




 本文介绍了数据集的结构,强调了特征工程在机器学习中的重要性,特别是特征抽取的过程。使用Pandas而非MySQL处理数据,以提高效率。文章提到了Scikit-learn作为Python的机器学习工具,提供了完善的文档和API,并详细讲解了如何进行字典数据的特征值化,包括使用DictVectorizer进行one-hot编码。
本文介绍了数据集的结构,强调了特征工程在机器学习中的重要性,特别是特征抽取的过程。使用Pandas而非MySQL处理数据,以提高效率。文章提到了Scikit-learn作为Python的机器学习工具,提供了完善的文档和API,并详细讲解了如何进行字典数据的特征值化,包括使用DictVectorizer进行one-hot编码。
2021/1/15
数据集
机器学习的数据大部分都是csv格式的。我们主要用Pandas来读取和整合数据。
不选择用mysql的原因:性能瓶颈,读取速度堪忧。
选择Pandas的原因:运用numpy 释放了GIL锁。实现正真的多线程。增加效率
一般从这3个数据集获得数据
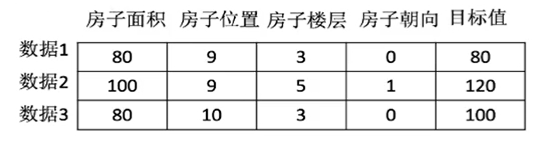
数据集的结构
其实就是特征值 + 目标值
如下图中:房子面积,房子位置,房子楼层,房子朝向 都代表着是数据的特征值,”目标值“就代表着目标值
当然有些数据 可以是没有目标值的。在机器学习中对于特征值缺失和重复值是不需要处理的,因为机器学习就是在不断的对样本进行学习,这样同一个样本 也可能会分析出来不同的信息。
特征工程(比较广的方面)
其实目的就是为了将知道的特征值处理好后,进入算法模型后 得到更有效更准确的预测。就像前我上一篇文章所介绍的,和炒菜一样 特征工程就是切菜,切的菜好适合菜的风格 炒出来就会更加入味。
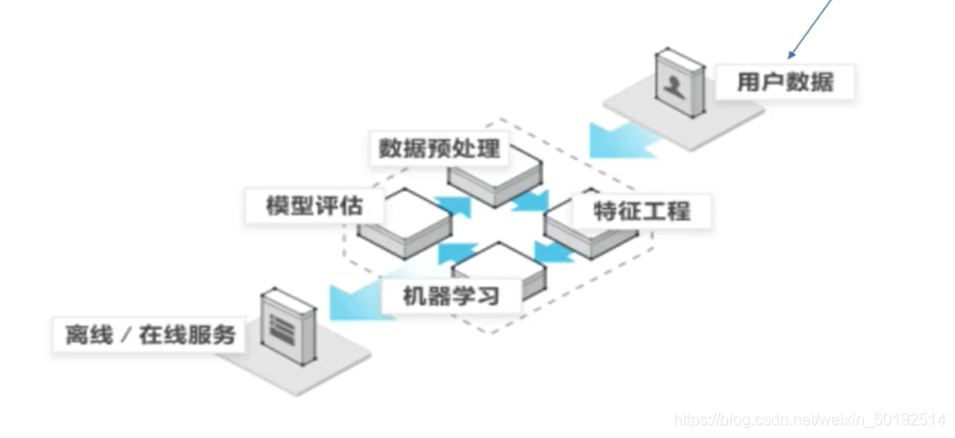
在像上图中可以看出来中间的4个部分 是一个循环工程。不断的进行微调,才会得出更好的预测结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









