







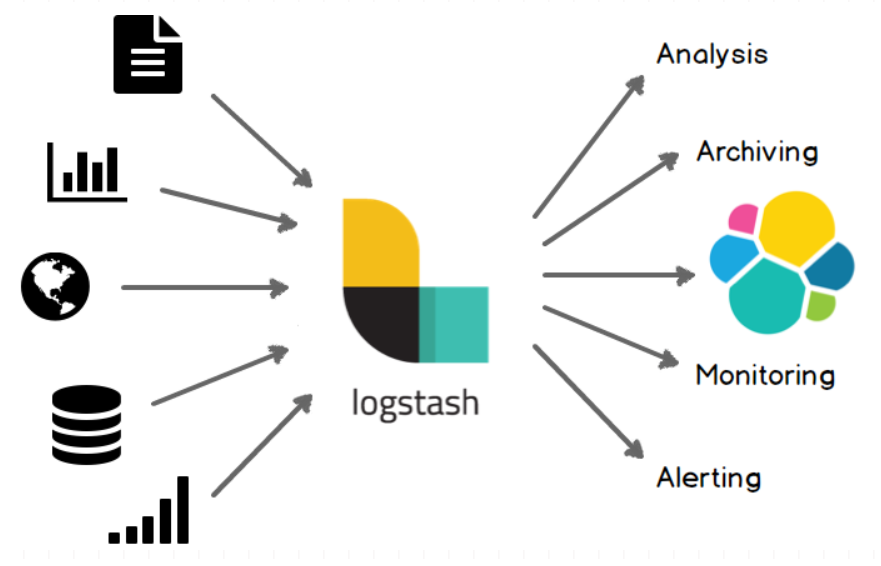
1、logstash介绍
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
2、工作原理
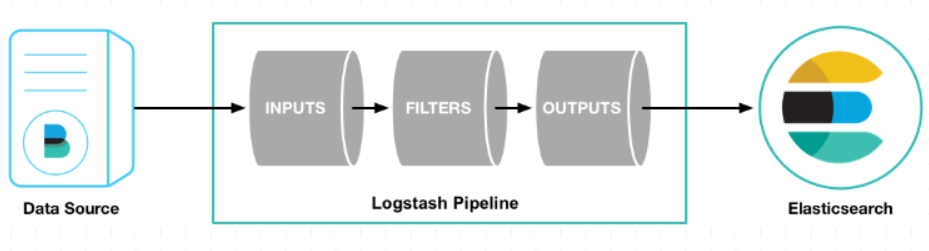
Logstash 事件处理管道有三个阶段:输入 → 过滤 → 输出。输入生成事件,过滤器修改事件,然后输出到其他地方。输入和输出支持编解码器,使您能够在数据进入或退出管道时对其进行编码或解码,而不必使用单独的过滤器。
详细可参考文档:
https://www.elastic.co/guide/en/logstash/current/pipeline.html#pipeline
2.1、input
input输入端,可以将数据通过配置 input 输入到 logstash 的管道中,常用的输入插件有:
- filebeat
- kafka
- redis
- syslog 等
2.2、filter
filter过滤器是 Logstash 管道中的中间处理设备。您可以使用各种筛选器及插件组合以满足达到最终需求的操作,一些有用的插件包括:
- grok: 解析和构造任意文本。Grok 是目前 Logstash 中解析非结构化日志数据为结构化和可查询数据的最佳方式。
- json: 对 json 格式的数据进行处理。
- drop: 完全删除事件,例如 debug 事件。
- mutate: 对事件字段执行通用转换。您可以重命名、删除、替换和修改事件中的字段。
- json_encode: 转换成 json 格式的数据。
2.3、output
output输出端,是logstash最后一步,也就是管道的出口, 事件可以通过多个输出,但是一旦所有输出处理完成,事件就完成了它的执行。一些常用的输出包括:
- es
- -fiel(磁盘文件)
3、logstash配置
项目中节点较多方便配置增加了kafka中间件。
配置文件如下:
vim test.conf
input {
kafka {
client_id => "test"
group_id => "test"
topics => ["test"]
auto_offset_reset => "latest"
consumer_threads => 5
bootstrap_servers => "10.x.x.x:9092"
type => "test"
codec => json
decorate_events => false
}
}
output {
if [type] == "test" {
elasticsearch {
index => "test-%{+YYYY.MM}"
hosts => ["10.x.x.1:9200"]
user => "user1"
password => "password"
}
}
}
详细了解可参考官方文档:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
4、logstash-grok
实际项目需求,也是本次笔记的重点
4.1、需求描述:
2021-12-30 09:40:59.088 INFO 1 [TID:testf0c839247de8effbd4397adc26e.61.1000000000000000] --- [ schedtest-1] com.test.test.test.test.TestTest : query = {"query":{"range":{"createTime":{"from":"1640828100000","to":"1640828400000","include_lower":true,"include_upper":false,"boost":1.0}}},"aggregations":{"agg_channel":{"terms":{"field":"channel.keyword","missing":"N/A","size":200,"min_doc_count":1,"shard_min_doc_count":0,"show_term_doc_count_error":false,"order":[{"_count":"desc"},{"_key":"asc"}]}}}}
