







一、安装scala
https://pan.baidu.com/s/1ukmh35rxG6_60DEf-IifPQ
提取码:c3p0
1.下载 scala 安装包并上传到 Linux 上
2.解压安装包到指定位置
tar -zxvf scala-2.11.8.tgz -C /opt/moudle并修改名字:
mv scala-2.11.8.tgz scala3.修改环境变量:vim /etc/profile 并添加
export SCALA_HOME=/opt/scala
export PATH=$PATH:$SCALA_HOME/bin 保存退出,并刷新修改文件 source /etc/profile
4.验证是否安装成功:在命令行输入 scala
二、安装spark
https://pan.baidu.com/s/1wguRsOu3OcPH50Y3c_SX4g
提取码:c3p0
1.下载并解压 spark 安装包到指定位置
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/moudle2.配置环境变量:vim /etc/profile 并添加
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin保存退出,并刷新修改文件 source /etc/profile
3.进入spark的coonf目录下复制 env.sh.template 文件并重命名
cp spark-env.sh.template spark-env.sh 打开 vim spark-env.sh并在末尾添加:
export JAVA_HOME=/opt/jdk1.8.0_144
export SCALA_HOME=/opt/scala
export SPARK_MASTER_IP=gz01
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMOERY=2g
export HADOOP_HOME=/opt/hadoop-2.5.1_x64_0/etc/hadoop保存并退出
4.进入conf 目录下并编辑 vim slaves.template ,添加主机名(worker节点), 保存并退出
gz01
gz02
gz035.将配置好的Spark拷贝到其他节点上,记得配置环境变量和更改配置文件中的一些细节
scp -r spark/ gz02:/opt/moudle
scp -r spark/ gz03:/opt/moudle6.启动hadoop集群 start-all.sh
7.在spark的sbin目录下执行 ./start-all.sh 启动spark
jps出现:Master 和 Worker
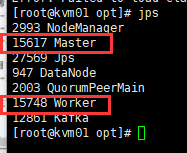
则成功并且可以在浏览器访问 gz01:8080 登录Spark 管理界面查看集群状态
8.进入spark 的 bin 目录 ,使用 spark-shell 控制台 并可以通过 gz01:4040 从web角度看SparkUI的情况
三、使用spark-submit 提交 jar包命令
在命令行输入:
/opt/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://gz01:7077 --executor-memory 512m --total-executor-cores 1 /opt/spark/examples/jars/spark-examples_2.11-2.0.2.jar 















 3725
3725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











