










前言
本文是对王道计算机考研《计算机组成原理》课程的总结,主讲咸鱼学长讲的确实清晰。
由于我们学校已经开设过汇编和计算机体系结构,所以计组的笔记内容会比较精炼,高屋建瓴,不适合无基础人听。
如果有不理解的,可以回去看看我前面的CSAPP笔记和汇编语言笔记(不过我感觉还是没啥必要,我这篇文章更多的是总结性质,不适合入门学习)
CSAPP笔记:
第一卷:程序结构与执行——信息表示、指令、处理器、性能优化、储存层次
第二卷:在系统上运行程序——链接、异常控制流、虚拟内存
第三卷:程序间的交流与通信——系统级IO、网络编程、并发编程
汇编语言笔记:
汇编语言笔记——微机结构基础、汇编指令基础
汇编语言笔记——汇编程序开发、汇编大作业
汇编语言笔记——接口技术与编程
概论
计算机的发展
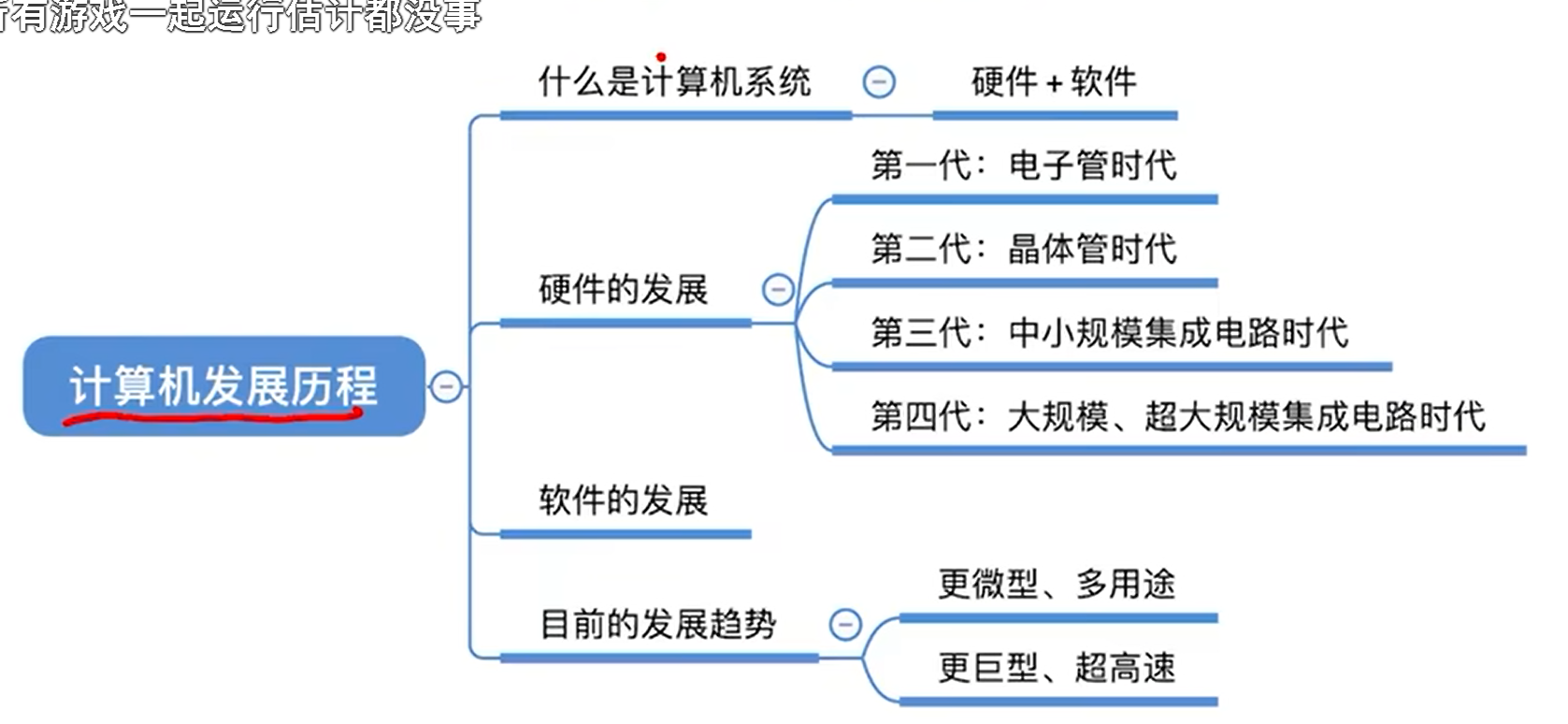
计算机系统
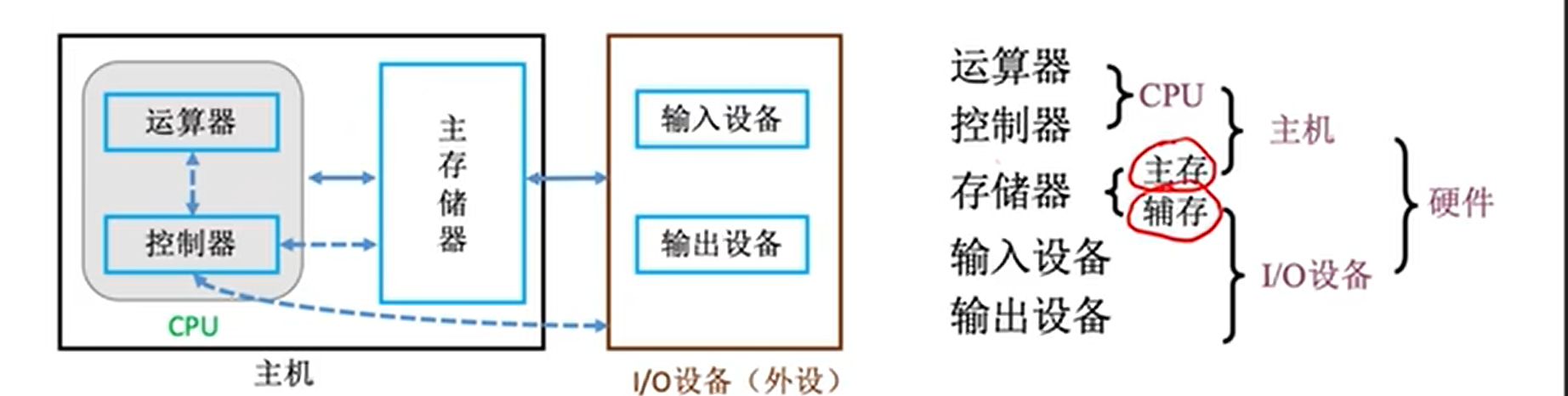
计算机硬件组成

最开始计算机是没有内存的,程序员给条指令,计算机就执行一个行为。
冯诺依曼提出了储存程序理论,程序记录了计算机要做的一系列流程,理应先放在储存器(内存)中,等计算机需要的时候按照规定顺序执行。
下图中,注意看实线,代表数据流。
输入设备把数据交给运算器,运算器和储存器进行交互,最后运算器再把结果输出给输出设备。控制器负责协调这4个部件,他只和储存器有数据交换,这是因为控制器需要从储存器中读取指令。虽然控制器负责协调,实际上还是以运算器为核心的。
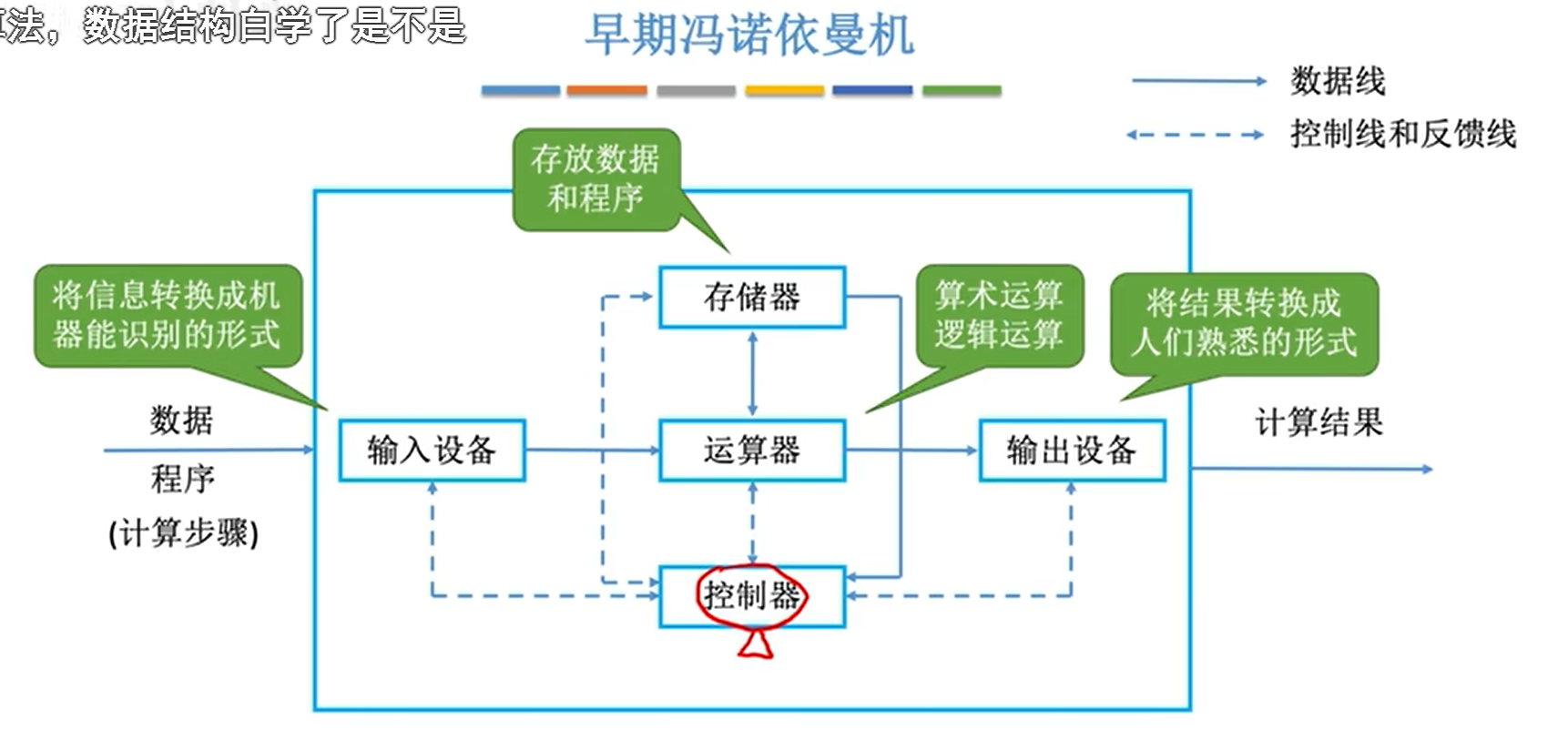
现代计算器为了减轻运算器的压力,将储存器作为中心,整体运行没什么变化,只不过输入是先送到储存器中,储存器的数据也可以直接输出,都不需要经过运算器了。
各个硬件的工作原理
这一节比较抽象,我学过5级流水线CPU了,所以就直接从宏观层面去总结。

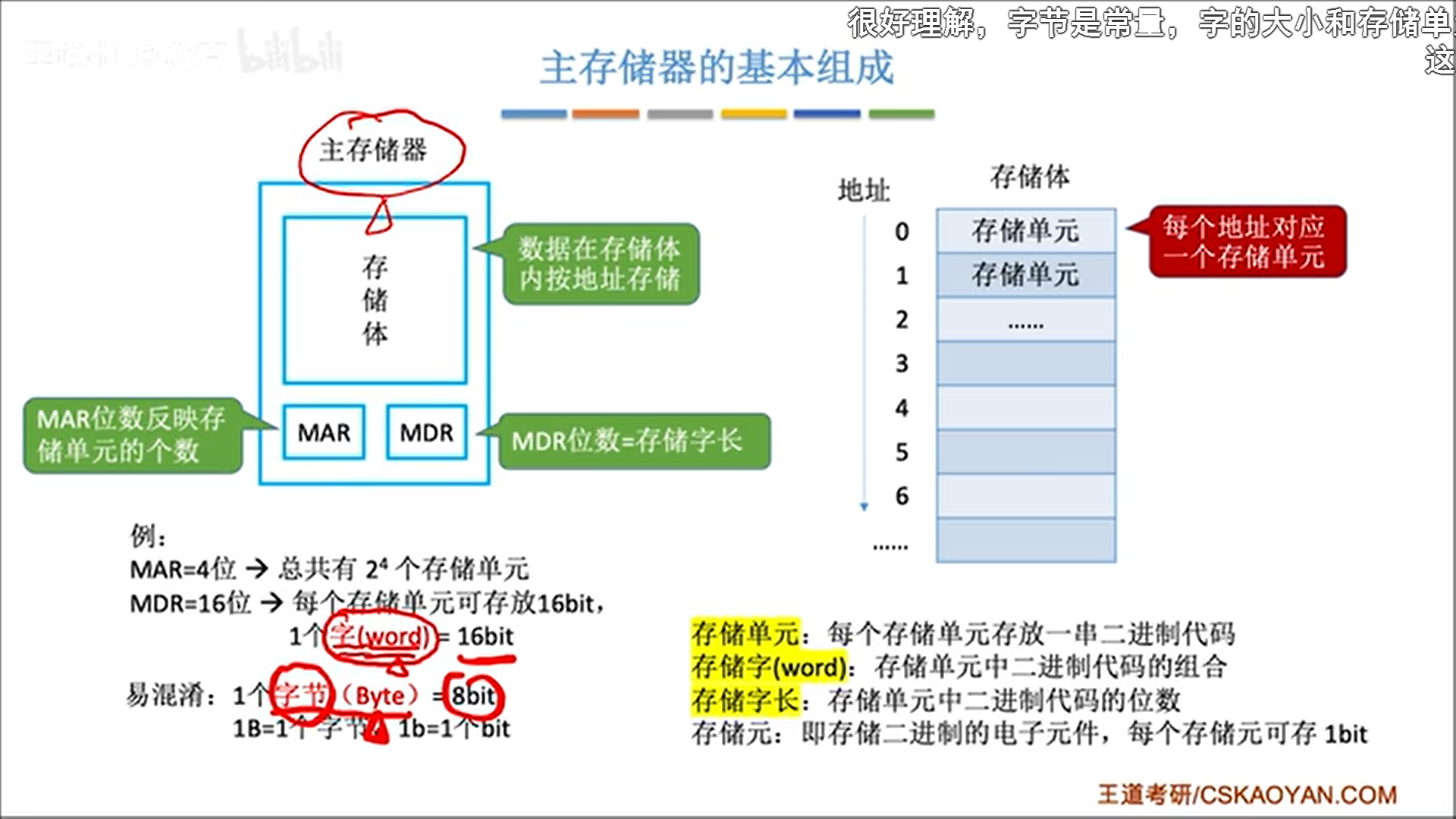
首先是主存:
- 储存体负责具体储存数据
- 储存单元指的是一个地址对应的空间
- 储存元指一个可以存1bit的电子元件
- 字就是储存单元具体的值,字长就是其bit数
- MAR。一个寄存器,储存了地址
- 即指向储存单元的指针
- 长度对应内存地址空间范围
- MDR。一个寄存器,储存一个字的数据
- 一般MDR长度=字长
- CPU存取数据都要经过MDR
CPU和主存通过寄存器交换着三个数据:地址,数据,指令,看一下交互过程:
- 假设CPU要取数据,就先设置MAR,然后发一个“取”指令给主存,然后主存把数据放到MDR里。
- 当CPU存数据时,CPU先把数据放MDR,然后设置MAR,发送一个“存”指令给主存,主存就会把MDR的数据放到目标位置。
现在CPU已经把MAR和MDR集成进去了。
再说运算器:
运算器是一个计算核心ALU+三个辅助寄存器构成:
- ALU负责计算
- ACC,默认的操作数和结果寄存器
- X,第二个操作数的寄存器
- MQ,执行乘除时会用到

一个完整的运算过程如下:
- 取指:控制器C收到运算指令
- 译码:取出操作符和操作数
- 执行:ALU计算,把结果放在对应寄存器
- 访存:输出到内存(有时候不执行)
- 写回
有时候要多执行一个周期,先去把内存的数放到辅助寄存器中,再进行一个周期的计算。
再论控制器:
控制器以CU为核心,IR和PC是两个辅助寄存器。IR存放指令内容,PC存放下一指令地址。
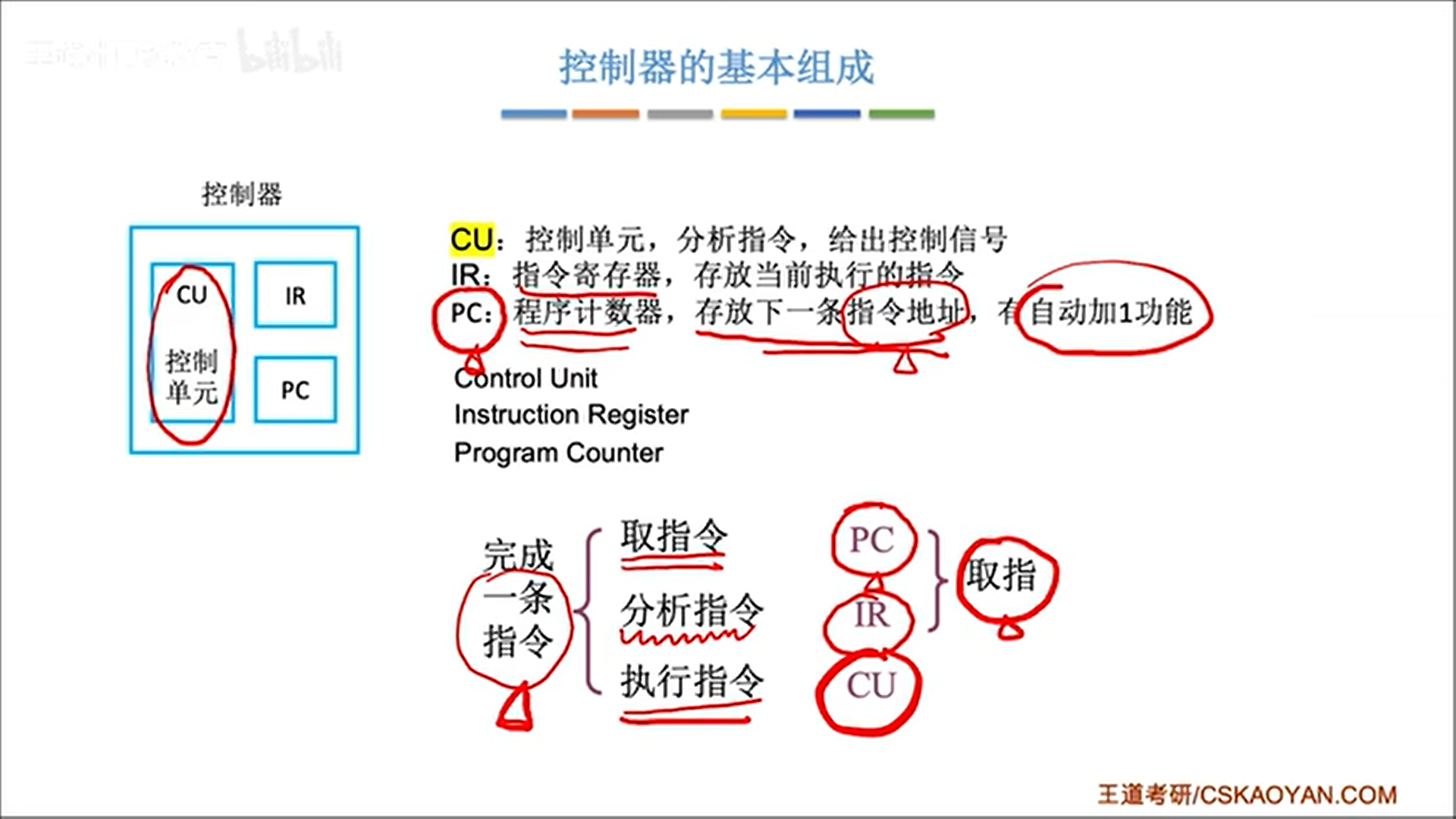
现在的CPU其实是把控制器和运算器集成在了一起,同时又集成了一大堆寄存器。指令的执行其实就是CPU和内存在反复打交道。
下图描述了一条指令被CPU执行的全过程。可以看到,无论是取指令,还是取数据,都要进行内存访问。
图灵机的神奇之处就在于,第一条指令存在IR之中,运行完毕后,会决定PC值是单纯+1还是做其他处理,也就是说一条指令可以决定下一条指令是什么,如此就可以自动执行,生生不息了,所以你的计算机只要开了机,指令就是在一直运行的。
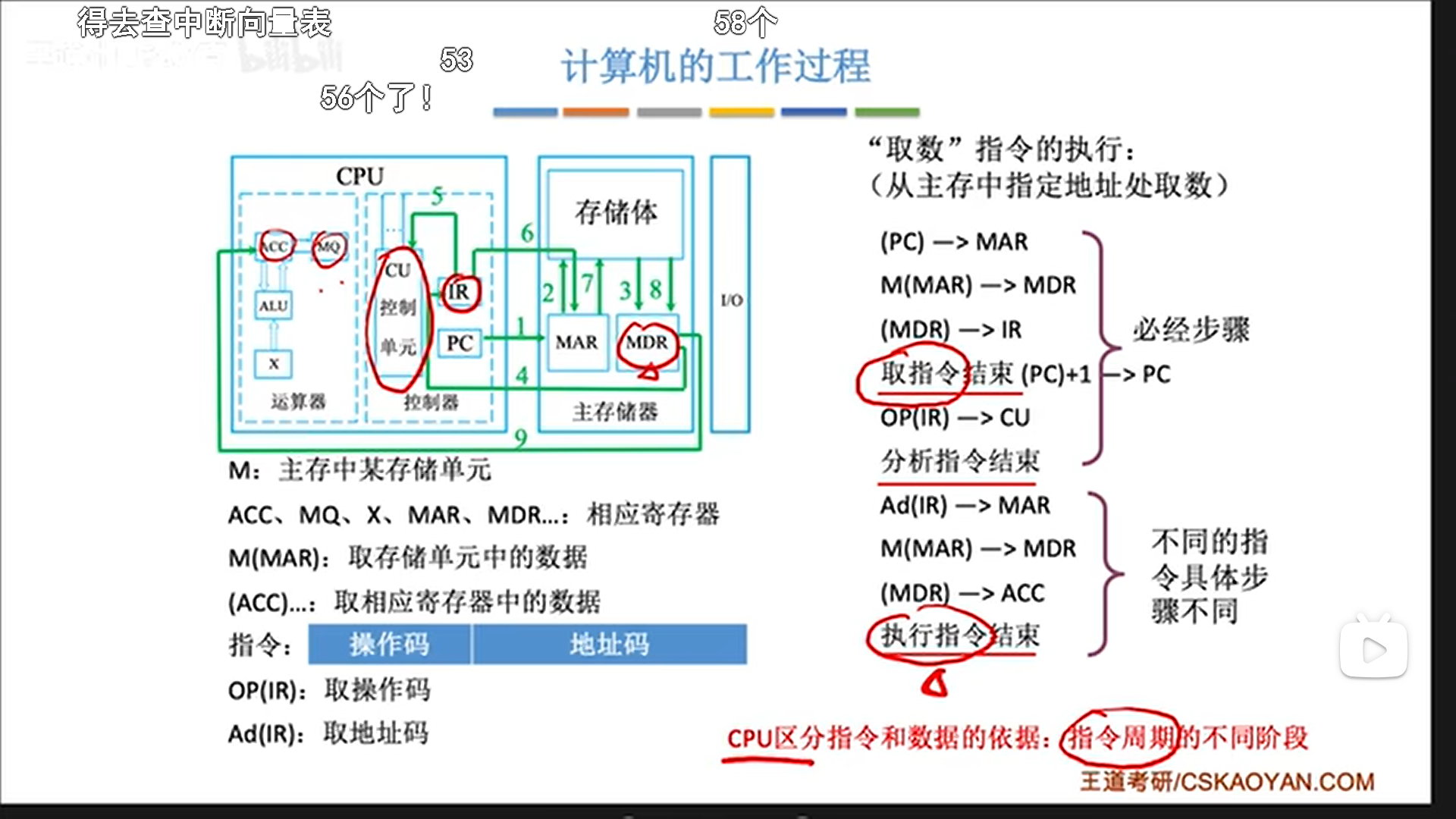

计算机系统的层次结构

计算机系统=软件+硬件/固件,实际上,在开发设计人员眼中,软硬件在逻辑上是等价的,乘法运算可以用软件去写(基于底层硬件),也可以直接用底层硬件实现,所以说软硬件只不过处在不同层次罢了。
从整体的角度来看,软硬件还可以继续细化成若干层,形成7(或者5)层结构,自下向上为:
- 硬联逻辑。最基础的硬件,比如晶体管构成的各种逻辑门。
- 微程序级。由基础硬件构成的功能单元。比如什么控制器,加法器,移位器等等。
- 机器语言级。用0和1来描述抽象的模块行为。
- 操作系统级。建立在裸机之上,上面的人看不懂机器语言,机器也看不懂人的汇编语言,在此之间操作系统构成软硬件交流的界面。
- 汇编语言级。比如x86指令集汇编。
- 高级语言级。用来开发的编程语言。
- 应用语言级。应用程序。
计算机系统结构、组成、实现
- 系统结构(体系结构):计算机硬件有哪些部分,有哪些功能。比如CPU就是一个系统结构部分,CPU可以进行寻址,可以操作寄存器,执行指令,这是功能。又比如有内存,这是结构部分,内存空间是如何管理的,这是功能。
- 组成:是硬件实际的结构,比如CPU的结构如何,有没有Cache,有没有片外Cache。
- 实现:计算机组成其实是用各种模块进行组合,形成一个大型功能单位;而模块(微程序级)的物理实现,就是计算机实现部分。
程序员一般只能看到系统结构,再往下看不到了,也没必要看到。既然看不到,就可以说这就是透明的。(这个透明和生活中的透明正好是反过来的)

我们之前那本CSAPP,讲的其实是体系结构,而计组学的是组成,电子信息那帮人学的是实现。
计算机性能指标

储存器
- 字长=MDR长度
- 地址空间= 2 M A R 长度 2^{MAR长度} 2MAR长度
- 容量=字长×地址空间
CPU
- 主频:内部时钟频率
- 时钟周期:主频倒数
- CPI(cycles per instruction):一条指令消耗的平均周期数
- IPS(instructions per second):一秒执行的指令数=主频/CPI
- FLOPS:一秒执行浮点指令数
CPU时间=通过CPU计算出来的时间=CPU消耗周期数/时钟频率。CPU时间仅仅是程序在CPU上消耗的时间,实际上消耗的还有其他部分,比如等待,调度啥的。
CPI即每条指令平均消耗周期,CPI=CPU时钟周期数/指令数
CPI还可以通过加权计算,CPI=不同类指令的CPI加权和。
通过加权公式可以看出,CPI受到权重影响,而不同程序会影响指令权重,所以CPI实际上受到程序影响。
CPU真正执行的时间=(指令数×CPI)/时钟频率,由此可得三个因素:
- 时钟频率。取决于计算机实现技术
- CPI。取决于计算机实现技术和指令集技术,指令集够不够好,如何用越少的周期实现一个指令
- IC。指令数量,取决于从编程技术到计算机实现的一系列流程。
平时使用计算机,CPU时间太过理想,综合考虑各种因素,于是有了吞吐量这个衡量参数,更加实用。
吞吐量常用MIPS(Million IPS)衡量,即每秒百万条指令计算。为什么是百万呢。百万其实就是兆指令,对应6次方的MHz单位,通过CPU时间计算方便。



整体指标
- 数据通路带宽。我们一般说带宽指的是速度,但是这里指的其实是
数据总线位宽 - 吞吐量。单位时间执行请求的数量。请求可以是指令,任务等。
- 响应时间。
性能指标的评判要用到基准程序,其实就是我们说的跑分。但是这个东西只能参考,因为我们日常的使用场景是丰富的,基准程序只能测量某一个方面。
正如我们前面说的,CPU时间很复杂,受时钟频率,CPI,IC三者约束。
Amdahl定律与加速比
Amdahl定律用于衡量一个部分的性能对于整体性能的重要性,具体用加速比计算,加速比=改进后性能/改进前性能=改进前时间/改进后时间。原理很简单,改进的加速比取决于这一部分的占比(可向量化百分比)与提升空间(优化部分可以提升到什么程度)。

数据的表示和运算
省流:数据表示还是一如既往的烦。
数制与编码
进位计数制
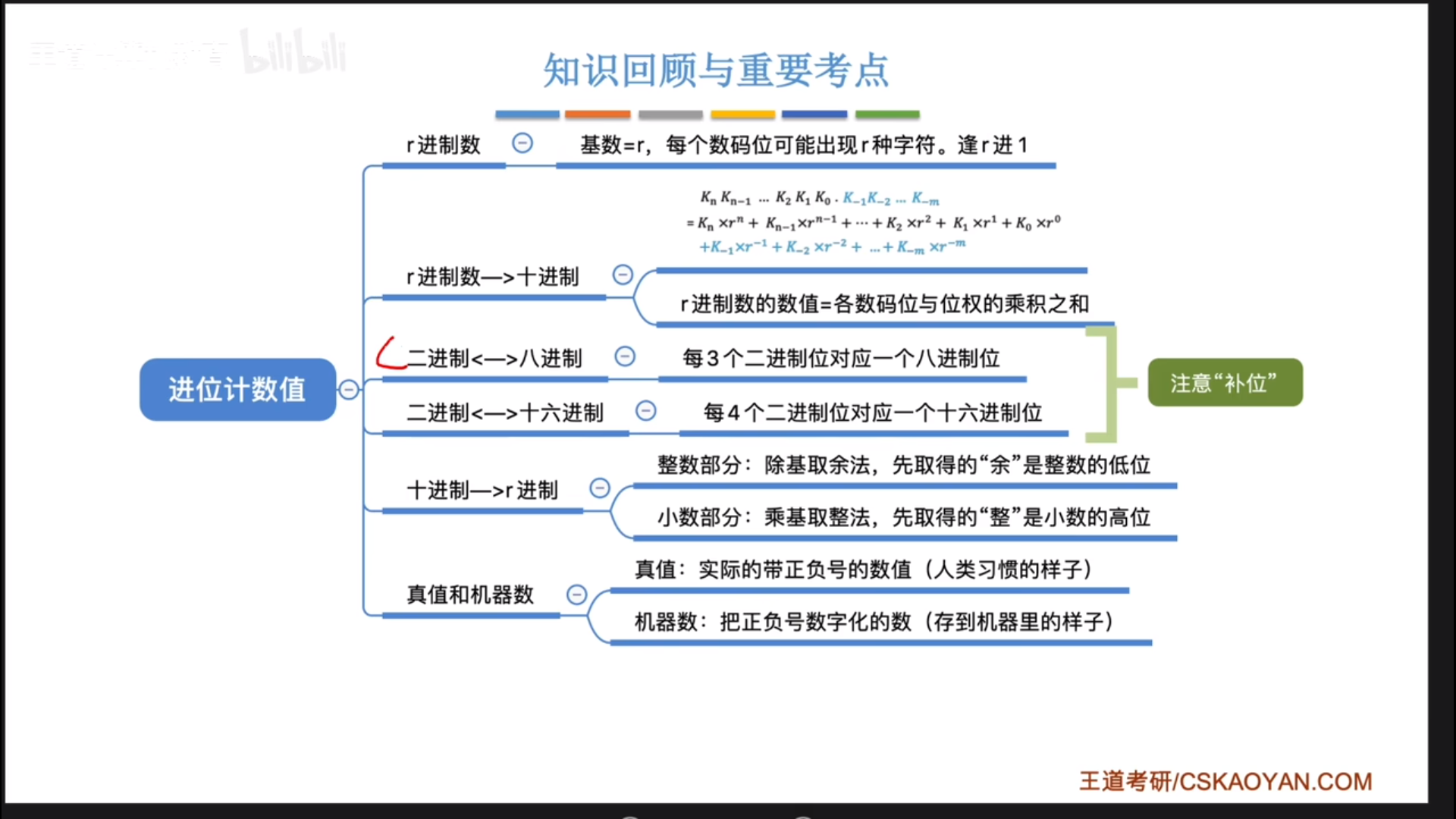
还有一个东西叫BCD码,可以用4bit表示0-9,如果在运算的时候出现4+9=13这种情况,卡在10-15之间,此时就会进行+6(0110)修正。
比如13是1101,超出BCD码范围,此时+0110,变成0001 0011,正好在BCD码里面代表10+3=13。
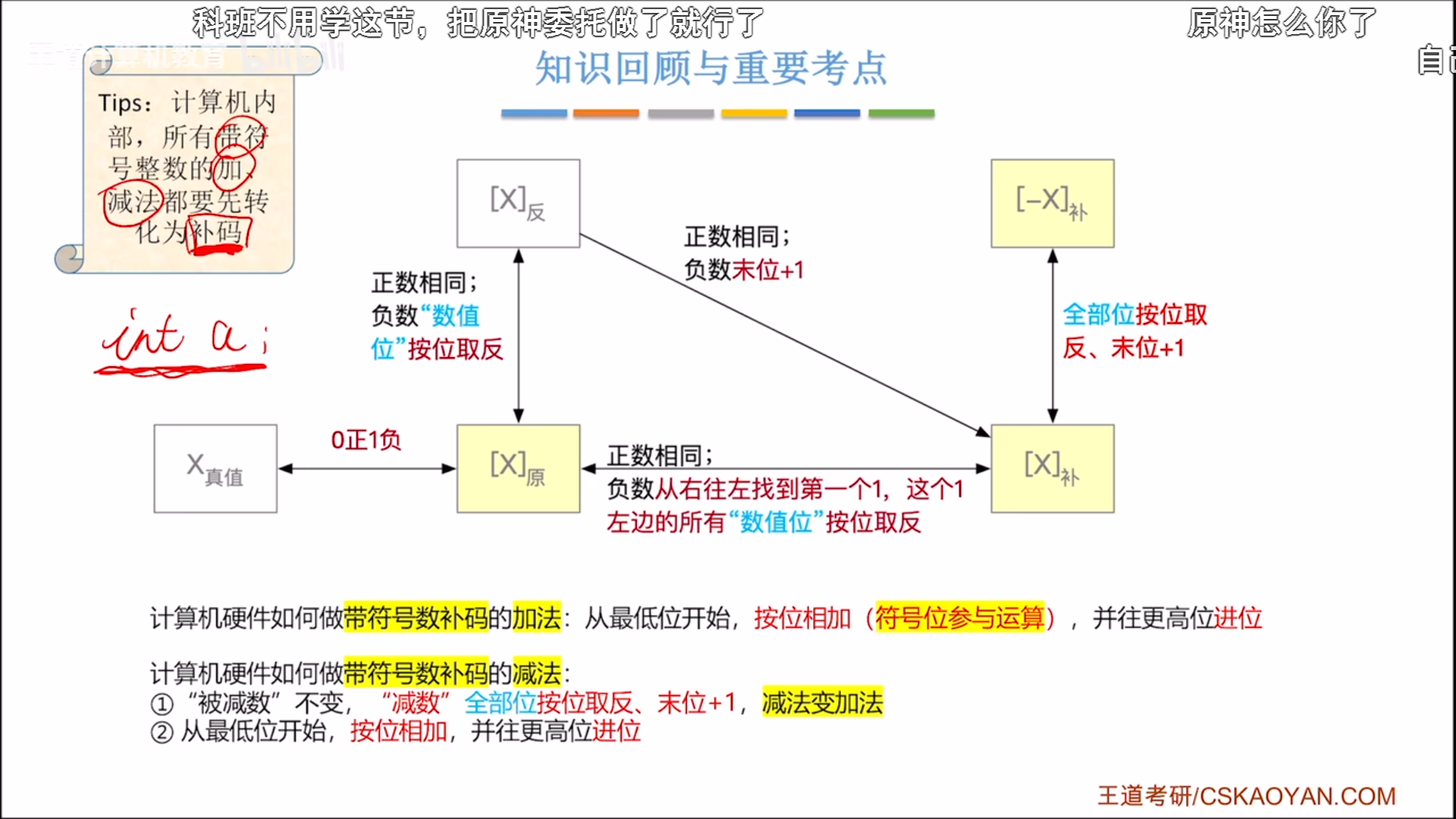
整数——原/反/补码
总结:
- 无符号的全部都是数值位,有符号的最高位是符号位
- 无符号和有符号补码的加减方法完全一致,只需要考虑结果是否溢出即可。
- 关于取反加一
- 原码到补码,是数值位取反加一(负数情况)
- 正数到负数,是所有位取反加一
- 负数补码到原码,理应末位减一,数值位取反,但是这么做比较麻烦,有一个快速方法。从右往左找到第一个1,左边的数值位全部取反。

最后再具体的从区间上区分一下:
负数反码的数值位是正数的按位取反,所以负数全0对应正数全1,是边界值。
因为补码的负数其实只是在反码基础上+1而已,所以补码的负区间可以理解为反码的负区间-1。
反码从0到 − ( 2 n − 1 ) -(2^n-1) −(2n−1)这个区间偏移一位,变成了-1到 − 2 n -2^n −2n。原来反码的两个0是重叠的,现在-0变成了-1,所以补码的0只有唯一表示,同时负数区间要多一个负数。
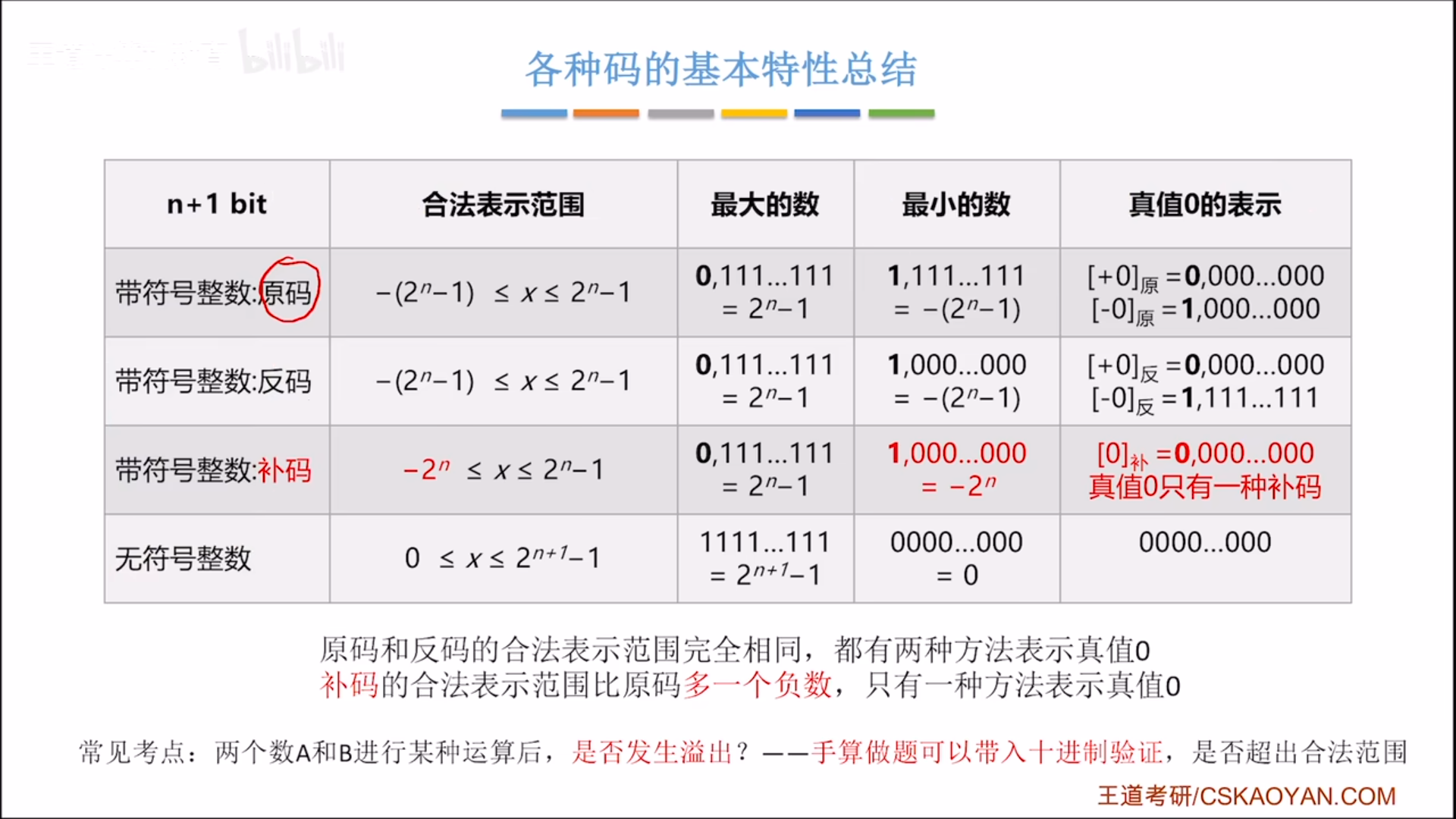
熟悉了这些区间,就可以快速的计算是否溢出。
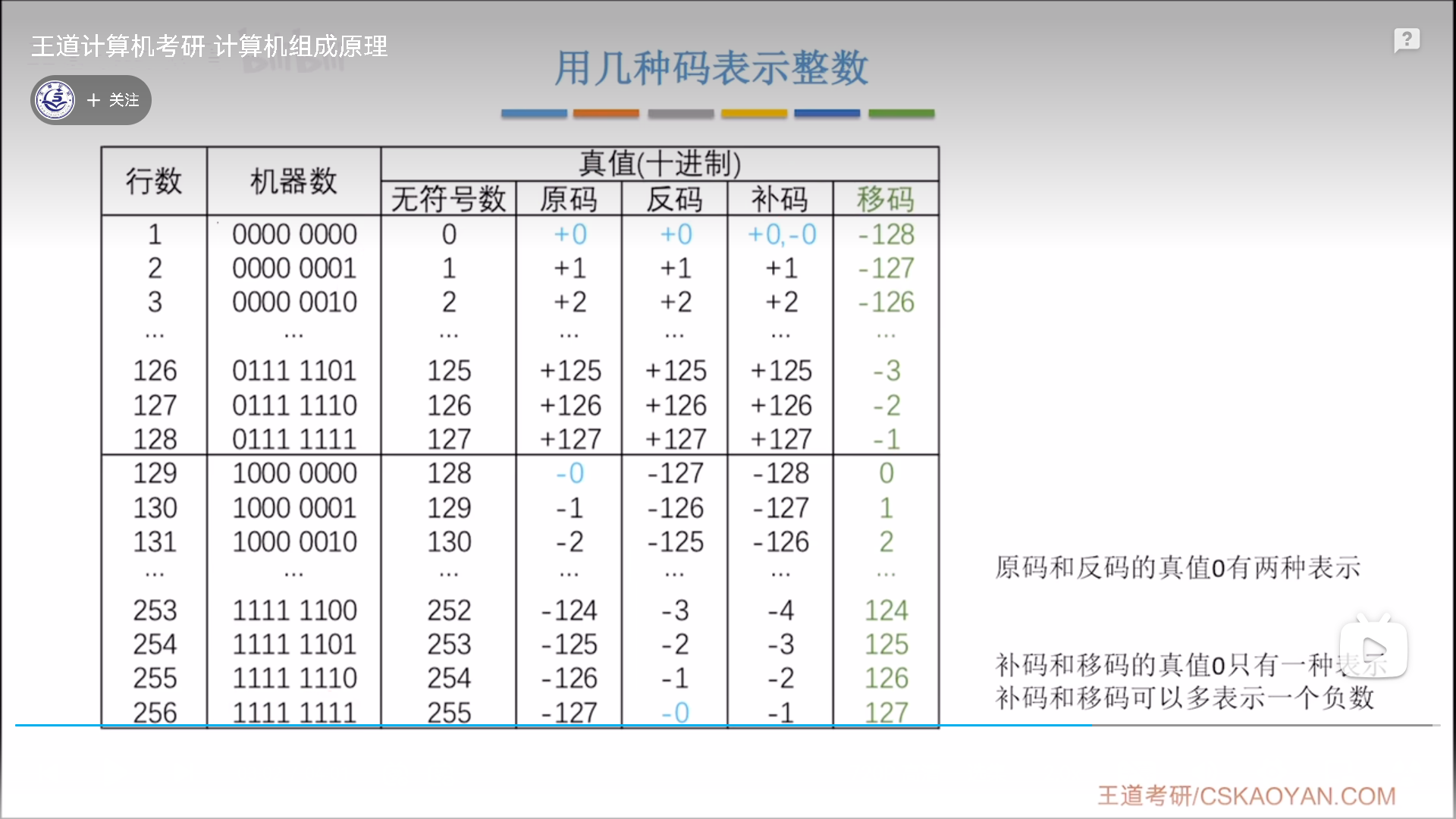
移码
移码这个概念主要用于浮点数阶码。
移码怎么来?本身是从补码过来的,只要把补码符号位取反,就可以得到真值相等的移码。所以移码其实是等价于补码的,范围特性也是一模一样。
移码的好处在于,既可以表示正负,又便于比较大小,因为其可以理解为,8bit无符号整数减去128,曾经的0-255变为现在的-128-127。


