析 | 大数据全文检索 | 海量数据CRUD | 强一致性ACID事务 |
| 劣势 | 不支持事务 写入实时性低 | 海量数据的性能不如ES 随着数据量的不断增大稳定性低于ES | 弱事务支持 不支持join查询 | 大数据全文搜索性能低 |
| 查询性能 | ★★★★★ | ★★★★ | ★★★★★ | ★★★ |
| 写入性能 | ★★ | ★★ | ★★★★ | ★★★ |
ElasticSearch对比Solr 检索速度:
当单纯的对已有数据进行搜索时,Solr更快。

当实时建立索引时, Solr产生io阻塞,查询性能较差, Elasticsearch具有明显的优势

搜索引擎从Solr转到Elasticsearch以后的平均查询速度有了50倍的提升。

ElasticSearch安装
Linux Centos7安装
官网:Install Elasticsearch from archive on Linux or MacOS | Elasticsearch Guide [7.17] | Elastic
注:在安装时:不能使用root用户安装,需要使用非root用户进行安装启动。
下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.21-linux-x86_64.tar.gz
tar -xzf elasticsearch-7.17.21-linux-x86_64.tar.gz
ElasticSearch文件目录结构
| 目录 | 描述 |
| bin | 脚本文件,包括启动elasticsearch,安装插件,运行统计数据等 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等。 |
| jdk | 7.x 以后特有,自带的 java 环境,8.x版本自带 jdk 17 |
| data | 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境需要修改。 |
| lib | elasticsearch依赖的Java类库 |
| logs | 默认的日志文件存储路径,生产环境需要修改。 |
| modules | 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等。 |
| plugins | 已安装插件目录 |
配置JDK环境
进入安装的非root用户在进行修改.bash_profile文件:
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
export ES_JAVA_HOME=/home/liupeng/es/elasticsearch-7.17.21/jdk
export ES_HOME=/home/liupeng/es/elasticsearch-7.17.21
如下图所示:
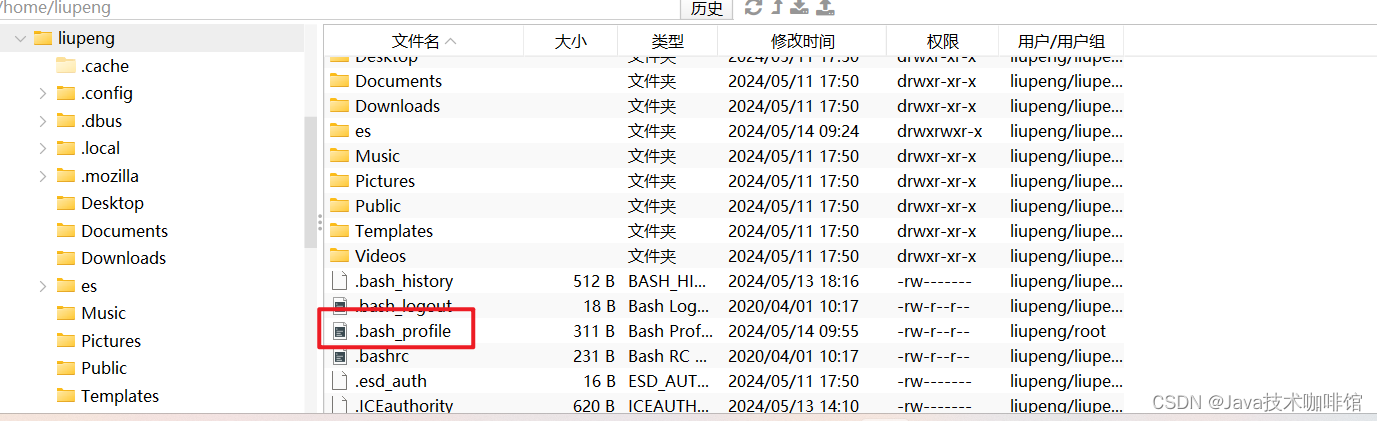

刷新 source .bash_profile
配置ElasticSearch
ElasticSearch配置参数:Important Elasticsearch configuration | Elasticsearch Guide [7.17] | Elastic
进入elasticsearch/config目录
修改elasticsearch.yml配置
#开启远程访问
network.host: 0.0.0.0
#单节点模式
discovery.type: single-nodeelasticsearch.yml中配置介绍:
- cluster.name
当前节点所属集群名称,多个节点如果要组成同一个集群,那么集群名称一定要配置成相同。默认值elasticsearch,生产环境建议根据ES集群的使用目的修改成合适的名字。不要在不同的环境中重用相同的集群名称,否则,节点可能会加入错误的集群。
- node.name
当前节点名称,默认值当前节点部署所在机器的主机名,所以如果一台机器上要起多个ES节点的话,需要通过配置该属性明确指定不同的节点名称。
- path.data
配置数据存储目录,比如索引数据等,默认值 $ES_HOME/data,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。
- path.logs
配置日志存储目录,比如运行日志和集群健康信息等,默认值 $ES_HOME/logs,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。
- bootstrap.memory_lock
配置ES启动时是否进行内存锁定检查,默认值true。
ES对于内存的需求比较大,一般生产环境建议配置大内存,如果内存不足,容易导致内存交换到磁盘,严重影响ES的性能。所以默认启动时进行相应大小内存的锁定,如果无法锁定则会启动失败。
非生产环境可能机器内存本身就很小,能够供给ES使用的就更小,如果该参数配置为true的话很可能导致无法锁定内存以致ES无法成功启动,此时可以修改为false。
- network.host
节点对外提供服务的地址以及集群内通信的ip地址,默认值为当前节点所在机器的本机回环地址127.0.0.1 和[::1],这就导致默认情况下只能通过当前节点所在主机访问当前节点。
- http.port
配置当前ES节点对外提供服务的http端口,默认 9200
- transport.port:
节点通信端口号,默认 9300
- discovery.seed_hosts
配置参与集群节点发现过程的主机列表,说白一点就是集群中所有节点所在的主机列表,可以是具体的IP地址,也可以是可解析的域名。
- cluster.initial_master_nodes
配置ES集群初始化时参与master选举的节点名称列表,必须与node.name配置的一致。ES集群首次构建完成后,应该将集群中所有节点的配置文件中的cluster.initial_master_nodes配置项移除,重启集群或者将新节点加入某个已存在的集群时切记不要设置该配置项。
配置JVM参数:修改jvm.options配置
#调整jvm堆内存大小
-Xms1g
-Xmx1g配置建议:
Advanced configuration | Elasticsearch Guide [7.17] | Elastic
- Xms和Xms设置成—样
- Xmx不要超过机器内存的50%
- 不要超过30GB
ElasticSearch启动
#非root用户启动
bin/elasticsearch
# -d 后台启动
bin/elasticsearch -d
ElasticSearch不允许使用root账号启动服务,如果你当前账号是root,启动会报错:

启动ElasticSearch常见错误和解决方案