上面是很常见的一条java程序的日志,我们首先要对该日志进行格式化,然后取出相应的字段,并希望在 elasticsearch 里能根据指定的字段进行快速查询和聚合。
4.2、调试
为了方便调试,我们可以修改配置文件,将日志打印在控制台。
修改如下:
vim test.conf
output {
if [type] == "test" {
elasticsearch {
index => "test-%{+YYYY.MM}"
hosts => ["10.x.x.1:9200"]
user => "user1"
password => "password"
}
stdout {
codec => "rubydebug"
}
}
}
启动:
./logstash -f test.conf
4.3、开始调试
使用 logstash 对原始日志进行日志格式化,这应该算是最常见的一种需求了,下面将通过filter中的grok来进行日志格式话,下面以上面的日志为例,我们来通过自定义日志格式。
使用调试工具:
https://www.5axxw.com/tools/v2/grok.html
https://grokdebug.herokuapp.com/
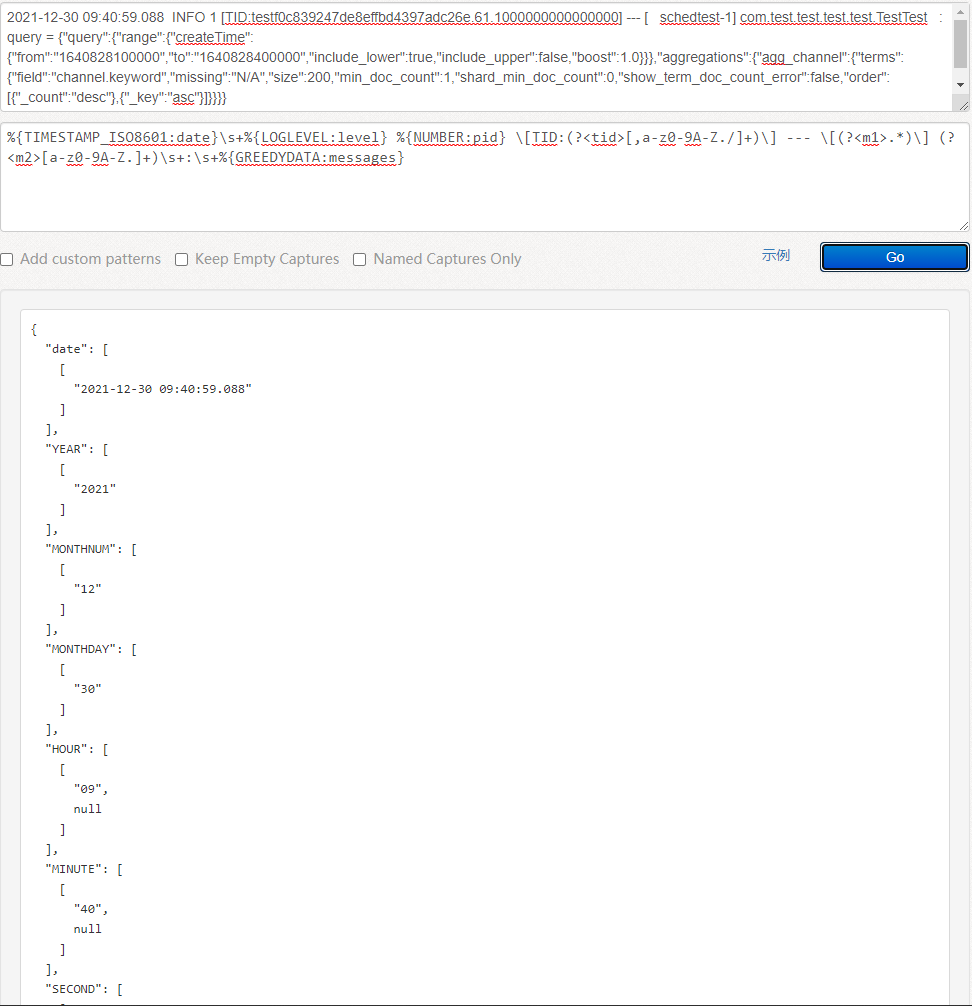
调试完成后可以把调好后的正则写进配置文件:
filter {
grok {
match => {"message" => '%{TIMESTAMP_ISO8601:date}\s+%{LOGLEVEL:level} %{NUMBER:pid} \[TID:(?<tid>[,a-z0-9A-Z./]+)\] --- \[(?<m1>.*)\] (?<m2>[a-z0-9A-Z.]+)\s+:\s+%{GREEDYDATA:messages}'}
}
}
这里格式化的就是message中的日志,通过一堆正则,然后来匹配出我们想要的关键日志。
4.4、grok语法。
在调试过程中浪费较多时间,在次也也苦苦整理出gork相关语法。以备急需。
4.4.1常用表达式:
| 表达式标识 | 名称 | 详情 | 匹配例子 |
|---|---|---|---|
| USERNAME 或 USER | 用户名 | 由数字、大小写及特殊字符(._-)组成的字符串 | 1234、Bob、Alex.Wong |
| EMAILLOCALPART | 用户名 | 首位由大小写字母组成,其他位由数字、大小写及特殊字符(_.+-=:)组成的字符串。注意,国内的QQ纯数字邮箱账号是无法匹配的,需要修改正则 | windcoder、windcoder_com、abc-123 |
| EMAILADDRESS | 电子邮件 | windcoder@abc.com、windcoder_com@gmail.com、abc-123@163.com | |
| HTTPDUSER | Apache服务器的用户 | 可以是EMAILADDRESS或USERNAME | |
| INT | 整数 | 包括0和正负整数 | 0、-123、43987 |
| BASE10NUM 或 NUMBER | 十进制数字 | 包括整数和小数 | 0、18、5.23 |
| BASE16NUM | 十六进制数字 | 整数 | 0x0045fa2d、-0x3F8709 |
| WORD | 字符串 | 包括数字和大小写字母 | String、3529345、ILoveYou |
| NOTSPACE | 不带任何空格的字符串 | ||
| SPACE | 空格字符串 | ||
| QUOTEDSTRING 或 QS | 带引号的字符串 | "This is an apple"、'What is your name?' | |
