






爬虫5-反爬问题和Xpath
1. 登录问题
1.1 resquests 的登录问题
- requests自动登录步骤
- 第一步:人工对自动登录的网页进行登录
- 第二步:获取网站登陆后的cookie信息
- 第三步:发送请求到时候在请求头中添加cookie值
import requests
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36',
'cookie': 'cookie: _zap=ed17347f-a0b9-4fcc-9151-fa5f6a4caa36; d_c0="AJBfjK4zHBSPTpqD6euH_nN1u_SyonmdU4E=|1638269979"; _9755xjdesxxd_=32; YD00517437729195%3AWM_TID=vszHQtFpvr1EAQQUVVY%2B49fAEhGTlXCN; _xsrf=0649db01-f4db-4e0e-86d7-8d3c16844cc4; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1679122159,1679454090,1680101058,1680318443; captcha_session_v2=2|1:0|10:1680318443|18:captcha_session_v2|88:bXBja0tQZ2pEVGV2bEdadXprOVFwOXg1eFM3WlA1alU2TDRtZjRyU1pVUUtJUWF3aWdyd1ZsQ3NGdW9JYXVqaQ==|471b86e3de25ca7d15c79cc23104feab297bf074f39ae8f8f7a1010b4c5dad2f; SESSIONID=VK2SVoKCNEWpPBLM8U2DDCfdJgZVvZOK1TUmyClvzUW; osd=UlwRC04nEkdDbxajLC5zHi2-CYQ8dVl5HTx96GNsUxA_MlHrYc-BYS9uEq8t_NBW6IjHOXJH2goFfOwZPtJ9VuY=; JOID=U18QCk8mEUZCbhegLS9yHy6_CIU9dlh4HD1-6WJtUhM-M1DqYs6AYC5tE64s_dNX6YnGOnNG2wsGfe0YP9F8V-c=; __snaker__id=bS1DlrKkmaNCoSwh; gdxidpyhxdE=UNnThIiUp%2FnSxdTzG0EVvGUCARfS%5Ckn45Y4NhM5v4e1yCzvkqze9AE8jeB6%5CffQ4PcADCdu9WqAZof80OhwM1hdgRCG%2F9IN40Mq3voC3o6OLjMZybLrJWIJlIOmRcP7pWmdYzbCkXWH57QC4yjTV9Q11ZjvIc1Ws1SQIy294Kv1sDgc3%3A1680319344655; YD00517437729195%3AWM_NI=s3RPSAJf1Ix%2F3ap4IbQ8q17uTSnAEhUHb9qYp47EWn9yB0X3jpC3tmRXC9Hv2rc2bXDJVfaT6DyIQKnK9jv03Xm7bZFpObK%2FFtpfjZ6GtO6pc2QzCAFXaPNSB%2FsgC5p%2FVk4%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6eea3d46aa1b88790dc649cac8ea6c84a939a9bacc848bcaa82d9e260a286baa7d42af0fea7c3b92ab1ed9eb1d24b8abaffaafb25f1bfc0d5cc6a93e8bfd2b67f988da2a2c8649798aedaf453b4ecf9a6d666fba78ed1db39aab08