







集群架构解决的问题
分布式系统的可用性与扩展性:
- 高可用性
- 服务可用性——允许有节点停止服务
- 数据可用性——部分节点丢失,不会丢失数据
- 可扩展性
- 请求量提升/数据的不断增长(将数据分布到所有节点上)
ES集群架构的优势:
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
- 存储的水平扩容
概念
集群
一个集群可以有一个或者多个节点
不同的集群通过不同的名字来区分,默认名字“elasticsearch“
通过配置文件修改,或者在命令行中 -E cluster.name=es-cluster进行设定
节点
节点是一个Elasticsearch的实例
本质上就是一个JAVA进程
一台机器上可以运行多个Elasticsearch进程,但是生产环境一般建议一台机器上只运行一个Elasticsearch实例
每一个节点都有名字,通过配置文件配置,或者启动时候 -E node.name=node1指定
每一个节点在启动之后,会分配一个UID,保存在data目录下
节点类型
- Master Node:主节点
- Master eligible nodes:可以参与选举的合格节点
- Data Node:数据节点
- Coordinating Node:协调节点
- 其他节点

Master eligible nodes和Master Node
- 每个节点启动后,默认就是一个Master eligible节点
- 可以设置 node.master: false禁止
- Master-eligible节点可以参加选主流程,成为Master节点
- 当第一个节点启动时候,它会将自己选举成Master节点
- 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息
- 集群状态(Cluster State) ,维护了一个集群中,必要的信息
- 所有的节点信息
- 所有的索引和其相关的Mapping与Setting信息
- 分片的路由信息
- 集群状态(Cluster State) ,维护了一个集群中,必要的信息
-
Master Node的职责
- 处理创建,删除索引等请求,负责索引的创建与删除
- 决定分片被分配到哪个节点
- 维护并且更新Cluster State
-
Master Node的最佳实践
- Master节点非常重要,在部署上需要考虑解决单点的问题
- 为一个集群设置多个Master节点,每个节点只承担Master 的单一角色
-
选主阶段流程
- 互相Ping对方,Node ld 低的会成为被选举的节点
- 其他节点会加入集群,但是不承担Master节点的角色。一旦发现被选中的主节点丢失,就会选举出新的Master节点
Data Node & Coordinating Node
- Data Node
- 可以保存数据的节点,叫做Data Node,负责保存分片数据。在数据扩展上起到了至关重要的作用
