






 本文介绍了作者将AIagent从文本对话升级为语音对话的过程,使用了MeloTTS的中文语音合成技术,评估了其速度和性能,并分享了安装和实时播放的实现方法。
本文介绍了作者将AIagent从文本对话升级为语音对话的过程,使用了MeloTTS的中文语音合成技术,评估了其速度和性能,并分享了安装和实时播放的实现方法。
之前做了一个AI agent可以和使用工具和和用户对话,但是这些形式都是文本的,现在尝试把文本转化为语音的方式。
从huggingface找了一下现场的可用的中文的语音合成,找到一个还可以用的,关键速度很快。
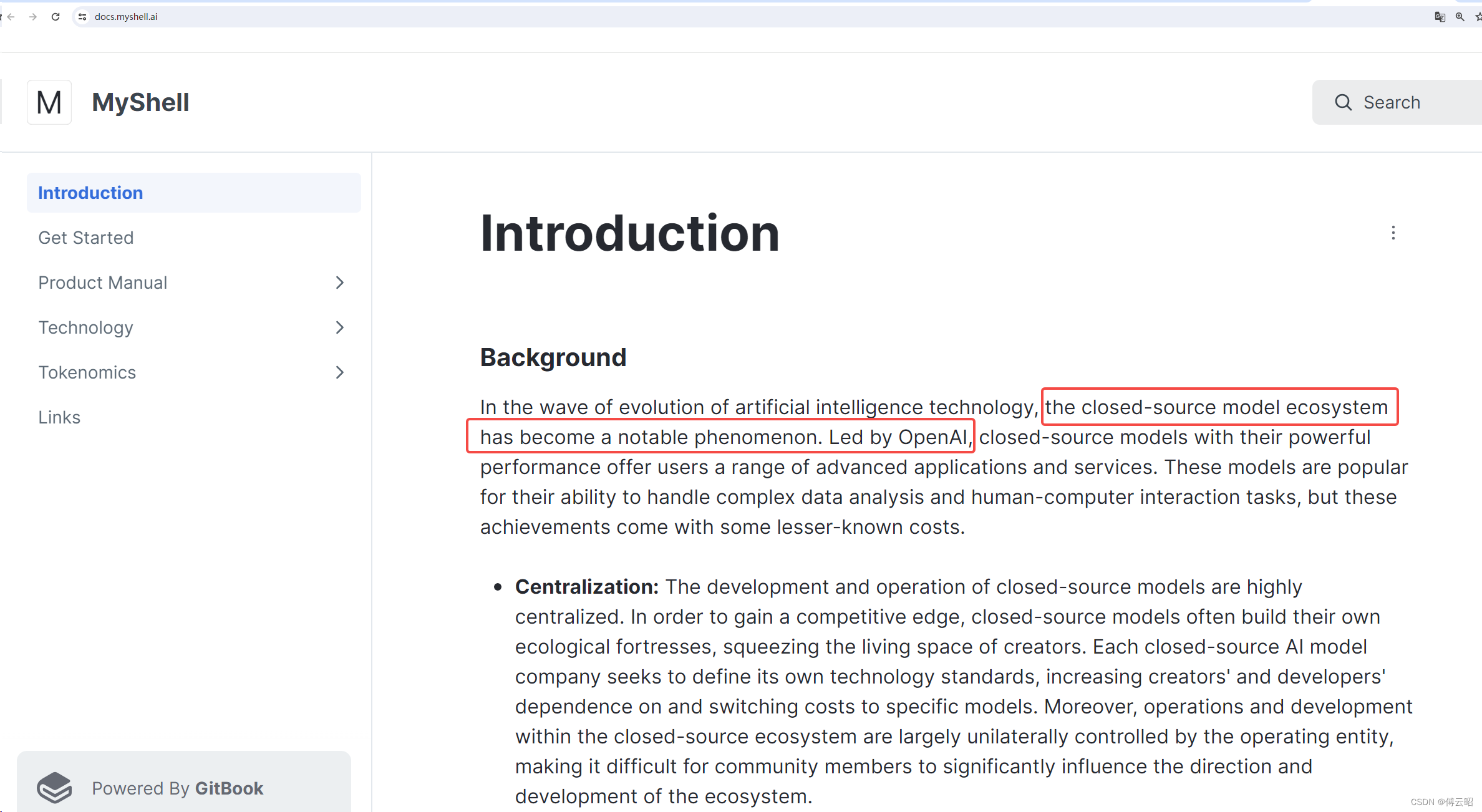
看了一下他们的官方,介绍里面一开始就argue 这种喜欢闭源的模型生态系统不好,特别指出openAI,哈哈,然后强调他们的愿景就是开源模型。感觉和年轻的openAI有点像哈,不知道最后他们融资几轮之后这个愿景还会不会存在,哈哈。
