






前言
编译环境是VS2019,学习笔记,希望你看了有用。
一、指针的基本知识
1.1 指针介绍
1、理解内存单元
拿房间举例子,计算机的内存就好比一个宿舍楼,你知道我在这栋宿舍楼内,而怎么才能找到我的具体位置呢?只要知道我的房间号就知道我在哪里了,比如我告诉你,我在启智4b621,那你就很清楚的明白,我在启智4B这栋楼的6楼,房间号是621.
而内存是如何管理的呢?就是切割成一个一个的内存单元(1个字节Byte,8个比特位),在计算机中对内存单元也进行了编号,也就是地址。
2、指针是什么
所以内存单元中的编号就是地址,也叫做指针,指针的本质就是地址而已
理解指针有两个要点:
(1)指针是内存的中一个最小单元的编号,也就是地址
(2)平时我们口头说的指针,是指指针变量,是一个用来存放内存地址的变量
3、指针变量
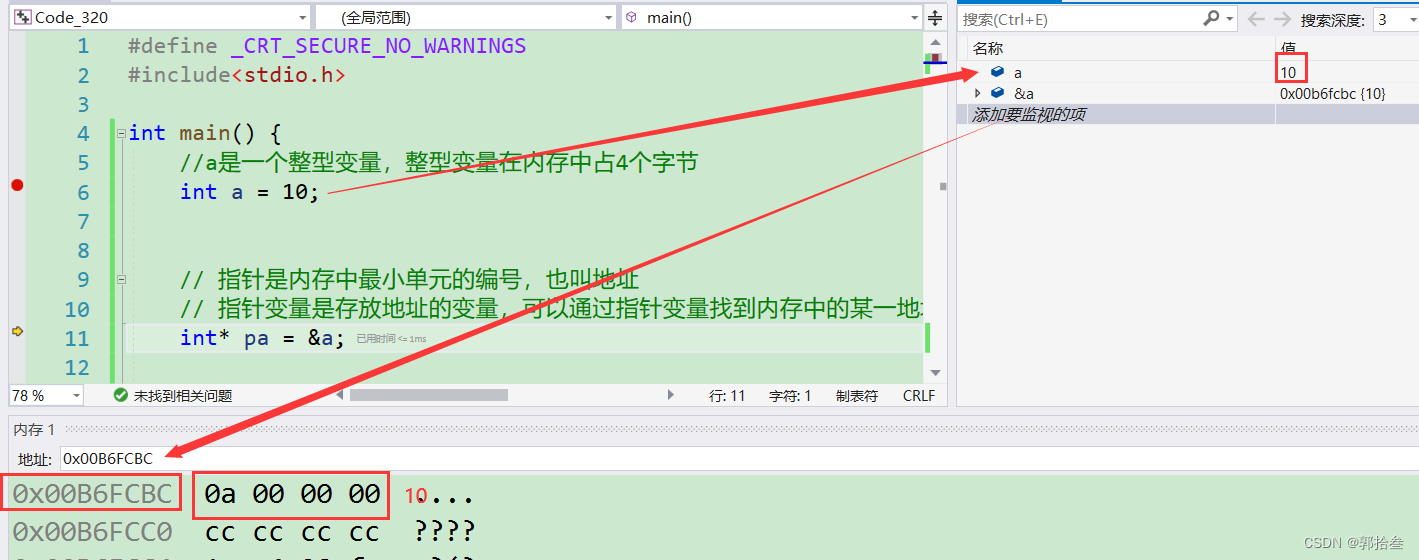
对于变量,例如 int a = 10;int类型的变量在内存中占据4个字节,也就是说,当我们写下这段代码时,就会在内存中开辟一块空间,这块空间的大小有4个字节,如下图。

当我们在计算机内存中 &a的时候,就可以看到,a确实占据4个直接的空间 ,并将10 存入了该空间,这里存储的是16进制下的10,即0a。
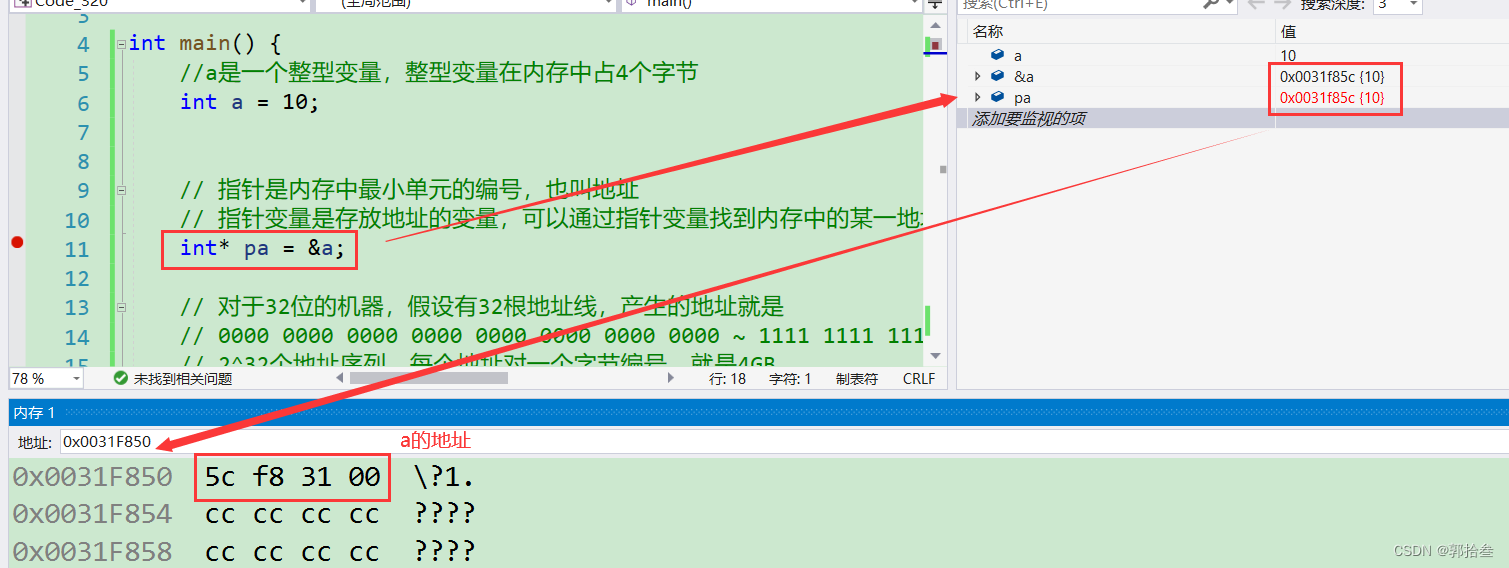
而对于一个指针变量来说,指针变量是存放地址的变量,可以通过指针变量找到内存中的某一地址。

在计算机内存中可以看到,指针变量pa存放的确实是a的地址 &a(这里拿到的是4个字节中的第一个地址)
1.2 不同类型指针的大小
int main() {
char c = 'w';
short si = 10;
int i = 10;
long l = 1000;
long long ll = 1000;
float f = 1.1;
double lf = 1.2;
char* pc = &c;
int* pi = &i;
long* pl = &l;
long long* pll = ≪
float* pf = &f;
double* plf = &lf;
printf("char*:%zu\n", sizeof(pc));
printf("int*:%zu\n", sizeof(pi));
printf("long*:%zu\n", sizeof(pl));
printf("long long*:%zu\n", sizeof(pll));
printf("float*:%zu\n", sizeof(pf));
printf("double*:%zu\n", sizeof(plf));
return 0;
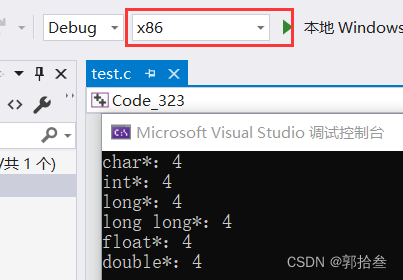
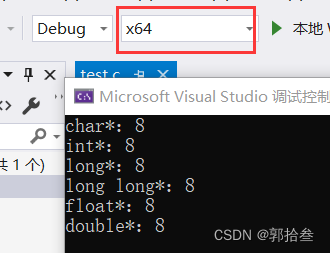
}利用sizeof操作符,可以求某个变量所占内存空间的大小(单位是字节)。
我们不难发现,不同类型指针的大小不取决与类型,只取决于当前系统环境
在32位系统下(x86),指针变量大小为 4 个字节
在64位系统下(x64),指针变量大小为 8 个字节
1.3 指针类型的意义
我们知道 指针有很多种类型,整型指针、字符指针、浮点型指针等。
int* pa; // int类型指针
char* pc; // char类型指针
float* pf; // float类型指针
double* pd; // double类型指针那不同类型的指针有什么区别呢?为什么要以不同的类型来定义指针呢?我们来看这段代码
int main() {
int a = 0x11223344;
int* pa = &a; // *pa = a= 0x11223344
*pa = 0; //内存中为0x44332211 改完之后为 0x00000000 4个字节全部修改
char* pc = &a; // 警告:从“int * ”到“char* ”的类型不兼容 *pa = a= 0x11223344
*pc = 0; // 内存中为0x44332211,说明char*可以存放int*的地址,字节相同 改完之后为 0x00332211 只修改一个字节
return 0;
}在给整型变量a赋值为 16进制数的11223344后,我们查看内存中的a,已经变为 0x 11223344,这里内存中显示为44332211的原因是大小端的问题,小端存储导致存储时数据反向,这里我们对此不做讨论,接着 将a的地址赋给了指针变量pa,接下来我们对pa指针进行解引用操作,并将a的值改为0;
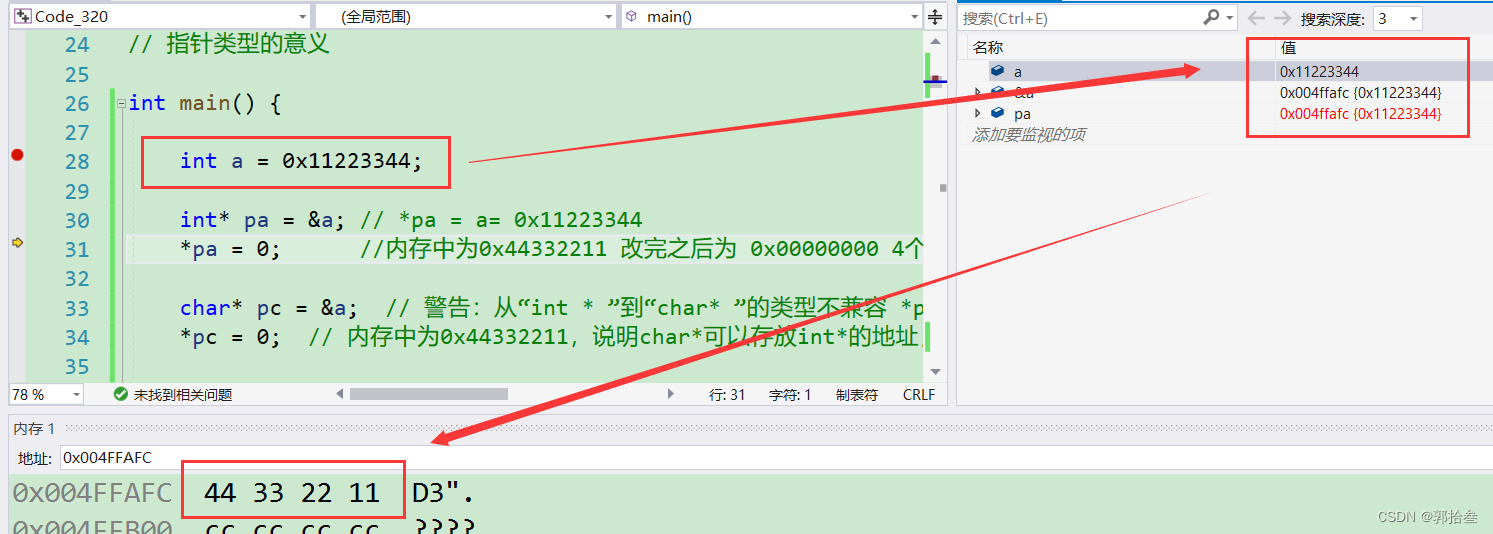
这里我们可以看到,在对pa指针进行解引用操作,并将a的值改为0之后,整型变量a的4个字节均变为了0,一次修改了4个字节的值。接下来,我们使用 char* 类型的指针pc来接收a的地址,然后再对pc指针进行解引用操作,并将a的值改为0,看看会发生什么。(此时将 pa的操作进行注释)a的值还是11223344
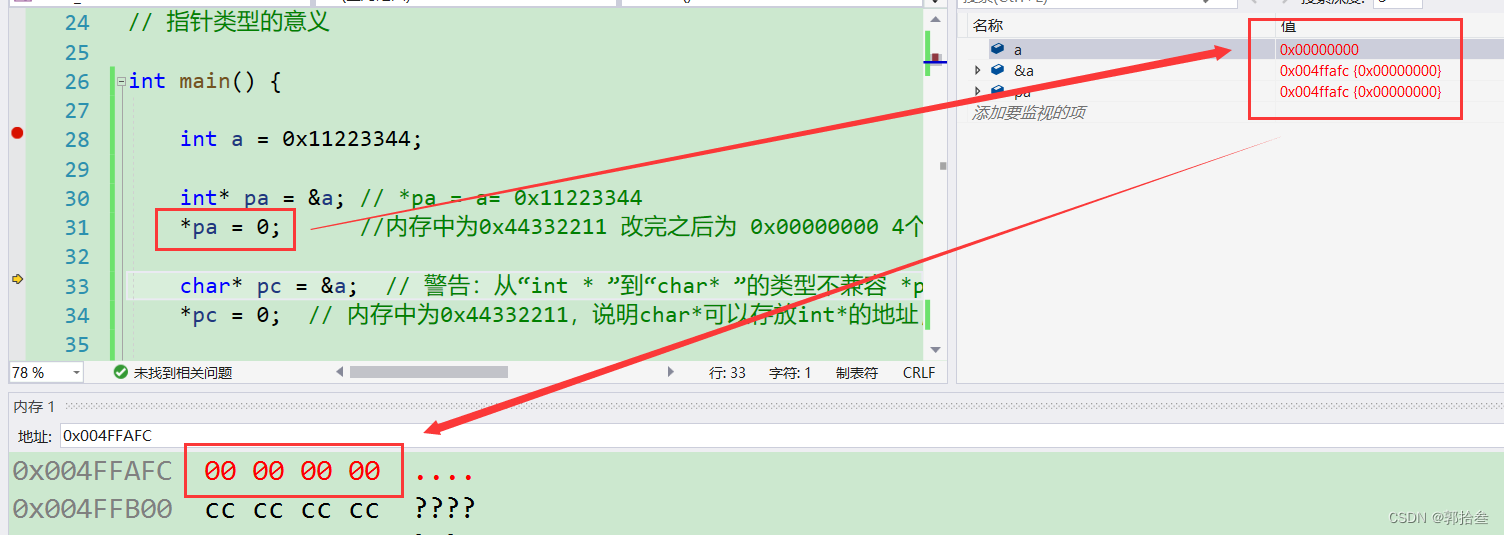