| UUID | 标准UUID | 550E8400-E29B-11D4-A716-446655440000 | |
| MAC | MAC地址 | 可以是Cisco设备里的MAC地址,也可以是通用或者Windows系统的MAC地址 | |
| IP | IP地址 | IPv4或IPv6地址 | 127.0.0.1、FE80:0000:0000:0000:AAAA:0000:00C2:0002 |
| HOSTNAME | IP或者主机名称 | ||
| HOSTPORT | 主机名(IP)+端口 | 127.0.0.1:3306、api.windcoder.com:8000 | |
| PATH | 路径 | Unix系统或者Windows系统里的路径格式 | /usr/local/nginx/sbin/nginx、c:\windows\system32\clr.exe |
| URIPROTO | URI协议 | http、ftp | |
| URIHOST | URI主机 | windcoder.com、10.0.0.1:22 | |
| URIPATH | URI路径 | //windcoder.com/abc/、/api.php | |
| URIPARAM | URI里的GET参数 | ?a=1&b=2&c=3 | |
| URIPATHPARAM | URI路径+GET参数 | /windcoder.com/abc/api.php?a=1&b=2&c=3 | |
| URI | 完整的URI | https://windcoder.com/abc/api.php?a=1&b=2&c=3 | |
| LOGLEVEL | Log表达式 | Log表达式 | Alert、alert、ALERT、Error |
4.4.2、日期时间表达式
| 表达式标识 | 名称 | 匹配例子 |
|---|---|---|
| MONTH | 月份名称 | Jan、January |
| MONTHNUM | 月份数字 | 03、9、12 |
| MONTHDAY | 日期数字 | 03、9、31 |
| DAY | 星期几名称 | Mon、Monday |
| YEAR | 年份数字 | |
| HOUR | 小时数字 | |
| MINUTE | 分钟数字 | |
| SECOND | 秒数字 | |
| TIME | 时间 | 00:01:23 |
| DATE_US | 美国时间 | 10-01-1892、10/01/1892/ |
| DATE_EU | 欧洲日期格式 | 01-10-1892、01/10/1882、01.10.1892 |
| ISO8601_TIMEZONE | ISO8601时间格式 | +10:23、-1023 |
| TIMESTAMP_ISO8601 | ISO8601时间戳格式 | 2016-07-03T00:34:06+08:00 |
| DATE | 日期 | 美国日期%{DATE_US}或者欧洲日期%{DATE_EU} | |
| DATESTAMP | 完整日期+时间 | 07-03-2016 00:34:06 |
| HTTPDATE | http默认日期格式 | 03/Jul/2016:00:36:53 +0800 |
4.4.3、自定义grok表达式
语法解释:
%{HOSTNAME}, 匹配请求的主机名
%{TIMESTAMP_ISO8601:time}, 代表时间戳
%{LOGLEVEL}, 代表日志级别
%{URIPATHPARAM}, 代表请求路径
%{INT}, 代表字符串整数数字大小
%{NUMBER}, 可以匹配整数或者小数
%{UUID}, 匹配类似091ece39-5444-44a1-9f1e-019a17286b48
%{IP}, 匹配ip
%{WORD}, 匹配请求的方式
%{GREEDYDATA}, 匹配所有剩余的数据
(?([\S+]*)), 自定义正则
\s*或者\s+, 代表多个空格
\S+或者\S*, 代表多个字符
