







给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
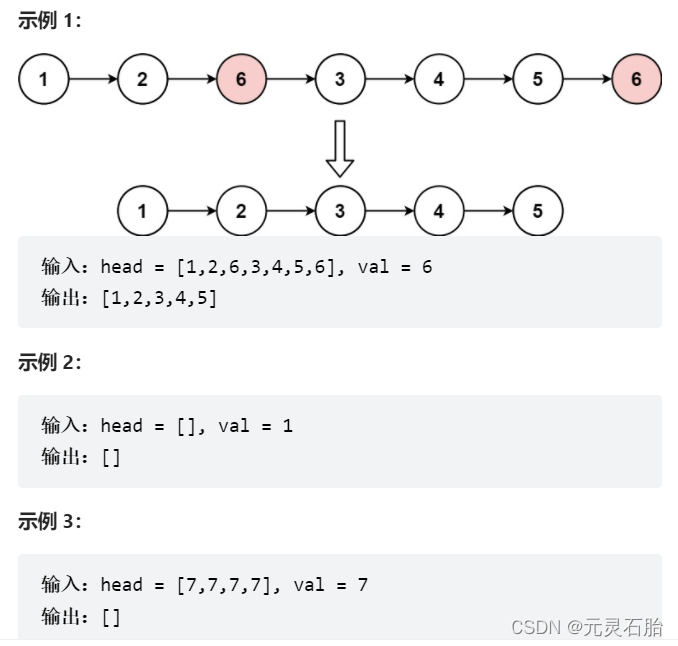
这道题要求我们删除一个链表中的val与特定值相等的节点,考察了链表的遍历和节点的删除。思路很简单,遍历链表的每个结点,直到遇到某个结点的val为指定值,然后将其删除。由于这里的链表是单向链表,要删除某个结点需要先找到该节点的前一个结点,所以我们在遍历每个结点的时候应该用前一个结点的索引去查看后一个结点的val。但是在实际代码中,我们要考虑这个链表只有一个结点,以及链表为空的情况,我们的解决方案是在头结点前插入一个傀儡结点,从傀儡结点开始遍历。
ListNode newHead=new ListNode();
newHead.next=head;
ListNode cur=newHead;
while(cur!=null&&cur.next!=null){
//此处比较每个结点的val是否为指定数值
//并作出处理。
cur=cur.next;
}
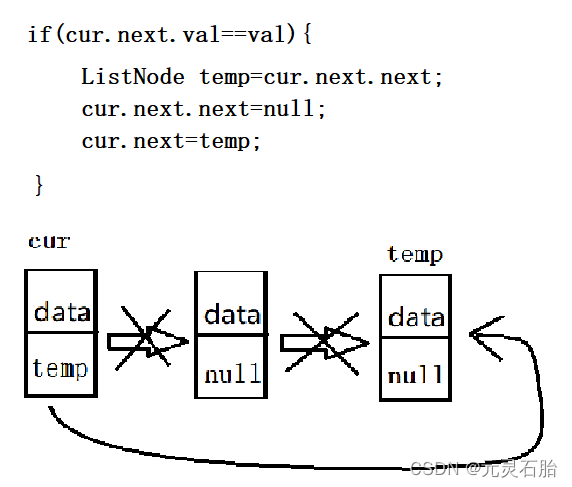
return newHead.next;循环内的代码看似较为简单,我们只需要比较每个cur结点的next.val是否为特定值,如果是则删除cur.next结点,然后继续遍历。对于删除某节点的操作且看下方图解:
当我们用这个代码测试时,示例一和示例二均能得出预期输出,但是对于示例三,我们得到的结果为[7,7]。为什么会出现这样的结果,莫非是我们没有把每个结点都比较一次吗,事实上确真

是这样的。我们的代码每次都比较的是cur.next的val是否为给定值,如果是的话,我们直接删除掉了cur.next结点,然后让cur直接指向了所删除结点的后一个结点,然而在下一轮循环中,我们并没有比较该结点本身的val是否和特定值相等。于是,我们对上述代码进行更改,每次往后找结点的时候加一步判断,当连续出现几个数据相同的结点,且都需要删除时,我们一次性删除,连接到后面无需删除的节点,或者是直接作为尾结点。
while(cur!=null&&cur.next!=null){
if(cur.next.val==val){
ListNode temp=cur.next.next;
while(temp!=null&&temp.val==val){
ListNode t=temp;
temp=temp.next;
t.next=null;
}
cur.next.next=null;
cur.next=temp;
}
cur=cur.next;
}这是我们改动后的循环体,内层循环会为我们找到下一个不需要删除的节点,并将需要删除的节点直接删除。走到这里,我自认为这段代码以及成熟了,能够通过力扣的大量用例测试。正当我总结代码的时候,我突然发现:原来的连续删除出现问题不就是由于一次性跳过了两个结点呗,只要在删除结点之后,cur不继续往后走,即可一个结点一个结点的判断。我继续调整代码,得到了如下代码:
class Solution {
public ListNode removeElements(ListNode head, int val) {
ListNode newHead=new ListNode();
newHead.next=head;
ListNode cur=newHead;
while(cur!=null&&cur.next!=null){
if(cur.next.val==val){
ListNode temp=cur.next.next;
cur.next.next=null;
cur.next=temp;
}else{
cur=cur.next;
}
}
return newHead.next;
}
}相比于之前,这段代码简单明了,无需内层循环判断要往后删除几个结点。对于这道题,看似不难,但是在单向链表问题中要考虑的情况比较多,有时候写出一段代码可以通过某个用例的测试,但遇到特殊情况直接凉凉。我想说的是写代码本就是一个步步精进的过程,我们先解决大部分情况,然后再一步步完善,没有完美的代码,只有不懈追求完美的代码人。














 4225
4225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