- 节点启动后,默认就是数据节点。可以设置node.data: false 禁止
- 由Master Node决定如何把分片分发到数据节点上
- 通过增加数据节点可以解决数据水平扩展和解决数据单点问题
- Coordinating Node
- 负责接受Client的请求, 将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordinating Node的职责
其他节点类型
- Hot & Warm Node
- 不同硬件配置 的Data Node,用来实现Hot & Warm架构,降低集群部署的成本
- Ingest Node
- 数据前置处理转换节点,支持pipeline管道设置,可以使用ingest对数据进行过滤、转换等操作
- Machine Learning Node
- 负责跑机器学习的Job,用来做异常检测
- Tribe Node
- Tribe Node连接到不同的Elasticsearch集群,并且支持将这些集群当成一个单独的集群处理
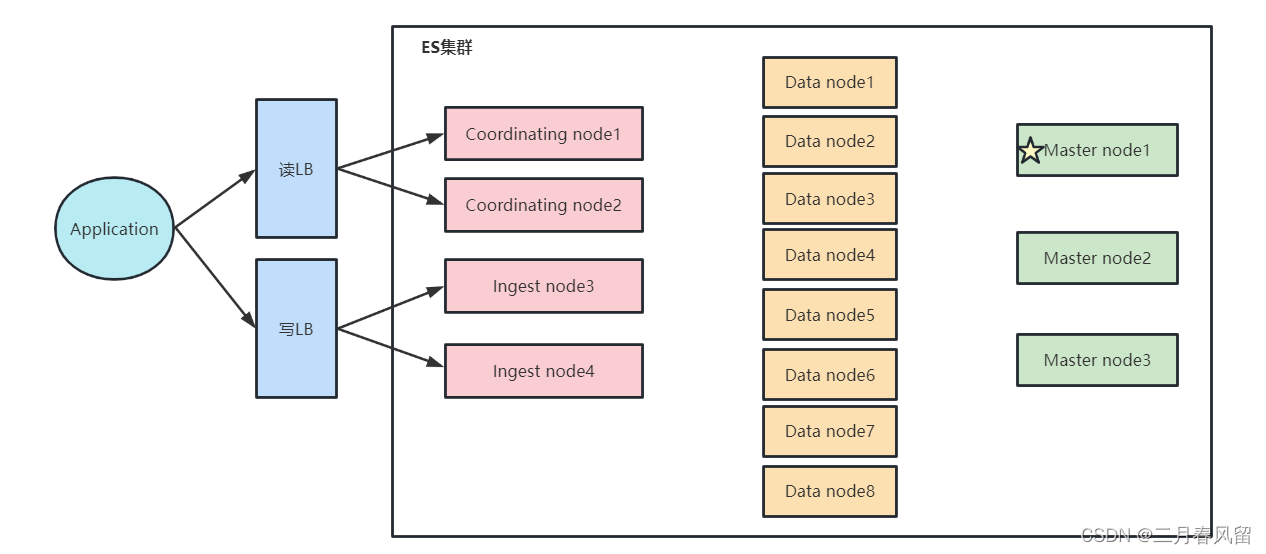
分片(Primary Shard & Replica Shard)
- 主分片(Primary Shard)
- 用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的Lucene的实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
- 副本分片(Replica Shard)
- 用以解决数据高可用的问题。 副本分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
# 指定索引的主分片和副本分片数
PUT /db
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}分片构成
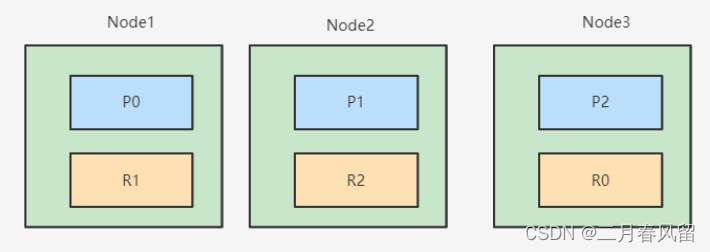
分片设定
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片数设置过大,7.0 开始,默认主分片设置成1,解决了over-sharding(分片过度)的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
集群状态
- Green: 主分片与副本都正常分配
- Yellow: 主分片全部正常分配,有副本分片未能正常分配
- Red: 有主分片未能分配。例如,当服务器的磁盘容量超过85%时,去创建了一个新的索引
GET /_cat/nodes?v #查看节点信息
GET /_cat/health?v #查看集群当前状态:红、黄、绿
GET /_cat/shards?v #查看各shard的详细情况
GET /_cat/shards/{index}?v #查看指定分片的详细情况
GET /_cat/master?v #查看master节点信息