Configuring system settings | Elasticsearch Guide [7.17] | Elastic
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
#切换到root用户
vim /etc/security/limits.conf
末尾添加如下配置:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf
#改为如下配置:
* soft nproc 4096[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存太小,调大系统的虚拟内存
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存退出之后执行如下命令:
sysctl -p[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
- discovery.seed_hosts: 集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
#或者指定配置单节点(集群单节点)
discovery.type: single-nodeDocker安装Elasticsearch
Install Elasticsearch with Docker | Elasticsearch Guide [7.17] | Elastic
Kibana安装
官网:Install Kibana from archive on Linux or macOS | Kibana Guide [7.17] | Elastic
下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.21-linux-x86_64.tar.gz
tar -xzf kibana-7.17.21-linux-x86_64.tar.gz
修改Kibana.yml配置
Configure Kibana | Kibana Guide [7.17] | Elastic
vim config/kibana.yml
#指定Kibana服务器监听的端口号
server.port: 5601
#指定Kibana服务器绑定的主机地址
server.host: "localhost"
#指定Kibana连接到的Elasticsearch实例的访问地址
elasticsearch.hosts: ["http://localhost:9200"]
#将 Kibana 的界面语言设置为简体中文
i18n.locale: "zh-CN" 启动:
bin/kibana
#后台启动
nohup bin/kibana &
CAT APIs
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cat.html
/_cat/aliases #查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} #查看指定索引的alias信息
/_cat/allocation #查看单节点的shard分配整体情况
/_cat/count #查看当前集群的doc数量
/_cat/count/{index} #查看指定索引的doc数量
/_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
/_cat/health #查看集群当前状态:红、黄、绿
/_cat/indices #查看集群中所有index的详细信息
/_cat/indices/{index} #查看集群中指定index的详细信息
/_cat/master #查看master节点信息
/_cat/nodes #查看所有节点信息
/_cat/nodeattrs #查看单节点的自定义属性
/_cat/pending_tasks #查看当前集群的pending task
/_cat/plugins #查看集群各个节点上的plugin信息
/_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
/_cat/recovery/{index}#查看指定索引shard的recovery过程
/_cat/repositories #输出集群中注册快照存储库
/_cat/shards #查看各shard的详细情况
/_cat/shards/{index} #查看指定分片的详细情况
/_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
/_cat/segments/{index}#查看指定index的segment详细信息
/_cat/templates #输出当前正在存在的模板信息
/_cat/thread_pool #返回集群中每个节点的线程池统计信息。返回的信息包括所有内置线程池和自定义线程池。
Docker安装Kibana
Install Kibana with Docker | Kibana Guide [7.17] | Elastic
Elasticsearch安装分词插件
Installing Plugins | Elasticsearch Plugins and Integrations [7.17] | Elastic
Elasticsearch提供插件机制对系统进行扩展,以安装分词插件为例:
安装analysis-icu分词插件
#查看已安装插件
bin/elasticsearch-plugin list
#安装插件
bin/elasticsearch-plugin install analysis-icu
#删除插件
bin/elasticsearch-plugin remove analysis-icu注意:安装和删除完插件后,需要重启ES服务才能生效。
# _analyzer API可以用来查看指定分词器的分词结果
POST _analyze
{
"analyzer":"icu_analyzer",
"text":"去码头整点薯条"
}
安装ik中文分词插件
下载analysis-ik插件,解压,到elasticsearch的plugins目录,然后重启ES实例就可以了。
wget https://github.com/infinilabs/analysis-ik/releases/download/v7.17.18/elasticsearch-analysis-ik-7.17.18.zip
java.lang.IllegalArgumentException: Plugin [analysis-ik] was built for Elasticsearch version 7.17.18 but version 7.17.21 is running
异常处理:
将解压后的plugin-descriptor.properties文件中的配置进行修改
# 'version': plugin's version
version=7.17.21
#
# 'elasticsearch.version' version of elasticsearch compiled against
# You will have to release a new version of the plugin for each new
# elasticsearch release. This version is checked when the plugin
# is loaded so Elasticsearch will refuse to start in the presence of
# plugins with the incorrect elasticsearch.version.
elasticsearch.version=7.17.21测试分词效果:
POST _analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
#ik_smart:会做最粗粒度的拆
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_max_word:会将文本做最细粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}ElasticSearch快速开始
ElasticSearch核心概念
节点:Node
一个节点就是一个Elasticsearch的实例,可以理解为一个 ES 的进程。

角色:Roles
- 主节点(active master):一般指活跃的主节点,一个集群中只能有一个,主要作用是对集群的管理。
- 候选节点(master-eligible):当主节点发生故障时,参与选举,也就是主节点的替代节点。
- 数据节点(data node):数据节点保存包含已编入索引的文档的分片。数据节点处理数据相关操作,如 CRUD、搜索和聚合。这些操作是 I/O 密集型、内存密集型和 CPU 密集型的。监控这些资源并在它们过载时添加更多数据节点非常重要。
- 预处理节点(ingest node):预处理节点有点类似于logstash的消息管道,所以也叫ingest pipeline,常用于一些数据写入之前的预处理操作。
注:如果 node.roles 为缺省配置,那么当前节点具备所有角色。
索引:Index
索引在不同的特定条件下可以表示三种不同的意思:
- 表示源文件数据:当做数据的载体,即类比为数据表,通常称作 index 。例如:通常说 集群中有 product 索引,即表述当前 ES 的服务中存储了 product 这样一张“表”。
- 表示索引文件:以加速查询检索为目的而设计和创建的数据文件,通常承载于某些特定的数据结构,如哈希、FST 等。例如:通常所说的 正排索引 和 倒排索引(也叫正向索引和反向索引)。就是当前这个表述,索引文件和源数据是完全独立的,索引文件存在的目的仅仅是为了加快数据的检索,不会对源数据造成任何影响,
- 表示创建数据的动作:通常说创建或添加一条数据,在 ES 的表述为索引一条数据或索引一条文档,或者 index 一个 doc 进去。此时索引一条文档的含义为向索引中添加数据。
索引的组成部分:
- aliases:索引别名
- settings:索引设置,常见设置如分片和副本的数量等。
- mapping:映射,定义了索引中包含哪些字段,以及字段的类型、长度、分词器等。

文档:Document
文档是ES中最小的数据单元,他具有结构化JSON格式。文档可以被索引并进行搜索、更新、删除

文档元数据,所有字段均以下划线开头,为系统字段,用于标注文档的相关信息:
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯一id
- _version: 文档的版本号,修改删除操作_version都会自增1
- _seq_no: 和_version一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
- _primary_term: 主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。
- _source: 文档的原始Json数据
ElasticSearch索引操作
Index modules | Elasticsearch Guide [7.17] | Elastic
创建索引
格式: PUT /索引名称
索引命名规范:
- 以小写英文字母命名索引
- 不要使用驼峰命名法则
- 如过出现多个单词的索引名称,以全小写 + 下划线分隔的方式:如test_index。
ES 索引创建成功之后,以下属性将不可修改
- 索引名称
- 主分片数量
- 字段类型
PUT /es_test查询索引
格式: GET /索引名称