他们开源的这个模型,支持中文。
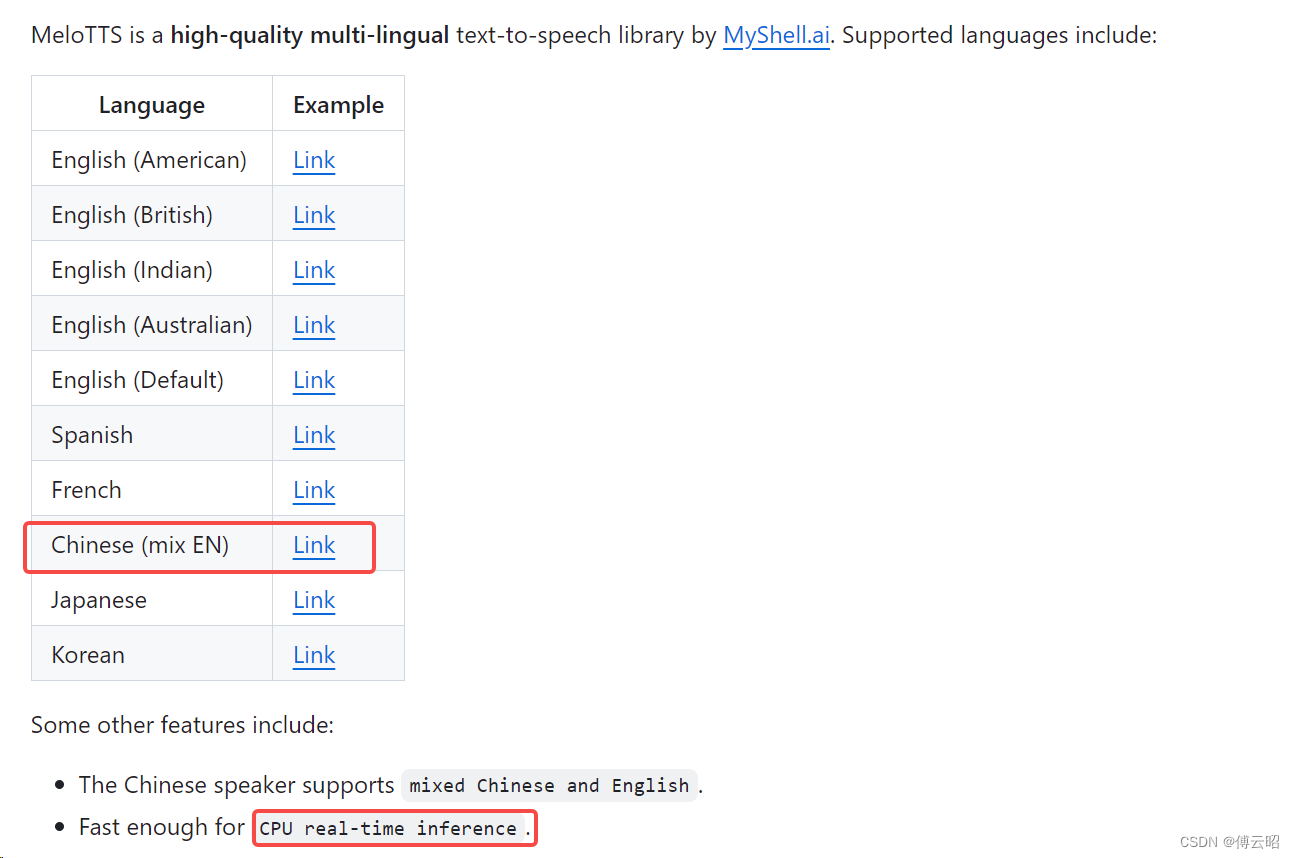
据说cpu可以实时,我的感觉是一个字一个字的可以实时把,我使用3060测试,
20ms / 字, 显存占用2.6 G
确实速度还不错。我使用cpu测试了一下,如果一个短句一个短句的输入的话,时间gap大概是0.7s左右,还是3060好,gap基本是0.1s左右,类似于人的讲话中的停顿。
1.安装
MeloTTS/docs/install.md at main · myshell-ai/MeloTTS (github.com)
参考官方的安装教程
git clone https://github.com/myshell-ai/MeloTTS.git
cd MeloTTS
pip install -e .
