






 文章介绍了ChatGLM3,一个由清华大学KEG实验室和智谱AI合作的大语言对话模型,通过GLM预训练框架和自回归空格填充任务实现文本生成和理解。文章详细阐述了模型的原理、实战应用(包括推理、流式问答和模型微调),并提及了大模型微调方法,如LoRA,以减少参数量并加速训练和推理过程。
文章介绍了ChatGLM3,一个由清华大学KEG实验室和智谱AI合作的大语言对话模型,通过GLM预训练框架和自回归空格填充任务实现文本生成和理解。文章详细阐述了模型的原理、实战应用(包括推理、流式问答和模型微调),并提及了大模型微调方法,如LoRA,以减少参数量并加速训练和推理过程。
目录
官方链接:
THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型 (github.com)
1.简介
chatglm是清华KEG实验室和智谱AI联合发布的大语言对话模型。主要有两篇论文:
1.GLM: General Language Model Pretraining with Autoregressive Blank Infilling
2.GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL
chatglm-6b可以看作是chatglm-130b的一个迷你版,参数量少,可以本地运行。
接下来的都是关于第一篇论文的阅读笔记:
目的:因为bert是encoder自编码(autoencoding,AE)架构(完型填空,mask),可以双向attention(可以学习到前后的词),更加适合文本理解,但不适合生成,gpt自回归(autoregressive:AR)适合生成,只能单向attention(看不到后面的词),但不适合文本理解。GLM想做一统,即一种大语言模型,既可以做文本生成,又可以做文本理解。
方法:自回归的填空,2D的位置编码,填空序列乱序。
Introduction
-
三种框架:Transformer 的encoder架构(BERT),Transformer 的decoder架构(GPT),Transformer 的encoder-edcoder架构(T5)
-
BERT,完形填空,就是把句子随机mask一部分,(bidirectional attention)然后可以根据句子的前后理解来复原这个mask的词,适合阅读理解,不适合生成 (bidirectional attention:双向注意力,模型同时关注从左到右和从右到左两个方向的上下文信息,一个前向注意力权重,一个反向,GPT只能前向)
-
T5这种encoder-decoder架构,encoder使用的bidirectional attention,deocder使用unidirectional attention,然后使用cross attention 来结合encoder和decoder,既可以做语言理解有可以条件生成,不过参数量更大
-
GLM:随机空白(mask)一些连续的inputs tokens(AE),然后训练模型依次重构这些空白(AR)
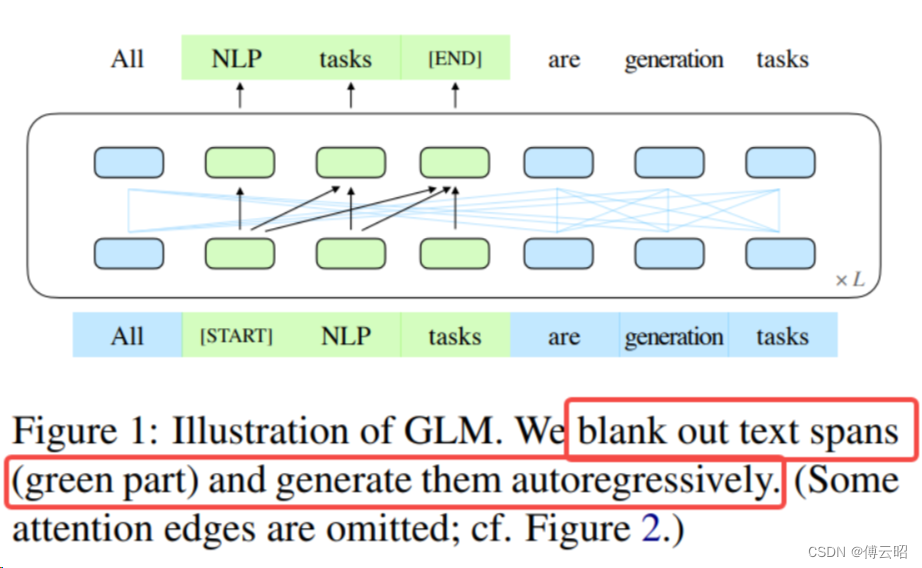
Method
GLM Pretraining Framework
Pretraining Objective
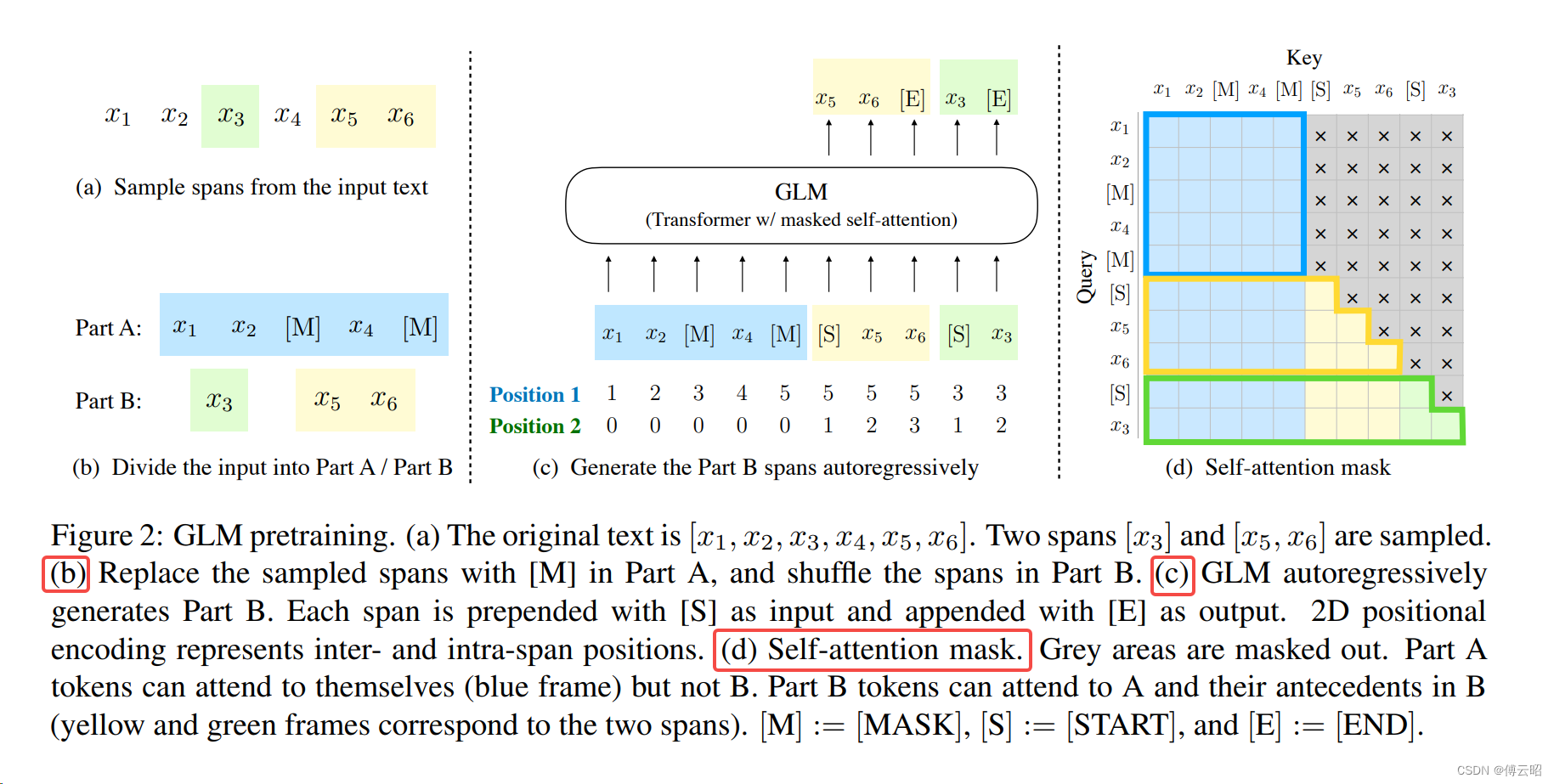