我们发现,在对于char* 类型的指针 pc,在通过*pc 解引用操作,来对int类型的变量a进行内容修改时,不再是全部修改为0;而是将44 修改为了 00。 这里是因为,char*类型的指针在解引用时,每次只访问一个字节的数据,而int*类型的指针,每次解引用访问4个字节的数据。
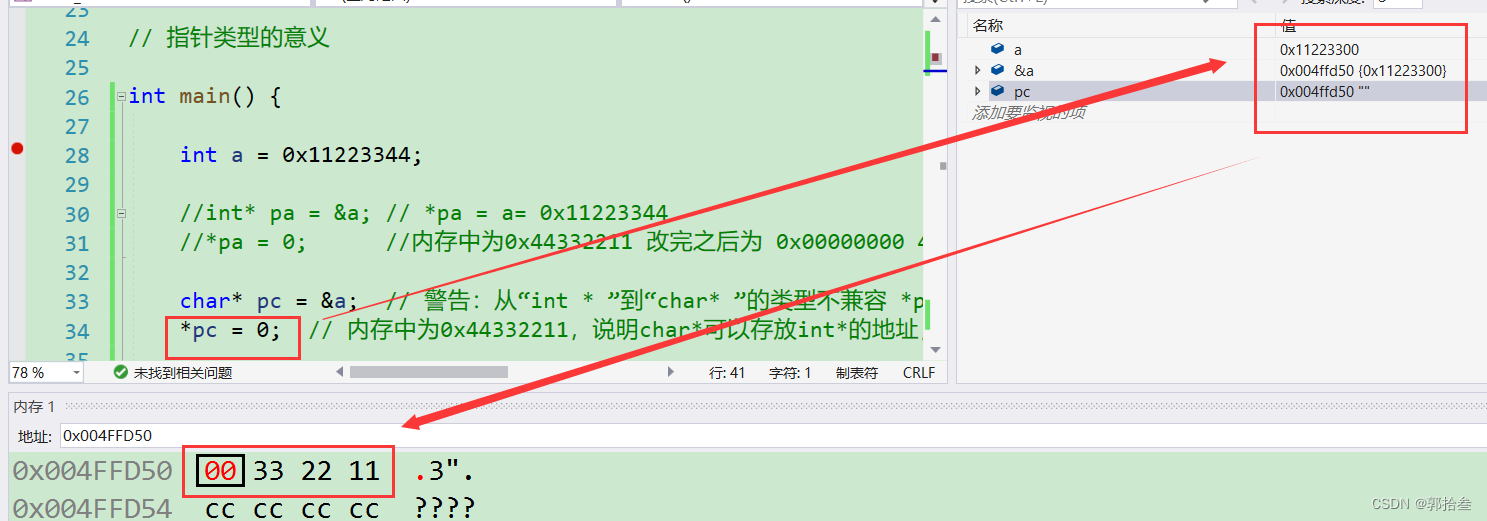
所以, 指针类型决定了,该指针被 解引用的时候访问几个字节。例如,int*的指针解引用,访问了4个字节,char*类型的指针,解引用访问了1个字节。推广到其他类型,double*类型的指针,被解引用时,访问8个字节。
在对指针进行操作时,不同类型的指针同样如此。
int main() {
int a = 0x11223344;
int* pa = &a;
char* pc = (char*)&a;
printf("%p\n", pa); // 0079F9BC
printf("%p\n", pa+1); // 0079F9C0 跳过4个字节
printf("%p\n", pc); // 0079F9BC
printf("%p\n", pc+1); // 0079F9BD 跳过一个字节
return 0;
}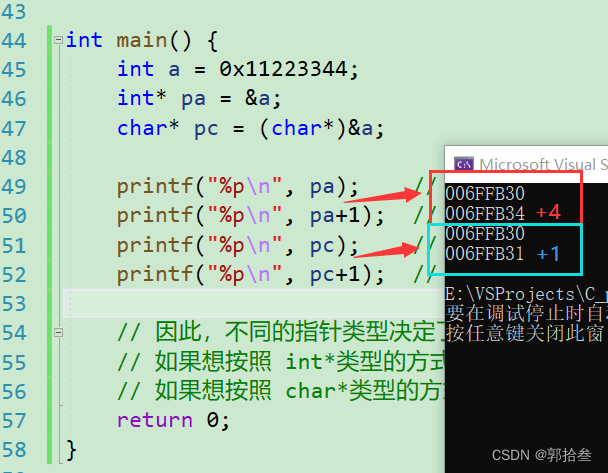
因此,不同的指针类型决定了 在对指针变量进行操作时,访问地址的方式。
如果想按照 int*类型的方式,他就会跳一个整型的大小 -- 4byte
如果想按照 char*类型的方式,他就会跳一个char的大小 -- 1byte
1.3 野指针
1.未初始化的指针
2.指针越界访问
3.指针指向内存空间释放的地址
1.3.1 未初始化的指针
根据函数栈帧的创建与销毁,我们知道,这里的指针变量p是未初始化的,而未初始化的内容,编译器一般会给一个随机值,这里一般是0x cccccccc,而你通过解引用对这个地址里的内容进行修改,这是很危险的!!!!
int main() {
int* p;
// 根据函数栈帧的创建与销毁,这里 p未初始化,给的是一个随即值,一般是 0xcccccccc
*p = 10; //这里给 0xcccccccc 赋值,就属于野指针了
return 0;
}1.3.2 指针越界访问
这里arr数组的下标范围是0-9,而for循环i能够访问到arr[10],属于越界访问,此时指针p就是野指针。
int main() {
int arr[10] = {0};
int* p = &arr;
int i = 0;
// 这里i=10 就是 越界访问,此时p是野指针
for (i = 0; i <= 10; i++) {
*p = i;
p++;
}
return 0;
}越界访问是非常危险的!例如下面这段代码,就会陷入死循环。(不同编译器可能效果不同)
int main() {
// 局部变量
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++) { // 越界的访问,可能会进入死循环,这里&i 与 &arr[12] 一样
arr[i] = 0;
printf("weihong %d\n",i);
}
return 0;
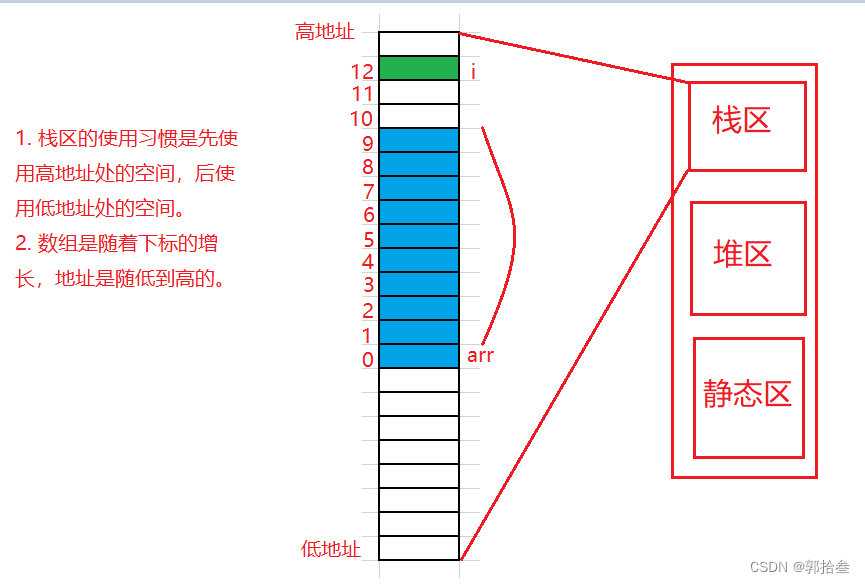
}由于局部变量在栈区里是从高到低存储的,而数组在内存中是 由低到高 存储的,因此 i 在高位,而 arr从低到高访问到越界元素之后,就很有可能会访问到 高位的 i,这里 在 arr[12] 就越界访问到了i,并将 i 的值修改为0。因此 导致了 死循环。
1.3.3 指针指向内存空间释放的地址
int* test() {
int a = 10; // 局部变量,在函数结束调用之后就被销毁了
return &a;
}
int main() {
// 这里 test()函数在调用完后,a就销毁了,但是 p指针 还拿着a的地址,属于野指针
int* p = test();
printf("Hello");
if(p != NULL){
printf("%d",*p); // 不是10了
}
return 0;
}这里我们使用指针接收一个 test 函数内部局部变量 a 的地址,而局部变量 a 的生命周期是在 test 函数内部,在调用完 test 函数之后,a 就被销毁了,而指针 p 还拥有 a 的地址,这里就属于野指针,此时,如果通过对指针 p 解引用 *p 对该块地址进行操作,是很危险的。
举个通俗的例子,a 是 p 的线上女友,p 中存着 a 的电话,而在 test 调用结束之后(线下见面),a 就消失不见了,而 p 还拿着 a 的电话,这里虽然 p 能打通 a 的电话,但这里就属于是野电话(骚扰电话)。
1.4 指针运算
1.4.1 指针 + - 整数
// 指针 + 整数
#define arr_value 5
int main() {
int arr[arr_value];
int* pa;
// 指针初始化、指针关系运算
for (pa = &arr[0]; pa < &arr[arr_value];) {