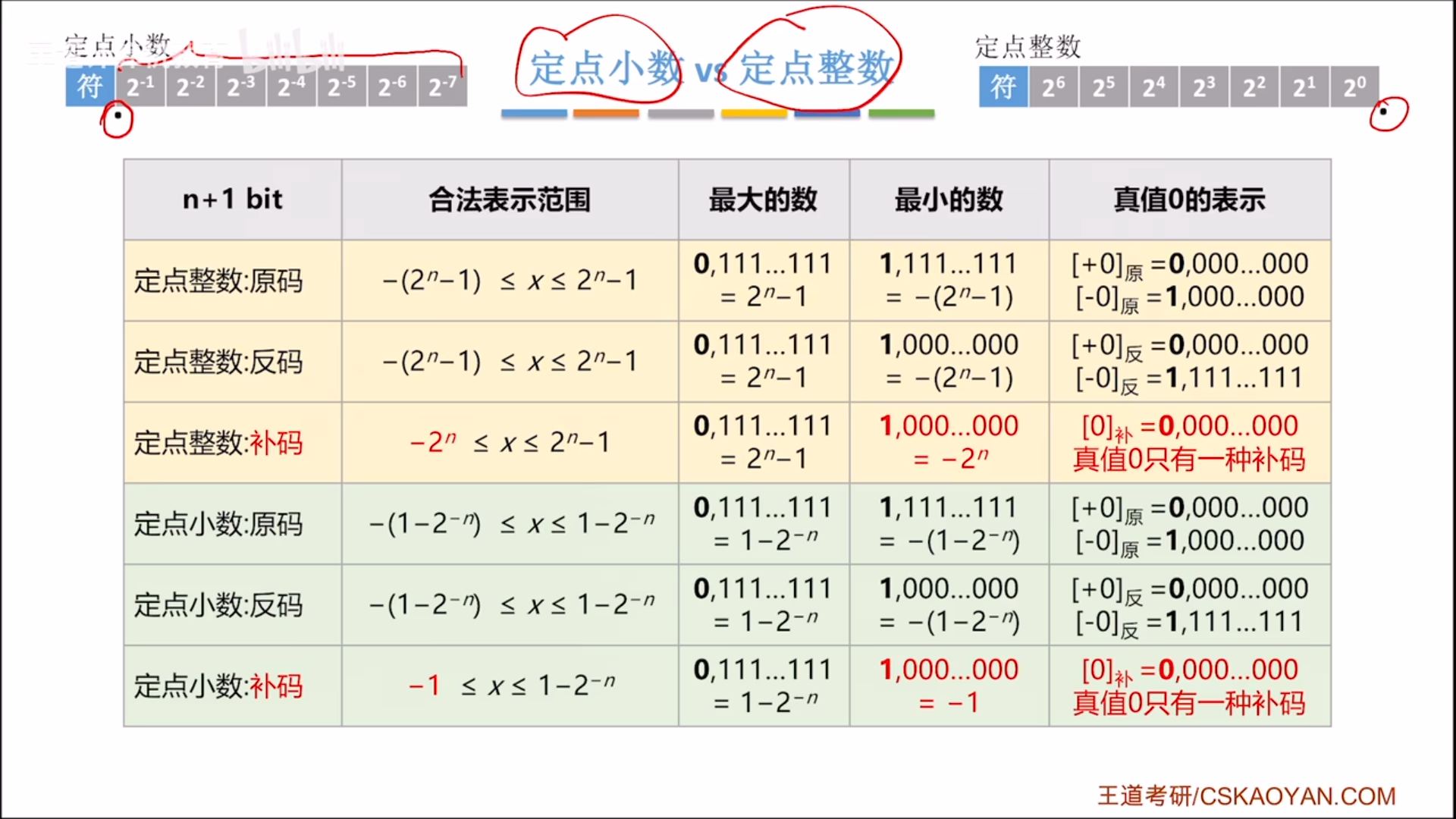
定点小数
我们先说定点小数和定点整数的不同,总的来说不同很少:
- 默认小数点位置不同,导致权重不同,范围不同(但是规律一样)
- 定点小数,小数点紧跟符号位
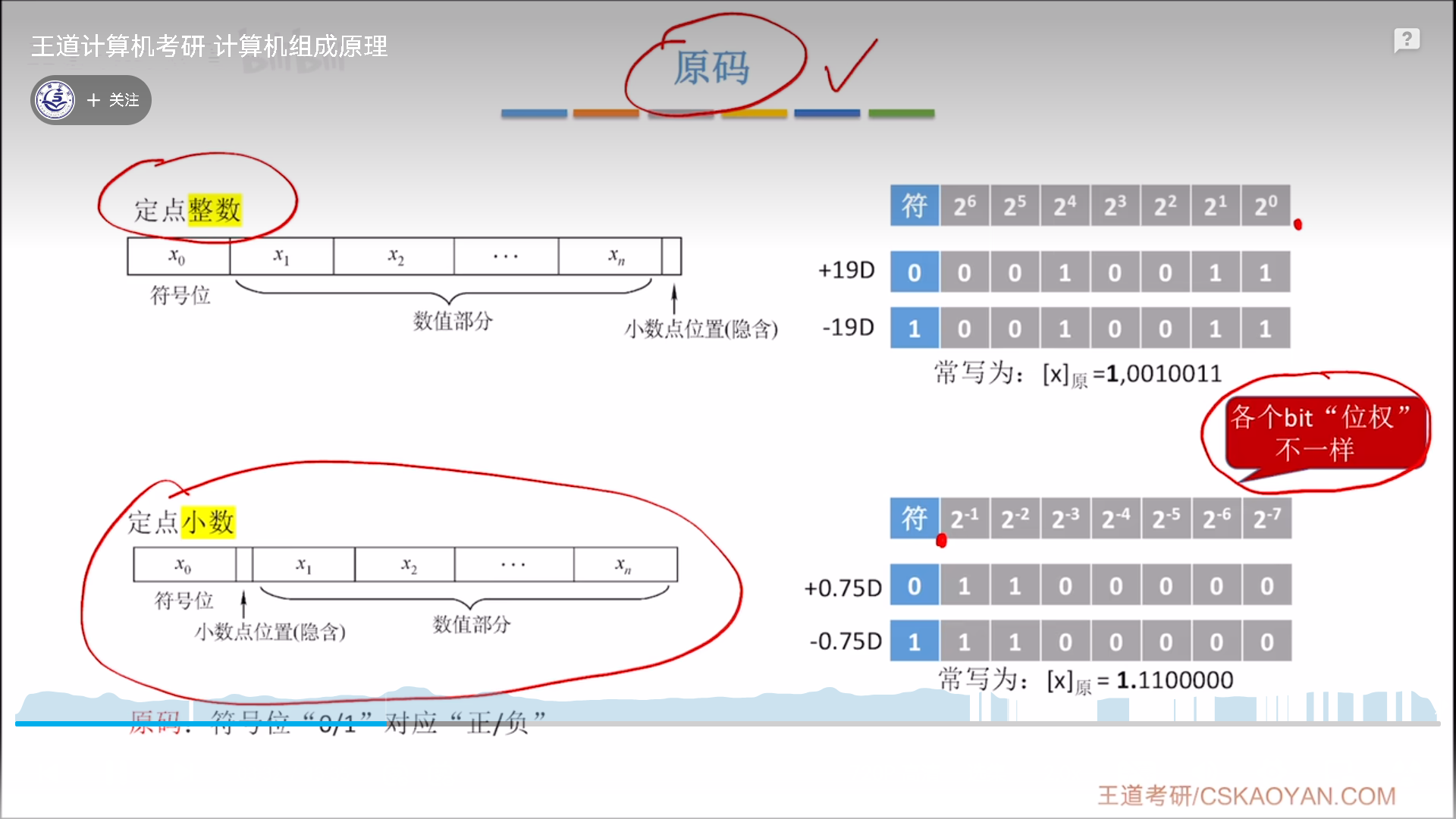
- 对定点小数的不同位进行数列求和,可以算出其区间。变化规律一样,补码的负区间是反码负区间减去偏移,只是整数是-1,小数是-
2
−
n
2^{-n}
2−n
- 定点小数,小数点紧跟符号位
- 0扩展方向不同,然而本质还是一样,远离小数点,所以整数扩展0要朝左,小数扩展0要朝右。

- 定点小数没有移码表示。这是因为移码是针对整数的修正补码,所以不适用于小数。
以上是不同,除了不同以外,定点小数和定点整数一模一样。无论是原反补码与补码负值的转化方式,还是补码的算术运算规则,全部一样,所以硬件上很省钱,是现行的解决方案。
运算方法与运算电路
这一章开始真正接触到计组的核心,其实我感觉计组和数字逻辑有点像的,比数字逻辑更高级一点,但是也高级不到哪去。
电路基本原理与加法器
ALU是CPU的核心,本节从ALU入手,介绍数电基础知识,最后从ALU的基本部件:加法器入手,打好计组的基础。
ALU
从简化的逻辑上看,ALU有两个输入值,一个控制信号,一个输出值。ALU可以实现算数(Arithmetic)和逻辑(Logical)运算,还有一些辅助运算
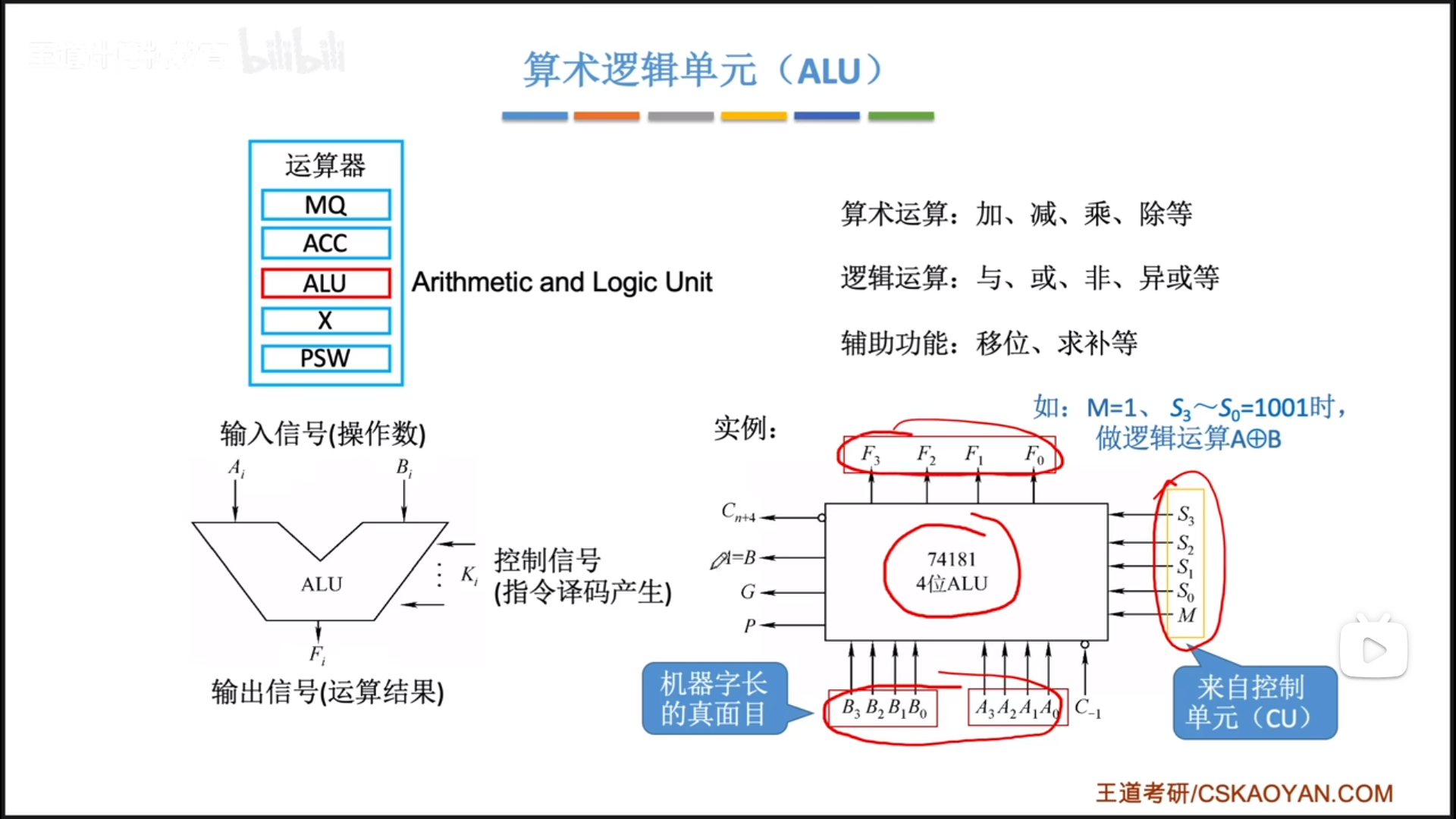
具体到数字逻辑上,每个值其实都是nbit,这个n从根本上决定了一台计算机的字长。而控制信号也是若干个针脚。
除此之外,其实还有一些其他的针脚,负责与其他硬件进行连接组合。
ALU说完了,它虽然功能复杂,但是最后其实都可以变成加法,所以继续深挖,讲一下加法器是怎么做的。
一位全加器
首先是一位全加器。所谓全加,指的是输入有上一位的进位,输出有进位。
具体实现如下图,比较复杂,不用去刻意记,就是知道分成两条线去设计即可,还有就是两条线都要复用A ⊕ \oplus ⊕B,之后你通过那个公式就可以画出电路图。
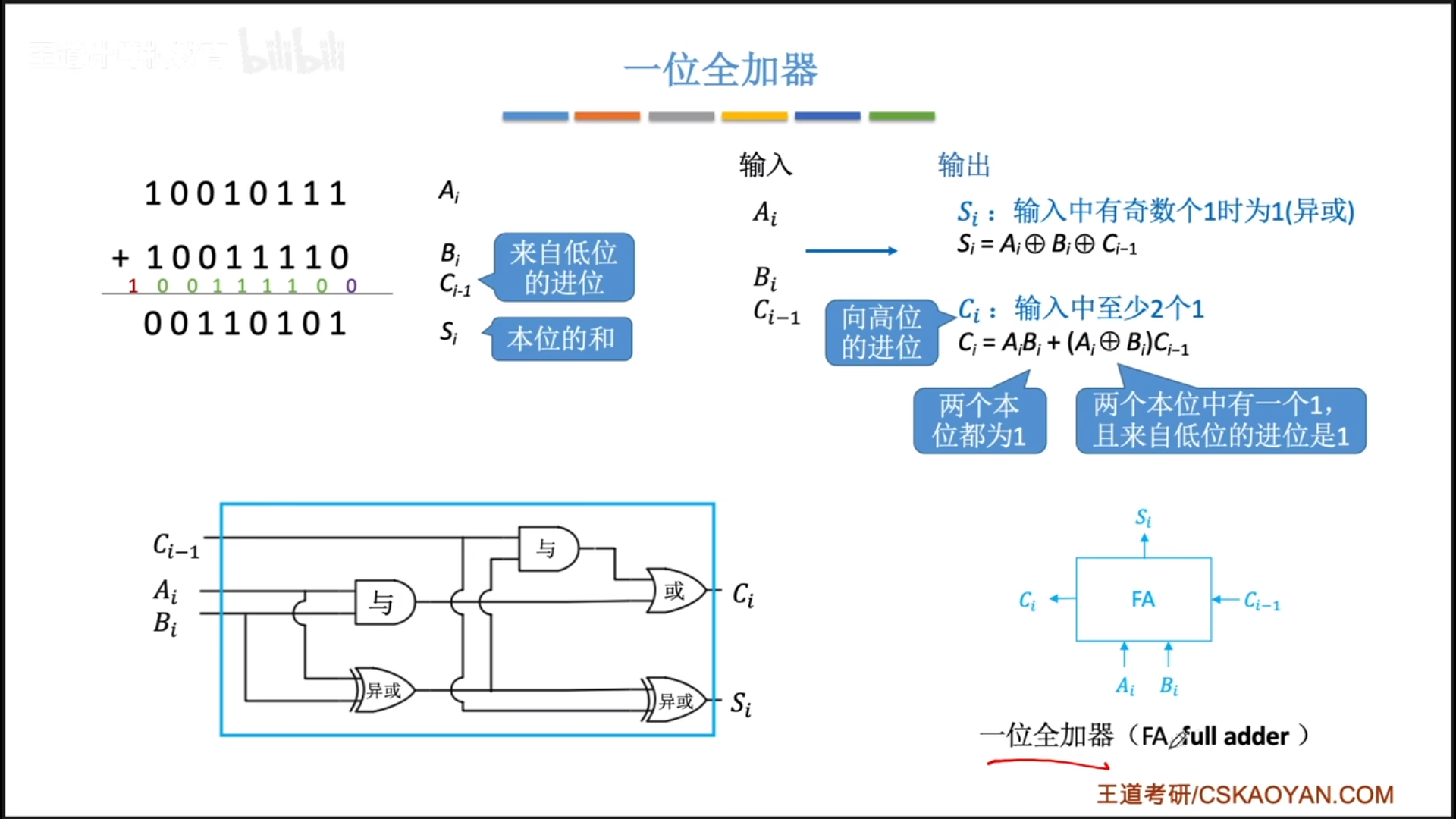
最后变成一个模块:
- 两个输入值,一个输出值
- 一个输入进位,一个输出进位
多位全加器
如何实现多位加法呢?迭代就可以。
使用一个全加器+触发器就可以实现每个时钟周期进行一次加法。在每个时钟周期, C i C_i Ci被保存在触发器,用于下一次加法,而 S i S_i Si被输出保存在寄存器的对应位上。最后还要考虑残留的进位,总之是比较麻烦且慢的。
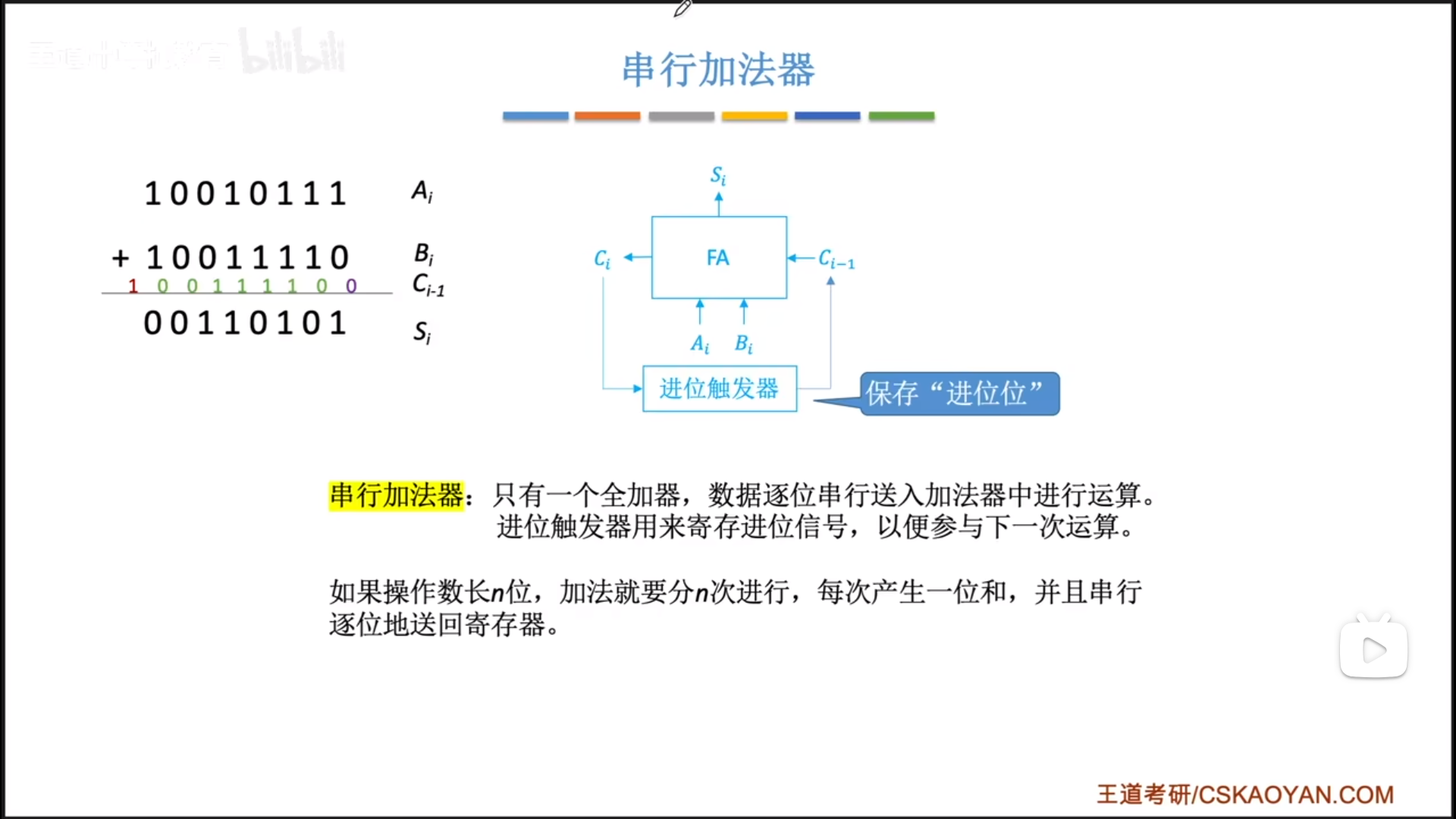
并行加法器更快,用空间换时间,以空间级联代替时间迭代。
把n位全加器级联,然后把n位的AB按位放到对应位置,一个时钟周期就可以计算完毕,得到n+1位的结果。
这里的并行并不是同时,只是代表一个时钟周期内完成。
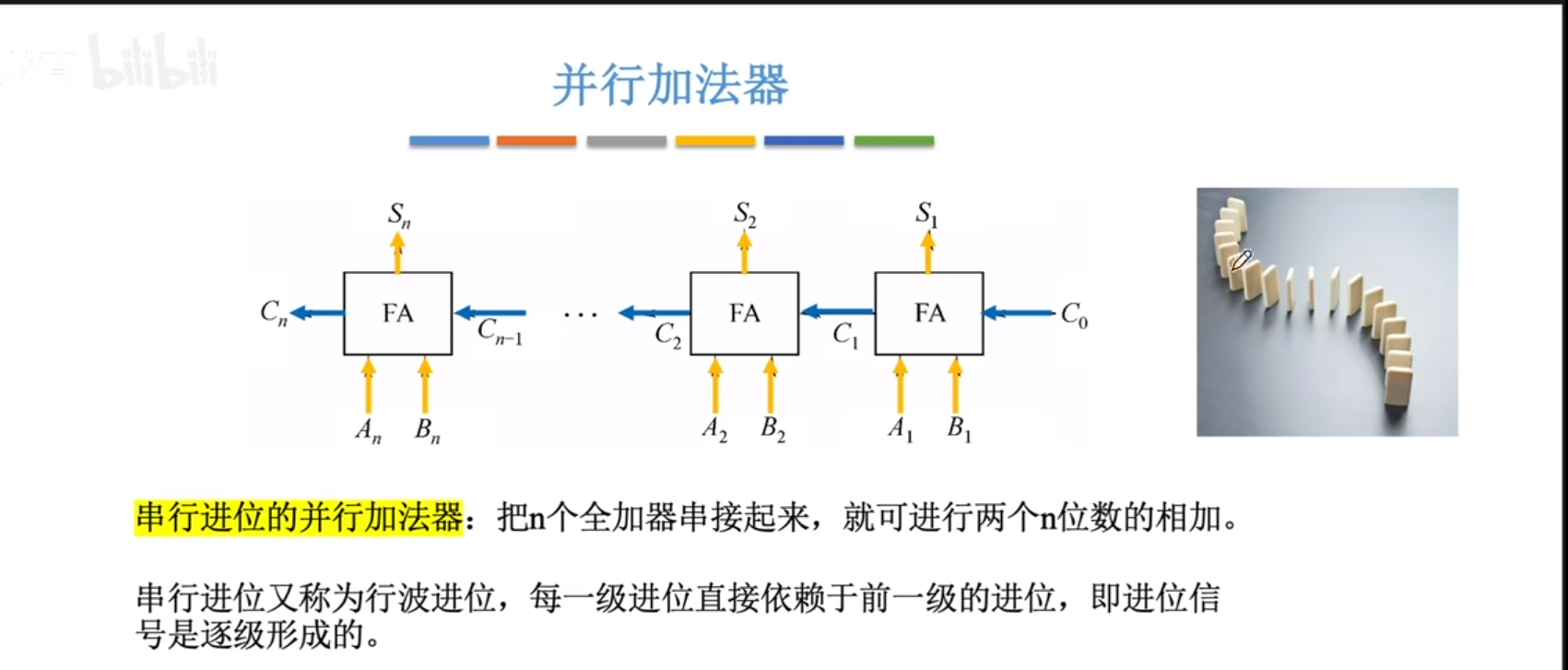
并行进位加法器
并行全加器虽然可以在一个时钟周期内实现全加,但是本质上仍然是一级一级的串行进位,如果位数太多,就必须保证时钟周期够长才能够走完加法过程。
能不能做到真正的并行呢?可以,此时需要数字逻辑的数学优化了,去提前进位,同时进位。
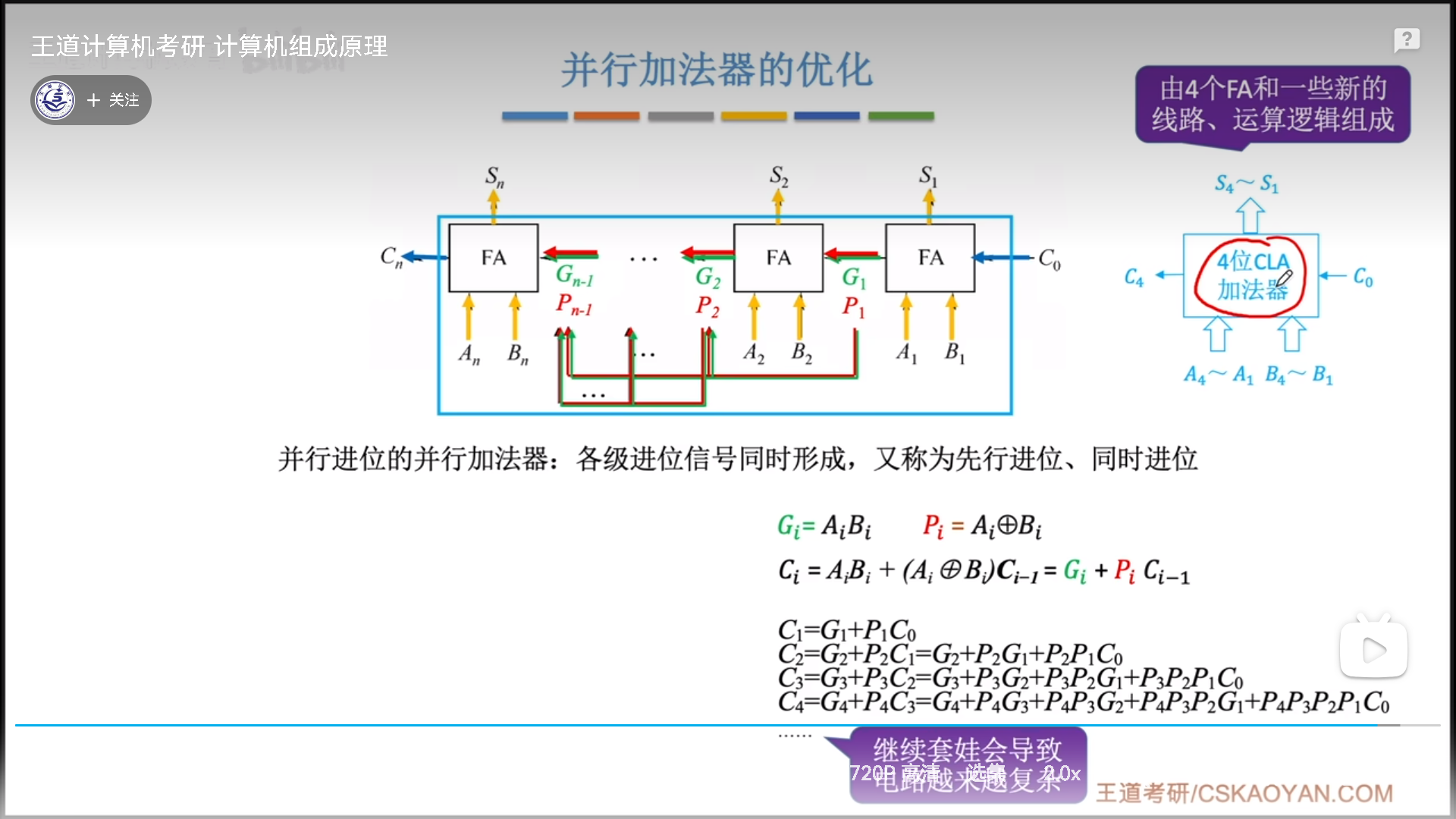
看下图。假设我们并行计算4位加法,经过公式展开,我们可以发现, C n C_n Cn只需要知道 C 0 C_0 C0以及 P n − P 1 P_n-P_1 Pn−P1,P不需要进位就可以直接算出,通过增加线路提前传输到后面,因此 C 4 C_4 C4不需要知道前面的进位就可以算出来。
由此,真正做到了同时计算4个进位。
其实进位还可以这么继续展开下去,但是这会导致电路极其复杂,所以可以准备4位的CLA加法器,内部同时进位,外部级联串行进位,这样就既可以加快求和速度,又不至于把成本搞太高。
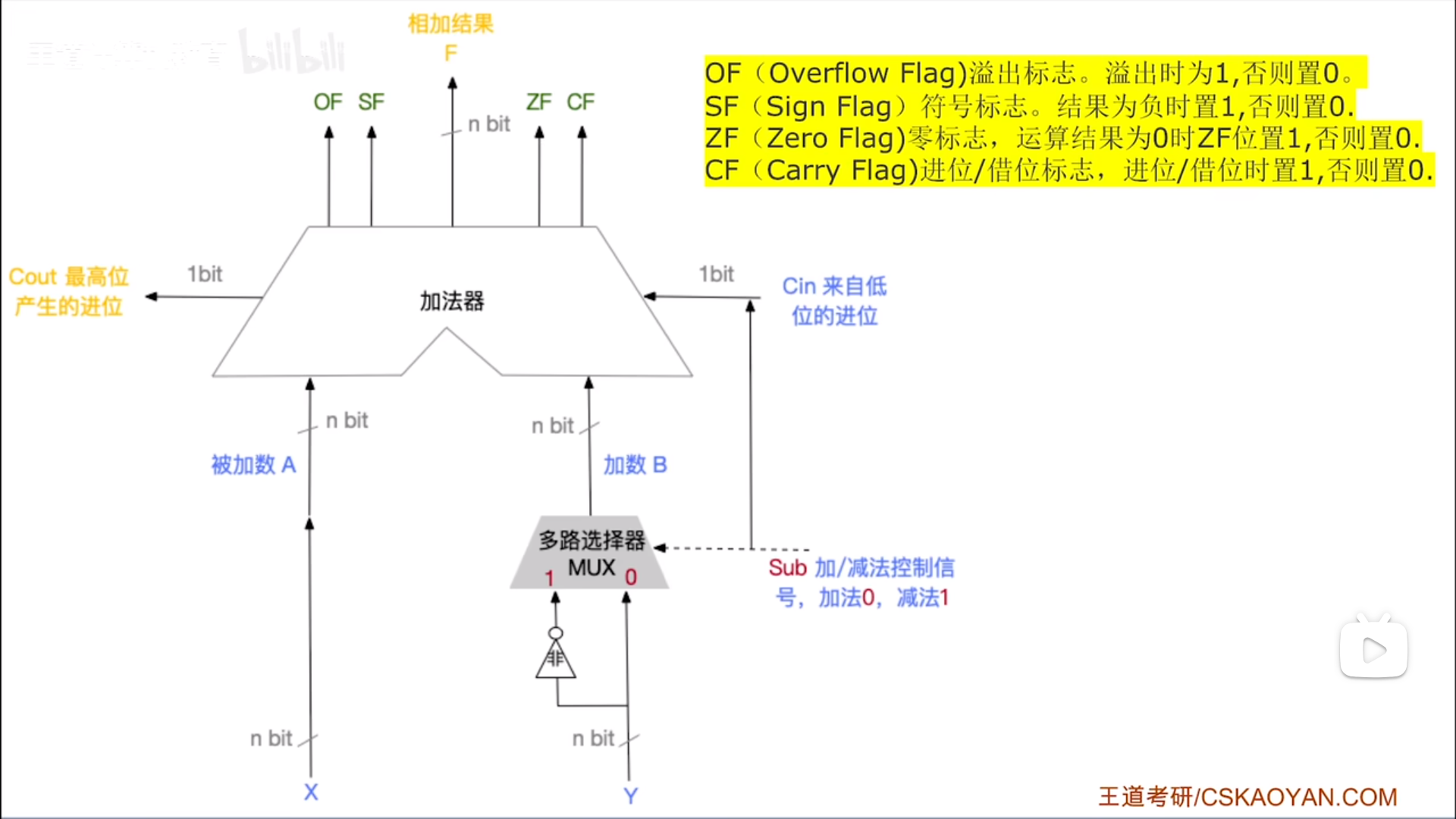
加减运算
首先要明白,无论是有符号的补码还是无符号整数,无论是定点整数还是定点小数,其运算逻辑都是一模一样的,这也是补码存在的意义:省钱。唯一的区别就在于溢出解释不一样,这个就要涉及到后面标志位的生成了。
所以不要管下面是什么码,反正都一样,就直接上图。减法是基于加法的,所以我们直接用现成的并行进位加法器:
- 输入两个nbit数,输出一个nbit数
- 输入一个进位,输出一个进位
上半个是并行进位加法器,下半部分是用于实现加减法的额外的控制电路。
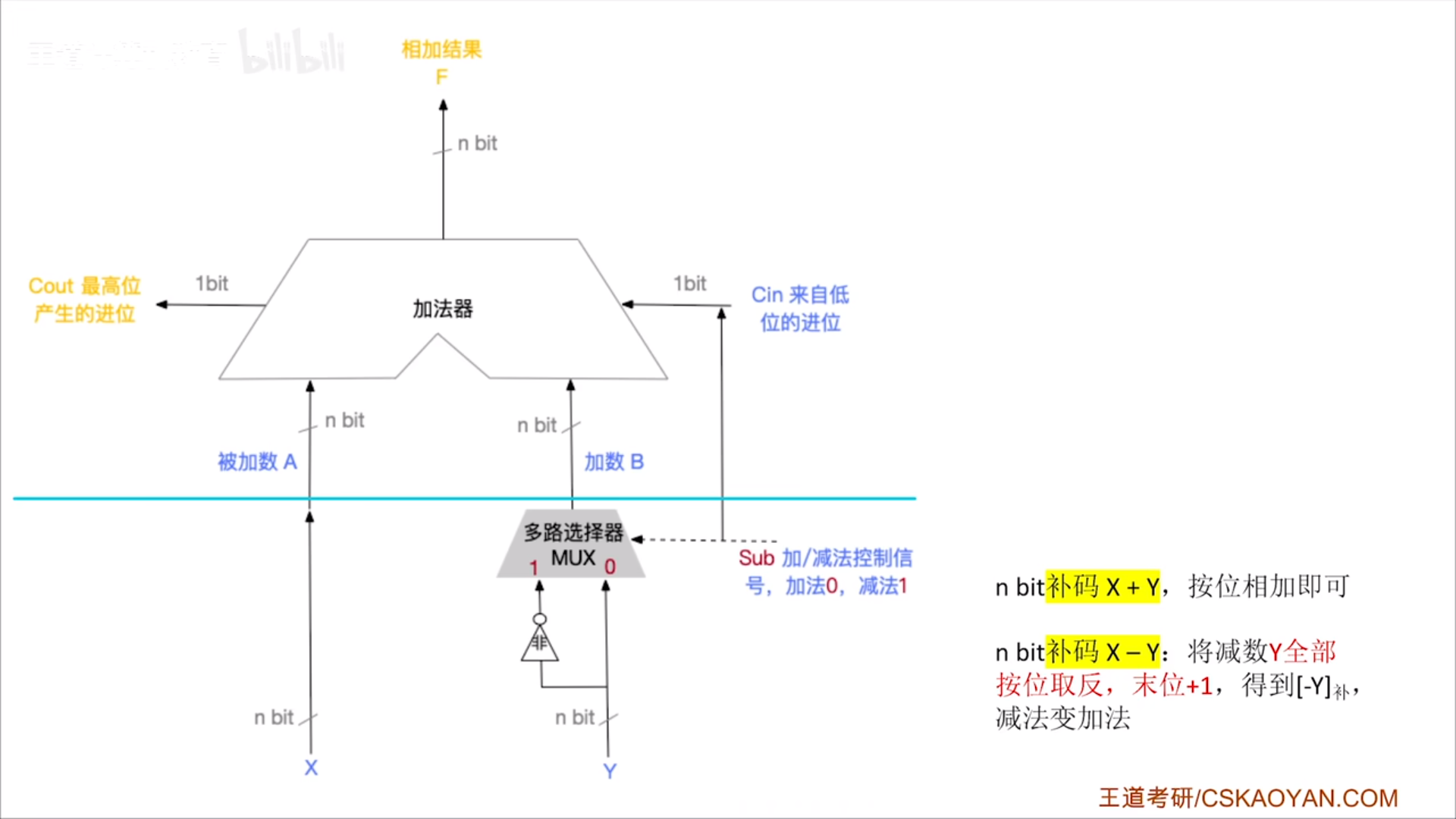
Sub是控制信号,1代表要减,0代表是加,来模拟一下这个神奇的过程。
- Sub=1。
- 多路选择器将Y按位取反的结果输入加法器
- 进位Cin=Sub=1。
- Sub=1实现了按位取反+1,之后就是加法本身了。
- Sub=0。
- 多路选择器将Y直接输入加法器
- 无进位。Cin=Sub=0。
很神奇的过程,Sub名义上是控制信号,实际上是控制取反和+1这两个过程的。
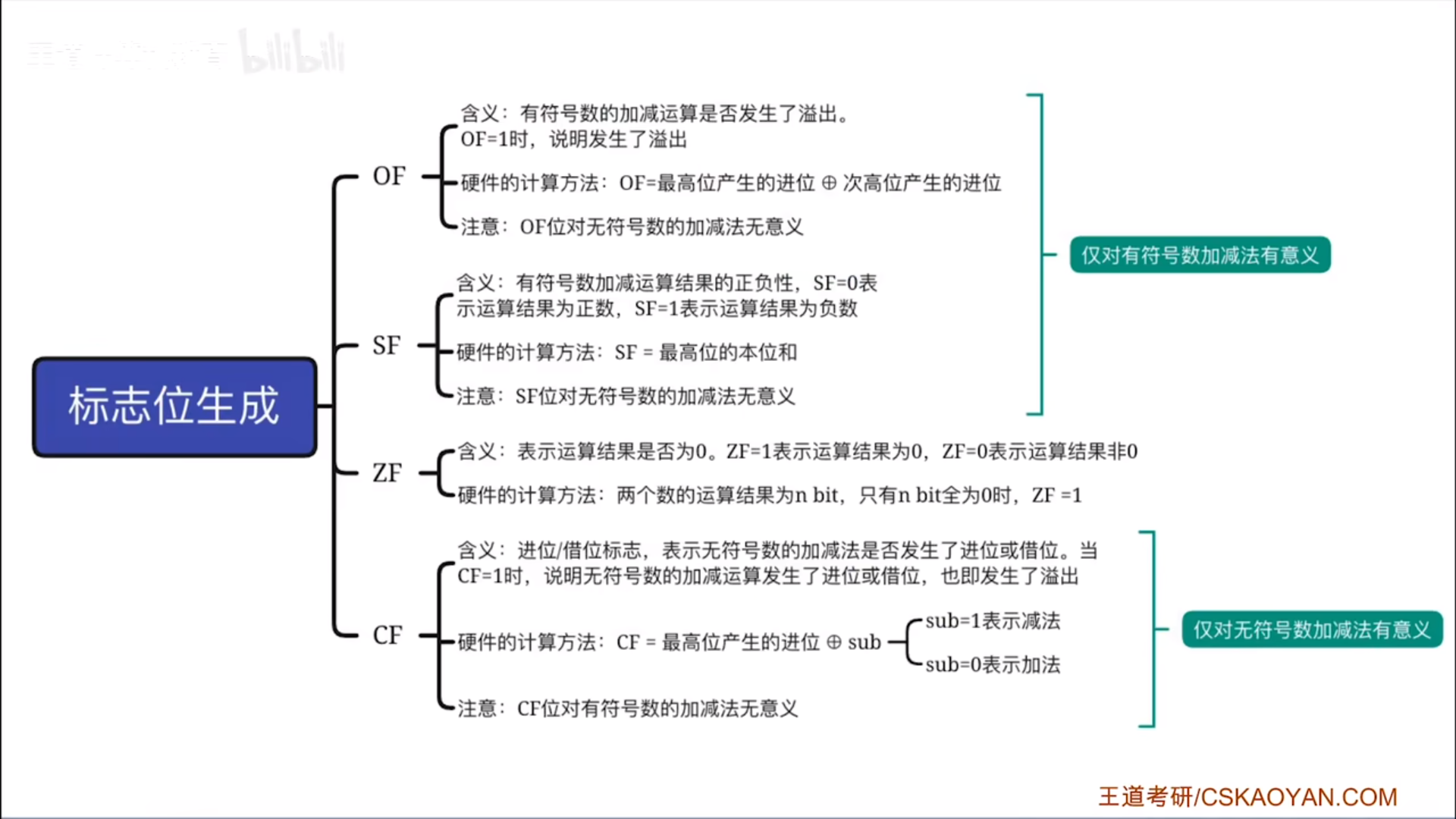
标志位的生成
前面已经实现了加减法,如何区分不同的码呢?如何判断运算结果是否合法呢?这就涉及到标志位了:
- OF和CF分别是有符号数和无符号数的溢出判断
- SF(正负)和ZF(零和非零)结合起来,可以判断结果是正/负/零
接下来具体理解一下各个标志位是怎么生成的:
- OF
- 这里我们仅讨论加法,减法本质还是加法。OF是对最高位和次高位的进位进行异或判断,
本质上就是对符号位是否变化进行判断 - 00代表两正相加,不上溢,11代表两负相加,不下溢,这两个都表示符号位没有变化。比如11情况下,虽然两个数的符号位1+1进位了,但是次高位又补上了一个1,所以符号位保持住了,没有溢出。
- 01和10,其实都代表符号位发生了改变,这就是溢出了。
- 这里我们仅讨论加法,减法本质还是加法。OF是对最高位和次高位的进位进行异或判断,
- CF
- 加法的时候,直接看进位即可。如果进位了,那么就发生上溢,Cout=1,和Sub=0异或后CF=1
- 减法实际上是在比较两个数的大小,通过Cout可以间接反映出大小关系。
- 减法的时候,会有一个数按位取反+1,此时再进行加法。无符号数按位取反后,就有一种否极泰来的感觉,原来越小的,取反以后就越大。总的来说就是,
减的时候你不溢出反而代表你缺了,发生了借位 - 如果是大-小,小的取反后会变成一个很大的数,大+很大=溢出,所以此时进位1,和Sub异或后CF=0
- 如果是小-大,大取反后会变成一个普通大数,小+普通大=不溢出,此时和Sub异或后就CF=1
- 减法的时候,会有一个数按位取反+1,此时再进行加法。无符号数按位取反后,就有一种否极泰来的感觉,原来越小的,取反以后就越大。总的来说就是,
- SF。结果的最高位就是结果的SF位,1负0正。
- ZF。结果全0,ZF=1,实际上是一个或非运算。
移位运算
移位运算是计算机底层支持的一种运算,速度很快,经常用于和加减配合实现其他运算。
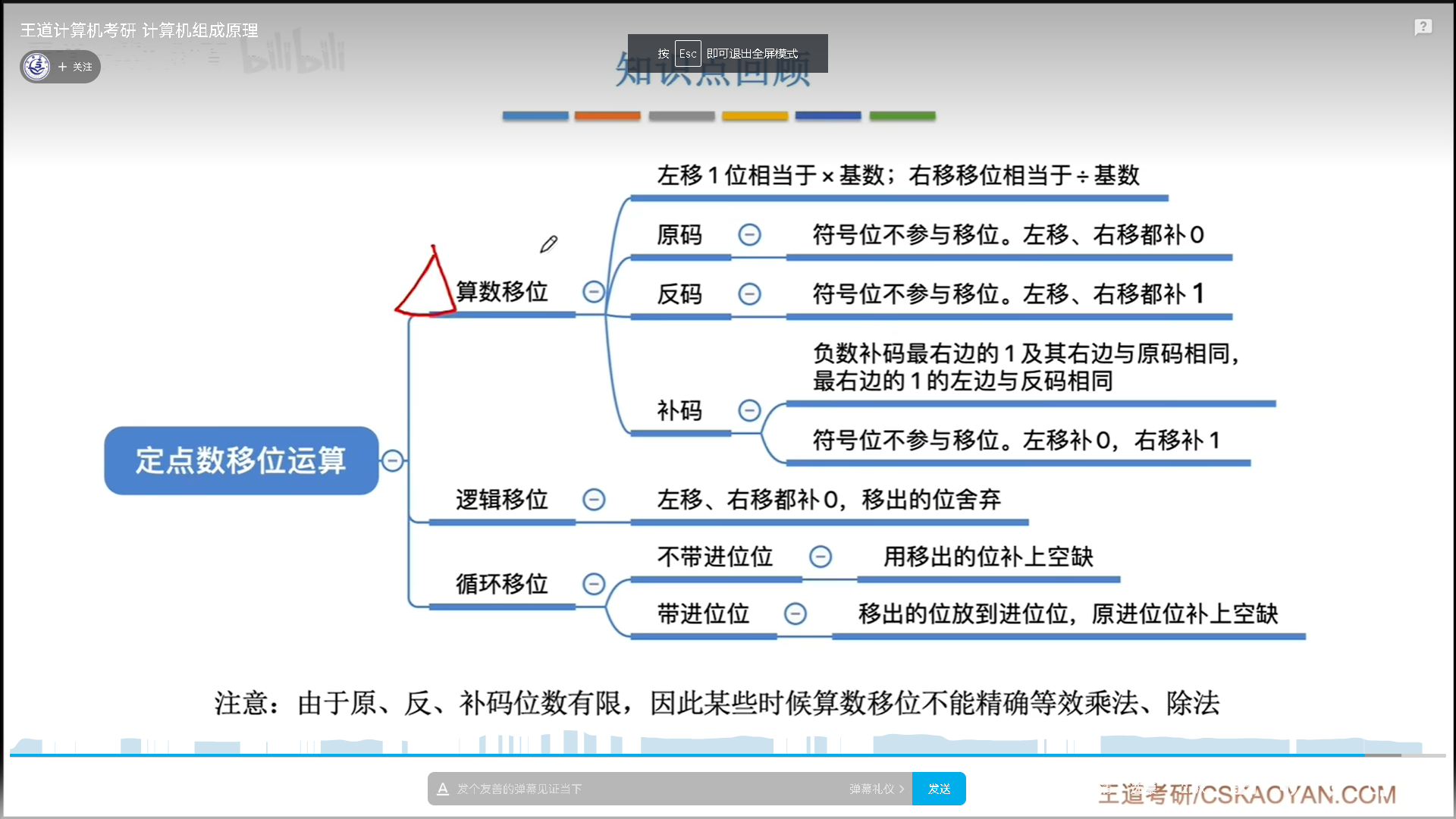
- 算数移位是要实现乘除2的,所以符号位都不变
- 原码的数值位是正值,所以补0,反码数值位是反值,所以补1
- 补码之所以这么特殊,是因为其原码的数值位按位取反+1后,会从右到左产生连续进位,直到停止进位,出现第一个1。比如1000 100,其实+1之前是1000 011,所以从右到左第一个1是一个分界线。
- 分界线左边是反码规则,右边是原码规则。
- 逻辑移位就是纯粹的移位
- 循环移位是逻辑移位的加强版变体
- 不带进位的循环移位可以用于大小端表示转换,nbit就移位n次。
- 带进位的用途广泛
定点数乘法运算(妙!)
原码乘法
对于十进制乘法来说,结果实际相当于把乘数的每一位单独取出来,和被乘数相乘,最后加和。

