






本章例子默认最前面导入了下面句子
>>> from __future__ import division
>>> import nltk, re, pprint
从网络和硬盘访问文本
电子书
http://www.gutenberg.org/catalog/免费在线书籍中获得 ASCII 码文本文件的 URL
编号 2554 的文本是《罪与罚》的英文翻译,我们可以如下方式访问它
>>> from urllib import urlopen
>>> url = "http://www.gutenberg.org/files/2554/2554.txt"
>>> raw = urlopen(url).read()
>>> type(raw)
<type 'str'>
>>> len(raw)
1176831
>>> raw[:75]
'The Project Gutenberg EBook of Crime and Punishment, by Fyodor Dostoevsky\r\n'
注:输入第一句后或许会报错:ImportError: cannot import name ‘urlopen’ from ‘urllib’,这是因为python版本问题导致,将第一句改为from urllib.request import urlopen即可
如果你使用的 Internet 代理 Python不能正确检测出来,你可能需要用下面的方法手动指定代理:
>>> proxies = {'http': 'http://www.someproxy.com:3128'}
>>> raw = urlopen(url, proxies=proxies).read()
分词:将字符串分解成词和标点符号,删掉回车和换行
>>> tokens = nltk.word_tokenize(raw)
>>> type(tokens)
<type 'list'>
>>> len(tokens)
255809
>>> tokens[:10]
['The', 'Project', 'Gutenberg', 'EBook', 'of', 'Crime', 'and', 'Punishment', ',', 'by']
从这个链表创建一个 NLTK 文本
>>> text = nltk.Text(tokens)
>>> type(text)
<type 'nltk.text.Text'>
>>> text[1020:1060]
['CHAPTER', 'I', 'On', 'an', 'exceptionally', 'hot', 'evening', 'early', 'in',
'July', 'a', 'young', 'man', 'came', 'out', 'of', 'the', 'garret', 'in',
'which', 'he', 'lodged', 'in', 'S', '.', 'Place', 'and', 'walked', 'slowly',
',', 'as', 'though', 'in', 'hesitation', ',', 'towards', 'K', '.', 'bridge', '.']
>>> text.collocations()
Katerina Ivanovna; Pulcheria Alexandrovna; Avdotya Romanovna; Pyotr
Petrovitch; Project Gutenberg; Marfa Petrovna; Rodion Romanovitch;
Sofya Semyonovna; Nikodim Fomitch; did not; Hay Market; Andrey
Semyonovitch; old woman; Literary Archive; Dmitri Prokofitch; great
deal; United States; Praskovya Pavlovna; Porfiry Petrovitch; ear rings
手工检查文件以发现标记内容开始和结尾的独特的字符串
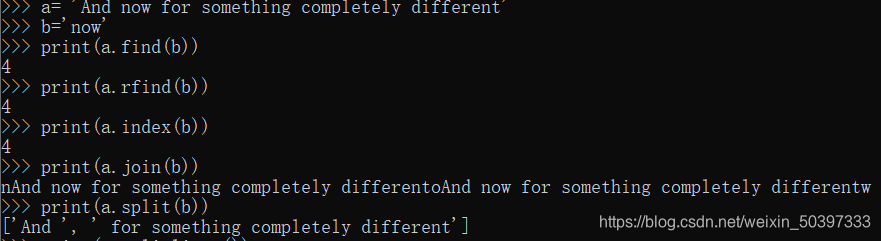
方法 find()和 rfind()(反向的 find)帮助我们得到字符串切片需要用到的正确的索引值
>>> raw.find("PART I")
5303
>>> raw.rfind("End of Project Gutenberg's Crime")
1157681
>>> raw = raw[5303:1157681]
>>> raw.find("PART I")
0
处理的HTML
>>> url = "http://news.bbc.co.uk/2/hi/health/2284783.stm"
>>> html = urlopen(url).read()
>>> html[:60]
'<!doctype html public "-//W3C//DTD HTML 4.0 Transitional//EN'
输入 print html 可以看到 HTML 的全部内容,包括 meta 元标签、图像标签、map 标签、JavaScript、表单和表格
辅助函数 nltk.clean_html()将 HTML 字符串作为参数,返回原始文本。然后我们可以对原始文本进行分词,获得我们熟悉的文本结构:
>>> raw = nltk.clean_html(html)
>>> tokens = nltk.word_tokenize(raw)
>>> tokens
['BBC', 'NEWS', '|', 'Health', '|', 'Blondes', "'", 'to', 'die', 'out', ...]
