







本系列为大数据学习个人笔记,如有错误,欢迎指正,也欢迎各路朋友交流讨论。
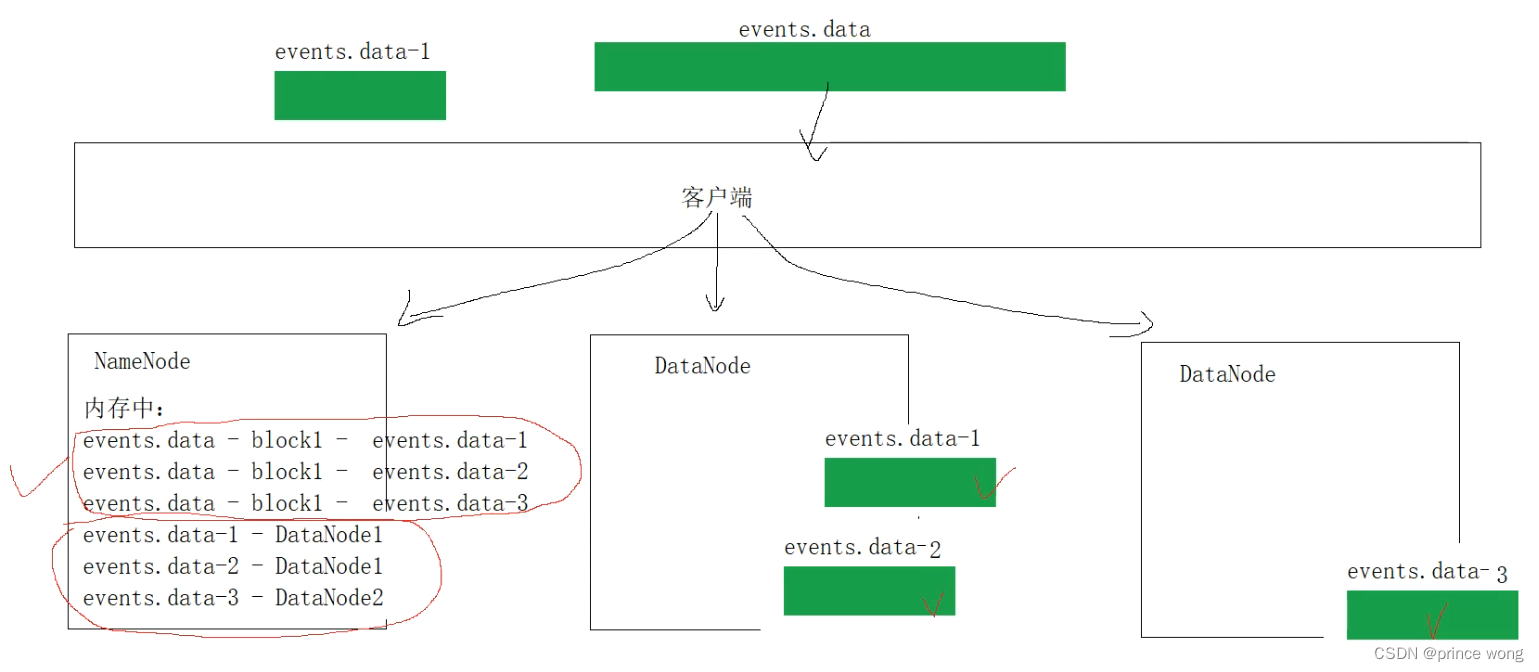
NameNode:
- 管理文件系统命名空间/元数据/文件块
- 保存文件和数据块之间的映射关系
- 一个文件对应多少个数据块,几乎不会发生变化
- 保存每个 数据块 存储在 哪个 机器列表 DataNode上
DataNode (DN):
- DN存储HDFS上的block文件块,在一个HDFS分布式文件系统里有多个DN
- 存储和处理数据
- 报告给NameNode,HDFS启动时会把DN的数据块汇报给NN
- 在许多机器上运行
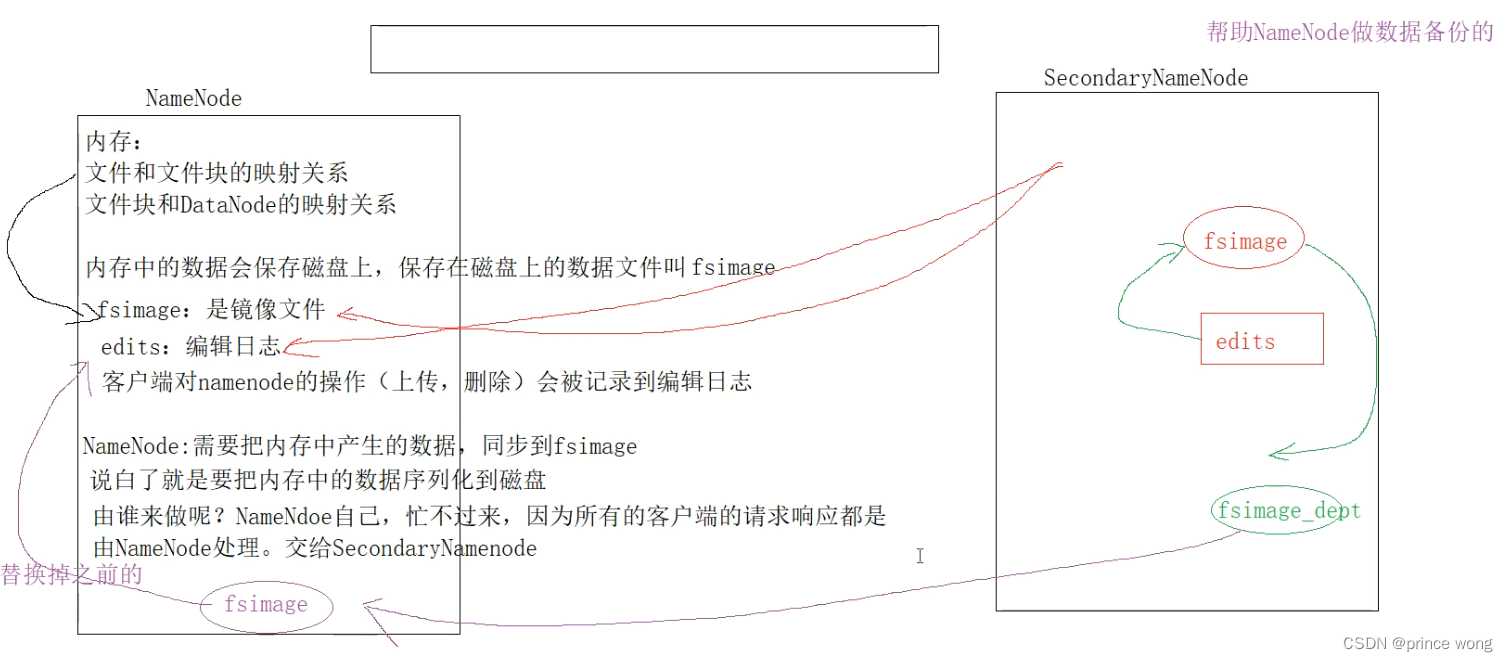