二进制比较特殊,每一位不是0就是1,0代表没有加,1代表加上被乘数本身。逻辑简单粗暴,非常适合电路实现。
- 初始化:在ALU内部,首先把ACC置0,X置被乘数
数值位,MQ置乘数数值位。在乘积的过程中,ACC会逐渐变成乘积的高位,MQ会逐渐变成乘积低位。 - n次循环:
- 累加。判断MQ最低位是0还是1
- 0则ACC不变
- 1则ACC累加一个X
- 移位
- ACC和MQ整体逻辑右移一位
- ACC最高位补0,ACC最低位移到MQ最高位
- MQ最低位移出。这一位作为参与乘法的最低位,已经没有利用价值了
- 累加。判断MQ最低位是0还是1
- 异或运算计算符号位
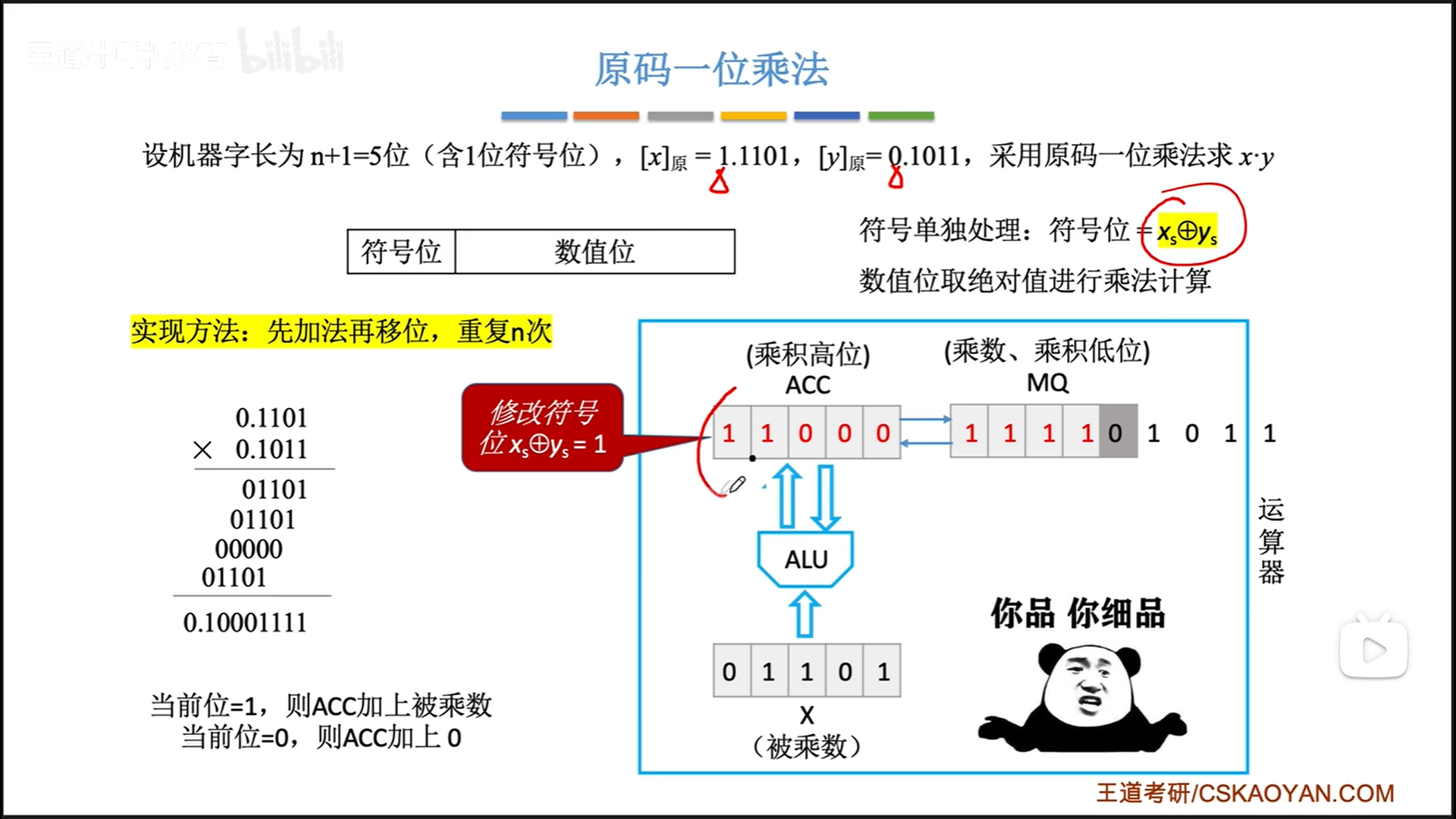
无论是定点小数,还是定点整数,算法都是一样的,只是最后解释的时候,小数点位置不一样罢了。
做题手算的时候,就是按照下面这个图来走,比较清晰规范。

补码乘法
补码和原码的整体流程类似,但是因为其取反加一的特殊生成过程,我们计算的过程也要有所修改。

具体讲解一下细节。
首先是位数要多一位。MQ增加一位辅助位,所以实际上MQ最低位已经变成了辅助位,现在的“最低位”特指辅助位前一位。
因为要统一寄存器长度,所以ACC和X也要加一位,只是在最前面加了一位,构成双符号位,多出来的那个便于判断补码是否溢出,没啥大用。
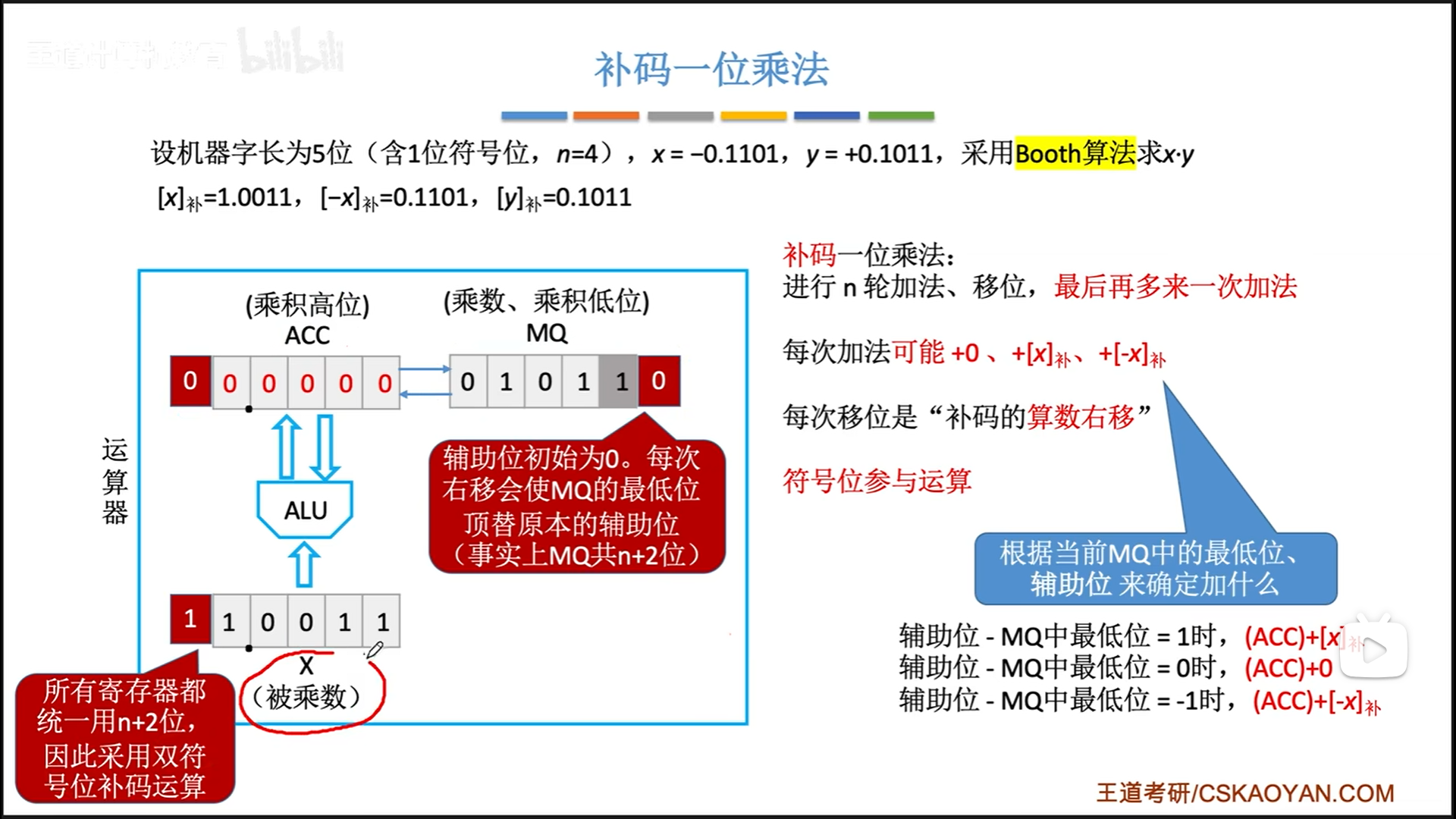
我们直接结合实例来看:
整体过程还是:
- 初始化,ACC赋0,MQ赋乘数
带符号位,辅助位=0,X被乘数(额外符号位=符号位) - n次累加移位循环
- 额外加法。这一步实际上是在生成补码的符号位,代替了原码的异或运算。

定点数除法运算
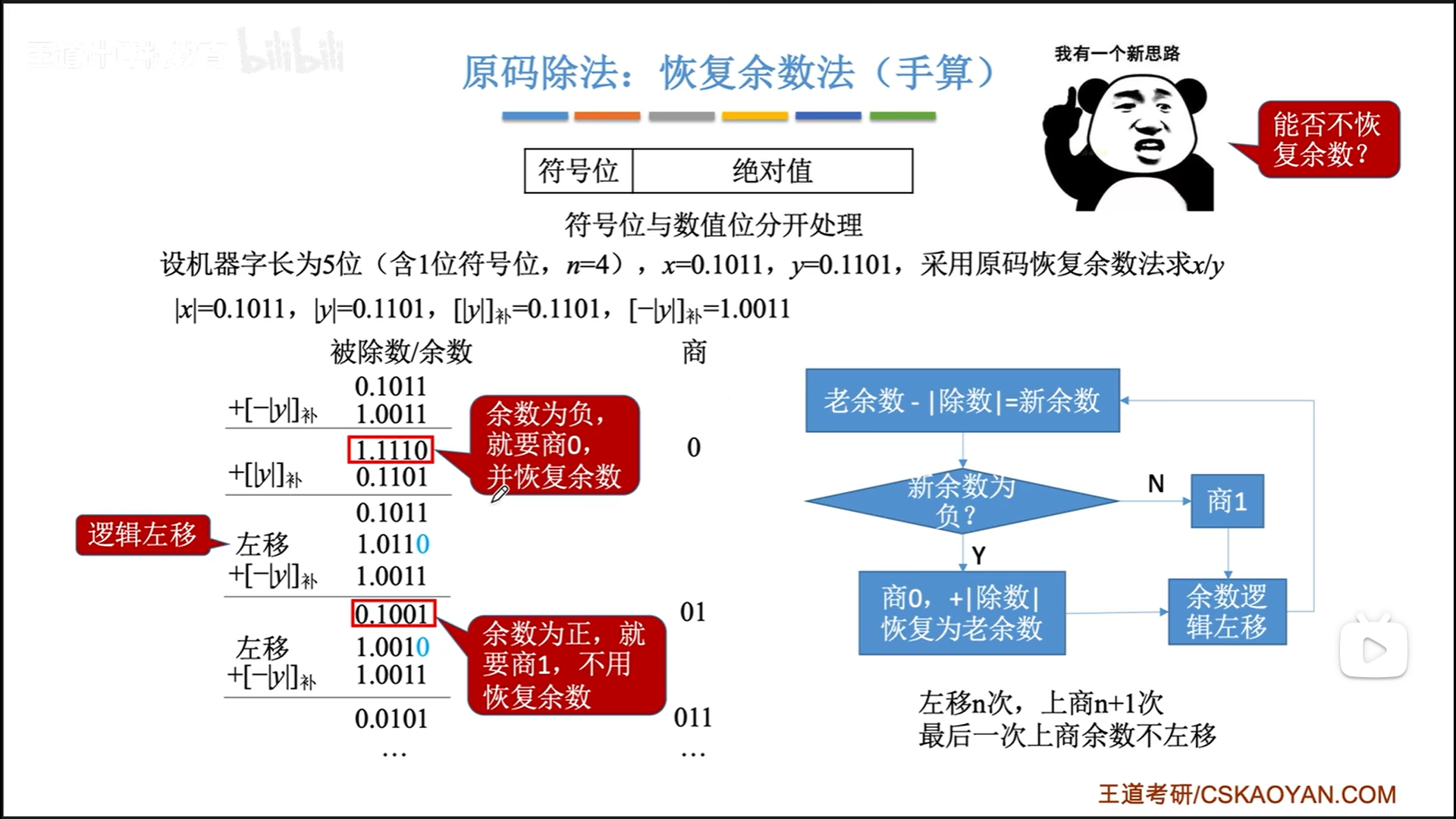
原码除法:恢复余数法
手算除法的时候,我们是估计一个商,然后用商×除数,与当前的被除数(之前的余数×k)比大小,选出一个合适的商。
二进制很特殊,真的是一个优秀的进制。
二进制中,我们只需要比较除数和当前被除数(之前的余数×2)谁更大即可,被除数更大就取1为商,否则就取0。
来看一下恢复余数法的具体操作,直接看手算吧,右边有流程图。
这里打了个哑谜: [ − ∣ y ∣ ] 补 [-|y|]_补 [−∣y∣]补=全部取反+1。说白了就|y|的负值呗,这么说只是因为这种方式是电路中实际的实现,因为电路中只有补码电路。而 [ ∣ y ∣ ] 补 [|y|]_补 [∣y∣]补=|y|,其实恢复余数就是要加上|y|的,和补码没什么关系,大概也是必须要走一趟补码电路,才强行加了一个补。
总的来说就是:
- 上商+左移循环n次
- 最后再上第n+1次商,最后一次上商后就已经圆满,不需要再左移了。
- 最后再通过异或运算出余数的符号,覆盖n+1位商的最高位。
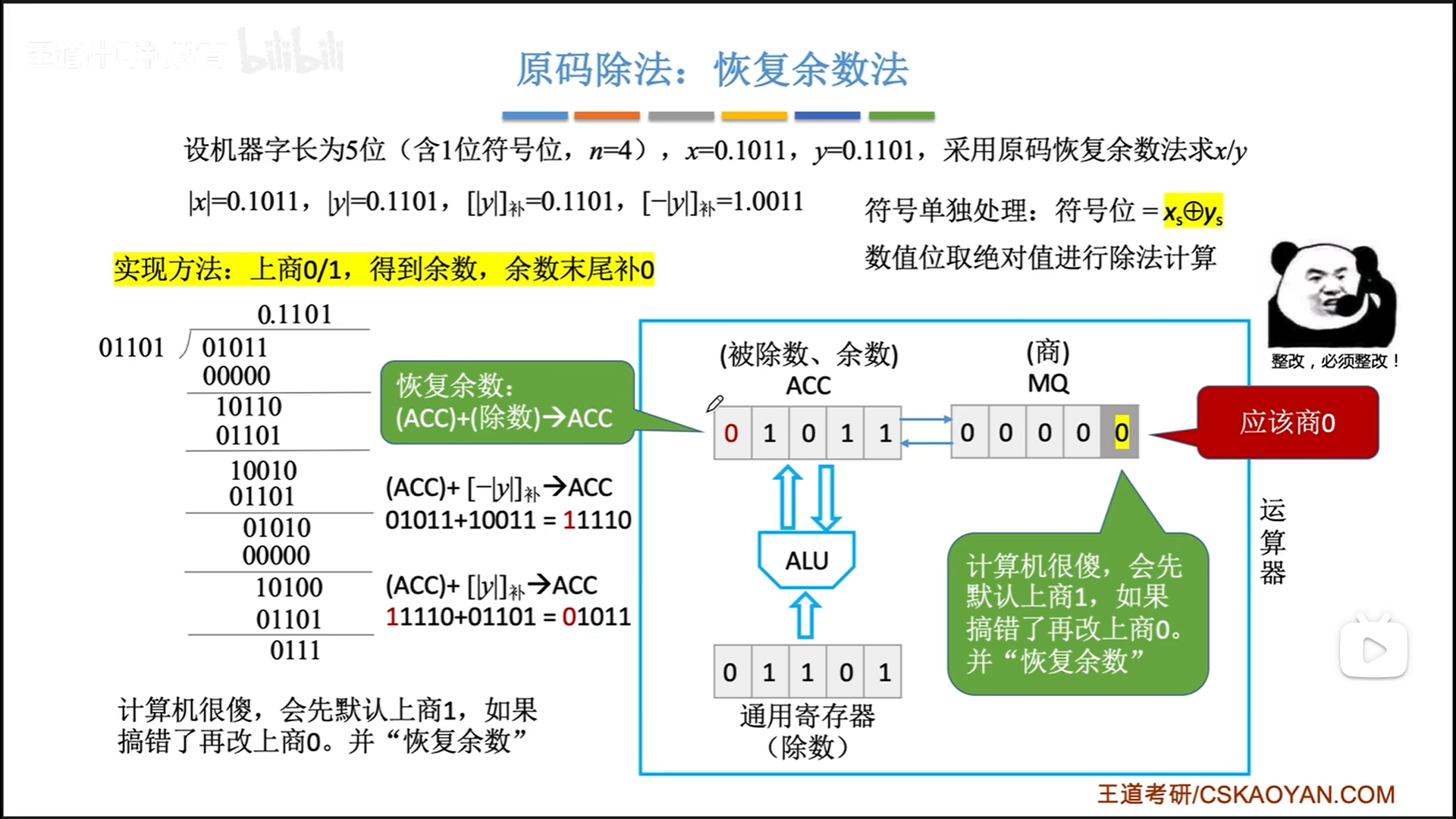
具体到硬件组成细节如下:
- ACC置被除数
数值位,X准备除数数值位,MQ置0,最后会随着左移变成商 - MQ最后一位默认上1为商,得到余数,判断后决定是否还原。
- 正常情况下,减完以后,新余数的符号位必然等于0,正因此,逻辑左移才没有任何副作用。
- 符号位如果是1代表有问题。重新取商为0,且恢复余数。
- 逻辑左移是整体左移,但是因为MQ前面都是0,所以就无所谓整体不整体的
- 最后通过异或求出的符号直接覆盖MQ最高位
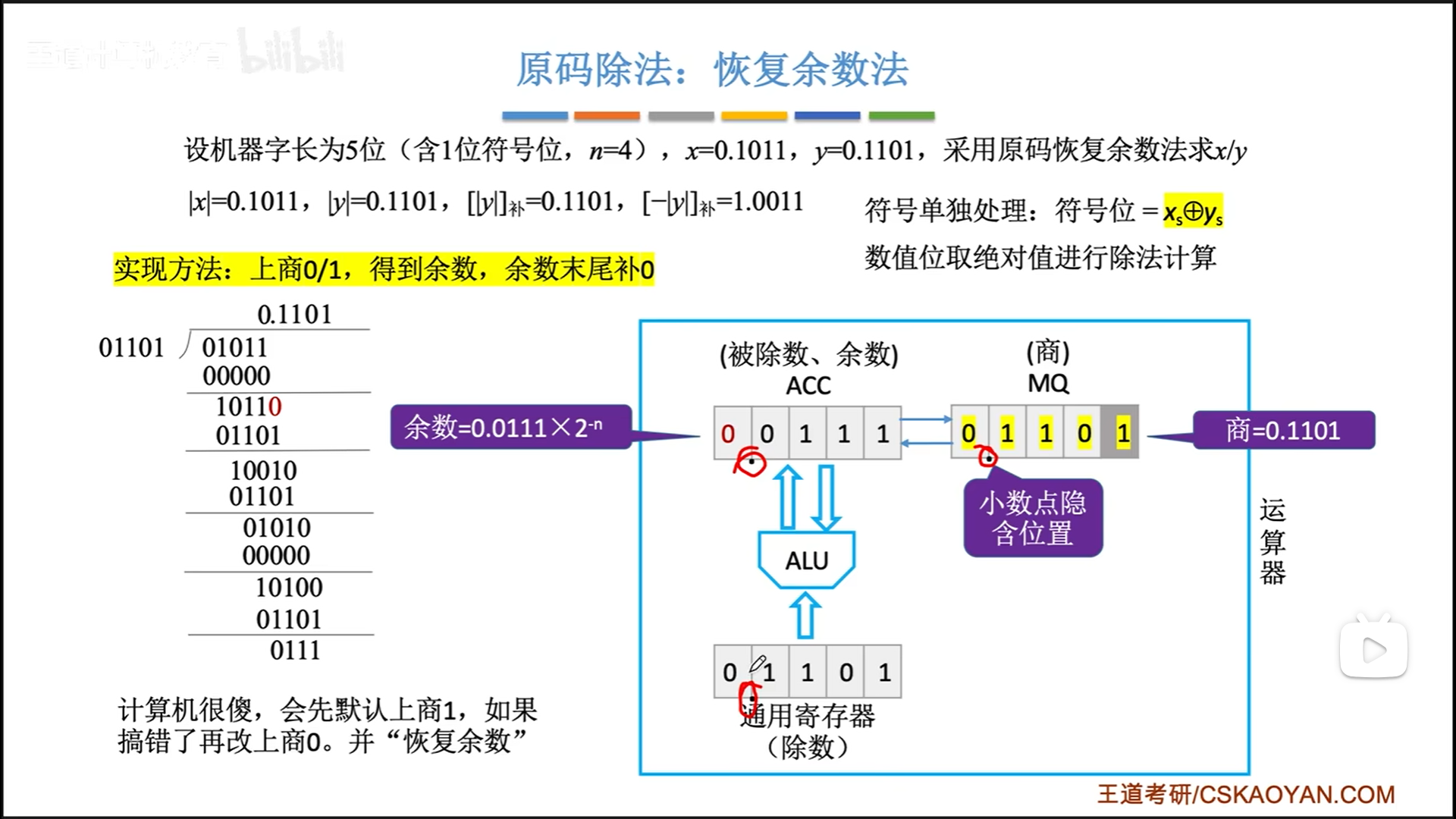
最后注意小数点隐含位置就可以了。
加减交替法
恢复余数是一个比较麻烦的过程,可不可以跳过呢?此时再次请出数学工具。
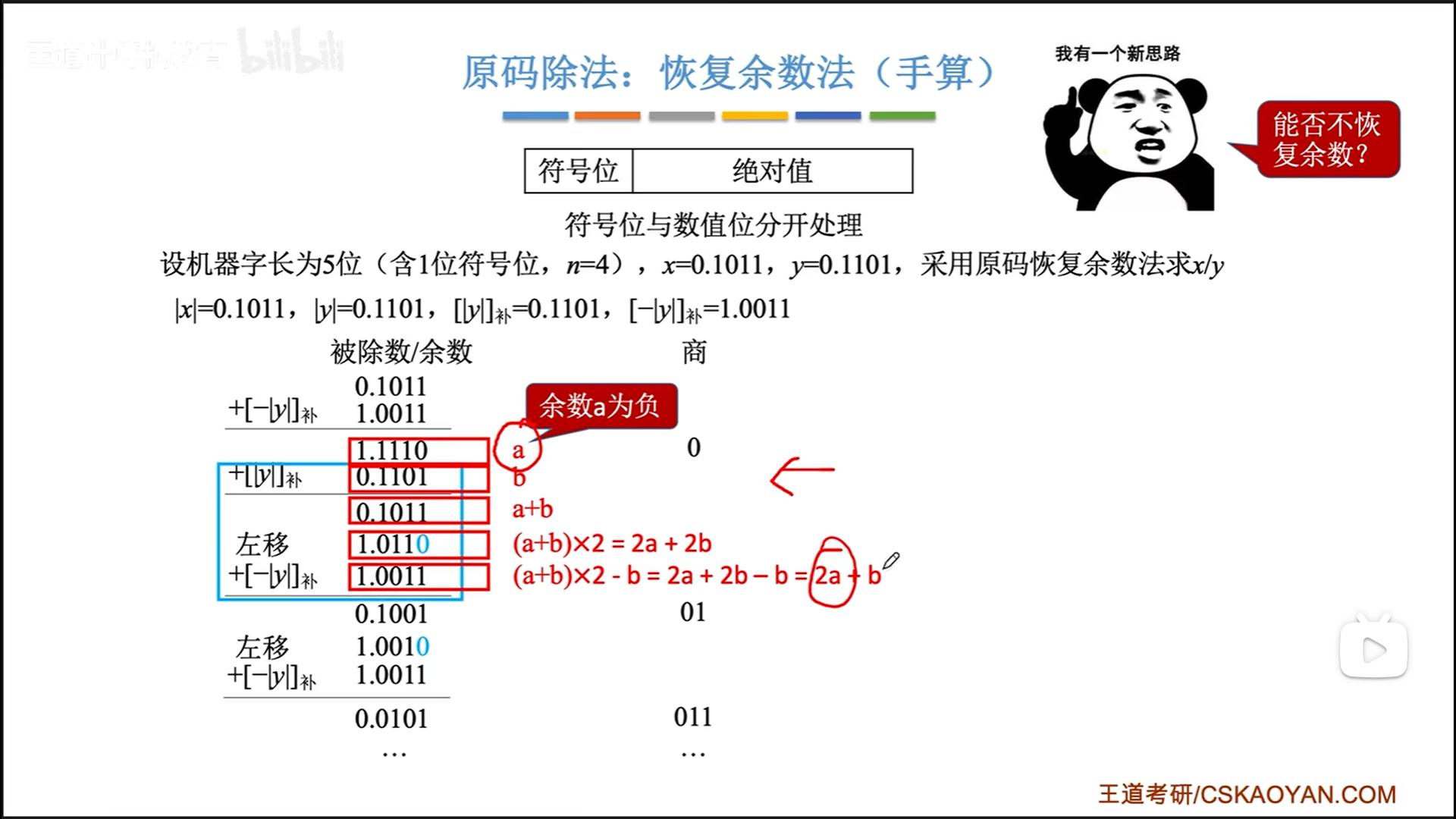
经过上面的演算,可以把恢复余数的一大步合并到计算下一个余数的步骤里。
具体步骤就是:
- 第1次是减,马上得出第一个商
- 之后循环n次,左移,加/减,得商
- 最后商0(余数结果为负),需要进行一次加法恢复余数。注意这次恢复之前不用再左移了。