// *pa = 1; pa++;
*pa++ = 1; // 指针+ -
}
return 0;
}1.4.2 指针 - 指针
int main() {
int arr[10] = { 0 };
printf("%d ", &arr[9] - &arr[0]); // 9
return 0;
}指针 - 指针 绝对值 得到的是 指针之间的元素个数,不是所有的指针都能相减,指向同一个空间的指针相减才有意义。
1、求字符串长度
我们知道,字符串的结束标志是 '\0',因此,我们可以利用指针,当指针指向 '\0' 时,说明该字符串已经结束,此时我们使用 字符串开始的指针 - 结束的指针,中间为指针直接的元素个数,即为字符串长度。
// 指针-指针
int my_strlen(char* str) {
char* star = str;
while (*str != '\0') {
str++;
}
return (str-star);
}
int main() {
char str[10] = "weihong";
// 使用库函数
// int len = strlen(str);
// 自己写函数
int len = my_strlen(str); // 这里字符传入的 也是指针,是首个字符的地址
printf("%d", len);
return 0;
}1.4.2 指针与指针关系运算
下面这种写法在绝大部分编译器是可以执行的,当我们应该避免写出这样的代码,这里只是做示范用, 绝大多数编译器可以执行,但标准不保证可以执行。
标准规定:数组内的指针可以和数组最后一个元素后面的指针进行比较,但不能和数组第一个元素之前的指针进行比较。
int main() {
int arr[arr_value];
int* p;
// 倒序输入
for (p = &arr[arr_value-1]; p >= &arr[0];p--) {
*p = 1;
}
// 输出
for (int i = 0; i < arr_value; i++) {
printf("%d ", arr[i]);
}
return 0;
}1.5 指针与数组的关系
数组:一组相同类型的元素
指针:地址
数组名:首元素地址(两个特殊情况下不是,1.sizeof 2. &数组名)
int main() {
int arr[10] = { 0 };
int* p = arr; // 首元素地址
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz; i++) {
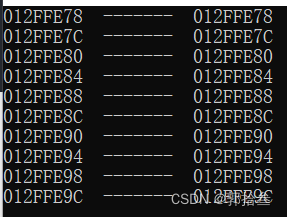
printf("%p ------- %p\n", &arr[i], p+i);
}
// arr[i] = *(arr+i) = *(p+i)
return 0;
}这里我们通过数组名得到元素地址和通过指针得到元素地址进行比较,地址是一样的。
1.6 二级指针
二级指针,存放一级指针地址的指针 ,详细内容后面再细讲。
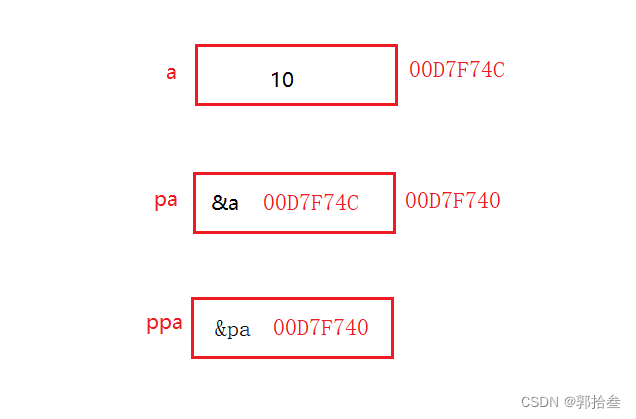
int main() {
// 整型变量
int a = 10;
// 一级指针 - 存放变量地址
int* pa = &a;
// 二级指针 - 存放一级指针地址
int** ppa = &pa;
return 0;
}
1.7 指针数组
数组:存放一组相同类型元素的集合
整型数组:存放一组整型元素的集合
指针数组,本质上还是数组,只不过该数组里存放的元素是指针。
这里 int* [3] 是类型,[3]说明数组有3个元素、int*说明元素类型是指针,代表指针数组,parr是变量名
// 存放指针的数组
int main() {
int a = 10;
int b = 20;
int c = 30;
// 指针
int* pa = &a;
int* pb = &b;
int* pc = &c;
// 整型指针数组
int* parr[3] = { pa,pb,pc};
return 0;
}二、指针进阶
2.1 字符指针
对于char类型的指针,那我们能否通过对char* 指针 p 进行解引用操作,来进行修改呢?
int main() {
char* p = "abcdef"; // 把字符串首字母a的地址,给了p
*p = 'w';
printf("%s", p); //引发了异常: 写入访问权限冲突。
return 0;
}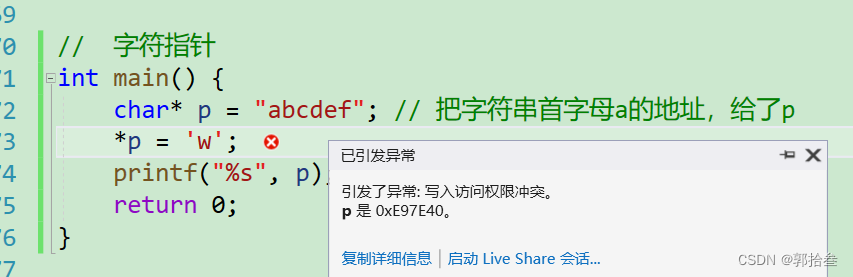
很显然,这是不可以的,我们来分析一下具体原因。
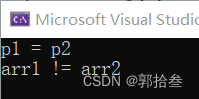
int main() {
// 既然不能修改,最好用const 修饰
const char* p1 = "abcdef";
const char* p2 = "abcdef";
// 这里属于局部变量,存储在栈区,俩个数组地址不同
char arr1[] = "abcdef";
char arr2[] = "abcdef";
if (p1 == p2) {