GLM自回归空格填充任务的技术细节:
1、输入x可以被分成两部分:Part A是masked 的文本 ,Part B由masked spans组成。假设原始输入文本是[x1, x2, x3, x4, x5, x6],采样的两个文本片段是[x3]以及[x5, x6]。那么mask后的文本序列是:x1, x2, [M], x4, [M],即Part A;同时我们需要对Part B的片段进行shuffle。每个片段使用[S]填充在开头作为输入,使用[E]填充在末尾作为输出。
2、二维位置编码:position1:记录词如x2在part A句子中的位置2,x1就是,x5就是5。position2:记录的是part B中的被span的词的位置。S=1,然后2,3连接。
3、GLM中attention mask:part A可以和part A进行self-cross attention,即该句子后面的词可以和前面的词attention,类似bert中的双向attention。part B中的每个词都只能和他前面的词做attention,不能和后面的词做attention,这就非常类似gpt的思想了。总之可以理解为被mask的词只能单向attention,没被mask的词可以双向attention。所以这就是GLM既可以做阅读理解又可以做生成的原理。part A encoder 学习,part B decoder预测被mask的token。
2.实战
2.1 推理
主要环境:huggingface的transformers
pip install transformers torch
import time
import torch
from transformers import AutoTokenizer, AutoModel
"""accelerate 实现多卡训练和推理"""
# torch.cuda.set_device(1)
tokenizer = AutoTokenizer.from_pretrained("chatglm3-6b/snapshots/9addbe01105ca1939dd60a0e5866a1812be9daea/",
trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm3-6b/snapshots/9addbe01105ca1939dd60a0e5866a1812be9daea/",
trust_remote_code=True).quantize(4).half().cuda() # 8
model = model.eval()
response , history = model.chat(tokenizer,"你好,宝宝", history = [])
print(88)
print(response)
t0 = time.time()
response , history = model.chat(tokenizer,"1+1=几阿", history = [])
print("time:",time.time() - t0)
print(response)
t0 = time.time()
response , history = model.chat(tokenizer,"我很累", history = []) # 如何变成一个个字的出来?