最后还有一个小细节就是,在定点小数中,不允许大除小,因为定点小数不能大于1,自然除法结果也不能超过1。
如果发生大除小,那么第一次被除数-除数结果就会是正值,这时直接中止过程报错即可。
补码加减交替法
正如补码乘法之于原码乘法,补码除法也需要把符号位加入计算。
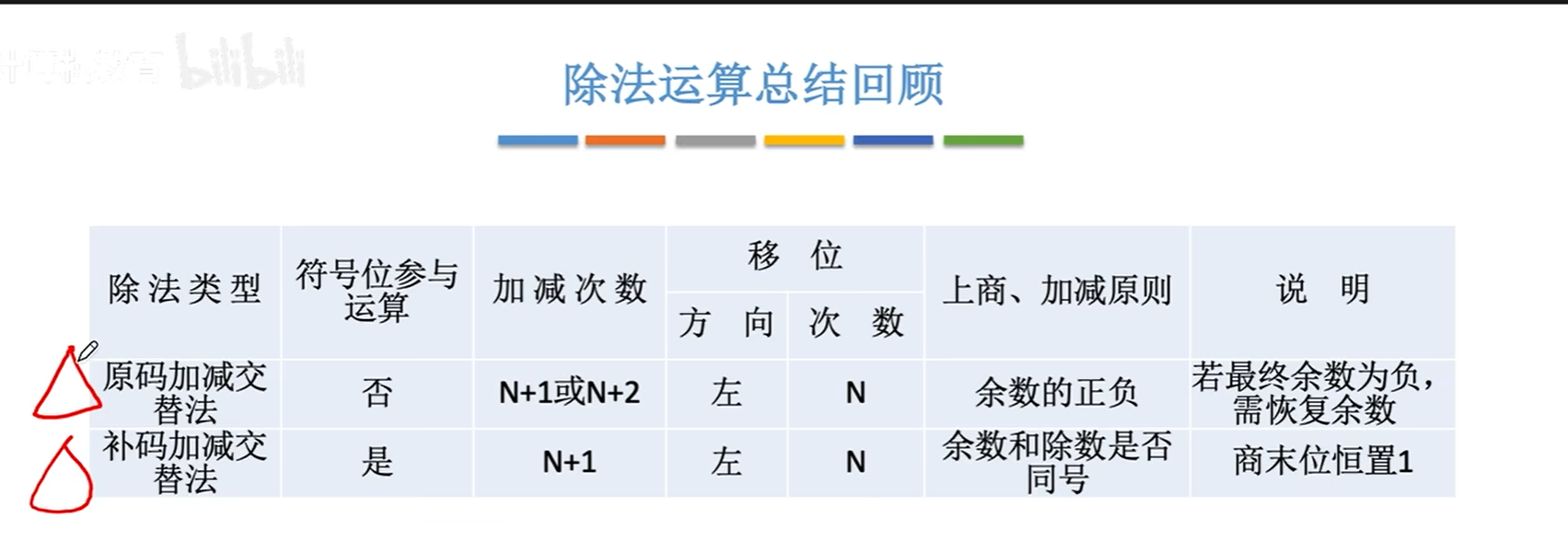
具体做法如下,和原码加减交替流程是一样的,商1以后就左移减,商0则移位加,差异如下:
- 判断依据从结果正负变成了是否同号。具体原因我也不深究了,可以理解为,同号≈原码中余数大于除数≈能上商,对应着记。
- 求商n次,最后左移,加/减完了以后,不需要再求第n+1位商了,直接置1,省事(少一次移位加减)误差又小。
定点类型转换、储存、对齐
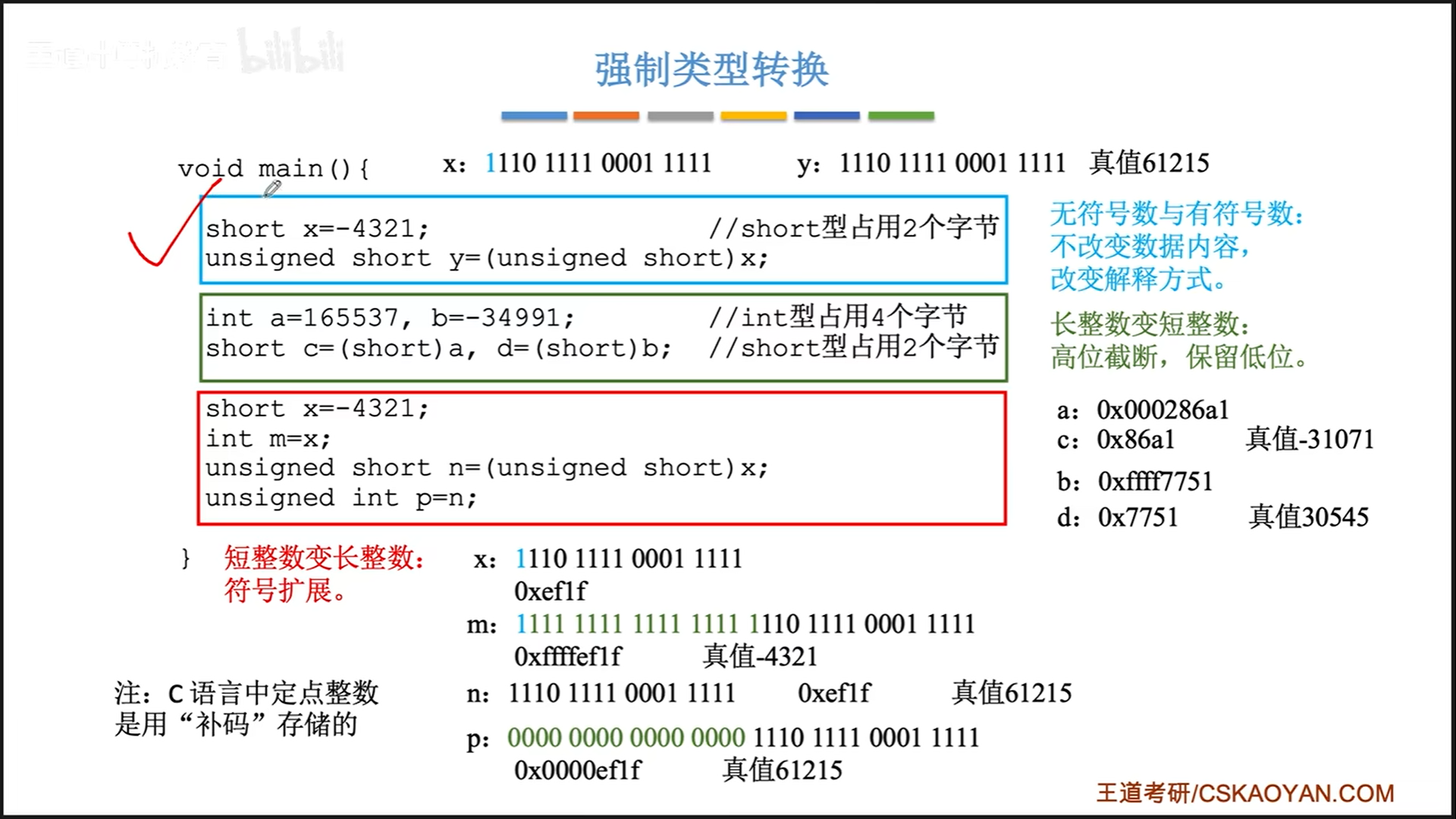
C语言中,采用补码储存数字,C语言定点数的强制类型转换有两种规则:
- 有无符号转换:不改变数据内容,直接变解释方式
- 长度变化:截断或者扩位
- 长变短:直接截掉高位,产生新的符号位
- 短变长:算术右移
此外,计算机储存二进制的方式一般是小端法。虽然大端法更便于人看,但是机器处理小端法更加方便。
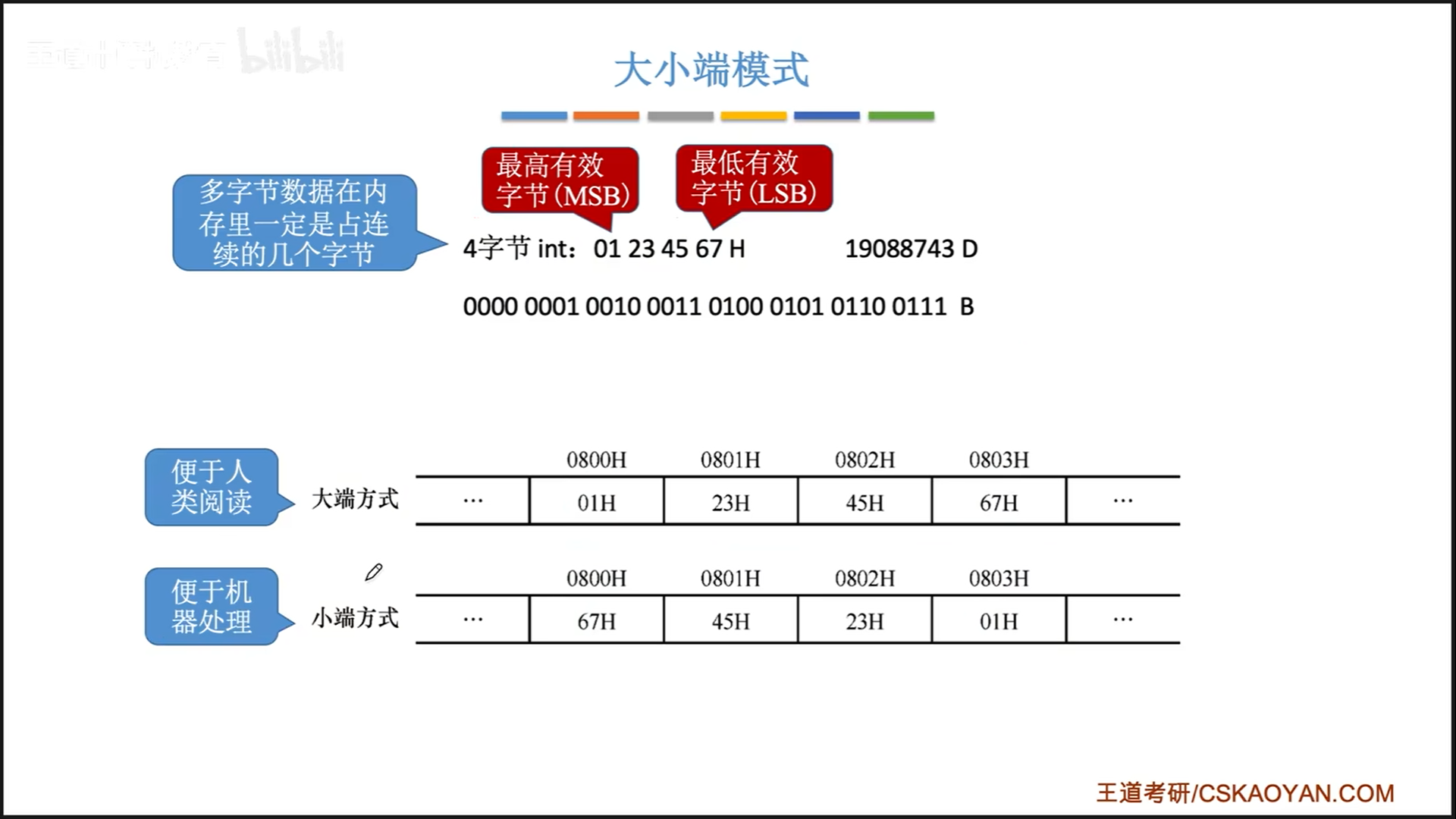
我们前面说,一个地址对应一个储存单元,其实这句话并不准确。
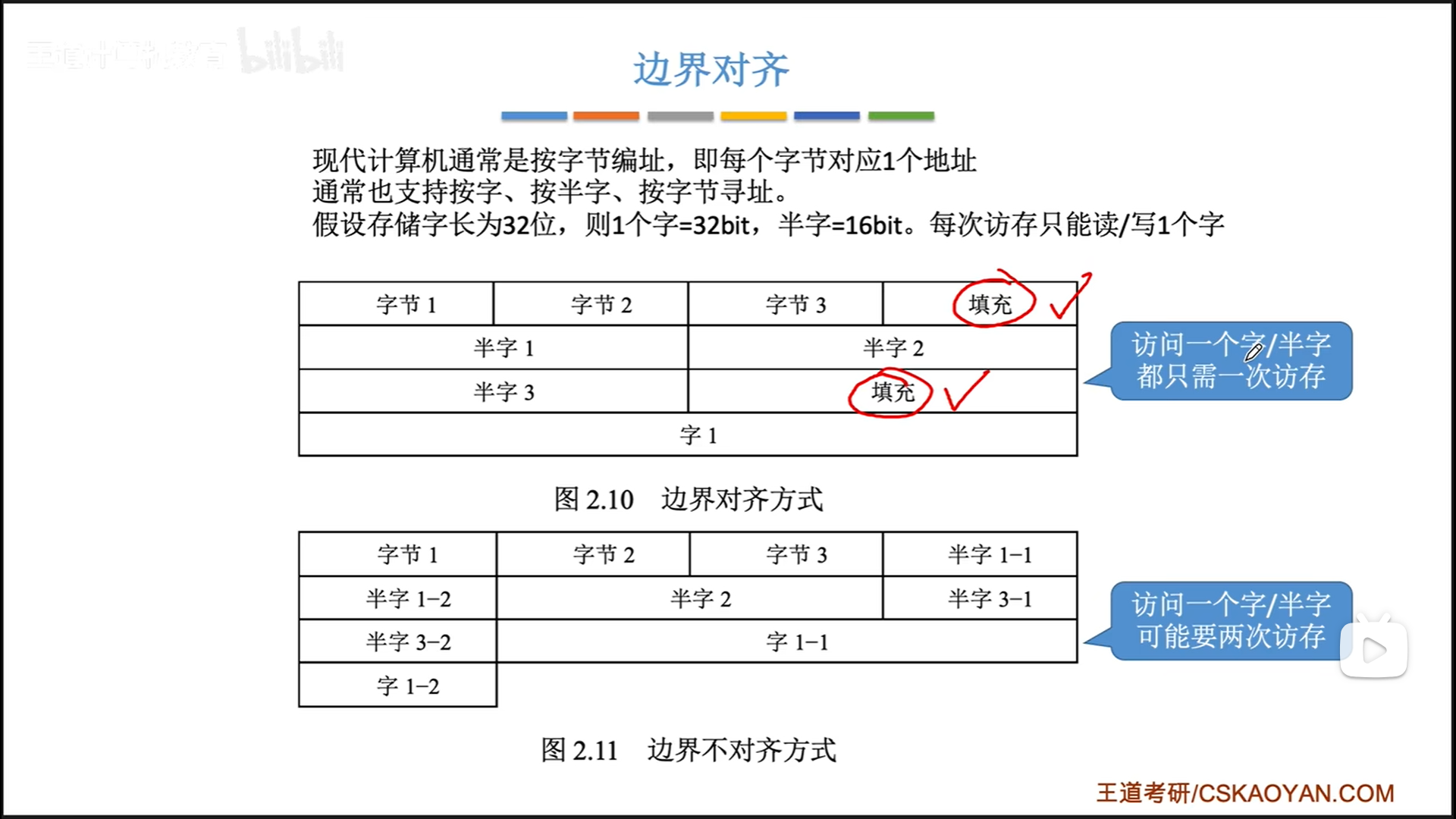
现代计算机的字长是64,但是实际上是以字节为地址单位的,即字节寻址。当然,我们也支持按字,半字寻址。
那字长到底有什么意义呢?字长规定了一次读取的宽度,也就是说,虽然我是按照字节寻址的,但是每次访存必须读写一个字(64bit),不能多也不能少,因为数据线从物理上已经把位宽定死了。
既然读取内容固定了,那么为了一次读取一定能读完一个数据,数据的存放也应该进行边界对齐,一个数据的起始地址一定是其长度的整数倍。
如果不对齐,可能就像下面的半字1-1和半字1-2,读两次才行。
浮点数的表示和运算
IEEE 754计算机浮点标准
之前在CSAPP笔记里写过了,此处直接复制粘贴,懒得再写了,已经很详细了。
考试无非就是考10进制浮点数和754的相互转换,注意要点:
- 阶码:
- 规格情况下frac非全1,非全0
- 偏置和传统阶码差1,偏正
- 尾数:
- 前导1别忘了
因为随着小数点位置的不同,相同的二进制码会有不同的解释,小数的表示也是百花齐放,所以IEEE就指定了IEEE 754标准。
总的来说,好的浮点数标准,应该有足够的精度,且可以适应各种舍入,溢出情况。
浮点表达
从形式上来说,这是一种科学计数法表示。S确定整体的正负,E有8位,本身也可以表示负的指数。

从具体实现来看,exp和frac表示E和M。但是绝对不等同,而且根据情况不同还会有不同的解释,具体请看IEEE 标准

精度
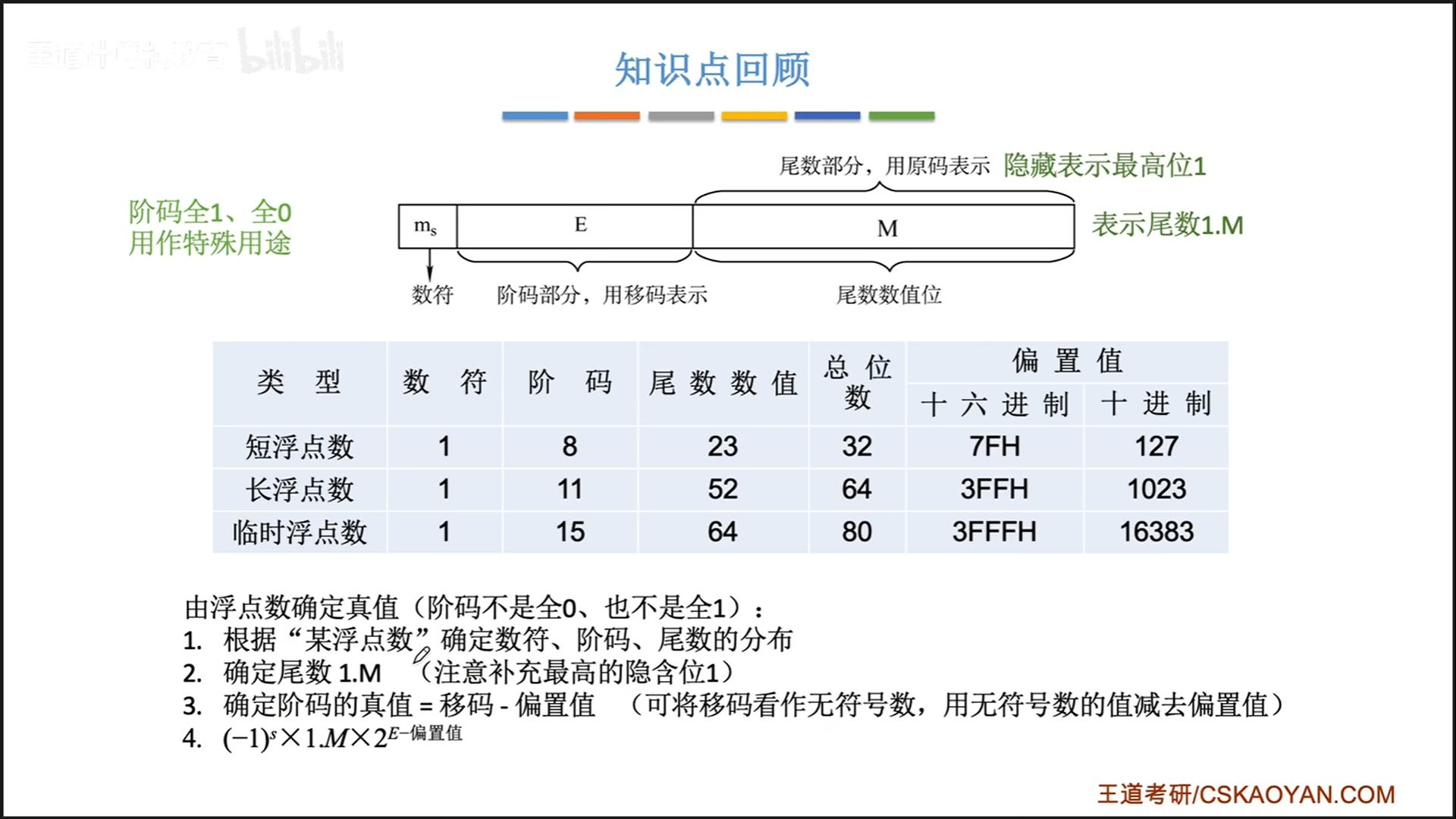
精度由位数决定,最常用的是32位,但是很明显,32位的尾数只有23位,如果从10进制转到2进制时,数字长度太长,超过23位,就会损失精度。所以出现了双精度,在exp(11)和frac(52)上都有扩展
所以在与32位int转换的时候,不一定完全等价,且不说有效二进制位就不够,浮点exp能表示的范围也和int不同(详见CSAPP-datalab : floatFloat2Int函数)

规格数
如果exp是非全0,以及非全1,总的来说就是正常的数,就都是规格化表示。
在规格化情况下:
- 尾数部分必然是1.xxx,所以大可把1省去,用frac表示小数部分,最后+1表示M,这样可以说是凭空增加了1位。
- 阶码是移码表示,本身是无符号数,换算成带符号的要偏置一下。实际的阶码=E-127,实际的阶码可以取到-127-128(这一点和补码稍微有些差距,补码是-128-127)
这里给出一个从实数到单精度的计算过程,你也可以倒着算回去:
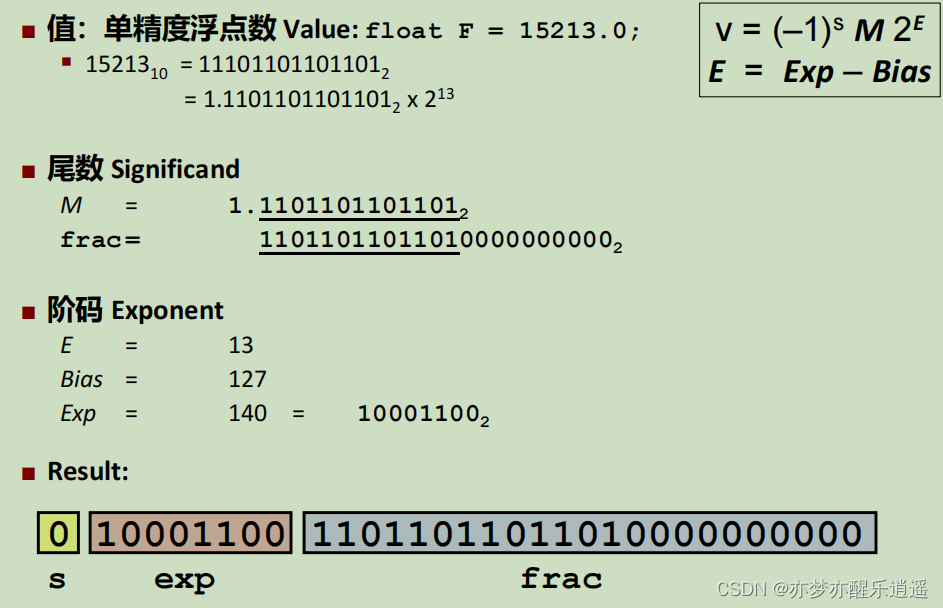
从极小规格数到非规格数再到0(特殊非规格数)
当exp全0,这时E不是-127,而是-127+1,E=-126。
浮点数极其趋近于0,那这个时候frac默认补1就没有意义了,此时前导1就变成了前导0,因为此时我们要以最大的精度表示趋近于0的数字。
当exp为 0000 0001,此时E=exp-127=-126,和exp为 0000 0000时一样。这就有趣了,既然极小规格数和非规格数的E是一样的,那这两个又有什么区别呢?即前导1和前导0的区别。本质上说,非规格数是把E中最后一位能表示的信息转移到了frac位,让frac位有了更强的表达能力,这就是所谓的精度提升。具体来说,我没有去细究的想法,就此略过。
从当非规格数(exp=0)的frac=0,此时表示0,随S的不同而表示+0,-0
提问:exp不为0且不全1(规格数)的时候frac=0,表示的是0吗?
不是,因为exp=0的时候,前导1变成0了,但是exp不为0的时候,frac是1.xxxx,不可能表示0。所以,0一定是非规格数。
最后,非规格数与exp=1的极小规格数这个区间,是罕见的均匀分布。因为E是固定为-126的,所以尾数部分就决定了实际的值。从极小规格数的1.1111 1111 1111 1111 1111 111到1.0000 0000 0000 0000 0000 000到最大非规格数的0.1111 1111 1111 1111 1111 111到0.0000 0000 0000 0000 0000 000,是连续的,间距稳定的,很神奇。
特殊值总结
exp全1,当frac全为0,则E=exp-127=128
此时指数是最大的,所以表示Inf
exp全1,但是frac不全0,比Inf都大,显然不合理,所以就表示Nan(Not a number——不是数,一般溢出以后是这个表达)
exp全0,当frac不为0,则表示E=-126,前导0为0,即M为0.xxxxx的极小数。
exp全0,当frac全0,就变成了0。根据符号位为0或1,就有+0 -0之分(这里强调,浮点数不是补码)。从这一点看,浮点数+0和补码0是一样的,浮点数-0和补码最小数一样。
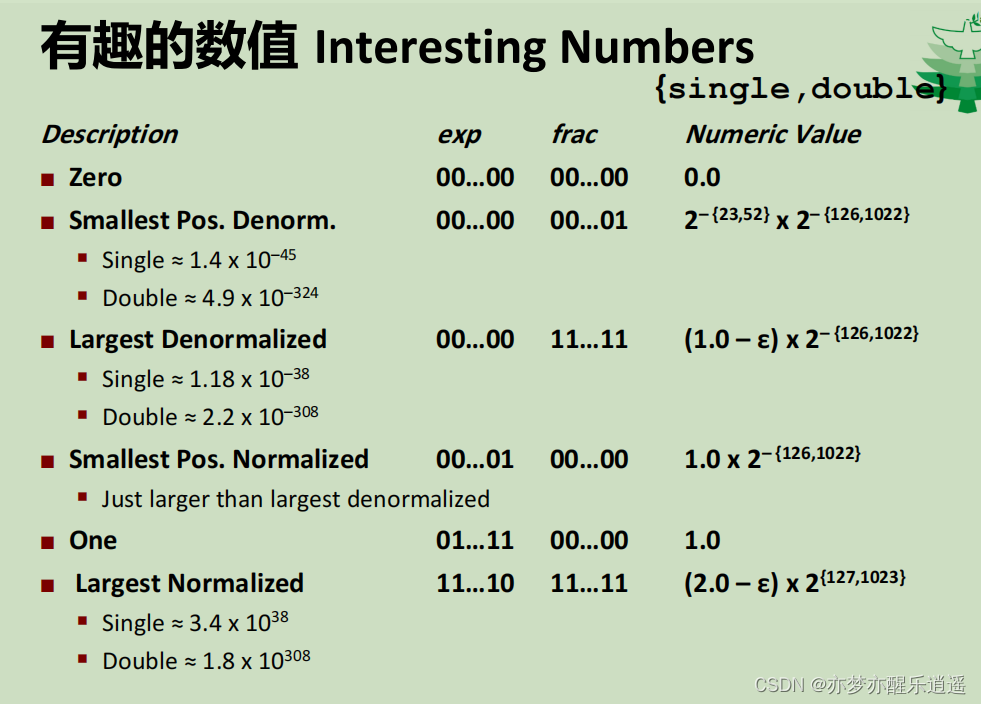
范围可视化与值的表达
exp全1,frac非0,表示Nan
exp全1,frac为0,表示Inf
exp介于全1全0之间,frac任意,表示规格数,在正数部分最小为frac全0,exp为1的时候,此时frac为1(仅有前导1),最大为exp为1111 1110的时候,frac全1的时候。
exp全0,frac任意,表示非规格数,在非负数部分,最小为frac全0,代表0,最大为frac全1,前导为0。
从大到小,浮点数在数轴上顺序排列,而且从极小规格数到非规格数不会发生重叠,这一个优秀的结果是非常令人意外的。
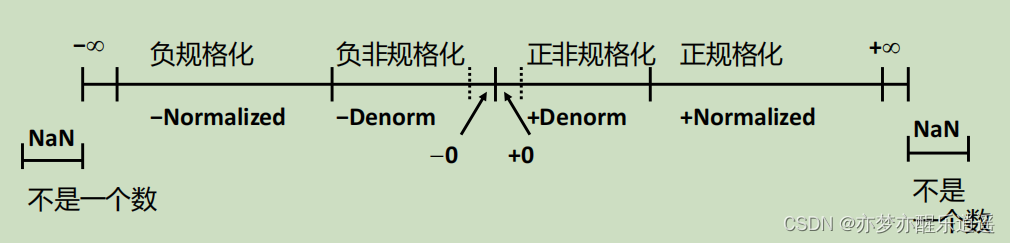
我们用6位的IEEE格式检验一下,就会发现,整体分布是外部稀疏,内部稠密的,逐渐变密集,而再往内部走,间距就稳定了,极小规格与非规格是区间连续+间距稳定的
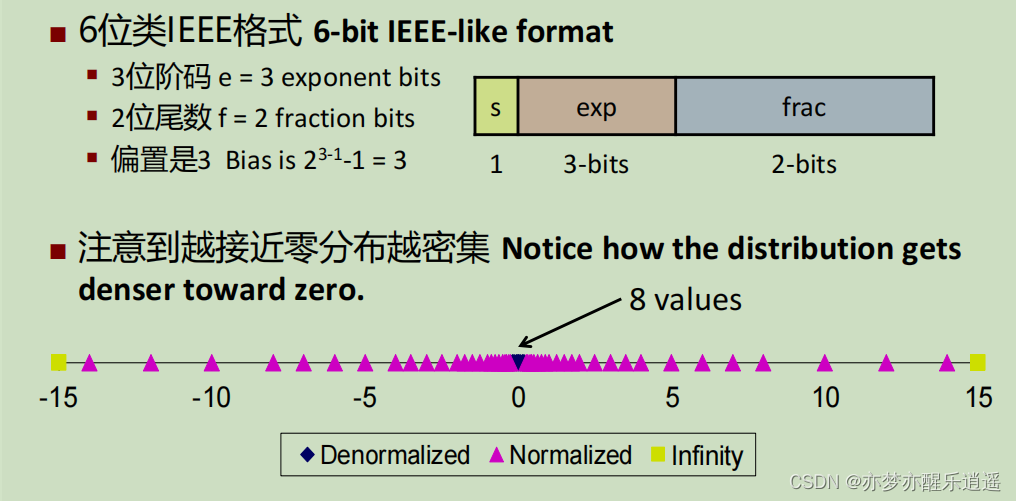
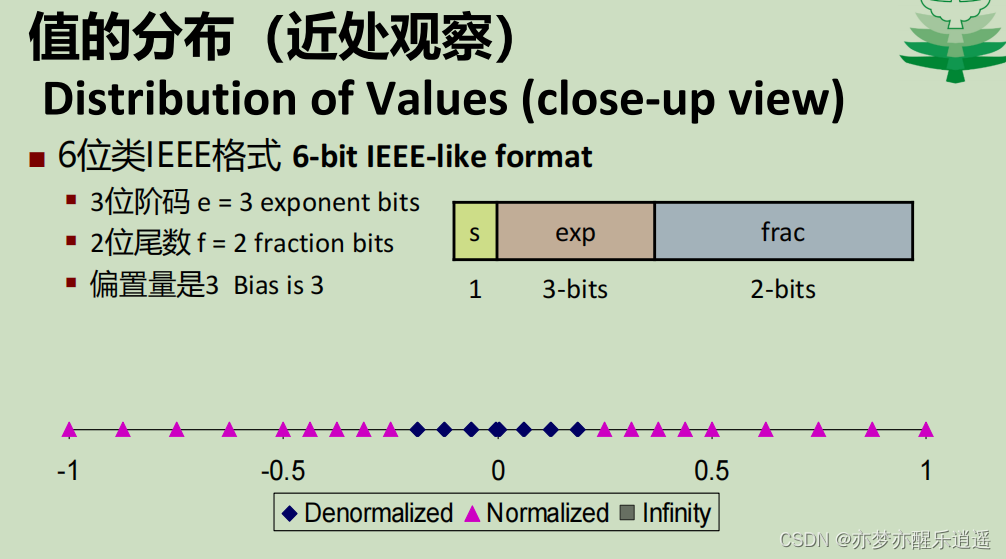
示例
这是一个规范化数。
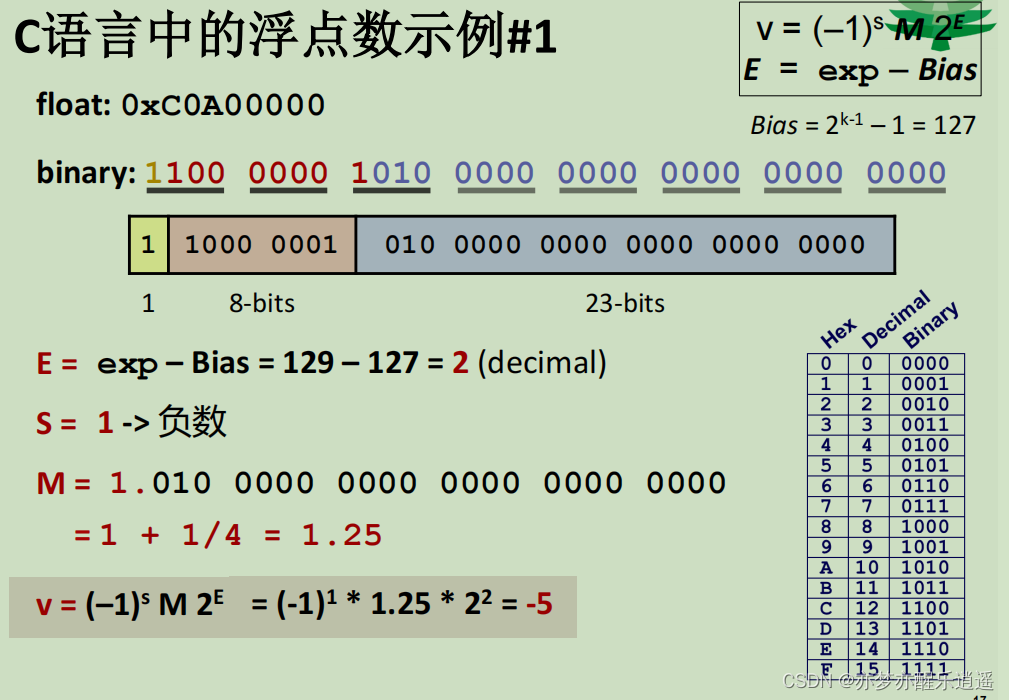
exp全0,是非规范化数,E=-126,frac前导为0
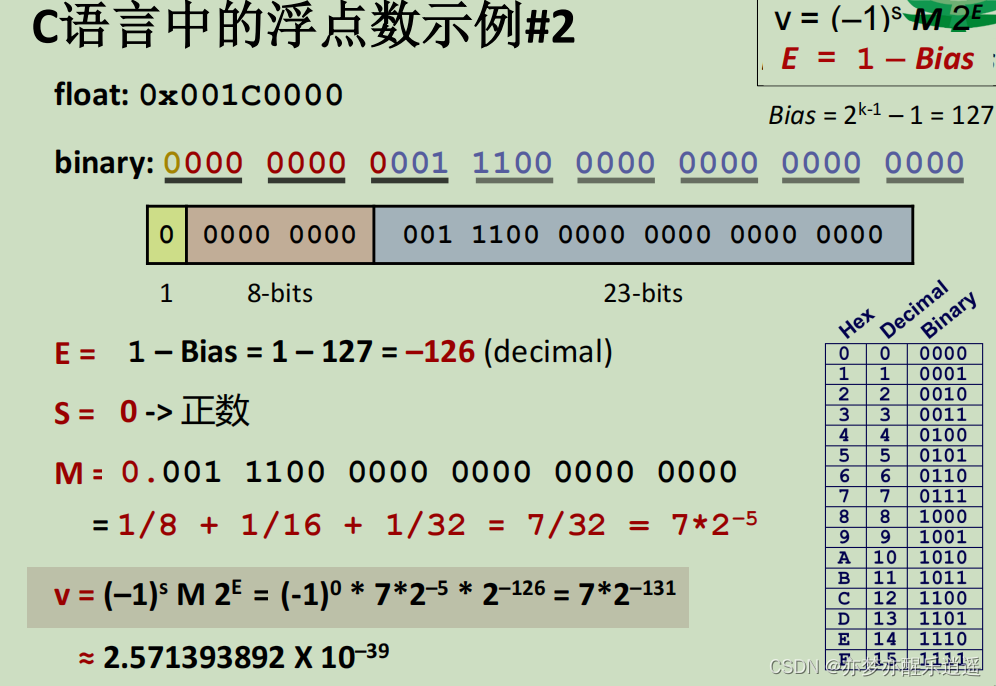

非754浮点加减
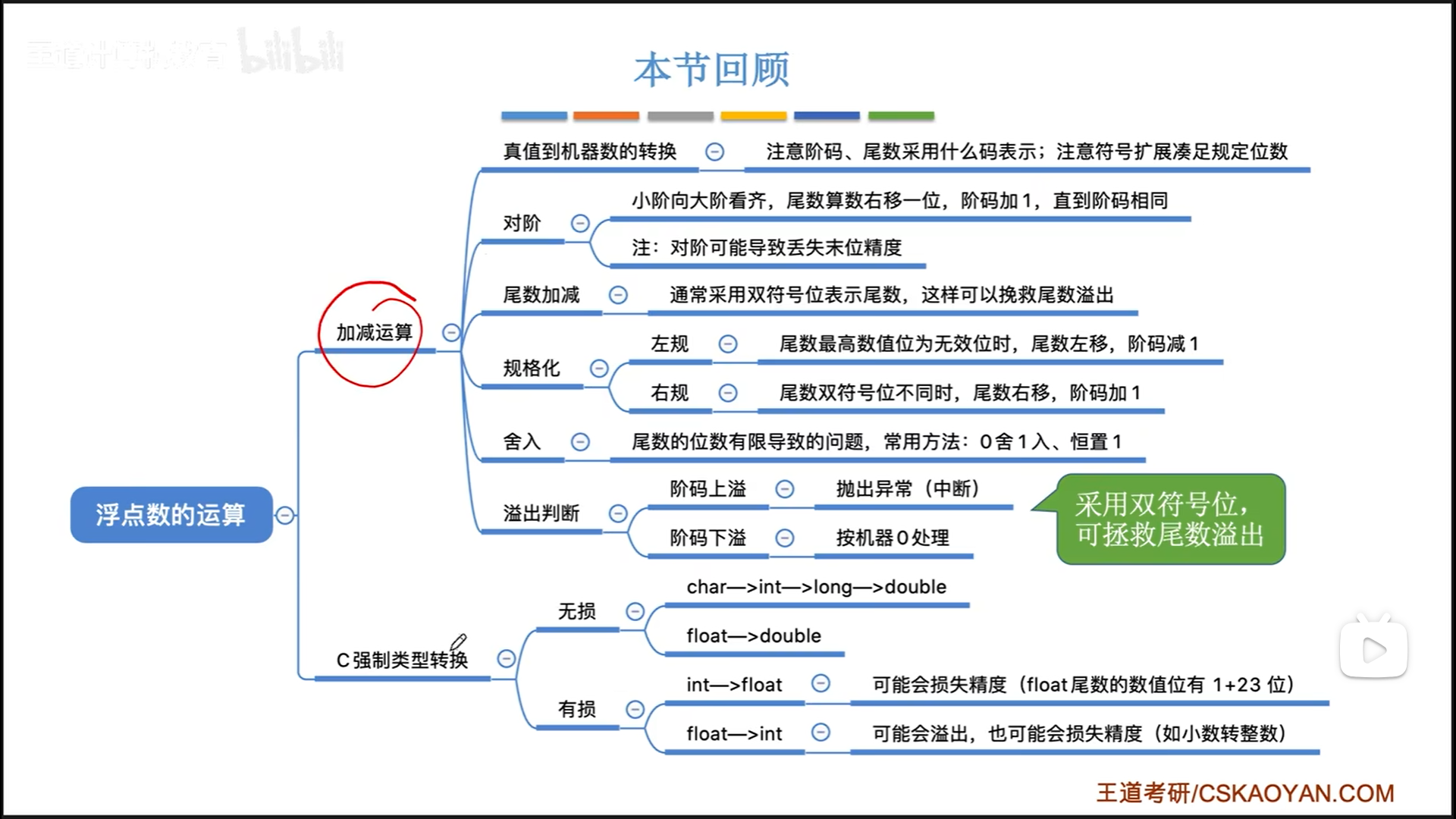
非IEEE格式加减与舍入
浮点加减是比较复杂的,尤其是浮点数格式规定各有不同,可能考出来的和IEEE 格式压根不一样,所以具体到做题,还是应该有所改变。
比如下面这道题,浮点数格式和IEEE完全不同,压根就是两个补码定点小数。
- 第0步首先要得到科学计数法情况下的真值,尾数要是定点小数,阶码是定点整数。之后变成补码格式。
- 比如X,尾数是-0.101,变成原码是1.101,补码是1.011,扩展一下符号位就是11.011,扩展后续位就是后面补0;阶码是-101,变成原码是1101,补码是1011,扩展符号位就是11011
- 再比如Y,尾数是+0.111011,正数补码还是原来的0.111011,扩展符号位是00.111011;阶码是-100,变成原码1100,补码是1100,扩充符号位是11100。
- 对阶的时候,先求阶差n。之后位移,小阶的尾数右移n位,则阶码+n
- 此处规格化是针对尾数的,阶码是整数,不需要规格化

几个注意点:
-
真值转换时,尤其要注意阶码,尾数用什么码表示,是补码,还是移码,还是无符号数。
-
对阶要求小阶向大阶对齐。
- 小阶变大阶,对应的尾数在计算机内部只需要算术右移即可,仍然可以满足定点小数的储存原则。
- 反之,如果大阶变小阶,就会出现大于1的数,这个既不是定点整数,也不是定点小数,比较难处理。
- 算术右移可能丢失末位精度,但是影响很小。
-
规范化。这里的规格化不是针对IEEE的,而是补码尾数的规格化
- 左归的最终目标是为了构成定点小数0.xxxx
- 右归是为了修正尾数符号位溢出,双符号位不同代表溢出,此时把溢出的一位挪回来就行。
-
舍入。下面的0舍1入其实和偶数舍入一样,如果舍入的数大于中间值(舍3位就是100),就末尾+1,小于就直接舍去,等于就要看情况让结果是偶数。恒1就是比较粗暴的了,末尾=1。

-
阶码没有右归,溢出就是真溢出了,尾数上溢还可以通过右归救回来。
补充一点偶数舍入的例子:
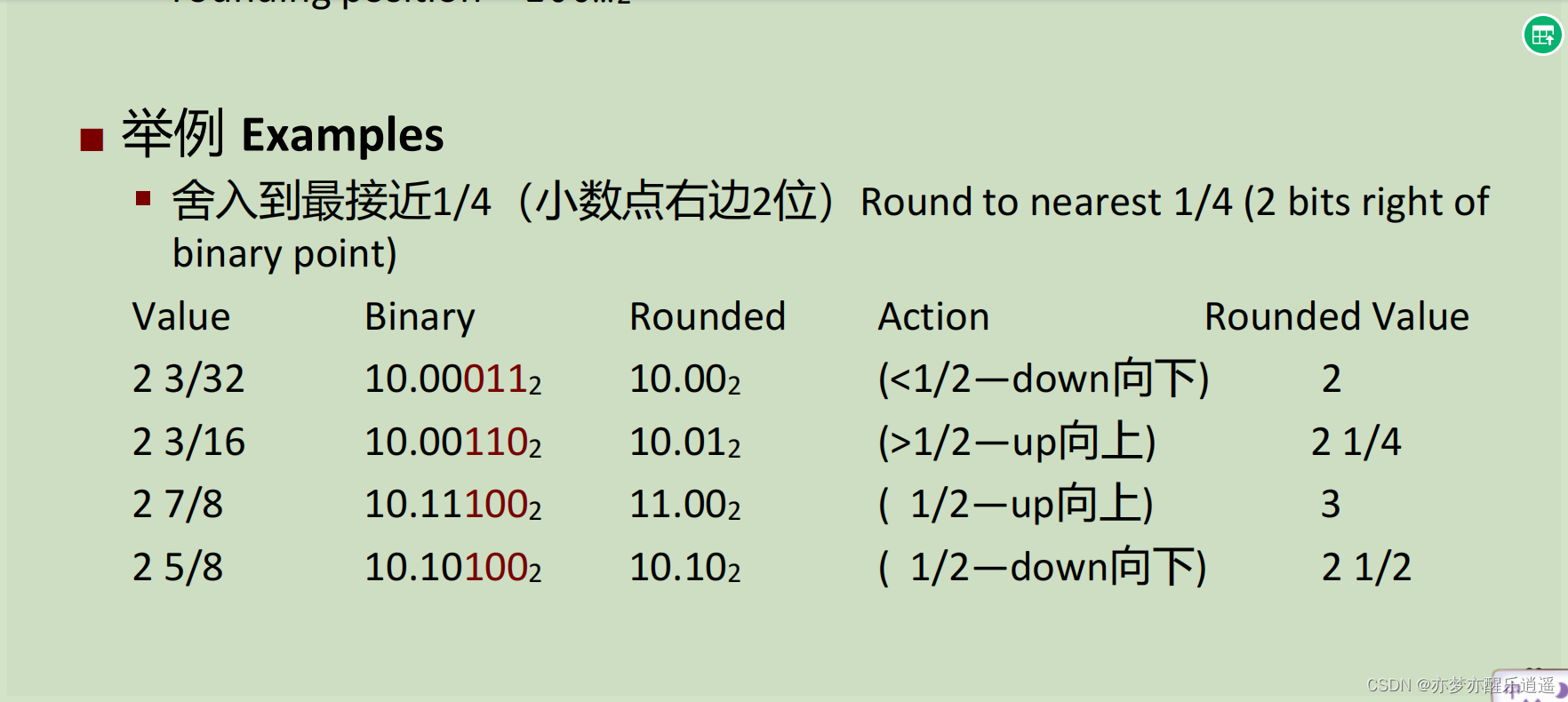
在这道题中,要舍入到第二位小数,那就要比较剩下的小数与中间数的大小了。中间数就是100,如果大于100,就向上进位,小于100,就直接截断,等于100,就要让结果为偶数。
第三个例子,是10.11,因为最后一位是1,所以偶数舍入要进位,最终变成11.00
第四个例子,是10.10,最后一位是0,所以偶数舍入不进位,变成10.10,无论是11.00还是10.10,都是偶数。
754与非754对比
408考试无非就是考两种浮点数,默认情况下会考你754,但是有时候题目也会给出特定的格式。
一般来说,特定的格式都是告诉你诸如下图之类的位数,格式,此时就万万不可套用754的思路。