dd4f76792888ddacb7ef2aeadd3e15488969a87e460f69cb7aad441ae95f78bf53cf188a3d8e15286b08183ca2586acc087e952f699bcb0b57ca1ee9f9bc24b8688afb1cd5982f1bd88c23fb4f19a8cb737e2a3; q_c1=411a6a4dded943fbb14e4a1c7ac13427|1680318717000|1680318717000; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1680318720; z_c0=2|1:0|10:1680318720|4:z_c0|92:Mi4xTTRLQUVBQUFBQUFBa0YtTXJqTWNGQ1lBQUFCZ0FsVk5fZTRVWlFCeHdTc2toMTdfeHE5UUhmTWFIaVpPSTlqRlVn|d4150da1285e8366e4a9cf1b87ce46365ee9756187a1371ab5f186cd5a73a5a6; tst=r; KLBRSID=ed2ad9934af8a1f80db52dcb08d13344|1680318832|1680318442'
}
response = requests.get('https://www.zhihu.com/', headers=header)
print(response.text)
1.2 selenium 的登录问题
1)selenium获取cookie
from selenium.webdriver import Chrome
# 1.创建浏览器打开需要自动登录的网站
b = Chrome()
b.get('https://www.taobao.com')
# 2.留足够长的时间,人工完成登录(必须得保证b指向的窗口的网页中能看到登陆成功以后的信息)
# 输入前记得切换回原网页,重新刷新
input('是否已经完成登录:')
# 3.获取登录成功后的cookie信息,保存到本地文件
result = b.get_cookies()
with open('files/taobao.txt', 'w', encoding='utf-8') as f:
f.write(str(result))
2)selenium使用cookie
- 创建浏览器打开需要自动登录的网站
- 获取本地保存的cookie
- 添加cookie
- 重新打开网页
from selenium.webdriver import Chrome
# 1.创建浏览器打开需要自动登录的网站
b = Chrome()
b.get('https://www.taobao.com')
# 2.获取本地保存的cookie
with open('files/taobao.txt', encoding='utf-8') as f:
result = eval(f.read())
# 3. 添加cookie
for x in result:
b.add_cookie(x)
# 4. 重新打开网页
b.get('https://www.taobao.com')
input('end:')
2. 代理
当IP被封,网站无法打开时,可以通过获取代理的方法爬取数据

1)购买代理
例如极光代理
将当前IP(可以直接通过百度IP地址查询当前IP)加入白名单中
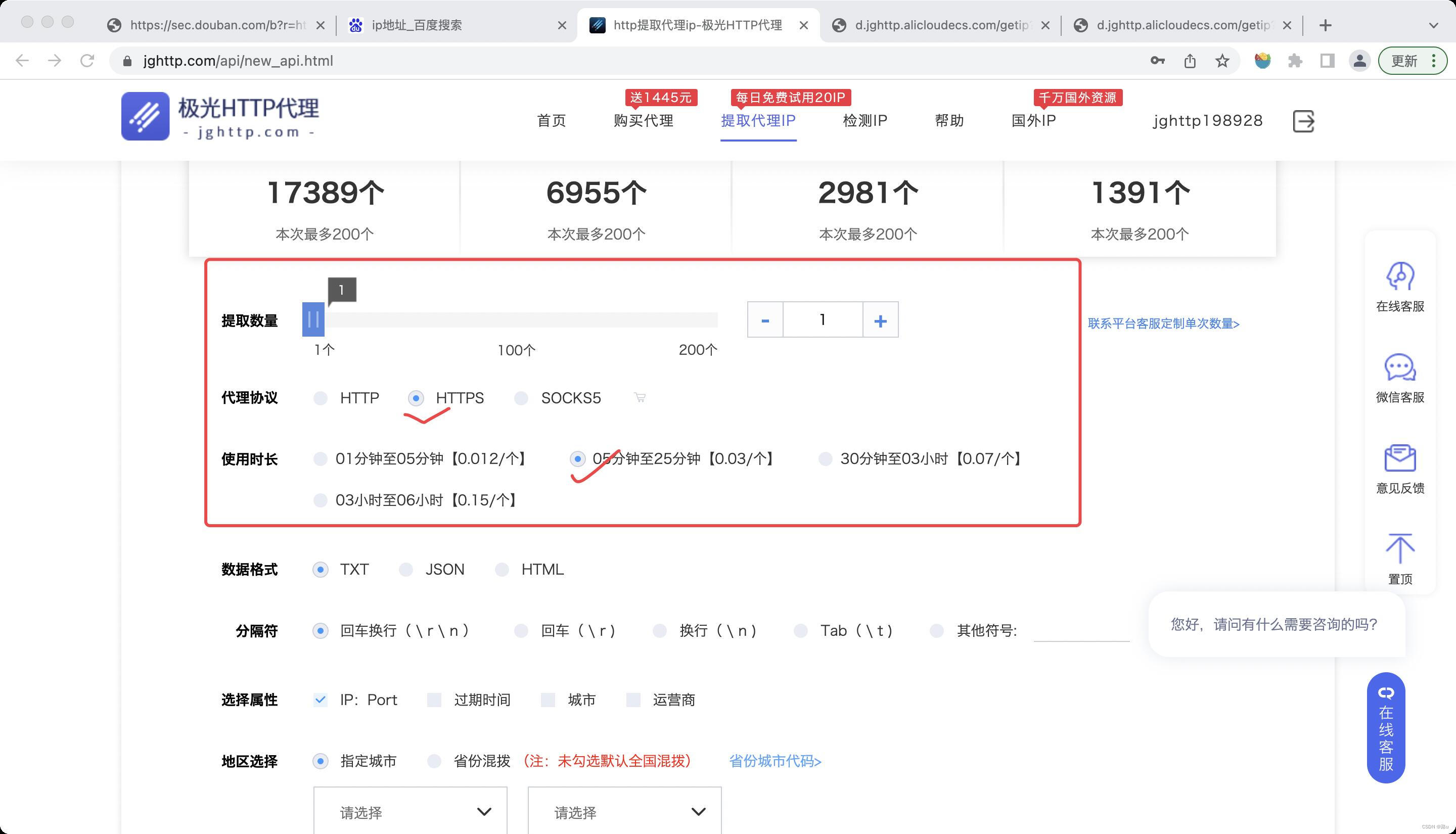
将获得的网址加载得到代理IP
2.1 代理IP
- 添加proxies = { ‘https’: ‘代理IP’}
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
proxies = {
'https': '114.106.171.182:4554'