print("time:",time.time() - t0)
print(response)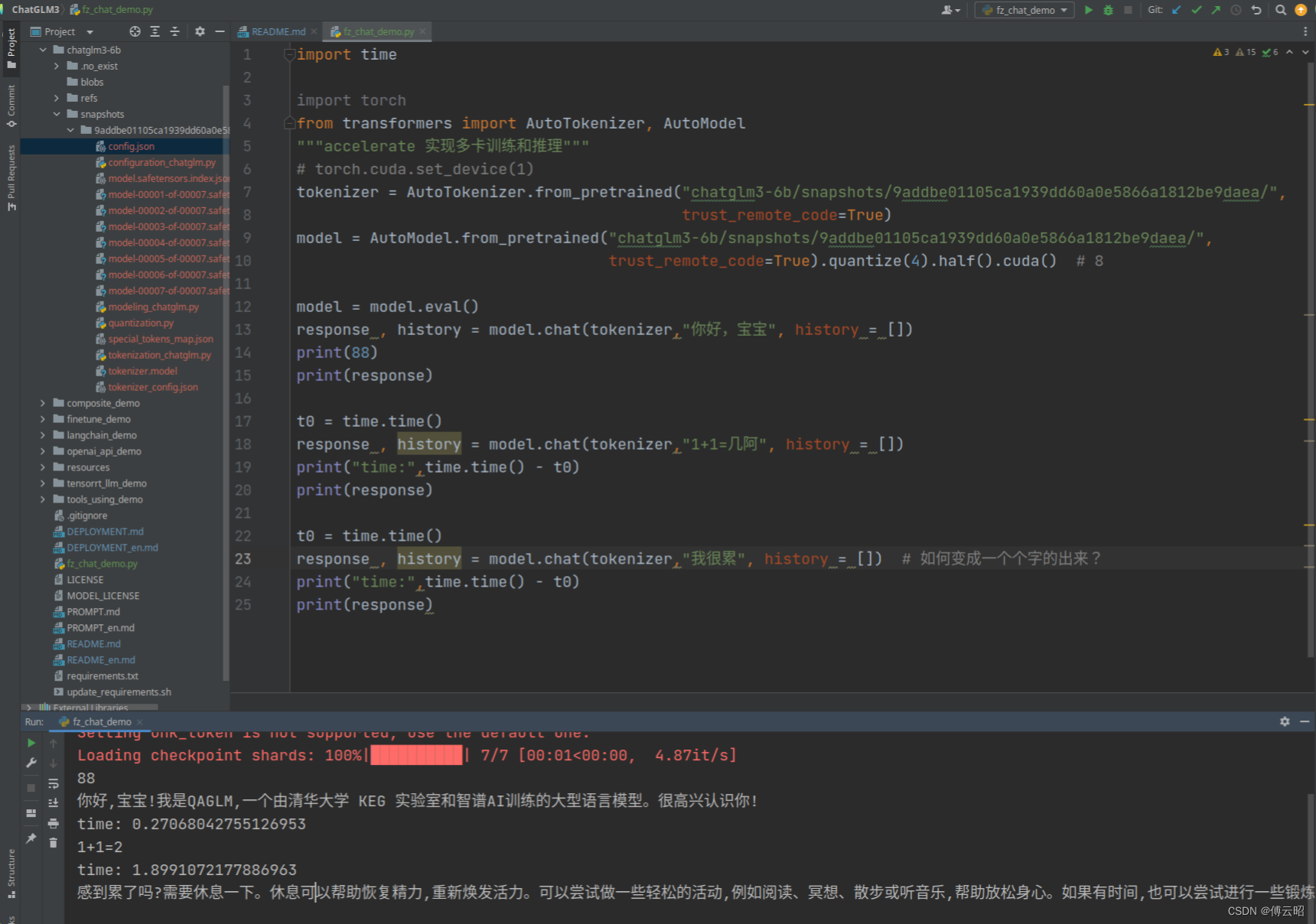
上面的结果都是等glm把结果全部生成后再返回response,需要很多时间,尝试流式问答。
2.2 流式问答
import time
import torch
from transformers import AutoTokenizer, AutoModel
"""accelerate 实现多卡训练和推理"""
torch.cuda.set_device(1)
tokenizer = AutoTokenizer.from_pretrained("chatglm3-6b/snapshots/9addbe01105ca1939dd60a0e5866a1812be9daea/",
trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm3-6b/snapshots/9addbe01105ca1939dd60a0e5866a1812be9daea/",
