







 该教程介绍了如何利用DANN(域适应神经网络)在MNIST和MNIST-M数据集之间进行迁移学习。通过加载数据、构建模型、定义损失函数和优化器,然后训练和评估模型,展示了一种在不同图像分布间转移知识的方法。
该教程介绍了如何利用DANN(域适应神经网络)在MNIST和MNIST-M数据集之间进行迁移学习。通过加载数据、构建模型、定义损失函数和优化器,然后训练和评估模型,展示了一种在不同图像分布间转移知识的方法。
DANN(Domain Adaptation Neural Network,域适应神经网络)是一种常用的迁移学习方法,在不同数据集之间进行知识迁移。本教程将介绍如何使用DANN算法实现在MNIST和MNIST-M数据集之间进行迁移学习。
首先,我们需要了解两个数据集:MNIST和MNIST-M。MNIST是一个标准的手写数字图像数据集,包含60000个训练样本和10000个测试样本。MNIST-M是从MNIST数据集中生成的带噪声的手写数字数据集,用于模拟真实场景下的图像分布差异。
接下来,我们将分为以下步骤来完成这个任务:
1、加载MNIST和MNIST-M数据集
2、构建DANN模型
3、定义损失函数
4、定义优化器
5、训练模型
6、评估模型
加载MNIST和MNIST-M数据集
首先,我们需要下载并加载MNIST和MNIST-M数据集。你可以使用PyTorch内置的数据集类来完成这项任务。
import torch
from torch import nn
from torch.optim import Adam
from torch.utils.data import RandomSampler, Dataset, DataLoader
from torch.autograd import Function
from torchvision import datasets, transforms
from PIL import Image
from tqdm import tqdm
import numpy as np
import shutil
import os
# 工具函数
def adjust_learning_rate(optimizer, epoch):
lr = 0.001 * 0.1 ** (epoch // 10)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
return lr
def accuracy(output, target, topk=(1,)):
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100 / batch_size))
return res
class mnist_m(Dataset):
def __init__(self, root, label_file):
super(mnist_m, self).__init__()
self.transform = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
with open(label_file, "r") as f:
self.imgs = []
self.labels = []
for line in f.readlines():
line = line.strip("\n").split(" ")
img_name, label = line[0], int(line[1])
img = Image.open(root + os.sep + img_name)
self.imgs.append(self.transform(img.convert("RGB")))
self.labels.append(label)
def __len__(self):
return len(self.labels)
def __getitem__(self, index):
return self.imgs[index], self.labels[index]
def __add__(self, other):
pass
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
# Tensorboard
log_dir = "minist_experiment_1"
remove_log_dir = True
if remove_log_dir and os.path.exists(log_dir):
shutil.rmtree(log_dir)
# 读取数据
image_size = 28
batch_size = 128
transform = transforms.Compose([transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])])
train_ds = datasets.MNIST(root="mnist", train=True, transform=transform, download=True)
test_ds = datasets.MNIST(root="mnist", train=False, transform=transform, download=True)
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=batch_size, shuffle=False)
root_path = os.path.join("dataset", "mnist_m")
train_m_ds = mnist_m(os.path.join(root_path, "mnist_m_train"), os.path.join(root_path, "mnist_m_train_labels.txt"))
test_m_ds = mnist_m(os.path.join(root_path, "mnist_m_test"), os.path.join(root_path, "mnist_m_test_labels.txt"))
train_m_dl = DataLoader(train_m_ds, batch_size=batch_size, shuffle=True)
