






1、介绍
LinkedList的底层是通过链表来实现的,不存在扩容问题,它的随机访问速度是比较差的,尽管使用get方法查询的时候:源码中先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处,但是查询效率仍然会很低。但是它的删除,插入操作会很快。
1.1、链表介绍
链表是由一系列非连续的节点组成的存储结构。链表又分为单向链表和双向链表,而单向/双向链表又可以分为循环链表和非循环链表。
1.单向链表
单向链表就是通过每个结点的指针指向下一个结点从而链接起来的结构,最后一个节点的next指向null。
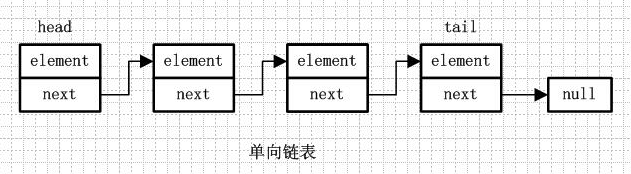
2.单向循环链表
单向循环链表和单向列表的不同是,最后一个节点的next不是指向null,而是指向head节点,形成一个“环”。
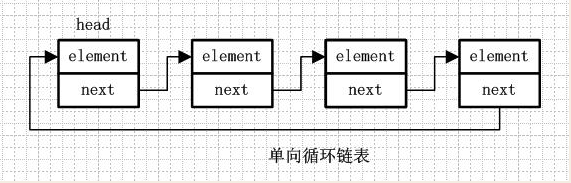
3.双向链表
从名字就可以看出,双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
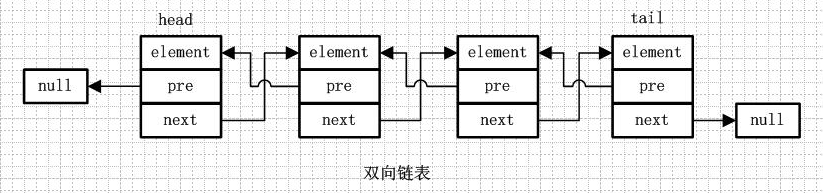
4.双向循环链表
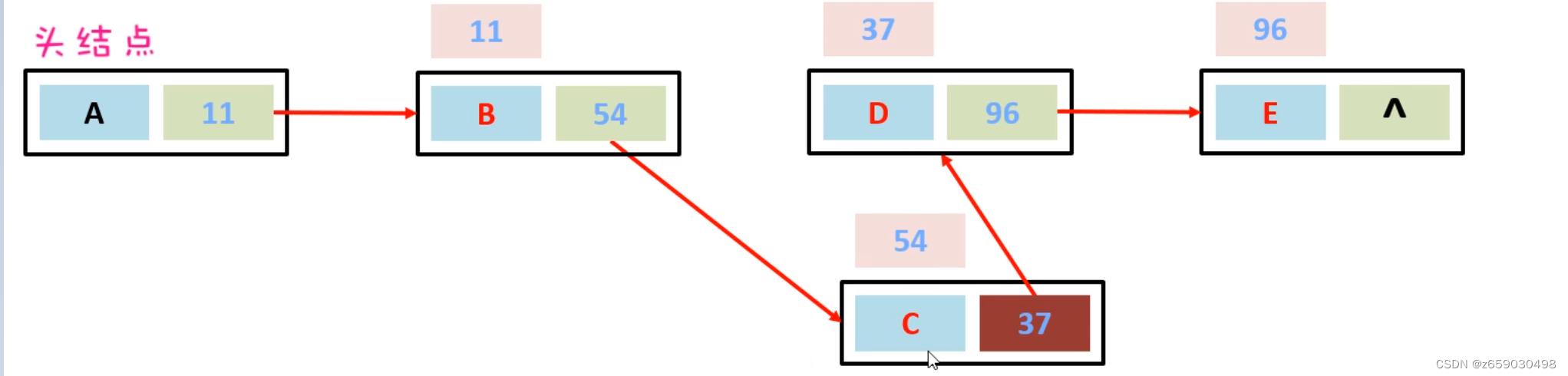
双向循环链表和双向链表的不同在于,第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。而LinkedList就是基于双向循环链表设计的。
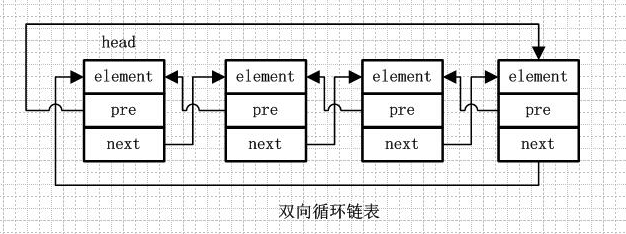
示例:
假如,现在要在B节点和D节点中间插入一个元素,只需要把B节点指向D节点的地址断掉,重新指向新的节点地址就可以了。如下图所示:
1.2、实现接口
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable1.3、常用属性
示例:
transient int size = 0; //LinkedList中存放的元素个数
transient Node<E> first; //头节点
transient Node<E> last; //尾节点2、节点结构
LinkedList由多个节点组成,每个节点包含三个部分。
- 节点的值(存储的数据)
- 指向下一个节点的引用
- 指向前一个节点的引用
双向链表实现的内部节点结构如下:
public class LinkedList<E> {
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
private Node<E> first; // 指向第一个节点
private Node<E> last; // 指向最后一个节点
private int size; // 当前链表中的元素数量
}
节点结构:
LinkedList由多个节点组成,每个节点包含数据和指向前驱节点和后继节点的引用。这个结构使得在集合中插入和删除操作的效率高。
动态大小:
与
ArrayList不同,LinkedList的大小是动态的,随着数据的添加和删除而变化,无需担心固定的容量。
有序集合:
LinkedList保持元素的插入顺序,可通过索引访问,可以包含 null 值。
3、构造方法
1.1 使用默认方法
创建一个空的 LinkedList,初始容量为 0。
public LinkedList() {
// 创建一个空的 LinkedList
}
1.2 使用 Collection 构造方法
可以将一个已有的集合,如 ArrayList 或其他 Collection 传递给 LinkedList,它会构建一个新的链表,并将元素逐一添加。
public LinkedList(Collection<? extends E> c) {
// 创建一个包含指定集合中元素的 LinkedList
}
示例:
import java.util.Arrays;
import java.util.LinkedList;
public class LinkedListConstructorsDemo {
public static void main(String[] args) {
// 使用默认构造方法
LinkedList<String> defaultList = new LinkedList<>();
System.out.println("Default LinkedList (empty): " + defaultList);
// 使用集合构造方法
LinkedList<String> arrayList = new LinkedList<>(Arrays.asList("Apple", "Banana", "Cherry"));
System.out.println("LinkedList with collection: " + arrayList);
}
}
输出:
Default LinkedList (empty): []
LinkedList with collection: [Apple, Banana, Cherry]
4、常用的方法
1.添加元素:
linkedList.add("Element"); // 在末尾添加元素
linkedList.addFirst("First Element"); // 在开头添加元素
linkedList.addLast("Last Element"); // 在末尾添加元素
2.获取元素:
E firstElement = linkedList.getFirst(); // 获取头部元素
E lastElement = linkedList.getLast(); // 获取尾部元素
E elementAtIndex = linkedList.get(index); // 根据索引获取元素
关于get方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
//先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}3.删除元素:
linkedList.remove("Element"); // 根据元素删除
