






K-近邻算法(KNN)
KNN算法是一种基于实例的学习方法,它使用已标记的训练样本集合来进行分类。算法的核心思想是根据样本之间的相似度,将测试样本归类到训练样本中最相似的K个邻居所属的类别中。
1.knn分类过程
1.1 导入所需的库
在示例代码中,我们使用了Pandas库来读取和处理数据,以及scikit-learn库中的KNeighborsClassifier和accuracy_score函数来实现KNN分类和评估分类准确率的功能。
1.2 读取数据集
示例代码中使用pd.read_csv函数读取名为’adults.txt’的数据集文件,这是一个包含个人特征和薪资水平的数据集。
1.3 数据预处理
在KNN算法中,目标变量通常需要转换为二元变量。示例代码通过应用lambda函数将原始目标变量转换为二元变量,其中’<=50K’表示0,'>50K’表示1。
1.4 特征选择和划分
根据问题的需求,选择适当的特征列和目标变量列。示例代码中选取了一系列特征作为自变量,目标变量为薪资水平。然后,使用train_test_split函数将数据集划分为训练集和测试集,其中测试集占比为0.2。
1.5 数据预处理
示例代码中使用独热编码(pd.get_dummies)对分类特征进行转换,将其转换为数值特征,以便在KNN算法中使用。
1.6 KNN模型训练与预测(训练时只存储,预测时才计算)
创建KNeighborsClassifier对象,并使用训练集数据进行模型拟合。然后,使用训练好的模型对测试集进行预测,得到预测结果。
1.7 评估分类准确率
使用accuracy_score函数比较预测结果和真实标签,计算分类准确率。

1.7 总结
优点:
- 简单易懂、易于实现。
- 对数据分布没有假设,适用于各种类型的数据。
- 可处理多分类问题。
- 不需要训练过程,直接根据相似度进行分类。
缺点:
-
计算开销较大,特别是对于大规模数据集,需要计算测试样本与所有训练样本之间的距离。
-
对异常值和噪声敏感,可能会导致错误的分类结果。k值过小容易受到异常值影响;k值过大,容易受到样本均衡问题
-
需要对数据进行归一化处理,以避免不同特征尺度对结果的影响。
-
对特征选择敏感,不同特征的权重可能对分类结果产生较大影响。
-
在高维特征空间中,由于"维度灾难"问题,KNN的分类效果可能不理想。
2. knn分类案例
标签
- 爱情电影
- 动作电影
判别依据是什么?
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
### 处理中文
plt.rcParams['font.sans-serif'].insert(0, 'SimHei')
plt.rcParams['axes.unicode_minus'] = False
data=pd.read_excel('./res/moive.xlsx')
data

2.1 特征构造
X = data[['动作镜头','爱情镜头']].copy()
y = data['电影类型'].copy()
2.2 待预测样本
# 电影A [4,21]
# 电影B [22,5]
X_test = np.array([[4,21],[22,5]])
X_test
'''
array([[ 4, 21],
[22, 5]])
'''
2.3 待分类样本可视化
plt.figure(figsize=(8,5))
plt.scatter(X['动作镜头'],X['爱情镜头'],s=100,c=y.map({'动作电影':0,'爱情电影':1}),cmap=plt.cm.Accent_r)
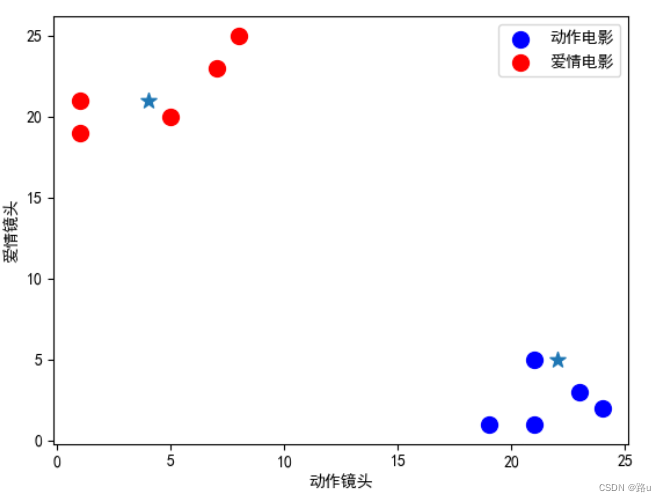
2.4 重新绘制 分别画图观察结果
# 动作电影或者爱情电影的特征
action =X.loc[y=='动作电影']
love = X.loc[y=='爱情电影']
s = 100
plt.scatter(action['动作镜头'],action['爱情镜头'],s=s,c='blue',label='动作电影')
plt.scatter(love['动作镜头'],love['爱情镜头'],s=s,c='red',label='爱情电影')
plt.scatter(X_test[:,0],X_test[:,1],marker='*',s=s)
plt.xlabel('动作镜头')
plt.ylabel('爱情镜头')
plt.legend()
2.5 算法验证
1)导入knn分类器
# 1. 导入knn分类器
from sklearn.neighbors import KNeighborsClassifier
2)实例化算法对象
# 2.实例化算法对象
knn = KNeighborsClassifier(n_neighbors=3)
3)训练模型
# 3.训练模型
knn.fit(X, y)
4)预测待遇测样本
# 4.预测待遇测样本
knn.predict(X_test) # array(['爱情电影', '动作电影'], dtype=object)
3. knn回归
3.1 原理
KNN回归算法基于邻近性原理,通过寻找与新样本最接近的K个训练样本,来预测其输出值。其核心思想是“近朱者赤”,即与新样本距离最近的K个训练样本对预测结果产生最大影响。在KNN回归中,我们通常使用欧氏距离或其他距离度量来衡量样本之间的相似性。
3.2 KNN回归应用场景
例如,当我们需要预测某个地区的房价时,可以使用KNN回归来找到与目标房屋最接近的K个房屋的价格,并通过平均或加权平均来估计目标房屋的价格。KNN回归也可以用于时间序列数据的预测,其中过去的数据点作为训练样本,预测未来的趋势。
3.3 knn回归案例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
# 创建训练数据
X_train = np.array([[1], [2], [3], [4], [5]])
y_train = np.array([2, 4, 6, 8, 10])
# 创建测试数据
X_test = np.array([[2.5], [3.7]])
# 定义不同的K值
k_values = [1, 3, 5]
# 对每个K值进行回归预测并可视化
for k in k_values:
# 创建KNN回归模型
knn = KNeighborsRegressor(n_neighbors=k)
# 拟合模型
knn.fit(X_train, y_train)
# 进行预测
y_pred = knn.predict(X_test)
# 可视化回归结果
plt.scatter(X_train, y_train, color='blue', label='Training data')
plt.scatter(X_test, y_pred, color='red', label='Predictions (k={})'.format(k))
plt.xlabel('X')
plt.ylabel('y')
plt.title('KNN Regression (k={})'.format(k))
plt.legend()
plt.show()

3.4 调参方法
在使用KNN回归时,选择合适的K值对预测结果至关重要。较小的K值可能会产生过拟合,导致对噪声敏感;而较大的K值可能会产生欠拟合,导致平滑预测结果。因此,我们需要通过交叉验证等方法选择最佳的K值。此外,还需要考虑特征的标准化、距离度量的选择等因素,以确保模型的准确性和稳定性。
3.5 归一化
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
data = pd.read_csv('dating.txt',sep=',')
print(data)
transfer = MinMaxScaler(feature_range=(0,1))
data = transfer.fit_transform(data[['milage','Liters','Consumtime']])
print(data)
return None
minmax_demo()














 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