test_m_dl = DataLoader(test_m_ds, batch_size=batch_size, shuffle=False)
# 在源域上独立训练CNN模型
class CNN(nn.Module):
def __init__(self, num_classes=10):
super(CNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Conv2d(32, 48, 5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
)
self.avgpool = nn.AdaptiveAvgPool2d((5, 5))
self.classifier = nn.Sequential(
nn.Linear(48 * 5 * 5, 100),
nn.ReLU(inplace=True),
nn.Linear(100, 100),
nn.ReLU(inplace=True),
nn.Linear(100, num_classes)
)
def forward(self, x):
x = x.expand(x.data.shape[0], 3, image_size, image_size)
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 用一个5层的神经网络在mnist上使用Adam训练,准确率约为99.3%
cnn_model = CNN()
optimizer = Adam(cnn_model.parameters(), lr=0.001)
Loss = nn.CrossEntropyLoss()
epochs = 5
train_loss = AverageMeter()
test_loss = AverageMeter()
test_top1 = AverageMeter()
train_top1 = AverageMeter()
train_cnt = AverageMeter()
print_freq = 200
cnn_model.cuda()
for epoch in range(epochs):
lr = adjust_learning_rate(optimizer, epoch)
# writer.add_scalar("lr",lr,epoch)
print("lr, epoch", lr, epoch)
train_loss.reset()
train_top1.reset()
train_cnt.reset()
test_top1.reset()
test_loss.reset()
for images, labels in tqdm(train_dl):
images = images.cuda()
labels = labels.cuda()
optimizer.zero_grad()
predict = cnn_model(images)
losses = Loss(predict, labels)
train_loss.update(losses.data, images.size(0))
top1 = accuracy(predict.data, labels, topk=(1,))[0]
train_top1.update(top1, images.size(0))
train_cnt.update(images.size(0), 1)
losses.backward()
optimizer.step()
if train_cnt.count % print_freq == 0:
print(
"Epoch:{}[{}/{}],Loss:[{:.3f},{:.3f}],prec[{:.4f},{:.4f}]".format(epoch, train_cnt.count, len(train_dl),
train_loss.val, train_loss.avg,
train_top1.val, train_top1.avg))
for images, labels in tqdm(test_dl):
images = images.cuda()
labels = labels.cuda()
predict = cnn_model(images)
losses = Loss(predict, labels)
test_loss.update(losses.data, images.size(0))
top1 = accuracy(predict.data, labels, topk=(1,))[0]
test_top1.update(top1, images.size(0))
print("Epoch:{},val,Loss:[{:.3f}],prec[{:.4f}]".format(epoch, test_loss.avg, test_top1.avg))
# writer.add_scalar("train_loss", train_loss.avg, epoch)
# writer.add_scalar("test_loss", test_loss.avg, epoch)
# writer.add_scalar("train_top1", train_top1.avg, epoch)
# writer.add_scalar("test_top1", test_top1.avg, epoch)
# 直接用mnist数据集训练的网络识别mnist_m数据集,准确率约为58%.可以看作领域适应方法准确率的下界。
test_m_top1 = AverageMeter()
test_m_loss = AverageMeter()
for images, labels in tqdm(test_m_dl):
images = images.cuda()
labels = labels.cuda()
predict = cnn_model(images)
losses = Loss(predict, labels)
test_m_loss.update(losses.data, images.size(0))