printf("p1 = p1\n"); // 输出等于
}
else {
printf("p1 != p1\n");
}
if (arr1 == arr2) {
printf("arr1 = arr2\n");
}
else {
printf("arr1 != arr2\n");// 输出不等于
}
return 0;
}
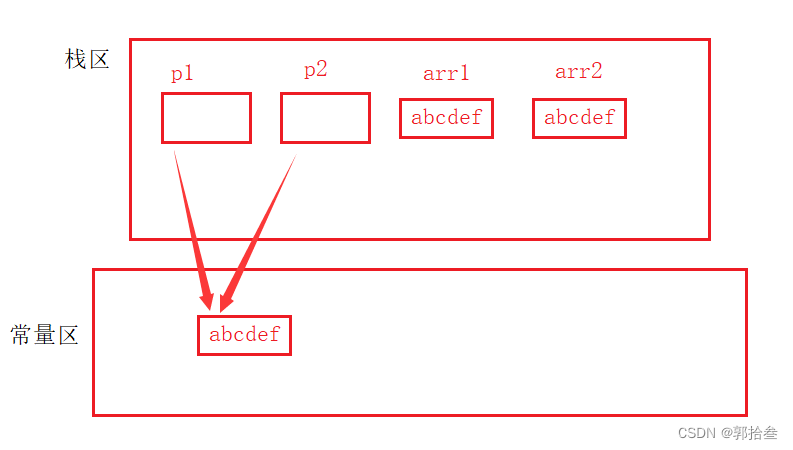
这里 "abcdef" 存储在常量区,属于常量常量字符串,常量区的内容存在只读性质,不可以修改,p1 和 p2 指向同一个位置
2.2 指针数组
指针数组,本质上还是数组,而数组里存放的都是指针变量。利用指针数组,我们可以实现类似二维数组。
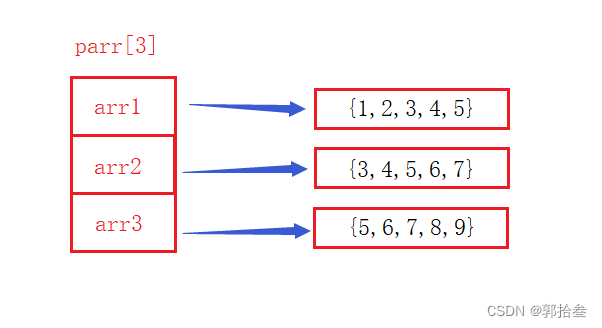
我们知道,数组名其实就是数组首元素的地址,下面我们将3个数组放入了一个数组指针当中。
这里 int* parr[3] = { arr1,arr2,arr3 };,parr先和[3]结合,说明parr 是数组。
int* [3] 是类型,[3]说明数组有3个元素、int*说明数组元素类型是指针,代表指针数组,parr是变量名
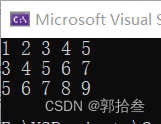
int main() {
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 3,4,5,6,7 };
int arr3[] = { 5,6,7,8,9 };
int* parr[3] = { arr1,arr2,arr3 };
int i = 0;
int j = 0;
for (i = 0; i < 3; i++) {
for (j = 0; j < 5;j++) {
printf("%d ", *(parr[i] + j)); // *(parr[i] + j) = parr[i][j]
}
printf("\n");
}
return 0;
} 
2.3 数组指针
2.3.1 &数组名 和 数组名
在讲数组指针之前,我们先讨论一下 &数组名 和 数组名之间的区别。
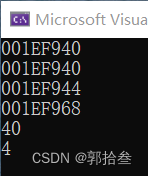
int main() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
// 两个地址相同
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%p\n", arr+1); // +4
printf("%p\n", &arr + 1);// +40
printf("%d\n", sizeof(arr)); // 40
printf("%d\n", sizeof(arr[0])); // 4
return 0;
}
数组名 一般认为是 数组首元素的地址,但有两个特殊情况
1. sizeof(数组名) 表示的是整个数组,计算的是整个数组的大小
2. &数组名,这里数组表示的是整个数组,取地址也是整个数组的地址,&arr+1 跳过的是整个数组
2.3.2 数组指针的定义
相比与指针数组,指针数组本质是数组,存的元素是指针。
int* parr[3] = { arr1,arr2,arr3 };
而对于指针p,int* p = arr; // 存的是数组首元素的地址
而数组指针,本质是指针,指针指向的地址是整个数组的地址(不是数组首元素地址)
我们来看指针数组的定义,这里 int* parr[3] = { arr1,arr2,arr3 };,parr先和[3]结合,说明parr 是数组。
int* [3] 是类型,[3]说明数组有3个元素、int*说明元素类型是指针,代表指针数组,parr是变量名。
我们来看数组指针的定义,int (*p2)[10] = &arr;
(*p2) * 先和p2 结合,说明p2 是指针,而指针数组中 parr 是先和[结合的]。
这里 int (* ) [10] 是类型,p2 是指针变量名,指针p2 指向数组arr地址,该数组有十个元素,每个元素是int类型。
int main() {
int arr[10] = { 0 };
int* p = arr; // 存的是数组首元素的地址
// 数组指针,用来存放 数组的指针;
// 指针p2 指向数组arr地址,该数组有十个元素,每个元素是int类型
int (*p2)[10] = &arr; // 整个元素的地址,想存入指针,就得用数组指针
// ch 是一个指针数组,存放5个 char类型的指针变量
char* ch[5] = { 0 };
// 指针pc 指向指针数组ch的地址,该指针数组有5个元素,每个元素是 char* 类型的指针
char* (*pc)[5] = &ch;
return 0;
}2.3.3 数组指针的使用-遍历二维数组
1、遍历二维数组的常用方法
这里我们通过两层for循环对二维数组进行了打印输出
// 正确用法,一般用于二维以上的数组
void print1(int arr[3][4], int r, int c) {