linkedList.removeFirst(); // 删除头部元素
linkedList.removeLast(); // 删除尾部元素
4.遍历:
LinkedList 可以使用增强的 for 循环或 Iterator 进行遍历。
实现栈和队列的功能使用场景:
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class LinkedListStackQueue {
public static void main(String[] args) {
// 实现栈
Stack<String> stack = new LinkedList<>();
stack.push("apple");
stack.push("banana");
System.out.println(stack.pop());
// 实现队列
Queue<String> queue = new LinkedList<>();
queue.offer("cherry");
queue.offer("date");
System.out.println(queue.poll());
}
}
5、性能分析:
- 添加/删除操作: 在链表的头部或尾部添加/删除元素的时间复杂度为 O(1)。
- 随机访问: 通过索引访问元素的时间复杂度为 O(n),因为需要遍历链表。
- 允许存储重复元素。
6、LLSpliterator
1.介绍
Arraylist和linkedlist在jdk1.8版本之后均可以使用。
在 Java 8 引入的一个接口,提供了一种快速的方式来遍历
LinkedList的元素。Spliterator的全称是 "Splittable Iterator",它不仅能够迭代元素,还支持分割操作,适合在并行处理时使用。
源码示例:
static final class LLSpliterator<E> implements Spliterator<E> {
static final int BATCH_UNIT = 1 << 10; // batch array size increment
static final int MAX_BATCH = 1 << 25; // max batch array size;
final LinkedList<E> list; // null OK unless traversed
Node<E> current; // current node; null until initialized
int est; // size estimate; -1 until first needed
int expectedModCount; // initialized when est set
int batch; // batch size for splits
LLSpliterator(LinkedList<E> list, int est, int expectedModCount) {
this.list = list;
this.est = est;
this.expectedModCount = expectedModCount;
}
final int getEst() {
int s; // force initialization
final LinkedList<E> lst;
if ((s = est) < 0) {
if ((lst = list) == null)
s = est = 0;
else {
expectedModCount = lst.modCount;
current = lst.first;
s = est = lst.size;
}
}
return s;
}
public long estimateSize() { return (long) getEst(); }
public Spliterator<E> trySplit() {
Node<E> p;
int s = getEst();
if (s > 1 && (p = current) != null) {
int n = batch + BATCH_UNIT;
if (n > s)
n = s;
if (n > MAX_BATCH)
n = MAX_BATCH;
Object[] a = new Object[n];
int j = 0;
do { a[j++] = p.item; } while ((p = p.next) != null && j < n);
current = p;
batch = j;
est = s - j;
return Spliterators.spliterator(a, 0, j, Spliterator.ORDERED);
}
return null;
}
public void forEachRemaining(Consumer<? super E> action) {
Node<E> p; int n;
if (action == null) throw new NullPointerException();
if ((n = getEst()) > 0 && (p = current) != null) {
current = null;
est = 0;
do {
E e = p.item;
p = p.next;
action.accept(e);
} while (p != null && --n > 0);
}
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
public boolean tryAdvance(Consumer<? super E> action) {
Node<E> p;
if (action == null) throw new NullPointerException();
if (getEst() > 0 && (p = current) != null) {
--est;
E e = p.item;
current = p.next;
action.accept(e);
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}2.特点
- 并行处理:
Spliterator允许将集合分成多个部分,以便在多线程环境中进行并行处理。这对于大集合的性能优化尤为重要。