GET /_cat/indices?v #查看集群中所有index的详细信息
GET /_cat/indices/{index}?v #查看集群中指定index的详细信息
GET _cluster/health #查看集群的健康状况架构
单节点单一角色配置
不同角色的节点:Master eligible / Data / Ingest / Coordinating /Machine Learning
在开发环境中,一个节点可承担多种角色。
在生产环境中:
- 根据数据量,写入和查询的吞吐量,选择合适的部署方式
- 建议设置单一角色的节点
单节点只承担单一角色的配置
#Master节点
node.master: true
node.ingest: false
node.data: false
#data节点
node.master: false
node.ingest: false
node.data: true
#ingest 节点
node.master: false
node.ingest: true
node.data: false
#coordinate节点
node.master: false
node.ingest: false
node.data: false这种单一角色职责分离的好处:
- 单一 master eligible nodes: 负责集群状态(cluster state)的管理
- 使用低配置的CPU,RAM和磁盘
- 单一 data nodes: 负责数据存储及处理客户端请求
- 使用高配置的CPU,RAM和磁盘
- 单一ingest nodes: 负责数据处理
- 使用高配置CPU; 中等配置的RAM; 低配置的磁盘
- 单一Coordinating Only Nodes(Client Node)
- 使用高配置CPU; 高配置的RAM; 低配置的磁盘
生产环境中,建议为一些大的集群配置Coordinating Only Nodes
- 扮演Load Balancers,降低Master和 Data Nodes的负载
- 负责搜索结果的Gather/Reduce
- 有时候无法预知客户端会发送怎么样的请求。比如大量占用内存的操作,一个深度聚合可能会引发OOM
从高可用&避免脑裂的角度出发:
- 一般在生产环境中配置3台master eligible nodes
- 一个集群只有1台活跃的主节点(master node)
- 负责分片管理,索引创建,集群管理等操作
- 如果和数据节点或者Coordinate节点混合部署
- 数据节点相对有比较大的内存占用
- Coordinate节点有时候可能会有开销很高的查询,导致OOM
- 这些都有可能影响Master节点,导致集群的不稳定
节点水平扩展
- 当磁盘容量无法满足需求时,可以增加数据节点;
- 磁盘读写压力大时,增加数据节点
- 当系统中有大量的复杂查询及聚合时候,增加Coordinating节点,增加查询的性能
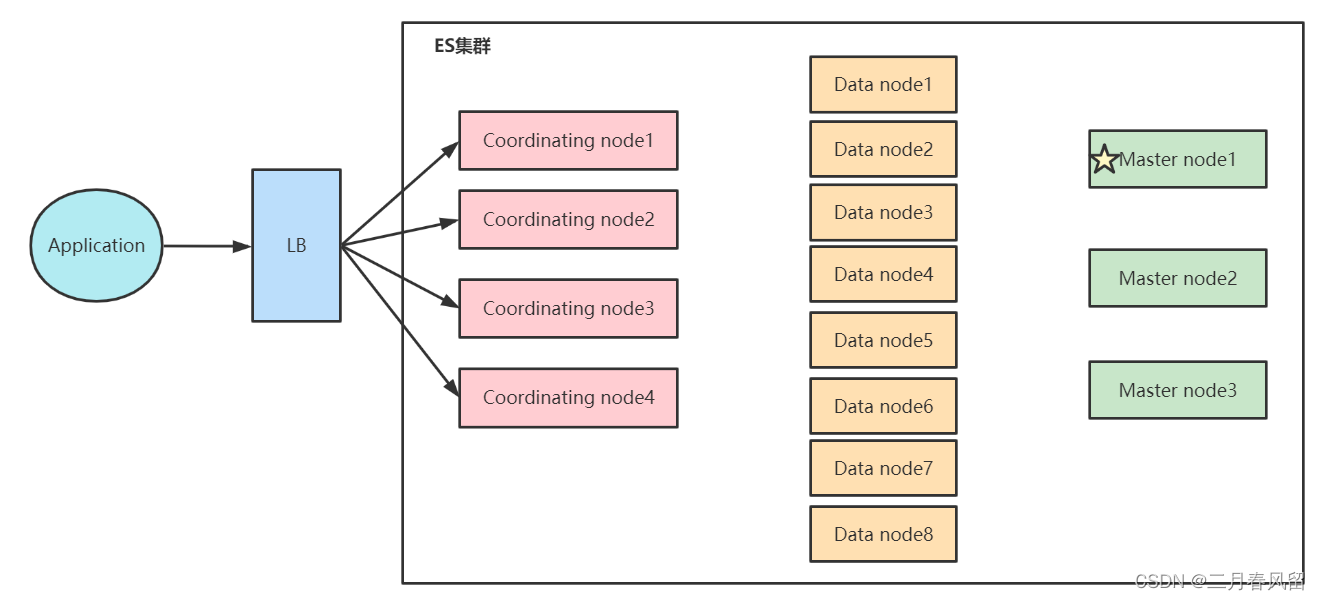
