







 这篇博客介绍了DANN(领域适应对抗网络)的工作原理,包括如何使用生成对抗网络(GAN)结合迁移学习来提取源域和目标域的不变特征。文章重点讨论了梯度反转层(GRL)的角色,它用于训练过程中反转特征提取层的梯度,以促进域不变性。博主分享了一段PyTorch实现DANN的代码片段,并邀请读者一起探讨学习。
这篇博客介绍了DANN(领域适应对抗网络)的工作原理,包括如何使用生成对抗网络(GAN)结合迁移学习来提取源域和目标域的不变特征。文章重点讨论了梯度反转层(GRL)的角色,它用于训练过程中反转特征提取层的梯度,以促进域不变性。博主分享了一段PyTorch实现DANN的代码片段,并邀请读者一起探讨学习。
没错,我就是那个为了勋章不择手段的屑(手动狗头)。快乐的假期结束了哭哭...
DANN 对抗迁移学习
域适应Domain Adaption-迁移学习;把具有不同分布的源域(Source Domain)和目标域(Target Domain)中的数据,映射到同一个特征空间。
GAN:生成对抗网络,包含生成器和判别器,有点类似博弈论的做法。
GAN+迁移学习:生成器不再是生成样本,而是进行特征提取工作。目标:从源域和目标域中提取特征,使得判别器无法区别提取的特征是来自哪个域。
好的可迁移特征:1-Domain-invariance,2.Discriminativeness
损失loss:训练损失和域判别损失
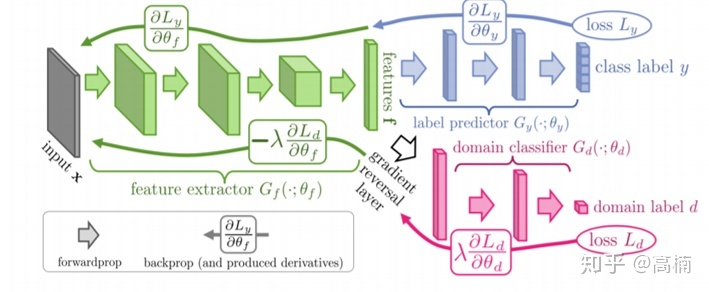
这里有一个疑惑,就是梯度反转层gradient reversal layer的作用?论文原文称之为GRL。
部分源码
下面对DANN的一个pytorch实现代码进行简要的分析。仅对网络的搭建代码进行说明。
1-梯度反转层的构建(GRL)
from torch.autograd import Function
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2646
2646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