top1 = accuracy(predict.data, labels, topk=(1,))[0]
test_m_top1.update(top1, images.size(0))
print("Epoch:{},val,Loss:[{:.3f}],prec[{:.4f}]".format(epoch, test_m_loss.avg, test_m_top1.avg))
# 直接使用mnist_m训练,准确率约为96%,可以看坐领域适应方法准确率的上界。
train_loss = AverageMeter()
test_loss = AverageMeter()
test_top1 = AverageMeter()
train_top1 = AverageMeter()
train_cnt = AverageMeter()
print_freq = 100
cnn_model.cuda()
epochs = 5
for epoch in range(epochs):
lr = adjust_learning_rate(optimizer, epoch)
# writer.add_scalar("lr",lr,epoch)
train_loss.reset()
train_top1.reset()
train_cnt.reset()
test_top1.reset()
test_loss.reset()
for images, labels in tqdm(train_m_dl):
images = images.cuda()
labels = labels.cuda()
optimizer.zero_grad()
predict = cnn_model(images)
losses = Loss(predict, labels)
train_loss.update(losses.data, images.size(0))
top1 = accuracy(predict.data, labels, topk=(1,))[0]
train_top1.update(top1, images.size(0))
train_cnt.update(images.size(0), 1)
losses.backward()
optimizer.step()
if train_cnt.count % print_freq == 0:
print(
"Epoch:{}[{}/{}],Loss:[{:.3f},{:.3f}],prec[{:.4f},{:.4f}]".format(epoch, train_cnt.count, len(train_dl),
train_loss.val, train_loss.avg,
train_top1.val, train_top1.avg))
for images, labels in tqdm(test_m_dl):
images = images.cuda()
labels = labels.cuda()
predict = cnn_model(images)
losses = Loss(predict, labels)
test_loss.update(losses.data, images.size(0))
top1 = accuracy(predict.data, labels, topk=(1,))[0]
test_top1.update(top1, images.size(0))
print("Epoch:{},val,Loss:[{:.3f}],prec[{:.4f}]".format(epoch, test_loss.avg, test_top1.avg))
# writer.add_scalar("train_loss", train_loss.avg, epoch)
# writer.add_scalar("test_loss", test_loss.avg, epoch)
# writer.add_scalar("train_top1", train_top1.avg, epoch)
# writer.add_scalar("test_top1", test_top1.avg, epoch)
# GRL
# 梯度反转层,这一层正向表现为恒等变换,反向传播是改变梯度的符号,alpha用来平衡域损失的权重。
class GRL(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
# DANN
class DANN(nn.Module):
def __init__(self, num_classes=10):
super(DANN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Conv2d(32, 48, 5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
)
self.avgpool = nn.AdaptiveAvgPool2d((5, 5))
self.task_classifier = nn.Sequential(
nn.Linear(48 * 5 * 5, 100),
nn.ReLU(inplace=True),
nn.Linear(100, 100),
nn.ReLU(inplace=True),
nn.Linear(100, num_classes)
)
self.domain_classifier = nn.Sequential(
nn.Linear(48 * 5 * 5, 100),
nn.ReLU(inplace=True),
nn.Linear(100, 2)
)
self.GRL = GRL()
def forward(self, x, alpha):
x = x.expand(x.data.shape[0], 3, image_size, image_size)
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
task_predict = self.task_classifier(x)
x = GRL.apply(x, alpha)
domain_predict = self.domain_classifier(x)