具体来说,754和普通浮点数的区别如下:
- 前导1
- 754有默认前导1,而且尾数部分一定是正的(前导1代表正常情况下尾数至少为1),相当于去掉符号和前导1的原码部分,符号位在最开头
- 一般浮点数没有前导1,是啥就是啥,而且符号位和尾数是连起来的
- 关于规格化
- 754不需要规格化,因为前导1已经隐藏固定了
- 普通浮点数会让你规格化,注意尾数的编码,如果是补码,那么1.0xx和0.1xx就是规格形式,而原码就得0.1xx和1.1xx形式,左归右归的时候是
算数移位 - 普通浮点数还有一个特殊的规格化,就是双符号位尾数
假溢出时,要进行一次右归,这次右归只是把溢出到低符号位的数移到最高数字位,在符号位上补0/1即可,补的位置和算数移位不一样
- 浮点数加减
- 非标准情况,就按照上一节那个例子来
- 754的加减,首先要转化为普通浮点数,注意前导1要写出来,符号也要连上去,这才能变成普通浮点数的格式。最后算完以后如果要转化为754格式,要进行规格化,把1放在最前面,隐藏为前导1。
强制类型转换
总结:
- 范围上
- int-float-double完美上升
- 论上升的精度
- int-float会损失——有效位可能不够
- int-double完美——有效位足够
- float-double完美上升,double完全碾压(且不用担心对阶损失)
- float和double不一定完美——float对阶右归损精度
- 论下降的精度
- float/double-int会趋0截断——舍去小数部分
接下来具体讲一下计算机中可能面对的一切精度问题。
类型转换要考虑范围和精度
首先是进制损失,从10到2进制,小数部分可能会损失。
比如1.2,小数部分用乘二取整法是无穷的,因此必然要截断一部分小数,精度就损失了,相比之下,1.25这种可以完美化成2进制的,就不会损失。
其次再说一下范围和精度,这两个的本质其实都是有效位数。
int向float转换,范围是可以包含的,但是精度会丢失。
这是因为int最多有31位有效数字,而float只有23+1位有效数字,所以即使范围很大,精度实际上是可能有所损失的。
为什么是可能呢?如果int的实际有效数字只有11位,比如1024,那么float就可以完美容纳,不会损失。
int到float的精度损失也可以从另一个角度理解,大家都是32bit,理论上再怎么排列组合,能表达的数字个数的上限都是有限的,之所以浮点数范围更大,就是因为用精度换取了范围。
所有的转换只需要看这两个东西就可以,不需要刻意去记。
不过需要注意,long型的位数会根据机器而变化,32位机器的long是32位,而64位机器的long是64位,所以说long->int会不会损失精度,这要看是什么机器。
储存系统
第二章终于结束,说实话第二章我是觉得真麻烦,补码算来算去的特别烦,还是第三章好点,有人说更难,但是我听下来感觉也不过尔尔,还是第二章难。
储存器概述
- cache和主存的交换是硬件完成的,而主存和辅存的交换是操作系统+硬件完成的
- 随机读取:访问时间不受空间影响,比如DRAM,顺序读写:访问数据前,需要先访问之前的数据,比如磁带。直接存取:机械盘介于二者之间,移动机械臂是随机,开始读取以后的都是顺序。
主储存器
主存的基本组成
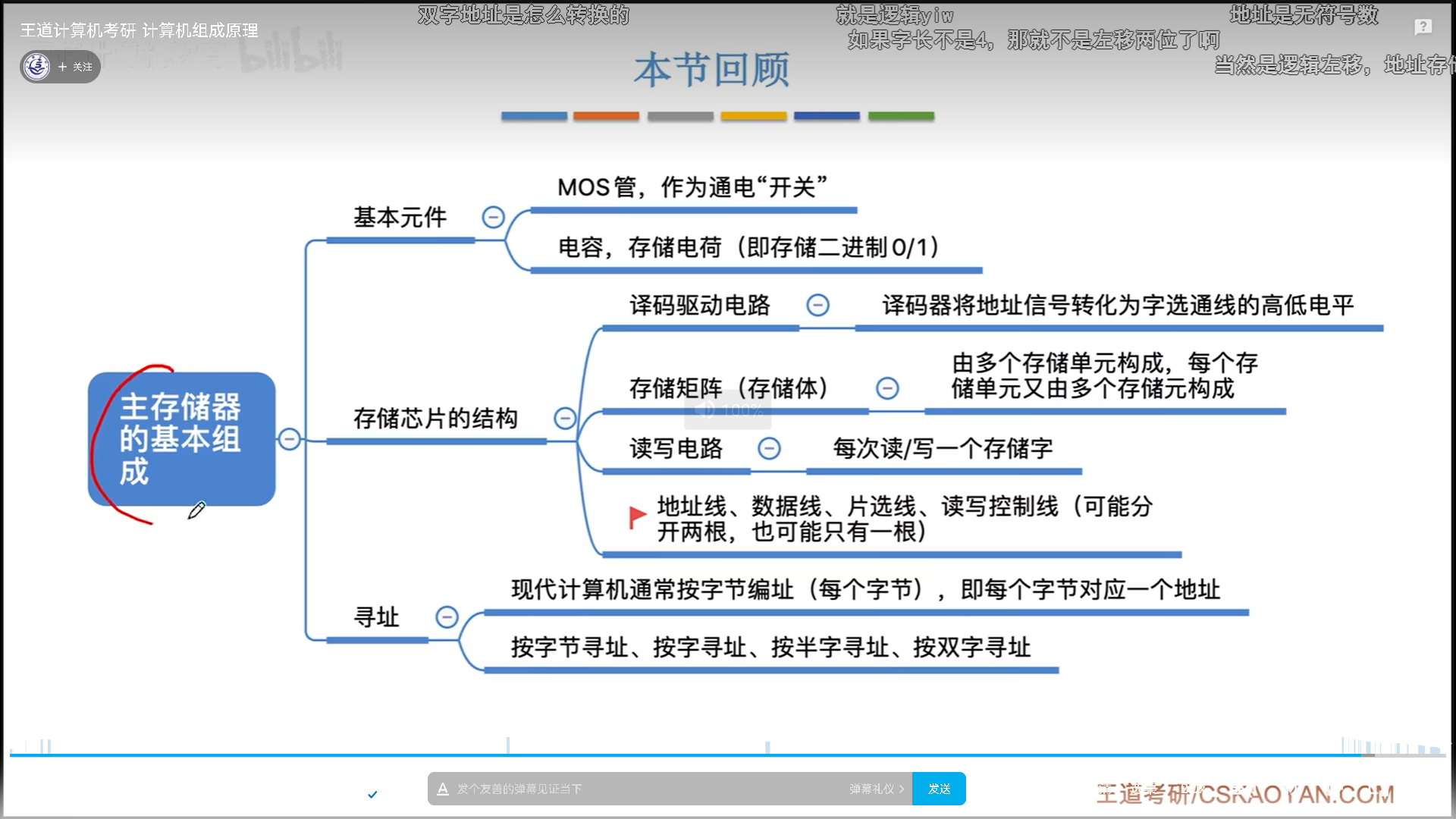
储存元=电容+MOS管。
电容负责储存具体的bit,高电平就是1,低电平就是0。MOS管是一个开关,如果接1,电容与外界接通,电荷就可以自行流入流出,这就是读写的原理。
一排储存元连起来,mos管接一个统一的开关信号,这样一次性就可以读写一排,这也就是字长的本质。
当然,这个过程是不稳定的,所以会有一个延迟,这个延迟由电路控制。
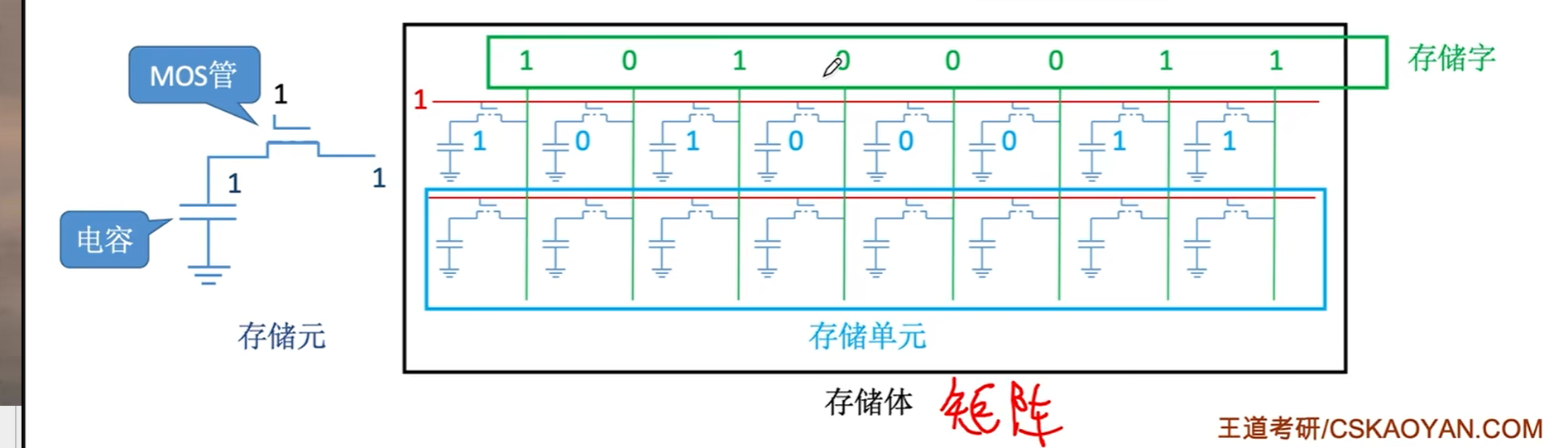
实际上,我们会有很多排,也就是若干个储存单元(字),这些字每列都是串在一起的,使用一个统一的输出。为了防止冲突,同一时间只能有一个字进行读写,为了实现这个,使用译码器进行唯一的字选。
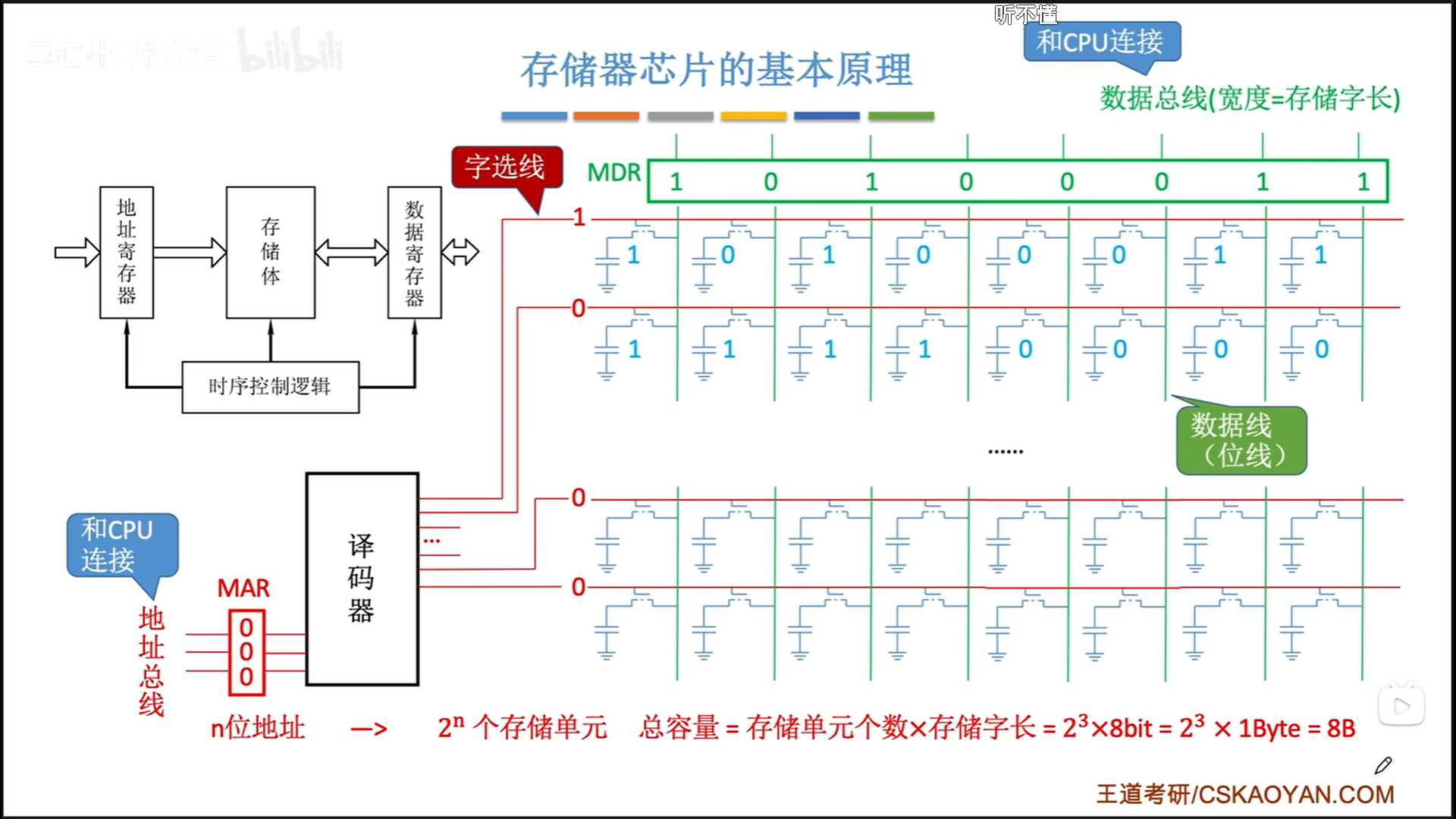
所以主存的工作流程就是,CPU先把地址送到MAR,然后等地址稳定了以后触发一个时钟周期,等待取数据流到MDR,等待数据稳定后再触发一个时钟周期进行后续操作。
为了实现上述流程,还需要一个控制电路控制这个时间。控制电路有两个功能:
- 片选:其实就是个使能信号,负责区分这块芯片是否能工作
- 读写控制:两根或者一根,负责区分读写操作
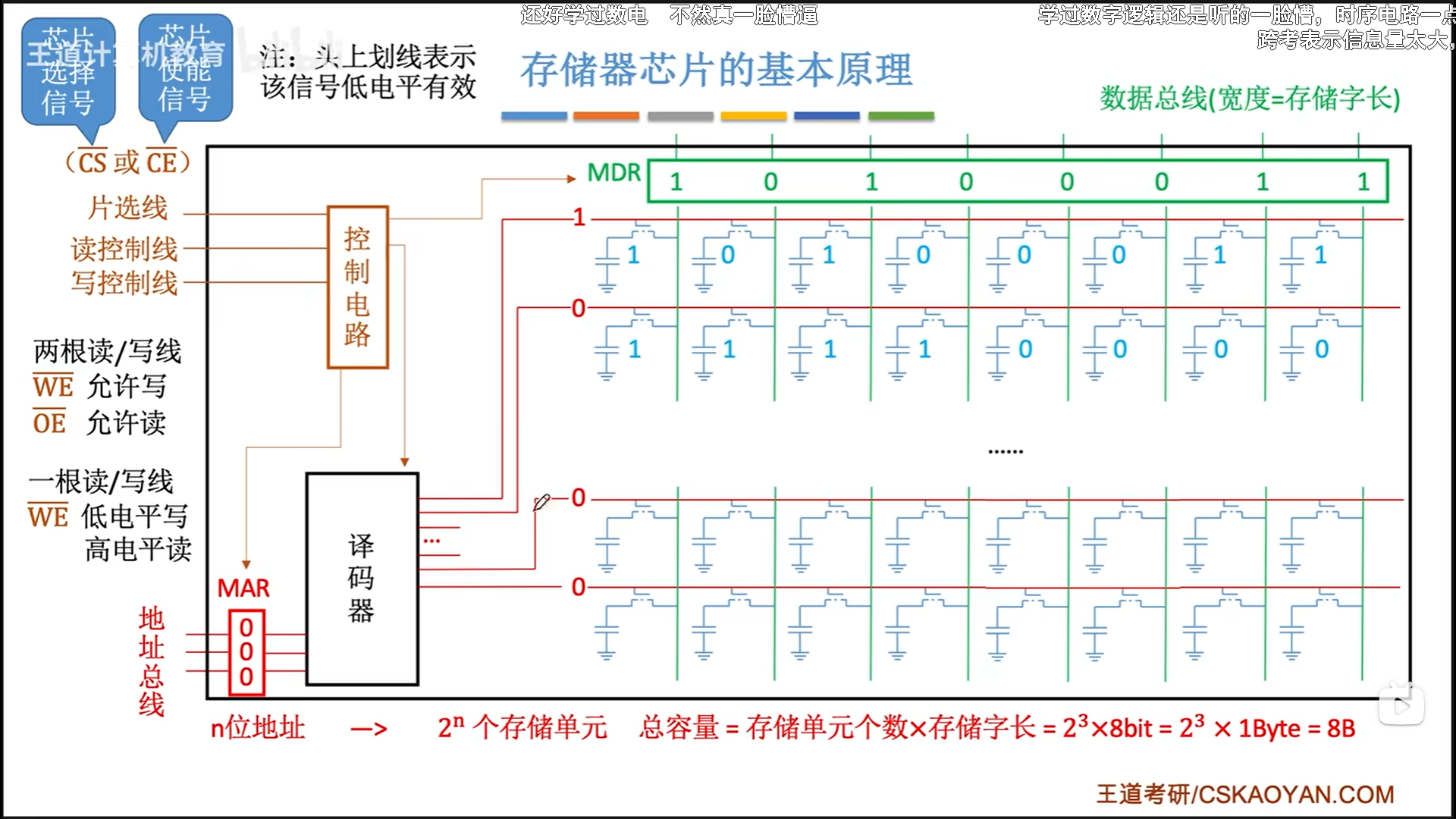
把这些封装一下就是下图,输入n位地址,输出m位数据,然后有一个片选,1/2根读写控制线。其他引脚我们是忽略的。

最后说一下寻址吧。虽然我们可以按照字编址,但是现代计算机都是字节编制,所以假设有1kB,那么我们就给10根地址线,默认字节寻址。
当然你想要用字寻址也可以,左移就可以。

