







参考:
https://www.cnblogs.com/jiaxin359/p/8559029.html
https://www.jianshu.com/p/7fc9aa03ec11
前言
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
一、概念理解
Stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。Stacking 的基础层通常包括不同的学习算法,因此stacking ensemble往往是异构的。
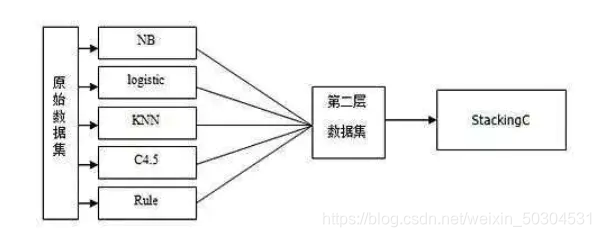
二、执行步骤
假设有1000个样本,70%的样本作为训练集,30%的样本作为测试集:
STEP1:在训练集上采用算法A、B、C等训练出一系列基学习器。
STEP2:用这些基学习器的输出结果组成新的训练集,在其上训练一个元学习器(meta-classifier,通常为线性模型LR),用于组织利用基学习器的答案,也就是将基层模型的答案作为输入,让元学习器学习组织给基层模型的答案分配权重。
三、使用mlxtend库实现Stacking方法
3.1 基于类别或者概率
最基本的使用方法,即使用前面分类器产生的特征输出或者概率输出作为meta-classifier的输入数据。
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import warnings; warnings.filterwarnings(action='ignore')
scaler = StandardScaler() # 标准化转换,逻辑回归模型特征需要标准化
scaler.fit(X) # 训练标准化对象
traffic_feature= scaler.transform(X) # 转换数据集
feature_train, feature_test, target_train, target_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=0)
# 第一层模型
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
# 第二层模型
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
# use_probas=True, 类别概率值作为meta-classfier的输入
# average_probas=False, 是否对每一个类别产生的概率值做平均
meta_classifier=LogisticRegression())
sclf.fit(feature_train, target_train)
# 模型评估
predict_results = sclf.predict(feature_test) # 预测类别
print(accuracy_score(predict_results, target_test)) # 输出准确率
conf_mat = confusion_matrix(target_test, predict_results) # 混淆矩阵
print(conf_mat)
print(classification_report(target_test, predict_results))
'''5折交叉验证,这里只输出了模型的准确率,对于采用5折交叉验证后如何训练预测模型,暂未知'''
for clf, label in zip([clf1, clf2, clf3, sclf], ['Logistic Regression', 'Random Forest', 'naive Bayes', 'StackingModel']):
scores = model_selection.cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
3.2 基于特征
另外一种方法是对训练集中的特征维度进行操作的,这次不是给每一个基分类器全部的特征,而是给不同的基分类器分配不同的特征,即比如基分类器1训练前半部分特征,基分类器2训练后半部分特征(可以通过sklearn 的pipelines 实现)。最终通过StackingClassifier组合起来。
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from mlxtend.feature_selection import ColumnSelector
from mlxtend.classifier import StackingClassifier
from sklearn.pipeline import make_pipeline
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import warnings; warnings.filterwarnings(action='ignore')
pipe1 = make_pipeline(ColumnSelector(cols=(0, 1)), LogisticRegression()) #特征取前2个指标
pipe2 = make_pipeline(ColumnSelector(cols=(2, 3, 4)), LogisticRegression()) #特征取第3-第5个指标
sclf = StackingClassifier(classifiers=[pipe1, pipe2],meta_classifier=LogisticRegression())
#训练模型
sclf.fit(feature_train, target_train)
# 模型评估
predict_results = sclf.predict(feature_test) # 预测类别
print(accuracy_score(predict_results, target_test)) # 输出准确率
conf_mat = confusion_matrix(target_test, predict_results) # 混淆矩阵
print(conf_mat)
print(classification_report(target_test, predict_results))














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









