






一、引言:从“整体”到“部件”,物体解析为何重要?
人类能轻松将物体分解为语义明确的部件(如“狗头”“鸟翅”),这种能力不仅帮助理解物体结构,还能推断姿态和动作。但在计算机视觉领域,现有方法多关注整体分割,忽视部件级解析的独特挑战:
1. 部件语义模糊:相似部件(如不同动物的头部)易混淆;
2. 逻辑不一致性:部件与所属物体缺乏关联(如分割出“车轮”却未归类到“汽车”);
3. 模型可解释性差:传统方法依赖黑箱模型,难以追踪分割逻辑。
针对这些问题,约翰霍普金斯大学团队提出CoCal框架,通过字典组件和逻辑约束,在PartImageNet和Pascal-Part-108上刷新SOTA性能,部分分割mIoU提升高达2.08%!
二、CoCal的核心创新:字典+对比学习+逻辑约束
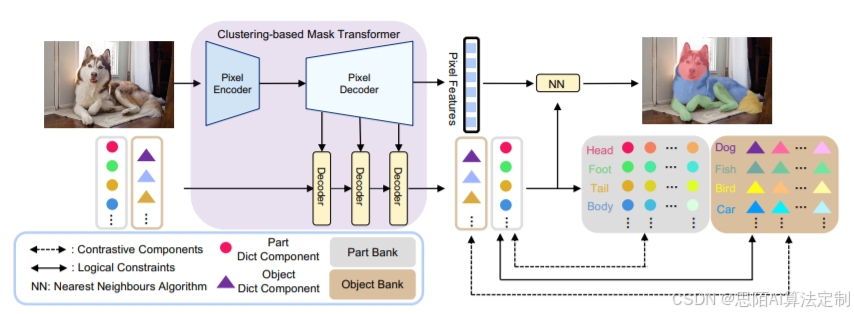
1. 字典组件:让每个语义类拥有专属“聚类中心”
传统分割模型使用大量冗余的“物体查询”,而CoCal引入全局字典,每个语义类(如“狗头”“汽车轮”)对应唯一的字典组件,实现一对一的像素聚类。
- 优势:训练时直接优化字典,推理时通过最近邻搜索快速分类,无需复杂后处理。
2. 对比学习:拉开不同类,拉近同类
CoCal在部件级和物体级分别构建字典,通过对比学习增强区分度:
- 同类靠近:同类部件(如不同狗的头部)在特征空间更接近;
- 异类远离:不同类部件(如“狗头”与“鸟头”)特征差异被放大。
引用:对比学习借鉴了Wang等人(2021)的像素对比思路,但CoCal将其扩展到字典组件级别,提升聚类效果。
3. 逻辑约束:部件必须属于某个物体
人类知道“车轮属于汽车”,CoCal通过跨层级对比损失建模这种逻辑:
- 部件-物体关联:部件字典组件与其所属物体组件特征对齐(如“车轮”靠近“汽车”);
- 后处理校正:若某像素被分类为“车轮”,但对应“汽车”概率低,则强制修正为最相关物体。
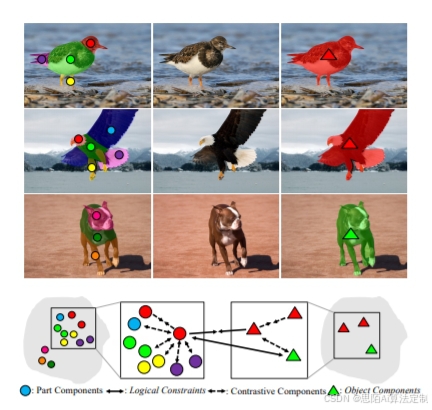
三、实验结果:性能全面领先,细节更精准
1. 基准测试表现
- PartImageNet:CoCal以70.31%的部件mIoU刷新纪录,超越前SOTA模型kMaX-DeepLab 1.79%;
- Pascal-Part-108:部件mIoU达49.8%,物体级分割指标提升2.1%。
2. 可视化对比
如图1所示,CoCal的分割边界更清晰,漏检率更低(如准确识别“鸟喙”等细小部件)。
四、为什么CoCal更优秀?关键设计拆解
1. 记忆库大小:实验表明,记忆库容量为100时效果最佳,过大或过小均导致性能下降(冗余或样本不足);
2. 负样本数量:选择Top 100最难负样本,平衡学习难度与效率;
3. 通用性:CoCal可适配MaskFormer等主流框架,均带来2-3%的mIoU提升。

五、总结:可解释分割的新范式
CoCal通过字典组件明确语义关联,结合对比学习与逻辑约束,不仅提升分割精度,还让模型决策过程更透明。未来可应用于自动驾驶(精确识别车辆部件)、医学影像(器官与病灶关联分析)等领域。
> 论文信息:
> Zhang T, Yu Q, Yuille A, et al. CoCal: A Dictionary-based Framework for Interpretable and Consistent Object Parsing. arXiv:2502.19540, 2024.
> 代码开源:https://github.com/ollie-ztz/CoCal
关注我们,获取更多AI前沿技术解读!


















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