代码示例:
import java.util.LinkedList;
import java.util.Spliterator;
public class SpliteratorExample {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("Apple");
list.add("Banana");
list.add("Cherry");
// 获取 LLSpliterator
Spliterator<String> spliterator = list.spliterator();
// 打印出所有元素
spliterator.forEachRemaining(System.out::println);
}
}
输出:
Apple
Banana
Cherry
- 分割能力: 通过
trySplit()方法,Spliterator可以将集合分割成两个部分,这样可以在多线程中利用。 - 遍历元素:
Spliterator提供了tryAdvance()方法,用于一次处理一个元素。
ArrayList的Spliterator能正确分割元素,因为它是基于数组的随机访问结构,trySplit()会均分元素。
3.缺点
而linkedlist则1.8版本则不能均分,这块不知道具体为什么原因?
在Java中,Spliterator的trySplit()方法的行为依赖于底层数据结构。对于LinkedList,其Spliterator的实现(尤其在Java 8中)存在以下关键问题:
-
非随机访问结构:
LinkedList是链表结构,无法像ArrayList那样通过索引快速定位中间节点。因此,trySplit()方法在分割时需要遍历链表以找到中间点,这会导致性能问题。Java的Spliterator实现为了效率,可能会直接返回整个链表给拆分后的split,而将原spliterator置空。 -
估计大小不准确:
LinkedList的Spliterator的estimateSize()方法返回Integer.MAX_VALUE(Java 8中),因为它无法高效计算剩余元素数量。这导致trySplit()无法正确分割元素,直接将所有元素分配给split,原spliterator不再包含任何元素。
原因分析:
- 调用
spliterator.trySplit()后,原spliterator实际上没有剩余元素,而split包含了所有元素。 - 因此,处理原
spliterator时没有输出,而split处理了全部100个元素。
解决方案:
改用ArrayList或检查Java版本可解决此问题。
代码示例:
import java.util.LinkedList;
import java.util.Spliterator;
public class LinkedListSpliteratorDemo {
public static void main(String[] args) {
// 创建一个 LinkedList 并添加元素
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Cherry");
list.add("Date");
list.add("Elderberry");
list.add("Fig");
list.add("Grape");
// 获取 Spliterator
Spliterator<String> spliterator = list.spliterator();
// 尝试分割 Spliterator
Spliterator<String> split = spliterator.trySplit();
System.out.println("Processing first half:");
// 处理第一个分隔部分
spliterator.forEachRemaining(System.out::println);
System.out.println("Processing second half:");
// 处理第二部分
if (split != null) {
split.forEachRemaining(System.out::println);
}
}
}
7、线程安全
本身并不是线程安全的,如果多个线程同时访问和修改同一个
LinkedList实例,且至少有一个线程对该列表进行了结构上的修改(如添加或删除元素),那么可能会导致不稳定的行为或数据不一致问题。例如ConcurrentModificationException。
1.Collections.synchronizedList:
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
List<String> synchronizedList = Collections.synchronizedList(new LinkedList<>());
使用这种方法时,在迭代列表时,仍然需要手动同步:
synchronized (synchronizedList) {
for (String element : synchronizedList) {
// 处理元素
}
}
2. CopyOnWriteArrayList
应用程序有较多的读取操作,少量的写入操作,考虑使用 CopyOnWriteArrayList。该类在每次写入操作时都会复制基础数组,因此读取时不会受到影响。
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
List<String> threadSafeList = new CopyOnWriteArrayList<>();
3.使用其他并发数据结构:
Java 的 java.util.concurrent 包中还提供了一些其他的并发数据结构,你可以考虑使用它们,比如 ConcurrentLinkedQueue。
总结:
LinkedList 本身不是线程安全的,如果需要线程安全的操作,应结合以上方法进行适当处理。选择合适的方法取决于你的应用程序的特定需求,包括并发访问的频率、数据结构的大小以及性能考虑。
参考文章:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