int i = 0;
int j = 0;
for (i = 0; i < r; i++) {
for (j = 0; j < c; j++) {
printf("%d ",arr[i][j]);
}
printf("\n");
}
}
int main() {
int arr[3][4] = {1,2,3,4,2,3,4,5,3,4,5,6};
print1(arr, 3, 4);
return 0;
}2、使用数组指针遍历二维数组
我们明白,传入的arr 是二维数组的首元素地址,二维数组的首元素是 第一行的地址,也就是一个有4个int类型的数组 int arr_1[4]; ,因此可以使用一个数组指针来就收arr。
int (*p) [4] = &arr,p 的类型是 int (*) [4],指针p 是指向一个数组的,数组有4个元素,int [4]
p+1 ---> 跳过一个5个int元素的数组,而 int* p2 = arr; p2+1 ---> 跳过一个int元素
void print2(int(*p)[4], int r, int c) {
int i = 0;
int j = 0;
for (i = 0; i < r; i++) { // 遍历每一行
for (j = 0; j < c; j++) {
printf("%d ", *(*(p + i) + j)); // *(*(p + i) + j) = *(p[i] + j) = p[i][j]
// printf("%d ", p[i][j]); // ok
}
printf("\n");
}
}
int main() {
int arr[3][4] = {1,2,3,4,2,3,4,5,3,4,5,6};
print2(arr, 3, 4);
return 0;
}数组指针p 是指向 arr的首个元素,即二维数组arr的第一行的数组的地址
*(p+i) 对 二维数组的 某一行地址 解引用,得到某一行的数组名,得到的是某一行的首元素地址
*(p+i)+ j , 每一行的首元素地址加j,得到的是 某一行内的 第j个元素地址
*(*(p + i) + j) , 对某一行内的 第j个元素地址解引用,得到i行j列的元素

小总结
int arr[5]; // 整型数组---存放5个int类型元素的数组
int* parr1[5]; // 指针数组---存放5个int*指针
int(*parr2)[5]; // 数组指针---parr2指针 指向一个有5个int元素的数组的地址
int(*parr3[10])[5]; // 数组指针数组---parr3是一个有10个元素的数组,元素的类型是数组指针-每个数组指针指向一个有5个int元素的数组的地址
int main() {
int arr[5]; // 整型数组---存放5个int类型元素的数组
int* parr1[5]; // 指针数组---存放5个int*指针
int(*parr2)[5]; // 数组指针---parr2指针 指向一个有5个int元素的数组的地址
int(*parr3[10])[5]; // 数组指针数组---parr3是一个有10个元素的数组,元素的类型是数组指针-每个数组指针指向一个有5个int元素的数组的地址
return 0;
}2.4 数组参数、指针参数
2.4.1 一维数组传参
对于一维整型数组,函数有两种接收方式:
1、以数组形式传参。 int arr1[], arr1 是形参名,int [] 说明是整数数组类型
2、arr也是数组首元素地址,所以使用指针接收也可以。arr1 是形参名,int*说明是整型指针类型
类比一位整型数组,对于一维指针数组,函数也有两种接收方式:
1、以数组形式传参: int* arr2[], arr2 是形参名,int* [] 说明是指针 数组类型。
2、使用指针传参:arr2 也是数组首元素地址,而指针数组arr2的首元素也是指针(一级指针)所以传入的是一级指针的地址,前面我们说过,指向一级指针的地址,所以可以用二级指针接收,因此 使用 int** arr2 二级指针接收。
// 一维数组传参
void test1(int arr1[]) { // 以数组形式传参
;
}
void test2(int* arr1) { // arr也是数组首元素地址,使用指针传参也可以
;
}
void test3(int* arr2[]) { // 使用数组名传参
;
}
// arr2 也是数组首元素地址,而数组首元素也是指针,所以可以用二级指针接收
void test4(int** arr2) {
;
}
int main() {
int arr1[10] = { 0 }; // 数组
int* arr2[20] = { 0 }; // 指针数组
test1(arr1);
test2(arr1);
test3(arr2);
test4(arr2);
return 0;
}2.4.2 二维数组传参
对于二维整型数组,函数有两种接收方式:
1、以数组形式传参: int arr[3][5] 或者 int arr[][5],行可以省略,但列不能省略!!
