







堆排序
https://www.kuangstudy.com/bbs/1402601383655378946
线索二叉树 不是重点
本质
二叉树的遍历本质上是将一个复杂的非线性结构转换为线性结构,使每个结点都有了唯一前驱和后继(第一个结点无前驱,最后一个结点无后继)。对于二叉树的一个结点,查找其左右子女是方便的,其前驱后继只有在遍历中得到。为了容易找到前驱和后继,有两种方法。一是在结点结构中增加向前和向后的指针,这种方法增加了存储开销,不可取;二是利用二叉树的空链指针。
存储结构
线索二叉树中的线索能记录每个结点前驱和后继信息。为了区别线索指针和孩子指针,在每个结点中设置两个标志ltag和rtag。
当tag和rtag为0时,leftChild和rightChild分别是指向左孩子和右孩子的指针;否则,leftChild是指向结点前驱的线索(pre),rightChild是指向结点的后继线索(suc)。由于标志只占用一个二进位,每个结点所需要的存储空间节省很多。 [3]
现将二叉树的结点结构重新定义如下:
| lchild | ltag | data | rtag | rchild |
|---|---|---|---|---|
其中:ltag=0 时lchild指向左儿子;ltag=1 时lchild指向前驱;rtag=0 时rchild指向右儿子;rtag=1 时rchild指向后继。
讲的太乱 实现错误 ,以后再补;
霍夫曼树 重点
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
哈夫曼树又称为最优树.
1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
2、结点的权及带权路径长度
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
3、树的带权路径长度
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
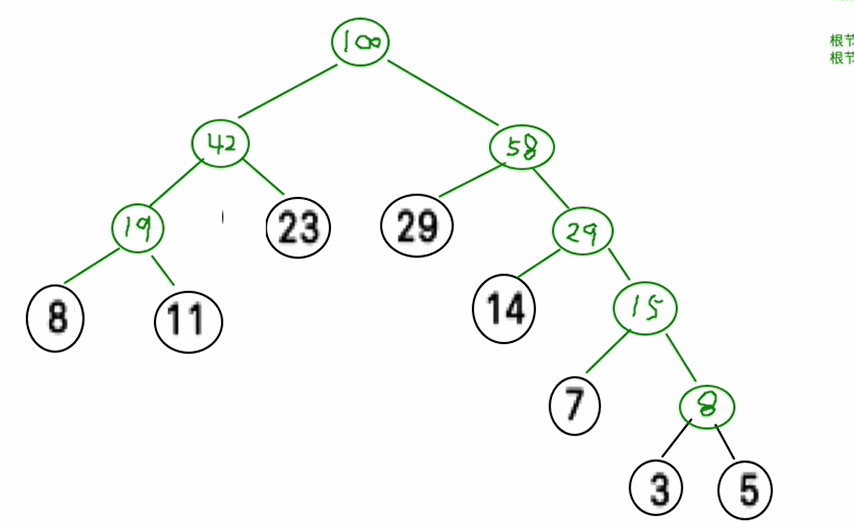
wpl最小成为霍夫曼树

霍夫曼树的实现
思路图
节点类
package suanfa03;
public class node implements Comparable<node> {
int data;
node left;
node right;
public node(int data) {
this.data = data;
}
@Override
public int compareTo(node o) {
return -(this.data-o.data);
}
@Override
public String toString() {
return "node{" +
"data=" + data +
'}';
}
}
实现类
package suanfa03;
import java.util.ArrayList;
import java.util.Collections;
import static org.junit.jupiter.api.Assertions.*;
class nodeTest {
public static void main(String[] args) {
int[] arr={8,11,23,29,14,7,3,5};
node node = huFMan(arr);
System.out.println(node);
}
public static node huFMan(int[] arr){
//将数组分割为一个个二叉树,存入集合
ArrayList<node> nodes = new ArrayList<>();
for (int node:arr){
nodes.add(new node(node));
}
// 循环进行 ==》 排序 / 取出最小的二叉树/移除/ 放入原来的集合
while (nodes.size()>1){
Collections.sort(nodes);
//取出最后两个节点
node left= nodes.get(nodes.size()-1);
node right= nodes.get(nodes.size()-2);
node parent= new node(left.data+right.data);
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
// System.out.println(nodes);
return nodes.get(0);
}
}
霍夫曼编码