SRAM和DRAM
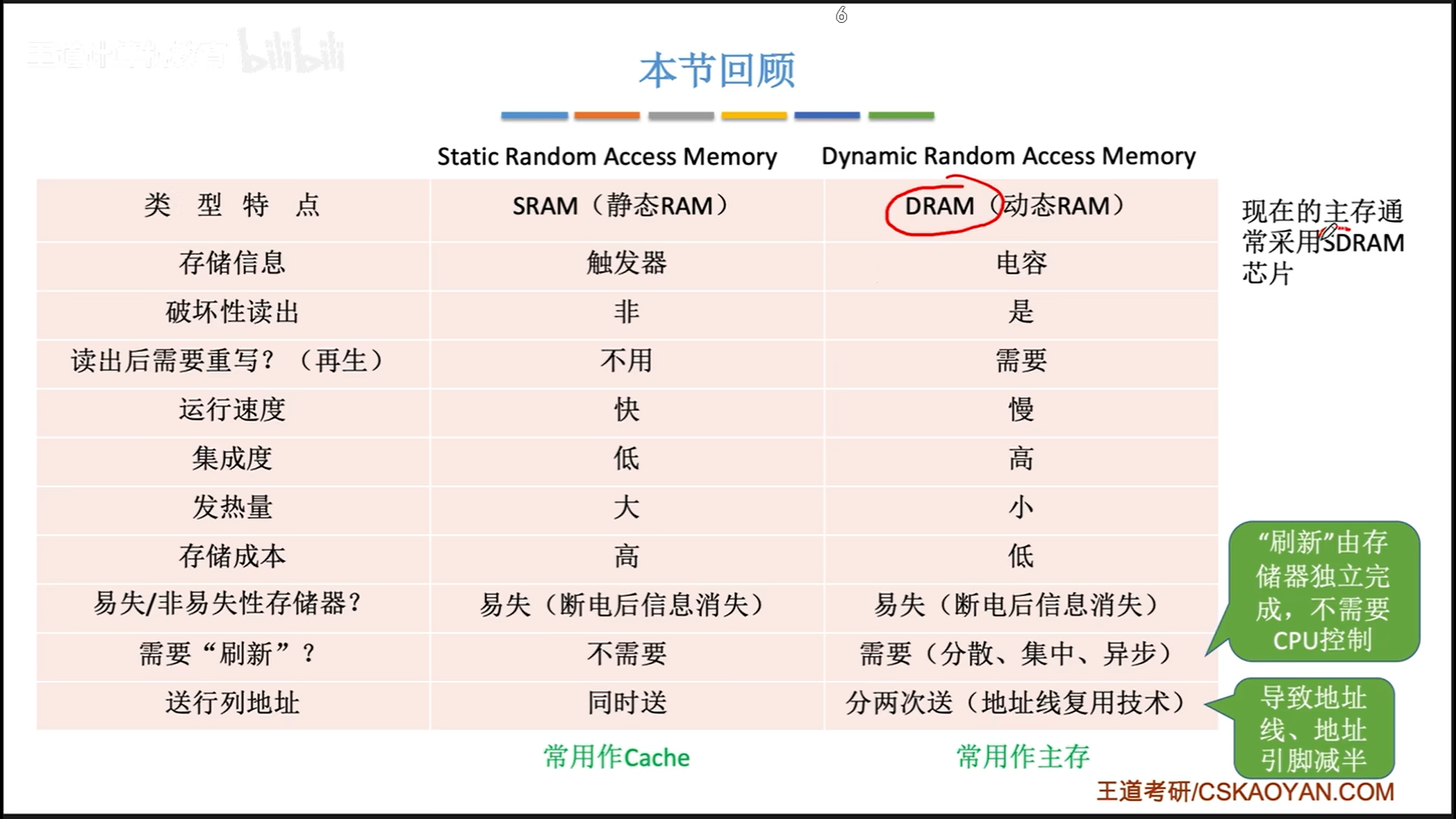
DRAM和SRAM的核心区别是储存元不一样:
- DRAM:栅极电容=电容+MOS×1
- SRAM:双稳态触发器=MOS×6
双稳态比较有意思,电容是和外界进行能量交换,所以是破坏性的,需要恢复。而双稳态的能量是在两级之间交换,所以都很稳定,是非破坏性的,就好比是用MOS管模拟出类似于电磁铁的东西,写入时只需要给他加个点平,双稳态触发器就会进行状态转换(当然,断电也还是会寄的)。
他俩的本质区别就是,栅极电容的读写原理是电荷的流入流出,而双稳态的读写原理是点平检测与施压。
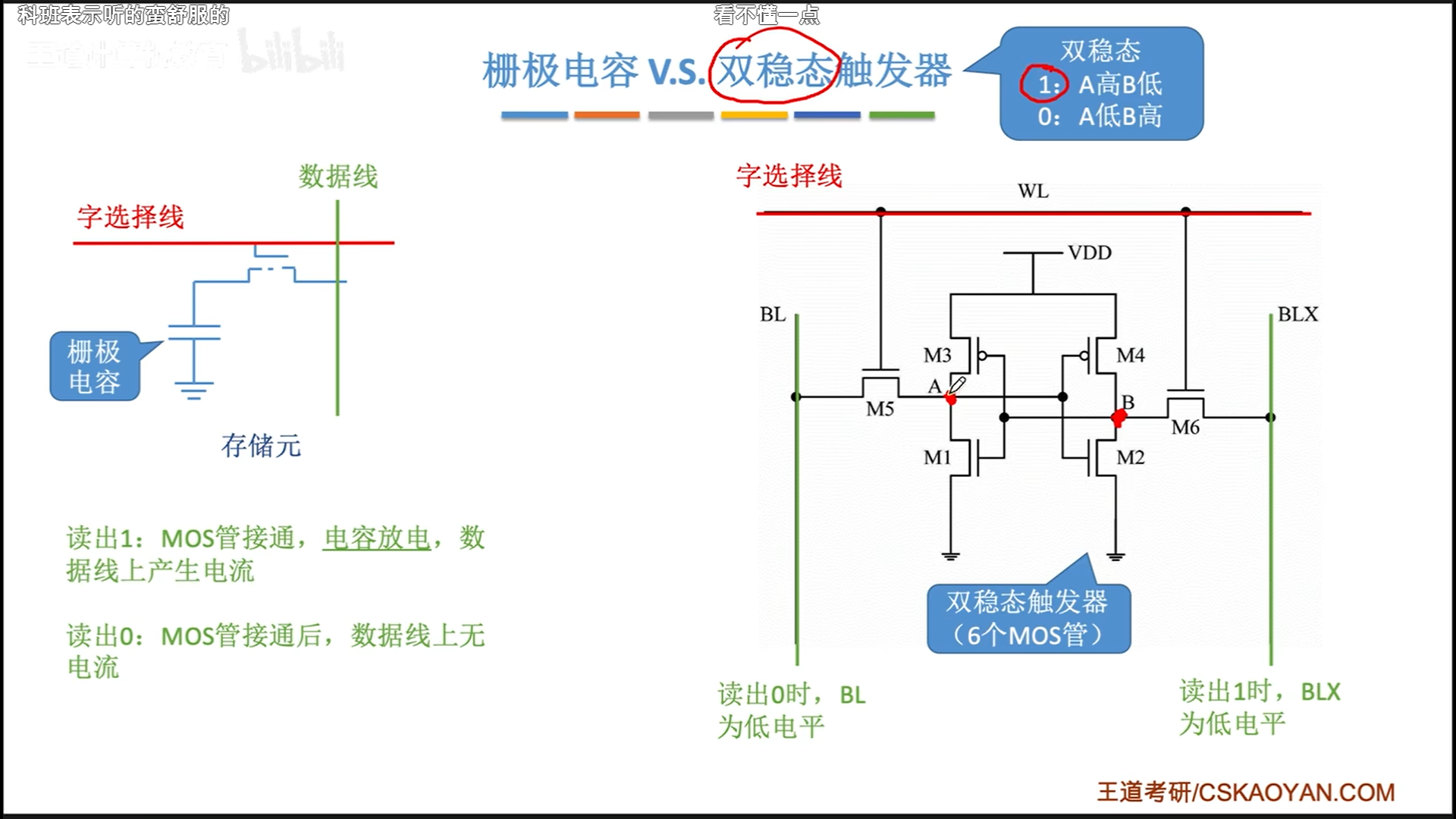
正因为栅极电容是电容储存,所以会逐渐流失,周期大约是2ms,所以需要定期充电。即DRAM的刷新。注意这个词和再生还不一样,再生是开闸放水以后的充电,而刷新是流失了一段时间后的主动充电。
这里补充一下行列地址。行列地址可以把选通线二进制数量级减少一半,原理自己算一下就好,关键是这么做以后,地址空间并没有什么变化,所以过渡很自然。
说一下这个二维布局,其实一个储存单元里面可能有若干字节,但是现在我们都是字节编址的,所以其实一个储存单元里面也就是一个字节,可以理解为把字节铺开成一个矩阵了。
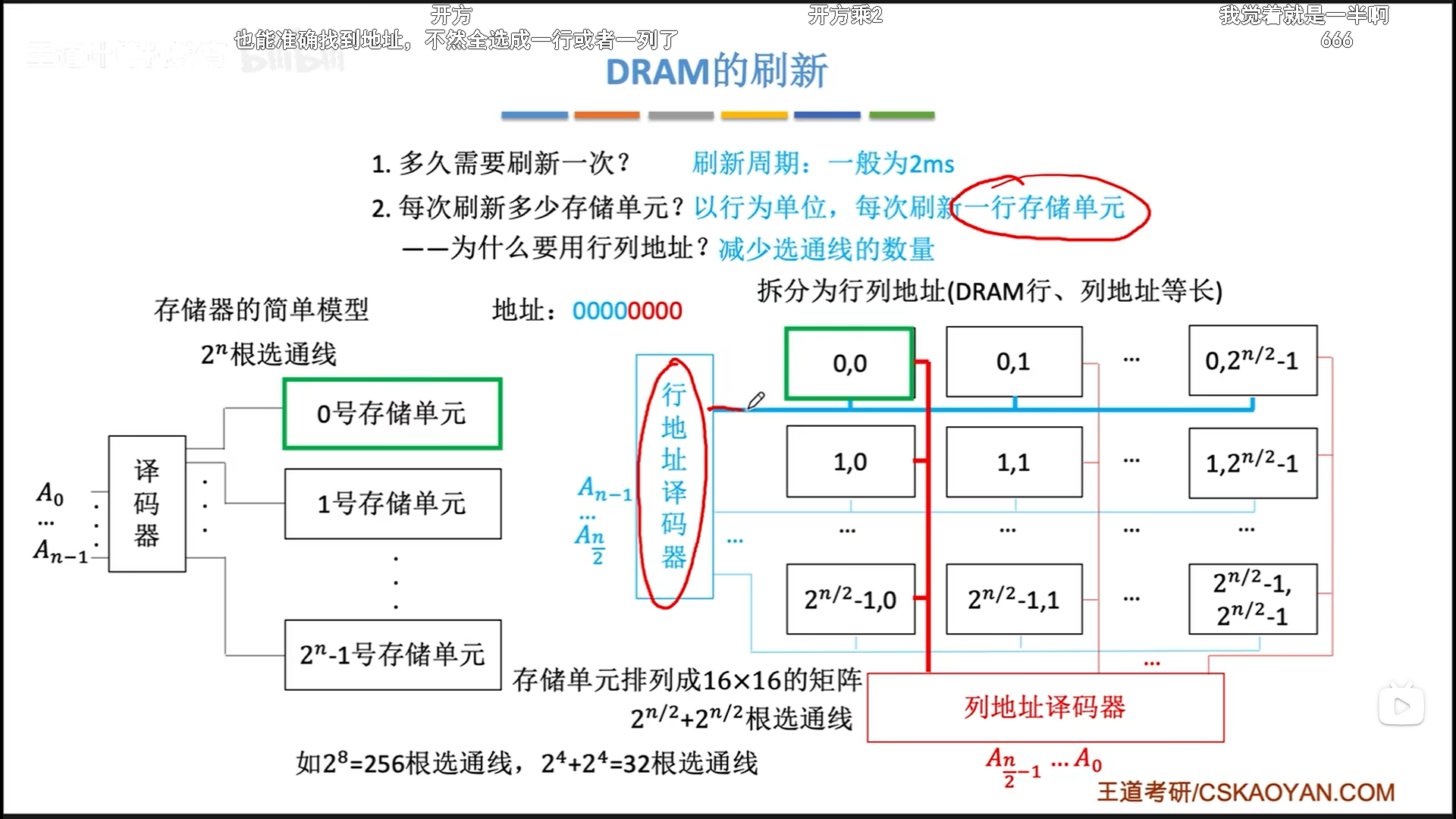
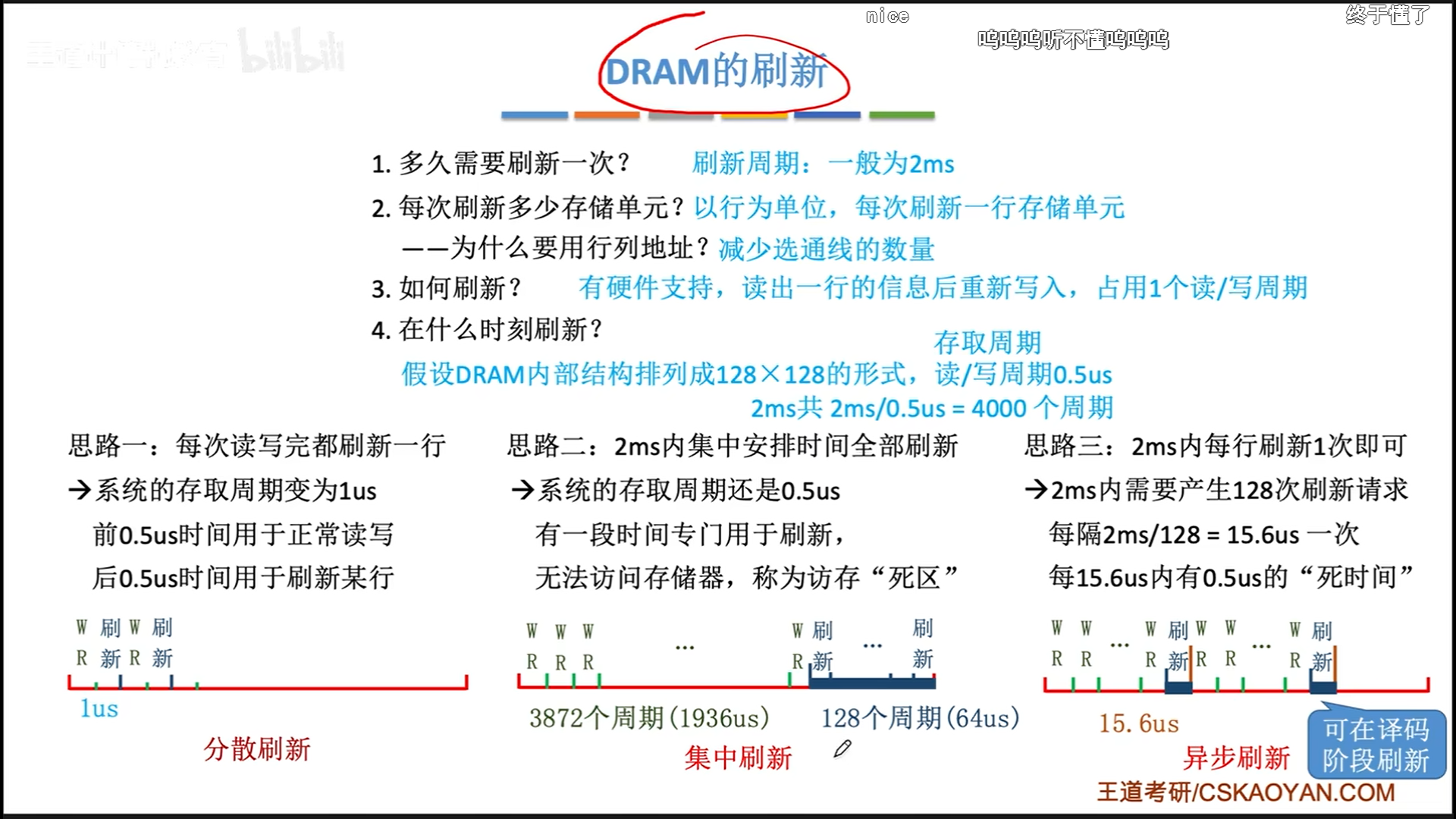
具体讨论一下刷新策略。首先要明确,读写要占用一个读写周期,而读写后的充电,同样需要一个读写周期。我们以周期为单位计算,所以先计算出2ms(一个刷新周期)里面有多少个读写周期。
下面是4000
- 分散刷新:读写与刷新就各分一半时间,2000次的刷新即使是乱序,也足够刷新完128行储存单元。很明显,浪费了一半的时钟周期。
- 集中刷新:这样倒是比较节省时间,但是会有一个集中的时间内存什么都干不了,拖累CPU。
- 异步刷新:优化了集中刷新,虽然还是128次(不浪费资源),但是时间分散,每隔2ms/128的时间就刷新一行,这个刷新时间可以放在CPU译码阶段,正好不影响CPU(因为刷新和再生是储存器内部的机制)。为了防止不重复,我觉得最粗暴的方式就是从上到下扫描。
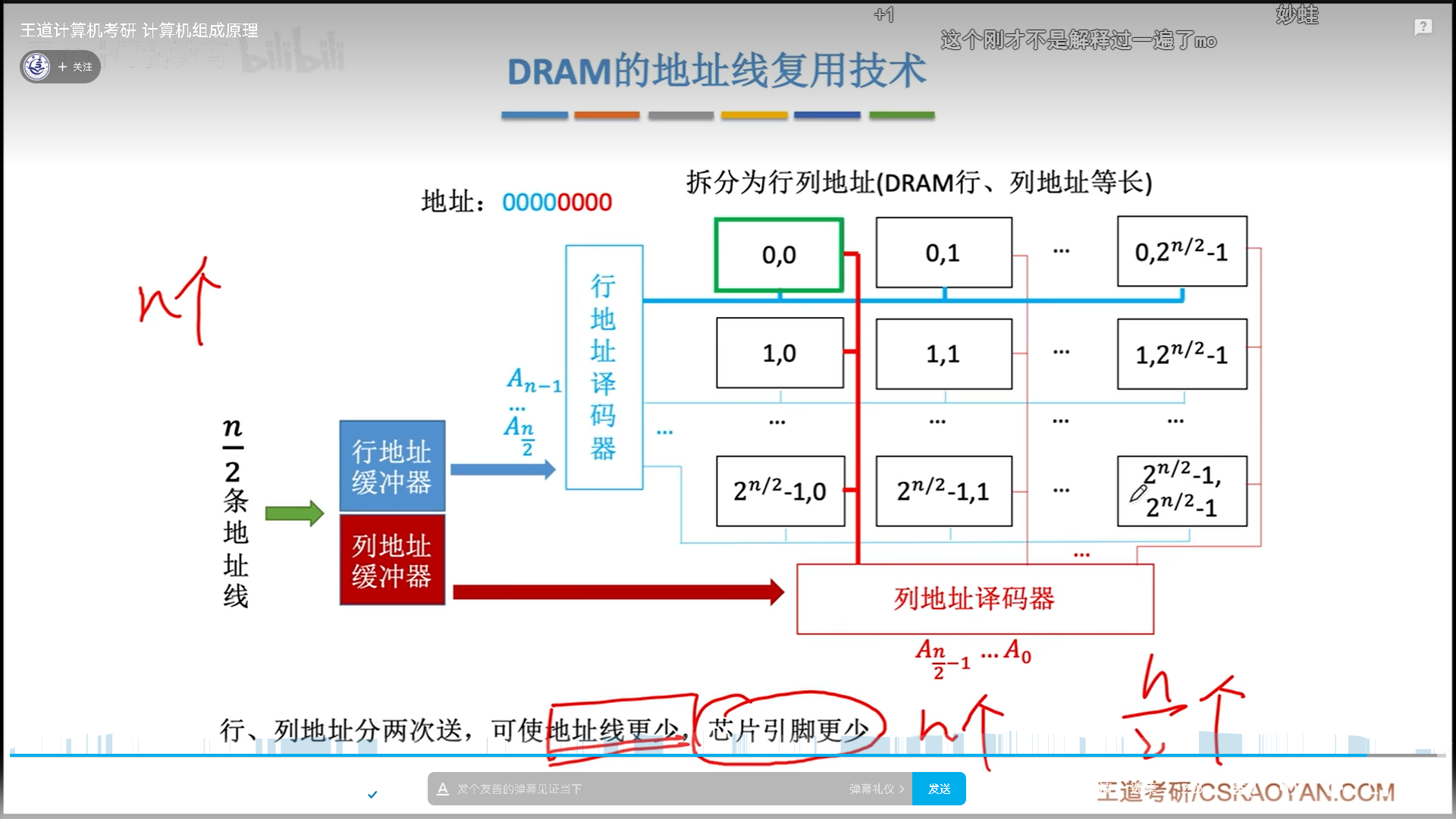
最后说一下DRAM特有的地址线复用技术。之所以要有这个技术,是因为DRAM太大了,比如我们现在的4G内存,就要32根地址线,确实有点多,所以有人就想出来,我们既然已经把行列地址分开了,不如用16根地址线,第一次送行地址,第二次送列地址。
这就是地址线复用的思路,可以减少DRAM一般的地址引脚,这个在计算中会考虑到。为什么SRAM没有呢?因为这玩意集成度低又贵,所以一般顶天也就是个12M(intel i5的cache容量),折合下来也就是20来根线,没必要复用。
最后,SRAM比较贵,效果好,一般用于Cache,DRAM便宜量大,一般用于主存。当然,现在有更好的SDRAM,也就是我们现在的DDR技术。
ROM
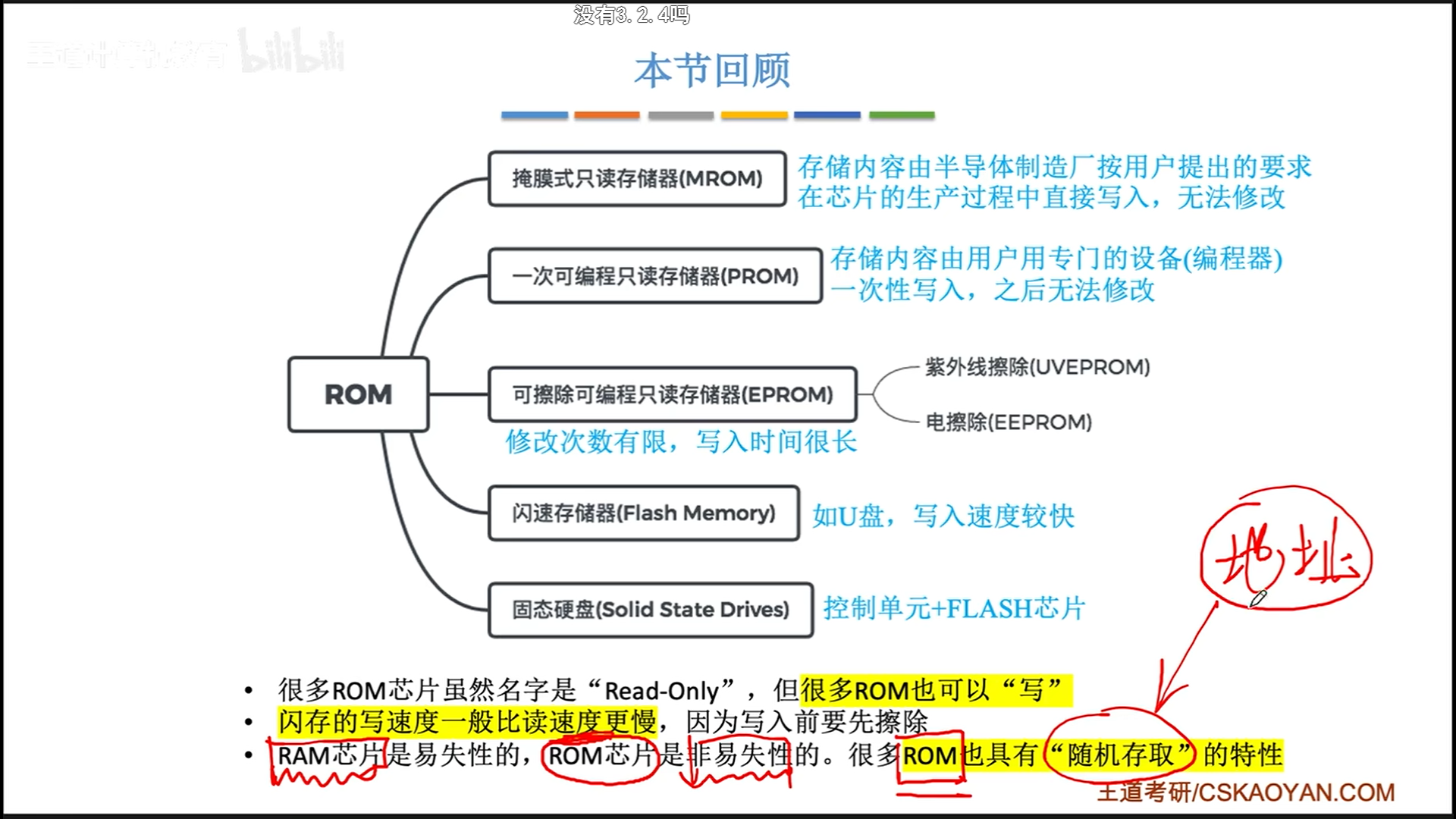
RAM断电以后会丢失,我们需要一种断电后还能保存的芯片。RAM和ROM都可以随机存取,区别只在于断电以后是否丢失信息。
- MROM:Mask,厂家生产时写一次
- PROM:Programable,用户用编程器写一次
- EPROM:Erasable,用户可以反复擦除编写
- UV-EPROM:紫外线擦除
- E-EPROM:电擦除
- Flash Memory:闪存其实是EEPROM的一种,只是太牛逼了,单独列出。
- SSD:特殊控制单元+闪存芯片
主储存器与CPU的连接
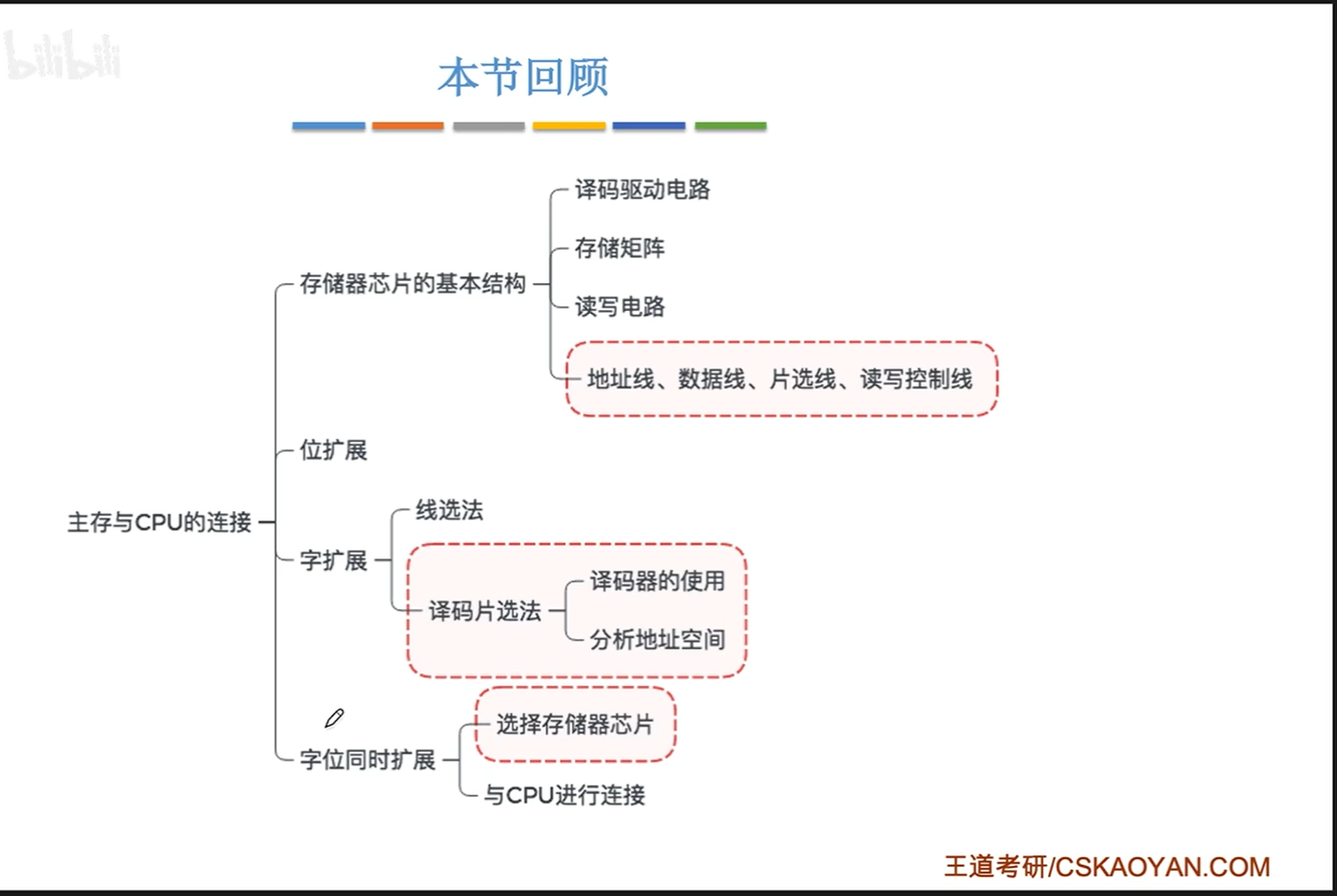
多芯片连接——一根完整的内存条
以下是最基础的单个芯片与CPU的连接。虽然主存里面是行列排列(行列地址线),但是每次取仍然也只是取出一个字。假设我们这里的一个字就是1bit,连接方式如下:
CPU地址线和主存芯片地址线连接,然后输出的字引脚与CPU引脚相连。还有一个WE引脚,用于控制读写。
CS引脚、一部分地址引脚、一部分数据引脚暂时空着,后面多芯片的时候才会用。
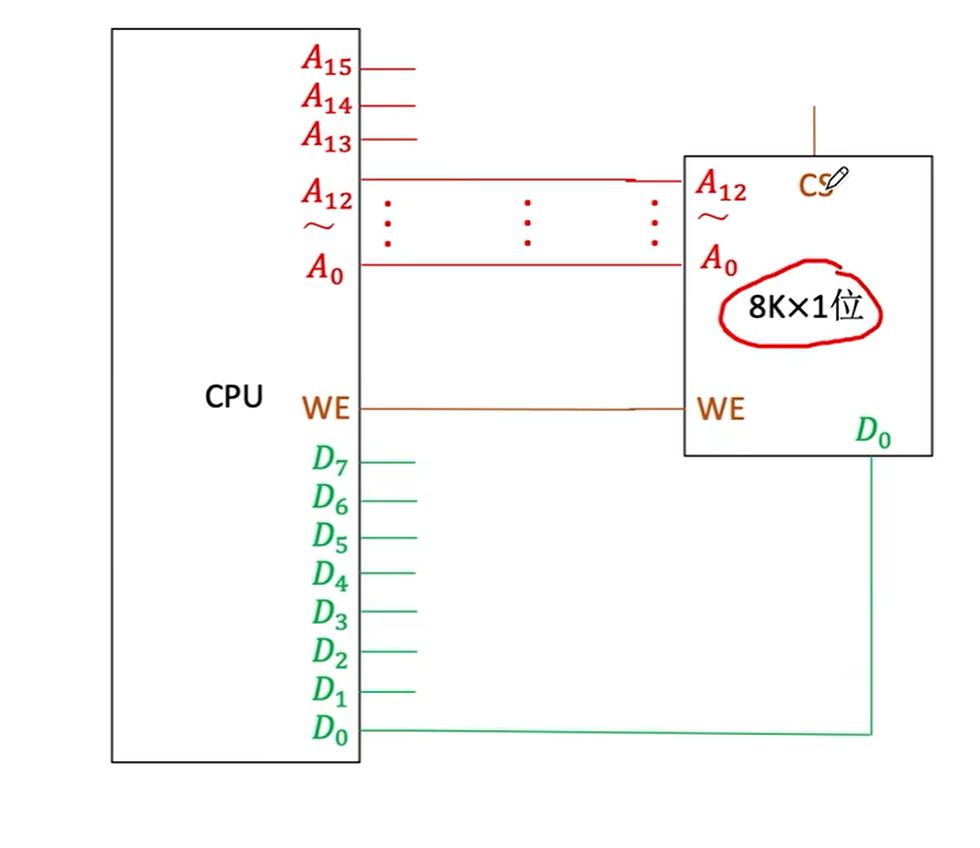
位扩展:提升读写性能和容量
很明显,CPU同时可以读取8bit的,现在一个芯片只能给1bit,所以我们就多弄几个芯片,8个同时读写,使用同一个CS信号和WE信号。
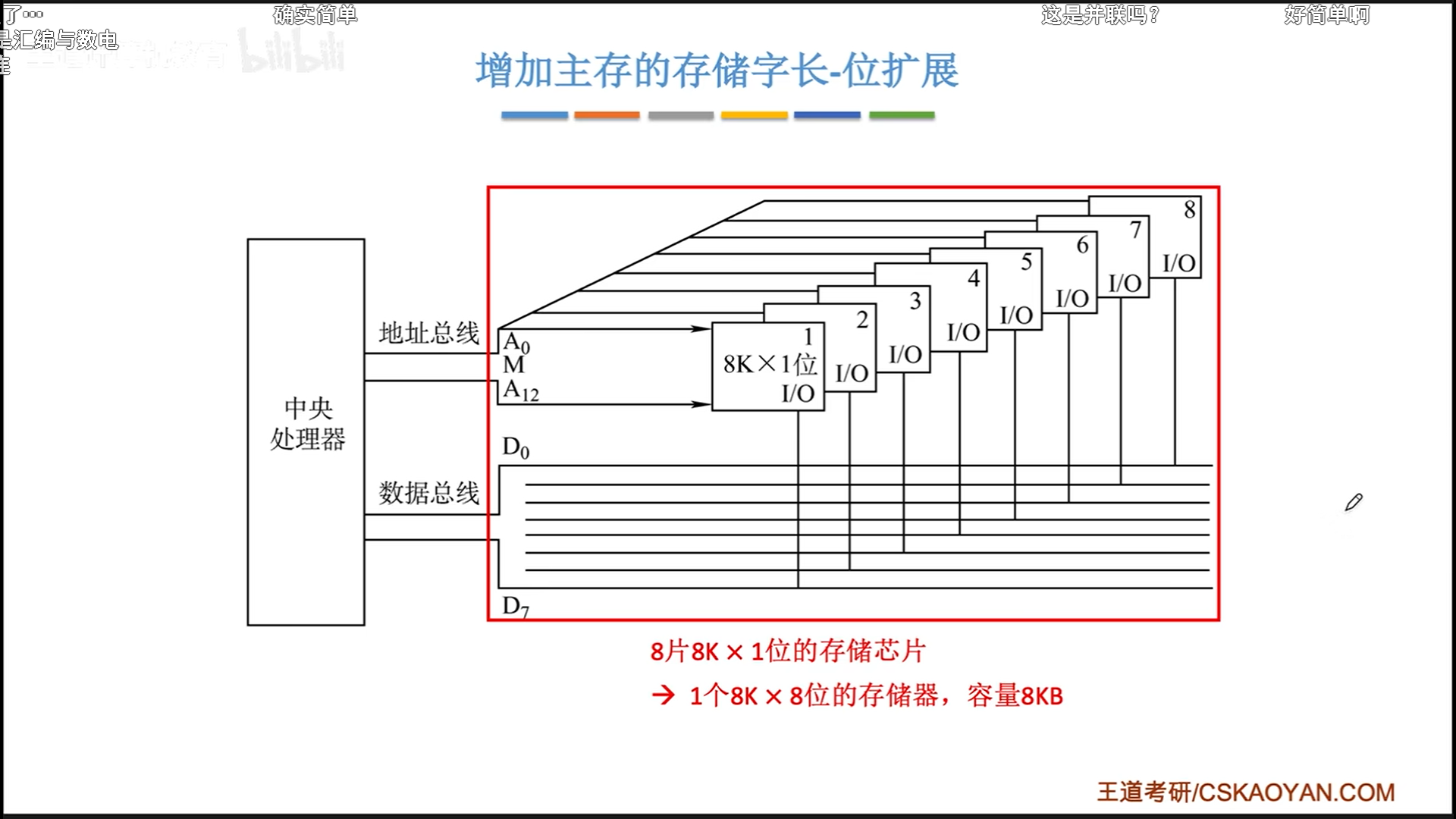
实际上,我们平时看到的储存器芯片应该都是8K×8这种的,我也不知道8K×8这种是本身就以1B作为储存单元,还是用8个1bit储存单元的芯片位扩展得到的,又或者位扩展本身就是1B储存单元的实现原理呢?
总之,我们平时看到的储存器芯片应该都是8K×8这种的,假定他的输出是可以接满数据线的,下面会以这个为基础扩展。
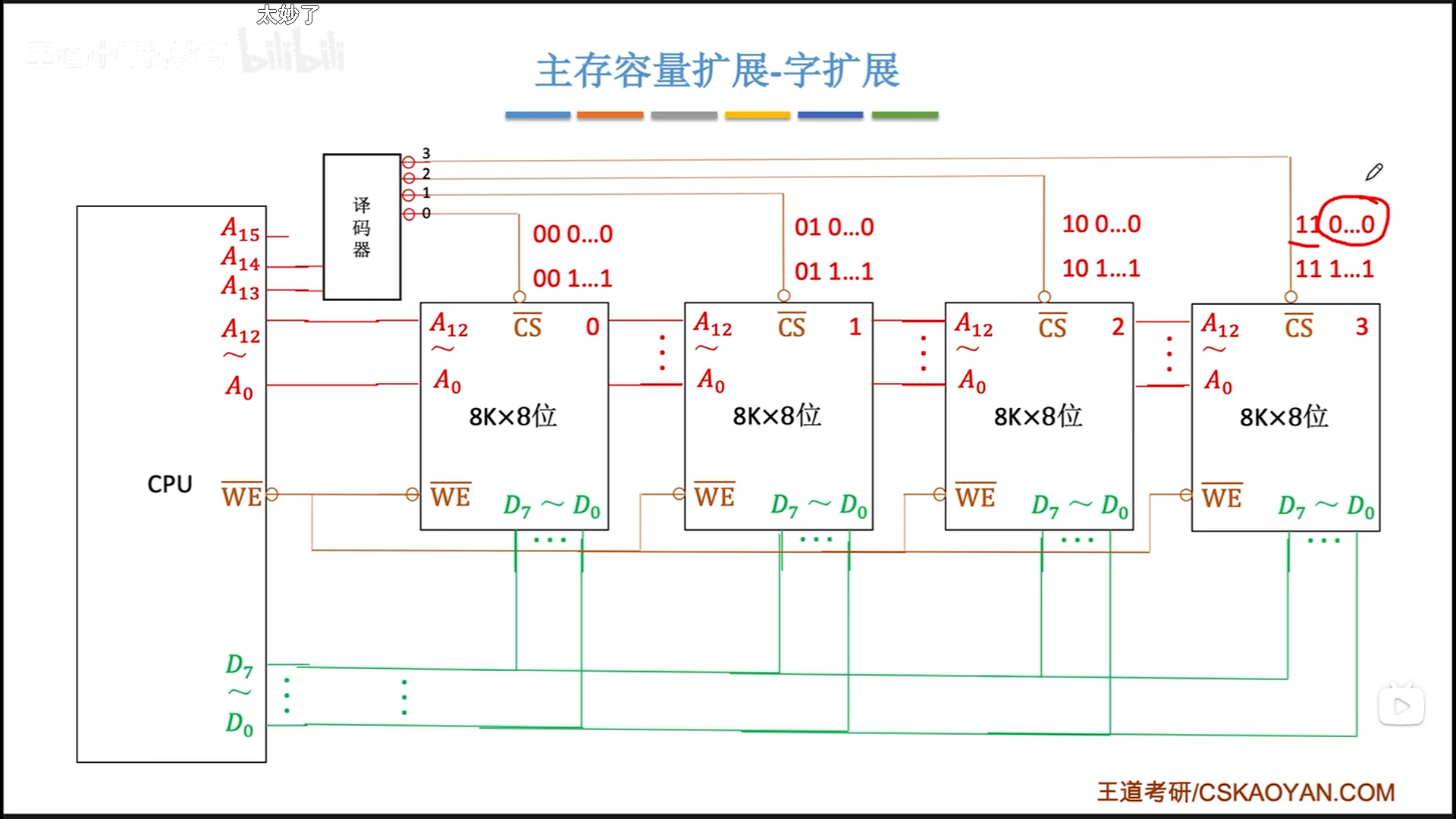
字扩展:仅提升主存容量
书接上回,现在有两片芯片,但是数据线一个芯片就占满了,我想扩展容量,怎么才能把这两个接到一起呢?
其实单纯想扩展容量的话,一次只读写一个芯片不就可以了吗,这就是字扩展的原理:保证同一时间只有一个芯片工作,保证数据线不会有电信号冲突
一种原理是线选法,n根线控制n个芯片。
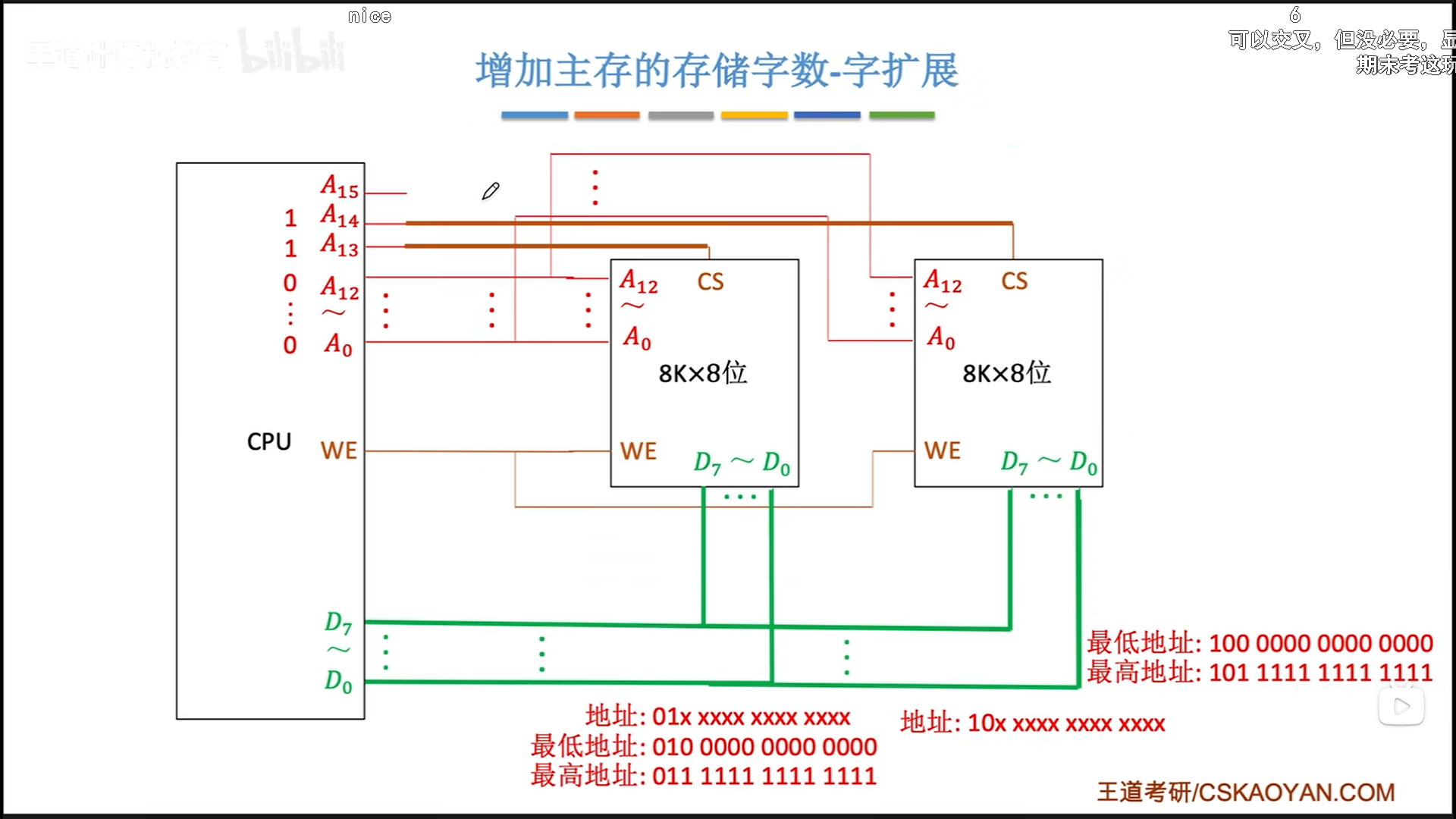
但凡稍微懂一点数字逻辑的同学都会觉得不合理,浪费线了。事实也是如此,不仅浪费,而且地址空间还不连续。所以就有了译码片选法。
一个译码器就可以解决片选,下图理论上应该接8个芯片,因为有3个空闲地址线,图里只接了4个。考试的时候可能会接的奇形怪状,让你分析,但是实际上就是按顺序接满。
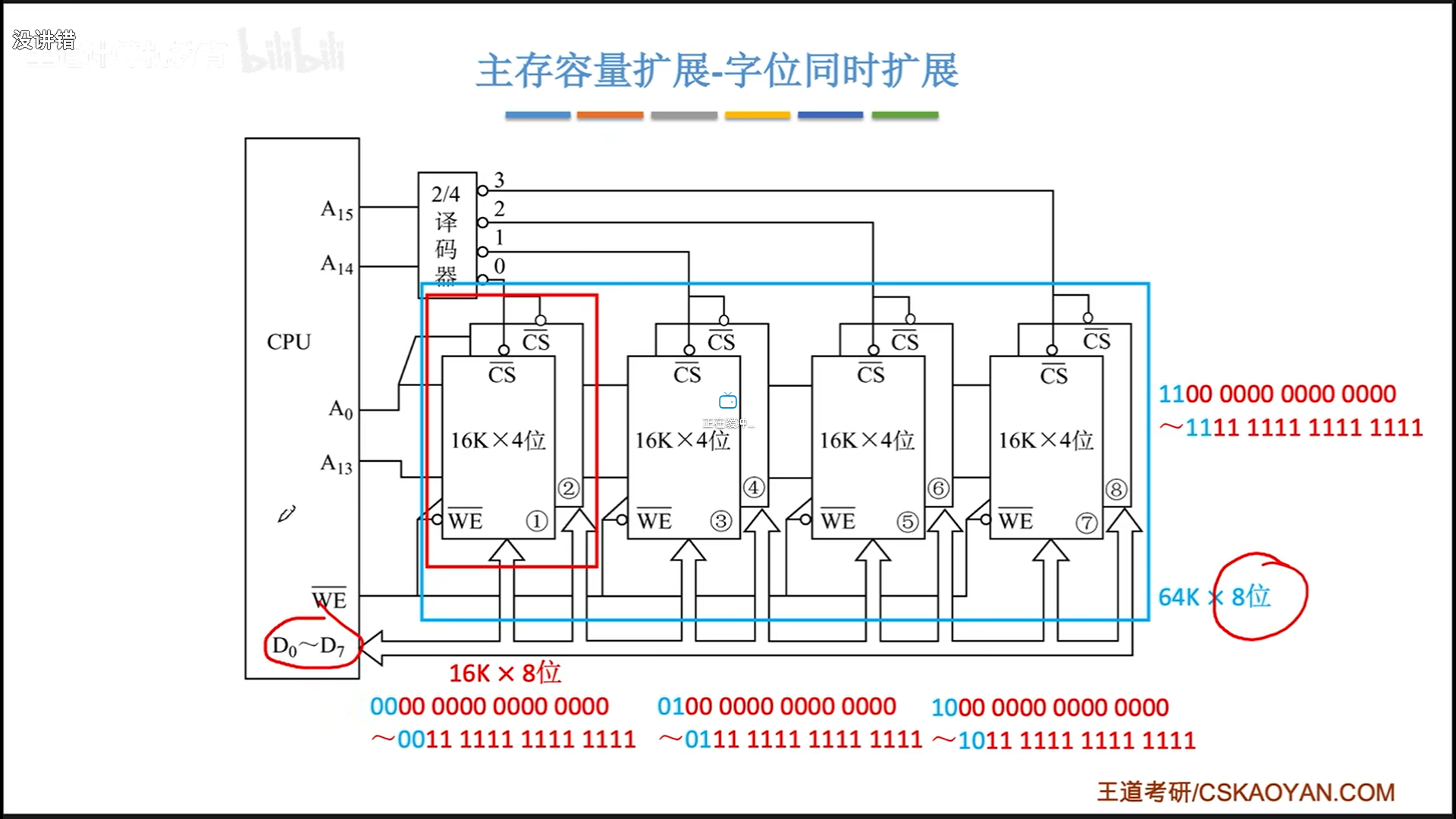
字位扩展法
假定现在一个芯片的输出占不满数据线,此时可以同时采用字位扩展法:
- 通过位扩展提升读写性能和容量,位扩展的芯片使用同一个CS信号
- 字扩展提升读写容量,字扩展的芯片之间,同时只有一个CS信号激活
- 所有芯片公用一个WE信号
到此为止,你就拥有了一条不错的内存条,如果你买来内存条,就可以看到上面有很多颗粒,这些都是芯片。
译码器
译码器还有一些细节可能会考。
首先是是否加取反信号。如果CS加了取反,那么译码器也要加取反信号。
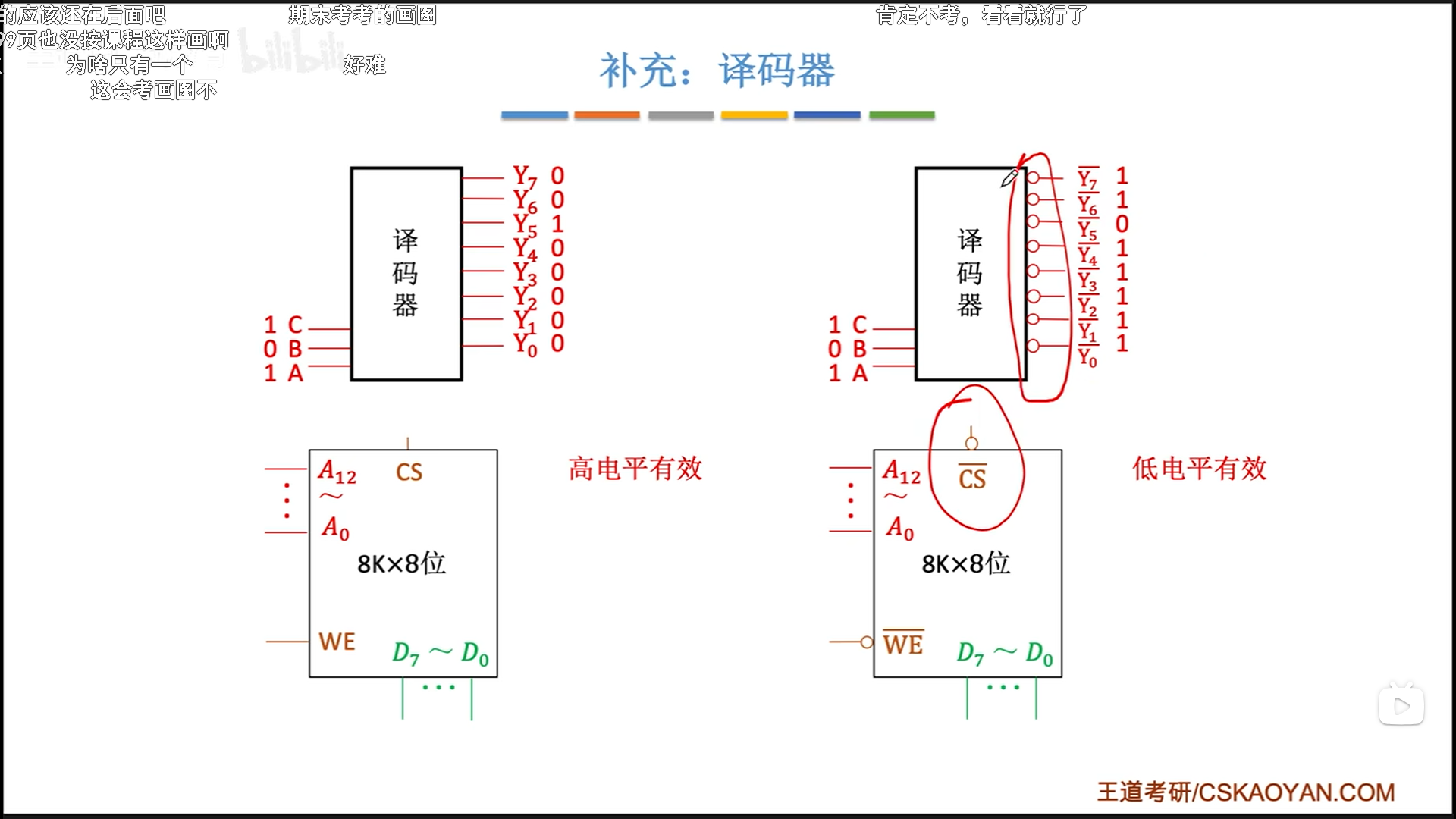
74ls138:
- 3-8译码器,输出加取反信号
- 三个使能,两负一正
- 一个clock
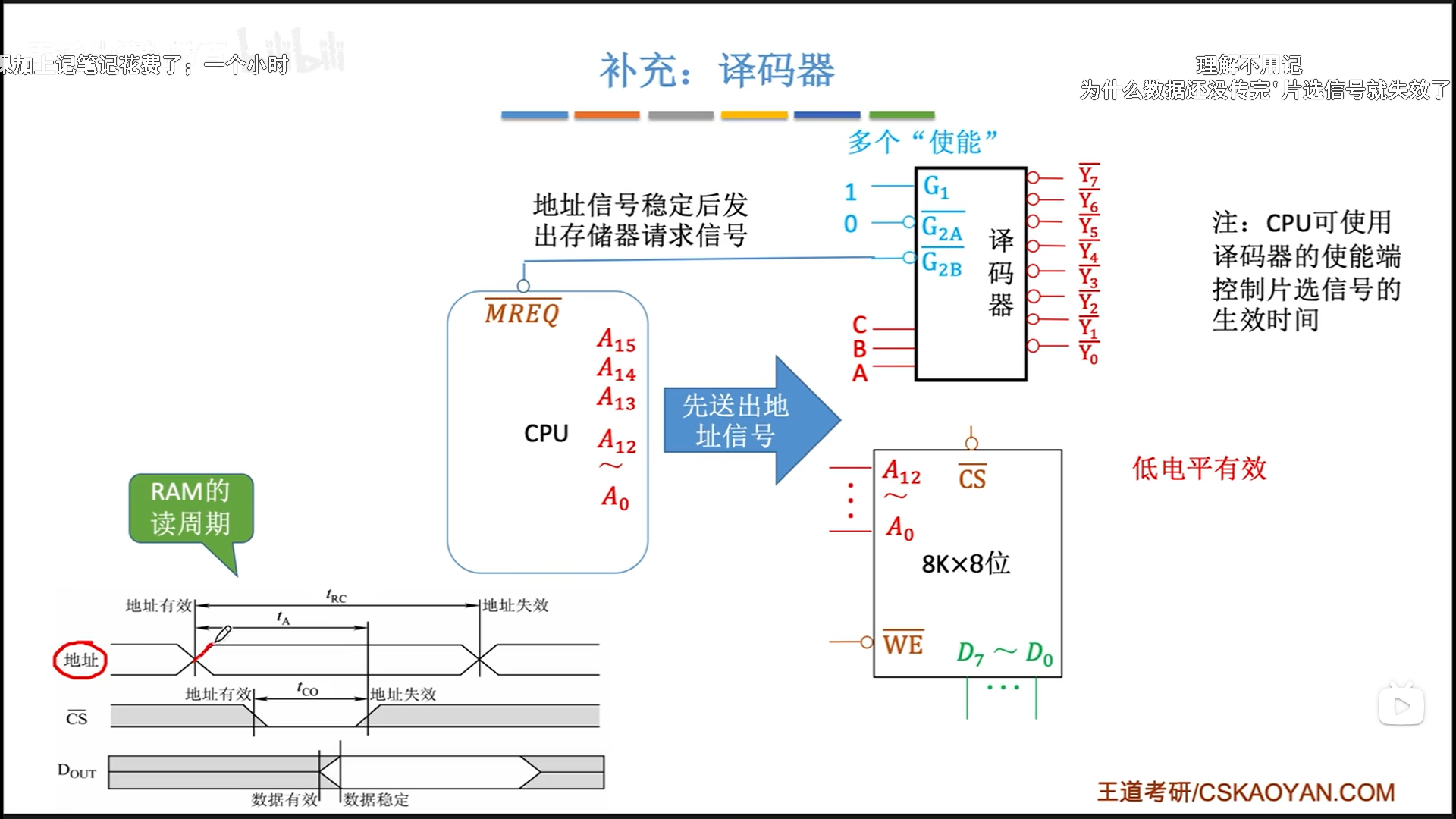
下面给出一个工作流程:
- CPU先送地址信号,等待稳定
- CPU送出使能信号,激发片选
- 主存给出数据,稳定后有效,读取流程结束
主存性能提升
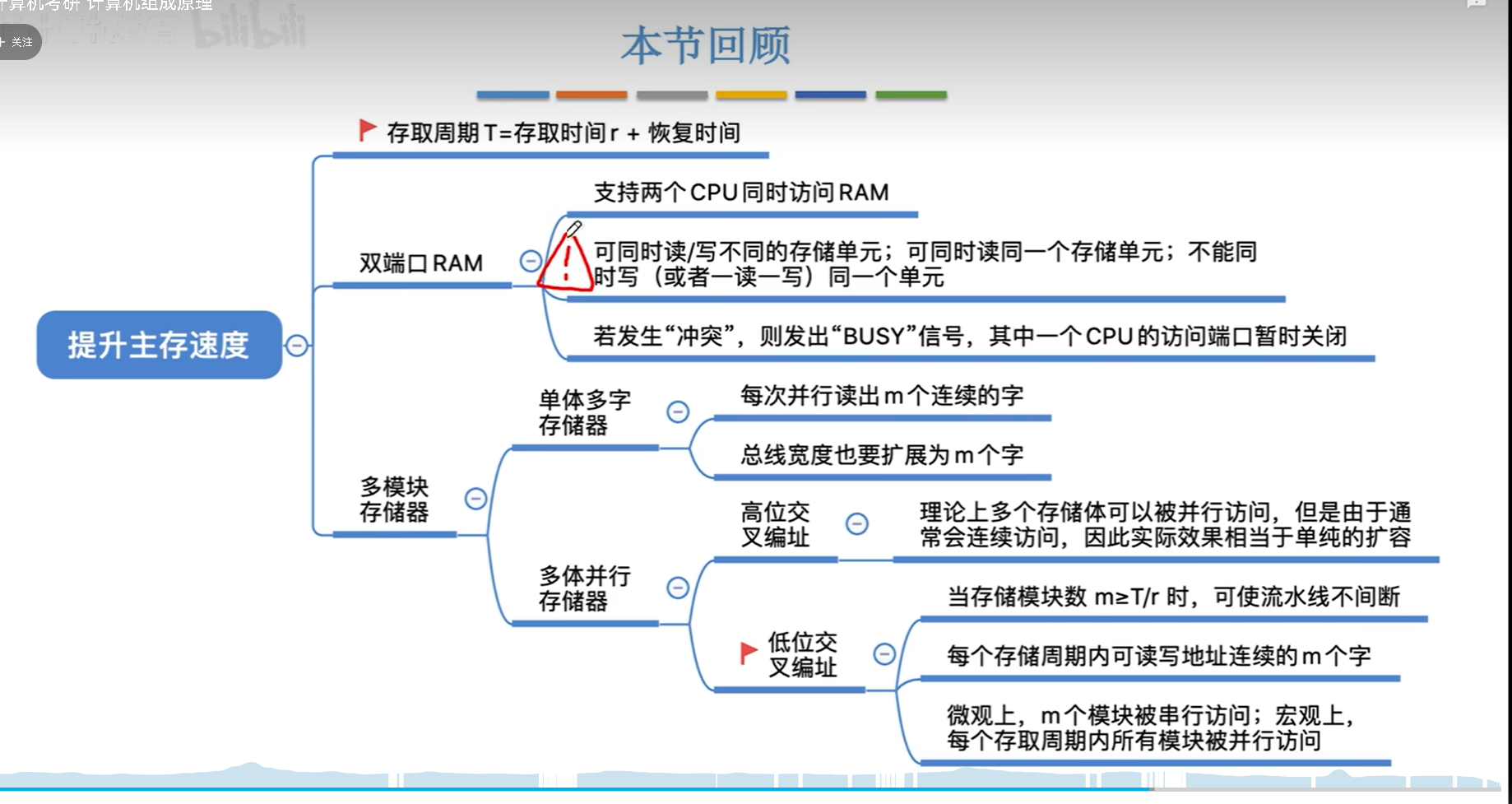
双端口RAM
双端口RAM暴露两套完整的端口,可以同时给两个CPU进行读写。但是考虑到数据一致性问题,需要有一个复杂的逻辑,很像操作系统的读着写者问题。
为了解决这个问题,加锁就可以,也就是下面的忙信号。具体如何,参考读者写者问题。
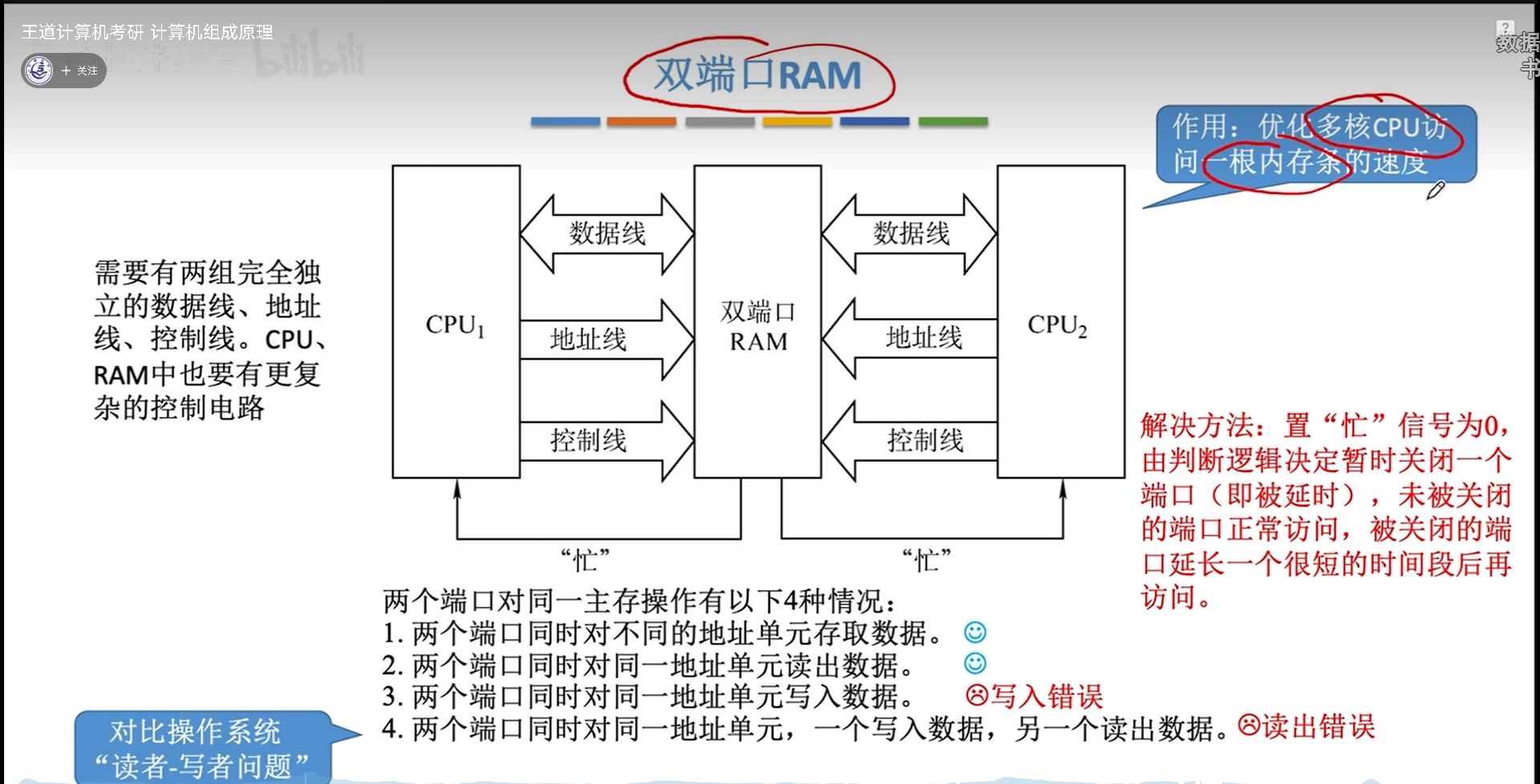
多体并行储存器
然而第一种方式其实对速度提升没什么用,因为CPU的频率本来就比内存大很多,两个CPU都读一个内存,对内存的压力更大,所以我觉得双端口RAM没太大用。
真正提升容量或者性能的,是多模块储存器,也就是我们说的多插几条内存。
有低位交叉编址和高位交叉编址两种方法。看似高位交叉编址可以让地址空间连续,但是实际对数据提速没什么帮助,反而是低位交叉效果更好,这样可以吧连续数据打乱,分散到不同的内存条的同一行上,实现CPU对内存的流水线访问。
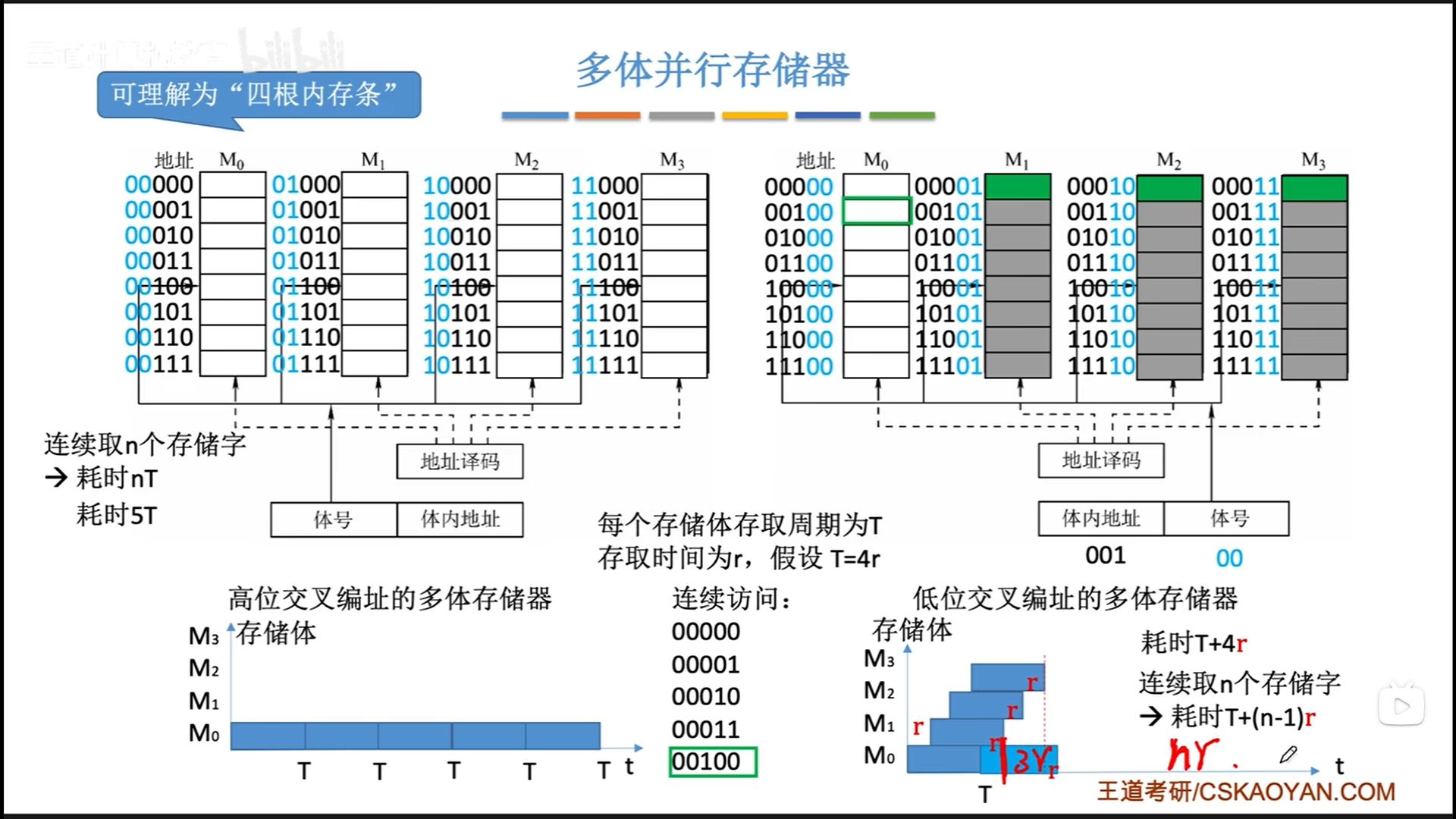
公式解读:T+(n-1)r=最后一个数据的读取时间+前n-1个数据的流水线读取
CPU的频率肯定是要远大于内存的,所以内存条数量是不需要考虑CPU的。理想情况应该是内存条数量=内存读写周期/内存读写时间(总线传输周期)。
做到这个以后,你的平均内存读写周期就约定于内存读写时间了,性能翻了m倍。其实这就是双通道内存的原理,双通道其实并不是同时读,而是交替流水线读取,宏观并行,微观流水线。
现实生活中,主板可能会给两对内存插槽,我们购买两条内存,如果插到同色的插槽里,就是双通道(低位交叉编址),如果插在同一侧的异色插槽李,那就是高位交叉编址。高位交叉编址只能单纯的扩展空间,而低位交叉编址两者兼顾,碾压高位交叉编址。
不过高位交叉也不是一无是处,如果两根内存参数差的比较多,组双通道很容易蓝屏,这也是内存套条的意义。如果只是两根随便找的内存,高位交叉更加稳定。
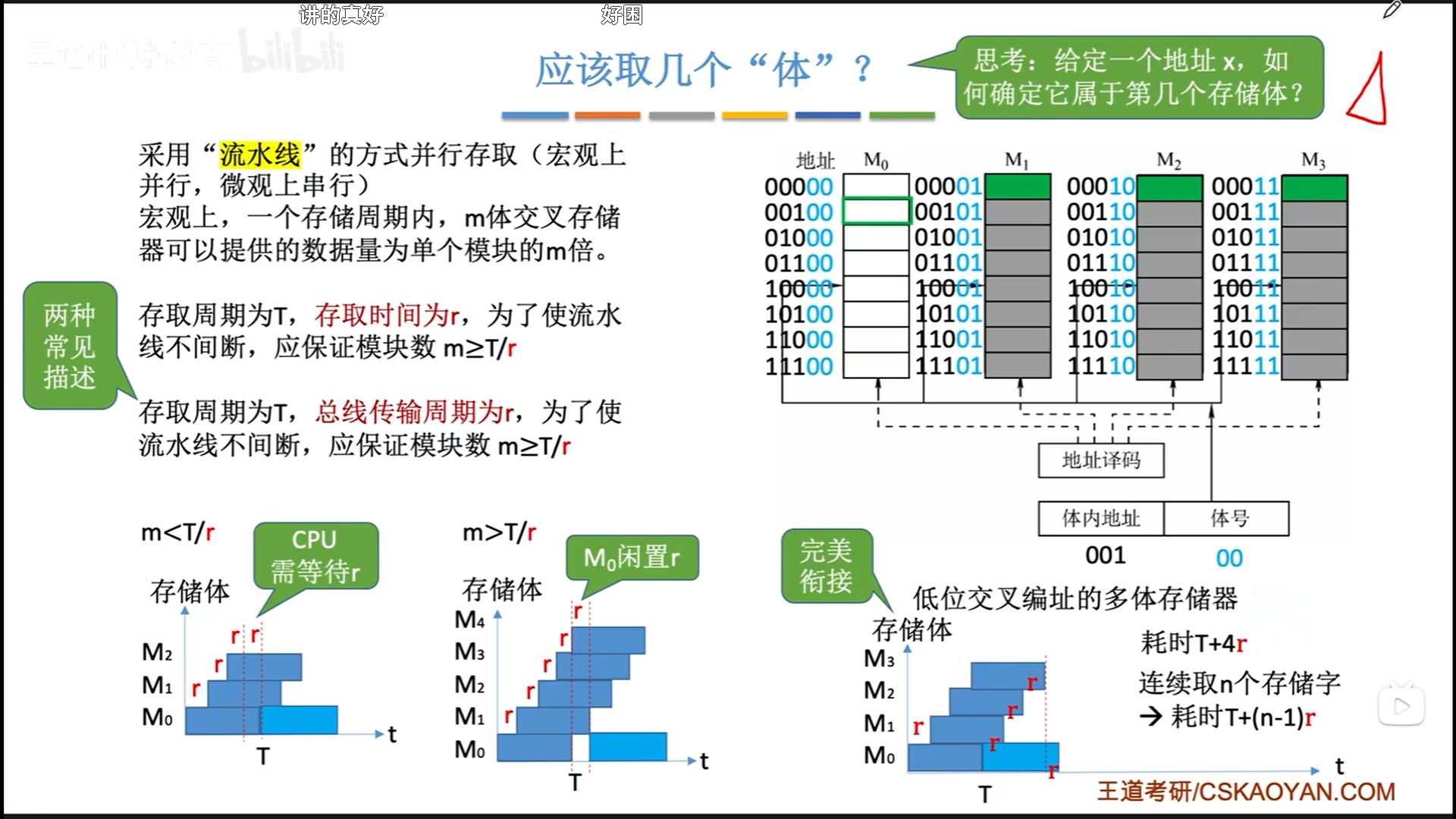
其实还有一种单体多字储存器,虽然一次性可以同时读取m条内存,但是不够灵活,因为一次读取的是同一行。
外部储存器
机械硬盘(磁盘)
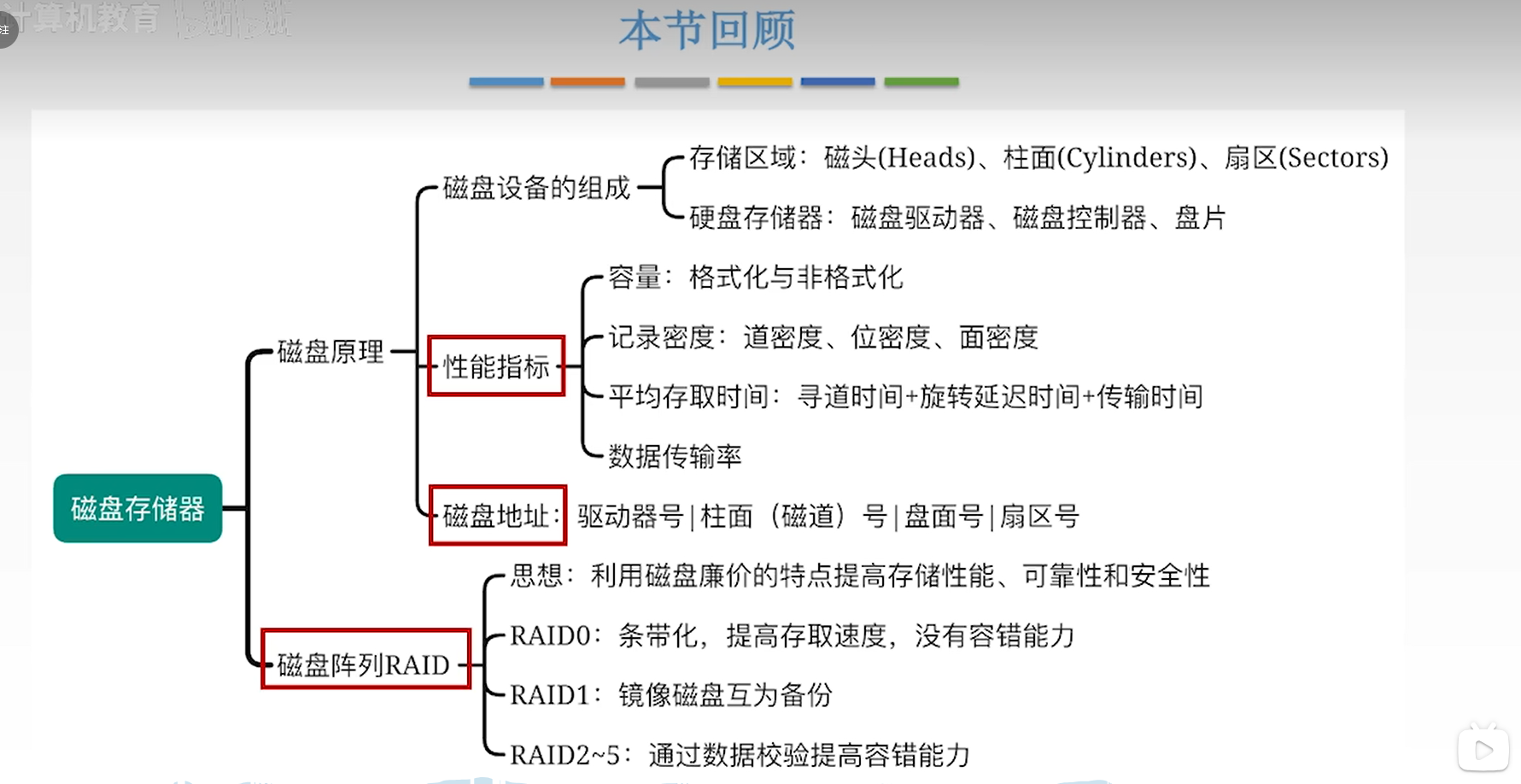
虽然这个原理不考,但是我还是要总结一下,很有意思的东西。磁盘的原理就是上面的磁性材料,磁极方向代表01。读写通过磁头实现,磁头是一个电磁铁,有两个功能:
- 写的时候,磁头通电,电生磁,改变磁性材料的磁极,实现01转换
- 读的时候,通过电磁感应,用磁头切割磁性材料的磁感线,产生感应电流,这个电流的方向代表01。
所以机械硬盘真是一个很有趣的东西。
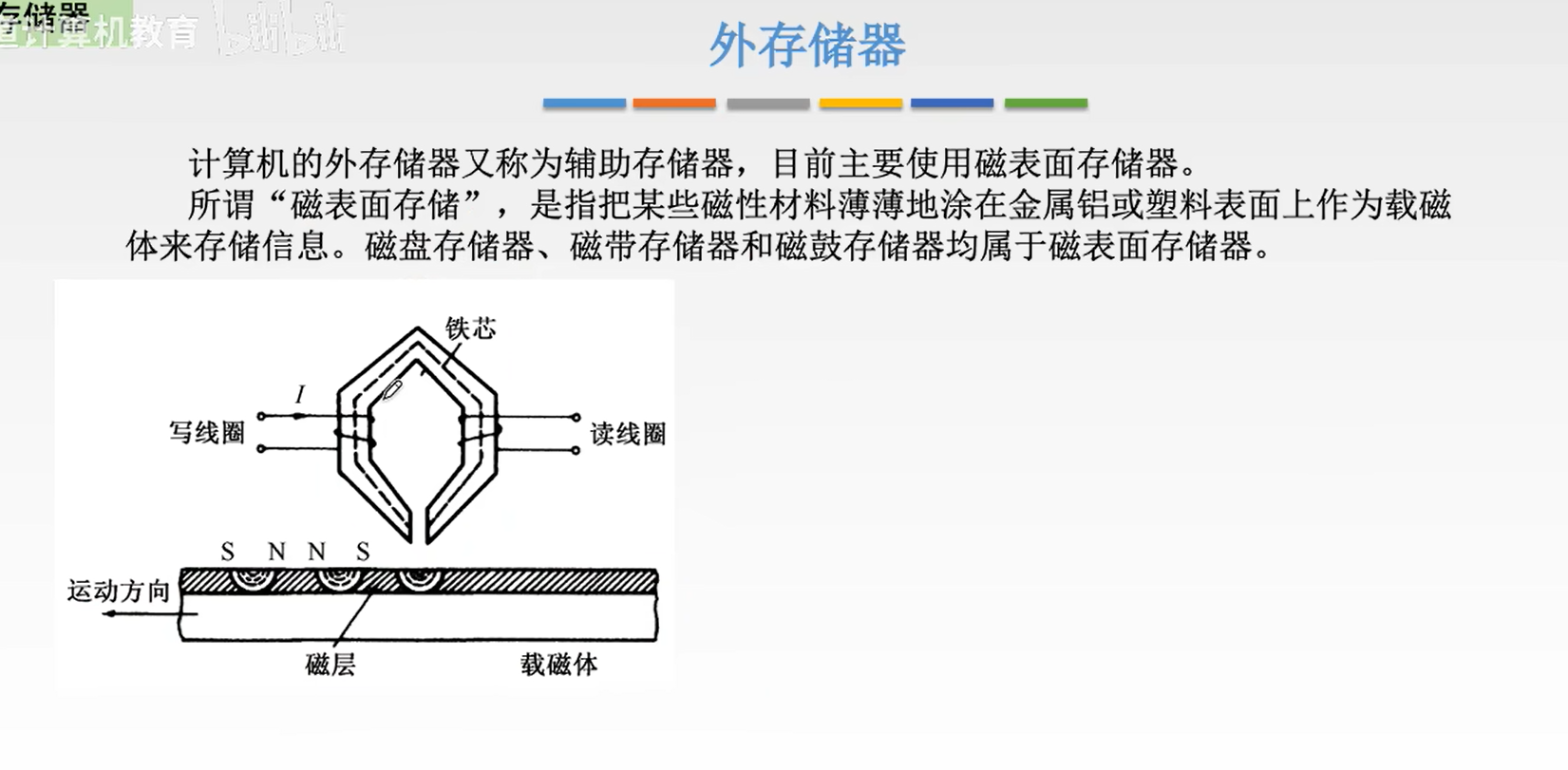
一个机械硬盘构件还是挺多的:
- 磁盘驱动器。让磁盘转起来,支架之类的东西都是驱动器的部分。
- 磁盘控制器。控制磁盘读写的芯片,向外暴露出接口,有IDE,SCSI,SATA等。机械盘主流的是SATA。
- 盘片。
需要注意的是,磁盘读写,内部一定是串行的,只是对外暴露的接口是并行的,这中间有一个串并行缓存转化电路,这就是磁盘控制器要做的工作之一。
性能指标方面,也有一些细节:
- 记录密度:因为每个磁道的扇区数量恒定,所以磁道密度其实是越往里越大的,技术难度也就越高。对应的,面密度肯定也是越往里越大
- 磁盘地址:我们以前在操作系统里学的是三元组,其实还有一个驱动器号,因为一个电脑很可能有多个机械盘(尤其是台式机)
最后说下RAID,以前就听说过这个东西,后面没继续了解,现在没想到学了,很好。接下来整理多硬盘的玩法:
- 多硬盘的最基本玩法就是啥也不干,单纯用来扩容。
- RAID0类似于低位交叉编址,通过磁盘阵列软件管理实现
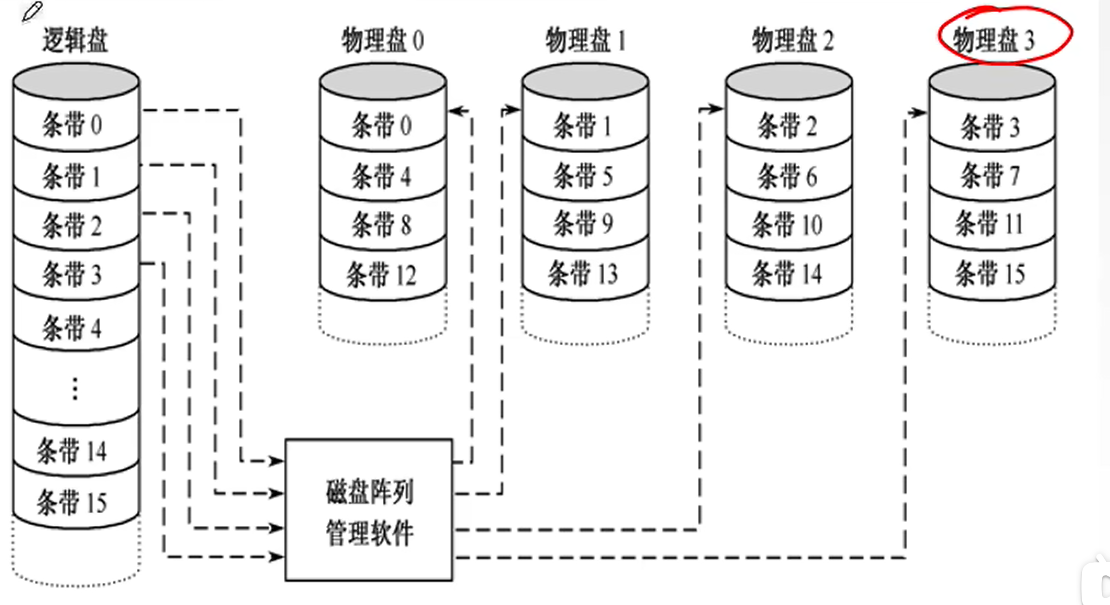
- RAID1是镜像,这种镜像会浪费一半空间,但是该有的提速功能还有,也可以交叉读取,而且抗干扰能力更强。
- RAID2用了海明码,相比于RAID1来说,冗余率更小一些,是4:3,效果相同。
我感觉,一般人用到RAID2就可以了,挺好玩的。
固态硬盘(SSD)
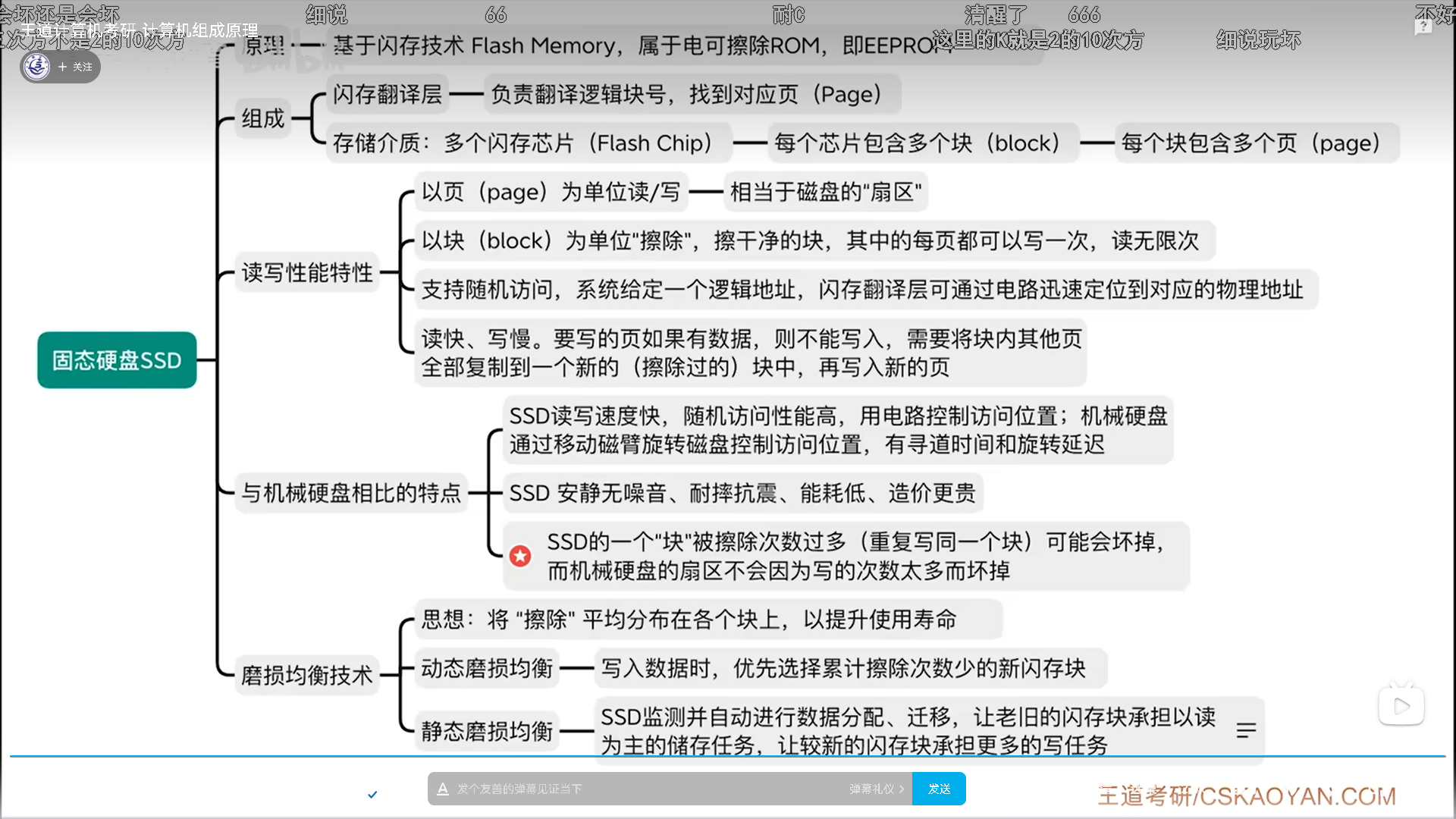
SSD虽然是硬盘,但是采用的技术是ROM,而且是EEPROM。
- 闪存芯片。类似于机械盘的盘面
- 闪存块。类比机械盘磁道
- 闪存页。类比机械盘扇区
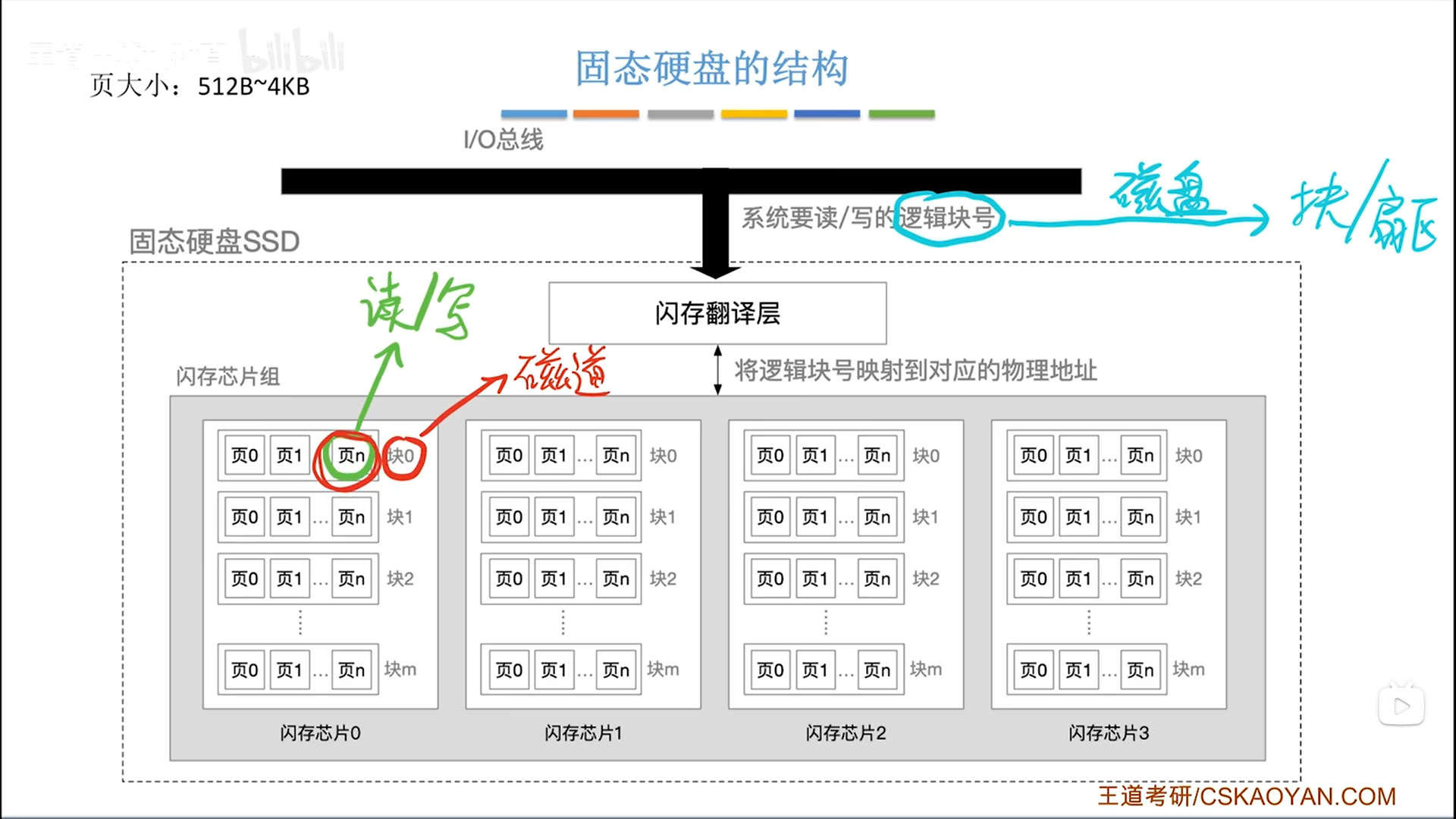
闪存翻译层是软硬件之间的界面。闪存翻译层记录了逻辑地址到物理地址的映射,而且这个映射是可以被修改的,后面如果有数据迁移,则映射关系也要修改。
向下,闪存芯片的读写特性很特别,以块为单位擦除,擦了以后每页都有一条命,写一次就用完了,以后只能读。
所以要想重复写,只能擦除一整块,问题这就来了,你为了重写一页,要擦掉其他页,不合适。所以就把其他页先复制到另一个地方(迁移),然后再擦这一块,重写这一页。正因为这个特性,所以SSD写的虽然快,但是还是要比读慢很多。
最后,动态磨损均衡比较好理解,就是写之前看看那些块健康度比较高,而静态磨损均衡的原理就是有些数据不会频繁读写,比如电影,有些会频繁读写。具体做就是定期扫描检测(注意不是扫描坏道,乐),把频繁读写的数据放到健康的块上。
只要磨损均衡做得好,一个盘的健康度是可以坚持很久的(10年没啥问题),健康度掉得快,要么是闪存芯片质量不行,要么是磨损均衡做的不好。
高速缓冲储存器
基本概念和原理
Cache使用SRAM,速度更快,但是容量更小。逻辑上,Cache相当于一块小的主存。
cache和主存的数据单元都是一样的,交换的时候统称“块”,只是在各自里面名称有所不同。主存中的块叫做“页”,cache中的块叫做行。
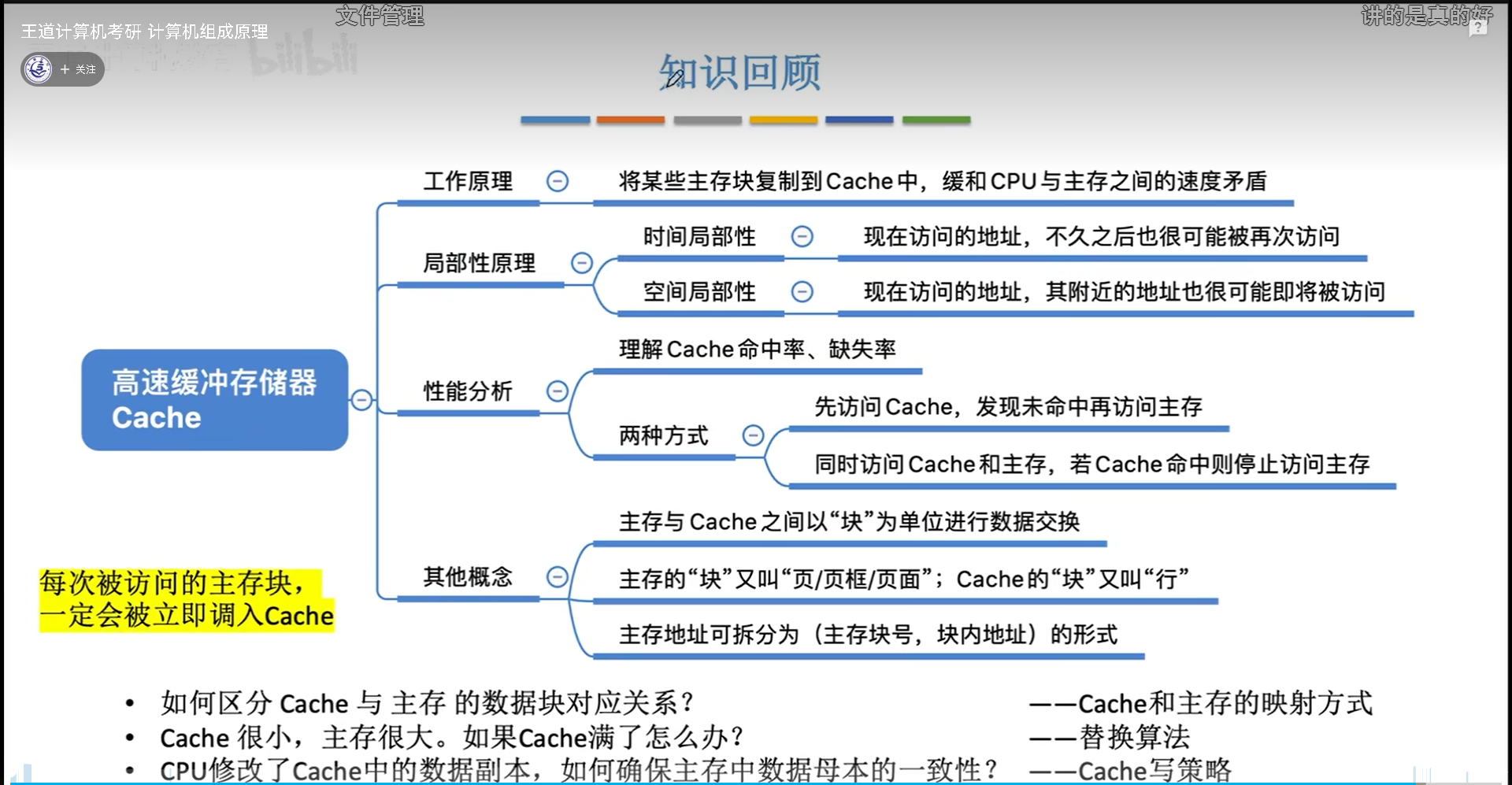
cache映射方式
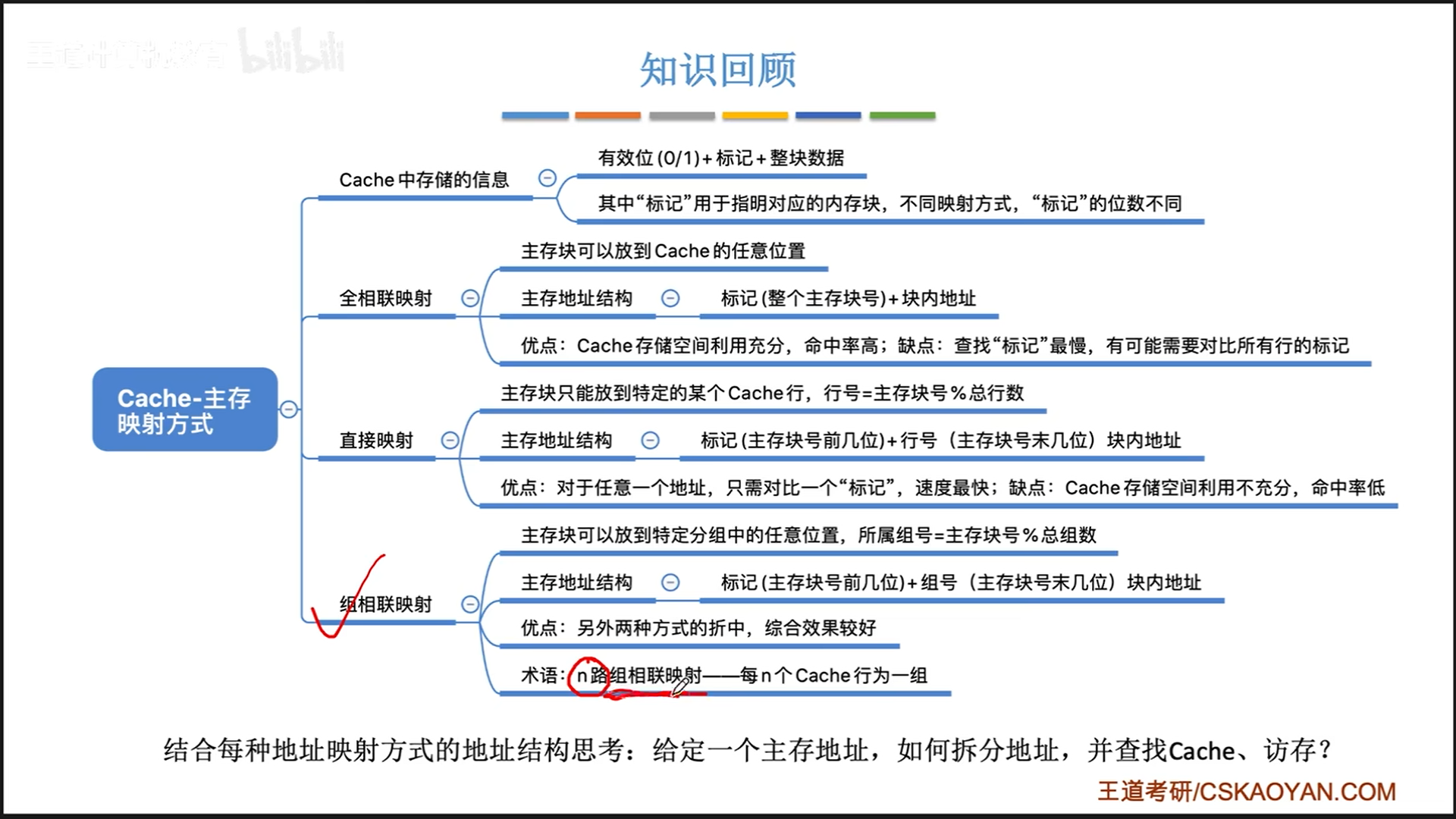
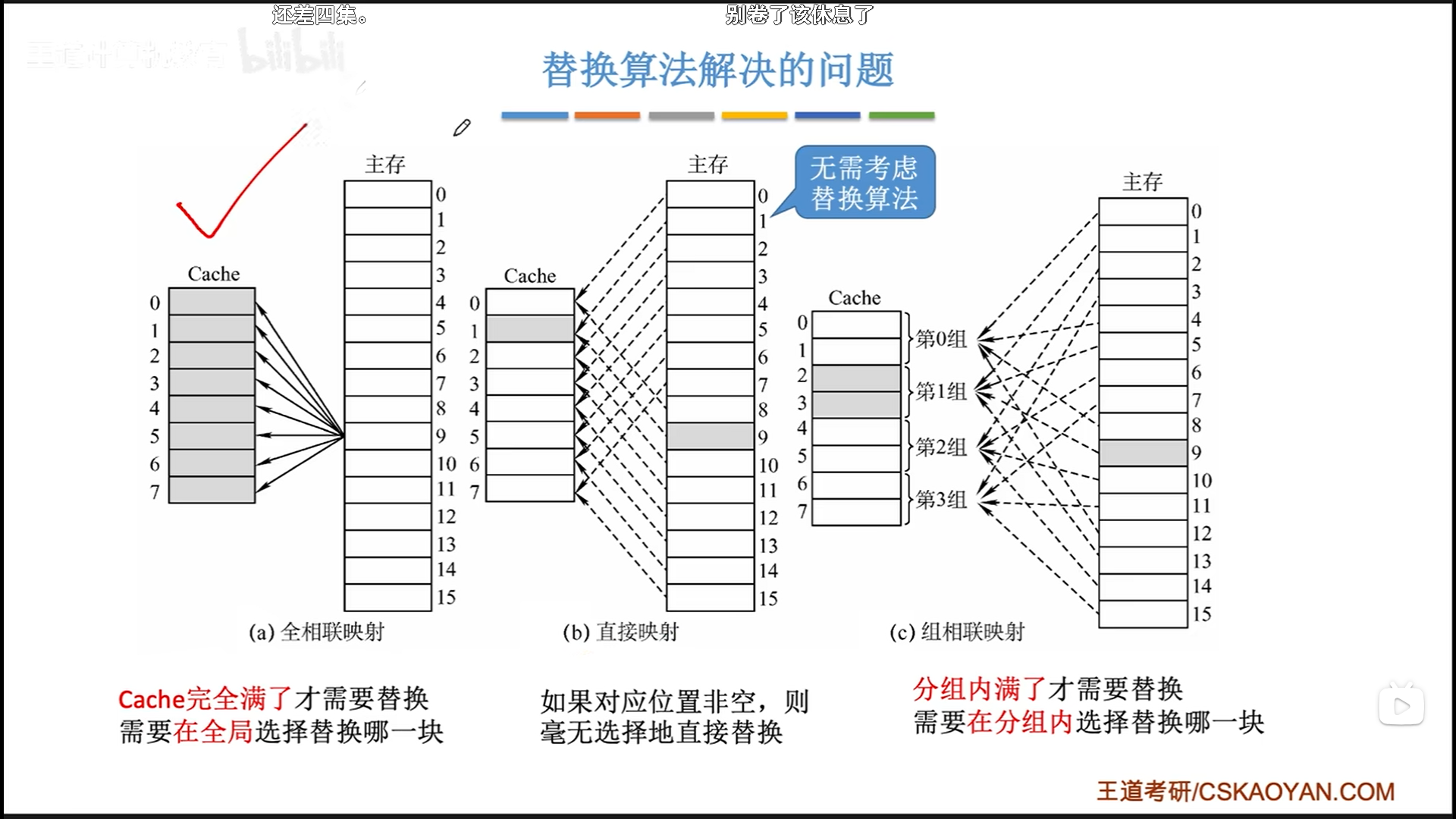
总结:
- 全相联具备极致的
空间效率- 优点:可以保证cache总是满的,命中率高
- 缺点:需要遍历整个cache才能确定主存的块号
- 直接相联具备极致的
时间效率- 优点:不需要任何遍历,直接锁定目标位置
- 缺点:cache中的块有一定可能处于闲置状态,命中率低
- 组相联介于两者之间,
本质上就是时间效率和空间效率的平衡!- 一个分组整体上是直接相联,但是内部是全相联的,所以外部直接定位,内部再进行少量的遍历
- 选择合适的组数量,可以达到最好的平衡效果。
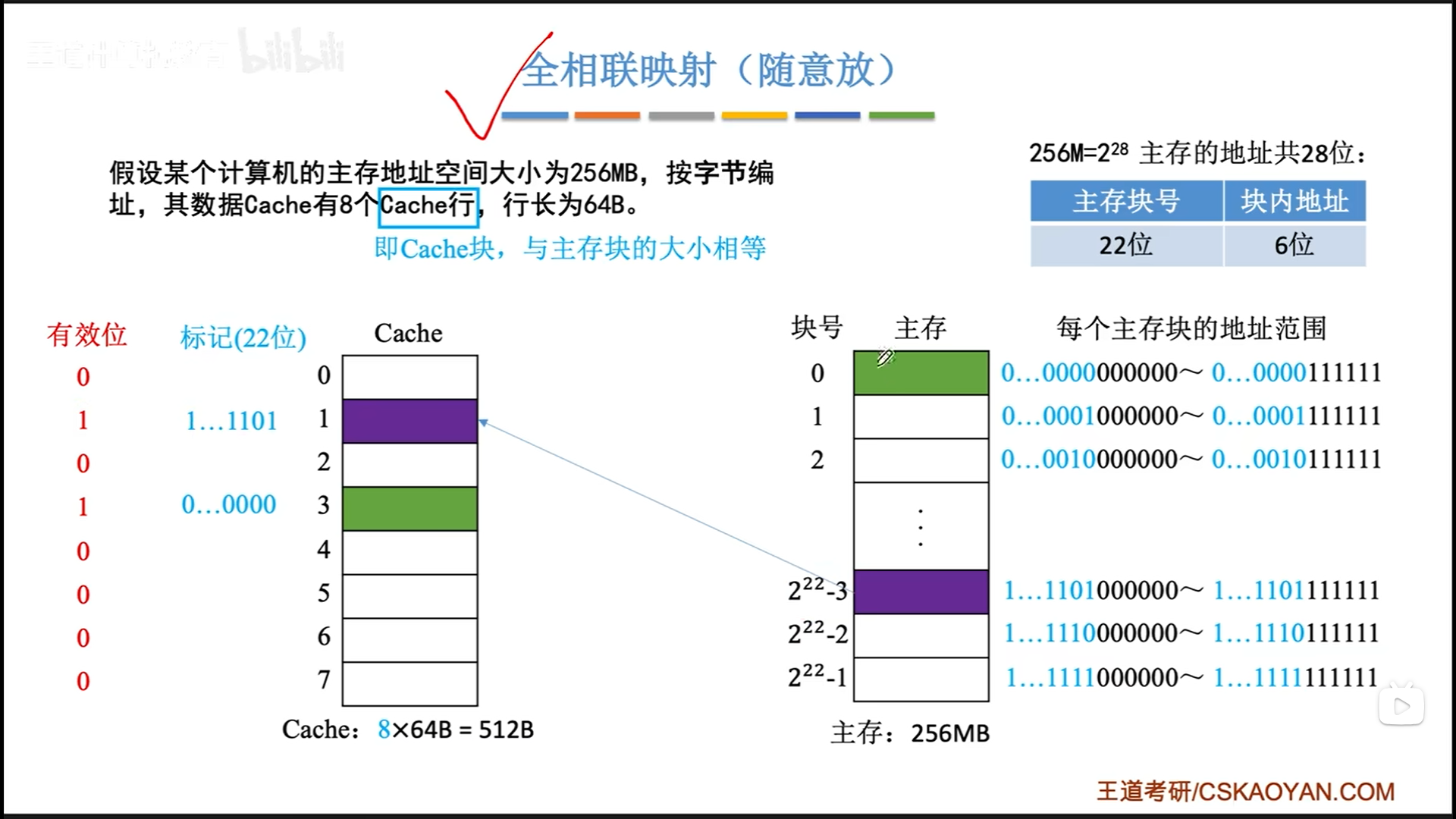
全相联映射
先理解全相联映射,这是最粗暴的。
主存按照块与cache交换,所以主存地址可以分解为两部分。全相联的意思就是,主存块号被完整地记录在标记位上(这个其实就是TLB快表)。
当来了一个地址,访问cache的流程如下:
- 截取主存块号
- 然后遍历cache,逐个对比标记位
- 找到匹配的标记位后查看有效位
如果hit,就好,miss则直接访存就好。可以看到,遍历cache是不是有点麻烦呢,这就是全相联的缺点。
直接映射
再来看另一个极端,直接映射。
将主存地址分为(标记位+行号+块内地址),观察一下规律,比如主存中块号为0-7的,标记位是一样的,区别只在于3位行号,而这3位行号恰好就是cache的行号。
所以只要知道主存地址,我就可以直接锁定其在cache中的行号,不需要去遍历。缺点就是空间效率低,比如我同时使用0,8,16号主存块,理论上把这三个都放到cache就好,但是直接映射只能允许这三个中的一个在cache的第0行。