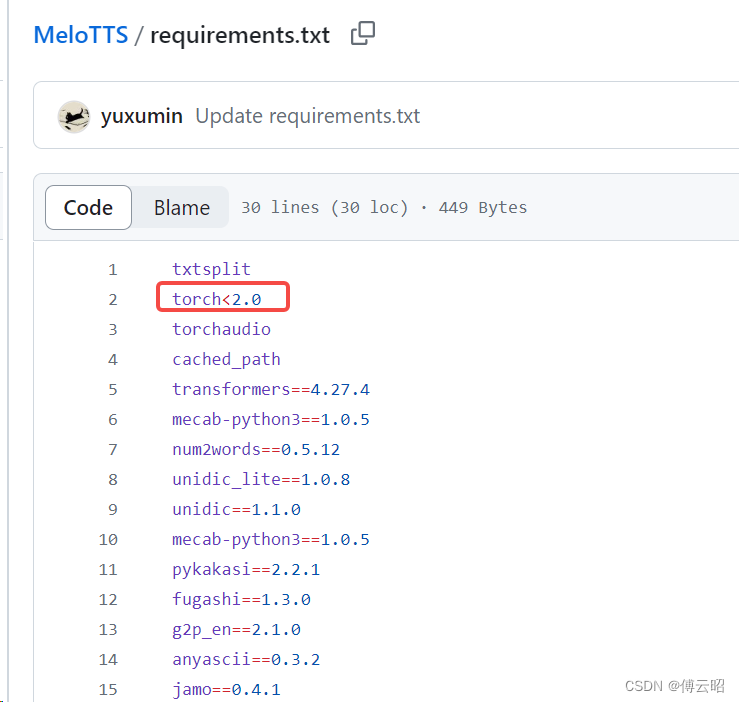
python -m unidic download唯一变态的是要求torch必须<2
2.推理
基本上就是使用人家已经训练好的中文的模型权重,如果你想自定义声音,就要重新训练。暂时先做一个demo,后续根据需在再来优化。
官方的推理代码是把结果保存为一个.wav文件,但是我想做实时的,所以又添加了一个实时播放的功能,使用pyaudio和wave这两个库实现的。然后对文本按照标点符号进行分割,因为如果一个字一个字的传入会显得很生硬,而一句完整的话可能又很长,会导致延迟,所以采取小分局的方式,达到几乎0延迟的效果。
import time
from melo.api import TTS
import pyaudio
import re
import wave
def play(file):
chunk = 1024
wf = wave.open(file, 'rb')
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(),
rate=wf.getframerate(), output=True)
data = wf.readframes(chunk) # 读取数据
print(data)