长度396


长度122 压缩70%
霍夫曼编码实现
节点类
package suanf04;
public class zipNode implements Comparable<zipNode> {
//可能为空所以使用封装类
Byte data;
//权重
int weight;
//左右 节点
zipNode left ;
zipNode right;
public zipNode(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(zipNode o) {
return o.weight-this.weight;
}
@Override
public String toString() {
return "zipNode{" +
"data=" + data +
", weight=" + weight +
'}';
}
}
霍夫曼编码
package suanf04;
import java.io.*;
import java.util.*;
public class zipHuffMan {
public static void main(String[] args) {
/* String msg= "can you can a can as a can canner can a can.";
// //我们编码的不是具体字符串而是具体是数组;
byte[] bytes = msg.getBytes();
// //进行huffman 编码
byte[] bytes1 = huffMan(bytes);
// System.out.println(bytes.length);
// System.out.println(bytes1.length);
byte[] reByte= reZip(bytes1,huffCode);
System.out.println(new String(reByte));*/
String input= "F:\\A-所有学习的代码测试\\interview\\first01\\25.docx";
String ouput="8.zip";
try {
zipFile(input,ouput);
} catch (IOException e) {
e.printStackTrace();
}
try {
unZip("F:\\A-所有学习的代码测试\\interview\\8.zip","81.docx");
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void unZip(String input,String output) throws IOException, ClassNotFoundException {
//创建一个输入流,用对象流获取
FileInputStream fos = new FileInputStream(input);
ObjectInputStream oos = new ObjectInputStream(fos);
// 读取byte数组
byte[] bytes = (byte[]) oos.readObject();
//获取霍夫曼编码表,关闭流
Map<Byte, String> byteStringMap = (Map<Byte, String>) oos.readObject();
oos.close();
fos.close();
//解码 /创建输出流 /写出数据
byte[] zip = zip(bytes, byteStringMap);
FileOutputStream fileOutputStream = new FileOutputStream(output);
fileOutputStream.write(zip);
}
public static void zipFile(String input,String output) throws IOException {
//创建一个输入流
FileInputStream fileInputStream = new FileInputStream(input);
//创建一个输入流指向 存入一个大小相同的byte数组
byte[] bytes = new byte[fileInputStream.available()];
//读取文件内容
fileInputStream.read(bytes);
fileInputStream.close();
//使用霍夫曼进行编码
byte[] huffZip = huffMan(bytes);
//输出流
FileOutputStream fileOutputStream = new FileOutputStream(output);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(huffZip);
objectOutputStream.writeObject(huffCode);
objectOutputStream.close();
fileInputStream.close();
}
static Map<Byte,String> huffCode=new HashMap<>();
private static byte[] huffMan(byte[] bytes) {
//统计每一个字符出现的次数,放入一个集合,
List<zipNode> nodes = getNodes(bytes);
//船舰一个霍夫曼树
zipNode tree = getHuffMantree(nodes);
// System.out.println(tree);
//床架你一个霍夫曼编码表
huffCode=getCodes(tree);
// System.out.println(huffCode);
//编码
byte[] b =zip(bytes,huffCode);
// System.out.println(b);
//使用霍夫曼编码进行解压缩
return b;
}
private static byte[] reZip(byte[] b, Map<Byte, String> huffCode) {
StringBuilder sb= new StringBuilder();
for (int i = 0; i <b.length ; i++) {
byte b1 = b[i];
//判断是否是最后一个
boolean b2 = (i == b.length - 1);
//是最后一个取反
sb.append(byteToEight(!b2,b1));
}
//传入的 byte类型的数字 转化为int 就是三十2 位 需要调整
// String s =Integer.toBinaryString(b1);
// System.out.println(sb);
//使用霍夫曼编码进行解码 ,
// 1.键值对调换
// System.out.println(huffCode);
Map<String,Byte> re =new HashMap<>();
huffCode.forEach((a,c)->{
re.put(c,a);
});
// System.out.println(re);
//创建一个集合存储不定长的byte
List<Byte> list= new ArrayList<>();