其中仍然含有不需要的内容。我们可以找到内容索引的开始和结尾,并选择感兴趣的标识符,按照前面讲的那样初始化一个文本
>>> tokens = tokens[96:399]
>>> text = nltk.Text(tokens)
>>> text.concordance('gene')
they say too few people now carry the gene for blondes to last beyond the next tw
t blonde hair is caused by a recessive gene . In order for a child to have blonde
to have blonde hair , it must have the gene on both sides of the family in the gra
there is a disadvantage of having that gene or by chance . They don ' t disappear
ondes would disappear is if having the gene was a disadvantage and I do not think
读取本地文件
使用 Python 内置的 open()函数,然后是 read()方法,读取文件document.txt
>>> f = open('document.txt')
>>> raw = f.read()
使用 IDLE,在“文件”菜单中选择“新建窗口”命令,在新窗口中输入所需的文本,然后在 IDLE 提供的弹出式对话框中的文件夹内保存文件为 document.txt。然后在 Python 解释器中使用 f = open(‘document.txt’)打开这个文件,并使用 print f.read()检查其内容
若解释器无法找到文件,要检查文件是否在正确目录。
方法1:使用 IDLE“文件”菜单上的“打开”命令;这将显示 IDLE 当前目录下所有文件的清单
方法2:在python中检查当前目录
>>> import os
>>> os.listdir('.')
内置的 open()函数的第二个参数用于控制如何打开文件:open(‘document.txt’, ‘rU’)。'r’意味着以只读方式打开文件(默认),'U’表示“通用”,它让我们忽略不同的换行约定
打开了该文件,有几种方法可以阅读此文件。read()方法创建了一个包含整个文件内容的字符串:
>>> f.read()
'Time flies like an arrow.\nFruit flies like a banana.\n'
也可以使用一个 for 循环一次读文件中的一行:
>>> f = open('document.txt', 'rU')
>>> for line in f:
... print line.strip()
Time flies like an arrow.
Fruit flies like a banana.
使用 strip()方法删除输入行结尾的换行符
NLTK 中的语料库文件也可以使用这些方法来访问。我们只需使用 nltk.data.find()来获取语料库项目的文件名。然后就可以使用我们刚才讲的方式打开和阅读它
>>> path = nltk.data.find('corpora/gutenberg/melville-moby_dick.txt')
>>> raw = open(path, 'rU').read()
字符串:最底层的文本处理
我们可以追加元素到一个链表,但不能追加元素到一个字符串
我们可以连接字符串与字符串,列出链表内容,但我们不能连接字符串与链表
字符串的基本操作
指定字符串
>>> monty = 'Monty Python' #用单引号指定
>>> monty
'Monty Python'
>>> circus = "Monty Python's Flying Circus" #用双引号指定
>>> circus
"Monty Python's Flying Circus"
>>> circus = 'Monty Python\'s Flying Circus' #一个字符串中包含一个单引号,在单引号前加反斜杠让 Python 知道这是字符串中的单引号
>>> circus
"Monty Python's Flying Circus"
>>> circus = 'Monty Python's Flying Circus' #字符串内的单引号将被解释为字符串结束标志,报错
File "<stdin>", line 1
circus = 'Monty Python's Flying Circus'
^
SyntaxError: invalid syntax
对于较长的字符串
>>> couplet = "Shall I compare thee to a Summer's day?"\
... "Thou are more lovely and more temperate:" #反斜杠,表明第一行表达式不完整
>>> print couplet
Shall I compare thee to a Summer's day?Thou are more lovely and more temperate:
>>> couplet = ("Rough winds do shake the darling buds of May,"
... "And Summer's lease hath all too short a date:") #括号,表明第一行表达式不完整
>>> print couplet
Rough winds do shake the darling buds of May,And Summer's lease hath all too short a date:
字符串两行之间的换行,使用三重引号的字符串
>>> couplet = """Shall I compare thee to a Summer's day?
... Thou are more lovely and more temperate:"""
>>> print couplet
Shall I compare thee to a Summer's day?
Thou are more lovely and more temperate:
>>> couplet = '''Rough winds do shake the darling buds of May,
... And Summer's lease hath all too short a date:'''
>>> print couplet
Rough winds do shake the darling buds of May,
And Summer's lease hath all too short a date:
连接字符串
>>> 'very' + 'very' + 'very'
'veryveryvery'
>>> 'very' * 3
'veryveryvery'
我们不能对字符串用减法或除法
>>> 'very' - 'y'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for -: 'str' and 'str'
>>> 'very' / 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for /: 'str' and 'int'
输出字符串
>>> monty ='Monty Python'
>>> print(monty)
Monty Python
>>> grail = 'Holy Grail'
>>> print (monty + grail)
Monty PythonHoly Grail
>>> print (monty, grail)
Monty Python Holy Grail
>>> print (monty, "and the", grail)
Monty Python and the Holy Grail
访问单个字符
>>> monty[0]
'M'
>>> monty[3]
't'
>>> monty[5]
' '
注:和链表一样,不能超出字符串的索引范围
可以使用字符串的负数索引
>>> monty[-1] #最后一个
'n'
>>> monty[5]
' '
>>> monty[-7] #倒数第七个
' '
写一个 for 循环,遍历字符串中的字符。print 语句结尾加一个逗号,这是为了告诉 Python 不要在行尾输出换行符
>>> sent = 'colorless green ideas sleep furiously'
>>> for char in sent:
... print char,
...