(?<class_info>([\S+]*)), 自定义正则匹配多个字符
4.5、删除不必要的字段
经过处理后,其实已经满足项目需求,为了测试及学习我们进一步解析。
在解析后我们得到了一个新的message,我们只保留该字段,其他的字段都不需要,因此把没有用的字段删除, 这里用到了mutate中的remove_field来删除字段:
官方参考文档:
https://www.elastic.co/guide/en/logstash/current/plugins-filters-mutate.html#plugins-filters-mutate-remove_field
filter {
grok {
match => {"message" => '%{TIMESTAMP_ISO8601:date}\s+%{LOGLEVEL:level} %{NUMBER:pid} \[TID:(?<tid>[,a-z0-9A-Z./]+)\] --- \[(?<m1>.*)\] (?<m2>[a-z0-9A-Z.]+)\s+:\s+%{GREEDYDATA:messages}'
}
mutate {
remove_field => ["message", "level", "pid", "tid", "m1", "m2"]
}
}
经过此次处理后,会去掉meassge,level,pid等字段。
4.6、将所需日志进行 json 解析
然后我们想将messages这个json中的字段放到顶层中,这里用到了filter中的json选项,用来解析json数据类型的日志,这里面有两个关键字段需要知道:
- source: 指定要处理的 json 字段,这里对应的就是originBody
- target: 解析后的 json 数据存放位置,如果不指定将输出到顶层, 由于我这里就是要将解析好的数据放到顶层,因此不指定target
filter {
grok {
match => {"message" => '%{TIMESTAMP_ISO8601:date}\s+%{LOGLEVEL:level} %{NUMBER:pid} \[TID:(?<tid>[,a-z0-9A-Z./]+)\] --- \[(?<m1>.*)\] (?<m2>[a-z0-9A-Z.]+)\s+:\s+%{GREEDYDATA:messages}'
}
json {
source => "messages"
mutate {
remove_field => ["message", "level", "pid", "tid", "m1", "m2"]
}
}
4.7、转换数据类型
至此,已经满足大部分需求,接下来是最后一步,将某些字段的字符串转成指定类型
filter {
grok {
match => {"message" => '%{TIMESTAMP_ISO8601:date}\s+%{LOGLEVEL:level} %{NUMBER:pid} \[TID:(?<tid>[,a-z0-9A-Z./]+)\] --- \[(?<m1>.*)\] (?<m2>[a-z0-9A-Z.]+)\s+:\s+%{GREEDYDATA:messages}'
}
json {
source => "messages"
mutate {
remove_field => ["message", "level", "pid", "tid", "m1", "m2"]
convert => {
"size" => "integer"
"min_doc_count" => "integer"
}
}
5、总结
本次记录只说了logstash的其中一种日志处理方式,用的是它自带的一些插件,基本上可以满足我们日常的一些需求,但是如果加入一些逻辑处理的话,我们也可以通过自定义ruby代码段来进行处理。















 1880
1880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