return task_predict, domain_predict
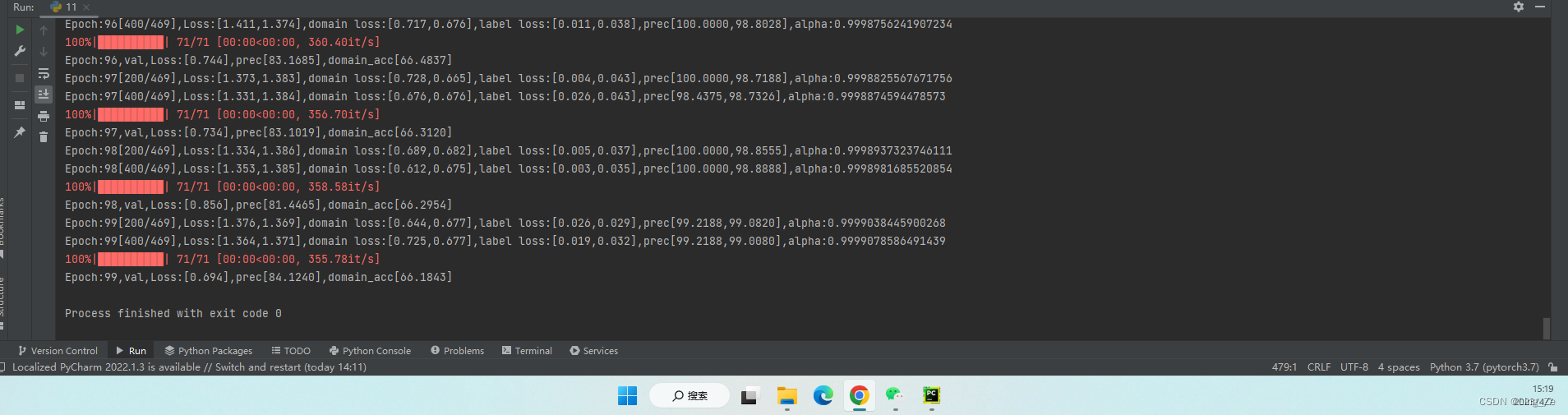
# 使用DANN进行领域迁移训练,使用mnist上的有标签数据和mnist_m上的无标签数据,准确率约为84%.
train_loss = AverageMeter()
train_domain_loss = AverageMeter()
train_task_loss = AverageMeter()
test_loss = AverageMeter()
test_top1 = AverageMeter()
test_domain_acc = AverageMeter()
train_top1 = AverageMeter()
train_cnt = AverageMeter()
print_freq = 200
domain_model = DANN()
domain_model.cuda()
domain_loss = nn.CrossEntropyLoss()
task_loss = nn.CrossEntropyLoss()
lr = 0.001
optimizer = Adam(domain_model.parameters(), lr=lr)
epochs = 100
for epoch in range(epochs):
# lr=adjust_learning_rate(optimizer,epoch)
# writer.add_scalar("lr", lr, epoch)
train_loss.reset()
train_domain_loss.reset()
train_task_loss.reset()
train_top1.reset()
train_cnt.reset()
test_top1.reset()
test_loss.reset()
for source, target in zip(train_dl, train_m_dl):
train_cnt.update(images.size(0), 1)
p = float(train_cnt.count + epoch * len(train_dl)) / (epochs * len(train_dl))
alpha = torch.tensor(2. / (1. + np.exp(-10 * p)) - 1)
src_imgs = source[0].cuda()
src_labels = source[1].cuda()
dst_imgs = target[0].cuda()
optimizer.zero_grad()
src_predict, src_domains = domain_model(src_imgs, alpha)
src_label_loss = task_loss(src_predict, src_labels)
src_domain_loss = domain_loss(src_domains, torch.ones(len(src_domains)).long().cuda())
_, dst_domains = domain_model(dst_imgs, alpha)
dst_domain_loss = domain_loss(dst_domains, torch.zeros(len(dst_domains)).long().cuda())
losses = src_label_loss + src_domain_loss + dst_domain_loss
train_loss.update(losses.data, images.size(0))
train_domain_loss.update(dst_domain_loss.data, images.size(0))
train_task_loss.update(src_label_loss.data, images.size(0))
top1 = accuracy(src_predict.data, src_labels, topk=(1,))[0]
train_top1.update(top1, images.size(0))
losses.backward()
optimizer.step()
if train_cnt.count % print_freq == 0:
print(
"Epoch:{}[{}/{}],Loss:[{:.3f},{:.3f}],domain loss:[{:.3f},{:.3f}],label loss:[{:.3f},{:.3f}],prec[{:.4f},{:.4f}],alpha:{}".format(
epoch, train_cnt.count, len(train_dl), train_loss.val, train_loss.avg,
train_domain_loss.val, train_domain_loss.avg,
train_task_loss.val, train_task_loss.avg, train_top1.val, train_top1.avg, alpha))
for images, labels in tqdm(test_m_dl):
images = images.cuda()
labels = labels.cuda()
predicts, domains = domain_model(images, 0)
losses = task_loss(predicts, labels)
test_loss.update(losses.data, images.size(0))
top1 = accuracy(predicts.data, labels, topk=(1,))[0]
domain_acc = accuracy(domains.data, torch.zeros(len(domains)).long().cuda(), topk=(1,))[0]
test_top1.update(top1, images.size(0))
test_domain_acc.update(domain_acc, images.size(0))
print("Epoch:{},val,Loss:[{:.3f}],prec[{:.4f}],domain_acc[{:.4f}]".format(epoch, test_loss.avg, test_top1.avg,
test_domain_acc.avg))
# writer.add_scalar("train_loss", train_loss.avg, epoch)
# writer.add_scalar("test_loss", test_loss.avg, epoch)
# writer.add_scalar("train_top1", train_top1.avg, epoch)
# writer.add_scalar("test_top1", test_top1.avg, epoch)
# writer.add_scalar("test_domain", test_domain_acc.avg, epoch)
运行结果
需要数据私聊我

















 2676
2676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