2、使用指针接收:以指针形式传参,传入的是首元素地址,而二维数组首元素是第一行数组,传入的是一个数组的地址,所以接收时,需要一个指向数组地址的数组指针来接收。
int (*parr)[5] :parr是 形参名, int (* )[5] 是参数类型,(* parr) parr先和*结合说明是一个指针,指向的是一个 int [5] 有五个整型元素的数组。
// 以数组形式传参
void test(int arr[3][5]) {
;
}
void test(int arr[][5]) { // 行可以省略,列不能省
;
}
// 以指针形式传参
void test(int (*parr)[5]) {
// 以指针形式传参,传入的是首元素地址,首元素是第一行数组
// 传入的是一个,第一行数组的地址,所以接收时,需要一个数组指针来接收
;
}
int main() {
int arr[3][5] = { 0 };
// 以指针形式传参,传入的是首元素地址,首元素是第一行数组
// 传入的是一个,数组的地址,所以接收时,需要一个数组指针来接收
test(arr);
return 0;
}2.4.3 一级指针传参
形参为整型的一级指针,可以传入的值有,整型的地址、整型的一级指针,整型数组名
void test(int* p) {
;
}
int main() {
int a = 20;
int* p = &a;
int arr[10] = { 0 };
test(&a);
test(p);
test(arr);
return 0;
}2.4.4 二级指针传参
二级指针做形参,可传入的有一级指针地址、二级指针、指针数组的数组名
void test(int** pp) {
;
}
int main() {
int a = 10;
int* p = &a;
int** pp = &p;
int* arr[10]; // 指针数组
test(pp);
test(&p);
test(arr); // 指针数组的数组名,是指针数组首元素的地址,指针数组首元素也是地址,所以是二级指针
return 0;
}三、函数指针
3.1 函数指针
理解函数指针,就记住一句话,指向函数的指针!
3.1.1 函数指针定义
我们来看数组指针的定义,int (*p2)[10] = &arr;
(*p2) * 先和p2 结合,说明p2 是指针,而指针数组中 parr 是先和[结合的]。
这里 int (* ) [10] 是类型,p2 是指针变量名,指针p2 指向数组arr地址,该数组有十个元素,每个元素是int类型。
类比数组指针,我们看函数指针的定义, int (*padd)(int, int) = &Add;
(*padd) * 先和padd 结合,说明padd 是指针,
这里 int (* ) (int,int) 是类型,padd 是指针变量名,指针padd 指向函数 Add()的地址
int (* ) (int,int) ,第一个int 说明函数返回值是int类型,(int,int) 说明 该函数有两个参数,两个参数类型都是int。
// 函数指针--- 指向函数的指针
int Add(int x, int y) {
return x + y;
}
int main()
{
// 数组指针--就是取出数组的地址 &arr
int arr[5];
int(*parr)[5] = &arr;
// 函数指针--取出函数的地址 &Add
printf("%p\n", &Add);
printf("%p\n", Add); // 输出相同
// 说明,对于函数来说 &函数名 和 函数名 都是函数的地址
// 那么,类比数组指针,函数指针表示方法为
int (*padd)(int, int) = &Add; // int (*padd) (int, int)
//返回值类型 指针名 函数参数类型
// 又因为 &函数名 和 函数名 都是 函数地址
int (*padd1)(int, int) = Add;
// 对与 int* p = &a; *p = a
// 对 padd 解引用,得到的就是Add函数
int ret1 = (*padd)(2, 3); // 可以通过对函数指针解引用,得到函数名,来调用函数
// 又因为 &函数名 和 函数名 都是 函数地址,
int ret2 = Add(2, 3);
// 那么函数指针 padd 也是函数地址
int ret3 = padd(2, 3); //都可以调用到函数
return 0;
}3.1.2 函数指针用途-回调函数
1、实现一个计算器-能够加减乘除
void menu() {
printf("***************************\n");
printf("*******1.Add 2.Sub*******\n");
printf("*******3.Mul 4.Div*******\n");
printf("******* 0.exit *******\n");
printf("***************************\n");
}
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int Mul(int x, int y) {
return x * y;
}
int Div(int x, int y) {
return x / y;
}
int main() {
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do {
menu();
printf("请选择:>");
scanf("%d", &input);
printf("请输入两个操作数:>");
scanf("%d %d", &x, &y);
switch(input){
case 1:
ret = Add(x, y);
printf("%d\n", ret);
break;
case 2:
ret = Sub(x, y);
printf("%d\n", ret);
break;
case 3:
ret = Mul(x, y);
printf("%d\n", ret);
break;
case 4:
ret = Div(x, y);
printf("%d\n", ret);
break;
case 0:
printf("退出计算机!");
break;
default:
printf("输入错误!\n");
break;
}
} while (input);
return 0;
}通过运行可以发现,上面的代码是有bug的,当你输入错误的时候,或者要退出计算器时,程序还是会让你先输入两个操作数。
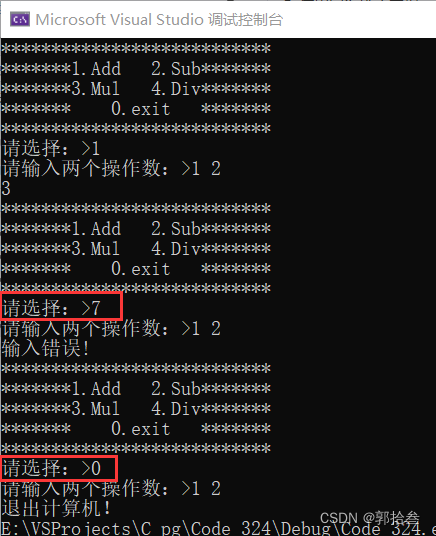
我们只能讲输出操作数的代码放入到每个case中,但是这样会导致每个case中的代码太过冗余,这样在后期维护代码,或者我们想对计算机添加新的功能时,每添加一个功能就要重复一段。这对一个程序员来说是很low的。下面的代码是不可取的!!
int main() {
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do {
menu();
printf("请选择:>");
scanf("%d", &input);
switch(input){
case 1:
printf("请输入两个操作数:>");
scanf("%d %d", &x, &y);
ret = Add(x, y);
printf("%d\n", ret);
break;
case 2:
printf("请输入两个操作数:>");
scanf("%d %d", &x, &y);
ret = Sub(x, y);
printf("%d\n", ret);
break;
case 3:
printf("请输入两个操作数:>");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("%d\n", ret);
break;
case 4:
printf("请输入两个操作数:>");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("%d\n", ret);
break;
case 0:
printf("退出计算机!");
break;
default:
printf("输入错误!\n");
break;
}
} while (input);
return 0;
}通过冗余的代码,我们不难发现,不同case下的代码只是在调用函数时使用了不同的函数,其他的内容没有区别,那我们是否可以将其封装成一个函数呢?这个函数需要传入什么样的参数呢?而传入参数之后,我们又应该使用什么类型进行接收呢?
