







索引失效的场景
典型失效的场景
- 没有满足最左前缀匹配原则-联合索引
- like “bob%” 可以使用索引 ; like ”%bob“这是不能走索引的
- where语句有函数是不会走索引的;比如下面的sql;因为使用了函数之后,值会发生变化的,值发生变化了,在B+树的有序性就不一定正确,所以要进行全表扫描

- 用in不会造成索引失效,not in 会造成索引失效
MySQL走不走索引不是绝对的,MySQL会去分析这个sql语句分别走什么索引好,还是不走索引走全表扫描比较好

索引优化-如何建立索引
-
为搜索,排序和分组的列建立索引

-
考虑列中不重复的个数
比如没有必要在性别这样的字段上进行建立索引,这样的话会让b+树层数很低,然后在b+树两端进行从左到右扫描,然后加上回表操作就很慢了 -
索引列的类型尽量小

-
为列前缀建立索引
比如:

-
合理的建立覆盖索引
我们要谨慎用select * from ,他可能会增加回表查询的次数,造成:

- 在建立索引的时候我们要思考有没有必要建立索引,因为建立索引需要花费空间,建立好索引之后每次我们修改或者插入,删除数据都会去维护这个索引,性能会降低,索引会失效的
- 让索引列以列明的形式在搜索条件中单独出现,比如:
我们尽量用上面的那种写法

- 我们不建议用uuid作为主键,因为uuid是无序的,b+树维持数据的顺序性不方便,会使b+树操作复杂,可能造成页裂变,但很多时候我们不希望使用mysql的自增id,我们也要保证我们的id的自增性
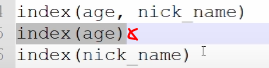
- 下面的情况我们有age和nick_name联合索引的情况下,我们没有必要建立一个单独的age索引,但是可以建立一个nick_name索引,因为联合索引的第一列是有序的
优化器成本计算原理
优化器的功能
- 在不改变语义的情况下,重写sql
- 根据成本分析(要不要走索引?走哪一个索引?),指定执行计划
重写sql
比如:
- 一处不必要的括号
- 常量传递;如;a=5 and b>a -> a=5 and b>5
- 等值传递
- 移除没用的条件
成本分析
- IO成本:这个从磁盘到内存的加载过程损耗的时间
- cpu成本:读取记录以及检测记录是否满足对应的搜索条件,对结果集进行排序等这些操作耗费的时间称之为CPU成本
基于成本的优化步骤

实际使用过程中
















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