c o l o r l e s s g r e e n i d e a s s l e e p f u r i o u s l y
访问子字符串
切片:同链表的操作一样,切片[m,n]包含从位置 m 到 n-1 中的字符
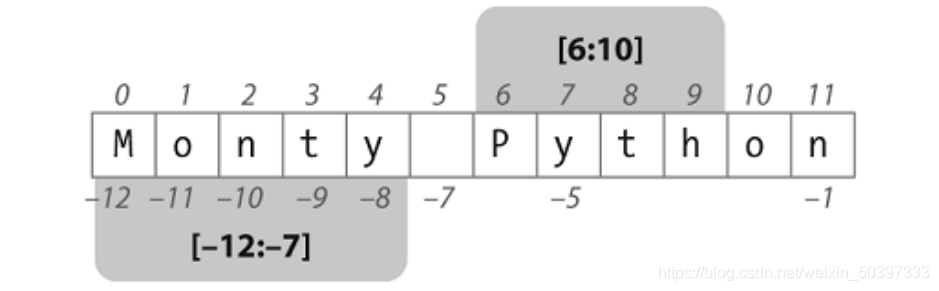
>>> monty[6:10]
'Pyth'
>>> monty[-12:-7]
'Monty'
>>> monty[:5]
'Monty'
>>> monty[6:]
'Python'
in操作
>>> phrase = 'And now for something completely different'
>>> if 'thing' in phrase:
... print ('found "thing"')
found "thing"
使用 find()找到一个子字符串在字符串内的位置
>>> monty.find('Python')
6
更多的字符串操作
| 方法 | 功能 |
|---|---|
| s.find(t) | 字符串 s 中包含 t 的第一个索引(没找到返回-1) |
| s.rfind(t) | 字符串 s 中包含 t 的最后一个索引(没找到返回-1) |
| s.index(t) | 与 s.find(t)功能类似,但没找到时引起 ValueError |
| s.rindex(t) | 与 s.rfind(t)功能类似,但没找到时引起 ValueError |
| s.join(text) | 连接字符串 s 与 text 中的词汇 |
| s.split(t) | 在所有找到 t 的位置将 s 分割成链表(默认为空白符) |
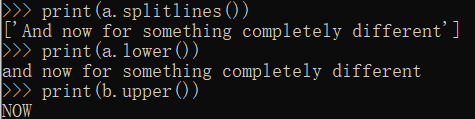
| s.splitlines() | 将 s 按行分割成字符串链表 |
| s.lower() | 将字符串 s 小写 |
| s.upper() | 将字符串 s 大写 |
| s.titlecase() | 将字符串 s 首字母大写 |
| s.strip() | 返回一个没有首尾空白字符的 s 的拷贝 |
| s.replace(t, u) | 用 u 替换 s 中的 t |
链表与字符串的差异
字符串和链表之间不能连接
>>> query = 'Who knows?'
>>> beatles = ['John', 'Paul', 'George', 'Ringo']
>>> query[2]
'o'
>>> beatles[2]
'George'
>>> query[:2]
'Wh'
>>> beatles[:2]
['John', 'Paul']
>>> query + " I don't"
"Who knows? I don't"
>>> beatles + 'Brian'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate list (not "str") to list
>>> beatles + ['Brian']
['John', 'Paul', 'George', 'Ringo', 'Brian']
字符串是不可变的,链是可变的,其内容可以随时修改
>>> beatles[0] = "John Lennon"
>>> del beatles[-1]
>>> beatles
['John Lennon', 'Paul', 'George']
>>> query[0] = 'F'
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: object does not support item assignment
使用正则表达式检测词组搭配
在 Python 中使用正则表达式,需要使用 import re 导入 re 函数库。还需要一个用于搜索的词汇链表;我们再次使用词汇语料库,对它进行预处理消除某些名称。
>>> import re
>>> wordlist = [w for w in nltk.corpus.words.words('en') if w.islower()]
使用基本元字符
们使用正则表达式«ed$»查找以 ed 结尾的词汇。函数 re.search(p, s)检查字符串 s 中是否有模式 p
>>> [w for w in wordlist if re.search('ed$', w)]
['abaissed', 'abandoned', 'abased', 'abashed', 'abatised', 'abed', 'aborted', ...]