trust_remote_code=True).quantize(4).half().cuda() # 8
model = model.eval()
# history = [("你是谁","帕西尼人形机器人tora"),
# ("who are you","paxini's robot tora")]
history = []
t0 = time.time()
# response , history = model.chat(tokenizer,"爱因斯坦是谁", history = history) # 如何变成一个个字的出来?
# 调用 stream_chat 函数
response0 = ''
for response, new_history in model.stream_chat(tokenizer,"你知道爱因斯坦", history = history):
result = response.replace(response0, "")
print(result,end="")
response0 = response
print("time:",time.time() - t0)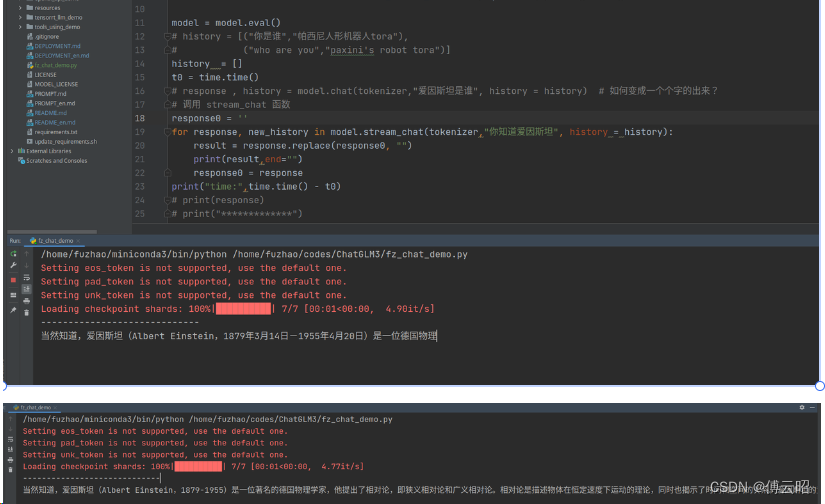
2.3 模型微调
参考:https://github.com/THUDM/ChatGLM3/blob/main/finetune_demo/lora_finetune.ipynb
总结:大模型是不适合直接train的,因为参数量大,你没那么多卡。所以微调的手段是,从一开始的最简单的就是类似于CV里面的比如冻结backbone,然后只训练head去微调一样。大模型的微调的主要方法是:
1.选取一部分参数更新,其他部分冻结
2.增加额外参数,如Prefix Tuning,prompt tuning在模型的头部引入新参数,Adapter在transformer里面的FFN的后面添加一层结构。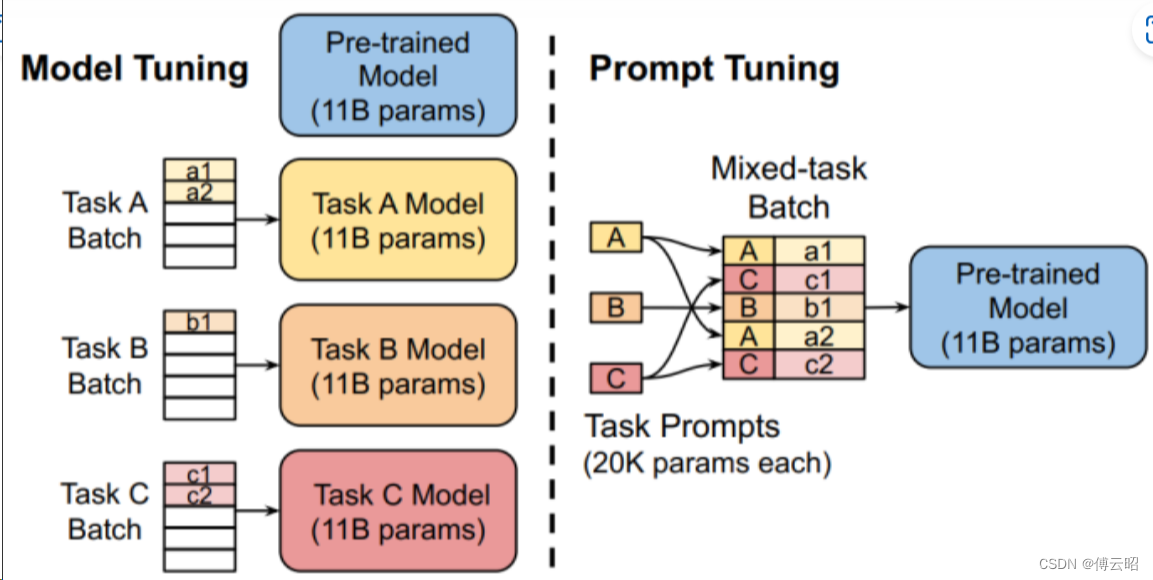
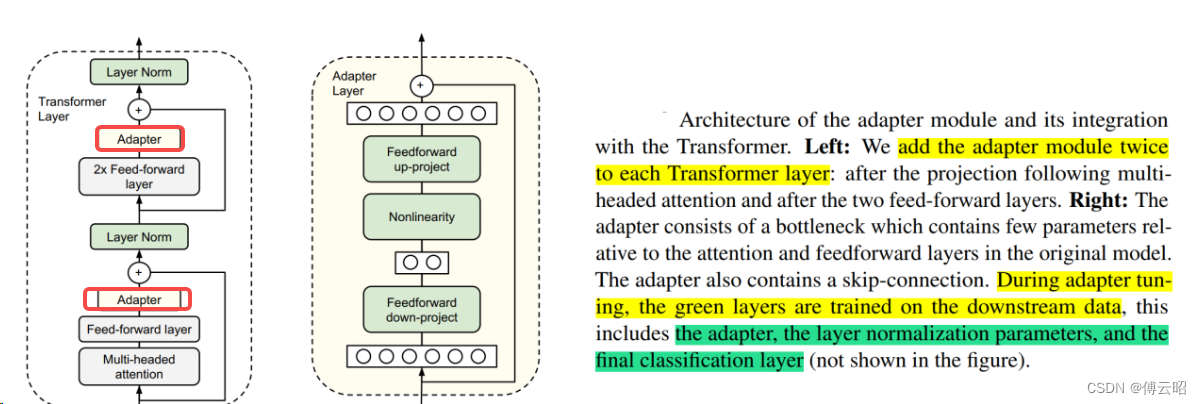