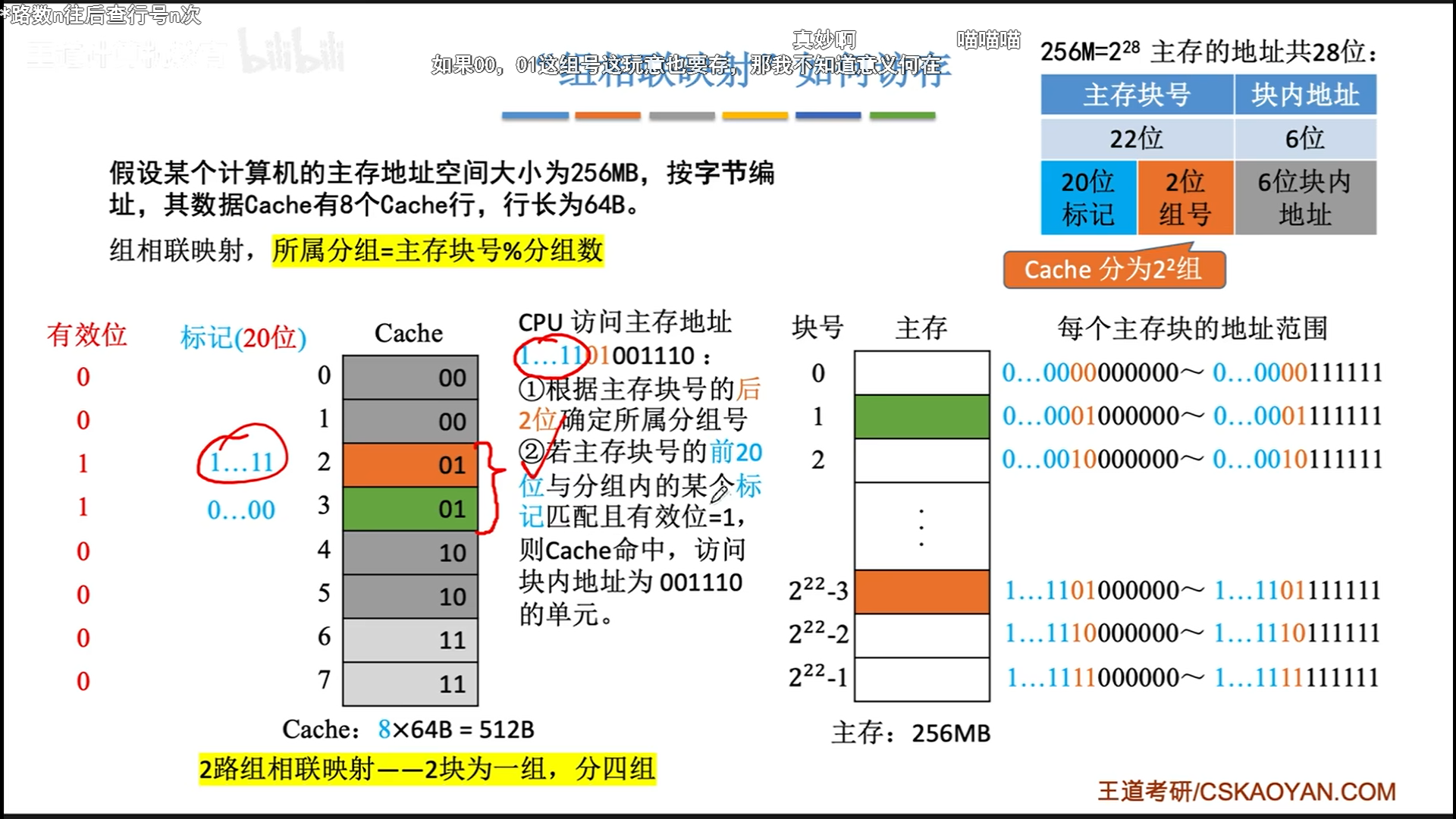
组相联映射
组相联映射介于两者之间。
先使用组号直接定位组,然后在组内遍历匹配,最后确定有效位。
从这个角度来讲,其实全相联映射就是行号分配了0bit的组相联映射,而直接映射就是分配了nbit行号的组相联映射,n=log(cache行数)
cache交换算法
首先要明白,如果是直接映射,那么即将调入cache的主存块,只能被放在固定位置,所以一定会直接替换,不需要替换算法。而全相联需要在整个cache寻找要替换的行,组相联映射需要在组内寻找要替换的行,所以这两者是替换算法应用的场景。
接下来介绍替换算法
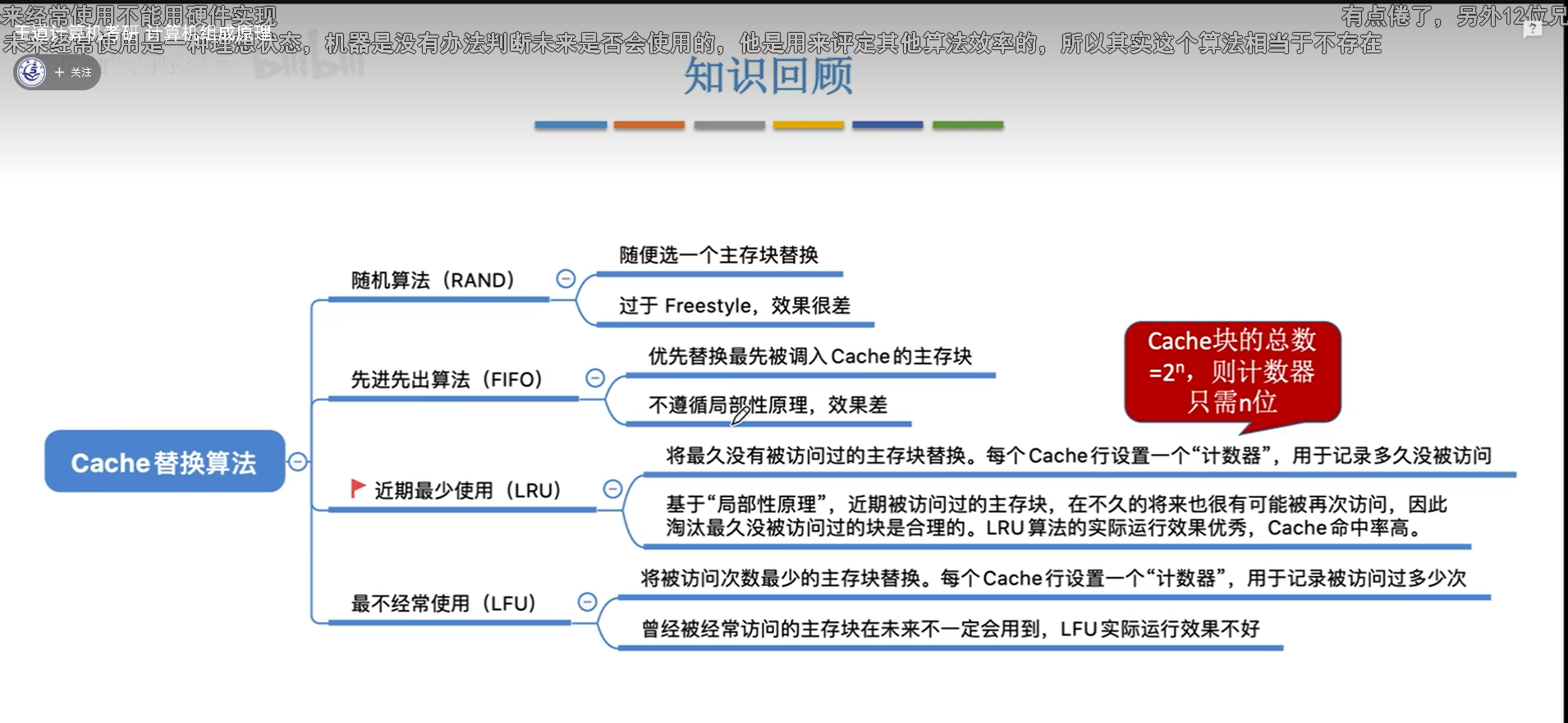
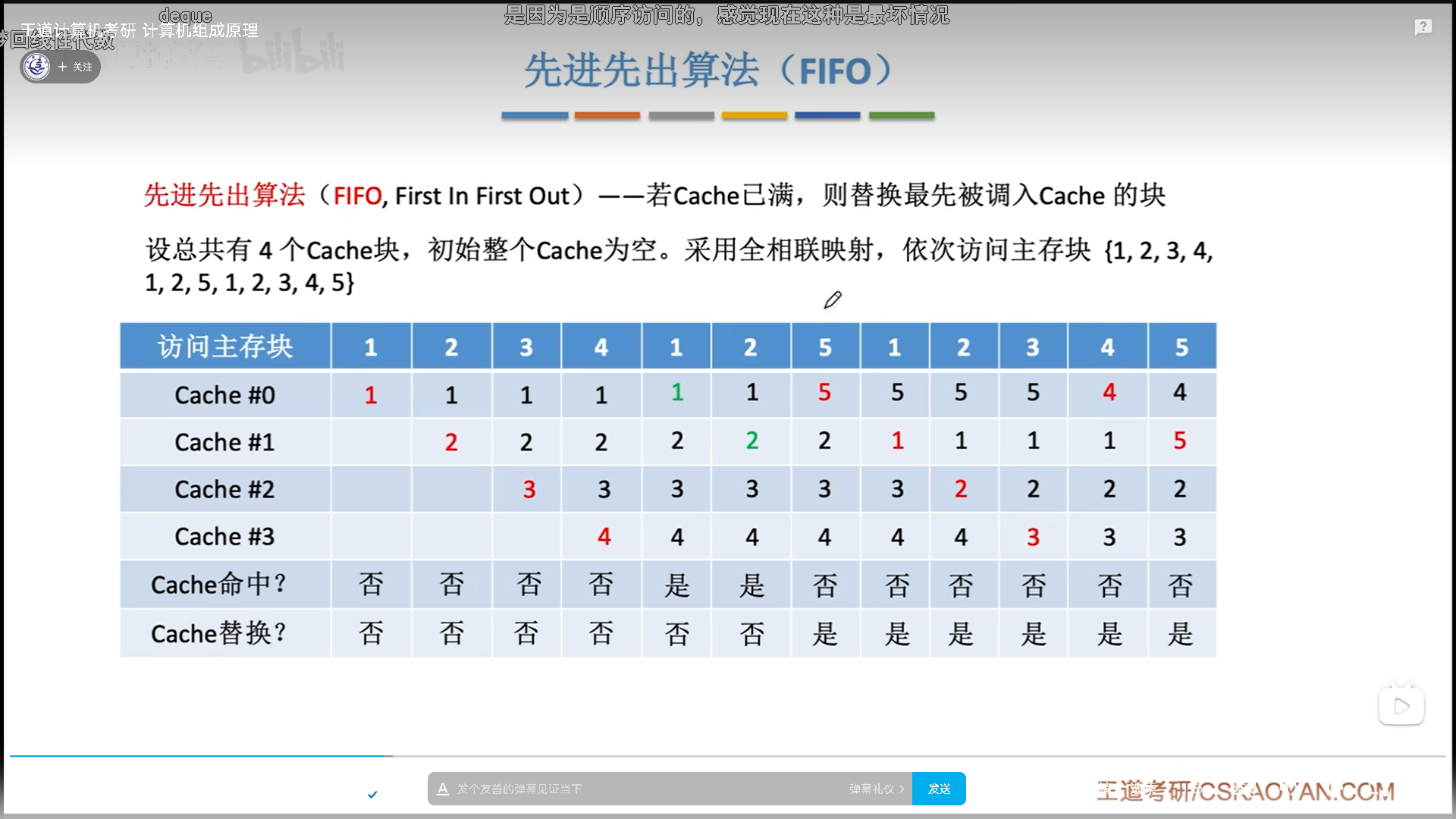
随机替换与FIFO(先进先出)
随机替换就是在cache满了以后,替换的时候随机找一个cache行进行替换,很明显,没有考虑到局部性原理,稳定性很差。
FIFO也好不到哪去,先进的就先出,同样没有考虑到局部性原理,毕竟最开始被调入的块也完全有可能被频繁访问。FIFO容易出现抖动
这个东西的硬件实现也很简单,只需要记录一个指针就可以,替换后指针(指针++)%n就可以。
LRU(最近最少使用)
LRU(Least Recently Used)。其实叫这个中文名字不是很合适,容易误导人,因为这个最少很容易理解为频率。实际上,最少应该指的是最近最没有被使用过的一个块。
做题的时候,当需要替换的时候,就倒着数哪个块最近没有被用到,就把哪个替换了就行。比如5号来的时候,往前数分别是2,1,4,3,那么就替换3号。
LRU算法很优秀,效果是最好的,充分考虑到了局部性原理,因为cache的目标就是存放被频繁访问的块,那频繁访问=计时器值小,所以LRU的效果和cache的目标一致,这才是LRU效果好的原因。但是呢,如果主存中活跃的块比cache大小更大,那就没办法了,还是会抖动。