}
res = requests.get('https://movie.douban.com/top250?start=0&filter=', headers=headers,proxies=proxies)
print(res.text)
2.2 selenium的代理
- 添加options.add_argument(‘–proxy-server=http://代理IP’)
from selenium.webdriver import Chrome, ChromeOptions
options = ChromeOptions()
# 设置代理
options.add_argument('--proxy-server=http://114.106.171.182:4554')
b = Chrome(options=options)
b.get('https://movie.douban.com/top250?start=0&filter=')
input()
3. Xpath
- Xpath用来解析网页数据或者xml数据的一种解析方法,它是通过路径来获取标签
3.1 常见的几个概念
1)树:整个网页结构或者xml就是一个树结构
2)元素(节点):html树结构中的每个标签
3)根节点:树结构中的第一个节点
4)内容:标签内容
5)属性:标签属性
3.2 Xpath语法
1)路径
-
绝对路径:以’/'开头,然后从根节点层层往下写路径
-
相对路径:写路径的时候用’.‘或者’…‘开头,期中’.‘表示当前节点,’…'表示当前节点父节点
注意:如果路径是以’./'开头,可省略
-
全路径:以’//'开头的路径
2)获取标签内容:在获取标签路径的最后加’/text()’
3)获取标签属性:在获取标签路径的最后加’/@属性名’
4)加谓语(加条件) - 路径中的节点[]
- 位置相关谓语
- [N] - 第N个指定标签
- [last()] - 最后一个指定标签
- [last()-N]
- [position()>N]、[position()>=N]、[position()<N]、[position()<=N]
- 属性相关谓语
- [@属性名=属性值]
5)通配符
- xpath中可以通过来表示任意标签或者任意属性*
3.3 应用
from lxml import etree
# 1.创建树结构,获取节点
html = open('data.html', encoding='utf-8').read()
root = etree.HTML(html)
# 2. 通过路径获取标签
# 节点对象.xpath(路径) - 根据获取所有标签,返回值是列表,列表中的元素是节点对象
# ------------------------------绝对路径-----------------------------
# 1)绝对路径
result = root.xpath('/html/body/div/a')
print(result)
# 获取标签内容
result = root.xpath('/html/body/div/a/text()')
print(result) # ['我是超链接2', '我是超链接4']
# 获取标签属性
result = root.xpath('/html/body/div/a/@href')
print(result) # ['https://www.baidu.com', 'https://www.taobao.com']
# 注意:就绝对路径写法跟xpath前面用谁去点无关
div = root.xpath('/html/body/div')[0]
result = div.xpath('/html/body/div/a/text()')
print(result) # ['我是超链接2', '我是超链接4']