通配符“.”匹配任何单个字符。假设我们有一个 8 个字母组成的词的字谜室,j 是其第三个字母,t 是其第六个字母。空白单元格中的每个地方,我们用一个句点:
>>> [w for w in wordlist if re.search('^..j..t..$', w)]
['abjectly', 'adjuster', 'dejected', 'dejectly', 'injector', 'majestic', ...]
注:插入符号“^”匹配字符串的开始,“$”符号匹配字符串的结尾
范围与闭包
>>> [w for w in wordlist if re.search('^[ghi][mno][jlk][def]$', w)]
['gold', 'golf', 'hold', 'hole']
«^ [ghi]»匹配以 g、h 或 i 开始的词。«[mno]»限制了第二个字符是 m、n 或 o。第三部分和第四部分也是限制。四个字母要满足所有这些限制。注意,方括号内的字符的顺序是没有关系的,所以我们可以写: «^ [hig][nom][ljk][fed]$»匹配同样的词汇。
“+”表示的是“前面的项目的一个或多个实例,”它可以是单独的字母如 m,可以是一个集合如[fed],可以是一个范围如[d-f],“*”表示“前面的项目的零个或多个实例。
>>> chat_words = sorted(set(w for w in nltk.corpus.nps_chat.words()))
>>> [w for w in chat_words if re.search('^m+i+n+e+$', w)]
['miiiiiiiiiiiiinnnnnnnnnnneeeeeeeeee', 'miiiiiinnnnnnnnnneeeeeeee', 'mine',
'mmmmmmmmiiiiiiiiinnnnnnnnneeeeeeee']
>>> [w for w in chat_words if re.search('^[ha]+$', w)]
['a', 'aaaaaaaaaaaaaaaaa', 'aaahhhh', 'ah', 'ahah', 'ahahah', 'ahh',
'ahhahahaha', 'ahhh', 'ahhhh', 'ahhhhhh', 'ahhhhhhhhhhhhhh', 'h', 'ha', 'haaa',
'hah', 'haha', 'hahaaa', 'hahah', 'hahaha', 'hahahaa', 'hahahah', 'hahahaha', ...]
正则表达式«^ m* i* n* e* $ »将匹配所有我们用«^m+i+n+e+$»找到的,同时包括其中一些字母不出现的词汇,例如:me、min 和 mmmmm。请注意“+”和“*”符号有时被称为的 Kleene 闭包,或者干脆闭包。
运算符“^ ”当它出现在方括号内的第一个字符位置时有另外的功能。例如:« [ ^ aeiouAEIOU]»匹配除元音字母之外的所有字母
\,{},()和|功能:
>>> wsj = sorted(set(nltk.corpus.treebank.words()))
>>> [w for w in wsj if re.search('^[0-9]+\.[0-9]+$', w)]
['0.0085', '0.05', '0.1', '0.16', '0.2', '0.25', '0.28', '0.3', '0.4', '0.5',
'0.50', '0.54', '0.56', '0.60', '0.7', '0.82', '0.84', '0.9', '0.95', '0.99',
'1.01', '1.1', '1.125', '1.14', '1.1650', '1.17', '1.18', '1.19', '1.2', ...]
>>> [w for w in wsj if re.search('^[A-Z]+\$$', w)]
['C$', 'US$']
>>> [w for w in wsj if re.search('^[0-9]{4}$', w)]
['1614', '1637', '1787', '1901', '1903', '1917', '1925', '1929', '1933', ...]
>>> [w for w in wsj if re.search('^[0-9]+-[a-z]{3,5}$', w)]
['10-day', '10-lap', '10-year', '100-share', '12-point', '12-year', ...]
>>> [w for w in wsj if re.search('^[a-z]{5,}-[a-z]{2,3}-[a-z]{,6}$', w)]
['black-and-white', 'bread-and-butter', 'father-in-law', 'machine-gun-toting',
'savings-and-loan']
>>> [w for w in wsj if re.search('(ed|ing)$', w)]
['62%-owned', 'Absorbed', 'According', 'Adopting', 'Advanced', 'Advancing', ...]