while data != b'': # 播放
stream.write(data)
data = wf.readframes(chunk)
print(data)
stream.stop_stream() # 停止数据流
stream.close()
p.terminate() # 关闭 PyAudio
# Speed is adjustable
speed = 1.0 # 讲话的速度,不是生成的速度
device = 'cuda:0' # or cuda:0
model = TTS(language='ZH', device=device)
speaker_ids = model.hps.data.spk2id
print("_____________________")
t0 = time.time() # 20ms / 字, 2.6 G
text = "你是不是油饼啊,你是不是有病啊,你是不是油饼啊,你是不是人啊,你是不是坤坤啊," \
"PyAudio对象只负责播放音频,不负责从文件中读取二进制数据,所以读取要在外面进行,给到它的是二进制数据," \
"一般会结合wave库一起使用,wave库负责读数据以及获取音频的一些基本信息。"
# 按照标点符号分句子
pattern = r',|\.|/|;|\'|`|\[|\]|<|>|\?|:|"|\{|\}|\~|!|@|#|\$|%|\^|&|\(|\)|-|=|\_|\+|,|。|、|;|‘|’|【|】|·|!| |…|(|)'
split_text = re.split(pattern, text)
for i in range(len(split_text)):
sub_test = split_text[i]
output_path = 'zh.wav'
model.tts_to_file(sub_test, speaker_ids['ZH'], output_path, speed=speed)
play("./zh.wav")
print(time.time() - t0)分句子的效果:
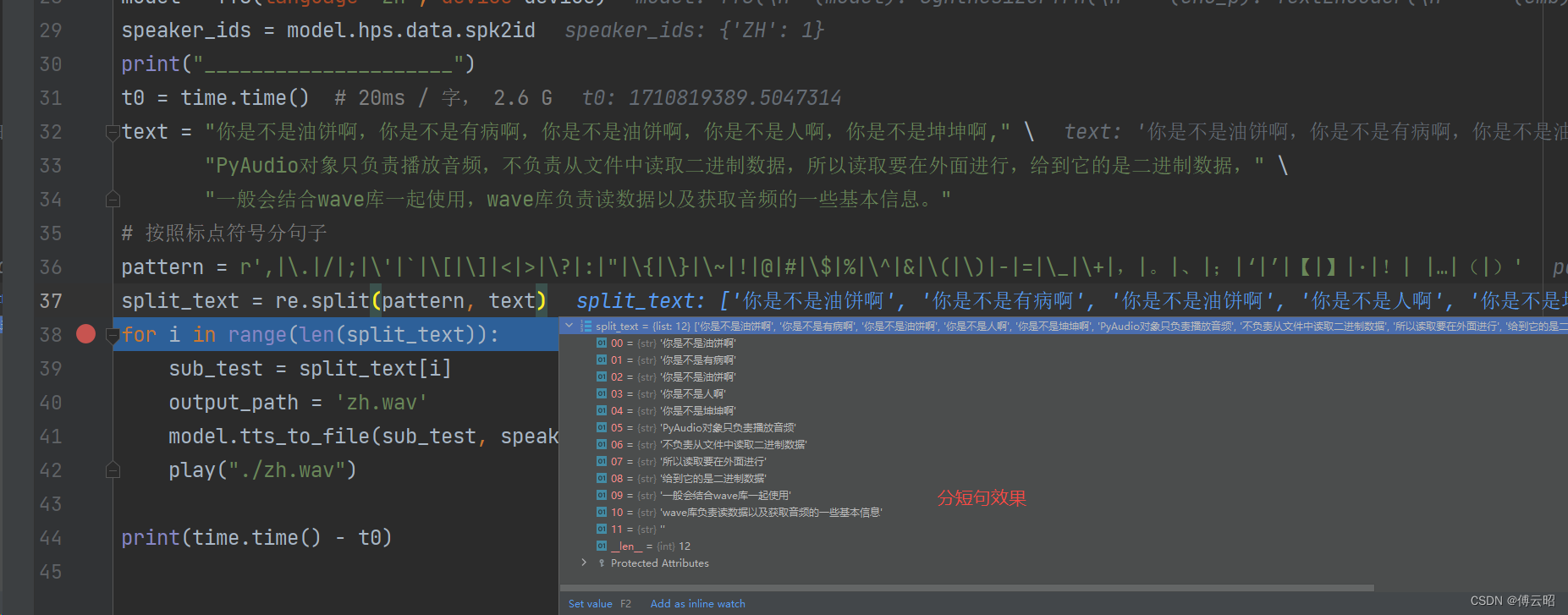
保存的结果如下:
实时的运行结果,我听上去还不错,每个分句子之前基本又0.1s作用的延迟,可以看作正常人说两句话之间的停顿,还挺好的。
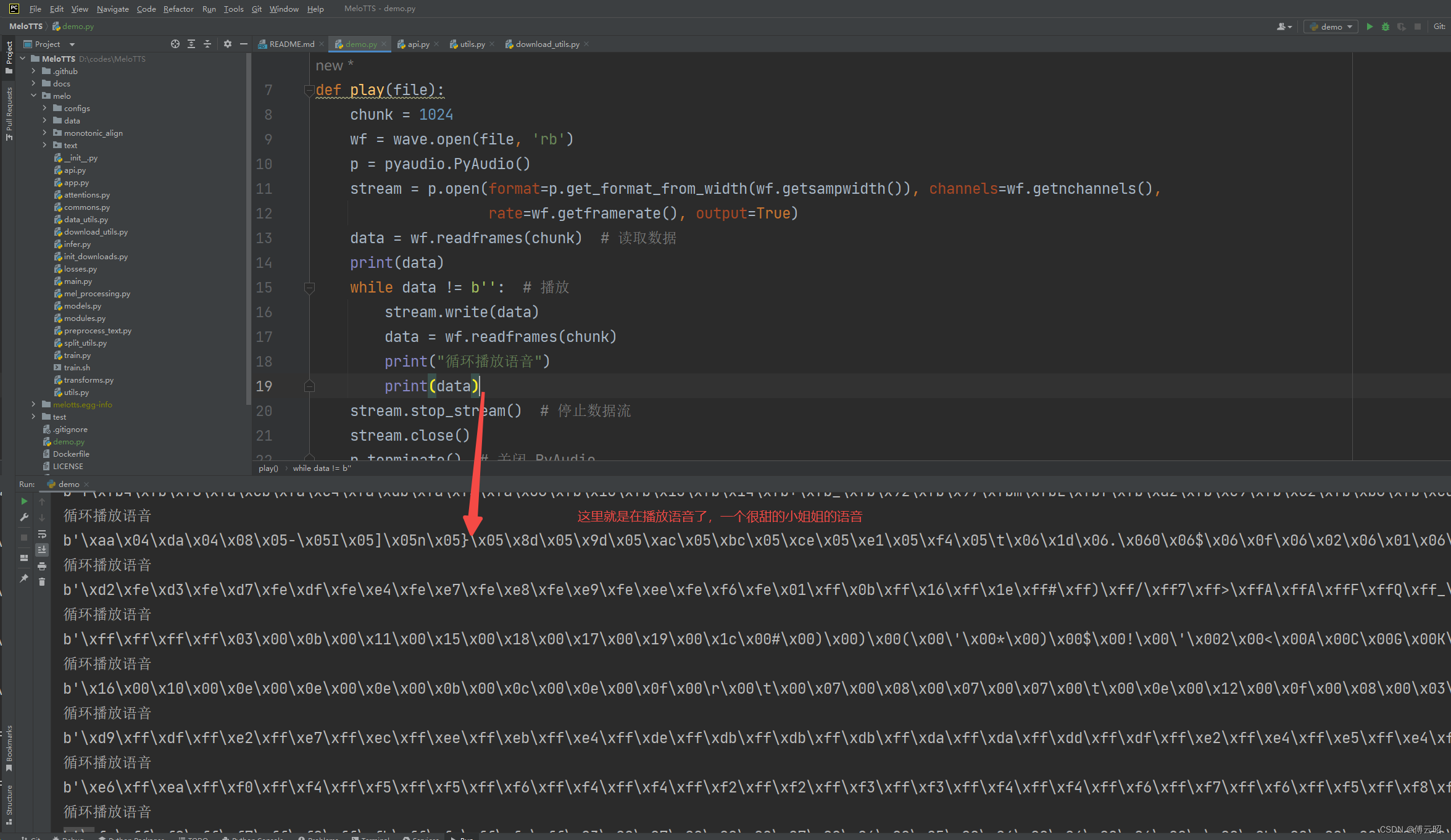


















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









