






导语
在图像与文本的跨模态学习掀起热潮后,音频与文本的融合成为AI领域新焦点。近日,一项研究重磅推出LAION-Audio-630K——目前全球最大的公开音频-文本配对数据集,并基于此构建了多模态对比学习模型,在音频检索、零样本分类等任务中刷新纪录!这项技术如何突破传统瓶颈?又将为语音助手、内容创作带来哪些变革?一文揭秘!
一、为何音频多模态学习如此重要?
音频是仅次于图像和文本的第三大信息载体,但传统音频模型依赖人工标注数据,成本高、规模受限。例如,训练一个“听音辨物”的AI,需预先标注海量声音类别(如“狗叫”“雨声”),耗时耗力。
多模态对比学习的突破在于:无需精细标注,仅需“音频-文本”配对数据,即可让AI自主学习声音与语义的关联,实现“听到声音就能联想描述,看到文本就能匹配声音”。
二、全球最大音频-文本数据集:LAION-Audio-630K
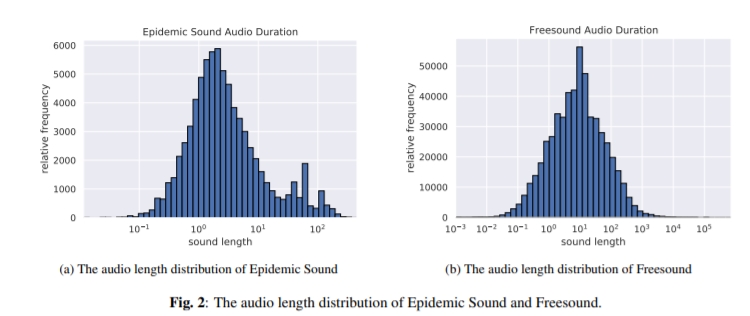
研究团队从BBC音效库、Freesound等8个公开平台收集了63万+音频-文本对,总时长超4300小时,涵盖人声、自然音效、工具声等多元场景。其规模远超此前同类数据集(如Clotho仅5929对),堪称“音频界的ImageNet”。
关键创新:
1. 关键词到描述的智能增强:利用T5模型将简单标签(如“洗衣机门关闭”)自动扩展为自然语句(“某人关闭洗衣机金属门并发出闷响”),提升语义丰富度。
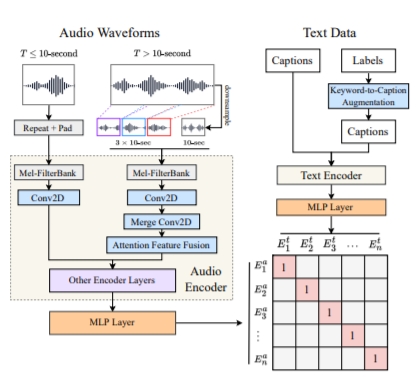
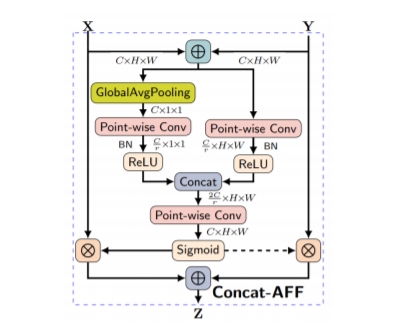
2. 兼容可变长度音频:通过特征融合技术,模型既能捕捉长音频的全局特征(如整段对话),又能聚焦局部细节(如特定音效),解决了传统模型处理长音频效率低下的痛点。
三、实验结果:零样本学习表现惊艳
模型在三大任务中表现亮眼:
1. 文本到音频检索:输入“海浪声”,模型从数万音频中精准匹配,Top1准确率提升至36.7%(较前最佳模型提高4%)。
2. 零样本音频分类:无需训练数据,直接根据文本提示(如“这是XX类声音”)分类,在ESC-50数据集上准确率达91%,超越此前最优结果8.4%。
3. 监督式分类:微调后模型在VGGSound数据集上分类准确率75.4%,逼近专业音频模型的性能。
四、应用场景:让AI更懂“听”与“说”
1. 智能内容创作:短视频平台可自动为UGC音频生成描述标签,提升搜索效率。
2. 无障碍技术:为视障用户实时解析环境声音(如“前方有车辆靠近”)。
3. 语音助手升级:更精准理解模糊指令(如“播放那个下雨还有雷声的音乐”)。
4. 影视音效库:通过文本快速检索匹配音效,节省后期制作时间。
五、未来展望
研究团队计划进一步扩大数据集规模,并探索音频合成、分离等新任务。随着多模态技术的成熟,“听-说-看”全感知AI或将加速到来。
结语
这项研究不仅为音频AI开辟了新范式,更验证了“数据规模+多模态融合”的技术潜力。或许不久的将来,AI不仅能“看图说话”,还能“听音作文”,真正打破感官界限,重塑人机交互体验。
论文链接:https://arxiv.org/abs/2211.06687


















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