Secondary NameNode (SNN)(了解):
- 执行备份工作,因此NameNode不会
- 需要与NameNode机器类似的硬件
- 不用于高可用性 - 不是NameNode的备份
Hadoop(HDFS) Components:
-
Client
- 用户/应用程序界面与群集,DN进行交互
- HDFS命令
- HDFS的java客户端
-
Namespace
-
文件/目录 - 与拆分为块的常规文件系统相同
-
Blocks
-
Default: 64M (v1); 128M (v2)
-
阻止在NN中保存的元数据 - 小文件问题
-
-
-
Block Storage:
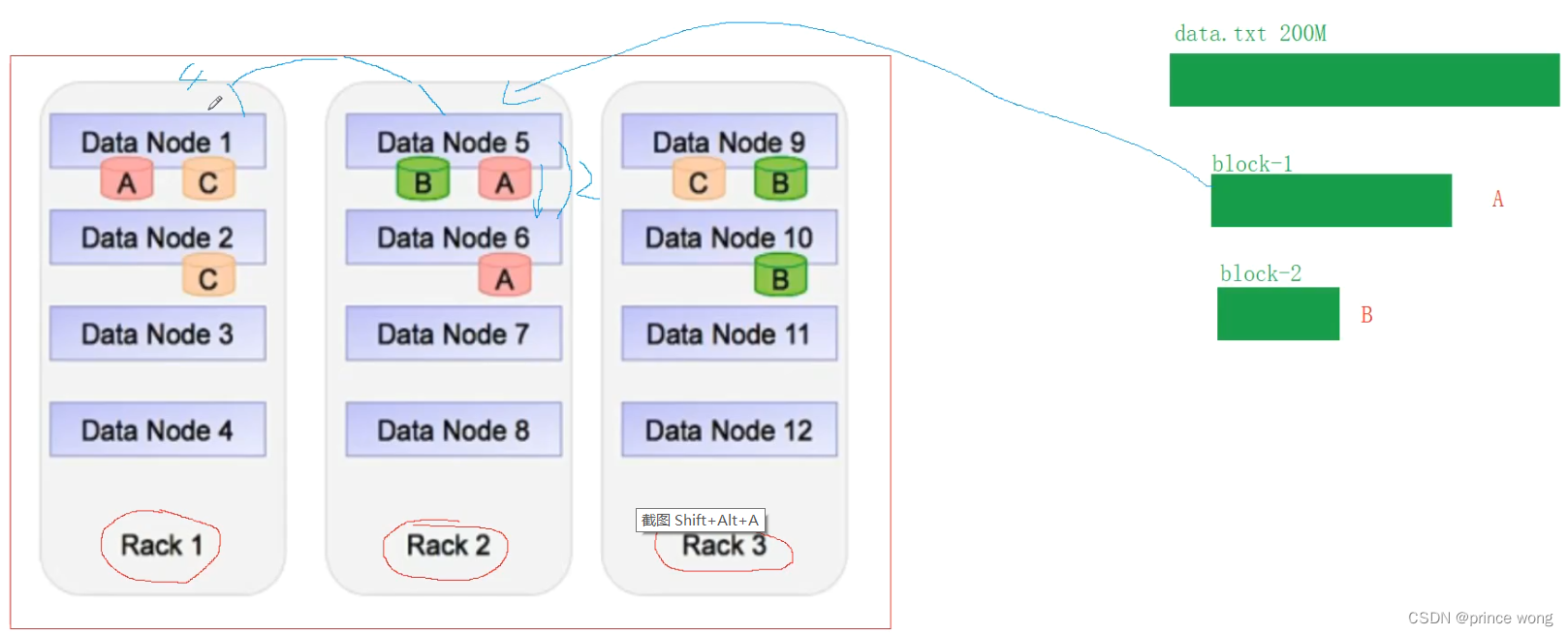
-