\表示转义,{}表示前面项目重复次数,()表示操作符的范围,|表示析取
注:(),|常搭配使用,如«w(i|e|ai|oo)t»,匹配 wit、wet、wait 和 woot
正则表达式基本元字符,其中包括通配符,范围和闭包


注:python语法中“\b”会被解释为一个退格符号。通过给字符串加一个前缀“r”来表明它是一个原始字符串。例如:原始字符串 r’\band\b’包含两个“\ b”符号会被 re 库解释为匹配词的边界而不是解释为退格字符
正则表达式的有益应用
提取字符块
通过 re.findall() (“find all”即找到所有)方法找出所有(无重叠的)匹配指定正则表达式的
# 找出一个词中的元音,再计数它们
>>> word = 'supercalifragilisticexpialidocious'
>>> re.findall(r'[aeiou]', word)
['u', 'e', 'a', 'i', 'a', 'i', 'i', 'i', 'e', 'i', 'a', 'i', 'o', 'i', 'o', 'u']
>>> len(re.findall(r'[aeiou]', word))
16
# 找出一些文本中的两个或两个以上的元音序列,并确定它们的相对频率:
>>> wsj = sorted(set(nltk.corpus.treebank.words()))
>>> fd = nltk.FreqDist(vs for word in wsj
... for vs in re.findall(r'[aeiou]{2,}', word))
>>> fd.items()
[('io', 549), ('ea', 476), ('ie', 331), ('ou', 329), ('ai', 261), ('ia', 253),
('ee', 217), ('oo', 174), ('ua', 109), ('au', 106), ('ue', 105), ('ui', 95),
('ei', 86), ('oi', 65), ('oa', 59), ('eo', 39), ('iou', 27), ('eu', 18), ...]
>>> [int(n) for n in re.findall(r'[0-9]{2,4}','2009-12-31')]
[2009, 12, 31]
查找词干
方法1:函数
>>> def stem(word):
... for suffix in ['ing', 'ly', 'ed', 'ious', 'ies', 'ive', 'es', 's', 'ment']:
... if word.endswith(suffix):
... return word[:-len(suffix)]
... return word
方法二:正则表达式
>>> re.findall(r'^.*(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processing')
['ing']
改进1:如果要使用括号来指定连接的范围,但不想选择要输出的字符串,必须添加“?:”
>>> re.findall(r'^.*(?:ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processing')
['processing']
改进2:想将词分成词干和后缀。应该用括号括起正则表达式的这两个部分
>>> re.findall(r'^(.*)(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processing')
[('process', 'ing')]
改进3:上述方法匹配“processes”会得到[(‘processe’, ‘s’)],因为“ * ”操作符是“贪婪的”,所以表达式的“. * ”部分试图尽可能多的匹配输入的字符串。如果我们使用“非贪婪”版本的“ * ”操作符,写成“*?”,我们就得到我们想要的
>>> re.findall(r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processes')
[('process', 'es')]
改进4:通过使第二个括号中的内容变成可选,来得到空后缀
>>> re.findall(r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$', 'language')
[('language', '')]
搜索已分词文本
>>> from nltk.corpus import gutenberg, nps_chat
>>> moby = nltk.Text(gutenberg.words('melville-moby_dick.txt'))
>>> moby.findall(r"<a> (<.*>) <man>") # 匹配所有单个标识符,将它括在括号里,于是只匹配词(例如:monied)而不匹配短语(例如:a monied man)
monied; nervous; dangerous; white; white; white; pious; queer; good;
mature; white; Cape; great; wise; wise; butterless; white; fiendish;
pale; furious; better; certain; complete; dismasted; younger; brave;
brave; brave; brave
>>> chat = nltk.Text(nps_chat.words())
>>> chat.findall(r"<.*> <.*> <bro>") # 找出以词“bro”结尾的三个词组成的短语
you rule bro; telling you bro; u twizted bro
>>> chat.findall(r"<l.*>{3,}") # 找出以字母“l”开始的三个或更多词组成的序列
lol lol lol; lmao lol lol; lol lol lol; la la la la la; la la la; la
la la; lovely lol lol love; lol lol lol.; la la la; la la la
规范化文本
本节中使用的数据:
>>> raw = """DENNIS: Listen, strange women lying in ponds distributing swords
... is no basis for a system of government. Supreme executive power derives from
... a mandate from the masses, not from some farcical aquatic ceremony."""
>>> tokens = nltk.word_tokenize(raw)
词干提取器
Porter 和 Lancaster 词干提取器按照它们自己的规则剥离词缀
>>> porter = nltk.PorterStemmer()
>>> lancaster = nltk.LancasterStemmer()
>>> [porter.stem(t) for t in tokens]
['DENNI', ':', 'Listen', ',', 'strang', 'women', 'lie', 'in', 'pond',
'distribut', 'sword', 'is', 'no', 'basi', 'for', 'a', 'system', 'of', 'govern',
'.', 'Suprem', 'execut', 'power', 'deriv', 'from', 'a', 'mandat', 'from',
'the', 'mass', ',', 'not', 'from', 'some', 'farcic', 'aquat', 'ceremoni', '.']
