




 本文介绍了集成学习的概念,包括同质和异质集成,并重点讲解了Bagging、随机森林、AdaBoost和梯度提升树(GBDT)以及XGBoost的原理和应用。通过实例分析,展示了它们在数据分类任务中的效果,其中Bagging在预测错误率和计算效率之间取得了平衡。
本文介绍了集成学习的概念,包括同质和异质集成,并重点讲解了Bagging、随机森林、AdaBoost和梯度提升树(GBDT)以及XGBoost的原理和应用。通过实例分析,展示了它们在数据分类任务中的效果,其中Bagging在预测错误率和计算效率之间取得了平衡。
一、集成学习
集成学习是将多个弱机器学习器结合,构建一个有较强性能的机器学习器的方法,也就是通过构建并合并多个学习器来完成学习任务,其中构成集成学习的弱学习器称为基学习器、基估计器。
1、根据集成学习的各基估计器类型是否相同,可以分为:同质和异质。
同质:指个体学习器全是同一类型。
异质:指个体学习器包含不同类型的学习算法。
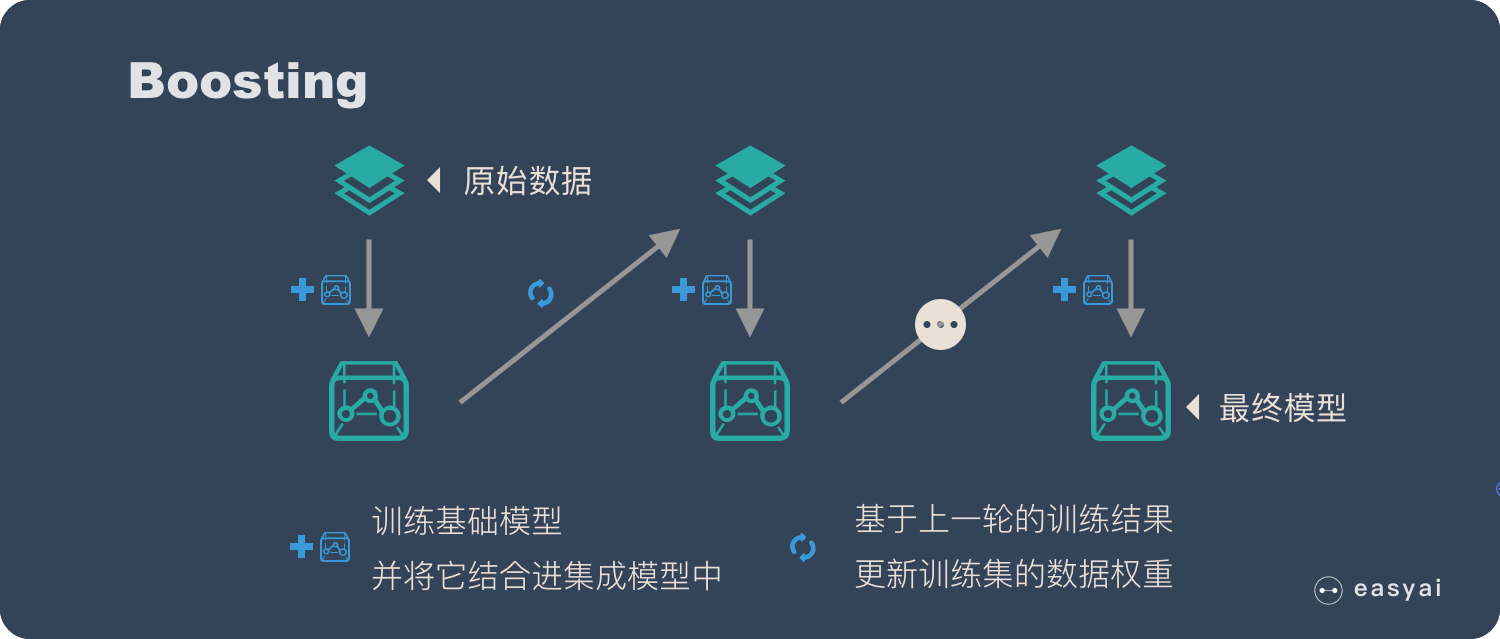
2、根据个体学习器的生成方式,将集成学习方法可以分为两类:boosting和bagging
boosting:它的特点是各个弱学习器之间有依赖关系。
bagging:它的特点是各个弱学习器之间没有依赖关系,可以并行拟合。
二、集成学习常用的方法
1、Bagging
(1)Bagging算法流程:
输入为样本集D={(x,y1),(x2,y2),...(xm,ym )} ,弱学习器算法, 弱分类器迭代次数T。
输出为最终的强分类器f(x)
对于t=1,2...,T:
a)对训练集进行第t次随机采样,每个样本被采样的概率为1/m,共采集m次,得到包含m个样本的采样集Dm
b)用采样集Dm训练第m个弱学习器Gm(x)
如果是分类算法预测,则T个弱学习器投出最多票数的类别或者类别之一为最终类别。如果是回归算法,T个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
(2)在scikit-learn中,Bagging方法使用统一的分类元估计器BaggingClassifier或者回归元估计器BaggingRegressor,输入的参数和随机子集抽取策略可指定。其中控制着子集大小(对于样例和特征)的参数为max_samples和max_features,bootstrap和bootstrap_features控制着样例和特征的抽取是有放回还是无放回的。
(3)使用BaggingClassifier()进行集成学习
# SVM
import numpy as np
from sklearn import svm,datasets
import matplotlib.pyplot as plt
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
kernel='poly'
clf_svm=svm.SVC(kernel=kernel,gamma=2) # 设置模型参数
clf_svm.fit(X_train,y_train)
y_svm_pred=clf_svm.predict(X_test)
svm_wrong_num=len(y[np.where(y_svm_p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