Replications 副本
-
默认值为3,并为新添加的节点重新平衡
-
当地的第一个复制品。 在本地但不同的节点上排名第二。 第三个在不同的机架上
-
-
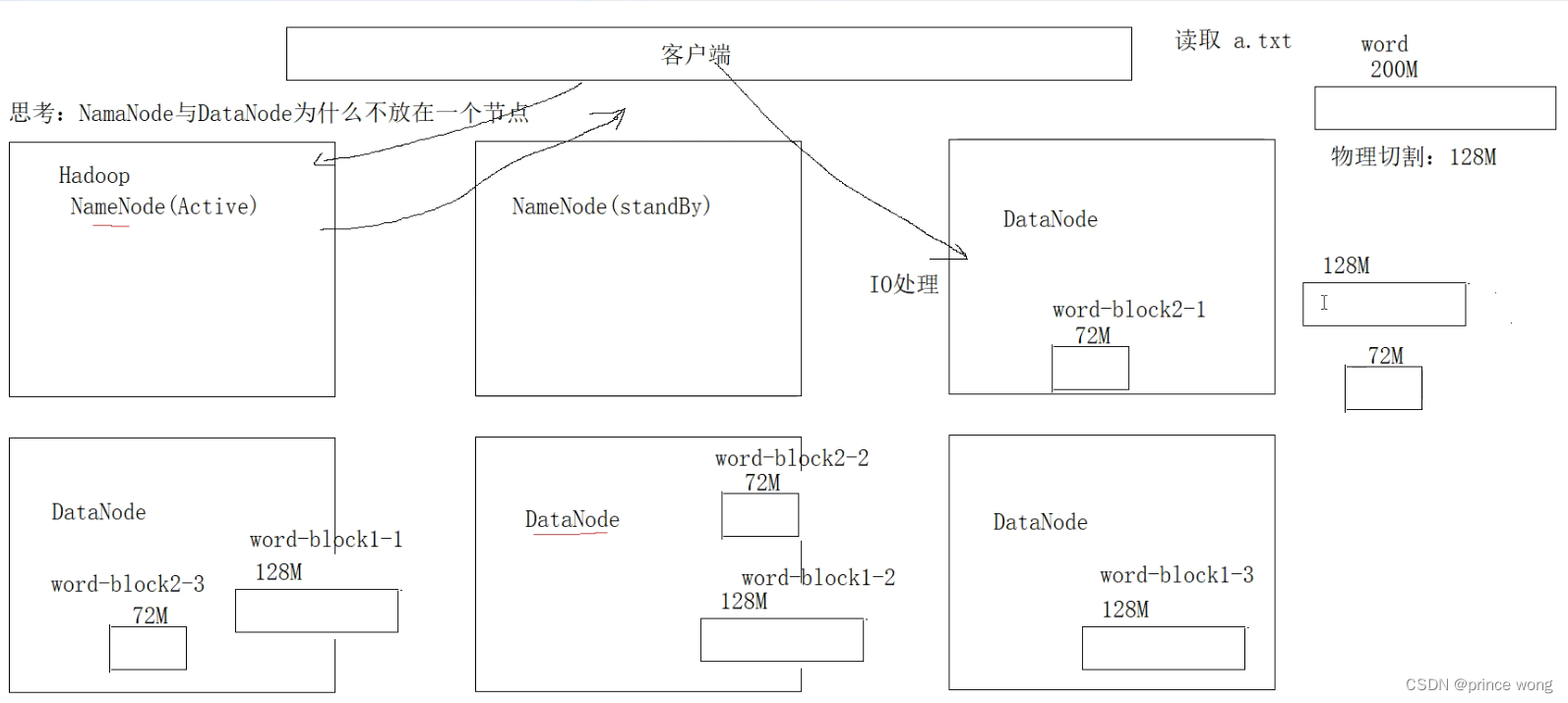
How is Hadoop High Availability (高可用性)
-
在Hadoop v1中,NN具有单点故障
-
What are the solutions? (解决方案)
- HDFS联合通过在多个分隔的NameNode上对文件系统命名空间进行分区
-
Hadoop的高可用,主要指的就是NN的高可用,官方支持HA方案,通过zookeeper来进行管理和实现
-
依赖zookeeper框架(重点掌握)