>>> [lancaster.stem(t) for t in tokens]
['den', ':', 'list', ',', 'strange', 'wom', 'lying', 'in', 'pond', 'distribut',
'sword', 'is', 'no', 'bas', 'for', 'a', 'system', 'of', 'govern', '.', 'suprem',
'execut', 'pow', 'der', 'from', 'a', 'mand', 'from', 'the', 'mass', ',', 'not',
'from', 'som', 'farc', 'aqu', 'ceremony', '.']
Porter 词干提取器正确处理了词 lying(将它映射为 lie),而 Lancaster 词干提取器并没有处理好
词形归并
WordNet 词形归并器删除词缀产生的词都是在它的字典中的词。这个额外的检查过程使词形归并器比刚才提到的词干提取器要慢。请注意,它并没有处理“lying”,但它将“women”转换为“woman”。
>>> wnl = nltk.WordNetLemmatizer()
>>> [wnl.lemmatize(t) for t in tokens]
['DENNIS', ':', 'Listen', ',', 'strange', 'woman', 'lying', 'in', 'pond',
'distributing', 'sword', 'is', 'no', 'basis', 'for', 'a', 'system', 'of',
'government', '.', 'Supreme', 'executive', 'power', 'derives', 'from', 'a',
'mandate', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcical',
'aquatic', 'ceremony', '.']
用正则表达式为文本分词
分词的简单方法
空格符处分割文本
>>> raw = """'When I'M a Duchess,' she said to herself, (not in a very hopeful tone
... though), 'I won't have any pepper in my kitchen AT ALL. Soup does very
... well without--Maybe it's always pepper that makes people hot-tempered,'..."""
>>> re.split(r' ', raw) # 只匹配了空格符
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in',
'a', 'very', 'hopeful', 'tone\nthough),', "'I", "won't", 'have', 'any', 'pepper',
'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very\nwell', 'without--Maybe',
"it's", 'always', 'pepper', 'that', 'makes', 'people', "hot-tempered,'..."]
>>> re.split(r'[ \t\n]+', raw) # 匹配了空格、制表、换行符,可以改写为 re.split(r'\s+', raw)
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in',
'a', 'very', 'hopeful', 'tone', 'though),', "'I", "won't", 'have', 'any', 'pepper',
'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very', 'well', 'without--Maybe',
"it's", 'always', 'pepper', 'that', 'makes', 'people', "hot-tempered,'..."]
分割如“(not”和“herself,”这些符号分割的文本,用“\W”即所有字母、数字和下划线以外的字符
>>> re.split(r'\W+', raw)
['', 'When', 'I', 'M', 'a', 'Duchess', 'she', 'said', 'to', 'herself', 'not', 'in',
'a', 'very', 'hopeful', 'tone', 'though', 'I', 'won', 't', 'have', 'any', 'pepper',
'in', 'my', 'kitchen', 'AT', 'ALL', 'Soup', 'does', 'very', 'well', 'without',
'Maybe', 'it', 's', 'always', 'pepper', 'that', 'makes', 'people', 'hot', 'tempered','']
匹配词中字符的所有序列。如果没有找到匹配的,它会尝试匹配后面跟着词中字符的任何非空白字符(“\S”是“\s”的补)。这意味着标点会与跟在后面的字母(如’s)在一起,但两个或两个以上的标点字符序列会被分割
>>> re.findall(r'\w+|\S\w*', raw)
["'When", 'I', "'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',',
'(not', 'in', 'a', 'very', 'hopeful', 'tone', 'though', ')', ',', "'I", 'won', "'t",
'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup', 'does',
'very', 'well', 'without', '-', '-Maybe', 'it', "'s", 'always', 'pepper', 'that',
'makes', 'people', 'hot', '-tempered', ',', "'", '.', '.', '.']
«\w+([-’]\w+)*»。这个表达式表示“\w+”后面跟零个或更多“[-’]\w+”的实例;它会匹配 hot-tempered 和 it’s。
>>> print re.findall(r"\w+(?:[-']\w+)*|'|[-.(]+|\S\w*", raw)
["'", 'When', "I'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',',
'(', 'not', 'in', 'a', 'very', 'hopeful', 'tone', 'though', ')', ',', "'", 'I',
"won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup',
'does', 'very', 'well', 'without', '--', 'Maybe', "it's", 'always', 'pepper',
'that', 'makes', 'people', 'hot-tempered', ',', "'", '...']
正则表达式符号

分割
断句
Punkt 句子分割器
>>> sent_tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')
>>> text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt')
>>> sents = sent_tokenizer.tokenize(text)
>>> pprint.pprint(sents[171:181])
['"Nonsense!',
'" said Gregory, who was very rational when anyone else\nattempted paradox.',
'"Why do all the clerks and navvies in the\nrailway trains look so sad and tired,...',
'I will\ntell you.',
'It is because they know that the train is going right.',
'It\nis because they know that whatever place they have taken a ticket\nfor that ...',
'It is because after they have\npassed Sloane Square they know that the next stat...',
'Oh, their wild rapture!',
'oh,\ntheir eyes like stars and their souls again in Eden, if the next\nstation w...'