读写分离架构
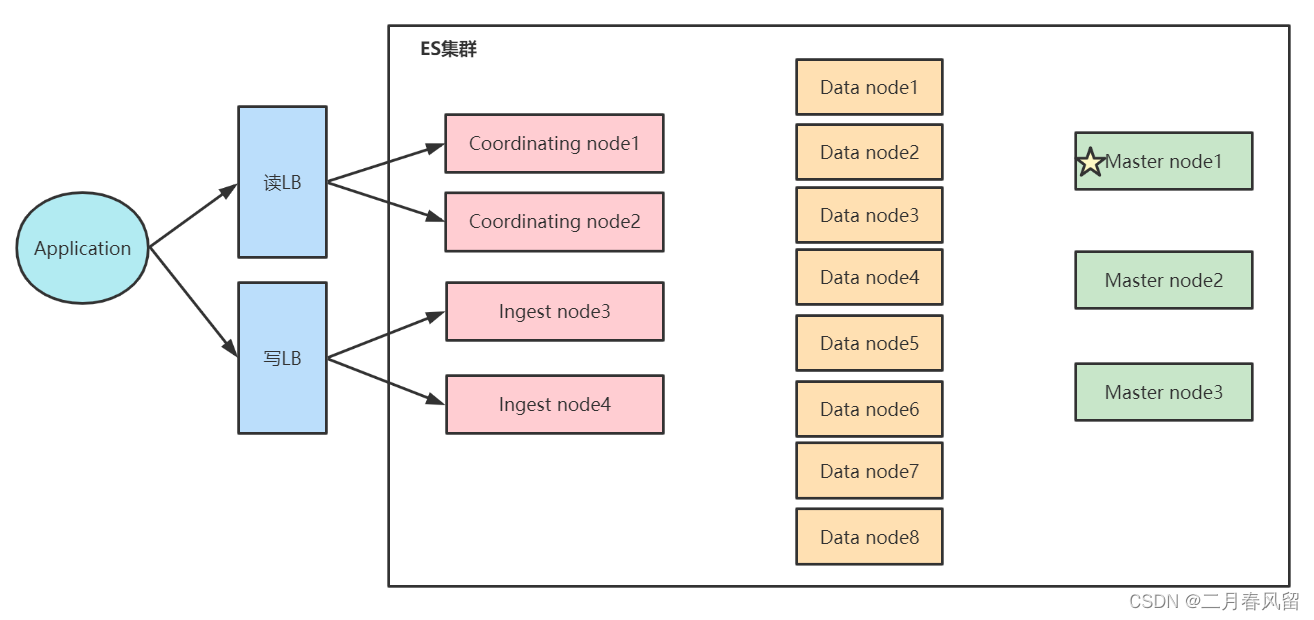
异地多活架构
集群处在三个数据中心,数据三写,GTM分发读请求
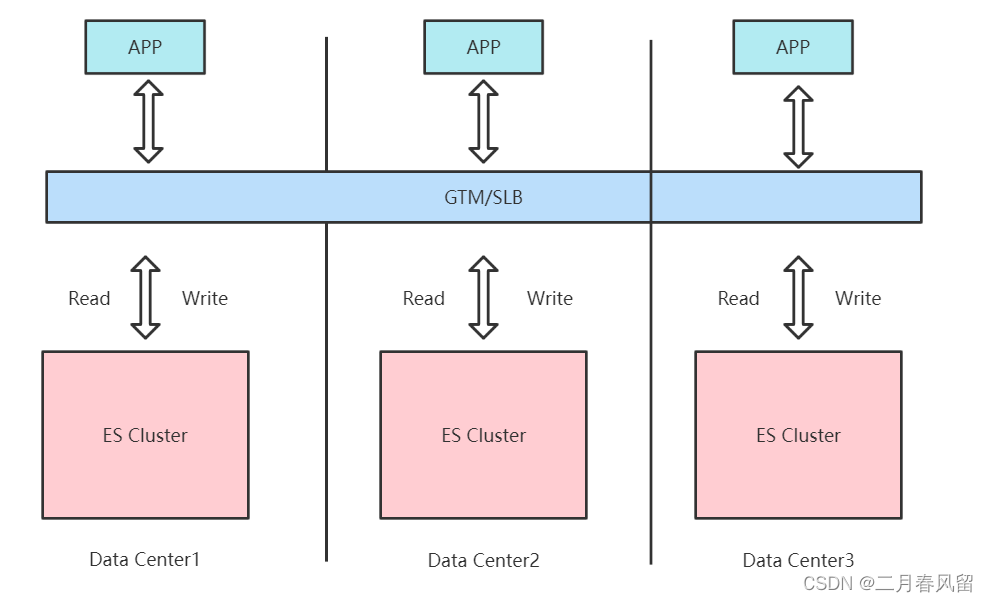
全局流量管理(GTM)和负载均衡(SLB)的区别:
GTM 是通过DNS将域名解析到多个IP地址,不同用户访问不同的IP地址,来实现应用服务流量的分配。同时通过健康检查动态更新DNS解析IP列表,实现故障隔离以及故障切换。最终用户的访问直接连接服务的IP地址,并不通过GTM。而 SLB 是通过代理用户访问请求的形式将用户访问请求实时分发到不同的服务器,最终用户的访问流量必须要经过SLB。 一般来说,相同Region使用SLB进行负载均衡,不同region的多个SLB地址时,则可以使用GTM进行负载均衡。
ES 跨集群复制 (Cross-Cluster Replication)是ES 6.7的的一个全局高可用特性。CCR允许不同的索引复制到一个或多个ES 集群中。
Cross-cluster replication APIs | Elasticsearch Guide [7.17] | Elastic
Hot & Warm 架构
热节点存放用户最关心的热数据;温节点或者冷节点存放用户不太关心或者关心优先级低的冷数据或者暖数据。
典型的应用场景
在成本有限的前提下,让客户关注的实时数据和历史数据硬件隔离,最大化解决客户反应的响应时间慢的问题。业务场景描述:每日增量6TB日志数据,高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
- ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储热数据,提升查询效率。
- 若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
ES为什么要设计Hot & Warm 架构?
- ES数据通常不会有 Update操作;
- 适用于Time based索引数据,同时数据量比较大的场景。
- 引入 Warm节点,低配置大容量的机器存放老数据,以降低部署成本
两类数据节点,不同的硬件配置:
- Hot节点(通常使用SSD)︰索引不断有新文档写入。
- Warm 节点(通常使用HDD)︰索引不存在新数据的写入,同时也不存在大量的数据查询
Hot Nodes
用于数据的写入:
- lndexing 对 CPU和IO都有很高的要求,所以需要使用高配置的机器
- 存储的性能要好,建议使用SSD
Warm Nodes
用于保存只读的索引,比较旧的数据。通常使用大容量的磁盘
配置Hot & Warm 架构
Index-level shard allocation filtering | Elasticsearch Guide [7.17] | Elastic
使用Shard Filtering实现Hot&Warm node间的数据迁移