通过函数指针,我们知道,函数名 和 &函数名,拿到的都是函数的地址,那我们就可以将函数名传入我们封装好的函数。而传入的是一个函数的地址,因此我们可以使用一个函数指针来接收这个地址。代码实现如下。
void calc(int (*pf)(int, int)) {
int x = 0;
int y = 0;
int ret = 0;
printf("请输入两个操作数:>");
scanf("%d %d", &x, &y);
ret = (*pf)(x, y);
printf("%d\n", ret);
}这样,我们只要在case 中 调用这个函数,并在调用的时候传入我们要用的函数就可以了。
int main() {
int input = 0;
do {
menu();
printf("请选择:>");
scanf("%d", &input);
switch(input){
case 1:
calc(Add); // 减少代码量
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 0:
printf("退出计算机!");
break;
default:
printf("输入错误!\n");
break;
}
} while (input);
return 0;
}这个过程成为回调函数,回调函数就是一个通过函数指针调用的函数,如果你将一个函数的指针,作为参数传递给另一个函数,当这个函数通过指针来调用指针所指向的函数时,就称为回调函数。
3.2 函数指针数组
3.2.1 函数指针数组定义
函数指针数组,本质上是数组,数组元素为 函数指针(函数地址)也就是函数名。
// Add,Sub,Mul,Div 都是函数
int (*pfArr[4])(int, int) = { Add,Sub,Mul,Div};我们拿指针数组来类比:
int* parr[3] = { arr1,arr2,arr3 }; int* [3] 是类型,[3]说明数组有3个元素、int*说明数组元素类型是指针,代表指针数组,parr是变量名
int (*pfArr[4])(int, int) ;
这里pfArr是变量名,pfArr先和[4]结合,说明是数组,
int (* [4])(int, int) ;是类型,
pfArr[4] 说明是数组,数组有4个元素
int (* )(int, int) 说明 数组中元素 的类型是 函数指针,该指针指向一个返回值是int,参数类型是(int,int)的函数。
3.2.2 函数指针数组用途
这里我们还是以实现一个计算机-加减乘除为例子。以下是实现代码。
void menu() {
printf("***************************\n");
printf("*******1.Add 2.Sub*******\n");
printf("*******3.Mul 4.Div*******\n");
printf("******* 0.exit *******\n");
printf("***************************\n");
}
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int Mul(int x, int y) {
return x * y;
}
int Div(int x, int y) {
return x / y;
}
#define FUNC_COUNT 4 // 计算机功能数量
int main() {
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
// 函数指针数组pfArr[],函数内部有5个元素,元素类型是函数指针,0,Add,Sub,Mul,Div...
int (*pfArr[FUNC_COUNT+1])(int, int) = { 0,Add,Sub,Mul,Div }; // 后续可添加其他函数
do
{ // 输出菜单
menu();
printf("请选择:>"); // 选择操作
scanf("%d", &input);
if (0 == input)
{
printf("退出计算器\n");
}
else if (input > 0 && input <= FUNC_COUNT)
{
printf("请输入两个操作数:>");
scanf("%d %d",&x,&y);
ret = pfArr[input](x, y);
printf("%d\n", ret);
}
else
{
printf("输入错误\n");
}
} while (input);
return 0;
}这里我们将计算机不同的功能封装为函数,再将这些函数放到一个函数指针数组中,这样在使用不同的功能时,就可以通过数组的下标来调用某一函数,而在后期添加其他功能时,只需要将新添加功能的函数加入到该函数指针数组中即可!
3.3 指向函数指针数组的指针
指向函数指针数组的指针,本质上是指针,指向的是一个函数指针数组。
int main() {
// 函数指针数组
int (*pfArr[])(int, int) = { 0,Add,Sub,Mul,Div };
// 指向函数指针数组的指针
int (*(*ppfArr)[5])(int, int) = &pfArr;
// 分为两部分 (*ppfArr) 和 int (* [5])(int, int)
// (*ppfArr) 说明他是一个指针
// int (* [5])(int, int) 说明 ppfArr 是一个 函数指针数组类型的指针。
return 0;
}这里不做太多分析,无限套娃 。
3.4 回调函数
上面我们在实现一个简单的计算机时,已经介绍了回调函数的概念。 回调函数就是一个通过函数指针调用的函数,如果你将一个函数的指针,作为参数传递给另一个函数,当这个函数通过指针来调用指针所指向的函数时,就称为回调函数。
3.4.1 冒泡排序的简单实现
将一个整型序列变为升序(或降序)然后输出。
// 冒泡排序简单实现
void bubbleSort(int arr[], int sz) {
int i = 0;
int j = 0;
int temp = 0;
for (i = 0; i < sz - 1; i++) { // 趟数
// 一趟冒泡排序
int flag = 1; // 假设已经是升序的序列
for (j = 0; j < sz - i - 1; j++) {
if (arr[j] >= arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = 0; // 交换了,说明不是有序的
}
}
if (1 == flag) {
break;
}
}
}
int main() {
// 输入
int arr[] = { 1,4,5,8,6,7,10,11,14,9,3 };
int sz = sizeof(arr) / sizeof(arr[0]);
// 排序
bubbleSort(arr, sz);
// 输出
int i = 0;
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}冒泡排序的核心就是对两个相邻的变量进行位置交换,上述代码使用了两层循环,内层循环用来交换两个变量的位置,
内层完成一轮循环,就会将最大的值放到最后的位置,然后外层让内存进入第二次循环,第二轮将第二大的值,放到倒数第二个位置,......, 以此类推,完成排序。
这里主要讲回调函数,不懂冒泡排序可以参考下面这篇文章:
3.4.2 利用qsort 实现int排序
qsort 快速排序的库函数 -- 可以排序任意类型的序列,通过冒泡排序可以实现对int类型数据的数组进行排序,而qsort可以对任意类型数据的序列 进行排序,具体是如何实现的呢?
通过MSDN 搜索 qsort,可以看到该函数的使用说明
void qsort( void *base, // 你要排序的数据的起始位置,// 因为不知道传入的是什么类型,void* base 传入一个泛型
size_t num, // 待排序的元素个数
size_t width, // 待排序的每个元素的大小(单位是字节)
int (__cdecl *compare )(const void *elem1, const void *elem2 ) );
__cdecl是函数调用规定,无意义
int (* compare )(const void *elem1, const void *elem2 ) );
这是一个函数指针,compare指向一个 用于比较两个参数大小的函数地址--这个函数需要你自己写
该函数的参数是 const void *elem1, const void *elem2,// 因为不知道传入的是什么类型,void* 传入一个泛型
返回值类型为 int
void* 代表的是无具体类型的指针,可以接收任意类型的指针,但不能对void*进行解引用操作,也不能对指针进行 +- 操作
int main() {
// 输入
int arr[] = { 1,4,5,8,6,7,10,11,14,9,3 };
int sz = sizeof(arr) / sizeof(arr[0]);
// 利用qsort实现排序
qsort(arr, sz, sizeof(arr[0]), compare);
// 输出
int i = 0;
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}qsort(arr, sz, sizeof(arr[0]), compare);
arr 是数组首元素地址,也就是需要排序的起始位置
sz是数组元素个数,也就是待排序的元素个数
sizeof(arr[0]),是数组每个元素大小,即待排序元素的大小(单位是字节)
compare是函数名,传入一个函数地址,用来比较两个int类型元素的大小,这个函数需要你自己写。
通过查看MSDN,qsort函数对你自己写的函数 的返回值进行了明确规定。
当第一个元素小于第二个元素时,需要返回一个小于0 的数
当第一个元素等于第二个元素时,需要返回 0
当第一个元素大于第二个元素时,需要返回一个大于0 的数
下面我们实现比较两个元素大小的功能
int compare(const void* e1, const void* e2) {
// 根据MSDN 对 compare返回值的要求
if (*(int*)e1 > *(int*)e2) {
return 1; // e1 > e2 ,返回一个大于0 的数
}
else if (*(int*)e1 < *(int*)e2) {
return -1;// e1 < e2 ,返回一个小于0 的数
}
else {
return 0; // e1 = e2 ,返回0
}
}因为 e1 e2 是void* 类型的指针,不能进行解引用操作直接解引用 *e1 // err,但是,我们知道现在是比较 两个int 元素的大小,因此我们可以直接将其强制类型转换为 int*, 然后进行解引用操作。
仔细想想,qsort要求你返回的是大于0 或者小于0 的数,并不要求返回的数是多少,而 e1 大于 e2 的话,e1 - e2 一定是大于0的,而 e1 小于 e2 的话,e1 - e2 一定是小于0的,等于时 e1-e2 =0;因此我们可以简化上面的代码,
int compare(const void* e1, const void* e2) {
// 直接返回两者的差值即可 -- 升序
return (*(int*)e1 - *(int*)e2);
// 降序 返回 e2 - e1 的差值
// return (*(int*)e2 - *(int*)e1);
}这样就实现了使用库函数qsort对int类型的序列进行排序,完整的代码如下
// 比较两个int元素
int compare(const void* e1, const void* e2) {
// 直接返回两者的差值即可 -- 升序
return (*(int*)e1 - *(int*)e2);
// 降序 返回 e2 - e1 的差值
// return (*(int*)e2 - *(int*)e1);
}
int main() {
// 输入
int arr[] = { 1,4,5,8,6,7,10,11,14,9,3 };
int sz = sizeof(arr) / sizeof(arr[0]);
// 利用qsort实现排序
qsort(arr, sz, sizeof(arr[0]), compare);
// 输出
int i = 0;
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}3.4.3 利用qsort 对结构体排序
上面我们说到,库函数qsort可以对任意数据类型的序列进行排序,接下来我们利用qsort来对结构体类型的序列进行排序。
我们先定义一个简单的结构体:包含姓名、年龄
struct Stu {
char name[20];
int age;
};然后我们在主函数中创建一个结构体序列,再利用sqort 对 结构体 按照姓名进行排序
int main() {
// 测试使用sqort 排序结构体类型的数据
struct Stu s[] = { {"zhangsan",15} ,{"lisi",30} ,{"wangwu",25} };
int sz = sizeof(s) / sizeof(s[0]);
// 按照姓名排序
qsort(s, sz, sizeof(s[0]), qsort_stu_by_name);
// 按照年龄排序
// qsort(s, sz, sizeof(s[0]), qsort_stu_by_age);
return 0;
}这里比较两个姓名大小的函数 qsort_stu_by_name 需要我们自己实现,然后给qsort调用
int qsort_stu_by_name(const void* e1,const void* e2) {
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);代码分析
strcmp( ); 比较字符串大小的库函数,需要传入两个字符串
((struct Stu*)e1)->name, ((struct Stu*)e2)->name 传入的两个字符串
((struct Stu*)e1)->name , 传入结构体元素1的name
这里我们知道传入的是一个struct Stu* 类型的一个变量,因此我们之间将e1强制类型转换为该类型,然后通过 -> 获取该成员变量。
再写一个比较两个年龄大小的函数 qsort_stu_by_age 需要我们自己实现,然后给qsort调用
int qsort_stu_by_age(const void* e1, const void* e2) {
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
这样就可以通过给qsort传入不同的函数来实现按照不同的类型进行排序。
而在qsort函数中利用函数名qsort_stu_by_name、qsort_stu_by_age,通过函数地址来调用这两个函数的操作,就是回调函数!!