# ------------------------------相对路径-----------------------------
# 2)相对路径
result = root.xpath('./body/div/a/text()')
print(result) # ['我是超链接2', '我是超链接4']
result = div.xpath('./a/text()')
print(result) # ['我是超链接2', '我是超链接4']
result = div.xpath('a/text()')
print(result) # ['我是超链接2', '我是超链接4']
# 注意:相对路径写法跟xpath前面用谁去点有关
# ------------------------------全路径-----------------------------
# 3)全路径
result = root.xpath('//a/text()')
print(result) # ['我是超连接1', '我是超链接2', '我是超链接4', '我超链接3']
result = div.xpath('//a/text()')
print(result) # ['我是超连接1', '我是超链接2', '我是超链接4', '我超链接3']
result = root.xpath('//div/a/text()')
print(result) # ['我是超链接2', '我是超链接4', '我超链接3']
# div和a只能是父子关系
# 注意:全路径写法跟xpath前面用谁去点无关
# ------------------------------位置相关谓语-----------------------------
# 第二个
result = root.xpath('//span/p[2]/text()')
print(result) # ['我是段落22']
# 最后一个
result = root.xpath('//span/p[last()]/text()')
print(result) # ['我是段落55']
# 倒数第三个
result = root.xpath('//span/p[last()-2]/text()')
print(result) # ['我是段落33']
#
result = root.xpath('//span/p[position()>=4]/text()')
print(result) # ['我是段落44', '我是段落55']
# ------------------------------属性相关谓语-----------------------------
# span下p标签中class属性是c2的p标签
result = root.xpath('//span/p[@class="c2"]/text()')
print(result) # ['我是段落22', '我是段落44']
result = root.xpath('//span/span[@title="hello"]/text()')
print(result) # ['我是span11']
# ------------------------------通配符-----------------------------
# span下所有标签
result = root.xpath('//span/*/text()')
print(result)
# span下p标签属性是c1的p标签
result = root.xpath('//span/p[@class="c1"]/text()')
print(result) # ['我是段落11', '我是段落33', '我是段落55']
# span下class属性是c1的标签
result = root.xpath('//span/*[@class="c1"]/text()')