'"\n\n"It is you who are unpoetical," replied the poet Syme.']
分词
从分词表示字符串 seg1 和 seg2 中重建文本分词
def segment(text, segs):
words = []
last = 0
for i in range(len(segs)):
if segs[i] == '1':
words.append(text[last:i+1])
last = i+1
words.append(text[last:])
return words
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> seg2 = "0100100100100001001001000010100100010010000100010010000"
>>> segment(text, seg1)
['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
>>> segment(text, seg2)
['do', 'you', 'see', 'the', 'kitty', 'see', 'the', 'doggy', 'do', 'you',
'like', 'the', kitty', 'like', 'the', 'doggy']
计算存储词典和重构源文本的成本
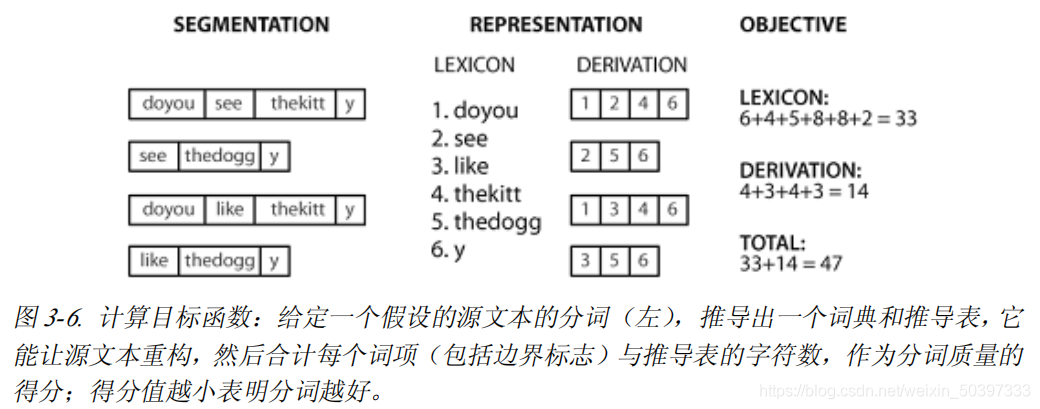
def evaluate(text, segs):
words = segment(text, segs)
text_size = len(words)
lexicon_size = len(' '.join(list(set(words))))
return text_size + lexicon_size
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> seg2 = "0100100100100001001001000010100100010010000100010010000"
>>> seg3 = "0000100100000011001000000110000100010000001100010000001"
>>> segment(text, seg3)
['doyou', 'see', 'thekitt', 'y', 'see', 'thedogg', 'y', 'doyou', 'like',
'thekitt', 'y', 'like', 'thedogg', 'y']
>>> evaluate(text, seg3)
46
>>> evaluate(text, seg2)
47
>>> evaluate(text, seg1)
63
格式化:从链表到字符串
从链表到字符串
>>> silly = ['We', 'called', 'him', 'Tortoise', 'because', 'he', 'taught', 'us', '.']
>>> ' '.join(silly)
'We called him Tortoise because he taught us .'
>>> ';'.join(silly)
'We;called;him;Tortoise;because;he;taught;us;.'
>>> ''.join(silly)
'WecalledhimTortoisebecausehetaughtus.'
’ ‘.join(silly)的意思是:取出 silly 中的所有项目,将它们连接成一个大的字符串,使用’ '作为项目之间的间隔符
字符串与格式
>>> word = 'cat'
>>> sentence = """hello
... world"""
>>> print(word)
cat
>>> print(sentence)
hello
world
>>> word
'cat'
>>> sentence
'hello\nworld'
print 命令产生的是 Python 尝试以人最可读的形式输出的一个对象的内容。第二种方法——叫做变量提示——向我们显示可用于重新创建该对象的字符串
给定一个频率分布 fdist
>>> fdist = nltk.FreqDist(['dog', 'cat', 'dog', 'cat', 'dog', 'snake', 'dog', 'cat'])
>>> for word in fdist:
... print (word, '->', fdist[word], ';')
dog -> 4 ; cat -> 3 ; snake -> 1 ;
字符串格式化表达式
>>> for word in fdist:
... print ('%s->%d;' % (word, fdist[word]))
dog->4; cat->3; snake->1;
特殊符号%s 和%d 是字符串和整数(十进制数)的占位符
>>> '%s->%d;' % ('cat', 3)
'cat->3;'
>>> '%s->%d;' % 'cat'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: not enough arguments for format string
>>> '%s->' % 'cat'
'cat->'
>>> '%d' % 3
'3'
>>> 'I want a %s right now' % 'coffee'
'I want a coffee right now'
可以有多个占位符,但%操作符后面必须指定数目完全相同的数值的元组
>>> "%s wants a %s %s" % ("Lee", "sandwich", "for lunch")
'Lee wants a sandwich for lunch'
间接的提供占位符的值
>>> template = 'Lee wants a %s right now'
>>> menu = ['sandwich', 'spam fritter', 'pancake']
>>> for snack in menu:
... print template % snack
...