- node.attr来指定node属性:hot或是warm。
- 在index的settings里通过index.routing.allocation来指定索引(index)到一个满足要求的node
| 设置 | 分配索引到节点,节点的属性规则 |
| index.routing.allocation.include.{attr} | 至少包含一个值 |
| index.routina.allocation.exclude.{attr} | 不能包含任何一个值 |
| index.routina.allocation.require. {attr} | 所有值都需要包含 |
使用 Shard Filtering,步骤分为以下几步:
- 标记节点(Tagging)
- 配置索引到Hot Node
- 配置索引到 Warm节点
1) 标记节点
需要通过“node.attr”来标记一个节点
- 节点的attribute可以是任何的key/value
- 可以通过elasticsearch.yml 或者通过-E命令指定
# 标记一个 Hot 节点
elasticsearch.bat -E node.name=hotnode -E cluster.name=tulingESCluster -E http.port=9200 -E path.data=hot_data -E node.attr.my_node_type=hot
# 标记一个 warm 节点
elasticsearch.bat -E node.name=warmnode -E cluster.name=tulingESCluster -E http.port=9201 -E path.data=warm_data -E node.attr.my_node_type=warm
# 查看节点
GET /_cat/nodeattrs?v2)配置Hot数据
创建索引时候,指定将其创建在hot节点上
# 配置到 Hot节点
PUT /index-2024-06
{
"settings":{
"number_of_shards":2,
"number_of_replicas":0,
"index.routing.allocation.require.my_node_type":"hot"
}
}
POST /index-2024-06/_doc
{
"create_time":"2024-06-03"
}
#查看索引文档的分布
GET _cat/shards/index-2024-06?v3)旧数据移动到Warm节点
# 配置到 warm 节点
PUT /index-2024-06/_settings
{
"index.routing.allocation.require.my_node_type":"warm"
}
GET _cat/shards/index-2024-06?v














 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