print(result) # ['我是段落11', '我是段落33', '我是段落55', '我是超链接11']
# span下span的任意属性
result = root.xpath('//span/span/@*')
print(result) # ['hello', 'world']
# class属性是c1的所有标签
result = root.xpath('//*[@class="c1"]/text()')
print(result) # ['我是段落11', '我是段落33', '我是段落55', '我是超链接11']
data.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<span>
<span title="hello">我是span11</span>
<span typeof="world">我是span22</span>
<p class="c1">我是段落11</p>
<p class="c2">我是段落22</p>
<p class="c1" id="p1">我是段落33</p>
<p class="c2">我是段落44</p>
<p class="c1">我是段落55</p>
<a class="c1">我是超链接11</a>
<a class="c2">我是超链接22</a>
<a class="c2">我是超链接33</a>
</span>
<div>
<p>
<span>我是span1</span>
<a href="">我是超连接1</a>
</p>
<a href="https://www.baidu.com">我是超链接2</a>
<p>我是段落2</p>
<a href="https://www.taobao.com">我是超链接4</a>
<div>
<div>
<a href="">我超链接3</a>
</div>
<div>
<p>我是段落3</p>
</div>
</div>
</div>
</body>
</html>
补充
xml、json属于通用语言,用来实现服务端和客户端不同于语言的转换
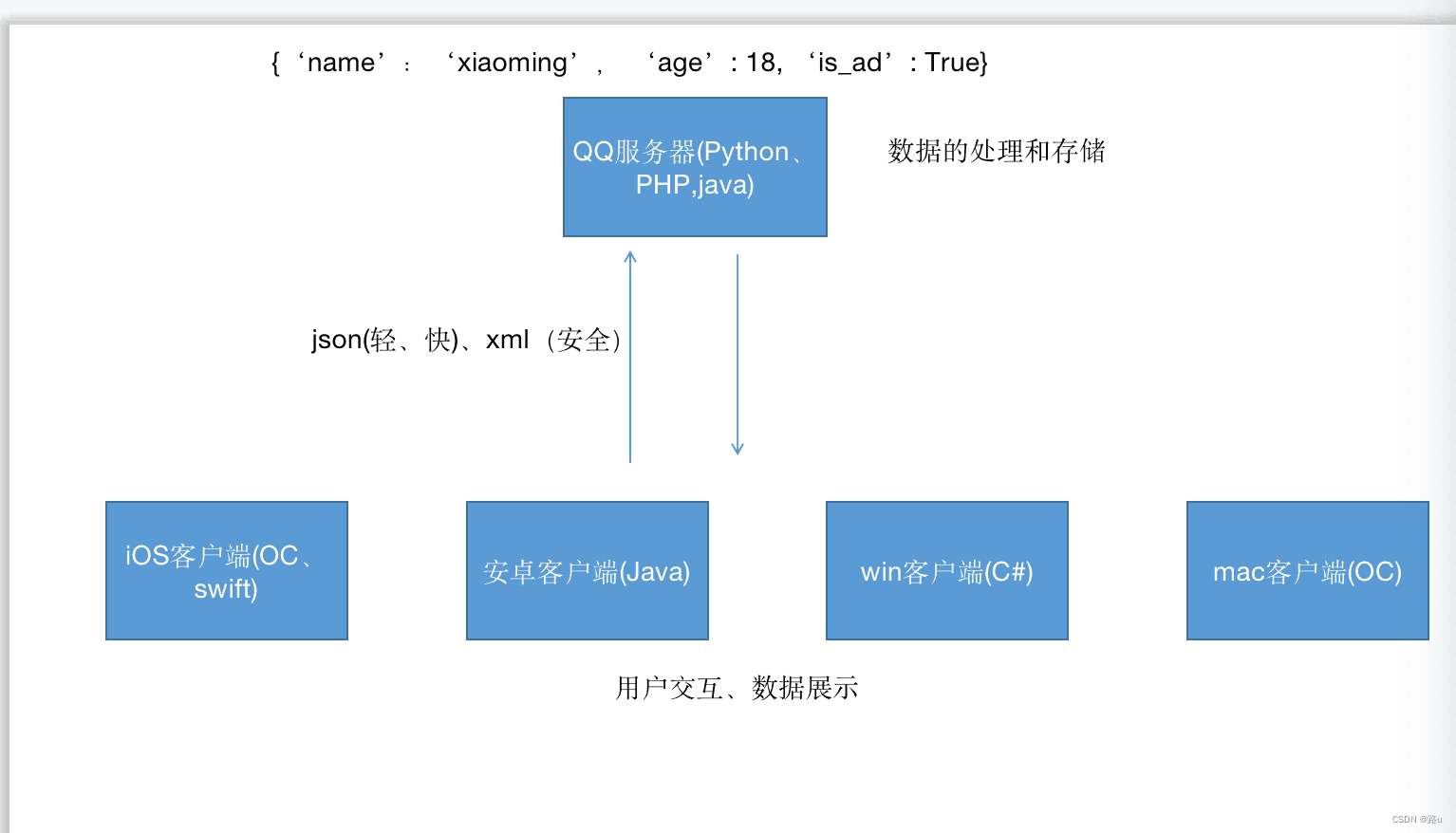
例如:python转换成json、xml
Python数据:{'name': 'xiaoming', 'age': 18, 'is_ad': True, 'car_no': None}
Json数据:{"name": "xiaoming", "age": 18, "is_ad": true, "car_no": null}
xml数据:
<student class="优秀学员">
<name>xiaoming</name>
<age>18</age>
<is_ad>是</is_ad>
<car_no></car_no>
</student>
…(img-hOTgKqTi-1680430749480)]
例如:python转换成json、xml
Python数据:{'name': 'xiaoming', 'age': 18, 'is_ad': True, 'car_no': None}
Json数据:{"name": "xiaoming", "age": 18, "is_ad": true, "car_no": null}
xml数据:
<student class="优秀学员">
<name>xiaoming</name>
<age>18</age>
<is_ad>是</is_ad>
<car_no></car_no>
</student>















 1538
1538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