Lee wants a sandwich right now
Lee wants a spam fritter right now
Lee wants a pancake right now
排列
指定宽度,如%6s,产生一个宽度为 6 的字符串
>>> '%6s' % 'dog' # 缺省情况右对齐
' dog'
>>> '%-6s' % 'dog' # 包括一个减号使它左对齐
'dog '
>>> width = 6
>>> '%-*s' % (width, 'dog') #事先不知道要显示的值应该有多宽时,可以在格式化字符串中用*替换宽度值,然后指定一个变量
'dog
其他控制字符用于十进制整数和浮点数。因为百分号%在格式化字符串中有特殊解释,我们要在它前面加另一个%才能输出它
>>> count, total = 3205, 9375
>>> "accuracy for %d words: %2.4f%%" % (total, 100 * count / total)
'accuracy for 9375 words: 34.1867%'
将结果写入文件
打开可写文件 output.txt,将程序的输出保存到文件
>>> output_file = open('output.txt', 'w')
>>> words = set(nltk.corpus.genesis.words('english-kjv.txt'))
>>> for word in sorted(words):
... output_file.write(word + "\n")
注:应该避免文件名包含空格字符,例如:output file.txt,避免使用除了大小写区别外其他都相同的文件名,例如:Output.txt 与 output.TXT
文本换行
在 Python 的 textwrap 模块的帮助下采取换行
>>> from textwrap import fill
>>> format = '%s (%d),'
>>> pieces = [format % (word, len(word)) for word in saying]
>>> output = ' '.join(pieces)
>>> wrapped = fill(output)
>>> print wrapped
After (5), all (3), is (2), said (4), and (3), done (4), , (1), more
(4), is (2), said (4), than (4), done (4), . (1),
小结
- 在本书中,我们将文本作为一个词链表。“原始文本”是一个潜在的长字符串,其中包含文字和用于设置格式的空白字符,也是我们通常存储和可视化文本的原料。
- 在 Python 中指定一个字符串使用单引号或双引号:‘Monty Python’,“Monty Python”。
- 字符串中的字符是使用索引来访问的,索引从零计数:‘Monty Python’[0]的值是 M。求字符串的长度可以使用 len()。
- 子字符串使用切片符号来访问: ‘Monty Python’[1:5]的值是 onty。如果省略起始索引,子字符串从字符串的开始处开始;如果省略结尾索引,切片会一直到字符串的结尾处结束。
- 字符串可以被分割成链表:‘Monty Python’.split()得到[‘Monty’, ‘Python’]。链表可以连接成字符串:’/’.join([‘Monty’, ‘Python’])得到’Monty/Python’。
- 我们可以使用 text = open(f).read()从一个文件 f 读取文本。可以使用 text = urlopen(u).read()从一个 URL u 读取文本。我们可以使用 for line in open(f)遍历一个文本文件的每一行。
- 在网上找到的文本可能包含不需要的内容(如页眉、页脚和标记),在我们做任何语言处理之前需要去除它们。
- 分词是将文本分割成基本单位或标记,例如词和标点符号等。基于空格符的分词对于许多应用程序都是不够的,因为它会捆绑标点符号和词。NLTK 提供了一个现成的分词器nltk.word_tokenize()。
- 词形归并是一个过程,将一个词的各种形式(如:appeared,appears)映射到这个词标准的或引用的形式,也称为词位或词元(如:appear)。
- 正则表达式是用来指定模式的一种强大而灵活的方法。只要导入了 re 模块,我们就可以使用== re.findall()==来找到一个字符串中匹配一个模式的所有子字符串。
- 如果一个正则表达式字符串包含一个反斜杠,你应该使用原始字符串与一个 r 前缀:r’regexp’,告诉 Python 不要预处理这个字符串。
- 当某些字符前使用了反斜杠时,例如:\n,处理时会有特殊的含义(换行符);然而,当反斜杠用于正则表达式通配符和操作符时,如:.,|,$,这些字符失去其特殊的含义,只按字面表示匹配。
- 一个字符串格式化表达式 template % arg_tuple 包含一个格式字符串 template,它由如%-6s 和%0.2d 这样的转换标识符符组成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