//处理字符串
for (int i = 0; i <sb.length() ;) {
int count= 1 ;
boolean flag=true;
Byte aByte=null;
while (flag){
String key =sb.substring(i,i+count);
aByte = re.get(key);
if (aByte==null){
count++;
}else flag=false;
}
// System.out.println(aByte);
list.add(aByte);
i+=count;
}
// System.out.println(list);
//list 集合转为数组
byte[] bz = new byte[list.size()];
for (int i = 0; i < bz.length; i++) {
bz[i]=list.get(i);
}
return bz;
}
private static String byteToEight(boolean flag,byte b1) {
int temp = b1;
//-1 的值是-1的正确表示应该是1111 1111 因为C语言里,对整型数是采用Two’s complement表示法,
// 而前面我的理解则是Sign-Magnitude表示法(浮点数采用该法)。
// 在Two’s complement表示法里,1000 0001表示的是-127。
if (flag){
temp|=256;
}
String s = Integer.toBinaryString(temp);
if (flag){
// System.out.println(s.length());
// System.out.println(s);
// return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
return s.substring(s.length()-8);
}else {
return s;
}
}
/**
* 进行霍夫曼变化
* @param bytes
* @param huffCode
* @return
*/
private static byte[] zip(byte[] bytes, Map<Byte, String> huffCode) {
StringBuilder sb =new StringBuilder();
for (byte aByte : bytes) {
sb.append(huffCode.get(aByte));
}
// System.out.println(sb);
int len;
if (sb.length()%8==0){
len=sb.length()/8;
}else {
len=sb.length()/8+1;
}
//压缩后的byte
byte[] a= new byte[len];
int index=0;
for (int i = 0; i <sb.length() ; i+=8) {
String str;
if (i+8>sb.length()){
str=sb.substring(i);
}else {
str=sb.substring(i,i+8);
}
// System.out.println(str);
//Integer的10111010 二进制 转化十进制
byte b = (byte) Integer.parseInt(str, 2);
// System.out.println(str+"+"+b);
a[index]=b;
index++;
}
return a;
}
static StringBuilder sb=new StringBuilder();
static Map<Byte,String> bs=new HashMap<>();
private static Map<Byte, String> getCodes(zipNode tree) {
if (tree==null){return null;}
getCode(tree.left,"0",sb);
getCode(tree.right,"1",sb);
return bs;
}
private static void getCode(zipNode node, String code, StringBuilder sb) {
StringBuilder sb2=new StringBuilder(sb);
sb2.append(code);
if (node.data==null){
getCode(node.left,"0",sb2);
getCode(node.right,"1",sb2);
}else {
bs.put(node.data,sb2.toString());
}
}
private static zipNode getHuffMantree(List<zipNode> nodes) {
while (nodes.size()>1){
//排序,权值大在前
Collections.sort(nodes);
zipNode left = nodes.get(nodes.size() - 1);
zipNode right = nodes.get(nodes.size() - 2);
zipNode zipNode = new zipNode(null, left.weight + right.weight);
//取出二叉树变成新的树的孩子
zipNode.left=left;
zipNode.right=right;
//删除原先的二叉树
nodes.remove(left);
nodes.remove(right);
//把新树加入 原本的集合中
nodes.add(zipNode);
}
return nodes.get(0);
}
//把byte数组转为弄得集合
private static List<zipNode> getNodes(byte[] bytes) {
List<zipNode> nodes =new ArrayList<>();
//存储每一个出现多少次
HashMap<Byte, Integer> count = new HashMap<>();
for (byte aByte : bytes) {
//每次先从 hashmap数组中获取 对应的byte
Integer integer = count.get(aByte);
//不存在赋予一个
if (integer==null){
count.put(aByte,1);
}else {
//存在数量加一
count.put(aByte,integer+1);
}
}
// System.out.println(count);
//把每一个键值对 变成 node
count.forEach((a,b)->{
nodes.add(new zipNode(a,b));
});
// nodes.forEach(a->{
// System.out.println(a.data);
// });
return nodes;
}
}
这里成功了这没有成功 ,成功压缩了,到会导致乱码















 1773
1773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