#查询索引
GET /es_test
#e是否存在
HEAD /es_test删除索引
格式: DELETE /索引名称
DELETE /es_testSettings设置
创建索引的时候指定 settings
PUT <index_name>
{
"settings": {}
}创建索引时设置分片数和副本数
#创建索引指定其主分片数量为 3,每个主分片的副本数量为2
PUT /es_test
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
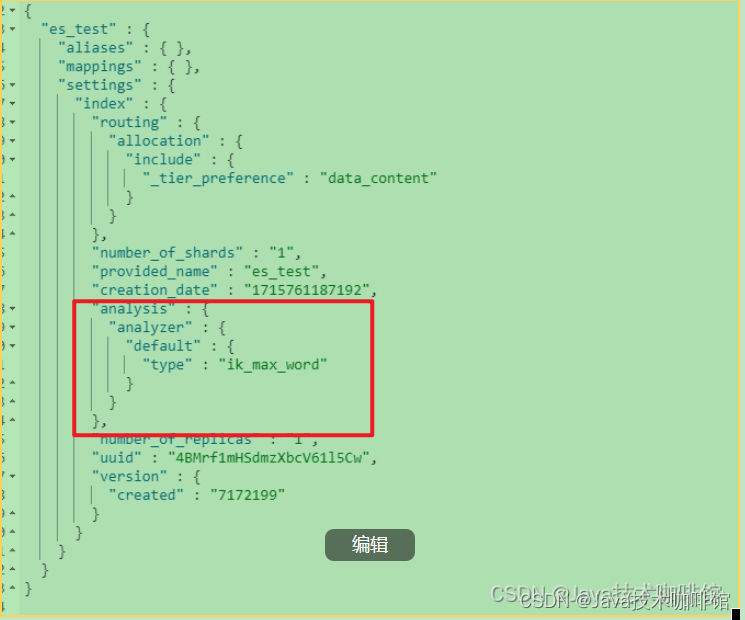
}创建索引指定IK分词器作为默认分词器
PUT /es_test
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
静态索引设置
只能在创建索引时或在关闭状态的索引上设置。
- index.number_of_shards:索引的主分片的个数,默认为 1,此设置只能在创建索引时设置
动态索引设置
即可以使用 _setting API 在实时修改的配置项。
- index.number_of_replicas:每个主分片的副本数。默认为 1,允许配置为 0。
- index.refresh_interval:执行刷新操作的频率,默认为1s. 可以设置 -1 为禁用刷新。
- index.max_result_window:from + size 搜索此索引 的最大值,默认为 10000。
使用 _setting 只能修改允许动态修改的配置项
PUT /es_test/_settings
{
"index" : {
"number_of_replicas" : 1
}
}文档映射Mapping设置
ES 中的 mapping 有点类似与关系数据库中表结构的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在 ES 中一个字段可以有多个类型。ES中Mapping可以分为动态映射和静态映射。
查看完整的索引 mapping
GET /<index_name>/_mappings
查看索引中指定字段的 mapping
GET /<index_name>/_mappings/field/<field_name>mapping 的使用禁忌
- ES 没有隐式类型转换
- ES 不支持类型修改
- 生产环境尽可能的避免使用 动态映射(dynamic mapping)
动态映射
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射,在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射
自动类型推断规则

PUT /user/_doc/1
{
"name":"lp",
"age":18,
"address":"四川成都"
}
GET /user/_mapping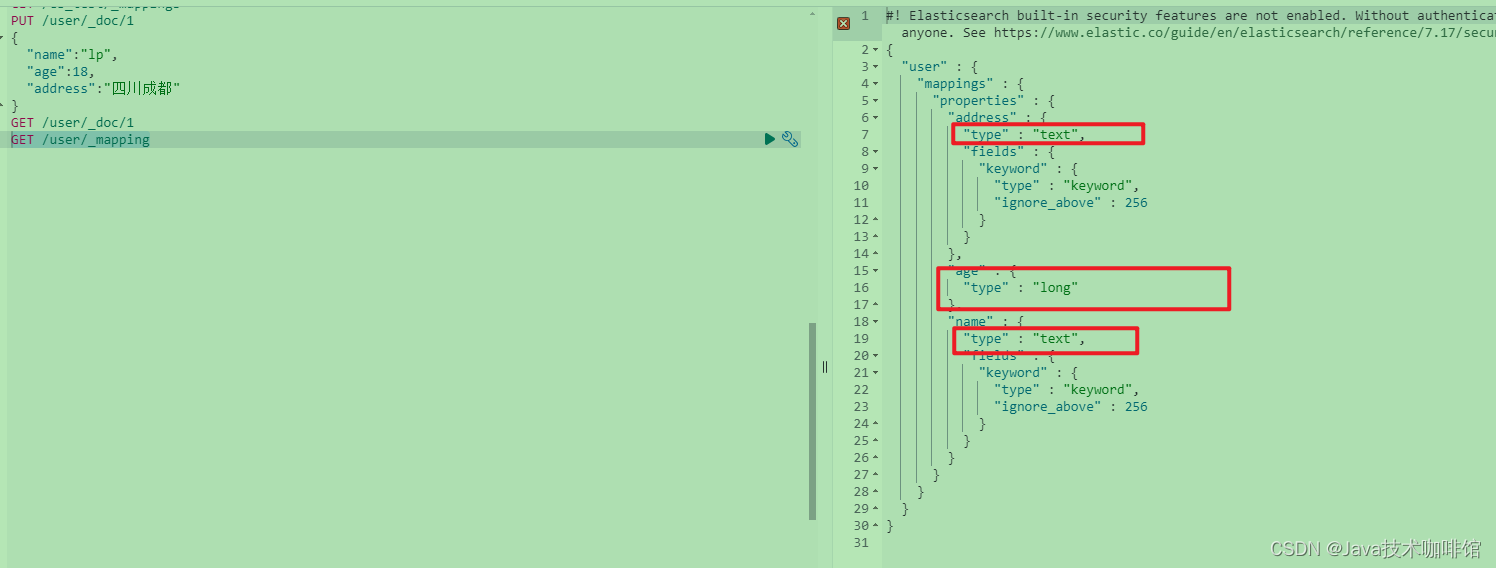
静态映射
静态映射也叫做显式映射,即:在索引文档写入之前,人为创建索引并且指定索引中每个字段类型、分词器等参数。
PUT /user
{
"settings": {
"number_of_shards": "1",
"number_of_replicas": "1"
},
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age" : {
"type" : "long"
},
"address" : {
"type" : "text"
}
}
}
}
常用Mapping参数配置
| 参数名称 | 释义 |
| analyzer | 指定分析器,只有 text 类型字段支持。 |
| copy_to | 该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询 |
| dynamic | 控制是否可以动态添加新字段,支持以下四个选项: true:(默认)允许动态映射 false:忽略新字段。这些字段不会被索引或搜索,但仍会出现在_source返回的命中字段中。这些字段不会添加到映射中,必须显式添加新字段。 runtime:新字段作为运行时字段添加到索引中,这些字段没有索引,是_source在查询时加载的。 strict:如果检测到新字段,则会抛出异常并拒绝文档。必须将新字段显式添加到映射中。 |
| doc_values | 为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持 text 和 annotated_text) |
| eager_global_ordinals | 用于聚合的字段上,优化聚合性能。 |
| enabled | 是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,任然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。 |
