







1、目的:
项目用的是filebeat日志采集那一套,因业务问题或技术层面更方便,需将json中的数组拆分成多条入到es当中。
2、消息体:
(1)测试消息体
{
"ecProvince": "北京",
"ecId": 1,
"ecName": "测试企业名称",
"mobiles": [{
"bizCode": "1",
"mobile": "10000000000"
}, {
"bizCode": "2",
"mobile": "20000000000"
}],
"type": 1
}(2)目标消息体
{
"ecProvince": "北京",
"ecId": 1,
"ecName": "测试企业名称",
"bizCode": "1",
"mobile": "10000000000",
"type": 1
}
{
"ecProvince": "北京",
"ecId": 1,
"ecName": "测试企业名称",
"bizCode": "2",
"mobile": "20000000000",
"type": 1
}3、Logstash运行环境:
环境:windows
logstash.conf读取本地txt文件
input {
file {
#type => "type_a"
start_position => "beginning"
path => ["D:/1.txt"]
codec => json
}
}4、Logstash实现:
如需转为json添加
json {
source => "message"
}
filter{
split {
field => "mobiles"
}
mutate {
add_field => {"field1" => "%{mobiles}"}
}
json {
source => "field1"
}
mutate {
remove_field => ["field1","mobiles"]
}
}
5、运行效果:
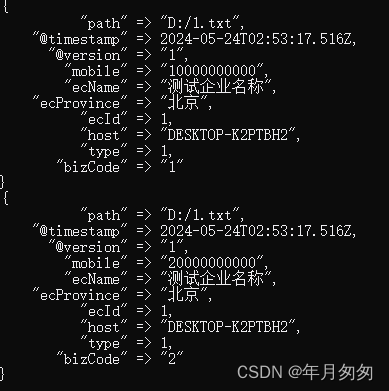
根据业务场景,又对文章补充了采集消息体过大进行压缩解析















 2924
2924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









