







1.类型的转换
int和str
v1=int("123")
v2=str(123)
list和tuple
v1=tuple([11,22,33,44])
v2=list[(11,22,33,44)]
其他
v1=list("我爱中国") #["我","爱","中","国"]
dict——>list
v1={"k1":123,"k2":456}
v2=list( v1.keys() ) #["k1","k2"]
v3=list( v1.values() ) #[123,456]
其他——>bool
所有的类型转换成布尔值只有;None,0,空字符串,空元组,空列表,空字典为False,其他均为True2.编码
*ascli编码,256种对应关系 1个字节表示对应关系,1个字节8位
W 01010111
00000000-111111111*GB2312/GBK编码 2个字节表示对应关系
000000000 000000000
111111111 111111111*unicode万国码 4个字节表示对应关系
000000000 000000000 000000000 000000000
111111111 111111111 111111111 111111111v1="辽宁省" #12个字节
网络传输或文件存储
好处:包括所有字符
坏处:浪费存储空间*utf-8编码,对unicode进行压缩处理
v1="辽宁省" #字符串类型str ——>unicode
v2=v1.encode('utf-8') #压缩成字节类型 bytes
print(v1) v1=v2.decode('utf-8')
print(v1) #"辽宁省"name="中国联通"
data=name.encode('utf-8')
#打开文件
f=open("db.txt",mode='wb')
#写入内容
f.write(data)
#关闭文件
f.close3.文件操作
打开文件 操作文件:读取,写入 关闭文件
*打开
相对路径:相对于当前运行的代码文件的路径
绝对路径:直接路径
打开模式:write+字节(压缩) wb
w文件不存在就创建,打开前会清空文件内容
append+字节(压缩) ab
a文件不在就创建,在尾部追加内容
name="中国\n联通" #\n换行
data=name.encode('utf-8')
#打开文件
f=open("db.txt",mode='wb')
#写入内容
f.write(data)
#关闭文件
f.close
中国
联通将用户注册的信息保存在文件中
while True:
name=input("请输入姓名")
if name.upper()=="Q":
break
line="{}\n".format(name)
data=line.encode('utf-8')
#打开文件
f=open("account.txt",mode='ab')
#写入内容
f.write(data)
#关闭文件
f.close()网络传输数据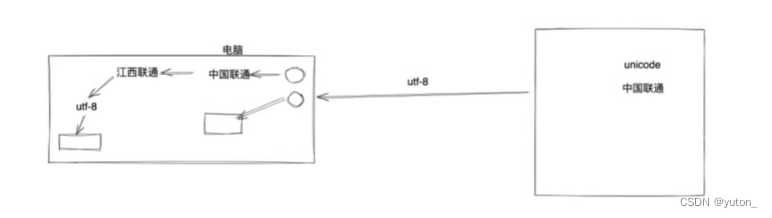
import requests
#去网络上发送请求并获取数据
res=requests.get("url")
#原始数据——>压缩编码之后的数据=字节类型
print(res.content)
f=open('new1.txt',mode='wb')
f.write(res.content)
f.close
text=res.content.decode('uts-8')
new_text=text.replace("code","coding")
f=open("new2.txt",mode='wb')
f.write(new_text.encode('utf-8'))
f.close()*读取文件内容
unicode utf-8/gbk
字符串str 字节bytes
"张三" b'\xe6\xad\xa6\xe6\x9b'
代码 网络和文件存储
——>"xx".encode('utf-8')
b'\xe6\xad\xa6\xe6\x9b'.decode('gbk') <——f=open('account.txt',mode='rb')
#读取压缩后的数据
content=f.read()
f.close
#字节转换字符串
data_string=content.decode('utf-8')
print(data_string)
data_list=data_string.split("\n")
print(data_list) #列表字符串转换成字节,压缩——>写入文件
name="张三"
v1=name.encode('utf-8')
字节转换成字符串,还原——>文件处理
data_str=content.decode('utf-8')
print(data_str)读取信息,并
f=open("account.txt",mode='rb')
count=f.read()
f.close()
data_string=count.decode('utf-8')
data_list=data_string.split("\n")
print(data_list)4.练习题
实现用户注册,包括用户名、密码、邮箱
f=open("massage.txt",mode='ab')
while 1:
name=input("请输入姓名:")
if name.upper()=="Q":
break
pwd=input("请输入密码:")
email=input("请输入邮箱:")
line="{},{},{}\n".format(name,pwd,email)
data=line.encode('utf-8')
f.write(data)
f.flush() #防止宕机,及时保存
f.close()
f=open("massage.txt",mode='rb')
count=f.read()
f.close()
data_str=count.decode('utf-8')
data_list=data_str.split("\n")
print(data_list)info={
"name":"lisa"
"data":[
{"id":"1","title":"xxx","url":"..."}
{"id":"2","title":"xxx","url":"..."}
]
}
for item in info["data"]: #for item in info["data"]["date"]:
id=item['id']
title=item['title']
url=item['url']
import requests
#去网络上发送请求并获取数据
res=requests.get("url")
data_dict=res.json()
f=open("a.txt",'ab')
for item in data_dict['data']['result']:
a1=item['a']
b1=item['b']
line="{}|{}\n".format(a,b)
f.write(line.encode('utf-8'))
f.flush()
f.close()#打开文件
#读取每一行数据并输出
#对每一行数据通过,分割,取0 1 索引
#构建字典
data_dict={}
f=open("db.txt",'rb')
content=f.read()
data_str=content.decode('utf-8')
data_str=data_str.strip()
massage=data_str.split("\n")
for item in massage:
line=item.split(",")
a1=line[0]
a2=line[1]
data_dict[a1]=a2
print(data_dict)发送网络请求下载图片
import requests
res=requests.get("https://seopic.699pic.com/photo/50115/6108.jpg_wh1200.jpg")
f=open("v1.jpg,",mode='wb')
f.write(res.content)
print(res)读取并下载db.txt文档内容
import requests
f=open('db.txt',mode='rb')
content=f.read()
f.close()
data_str=content.decode('utf-8')
data_str=data_str.strip()
data_list=data_str.split('\n')
for line in data_list:
ele_list=line.split(',')
file_name="{}.png".format(ele_list[0])
url=ele_list[-1]
res=requests.get(url)
img=open(file_name,mode='wb')
img.write(res.content)
img.close()5.关于模式
f=open("文件路径",mode='wb')
f.write("张三".encode('utf-8'))
f=open("文件路径",mode='w',encoding='utf-8')
f.write("张三")f=open("文件路径",mode='rb')
data=f.read()
content=data.decode('utf-8')
f=open("文件路径",mode='r',encoding='utf-8')
content=f.read()开发时,如果文档中写入的是字符串文本,建议:mode='r',encoding='utf-8'
如果图片/视频...建议:mode='rb'
6.关于大文件
txt文档,100G文件
f=open("文件路径",mode='r',encoding='utf-8')
content=f.read() #把所有的内容读取到内存f=open("文件路径",mode='r',encoding='utf-8')
#逐行读取文件
for line in f:
line=line.strip()
if not line:
continue
print(line)
f.close()mp4文件,100G
import os
total_size=os.stat("文件路径").st_size
print(total_size)
f=open("文件路径",mode='rb')
has_read_size=0
while has_read_size<total_size:
data=f.read(3) #先读3个字节
print(data)
has_read_size=has_read_size+len(data)
f.close()7.with打开
with open("文件路径",mode='r',encoding='utf-8') as f: #自动关闭文件
content=f.read()
print(content)














 2600
2600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