| fielddata | 查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中 |
| fields | 给 field 创建多字段,用于不同目的(全文检索或者聚合分析排序) |
| format | 用于格式化代码,如 "data":{ "type": "data", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } |
| index | 是否对创建对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示。 |
| norms | 是否禁用评分(在filter和聚合字段上应该禁用) |
| null_value | 为 null 值设置默认值 |
| search_analyzer | 设置单独的查询时分析器 |
示例:
- index: 控制当前字段是否被索引,默认为true。如果设置为false,该字段不可被搜索
DELETE /user
PUT /user
{
"mappings" : {
"properties" : {
"address" : {
"type" : "text",
"index": false
},
"age" : {
"type" : "long"
},
"name" : {
"type" : "text"
}
}
}
}
PUT /user/_doc/1
{
"name":"lp",
"age":18,
"address":"四川成都"
}
GET /user
GET /user/_search
{
"query": {
"match": {
"address": "四川成都"
}
}
}
- dynamic设为true时,一旦有新增字段的文档写入,Mapping 也同时被更新;dynamic设置成strict(严格控制策略),文档写入失败,抛出异常
DELETE /user
PUT /user
{
"mappings": {
"dynamic": "strict",
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true"
}
}
}
}
# 插入文档报错,原因为age为新增字段,会抛出异常
PUT /user/_doc/1
{
"name":"lp",
"age":18,
"address":{
"province":"四川",
"city":"资阳"
}
}
#正常
PUT /user/_doc/2
{
"name":"lp2",
"address":{
"province":"四川",
"city":"资阳",
"area":"雁江区"
}
}
dynamic设置成strict,新增age字段导致文档插入失败
修改dynamic后再次插入文档成功
#修改daynamic
PUT /user/_mapping
{
"dynamic":true
}注意:对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene 实现的倒排索引,一旦生成后,就不允许修改
- 如果希望改变字段类型,可以利用 reindex API,重建索引
使用ReIndex重建索引
步骤:
- 如果要推倒现有的映射, 你得重新建立一个静态索引
- 然后把之前索引里的数据导入到新的索引里
- 删除原创建的索引
- 为新索引设置别名, 设置为原索引名
# 1. 重新建立一个静态索引
PUT /user2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 2. 把之前索引里的数据导入到新的索引里
POST _reindex
{
"source": {
"index": "user"
},
"dest": {
"index": "user2"
}
}
# 3. 删除原创建的索引
DELETE /user
# 4. 为新索引起个别名, 为原索引名
PUT /user2/_alias/user
GET /userElasticSearch文档操作
索引文档
- 格式: [PUT | POST] /索引名称/[_doc | _create ]/id
GET /es_db_test/_doc/_search
PUT /es_db_test/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "成都人民公园",
"remark": "java developer"
}
#创建文档,ES生成id
POST /es_db_test/_doc
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "成都人民公园",
"remark": "java developer"
}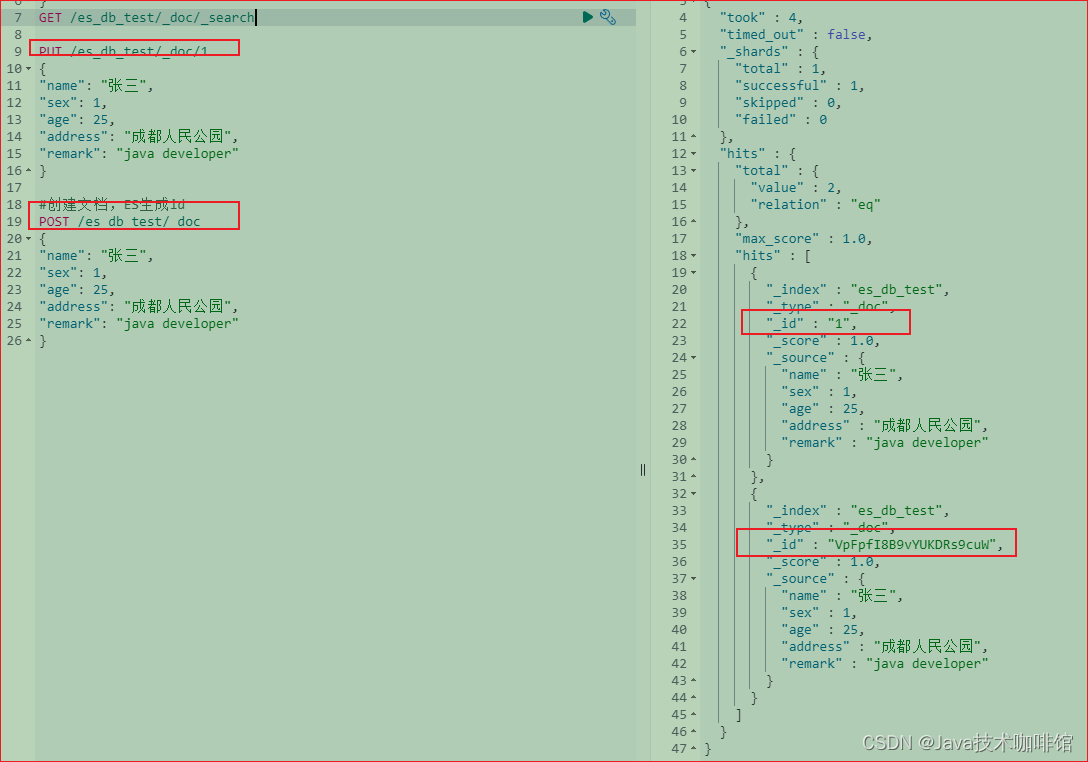