3.引入重参数化
数据格式AdvertiseGen:
{"conversations": [{"role": "user", "content": "类型#裙*裙长#半身裙"}, {"role": "assistant", "content": "这款百搭时尚的仙女半身裙,整体设计非常的飘逸随性,穿上之后每个女孩子都能瞬间变成小仙女啦。料子非常的轻盈,透气性也很好,穿到夏天也很舒适。"}]}

大模型微调概述
https://zhuanlan.zhihu.com/p/635152813
lora原理
What is Low-Rank Adaptation (LoRA) | explained by the inventor - YouTube 原作者的介绍
LoRA(论文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
lora的本质就是在PLM(pre_trained language model)旁边增加一个旁路,这个旁路是一个先降低维度再升高维度的操作,来模拟内秩。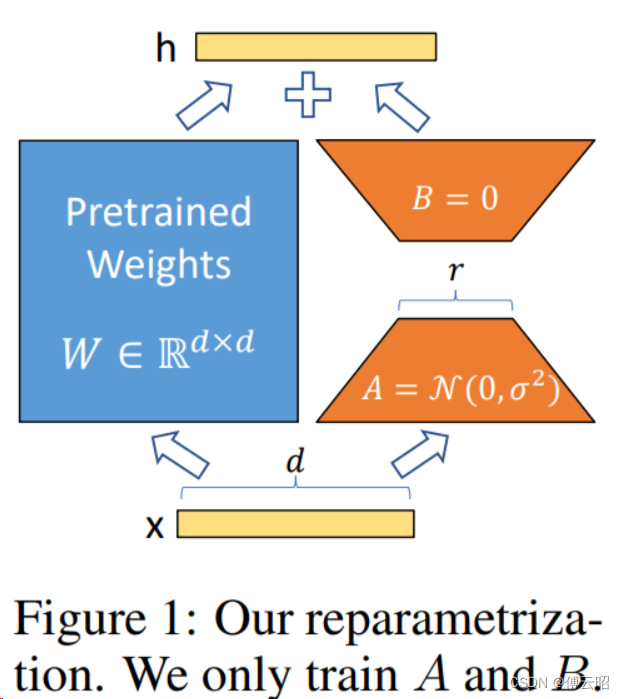
训练的时候固定PLM,只训练旁路,推理的时候把旁路先相乘合并再和PLM权重相加从而更新权重,几乎不影响速度,就一个相乘相加。
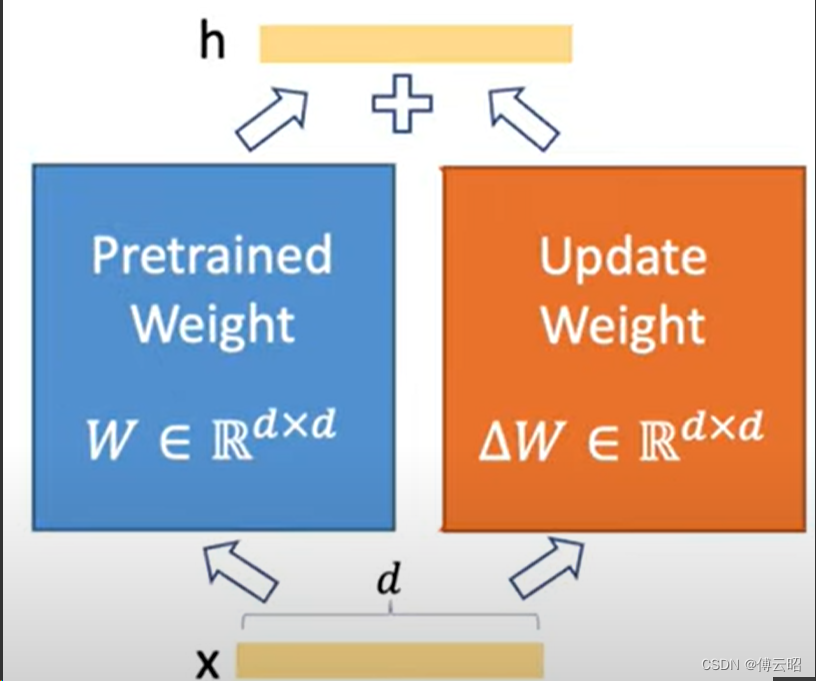
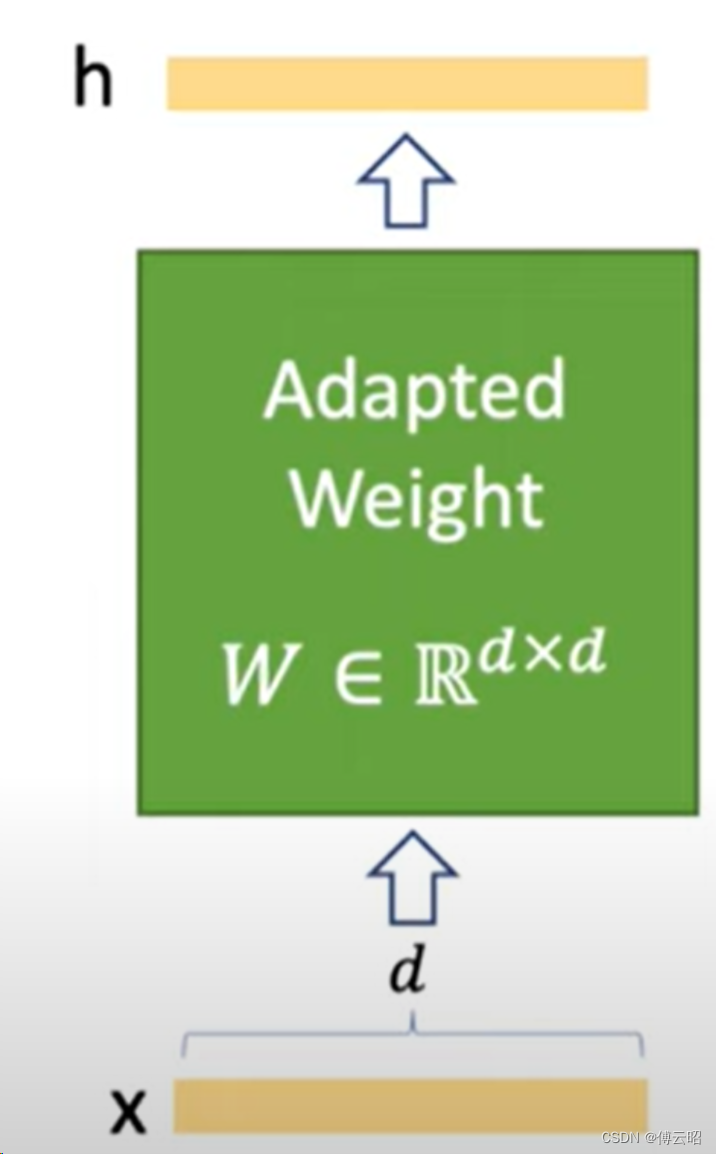
简单举例:
1000*1000的PLM weights --> lora 旁路:1000*10 + 10*1000
参数量:1000000 --> 20000
比例:1000000 / 20000 = 50倍
其实有点类似repconv,增加旁路,结果相加,可以参数合并
但lora是冻结主干,通过更新旁路来微调,然后把旁路的参数合并到主干PLM从而实现一个PLM参数的变化
repconv目前是为了增加梯度的丰富性(shortcut)和参数量,更好的fit,而参数合并是未来推理加速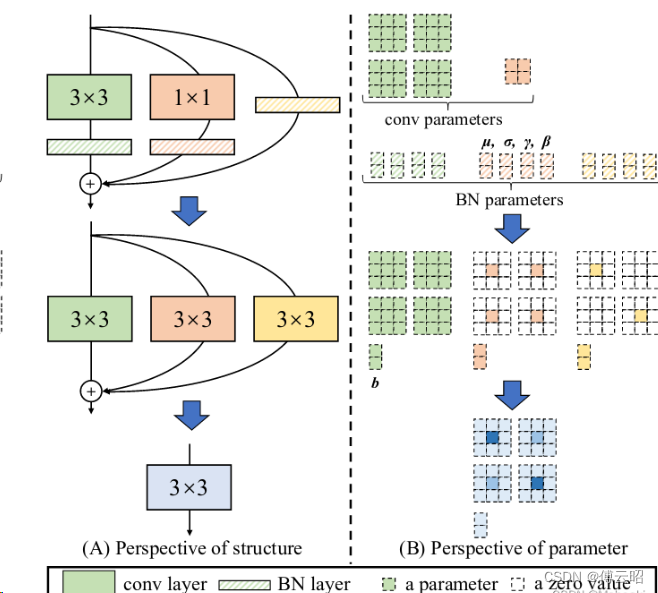