3.4.4 利用冒泡排序实现qsort
前面我们在实现冒泡排序时讲到,冒泡排序的核心就行交换两个相邻元素的位置,这里和qsort的思路不谋而合,而上面实现的冒泡排序只能实现对 int类型的序列进行排序,下面我们来实现一下 利用 冒泡排序 对任意类型的序列进行排序。
// 实现qsort // 因为不知道传入的是什么类型,void* base 传入一个泛型
void bubbleSort(void* base, int sz, int width, int(*cmp)(const void* e1,const void* e2)) {
int i = 0;
int j = 0;
int temp = 0;
for (i = 0; i < sz - 1; i++) { // 趟数
// 一趟冒泡排序
int flag = 1; // 假设已经是升序的序列
for (j = 0; j < sz - i - 1; j++) {
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0) {
// 交换传入函数的内容
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
flag = 0; // 交换了,说明不是有序的
}
}
if (1 == flag) {
break;
}
}
}void bubbleSort(void* base, int sz, int width, int(*cmp)(const void* e1,const void* e2))
void *base, // 你要排序的数据的起始位置,// 因为我们也不知道传入的是什么类型的序列,void* base 传入一个泛型
int sz, // 待排序的元素个数
int width, // 待排序的每个元素的大小(单位是字节)
int ( *cmp)(const void *elem1, const void *elem2 ) );
int (* compare )(const void *e1, const void *e2 ) );
这是一个函数指针,compare指向一个 用于比较两个参数大小的函数地址--这个函数需要你自己写
该函数的参数是 const void *elem1, const void *elem2,// 因为不知道传入的指针是什么类型,void* 传入一个泛型
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0) 用来判断传入 的两个参数的大小
cmp((char*)base + j * width, (char*)base + (j + 1) * width) 这个是客户自己需要写的比较函数,需要返回一个int类型的数据。
(char*)base + j * width
这里,我们将base强制转换为char*的数据,使得它每次只能跳转一个字节
然后我们根据传入的每个元素宽度 width ,对每次跳转的大小进行了设置
这样就可以选取到正确的位置
这里我们利用 自己写的cmp进行两个元素的比较,传入的是待比较的两个元素的地址
如果e1 大于 e2 ,说明需要对e1 和 e2 进行位置交换
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
这里我们自己写一个Swap函数 对传入的两个元素进行交换,并传入元素的宽度来限制交换的范围
void Swap(char* buf1,char* buf2,int width) {
int i = 0;
char temp = 0;
for (i = 0; i < width; i++) {
temp = buf1[i];
buf1[i] = buf2[i];
buf2[i] = temp;
}
}Swap用来交换两个元素的位置,这里我们传入了一个元素的宽度,以每个元素的宽度为限制,可以很好的确定要交换的元素在那个位置停止,避免越界访问。
这样我们就完成了 利用 冒泡排序 对任意类型的序列进行排序的功能实现,下面在主函数中创建结构体,然后调用自己的bubbleSort 来实现排序即可,当然,还需要自己编写两个元素比较的函数(这个本来是需要调用bubbleSort函数的人来写的),这里只能是自己写啦!
这里主函数部分和比较元素大小部分与3.4.3中的内容一样,只不过将排序函数换为了自己的bubbleSort
struct Stu {
char name[20];
int age;
};
// strcmp 比较两个字符串大小 返回值是 <0, 0 ,>0
int qsort_stu_by_name(const void* e1,const void* e2) {
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
int qsort_stu_by_age(const void* e1, const void* e2) {
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
int main() {
// 测试使用sqort 排序结构体类型的数据
struct Stu s[] = { {"zhangsan",15} ,{"lisi",30} ,{"wangwu",25} };
int sz = sizeof(s) / sizeof(s[0]);
// 按照姓名排序
bubbleSort(s, sz, sizeof(s[0]), qsort_stu_by_name);
// 按照年龄排序
// bubbleSort(s, sz, sizeof(s[0]), qsort_stu_by_age);
return 0;
}到这里,回调函数所有的内容就完成了。指针讲解也完成,希望你看完之后有所收获。
课后小题
解释下面的两段代码,欢迎大家在评论区进行讨论。
int main() {
// 1
( * (void(*)()) 0 )();
// 2
void (*signal(int, void(*)(int)))(int);
return 0;
}感谢与总结
感谢
首先,特别感谢比特鹏哥,他在B站上的C语言的课程真的是循序渐进,深入浅出,浅显易懂,我也是听了鹏哥的课程才做了如此总结,没有鹏哥的金玉在前,我也写不出来这些,这里跪谢鹏哥。推荐新手小白打算学C语言的一定去听鹏哥的课程。我觉得这是一个好的程序员的开始。C语言程序设计从入门到进阶【比特鹏哥c语言2024完整版视频教程】(c语言基础入门c语言软件安装C语言指针c语言考研C语言专升本C语言期末计算机二级C语言c语言_哔哩哔哩_bilibili
总结
在看完指针部分,觉得自己在看这部分内容的时候总是模模糊糊的,不太通透,需要自己做一个总结,洋洋洒洒写了2w多字,写完也是对知识的再次巩固,希望大家看完之后也有所收获,如果文章内容有任何的错误,请私聊我,我会进行改正。
课后小题属于是卖弄了,来自一本名为《C陷阱与缺陷》的书籍,我也是多次听鹏哥讲解才弄明白其中含义,这本书非常好,值得大家看看,我把链接挂在下面。
链接:https://pan.baidu.com/s/1pmxQUMaUXR28OrBPj7rDUg?pwd=1223
提取码:1223
希望这篇文章能给你带来一些帮助!!感谢你的阅读!
















 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









