







问题:当我们想把word里面的json数据复制到我们创建的json文件里面时可能会出现下面的错误

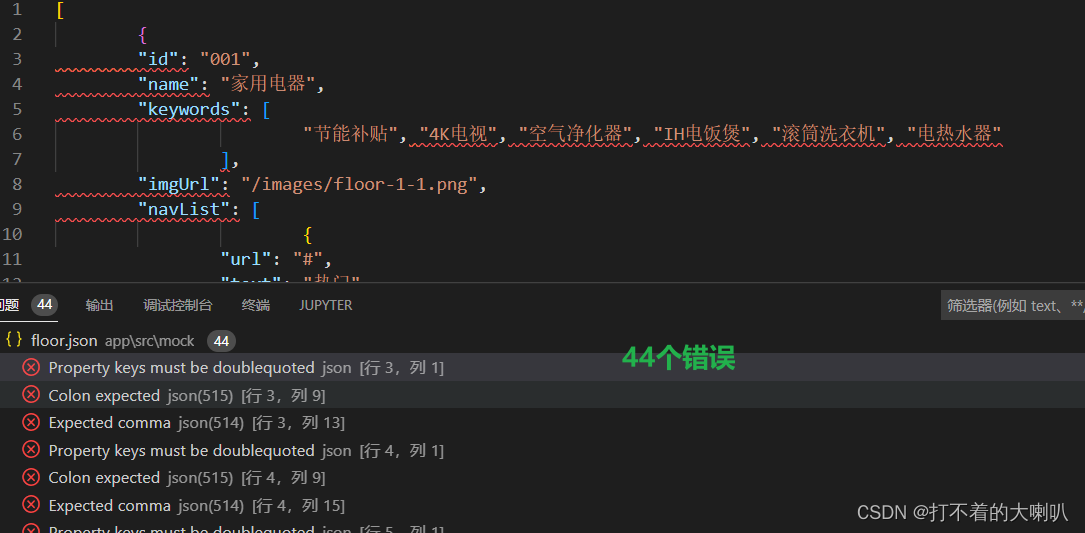
很容易判断的是我们的代码是没有问题的,报错的原因是复制过来的空格报错的原因
解决方法:
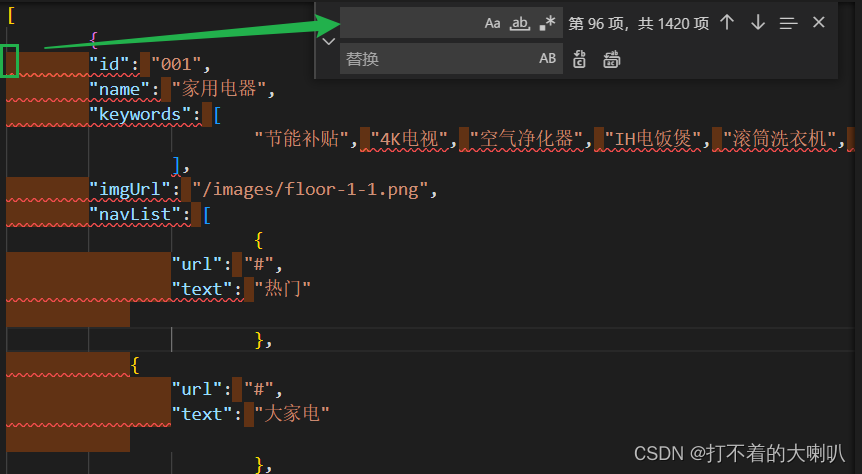
- 在vscode里面 Ctrl+H ,使用替换功能
- 然后复制word带过来的空格进去
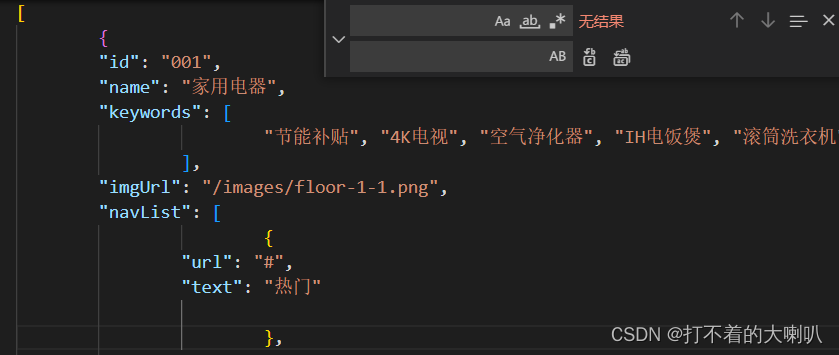
- 然后在替换栏里面打一个空格,进行替换,然后,问题就解决了
很容易判断的是我们的代码是没有问题的,报错的原因是复制过来的空格报错的原因
- 在vscode里面 Ctrl+H ,使用替换功能
- 然后复制word带过来的空格进去
- 然后在替换栏里面打一个空格,进行替换,然后,问题就解决了

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






















 844
844