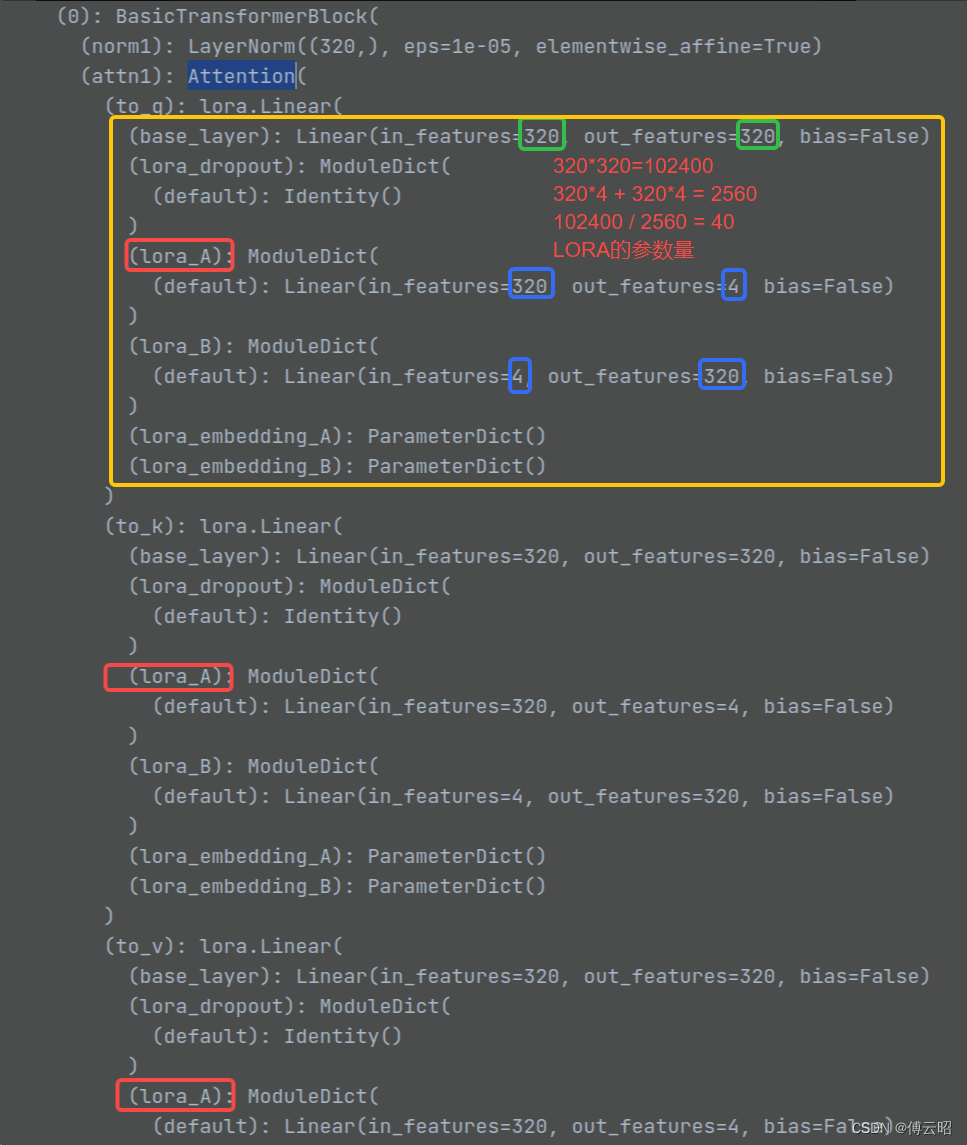
上面的案例表面参数量整整40倍
运行
参考官方教程部署即可。
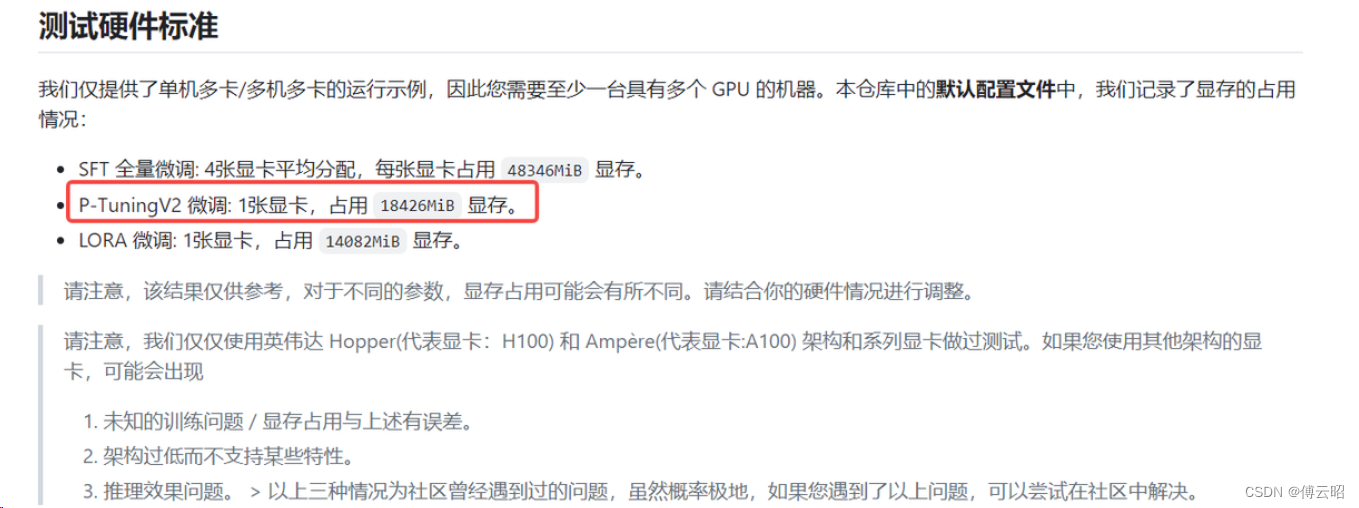
4090显存占用: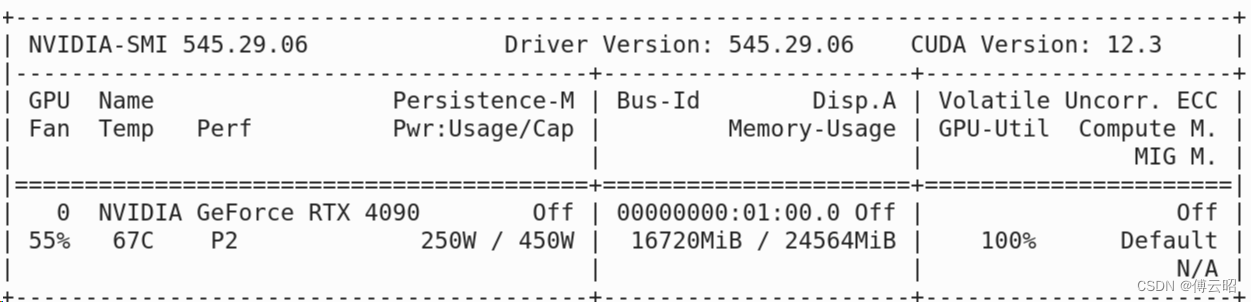
遇到的问题:loss = 0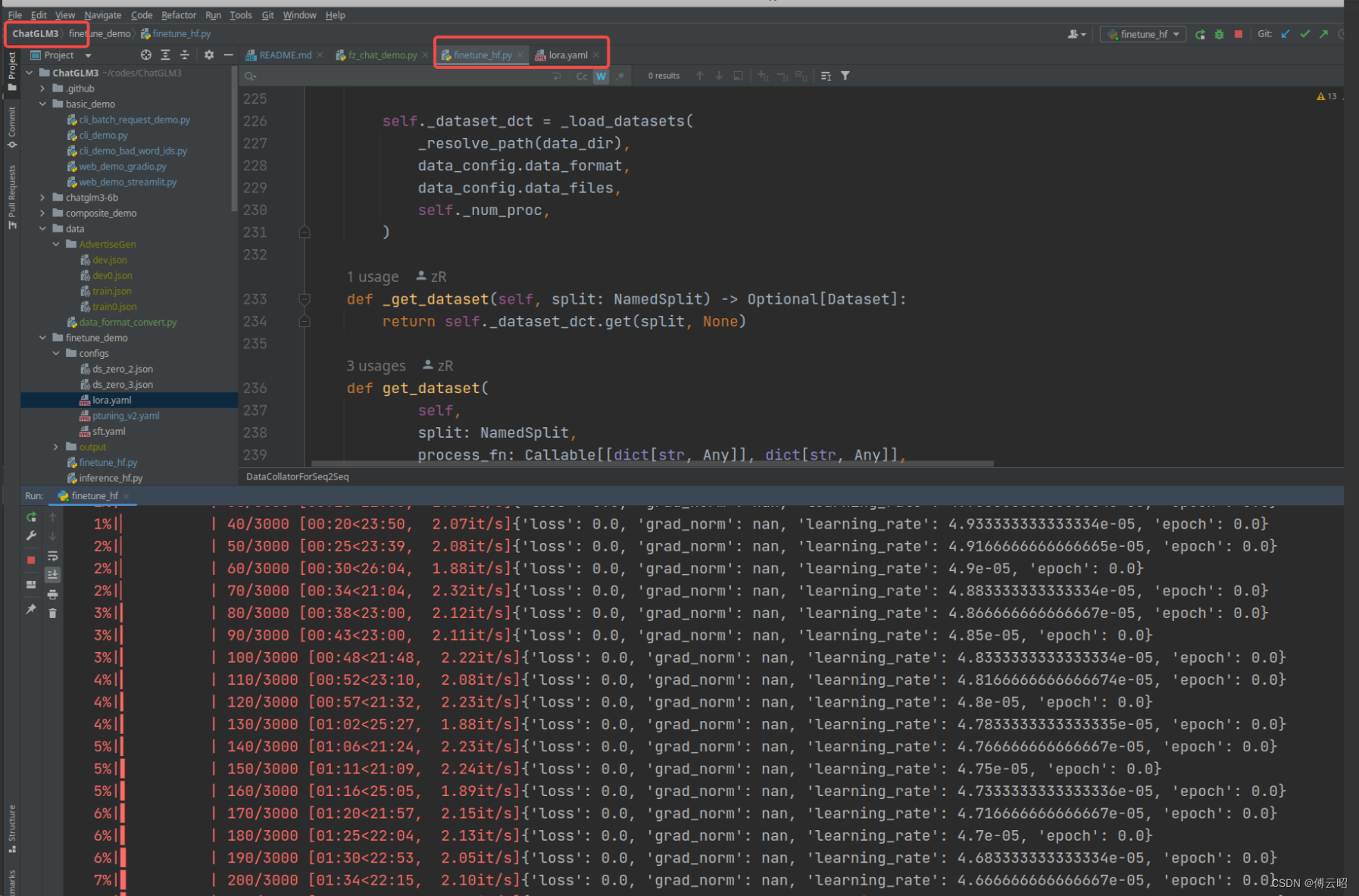
参考:https://github.com/THUDM/ChatGLM3/issues/767
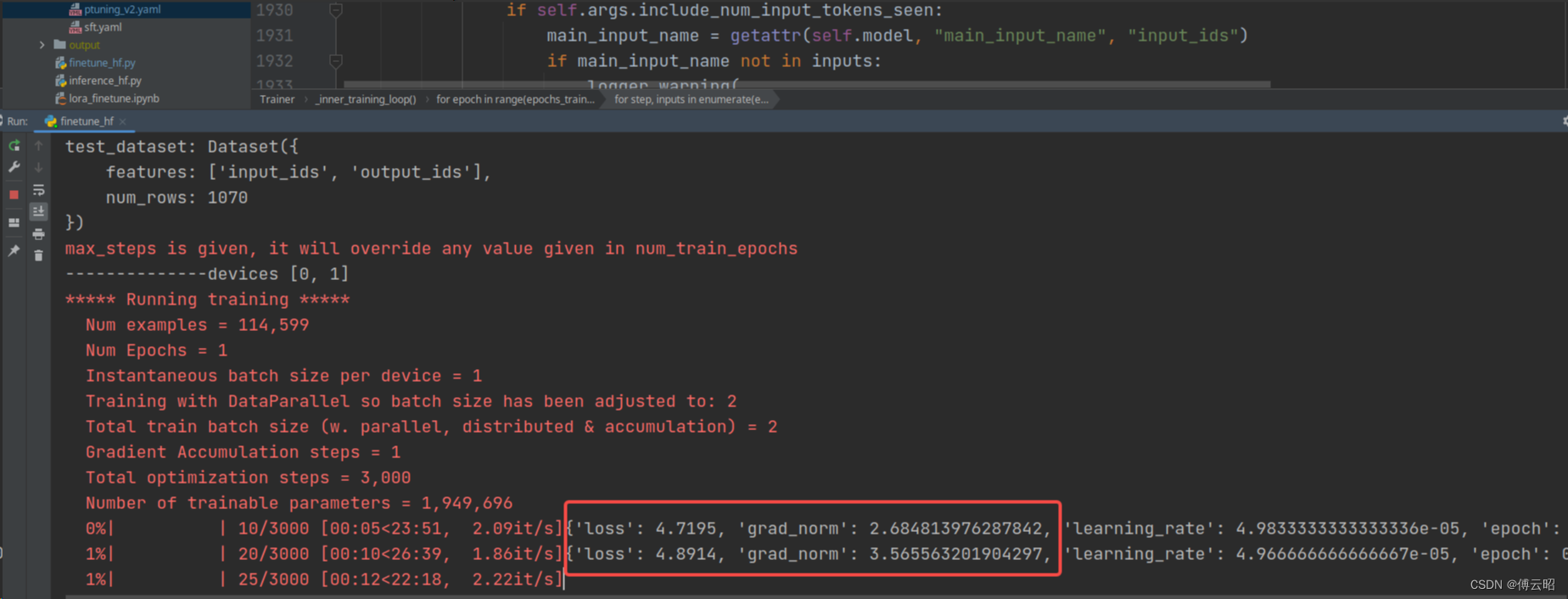
finetune完成: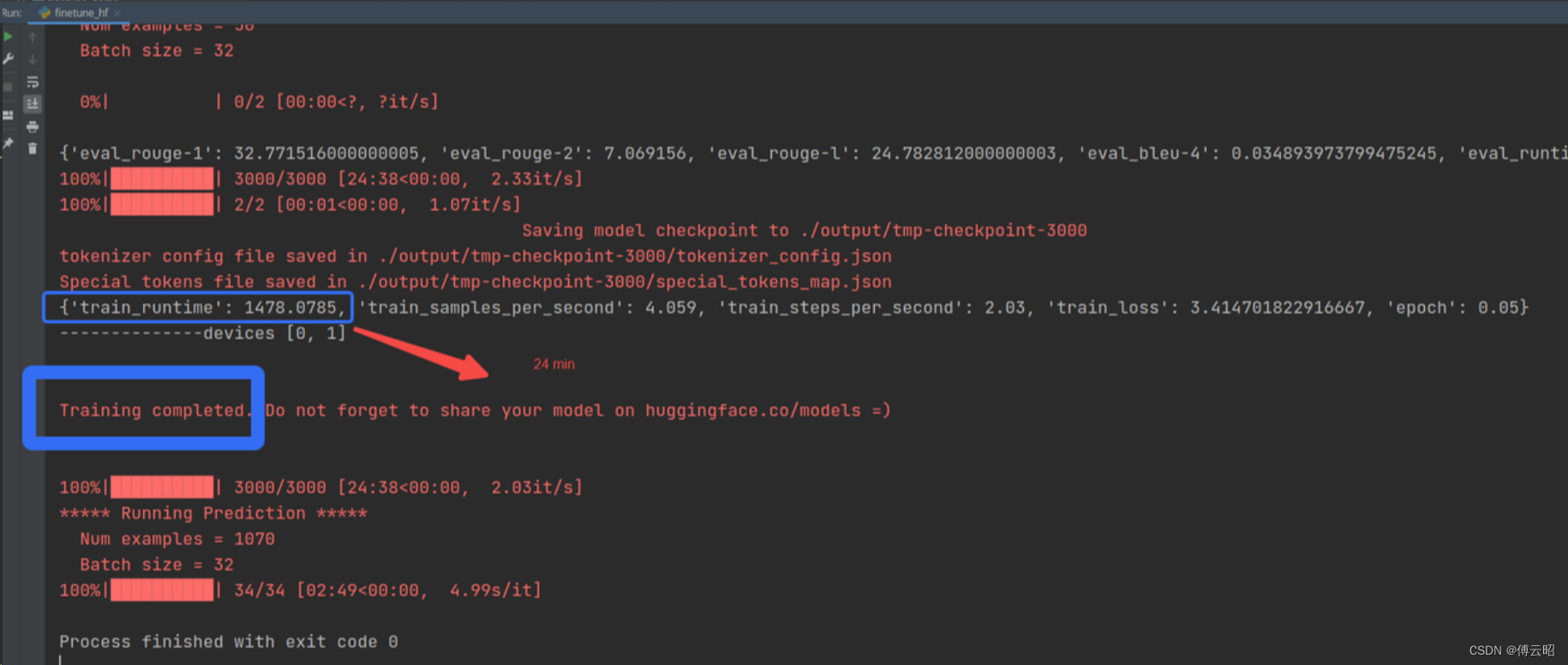
test:

















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









