






MapJoin和ReduceJoin区别及优化
1 Map-side Join(Broadcast join)
思想:
小表复制到各个节点上,并加载到内存中;大表分片,与小表完成连接操作。
两份数据中,如果有一份数据比较小,小数据全部加载到内存,按关键字建立索引。大数据文件作为map的输入,对map()函数每一对输入,都能够方便的和已加载到内存的小数据进行连接。把连接结果按key输出,经过shuffle阶段,reduce端得到的就是已经按key分组的,并且连接好了的数据。
这种方法,要使用Hadoop中的DistributedCache把小数据分布到各个计算节点,每个map节点都要把小数据加载到内存,按关键字建立索引。
Join操作在map task中完成,因此无需启动reduce task
适合一个大表,一个小表的连接操作
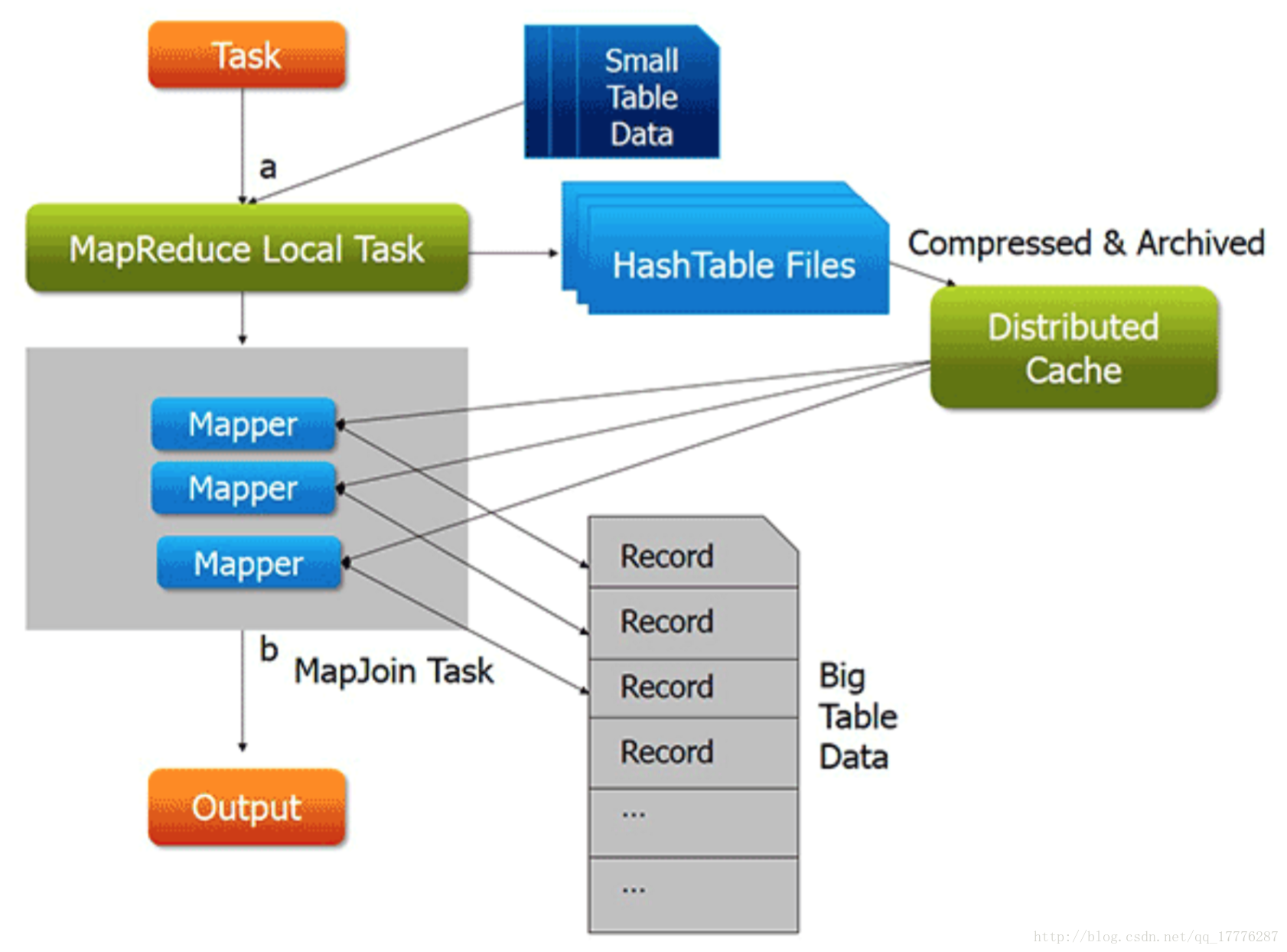
- 这种方法有明显的局限性:
- 有一份数据比较小,在map端,能够把它加载在内存,并进行join操作。
2 Reduce-side Join(shuffle join)
思想:
map端按照连接字段进行hash,reduce端完成连接操作
在map阶段,把关键字作为key输出,并在value中标记出数据是来自data1还是data2。因为在shuffle阶段已经自然按key分组,reduce阶段,判断每一个value是来自data1还是data2,在内部分成两组,做集合的成绩。
Join操作在reduce task中完成
适合两个大表的连接操作
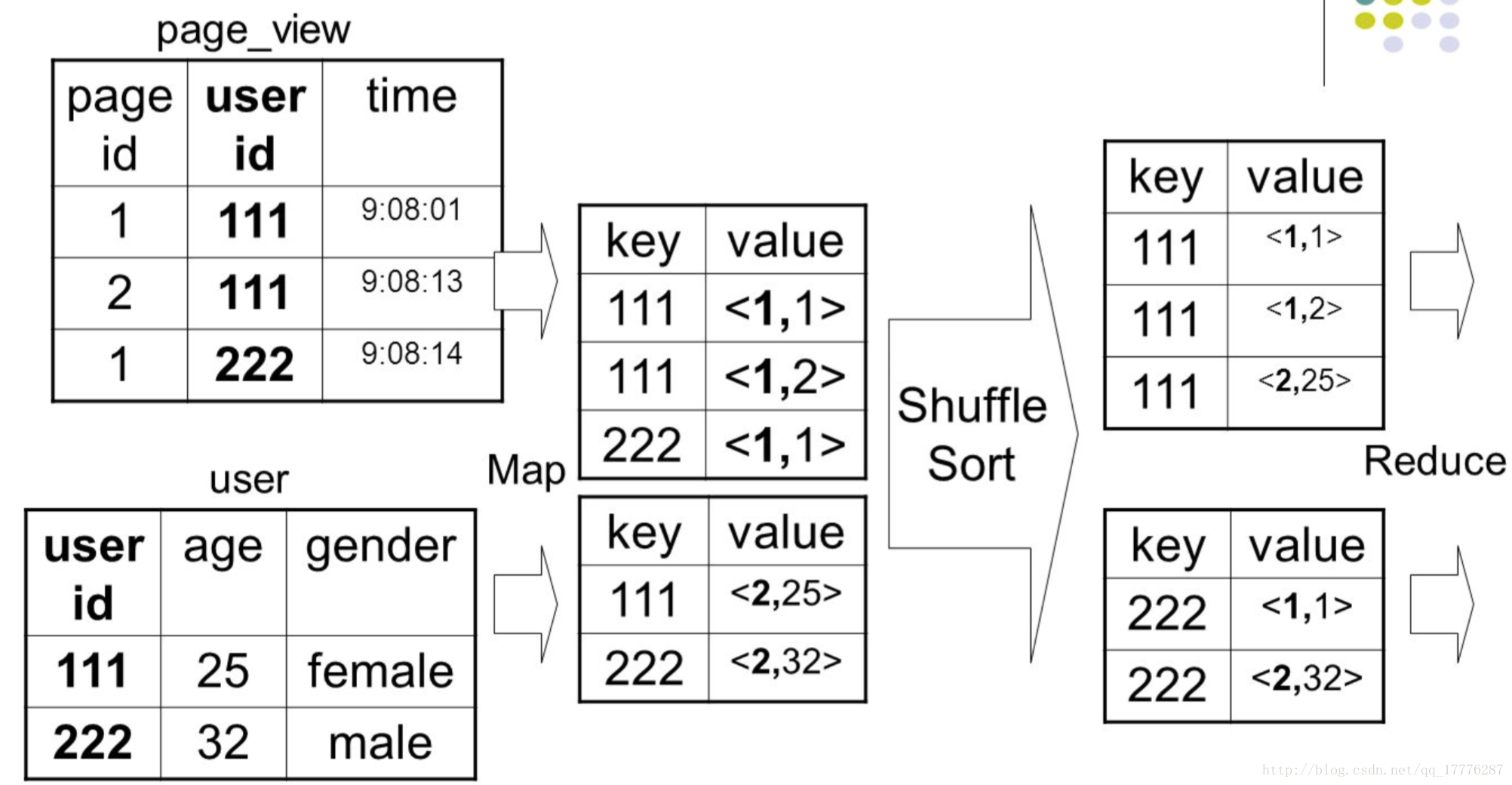
- 这种方法有2个问题:
- map阶段没有对数据瘦身,shuffle的网络传输和排序性能很低。
- reduce端对2个集合做乘积计算,很耗内存,容易导致OOM。
3 优化方案
使用内存服务器,扩大节点的内存空间
针对map join,可以报一份数据放到专门的内存服务器,在map()方法中,对每一个的输入对,根据key到内存服务器中取出数据,进行连接。使用BloomFilter过滤空连接的数据
对其中一份数据在内存中建立BloomFilter,另外一份数据在连接之前,用BloomFilter判断它的key是否存在,如果不存在,那这个记录是空连接,可以忽略。使用map reduce专为join设计的包
在map reduce包看到有专门为join设计的包,对这些包还没有学习,不知道怎么使用,只是在这里记录下来,做个提醒。
jar: mapreduce-client-core.jar
package: org.apache.hadoop.mapreduce.lib.join
- 1
- 2
- 3
Reference Link
[1] hive mapjoin使用和个人理解
[2] hive优化(1)之mapjoin
[3] 董西成,Apache Spark探秘:实现Map-side Join和Reduce-side Join
##原文出自https://blog.csdn.net/qq_17776287/article/details/78567514,转载自buildupchao的博客















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