具体到计算机实现,是使用一个叫计数器的东西。计数器可以理解为没有被用过的时间,也可以理解为没有被用过的次数,这两个是一致的。没有被用过的时间越久,就越要淘汰这个块。
计时器的最大值=cache行最大值,只要用一样的位数,cache装满后计时器的值就一定不会重复,每次都能找到那个最大的进行淘汰,有趣的是,只要cache满了,那么最大值=cache行最大值。
LFU(最不经常使用算法)
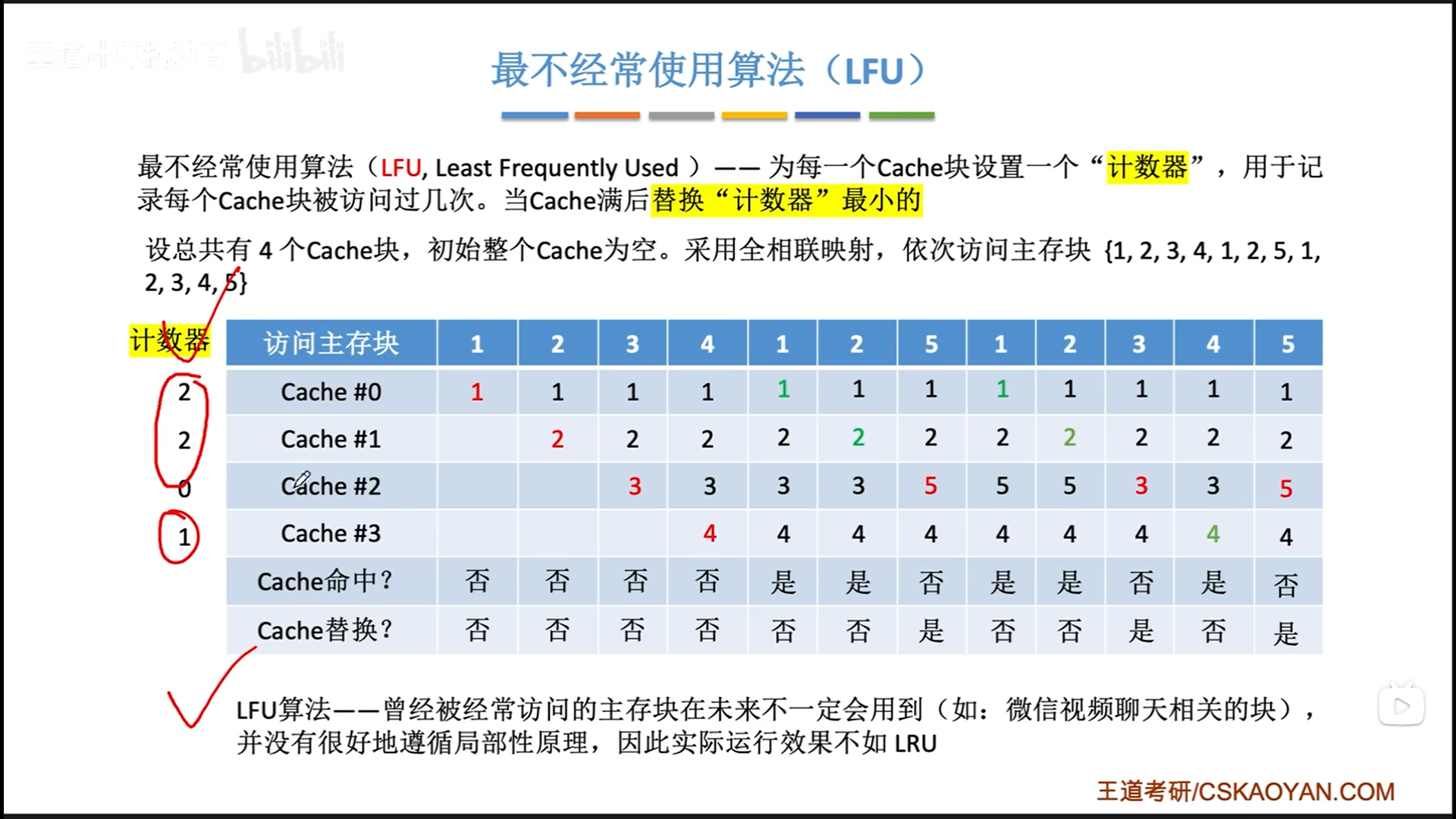
LFU(Least Frequently Used)。
设置计数器,存放cache块被访问的次数,cache满了以后,就会进行替换,把计数器最小的替换了。LFU有两大问题:
- 计数器的大小可能会很大,比较浪费空间
- 曾经被经常访问≠未来被经常访问,比如程序预加载的东西,其实就刚开始频繁用,后面不用了,但是却要占位置很久
所以实际中LFU效果不如LRU。
cache写策略
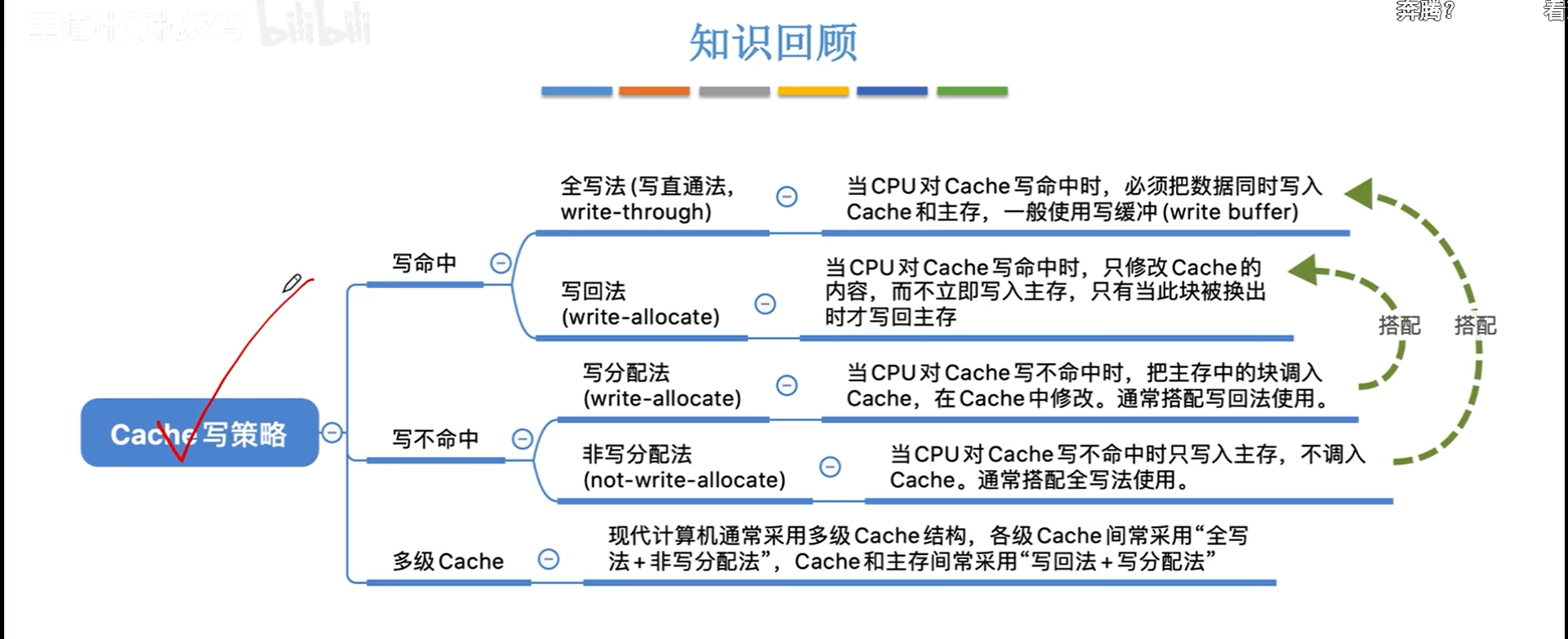
hit时:
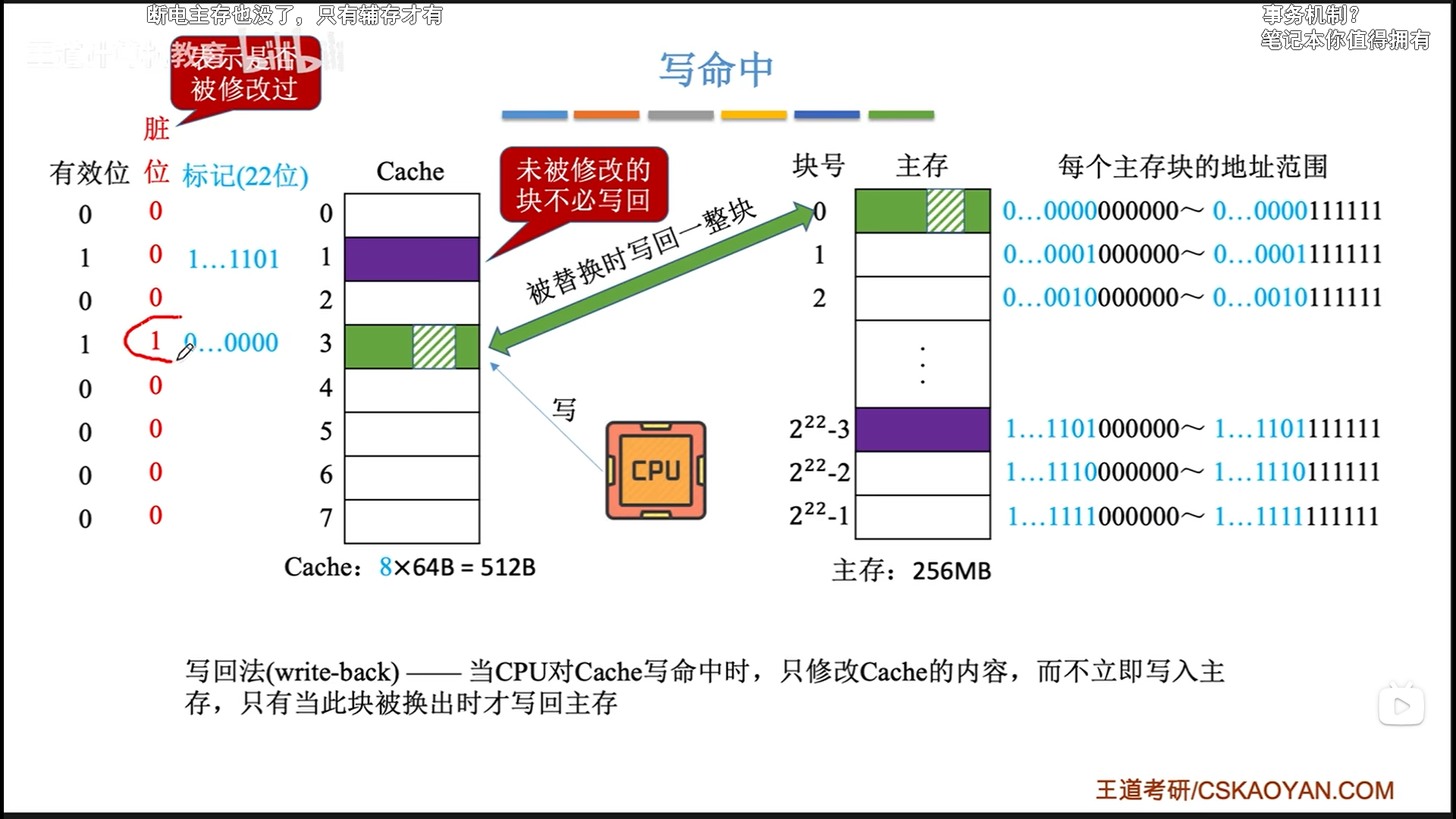
- 写回法
- 优点:能节省访存次数
- 缺点:数据一致性略差,为了保证数据一致性,还需要搭配一个
脏位使用,
- 全写法(直写法)
- 优点:数据一致性好
- 缺点:但是速度慢(CPU要访存) 。为了提速,指定一个
写缓冲,使用SRAM实现,CPU写到写缓冲里的速度很快,之后就去干别的,这个时候有一个专门的控制电路会慢慢把写缓冲的东西挪到主存里。
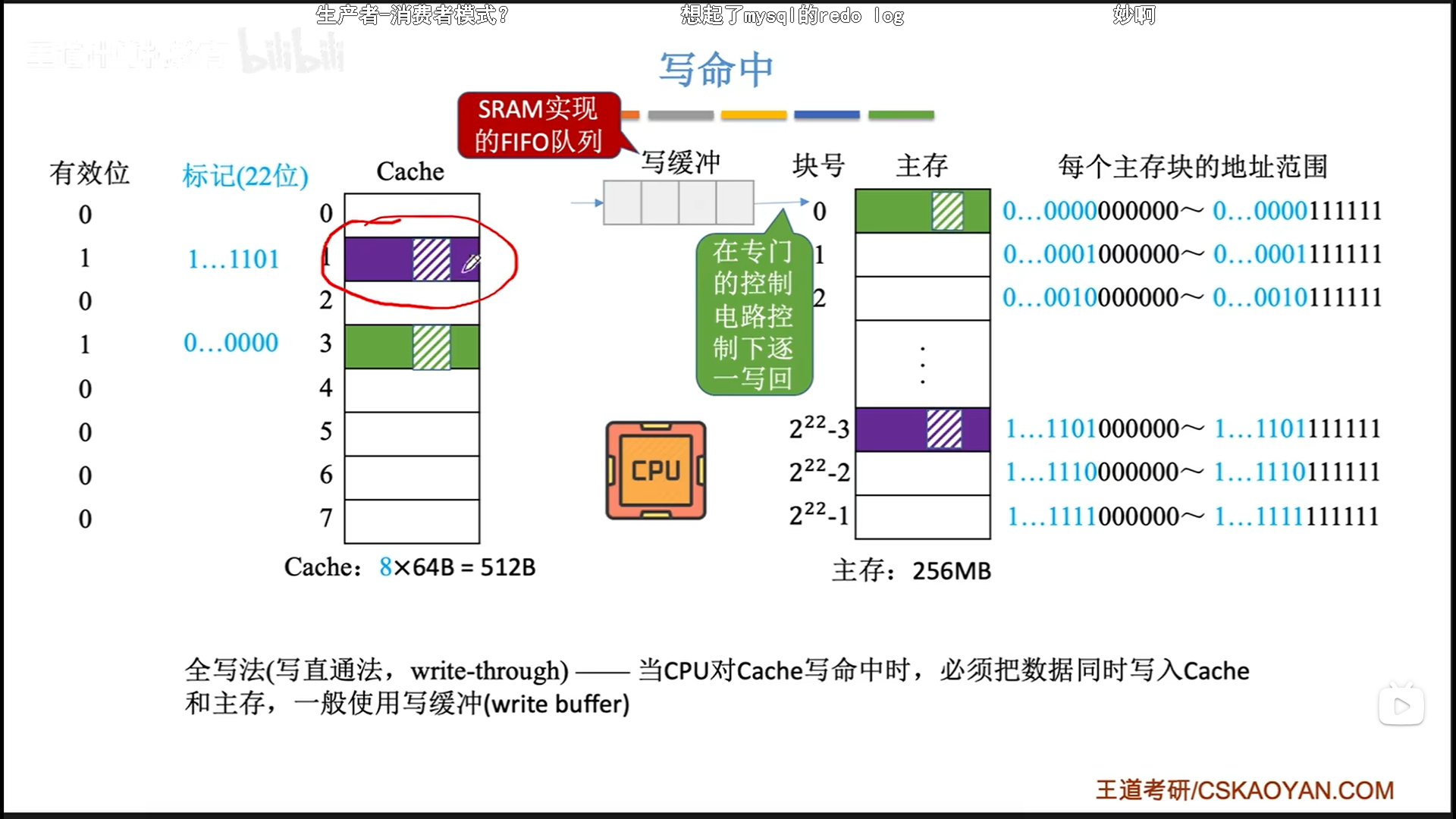
当miss时
- 写分配是回写法的逆过程,搭配使用
- 非写分配法,不调入,直接写主存,搭配全写法使用。
- 这种方法下,只有当CPU读不命中,才会调入cache。
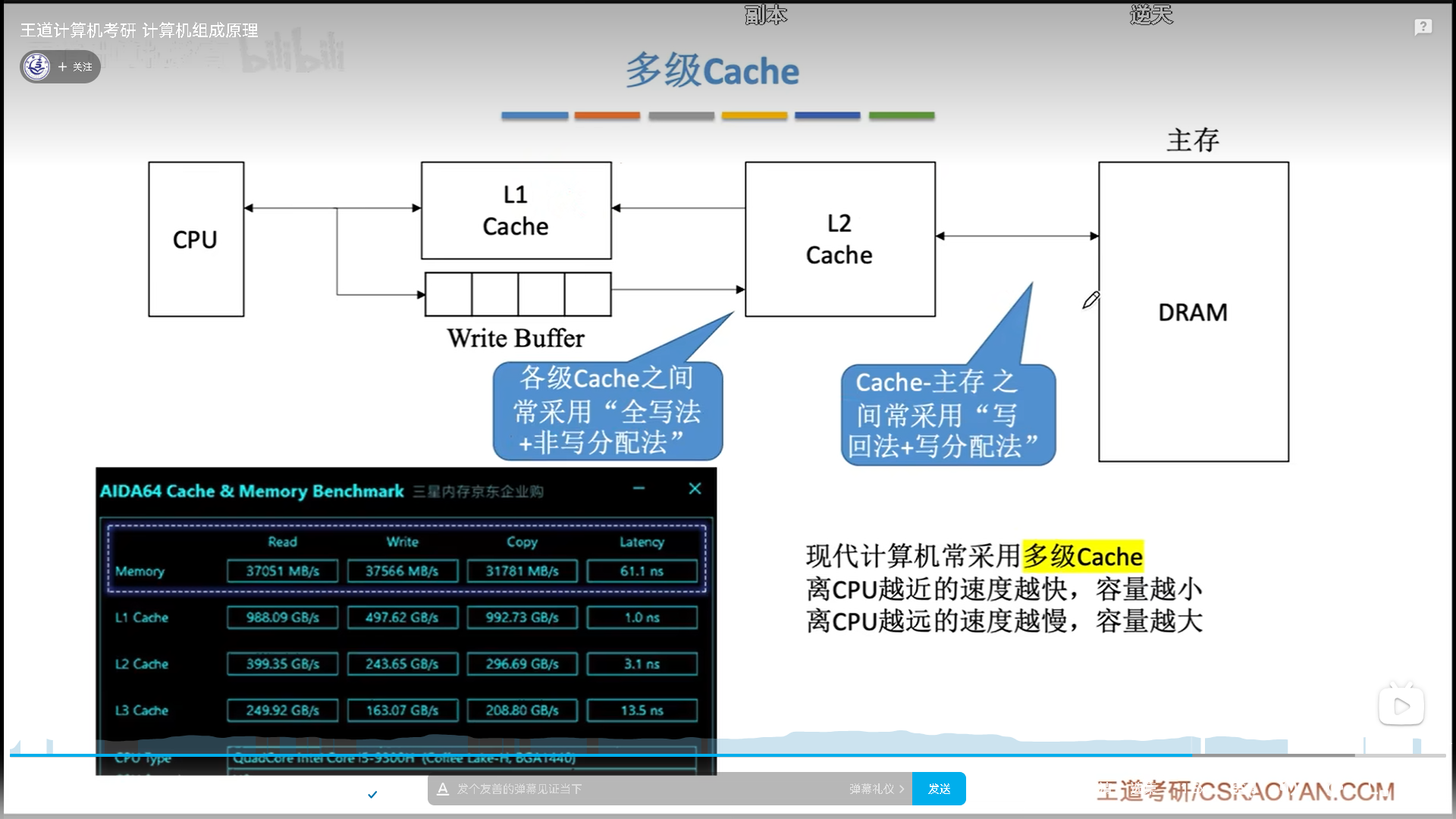
这两套方法没有谁对谁错,算是各有优劣吧。现在cache是多级的:
- cache内部优先使用全写+非写分配,为了保证内部的数据一致性
- cache外部与主存之间用写回和写分配法,成本较低。
虚拟储存器
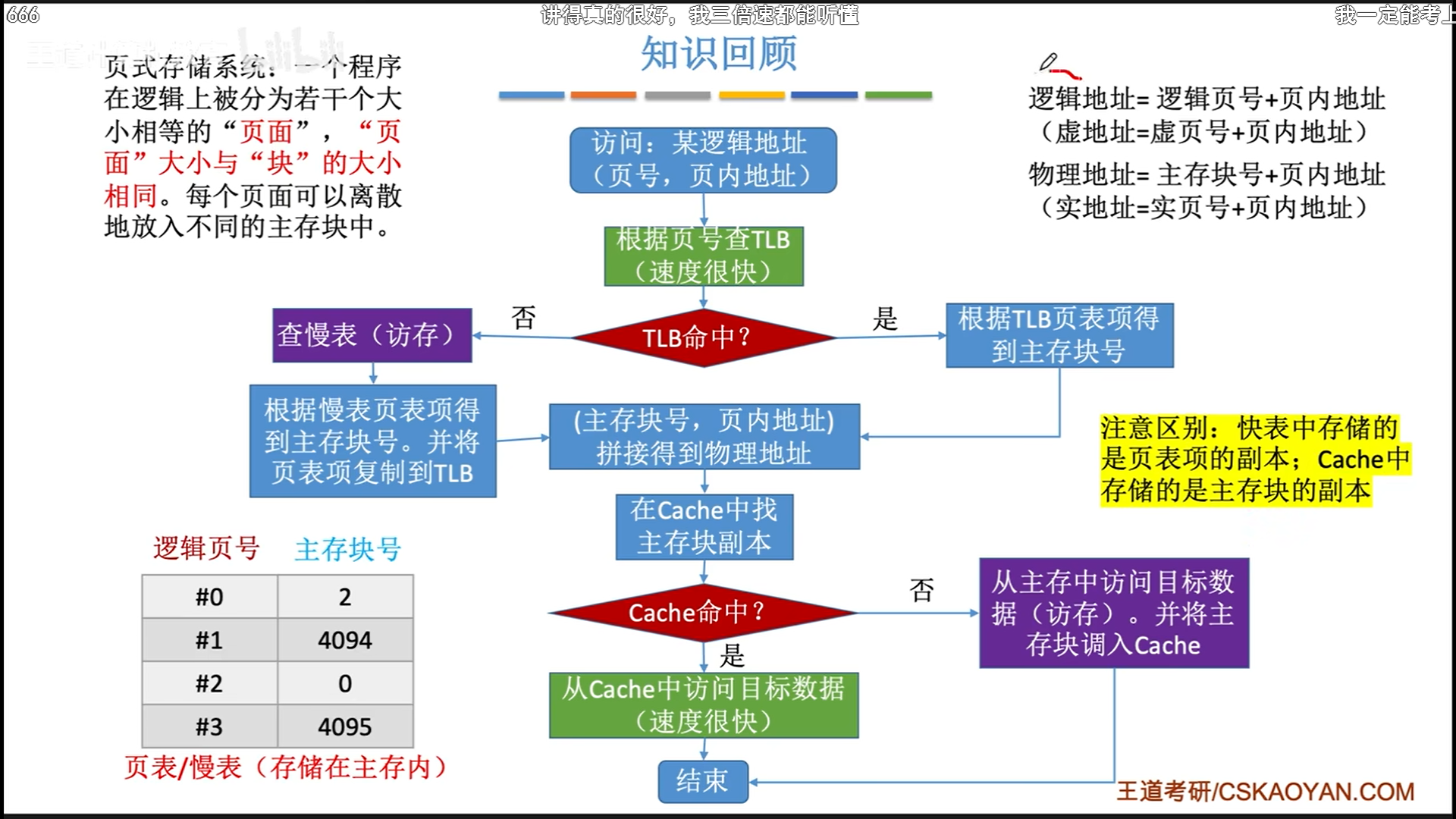
这一块建议直接看我OS的笔记,我简单概括一下就好:
- 虚拟储存的作用有两个,一是主存分区,二是保护物理地址。为此,会有页表,甚至二级页表的出现。具体转换过程还是比较简单的。
- 访问页表也是一次访存,访问数据还是一次访存,这两次访存分别以TLB和cache作为缓存。
- 页式管理和段式管理通常结合起来,变成虚拟段页式管理,说白了就是把二级页表变成了段表,使得页表大小更加灵活,共享页表也非常简单。
- 之所以是虚拟,是因为还要和辅存进行交换,因此需要在虚页表里增加访问位和有效位,脏位这些东西,说白了还是一种cache原理。















 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