注:POST和PUT都能起到创建/更新的作用,PUT需要对一个具体的资源进行操作也就是要确定id才能进行更新/创建,而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新
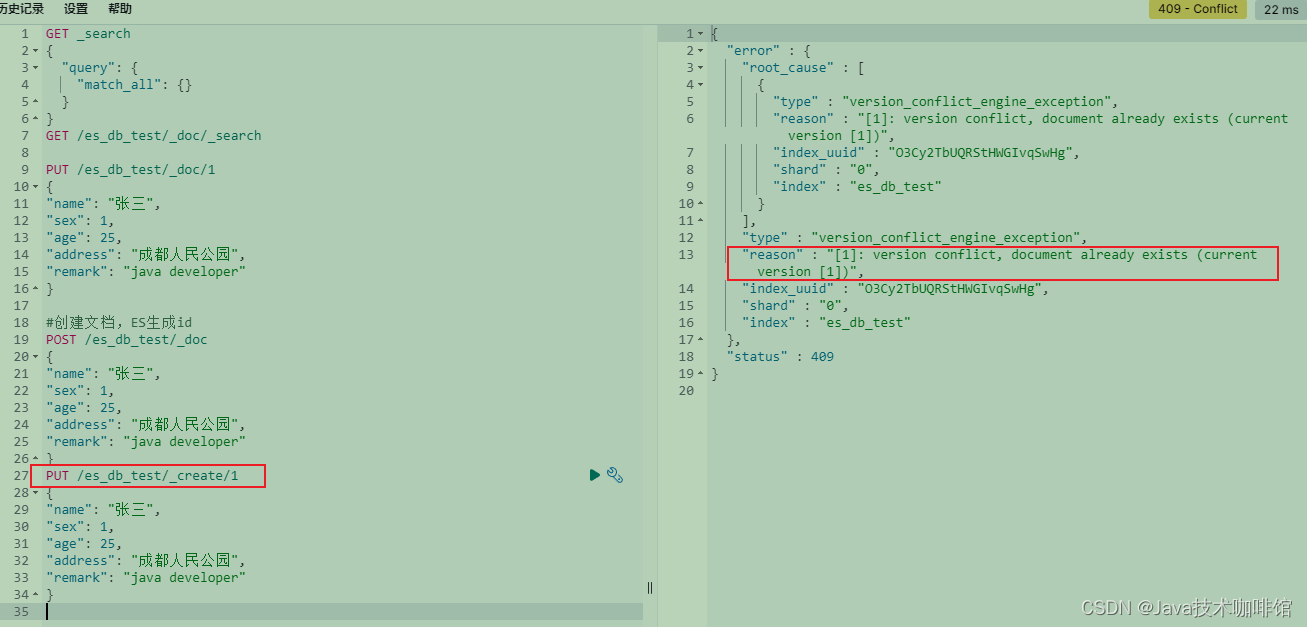
create: ID存在,会失败
查询文档
- 根据id查询文档,格式: GET /索引名称/_doc/id
GET /es_db_test/_doc/1- 条件查询 _search,格式: /索引名称/_doc/_search
GET /es_db_test/_doc/_searchES Search API提供了两种条件查询搜索方式:
- REST风格的请求URI,直接将参数带过去
- 封装到request body中,这种方式可以定义更加易读的JSON格式
DSL Query
DSL(Domain Specific Language领域专用语言)查询是使用Elasticsearch的查询语言来构建查询的方式。
GET /es_db_test/_search
{
"query": {
"match": {
"address": "成都"
}
}
}
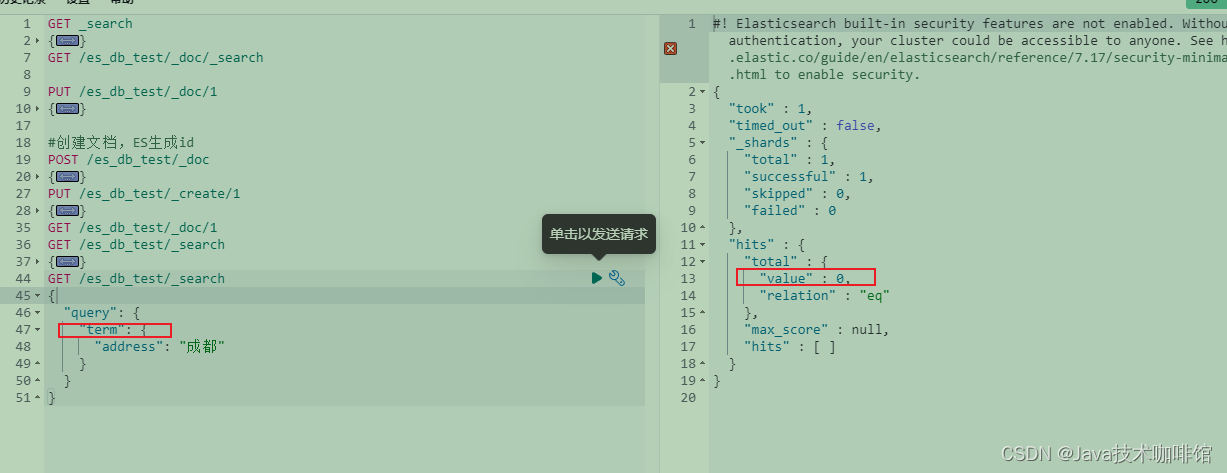
# term 词项查询,属于精确查询(类似msql中的“=”符号),不会对查询文本分词
GET /es_db_test/_search
{
"query": {
"term": {
"address": "成都"
}
}
}
修改文档
- 全量更新:整个json都会替换,格式: [PUT | POST] /索引名称/_doc/id
如果文档存在,现有文档会被删除,新的文档会被索引
PUT /es_db_test/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25
}- _update部分更新,格式: POST /索引名称/_update/id
update不会删除原来的文档,而是数据更新
POST /es_db_test/_update/1
{
"doc": {
"age": 28
}
}- 使用 _update_by_query 更新文档
POST /es_db_test/_update_by_query
{
"query": {
"match": {
"_id": 1
}
},
"script": {
"source": "ctx._source.age = 18"
}
}并发修改文档
_seq_no和_primary_term是对_version的优化,7.X版本的ES默认使用这种方式控制版本,所以当在高并发环境下使用乐观锁机制修改文档时,要带上当前文档的_seq_no和_primary_term进行更新
POST /es_db_test/_doc/1?if_seq_no=5&if_primary_term=2
{
"name": "张三xxx"
}版本号错误会出现版本不一致异常,如图:
删除文档
格式: DELETE /索引名称/_doc/id
DELETE /es_db_test/_doc/1批量操作
批量操作可以减少网络连接产生的io开销,提升性能
- 支持在一次API调用中,对不同的索引进行操作
- 可以在URI中指定Index,也可以在请求的Payload中进行
- 操作中单条操作失败,并不会影响其他操作
- 返回结果包括了每一条操作执行的结果
参数示例:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}- actionName:表示操作类型,主要有create,index,delete和update
批量创建文档-create
POST _bulk
{"create":{"_index":"es_db_batch", "_type":"_doc", "_id":1}}
{"id":1,"name":"lp1","adress":"四川成都"}
{"create":{"_index":"es_db_batch", "_type":"_doc", "_id":2}}
{"id":2,"name":"lp2","adress":"四川成都"}普通创建/全量替换-index
- 如果原文档不存在,创建
- 如果原文档存在,则是替换(全量修改原文档)
POST _bulk
{"index":{"_index":"es_db_batch", "_type":"_doc", "_id":1}}
{"id":1,"name":"lp1xxxxxxx","adress":"四川成都"}
{"index":{"_index":"es_db_batch", "_type":"_doc", "_id":3}}
{"id":3,"name":"lp3","adress":"四川成都3"}批量修改update
POST _bulk
{"update":{"_index":"es_db_batch", "_type":"_doc", "_id":5}}