- Active and Standby NNs share the storage for edit logs; (共享存储以进行编辑日志)
- 官方支持的方案
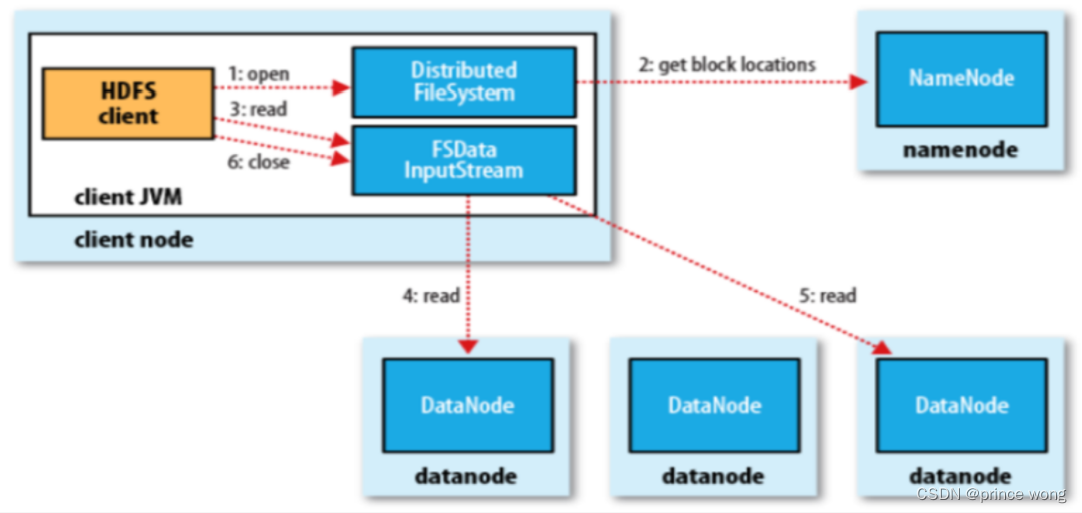
HDFS – Read a File
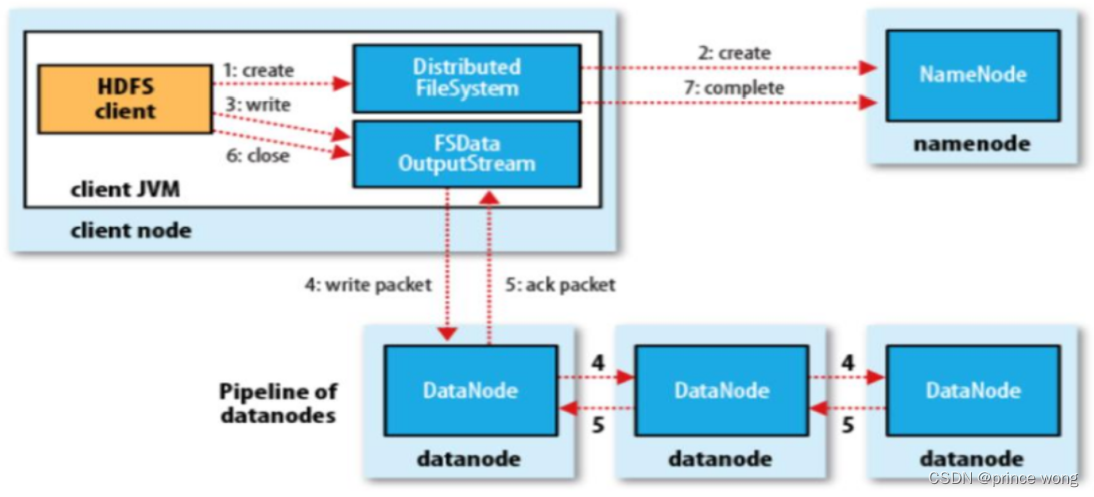
HDFS – Write a File
官方命令 https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html















 2133
2133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