{"doc":{"adress":"上海"}}
{"update":{"_index":"es_db_batch", "_type":"_doc", "_id":6}}
{"doc":{"adress":"上海"}}批量删除-delete
POST _bulk
{"delete":{"_index":"es_db_batch", "_type":"_doc", "_id":1}}
{"delete":{"_index":"es_db_batch", "_type":"_doc", "_id":3}}组合
POST _bulk
{"index":{"_index":"es_db_batch", "_type":"_doc", "_id":1}}
{"id":1,"name":"lp1xxxxxxx","adress":"四川成都"}
{"create":{"_index":"es_db_batch", "_type":"_doc", "_id":3}}
{"id":3,"name":"lp3","adress":"四川成都3"}
{"delete":{"_index":"es_db_batch", "_type":"_doc", "_id":3}}批量查询
批量查询可以使用mget和msearch两种。其中mget是需要我们知道id,可以指定不同的index,也可以指定返回值source。msearch可以通过字段查询来进行一个批量查找。
_mget
#通过id批量获取不同index的数据
GET _mget
{
"docs": [
{
"_index": "es_db_batch",
"_id": 2
},
{
"_index": "es_db_test",
"_id": 1
}
]
}
#可以通过id批量获取es_db_batch的数据
GET /es_db_batch/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 4
}
]
}
#简化
GET /es_db_batch/_mget
{
"ids":["1","2"]
}_msearch
_msearch中,请求格式和bulk类似。查询一条数据需要两个对象,第一个设置index和type,第二个设置查询语句。查询语句和search相同。如果只是查询一个index,我们可以在url中带上index,这样,如果查该index可以直接用空对象表示。
GET /es_db_batch/_msearch
{}
{"query" : {"match" : {"name": "lp2"}}, "from" : 0, "size" : 2}
{"index" : "es_db_batch"}
{"query" : {"match_all" : {}}}

Spring Boot中使用ElasticSearch
官网:Spring Data Elasticsearch - 参考文档
版本映射:

Maven依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>yml配置:
spring:
elasticsearch:
uris: http://ip:9200
connection-timeout: 2s创建ES实体:
@Data
@Document(indexName = "user")
public class User {
@Id
private Long id;
@Field(type= FieldType.Keyword)
private String name;
private int sex;
private int age;
@Field(type= FieldType.Text,analyzer="ik_max_word")
private String address;
@Field(type= FieldType.Text,analyzer="ik_max_word")
private String notes;
}ElasticsearchRepository
操作Elastsearch的接口
@Repository
public interface UserRepository extends ElasticsearchRepository<User, Long> {
List<User> findByName(String name);
List<User> findByAddress(String address);
}测试验证
@Autowired
UserRepository userRepository;
@Test
public void test() {
User user = new User();
user.setId(10086L);
user.setName("测试1号");
user.setAge(18);
user.setAddress("四川成都");
user.setNotes("去码头整点薯条");
//插入文档
userRepository.save(user);
//根据id查询
Optional<User> optionalUser = userRepository.findById(10086L);
log.info(String.valueOf(optionalUser.get()));
//根据name查询
List<User> list = userRepository.findByName("测试1号");
log.info(String.valueOf(list.get(0)));
//根据地址查询
List<User> list2 = userRepository.findByAddress("四川");
log.info(String.valueOf(list2.get(0)));
}ElasticsearchRestTemplate
@Resource
ElasticsearchRestTemplate elasticsearchRestTemplate;操作索引
@Resource
ElasticsearchRestTemplate elasticsearchRestTemplate;
private final String index_name = "user";
@Test
public void testCreateIndex(){
//创建索引
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(index_name));
if (indexOperations.exists()) {
log.info("索引已经存在");
}else {
//创建索引
indexOperations.create();
}
}
@Test
public void testDeleteIndex(){
//删除索引
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(index_name));
indexOperations.delete();
}操作文档
@Test
public void testBatch(){
List<User> users = new ArrayList<>();
users.add(new User(10087L,"张三",0,18,"四川成都青羊区","去码头整点薯条1"));
users.add(new User(10088L,"李四",1,28,"四川成都高新区","去码头整点薯条2"));
users.add(new User(10089L,"王五",0,38,"四川成都武侯区","去码头整点薯条3"));
List<IndexQuery> queries = new ArrayList<>();
for (User user : users) {
IndexQuery indexQuery = new IndexQuery();
indexQuery.setId(user.getId().toString());
String json = JSONValue.toJSONString(user);
indexQuery.setSource(json);
queries.add(indexQuery);
}
//bulkIndex批量插入
elasticsearchRestTemplate.bulkIndex(queries,User.class);
}
@Test
public void testSearchDocument(){
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
//查询
builder.withQuery(QueryBuilders.matchQuery("address","四川"));
// 设置分页信息
builder.withPageable(PageRequest.of(0, 5));
// 设置排序
builder.withSorts(SortBuilders.fieldSort("age").order(SortOrder.ASC));
SearchHits<User> search = elasticsearchRestTemplate.search(builder.build(), User.class);
List<SearchHit<User>> searchHits = search.getSearchHits();
for (SearchHit hit: searchHits){
log.info("result:"+hit.toString());
}
}
@Test
public void testBase(){
String delete = elasticsearchRestTemplate.delete("10086", User.class);
log.info(delete);
}














 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









